Embed Size (px)
Citation preview

10
BAB 2
LANDASAN TEORI
2.1. Database
Perkembangan dunia teknologi akan media penyimpanan Data yang besar
dan efisien dapat direalisasikan dengan Database.
Menurut Conolly dan Begg (2005, p14), Database adalah sekumpulan Data
yang saling terhubung secara logikal, yang dirancang dalam rangka memenuhi
kebutuhan informasi dalam suatu organisasi.
Menurut Satzinger et al., (2008, p398), Database adalah kumpulan Data
yang disimpan dan terintegrasi serta dapat diatur dan dikontrol secara terpusat.
Menurut Rainer dan Turban (2009, p412) Database adalah sekelompok file
yang berhubungan secara logika yang menyimpan Data dan saling berkaitan.
Berdasarkan definisi diatas, maka dapat ditarik kesimpulan bahwa Database
adalah kumpulan logical Data yang saling berhubungan dan disimpan untuk dapat
diolah menjadi informasi yang berguna bagi organisasi.
Setiap Database berisi sejumlah Database Object, antara lain yaitu :
a. Field
Field adalah sekumpulan kecil dari kata atau sebuah deretan angka.
b. Record
Record adalah kumpulan dari field yang berelasi secara logis.

11
c. File
File adalah kumpulan dari record yang berelasi secara logis.
d. Entity
Entity adalah orang, tempat, benda, atau kejadian yang berkaitan dengan
informasi yang disimpan.
e. Attribute
Attribute adalah setiap karakteristik yang menjelaskan suatu entity.
f. Primary Key
Primary Key adalah sebuah field yang nilainya unik yang tidak sama antara
satu record dan record yang lain. Primary key digunakan sebagai tanda
pengenal dari suatu field.
g. Foreign Key
Foreign key adalah sebuah field yang nilainya berguna untuk
menghubungkan primary key lain yang berada pada tabel yang berbeda.
2.2. Database Management System (DBMS)
Database elektronik yang berupa perangkat lunak disebut dengan Database
Management System (DBMS).
Menurut Satzinger et al., (2008, p398), DBMS adalah sistem software yang
mengelola dan memberikan akses kontrol ke Database.
Menurut Rainer and Turban (2009, p111), DBMS adalah kumpulan program
yang dilengkapi dengan tools untuk menambah, menghapus, mengakses, dan
menganalisa Data didalam satu lokasi (Database).

12
Menurut Connoly dan Begg (2005, p16) DBMS adalah suatu sistem
perangkat lunak yang memungkinkan user untuk mendefinisikan (define),
membuat (create), memelihara (maintain) basis Data, dan menyediakan kendali
dalam mengakses basis Data.
Komponen-komponen DBMS (Connolly & Begg, 2005, p18-21), di
antaranya:
• Hardware
DBMS dan aplikasi membutuhkan hardware untuk berjalan.
• Software
Komponen software terdiri dari perangkat lunak DBMS itu sendiri dan
program aplikasi, bersama dengna sistem operasi, meliputi perangkat
lunak jaringan jika digunakan dalam jaringan.
• Data
Merupakan komponen yang paling penting dalam lingkungan DBMS.
• Procedure
Mengacu pada instruksi dan aturan yang menentukan desain dan
kegunaan dari basis Data.
• People
Komponen terakhir adalah orang yang terlibat dengan sistem yang
dibangun tersebut.
Berdasarkan definisi diatas, dapat diambil kesimpulan bahwa DBMS adalah
kumpulan program yang memungkinkan pengguna untuk melakukan akses kontrol

13
ke Database. Contoh dari DBMS adalah: Microsoft access, Microsoft SQL,
Oracle.
2.3. Business Intelligence
Business Intelligence (BI) bukan merupakan sebuah produk maupun sistem.
BI adalah sebuah arsitektur dan kumpulan dari operasional yang terintegrasi dan
juga merupakan aplikasi pengambil keputusan untuk aplikasi dan Database untuk
menyediakan akses yang mudah untuk Data bisnis untuk komunitas bisnis.
Business Intelligence mengarah pada pokok Decision-Support untuk aplikasi dan
Database. Moss (2005, p29)
Menurut Larson (2009, p11) Business Intelligence adalah penyampaian
informasi yang akurat dan berguna untuk pembuat keputusan dalam timeframe
untuk mendukung keefektifan pembuat keputusan.
Menurut Loshin (2012, p6) Business Intelligence adalah proses, teknologi,
dan alat-alat yang dibutuhkan untuk mengubah Data menjadi informasi, informasi
menjadi pengetahuan, dan pengetahuan menjadi rencana yang menDatangkan
keuntungan.
Business Intelligence biasanya dikaitan dengan usaha memaksimalkan
kinerja suatu organisasi. Business Intelligence dimanfaatkan untuk meningkatkan
kinerja melalui pemilihan strategi bisnis yang tepat dan dapat juga membantu suatu
organisasi dalam menganalisis perubahan tren yang terjadi untuk menentukan
strategi yang diperlukan dalam mengantisipasi perubahan tren tersebut.

14
Olszak dan Ziemba (2012, p146) menyimpulkan bahwa menggunakan
Business Intelligence akan memberikan dampak kepada keberhasilan bisnis jika
kebutuhan bisnisnya dapat diketahui. Singkatnya, dalam proyek
pengimplementasian Business Intelligence terdapat beberapa kondisi dasar yang
harus terpenuhi, yaitu :
• Sistem BI harus menjadi bagian dari strategi bisnis perusahaan. Ini harus
sesuai dengan kebutuhan nyata pengguna dan mendukung proses kunci dan
keputusan bisnis di semua tingkat manajemen (strategis, taktis dan
operasional). Untuk melakukan hal ini pengetahuan tentang peluang sistem
BI dalam konteks tantangan bisnis menjadi sangat diperlukan untuk
perusahaan. Sebuah pemahaman yang baik tentang proses pengambilan
keputusan juga diperlukan, karena hanya maka sistem BI dapat digunakan
secara efektif.
• Mengelola implementasi sistem BI harus terpusat, tetapi semua calon
pengguna harus terlibat dalam pelaksanaannya. Dengan situasi seperti itu,
maka akan memungkinkan pengguna untuk menyesuaikan fungsi sistem BI
dengan kebutuhan individu sementara memastikan pelaksanaan yang tepat
dan keberhasilan pelaksanaan.
• Penerapan sistem BI membutuhkan pengetahuan dan keterampilan yang
sesuai untuk implementasi BI. Sebuah tim proyek yang kompeten, yang
terdiri dari manajer, karyawan dan IT spesialis, sangatlah penting.
• Pelaksanaan proyek BI harus memiliki sponsor yang diposisikan dalam
hirarki organisasi setinggi mungkin. Komitmen manajer, khususnya dewan,

15
dalam proses memilih dan menerapkan sistem BI diperlukan. Hal ini akan
memastikan sumber daya yang memadai dan menjadi tanda yang jelas
kepada karyawan bahwa manajemen menekankan karena penting untuk
proyek.
• Sistem BI membutuhkan pengembangan dan adaptasi permanen terhadap
tantangan baru dan harapan dari perusahaan. Konsekuensi dari sistem BI
non-pembangunan adalah penyusutan dan penarikan.
• Sangatlah penting bagi pengguna untuk dapat bisa menggunakan sistem BI.
Untuk itu dapat diberikan pelatihan staf dan sistem yang user-friendly.
• Biaya pelaksanaan BI tidak hanya harus menutupi biaya teknologi, tetapi
juga memperhitungkan langkah-langkah untuk membentuk tim proyek,
dukungan teknis, dukungan substantif, perubahan manajemen, pelatihan
karyawan serta memelihara dan mengembangkan sistem BI di masa depan.
Jika tidak terpenuhi, maka perusahaan akan mempunyai alat yang canggih
tetapi tidak ada yang dapat menggunakannya.
2.3.1 Keuntungan Menggunakan Business Intelligence
Menurut Loshin (2012, p2), ada beberapa keuntungan yang didapat
dengan menggunakan Business Intelligence yaitu:
• Peningkatan profit. Menurut konsultan keuangan dalam portofolio bank
yang khas ritel, 20% dari rekening berkontribusi keuntungan setara
dengan 200% dari keseluruhan laba, sedangkan lebih dari setengah
rekening menghasilkan kerugian, Business Intelligence dapat

16
membantu bisnis klien untuk mengevaluasi nilai pelanggan seumur
hidup dan profitabilitas harapan jangka pendek dan menggunakan
pengetahuan ini untuk membedakan antara menguntungkan dan
nonprofitable pelanggan.
• Penurunan biaya. Apakah itu ditingkatkan manajemen logistik,
menurunkan biaya operasional (seperti pergudangan menurun dan
pengiriman biaya) atau penurunan investasi yang dibutuhkan untuk
membuat penjualan, BI dapat digunakan untuk membantu
mengevaluasi biaya organisasi.
• Customer Relationship Management (CRM). Ini pada dasarnya aplikasi
BI yang menerapkan analisis informasi pelanggan agregat untuk
menyediakan respon layanan pelanggan yang lebih baik untuk
menemukan cross-sell dan up-sell dan meningkatkan keseluruhan
loyalitas pelanggan.
• Penurunan resiko. Menerapkan metode BI untuk Data kredit dapat
meningkatkan analisis resiko kredit, sedangkan mengalisis baik
pemasok dan konsumen serta kehandalan dapat memberikan wawasan
tentang bagaimana merampingkan supply chain.

17
Gambar 2.1 Keuntungan Business Intelligence (Vercellis, 2009, p6)
2.3.2 Arsitektur Business Intelligence
Menurut Carlo Vercellis (2009, p9), Arsitektur BI terdiri dari 3
komponen penting yaitu:
• Sumber Data. Pada tahap pertama, perlu untuk mengumpulkan dan
mengintegrasikan Data yang disimpan dalam sumber-sumber primer
dan sekunder yang heterogen sesuai dengan jenisnya.
• Data Warehouse dan Data Mart. Menggunakan alat ekstraksi,
transformasi dan load yang dikenal sebagai ETL Data yang berasal dari
berbagai sumber yang disimpan di dalam Database untuk mendukung
analisis BI.
• Metodologi BI. Data akhirnya diambil dan digunakan untuk
membuat model matematika dan metodologi analisis dimaksudkan
untuk mendukung keputusan pembuat.

