-
【論論⽂文紹介】
階層モデルの分散パラメータの事前分布について
2016/03/11@hoxo_̲m
1
-
本⽇日紹介する論論⽂文• “Prior distributions for variance
parameters in hierarchical models” • (階層モデルの分散パラメータの事前分布)
• by Andrew Gelman
• Bayesian Analysis 2006
https://projecteuclid.org/euclid.ba/13403710482
-
論論⽂文概要• 【背景】 階層モデルの分散パラメータの事前分布として、⼀一般的に逆ガンマ分布が使⽤用されている。
• 【結論論】
逆ガンマ分布は使ってはいけない。グループ数が⼤大きいときは⼀一様分布を、 ⼩小さいときは弱い情報を持たせた半コーシー分布を使うのが良良い。
3
-
この論論⽂文を読んだ理理由• ベイズモデルにおいて事前分布の選択は重要である。
• にもかかわらず、(⾃自分は)あんまりよく分からずに適当に使っている。
• Stan のマニュアルに事前分布について、最低限これ読んどけ的な論論⽂文が3つ紹介されている。
• そのうちの⼀一つ。
4
-
論論⽂文著者について• Andrew Gelman
– コロンビア⼤大学教授– 実践的ベイジアン– ⽶米国統計学会の賞を3回受賞– 応⽤用統計学の巨⼈人– Stan の開発者
https://en.wikipedia.org/wiki/Andrew_Gelman5
-
発表の流流れ1. 背景、使⽤用モデル 2. ⽤用語説明 3. 理理論論的考察 4. 実際のデータに適⽤用 5. 結論論
6
-
1. 背景• 階層モデルの各パラメータに対して事前分布を与える必要がある。
• 本論論⽂文では階層分散パラメータに対してどのような事前分布を使えば良良いかを調査した。
7
-
階層モデル• この論論⽂文では、次のモデルに議論論を絞る
• データ yij は正規分布に従うが、平均値はグループごとに異異なる。
• グループごとの平均値の分散 σα2
516 Prior distributions for variance parameters in hierarchical
models
A hierarchical model requires hyperparameters, however, and
these must be giventheir own prior distribution. In this paper, we
discuss the prior distribution for hier-archical variance
parameters. We consider some proposed noninformative prior
distri-butions, including uniform and inverse-gamma families, in
the context of an expandedconditionally-conjugate family. We
propose a half-t model and demonstrate its use asa
weakly-informative prior distribution and as a component in a
hierarchical model ofvariance parameters.
1.1 The basic hierarchical model
We shall work with a simple two-level normal model of data yij
with group-level effectsαj :
yij ∼ N(µ + αj , σ2y), i = 1, . . . , nj , j = 1, . . . , J
αj ∼ N(0, σ2α), j = 1, . . . , J. (1)
We briefly discuss other hierarchical models in Section 7.2.
Model (1) has three hyperparameters—µ, σy, and σα—but in this
paper we concernourselves only with the last of these. Typically,
enough data will be available to esti-mate µ and σy that one can
use any reasonable noninformative prior distribution—forexample,
p(µ, σy) ∝ 1 or p(µ, log σy) ∝ 1.
Various noninformative prior distributions for σα have been
suggested in Bayesianliterature and software, including an improper
uniform density on σα (Gelman et al.,2003), proper distributions
such as p(σ2α) ∼ inverse-gamma(0.001, 0.001) (Spiegelhalteret al.,
1994, 2003), and distributions that depend on the data-level
variance (Box andTiao, 1973). In this paper, we explore and make
recommendations for prior distributionsfor σα, beginning in Section
3 with conjugate families of proper prior distributions andthen
considering noninformative prior densities in Section 4.
As we illustrate in Section 5, the choice of “noninformative”
prior distribution canhave a big effect on inferences, especially
for problems where the number of groups J issmall or the
group-level variance σ2α is close to zero. We conclude with
recommendationsin Section 7.
