Embed Size (px)
Citation preview

Pergamon Information Processing & Management, Vol. 33, No. 5, pp. 615-632, 1997
© 1997 Elsevier Science Ltd All rights reserved. Printed in Great Britain
0306-4573/97 $17 +0.00
PII: S0306-4573(97)00021-6
A U T O M A T I C A S S O C I A T I O N O F N E W S I T E M S
CHRISTINA CARRICK ~ and CAROLYN WAT'rERS 2 Department of Computer Science, Simon Fraser University, Burnaby, British Columbia, Canada
' Jodrey School of Computer Science, Acadia University, Wolfville, Nova Scotia, Canada.
Abstraet--A new media for news delivery has emerged in which print, photographs, video, and audio can be integrated into personalized multimedia news presentations. An electronic news delivery system produces personal 'editions' by selecting news items from various sources in a variety of media types and ordering and/or grouping these items for presentation. Clearly, if personalized and dynamic 'editions' of news are to be a reality then algorithms are needed that select and group items with minimal human intervention. In this paper we will examine only one of the problems involved in the automatic generation of electronic editions: the association of related items of different media type, specifically photos and stories. The goal of this research is to be able to determine to what degree any two news items refer to the same news event. This metric has several uses. First, it can be used to link multimedia items that can be shown together, such as a video, photo, and text story related to a shipwreck or state visit. Second, it can be used to form clusters of very similar items from a variety of sources so that one or two can be chosen to represent that event in an edition. In this paper we discuss the specific association of text and photo news items although our approach to the problem of defining relationships between photos and stories applies to a larger domain of news items including scripted news video clips and scripted radio broadcasts. © 1997 Elsevier Science Ltd
1. INTRODUCTION
A new media for news delivery has emerged in which print, photographs, video, and audio can be integrated into personalized multimedia news presentations. An electronic news delivery system produces personal 'editions' by selecting news items from various sources in a variety of media types and ordering and/or grouping these items for presentation. Currently, editions of news for mass consumption, whether print, television, or radio are produced by human editors who sift through the masses of source data produced locally and remotely in order to select a cross section of items appropriate to their intended audience. Clearly, if personalized and dynamic 'editions' of news are to be a reality then algorithms are needed that select and group items with minimal human intervention.
The Electronic News Project is a joint research effort investigating the design and delivery of personalized news in the electronic medium. We have developed an overall architecture as well as several prototypes (Shepherd et al., 1995). In June, 1995 a prototype was demonstrated at the G-7 Economic Summit in Halifax, Canada, integrating newspaper text and photographs with television news video clips on a daily basis across an ATM network. Figure 1 shows a sample front page from one of those editions.
In this paper we will examine only one of the problems involved in the automatic generation of electronic editions: the association of related items of different media type, specifically photos and stories. Our approach to the problem of defining relationships between photos and stories applies to news video clips also. Photos, videos, and text each have a text component that can be used as a representation of the content of the item. The goal of this research is to be able to determine to what degree any two news items refer to the same news event. This metric has several uses. First, it can be used to link multimedia items that can be shown together, such as a video, photo, and text story related to a shipwreck or state visit. Second, it can be used to form clusters of very similar items from a variety of sources so that one or two can be chosen to
615

ox
ox
=~
e~
¢'3
o
Fig.
1. S
ampl
e ne
wsp
aper
scr
een.

Automatic association of news items 617
represent that event in an edition. Human editors are continually selecting stories from multiple sources, Reuters, Associated Press, UP (United Press), etc., each of which covers essentially the same events. In this paper we discuss the specific association of text and photo news items.
The algorithm presented in this paper examines the text component of each item to extract values for who, where, when, and to a lesser extent what as identified by proper nouns occurring within the text. Our premise is that similarity in persons, places, governments, and companies, should be sufficient to determine similarity of event coverage. We are not attempting a definitive description, abstraction, summation, or understanding of the content of news items. This would take too long. Any analysis of news items must be fairy fast and not require preprocessing as news data is unique in two ways. First, news data has a very short shelf-life measured in minutes and hours during which time it is considered current. Second, the domain of news is very broad and ill defined with locations and names coming in and drifting out of heavy usage on a continual basis. This means that algorithms must be fast to be useful and so attempting to actually understand the text is not feasible, nor is the maintenance of large highly specific domain vocabularies.
2. BACKGROUND
News data is often used in text analysis and querying research largely because of its general interest and copious supply. News data is generated around the clock. In the USA alone, there are over 1000 daily newspapers, in addition to radio and television stations. Although much of the news broadcast is duplicated from a handful of large news sources, such as Associated Press and Reuters, almost all local news is generated in a very distributed manner. Gigabytes of news data, text, photos, and video, are generated each day. The TREC and TREC-2 (Harmon, 1995) experiments on retrieval effectiveness on large data sets, for example, uses news data in a marked up form as one of its test data sets.
Several research and commercial groups are actively investigating the delivery of electronic versions of current news data. Many of the current electronic systems, such as San Jose Mercury or Halifax Herald, are actually electronic versions of the broadcast print edition. Other delivery systems, such as America OnLine or NewsPage, although not personal editions, do capture items from a variety of sources. It is a non-trivial task to select 20-50 items from a daily supply of thousands of items where much of the coverage is redundant. For personalized electronic editions, this selection must proceed quickly, be largely automatic, and cover individual definitions of interest areas. Currently several groups, both academic and commercial, are working on the delivery of electronic news. Both the Fishwrap edition at Media Lab at MIT (Bender et al., 1991) and Electronic News Project (Shepherd et al., 1995) at Dalhousie, Acadia, and Waterloo Universities are experimenting with the delivery of personal editions.
Much related work of interest has been done in story summarization and content analysis for retrieval using news data (Masand et al., 1992; McKeown & Radev, 1995). Practical summarization requires success in each of the three following areas: clear understanding of the text, determination of the importance of components, and synthesis of coherent output (Brandow et al., 1995). Several research efforts have been focussed on this area including the ANES (Automatic News Extraction System) (Brandow et al., 1995), which generates summaries from full news articles, and SumGen project (Maybury, 1995), which generates summaries of data from structured sources including databases.
RUBRIC (Tong et al., 1987) is a good example of classification of news items for retrieval using a frame or script-like knowledge representation. A natural language parser for restricted domains is used to instantiate attributes of actions, actors, targets, objects, and effects. A similarity is then determined between a given query and each news item in the database. The FERRET system (Mauldin, 1991) used case frames also for specific subject areas. SCISOR project (Jacobs & Rau, 1990) reported good results using extensive linguistic analysis to instantiate slots of frames for financial stories.
Most of these systems of analysis work in restricted domains of discourse. News, however, is by its nature non-domain specific and covers topics from sports and entertainment to

