Embed Size (px)
Citation preview

August 2009Bachelor of Science in Information Technology (BScIT) – Semester 4
BT0049 – Software Engineering – 4 Credits (Book ID: B0808)
Assignment Set – 1 (60 Marks)
Answer all questions 10 x 6 = 60
Ques 1 Discuss the impact of “information era”.The Information Age, also commonly known as the Computer Age or Information Era, is an idea that the current age will be characterized by the ability of individuals to transfer information freely, and to have instant access to knowledge that would have been difficult or impossible to find previously. The idea is linked to the concept of a Digital Age or Digital Revolution, and carries the ramifications of a shift from traditional industry that the Industrial Revolution brought through industrialization, to an economy based around the manipulation of information. The period is generally said to have begun in the latter half of the 20th century, though the particular date varies. Since the invention of social media in the early 21st century, some have claimed that the Information Age has evolved into the Attention Age.The term has been widely used since the late 1980s and into the 21st century.
The InternetThe Internet was originally conceived as a distributed, fail-proof network that could connect computers together and be resistant to any one point of failure; the Internet cannot be totally destroyed in one event, and if large areas are disabled, the information is easily re-routed. It was created mainly by ARPA; its initial software applications were email and computer file transfer.It was with the invention of the World Wide Web in 1989 that the Internet truly became a global network. Today the Internet has become the ultimate platform for accelerating the flow of information and is, today, the fastest-growing form of media.
ProgressionIn 1956 in the United States, researchers noticed that the number of people holding "white collar" jobs had just exceeded the number of people holding "blue collar" jobs. These researchers realized that this was an important change, as it was clear that the Industrial Age was coming to an end. As the Industrial Age ended, the newer times adopted the title of "the Information Age".At that time, relatively few jobs had much to do with computers and computer-related technology. There was a steady trend away from people holding Industrial Age manufacturing jobs. An increasing

number of people held jobs as clerks in stores, office workers, teachers, nurses, etc. The Western world was shifting into a service economy.Eventually, Information and Communication Technology—computers, computerized machinery, fiber optics, communication satellites, Internet, and other ICT tools—became a significant part of the economy. Microcomputers were developed and many business and industries were greatly changed by ICT.
Nicholas Negroponte captured the essence of these changes in his 1995 book, Being Digital.His book discusses similarities and differences between products made of atoms and products made of bits. In essence, one can very cheaply and quickly make a copy of a product made of bits, and ship it across the country or around the world both quickly and at very low cost.Thus, the term "Information Age" is often applied in relation to the use of cell phones, digital music, high definition television, digital cameras, the Internet, computer games, and other relatively new products and services that have come into widespread use.
Ques 2: Explain whether the linear sequential model of the software process is an accurate reflection of software development activities or not.
Linear Sequential ModelIt is also called “Classic Life Cycle” or “Waterfall” model or “Software Life Cycle” suggests a systematic and sequential approach to software development that begins at the system level and progresses through analysis, design, coding, testing and support. The waterfall model derives its name due to the cascading effect from one phase. In this model each phase well defined starting and ending point, with identifiable deliveries to the next phase
Analysis-->Design-->Coding-->Testing

Advantages
• Simple and a desirable approach when the requirements are clear and well understood at the beginning. • It provides a clear cut template for analysis, design, coding, testing and support. • It is an enforced disciplined approach
Disadvantages• It is difficult for the customers to state the requirements clearly at the beginning. There is always certain degree of natural uncertainty at beginning of each project.
• Difficult and costlier to change when the changes occur at a later stages.
• Customer can see the working version only at the end. Thus any changes suggested here are not only difficult to incorporate but also expensive. This may result in disaster if any undetected problems are precipitated to this stage
Ques 3: Why it is inappropriate to use reliability metrics, which were developed for hardware systems in estimating software system reliability? Illustrate your answer with example.
Since Software Reliability is one of the most important aspects of software quality, Reliability Engineering approaches are practiced in software field as well. Software Reliability Engineering (SRE) is the quantitative study of the operational behavior of software-based systems with respect to user requirements concerning reliability
Software Reliability Models A proliferation of software reliability models have emerged as people try to understand the characteristics of how and why software fails, and try to quantify software reliability. Over 200 models have been developed since the early 1970s, but how to quantify software reliability still remains largely unsolved. As many models as there are and many more emerging, none of the models can capture a satisfying amount of the complexity of software; constraints and assumptions have to be made for the quantifying process. Therefore, there is no single model that can be used in all situations. No model is complete or even representative. One model may work well for a set of certain software, but may be completely off track for other kinds of problems.

Most software models contain the following parts: assumptions, factors, and a mathematical function that relates the reliability with the factors. The mathematical function is usually higher order exponential or logarithmic.
Software modeling techniques can be divided into two subcategories: prediction modeling and estimation modeling. Both kinds of modeling techniques are based on observing and accumulating failure data and analyzing with statistical inference. The major difference of the two models is shown in Table 1.
ISSUES PREDICTION MODELS ESTIMATION MODELS
DATA REFERENCE Uses historical data Uses data from the current software development effort
WHEN USED IN DEVELOPMENT CYCLE
Usually made prior to development or test phases; can be used as early as concept phase
Usually made later in life cycle(after some data have been collected); not typically used in concept or development phases
TIME FRAME Predict reliability at some future time Estimate reliability at either present or some future time
Table 1. Difference between software reliability prediction models and software reliability estimation models
Representative prediction models include Musa's Execution Time Model, Putnam's Model. and Rome Laboratory models TR-92-51 and TR-92-15, etc. Using prediction models, software reliability can be predicted early in the development phase and enhancements can be initiated to improve the reliability. Representative estimation models include exponential distribution models, Weibull distribution model, Thompson and Chelson's model, etc. Exponential models and Weibull distribution model are usually named as classical fault count/fault rate estimation models, while Thompson and Chelson's model belong to Bayesian fault rate estimation models. The field has matured to the point that software models can be applied in practical situations and give meaningful results and, second, that there is no one model that is best in all situations. [Lyu95] Because of the complexity of software, any model has to have extra assumptions. Only limited factors can be put into consideration. Most software reliability models ignore the software development

process and focus on the results -- the observed faults and/or failures. By doing so, complexity is reduced and abstraction is achieved, however, the models tend to specialize to be applied to only a portion of the situations and a certain class of the problems. We have to carefully choose the right model that suits our specific case. Furthermore, the modeling results can not be blindly believed and applied.
Software Reliability Metrics
Measurement is commonplace in other engineering field, but not in software engineering. Though frustrating, the quest of quantifying software reliability has never ceased. Until now, we still have no good way of measuring software reliability. Measuring software reliability remains a difficult problem because we don't have a good understanding of the nature of software. There is no clear definition to what aspects are related to software reliability. We cannot find a suitable way to measure software reliability, and most of the aspects related to software reliability. Even the most obvious product metrics such as software size have not uniform definition. It is tempting to measure something related to reliability to reflect the characteristics, if we cannot measure reliability directly. The current practices of software reliability measurement can be divided into four categories:
Product metricsSoftware size is thought to be reflective of complexity, development effort and reliability. Lines Of Code (LOC), or LOC in thousands (KLOC), is an intuitive initial approach to measuring software size. But there is not a standard way of counting. Typically, source code is used (SLOC, KSLOC) and comments and other non-executable statements are not counted. This method cannot faithfully compare software not written in the same language. The advent of new technologies of code reuses and code generation technique also cast doubt on this simple method. Function point metric is a method of measuring the functionality of a proposed software development based upon a count of inputs, outputs, master files, inquires, and interfaces. The method can be used to estimate the size of a software system as soon as these functions can be identified. It is a measure of the functional complexity of the program. It measures the functionality delivered to the user and is independent of the programming language. It is used primarily for business systems; it is not proven in scientific or real-time applications. Complexity is directly related to software reliability, so representing complexity is important. Complexity-oriented metrics is a method of determining the complexity of a program’s control structure, by simplifies the code into a graphical representation. Representative metric is McCabe's Complexity Metric.