2 Concepts relating to the choice of prior distribution
2.1 Conditionally-conjugate families
Consider a model with parameters θ, for which φ represents one
element or a subsetof elements of θ. A family of prior
distributions p(φ) is conditionally conjugate for φif the
conditional posterior distribution, p(φ|y) is also in that class.
In computationalterms, conditional conjugacy means that, if it is
possible to draw φ from this classof prior distributions, then it
is also possible to perform a Gibbs sampler draw of φin the
posterior distribution. Perhaps more important for understanding
the model,
8
-
• この論論⽂文では、階層分散パラメータ σα の事前分布をどうすればいいかを考える。
http://www.slideshare.net/simizu706/ss-38292230
・・・
集団ごとに平均値を持つ。その分散が σα2
9
-
発表の流流れ1. 背景、使⽤用モデル 2. ⽤用語説明 3. 理理論論的考察 4. 実際のデータに適⽤用 5. 結論論
10
-
2. ⽤用語説明• 基本的な⽤用語および次の 3 つを説明する。
(2-1) 条件付き共役事前分布
(2-2) Improper な事前分布
(2-3) 弱情報事前分布
11
-
ベイズの定理理• 事後分布は尤度度と事前分布をかけたものに⽐比例例する
12
-
共役事前分布• 共役事前分布
尤度度関数に対して、事前分布と事後分布が同じ分布族に属するとき、これらを共役分布と⾔言い、このときの事前分布を共役事前分布と⾔言う。
• 例例:⼆二項分布 → ベータ分布
13
-
(2-1) 条件付き共役事前分布• 条件付き共役事前分布
パラメータが複数ある場合、特定のパラメータに着⽬目し、それ以外を固定した尤度度関数に対して共役となるような事前分布を、そのパラメータに対する条件付き共役事前分布という。
• 分散に着⽬目した正規分布 → 逆ガンマ分布 Normal(σ ; µ) → InvGamma(α,
β)
http://d.hatena.ne.jp/teramonagi/20141011/141299127514
-
(2-1) 条件付き共役事前分布• 階層分散パラメータ σα
には、シンプルな共役分布は無い Hill(1965), Tiao & Tan(1965)
• なので、条件付き共役事前分布を使う
15
-
無情報事前分布• 事後分布にできるだけ影響しないような事前分布
• 事前知識識が無い場合は無情報事前分布を使う
• 簡単そうに⾒見見えて、実は難しい概念念
http://ibisforest.org/index.php?無情報事前分布16
-
無情報事前分布• 例例:⼆二項分布に対して、Beta(1, 1) は⼀一⾒見見して無情報である
http://www.eeso.ges.kyoto-u.ac.jp/emm/?page_id=52917
-
無情報事前分布• これはある解釈のもとでは正しいが、 変数変換により偏りが⽣生じてしまう
• 真に無情報と⾔言えるのは、Beta(0, 0) ? • しかし、これは improper である
• 無情報には様々な解釈がある 変数変換に強い無情報事前分布として Jeffreys 事前分布 Beta(0.5,
0.5) が有名
http://ibisforest.org/index.php?Jeffreys事前分布18
-
(2-2) Improper な事前分布• ベイズの定理理において、事前分布を定数倍しても事後分布に影響はない
• すなわち、事前分布の積分は 1 でなくて良良い • さらに進めて、積分が発散するものを考える • 積分が発散するとき
improper な分布と呼ぶ
https://en.wikipedia.org/wiki/Prior_probability#Improper_priors19
-
(2-2) Improper な事前分布• 例例: ⼀一様分布 Uniform(-‐‑‒∞, ∞) 逆ガンマ分布
InvGamma(0, 0) ベータ分布 Beta(0, 0)
• ある意味、理理想的な無情報事前分布
• ただし、improper な事前分布を使うと、事後分布も improper となる可能性がある
20
-
(2-2) Improper な事前分布• ソフトウェアの制約により、improper
な事前分布が使えない(※BUGSの場合。Stanでは使える)
• Improper な事前分布の極限表現を使う。 • 例例: ⼀一様分布 Uniform(-A, A), A
→ ⼤大 逆ガンマ分布 InvGamma(ε, ε), ε →
⼩小
-
(2-3) 弱情報事前分布• 無情報事前分布に近いが、少しだけ情報を持っている事前分布
• 実際、我々はどんな問題に対しても多少は事前知識識を持っている
• 例例: 成⼈人⼥女女性の平均⾝身⻑⾧長について、少なくとも 1m〜~2m の間に⼊入っているだろう
22
-
(2-3) 弱情報事前分布• 成⼈人⼥女女性の平均⾝身⻑⾧長について、少なくとも 1m 〜~ 2m
の間に⼊入っているだろう
Normal(1.5, 0.3)
23
-
論論⽂文の流流れ①• 階層分散パラメータの事前分布として、良良いものを⾒見見つけたい。
• 無情報事前分布として、improper な事前分布の極限表現を調べる。
• 評価基準: • 事後分布に対する影響が少ない
