Embed Size (px)
Citation preview

0
SAKARYAÜNİVERSİTESİ
BİLİŞİMTEKNOLOJİLERİİÇİNİŞLETMEİSTATİSTİĞİ
Hafta11
Yrd. Doç. Dr. Halil İbrahim CEBECİ
Bu ders içeriğinin basım, yayım ve satış hakları Sakarya Üniversitesi’ne aittir. "Uzaktan Öğretim" tekniğine uygun olarak hazırlanan bu ders içeriğinin bütün hakları saklıdır. İlgili kuruluştan izin almadan ders içeriğinin tümü ya da bölümleri mekanik, elektronik, fotokopi, manyetik kayıt veya başka şekillerde çoğaltılamaz, basılamaz ve dağıtılamaz.
Her hakkı saklıdır © 2013 Sakarya Üniversitesi

1
BÖLÜM 5
ÇIKARIMSAL İSTATİSTİK
BÖLÜMÜN AMACI
Bu bölümün amacı ikiden fazla örneklem üzerinde karşılaştırmalı analizler gerçekleştirmek adına
kullanılacak istatistiksel yöntemler hakkında temel bilgiler vermek, sonuçlarının yorumlanabilmesi
kabiliyetinin öğrenciye kazandırılmasıdır.
5.4. İkiden Fazla Örneklem Testleri
İkiden fazla örneklemin birbiri ile arasındaki farklılıkların istatistiksel açıdan anlamlı olup olmadığının
analiz edilmesi için çift örneklem testleri kullanılır. Bu testlerde esas olan herhangi bir grubun diğer
gruplara göre farklılık göstermesidir. Örneğin A grubu B ve C gruplarından farklı bir ortalamaya
sahipse (istatistiki açıdan) o zaman testler farklılık olduğunu öngörür. Ama test sonucu B ile C nin
birbiri ile çok yakın sonuç üretmesi ile ilgilenmez, yani bu iki grup tamamen aynı sonuçları üretebilir.
Veri analizleri için kullanılacak testler verilerin bağımsız veya eşleştirilmiş olması ve verilerin normal
dağılıma uyup uymaması ile birlikte farklılık gösterilir.
Karşılaştırmalı Veri Analizi
Tek Örneklem Bağımsız Veri
Parametrik VeriTek Örneklem T
Testi
Parametrik Olmayan Veri
Wilcoxon İşaretli Sıralar testi
Çift Örneklem
Bağımsız Veri
Parametrik VeriBağımsız
Örneklem T‐Testi
Parametrik Olmayan Veri
Mann Whitney U Testi
Eşleştirilmiş Veri
Parametrik VeriEşleştirilmiş
Örneklem T Testi
Parametrik Olmayan Veri
WilcoxonEşleştirilmiş Çiftler Testi
İkiden Fazla Örneklem
Bağımsız Veri
Parametrik Veri Varyans Analizi
Tek Faktör (ANOVA)
Çift Faktör
Çok Faktör (MANOVA)
Parametrik Olmayan Veri
Kruskal Wallis Testi
Bağımlı Veri
Parametrik VeriRastgele Blok
Dizaynı
Parametrik Olmayan Veri
Friedman Testi

2
5.4.1. Tek Yönlü Varyans Analizi (ANOVA)
Eğer 2 veya daha fazla grubun (genelde 3 den fazla) farklılıklarının incelenmesi isteniyorsa bu
durumda ANOVA tercih edilmelidir.
Aşağıda verilen örnek yardımıyla analizin işleyişini inceleyelim.
ÖRNEK
Bir araştırmacı üniversitelerin işletme fakültelerinde verilen analitik çözümleme yeteneği gerektiren 4 farklı derste, yüksek başarı ile bitirme durumlarının farklılıklarını analiz etmek istemektedir. Araştırmacı dört dersin farklı başarı düzeylerine sahip olabileceğini düşünmektedir. Aşağıdaki tabloyu dikkate alarak bu durumu analiz ediniz. (Verilerin normal dağıldığı düşünülmektedir.)
Başarılı Not Alan Öğrenci Sayısı (AA ve BA)
Karar Destek Sis. Zeki Sistemler Sistem Analizi Girişimcilik
35 27 25 34
30 38 33 16
32 35 29 26
45 33 33 28
35 36 31 34
53 32 49 16
52 26 38 43
56 42 30 42
60 33 45 31
54 44 46 45
ÇÖZÜM
Öncelikle araştırma hipotezleri belirlenmelidir.
: çö ü ğ ş ü . : çö ü ğ ş ü .
Uygun test yöntemi ve anlamlılık düzeylerinin belirlenmesi bu sorunun ikinci adımıdır. İkiden farklı grubun analizi yapıldığı, verilerin normal dağıldığı soruda verildiğinden ve örneklemlerin bağımsız olduğu da dikkate alındığında “ANOVA” yöntemini 0,05 değerinde test etmeyi tercih ediyoruz.
Daha sonra analizler Excel yardımıyla gerçekleştirilebilir.

