Embed Size (px)
Citation preview

Microcomnpurerr Civil Enginerring 9 ( 1994) 129- I43
Automated Knowledge Acquisition in a Neural Network-Based Decision Support System for
Incomplete Database Systems
A. R. Hurson, S. Pakzad & B. Jin
Department of Eiectrical and Computer Engineering, The Pennsyivania State University, University Park, Pennsylvania 16802, USA
Abstract: A neural network-based decision support sys- tem has been designed and simulated to be used as a filter to improve the system performance of large incomplete databases enhanced with maybe algebra. To train the net- work, a knowledge-acquisition module equipped with a fuzzy logic technique was used to automatically generate a set of training pairs according to the semantics of the under- lying database, the specific characteristics of the user que- ry, and user requirements. Based on the notion of relative graded membership, a fuzzy logic-based controller was used to monitor and measure the quality of each training pattern as a means to generate a set of “good” training pairs. Finally, the proposed scheme has been simulated and analyzed to determine the effectiveness training pairs generation process.
of the automatic
1 INTRODUCTION
Since the early 1970s, the complexity of database manage- ment systems has increased drastically in terms of the num- ber and size of databases, the number and type of applica- tion programs, and the number and type of on-line users. Many current applications require efficient storage and ma- nipulation of very large volumes of data which, by their very nature, are incomplete. ‘3 With the increasing applica- tion of large database systems, information incompleteness presents a problem for any data model. Incomplete databases cannot be handled by using the operators found in traditional query languages.
As the relational database models have matured, re- searchers have examined the question of how to handle missing data. 1,4,12 Maybe algebra and attribute maybe alge- bra, as extensions of relational algebra, allow the user to
probe the database for potential data relationships that might be useful but cannot be retrieved by true relational alge- bra.l~*~12 Naturally, this comes at the expense of increased complexity, lower performance, and lower resource utiliza- tion. Moreover, some of these operators have the potential to generate data which are enormous in size, erroneous in semantics, and not very informative.6
In this work, to make the maybe algebra operations more practical, a neural network-based decision support system is proposed and implemented.5,6,8,Y This system filters out the erroneous and not very informative data to increase the integrity and quality of the resultant data. Considering the issue of data independence embedded in the definition of the relational data model and the dynamic nature of the database applications, the neural network provides a strong dynamic learning capability to adjust itself according to the specific characteristics of the underlying database and the requirements of the user.
Each time a query is submitted to the database system, it is required to automatically generate a set of training pairs. The training data must include both good “keep” examples, i.e., a high-confidence keep decision, and good “drop” ex- amples, i.e., a high-confidence drop decision. Due to the limited training time allowed, a decision-making network can only accept a certain number of training pairs. There- fore, the key objective of the training pair generation is to produce a set of high-quality training pairs. Section 2 gives a brief overview of the neural network-based decision sup- port system. Section 3 discusses the design and implemen- tation of an automated knowledge-acquisition module. A set of simulation runs were conducted, and the simulation results and their analysis are presented in section 4. Finally, section 5 presents the conclusions.
0 1994 Microcomputers in Civil Engineering. Published by Blackwell Publishers, 238 Main Street, Cambridge, MA 02142, USA, and 108 Cowley Road, Oxford OX4 IJF, UK.
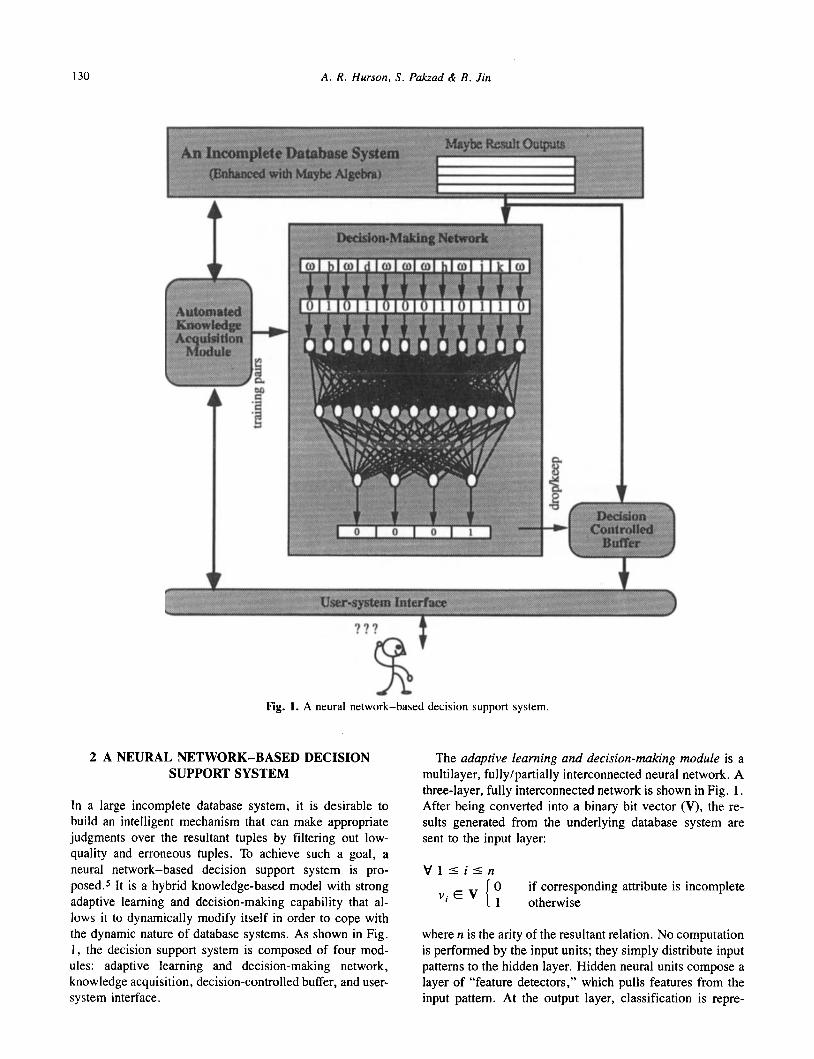
130 A. R . Hurson, S. Pakzad & B . Jin
? ? ? w’ Fig. 1. A neural network-based decision support system.
2 A NEURAL NETWORK-BASED DECISION SUPPORT SYSTEM
In a large incomplete database system, it is desirable to build an intelligent mechanism that can make appropriate judgments over the resultant tuples by filtering out low- quality and erroneous tuples. To achieve such a goal, a neural network-based decision support system is pro- posed.5 It is a hybrid knowledge-based model with strong adaptive learning and decision-making capability that al- lows it to dynamically modify itself in order to cope with the dynamic nature of database systems. As shown in Fig. 1, the decision support system is composed of four mod- ules: adaptive learning and decision-making network, knowledge acquisition, decision-controlled buffer, and user- system interface.
The adaptive learning and decision-making module is a multilayer, fully/partially interconnected neural network. A three-layer, fully interconnected network is shown in Fig. 1. After being converted into a binary bit vector (V), the re- sults generated from the underlying database system are sent to the input layer:
t l l s i l n if corresponding attribute is incomplete otherwise
where n is the arity of the resultant relation. No computation is performed by the input units; they simply distribute input patterns to the hidden layer. Hidden neural units compose a layer of “feature detectors,” which pulls features from the input pattern. At the output layer, classification is repre-

Automated knowledge acquisition in a neural network-based decision support system for incomplete database systems I 3 1
sented by a binary vector and can be interpreted as a number of certain decision categories.
The decision-making network operates in one of two op- erational modes, a learning mode and a decision-making mode. The network is trained in its learning mode, during which a set of training data (representing high-quality proto- types as well as low-quality ones) is presented to the net- work by the knowledge-acquisition module. The gener- alized delta rule, along with the back-error propagation paradigm, is used to train the decision-making network. The network training can be viewed as a process to establish an appropriate set of feature detectors in the hidden layer and the proper response in the output layer. After the train- ing, the resulting discrimination rules can be used to classi- fy new pattern occurrences, thereby providing a form of generalization. Having been trained, the network is switched to the decision-making mode. Working in the decision-making mode, the network receives unknown re- sultant tuples generated by the maybe operations and makes a response corresponding to the closest classification (e.g., “keep” or “drop”). Generalization is considered to be suc- cessful if the network responds correctly most of the time. Whenever a new query is submitted to the underlying database, this procedure is repeated. Accordingly, the adap- tive learning and decision-making module will adapt itself to the new situation by a new set of training data.
