Embed Size (px)
Citation preview

Anshul Kumar, CSE IITD
CSL718 : Memory HierarchyCSL718 : Memory HierarchyCSL718 : Memory HierarchyCSL718 : Memory Hierarchy
Cache Performance Improvement
23rd Feb, 2006

Anshul Kumar, CSE IITD slide 2
PerformancePerformancePerformancePerformance
Average memory access time =
Hit time + Mem stalls / access =
Hit time + Miss rate * Miss penalty
Program execution time =
IC * Cycle time * (CPIexec + Mem stalls / instr)
Mem stalls / instr =
Miss rate * Miss Penalty * Mem accesses / instr
Miss Penalty in OOO processor =
Total miss latency - Overlapped miss latency

Anshul Kumar, CSE IITD slide 3
Performance ImprovementPerformance ImprovementPerformance ImprovementPerformance Improvement
• Reducing miss penalty
• Reducing miss rate
• Reducing miss penalty * miss rate
• Reducing hit time

Anshul Kumar, CSE IITD slide 4
Reducing Miss PenaltyReducing Miss PenaltyReducing Miss PenaltyReducing Miss Penalty
• Multi level caches
• Critical word first and early restart
• Giving priority to read misses over write
• Merging write buffer
• Victim caches

Anshul Kumar, CSE IITD slide 5
Multi Level CachesMulti Level CachesMulti Level CachesMulti Level Caches
Average memory access time =
Hit timeL1 + Miss rateL1 * Miss penaltyL1
Miss penaltyL1 =
Hit timeL2 + Miss rateL2 * Miss penaltyL2
Multi level inclusion
and
Multi level exclusion

Anshul Kumar, CSE IITD slide 6
Misses in Multilevel CacheMisses in Multilevel CacheMisses in Multilevel CacheMisses in Multilevel Cache
• Local Miss rate– no. of misses / no. of requests, as seen at a level
• Global Miss rate– no. of misses / no. of requests, on the whole
• Solo Miss rate– miss rate if only this cache was present
Anshul Kumar, CSE IITD slide 7
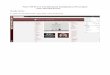
Two level cache miss exampleTwo level cache miss exampleTwo level cache miss exampleTwo level cache miss example
A: L1, L2
B: ~L1, L2
C: L1, ~L2
D: ~L1, ~L2
Local miss (L1) = (B+D)/(A+B+C+D)Local miss (L2) = D/(B+D)Global Miss = D/(A+B+C+D)Solo miss (L2) = (C+D)/(A+B+C+D)

Anshul Kumar, CSE IITD slide 8
Critical Word First and Early RestartCritical Word First and Early RestartCritical Word First and Early RestartCritical Word First and Early Restart
• Read policy
• Load policy
More effective when block size is large

Anshul Kumar, CSE IITD slide 9
Read Miss Priority Over WriteRead Miss Priority Over WriteRead Miss Priority Over WriteRead Miss Priority Over Write
• Provide write buffers
• Processor writes into buffer and proceeds (for write through as well as write back)
On read miss– wait for buffer to be empty, or– check addresses in buffer for conflict