18
Gambar 2.2 Business Intelligence Architecture (Vercellis, 2009, p9)
2.3.3 Jenis-jenis Business Intelligence
Disebutkan (Turban, Aronson, Liang, & Sharda, 2007, p257) jenis-jenis
dari Business Intelligence adalah:
• Enterprise reporting
Produk laporan enterprise digunakan untuk menghasilkan laporan statis
yang didistribusikan secara luas dan akan digunakan oleh banyak orang.
Merupakan laporan dengan format yang tepat untuk laporan operasional
dan dashboard.
• Cube analysis
Cube digunakan untuk menyediakan kemampuan analitis OLAP
multidimensional untuk manajer bisnis dalam lingkungan yang terbatas.
• Ad hoc Querying and Analysis
Tools relational OLAP digunakan untuk memberikan akses user untuk
melakukan query pada basis Data hingga informasi transaksional.

19
• Statistical Analysis and Data Mining
Tools statistic, matematis dan Data mining digunakan untuk melakukan
analisis prediksi atau untuk menemukan korelasi sebab akibat.
• Report Delivery and Alerting
Mesin distribusi laporan digunakan secara proaktif untuk mengirimkan
laporan lengkap atau peringatan kepada populasi user yang besar.
Distribusi ini didasarkan pada jadwal dan event yang disimpan didalam
basis Data.
2.4. Data Warehouse
Menurut Inmon (2005, p495), Data Warehouse adalah koleksi Database
yang terintegrasi yang dirancang untuk mendukung fungsi sistem pengambilan
keputusan, di mana setiap unit Data relevan pada beberapa waktu.
Data Warehouse tidak hanya berfokus pada penyimpanan Data tapi juga
merupakan sistem dengan kemampuan menerima (retrieve), menganalisis Data
(analyze), mengekstrak (extract), mengubah (transform), load Data, mengatur
dictionary Data. Data Warehouse merupakan salah satu bagian dari Business
Intelligence.
Menurut Connolly & Begg (2005, p1197) Data Warehouse adalah suatu
kumpulan Data yang bersifat subject-oriented, integrated, time-variant, dan non-
volatile dalam mendukung proses pengambilan keputusan. Data Warehouse
bertujuan agar perusahaan dapat menggunakan arsip Datanya untuk mendapatkan
keunggulan bisnis.

20
Menurut Turban (2008, p39) Data Warehouse adalah kumpulan Data yang
dihasilkan untuk mendukung pengambilan keputusan, juga merupakan tempat
penyimpanan Data sekarang dan Data historis yang berpotensi untuk digunakan
manager pada perusahaan atau organisasi.
2.4.1 Karakteristik Data Warehouse
Karakteristik Data Warehouse menurut Connolly & Begg (2005, p1151)
yang mengacu kepada Inmon (2005) :
1. Subject Oriented
Subject Oriented berarti bahwa Data Warehouse dibuat atau disusun
berdasarkan pada subjek utama dalam lingkungan perusahaan, bukan
berorientasi pada proses atau fungsi aplikasi. Subject area biasa meliputi
customer (pelanggan), product (produk), transaction (transaksi).Setiap area
subjek utama yang diimplementasikan secara fisik sebagai sekumpulan tabel
yang saling berhubungan dalam Data Warehouse (Inmon, 2005, p34-35).
2. Integrated
Karena sumber Data di dapat dari sistem aplikasi enterprise yang berbeda-
beda, sumber Data ini sering tidak konsisten, misalnya memiliki format yang
berbeda. Sumber Data yang terintegrasi harus dibuat konsisten untuk
menyajikan pandangan bersatu mengenai Data kepada pengguna (Inmon,
2005, p29-31).

21
3. Time Variant
Data pada Data Warehouse hanya akurat dan valid pada waktu tertentu atau
dalam interval waktu tertentu. Tetapi dalam setiap kasus, ada beberapa
bentuk yang menandai waktu untuk menunjukkan saat dalam waktu di mana
record akurat. Perbedaan waktu dari Data Warehouse memperlihatkan Data-
Data yang ada dari waktu ke waktu secara keseluruhan (Inmon, 2005, p32).
4. Non Volatile
Proses update tidak dilakukan secara real-time melainkan di-refresh dari
sistem operasional dalam basis regular. Data baru selalu ditambahkan
sebagai supplement (tambahan), pada Database, bukan sebagai replacement
(penggantian). Database secara terus menerus mengambil Data baru dan
menggabungkannya dengan Data sebelumnya (Inmon, 2005, p31-32).
2.4.2 Extract, Transform, Loading Data (ETL)
Data Warehouse dibangun dengan mengintegrasikan kumpulan Data
dari berbagai sumber, seperti Data operasional. Proses mengintegrasikan
kumpulan Data disebut Extract, Transform, Loading Data (ETL) oleh
Connolly & Begg (2005, p1165).
• Extraction
Proses ekstraksi adalah pengambilan Data dari sumber Data internal dan
eksternal yang dilanjutkan ke Database tujuan. Pada dasarnya, tujuan
proses ekstraksi ini adalah menyiapkan Data untuk diproses lebih lanjut
pada proses selanjutnya.

22
• Transform
Proses transformasi adalah proses pengubahan bentuk Data agar sesuai
dan seragam dengan tujuan Data menjadi lebih terintegrasi satu sama
lain, hingga Data dalam Database tujuan menjadi lebih konsisten.
Sebagai contoh adalah proses transformasi format tanggal, dalam
Database A, format tanggal adalah 11-09-07, sedangkan Database C
adalah 11 September 2007, Data dari Database A dan C akan
ditransformasikan sesuai dengan Database tujuan, misalnya menjadi 11-
Sept-07.
• Load
Setelah Data diproses di tahap ekstraksi dan transformasi, Data sudah
siap untuk dimuat kedalam Database tujuan lewat proses loading,
sehingga Data dapat membantu dalam proses analisis lebih lanjut
kedepannya.
Menurut Vishal (2010, p786) Extract, transform dan load (ETL) adalah
proses inti dari integrasi data dan biasanya berhubungan dengan data
warehouse. Tools ETL mengambil data dari sumber yang dipilih,
mengubahnya menjadi format baru sesuai dengan aturan bisnis, dan
kemudian memuatnya ke dalam struktur data sasaran. Mengelola aturan dan
proses untuk iversity peningkatan sumber data dan data volume tinggi olahan
yang ETL harus ccommodate, membuat manajemen, kinerja dan biaya
primer dan tantangan bagi pengguna. ETL adalah proses kunci untuk
membawa semua data bersama-sama dalam lingkungan, standar homogen.

23
Fungsi ETL membentuk kembali data yang relevan dari sistem sumber
menjadi informasi yang berguna untuk disimpan di data warehouse. Tanpa
fungsi ini, tidak akan ada informasi strategis dalam data warehouse. Jika
sumber data yang diambil dari berbagai sumber tidak membersihkan,
diekstraksi dengan benar, berubah, dan terintegrasi dalam cara yang tepat,
proses query yang merupakan tulang punggung dari gudang data tidak bisa
terjadi Dalam tulisan ini kita tujuan pendekatan muka utama yang akan
meningkatkan kecepatan extract, transform dan load data gudang dengan
dukungan cache query. Karena proses query adalah tulang punggung dari
data warehouse Ini akan mengurangi waktu respon dan meningkatkan kinerja
data warehouse.
Arsitek ETL harus memiliki peran dan tanggung jawab yaitu :
• Arsitek ETL harus menutup mata pada kebutuhan dan persyaratan
organisasi. Dia harus memahami lingkungan operasional secara
keseluruhan dan persyaratan kinerja strategis dari sistem yang
diusulkan. Arsitek harus berinteraksi dengan staf sistem sumber
operasional dan teknis, proyek database administrator (DBA) dan
arsitek infrastruktur teknis untuk mengembangkan metode yang
paling efisien untuk mengekstrak sumber data, mengidentifikasi set
yang tepat dari indeks untuk sumber, arsitek platform pementasan
database desain, menengah diperlukan untuk transformasi data yang
efisien dan menghasilkan infrastruktur pemrograman untuk operasi
ETL sukses.

24
• Programmer ETL seharusnya tidak hanya melihat satu inti dari
programnya. Arsitek harus melihat seluruh sistem dari program, dia
harus memastikan tim teknis memahami desain database target dan
penggunaannya sehingga transformasi yang mengkonversi sumber
data ke dalam struktur data sasaran secara jelas didokumentasikan dan
dipahami. Arsitek ETL mengawasi masing-masing dan setiap
komponen dan subkomponen ETL mereka.
• Sebuah pertimbangan utama bagi arsitek ETL adalah untuk
mengenali perbedaan yang signifikan bahwa metode desain dan
implementasi untuk sistem intelijen bisnis memiliki dari sebuah
proses transaksi online (OLTP) pendekatan sistem.
• Peran arsitek ETL juga meluas dengan konsultan bagi upaya
pemrograman. Arsitek bekerja sama dengan programmer untuk
menjawab pertanyaan dan memainkan peran penting dalam
penyelesaian masalah. Tergantung pada ukuran dari upaya
pemrograman dan organisasi proyek, arsitek ETL juga dapat
mengawasi perkembangan spesifikasi pemrograman. Dalam kasus
apapun, arsitek ETL memainkan peran penting sebagai reviewer dan
pemberi persetujuan selama proses megnkaji ulang.
• Peran terakhir untuk arsitek ETL harus memastikan bahwa berbagai
software yang diperlukan untuk melakukan berbagai jenis pengolahan
data yang benar dipilih.

25
Query cache akan menyimpan catatan permintaan baru dieksekusi.
Tujuan utama dari query cache adalah untuk mengurangi waktu respon
query. Ini akan meningkatkan kemampuan otak data gudang sehingga sistem
yang akan mengingat karya terbaru telah dilakukan. Memori ini akan
digunakan sesudahnya untuk menjawab hasil dari pertanyaan yang telah
sebelumnya dilakukan oleh pengguna.
Cache akan mempertahankan dua keadaan yang valid dan tidak valid.
Ketika permintaan apapun yang diajukan oleh pengguna, memori cache
pertama kali diperiksa untuk memeriksa apakah permintaan yang diminta
sudah menyimpan dalam cache. Jika query disimpan, kemudian memeriksa
keadaan tersebut valid atau tidak valid. Jika negara valid, maka data dapat
diakses dan jika negara tidak valid maka data tidak dapat diakses. tetapi Jika
pengguna mengirim query insert, update, delete dan drop kemudian data
akan mengubah dalam database dan keadaan permintaan terkait akan valid.
sekarang keadaan data yang tidak valid dan permintaan tidak dapat diakses
oleh pengguna. Hal ini dapat menghemat waktu penting dan meningkatkan
kinerja data warehouse dengan tidak mengevaluasi ulang query yang sudah
disimpan dalam cache.

