Embed Size (px)
Citation preview

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Basi di Dati
BUSINESS INTELLIGENCE E BIG DATA ANALYTICS
Anno Accademico 2014/2015 Candidato: Umberto Fattore matr. N46 / 1248

Ai Nonni Antonietta, Elisa, Giovanni e Umberto. Alcuni oggi lontani; tutti per sempre vicini.

Indice
Introduzione ....................................................................................................................................... 4
Capitolo 1: Business Intelligence ...................................................................................................... 7 1.1 Un semplice esempio di Business Intelligence .......................................................................... 8
1.2 Architettura di un sistema di Business Intelligence ................................................................. 12
1.3 Le applicazioni di supporto alle decisioni................................................................................ 17
1.4 Confronto tra i fornitori: il Magic Quadrant di Gartner ........................................................... 19
Capitolo 2: Big Data Analytics ........................................................................................................ 22 2.1 Il modello di crescita tridimensionale: Volume, Velocità, Varietà .......................................... 23
2.2 Utilizzi di Big Data: alcuni esempi .......................................................................................... 25
2.4 Il ciclo di vita dei Big Data ...................................................................................................... 27
2.4.1 Acquisizione...................................................................................................................... 27
2.4.2 Immagazzinamento ed Organizzazione ............................................................................ 28
2.4.3 Integrazione ....................................................................................................................... 29
2.4.4 Analisi ............................................................................................................................... 29
Capitolo 3: Il fenomeno “dati” in Italia ......................................................................................... 32
Conclusioni ....................................................................................................................................... 34
Bibliografia ....................................................................................................................................... 36

4
Introduzione
Immaginiamo due bambini che, durante le vacanze estive, mettono su un piccolo banchetto
per vendere biscotti al cioccolato ai passanti. Hanno l'opportunità di scegliere se
posizionarsi fuori casa di Marco oppure di Matteo. Marco sa che la maggior parte dei suoi
vicini sono anziani e di rado escono di casa e inoltre, causa l'età e un gran numero di
acciacchi, non possono mangiare troppo cioccolato. Dove sceglieranno ragionevolmente di
posizionarsi Marco e Matteo? Supponiamo che i bambini siano furbi e dunque decidano di
posizionarsi fuori casa di Matteo.
In sostanza, i due bambini hanno raccolto informazioni dalla realtà che li circonda e le
hanno usate per ottenere risultati migliori nel loro piccolo marketing: venderanno
probabilmente più biscotti, otterranno probabilmente più soldi.
Nella realtà aziendale, ancora più di Marco e Matteo, il filo conduttore sono i profitti. A
seconda del tipo di azienda alla quale ci si riferisca, tali profitti possono derivare dalla
vendita di prodotti o di servizi di vario genere; ma in tutte le aziende serve un capitale
iniziale da investire, ed è di vitale importanza gestirlo in maniera appropriata per ottenere da
esso quanto più margine di guadagno. Gestire in maniera appropriata un investimento
significa prendere le giuste decisioni per il suo utilizzo, così come (nel loro piccolo) i due
bambini prendono una giusta decisione vendendo fuori casa di Matteo.

5
L'azienda prende queste decisioni sulla base delle informazioni che accumula. Ma il
mercato di un'azienda è, come si può ben immaginare, infinitamente più grande di quello dei
due bambini; i dati e le variabili da tenere in considerazione sono sicuramente molte di più.
Non possono i soli responsabili delle vendite, con carta e penna, riuscire a tener conto di
tutti i possibili scenari e di tutte le possibili informazioni a disposizione. Servono allora
degli strumenti automatici che possano aiutare i manager ed i responsabili dell'azienda a
prendere le decisioni giuste per massimizzare i profitti ed evitare gli sprechi dovuti alle
scelte sbagliate, soprattutto negli ultimi anni in cui la crisi economica lascia ancora meno
margini per gli errori. Serve, cioè, la Business Intelligence.
In questa tecnologia, molte aziende hanno investito negli ultimi anni, analizzando i dati per
ottenere informazioni preziose per le scelte aziendali.
Ma la mole dei possibili dati da analizzare, complici le nuove tecnologie dirompenti, i social
network e la conseguente possibilità di “condividere tutto in un secondo con un click”, è
aumentata a dismisura negli ultimi anni, causando un nuovo boom: quello dei Big Data
Analytics, l'analisi dei grandi dataset di informazioni reperibili ovunque.
E così, con strumenti opportuni, analizzando anche solo il profilo Facebook e i post di un
ragazzo è possibile capirne interessi, ambizioni, sogni. Se si è un azienda di scommesse
sportive, si può capire se è un appassionato di sport analizzando i suoi post; se si è un sito di
e-commerce, si può capire quali prodotti probabilmente gli interesseranno di più
analizzando la cronologia pregressa, le pagine visualizzate, i cookie; se si è un partito
politico, si può capire se quel ragazzo è un potenziale nuovo elettore e che tipo di scelte del
partito potrebbero attirarlo maggiormente.
Insomma, un mondo di possibilità apertosi negli ultimi anni, che grandi colossi (si pensi a
Google, Facebook) stanno già sfruttando da tempo e che presto molte altre aziende e enti di
ogni tipo potrebbero sfruttare.
Questa tesi tratta nella prima parte il fenomeno della Business Intelligence. Ne introduce
brevemente la terminologia, fornisce un semplice esempio e presenta poi sia l'architettura

6
generale della Business Intelligence e sia i vari tools che vengono usati nella parte finale di
analisi dei dati (quella solitamente definita di Front End), introducendo il Magic Quadrant di
Gartner come strumento di confronto tra le varie tecnologie.
Nella seconda fase, viene invece introdotto il mondo dei Big Data e le metodologie per la
loro analisi, con alcuni esempi dei numerosi campi applicativi che questa tecnologia ha già
avuto nei suoi primi anni di vita. Viene, inoltre, presentato il ciclo di vita dei Big Data, con
accenni a diversi possibili strumenti per l'organizzazione e le analisi di queste grandi moli di
dati.
Infine, vi è un breve capitolo finale che fotografa la situazione attuale della Business
Intelligence e dei Big Data in Italia.

7
Capitolo 1: Business Intelligence
Il termine Business Intelligence viene utilizzato per la prima volta da un ricercatore tedesco
dell'IBM, Hans Peter Luhn, che in un articolo1 la definisce “an automatic method to provide
current awareness services to scientists and engineers”, ossia “un metodo automatico per
fornire servizi di consapevolezza per scienziati e ingegneri”.
Successivamente, nel 1989, Howard Dresder del Gartner Group, la ridefinisce come “the
ability to access and explore […] and analyze information to develop insights and
understanding, which leads to improved and informed decision making”; cioè Dresder
definisce la Business Intelligence come l'abilità di accedere ed analizzare informazioni,
ottenendo da queste un migliore processo decisionale.
La Business Intelligence è dunque un termine abbastanza ampio, che comprende tutti i
modelli, metodi e processi per raccogliere, conservare e trasformare opportunamente i dati
di un'azienda, per poi presentarli in una forma semplice e flessibile, tale che permetta
l'utilizzo di questi dati come supporto alle decisioni aziendali.
Per questo, spesso ci si riferisce alla Business Intelligence semplicemente con l’acronimo
DSS (Decision Support Systems).
Sempre più aziende oggi si orientano all'utilizzo dei sistemi di Business Intelligence,
apprezzati sia per la loro semplicità, che per la loro rapidità e soprattutto flessibilità. Infatti,
con questi sistemi, è possibile monitorare tanto l'andamento globale dell'azienda, quanto
concentrarsi nei vari settori specifici (es. marketing, commerciale, logistica); ed è possibile,
1 A Business Intelligence System”, Hans Peter Luhn, IBM Jornal – Ottobre 1958