Anshul Kumar, CSE IITD slide 10
Merging Write BufferMerging Write BufferMerging Write BufferMerging Write Buffer
Merge writes belonging to same block in case of write through
Anshul Kumar, CSE IITD slide 11
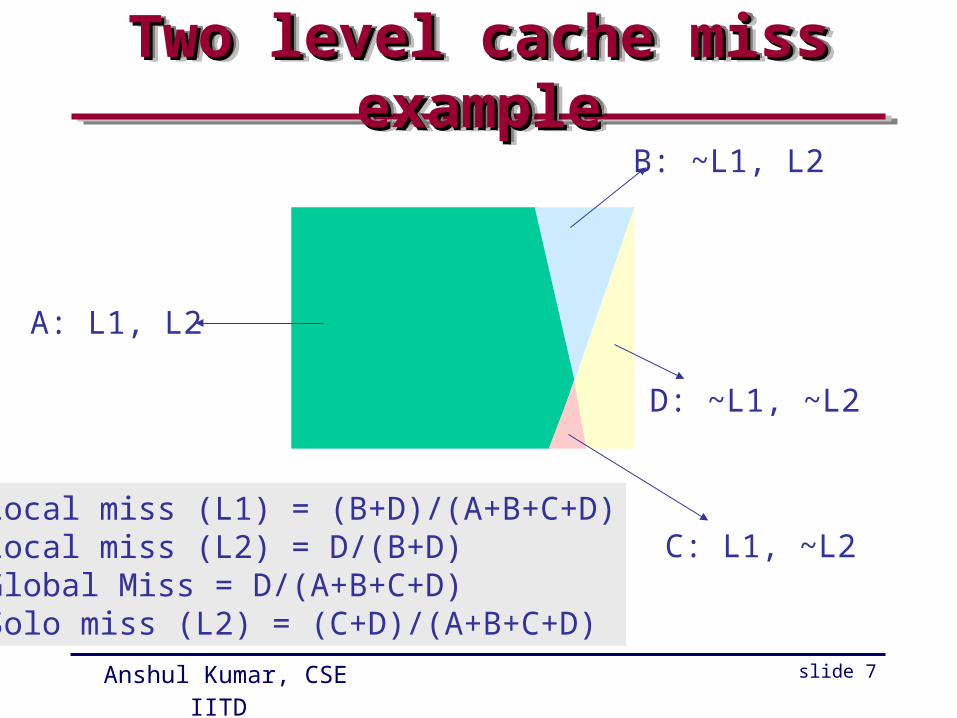
Victim Cache Victim Cache (proposed by Jouppi)(proposed by Jouppi)Victim Cache Victim Cache (proposed by Jouppi)(proposed by Jouppi)
• Evicted blocks are recycled
• Much faster than getting a block from the next level
• Size = 1 to 5 blocks
• A significant fraction of misses may be found in victim cache
Cache
VictimCache
from mem
to proc

Anshul Kumar, CSE IITD slide 12
Reducing Miss RateReducing Miss RateReducing Miss RateReducing Miss Rate
• Large block size
• Larger cache
• Higher associativity
• Way prediction and pseudo-associative cache
• Warm start in multi-tasking
• Compiler optimizations

Anshul Kumar, CSE IITD slide 13
Large Block SizeLarge Block SizeLarge Block SizeLarge Block Size
• Reduces compulsory misses
• Too large block size - misses increase
• Miss Penalty increases

Anshul Kumar, CSE IITD slide 14
Large CacheLarge CacheLarge CacheLarge Cache
• Reduces capacity misses
• Hit time increases
• Keep small L1 cache and large L2 cache

Anshul Kumar, CSE IITD slide 15
Higher AssociativityHigher AssociativityHigher AssociativityHigher Associativity
• Reduces conflict misses
• 8-way is almost like fully associative
• Hit time increases

Anshul Kumar, CSE IITD slide 16
Way Prediction and Pseudo-Way Prediction and Pseudo-associative Cacheassociative Cache
Way Prediction and Pseudo-Way Prediction and Pseudo-associative Cacheassociative Cache
Way prediction: low miss rate of SA cache with hit time of DM cache
• Only one tag is compared initially• Extra bits are kept for prediction• Hit time in case of mis-prediction is highPseudo-assoc. or column assoc. cache: get
advantage of SA cache in a DM cache• Check sequentially in a pseudo-set• Fast hit and slow hit

Anshul Kumar, CSE IITD slide 17
Warm Start in Multi-taskingWarm Start in Multi-taskingWarm Start in Multi-taskingWarm Start in Multi-tasking
• Cold start– process starts with empty cache– blocks of previous process invalidated
• Warm start– some blocks from previous activation are still
available

Anshul Kumar, CSE IITD slide 18
Compiler optimizationsCompiler optimizationsCompiler optimizationsCompiler optimizations
Loop interchange
• Improve spatial locality by scanning arrays row-wise
Blocking
• Improve temporal and spatial locality

Anshul Kumar, CSE IITD slide 19
Improving LocalityImproving LocalityImproving LocalityImproving Locality
MNNLML
BAC
Matrix Multiplication example

Anshul Kumar, CSE IITD slide 20
Cache Organization for the exampleCache Organization for the exampleCache Organization for the exampleCache Organization for the example
• Cache line (or block) = 4 matrix elements.• Matrices are stored row wise.• Cache can’t accommodate a full row/column.
(In other words, L, M and N are so large w.r.t. the cache size that after an iteration along any of the three indices, when an element is accessed again, it results in a miss.)
• Ignore misses due to conflict between matrices. (as if there was a separate cache for each matrix.)