26
2.4.3 Online Transaction Processing (OLTP)
Perusahaan menyimpan semua hal yang terjadi dalam kegiatan
transaksi harian mereka dalam OLTP.
Menurut Larson (2009, p27) Online Transaction Processing (OLTP)
System mencatat interkasi bisnis yang terjadi dan mendukung kegiatan
operasional sehari-hari sebuah organisasi.
Menurut Hill (2009, p32) extract, transform, and load mengekstraksi
Data dari satu atau lebih sistem OLTP, menjalankan beberapa kebutuhan
Data cleansing untuk mengubah Data menjadi format yang konsisten, dan
memasukkan Data yang sesuai format dengan memasukkannya ke dalam
Data Mart dengan menggunakan Extraction, Tramsform, Load (ETL).
Sistem OLTP dirancang untuk memungkinkan banyak user untuk
mengakses Data pada waktu bersamaan serta melakukan proses yang mereka
perlukan. Seluruh penjumlahan yang disimpan dari transaksi-transaksi harian
perusahaan adalah history dari perusahaan tersebut.
2.4.4 Online Analytical Processing (OLAP)
Menurut Larson (2009, p44) Online Analyrical Processing (OLAP)
System memungkinkan pengguna untuk mengambil informasi dengan cepat
dan mudah dari Data, biasanya dalam Data Mart, untuk analisis. Sistem
OLAP menyajikan Data menggunakan measures, dimensions, hierarchies,
and cubes sebagai fokus utama.

27
Cube adalah struktur yang berisi nilai untuk satu atau lebih pengukuran
untuk setiap kombinasi unik dari anggota dalam semua dimensi. Semua
adalah detail, atau leaf-level, nilai. Cube juga mengandung nilai-nilai agregat
yang dibentuk oleh hirarki dimensi atau ketika satu atau lebih dari dimensi
yang tersisa keluar dari hirarki.
Gambar 2.3 Contoh Total Sales Cube (Larson 2009, p34)
Agregat adalah nilai yang dibentuk dengan menggabungkan nilai-nilai
dari dimensi tertentu atau seperangkat dimensi untuk menciptakan nilai
tunggal. Hal ini sering dilakukan dengan menambahkan nilai-nilai bersamaan
dengan menggunakan agregat jumlah, namun perhitungan agregasi lain juga
dapat digunakan.
OLAP biasanya memakai salah satu dari tiga arsitektur untuk
menyimpan Cube Data. Arsitektur tersebut adalah Relational OLAP,
Multidimensional OLAP, dan Hybrid OLAP.

28
Gambar 2.4 Arsitektur OLAP (Larson 2009, p50)
2.4.4.1 Relational OLAP
Relational OLAP (ROLAP) menyimpan struktur kubus dalam
Database multidimensi. Pengukuran leaf-level yang terdapat dalam
Data Mart relasional berfungsi sebagai sumber kubus. Agregat yang
belum diproses juga disimpan dalam tabel Database relasional.
Ketika pengambil keputusan meminta nilai ukuran untuk satu
set dari anggota dimensi, sistem ROLAP pertama mengecek untuk
menentukan apakah anggota dimensi menentukan agregat atau nilai
leaf-level. Jika suatu agregat ditentukan, nilai tersebut dipilih dari
tabel relasional. Jika nilai leaf-level yang ditentukan, nilai tersebut
dipilih dari Data Mart.

29
Keuntungan arsitektur ROLAP yaitu mempunyai
ketergantungan pada tabel relasional, dapat menyimpan sejumlah
besar Data dari arsitektur OLAP lainnya. Juga, karena arsitektur
ROLAP mengambil nilai leaf-level langsung dari Data Mart, nilai
leaf-level yang dikembalikan oleh sistem ROLAP selalu up-to-date
sebagai Data Mart sendiri. Dengan kata lain, sistem ROLAP tidak
menambahkan latensi ke Data leaf-level. Kerugian dari sistem
ROLAP adalah pengambilan nilai-nilai agregat dan leaf-level lebih
lambat dibandingkan dengan arsitektur OLAP lainnya.
2.4.4.2 Multidimensional OLAP
Multidimensional OLAP (MOLAP) menyimpan struktur kubus
dalam Database multidimensi. Baik nilai-nilai agregat yang belum
diproses dan salinan dari nilai leaf-level ditempatkan dalam Database
multidimensi. Karena itu, semua Data yang diminta diberikan dari
Database multidimensi, membuat MOLAP sistem menjadi sangat
responsif.
Waktu tambahan diperlukan ketika loading sistem MOLAP
karena semua Data leaf-level akan disalin ke Database multidimensi.
Karena hal tersebut, ketika Data leaf-level yang dikembalikan oleh
sistem MOLAP tidak sesuai dengan Data leaf-level dalam Data Mart
sendiri. Sistem MOLAP tidak menambahkan latensi ke Data leaf-
level. Arsitektur MOLAP juga membutuhkan tempat penyimpanan

30
lebih banyak untuk menyimpan salinan dari nilai leaf-level dalam
Database multidimensi. Namun, karena MOLAP sangat efisien dalam
menyimpan nilai-nilai, ruang tambahan yang dibutuhkan biasanya
tidak signifikan.
2.4.4.3 Hybrid OLAP
Hybrid OLAP (HOLAP) menggabungkan storage ROLAP dan
MOLAP. HOLAP mencoba untuk mengambil kelebihan dari setiap
arsitektur lain sambil meminimalkan kekurangan mereka.
HOLAP menyimpan struktur Cube dan agregat yang belum
diproses dalam Database multidimensi sehingga menyediakan
pengambilan cepat agregat yang ada dalam struktur MOLAP.
HOLAP menyimpan Data leaf-level dalam Data Mart relasional yang
berfungsi sebagai sumber Cube. Hal tersebut menyebabkan waktu
pengambilan lebih lama ketika mengakses nilai leaf-level. Namun,
HOLAP tidak perlu waktu untuk menyalin Data leaf-level dari Data
Mart. Segera setelah Data diperbarui dalam Data Mart, Data tersedia
untuk pengambil keputusan. Oleh karena itu, HOLAP tidak
menambahkan latensi ke Data leaf-level. Pada intinya, HOLAP
mengorbankan kecepatan pengambilan Data pada leaf-level untuk
mencegah menambahkan latensi ke Data leaf-level dan untuk
mempercepat beban Data.
31
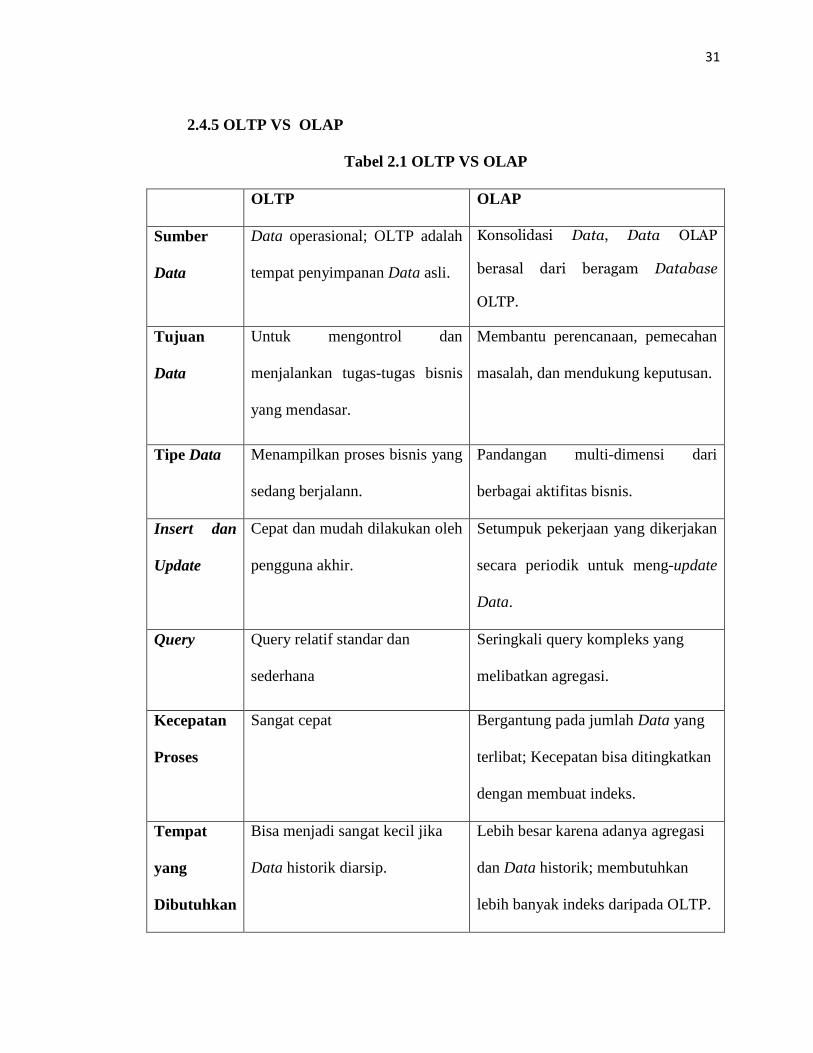
2.4.5 OLTP VS OLAP
Tabel 2.1 OLTP VS OLAP
OLTP OLAP
Sumber
Data
Data operasional; OLTP adalah
tempat penyimpanan Data asli.
Konsolidasi Data, Data OLAP
berasal dari beragam Database
OLTP.
Tujuan
Data
Untuk mengontrol dan
menjalankan tugas-tugas bisnis
yang mendasar.
Membantu perencanaan, pemecahan
masalah, dan mendukung keputusan.
Tipe Data Menampilkan proses bisnis yang
sedang berjalann.
Pandangan multi-dimensi dari
berbagai aktifitas bisnis.
Insert dan
Update
Cepat dan mudah dilakukan oleh
pengguna akhir.
Setumpuk pekerjaan yang dikerjakan
secara periodik untuk meng-update
Data.
Query Query relatif standar dan
sederhana
Seringkali query kompleks yang
melibatkan agregasi.
Kecepatan
Proses
Sangat cepat Bergantung pada jumlah Data yang
terlibat; Kecepatan bisa ditingkatkan
dengan membuat indeks.
Tempat
yang
Dibutuhkan
Bisa menjadi sangat kecil jika
Data historik diarsip.
Lebih besar karena adanya agregasi
dan Data historik; membutuhkan
lebih banyak indeks daripada OLTP.

