Embed Size (px)
Citation preview

Artificial Intelligence in Medicine 12 (1998) 1–24
Case-based reasoning in IVF: prediction andknowledge mining
Igor Jurisica a,*, John Mylopoulos a, Janice Glasgow b,Heather Shapiro c, Robert F. Casper c
a Department of Computer Science, Uni6ersity of Toronto, Toronto, Ontario M5S 1A4, Canadab Department of Computing and Information Science, Queen’s Uni6ersity, Kingston,
Ontario K7L 3N6, Canadac Di6ision of Reproducti6e Science, Toronto General Hospital, Toronto, Ontario M5G 2C4, Canada
Received 30 November 1996; received in revised form 10 March 1997; accepted 30 April 1997
Abstract
In vitro fertilization (IVF) is a medically-assisted reproduction technique, enabling infertilecouples to achieve successful pregnancy. Given the unpredictability of the task, we proposeto use a case-based reasoning system that exploits past experiences to suggest possiblemodifications to an IVF treatment plan in order to improve overall success rates. Once thesystem’s knowledge base is populated with a sufficient number of past cases, it can be usedto explore and discover interesting relationships among data, thereby achieving a form ofknowledge mining. The article describes the TA3IVF system—a case-based reasoning systemwhich relies on context-based relevance assessment to assist in knowledge visualization,interactive data exploration and discovery in this domain. The system can be used as anadvisor to the physician during clinical work and during research to help determine whatknowledge sources are relevant for a treatment plan. © 1998 Elsevier Science B.V.
Keywords: Case-based reasoning; In vitro fertilization; Relevance; Similarity; Context; Pre-diction; Knowledge mining
* Corresponding author. Tel.: +1 416 978-7589/5180; fax: +1 416 978-1455; e-mail:[email protected]
0933-3657/98/$19.00 © 1998 Elsevier Science B.V. All rights reserved.
PII S0933 -3657 (97 )00037 -7

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–242
1. Introduction
Almost one out of ten couples in North America is infertile. One of the mostwidely used treatments for human infertility is the in vitro fertilization (IVF)procedure. IVF is a fairly complex assisted reproductive technology which has beenevolving since the first pregnancy achieved by this method in 1978. Althoughcertain parts of the procedure have been improved over the years, the pregnancyrates have not changed and are at best 30%.
The IVF procedure consists of patient selection by diagnosis of infertility,controlled ovarian stimulation for multiple oocyte recruitment and maturation,close monitoring of follicular development by ultrasound and hormonal assessment,oocyte retrieval, insemination of oocytes in vitro, determination of fertilization,assessment of embryo development and quality, assessment of endometrial quality,and intrauterine transfer of one or more cleaved embryos. At each step of theprocedure, many dependent and independent variables may impact the outcome,i.e. pregnancy [1]. For example, a patient’s response to controlled ovarian stimula-tion may depend on her age, diagnosis of infertility, size of ovaries, baseline serumfollicle stimulating hormone concentration, type and dose of fertility drug used andwhether endogenous gonadotrophin secretion has been suppressed by go-nadotrophin releasing hormone (GnRH) agonist. Pregnancy rates may depend onage, presence of oocyte dysmorphisms, sperm quality, fertilization rate, rate ofcleavage and embryo quality, number of embryos transferred, endometrial thick-ness and uterine blood flow on ultrasound and number of previous cycles oftreatment. With so many variables, it is difficult for the clinician to discern trendsand make informed decisions to optimize success rates for each individual infertilecouple.
There are many factors that influence the outcome of IVF. Intelligent decision-support systems may enable IVF practitioners to cope with the complexity of thedomain during treatment planning and help them discover relationships betweenindividual knowledge sources, which can then be used to potentially improve thepregnancy rate. Since the IVF treatment is a relatively expensive procedure, such adecision system helps the patient in deciding whether to go ahead with theprocedure or not, based on the probability of success.
This paper proposes a novel decision-support system for IVF practitioners, calledTA3 (pronounced tah-tree)1. It incorporates case-based reasoning (CBR) and isbased on a notion of relevance assessment, used for flexible retrieval of usefulinformation. Our thesis supports the hypothesis that CBR techniques are useful forproblem solving in medicine. We propose a CBR system that can help in addressingthe problem of treatment in the area of IVF [2].