Anshul Kumar, CSE IITD slide 21
Matrix Multiplication : Code IMatrix Multiplication : Code IMatrix Multiplication : Code IMatrix Multiplication : Code I
for (i = 0; i < L; i++)
for (j = o; j < M; j++)
for (k = 0; k < N; k++)
c[i][j] += A[i][k] * B[k][j];
C A B
accesses LM LMN LMN
misses LM/4 LMN/4 LMN
Total misses = LM(5N+1)/4

Anshul Kumar, CSE IITD slide 22
Matrix Multiplication : Code IIMatrix Multiplication : Code IIMatrix Multiplication : Code IIMatrix Multiplication : Code II
for (k = 0; k < N; k++)
for (i = 0; i < L; i++)
for (j = o; j < M; j++)
c[i][j] += A[i][k] * B[k][j];
C A B
accesses LMN LN LMN
misses LMN/4 LNLMN/4
Total misses = LN(2M+4)/4

Anshul Kumar, CSE IITD slide 23
Matrix Multiplication : Code IIIMatrix Multiplication : Code IIIMatrix Multiplication : Code IIIMatrix Multiplication : Code III
for (i = 0; i < L; i++)
for (k = 0; k < N; k++)
for (j = o; j < M; j++)
c[i][j] += A[i][k] * B[k][j];
C A B
accesses LMN LN LMN
misses LMN/4 LN/4LMN/4
Total misses = LN(2M+1)/4
Anshul Kumar, CSE IITD slide 24
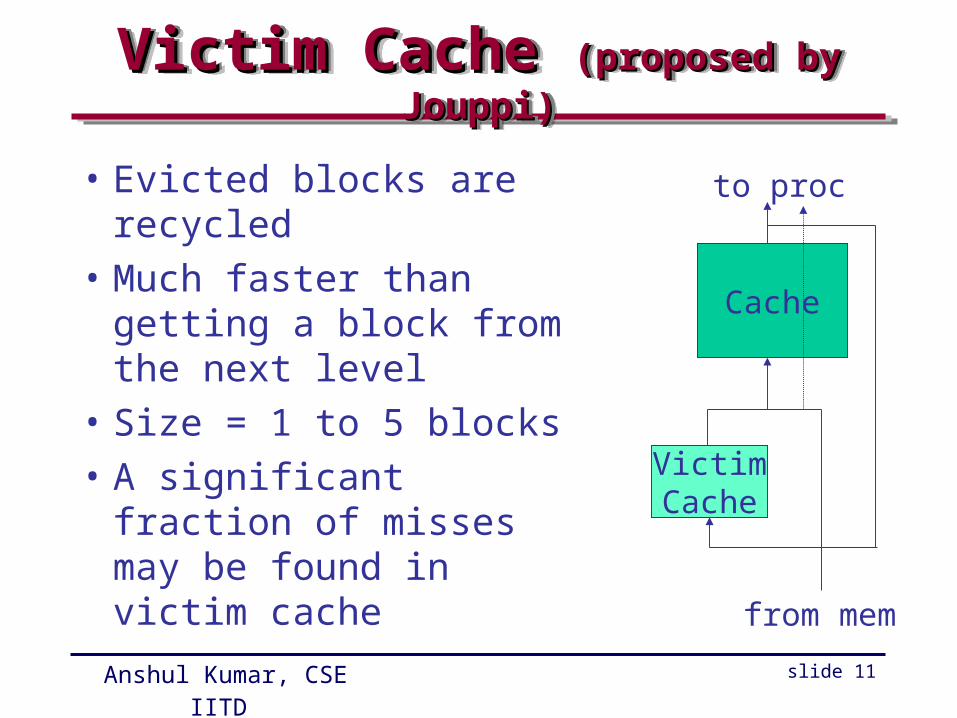
BlockingBlockingBlockingBlocking
= k
j
jj
kk
k
kk
ij
jj
i
jjkk
ij
k5 nested loops
blocking factor = b
C A BaccessesLMN/b LMN/b LMNmisses LMN/4b LMN/4b MN/4Total misses = MN(2L/b+1)/4