32
Database
Design
Dinormalisasi dengan tabel yang
banyak.
Didenormalisasi dengan tabel yang
lebih sedikit.
Backup dan
Recovery
Data operasional sangat penting
untuk menjalankan bisnis,
kehilangan Data kemungkinan
akan memerlukan kerugian
keuangan yang signifikan dan
tanggung jawab hokum
Beberapa lingkungan dapat
mempertimbangkan hanya reload
Data OLTP sebagai metode
pemulihan.
Larson (2009, p62)
2.4.6 Data Mart
Menurut Larson (2009, p27) Data Mart adalah bagian utama dari Data
historik dalam tempat penyimpanan elektronik.yang tidak ikut serta dalam
kegiatan operasional harian organisasi. Sebaliknya, Data ini digunakan untuk
membuat BI. Data dalam Data Mart biasanya berlaku untuk area spesifik
dari sebuah organisasi.
Data yang digunakan untuk BI bisa dibagi menjadi 4 kategori yaitu :
• Measure
Pengukuran adalah sebuah kuantitas numeric yang mengungkapkan
aspek dari kinerja organisasi. Informasi yang ditampilkan dari
kuantitas ini digunakan untuk mendukung atau mengevaluasi

33
pengambilan keputusan dan kinerja organisasi. Mengukur juga bisa
disebut fakta.
• Dimensions
Sebuah dimensi memungkinkan kita untuk menerapkan kategorisasi
untuk ukuran agregat. Kategorisasi ini memungkinkan kita melihat
unsur angka yang menciptakan ukuran agregat.
• Attributes
Atribut dapat digunakan untuk menggambarkan anggota dimensi.
Atribut mungkin berisi informasi tentang anggota dimensi yang
penggunanya cenderung ingin menjadi bagian dari output intelijen
BI mereka. Atribut juga digunakan untuk menyimpan informasi
yang dapat digunakan untuk membatasi atau menyaring catatan
yang dipilih dari Data Mart selama analisis Data.
• Hierarchies
Hierarki adalah struktur yang terdiri dari dua atau lebih tingkat
dimensi yang terkait. Dimensi yang terdapat pada tingkat atas
hirarki sepenuhnya mengandung satu atau lebih dimensi dari tingkat
yang lebih rendah sebuah hirarki.
34
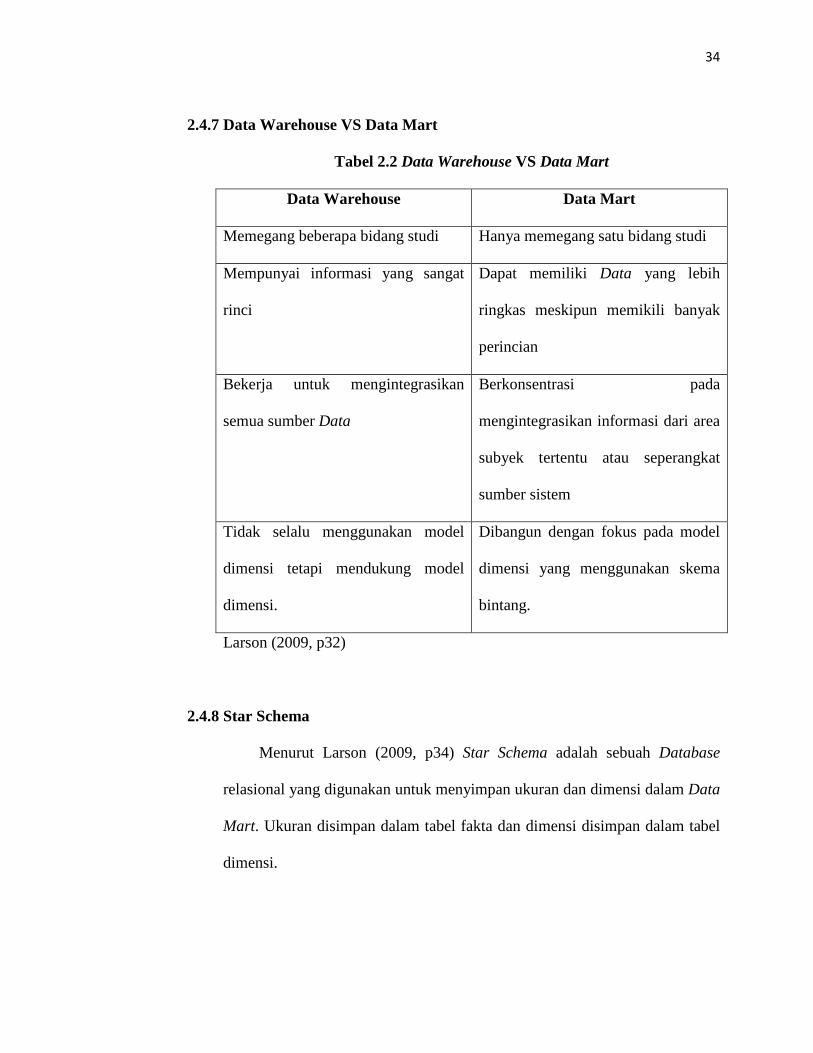
2.4.7 Data Warehouse VS Data Mart
Tabel 2.2 Data Warehouse VS Data Mart
Data Warehouse Data Mart
Memegang beberapa bidang studi Hanya memegang satu bidang studi
Mempunyai informasi yang sangat
rinci
Dapat memiliki Data yang lebih
ringkas meskipun memikili banyak
perincian
Bekerja untuk mengintegrasikan
semua sumber Data
Berkonsentrasi pada
mengintegrasikan informasi dari area
subyek tertentu atau seperangkat
sumber sistem
Tidak selalu menggunakan model
dimensi tetapi mendukung model
dimensi.
Dibangun dengan fokus pada model
dimensi yang menggunakan skema
bintang.
Larson (2009, p32)
2.4.8 Star Schema
Menurut Larson (2009, p34) Star Schema adalah sebuah Database
relasional yang digunakan untuk menyimpan ukuran dan dimensi dalam Data
Mart. Ukuran disimpan dalam tabel fakta dan dimensi disimpan dalam tabel
dimensi.

35
Gambar 2.5 Contoh Star Schema (Larson 2009, p36)
Menurut Muheet Ahmed Butt, Quadri S.M.K., dan Majid Zaman (2012, p19)
keuntungan utama dari star schema adalah sebagai berikut :
• Menyediakan pemetaan secara langsung dan intuitif antara entitas bisnis
yang sedang dianalisis oleh pengguna akhir dan desain skema.
• Memberikan kinerja yang dioptimalkan untuk star query khusus.
• Secara luas didukung oleh sejumlah besar alat business intelligence, yang
dapat mengantisipasi atau bahkan mengharuskan skema data warehouse
berisi tabel dimensi.

36
2.5. Data Mining
Menurut Loshin (2012, p205) Data Mining, seperti pada jaman dulu,
menggunakan alat semacam penyaringan untuk mengumpulkan kotoran dan debu
yang mengalir di sungai untuk mencari serbuk-serbuk emas yang berharga.
Dimana untuk arti sekarang, dapat diterjemahkan sebagai seorang Data Analyst
“menyaring” Data yang berukuran beberapa terabytes untuk mencari “bongkahan”
pengetahuan.
Pada Business Intelligence, Data Mining digunakan untuk mencari informasi
yang dibutuhkan untuk membuat sebuah “intelligence” baru dari kumpulan Data
yang telah di “mining” tersebut.
Menurut Ballard (2009, p190) Data Mining menggunakan algoritma
matematika yang kompleks untuk menyaring Data detail untuk mengidentifikasi
pola-pola, korelasi, dan pengelompokan Data.
Algoritma Data Mining sendiri ada 9 jenis, yaitu :
• Decision Tree
• Linear Regression
• Naïve Bayes
• Clustering
• Association Rules
• Sequence Clustering
• Time Series
• Neural Network
• Logistic Regression Algorithm

37
2.5.1 Data Mining Algorithm Clustering
Menurut Larson (2009, p487) algoritma Clustering membangun
kelompok entitas karena proses training set Data. Setelah kelompok
diciptakan, algoritma menganalisis susunan tiap kelompok. Hal ini terlihat
pada nilai-nilai setiap atribut untuk entitas di setiap kelompok.
Algoritma Clustering di Business Intelligence Development Studio
mempunyai diagram yang mirip dengan Gambar 2.6, Dengan memasukkan
nilai atribut yang diinginkan, maka dapat memiliki kode warna kelompok
sesuai dengan konsentrasi nilai yang diinginkan.
Gambar 2.6 Clustering (Larson 2009, p487)
Sebagai contoh, saat mencoba untuk menentukan karakteristik yang
membedakan dari pelanggan yang cenderung untuk pergi ke kompetisi dalam
dua bulan ke depan. Maka diciptakan pengelompokan pelanggan dari Data
training. Selanjutnya, Business Intelligence Development Studio akan
menunjukkan konsentrasi pelanggan dari set Data pelatihan yang tidak pergi
dalam waktu dua bulan. Semakin gelap kelompok, semakin banyak
pelanggan yang pergi didalamnya. Akhirnya, kelompok dapat diperiksa mana
atribut yang paling membedakan dengan kelompok lain.

38
2.5.2 Data Mining Algorithm Time Series
Menurut Larson (2009, p491) Time Series digunakan untuk
menganalisis dan memprediksi waktu-data dependen. Algoritma ini
sebenarnya merupakan kombinasi dari dua algoritma dalam satu: algoritma
ARTxp dikembangkan oleh Microsoft dan industri-standar algoritma
ARIMA (Auto-Regressive Integrated Moving Average), yang dikembangkan
oleh Box dan Jenkins.
Jika data time series mengandung kesalahan, maka langkah pertama
adalah melakukan smoothing. Smoothing selalu melibatkan beberapa bentuk
rata-rata data lokal sedemikian rupa sehingga komponen nonsistematik dari
pengamatan individu membatalkan satu sama lain. Teknik yang paling umum
bergerak smoothing rata-rata yang menggantikan setiap elemen seri baik oleh
rata-rata sederhana atau tertimbang dari n elemen sekitarnya, di mana n
adalah lebar "jendela" smoothing (Box & Jenkins) Median dapat digunakan
sebagai pengganti sarana. Keuntungan utama dari median dibandingkan
dengan rata-rata bergerak smoothing adalah bahwa hasilnya kurang bias oleh
outlier (dalam jendela smoothing). Dengan demikian, jika ada outlier dalam
data (misalnya, karena kesalahan pengukuran), smoothing median biasanya
menghasilkan halus atau setidaknya lebih "handal" kurva dari rata-rata
bergerak berdasarkan lebar jendela yang sama. Kerugian utama dari
pemulusan median adalah bahwa tanpa adanya outlier jelas mungkin
menghasilkan kurva yang lebih "bergerigi" daripada bergerak rata-rata dan
tidak memungkinkan untuk pembobotan.