To train the adaptive learning and decision-making mod- ule, the knowledge-acquisition module automatically gener- ates a set of high representative training data every time a query is submitted. The set of training data is generated based on the semantics of the underlying database system and user requirements (as long as they do not violate the semantics of the underlying database). How the training quality of the training data can be measured and how a set of training data that possesses high training quality can be generated are the key concerns of the knowledge- acquisition module. More detailed discussion is presented in the next section.
The decision-controlled buffer is a delay device. Upon receiving the decision signals from the network, the decision-controlled buffer will act accordingly, i.e., either pass a resultant tuple to the user if a “keep” decision has been made or filter out (i.e., drop) the tuple if a “drop” decision has been made. The user-system interface module establishes a communication path between the decision sup- port system and the user. On the one hand, during knowl- edge acquisition, it opens a channel that allows the system to interactively receive any special requests or requirements from the user. On the other hand, when sending out the resultant tuples through the decision-controlled buffer, this moduie provides an explanation medium that interprets the decision results to the user.
The proposed decision support system has been simulated and analyzed. An incomplete database was set up and used as the test bed. Attempts were made to simulate the system
with various configurations-i .e., a different number of input, hidden, and output neurons-on databases of varying cardinalities and arities. The training rime and classification accuracy were used as the performance measures in order to investigate the feasibility of the model. For each simulation run, the network was trained by a set of randomly selected training pairs. The simulation results indicated that the training time and accuracy are crucially dependent on net- work configuration. Moreover, there is a strong correlation between the performance measures and the number and quality of the training pairs. Finally, due to the concept of the data dependence embedded in the definition of the rela- tional data model, one has to devise a scheme that allows automatic generation of high-quality training pairs.
3 AN AUTOMATED KNOWLEDGE-ACQUISITION MODULE
In the decision support system, the procedure of generating a set of high representative training pairs is referred to as knowledge acquisition. A training pair consists of an n-bit binary input pattern and a desired output pattern. The input pattern represents the incompleteness states of n attributes in a resultant tuple-a 0 denotes a missing attribute, and a 1 is used to represent a complete (or nonnull) attribute. The associated output pattern exemplifies a desired classifica- tion based on the information quality possessed by the cor- responding input pattern. Our earlier experience demon- strated the need to design and implement a knowledge- acquisition module that generates a set of high-quality train- ing pairs automatically.
The difficulty of the knowledge-acquisition task arises from the fact that any knowledge, such as facts, rules, or frame structures, is not initially available or well identified. Therefore, knowledge needs to be sought out. In our model, the knowledge-acquisition task is even more difficult be- cause relations are at least in the first normal form- complex objects are mapped into a collection of “flat” rela- tions. As a result, much of the inherent semantics among data elements are lost due to such a data decomposition.
Based on these observations, the proposed knowledge- acquisition module is designed to generate a set of training pairs according to
1. The semantics of the database 2 . The implied interrelationships among the data values 3. The structural characteristics of the underlying rela-
4. The user’s special requirements (as long as they do not tions
violate the integrity and security)
The knowledge implied in the key attributes and depen- dency set of the database can be used to meet requirements
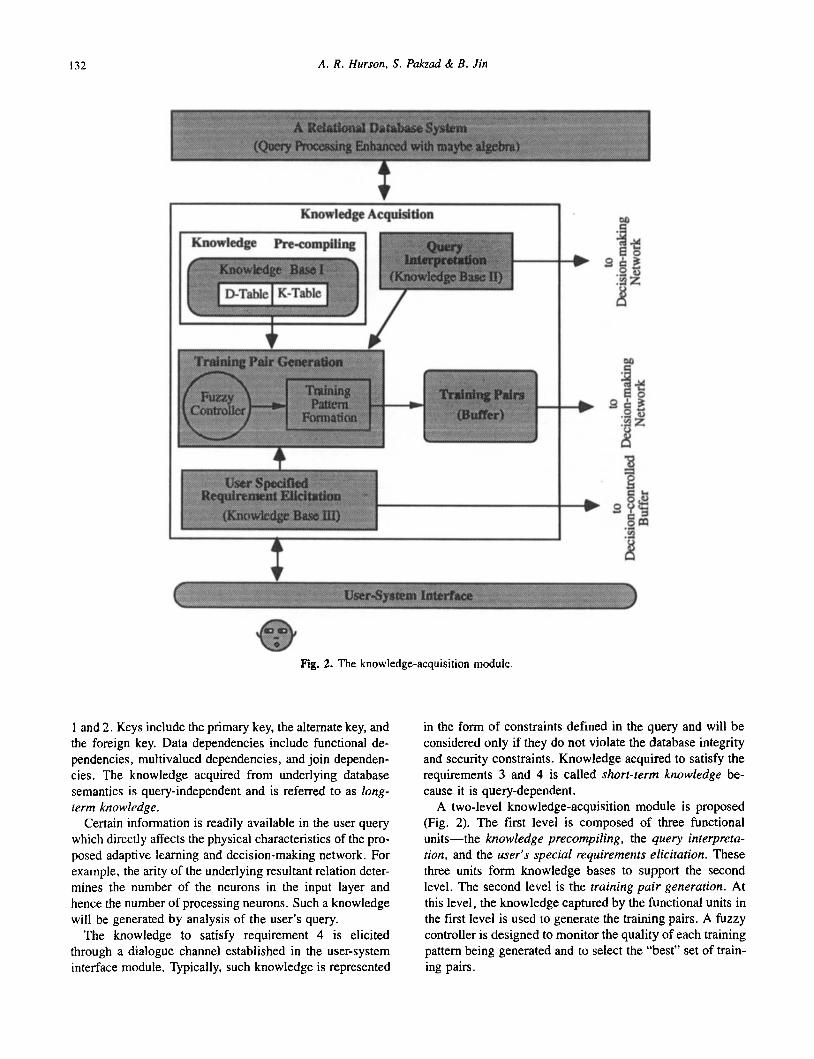
I32 A. R. Hurson, S. Pakzad & B . Jin
1 Knowledge Acquisition
Fig. 2. The knowledge-acquisition module.
1 and 2. Keys include the primary key, the alternate key, and the foreign key. Data dependencies include functional de- pendencies, multivalued dependencies, and join dependen- cies. The knowledge acquired from underlying database semantics is query-independent and is referred to as long- term knowledge.
Certain information is readily available in the user query which directly affects the physical characteristics of the pro- posed adaptive learning and decision-making network. For example, the arity of the underlying resultant relation deter- mines the number of the neurons in the input layer and hence the number of processing neurons. Such a knowledge will be generated by analysis of the user’s query.
The knowledge to satisfy requirement 4 is elicited through a dialogue channel established in the user-system interface module. Typically, such knowledge is represented
in the form of constraints defined in the query and will be considered only if they do not violate the database integrity and security constraints. Knowledge acquired to satisfy the requirements 3 and 4 is called short-term knowledge be- cause it is query-dependent.
A two-level knowledge-acquisition module is proposed (Fig. 2). The first level is composed of three functional units-the knowledge precompiling, the query interpreta- tion, and the user’s special requirements elicitation. These three units form knowledge bases to support the second level. The second level is the training pair generation. At this level, the knowledge captured by the functional units in the first level is used to generate the training pairs. A fuzzy controller is designed to monitor the quality of each training pattern being generated and to select the “best” set of train- ing pairs.

Automated knoxiedge nc.qui.sition in n neurnl rtetnwk-bosed decision support system for incomplete dambase systems I 33
3.1 Building knowledge bases
At this stage, the long- and short-term knowledge bases are generated from three different sources by the aforemen- tioned functional units.