• 結論論①:⼀一様分布が良良い。 24
-
論論⽂文の流流れ②• グループ数が⼩小さい場合、⼀一様分布では 事後分布への影響が⼤大きい。
• 弱情報事前分布を使うことを考える。 • ⼀一様分布に弱情報を持たせても、事後分布への影響は⼤大きいまま。
• 弱情報事前分布として、条件付き共役である半コーシー分布を使うと良良い。
25
-
発表の流流れ1. 背景、使⽤用モデル 2. ⽤用語説明 3. 理理論論的考察 4. 実際のデータに適⽤用 5. 結論論
26
-
3. 理理論論的考察• 階層ベイズモデルの階層分散パラメータ σα
に対して、どんな無情報事前分布を 使⽤用したらいいかについて考察する。
516 Prior distributions for variance parameters in hierarchical
models
A hierarchical model requires hyperparameters, however, and
these must be giventheir own prior distribution. In this paper, we
discuss the prior distribution for hier-archical variance
parameters. We consider some proposed noninformative prior
distri-butions, including uniform and inverse-gamma families, in
the context of an expandedconditionally-conjugate family. We
propose a half-t model and demonstrate its use asa
weakly-informative prior distribution and as a component in a
hierarchical model ofvariance parameters.
1.1 The basic hierarchical model
We shall work with a simple two-level normal model of data yij
with group-level effectsαj :
yij ∼ N(µ + αj , σ2y), i = 1, . . . , nj , j = 1, . . . , J
αj ∼ N(0, σ2α), j = 1, . . . , J. (1)
We briefly discuss other hierarchical models in Section 7.2.
Model (1) has three hyperparameters—µ, σy, and σα—but in this
paper we concernourselves only with the last of these. Typically,
enough data will be available to esti-mate µ and σy that one can
use any reasonable noninformative prior distribution—forexample,
p(µ, σy) ∝ 1 or p(µ, log σy) ∝ 1.
Various noninformative prior distributions for σα have been
suggested in Bayesianliterature and software, including an improper
uniform density on σα (Gelman et al.,2003), proper distributions
such as p(σ2α) ∼ inverse-gamma(0.001, 0.001) (Spiegelhalteret al.,
1994, 2003), and distributions that depend on the data-level
variance (Box andTiao, 1973). In this paper, we explore and make
recommendations for prior distributionsfor σα, beginning in Section
3 with conjugate families of proper prior distributions andthen
considering noninformative prior densities in Section 4.
As we illustrate in Section 5, the choice of “noninformative”
prior distribution canhave a big effect on inferences, especially
for problems where the number of groups J issmall or the
group-level variance σ2α is close to zero. We conclude with
recommendationsin Section 7.
2 Concepts relating to the choice of prior distribution
2.1 Conditionally-conjugate families
Consider a model with parameters θ, for which φ represents one
element or a subsetof elements of θ. A family of prior
distributions p(φ) is conditionally conjugate for φif the
conditional posterior distribution, p(φ|y) is also in that class.