3
EXCEL
Öncelikle elimizde bulunan verileri analize uygun şekilde Excel’e yerleştirmeliyiz.
Veri girildikten sonra Veri Çözümleme aracına gidilerek, “Anova: Tek Etken” testi seçilir. Aşağıdaki ekranda ilgili yerler girilir.
Gelen ekranda “Giriş Aralığı” alanına test için girdiğimiz “Ders Sütunları” seçilir. Eğer veri seçimlerinde açıklama satırları seçildi ise (Bu soruda seçilmiştir), o zaman “Etiketler” kutucuğu seçilmelidir. Son olarak “Alfa” kutucuğuna anlamlılık düzeyi değeri girilmelidir. Bu işlemler bittikten sonra analiz sonuçlarını istediğimiz alan “Çıkış Aralığı” kısmından seçilmelidir.
Yukarıdaki sonuç tablosu incelendiğinde F testi değerinin yüksek çıktığı ve buna bağlı olarak hipotezi kabul olasılığının da anlamlılık düzeyinden düşük hesaplandığı görülmektedir. Sonuç olarak
hipotezi red edilip, hipotezi kabul edilecek, yani analitik çözümleme gerektiren derslerdeki başarı düzeylerinin farklık gösterdiği sonucuna ulaşılacaktır.
Tabloda verilen ortalama değerleri dikkatlice incelendiğinde “Karar Destek Sistemleri” dersinin ortalamasının çok farklı olması analiz sonucunu doğurmaktadır. “Zeki Sistemler” ve “Sistem Analizi”

4
ortalamalarının birbirine çok yakın olduğu sonucuna dikkat ediniz. Bu gibi durumlarda TUKEY HSD ismiyle anılan özel bir istatistiksel değer tablosunun incelenmesi uygun olacaktır. (Bu test Excel yardımıyla gerçekleştirilememektedir. Bu durumda diğer istatistiksel paket programlardan faydalanabilirsiniz)
TUKEY HSD SONUÇLARI (Kabul Olasılıkları)
Karar Destek Sis. Zeki Sistemler Sistem Analizi Girişimcilik
Karar Destek Sis. 1,000 0,062 0,122 0,010
Zeki Sistemler 0,062 1,000 0,989 0,872
Sistem Analizi 0,122 0,989 1,000 0,705
Girişimcilik 0,010 0,872 0,705 1,000
Yukarıdaki tablo incelendiğinde Sarı ile gösterilen “Karar Destek Sistemleri” ile “Girişimcilik” Dersleri farklılığının anlamlı olduğu görülmektedir.
ÖRNEK
Bir araştırmacı üniversitelerin işletme fakültelerinde verilen sayısal 4 farklı derste, yüksek başarı ile bitirme durumlarının farklılıklarını analiz etmek istemektedir. Araştırmacı dört dersin farklı başarı düzeylerine sahip olabileceğini düşünmektedir. Aşağıdaki tabloyu dikkate alarak bu durumu analiz ediniz. (Verilerin normal dağıldığı düşünülmektedir.)
Başarılı Not Alan Öğrenci Sayısı (AA ve BA)
İstatistik Olasılık Yöneylem Üretim
Planlama 18 24 19 24
18 22 22 19
20 20 14 12
18 14 23 13
21 24 22 14
20 23 18 13
23 24 24 18
16 20 12 19
19 16 12 17
16 19 16 20