618 Christina Carrick and Carolyn Watters
places, and organizations), can be expected to expand continuously. Additionally, the stream of news items is continual and the half-life of these items is very short so that reasonable processing time is critical. Consequently, natural language and domain-specific scripts or vocabularies do not satisfy the criteria of breadth and speed.
Other research is more directly related to photo-story association using names. Rowe (1994) used a natural language parse of photo captions as the basis of retrieving photographs. Rau (1991) developed an algorithm to extract corporate names from financial news stories and Kilgour (1995) argues convincingly the importance of surnames in topic analysis. Spink and Leatherbury (1994) examined the importance of authority name files in searching humanities databases. Misspelling and transliterated close-spellings can be dealt with using standard algorithms such as those used in SOUNDEX to map variations of names onto codes to compensate for variations in spelling and, in the Synoname project (Gross, 1991), to match names with names.
3. NAME MATCHING FOR TOPIC SIMILARITY ANALYSIS
We found that in news data from 3 sources (San Jose Mercury, Wall Street Journal, and Halifax Chronicle-Herald), proper names, i.e. capitalized words, accounted for 8-10% of the words in the text items and 20% of the words in the photo captions. We hypothesize that we can use these names effectively to determine a degree of similarity between photos and stories for the purpose of finding appropriate photos to go with stories in an electronic news edition. Furthermore, if an effective algorithm can be developed then we only need to apply it to roughly 10% of the news data.
A non-domain specific name extraction and matching algorithm for news stories and photo captions would provide the following advantages:
• accurate identification of people, places, and institutions by the elimination of ambiguities arising when names may identify persons, places, or corporations, such as Bob Jones' Plumbing, Bob Jones, or Bob Jones River The same disambiguation is required when two people of similar names are mentioned, such as Bill Clinton or Hilary Clinton;
• weighing the relative importance of individual people, places, or organizations to items; • weighing the similarity of topic of items for the purposes of association, selection, or retrieval,
whether the items are photographs with captions, videos with scripts, or straight text.
The resultant algorithm must be fast and reasonably effective. In the scenario of dynamic distribution of news items, we chose to trade off effectiveness for efficiency, so that in the interest of speed we will accept less accuracy than optimal. The algorithm must provide a timely and efficient analysis of dynamic collections of news items that may be text, video and script, or photographs and captions. Each item should result in the instantiation of a relatively simple frame that can be used to generate a numeric similarity of items.
3.1. Frame representation
Standard journalistic practice as well as communication research (McQuail, 1992) would suggest that attributes of news items should include: who, what, where, when, and why. Deeper understanding of the language is required to evaluate what and why while detection of proper names can often satisfy who, where, and when. Since the objective of this project is to match items rather than analyze them, the tradeoff in processing time and generalizability seems worthwhile. Let us look at the three remaining questions more closely.
Who? This attribute almost always refers to a person, organization, government, or corporation. Each of these are formally represented by proper names. We do, however, find phrases like the man next door in news articles but seldom as the only reference to the main person or corporation in a news item.
Where? Place names mentioned in news articles are also identified as proper nouns.
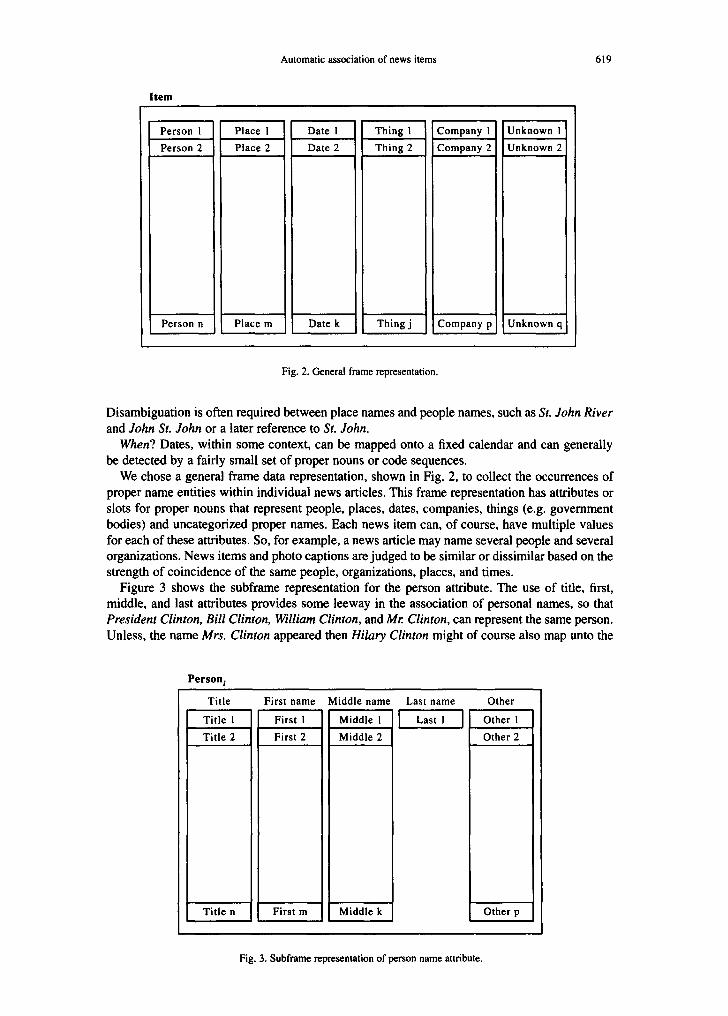
Automatic association of news items 619
I tem
Person I Place I Date I Thing 1 Company I Unknown I
Person 2 Place 2 Date 2 Thing 2 Company 2 Unknown 2
Person n Place m Date k Thing j Company p Unknown q
Fig. 2. General frame representation.
Disambiguation is often required between place names and people names, such as St. John River and John St. John or a later reference to St. John.
When? Dates, within some context, can be mapped onto a fixed calendar and can generally be detected by a fairly small set of proper nouns or code sequences.
We chose a general frame data representation, shown in Fig. 2, to collect the occurrences of proper name entities within individual news articles. This frame representation has attributes or slots for proper nouns that represent people, places, dates, companies, things (e,g. government bodies) and uncategorized proper names. Each news item can, of course, have multiple values for each of these attributes. So, for example, a news article may name several people and several organizations. News items and photo captions are judged to be similar or dissimilar based on the strength of coincidence of the same people, organizations, places, and times.
Figure 3 shows the subframe representation for the person attribute. The use of title, first, middle, and last attributes provides some leeway in the association of personal names, so that President Clinton, Bill Clinton, William Clinton, and Mr. Clinton, can represent the same person. Unless, the name Mrs. Clinton appeared then Hilary Clinton might of course also map unto the
P e r s o n i
Title First name Middle name Last name
Title 1 First 1 Middle 1 ] Last 1
Title 2 First 2 Middle 2
Title n First m Middle k
Other
Other 1
Other 2
Other p
Fig. 3. Subframe representation of person name attribute.