In computationalterms, conditional conjugacy means that, if it is
possible to draw φ from this classof prior distributions, then it
is also possible to perform a Gibbs sampler draw of φin the
posterior distribution. Perhaps more important for understanding
the model,
27
-
逆ガンマ分布• σα 〜~ InvGamma(ε, ε) • 条件付き共役事前分布 • 昔からよく使われている •
事後分布が ε の値に影響される • 結論論:使えない
28
-
逆ガンマ分布• σα 〜~ InvGamma(ε, ε)
σα0
ε → 0 としても ⼭山が残る
ε = 0.01
ε = 0.05 ε = 0.1
29
-
⼀一様分布• σα 〜~ Uniform(0, A) • 先ほどのような問題が発⽣生しないので良良い •
ただし、J=1,2 のとき事後分布が improper • J が⼩小さいとき、miscalibration が⼤大きい
• 結論論:J が⼤大きいなら使える
30
-
⼀一様分布• σα 〜~ Uniform(0, A)
σα0 A31
-
半コーシー分布• σα 〜~ HalfCauchy(A)• コーシー分布の正の範囲だけ • 条件付き共役事前分布 •
σα = 0 で最⼤大値を取り、なだらかに減少 • 弱情報事前分布 • J
が⼩小さい場合に良良さそう
32
-
半コーシー分布• σα 〜~ HalfCauchy(A)
A = 5
A = 25
σα0
なだらかに減少
33
-
発表の流流れ1. 背景、使⽤用モデル 2. ⽤用語説明 3. 理理論論的考察 4. 実際のデータに適⽤用 5. 結論論
34
-
4. 実際のデータに適⽤用• 8-schools データ • 8 つの学校で⾏行行われた共通テストの点数 •
階層モデルにより学校間の得点差をモデル化
• σα に対して無情報事前分布を適⽤用してみる
516 Prior distributions for variance parameters in hierarchical
models
A hierarchical model requires hyperparameters, however, and
these must be giventheir own prior distribution. In this paper, we
discuss the prior distribution for hier-archical variance
parameters. We consider some proposed noninformative prior
distri-butions, including uniform and inverse-gamma families, in
the context of an expandedconditionally-conjugate family. We
propose a half-t model and demonstrate its use asa
weakly-informative prior distribution and as a component in a
hierarchical model ofvariance parameters.
1.1 The basic hierarchical model
We shall work with a simple two-level normal model of data yij
with group-level effectsαj :
yij ∼ N(µ + αj , σ2y), i = 1, . . . , nj , j = 1, . . . , J
αj ∼ N(0, σ2α), j = 1, . . . , J. (1)
We briefly discuss other hierarchical models in Section 7.2.
Model (1) has three hyperparameters—µ, σy, and σα—but in this
paper we concernourselves only with the last of these. Typically,
enough data will be available to esti-mate µ and σy that one can
use any reasonable noninformative prior distribution—forexample,
p(µ, σy) ∝ 1 or p(µ, log σy) ∝ 1.
Various noninformative prior distributions for σα have been
suggested in Bayesianliterature and software, including an improper
uniform density on σα (Gelman et al.,2003), proper distributions
such as p(σ2α) ∼ inverse-gamma(0.001, 0.001) (Spiegelhalteret al.,
1994, 2003), and distributions that depend on the data-level
variance (Box andTiao, 1973). In this paper, we explore and make
recommendations for prior distributionsfor σα, beginning in Section
3 with conjugate families of proper prior distributions andthen
considering noninformative prior densities in Section 4.
As we illustrate in Section 5, the choice of “noninformative”
prior distribution canhave a big effect on inferences, especially
for problems where the number of groups J issmall or the
group-level variance σ2α is close to zero. We conclude with
recommendationsin Section 7.
2 Concepts relating to the choice of prior distribution
2.1 Conditionally-conjugate families
Consider a model with parameters θ, for which φ represents one
element or a subsetof elements of θ. A family of prior
distributions p(φ) is conditionally conjugate for φif the
conditional posterior distribution, p(φ|y) is also in that class.