8
inoltre, analizzare sia l'andamento passato dei dati, che fare previsioni sulle possibili
performance future dell'azienda, sulla base di scelte presenti (si parla di funzionalità what
if).
È possibile, dunque, suddividere il sistema informativo di un azienda in un modello a due
categorie: un sistema direzionale e un sistema operazionale.
- Il sistema direzionale (o anche
decisionale) si occupa di definire gli
obiettivi da raggiungere e controllare
i risultati ottenuti. Tramite esso, si
mettono in pratica eventuali decisioni
correttive per eliminare (o almeno
limitare) il gap tra obiettivi attesi e
risultati ottenuti. Figura 1 – Divisione del sistema informativo aziendale
- Il sistema operazionale, invece, comprende le attività esecutive che riguardano i
servizi veri e propri offerti dall'azienda.
Queste due macro-categorie sono interconnesse tra loro e scambiano continuamente
informazioni e dati. Naturalmente, la Business Intelligence è da collocarsi nel sistema
direzionale, di cui costituisce il fulcro; tuttavia, visto il suo ruolo sempre più importante
anche nelle normali attività giornaliere dell'azienda, essa è collocabile in parte anche nel
sistema operazionale.
1.1 Un semplice esempio di Business Intelligence
Si consideri una realtà aziendale molto diffusa, come quella di una catena di librerie. La
catena è formata da tanti negozi, sparsi su tutto il territorio nazionale; compra i libri dai
9
fornitori (le case editrici) e li rivende poi alla clientela nei vari punti vendita, con un certo
margine ovviamente, al fine di ottenere dei guadagni.
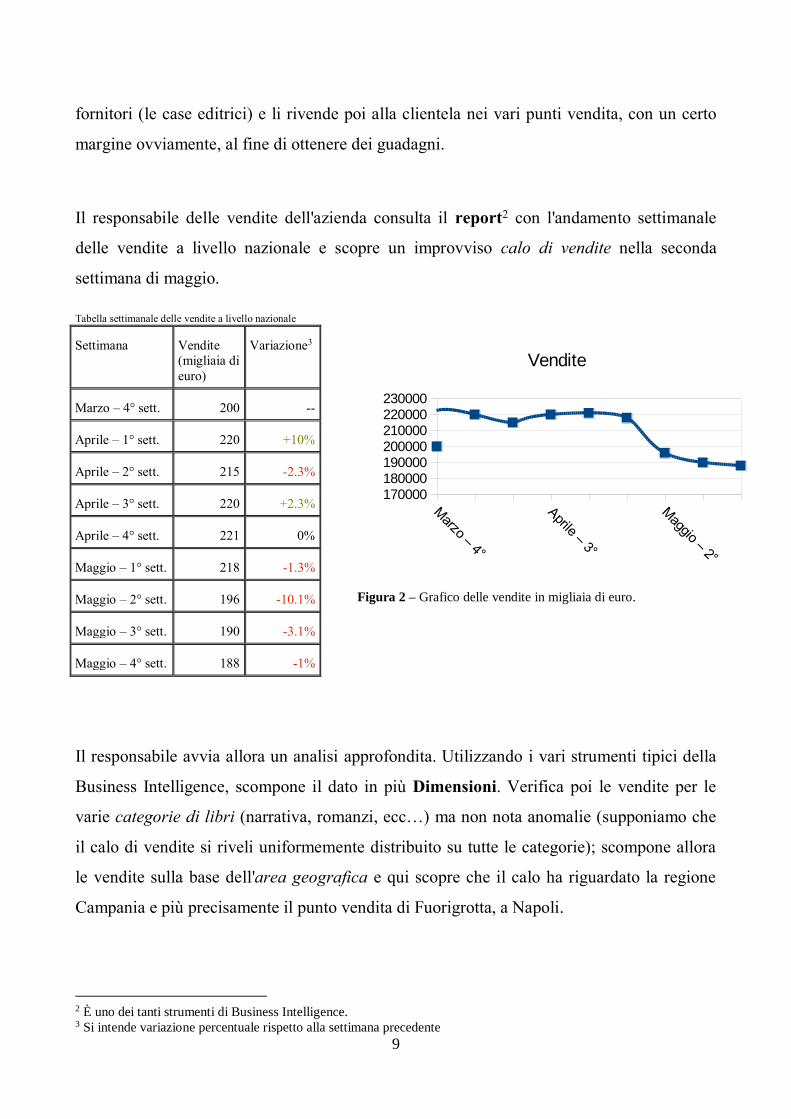
Il responsabile delle vendite dell'azienda consulta il report2 con l'andamento settimanale
delle vendite a livello nazionale e scopre un improvviso calo di vendite nella seconda
settimana di maggio.
Tabella settimanale delle vendite a livello nazionale
Il responsabile avvia allora un analisi approfondita. Utilizzando i vari strumenti tipici della
Business Intelligence, scompone il dato in più Dimensioni. Verifica poi le vendite per le
varie categorie di libri (narrativa, romanzi, ecc…) ma non nota anomalie (supponiamo che
il calo di vendite si riveli uniformemente distribuito su tutte le categorie); scompone allora
le vendite sulla base dell'area geografica e qui scopre che il calo ha riguardato la regione
Campania e più precisamente il punto vendita di Fuorigrotta, a Napoli.
2 È uno dei tanti strumenti di Business Intelligence. 3 Si intende variazione percentuale rispetto alla settimana precedente
Settimana Vendite
(migliaia di
euro)
Variazione3
Marzo – 4° sett. 200 --
Aprile – 1° sett. 220 +10%
Aprile – 2° sett. 215 -2.3%
Aprile – 3° sett. 220 +2.3%
Aprile – 4° sett. 221 0%
Maggio – 1° sett. 218 -1.3%
Maggio – 2° sett. 196 -10.1%
Maggio – 3° sett. 190 -3.1%
Maggio – 4° sett. 188 -1%
Marzo – 4°
Aprile – 3°
Maggio – 2°
170000180000190000200000210000220000230000
Vendite
Figura 2 – Grafico delle vendite in migliaia di euro.
10
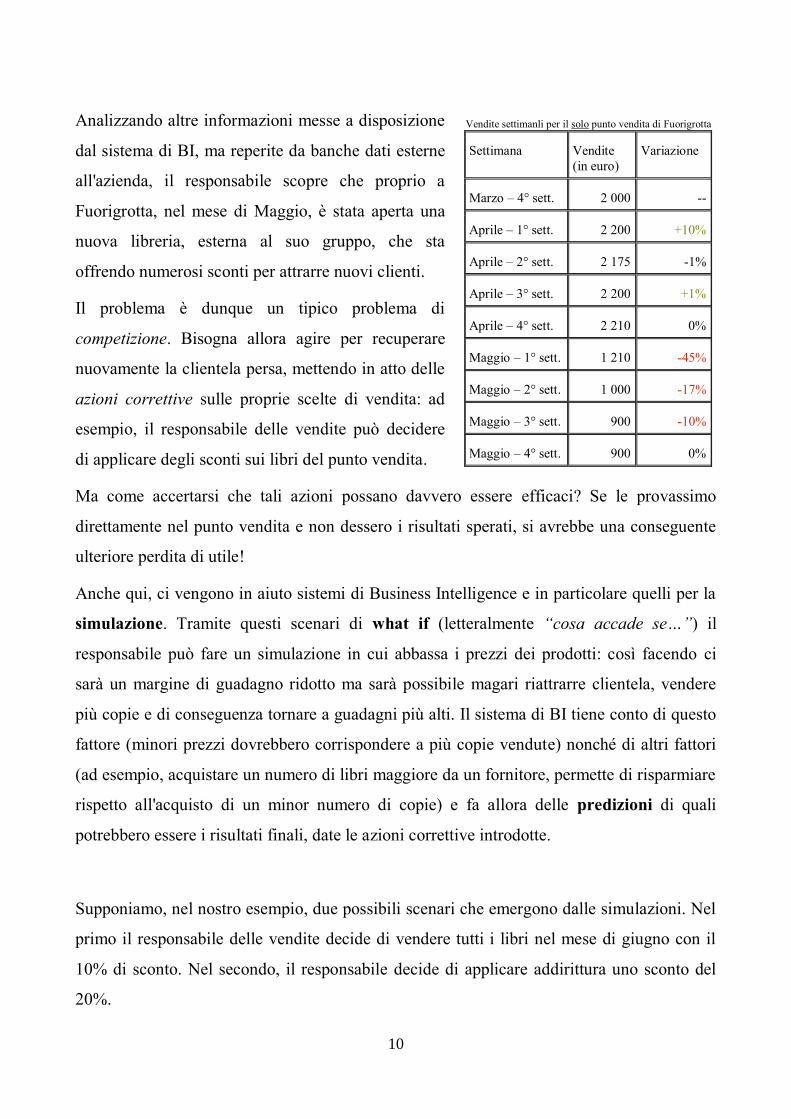
Analizzando altre informazioni messe a disposizione
dal sistema di BI, ma reperite da banche dati esterne
all'azienda, il responsabile scopre che proprio a
Fuorigrotta, nel mese di Maggio, è stata aperta una
nuova libreria, esterna al suo gruppo, che sta
offrendo numerosi sconti per attrarre nuovi clienti.
Il problema è dunque un tipico problema di
competizione. Bisogna allora agire per recuperare
nuovamente la clientela persa, mettendo in atto delle
azioni correttive sulle proprie scelte di vendita: ad
esempio, il responsabile delle vendite può decidere
di applicare degli sconti sui libri del punto vendita.
Vendite settimanli per il solo punto vendita di Fuorigrotta
Settimana Vendite
(in euro) Variazione
Marzo – 4° sett. 2 000 --
Aprile – 1° sett. 2 200 +10%
Aprile – 2° sett. 2 175 -1%
Aprile – 3° sett. 2 200 +1%
Aprile – 4° sett. 2 210 0%
Maggio – 1° sett. 1 210 -45%
Maggio – 2° sett. 1 000 -17%
Maggio – 3° sett. 900 -10%
Maggio – 4° sett. 900 0%
Ma come accertarsi che tali azioni possano davvero essere efficaci? Se le provassimo
direttamente nel punto vendita e non dessero i risultati sperati, si avrebbe una conseguente
ulteriore perdita di utile!
Anche qui, ci vengono in aiuto sistemi di Business Intelligence e in particolare quelli per la
simulazione. Tramite questi scenari di what if (letteralmente “cosa accade se…”) il
responsabile può fare un simulazione in cui abbassa i prezzi dei prodotti: così facendo ci
sarà un margine di guadagno ridotto ma sarà possibile magari riattrarre clientela, vendere
più copie e di conseguenza tornare a guadagni più alti. Il sistema di BI tiene conto di questo
fattore (minori prezzi dovrebbero corrispondere a più copie vendute) nonché di altri fattori
(ad esempio, acquistare un numero di libri maggiore da un fornitore, permette di risparmiare
rispetto all'acquisto di un minor numero di copie) e fa allora delle predizioni di quali
potrebbero essere i risultati finali, date le azioni correttive introdotte.
Supponiamo, nel nostro esempio, due possibili scenari che emergono dalle simulazioni. Nel
primo il responsabile delle vendite decide di vendere tutti i libri nel mese di giugno con il
10% di sconto. Nel secondo, il responsabile decide di applicare addirittura uno sconto del
20%.
11
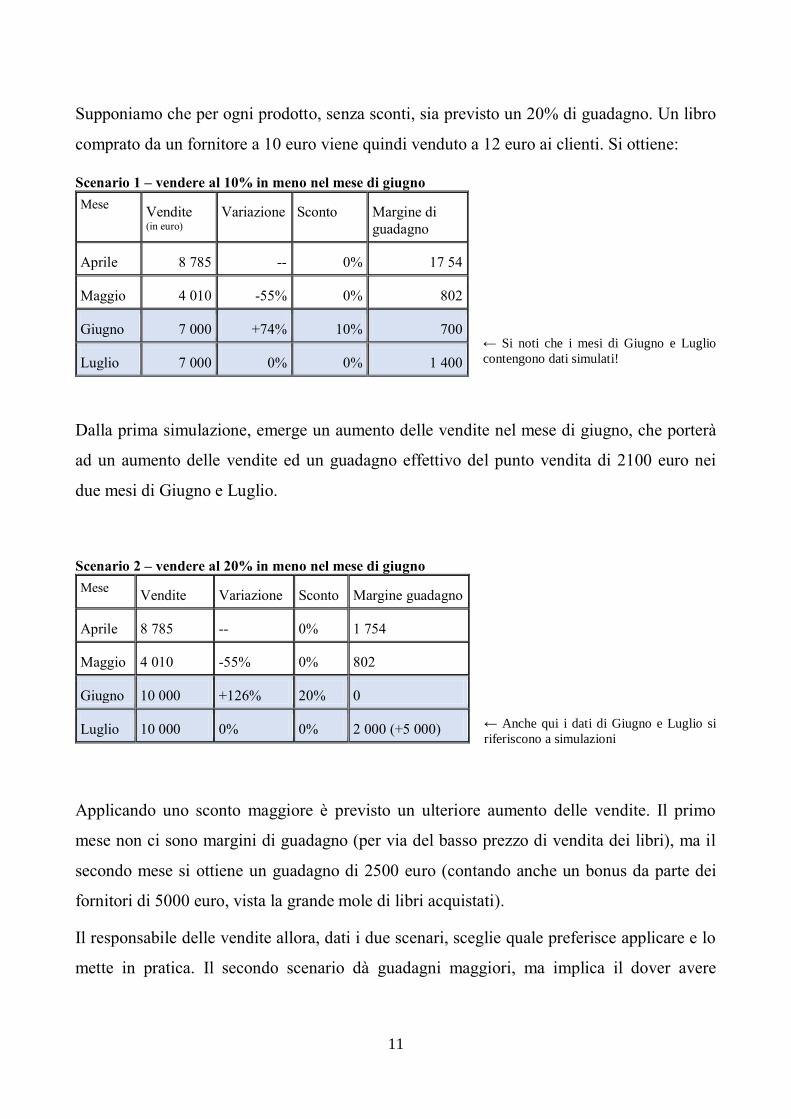
Supponiamo che per ogni prodotto, senza sconti, sia previsto un 20% di guadagno. Un libro
comprato da un fornitore a 10 euro viene quindi venduto a 12 euro ai clienti. Si ottiene:
Scenario 1 – vendere al 10% in meno nel mese di giugno
Mese Vendite (in euro)
Variazione Sconto Margine di
guadagno
Aprile 8 785 -- 0% 17 54
Maggio 4 010 -55% 0% 802
Giugno 7 000 +74% 10% 700
Luglio 7 000 0% 0% 1 400
← Si noti che i mesi di Giugno e Luglio
contengono dati simulati!
Dalla prima simulazione, emerge un aumento delle vendite nel mese di giugno, che porterà
ad un aumento delle vendite ed un guadagno effettivo del punto vendita di 2100 euro nei
due mesi di Giugno e Luglio.
Scenario 2 – vendere al 20% in meno nel mese di giugno
Mese Vendite Variazione Sconto Margine guadagno
Aprile 8 785 -- 0% 1 754
Maggio 4 010 -55% 0% 802
Giugno 10 000 +126% 20% 0
Luglio 10 000 0% 0% 2 000 (+5 000)
← Anche qui i dati di Giugno e Luglio si
riferiscono a simulazioni
Applicando uno sconto maggiore è previsto un ulteriore aumento delle vendite. Il primo
mese non ci sono margini di guadagno (per via del basso prezzo di vendita dei libri), ma il
secondo mese si ottiene un guadagno di 2500 euro (contando anche un bonus da parte dei
fornitori di 5000 euro, vista la grande mole di libri acquistati).
Il responsabile delle vendite allora, dati i due scenari, sceglie quale preferisce applicare e lo
mette in pratica. Il secondo scenario dà guadagni maggiori, ma implica il dover avere