Knowledge precompiling Underlying database semantics, i.e., key attributes and data dependency rules, provide a means of identifying tuples uniquely, establishing associations among tuples of different relations, and investigating the validity of the resultant tu- ples. Upon the creation of a relational database, information about the key attributes and the data dependencies of the base relations, i.e., long-term knowledge, is collected, coded, and stored in the K-table and the D-table of knowl- edge base I (Fig. 2).
Query interpretation User queries can be used as a source to acquire a portion of the knowledge to facilitate the generation of the training pairs. This type of information, i.e., the arity and structure of the resultant tuples, will be recognized and gathered during the compilation phase of the query.
User’s special requirement elicitation A dialogue interface facilitates the communication between the user and the knowledge-acquisition module. Via this mechanism, the user is allowed to impose some constraints on the quality of the generated tuples, e.g., associate weights to the attributes.
3.2 Training pair generation
The second level of knowledge acquisition is training pair generation (see Fig. 2). At this level, the long-term knowl- edge (base I) and the short-term knowledge (bases I1 and 111) will be combined to generate a set of training pairs. To guide the training pair generation, a set of generation rules is defined and formed based on the categories of the knowl- edge bases. The five generation rules used in our current design are listed in Table 1.
Table 1 Training pair generation rules
Generation rules Weight
Rule 1 Primary keys 5 Rule 2 Alternate keys 3 Rule 3 Functional dependencies 2 Rule 4 User special requirements 4 Rule 5 Total number of null attributes 7
Using a top-down approach (Fig. 3), based on these gen- eration rules, the system generates small groups of training patterns, i.e., immature training patterns (IMTPs). Each group of IMTPs only engages one particular generation rule, hence it represents a specific aspect of the domain knowledge. To achieve a more accurate knowledge repre- sentation, these groups of IMTPs are then used as “seeds” from which combined patterns of knowledge are created. When the training patterns are combined, isolated pieces of knowledge are blended together to form combined patterns. The final set of combined training patterns represents a set of matured training patterns (MTPs).
The measurement of the information quality of a training pair is fuzzy in nature and cannot be represented by numeri- cal values. To cope with the fuzzy nature of the training pairs, the knowledge-acquisition module has been aug- mented by a fuzzy controller. This controller monitors the generation and selection of the high-quality training pairs. Figure 4 shows a detailed diagram of the fuzzy logic-aided training pair generation unit. It involves five basic building blocks: individual rule enforcement (IRE), pattern combin- ing and status modification (PCSM), fuzzy associative mem- ory (FAM) evaluation, defuzzification, and training pattern selection (TPS).
Individual rule enforcement (IRE) To enforce each generation rule, the individual rule enforce- ment (IRE) algorithm forms a set of immature training pat- terns (IMTPs) and assigns a status {kp, dp} to each IMTP. The IRE consists of a pattern generation routine and a fuzz- ification routine.
Each pattern generation routine forms a set of IMTPs based on the enforced generation rule. An IMTP is a binary pattern that has the format coinciding with the resultant tuple generated by the present database query. The number of positions in an IMTP is equal to the number of attributes in a resultant relation, and every position in the pattern corresponds to an attribute of the resultant relation. This information is provided by knowledge Base 11 in the query interpretation unit. Note that, except generation rule 5 (i.e., “total number of null attributes” rule), each generation rule only concerns some, but not all, attributes in the resultant relation. For example, assume an eight-attribute relation R , with the schema [ss#, name, standing, GPA, interest-I, interest-2, course#, grade]. If the current enforced rule is “primary key attributes,” then it only affects “ss#” and “course#” because these two attributes form a compound primary key for the resultant relation and other attributes are not applicable to the current enforced rule.
The pattern generation routine creates all possible combi- nations of IMTPs constrained by the current generation rule. For an n-arity relation, an IMTP is an n-valued vector in which each unconstrained attribute assumes value X (don’t care) and engaged attributes assume values 0 (missing attri-
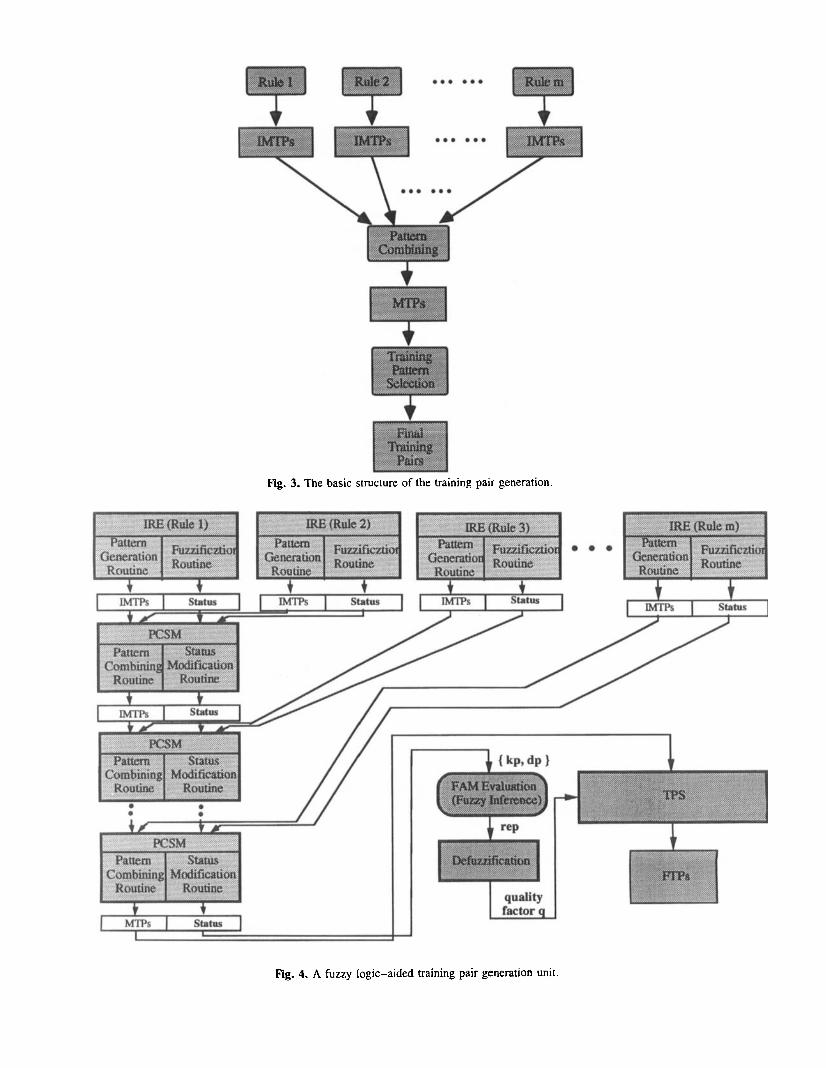
Fig. 3. The basic structure of the training pair generation.
Fig. 4. A fuzzy logic-aided training pair generation unit.