Test coverage metrics are a way of estimating fault and reliability by performing tests on software products, based on the assumption that software reliability is a function of the portion of software that has been successfully verified or tested. Detailed discussion about various software testing methods can be found in topic Software Testing.
Project management metricsResearchers have realized that good management can result in better products. Research has demonstrated that a relationship exists between the development process and the ability to complete projects on time and within the desired quality objectives. Costs increase when developers use inadequate processes. Higher reliability can be achieved by using better development process, risk management process, configuration management process, etc.
Process metricsBased on the assumption that the quality of the product is a direct function of the process, process metrics can be used to estimate, monitor and improve the reliability and quality of software. ISO-9000 certification, or "quality management standards", is the generic reference for a family of standards developed by the International Standards Organization(ISO).
Fault and failure metricsThe goal of collecting fault and failure metrics is to be able to determine when the software is approaching failure-free execution. Minimally, both the number of faults found during testing (i.e., before delivery) and the failures (or other problems) reported by users after delivery are collected, summarized and analyzed to achieve this goal. Test strategy is highly relative to the effectiveness of fault metrics, because if the testing scenario does not cover the full functionality of the software, the software may pass all tests and yet be prone to failure once delivered. Usually, failure metrics are based upon customer information regarding failures found after release of the software. The failure data collected is therefore used to calculate failure density, Mean Time between Failures (MTBF) or other parameters to measure or predict software reliability.
Software Reliability Improvement Techniques
Good engineering methods can largely improve software reliability. Before the deployment of software products, testing, verification and validation are necessary steps. Software testing is heavily used to trigger, locate and remove software defects. Software testing is still in its infant stage; testing is crafted to suit specific needs in various software development projects in an ad-hoc manner. Various analysis tools such as trend analysis, fault-tree analysis, Orthogonal Defect classification and formal methods, etc, can also be used to minimize the possibility of defect occurrence after release and therefore improve software reliability. After deployment of the software product, field data can be gathered and analyzed to study the behavior of software defects. Fault tolerance or fault/failure forecasting

techniques will be helpful techniques and guide rules to minimize fault occurrence or impact of the fault on the system.
Ques 4: Explain why it is necessary to design the system architecture before the specifications are written. Systems development phasesSystems Development Life Cycle (SDLC) adheres to important phases that are essential for developers, such as planning, analysis, design, and implementation, and are explained in the section below. There are several Systems Development Life Cycle Models in existence. The oldest model, that was originally regarded as "the Systems Development Life Cycle" is the waterfall model: a sequence of stages in which the output of each stage becomes the input for the next. These stages generally follow the same basic steps but many different waterfall methodologies give the steps different names and the number of steps seems to vary between 4 and 7. There is no definitively correct Systems Development Life Cycle model, but the steps can be characterized and divided in several steps.
The SDLC can be divided into ten phases during which defined IT work products are created or modified. The tenth phase occurs when the system is disposed of and the task performed is either eliminated or transferred to other systems. The tasks and work products for each phase are described in subsequent chapters. Not every project will require that the phases be sequentially executed.

However, the phases are interdependent. Depending upon the size and complexity of the project, phases may be combined or may overlap. Initiation/planningTo generate a high-level view of the intended project and determine the goals of the project. The feasibility study is sometimes used to present the project to upper management in an attempt to gain funding. Projects are typically evaluated in three areas of feasibility: economical, operational, and technical. Furthermore, it is also used as a reference to keep the project on track and to evaluate the progress of the MIS team.[8] The MIS is also a complement of those phases. This phase is also called the analysis phase.
Requirements gathering and analysisThe goal of systems analysis is to determine where the problem is in an attempt to fix the system. This step involves breaking down the system in different pieces and drawing diagrams to analyze the situation. Analyze project goals, break down functions that need to be created, and attempt to engage users so that definite requirements can be defined. Requirement Gathering sometimes require individual/team from client as well as service provider side to get a detailed and accurate requirements.
DesignIn systems design functions and operations are described in detail, including screen layouts, business rules, process diagrams and other documentation. The output of this stage will describe the new system as a collection of modules or subsystems.The design stage takes as its initial input the requirements identified in the approved requirements document. For each requirement, a set of one or more design elements will be produced as a result of interviews, workshops, and/or prototype efforts. Design elements describe the desired software features in detail, and generally include functional hierarchy diagrams, screen layout diagrams, tables of business rules, business process diagrams, pseudo code, and a complete entity-relationship diagram with a full data dictionary. These design elements are intended to describe the software in sufficient detail that skilled programmers may develop the software with minimal additional input.
Build or codingModular and subsystem programming code will be accomplished during this stage. Unit testing and module testing are done in this stage by the developers. This stage is intermingled with the next in that individual modules will need testing before integration to the main project.code will be test in every sections.

TestingThe code is tested at various levels in software testing. Unit, system and user acceptance testing are often performed. This is a grey area as many different opinions exist as to what the stages of testing are and how much if any iteration occurs. Iteration is not generally part of the waterfall model, but usually some occurs at this stage.Types of testing:
Data set testing. Unit testing System testing Integration testing Black box testing White box testing Module testing Back to back testing Automation testing User acceptance testing Performance testing
Operations and maintenanceThe deployment of the system includes changes and enhancements before the decommissioning or sunset of the system. Maintaining the system is an important aspect of SDLC. As key personnel change positions in the organization, new changes will be implemented, which will require system updates.
Systems development life cycle topicsManagement and control

SDLC Phases Related to Management Controls. The Systems Development Life Cycle (SDLC) phases serve as a programmatic guide to project activity and provide a flexible but consistent way to conduct projects to a depth matching the scope of the project. Each of the SDLC phase objectives are described in this section with key deliverables, a description of recommended tasks, and a summary of related control objectives for effective management. It is critical for the project manager to establish and monitor control objectives during each SDLC phase while executing projects. Control objectives help to provide a clear statement of the desired result or purpose and should be used throughout the entire SDLC process. Control objectives can be grouped into major categories (Domains), and relate to the SDLC phases as shown in the figure. To manage and control any SDLC initiative, each project will be required to establish some degree of a Work Breakdown Structure (WBS) to capture and schedule the work necessary to complete the project. The WBS and all programmatic material should be kept in the “Project Description” section of the project notebook. The WBS format is mostly left to the project manager to establish in a way that best describes the project work. There are some key areas that must be defined in the WBS as part of the SDLC policy. The following diagram describes three key areas that will be addressed in the WBS in a manner established by the project manager.
Work breakdown structure organization