5
ÇÖZÜM
Öncelikle araştırma hipotezleri belirlenmelidir.
: ş ü . : ş ü .
Uygun test yöntemi ve anlamlılık düzeylerinin belirlenmesi bu sorunun ikinci adımıdır. İkiden farklı grubun analizi yapıldığı, verilerin normal dağıldığı soruda verildiğinden ve örneklemlerin bağımsız olduğu da dikkate alındığında “ANOVA” yöntemini 0,05 değerinde test etmeyi tercih ediyoruz.
Daha sonra analizler Excel yardımıyla gerçekleştirilebilir.
EXCEL
Önceki sorudakine benzer şekilde “Veri Çözümleme” ile soruyu çözersek, aşağıdaki sonuç tablosunu elde ederiz.
Yukarıdaki sonuç tablosu incelendiğinde F testi değerinin çok yüksek çıkmamış ve buna bağlı olarak hipotezi kabul olasılığının da anlamlılık düzeyinden yüksek hesaplandığı görülmektedir. Sonuç
olarak hipotezi kabul edilecek, hipotezi red edilecektir, yani analitik çözümleme gerektiren derslerdeki başarı düzeylerinin farklık göstermediği sonucuna ulaşılacaktır.
TUKEY HSD değer tablosu aşağıdaki gibidir
TUKEY HSD SONUÇLARI
İstatistik Olasılık Yöneylem Üretim Planlama
İstatistik 1,000 0,721 0,973 0,609
Olasılık 0,721 1,000 0,458 0,120
Yöneylem 0,973 0,458 1,000 0,853
Üretim Planlama 0,609 0,120 0,853 1,000
Yukarıdaki tablodan bütün grupların birbiri arasındaki farklılıklarının istatistiksel açıdan değerli olmadığı görülmektedir. Analiz sonuçları incelendiğinde de 0,16 kabul olasılığı değeri bu tablonun bir kanıtıdır.

6
Yukarıda verilen iki örnekte de verilerin alındığı üniversitelerin bir önemi yoktur. Yani 10 farklı
üniversitenin rastgele seçildiği varsayılmaktadır. Fakat bazı durumlarda üniversitelerin önemli olduğu
(yani satırların önemli olduğu) durumlarda mevcuttur. Bu anlamda test biraz farklılaşacaktır.
“ANOVA: Çift Etken Testi” olarak adlandırılan bu durum bize önemli yorum avantajları sunabilir.
Eğer her bir satıra bir üniversite geliyorsa, yani yineleme yoksa o zaman “ANOVA: Yinelemesiz Çift
Etken Testi” tercih edilmelidir.
ÖRNEK
Bir araştırmacı üniversitelerin işletme fakültelerinde verilen sayısal 4 farklı derste, yüksek başarı ile bitirme durumlarının farklılıklarını analiz etmek istemektedir. Araştırmacı dört dersin farklı başarı düzeylerine sahip olabileceğini düşünmektedir. Ayrıca araştırmacı üniversiteler arasında da farklılık olabileceğini öngörmektedir. Aşağıdaki tabloyu dikkate alarak bu durumu analiz ediniz. (Verilerin normal dağıldığı düşünülmektedir.)
Başarılı Not Alan Öğrenci Sayısı (AA ve BA)
Üniversite
Karar Destek Sis.
Zeki Sistemler
Sistem Analizi Girişimcilik
1 35 27 25 34 2 30 38 33 16 3 32 35 29 26 4 45 33 33 28 5 35 36 31 34 6 53 32 49 16 7 52 26 38 43 8 56 42 30 42 9 60 33 45 31
10 54 44 46 45
ÇÖZÜM
İki farklı durum için iki farklı hipotez grubu hazırlanmalıdır.
Dersler bazında farklılık:
: çö ü ğ ş ü . : çö ü ğ ş ü .
Üniversite bazında farklılık:
: çö ü ğ ş ü ü
ç . : çö ü ğ ş ü ü
ç .
Uygun test yöntemi ve anlamlılık düzeylerinin belirlenmesi bu sorunun ikinci adımıdır. İkiden farklı grubun analizi yapıldığı, verilerin normal dağıldığı soruda verildiğinden ve örneklemlerin bağımsız