In computationalterms, conditional conjugacy means that, if it is
possible to draw φ from this classof prior distributions, then it
is also possible to perform a Gibbs sampler draw of φin the
posterior distribution. Perhaps more important for understanding
the model,
35
-
http://www.slideshare.net/simizu706/ss-38292230
・・・
• 集団 = 学校 • 個⼈人 = テストの点数 •
学校ごとに平均点が異異なる • 学校ごとの平均点の分散が σα2
36
-
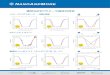
8-schools 逆ガンマ分布• 左: ε = 1, 右: ε =
0.001 • ε によって事後分布が⼤大きく異異なるAndrew Gelman 523
σα0 5 10 15 20 25 30
8 schools: posterior on σα givenuniform prior on σα
σα0 5 10 15 20 25 30
8 schools: posterior on σα giveninv−gamma (1, 1) prior on σα
2
σα0 5 10 15 20 25 30
8 schools: posterior on σα giveninv−gamma (.001, .001) prior on
σα
2
Figure 1: Histograms of posterior simulations of the
between-school standard deviation,σα, from models with three
different prior distributions: (a) uniform prior distributionon σα,
(b) inverse-gamma(1, 1) prior distribution on σ2α, (c)
inverse-gamma(0.001, 0.001)prior distribution on σ2α. Overlain on
each is the corresponding prior density functionfor σα. (For models
(b) and (c), the density for σα is calculated using the
gammadensity function multiplied by the Jacobian of the 1/σ2α
transformation.) In models (b)and (c), posterior inferences are
strongly constrained by the prior distribution. Adaptedfrom Gelman
et al. (2003, Appendix C).
inferences. In particular, the posterior mean and median of σα
are lower and shrinkageof the αj ’s is greater than in the
previously-fitted model with a uniform prior distributionon σα. To
understand this, it helps to graph the prior distribution in the
range for whichthe posterior distribution is substantial. The graph
shows that the prior distributionis concentrated in the range [0.5,
5], a narrow zone in which the likelihood is close toflat compared
to this prior (as we can see because the distribution of the
posteriorsimulations of σα closely matches the prior distribution,
p(σα)). By comparison, inthe left graph, the uniform prior
distribution on σα seems closer to “noninformative”for this
problem, in the sense that it does not appear to be constraining
the posteriorinference.
Finally, the rightmost histogram in Figure 1 shows the
corresponding result withan inverse-gamma(0.001, 0.001) prior
distribution for σ2α. This prior distribution iseven more sharply
peaked near zero and further distorts posterior inferences, with
theproblem arising because the marginal likelihood for σα remains
high near zero.
In this example, we do not consider a uniform prior density on
log σα, which wouldyield an improper posterior density with a spike
at σα = 0, like the rightmost graph inFigure 1, but more so. We
also do not consider a uniform prior density on σ2α, whichwould
yield a posterior distribution similar to the leftmost graph in
Figure 1, but witha slightly higher right tail.
This example is a gratifying case in which the simplest
approach—the uniform priordensity on σα—seems to perform well. As
detailed in Gelman et al. (2003, AppendixC), this model is also
straightforward to program directly using the Gibbs sampler orin
Bugs, using either the basic model (1) or slightly faster using the
expanded parame-terization (2).
The appearance of the histograms and density plots in Figure 1
is crucially affected
37
-
8-schools 逆ガンマ分布• 逆ガンマ分布にはピークがあり、ε を変更更するとピークが移動する。
• このピークの位置に依存して事後分布が変わってしまう。
• ε をどれだけ⼩小さくしても、この状況は変わらない(⼗十分⼩小さな ε
が存在しない)
• 無情報事前分布としては不不適切切
38
-
8-schools ⼀一様分布• σα 〜~ Uniform(0, A) • 事後分布は A
の⼤大きさに依存しない。Andrew Gelman 523
σα0 5 10 15 20 25 30
8 schools: posterior on σα givenuniform prior on σα
σα0 5 10 15 20 25 30
8 schools: posterior on σα giveninv−gamma (1, 1) prior on σα
2
σα0 5 10 15 20 25 30
8 schools: posterior on σα giveninv−gamma (.001, .001) prior on
σα
2
Figure 1: Histograms of posterior simulations of the
between-school standard deviation,σα, from models with three
different prior distributions: (a) uniform prior distributionon σα,
(b) inverse-gamma(1, 1) prior distribution on σ2α, (c)
inverse-gamma(0.001, 0.001)prior distribution on σ2α. Overlain on
each is the corresponding prior density functionfor σα. (For models
(b) and (c), the density for σα is calculated using the
gammadensity function multiplied by the Jacobian of the 1/σ2α
transformation.) In models (b)and (c), posterior inferences are
strongly constrained by the prior distribution. Adaptedfrom Gelman
et al. (2003, Appendix C).