Work Breakdown Structure. The upper section of the Work Breakdown Structure (WBS) should identify the major phases and milestones of the project in a summary fashion. In addition, the upper section should provide an overview of the full scope and timeline of the project and will be part of the initial project description effort leading to project approval. The middle section of the WBS is based on the seven Systems Development Life Cycle (SDLC) phases as a guide for WBS task development. The WBS elements should consist of milestones and “tasks” as opposed to “activities” and have a definitive period (usually two weeks or more). Each task must have a measurable output (e.g. document, decision, or analysis). A WBS task may rely on one or more activities (e.g. software engineering, systems engineering) and may require close coordination with other tasks, either internal or external to the project. Any part of the project needing support from contractors should have a Statement of work (SOW) written to include the appropriate tasks from the SDLC phases. The development of a SOW does not occur during a specific phase of SDLC but is developed to include the work from the SDLC process that may be conducted by external resources such as contractors. Baselines in the SDLCBaselines are an important part of the Systems Development Life Cycle (SDLC). These baselines are established after four of the five phases of the SDLC and are critical to the iterative nature of the model Each baseline is considered as a milestone in the SDLC.
Functional Baseline: established after the conceptual design phase. Allocated Baseline: established after the preliminary design phase. Product Baseline: established after the detail design and development phase. Updated Product Baseline: established after the production construction phase.
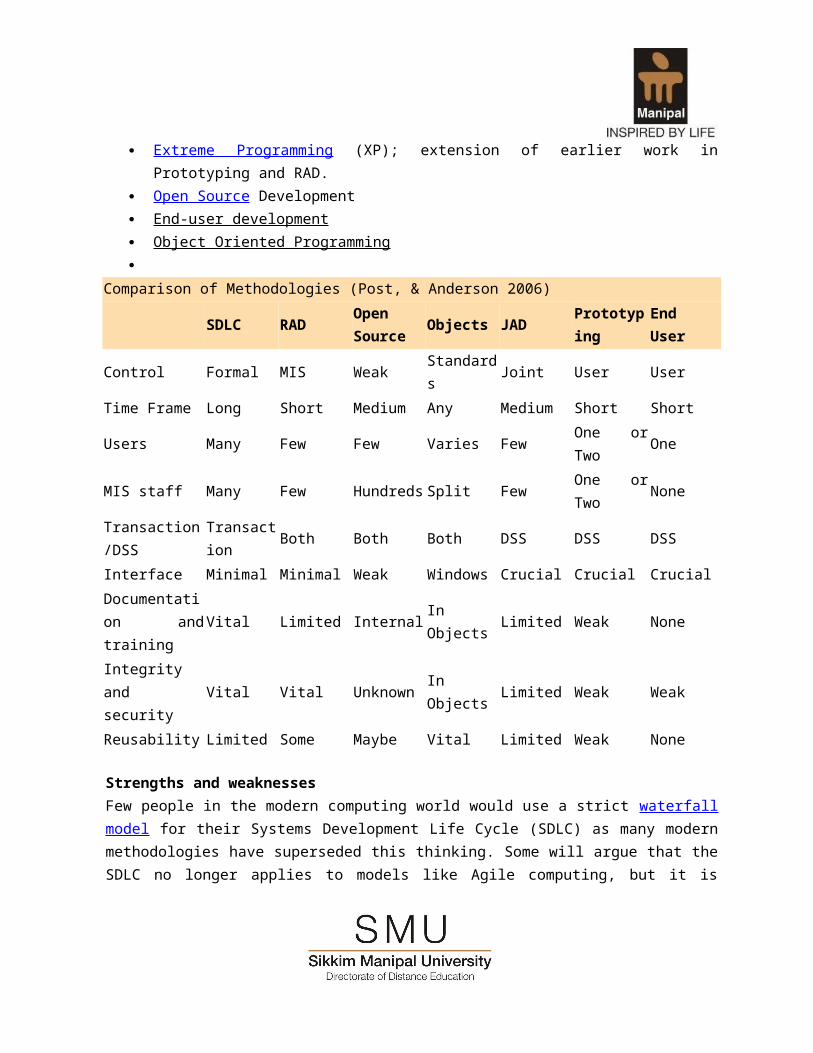
Complementary to SDLCComplementary Software development methods to Systems Development Life Cycle (SDLC) are:
Software Prototyping Joint Applications Design (JAD)

Rapid Application Development (RAD) Extreme Programming (XP); extension of earlier work in Prototyping and RAD. Open Source Development End-user development Object Oriented Programming
Comparison of Methodologies (Post, & Anderson 2006)
SDLC RADOpen Source
Objects JAD Prototyping End User
Control Formal MIS Weak Standards Joint User UserTime Frame Long Short Medium Any Medium Short ShortUsers Many Few Few Varies Few One or Two OneMIS staff Many Few Hundreds Split Few One or Two NoneTransaction/DSS Transaction Both Both Both DSS DSS DSSInterface Minimal Minimal Weak Windows Crucial Crucial CrucialDocumentation and training
Vital Limited Internal In Objects Limited Weak None
Integrity and security
Vital Vital Unknown In Objects Limited Weak Weak
Reusability Limited Some Maybe Vital Limited Weak None
Strengths and weaknessesFew people in the modern computing world would use a strict waterfall model for their Systems Development Life Cycle (SDLC) as many modern methodologies have superseded this thinking. Some will argue that the SDLC no longer applies to models like Agile computing, but it is still a term widely in use in Technology circles. The SDLC practice has advantages in traditional models of software development that lends itself more to a structured environment. The disadvantages to using the SDLC methodology is when there is need for iterative development or (i.e. web development or e-commerce) where stakeholders need to review on a regular basis the software being designed. Instead of viewing SDLC from a strength or weakness perspective, it is far more important to take the best practices from the SDLC model and apply it to whatever may be most appropriate for the software being designed.
A comparison of the strengths and weaknesses of SDLC:

Strength and Weaknesses of SDLC Strengths WeaknessesControl. Increased development time.Monitor Large projects. Increased development cost.Detailed steps. Systems must be defined up front.Evaluate costs and completion targets. Rigidity.Documentation. Hard to estimate costs, project overruns.Well defined user input. User input is sometimes limited.Ease of maintenance.Development and design standards.Tolerates changes in MIS staffing.
An alternative to the SDLC is Rapid Application Development, which combines prototyping, Joint Application Development and implementation of CASE tools. The advantages of RAD are speed, reduced development cost, and active user involvement in the development process.It should not be assumed that just because the waterfall model is the oldest original SDLC model that it is the most efficient system. At one time the model was beneficial mostly to the world of automating activities that were assigned to clerks and accountants. However, the world of technological evolution is demanding that systems have a greater functionality that would assist help desk technicians/administrators or information technology specialists/analysts.
Ques 5 Discuss the difference between object oriented and function oriented design strategies.
Object-oriented design is the process of planning a system of interacting objects for the purpose of solving a software problem. It is one approach to software design. A N object contains encapsulated data and procedures grouped together to represent an entity. The 'object interface', how the object can be interacted with, is also defined. An object-oriented program is described by the interaction of these objects. Object-oriented design is the discipline of defining the objects and their interactions to solve a problem that was identified and documented during object-oriented analysis.
From a business perspective, Object Oriented Design refers to the objects that make up that business. For example, in a certain company, a business object can consist of people, data files and database tables, artifacts, equipment, vehicles, etc. What follows is a description of the class-based subset of

object-oriented design, which does not include object prototype-based approaches where objects are not typically obtained by instancing classes but by cloning other (prototype) objects.
Input (sources) for object-oriented design
The input for object-oriented design is provided by the output of object-oriented analysis. Realize that an output artifact does not need to be completely developed to serve as input of object-oriented design; analysis and design may occur in parallel, and in practice the results of one activity can feed the other in a short feedback cycle through an iterative process. Both analysis and design can be performed incrementally, and the artifacts can be continuously grown instead of completely developed in one shot.
Some typical input artifacts for object-oriented design are:
Conceptual model : Conceptual model is the result of object-oriented analysis, it captures concepts in the problem domain. The conceptual model is explicitly chosen to be independent of implementation details, such as concurrency or data storage.
Use case : Use case is description of sequences of events that, taken together, lead to a system doing something useful. Each use case provides one or more scenarios that convey how the system should interact with the users called actors to achieve a specific business goal or function. Use case actors may be end users or other systems. In many circumstances use cases are further elaborated into use case diagrams. Use case diagrams are used to identify the actor (users or other systems) and the processes they perform.
System Sequence Diagram : System Sequence diagram (SSD) is a picture that shows, for a particular scenario of a use case, the events that external actors generate, their order, and possible inter-system events.
User interface documentations (if applicable): Document that shows and describes the look and feel of the end product's user interface. It is not mandatory to have this, but it helps to visualize the end-product and therefore helps the designer.
Relational data model (if applicable): A data model is an abstract model that describes how data is represented and used. If an object database is not used, the relational data model should usually be created before the design, since the strategy chosen for object-relational mapping is an output of the OO design process. However, it is possible to develop the