Decision making in IVF is usually based on a combination of the patient’sparticular characteristics, and on the physician’s knowledge and clinical experience.For most clinicians, the synthesis of previous experience with the current situation
1 The name is derived from the pronunciation of the Slovak mountain region, called Tatry.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 3
becomes almost intuitive with time. This phenomenon is commonly referred to as‘clinical judgment’. However, as the number of variables increase, the ease andaccuracy of this approach decreases. A reasoning system based on past experiences,a CBR system, may be used as a computational aid in this decision making.
Our objective is to apply and evaluate the performance of TA3 in the IVFdomain2. The main goals are to: (1) create a case base of patients who have beenassessed for infertility and treated by means of IVF procedure using the TA3IVF
system; (2) use the case base for suggesting an appropriate approach for hormonalstimulation for new patients (prediction); and (3) use the case base to deriveinteresting relationships among data (knowledge mining). In the following sectionswe present the theory behind the TA3IVF system, its implementation and evaluation.
1.1. Introduction to case-based reasoning
A CBR approach [3] relies on the concept that similar problems have similarsolutions. Facing a new problem, a case-based system retrieves similar cases storedin a case base and adapts them to fit the problem at hand. Informally, a casecomprises an input (the problem), an output (the solution) and feedback (anevaluation of the solution). CBR involves: (1) accepting a new problem description(a case without a solution and feedback); (2) retrieving relevant cases from a casebase (solved problems with similar input); (3) adapting retrieved cases to fit theproblem at hand and producing the solution for it; (4) evaluating the solution.
Considering the CBR cycle, one can say that the more similar the cases are theless adaptation is necessary and consequently, the proposed solution may be morecorrect. Then, an important task is how to measure case relevance (similarity orcloseness) to guarantee retrieving only highly relevant cases, i.e. cases that aresimilar according to specified criteria and thus can be useful in solving the currentproblem. In many processes, it is better to retrieve fewer cases, or none, than toretrieve less useful cases that would result in a poor solution. Since relevancycriteria are usually different for different tasks it is better not to predefine them.This is our motivation for designing a flexible retrieval approach in TA3, instead ofusing a standard indexed-based retrieval.
1.2. Introduction to case-based classification and knowledge mining
The classification task involves associating cases with particular classes. Based onthe case description, a classification system determines a class membership for agiven case. In general, this process consists of: (1) generating a set of classes; and(2) classifying cases into the created class structure. If the classes are known fromthe domain knowledge, e.g. pregnancy outcome, then the process of associatinginstances with classes is called a classification process. If, however, the system issupposed to generate classes and categorize given cases then we use the termconceptual clustering, i.e. grouping objects into conceptually meaningful classes [4].
2 We shall refer to this system as TA3IVF.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–244
Various techniques have been utilized for the classification task, including neuralnetworks [5], genetic algorithms [6], inductive and instance-based learning [7] andcase-based reasoning [8,9]. Individual approaches are comparable based on themethod they deploy, the accuracy they achieve and the complexity of the algorithmused.
Knowledge mining is the nontrivial extraction of implicit, previously unknownand potentially useful information from data [10]. Current research in the areadistinguishes autonomous and semi-autonomous algorithms.