620 Christina Carrick and Carolyn Watters
same person if it occurs in the same story. We allowed up to three different instantiations for each of these attributes, except last name which is allowed only one instance, giving 256 different ways of referring to a single person.
3.2. Algorithm
3.2.1. Algorithm in PseudoCode.
For each news item: Extract a list of potential names. For each potential name:
if DATE then add name to date attribute else if PLACE then add name to place attribute
else if THING add name to thing attribute else if PERSON add name to person attribute
else add name to unknown attribute.
3.2.2. Potential names. The first step in the algorithm is to extract a list of potential names from the text of the news items, scripts of videos, and captions of photographs. Potential names are defined as adjacent word sequences were each word in the sequence is capitalized. We allow the embedding of a short list of connector words such as 'of, de, van, the' within potential names. We use a stop list of 292 frequently occurring words, drawn from the news text database, to discard most of the capitalized words that started sentences. Empirical data from the 20 August 1994 edition of the Chronicle-Herald newspaper showed that out of 8702 capitalized words found in the text, 2100 were not useful and of these 1619 were discarded by the stop list. The same stop list discarded 30 out of 50 useless capitalized words from 489 capitalized words occurring in the photo captions.
Names occurring at the end of sentences are also difficult to detect. Look at the following two sequences of capitalized words: 'Bob Jones. Finally' and 'Capt. Bob Jones' . A list of common titles is used to check if an abbreviation has been used, single characters are assumed to be initials, and otherwise the period is assumed to end a sentence.
Commas, periods, colons, and semicolons indicate name separation while hyphens and apostrophes are considered to be part of the name. This gives us 'Clinton, Chretien, and Castro' correctly but misses 'Bill, Bob, and Joe Smith'. Interior apostrophes with names such as 'Canada 's Chretien' are left but trailing apostrophes, such as 'Jean MacDonald 's ' , are eliminated.
3.2.3. Date, place instantiation, company, and thing. Each potential name from a news item must be assigned to one of the attributes: date, place, person, company, thing, or unknown. The order of checking is based on how easy it is to determine that a potential name fits the criteria of a given attribute and the probability of mis-selection. Each potential name is first matched for date and then place. Each of these are fairly straightforward to determine and, particularly in the case of place names, are easy to mistake as personal names. By eliminating these two attributes first the more extensive analysis required to fit the criteria for personal or corporate names can often be avoided.
Each potential name for a news item is first checked as a date. A simple function involving 55 clues to date values is used. If a date string is identified and does not already exist for that news item it is added to the end of the list of date attributes for that news item and the name is removed from the potential name list.
The remaining potential names are then tested for fit as geographic names for full or partial matching, nbdm files containing 18,602 geographical names for Nova Scotia, 1494 geographical names from across Canada and another 2444 geographical names world-wide (from Energy, Mines and Resources Canada) are used in this function. Place names are checked before people names so that tokens such as St. John River or Clinton, Ontario are less likely to be mistakenly identified as personal names.
Names in the potential name list not satisfying the geographic criteria are then tested as