relational data model and the object-oriented design artifacts in parallel, and the growth of an artifact can stimulate the refinement of other artifacts.
Object-oriented concepts
The five basic concepts of object-oriented design are the implementation level features that are built into the programming language. These features are often referred to by these common names:
Object/Class : A tight coupling or association of data structures with the methods or functions that act on the data. This is called a class, or object (an object is created based on a class). Each object serves a separate function. It is defined by its properties, what it is and what it can do. An object can be part of a class, which is a set of objects that are similar.
Information hiding : The ability to protect some components of the object from external entities. This is realized by language keywords to enable a variable to be declared as private or protected to the owning class.
Inheritance : The ability for a class to extend or override functionality of another class. The so-called subclass has a whole section that is the superclass and then it has its own set of functions and data.
Interface : The ability to defer the implementation of a method. The ability to define the functions or methods signatures without implementing them.
Polymorphism : The ability to replace an object with its subobjects. The ability of an object-variable to contain, not only that object, but also all of its subobjects.
Designing concepts
Defining objects, creating class diagram from conceptual diagram: Usually map entity to class.
Identifying attributes.
Use design patterns (if applicable): A design pattern is not a finished design, it is a description of a solution to a common problem, in a context [1]. The main advantage of using a design pattern is that it can be reused in multiple applications. It can also be thought of as a template for how to solve a problem that can be used in many different situations and/or applications. Object-oriented design patterns typically show relationships and interactions between classes or objects, without specifying the final application classes or objects that are involved.
Define application framework (if applicable): Application framework is a term usually used to refer to a set of libraries or classes that are used to implement the standard structure of an application for a specific operating system. By bundling a large amount of reusable code into a framework, much time is saved for the developer, since he/she is saved the task of rewriting large amounts of standard code for each new application that is developed.
Identify persistent objects/data (if applicable): Identify objects that have to last longer than a single runtime of the application. If a relational database is used, design the object relation mapping.
Identify and define remote objects (if applicable).
Output (deliverables) of object-oriented design
Sequence Diagrams : Extend the System Sequence Diagram to add specific objects that handle the system events.
A sequence diagram shows, as parallel vertical lines, different processes or objects that live simultaneously, and, as horizontal arrows, the messages exchanged between them, in the order in which they occur.
Class diagram : A class diagram is a type of static structure UML diagram that describes the structure of a system by showing the system's classes, their attributes, and the relationships between the classes. The messages and classes identified through the development of the sequence diagrams can serve as input to the automatic generation of the global class diagram of the system.
Some design principles and strategies
Dependency injection : The basic idea is that if an object depends upon having an instance of some other object then the needed object is "injected" into the dependent object; for example, being passed a database connection as an argument to the constructor instead of creating one internally.
Acyclic dependencies principle : The dependency graph of packages or components should have no cycles. This is also referred to as having a directed acyclic graph. For example, package C depends on package B, which depends on package A. If package A also depended on package C, then you would have a cycle.

Composite reuse principle : Favor polymorphic composition of objects over inheritance.
Ques 6 Explain why a software system which is used in a real-world environment must change or become progressively less useful.
Software, or just software is a general term used to describe the role that computer programs, procedures and documentation play in a computer system. The term includes:
Application software , such as word processors which perform productive tasks for users. Firmware , which is software programmed resident to electrically programmable memory
devices on board main boards or other types of integrated hardware carriers. Middleware , which controls and co-ordinates distributed systems. System software such as operating systems, which interface with hardware to provide the
necessary services for application software. Software testing is a domain dependent of development and programming. Software testing
consists of various methods to test and declare a software product fit before it can be launched for use by either an individual or a group.
Testware , which is an umbrella term or container term for all utilities and application software that serve in combination for testing a software package but not necessarily may optionally contribute to operational purposes. As such, testware is not a standing configuration but merely a working environment for application software or subsets thereof.
Software includes things such as websites, programs or video games, that are coded by programming languages like C or C++."Software" is sometimes used in a broader context to mean anything which is not hardware but which is used with hardware, such as film, tapes and records.
OverviewComputer software is often regarded as anything but hardware, meaning that the "hard" are the parts that are tangible while the "soft" part is the intangible objects inside the computer. Software encompasses an extremely wide array of products and technologies developed using different techniques like programming languages, scripting languages, microcode, or an FPGA configuration. The types of software include web pages developed by technologies like HTML, PHP, Perl, JSP, ASP.NET, XML, and desktop applications like OpenOffice, Microsoft Word developed by technologies like C, C++, Java, C#, or Smalltalk. Software usually runs on an underlying software operating systems such as the

Linux or Microsoft Windows. Software also includes video games and the logic systems of modern consumer devices such as automobiles, televisions, and toasters.
Computer software is so called to distinguish it from computer hardware, which encompasses the physical interconnections and devices required to store and execute (or run) the software. At the lowest level, software consists of a machine language specific to an individual processor. A machine language consists of groups of binary values signifying processor instructions that change the state of the computer from its preceding state. Software is an ordered sequence of instructions for changing the state of the computer hardware in a particular sequence. It is usually written in high-level programming languages that are easier and more efficient for humans to use (closer to natural language) than machine language. High-level languages are compiled or interpreted into machine language object code. Software may also be written in an assembly language, essentially, a mnemonic representation of a machine language using a natural language alphabet. Assembly language must be assembled into object code via an assembler.The term "software" was first used in this sense by John W. Tukey in 1958.[3] In computer science and software engineering, computer software is all computer programs. The theory that is the basis for most modern software was first proposed by Alan Turing in his 1935 essay Computable numbers with an application to the Entscheidungsproblem. Software Characteristics
Software is developed and engineered. Software doesn't "wear-out". Most software continues to be custom built.
Types of softwareA layer structure showing where Operating System is located on generally used software systems on desktopsPractical computer systems divide software systems into three major classes system software, programming software and application software, although the distinction is arbitrary, and often blurred.
System software

System software helps run the computer hardware and computer system. It includes a combination of the following:
device drivers operating systems servers utilities windowing systems
The purpose of systems software is to unburden the applications programmer from the often complex details of the particular computer being used, including such accessories as communications devices, printers, device readers, displays and keyboards, and also to partition the computer's resources such as memory and processor time in a safe and stable manner. Examples are- Windows XP, Linux and Mac.
Programming softwareProgramming software usually provides tools to assist a programmer in writing computer programs, and software using different programming languages in a more convenient way. The tools include:
compilers debuggers interpreters linkers text editors
An Integrated development environment (IDE) is a single application that attempts to manage all these functions.
Application softwareApplication software allows end users to accomplish one or more specific (not directly computer development related) tasks. Typical applications include:
industrial automation business software computer games quantum chemistry and solid state physics software telecommunications (i.e., the internet and everything that flows on it) databases educational software medical software military software

molecular modeling software image editing spreadsheet simulation software Word processing Decision making software
Application software exists for and has impacted a wide variety of topics.
Ques 7: Explain why regression testing is necessary and how automated testing tools can assist with this type of testing
Regression testing is any type of software testing that seeks to uncover software regressions. Such regressions occur whenever previously working software functionality stops working as intended. Typically, regressions occur as an unintended consequence of program changes. Common methods of regression testing include rerunning previously run tests and checking whether previously fixed faults have re-emerged.
Experience has shown that as software is fixed, emergence of new and/or reemergence of old faults is quite common. Sometimes reemergence occurs because a fix gets lost through poor revision control practices (or simple human error in revision control). Often, a fix for a problem will be "fragile" in that it fixes the problem in the narrow case where it was first observed but not in more general cases which may arise over the lifetime of the software. Frequently, a fix for a problem in one area inadvertently causes a software bug in another area. Finally, it has often been the case that when some feature is redesigned, the same mistakes that were made in the original implementation of the feature were made in the redesign.
Therefore, in most software development situations it is considered good practice that when a bug is located and fixed, a test that exposes the bug is recorded and regularly retested after subsequent changes to the program. Although this may be done through manual testing procedures using programming techniques, it is often done using automated testing tools. Such a test suite contains software tools that allow the testing environment to execute all the regression test cases automatically; some projects even set up automated systems to automatically re-run all regression tests at specified intervals and report any failures (which could imply a regression or an out-of-date test). Common strategies are to run such a system after every successful compile (for small projects), every night, or once a week. Those strategies can be automated by an external tool, such as BuildBot.