2. The TA3IVF system
2.1. Case representation
A case corresponds to a real world situation, represented as structured objectswith relations [11]. Formally, a case, C, is represented as a finite set of attribute/value pairs:
C={�a0:V0�, �a1:V1�,. . ., �an :Vn�},
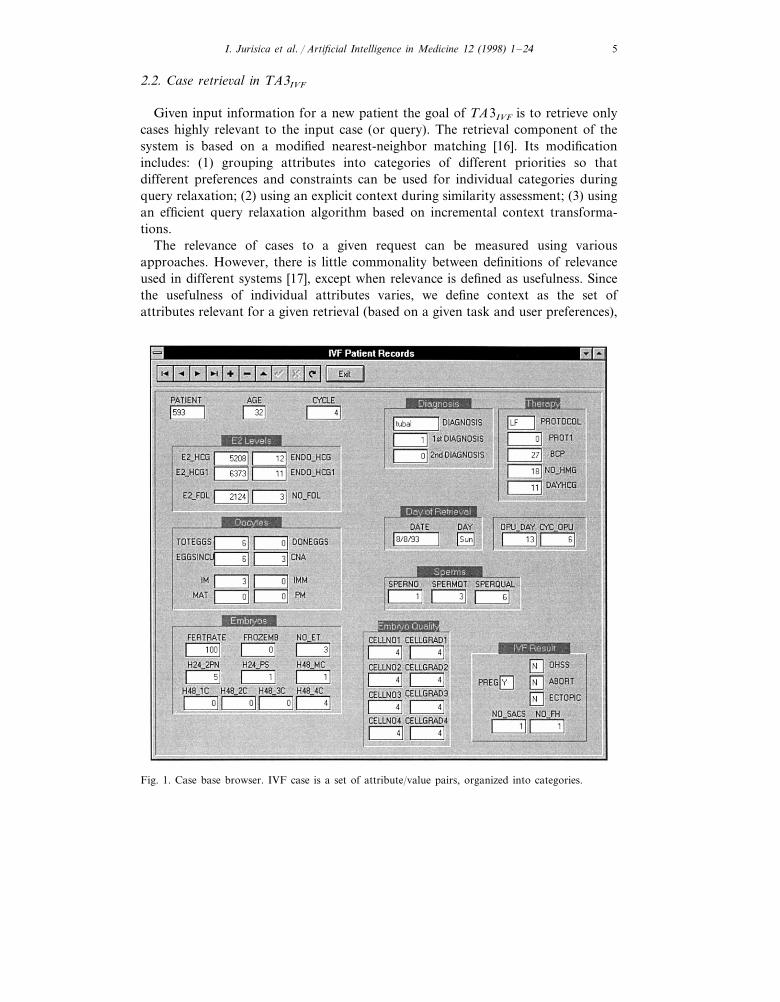
where Ai= (ai :Vi) is an attribute/value pair. Fig. 1 presents a case example, using acase base editor/browser. We distinguish two types of cases: (1) an input case(target) describes the problem and is represented as a case without a solution and(2) a source case is a case stored in a case base that contains both a problemdescription and a solution.
Individual attributes in a case are grouped into Telos-style categories [11], e.g. theE2 Le6els category (level of estrogen) in Fig. 1. Each case can have one or morecategories and category membership is based on the usefulness of the attribute andits properties. Category membership can be determined using domain knowledge orthrough machine learning techniques [12]. Attribute grouping allows for ascribingdifferent constraints to different sets of attributes and the process of retrievingrelevant cases can be described as a constraint satisfaction process [13–15].
Case acquisition is carried out by storing IVF patients’ medical records in thecase base. The case base considered for this paper consists of the 788 cases with 55attributes per case.3 Out of 788 cases, there are 149 clinically successful pregnancies,ten are pregnancies with ovarian hyper-stimulation syndrome (OHSS) complica-tion, 12 are pregnancies ended by abortion, four are ectopic pregnancies (implanta-tion occurred outside of uterus) and 632 are unsuccessful pregnancies. There is noinformation about the IVF outcome in the remaining seven cases. The expectedgrowth of the case base is 1000 cases per year. In addition, as our experience shows,the number and selection of attributes used during problem solving is bound toincrease as a result of accommodating new knowledge about factors influencingpregnancy outcome [2].
3 For some experiments we have used more complex case representation, namely a series of estrogenlevels instead of a single value. This changed the count for number of attributes to 70.
I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 5
2.2. Case retrie6al in TA3IVF
Given input information for a new patient the goal of TA3IVF is to retrieve onlycases highly relevant to the input case (or query). The retrieval component of thesystem is based on a modified nearest-neighbor matching [16]. Its modificationincludes: (1) grouping attributes into categories of different priorities so thatdifferent preferences and constraints can be used for individual categories duringquery relaxation; (2) using an explicit context during similarity assessment; (3) usingan efficient query relaxation algorithm based on incremental context transforma-tions.