Automatic association of news items 621
companies. A short list of 16 company identifiers is used to check for the occurrence of words such as 'Ltd ' or 'Company ' within potential name strings. Again this processing precedes personal name testing to avoid misidentification of strings such as 'Bob Jones' Plumbing Ltd.'
The things category is a catch-all category for institutional names and uses a list of 41 thing indicators, such as 'Government ' , 'University' or 'Statue' so that names such as 'Statue of Liberty' 'Government House' or 'Dalhousie University' could be picked out.
3.3. Personal name instantiation
Personal names are instantiated last because of the complexity and variant nature of personal names. Several indicators are used to determine if a potential name is in fact a person's name; inclusion of a title, inclusion of a common first name, and match to an existing personal name. The algorithm first looks for one of these three name indicator conditions to trigger instantiation of one or more attributes of a personal name: description, title, last name, first name, middle name, where each attribute may be instantiated by zero or more strings. The last name attribute is an exception and must be instantiated by one and only one string.
Any names remaining on the potential name list are used to instantiate the unknown attribute. Interesting enough, the strings in the unknown attribute were often found to be important later in the match stage.
3.3.1. Identifying and instantiating personal names. Let us consider the following examples:
Mr. John James T. Smith Justice E. Colhoun American Jane Doe The first indicator that a potential name is a personal name is the detection of common titles
(from a list of 33 titles) such as Mr or Justice, or President. Titles can be found anywhere in a potential name, for example Pres. in United States Pres. Bill Clinton. Titles were quite effective as indicators of personal names and were found in almost one-third of the articles used in the test set.
The second indicator used to detect personal names is the inclusion of a common first name in the potential name. Each word in the potential name is scanned for a match in a list of 3190 common first names. First names were quite effective as person determiners and found in 96% of the personal names in the training set (1816 out of 1886).
The third indicator that a potential name is a personal name is a match of the last word in the potential name with the last name of known people, where known simple means a personal name that has been identified previously. The last word in the potential name is compared against the last name attributes of all current personal name frames. If a match occurs then it is assumed that the potential name is a personal name. This means that Clinton or Smith used alone in items after a first occurrence of a full name would be recognized as personal names.
3.3.2. Instantiation of attributes for personal names. The identification of a potential name as a personal name triggers more elaborate instantiations for the individual personal name attributes: descriptive, title, first name, middle name, and last name. The attributes forfirst name, middle name, descriptive, and title can be instantiated with more than one string value, while the last name attribute is restricted to single strings.
The string consisting of all words in the potential name that occur before either a title or a first name is used to instantiate the descriptive attribute for that name frame. In the earlier example, United States Pres. Bill Clinton, the string United States would be the descriptive value. Each word between the first name and the last name are classified as individual middle names. So in the example, Mr. John James T. Smith, the words James and T would be treated as middle names. If no first name was found then we assumed that middle names where also missing.
Before a new personal name frame is added to a news item, the name frame is compared against each of the existing name frames for that item. Variations in name form, especially within single articles, can be significant. For example, Mr. Jones may also be referred to as Bob Jones, Jones, Robert Jones, or R. Jones and these may be variations of the name of a single person and where possible should be identified as such. Because of the complexities and

622 Christina Carrick and Carolyn Watters
Table 1. Importance weights for the test and training sets
Attribute Importance weight
Title 0.20 First name 0.20 Middle name 0.15 Last name 0.40 Other 0.05 Threshold 0.80
ambiguities of this analysis we generated a metric called the degree of certainty to measure the closeness of the match between the new name and each existing name with same last name. This metric is based on weights associated with matches in each of the name attributes: descriptive, rifle, first name, and middle name. The degree of certainty of sameness between two names, A and B, with the same last name is calculated by
Cert(A, B) = 2~lt
where
Cert = e-[0,1 ]
and It is the importance weight of attributet, where the value of attributet is the same in A and B or is blank in A or B or both.
The values given in Table 1 were used as the importance weights for the test and training sets. These values for importance weight were chosen by trial and error on the training data set. The last name was given a relatively high weight to prevent matches with different last names. Title and first names occur more frequently than do middle names and so were given a higher weight than middle names. It is possible, of course, for names to agree on last name and a combination of other names and be accepted as the same name. The threshold was also chosen on behavior with the training set.
If the certainty value exceeds the threshold then we presume that the new name frame is a variation of the existing name and the new values are incorporated into the attributes for the existing name rather than standing as a new name. Otherwise the new name is added to the list of name frames for that news item.
Using this technique, 92.4% of the personal names appearing in the articles of the 20 August 1994 edition of the Chronicle Herald and 85.4% of the personal names in the photo captions of the same edition were correctly identified and mapped.
As an example, the names Mr. Smith, Robert Smith, Bob Smith, and Smith result in the instantiation of two personal name frames, shown in Fig. 4, and from this the following final
P e r s o n 1
Title First name
Mr.
Middle name Last name
I I Smith
Other
I
Person 2
Title First name
Bob
Robert
Middle name Last name
I I Smith
Other 'l Fig. 4. Name subframe instantiations.

Automatic association of news items 623
name frame would be generated
Title {Mr} First name {Bob, Robert } Last name Smith.
3.4. Unknowns
About one-half of the strings in the potential name list from the test edition did not satisfy the criterion for any of the previous categories. Many of these potential names were, nonetheless, useful as auxiliary strings for matching and so were added to a catch-all category called unknowns. The distribution of attribute type in the list of potential names for the 106 articles of the test paper were:
Dates 7.4% Places 16.5% Companies 1.3% Things 0.7% Persons 23.8% Unknown 50.3%
We found that strings in the unknown class fell into the following types in the test data: valid proper names, such as 'Commonwealth Games', that our algorithm missed (67.6%); partial names that were incorrectly extracted from the original text, such as 'Brunswick' from 'New Brunswick' from which the stop list had stripped off the 'New' (12.6%); or capitalized words which were not proper names, such as 'Although', (19.8%). As a last attempt to place names in the proper category, each word in an unknown string is compared with substrings of all names already used. In the case of personal names the last name had to match for the string to be removed from the unknown category.
3.5. Examples
Let us first examine a simple case of a photograph with its caption and a full text item known to be related. The photograph and story from the 20 August 1994 edition of the Halifax Herald morning newspaper can be found in Appendix A and Appendix B.
Using the algorithm as described, the following frame instantiations were made by the algorithm:
People { (title Lt-Col first name Ed last name Mitchell)
(title Col. first name John last name Cody)}
Places { null } Dates { Friday } Comp { null } Things {null} Unknown {CFB Shearwater Sea
Kings}.
From the story the following frame instantiations were made:

624 Christina Carrick and Carolyn Watters
People {(title Dartmouth MP Mr. first name Ron last name MacDonald)
(title Col. first name John last name Cody)
(title Capt. first name Harry last name Munro) }
Places { Dartmouth, Ottawa, Windsor, Yugoslavia, Hawaii, Ontario}
Dates {Friday, Wednesday, Monday, Aug, June, April, July}
Comp {none} Things {none} Unknown {Brunswick, Liberal UP, Base,
Technicians, Sea Kings, HMCS Halifax, UN, HMCS Toronto, HMCS Provider, Ejection, CFB Shearwater-based Sea King, T- 33 Silver Star, Canada's Sea King, Modifications, Defense Department, Adriatic, Nol, T- Bird}.
We can see that the photo caption has a coincidence with the story based on one person, (Cody), two unknowns, (CFB Shearwater and Sea King) and one date (Friday). More importantly, only one of the items in the caption, (Mitchell), is not represented in the story. In the next section we will discuss a more rigorous method of determining similarity between items.
4. MEASURING SIMILARITY BETWEEN NEWS ITEMS AND PHOTOS
Once the news items and photos have been processed and the proper names used to instantiate attributes, we look for similarity between news items and photos based on these attributes. The instantiated attribute lists for individual news articles varies greatly in length, with some articles light on specifics and others naming names and places.
4.1. Similarity function
A similarity function. Sim, was developed to calculate a value between 0 and 1 that represented the similarity between a news article, A, and a photo, B.
Sim(A.B) =.,~a,a.
where ai is similarity of ith attribute of A to ith attribute of B and ai is the importance value of the ith attribute calculated by
rrfin(IAil,IBil) ~ i= ~.0~ k
The numerator of this expression gives an importance value proportional to the length of the smaller of the two lists while the denominator normalizes the values so that ,,~a~= 1.
Although the upper bound of Sim may be infinity we rarely encountered values greater than 3.

Automatic association of news items 625
4.2. Attribute similarity
The individual similarities, ai, between attributes of a news article, A and a photo, B, were calculated in the following ways. Similarity values for place, date, company, and unknown attributes were generated by
Zi2,0(X,,Y~) a(x,r)= min(IXl,lY1)
where IXI is the number of times that name occurred in the news article and II'1 the number of times that name occurred in the photo caption.
The value for 0(X~, Yk) was calculated by
O( X~,Yk) = min(IX~l,l Ykl)
if Xi and Yk are the same, or one is a substring of the other, and 0 otherwise. Personal name attributes were compared by calculating
21maxk O(X i, Yk) a(X,Y)=
min(IXl,lYI)
Where O(X~,Yk)=min (IXil,lYkl) if Cert(X~,Yk)>threshold, and 0 otherwise. Unknown attributes were compared simply as
a( X, Y) = Y,a( X, ri) + Y.a( Y,Xi).
5, RESULTS
The algorithm was tested, first against a training set, and then against new data sets. The algorithm generated pairs of news items and photos that it determined where about the same event. Each of these pairs of news items and photos were then evaluated by humans and labeled as one of the following: same, similar, or different. A pair was determined to be the same, i.e. about exact same topic or event, if the same association was made by either the newspaper staff or by manual inspection. A pair was determined by inspection to be similar, i.e. about generally same topic, if one of the items was about a subset of the other. For example, a storm picture and the weather report or a photo of a cycle race and the story of the Commonwealth Games would be considered similar. All other pairs were considered to be different. The resultant pairs generated by the algorithm were then measured against human evaluations.
The evaluation metrics used were simple variations of standard recall and precision defined as follows:
Association_Recall = #Associations madeA#Valid Associations
#Valid Associations
#Associations madeA#Valid Associations Association_Precision =
#Associations made
Only those associations designated by the Herald staff or from the algorithm were included in the analysis as #Valid Associations. Any other matches were not included in this set as the manual labor involved would be significant. For example, for the test day of the Herald there were 6254 possible associations.
As a baseline for comparison, a keyword match, using the same stop list as the algorithm, was run on the test data set using a similarity measure based on number of times each word occurred in the articles and in the captions. The amounts of CPU time used by the keyword algorithm and the name algorithm were very similar because although the keyword algorithm does less work it does it for every single word it finds, while the name algorithm does more work but only on about 10% of the available strings.