12
guadagni nulli per tutto il mese di giugno, quindi sarà compito del responsabile valutare se
questo scenario sarà applicabile (magari il punto vendita ha bisogno di introiti immediati!).
Naturalmente, l'esempio proposto è un estrema semplificazione di possibili casi reali, ma
evidenzia in maniera chiara un concetto basilare: gli strumenti di Business Intelligence sono
utilissimi per automatizzare la raccolta dei dati e la loro trasformazione in informazioni per
avere una chiara descrizione della situazione e possibili predizioni dei casi futuri (si può ben
immaginare come sarebbe stato difficile per il responsabile dover reperire manualmente, o
da basi di dati differenti, tutte le informazioni sopra esposte).
Allo stesso tempo, però, si noti che gli strumenti di Business Intelligence non possono agire
in autonomia, ma sono solo di supporto alle decisioni (appunto da qui deriva il suddetto
acronimo DSS) che vengono fisicamente prese dalle figure professionali dell'azienda
(responsabile vendite, manager, ecc).
1.2 Architettura di un sistema di Business Intelligence
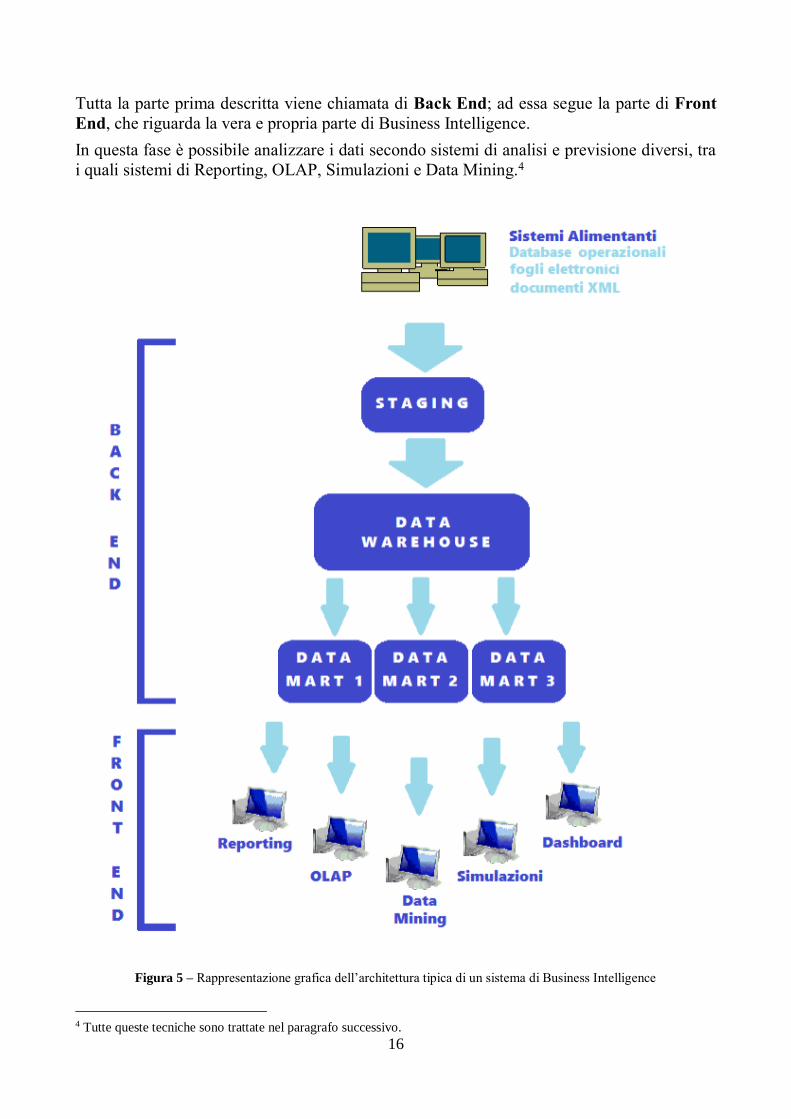
L'architettura generale di un sistema di Business Intelligence è articolata su tre livelli:
- I sistemi che contengono dati elementari (detti sistemi alimentanti poiché
alimentano il sistema di Business Intelligence);
- I sistemi per l'archiviazione dei dati integrati e semilavorati (in questo livello si
collocano i Data warehouse);
- I sistemi per la produzione di informazioni finite tramite l'applicazione delle
metodologie di Business Intelligence.
Si parte dunque dai dati elementari, che si trovano su numerose sorgente di dati differenti:
database, fogli di calcolo elettronici, documenti XML, ecc.
I dati sono estratti da questi sistemi e ripuliti da eventuali errori di inserimento o valori
inconsistenti. Tutti i dati vengono infine convertiti secondo un unico standard, passaggio