inferences. In particular, the posterior mean and median of σα
are lower and shrinkageof the αj ’s is greater than in the
previously-fitted model with a uniform prior distributionon σα. To
understand this, it helps to graph the prior distribution in the
range for whichthe posterior distribution is substantial. The graph
shows that the prior distributionis concentrated in the range [0.5,
5], a narrow zone in which the likelihood is close toflat compared
to this prior (as we can see because the distribution of the
posteriorsimulations of σα closely matches the prior distribution,
p(σα)). By comparison, inthe left graph, the uniform prior
distribution on σα seems closer to “noninformative”for this
problem, in the sense that it does not appear to be constraining
the posteriorinference.
Finally, the rightmost histogram in Figure 1 shows the
corresponding result withan inverse-gamma(0.001, 0.001) prior
distribution for σ2α. This prior distribution iseven more sharply
peaked near zero and further distorts posterior inferences, with
theproblem arising because the marginal likelihood for σα remains
high near zero.
In this example, we do not consider a uniform prior density on
log σα, which wouldyield an improper posterior density with a spike
at σα = 0, like the rightmost graph inFigure 1, but more so. We
also do not consider a uniform prior density on σ2α, whichwould
yield a posterior distribution similar to the leftmost graph in
Figure 1, but witha slightly higher right tail.
This example is a gratifying case in which the simplest
approach—the uniform priordensity on σα—seems to perform well. As
detailed in Gelman et al. (2003, AppendixC), this model is also
straightforward to program directly using the Gibbs sampler orin
Bugs, using either the basic model (1) or slightly faster using the
expanded parame-terization (2).
The appearance of the histograms and density plots in Figure 1
is crucially affected
39
-
8-schools ⼀一様分布• 逆ガンマ分布とは異異なり、⼗十分⼤大きな A
を選べば、事後分布には影響しない。
• 無情報事前分布として良良い。
• σα ≦ 20 にだいたい収まっている。 • J=8 ではこれ以上の推定は困難。
(注:今は推定の良良さではなく、無情報事前分布としての良良さを調べている)
40
-
3-schools データ • グループ数が少ない場合はどうなるか?
• 8-schools データのうち最初の3つを抽出
• J=3 に対して無情報事前分布を適⽤用する
41
-
3-schools ⼀一様分布• σα 〜~ Uniform(0, A) •
事後分布が⾮非常に⻑⾧長い裾を引いている。
524 Prior distributions for variance parameters in hierarchical
models
σα0 50 100 150 200
3 schools: posterior on σα givenuniform prior on σα
σα0 50 100 150 200
3 schools: posterior on σα givenhalf−Cauchy (25) prior on σα
Figure 2: Histograms of posterior simulations of the
between-school standard deviation,σα, from models for the 3-schools
data with two different prior distributions on σα:(a) uniform
(0,∞), (b) half-Cauchy with scale 25, set as a weakly informative
priordistribution given that σα was expected to be well below 100.
The histograms arenot on the same scales. Overlain on each
histogram is the corresponding prior densityfunction. With only J =
3 groups, the noninformative uniform prior distribution is tooweak,
and the proper Cauchy distribution works better, without appearing
to distortinferences in the area of high likelihood.
by the choice to plot them on the scale of σα. If instead they
were plotted on the scaleof log σα, the inverse-gamma(0.001, 0.001)
prior density would appear to be the flattest.However, the
inverse-gamma(ϵ, ϵ) prior is not at all “noninformative” for this
problemsince the resulting posterior distribution remains highly
sensitive to the choice of ϵ. Asexplained in Section 4.2, the
hierarchical model likelihood does not constrain log σα inthe limit
log σα → −∞, and so a prior distribution that is noninformative on
the logscale will not work.