626 Christina Carrick and Carolyn Watters
Table 2. Results of the keyword baseline and the results of the algorithm for the training data set
Keyword Algorithm
#Known matches 33 29 #Known matches missed 19 23 #Extra matches 36 29 #False matches 58 29 Recall 78.4% 71.6% Precision 54.3% 66.7%
5.1. Training set
A set of data consisting of all of the text items and photos with captions from the 20 August 1994 edition of the Chronicle Herald newspaper was used as a training set to fine tune the algorithm before applying it to other new data sets. The Chronicle Herald is the main daily newspaper in Nova Scotia and generously provided data as we needed it.
The training set edition contained 59 photographs and 106 articles covering all areas expected in a general domain newspaper: international news, national news, provincial news, local news, sports, business, entertainment, editorials, and news briefs. The data from the newspaper included the assignments that the Herald staff had made associating photos with 32 of the stories. Of the 59 photos only 7 were 'stand-alone' photos, i.e. not associated with any particular story, and 4 articles had been assigned more than one photo.
Table 2 shows the results of the keyword baseline and the results of the algorithm for the training data set. From this table we can see that the simple keyword approach gave comparable results on the training data set.
Table 3 shows the effect of variations in the threshold for similarity evaluation for both same and similar associations in the training data set. The designation similar included story-photo pairs picked by the algorithm that the human evaluators decided were actually reasonable, if not exact, matches as described above. In Table 3, and in the graph in Fig. 5, the recall and precision results are shown for the training data set for two levels of sameness of story and photos as we varied the threshold value in the calculation of degree of certainty of sameness.
Allowing similar news items to be considered as valid associations resulted in significant and consistent increases in both recall and precision, although the same general relationship of recall to precision remains pretty much the same. Figure 6 shows this relationship graphically for both same and similar evaluations. One of the advantages of electronic delivery of news is, of course, that photos are no longer stationary objects and can be associated with more than one item in any given edition and so more of the associations can be used. Overall, considering similar associations to be valid increased recall by 11.4% and precision by 20.9%.
Using the results from the training data set we chose 0.6 as the optimal similarity threshold and used that threshold value in the processing of new data sets.
The training data set revealed some interesting problems with both Association_recall and Association__precision for photo caption to news story associations. For example, the algorithm missed 23 of 52 matches in the training news but of these 18 photos went with a single story and missing these matches had a drastic effect on the overall Association_recall. Upon
Table 3. Effect of variations in the threshold for similarity evaluation for both same and similar associations in the training data set
Threshold value
0.5 0.6 0.7 0.8 1.0 I.l
Same Recall 71.2 66.2 61.5 54.7 44.4 7.4 Precision 23.5 51.7 65.6 63.6 66.7 90.0
Similar Recall 76.7 71.6 67.1 59.7 46.2 9.1 Precision 31.2 66.7 78.7 78.2 73.2 100.0
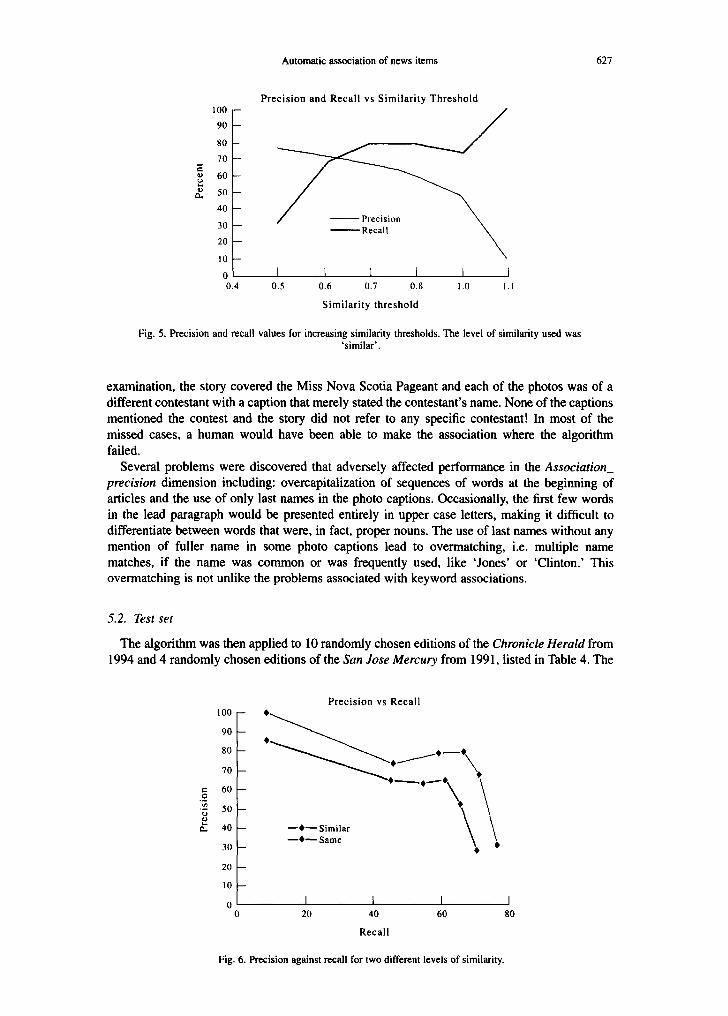
A u t o m a t i c a s soc ia t ion o f n e w s i t ems 627
e -
Y,
1 0 0 -
9 0 -
80 -
70 -
60 -
50 -
40 -
30 -
20 -
1 0 -
0.4
P r e c i s i o n a n d R e c a l l v s S i m i l a r i t y T h r e s h o l d _ / I ~ 1 I I I
0.5 0.6 0.7 0.8 1.0 1.1
S i m i l a r i t y t h r e s h o l d
F ig . 5. P rec i s ion and recal l v a l u e s for i nc reas ing s imi la r i ty thresholds . T h e level o f s imi la r i ty used w a s
' s i m i l a r ' .
examination, the story covered the Miss Nova Scotia Pageant and each of the photos was of a different contestant with a caption that merely stated the contestant's name. None of the captions mentioned the contest and the story did not refer to any specific contestant! In most of the missed cases, a human would have been able to make the association where the algorithm failed.
Several problems were discovered that adversely affected performance in the Association_ precision dimension including: overcapitalization of sequences of words at the beginning of articles and the use of only last names in the photo captions. Occasionally, the first few words in the lead paragraph would be presented entirely in upper case letters, making it difficult to differentiate between words that were, in fact, proper nouns. The use of last names without any mention of fuller name in some photo captions lead to overmatching, i.e. multiple name matches, if the name was common or was frequently used, like 'Jones' or 'Clinton.' This overmatching is not unlike the problems associated with keyword associations.
5.2. Test set
The algorithm was then applied to 10 randomly chosen editions of the Chronicle Herald from 1994 and 4 randomly chosen editions of the San Jose Mercury from 1991, listed in Table 4. The
O
t~
I . t ~
100 - -
9 0 - -
80 -
70 -
60 -
50 -
40 -
30 -
20 -
1 0 -
0
0
P r e c i s i o n v s R e c a l l
I I I 20 40 60
R e c a l l
I 8O
Fig . 6. P rec i s ion aga ins t recal l for two d i f fe ren t l eve ls o f s imilar i ty .