Regression testing is an integral part of the extreme programming software development method. In this method, design documents are replaced by extensive, repeatable, and automated testing of the entire software package at every stage in the software development cycle.
Traditionally, in the corporate world, regression testing has been performed by a software quality assurance team after the development team has completed work. However, defects found at this stage are the most costly to fix. This problem is being addressed by the rise of developer testing. Although developers have always written test cases as part of the development cycle, these test cases have generally been either functional tests or unit tests that verify only intended outcomes. Developer testing compels a developer to focus on unit testing and to include both positive and negative test cases.
Uses
Regression testing can be used not only for testing the correctness of a program, but often also for tracking the quality of its output. For instance, in the design of a compiler, regression testing should track the code size, simulation time and time of the test suite cases.
"Also as a consequence of the introduction of new bugs, program maintenance requires far more system testing per statement written than any other programming. Theoretically, after each fix one must run the entire batch of test cases previously run against the system, to ensure that it has not been damaged in an obscure way. In practice, such regression testing must indeed approximate this theoretical idea, and it is very costly."
Ques 8 : Explain how back-to-back testing may be used to test critical system with replicated softwareBack to back is any type of software testing that seeks to uncover software back to backs. Such back to backs occur whenever previously working software functionality stops working as intended. Typically, back to backs occur as an unintended consequence of program changes. Common methods of back to back testing include rerunning previously run tests and checking whether previously fixed faults have re-emerged.
Experience has shown that as software is fixed, emergence of new and/or reemergence of old faults is quite common. Sometimes reemergence occurs because a fix gets lost through poor revision control practices (or simple human error in revision control). Often, a fix for a problem will be "fragile" in that it fixes the problem in the narrow case where it was first observed but not in more general cases which may arise over the lifetime of the software. Frequently, a fix for a problem in one area inadvertently

causes a software bug in another area. Finally, it has often been the case that when some feature is redesigned, the same mistakes that were made in the original implementation of the feature were made in the redesign.
Therefore, in most software development situations it is considered good practice that when a bug is located and fixed, a test that exposes the bug is recorded and regularly retested after subsequent changes to the program. Although this may be done through manual testing procedures using programming techniques, it is often done using automated testing tools. Such a test suite contains software tools that allow the testing environment to execute all the back to back test cases automatically; some projects even set up automated systems to automatically re-run all back to back tests at specified intervals and report any failures (which could imply a back to back or an out-of-date test). Common strategies are to run such a system after every successful compile (for small projects), every night, or once a week. Those strategies can be automated by an external tool, such as BuildBot.
Back to back testing is an integral part of the extreme programming software development method. In this method, design documents are replaced by extensive, repeatable, and automated testing of the entire software package at every stage in the software development cycle.
Traditionally, in the corporate world, back to back testing has been performed by a software quality assurance team after the development team has completed work. However, defects found at this stage are the most costly to fix. This problem is being addressed by the rise of developer testing. Although developers have always written test cases as part of the development cycle, these test cases have generally been either functional tests or unit tests that verify only intended outcomes. Developer testing compels a developer to focus on unit testing and to include both positive and negative test cases
Uses
Back to back testing can be used not only for testing the correctness of a program, but often also for tracking the quality of its output. For instance, in the design of a compiler, back to back testing should track the code size, simulation time and time of the test suite cases.
"Also as a consequence of the introduction of new bugs, program maintenance requires far more system testing per statement written than any other programming. Theoretically, after each fix one must run the entire batch of test cases previously run against the system, to ensure that it has not been damaged in an obscure way. In practice, such back to back testing must indeed approximate this theoretical idea, and it is very costly."

Ques 9 Write a note on Software Testing Strategy. Software testing is an empirical investigation conducted to provide stakeholders with information about the quality of the product or service under test, with respect to the context in which it is intended to operate. Software Testing also provides an objective, independent view of the software to allow the business to appreciate and understand the risks at implementation of the software. Test techniques include, but are not limited to, the process of executing a program or application with the intent of finding software bugs.Software Testing can also be stated as the process of validating and verifying that a software program/application/product:
meets the business and technical requirements that guided its design and development; works as expected; can be implemented with the same characteristics.
Software Testing, depending on the testing method employed, can be implemented at any time in the development process. However, most of the test effort occurs after the requirements have been defined and the coding process has been completed. As such, the methodology of the test is governed by the Software Development methodology adopted.Different software development models will focus the test effort at different points in the development process. In a more traditional model, most of the test effort occurs after the requirements have been defined and the coding process has been completed. Newer development models, such as Agile or XP, often employ test driven development and place an increased portion of the testing up front in the development process, in the hands of the developer.
HistoryThe separation of debugging from testing was initially introduced by Glenford J. Myers in 1979. Although his attention was on breakage testing ("a successful test is one that finds a bug",) it illustrated the desire of the software engineering community to separate fundamental development activities, such as debugging, from that of verification. Dave Gelperin and William C. Hetzel classified in 1988 the phases and goals in software testing in the following stages:
• Until 1956 - Debugging oriented• 1957–1978 - Demonstration oriented• 1979–1982 - Destruction oriented• 1983–1987 - Evaluation oriented• 1988–2000 - Prevention oriented

Software testing topicsScopeA primary purpose for testing is to detect software failures so that defects may be uncovered and corrected. This is a non-trivial pursuit. Testing cannot establish that a product functions properly under all conditions but can only establish that it does not function properly under specific conditions. The scope of software testing often includes examination of code as well as execution of that code in various environments and conditions as well as examining the aspects of code: does it do what it is supposed to do and do what it needs to do. In the current culture of software development, a testing organization may be separate from the development team. There are various roles for testing team members. Information derived from software testing may be used to correct the process by which software is developed.
Functional vs non-functional testingFunctional testing refers to tests that verify a specific action or function of the code. These are usually found in the code requirements documentation, although some development methodologies work from use cases or user stories. Functional tests tend to answer the question of "can the user do this" or "does this particular feature work".Non-functional testing refers to aspects of the software that may not be related to a specific function or user action, such as scalability or security. Non-functional testing tends to answer such questions as "how many people can log in at once", or "how easy is it to hack this software".
Defects and failuresNot all software defects are caused by coding errors. One common source of expensive defects is caused by requirement gaps, e.g., unrecognized requirements, that result in errors of omission by the program designer[14]. A common source of requirements gaps is non-functional requirements such as testability, scalability, maintainability, usability, performance, and security.Software faults occur through the following processes. A programmer makes an error (mistake), which results in a defect (fault, bug) in the software source code. If this defect is executed, in certain situations the system will produce wrong results, causing a failure. Not all defects will necessarily result in failures. For example, defects in dead code will never result in failures. A defect can turn into a failure when the environment is changed. Examples of these changes in environment include the software being run on a new hardware platform, alterations in source data or interacting with different software.[15] A single defect may result in a wide range of failure symptoms.
Finding faults early