The relevance of cases to a given request can be measured using variousapproaches. However, there is little commonality between definitions of relevanceused in different systems [17], except when relevance is defined as usefulness. Sincethe usefulness of individual attributes varies, we define context as the set ofattributes relevant for a given retrieval (based on a given task and user preferences),
Fig. 1. Case base browser. IVF case is a set of attribute/value pairs, organized into categories.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–246
Fig. 2. Context for the first stage of prediction. In addition to specifying the case description, constraintson attributes can be defined.
such as AGE, CYCLE, DIAGNOSIS, etc. Thus, the context can be seen as a viewor an interpretation of a case, where only a subset of the attributes are consideredrelevant. Formally, a context is defined as a finite set of attributes with associatedconstraints on their values:
V={�a0:CV0�, . . ., �ak :CVk�},
where ai is an attribute name and constraint CVi specifies the set of ‘allowable’values for attribute ai. By selecting only certain attributes for matching andimposing constraints on attribute values, a context allows for controlling what canand what cannot be considered as a partial match: all (and only) cases that satisfythe specified constraints for the context are considered similar and are relevant withrespect to the context. This allows for a controlled retrieval process, as well as foreasy context transformations, such as context restriction and relaxation.
Similarity is determined as a closeness of values for attributes defined in thecontext (note that closeness depends on attribute value distribution as well as onthe task being solved). These attributes can be specified directly by the user or aquery-by-example may be used (see Fig. 2). Here, the context is defined throughquery-by-example and is used for an initial prediction. It should be noted that if thepatient’s initial information is already entered into the case base, a query isconstructed by simple case selection. Since only a subset of all attributes is requiredduring matching (i.e. only a subset of all attributes is relevant for a given task), thiscontext contains only attributes AGE, CYCLE, DIAGNOSIS, FIRST–DIAG,SECOND–DIAG, PROTOCOL and BCP (birth control pill). If the interpretationof the target case is similar to a source case, we say that they match and thusretrieved source cases are relevant in a given context. In addition, it is possible to

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 7
impose constraints on the attribute values and on the number of attributes requiredto match.
A case C satisfies a context V, denoted sat(C, V), if and only if for all pairs�ai :CVi��V, there exists a pair �ai :Vi��C such that Vi is in CVi :
sat(C, V) iff Öai�ai :CVi��V�×Vi�ai :Vi��C�Vi�CVi.
A case C1 is similar to a case C2 with respect to a given context V, denoted:C1�VC2, if and only if both C1 and C2 satisfy context V: C1�VC2 l sat(C1, V)�sat(C2, V).
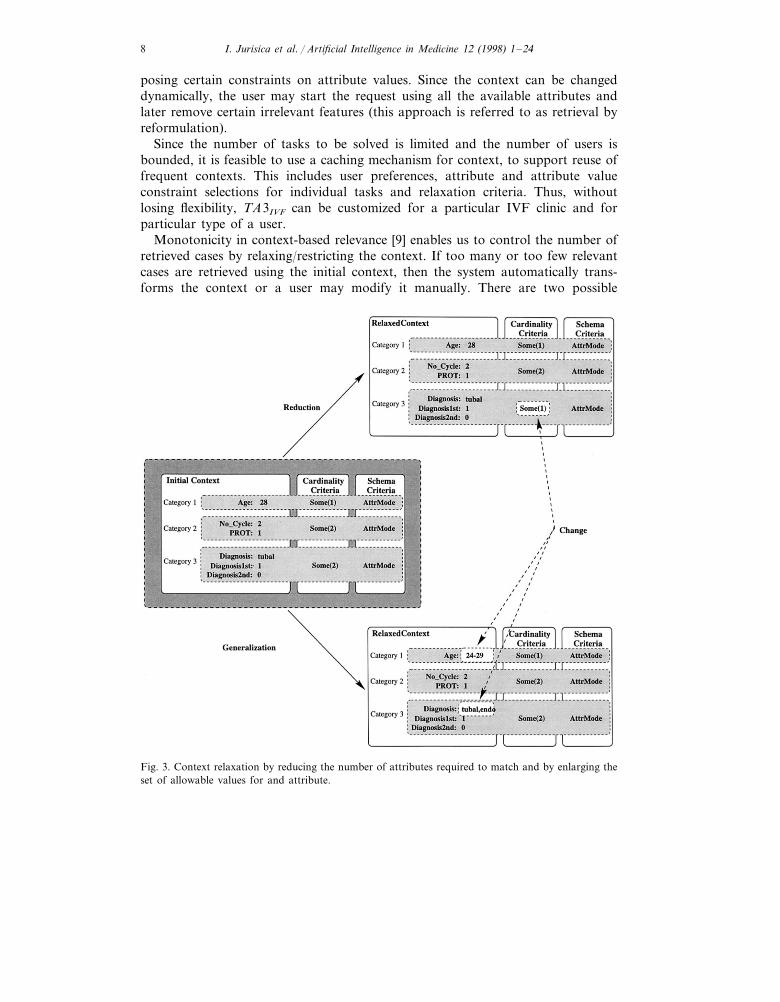
This notion of similarity and context subsumes traditional nearest-neighbor ortemplate matching in CBR systems, where the partial description of a case issubmitted as the query and the system locates all similar cases to a given description(similarly as in query-by-example). Our approach allows for initiating the query byusing query-by-example, which defines a context. A partial case description islocated either by browsing a case base or by entering a new case. The advantage ofour approach lies in the fact that using context allows for subsequent controlledcontext transformations (see Fig. 3). Besides specifying a context, a user can definecriteria which define the way the context should be handled and what criteriashould be used for matching during context relaxation and restriction. Thus,context permits easy implementation of retrieval by reformulation [18] and allowsfor iterative browsing through contextually similar cases. When the problem ofspecifying a query gets difficult, retrieval by reformulation is the best approach.Thus, the support of efficient iterative browsing is necessary.