7
olduğu da dikkate alındığında “ANOVA: Yinelemesiz Çift Etken” yöntemini 0,05 değerinde test etmeyi tercih ediyoruz.
Daha sonra analizler Excel yardımıyla gerçekleştirilebilir.
EXCEL
Önceki sorudakine benzer şekilde “Veri Çözümleme” ile soruyu çözersek, aşağıdaki sonuç tablosunu elde ederiz.
Yukarıdaki sonuç tablosu incelendiğinde satırlar açısından da, sütunlar açısından da farklılıkların anlamlı oldukları görülmektedir. (Satırlar= Üniversiteler arası farklılık (Kabul olasılığı = 0,038742), Sütunlar= Dersler açısından farklılık (Kabul olasılığı = 0,003956)) Yani hem üniversiteler açısından hem de dersler açısından farklılıklar anlamlıdır. Yani dersler ve üniversiteler farklı başarı düzeylerini öngörmektedir.
Burada Üniversite ve derslerin iki farklı etken olduğunu görmekteyiz. Her iki etkende tekrar
etmemektedir. Yani her bir satırda bir üniversite ve her bir sütunda bir ders mevcuttur. Bazı
durumlarda bu bilgi yeterli olmaz. Aşağıdaki soru ile beraber bu durumu daha iyi anlayabiliriz.

8
ÖRNEK
Bir araştırmacı üniversitelerin işletme fakültelerinde verilen sayısal 4 farklı derste, yüksek başarı ile bitirme durumlarının farklılıklarını analiz etmek istemektedir. Araştırmacı dört dersin farklı başarı düzeylerine sahip olabileceğini düşünmektedir. Ayrıca araştırmacı üniversitelerde bu derslerden önce verilen Modelleme ve araştırma yöntemleri derslerinin bu derslerdeki başarı düzeylerini nasıl etkilediklerini belirlemek istemektedir. Aşağıdaki tabloyu dikkate alarak bu durumu analiz ediniz. (Verilerin normal dağıldığı düşünülmektedir.)
Başarılı Not Alan Öğrenci Sayısı (AA ve BA)
Öncül Ders
Karar Destek Sis.
Zeki Sistemler
Sistem Analizi Girişimcilik
Araşt. Yönt. 35 27 25 34
Araşt. Yönt. 30 38 33 16
Araşt. Yönt. 32 35 29 26
Araşt. Yönt. 45 33 33 28
Araşt. Yönt. 35 36 31 34
Modelleme 53 32 49 16
Modelleme 52 26 38 43
Modelleme 56 42 30 42
Modelleme 60 33 45 31
Modelleme 54 44 46 45
ÇÖZÜM
Aşağıdaki verilen hipotezler araştırma amacını gerçeklemek adına oluşturulmalıdır.
Dersler bazında farklılık:
: çö ü ğ ş ü . : çö ü ğ ş ü .
Araştırma Yöntemleri dersinin öncül ders olarak alınması:
: çö ü ğ ş ü ö ü
AraştırmaYöntemleri ç . : çö ü ğ ş ü ö ü
AraştırmaYöntemleri ç .
Modelleme dersinin öncül ders olarak alınması:
: çö ü ğ ş ü ö ü
ç . : çö ü ğ ş ü ö ü
ç .

