Embed Size (px)
Citation preview

© Cloudera, Inc. All rights reserved. 1
APACHE KUDU: ANALYTICS & RANDOM ACCESS IN A SINGLE DISTRIBUTED DATABASEAttila Bukor
© Cloudera, Inc. All rights reserved. 6
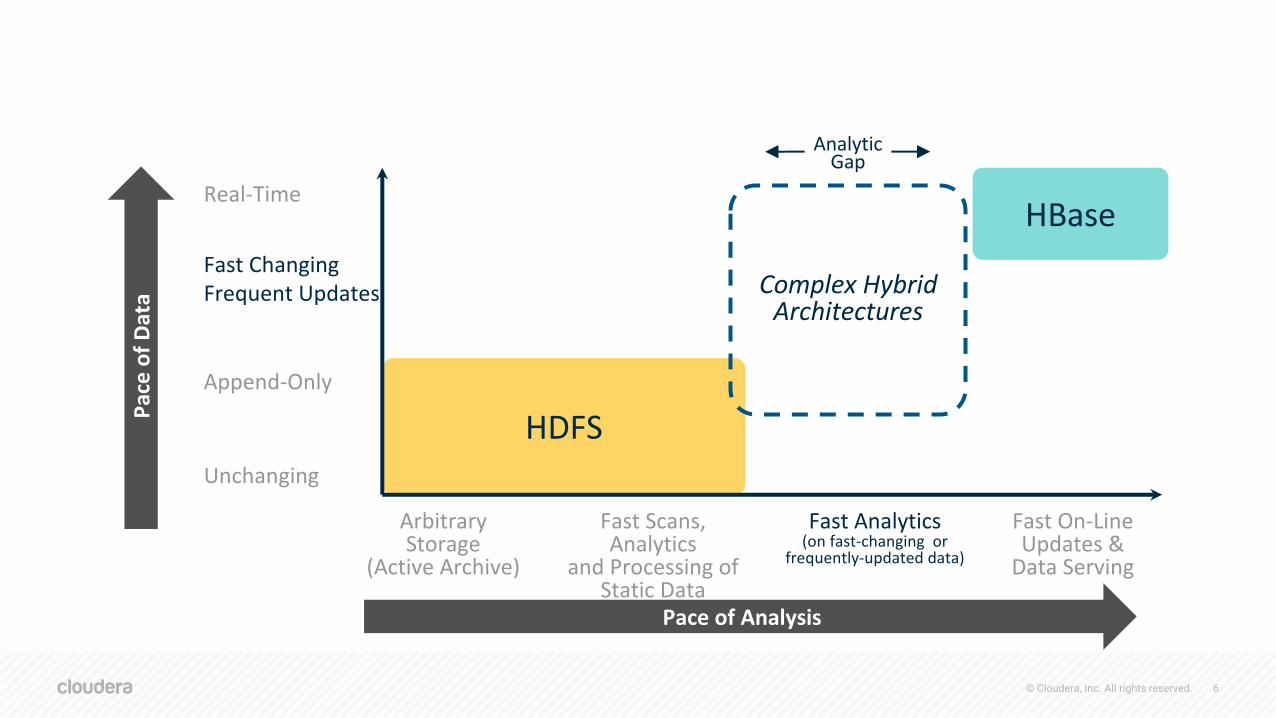
HDFS
Fast Scans, Analytics
and Processing of Static Data
Fast On-Line Updates &
Data Serving
Arbitrary Storage
(Active Archive)
Fast Analytics(on fast-changing or
frequently-updated data)
Unchanging
Fast ChangingFrequent Updates
HBase
Append-Only
Real-Time
Complex Hybrid Architectures
Analytic Gap
Pace of Analysis
Pace
of D
ata
© Cloudera, Inc. All rights reserved. 7
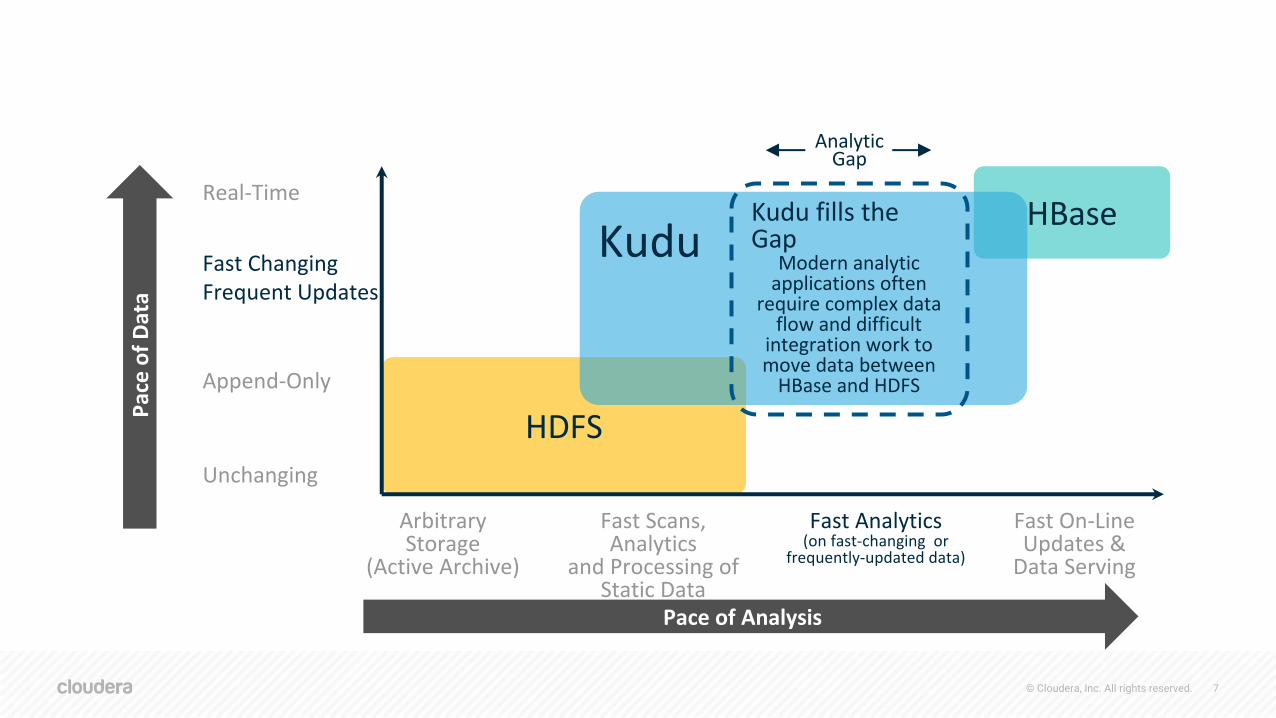
HDFS
Fast Scans, Analytics
and Processing of Static Data
Fast On-Line Updates &
Data Serving
Arbitrary Storage
(Active Archive)
Fast Analytics(on fast-changing or
frequently-updated data)
Unchanging
Fast ChangingFrequent Updates
HBase
Append-Only
Real-Time
KuduKudu fills the Gap
Modern analytic applications often
require complex data flow and difficult
integration work to move data between
HBase and HDFS
Analytic Gap
Pace of Analysis
Pace
of D
ata