13
fondamentale in quanto dati provenienti da fonti diverse potrebbero usare diverse
rappresentazioni.
Figura 3 – Esempio di una fase di staging
Questa prima fase viene chiamata di staging.
Successivamente, avviene la fase di caricamento dei dati. Questi vengono inseriti nel Data
warehouse (DWH), un grande archivio informatico contenente i dati dell'organizzazione.
Qualora i dati siano già presenti nel DWH, in questa fase ci si limita al loro aggiornamento,
che può avvenire secondo una modalità refresh (i dati sono riscritti integralmente) oppure
update (sono aggiornati soltanto i dati modificati).
Queste operazioni vengono effettuate con l'aiuto di specifici strumenti di estrazione,
trasformazione e caricamento dei dati, chiamati con l'acronimo ETL (Extract, Transform
and Load).
Il secondo livello dell'architettura è costituito dai sistemi di Data warehouse, che possono
essere considerati come il collegamento tra i classici sistemi transazionali e quelli invece
manageriali.
Come già esposto sopra, il DWH è un grande archivio informatico che raccoglie tutti i dati
di un organizzazione. In dettaglio, esso ha quattro importanti caratteristiche:
Integrato, poiché appunto integra tutti i dati aziendali provenienti da diverse fonti (e
quindi con diverse rappresentazioni) in un unico ambiente di analisi.
Subject-oriented, ossia orientato al soggetto e non più alle operazioni. Questo
significa che le scelte implementative ora sono fatte non per semplificare le
operazioni, bensì per semplificare la lettura all'utente.

14
Storicizzato, poiché contiene dati che si riferiscono non solo al presente ma
soprattutto alla storia passata dell’azienda. I vecchi dati allora non sono mai
sovrascritti, ma viene tenuta traccia di ogni versione (frequente è l'uso del metodo di
storiciazzione Slowly Changing di secondo tipo, in cui a ciascun dato è associato un
flag che vale 0 o 1 a seconda di se il dato è ancora valido o vecchio).
Non volatile, cioè il dato è caricato in sola lettura e può essere acceduto ma non
modificato.
I Data warehouse spesso vengono articolati su più livelli. In questo caso, non si accede
direttamente ai DWH, bensì ai Data Mart, che costituiscono semplicemente un estratto del
DWH.
I vantaggi dei Data Mart sono numerosi:
Sono più personalizzati alle esigenze, in quanto ciascun Data Mart contiene dati
riguardanti una precisa area aziendale, mentre il DWH è molto più generico;
Migliorano le performance, potendo eventualmente distribuire i Data Mart su
macchine diverse e dunque avere hardware dedicato per ciascuno di essi;
Migliorano la sicurezza, poiché sarà più semplice gestire l'autorizzazione ad un
sottoinsieme più ristretto di dati.
Tipicamente si tende a creare un Data Mart per ciascuna area aziendale (Data Mart per
Logistica, Finanza, Acquisti, ecc).
I Data warehouse (e di conseguenza i Data Mart) si basano sul cosiddetto modello
multidimensionale. In questo modello l'informazione è espressa in termini di dimensioni e
misure.
Le misure (o fatti) sono informazioni numeriche che rappresentano in modo quantitativo i
fenomeni di interesse aziendale. Sono espresse secondo determinate unità di misura e
possono essere elementari (ricavate direttamente dai sistemi alimentanti) oppure derivate
(calcolate dal sistema direzionale).

15
Le dimensioni di analisi, invece, rappresentano una prospettiva rispetto alla quale
effettuare l'analisi.
E' possibile rappresentare dati multidimensionali tramite uno schema a stella. Questo è
formato da una tabella principale, la tabella dei fatti, che memorizza i fatti misurabili
tramite funzioni matematiche. Questa tabella, inoltre, contiene un collegamento alle varie
tabelle delle dimensioni, che di fatto forniscono dei contesti al contenuto della tabella dei
fatti.
Ad esempio, con riferimento alla catena di librerie (par. 1.1), se si vogliono modellare i dati
delle vendite di prodotti in un certo numero di negozi del corso del tempo, si ottiene il
seguente schema:
← Figura 4 - Schema a stella per
modellare i dati delle vendite di
libri (prodotto) dei vari punti
vendita (negozio) nel corso del
tempo.
In rosso la tabella dei fatti,
collegata tramite chiavi esterne alle
tre tabelle delle dimensioni.
La tabella dei fatti contiene due funzioni, aventi come dominio quello descritto dal prodotto
delle tre dimensioni. Ovvero:
vendite_euro : NEGOZIO x TEMPO x PRODOTTO → R ;
vendite_prodotti : NEGOZIO x TEMPO x PRODOTTO → N ;
16
Tutta la parte prima descritta viene chiamata di Back End; ad essa segue la parte di Front
End, che riguarda la vera e propria parte di Business Intelligence.
In questa fase è possibile analizzare i dati secondo sistemi di analisi e previsione diversi, tra
i quali sistemi di Reporting, OLAP, Simulazioni e Data Mining.4
Figura 5 – Rappresentazione grafica dell’architettura tipica di un sistema di Business Intelligence
4 Tutte queste tecniche sono trattate nel paragrafo successivo.

17
1.3 Le applicazioni di supporto alle decisioni
Numerosissime e anche molto eterogenee sono le applicazioni di Business Intelligence che
possono essere utilizzate nella fase finale (di Front End) dei vari processi decisionali.
Si propongono le principali di seguito:
Reporting → Danno un informazione statica di una determinata situazione
aziendale, tramite grafici di vario tipo.
OLAP → Acronimo di On Line Analytical Processing; offrono analisi simili al
reporting, ma che danno anche un'ampia possibilità di personalizzazione all'utente
finale. L'informazione è infatti contenuta in cubi analizzabili secondo più dimensioni,
in accordo col sistema multidimensionale. Nel caso di più di tre dimensioni, si parla
nella fattispecie di ipercubi.
← Figura 6 – Un esempio di analisi OLAP con
riferimento alla catena di librerie (par 1.1).
Nell'esempio vengono esaminate le quantità
vendute rispetto alle tre dimensioni temporali, del
negozio e del tipo di prodotto.
Per ciascuna dimensione ci si sofferma su un
attributo, in accordo con quanto contenuto nella
tabella di figura 4.
In questi sistemi vengono offerte varie operazioni per personalizzare l'analisi. In
particolare operazioni di drill up e drill down (per scendere nel dettaglio o
viceversa; ad esempio, un operazione di drill down applicata sulla dimensione Tempo
nell'esempio di figura 6, può passare da un analisi riferita ai giorni ad una riferita ai