39
Formula simple untuk smoothing adalah St = *X t + (1- )*St-1. Bila
diterapkan secara rekursif untuk setiap pengamatan berturut-turut di dalam
suatu rangkaian, setiap nilai baru yang dirapikan (perkiraan) dihitung sebagai
rata-rata tertimbang dari pengamatan saat ini dan pengamatan merapikan
sebelumnya, pengamatan merapikan sebelumnya dihitung pada gilirannya
dari nilai diamati sebelumnya dan merapikan tersebut nilai sebelum
pengamatan sebelumnya, dan sebagainya. Dengan demikian, pada dasarnya,
setiap nilai merapikan adalah rata-rata tertimbang dari pengamatan
sebelumnya, di mana bobot menurun secara eksponensial tergantung pada
nilai parameter (alpha). Jika sama dengan 1 (satu) maka pengamatan
sebelumnya diabaikan seluruhnya, jika sama dengan 0 (nol), maka
pengamatan saat ini diabaikan seluruhnya, dan nilai merapikan seluruhnya
terdiri dari nilai merapikan sebelumnya (yang pada gilirannya dihitung dari
pengamatan merapikan sebelum, dan seterusnya, sehingga semua nilai
merapikan akan sama dengan nilai merapikan awal S0). Nilai-nilai di antara
akan menghasilkan hasil antara.
Formula untuk forecast adalah Forecastt = St + It-p atau Forecastt = St*I t-
p. Dalam rumus ini, St singkatan untuk (simple) eksponensial yang merapikan
serangkaian nilai pada waktu t, dan It-p singkatan faktor merapikan musiman
pada saat t dikurangi p (panjang musim). Dengan demikian, dibandingkan
dengan merapikan secara eksponensial sederhana, perkiraan
"disempurnakan" dengan menambahkan atau mengalikan nilai sederhana
dengan komponen musiman yang sudah diprediksi. Komponen musiman

40
berasal dari St tersebut yang sudah dirapikan secara eksponensial sederhana
seperti It = It-p + *(1- )*et atau It = It-p + *(1- )*et/St yang diprediksi
komponen musiman pada waktu t dihitung sebagai komponen musiman
masing-masing dalam siklus musiman terakhir ditambah sebagian dari
kesalahan (et, yang diamati dikurangi nilai perkiraan pada waktu t).
Mengingat rumus di atas, jelaslah bahwa parameter dapat mengasumsikan
nilai antara 0 dan 1. Jika itu adalah nol, maka komponen musiman untuk titik
tertentu dalam waktu diprediksi identik dengan komponen musiman
diperkirakan untuk waktu masing-masing selama siklus musiman
sebelumnya, yang pada gilirannya diperkirakan menjadi identik dengan yang
dari siklus sebelumnya, dan sebagainya. Dengan demikian, jika nol adalah,
komponen musiman konstan berubah digunakan untuk menghasilkan satu
langkah ke depan prakiraan. Jika parameter adalah sama dengan 1, maka
komponen musiman dimodifikasi "maksimal" pada setiap langkah oleh
kesalahan perkiraan masing-masing (kali (1 -), yang kita akan mengabaikan
untuk tujuan pengenalan singkat ini). Dalam kebanyakan kasus, ketika
musiman hadir dalam time series, parameter yang optimal akan jatuh di suatu
tempat antara 0 (nol) dan 1 (satu).
Algoritma dimulai dengan waktu-data terkait dalam data pengujian
yang ditetapkan. Pada Gambar 2.7, ini adalah data penjualan untuk setiap
bulan. Untuk menyederhanakan hal-hal, kita hanya melihat data untuk dua
produk dalam contoh kita.

41
Data penjualan diputar untuk membuat tabel di bagian bawah Gambar
2.7. Data untuk kasus 1 adalah pada bulan Maret 2008. Jumlah penjualan di
(t0) kolom untuk kasus ini berasal dari tahun 2008 penjualan bulan Maret
angka. Jumlah penjualan di (t-1), atau waktu minus satu bulan, kolom berasal
dari Februari 2008, dan jumlah penjualan di (t-2) kolom berasal dari Januari
2008. Kasus 2 menggeser bulan ke depan satu, sehingga (t0) menjadi April,
(t-1) menjadi Maret, dan (t-2) menjadi Februari.
Gambar 2.7 Time Series (Larson 2009, p492)
Algoritma kemudian menggunakan Data dalam tabel pivot untuk
datang dengan formula matematika yang menggunakan angka-angka dari (t-

42
1) dan (t-2) kolom untuk menghitung jumlah di kolom (t0) untuk setiap
produk. Bahkan, ia menggunakan baik ARTxp dan algoritma ARIMA untuk
melakukan perhitungan ini dan muncul dengan hasil dicampur. Dengan
menggunakan rumus, kita dapat memprediksi nilai penjualan untuk produk
masa depan.
Metodologi ARIMA yang dipakai adalah estimation dan forecasting.
parameter yang diperkirakan (menggunakan prosedur fungsi minimalisasi),
sehingga jumlah residual kuadrat diminimalkan. Estimasi parameter yang
digunakan dalam tahap terakhir (Forecasting) untuk menghitung nilai-nilai
baru dari serankaian (di luar yang termasuk dalam set input data) dan interval
yang dipecaya untuk memprediksi nilai-nilai. Proses estimasi dilakukan saat
merubah (membedakan) data, sebelum perkiraan dihasilkan, rangkaian perlu
diintegrasikan (integrasi adalah kebalikan dari membedakan) sehingga
perkiraan dinyatakan dalam nilai-nilai yang kompatibel dengan input data.
2.6. Business Performance Management
Berdasarkan jurnal Franco-Santos, Monica (2007, p7) Business Performance
Management (BPM) adalah sebuah sistem pengukuran kinerja strategis yang
memberikan informasi untuk memungkinkan perusahaan dalam mengidentifikasi
strategi menawarkan potensi tertinggi untuk mencapai tujuan organisasi, dan
menyelaraskan proses manajemen, seperti penetapan target, pengambilan
keputusan, dan evaluasi kinerja, dengan pencapaian tujuan strategis yang dipilih.

43
Menurut Ballard (2009, p13) BPM adalah proses yang memungkinkan
pengguna untuk memenuhi pengukuran kinerja bisnis dan tujuan. Hal ini
memungkinkan pengguna untuk secara proaktif memonitor dan mengelola proses
bisnis, dan mengambil tindakan yang tepat yang menghasilkan tercapainya tujuan
organisasi.
Gambar 2.8 BPM Framework (Ballard 2009, p6)
2.6.1 Keuntungan BPM
Keuntungan dari Business Performance Management menurut Ballard
(2009, p16) adalah sebagai berikut :
• Organisasi tidak lagi terpecah karena tindakan independen dari unit
bisnis. Sekarang organisasi lebih selaras dan bekerja menuju tujuan
bisnis yang sama.
• Sumber daya diarahkan kepada tindakan yang konsisten dengan cara
memenuhi tujuan bisnis. Hal ini memungkinkan perencanaan sumber
daya ditingkatkan dan diprioritaskan.

44
• Hasil dalam pandangan gabungan keadaan bisnis saat ini, dengan
menggabungkan proses informasi, status aktivitas operasional dan TI
status. Hal ini menempatkan keadaan bisnis saat ini didalam konteks,
memungkinkan menghindari masalah proaktif.
• Memungkinkan meningkatkan dan mengautomatisasi proses dan
alokasi sumber daya. Menyediakan kolaborasi terhadap seluruh tim
perusahaan dan proses untuk mempercepat perbaikan kinerja bisnis.
2.6.2 Key Performance Indicator
Menurut Ballard (2009, p32) Key Performance Indicator (KPI) adalah
pengukuran atau metrik dari kinerja bisnis membantu mengarahkan
keputusan bisnis. Metrik menunjukkan seberapa baik bisnis yang dilakukan
relatif terhadap strategi yang ditetapkan dan rencana operasi. Sebuah metrik
dapat menjadi sesuatu yang sederhana seperti berapa banyak bagian yang
baru saja menyelesaikan pekerjaannya, atau mungkin pengukuran yang lebih
kompleks yang melacak profitabilitas berdasarkan produk, jenis produk,
lokasi, dan musim.
Sebagian besar perusahaan memiliki sejumlah besar metrik, dan dalam
setiap proyek BPM salah satu tugas utama adalah untuk menentukan metrik
yang paling penting dan batasan yang dapat membantu manajemen
menentukan bagaimana usaha dijalankan. Metric yang seperti ini dinamakan
sebagai KPI.