9
Uygun test yöntemi ve anlamlılık düzeylerinin belirlenmesi bu sorunun ikinci adımıdır. İkiden farklı grubun analizi yapıldığı, verilerin normal dağıldığı soruda verildiğinden ve örneklemlerin bağımsız olduğu da dikkate alındığında “ANOVA: Yinelemeli Çift Etken” yöntemini 0,05 değerinde test etmeyi tercih ediyoruz.
Daha sonra analizler Excel yardımıyla gerçekleştirilebilir.
EXCEL
Önceki sorudakine benzer şekilde “Veri Çözümleme” ile soruyu çözersek, aşağıdaki sonuç tablosunu elde ederiz.
Yukarıdaki tablo incelendiğinde ANOVA alt tablosunda yer alan “Örnek” satırı iki farklı alt grubun dersler baz alınmadan farklılık gösterip göstermediği ile ilgilidir. Yani sorumuzda Modelleme öncül dersini almak ile araştırma yöntemleri öncül dersini almanın başarı düzeylerini farklılaştırdığı sonucuna ulaşılabilir. Sütunlar satırı ise öncül dersleri dikkate almadan derslerin başarı düzeylerini karşılaştırır. Bu durumda iki farklı grubun farklı başarı düzeylerine sahip olduğu görülmektedir. Son olarak etkileşim satırı ise derslerdeki başarı düzeylerini öncül dersleri dikkate alarak incelemektedir. Analiz sonuç tablosunda bu durumdaki farklılığında istatistiksel açıdan önemli olduğu sonucuna ulaşılabilir.