18
mesi); operazioni di slicing (riduzione del numero di dimensioni) e dicing (filtraggio
dei dati secondo un determinato criterio).
Data Mining → Le analisi OLAP descritte sono molto potenti, ma sono utili per
limitarsi ad una visione storica dei dati. A partire dal duemila, sono invece nate le
tecniche di data mining, atte a fornire delle analisi previsionali sul futuro,
semplicemente analizzando le relazioni e le tendenze tra i dati a disposizione.
Il data mining fa largo uso di tecniche matematiche e statistiche per raggiungere il
suo scopo. Esempi di queste tecniche sono l'analisi cluster (consistente nel
raggruppamento degli oggetti in insiemi in modo da meglio classificare la
popolazione), l'analisi fattoriale (tramite la quale si ottiene un numero ristretto di
variabili, minore del numero complessivo della variabili di partenza, che possano
spiegare un fenomeno), gli alberi decisionali (permettono di comprendere un
determinato fenomeno classificando, in ordine di importanza, le cause che
conducono ad esso) e così via.
Simulazioni what if → Tecnica predittiva che permette di eseguire semplici
simulazioni sulle tendenze future, in base alle scelte attuali dell'utente.
Dashboards → in italiano cruscotti; sono degli applicativi grafici che permettono di
visualizzare con facilità le informazioni d'interesse dell'azienda, in tempo reale,
tramite numerose rappresentazioni ed eventualmente applicare allarmi grafici e
cromatici per indicare subito scostamenti significativi dai valori di soglia. Sono
solitamente indirizzati ai vertici aziendali, al fine di avere una visione d'insieme
dell'azienda.

19
Un esempio di cruscotto è dato dal software Xcelsius, prodotto da SAP, azienda
considerata leader nel mercato della Business Intelligence.5 Ne esistono ovviamente
numerosi altri.
← Figura 7 - L'immagine ritrae un esempio
di utilizzo di Xcelsius; lo screenshot si
riferisce ad un'applicazione di Kalyan Verma,
che simula le elezioni presidenziali americane
del 2008. Cliccando sui vari stati, per
ciascuno di essi, si può assegnare la vittoria al
partito repubblicano o a quello democratico e,
di conseguenza, il sistema calcola
dinamicamente il punteggio ottenuto dai due
candidati presidenti.
1.4 Confronto tra i fornitori: il Magic Quadrant di Gartner
Il mercato della Business Intelligence è pieno di diversi marchi, che a loro volta possono
contare su strumenti di vario genere.
Secondo Gartner,6 il mercato per le piattaforme di Business Intelligence è uno dei più
dinamici nel mondo del software e, nonostante la crisi economica, è destinato a una
continua crescita nell'immediato futuro. Anzi, proprio la crisi economica dovrebbe spingere
maggiormente le azienda a trovare metodi decisionali quanto più efficaci possibili, in modo
da ottimizzare tutte le varie area aziendali, evitando sprechi di investimenti.
5 Secondo il Magic Quadrant di Gartner (febbraio 2014) 6 Resoconto 2014 sulla BI: http://www.gartner.com/technology/reprints.do?id=1-1QLGACN&ct=140210&st=sb

20
Proprio Gartner dà la possibilità ai vari acquirenti di valutare i numerosi fornitori sul
mercato, tramite un particolare grafico: il Magic Quadrant.
Questo grafico si sviluppa lungo due criteri di valutazione, che ne costituiscono anche gli
assi:
Capacità di esecuzione → Valuta i fornitori nella capacità di rendere la propria
visione una realtà sul mercato. Riguarda quindi la salute finanziaria dell'azienda, la
sua efficienza, la sua capacità in tutte le attività di pre-vendita e post-vendita, nonché
in quella di assistenza.
Completezza della visione → Valuta i fornitori nella capacità di sfruttare le forze di
mercato per creare opportunità per se stessi e per creare valori per i clienti. Riguarda
allora la capacità di comprendere le esigenze degli acquirenti, una buona strategia di
marketing e di avere uno sguardo sempre rivolto alle innovazioni.
Sulla base dei due criteri sopra descritti, il Magic Quadrant si suddivide in quattro aree:
Niche Players → E' l'area che racchiude i giocatori di nicchia, ossia quei fornitori
che hanno avuto buoni risultati in un solo segmento specifico del mercato dei BI (ad
esempio, per le dashboard), ma hanno limitata capacità di innovare la propria offerta.
Visionaries → riguarda i fornitori che hanno un grande occhio all'innovazione della
loro piattaforma, ma offrono almeno per il momento limitate funzionalità. Si
potrebbe dire che visionario è un fornitore dal grande pensiero innovatore, che per il
momento non ha parò avuto ancora la possibilità di crescere completamente.
Challengers → raccoglie i fornitori che offrono una buona ampiezza di funzionalità
e hanno un ottima posizione sul mercato; peccano, tuttavia, in una vera e propria
strategia e su una coordinazione tra i propri prodotti.
Leader → è l'area riguardante i fornitori forti sul mercato, che offrono ampie
funzionalità nei prodotti e un'ampia strategia.
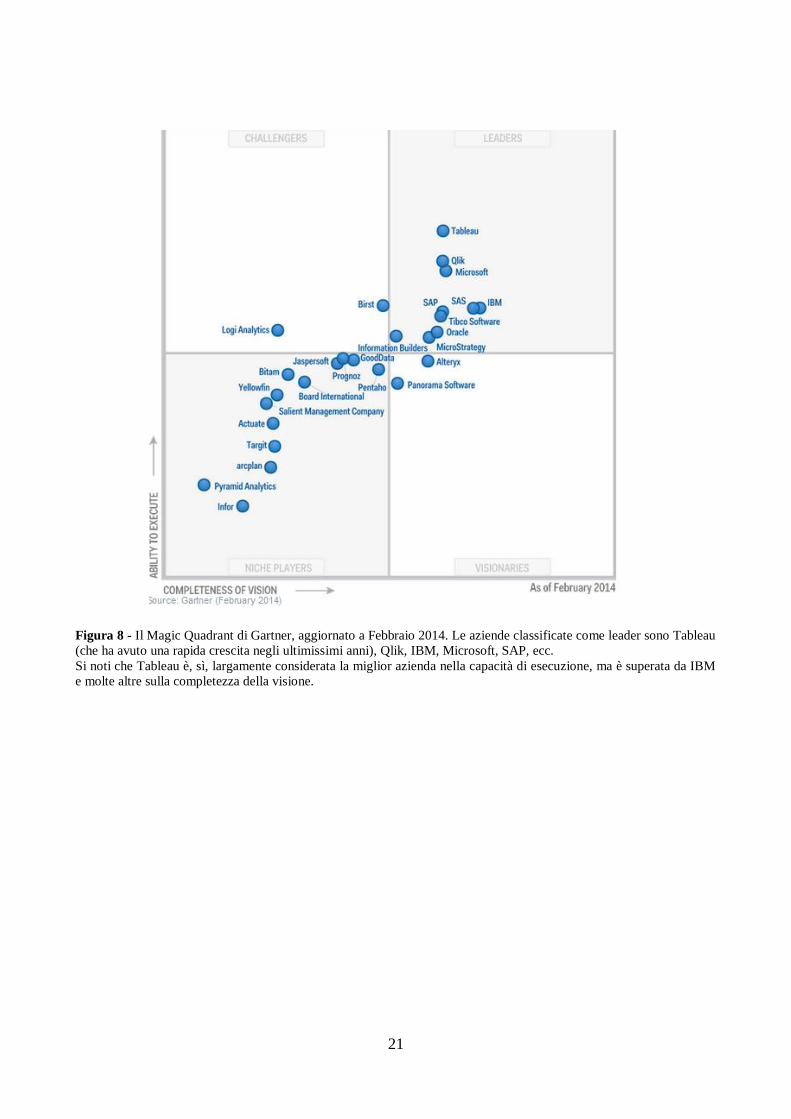
21
Figura 8 - Il Magic Quadrant di Gartner, aggiornato a Febbraio 2014. Le aziende classificate come leader sono Tableau
(che ha avuto una rapida crescita negli ultimissimi anni), Qlik, IBM, Microsoft, SAP, ecc.
Si noti che Tableau è, sì, largamente considerata la miglior azienda nella capacità di esecuzione, ma è superata da IBM
e molte altre sulla completezza della visione.