A context V1 is a relaxation of a context V2 (or a context V2 is a restriction of acontext V1), denoted V1cV2, if and only if the set of attributes for V1 is a subsetof the set of attributes for V2 and for all attributes in V1, the set of constraints inV2 is a subset of the constraints in V1. As well, contexts V1 and V2 are not equal.
V1cV2 iff Ö�ai :CVi��V1, ×�ai :CVj��V2:CVi±CVj�V1"V2
.The advantage of defining a context explicitly is the flexibility of matching it
supports. The resulting problem is specifying the context. In the simplest approach,which is similar to query-by-example, a context V is constructed by mapping aninput case into it in its entirety. The initial context may be subsequently changed(either automatically by the system or by the user) as a reaction to a returnedanswer4. This approach can also be considered a starting point for other, moresophisticated, approaches. A machine learning or knowledge mining algorithmcould also be used to select important attributes for a given task and to specifycharacteristic values for them. This information can then be used to derive an initialcontext specification and specify context transformation strategies. If the CBRsystem is used as an intelligent decision-support system, then the user is an expert,who can improve the system’s performance by selecting important features and
4 In general, an answer consists of a set of retrieved relevant cases.
I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–248
posing certain constraints on attribute values. Since the context can be changeddynamically, the user may start the request using all the available attributes andlater remove certain irrelevant features (this approach is referred to as retrieval byreformulation).
Since the number of tasks to be solved is limited and the number of users isbounded, it is feasible to use a caching mechanism for context, to support reuse offrequent contexts. This includes user preferences, attribute and attribute valueconstraint selections for individual tasks and relaxation criteria. Thus, withoutlosing flexibility, TA3IVF can be customized for a particular IVF clinic and forparticular type of a user.
Monotonicity in context-based relevance [9] enables us to control the number ofretrieved cases by relaxing/restricting the context. If too many or too few relevantcases are retrieved using the initial context, then the system automatically trans-forms the context or a user may modify it manually. There are two possible
Fig. 3. Context relaxation by reducing the number of attributes required to match and by enlarging theset of allowable values for and attribute.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 9
Fig. 4. Conceptual hierarchy for the AGE attribute.
transformations: relaxation—to allow for retrieving more cases and restriction—toallow for retrieving fewer cases.
The TA3IVF system supports two implementations of context relaxation—reduc-tion and generalization. Reduction removes constraints by reducing the number ofattributes required to match: given m–of–n matching, the required number ofattributes is reduced from m to p, where 0BpBm5n. Generalization is a contexttransformation that relaxes the context by enlarging the set of allowable values foran attribute.