© Cloudera, Inc. All rights reserved. 88
NEXT GENERATION HARDWARE
• Cheaper and faster every year.
• CPUs adding cores and SIMD width instead of clock speed
• Cheaper and bigger every year

© Cloudera, Inc. All rights reserved. 99
SCALABLE AND FAST TABULAR STORAGE
● ScalableTested up to 275 nodes (~3PB cluster)
Designed to scale to 1000s of nodes and tens of PBs
● FastMillions of read/write operations per second across cluster
Multiple GB/second read throughput per node
● TabularRepresents data in structured tables like a relational database
Individual record-level access to 100+ billion row tables

© Cloudera, Inc. All rights reserved. 1010
STORING RECORDS IN KUDU TABLES
● SQL-like schema○ Finite number of columns○ Strongly typed○ Primary keys - ordered subset of columns○ Fast ALTER TABLE (async)
● Java, Python, and C++ NoSQL-style APIs● SQL via integrations with Impala and Spark● CRUD with low-milliseconds latencies

© Cloudera, Inc. All rights reserved. 1111
TABLES, TABLETS AND TABLET SERVERS
● Horizontal partitions - tablets hosted on Tablet servers
○ Range and/or hash partitioning on primary key
● 2n+1 replicas with Raft consensus (http://raft.github.io)
○ MTTR ~5 seconds
● Hosted on local disks, decoupled from Hadoop
● HA Master servers
○ metadata operations (DDL)
○ tablet directory