22
Capitolo 2: Big Data Analytics
Con il termine Big Data si intende una raccolta di dati di grande dimensione, la cui
dimensione e la cui complessità è tale da non poter essere trattata con i classici strumenti
della Business Intelligence e di tradizionale analisi dei dati.
Big Data Analytics si riferisce allora al processo di raccolta, organizzazione e analisi di
queste grandi moli di dati, al fine di ricavare da essi delle informazioni utili per i vari domini
di applicazione della tecnologia.
La nascita dei Big Data è dovuta all'evoluzione esponenziale delle informazioni negli ultimi
anni. Sempre in più campi, infatti, è necessario reperire e analizzare tantissime informazioni
eterogenee in pochissimo tempo.
Un esempio classico è quello dato dal settore industriale, in cui migliaia di sensori
raccolgono dati ogni piccolo intervallo di tempo; tali dati vanno poi ovviamente conservati e
analizzati, magari in tempo reale per prendere eventuali decisioni tempestive (si immagini
se sono dati che controllano la temperatura di un reattore nucleare!). Nessuno di questi dati
può essere eliminato, poiché in futuro potrebbe essere di grande importanza. Questo
contribuisce senz’altro ad aumentare a dismisura la mole dei dati.
Ma i Big Data si stanno diffondendo oggi in ogni ambito della vita quotidiana: per ricerche
di mercato sempre più efficienti delle aziende; per tenere sotto controllo le minacce esterne
e interne ad uno Stato, tramite le agenzie di intelligence (si pensi al caso dell’NSA
americana7); per effettuare studi sulle abitudine e le tendenze degli utenti e così via.
7 Nel giugno 2013 è diventata di pubblico dominio la notizia che l’NSA, agenzia di intelligence americana, aveva
raccolto dati di ogni tipo su migliaia di utenti, non solo americani: chiamate, tweet, messaggi, profili, cronologie, ecc.

23
2.1 Il modello di crescita tridimensionale: Volume, Velocità, Varietà
Sono tre le caratteristiche fondamentali che distinguono i Big Data:
Volume → Come suggerisce lo stesso aggettivo “big”, una delle caratteristiche
principale è il volume dei dati.
Si pensi, ad esempio, ad un processo industriale con 100 sensori, ciascuno dei quali
legge un dato valore ogni millisecondo. Così facendo, si otterranno ben
100*1000*3600 = 360 milioni di record acquisiti ogni ora! E non si può pensare di
eliminare a mano a mano questi dati, poiché potrebbero essere utili in futuro; tutti i
dati vanno quindi conservati.
Ma questo non vale solamente nel contesto industriale, ma anche in numerosissimi
altri contesti. Ad esempio, si consideri un social network famoso quanto Facebook:
solo nel 2012 contava una mole di dati pari a 100 petabytes!8
Secondo IDC,9 è verosimile stimare per il 2020 che l'insieme di tutti i dati digitali
prodotti e consumati in un solo anno sarà circa pari a 44 zettabyte, ossia 44 biliardi di
gigabyte!
In realtà, grandi moli di dati si potrebbero gestire anche con semplici sistemi
relazionali, ma servirebbero investimenti enormi per le componenti hardware al fine
di ottenere buone performance nella gestione e nell'analisi dei dati.
Varietà → Un'importante caratteristica risiede anche nella forte eterogeneità dei dati:
su Facebook, ad esempio, milioni di utenti ogni giorno non pubblicano solo semplice
testo, ma fotografie, video e documenti di ogni sorta.
C'è poi la differenza tra dati generati dagli utenti (come appunto quelli dei social
network) e dati invece generati automaticamente (come nei processi industriali).
8 un petabyte corrisponde a mille terabytes, ossia ad un milione di gigabytes. 9 IDC è un azienda di ricerche di mercato, specializzata in particolar modo nell’Information Tecnology. Notizia tratta da
http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm (link consultato il 11/02/15)

24
Si parla allora di dati non strutturati, ossia dati che non possono essere salvati (o
per meglio dire che è difficile salvare) nei classici record dei sistemi tradizionali. Ci
si basa spesso allora su database NoSQL.
Velocità → I dati vengono prodotti in maniera sempre più rapida e chi li gestisce
deve essere in grado di immagazzinarli e sfruttarli con altrettanta prontezza e
rapidità.
Nel corso del tempo, proprio in virtù della richiesta di maggiore velocità, anche i
vendors dei sistemi relazionali si sono mossi in questa direzione, creando sistemi “ad
alta velocità” (vengono solitamente riconosciuti con il termine Streaming Data).
Ma in questo caso, per avere le performance migliori, le soluzioni ideali sono
particolari tipologie di database NoSQL (database colonnari, chiave/valore, ecc).
← Figura 9 – Rappresentazione del modello
tridimensionale dei Big Data. La Varietà
implica l’associazione ai dati strutturati di
quelli non strutturati; il volume è passato da
dimensioni Terabyte a Zettabyte; la velocità
implica la necessità anche dell’utilizzo di
particolari sistemi di Streaming Data.
Queste tre caratteristiche hanno avuto un costante (ed esponenziale) incremento nel corso
degli anni, in accordo con quanto predetto già nel 2001 dall'analista Doug Laney, che aveva
definito il modello di crescita dei Big Data come un modello di crescita tridimensionale.10
10Douglas Laney, 3D Data Management: Controlling Data Volume, Velocity and Variety, Gartner.

25
In realtà, negli ultimi anni si è iniziato a parlare di un modello con quattro fattori: per molti
si aggiunge infatti una quarta “V”, la veridicità delle informazioni. Con questo termine si
vuole intendere la quantità di valore informativo che è possibile estrarre dal dato (avere
tanti dati su un certo soggetto non implica necessariamente che quei dati siano utili e dunque
carichi di significato, anzi spesso si incontra molto “rumore” nelle informazioni che si
analizzano).
2.2 Utilizzi di Big Data: alcuni esempi
Numerosi e vari sono i campi di applicazione dei Big Dati.
Uno dei principali è sicuramente quello aziendale, dove è possibile ampliare il concetto di
Business Intelligence per offrire ai clienti campagne pubblicitarie e prodotti strettamente
mirati. Ad esempio, analizzando blog, tweet e commenti presenti sui social network,
l'azienda può farsi un'idea molto chiara di quelle che sono le idee e le percezioni dei clienti
sui vari prodotti. Basandosi su questi feedback, l'azienda può poi operare di conseguenza.
Utili sono anche gli strumenti di recommandation engine, che le aziende possono usare sui
propri portali di vendita online per suggerire ai clienti prodotti vicino ai loro interessi,
analizzando gli acquisti passati e altre informazioni di navigazione sul web dell’utente.
Ma le potenzialità dei Big Data non si limitano a questo. Ad esempio, durante la campagna
presidenziale americana del 2012, entrambi i candidati sfruttarono tecnologie di analisi del
web. In particolare, Obama e i suoi collaboratori puntarono alla creazione di un singolo
grande database che potesse raccogliere dati attraverso i sondaggi, i volontari, i contenuti
dei social network, ecc. Con questi dati, è stato possibile sia trovare potenziali votanti (gli
“indecisi” da poter convincere all'ultimo minuto) e sia effettuare simulazioni predittive per
capire quali tecniche potessero attirare un determinato target di elettori.
Alla fine, di pochi voti, vinse Obama e probabilmente un contributo significativo venne
anche dalle tecnologie utilizzate. Il sistema progettato dai sostenitori del suo avversario

26
Romney,11 tra l'altro, andò in crash proprio il giorno dell'elezione e non fu in grado di dare il
suo contributo finale.
Sempre in America, l'analisi dei Big Data non si limita solo all'esempio sopra, ma viene da
anni usato in tutto il settore pubblico. Sicuramente, lo utilizzano i già citati servizi di
intelligence, per scandagliare milioni di dati al giorno alla ricerca di potenziali pericoli per
la nazione. Ma vengono raccolti anche dati da tutti i Ministeri e gli enti pubblici, in modo da
poter identificare subito sprechi e inefficienze e prendere provvedimenti. Oppure, per gestire
i soccorsi nelle catastrofi naturali, analizzando i dati e integrandoli con informazioni sulla
localizzazione degli utenti, i cosiddetti GIS Data (Geographic Information System).
Durante l'uragano Irene12, queste tecniche sono state ampiamente utilizzate per analizzare
foto, tweet e video in tempo reale e, potendo capire ciascun dato da quale posizione
geografica era estratto, aiutare a direzionare i soccorsi in maniera efficiente. Il sito
FloridaDisaster.org, per citarne uno, offre una mappa interattiva della Florida a cui sono
aggiunti dati metereologici, incendi, catastrofi varie, integrati con i tweet dei vari utenti: un
modo immediato per capire subito quali zone sono a rischio e se vi sono persone isolate che
necessitano di soccorso.
Figura 10 – Una immagine tratta dal sistema GATOR del sito FloridaDisaster.org sopra citato.
11 Il sistema fu chiamato ORCA 12 Uragano atlantico che ha colpito il nord America e in particolare gli Stati Uniti nell’agosto 2011.