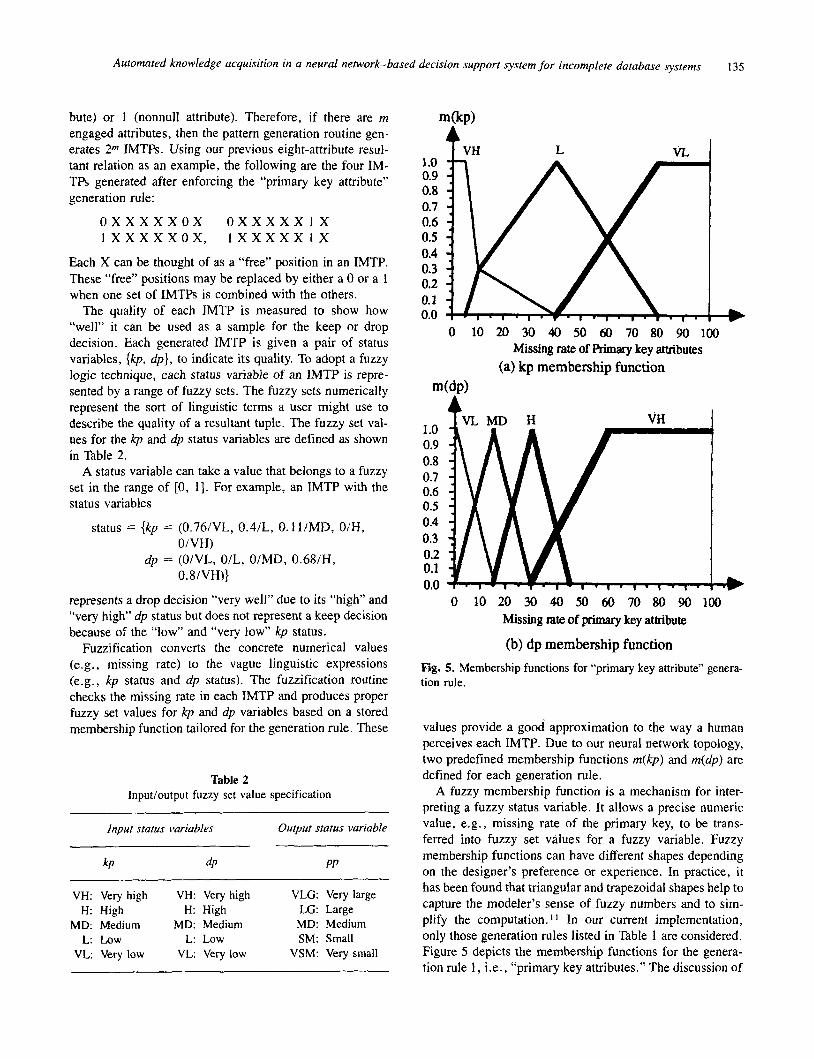
Automated knowledge acquisition in a neural network-based decision support system for incomplete database systems
bute) or 1 (nonnull attribute). Therefore, if there are m engaged attributes, then the pattern generation routine gen- erates 2” IMTPs. Using our previous eight-attribute resul- tant relation as an example, the following are the four IM- TPs generated after enforcing the “primary key attribute” generation rule:
o x x x x x o x 0 x x x x x 1 x 1 x x x x x o x , l X X X X X l X
Each X can be thought of as a “free” position in an IMTP. These “free” positions may be replaced by either a 0 or a 1 when one set of IMTPs is combined with the others.
The quality of each IMTP is measured to show how “well” it can be used as a sample for the keep or drop decision. Each generated IMTP is given a pair of status variables, {kp, dp} , to indicate its quality. To adopt a fuzzy logic technique, each status variable of an IMTP is repre- sented by a range of fuzzy sets. The fuzzy sets numerically represent the sort of linguistic terms a user might use to describe the quality of a resultant tuple. The fuzzy set val- ues for the kp and dp status variables are defined as shown in Table 2.
A status variable can take a value that belongs to a fuzzy set in the range of [0, 11. For example, an IMTP with the status variables
status = {kp = (0.76/VL, 0.4/L, O.ll/MD, O/H, O/VH)
0.8/VH)) dp = (O/VL, O/L, O/MD, 0.68/H,
represents a drop decision “very well” due to its “high’ and “very high” dp status but does not represent a keep decision because of the “low” and “very low” kp status.
Fuzzification converts the concrete numerical values (e.g., missing rate) to the vague linguistic expressions (e.g., kp status and dp status). The fuzzification routine checks the missing rate in each IMTP and produces proper fuzzy set values for kp and dp variables based on a stored membership function tailored for the generation rule. These
Table 2 Input/output fuzzy set value specification
lnpui starus variables Output siatus variable
kP dP PP -~ ~
VH: Very high VH: Very high VLG: Very large H: High H: High LG: Large
MD: Medium MD: Medium MD: Medium L: Low L: Low SM: Small
VL: Very low VL: Very low VSM: Very small
VH L
135
-b 0 10 20 30 40 50 60 70 80 90 100
Missing rate of Rimary key attributes (a) kp membership function
1 .o 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1 0.0
0 10 20 30 40 50 60 70 80 90 100 Missing rate of primary key attribute
(b) dp membership function Fig. 5. Membership functions for “primary key attribute” genera- tion rule.
values provide a good approximation to the way a human perceives each IMTP. Due to our neural network topology, two predefined membership functions m(kp) and rn(dp) are defined for each generation rule.
A fuzzy membership function is a mechanism for inter- preting a fuzzy status variable. It allows a precise numeric value, e.g., missing rate of the primary key, to be trans- ferred into fuzzy set values for a fuzzy variable. Fuzzy membership functions can have different shapes depending on the designer’s preference or experience. In practice, it has been found that triangular and trapezoidal shapes help to capture the modeler’s sense of fuzzy numbers and to sim- plify the computation. In our current implementation, only those generation rules listed in Table 1 are considered. Figure 5 depicts the membership functions for the genera- tion rule l , i.e., “primary key attributes.” The discussion of

I36 A. R . Hurson, S. Pakzad & B . Jin
the definition of the membership functions for other genera- tion rules can be found in ref. 10.
Using the membership functions depicted in Fig. 5 , the status variables of our four IMTPs are as follows:
0 X X X X X 0 X kp = (l.O/VL, O/L, O/MD, O/H, O/VH)
dp = (O/VL, O/L, O/MD, O/H, I.O/VH)
kp = (0.20/VL, 0.70/L, O/MD, O/H, O/VH)
dp = (O/VL, OIL, OlMD, O/H, 0.60/VH)
kp = (0.20/VL, 0.70/L, O/MD, O/H, O/VH)
dp = (OIVL, O/L, O/MD, OIH, 0.601VH)
1 X X X X X 1 X kp = (O/VL, OIL, O/MD, O/H, l.O/VH)
dp = (I.O/VL, OIL, O/MD, OIH, O/VH)
0 X X X X X 1 X
1 X X X X X 0 X
Pattern combining and status modification (PCSM) The PCSM step consists of two routines, the pattern com- bining algorithm and the status modification algorithm. The pattern combining algorithm exhaustively examines the IMTP members of two groups and combines pairs of com- patible IMTPs-two IMTPs are compatible if the embedded knowledge does not contradict each other. Algorithm 1 shows the sequence of the operations:
Algorithm 1. Pattern combining algorithm for any pair of IMTPs do forp = 1 to n /* n arity of the IMTPs */
ifIMTPi(p) = IMTPi(p) then IMTP,(p) t IMTP,(p) else ifIMTPi(p) = “ X then IMTP,(p) c IMTPj(p) else if IMTP,(p) = “X’ then IMTPii(p) t- IMTP,(p) else “incompatible IMTPs”
As a result, for each pair of compatible IMTPs, a new IMTP representing the collective knowledge of the incoming IM- TF’s will be generated.
The status modification algorithm generates new kp and dp status values for each combined IMTP based on the kp and dp values of the original IMTPs and the weights of the generation rules (see Table 1):
for each IMTP, do kpij = kp,* wi + kpj* wj and dpv = dpi* w, + dpj* wj
The final set of IMTPs, i.e., MTP, represents the collective knowledge of all individual generation rules.
FAM evaluation cfuzzy reasoning) Enforcing the IRE and PCSM routines generates a set of MTPs with their associated status variables. Note that each
fig. 6. FAM rule bank for the fuzzy controller.
status variable pair {kp, dp} represents the quality of the training pattern from a keep and drop decision point of view; i.e., a status variable pair that represents a “very high” keep fuzzy set value does not necessarily represent a “very high” quality pattern. This motivates one to generate a single status variable, i.e., p p variable (see Table 2), by combining both kp and dp status values to indicate the over- all quality of a training pattern. The larger the p p value a training pattern has, the higher the quality it has. Given an MTP and its associated status value, the fuzzy associative memory (FAM) evaluation routine will perform fuzzy infer- ence to obtain the corresponding fuzzy output status value PP.
Fuzzy inference methods are used to decide how to com- bine premises in a single fuzzy rule and how to combine the outcomes of fuzzy rules that have the same output variable. FAM is a collection of fuzzy rules that provide fuzzy rea- soning for every possible combination of {kp, dp} status values (Fig. 6).