45
Untuk kesuksesan proyek BPM, manajer bisnis harus mengidentifikasi
KPI yang tepat untuk bagian dari bisnis yang mereka kelola. Beberapa
contoh KPI adalah :
• Pertumbuhan fee based income
• Pertumbuhan jumlah pelanggan
• Utilisasi mesin produksi
• Jumlah dokter yang masuk kategori “active users”
2.6.3 Dashboard
Menurut Caroteno (2007, p2) berasumsi bahwa dashboard : Seorang
pengguna harus dapat melihat dashboard dan dengan cepat membuat
pengamatan tanpa scrolling, drilling , atau mengklik dari layar awal. Interaksi
pengguna minimal dapat diikutsertakan untuk meningkatkan pemahaman dan
memperjelas pengamatan, namun interaksi terlalu banyak mengalahkan
tujuan dashboard dan menjangkau seluruh wilayah analisis. Dan itu
dashboard juga:
• Menyediakan cara untuk memantau dan melacak kinerja
• Harus mampu menyampaikan apa yang terjadi secara cepat
• Biasanya mengandung indikator kinerja utama dan menggunakan
beberapa jenis visualisasi Data.
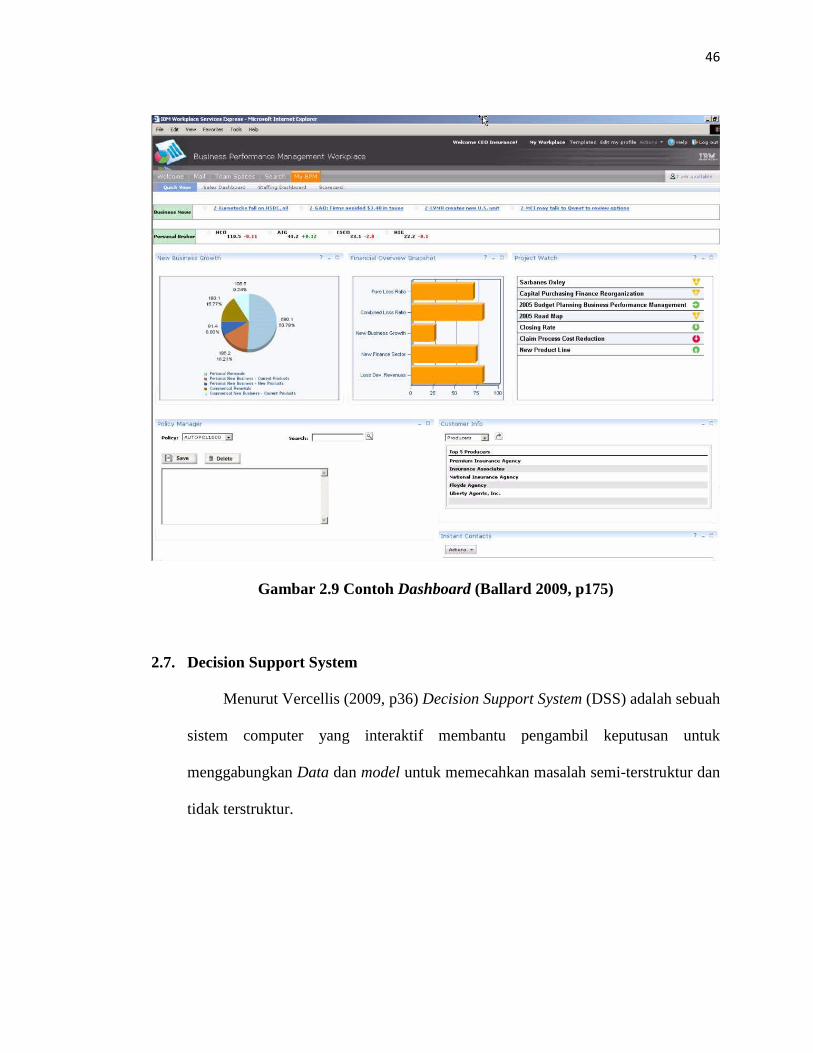
Menurut Ballard (2009, p190) Dashboard adalah sebuah tampilan
informasi bisnis yang menampilkan BI dengan grafik ikon yang mudah
dipahami.
46
Gambar 2.9 Contoh Dashboard (Ballard 2009, p175)
2.7. Decision Support System
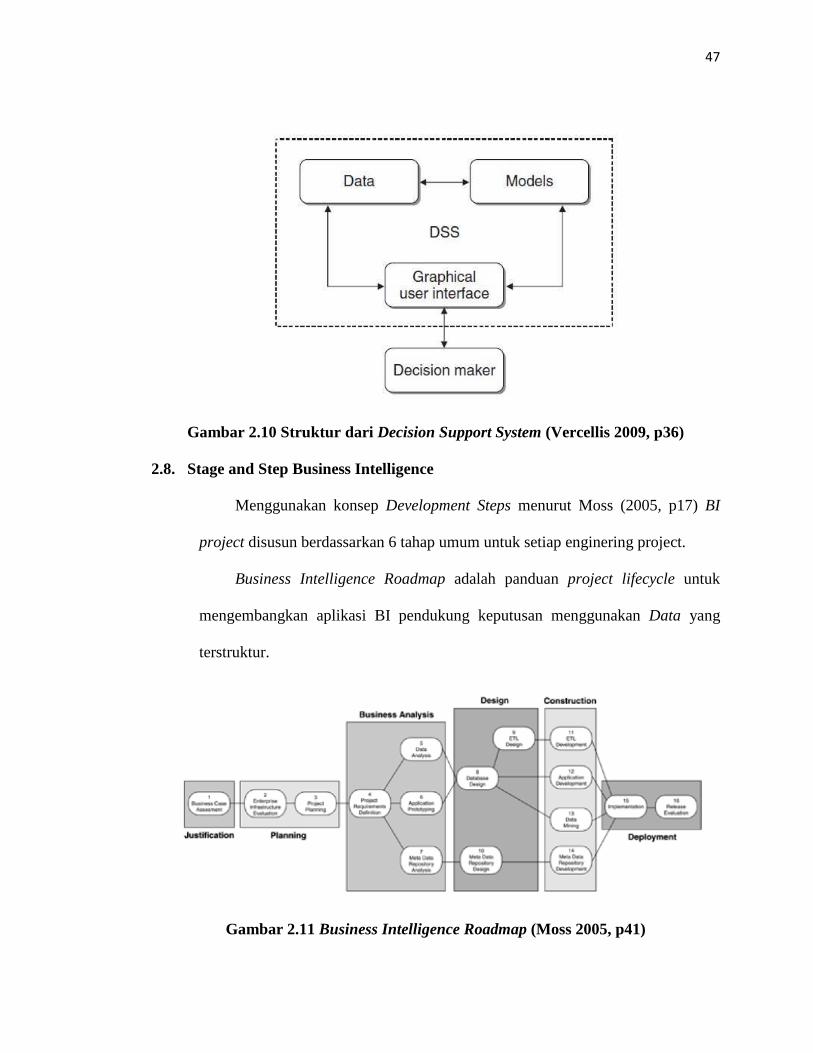
Menurut Vercellis (2009, p36) Decision Support System (DSS) adalah sebuah
sistem computer yang interaktif membantu pengambil keputusan untuk
menggabungkan Data dan model untuk memecahkan masalah semi-terstruktur dan
tidak terstruktur.
47
Gambar 2.10 Struktur dari Decision Support System (Vercellis 2009, p36)
2.8. Stage and Step Business Intelligence
Menggunakan konsep Development Steps menurut Moss (2005, p17) BI
project disusun berdassarkan 6 tahap umum untuk setiap enginering project.
Business Intelligence Roadmap adalah panduan project lifecycle untuk
mengembangkan aplikasi BI pendukung keputusan menggunakan Data yang
terstruktur.
Gambar 2.11 Business Intelligence Roadmap (Moss 2005, p41)

48
2.8.1 Business Justification
Karena pembuatan sebuah Business Intelligence memakan sumber daya
yang relatif besar, maupun dari segi materi dan waktu, sebuah perusahaan
dapat memikirkan inisiatif antara kebutuhan dari strategi BI dengan perataan
bisnis untuk memperlihatkan antara biaya yang dikeluarkan untuk pembuatan
strategi BI dengan keuntungan yang diperoleh perusahaan setelah
menggunakan BI tersebut.
Perataan untuk inisiatif Business Intelligence Decision Support harus
berdasarkan dengan bisnis yang berjalan, bukan teknologi yang berjalan.
Sangat tidak dianjurkan untuk membuat sebuah aplikasi BI yang
membutuhkan biaya yang sangat besar hanya untuk berfokus pada teknologi
saja. Jadi, setiap aplikasi BI harus dapat mengurangi “Business Pain”
(masalah yang berpengaruh pada keuntungan dan efisiensi perusahaan).
2.8.1.1 Four Business Justification Component
2.8.1.1.1 Business Driver
Mengidentifikasi Business Driver, Strategic Business
Goals, dan objektif dari aplikasi BI. Dan juga memastikan
bahwa objektif dari aplikasi BI mendukung tujuan dari
sebuah perusahaan.
2.8.1.1.2 Business Analysis Issue
Mendefinisikan masalah-masalah analisis bisnis dan
informasi yang diperlukan untuk membantu mencapai

49
tujuan dari perusahaan dengan cara mengadakan
persyaratan level tinggi untuk bisnis perusahaan.
2.8.1.1.3 Cost Benefit Analysis
Memperkirakan biaya untuk membangun dan menjaga
sebuah aplikasi BI berikut dengan sistem pengambilan
keputusan. Memastikan ROI (Return on Investment) atau
“balik modal” dengan cara menetapkan monetary value
pada manfaat nyata dan juga menyorot hasil dan
kentungan yang diperoleh oleh perusahaan.
2.8.1.1.4 Risk Assessment
Menilai resiko dalam hal teknologi, kompleksitas,
integrasi, perusahaan, projek tim, dan investasi finansial.
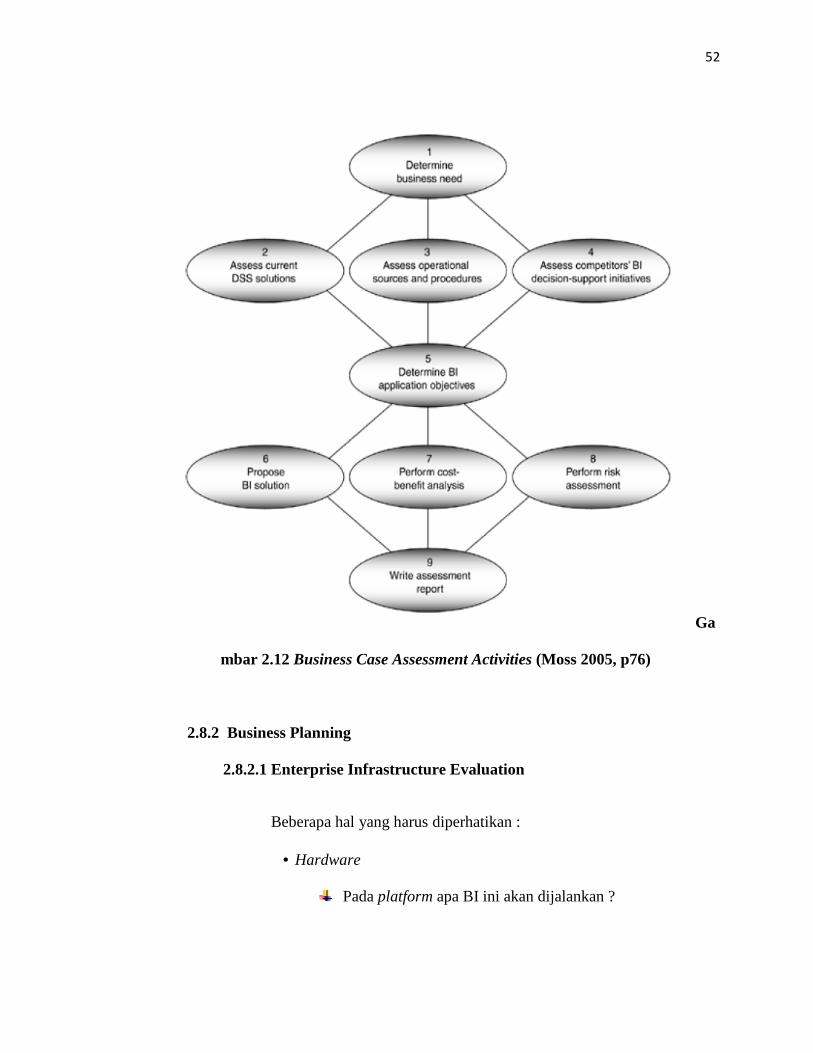
2.8.1.2 Business Case Assessment Activities
2.8.1.2.1 Determining the Business Need
Harus ada informasi bisnis yang jelas yang tidak hanya
cukup dengan metode pengambilan keputusan yang
simpel.
2.8.1.2.2 Assess the Current Decision-Support System Solutions
Mengecek solusi dari sistem pengambilan keputusan yang
lama dan mencari kekurangan yang ada.