27
2.4 Il ciclo di vita dei Big Data
Si può suddividere il ciclo di vita di un sistema di Big Data nelle seguenti fasi:
Acquisizione
Immagazzinamento
Organizzazione
Integrazione
Analisi
Figura 11 – Ciclo di vita dei Big Data
Queste fasi si susseguono in
maniera ciclica, perché vi è un
continuo aggiornamento del
processo. In queste fasi, interviene
in particolare la figura dell'analista
che ha il compito di organizzare i
dati nel modo più consono alle
proprie esigenze, di integrali e
estrapolarne le informazioni utili.
2.4.1 Acquisizione
Può avvenire tramite diversi mezzi:
API messe a disposizione dalle fonti dati: ad esempio Twitter mette a disposizione
le Twitter API; Facebook invece le Graph API. Utilizzandole, è possibile
interfacciarsi con le due piattaforme e esaminare tutti i contenuti che corrispondono a
determinate chiavi di interesse.
Web scraping: per raccogliere in maniera automatica informazioni dal web,
leggendo pagine HTML tramire l'utilizzo di parser.

28
Lettura di stream data: cioè gestire il trasferimento continuo dei dati, come può ad
esempio succedere nei processi industriali.
Import nel sistema tramite strumenti ETL magari a partire da altri database di tipo
operazionle/transazionale.
2.4.2 Immagazzinamento ed Organizzazione
Si tratta di riuscire ad organizzare una grandissima mole di dati, molti dei quali non
strutturati.
Servono allora degli strumenti di calcolo distribuiti tra reti di computer. Un esempio di un
software che si basa su questo principio è la piattaforma Handoop, che mette a disposizione
un file system distribuito (HDFS) dal quale vengono gestiti su più nodi tutti i dati.
L'organizzazione logica dei dati, come già più volte detto, non si basa ovviamente sul
modello relazionale; sono invece usati database NoSQL. Questi sono definiti come basi di
dati non relazionali, distribuite, open source e scalabili.13
La loro prima caratteristica è di non fare alcun uso del SQL e in particolare del DDL (Data
Defintion Layer) con il quale il quale si definisce la struttura dei classici database
relazionali. Si hanno così dei database più “elastici”, definiti come schemaless database.
Esistono diversi tipi di sistemi NoSQL: uno dei più usati è il database a grafo, che
consente di gestire in maniera efficiente i collegamenti tra dati, anche se in quantità molto
grandi. È utilizzato per rappresentare i dati dei social network oppure i già citati
reccomandation engine.
13 Così viene definito da un sito nato negli ultimi anni appositamente per descrivere i modelli NoSQL e farne una
classificazione nelle diverse tipologie. Il sito è consultabile all’url: www.nosql-database.org. Consultato il 30 gennaio
2015.

29
← Figura 12 – Un esempio di modello
del database a grafo. In realtà, nel
modello più specifico (chiamato
property graph), si indica per ciascuna
entità il ruolo (es. Umberto è nome,
Cucina è attività) e per ciascuna
relazione eventuali attributi (es.
fidanzato da marzo 2012).
2.4.3 Integrazione
Una volta che i dati sono organizzati in strutture del tipo Hadoop/NoSQL, si rende spesso
necessaria una fase di preparazione, in cui i avvengono alcune trasformazioni per preparare i
dati alla fase di analisi.
Una delle trasformazioni più frequenti riguarda l'estrazione dei contenuti in formato di testo.
Tra i tanti programmi utili a tale scopo, vi è Apache Tika14, che consente di trattare formati
anche molto differenti tra loro con una modalità uniforme.
2.4.4 Analisi
L'analisi dei dati può essere ottenuta con applicativi facenti parte della piattaforma Hadoop.
Vi è la componente MapReduce, sistema di parallel processing di grandi quantità di dati,
che lavora secondo il principio del divide et impera: si divide il problema complesso, con
tutta la sua mole di dati, su problemi più piccoli con minori quantità di dati; su di esse
MapReduce opera separatamente. La scrittura di funzioni di MapReduce è piuttosto
complessa, per questo viene messo a disposizione Pig, un tool che ha il suo linguaggio
14 http://tika.apache.org/. Consultato il 12 febbraio 2015.

30
(chiamato Pig Latin) con il quale si scrivono sequenze di operazioni; sarà poi Pig a tradurre
le istruzioni negli opportuni comandi di MapReduce.
Figura 13 – Esempio di codice scritto nel linguaggio Pig Latin. Nella fattispecie, il codice sopra serve ad effettuare il
conteggio delle diverse parole all’interno di un file.
Per analisi più complesse, ad esempio applicare tecniche di data mining sui dati, occorre
utilizzare strumenti più potenti come ad esempio Mahout, una piattaforma di machine
learning.15
Infine, nel caso di grandi moli di dati strutturati, è possibile anche usare soluzioni hardware
come le architetture MPP (Massive Parallel Processing). Queste architetture sono
caratterizzate dalla presenza di unità elaborative completamente dedicate: non solo
processori, ma anche una RAM e un bus dedicato per ciascuna unità. Così facendo, non si
creano i tipici problemi da “collo di bottiglia” che si causano sui sistemi SMP (Symmetric
MultiProcessing), in cui i processori sono sì separati, ma le restanti risorse (bus e memoria)
sono invece condivise.
15 Per machine learning si intendono sistemi capaci di imparare dai dati, senza essere stati esplicitamente programmati.
Si basa sul principio della generalizzazione di un problema per lavorare anche su situazioni nuove ma in qualche modo
simili a esperienze precedenti (è lo stesso principio sul quale si basano gli esseri umani).
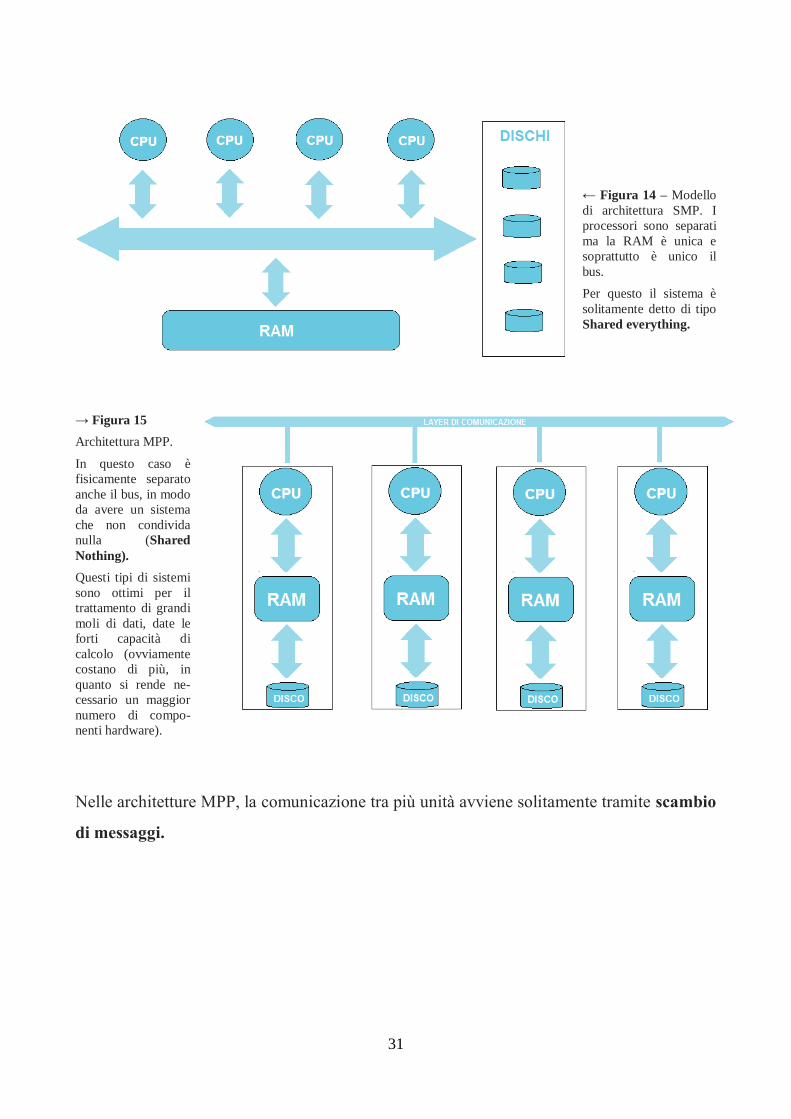
31
← Figura 14 – Modello
di architettura SMP. I
processori sono separati
ma la RAM è unica e
soprattutto è unico il
bus.
Per questo il sistema è
solitamente detto di tipo
Shared everything.
→ Figura 15
Architettura MPP.
In questo caso è
fisicamente separato
anche il bus, in modo
da avere un sistema
che non condivida
nulla (Shared
Nothing).
Questi tipi di sistemi
sono ottimi per il
trattamento di grandi
moli di dati, date le
forti capacità di
calcolo (ovviamente
costano di più, in
quanto si rende ne-
cessario un maggior
numero di compo-
nenti hardware).
Nelle architetture MPP, la comunicazione tra più unità avviene solitamente tramite scambio
di messaggi.