© Cloudera, Inc. All rights reserved. 1212
XIAOMI’S USE-CASE
• 4th largest smartphone maker
• RPC tracing
• Service monitoring & troubleshooting tool
• High write throughput
• Real-time querying
• Search for individual records
© Cloudera, Inc. All rights reserved. 13
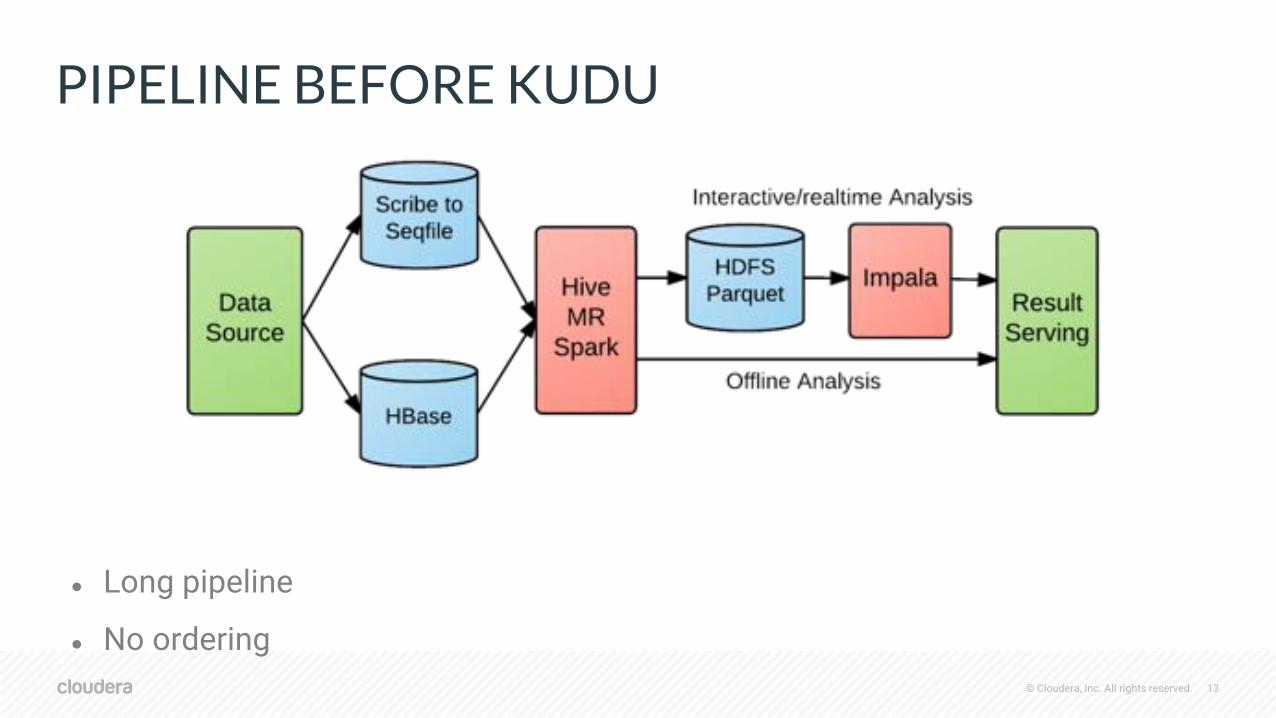
PIPELINE BEFORE KUDU
● Long pipeline
● No ordering
© Cloudera, Inc. All rights reserved. 14
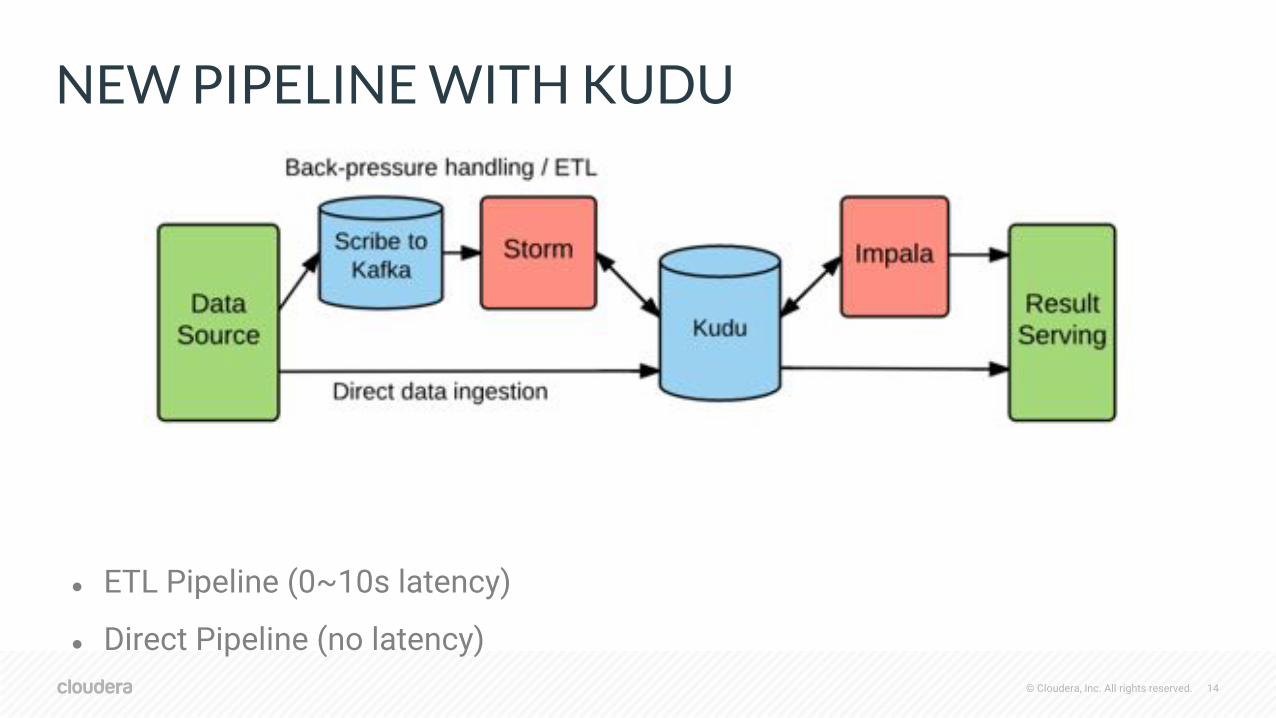
● ETL Pipeline (0~10s latency)
● Direct Pipeline (no latency)
NEW PIPELINE WITH KUDU