It is commonly believed that the earlier a defect is found the cheaper it is to fix it. The following table shows the cost of fixing the defect depending on the stage it was found. For example, if a problem in the requirements is found only post-release, then it would cost 10–100 times more to fix than if it had already been found by the requirements review.
Time DetectedRequirements Architecture Construction System Test Post-ReleaseTime IntroducedRequirements 1× 3× 5–10× 10× 10–100×Architecture - 1× 10× 15× 25–100×Construction - - 1× 10× 10–25×
CompatibilityA frequent cause of software failure is compatibility with another application, a new operating system, or, increasingly, web browser version. In the case of lack of backward compatibility, this can occur (for example...) because the programmers have only considered coding their programs for, or testing the software upon, "the latest version of" this-or-that operating system. The unintended consequence of this fact is that: their latest work might not be fully compatible with earlier mixtures of software/hardware, or it might not be fully compatible with another important operating system. In any case, these differences, whatever they might be, may have resulted in (unintended...) software failures, as witnessed by some significant population of computer users.This could be considered a "prevention oriented strategy" that fits well with the latest testing phase suggested by Dave Gelperin and William C. Hetzel, as cited below
Input combinations and preconditionsA very fundamental problem with software testing is that testing under all combinations of inputs and preconditions (initial state) is not feasible, even with a simple product. This means that the number of defects in a software product can be very large and defects that occur infrequently are difficult to find in testing. More significantly, non-functional dimensions of quality (how it is supposed to be versus what it is supposed to do)—usability, scalability, performance, compatibility, reliability—can be highly subjective; something that constitutes sufficient value to one person may be intolerable to another.
Static vs. dynamic testingThere are many approaches to software testing. Reviews, walkthroughs, or inspections are considered as static testing, whereas actually executing programmed code with a given set of test cases is referred to as dynamic testing. Static testing can be (and unfortunately in practice often is) omitted. Dynamic testing takes place when the program itself is used for the first time (which is generally considered the beginning of the testing stage). Dynamic testing may begin before the program is 100% complete in

order to test particular sections of code (modules or discrete functions). Typical techniques for this are either using stubs/drivers or execution from a debugger environment. For example, Spreadsheet programs are, by their very nature, tested to a large extent interactively ("on the fly"), with results displayed immediately after each calculation or text manipulation.Software verification and validationSoftware testing is used in association with verification and validation:
• Verification: Have we built the software right? (i.e., does it match the specification).• Validation: Have we built the right software? (i.e., is this what the customer wants).
The terms verification and validation are commonly used interchangeably in the industry; it is also common to see these two terms incorrectly defined. According to the IEEE Standard Glossary of Software Engineering Terminology:Verification is the process of evaluating a system or component to determine whether the products of a given development phase satisfy the conditions imposed at the start of that phase.Validation is the process of evaluating a system or component during or at the end of the development process to determine whether it satisfies specified requirements.The software testing teamSoftware testing can be done by software testers. Until the 1980s the term "software tester" was used generally, but later it was also seen as a separate profession. Regarding the periods and the different goals in software testing, different roles have been established: manager, test lead, test designer, tester, automation developer, and test administrator.Software Quality Assurance (SQA)Though controversial, software testing may be viewed as an important part of the software quality assurance (SQA) process. In SQA, software process specialists and auditors take a broader view on software and its development. They examine and change the software engineering process itself to reduce the amount of faults that end up in the delivered software: the so-called defect rate.What constitutes an "acceptable defect rate" depends on the nature of the software. For example, an arcade video game designed to simulate flying an airplane would presumably have a much higher tolerance for defects than mission critical software such as that used to control the functions of an airliner that really is flying! Although there are close links with SQA, testing departments often exist independently, and there may be no SQA function in some companies.Software Testing is a task intended to detect defects in software by contrasting a computer program's expected results with its actual results for a given set of inputs. By contrast, QA (Quality Assurance) is the implementation of policies and procedures intended to prevent defects from occurring in the first place.

Ques 10 Discuss whether it is possible for engineers to test their own programs in an objective way.OOA-object oriented analysis is based upon the concepts like objects and attributes, classes and number, wholes and parts
In order to build an analysis model five basic principle were applied.
The information domain is modeled Function is described
Behavior is represented Data functional and behavioral models are partitioned top expose greater details
Early models represent the essence of the problem while later models provide implementation details
To accomplish this, a number of tasks must occur Basic user requirements must be communicated between the customer and the software
engineer Classes must be identified
A class hierarchy must be specified Object-to-Object relationships should be represented
Object behavior must be modeled The above tasks are reapplied iteratively until the model is complete.
Apart from the above factor we have cycle to completed
Acceptance TestingAcceptance testing generally involves running a suite of tests on the completed system. Each individual test, known as a case, exercises a particular operating condition of the user's environment or feature of the system, and will result in a pass or fail boolean outcome. There is generally no degree of success or failure. The test environment is usually designed to be identical, or as close as possible, to the anticipated user's environment, including extremes of such. These test cases must each be accompanied by test case input data or a formal description of the operational activities (or both) to be performed—intended to thoroughly exercise the specific case—and a formal description of the expected results.
Regression Testing

Regression testing is any type of software testing that seeks to uncover software regressions. Such regressions occur whenever previously working software functionality stops working as intended. Typically, regressions occur as an unintended consequence of program changes. Common methods of regression testing include rerunning previously run tests and checking whether previously fixed faults have re-emerged.
So logically speaking for engineers to test their own programs is possible if all the above things in place but for all the practical reasons the professional projects are handling professionally based out of the test case functions.

August 2009Bachelor of Science in Information Technology (BScIT) – Semester 4
BT0049 – Software Engineering – 4 Credits (Book ID: B0808)
Assignment Set – 2 (60 Marks)
Answer all questions 10 x 6 = 60Ques 1 What do you understand by information determinacy?
Information content and determinacy are important factors in determining the nature of a software application. Content refers to the meaning and form of incoming and outgoing information. For example, many business applications use highly structured input data (a database) and produce formatted “reports”. Software that controls an automated machine (e.g., a numerical control) accepts discrete data items with limited structure and produces individual machine commands in rapid succession.
“Information determinacy” refer to the predictability of the order and timing of information. An engineering analysis algorithm(s) without interruption, and produces resultant data in report or graphical format. Such applications are determinate. A multi-user operating system, on the other hand, accepts inputs that have varied content and arbitrary timing, executes algorithms that can be interrupted by external conditions, and produces output that varies as a function of environment and time. Applications with these characteristics are indeterminate. It is somewhat difficult to develop meaningful generic categories for software applications. As software complexity grows, neat compartmentalization disappears. The following software areas indicate the breadth of potential applications:
System SoftwareSystem software is a collection of programs written to service other programs. Some system programs (e.g., compilers,editors, and file management utilities) process complex, but determinate, information structures. Other system applications (e.g. operating system components, drivers, telecommunications processors) process largely indeterminate data. In either case, the system software area is characterized by heavy interaction with computer hardware; heavy usage by multiple users; concurrent operation that requires scheduling, resource sharing, and sophisticated process management; complex data structures; and multiple external interfaces.