628 Christina Carrick and Carolyn Watters
Table 4. Ten randomly chosen editions of the Chronicle-HeraM from 1994 and 4 randomly chosen editions of the San Jose Mercury from 1991
Newspaper Da~ #Photos #Aaicles #Known mashes
Chronicle-Herald(1994) 7 Jan. 33 142 31 15 Apr. 36 148 34 22 Apr. 40 164 39 27 Ap~ 31 153 29 21 May 45 141 30 2 Jun. 31 194 24 4 Jun. 41 152 29 6 Sept. 47 167 39 27 Sept. 37 179 34 10 Nov. 38 166 35
San Jose Mercury (1991) 23Feb. 190 316 174 26Feb. 147 289 130 19 Jul. 140 336 131 1 Aug. 159 242 155
algorithm was run for each of these data sets finding matches between photo captions and stories within individual data sets. We restricted the algorithm to matches within individual editions so that we could use the associations made by the newspaper staff as the basic 'correct' set of associations against which we could measure the effectiveness of the algorithm.
The raw results of the algorithm applied to the other Chronicle Herald stories are presented in Table 5.
Table 6 and Fig. 7 show the Association_recall and Association__precision results for the trial runs. The mean Association_recall for the trials was 79.8% (standard deviation of 5.7) while the mean Association_precision was 57.5% (standard deviation of 14.9).
The results of the algorithm applied to the San Jose Mercury data are presented in Table 7. We see that for this small test set the mean values for Association_recaU and Association_ precision were 78.0% (standard deviation of 5.2) and 55.3% (standard deviation of 8.8), respectively.
5.3. Efficiency
The time required to extract names for persons, places, companies, dates, and unknowns was comparable with the time required to generate an inverted file. This is chiefly because only 10% of the words in the text need to be analyzed although each of these requires more processing than individual keywords. Storage requirements for the resultant instantiated frames are also much less than for the corresponding inverted file. Consequently, the additional time required to process the potential names is not a factor in choosing this processing option.
Table 5. Raw results of the algorithm applied to the other Chronicle-Herald stories
Date #Known #Matches #Known #Known #New #False matches found matches matches matches matches
(total) found missed found found
7 Jan. 31 113 23 8 9 81 15 Ap~ 34 69 25 9 7 37 22 Apr. 39 76 35 4 16 25 27 Apt 29 47 19 10 10 18 21May 30 33 22 8 4 7 2 Jun. 24 36 16 8 6 14 4 Jun. 29 52 24 5 4 24 6 Sept. 39 110 29 10 15 66 27 Sept. 34 45 22 12 12 11 10 Nov. 35 63 27 8 12 24

Automatic association of news items
Table 6. Association_recall and Associa- tion_precision results for the trial runs
Date Recall (%) Precision (%)
7 Jan. 80.0 28.3 15 Ap~ 78.0 46.4 22Ap~ 92.7 67.1 27Apr. 74.4 61.7 21 May 76.5 78.8 2 Jun. 73.3 61.1 4 Jun. 84.8 53.8 6 Sept. 81.5 40.0 27 Sept. 73.9 75.6 10Nov. 83.0 61.9
Average 79.8 57.5
629
The advantage of producing instantiated attributes in frames over keywords co-occurrence was not shown to be overwhelming for the designated task of photo-text associations. This is due, at least in part, to the cryptic nature of the photo captions. The disparity in number of words used in photo captions means that, in general, each word in the photo caption is relatively more significant. This would not be the case, however, for story to story associations and story to video script associations.
Once the frames have been established, however, they can be used for querying as well as for
cO t~
Recall and Precis ion for 10 trials
100
90
80
70
60
50
4° I 30 - - Recall Precision
20
10
0 I I I I I 1 I I I I 2 3 4 5 6 7 8 9 10
Sample
Fig. 7. Recall and precision for 10 Chronicle-Herald trials.
Table 7. Results of the algorithm applied to the San Jose Mercury data
Date Recall (%) Precision (%)
1 Aug. 72.6 64.6 23 Feb. 78.6 60.9 26 Feb. 86. I 54.3 19 Jul. 74.5 41.5
Average 78.0 55.3

630 Christina Carrick and Carolyn Watters
finding probable content associations. The semantics of the frame representation provides the basis for more sophisticated searching than does simple keyword extraction. It is easiest to see the effect on precision. Consider a query about Toronto. The sample Sea King article in Appendix A would be included by a keyword search but excluded from the answer set based on the frames because Toronto is part of an unknown name (actually the name of a boat) and not a place name in that article. More sophisticated searches are made possible based on frame- based reasoning, such as What MP's are mentioned in the paper today? or Who was the Sea King
captain?
The same algorithm has been used to generate personal editions based on personal profiles of individual newspaper readers (McGilvery & Shepherd, 1995). The profile consists of places, companies, things, unknowns, and people, that occur in the articles that the reader visits while reading an electronic version of news items. This data is used to update the personal profile and adjust the order that items are presented to the reader in the next edition.
6. CONCLUSIONS
The algorithm performed similarly (within one standard deviation) on the new data sets as it did on the training set and so we have confidence that it is generalizable. The algorithm produced results that were always as good as traditional keyword match and with similar processing times but with much more potential. Using a partial representation of news items is an intermediate level of 'understanding' that is not as complete as natural language parsing but not as computationally intensive, and much more complete than keyword extraction but requiring no extra processing time.
Further work will be done evaluating the effectiveness of such an algorithm in determining matches between stories, photos, and videos generated by different sources.
Our interest in an effective matching algorithm goes beyond simply matching photos to stories and includes the following:
• grouping of videos, photos, and text items into same-event super items, • grouping of perhaps dissimilar news items concerned with an individual to get a panorama of
events involving that person • generating a set of items from different news sources on the same event so that one may be
chosen.
Newspaper and current event coverage data is an important source of information for many people on a daily basis. The technology will soon make it possible for readers to have as much data of this type as they can handle. Currently, however, much work is needed to provide tools that allow users to benefit from access to more information.
REFERENCES
Bender, D., Lie, H., Orwant, J., Teodosio, L., & Abramson, N. (1991). Newspace: mass media and personal computing. USENIX Summer '91. Nashville, TN. pp. 329-349.
Brandow, R., Mitze, K., & Rau, L. (1995). Generating concise natural language summaries. Information Processing and Management, 31(5), 703-734.
Gross, A. D. (1991). Getty synoname: The development of software for personal name pattern matching. Proc. ofRIAO '91, Barcelona, Spain. pp. 718-737.
Harmon, D. (1995). Overview of the Second Text Retrieval Conference (TREC-2). Information Processing and Management, 31(3), 271-290.
Jacobs, P. S., & Rau, L. (1990). Scisor: Extracting information from on-line news. Communications of the ACM, 33(1 !), 88-97.
Kilgour, E G. (1995). Effectiveness of surname-title-word searches by scholars. JASIS, 46(2), 146-151. Masand, B., Linoff, G., & Waltz, D. (1992). Classifying news stories using memory based reasoning. Proc. of the
fourteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, N.Y. pp. 59-65.
Mauidin, M. (1991). Retrieval performance in ferret--a conceptual information retrieval system. Proc. of the fourteenth