As an example, consider the relaxation of a context specified in Fig. 3. In orderto increase versatility, we grouped attributes into three categories. Assume that allcategories have the same priority and value constraints but they require differentnumber of attributes to match. Consider two scenarios: (1) reduction of the originalcontext, and (2) generalization of the original context. It is not possible to applyreduction for category 1 since there is only one attribute, but it is possible to relaxcategory 2 or 3. Some(2), in the cardinality criteria for category 3, implies that atleast two of the attribute/value pairs need to match for the whole category tomatch. This constraint could be further relaxed to Some(1). Additionally, category2 could be relaxed from Some(2) to Some(1), as illustrated in Fig. 3.
In the second scenario, value constraints are relaxed. Since all categories requiredinstance matches, context values could be updated by using a conceptual hierarchy,presented in Fig. 4. Thus, the constraint for the AGE attribute could be changed to24–29 (as shown in Fig. 3), as an immediate generalization of 28. In addition, auser-guided relaxation may be a better option, since the user might have domainknowledge not represented in the system. Thus, the attribute value could alterna-tively be relaxed from 28 to for example, 26–30. The constraint of attribute 1 incategory 3 is also relaxed from constraint {tubal} to constraint set {tubal, endo}.
Contexts can also be iteratively restricted to retrieve successively fewer cases.There are two possible implementations of context restriction: expansion—strength-ening constraints by enlarging the number of attributes required to match; andspecialization—strengthening constraints by removing values from a constraint setfor an attribute.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2410
2.3. Retrie6al function complexity
Most information retrieval systems are optimized for achieving either high recalland moderate precision or vice versa. Precision can be explained as a measure ofavoidance of irrelevant cases: the higher the precision, the greater the percentage ofrelevant cases in the set of retrieved cases. Recall is a measure of completeness ofretrieval: the higher the recall, the smaller the set of relevant cases that remainsunretrieved. Flexibility of the TA3IVF system allows for precision-oriented retrieval,recall-oriented retrieval and retrieval where both recall and precision are high.
Since TA3IVF is a decision-support system, both high recall and precision aredesired. This can be achieved by conservative and novice approaches. Conser6ati6eapproach emphasizes retrieving only relevant cases, even if some relevant cases aremissed. After the initial set of relevant cases is available, iteratively considerneighbors and include only relevant ones. This approach is appropriate if the useris knowledgeable in the problem domain, since the retrieval process must beconstrained, to eliminate irrelevant matches, and similarity-based, to retrieve rele-vant neighbors of initial matches. The conservative approach can be explained as aprecision-oriented retrieval process with iterative query tuning, used to increaserecall, while preserving perfect precision.
No6ice approach emphasizes retrieving all relevant cases, even at the price ofincluding some irrelevant ones. After the initial pool of cases is retrieved, iterativelyremove all irrelevant cases. As the name suggests, this approach is suitable fornovices, i.e. users who do not have initial knowledge about the structure of therepository. Thus, they may not specify a query request completely to ensureretrieval with high precision, but based on initial retrievals and feedback informa-tion, they may iteratively prune the set of retrieved cases. The novice’s approachcan be explained as recall-oriented retrieval with iterative query tuning to increaseprecision, while preserving perfect recall.
With flexibility added to the retrieval algorithm it’s complexity increased. Theprocess of restricting and relaxing contexts can be repeated and interwoven until theagent is satisfied with the number and the relevancy of the retrieved cases. It isapparent that after the context is changed by relaxation/restriction, the system mustre-evaluate the query. A naive approach would take the new query and wouldsubmit it to the system. A more sophisticated approach can take advantage of analready processed query by incrementally modifying its result [19].
The basic idea of incremental computation is to store query results and reusethem when similar queries are computed [20]. Assuming that the number ofattributes per case is significantly smaller than the number of cases suggests that theincremental context restriction/relaxation outperforms re-computation of the an-swer from scratch.