Fuzzy rules can be interpreted as antecedent-consequent pairs or IF-THEN statements. Each antecedent/consequent rule corresponds to a specific fuzzy input/output, respec- tively. These FAM rules can be expressed as
if <fuzzy proposition>, then <fuzzy proposition>
A FAM evaluation technique called min-mar inference is used” to derive the numerical conclusions. Each {kp, dp} input pair to the FAM activates one or more stored FAM rules to a certain degree. The input fuzzy set values of these activated rules will be combined to generate the correspond- ing output fuzzy set values.
When a pair of {kp, dp} input values is read, any of the fuzzy rules that has nonzero values in its fuzzy set will be activated. At this point, there could be more than one FAM rule being activated, which may lead to an outcome of more than one nonzero value in the same output fuzzy set. FAM evaluation consists of determining the smallest (minimum) rule antecedent and then applying this value to all conse-
Automuted knowledge acquisition in a neural network-based decision support system for incomplete database systems I 31
quents of more than one rule. When this happens, that fuzzy output is set to the largest (maximum) value of all the rules that include it as a consequent.
For example, assume that an MTP has the following sta- tus values:
{kp = (0.75/VL, 0.25/L, O/MD, O/H, O/VH) dp = (O/VL, O/L, O/MD, 0.08/H, 0.92/VH)}
During the FAM evaluation, the following rules will be activated:
IF (kp has value in “VL” and dp has value in “VH”) THEN (pp has value in “VLG”) IF (kp has value in “L“ and dp has value in “VH’) THEN (pp has value in “LG’) IF (kp has value in “VL” and dp has value in “H”) THEN @p has value in “LG’) IF (kp has value in “L” and dp has value in “H”) THEN @p has value in “LG”) From the first FAM rule: MIN (0.75/VL, 0.92/VH) = 0.75 / VLG . From the second FAM rule: MIN (0.25/L, 0.92/VH) = 0.75/LG. From the third FAM rule: MIN (0.75/VL, O.O8/H) = 0.08/LG. From the fourth FAM rule: MIN (0,25/L, 0.08/H) = 0.08 / LG .
This will result in the status value p p = (O/VSM, O/SM, O/MD, 0.25/LG, 0.75iVLG).
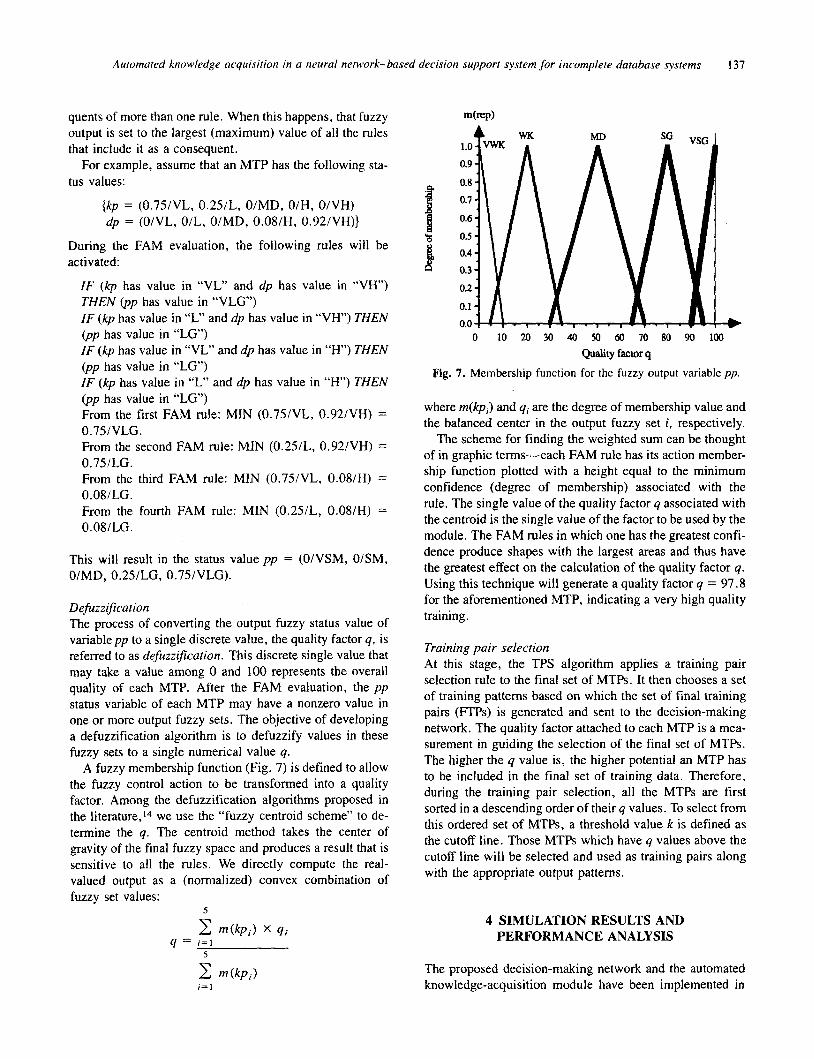
Defuzzification The process of converting the output fuzzy status value of variable pp to a single discrete value, the quality factor q, is referred to as defuzzi’cation. This discrete single value that may take a value among 0 and 100 represents the overall quality of each MTP. After the FAM evaluation, the p p status variable of each MTP may have a nonzero value in one or more output fuzzy sets. The objective of developing a defuzzification algorithm is to defuzzify values in these fuzzy sets to a single numerical value q.
A fuzzy membership function (Fig. 7) is defined to allow the fuzzy control action to be transformed into a quality factor. Among the defuzzification algorithms proposed in the literature,14 we use the “fuzzy centroid scheme” to de- termine the q. The centroid method takes the center of gravity of the final fuzzy space and produces a result that is sensitive to all the rules. We directly compute the real- valued output as a (normalized) convex combination of fuzzy set values:
5
C m(kpi ) x qi q = i = l
5
0 10 20 30 40 50 60 70 80 90 100
Quality factor q
Fig. 7. Membership function for the fuzzy output variable pp.
where m(kpi) and qi are the degree of membership value and the balanced center in the output fuzzy set i , respectively.
The scheme for finding the weighted sum can be thought of in graphic terms-each FAM rule has its action member- ship function plotted with a height equal to the minimum confidence (degree of membership) associated with the rule. The single value of the quality factor q associated with the centroid is the single value of the factor to be used by the module. The FAM rules in which one has the greatest confi- dence produce shapes with the largest areas and thus have the greatest effect on the calculation of the quality factor q. Using this technique will generate a quality factor q = 97.8 for the aforementioned MTP, indicating a very high quality training.
Training pair selection At this stage, the TPS algorithm applies a training pair selection rule to the final set of MTPs. It then chooses a set of training patterns based on which the set of final training pairs (FTPs) is generated and sent to the decision-making network. The quality factor attached to each MTP is a mea- surement in guiding the selection of the final set of MTPs. The higher the q value is, the higher potential an MTP has to be included in the final set of training data. Therefore, during the training pair selection, all the MTPs are first sorted in a descending order of their q values. To select from this ordered set of MTPs, a threshold value k is defined as the cutoff line. Those MTPs which have q values above the cutoff line will be selected and used as training pairs along with the appropriate output patterns.
4 SIMULATION RESULTS AND PERFORMANCE ANALYSIS
The proposed decision-making network and the automated knowledge-acquisition module have been implemented in i= I

138 A . R . Hurson, S . Pakzad & B. Jin
software. An incomplete database system was developed and five sample queries were designed and processed to generate the test-bed data. Attempts were made to generate test-bed data that represent a real-world environment with wide ranges of parameters, i.e., different arity and cardi- nality, different degree of incompleteness, etc. The database consists of 5 fundamental base relations ranging from 105 to 8000 tuples.1° A series of simulation runs has been con- ducted on the test-bed data. Before running the simulator, the network is trained by a set of training pairs generated either randomly (hand-picked) or by the automated knowledge-acquisition module (automated) for each query. Throughout the simulation runs, two performance measures were used as a means to investigate the feasibility of the system: (1) learning time and ( 2 ) classification accuracy. The number of the training iterations has been used to mea- sure the training time of the network independent of the physical characteristics of the underlying computer. Accu- racy is calculated as the number of correct classifications of the tuples over the total number of generated tuples. The performance of the system for different network configura- tions, i.e., a different number of neurons at the hidden and output layers, has been analyzed. In addition, we investi- gated how the value of the learning rate and the number of training pairs affect the performance measures. 10
In this section, the feasibility and the effectiveness of the automated knowledge-acquisition module will be studied. This will be achieved by comparing and contrasting the performance measures of the network using a hand-picked training set and an automated training set against each other. In addition, we have investigated the correlation between the performance measures and the cardinality of the training set. Table 3 shows the working environment of this experi- ment.