50
2.8.1.2.3 Assess the Operational Sources and Procedures
Pada saat kita memeriksa dan menganalisa kekurangan
dari sistem pengambilan keputusan yang lama, perhatikan
juga sumber Data operasional dan prosedur yang berjalan
di perusahaan.
2.8.1.2.4 Assess the Competitors’ BI Decision-support Initiatives
Menjadi yang terdepan dari kalangan kompetitor
merupakan sebuah hal yang sangat penting dalam
berbisnis. Agar dapat menjadi yang terdepan, kita harus
mengetahui apa yang para competitor kita lakukan.
Sangatlah penting untuk mengetahui kunci kesuksesan dan
kegagalan dari perusahaan kompetitor dengan cara
mengetahui inisatif BI yang mereka gunakan pada
perusahaan mereka.
2.8.1.2.5 Determine the BI Application Objectives
Jika kita sudah mengetahui masalah bisnis yang berjalan
serta kelemahan dan kekurangan dari lingkungan BI yang
ada, kita dapat memperjelas objektif dari aplikasi BI yang
akan kita bangun.
2.8.1.2.6 Propose a BI Solution
Penggunaan objektif aplikasi BI dan hasil analisis dari
lingkungan BI yang berjalan, termasuk sistem pengambil
keputusan, kita sekarang dapat mengajukan solusi BI.

51
2.8.1.2.7 Perform a Cost-Benefit Analysis
Memastikan biaya yang diperlukan untuk membangun
sebuah aplikasi BI berikut dengan sistem pengambilan
keputusannya. Termasuk juga dengan biaya hardware,
software, alat-alat yang diperlukan serta biaya
maintenance.
2.8.1.2.8 Perform a Risk Assessment
Membuat daftar-daftar tentang seluruh resiko yang
munkin terjadi dalam pembuatan aplikasi BI tersebut. Dan
membuat Risk Assessment Matrix. Jika tidak mempunyai
cukup informasi untuk membuat Risk Assessment Matrix,
kita dapat membuat dengan 6 kategori resiko basis, yaitu :
teknologi, kompleksitas, integrasi, organisasi, tim projek,
dan investasi financial.
2.8.1.2.9 Write the Assessment Report
Mendeskripsikan kebutuhan perusahaan dengan
menggunakan business need, baik itu masalah maupun
kesempatan, dan menyarankan tentang 1 atau lebih solusi
pengambilan keputusan.
52
Ga
mbar 2.12 Business Case Assessment Activities (Moss 2005, p76)
2.8.2 Business Planning
2.8.2.1 Enterprise Infrastructure Evaluation
Beberapa hal yang harus diperhatikan :
• Hardware
Pada platform apa BI ini akan dijalankan ?

53
Hardware apa yang kita perlukan? Jika ada, berapa biaya
yang dibutuhkan ?
Akankah hardware baru yang dipasang tersebut
terintegrasi dengan platform yang kita pakai ?
Apakah kita membutuhkan staff baru untuk maintenance
hardware baru tersebut ?
Bagaimana hardware baru tersebut dapat
mengakomodasikan kebutuhan yang selalu meningkat dan
jumlah Data yang naik secara konsisten ?
• Network
Apa tipe LAN (Local Area Network) yang akan kita
gunakan ?
Apa tipe WAN (Wide Area Network) yang akan kita
gunakan ?
Apakah bandwidth dari WAN tersebut cukup untuk
mengimbangi kebutuhan perusahaan ?
• Middleware
Apa tipe dari Middleware yang sekarang sedang
digunakan ?
Apakah kita mempunyai Middleware yang diperlukan
dalam menerima dan memproses Data dari platform yang
bermacam-macam dan memindahkannya ke linkungan
pengambil keputusan ?

54
Apakah kita membutuhkan Middleware ? Jika ya, berapa
biaya yang diperlukan ?’
Dari Hardware, Software, dan Middleware, yang mana
yang paling penting diantaranya ? Haruskah kita
membelinya ? Atau cukup dengan menyewa saja ?
• Database Management System
DBMS apa yang telah kita miliki ?
Apakah kita perlu untuk membeli DBMS baru ? Jika ya,
berapa biaya yang diperlukan untuk sebuah DBMS baru ?
Apakah DBMS baru tersebut akan kompatibel dengan
sistem kita?
Apakah kita perlu untuk memperkerjakan Database
Administrator baru ? Jika ya, berapa biaya yang
diperlukan?
• Tools and Standards
Bagaimana para Business Analyst sekarang menganalisa
Data perusahaan ? Apakah Reporting and Query Tools
yang mereka gunakan?
Apa peralatan dan perlengkapan tambahan yang
diperlukan?
Apakah kita mengetahui masalah besar pada infrastruktur
di dalam perusahaan?

55
2.8.2.2 Project Planning
Beberapa hal yang harus diperhatikan :
• Business Involvement
Apakah kita mempunya sponsor bisnis yang kuat ?
Apakah kita mempunyai pemegang saham yang kuat dan
bisa berkomunikasi dengan baik ?
• Project Scope and Deliverable
Apakah kita menerima permintaan formal akan projek BI
?
Seberapa detail persyaratannya ?
• Cost-Benefit Analysis
Apakah kita sudah melakukan Cost-Benefit Analysis ?
Kapankah sampai kita menuju ROI ?
• Infrastructure
Apakah kita telah membahas tentang komponen
infrastruktur yang bersifat teknikal maupun yang tidak ?
Apakah ada keganjilan dalam komponen tersebut ?
• Staffing and Skills
Sudahkah kita mengidentifikasi anggota kelompok ?
Apakah semua member memiliki kemampuan yang
diinginkan ?

56
2.8.3 Business Analysis
2.8.3.1 Project Requirement Definition
Pada bagian ini, akan dibahas beberapa hal tentang cara untuk
menentukan persyaratan, perbedaaan antara bisnis pada umumnya
dengan syarat yang berhubungan dengan projek.
Selain itu, akan dibahas juga bagaimana membuat report penuh
secara lengkap pada bisnis.
2.8.3.2 Data Analysis
Gambar 2.13 Perbandingan Teknik Data Analysis (Moss 2005, p178)
2.8.3.2.1 Top-Down Logical Data Modeling
Merupakan teknik yang paling efektif dalam pencarian dan
pendokumentasian setiap dokumen dan model perusahaan
yang terintegrasi, atau disebut juga Logical Data
Modeling.
Karena kemampuannya yang independen, sebuah logical
Data model ini lebih mengarah ke bisnis, bukan ke arah

57
Database atau aplikasi. Jadi, sebuah Data yang unik, yang
hanya ada di dunia bisnis nyata, juga ada di dalam logical
Data model meskipun secara fisik Data tersebut disimpan
di dalam tempat penyimpanan yang berbeda.
Gambar 2.14 Proses yang independen dari Logical Data Model (Moss 2005, p180)
2.8.3.2.2 Bottom-Up Source Data Analysis
Sebuah analis Data tidak bisa berhenti pada tahap top-
down logical model saja karena sumber Data-nya sering
tidak mengikuti aturan bisnis atau polisi yang berlaku
yang diambil pada saat pembuatan model.
Jika Bottom-Up Analysis ini tidak dilakukan, masalah akan
Data dan pelanggaran aturan bisnis tidak akan terdeteksi
sampai pada tahap ETL (Extract, Transform, Load)

58
dilakukan. Beberapa masalah kualitas Data munkin tidak
akan terdeteksi sama sekali sampai pada tahap
implementasi, atau pada saat pelanggan melakukan
complain.
2.8.3.3 Application Prototyping
Beberapa poin penting tentang prototyping adalah :
Limit the Scope : membatasi lingkup fungsional dan lingkp Data
dari settiap iterasi prototype ke subset aplikasi yang spesifik.
Understand Database requirement early : prototype akan
membantu Database Administrator mengerti kebutuhan akses
access path untuk Database tujuan BI.
Choose the right Data : mengambil Data yang tepat untuk
prototype.
Test tool usability : tes kegunaan dari peralatan akses dan
analisis.
Involve the business people : tes prototype dengan lebih dari
satu pebisnis.
2.8.3.4 MetaData Repository Analysis
Ada 2 kategori metadata:
1. Business metadata

59
Menyediakan pebisnis dengan roadmap untuk mengakses Data
bisnis dalam lingkungan pendukung keputusan BI.
2. Technical metadata
Mendukung teknisi dan power user dengan menyediakan para
teknisi dengan informasi tentang aplikasi dan Database mereka,
yang mereka butuhkan untuk menjaga aplikasi BI.
Gambar 2.15 Business Data vs Technical Data (Moss 2005, p231)
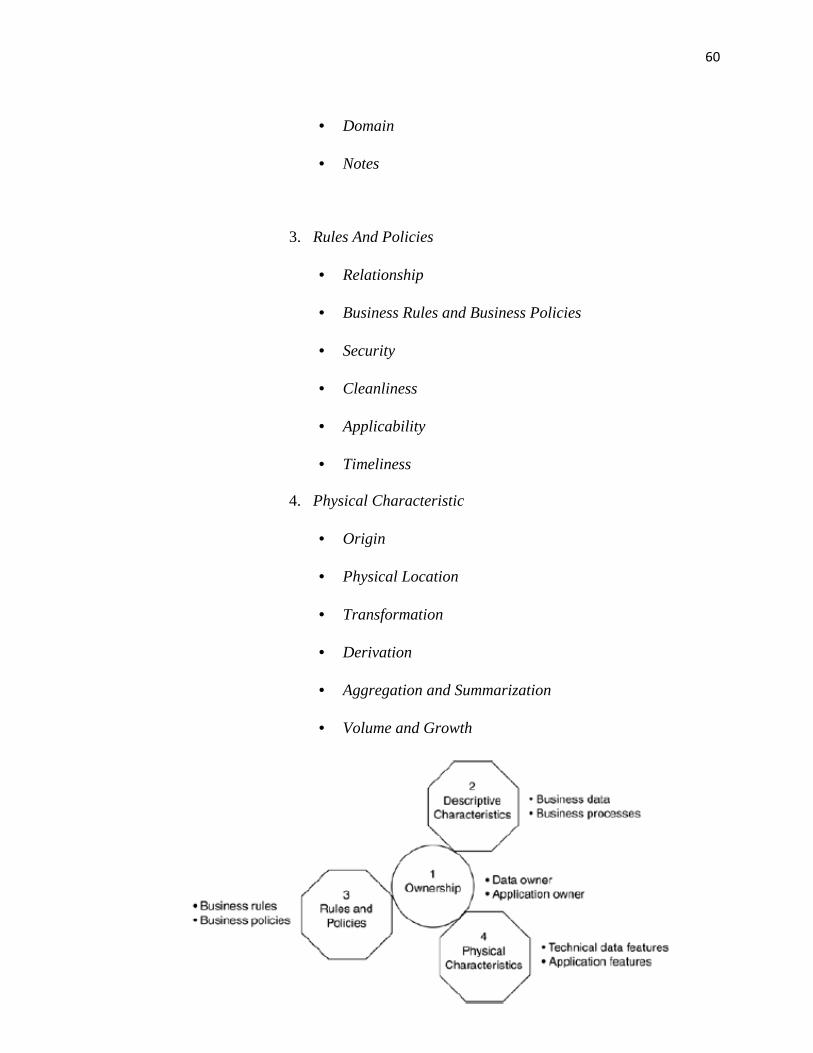
Meta Data Classification dibagi menjadi 4 :
1. Ownership
• Data Owner
• Application Owner
2. Descriptive Characteristic
• Name
• Definition
• Type and Length
60
• Domain
• Notes
3. Rules And Policies
• Relationship
• Business Rules and Business Policies
• Security
• Cleanliness
• Applicability
• Timeliness
4. Physical Characteristic
• Origin
• Physical Location
• Transformation
• Derivation
• Aggregation and Summarization
• Volume and Growth