Real-time SoftwareSoftware that monitors/analyzes/controls real world events as they occur is called real time. Elements of real-time software include a data gathering component that collects and formats information from an external environment, an analysis component that transforms information as required by the application, a control/output component that responds to the external environment, and a monitoring component that coordinates all other components so that real-time response (typically ranging from 1 millisecond to 1 second) can be maintained.
Business SoftwareBusiness information processing is the largest single software application area. Discrete “systems” (e.g., payroll, accounts receivable/payable, inventory) have evolved into management information system (MIS) software that accesses one or more large databases containing business information. Applications in this area restructure existing data in a way that facilitates business operations or more management decision-making. In addition to conventional data processing applications, business software applications also encompass interactive computing (e.g., point-of-sale transaction processing).
Engineering and Scientific SoftwareEngineering and scientific software have been characterized by “number crunching” algorithms. Applications range from astronomy to volcano logy, from automotive stress analysis to space shuttle orbital dynamics, and from molecular biology to automated manufacturing. However, modern applications within the engineering/scientific area are moving away from conventional numerical algorithms. Computer aided design, system simulation, and other interactive applications have begun to take on real-time and even system software characteristics.
Embedded SoftwareIntelligent products have become commonplace in nearly every consumer and industrial market. Embedded software resides in read-only memory and is used to control products and systems for the consumer and industrial markets. Embedded software can perform very limited and esoteric functions (e.g., keypad control for a microwave oven) or provide significant function and control capability (e.g., digital functions in an automobile such as fuel control, dashboard displays, and braking systems.
Personal Computer SoftwareThe personal computer software market has burgeoned over the past two decades. Word processing, spreadsheets, computer graphics, multimedia, entertainment, database management, personal and

business financial applications, external network,and database access are only a few of hundreds of applications.
Web-based SoftwareThe web pages retrieved by a browser are software that incorporates executable instructions (e.g., CGI, HTML, Perl, or java), and data(eg.,hypertext and a variety of visual and audio formats). In essence, the network becomes a massive computer providing an almost unlimited software resource that can be accessed by anyone within a modem.
Artificial Intelligence SoftwareArtificial Intelligence (AI) Software makes use of a non numerical algorithms to solve complex problems that are not amenable to computation or straight forward analysis. Expert systems, also called knowledge-based systems, pattern recognition (image and voice), artificial neural networks, theorem proving, and game playing are representative of applications within this category.
SummarySoftware has become the key element in the software evolution of computer based systems and products. Over the past 50 years, software has evolved from a specialized problem solving and information analysis tool to an industry in itself. But “early” programming culture and history have created a set of problems that persist today. Software has become the limiting factor in the continuing evolution of computer-based systems. Software is composed of programs, data and documents. Each of these items comprises a configuration that is created as part of the software engineering process. The intent of software engineering is to provide a framework for building software with high quality.
Ques 2 Describe the concurrent development model in your own words.
The concurrent process model can be represented schematically as a series of major technical activities, tasks, and their associated states. For example, the engineering activity defined for the spiral model is accomplished by invoking the following tasks: prototyping and/or analysis modeling, requirements specification, and design.

The activity-analysis-may be in any one of the states noted at any given time. Similarly, other activities (e.g., design or customer communication) can be represented in an analogous manner. All activities exist concurrently but reside in different states. For example, early in a project the customer communication activity has completed its first iteration and exists in the awaiting changes state. The analysis activity (which existed in the none state while initial customer communication was completed) now makes a transition into the under development state. If, however, the customer indicates that changes in requirements must be made, the analysis activity moves from the under development state into the awaiting changes state.
The concurrent process model defines a series of events that will trigger transitions from state to state for each of the software engineering activities.
Ques 3 Suggest six reasons why software reliability is important. Using an example, explain the difficulties of describing what software reliability means.
Software Reliability is the probability of failure-free software operation for a specified period of time in a specified environment. Software Reliability is also an important factor affecting system reliability. It differs from hardware reliability in that it reflects the design perfection, rather than manufacturing perfection. The high complexity of software is the major contributing factor of Software Reliability

problems. Software Reliability is not a function of time - although researchers have come up with models relating the two. The modeling technique for Software Reliability is reaching its prosperity, but before using the technique, we must carefully select the appropriate model that can best suit our case. Measurement in software is still in its infancy. No good quantitative methods have been developed to represent Software Reliability without excessive limitations. Various approaches can be used to improve the reliability of software, however, it is hard to balance development time and budget with software reliability.
Reliability should always take precedence over efficiency because:
Computers are now cheap and fastThere is a little need to maximize equipment usage. Paradoxically however, faster equipment leads to increasing expectations on the part of the user so efficient considerations cannot be completed ignored.
Unreliable software is liable to be discarded by usersIf a company attains a reputation for unreliability because of single unreliable product, it is likely to affect future sakes of all of that company’s products.
System failure costs may be enormousFor some applications, such as a reactor control system or an aircraft navigation system, the cost of system failure is orders of magnitude greater than the cost of the control system
Unreliable system are difficult to improveIt is usually possible to tune an inefficient system because most execution time is spent in small program sections; An unreliable system is more difficult to improve as un reliability tends to be distributed throughout the system.
Inefficiency is predictable. Programs can take long time to execute and users can adjust their work to take this into account. Unreliability by contrast usually surprises the users. Software that is unreliable can have hidden errors which can violate system and user data without warning and whose consequences are not immediately obvious. For example a fault in a CAD program used to design aircraft might not be discovered until several plane crashes occur.
Unreliable systems may cause information loss.Information is very expensive to collect and maintain, it may sometimes be worth more than the computer system on which it is processed, A great deal of effort and money is spent duplicating valuable data to guard against corruption caused by unreliable software.

The software processes used to develop that product influences the reliability of the software product. A repeatable process which is oriented towards defect avoidance is likely to develop a reliable system,. However there is not a simple relationship between product and process reliability.
Users often complain that systems are unreliable. This may be due to poor software engineering. However a common cause of perceived unreliability is incomplete specifications. The system performs as specified but the specifications do not set out how the software should behave in exceptional situations. As professional software engineers must do their best to produce reliable systems, which take meaningful and useful actions in such situations.
Question 4: Using graphical notation, design the following objects:
A telephone
A printer for a personal computer

A personal stereo system
A bank account
A library catalogue

Question 5: Using examples explain the difference between object & an object class
Classes and objects are separate but related concepts. Every object belongs to a class and every class contains one or more related objects.
A Class is static. All of the attributes of a class are fixed before, during, and after the execution of a program. The attributes of a class don't change.
The class to which an object belongs is also (usually) static. If a particular object belongs to a
certain class at the time that it is created then it almost certainly will still belong to that class right up until the time that it is destroyed.
An Object on the other hand has a limited lifespan. Objects are created and eventually destroyed. Also during that lifetime, the attributes of the object may undergo significant change.
So let's now use an example to clarify what the differences are between a class and an object.
Let us consider the class car. Cars have a body, wheels, an engine, seats, are used to transport people between locations, and require at least one person in the car for it to move by its own power. These are some of the attributes of the class - car - and all members that this class has ever or will ever have share these attributes. The members of the class - car - are objects and the objects are individual and specific cars. Each individual car has a creation date (an example of an object having an attribute that is static), an owner, a registered address (examples of attributes that may or may not change), a current location, current occupants, current fuel level (examples of attributes that change quickly), and it may be covered by insurance (an example of an attribute that may or may not exist).To use a more programming related example, the class window has edges, a title bar, maximize and

minimize buttons, and an area to display the window contents. A specific window has a location on the screen, a size, a title, and may or may not have something in the content area.
So basically the difference between a class and an object is that a class is a general concept while objects are the specific and real instances that embody that concept. When creating an object oriented program we define the classes and the relationships between the classes. We then execute the program to create, update, and destroy the objects which are the specific realization of these classes.
Question 6: Explain the difficulties of measuring program maintainability. Describe why maintainability is not simply related to a single complexity metric.
Maintainability metric can help management to make an informed decision on whether a component should be maintained or completely rewritten to reduce future maintenance costs.
Maintainability metrics do not measure the cost of making a particular change to a system nor do they predict whether or not a particular component will have to be maintained. Rather they are based on the assumption that the maintainability of a program is related to its complexity, The metric measure some aspects of the program complexity. It is suggested that high complexity values correlate with difficulties in maintaining a system account.
Examples of process metrics which may be used for assessing maintainability are
1. Number of requests for corrective maintenance
It the number of failure reports is increasing, this may indicate that more errors are being introduced into the program than are being repaired during the maintenance process. This may indicate a decline in maintainability.
2. Average time required for impact analysis
This reflects the number of program components that are affected by the change requests. If this time increases, it implies more and more components are affected and maintainability is decreasing.
3. Average time taken to implement a change request
This is not the same as the time for impact analysis although it may correlate with it. The activities involved are making changes to the system and its documentation rather than simply assessing what components are affected. This change time depends on the diffucilty of programming so those non-functional requirements such as performance are met. If the time to implements a change increases, this may indicate a decline in maintainability.