Table 3 Characteristics of the working environment
Number of hidden neural units = 80 Number of training pairs used = 10-200 Number of output neural units (decision categories) = 2 Network learning rate = 0.4
Arity of the Queries database relations Number of resultant tuples
Query I 18
Query 3 12 Query 4 9
Query 2 6
Query 5 15
6860 121290 24379
589 12010
4.1 Training time
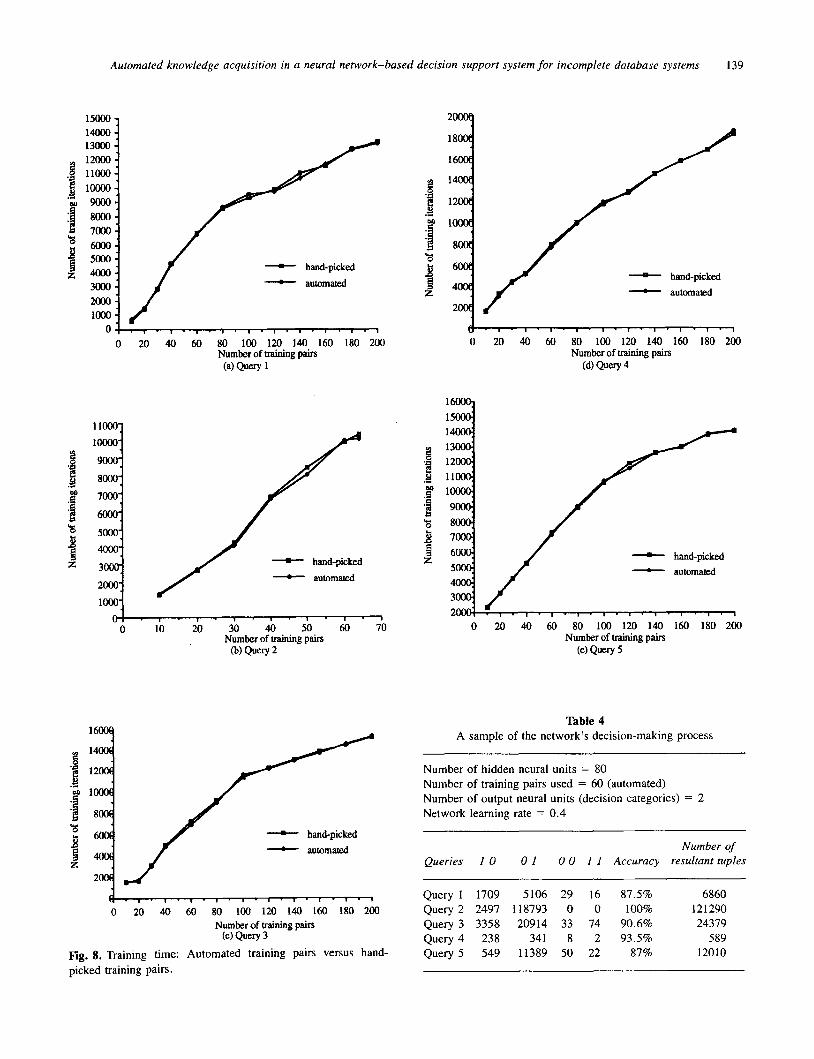
Figure 8 depicts the number of training iterations as a func- tion of the number of training pairs for all five queries. Two curves are shown for each query. It can be concluded that the larger a training set is, the longer it takes the decision- making network to learn, independent of the number of input units. This conclusion is justifiable, since for larger training set size the decision-making network is required to gain more knowledge, i.e., a greater number of training iterations for its weight. In addition, one can conclude that the network training time is about the same for hand-picked and automated training pairs. Furthermore, the number of training iterations increases very rapidly for the smaller number of training pairs (e.g., 10 to SO). This indicates that for each query, increasing the number of training pairs be- yond a certain limit does not necessarily affect the learning capacity of the network. It is worth mentioning that during the course of the experiment, the real CPU execution time also was observed. The CPU time increases much more rapidly than the number of iterations does when more train- ing pairs are used.
4.2 System accuracy
After each training process, the network is switched to the decision-making mode to measure its accuracy. Incorrect decisions are those for which the network (1) classifies a valid tuple as an invalid tuple or vice versa or (2) cannot make any decision. This indicates that during the training process, the network either (1) did not gain enough knowl- edge to classify such an unknown tuple correctly or (2) has not sensed enough evidence to make a decisive "keep"/"drop" decision.
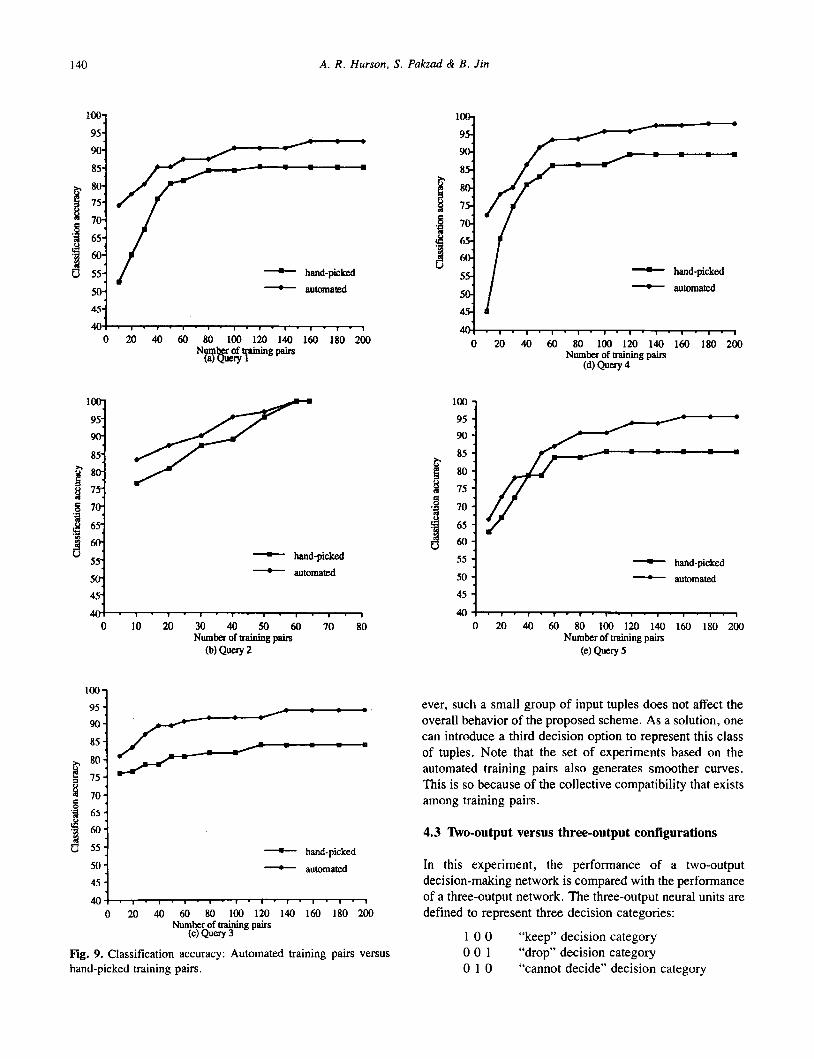
Table 4 shows a detailed example of the network classifi- cation process. Figure 9 depicts the relationship among classification accuracy, the number of training pairs, and the types of queries. Similar to Fig. 8, two curves are drawn for each query; i.e., the network is trained by automated train- ing data and hand-picked training data. Figure 9 indicates that regardless of the selection process of the training pairs, accuracy increases as the number of training pairs increases. However, beyond a certain point, increasing the number of training pairs does not affect the accuracy, as seen by the flat portion of the curves. In addition, this experiment fulfilled our earlier expectation that the proposed knowledge- acquisition module indeed generates high-quality training pairs.