5.2 Weakly informative prior distribution for the 3-schools
problem
The uniform prior distribution seems fine for the 8-school
analysis, but problems arise ifthe number of groups J is much
smaller, in which case the data supply little informationabout the
group-level variance, and a noninformative prior distribution can
lead toa posterior distribution that is improper or is proper but
unrealistically broad. Wedemonstrate by reanalyzing the 8-schools
example using just the data from the first 3of the schools.
Figure 2 displays the inferences for σα from two different prior
distributions. First wecontinue with the default uniform
distribution that worked well with J = 8 (as seen inFigure 1).
Unfortunately, as the left histogram of Figure 2 shows, the
resulting posteriordistribution for the 3-schools dataset has an
extremely long right tail, containing valuesof σα that are too high
to be reasonable. This heavy tail is expected since J is so low(if
J were any lower, the right tail would have an infinite integral),
and using this as aposterior distribution will have the effect of
undershrinking the estimates of the schooleffects αj , as explained
in Section 4.2.
The right histogram of Figure 2 shows the posterior inference
for σα resulting from ahalf-Cauchy prior distribution of the sort
described at the end of Section 3.2, with scale
42
-
3-schools ⼀一様分布• 事後分布が⾮非常に⻑⾧長い裾を引いている。
• 事前分布の影響が残っている。 • 無情報 = 事後分布に影響しない
• 無情報事前分布として不不適切切
43
-
3-schools 弱情報事前分布• 3-schools 問題では、improper
な⼀一様分布は、無情報事前分布として使えない。
• 弱い事前情報を考える。 • テストの点数は 200 〜~ 800点、平均は
500点程度度なので、標準偏差は 300 以下となる可能性が⾼高い。
• A=300 としてみる。
44
-
3-schools 弱情報事前分布• σα 〜~ Uniform(0, 300) •
⼀一様分布に弱い情報を持たせても、裾が⻑⾧長いまま。
524 Prior distributions for variance parameters in hierarchical
models
σα0 50 100 150 200
3 schools: posterior on σα givenuniform prior on σα
σα0 50 100 150 200
3 schools: posterior on σα givenhalf−Cauchy (25) prior on σα
Figure 2: Histograms of posterior simulations of the
between-school standard deviation,σα, from models for the 3-schools
data with two different prior distributions on σα:(a) uniform
(0,∞), (b) half-Cauchy with scale 25, set as a weakly informative
priordistribution given that σα was expected to be well below 100.
The histograms arenot on the same scales. Overlain on each
histogram is the corresponding prior densityfunction. With only J =
3 groups, the noninformative uniform prior distribution is tooweak,
and the proper Cauchy distribution works better, without appearing
to distortinferences in the area of high likelihood.
by the choice to plot them on the scale of σα. If instead they
were plotted on the scaleof log σα, the inverse-gamma(0.001, 0.001)
prior density would appear to be the flattest.However, the
inverse-gamma(ϵ, ϵ) prior is not at all “noninformative” for this
problemsince the resulting posterior distribution remains highly
sensitive to the choice of ϵ. Asexplained in Section 4.2, the
hierarchical model likelihood does not constrain log σα inthe limit
log σα → −∞, and so a prior distribution that is noninformative on
the logscale will not work.
5.2 Weakly informative prior distribution for the 3-schools
problem
The uniform prior distribution seems fine for the 8-school
analysis, but problems arise ifthe number of groups J is much
smaller, in which case the data supply little informationabout the
group-level variance, and a noninformative prior distribution can
lead toa posterior distribution that is improper or is proper but
unrealistically broad. Wedemonstrate by reanalyzing the 8-schools
example using just the data from the first 3of the schools.