4. Number of outstanding change requests.
It this Number increases with time, it may imply a decline in maintainability
Question 7 : Discuss the difference between verification and validation and explain why validation is particularly a difficult process.Verification and validation encompasses a wide array of SQA activities that include formal technical reviews, quality and configuration audits, performance monitoring, simulation, feasibility study, documentation review, database review, algorithm analysis, development testing, qualification testing and installation testing, Testing plays an extremely important role in V&V
The Test plan section describes the overall strategy for integration. Testing is divided into phases and builds that address specific functional and behavioral characteristics of the system. There are five different types of test strategies like Top-down testing, Bottom-up Testing, Thread testing, Stress testing, Back-to-back testing which are explained in detail. A software engineer must understand the basic principle that guide software testing. A detailed study of testing method and tools are also discussed through reviews, requirements, designs, programs and software changes.
Software testing is one element of a broader topic that is often referred to as verification and validation. Verification refers to the set of activities that ensure that software correctly implements specific functions. Validation refers to a different set of activities that ensure that the software that has been built is traceable to customer requirements. Boehm states this in another way
Verification: "Are we building the product right?" Validation: "Are we building the right product?"
VALIDATION TESTINGAt the culmination of integration testing the software is complete as a package and the interfacing errors have been uncovered and fixed, final tests- validation testing- may begin. Validation tests succeed when the software performs exactly in the manner as expected by the user.Software validation is done by a series of Black box tests that demonstrate the conformance with requirements. Alpha and betas testing fall in this category. We will not do beta testing but alpha testing will certainly will certainly be done.
Software validation is achieved through a combination of process, testing, and code review techniques. A process must be in place for designing, reviewing, testing, and validating the code. Test setups must

be employed to test the software on both the modular and system level using a variety of inputs. Code review techniques are critical in the verification of the software.
Software test validation can be divided into four categories:
Performance – does the input of good data generate good data out? Failure modes – if the setup is wrong, does the test results reflect it? Repeatability – if one tests with the same input vectors, does one get the same output results
time after time? Special Case – completely test dependent for specific requirements.
For a software developer, it is difficult to foresee how the customer will really use a program. Instructions for use may be misinterpreted; strange combination of data may be regularly used; and the output that seemed clear to the tester may be unintelligible to a user in the field. When custom software is built for one customer, a series of acceptance tests are conducted to enable the customer to validate all requirements. Acceptance test is conducted by customer rather than by developer. It can range from an informal “test drive” to a planned and systematically executed series of tests. In fact, acceptance testing can be conducted over a period of weeks or months, thereby uncovering cumulative errors that might degrade the system over time. If software is developed as a product to be used by many customers, it is impractical to perform formal acceptance tests with each one. Most software product builders use a process called alpha and beta testing to uncover errors that only the end user seems able to find.
Customer conducts the alpha testing at the developer’s site. The software is used in a natural setting with the developer. The developer records errors and usage problem. Alpha tests are conducted in a controlled environment. The beta test is conducted at one or more customer sites by the end user(s) of the software. Here, developer is not present. Therefore, the beta test is a live application of the software in an environment that cannot be controlled by the developer. The customer records all problems that are encountered during beta testing and reports these to the developer at regular intervals. Because of problems reported during beta test, the software developer makes modifications and then prepares for release of the software product to the entire customer base.
Question 8:Write a test specification outline for a banking system

Question 9: What is the importance of ‘Software Validation’, in testing?For every software project, there is an inherent conflict of interest that occurs as testing begins. The people who have built the software are now asked to test the software. This seems harmless in itself; after all, who knows the program better than its developers? Unfortunately, these same developers have a vested interest in demonstrating that the program is error free, that it works according to customer requirements, and that it will be completed on schedule and within budget. Each of these interests mitigate against thorough testing.
The software engineering process may be viewed as the spiral illustrated in Figure18.1. Initially, system engineering defines the role of software and leads to software requirements analysis, where the information domain, function, behavior, performance, constraints, and validation criteria for software are established. Moving inward along the spiral, we come to design and finally to coding. To develop computer software, we spiral inward along streamlines that decrease the level of abstraction on each turn.
A strategy for software testing may also be viewed in the context of the spiral (Figure18.1).
Unit testing begins at the vortex of the spiral and concentrates on each unit(i.e., component) of the software as implemented in source code. Testing progresses by moving outward along the spiral to integration testing, where the focus is on design and the construction of the software architecture. Taking another turn outward on the spiral, we encounter validation testing, where requirements established as part of software requirements analysis are validated against the software that has been constructed. Finally, we arrive at system testing, where the software and other system elements are tested as a whole. To test computer software, we spiral out along streamlines that broaden the scope of testing with each turn. Considering the process from a procedural point of view, testing within the context of software engineering is actually a series of four steps that are implemented sequentially.

The steps are shown in Figure 18.2. Initially, tests focus on each component individually, ensuring that it functions properly as a unit. Hence, the name unit testing .
Unit testing makes heavy use of white-box testing techniques, exercising specific paths in a module's control structure to ensure complete coverage and maximum error detection. Next, components must be assembled or integrated to form the complete software package. Integration testing addresses the issues associated with the dual problems of verification and program construction. Black-box test case design techniques are the most prevalent during integration, although a limited amount of white-box testing may be used to ensure coverage of major control paths. After the software has been integrated (constructed), a set of high-order tests are conducted. Validation criteria (established during requirements analysis) must be tested. Validation testing provides final assurance that software meets all functional, behavioral, and performance requirements. Black-box testing techniques are used exclusively during validation. The last high-order testing step falls outside the boundary of software engineering and into the broader context of computer system engineering. Software, once validated, must be combined with other system elements (e.g., hardware, people, databases). System testing verifies that all elements mesh properly and that overall system function/performance is achieved.
Question 10: Explain the process of Top-down integration and Bottom-up Integration.
Top-down Integration testing is an incremental approach to construction of program structure. Module are integrated by moving downward through the control hierarchy, beginning with the main

control module (main program) Modules subordinate ( and ultimately subordinate) to the main control module are incorporated into the structure in either a depth-first or breath-first manner. As you add lower level code, you will replace stubs with the actual components. Top Down integration can be performed and tested in breadth first or depth firs manner.
Advantages Drivers(Low level components) does not have to be written when top down testing is used. It provides early working module of the program and so design defects can be found and
corrected early.
Disadvantages Stubs have to be written with utmost care as they will simulate setting of output parameters. It is difficult to have other people or third parties to perform this testing, mostly developers
will have to spend time on this.

Bottom Up Testing is an approach to integrated testing where the lowest level components are tested first, then used to facilitate the testing of higher level components. The process is repeated until the component at the top of the hierarchy is tested.
All the bottom or low-level modules, procedures or functions are integrated and then tested. After the integration testing of lower level integrated modules, the next level of modules will be formed and can be used for integration testing. This approach is helpful only when all or most of the modules of the same development level are ready. This method also helps to determine the levels of software developed and makes it easier to report testing progress in the form of a percentage
In bottom up integration testing, module at the lowest level are developed first and other modules which go towards the 'main' program are integrated and tested one at a time. Bottom up integration also uses test drivers to drive and pass appropriate data to the lower level modules. As and when code for other module gets ready, these drivers are replaced with the actual module. In this approach, lower level modules are tested extensively thus make sure that highest used module is tested properly.
Advantages Behavior of the interaction points are crystal clear, as components are added in the controlled
manner and tested repetitively. Appropriate for applications where bottom up design methodology is used.
Disadvantages Writing and maintaining test drivers or harness is difficult than writing stubs. This approach is not suitable for the software development using top down approach





