Nevertheless, we found that there is still a group of tuples that the network cannot classify correctly. To remedy these cases, some low-quality training pairs, representing these tuples, need to be injected into the set of training pairs. This is in conflict with a fuzzy logic approach, which attempts to train the network with the best-quality training pairs. How-
Automated knowledge acquisition in a neural network-based decision support system for incomplete database systems I39
j c
o i . , . , . , . , . , . , . I . I . I . 1
(a) Query 1
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
1 1000
loo00
8000
9000
2000 7 lo00 o ! . , . , . I . , - 1 . 1 . 1
0 10 20 30 40 50 60 70 Number of trainimg pairs
(b) Query 2
----C hand-picked - automated
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(dl Query 4
15 l3 1
B 1 3 1 c! .- s 1
f 1 c
B 8 - hand-picked - automated
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(e) Query 5
Table 4 A sample of the network's decision-making process
Number of hidden neural units = 80 Number of training pairs used = 60 (automated) Number of output neural units (decision categories) = 2 Network learning rate = 0.4
Number of Queries I 0 0 I 0 0 I 1 Accuracy resultant tuples
1 . 1 . 1 . 1 . 1 - 1 . . Query 1 1709 5106 29 16 87.5% 6860
0 20 40 60 80 100 120 140 160 180 200 Query 2 2497 118793 0 0 100% 121290 Number of training pairs Query 3 3358 20914 33 74 90.6% 24379
(c) Query 3 Query 4 238 341 8 2 93.5% 589 fig. 8. Training time: Automated training pairs versus hand- Query 5 549 11389 50 22 87% 12010 picked training pairs.
I40 A. R . Hurson, S. Pakzad & B . Jin
50 - 45 - 404
100-
95-
90- 85-
80-
65
60
55-
M- *
-C automared
. I . I . I . I . I - I . I - I - I ’ I
/ 40 451
0 20 40 60 80 100 120 140 160 180 200 Ng&gpgi.i.spairs
““i 5
- hand-picked - automated 45
4 0 1 ’ 1 . 1 . 1 . 1 . 1 . 1 . 1 . 1
0 10 20 30 40 50 60 70 80 Number of waining pairs
(b) Qw 2
- hand-picked
Number of training pairs (c) Query 3
Fig. 9. Classification accuracy: Automated training pairs versus hand-picked training pairs.
t -C hand-picked I - automated y, . , . , , , . , . , . , . , . , . ,
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(d) Query 4
:! . , , , . , , , . , . -. hy:d ,
45
40
--C automated
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(el Quev 5
ever, such a small group of input tuples does not affect the overall behavior of the proposed scheme. As a solution, one can introduce a third decision option to represent this class of tuples. Note that the set of experiments based on the automated training pairs also generates smoother curves. This is so because of the collective compatibility that exists among training pairs.
4.3 Wo-output versus three-output configurations
In this experiment, the performance of a two-output decision-making network is compared with the performance of a three-output network. The three-output neural units are defined to represent three decision categories:
“keep” decision category “drop” decision category “cannot decide” decision category
1 0 0 0 0 1 0 1 0
Automated knowledge acquisition in n neural network-based decision support system for incomplete database systems 14 1
-----C 2 output network --C 3 output network
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(a) Query 1
-P- 2 output network 175
0 10 20 30 40 50 60 70 Number of training pars
(b) Query 2
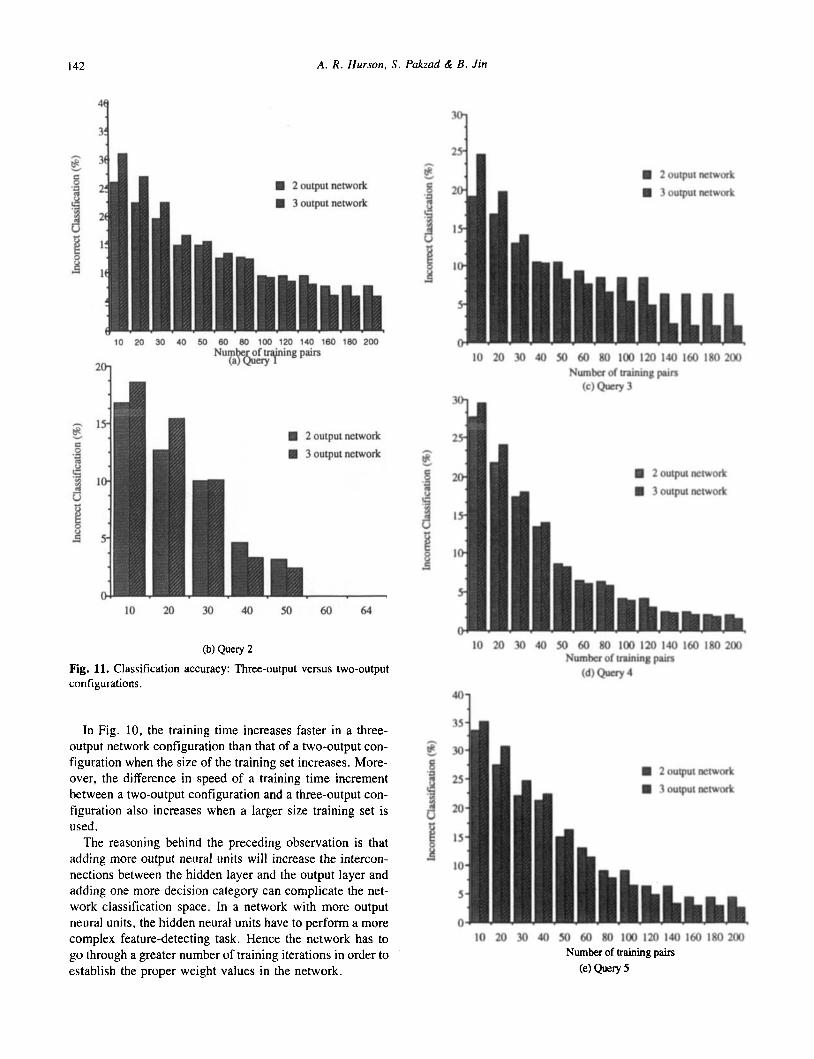
Ag. 10. Training time: Three-output versus two-output network configurations.
During the knowledge-acquisition process, a cutoff point of 75 on the quality factor is defined in order to prepare the training pairs for the two-output configuration. For the three- output configuration, training pairs that represent the “cannot decide” decision category are picked starting from the train- ing pattern that has the smallest quality factor (i.e., from the tail of the set of FTPs).