Anshul Kumar, CSE IITD slide 25
Loop BlockingLoop BlockingLoop BlockingLoop Blocking
for (k = 0; k < N; k+=4) for (i = 0; i < L; i++) for (j = o; j < M; j++) c[i][j] += A[i][k]*B[k][j] +A[i][k+1]*B[k+1][j] +A[i][k+2]*B[k+2][j] +A[i][k+3]*B[k+3][j];
C A Baccesses LMN/4 LN LMNmisses LMN/16 LN/4 LMN/4
Total misses = LN(5M/4+1)/4

Anshul Kumar, CSE IITD slide 26
Reducing Miss Penalty * Miss RateReducing Miss Penalty * Miss RateReducing Miss Penalty * Miss RateReducing Miss Penalty * Miss Rate
• Non-blocking cache
• Hardware prefetching
• Compiler controlled prefetching

Anshul Kumar, CSE IITD slide 27
Non-blocking CacheNon-blocking CacheNon-blocking CacheNon-blocking Cache
In OOO processor
• Hit under a miss– complexity of cache controller increases
• Hit under multiple misses or miss under a miss – memory should be able to handle multiple
misses

Anshul Kumar, CSE IITD slide 28
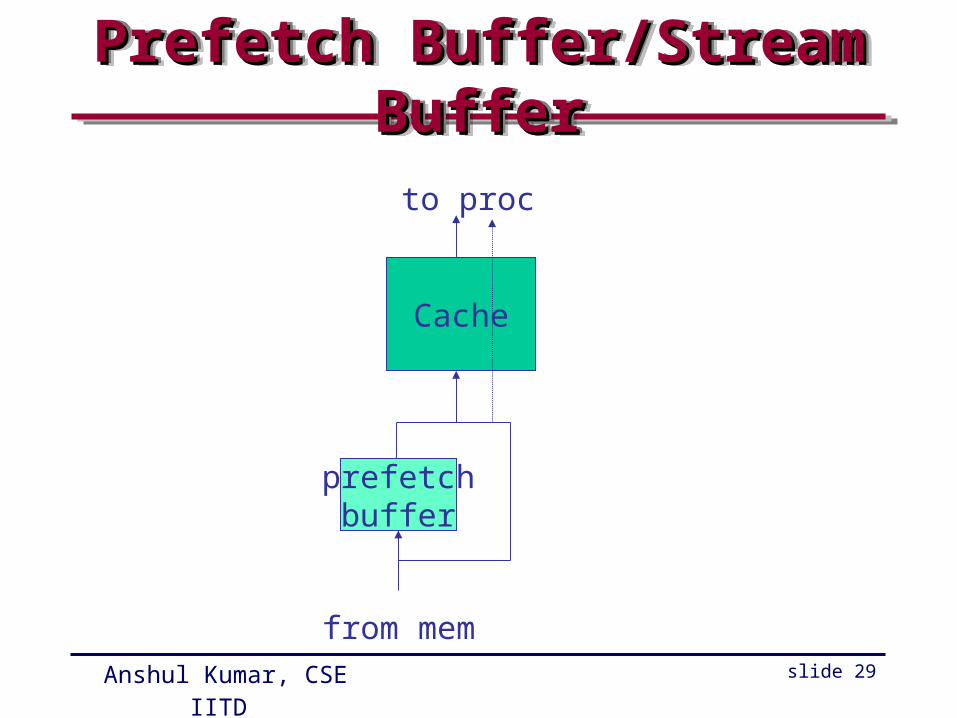
Hardware PrefetchingHardware PrefetchingHardware PrefetchingHardware Prefetching
• Prefetch items before they are requested– both data and instructions
• What and when to prefetch?– fetch two blocks on a miss (requested+next)
• Where to keep prefetched information?– in cache– in a separate buffer (most common case)
Anshul Kumar, CSE IITD slide 29
Prefetch Buffer/Stream BufferPrefetch Buffer/Stream BufferPrefetch Buffer/Stream BufferPrefetch Buffer/Stream Buffer
Cache
prefetchbuffer
from mem
to proc