32
Capitolo 3: Il fenomeno “dati” in Italia
Secondo diverse ricerche, anche il mercato italiano sta iniziando a comprendere le
potenzialità dei sistemi di analisi dei dati. La situazione viene ben fotografata da una ricerca
condotta nel novembre 2013 da EMC, promossa dall’Osservatorio Big Data Analytics &
Business Intelligence del Politecnico di Milano. L’indagine16 ha coinvolto 184 entità, tra
imprese e Pubblica Amministrazione.
Da questa ricerca è stato confermato il boom dei Big Data e della Business Intelligence
anche in Italia.
In particolare, si attesta una forte crescita per quanto riguarda il volume dei dati utilizzati sia
per i sistemi di Big Data Analytics che anche di Business Intelligence, dove si attesta una
crescita media del 24% circa. È però possibile notare che almeno per il momento questa
crescita si riferisce soprattutto ai dati strutturati (per ben l’84%) e solo per la restante parte
a quelli non strutturati (immagini, GIS, social network, ecc).
Quindi, soffermandosi particolarmente al solo fenomeno dei Big Data, intesi come dati
caratterizzati da volume, velocità e soprattutto varietà, la crescita è molto più attenuata.
Infatti, solo il 19% delle aziende dichiara di farne espressamente uso.
Un dato interessante è quello che sottolinea, in particolare, come le aziende italiane hanno
ben chiare le opportunità offerte da queste tecnologie, ma al momento non hanno avuto la
possibilità (magari economica o organizzativa) per sfruttarle appieno. Sono comunque in
forte ascesa le richieste per le figure professionali di data scientist, che sappiano combinare
16 URL: http://www.lastampa.it/2013/12/18/tecnologia/crescono-i-big-data-in-italia-ma-scarseggiano-ancora-
governance-e-competenze-7UdU4ot77HmmmI1KXT8VCK/pagina.html. Consultato il 3 febbraio 2013.

33
competenze informatiche e statistiche con quelle di analisi e interpretazione dei dati. Lo
stesso Osservatorio elenca alcuni esempi di aziende che hanno negli ultimi tempi avviato
sistemi di report direzionali. Si cita ad esempio l’esempio dell’azienda italiana Amadori,17
che ha avviato il progetto per un sistema direzionale integrato con dashboards visualizzabili
da vari dispositivi mobili.
Buona anche l’immagine che riguarda le startup italiane, che dimostrano di concentrarsi
molto su questo nuovo fenomeno ed, inoltre, associano ad esso le tecnologie mobili e
cloud. In particolare, quest’ultima permette all’azienda di investire quantità minori (i
risparmi derivano dal non dover spendere soldi per l’acquisto di sistemi hardware dedicati,
grazie alla possibilità di usare appunto appositi servizi remoti, pagabili tra l’altro in maniera
proporzionale rispetto al reale utilizzo).
Molto ancora si può comunque fare in Italia, soprattutto per quanto concerne l’utilizzo dei
Big Data per trovare soluzioni a problemi comuni del nostro paese, magari prendendo
spunto da quanto già fatto in altri.
Ad esempio, l’Italia è un paese fortemente soggetto a terremoti e catastrofi idrogeologiche;
un sistema come quello usato in Florida (si veda paragrafo 2.2) sarebbe di indubbia utilità
per la gestione di eventuali future emergenze.
Oppure, molto può la Big Data Analysis anche nel rendere più efficiente la Pubblica
Amministrazione italiana e le spese dei diversi ministeri (secondo ultimi dati ogni anno in
Italia si sprecano 1,5 miliardi nella cattiva amministrazione della sanità!)18. Sempre negli
Stati Uniti, vengono usati numerosi sistemi di ausilio al trattamento dei dati per prendere
decisioni nelle varie sfere dell’organizzazione pubblica, in modo da ottenere la massima
efficienza possibile.
17 Articolo tratto dall’Osservatorio sopra citato. Consultabile all’url: http://www.osservatori.net/business-case/dettaglio/
journal_content/56_INSTANCE_dhni/10402/1616706. Consultato il 2 dicembre 2014. 18 http://www.quotidianosanita.it/eventi.php?evento_id=3630. Consultato il 3 febbraio 2015.

34
Conclusioni
La Business Intelligence e la Big Data Analytics costituiscono dunque due importantissimi
strumenti che, prima l’una e poi l’altra, sono negli ultimi anni emersi con prepotenza nel
mercato globale.
La Business Intelligence fa largo uso della statistica descrittiva, analizzando dati con un
alta densità di informazioni per ottenere misurazioni (somma, medie, ecc), rilevare tendenze
e così via. Utilizza dunque dataset di limitate dimensioni, dati puliti e modelli semplici. Non
è dunque applicata a moli troppo grandi di dati.
La Big Data Analytics, invece, si basa su tecniche di statistica inferenziale per dedurre
leggi (effetti causali, relazioni non lineari) studiando invece grandi insieme di dati,
prevenendo risultati e comportamenti. I Big Data sono dataset eterogenei, con una minore
densità di informazioni: il quantitativo informativo deve dunque essere estratto in maniera
più complessa.
Non è comunque giusto affermare che le due tecnologie siano distinte l’una dall’altra o che
la Big Data Analytics sostituisca quella che prima era la Business Intelligence o possa
sostituire i database tradizionali!
Tutt’altro: per la maggior parte delle esigenze analitiche, i database di tipo relazionali sono
più che sufficienti. Quello a cui si punta (e si sta puntando) è l’integrazione assieme alle
tecnologie riguardanti il mondo Big Data.
Di solito, infatti, il corretto utilizzo dei Big Data insieme alla Business Intelligence è quello
di acquisire e organizzare le grandi moli di dati (secondo quanto visto nel ciclo di vita). Da

35
questi poi l’analista ha il compito di estrapolare le giuste informazioni che può poi andare ad
inserire nel Data warehouse aziendale, grazie ai tradizionali ETL.
Tanto i Big Data quanto la Business Intelligence, dunque, sembrano destinate a far parlare
di se ancora per molti anni, a ritagliarsi una fetta sempre più ampia nel mondo
dell’Information Technologies ed ad offrire numerose possibilità alle aziende (sempre più
numerose) e alle figure professionali (la sempre più richiesta figura di analista, ad esempio)
che decideranno di affidarsi ad esse.

36
Bibliografia
[1] Hans Peter Luhn, “A Business Intelligence System”, IBM Journal, Ottobre 1958
[2] Kopàckovà-Skrobàckova, “Decision Support Systems or Business Intelligence: what
can help in decision making”, https://dspace.upce.cz/bitstream/10195/32436/1/CL585.pdf
[3] Scattolaro, “Tecnologie di Business Intelligence per il Retail: il caso non solo
NonSoloSport”, Università di Padova, pag. 2-10.
[4] Rezzani, “Business Intelligence”, Apogeo Editore, 2012.
[5] Rezzani, “Big Data: architetture, tecnologie e metodi per l’utilizzo di grandi basi di
dati”, Maggioli Editore, 2013
[6] Sallam – Tapadinhas – Parenteau – Yuen – Hostmann, “Magic Quadrant for
Business Intelligence and Analytic Platforms”, www.gartner.com. Consultato il 12 febbraio
2015.
[7] http://www.nosql-database.org/. Consultato il 18 febbraio 2015.
[8] Luca Indemini, “Crescono I Big Data in Italia ma scarseggiano ancora governance e
competenze”, La Stampa, 18 dicembre 2013.
[9] www.wikipedia.it : “Big Data Analytics”, “Business Intelligence”, “Decision Support
System”.
Tutte le figure presenti sono state prodotte su Paint (o simili) dall’autore della tesi, tranne:
[Fig. 7] dall’applicazione di Kalyan Verma. Presa da http://myxcelsius.com/2008/09/15/2008-
electoral-college-calculator-using-crystal-xcelsius/
[Fig. 8] da http://www.gartner.com/technology/reprints.do?id=1-1QLGACN&ct=140210&st=sb
[Fig. 9] da http://www.weboptimeez.com/wp-content/uploads/2012/11/IBM-Big-Data.jpg
[Fig. 10] screenshot sul sito FloridaDisaster.org
[Fig. 13] dal libro di Rezzani, “Big Data” (rif. [5]), pag. 48.





