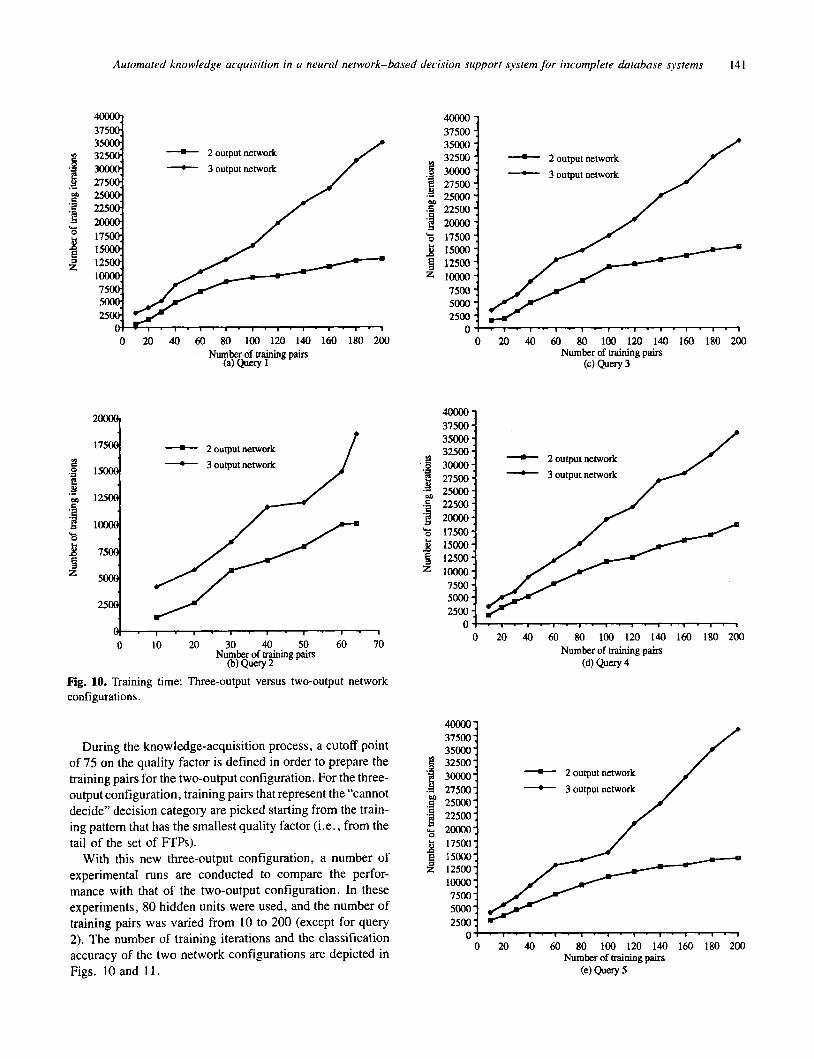
With this new three-output configuration, a number of experimental runs are conducted to compare the perfor- mance with that of the two-output configuration. In these experiments, 80 hidden units were used, and the number of training pairs was varied from 10 to 200 (except for query 2). The number of training iterations and the classification accuracy of the two network configurations are depicted in Figs. 10 and 11.
40000: 37500 : 35000 1 32500 ; - 2 output network
‘P 3oooo; - 3 output network f! 27500: .! 25000;
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(c) Query 3
- 2 output network - 3 output network
0 ‘ 1 . 1 . 1 ’ 1 ’ 1 . 1 . . . 1 . 1 . 1
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(d) Query 4
40000, 37500: 35000 :
8 32500:
.z 27500:
.$ 25000:
.j 22500:
’g 3 m :
% 2oooo:
;:;: 2 12500:
1ooOO: 7500 : 5000: 2500
- 2 output network --C 3 output network - 2 output network --C 3 output network
0 20 40 60 80 100 120 140 160 180 200 Number of training pairs
(e) Query 5
142 A. R . Hurson, S. Pakzad & B. Jin
4 3l 3 1
W 2 output network W 3 output network
" 10 20 30 40 50 60 80 100 120 140 160 180 200
W 2 3
output output
network network
c
10 20 30 40 50 60 64 Number of training pairs
(b) Query 2 Fig. 11. Classification accuracy: Three-output versus two-output configurations.
In Fig. 10, the training time increases faster in a three- output network configuration than that of a two-output con- figuration when the size of the training set increases. More- over, the difference in speed of a training time increment between a two-output configuration and a three-output con- figuration also increases when a larger size training set is used.
The reasoning behind the preceding observation is that adding more output neural units will increase the intercon- nections between the hidden layer and the output layer and adding one more decision category can complicate the net- work classification space. In a network with more output neural units, the hidden neural units have to perform a more complex feature-detecting task. Hence the network has to go through a greater number of training iterations in order to establish the proper weight values in the network.
2 output network 3 output network
10 20 30 40 50 60 80 100 120 140 160 180 200 Number of training pairs
(c) Query 3
2 output network W 3 output network
10 20 30 40 50 60 80 100 120 140 160 180 200 Number of training pairs (4 Query 4
40
35
30
'i 25
h
8
# 1 20
i 15
i
U
10
5
0 10 20 30 40 50 60 80 100 120 140 160 180 200
Number of training pairs (el Query 5
6 2 output network 6 3 output network

Automated knowledge acquisition in a neural neiwork-based decision support system for incomplete database systems 143
During the decision-making phase, the classification ac- curacy achieved by each network configuration was calcu- lated for each query. In all cases, the classification accuracy was represented by the error rate (i.e., incorrect classifica- tion rate). It is calculated as
x 100% Number of incorrectly classified tuples Total number of resultant tuples
The results are depicted in Fig. 11. Note that when a small number of training pairs are used, (e.g., 10 to 30), the two-output network configuration has a lower error rate (i.e., higher accuracy) than the three-output network con- figuration. However, this difference between the two con- figurations is reduced when the number of training pairs increases (e.g., number of training pairs > 30 in query I ) . In Fig. 1 1, it should be noted that beyond a certain point in each query, the three-output network outperforms the two- output network in achieving a lower classification error rate.
5 CONCLUSIONS
In a decision support system, incorporating fuzzy logic technology into training pair generation can aid in dealing with fuzziness when measuring the information quality of each training pair. More important, it provides an appropri- ate representation of the status variables for each training pattern. In addition, through fuzzy inference (approximate reasoning), the system is able to control the selection of a set of good training pairs. The advantages of using fuzzy logic technology derive from its ability to encode knowl- edge at a very high level of abstraction, to reduce the num- ber of rules in a system, to eliminate the high ratio of control rules needed in conventional systems, and to pro- vide more robust and more stable systems.
Simulation results clearly showed that the network, when trained by automated training pairs, achieved higher classi- fication accuracy than when trained by the randomly picked training pairs. High-quality training pairs strengthen the generalization ability of the decision-making network.
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14
REFERENCES
Codd, E. F., Extending the database relational model to cap- ture more meaning. ACM Trans. Dafubase Syst. 4(4) (1979), 397-434. Codd, E. F., More commentary on; missing information in relational databases (applicable and inapplicable). Sigmod Re- cord 16( 1) (1987) Cox, E., Fuzzy fundamentals. IEEE Spectrum, October 1992, pp. 58-61. Grant, J., Null values in a tabular database model. Inform. Process. Lett., August 1979, pp. 97-99. Hurson, A. R., Jin, B., Pakzad, S . & Miller, L. L., Applica- tion of artificial neural systems in decision-aiding for large in- complete databases. ./. Knowledge Eng. S(3) (1992), 16-40. Hurson, A. R., Jin, B. & Pakzad, S. H. , Neural network- based decision making for large incomplete databases. In Pro- ceedings of Parallel Architectures and Language Europe, PARLE 91, Springer-Verlag, Berlin, June 1991, pp. 321-37. Hurson, A. R., A mini-track on: Data/knowledge base sys- tems. In Proceedings of Hawaii International Conference On System Sciences. IEEE Computer Society Press, Washington,
Jin, B., Hurson, A. R. & Miller, L. L., Neural network-based decision support for incomplete database systems: Knowl- edge acquisition and performance analysis. In Proceedings of the I991 Analysis of Neural Net Applications Conference, ANNA-91, ACM Press, New York, May 1991, pp. 62-75. Jin, B., Pakzad, S. H. & Hurson, A. R., Application of neural networks in handling large incomplete databases: VLSI design and performance analysis. In Proceedings of Interna- tional Conference on Parallel Processing, CRC Press, Boca Raton, 1991, pp. 404-8. Jin, B., Neural network-based decision support for incom- plete databases. Ph.D. dissertation, The Pennsylvania State University, August 1993. Kosko, B., Neural Networks and Fuzzy Systems, Prentice- Hall, Englewood Cliffs, N.J., 1992. Pakzad, S., Hurson, A. R. & Miller, L. L., Maybe algebra and incomplete data in database machine ASLM. J. Database Technol. 3(2-4) (1990), 103-15. Suchenek, M. A., Two applications of model-theoretic forc- ing to Lipski’s data bases with incomplete information. Foun- damenta Informaticae 12 (1989), 269-88. Zadeh, L. A., The calculus of fuzzy ifithen rules. A1 Expert, March 1992, pp. 23-27.
D.C., VO~. 1, 1992, pp. 298-99.





