Anshul Kumar, CSE IITD slide 30
Hardware prefetching: Stream buffersHardware prefetching: Stream buffersHardware prefetching: Stream buffersHardware prefetching: Stream buffers
Joupi’s experiment [1990]:• Single instruction stream buffer catches 15% to
25% misses from a 4KB direct mapped instruction cache with 16 byte blocks
• 4 block buffer – 50%, 16 block – 72%• single data stream buffer catches 25% misses from
4 KB direct mapped cache• 4 data stream buffers (each prefetching at a
different address) – 43%

Anshul Kumar, CSE IITD slide 31
HW prefetching: HW prefetching: UltraSPARC III exampleUltraSPARC III exampleHW prefetching: HW prefetching: UltraSPARC III exampleUltraSPARC III example
64 KB data cache, 36.9 misses per 1000 instructions
22% instructions make data reference
hit time = 1, miss penalty = 15
prefetch hit rate = 20%
1 cycle to get data from prefetch buffer
What size of cache will give same performance?
miss rate = 36.9/220 = 16.7%
av mem access time =1+(.167*.2*1)+(.167*.8*15)=3.046
effective miss rate = (3.046-1)/15=13.6%=> 256 KB cache

Anshul Kumar, CSE IITD slide 32
Compiler Controlled PrefetchingCompiler Controlled PrefetchingCompiler Controlled PrefetchingCompiler Controlled Prefetching
• Register prefetch / Cache prefetch
• Faulting / non-faulting (non-binding)
• Semantically invisible (no change in registers or cache contents)
• Makes sense if processor doesn’t stall while prefetching (non-blocking cache)
• Overhead of prefetch instruction should not exceed the benefit

Anshul Kumar, CSE IITD slide 33
SW Prefetch ExampleSW Prefetch ExampleSW Prefetch ExampleSW Prefetch Example
• 8 KB direct mapped, write back data cache with 16 byte blocks.
• a is 3 100, b is 101 3
for (i = 0; i < 3; i++) for (j = o; j < 100; j++) a[i][j] = b[j][0] * b[j+1][0];
each array element is 8 bytesmisses in array a = 3 * 100 /2 = 150misses in array b = 101total misses = 251

Anshul Kumar, CSE IITD slide 34
SW Prefetch Example – contd.SW Prefetch Example – contd.SW Prefetch Example – contd.SW Prefetch Example – contd.
Suppose we need to prefetch 7 iterations in advancefor (j = o; j < 100; j++){ prefetch(b[j+7]][0]); prefetch(a[0][j+7]); a[0][j] = b[j][0] * b[j+1][0];};for (i = 1; i < 3; i++) for (j = o; j < 100; j++){ prefetch(a[i][j+7]); a[i][j] = b[j][0] * b[j+1][0];};
misses in first loop = 7 (for b[0..6][0]) + 4 (for a[0][0..6] )misses in second loop = 4 (for a[1][0..6]) + 4 (for a[2][0..6] )total misses = 19, total prefetches = 400

Anshul Kumar, CSE IITD slide 35
SW Prefetch Example – contd.SW Prefetch Example – contd.SW Prefetch Example – contd.SW Prefetch Example – contd.
Performance improvement?Assume no capacity and conflict misses,prefetches overlap with each other and with missesOriginal loop: 7, Prefetch loops: 9 and 8 cyclesMiss penalty = 100 cycles
Original loop = 300*7 + 251*100 = 27,200 cycles1st prefetch loop = 100*9 + 11*100 = 2,000 cycles2nd prefetch loop = 200*8 + 8*100 = 2,400 cyclesSpeedup = 27200/(2000+2400) = 6.2