10
5.4.2. Kruskal Wallis testi
Eğer verilerin dağılımı parametrik değilse, ve örneklem sayısı 2 den fazla ise, verilerde bağımsız
oldukları varsayıldığında “Kruskal Wallis testi” istatistiksel hipotezi test etmek adına kullanılır. Excel
paket programı ile parametrik olmayan testler gerçekleştirilmediğinden diğer paket programlar
yardımıyla bu analizler gerçekleştirilir.
Bu test sonuçlarının yorumlanması diğer hipotez testleri ile aynıdır.
ÖZET
İkiden fazla örneklem olduğunda parametrik testlerden ANOVA, Çift Etken ANOVA ve MANOVA
testleri tercih edilebilir. (Verilerin bağımsız oldukları varsayımı ile)
ANOVA testlerinde eğer örnek satırları açısından farklılık araştırılması söz konusu değilse, yani
rastgele seçilen örnekler arasındaki farklılıklar inceleniyorsa, bu durumda tek etken (sadece sütunlar)
ANOVA gerçekleştirilir. Eğer satırlar açısından farklılık araştırılmak isteniyor ise, fakat satırlar tekrarlı
değilse ANOVA: Yinelemesiz Çift Etken analizi gerçekleştirilmelidir. Eğer satırlarda gruplanmış ise
(veriler tekrar ediyorsa) yinelemeli test tercih edilmelidir. Yinelemeli testte satır ve sütunların
etkileşimi de ayrıca farklılık düzeyinde incelenir.
Parametrik olmayan veri seti durumunda ANOVA yerine Kruskal Wallis Testi tercih edilmelidir.
SON NOT
Verilerin bağımsız olup olmadıkları çok büyük önem arz etmektedir. Bu yüzden veri seti iyi
anlaşılmadan analiz yöntemi seçilmesi tercih edilmemelidir.
Normal dağılıma uyup uymadığı bilinmeyen bir veri seti eğer normal dağılan bir ana kütleden
çekildiği bilgisi mevcut ise parametrik testlerle değerlendirilebilir.
Parametrik olmayan testleri Excel içerisinde yapmak mümkün değildir.
Anlatılan analizlerin sadece sayısal (sayılabilir, aralık) verilerinde yapıldığına dikkat ediniz.
11
ÇALIŞMA SORULARI
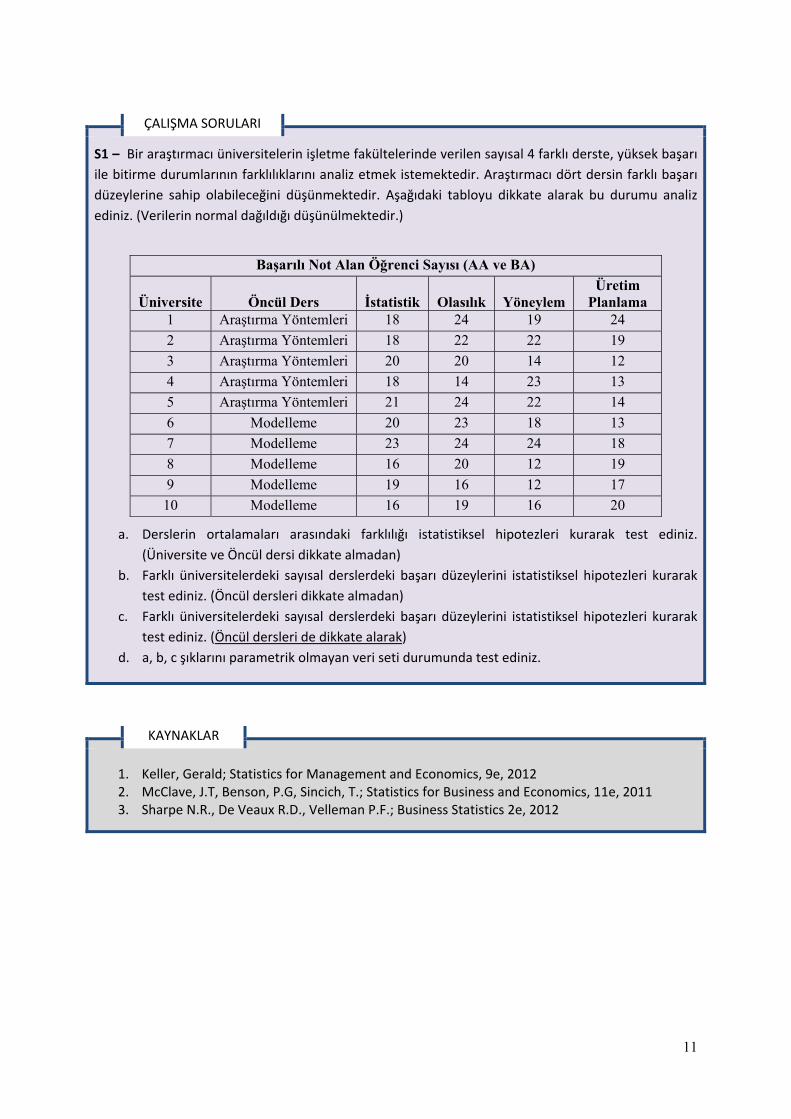
S1 – Bir araştırmacı üniversitelerin işletme fakültelerinde verilen sayısal 4 farklı derste, yüksek başarı
ile bitirme durumlarının farklılıklarını analiz etmek istemektedir. Araştırmacı dört dersin farklı başarı
düzeylerine sahip olabileceğini düşünmektedir. Aşağıdaki tabloyu dikkate alarak bu durumu analiz
ediniz. (Verilerin normal dağıldığı düşünülmektedir.)
Başarılı Not Alan Öğrenci Sayısı (AA ve BA)
Üniversite Öncül Ders İstatistik Olasılık Yöneylem Üretim
Planlama 1 Araştırma Yöntemleri 18 24 19 24
2 Araştırma Yöntemleri 18 22 22 19
3 Araştırma Yöntemleri 20 20 14 12
4 Araştırma Yöntemleri 18 14 23 13
5 Araştırma Yöntemleri 21 24 22 14
6 Modelleme 20 23 18 13
7 Modelleme 23 24 24 18
8 Modelleme 16 20 12 19
9 Modelleme 19 16 12 17
10 Modelleme 16 19 16 20
a. Derslerin ortalamaları arasındaki farklılığı istatistiksel hipotezleri kurarak test ediniz.
(Üniversite ve Öncül dersi dikkate almadan)
b. Farklı üniversitelerdeki sayısal derslerdeki başarı düzeylerini istatistiksel hipotezleri kurarak
test ediniz. (Öncül dersleri dikkate almadan)
c. Farklı üniversitelerdeki sayısal derslerdeki başarı düzeylerini istatistiksel hipotezleri kurarak
test ediniz. (Öncül dersleri de dikkate alarak)
d. a, b, c şıklarını parametrik olmayan veri seti durumunda test ediniz.
KAYNAKLAR
1. Keller, Gerald; Statistics for Management and Economics, 9e, 2012 2. McClave, J.T, Benson, P.G, Sincich, T.; Statistics for Business and Economics, 11e, 2011 3. Sharpe N.R., De Veaux R.D., Velleman P.F.; Business Statistics 2e, 2012





