61
Gambar 2.16 Meta Data Classification (Moss 2005, p234)
2.8.4 Business Design
2.8.4.1 Database Design
Aktifitas dari perancangan Database
Review the Data Access Requirements
Database Administrator harus memeriksa akses Data dan
menganalisa kebutuhan (report, queries), yang dianalisis dan
diselesaikan pada step 6, aplikasi prototyping.
Determine the Aggregation and Summarization requirements
Sebelum berlanjut ke design schema akhir untuk tujan Database
BI, Database Administrator menentukan Data agregat dan
rangkuman kebutuhan dengan representasi bisnis dan pimpinan
developer aplikasi.
Design the BI Target Database
Pernyataan rata-rata orang bahwa aplikasi BI hanya tentang
analisis multidimensional dan laporan multidimensional adalah
tidak benar.
Kebutuhan Data akses dan agregat Data dan rangkuman
kebutuhan akan menentukan Database design yang paling
cocok.
Design the Physical Database Structures

62
Clustering, partitioning, indexing dan meletakkan datasets
adalah 4 karakteristik yang paling penting untuk merancang
design Database.
Build the BI Target Databases
Database fisik dibangun pada saat DDL (Data Definition
Language) dijalankan bersama DBMS. Seorang Database
Administrator menggunakan DDL untuk medeskripsikan
struktur Database kepada DBMS.
Develop Database Maintenance Procedures
Pada saat Database menjalani tahan produksi, sangat penting
untuk membuat backup Database dan mengatur ulang tabel-
tabel yang berantakan.
Prepare to Monitor and Tune the Database Designs
Pada saat aplikasi BI diimplementasikan, tujuan dari BI
Database harus dimonitor dan dijaga. Design Database yang
paling baik tidak menjamin performa yang baik selama terus
menerus, sebagian karena tabelnya menjadi tidak tersusun, dan
sebagian karena penggunaan Database BI tujuan yang berganti
setiap saat.
Prepare to Monitor and Tune the Query Designs
Sejak performa adalah sesuatu tantangan pada aplikasi BI, kita
harus dapat mengeksplorasi trik didalamnya untuk mencari

63
sumber masalahnya. Parallel query execution adalah satu dari
beberapa trik untuk meningkatkan performa dari query.
Gambar 2.17 Database Design Activities (Moss 2005, p269)
2.8.4.2 ETL Design
Sumber Data untuk aplikasi BI berasal dari beberapa sumber
platform, dimana sumber tersebut diatur oleh beberapa aplikasi
dan sistem operasi. Tuuan dari penggunaan ETL ini sendiri adalah
untuk menggabungkan Data dari platform-platform yang berbeda
ini kedalam sebuah format standar untuk Database tujuan BI
didalam lingkungan pengambilan keputusan.

64
Gambar 2.18 Sumber Data Heterogen (Moss 2005, p278)
2.8.4.3 Meta Data Repository Design
Jika tempat penyimpanan meta Data berlisensi, maka kemungkinan
besar harus ditingkatkan dengan fitur yang didokumentasikan pada
meta model yang logis tetapi tidak disediakan oleh produk. Jika
tempat penyimpanan meta Data sedang dibangun, keputusan harus
dibuat apakah desain tempat penyimpanan Database akan berbasis
entitas-hubungan atau berorientasi objek. Dalam kedua kasus, desain
harus memenuhi persyaratan meta model yang logis.
2.8.5 Construction
2.8.5.1 ETL Development
Banyak alat yang tersedia untuk proses ETL, ada beberapa canggih
dan beberapa sederhana. Berdasarkan pada persyaratan untuk
pembersihan Data dan transformasi Data dikembangkan pada

65
Langkah 5, Analisis Data, dan Langkah 9, Desain ETL, alat yang
mungkin ETL atau mungkin bukan solusi terbaik. Dalam kedua
kasus, preprocessing Data dan penulisan ekstensi untuk melengkapi
kemampuan alat ETL sering diperlukan.
2.8.5.2 Application Development
Setelah upaya prototyping telah memenuhi persyaratan fungsional,
pengembangan aplikasi akses dan analisis yang sebenarnya dapat
dimulai. Mengembangkan aplikasi dapat menjadi masalah sederhana
dari menyelesaikan prototipe operasional, atau dapat menjadi upaya
pengembangan lebih dengan menggunakan hal yang berberbeda,
akses yang lebih kuat dan alat analisisnya. Dalam kedua kasus,
kegiatan aplikasi front-end pengembangan biasanya dilakukan secara
paralel dengan kegiatan pengembangan back-end ETL dan
pembangunan tempat penyimpanan metadata.
2.8.5.3 Data Mining
Banyak organisasi tidak menggunakan BI pendukung keputusan
dalam lingkungan untuk sepenuhnya. Aplikasi BI sering terbatas pada
laporan, beberapa di antaranya bahkan bukan laporan jenis baru,
tetapi penggantian dari laporan yang lama. Balasan nyata berasal dari
informasi yang tersembunyi dalam Data organisasi, yang dapat
ditemukan hanya dengan alat Data Mining.

66
2.8.5.4 Metadata Repository Development
Jika keputusan dibuat untuk membangun sebuah tempat penyimpanan
meta Data dibandingkan dengan untuk melisensi, sebuah tim yang
terpisah biasanya diisi dengan proses pengembangan. Ini menjadi
sub-proyek yang cukup besar dalam keseluruhan proyek BI.
2.8.6 Deployment
2.8.6.1 Implementation
Setelah tim telah menguji secara menyeluruh semua komponen dari
aplikasi BI, tim mengeluarkan Database dan aplikasi. Pelatihan
dijadwalkan untuk staf bisnis dan pemegang saham lainnya yang akan
menggunakan aplikasi BI dan tempat penyimpanan metadata. Fungsi
pendukung dimulai, yang meliputi operasi helpdesk, menjaga
Database sasaran BI, penjadwalan dan menjalankan batch ETL,
pemantauan kinerja, dan mengatur Database.
2.8.6.2 Release Evaluation
Dengan konsep rilis aplikasi, sangat penting untuk mendapatkan
keuntungan yang dipelajari dari proyek-proyek sebelumnya. Setiap
deadline yang terlewati, biaya overruns, perselisihan, dan resolusi
sengketa harus diperiksa, dan proses penyesuaian harus dilakukan
sebelum rilis berikutnya dimulai. Setiap alat, teknik, pedoman, dan
proses yang tidak membantu harus dievaluasi dan disesuaikan,

67
bahkan mungkin dibuang. Tidak perlu melakukan langkah-langkah
pembangunan secara berurutan, tim proyek kemungkinan biasanya
akan melakukan secara paralel. Namun, karena ada susunan alam dari
satu tahap engineering dengan yang lain, ketergantungan tertentu ada.
2.9. Teori Khusus
2.9.1 Perguruan Tinggi
Perguruan tinggi adalah satuan pendidikan penyelengara pendidikan
tinggi. Peserta didik perguruan tinggi disebut mahasiswa, sedangkan tenaga
pendidik perguruan tinggi disebut dosen. Menurut jenisnya, perguruan tinggi
dibagi menjadi dua :
• Perguruan tinggi negeri adalah perguruan tinggi yang diselengarakan
oleh pemerintah.
• Perguruan tinggi swasta adalah perguruan tinggi yang diselengarakan
oleh pihak swasta.
(Wikipedia)
2.9.2 Perguruan Tinggi di Indonesia
Di Indonesia, perguruan tinggi dapat berbentuk akademi, institut,
politeknik, sekolah tinggi, dan universitas. Perguruan tinggi dapat
menyelenggarakan pendidikan akademik, profesi, dan vokasi dengan
program pendidikan diploma (D1, D2, D3, D4), sarjana (S1), magister (S2),
doktor (S3), dan spesialis.

68
Universitas, institut, dan sekolah tinggi yang memiliki program doktor
berhak memberikan gelar doktor kehormatan (doktor honoris causa) kepada
setiap individu yang layak memperoleh penghargaan berkenaan dengan jasa-
jasa yang luar biasa dalam bidang ilmu pengetahuan, teknologi,
kemasyarakatan, keagamaan, kebudayaan, atau seni. Sebutan guru besar atau
profesor hanya dipergunakan selama yang bersangkutan masih aktif bekerja
sebagai pendidik di perguruan tinggi.
Pengelolaan dan regulasi perguruan tinggi di Indonesia dilakukan oleh
Kementerian Pendidikan Nasional. Rektor Perguruan Tinggi Negeri
merupakan pejabat eselon di bawah Menteri Pendidikan Nasional.
Selain itu juga terdapat perguruan tinggi yang dikelola oleh
kementerian atau lembaga pemerintah non-kementerian yang umumnya
merupakan perguruan tinggi kedinasan, misalnya Sekolah Tinggi Akuntansi
Negara yang dikelola oleh Kementerian Keuangan.
Selanjutnya, berdasarkan undang-undang yang berlaku, setiap
perguruan tinggi di Indonesia harus memiliki Badan Hukum Pendidikan yang
berfungsi memberikan pelayanan yang adil dan bermutu kepada peserta
didik, berprinsip nirlaba, dan dapat mengelola dana secara mandiri untuk
memajukan pendidikan nasional.
2.9.3 Kebutuhan Tenaga Kerja
Satuan yang menunjukan kebutuhan sumber daya manusia yang diperlukan
untuk mengisi lapangan pekerjaan pada divisi atau kelompok profesi tertentu.

69
Kebutuhan sumber daya manusia dapat digolongkan berdasarkan profesi,
skill, pendidikan, dan jenis kelamin. Pada thesis ini kebutuhan sumber daya
manusia dikelompokan berdasarkan profesi. Contohnya: Kedokteran,
akuntan, arsitek, teknik informatika, dll.





