Anshul Kumar, CSE IITD slide 36
Reducing Hit TimeReducing Hit TimeReducing Hit TimeReducing Hit Time
• Small and simple caches
• Avoid time loss in address translation
• Pipelined cache access
• Trace caches

Anshul Kumar, CSE IITD slide 37
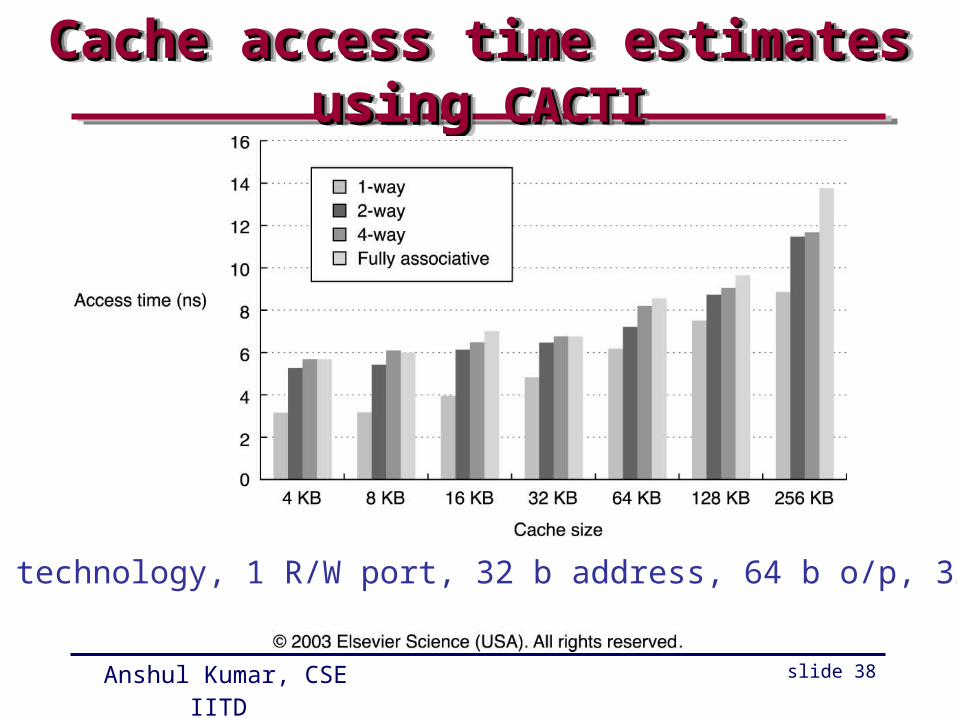
Small and Simple CachesSmall and Simple CachesSmall and Simple CachesSmall and Simple Caches
• Small size => faster access
• Small size => fit on the chip, lower delay
• Simple (direct mapped) => lower delay
• Second level – tags may be kept on chip
Anshul Kumar, CSE IITD slide 38
Cache access time estimates using Cache access time estimates using CACTICACTICache access time estimates using Cache access time estimates using CACTICACTI
.8 micron technology, 1 R/W port, 32 b address, 64 b o/p, 32 B block

Anshul Kumar, CSE IITD slide 39
Avoid time loss in addr translationAvoid time loss in addr translationAvoid time loss in addr translationAvoid time loss in addr translation
• Virtually indexed, physically tagged cache– simple and effective approach– possible only if cache is not too large
• Virtually addressed cache– protection?– multiple processes?– aliasing?– I/O?