Automatic association of news items 631
Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, N.Y. pp. 347-355.
Maybury, M. (1995). Generating summaries from event data. Information Processing and Management, 31(5), 735-752.
McGilvery, K., & Shepherd, M. (1995). Adaptive profiles for news selection (Technical Report Dal-CS-95-6). Halifax, Nova Scotia, Canada: Dalhousie University.
McKeown, K., & Radev, D. (1995). Generating summaries of multiple news items. Proc. of 18th ACM SIGIR Conference on Research and Development in Information Retrieval, Seattle, Washington, 9-13 July. pp. 74-82.
McQuail, D. (1992). Media performance. London: Sage Publications. Rau, L. (199 I). Extracting company names from text. Sixth IEEE Conference on Artificial Intelligence Applications.
Miami Beach, Florida. pp. 29-32. Rowe, N. C. (1994). Inferring depictions in natural-language captions for efficient access to picture data. Information
Processing and Management, 29(4), 453-461. Shepherd, M., Watters, C., & Burkowski, E (1995). Delivery of electronic news. Second International Workshop on Next
Generation Information Technologies and Systems. Naharia, Israel. pp. 124-131. Spink, A., & Leatherbury, M. (1994). Name authority files and humanities database searching. Online and CDROM
Review., 18(3), 143-147. Tong, R. A., Applebaum, L. A., Askman, V., & Cunningham, J. E (1987). Conceptual information retrieval using rubric.
Proc. of the Fourteenth Annual International A CM SIGIR Conference on Research and Development in Information Retrieval. New York, N.Y. pp. 247-253.
APPENDIX A
SEA KING NEWS STORY
Headline: Choppers Patched up Again: Fast-track Sea King's Successor, MP Urges Text: There is no link between a fuel link discovered in-flight in a CFB Shearwater-based Sea
King helicopter Wednesday and the fire and fatal crash of Sea King in New Brunswick this spring, an air force spokesman said Friday. But the Liberal MP for Dartmouth said Ottawa should get cracking on a replacement for the 30-year old helicopters before more incidents occur. Meanwhile, the venerable T-33 Silver Star jets, grounded after a fatal crash last month near Windsor, have been cleared for take-off again.
Base commander Col. John Cody said investigators suspect fuel leaked into the cabin of the Sea King that crashed April 28 in New Brunswick, killing two crew, but the fuel is believed to have come from a ruptured fuel line. The fuel leak Wednesday that led to the grounding of Canada's Sea King fleet came from a fitting, and even though fuel was also discovered in the cabin, the problems are unrelated, the colonel said.
Technicians have identified where Wednesday's leak occurred and will be fitting titanium patches on all 30 Sea Kings in the next week or two, he said. The first modified Sea Kings should be in the air by Monday, he said. Modifications will be done as soon as possible to the Sea King aboard HMCS Halifax with the UN embargo in the Adriatic, the helicopter aboard HMCS Toronto en route to the Adriatic, and West Coast-based Sea Kings. The federal government should immediately begin preparations to replace the trouble-plagued Sea King fleet, Dartmouth MP Ron MacDonald said Friday.
"It's almost predictable with a fleet this old that you're going to have more and more incidents like this," he said. The Defence Department should make a decision on a Sea King replacement program as soon as a defence review is completed, he said. "I think the department should know right now what the options are, and they should be preparing to present them to the minister, and the minister to cabinet, as soon as this review is done." The situation raises not only safety concerns but military ones as well, Mr. MacDonald said. "We now have the situation where our destroyers, which are off the former Yugoslavia, don't have air support so they've had to pull back from their duties," he said. "This has to be the No. 1 agenda, post-review, for new acquisitions." The Sea King helicopter serving with HMCS Halifax was out of service for more than a week earlier this summer because of high temperatures in its gearbox.
In June, a Sea King caught fire on the deck of HMCS Provider during exercises off Hawaii, and before that another Sea King had to make an emergency landing in Ontario after engine failure. Col. Cody said Friday those incidents were also caused by gearbox problems.

632 Christina Carrick and Carolyn Watters
Meanwhile, Col. Cody said investigators "are still not sure what happened" to the T-Bird that went down July 27, killing pilot Capt. Harry Munro, 40, but there is "no conclusive evidence...to continue the ban" on flying the 40-year old craft.
Capt. Munro ejected from the aircraft but died of massive trauma when he hit the ground. The 49-strong fleet was grounded immediately, then cleared to fly 10 days later, then grounded again when the canopy was recovered Aug. 10. Col. Cody said investigators have determined the canopy and ejection system "performed normally .... We peeled that onion, and this system works, that system works." But he admitted that investigators are still puzzled over what happened to the aircraft in the moments before it went down, and why the pilot did not successfully eject. Ejection seats work within certain parameters--speed, and angle of the aircraft relative to its direction of flight and to the ground--and pilot, flying at more than 2000 metres, "got into some difficulties...that may have put him outside the (performance) envelope" of the ejection seat, the colonel said.
APPENDIX B
One of Canada's 30 Sea Kings (Fig. B l) undergoes regular maintenance in a hanger at CH Shearwater on Friday. The fleet was grounded earlier this week because of a fuel leak in one chopper, but the problem is now being remedied, military officials say.
Fig. B I. Sea King.





