Figure 2 displays the inferences for σα from two different prior
distributions. First wecontinue with the default uniform
distribution that worked well with J = 8 (as seen inFigure 1).
Unfortunately, as the left histogram of Figure 2 shows, the
resulting posteriordistribution for the 3-schools dataset has an
extremely long right tail, containing valuesof σα that are too high
to be reasonable. This heavy tail is expected since J is so low(if
J were any lower, the right tail would have an infinite integral),
and using this as aposterior distribution will have the effect of
undershrinking the estimates of the schooleffects αj , as explained
in Section 4.2.
The right histogram of Figure 2 shows the posterior inference
for σα resulting from ahalf-Cauchy prior distribution of the sort
described at the end of Section 3.2, with scale
45
-
3-schools 弱情報事前分布• 半コーシー分布に弱い情報を持たせる • σα 〜~
HalfCauchy(25) • 95% の領領域で σα < 300 となる
σα0 30046
-
3-schools 半コーシー分布 • σα 〜~ HalfCauchy(25) •
半コーシーでは、右裾が抑えられる
524 Prior distributions for variance parameters in hierarchical
models
σα0 50 100 150 200
3 schools: posterior on σα givenuniform prior on σα
σα0 50 100 150 200
3 schools: posterior on σα givenhalf−Cauchy (25) prior on σα
Figure 2: Histograms of posterior simulations of the
between-school standard deviation,σα, from models for the 3-schools
data with two different prior distributions on σα:(a) uniform
(0,∞), (b) half-Cauchy with scale 25, set as a weakly informative
priordistribution given that σα was expected to be well below 100.
The histograms arenot on the same scales. Overlain on each
histogram is the corresponding prior densityfunction. With only J =
3 groups, the noninformative uniform prior distribution is tooweak,
and the proper Cauchy distribution works better, without appearing
to distortinferences in the area of high likelihood.
by the choice to plot them on the scale of σα. If instead they
were plotted on the scaleof log σα, the inverse-gamma(0.001, 0.001)
prior density would appear to be the flattest.However, the
inverse-gamma(ϵ, ϵ) prior is not at all “noninformative” for this
problemsince the resulting posterior distribution remains highly
sensitive to the choice of ϵ. Asexplained in Section 4.2, the
hierarchical model likelihood does not constrain log σα inthe limit
log σα → −∞, and so a prior distribution that is noninformative on
the logscale will not work.
5.2 Weakly informative prior distribution for the 3-schools
problem
The uniform prior distribution seems fine for the 8-school
analysis, but problems arise ifthe number of groups J is much
smaller, in which case the data supply little informationabout the
group-level variance, and a noninformative prior distribution can
lead toa posterior distribution that is improper or is proper but
unrealistically broad. Wedemonstrate by reanalyzing the 8-schools
example using just the data from the first 3of the schools.
Figure 2 displays the inferences for σα from two different prior
distributions. First wecontinue with the default uniform
distribution that worked well with J = 8 (as seen inFigure 1).
Unfortunately, as the left histogram of Figure 2 shows, the
resulting posteriordistribution for the 3-schools dataset has an
extremely long right tail, containing valuesof σα that are too high
to be reasonable. This heavy tail is expected since J is so low(if
J were any lower, the right tail would have an infinite integral),
and using this as aposterior distribution will have the effect of
undershrinking the estimates of the schooleffects αj , as explained
in Section 4.2.
The right histogram of Figure 2 shows the posterior inference
for σα resulting from ahalf-Cauchy prior distribution of the sort
described at the end of Section 3.2, with scale
47
-
発表の流流れ1. 背景、使⽤用モデル 2. ⽤用語説明 3. 理理論論的考察 4. 実際のデータに適⽤用 5. 結論論
48
-
5. 結論論• 階層モデルの階層分散パラメータについて、無情報事前分布として何が良良いかを調べた。
• グループ数 J > 5 の場合は A を⼗十分⼤大きくした⼀一様分布 Uniform(0, A) が良良い。
• J = 3,4,5 の場合は半コーシー分布が良良い。 • 逆ガンマ分布は使ってはダメ。
49