Anshul Kumar, CSE IITD slide 40
Cache AddressingCache AddressingCache AddressingCache Addressing
• Physical Address– first convert virtual address into physical
address, then access cache– no time loss if index field available without
address translation
• Virtual Address– access cache directly using the virtual address

Anshul Kumar, CSE IITD slide 41
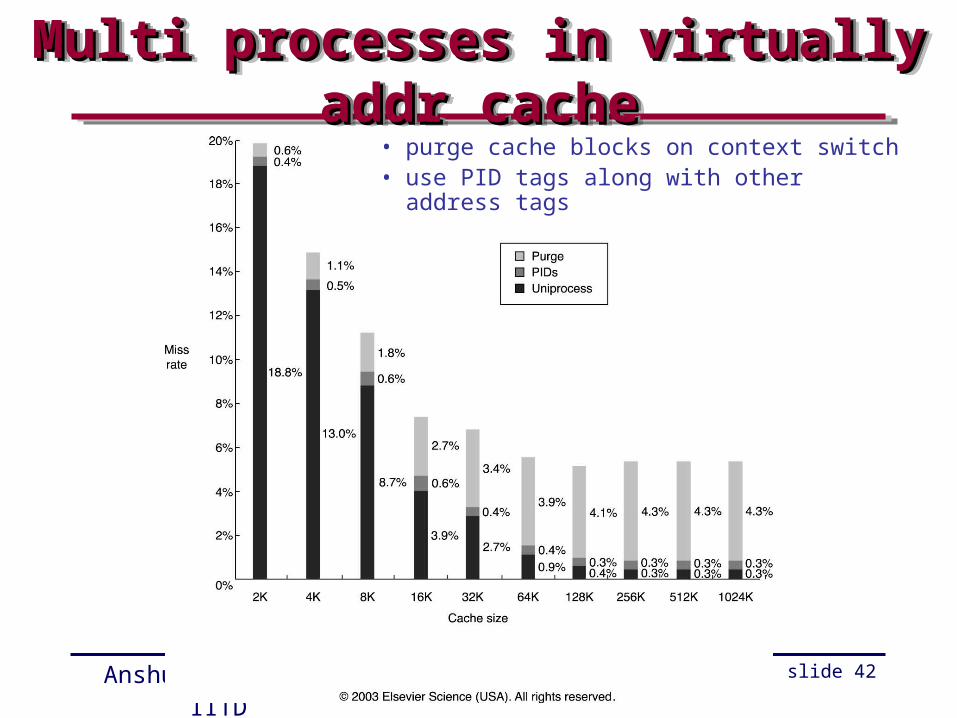
Problems with virtually addressed cacheProblems with virtually addressed cacheProblems with virtually addressed cacheProblems with virtually addressed cache
• page level protection? – copy protection info from TLB
• same virtual address from two different processes needs to be distinguished – purge cache blocks on context switch or use PID tags
along with other address tags
• aliasing (different virtual addresses from two processes pointing to same physical address) – inconsistency?
• I/O uses physical addresses
Anshul Kumar, CSE IITD slide 42
Multi processes in virtually addr cacheMulti processes in virtually addr cacheMulti processes in virtually addr cacheMulti processes in virtually addr cache• purge cache blocks on context switch• use PID tags along with other address
tags

Anshul Kumar, CSE IITD slide 43
Inconsistency in virtually addr cacheInconsistency in virtually addr cacheInconsistency in virtually addr cacheInconsistency in virtually addr cache
• Hardware solution (Alpha 21264)– 64 KB cache, 2-way set associative, 8 KB page– a block with a given offset in a page can map to 8
locations in cache– check all 8 locations, invalidate duplicate entries
• Software solution (page coloring)– make 18 lsbs of all aliases same – ensures that
direct mapped cache 256 KB has no duplicates– i.e., 4 KB pages are mapped to 64 sets (or colors)

Anshul Kumar, CSE IITD slide 44
Pipelined Cache AccessPipelined Cache AccessPipelined Cache AccessPipelined Cache Access
• Multi-cycle cache access but pipelined
• reduces cycle time but hit time is more than one cycle
• Pentium 4 takes 4 cycles
• greater penalty on branch misprediction
• more clock cycles between issue of load and use of data

Anshul Kumar, CSE IITD slide 45
Trace CachesTrace CachesTrace CachesTrace Caches
• what maps to a cache block?– not statically determined – decided by the dynamic sequence of instructions,
including predicted branches
• Used in Pentium 4 (NetBurst architecture)• starting addresses not word size * powers of 2• Better utilization of cache space• downside – same instruction may be stored
multiple times