© Cloudera, Inc. All rights reserved. 15
● ATLAS EventIndex - catalogue of all events
● Tens of billions of ~1kB records
● Needs a fast and efficient selection of events of interest
○ various criteria
○ referencing events in millions of files scattered around a world-wide
distributed computing system
CERN’S USE-CASE

© Cloudera, Inc. All rights reserved. 16
● Benchmark
○ same dataset
○ same Hadoop cluster
○ data access with Apache Impala
○ 14 machines with 2 x 8 cores @2.60GHz, 64GB RAM, 24x2TB SAS drives
CERN’S USE-CASE

© Cloudera, Inc. All rights reserved. 18
● Storage efficiency○ Total volume reduced by a factor of 10 in Kudu and Parquet with Snappy
● Ingestion speed○ Ingestion rate 2 to 50 times faster in all tested solutions
● Random access○ Random lookup typically below 200ms in HBase or Kudu
● Analytics○ 300k records/s per CPU for aggregation, filtering and reporting with
Parquet and Kudu● Data mutability
○ Kudu and HBase can modify records in place.
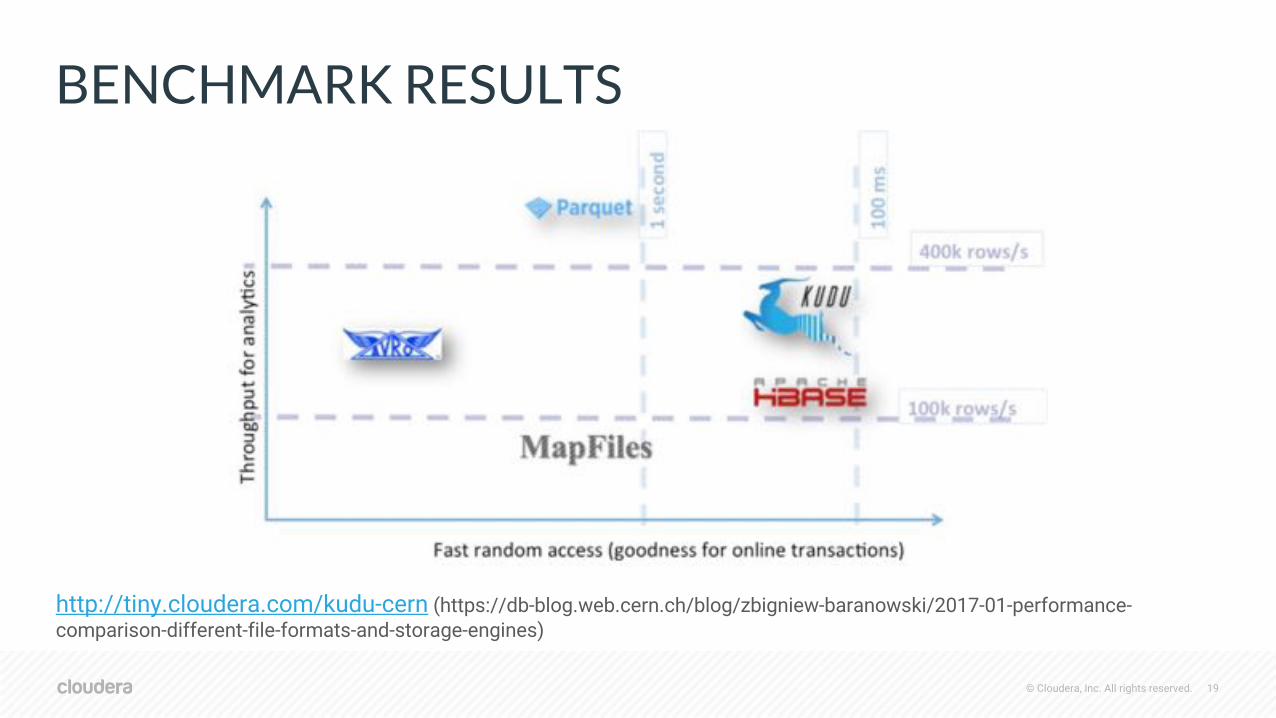
BENCHMARK RESULTS
© Cloudera, Inc. All rights reserved. 19
http://tiny.cloudera.com/kudu-cern (https://db-blog.web.cern.ch/blog/zbigniew-baranowski/2017-01-performance-comparison-different-file-formats-and-storage-engines)
BENCHMARK RESULTS
© Cloudera, Inc. All rights reserved. 20
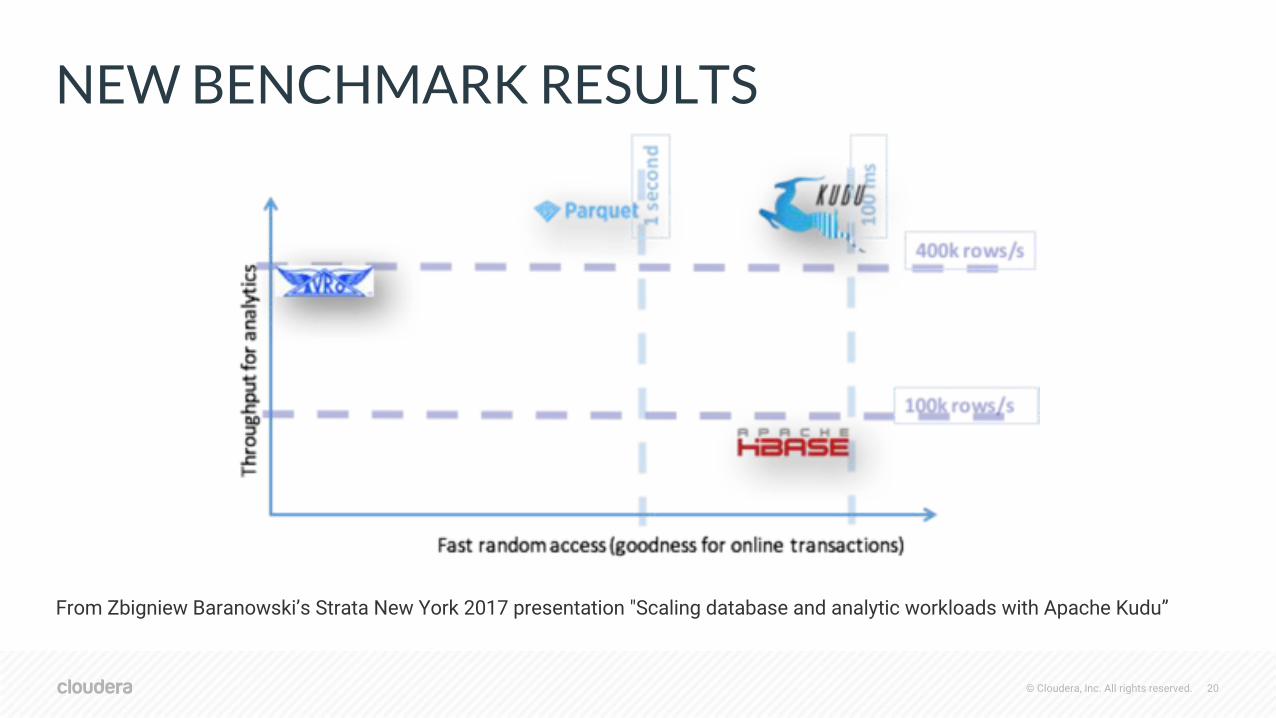
From Zbigniew Baranowski’s Strata New York 2017 presentation "Scaling database and analytic workloads with Apache Kudu”
NEW BENCHMARK RESULTS

© Cloudera, Inc. All rights reserved. 21
THANK YOUAttila [email protected]@r1pp3rj4ck
http://kudu.apache.orghttp://github.com/apache/kudu