In order to support efficient iterative browsing and retrieval by reformulation[18], we implemented context restriction/relaxation using incremental algorithms.TA3IVF supports two types of incremental context transformation: (1) partial resultsare kept at the attribute level; (2) partial results are kept at the category level. It isobvious that the first approach poses more requirements on storage. However, it is
I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 11
more versatile and thus is more suitable for case bases with frequent contexttransformations and with fewer attributes per case. The second approach is acompromise between performance gains from an incremental approach and modeststorage requirement. This approach is useful for less frequent context changes andfor case bases containing cases with a large number of attributes.
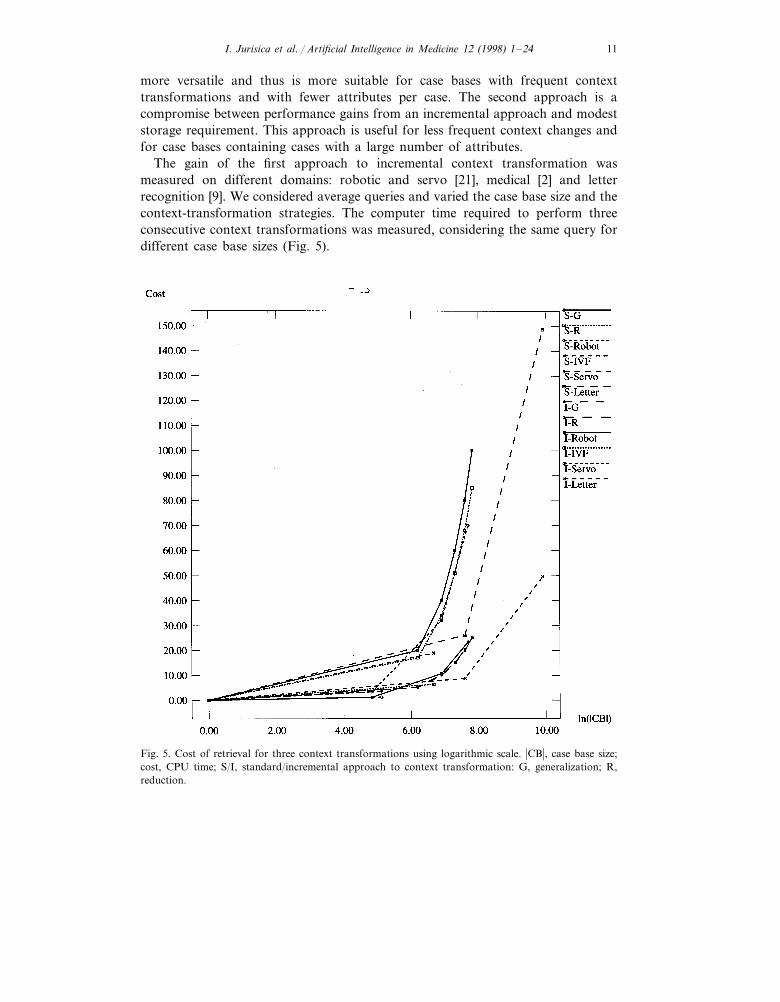
The gain of the first approach to incremental context transformation wasmeasured on different domains: robotic and servo [21], medical [2] and letterrecognition [9]. We considered average queries and varied the case base size and thecontext-transformation strategies. The computer time required to perform threeconsecutive context transformations was measured, considering the same query fordifferent case base sizes (Fig. 5).
Fig. 5. Cost of retrieval for three context transformations using logarithmic scale. �CB�, case base size;cost, CPU time; S/I, standard/incremental approach to context transformation: G, generalization; R,reduction.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2412
System performance during case retrieval in TA3IVF is improved by usingcontext-based clustering. This can be performed via user input, for example,clustering patients into three age categories or clustering patients according topregnancy outcome. In addition, TA3IVF supports system-assisted clustering,namely, the system finds features, and corresponding values, that are good predic-tors for pregnancy outcome and thus can be used as discrimination factors.
2.4. The adaptation module
Adaptation process in CBR manipulates the solution of the source case to betterfit the target case. This can be done automatically, semi-automatically or by theuser. A domain knowledge or generally applicable adaptation rules can be utilized.The complexity of the domain and availability of domain knowledge dictates whichapproach can be used.
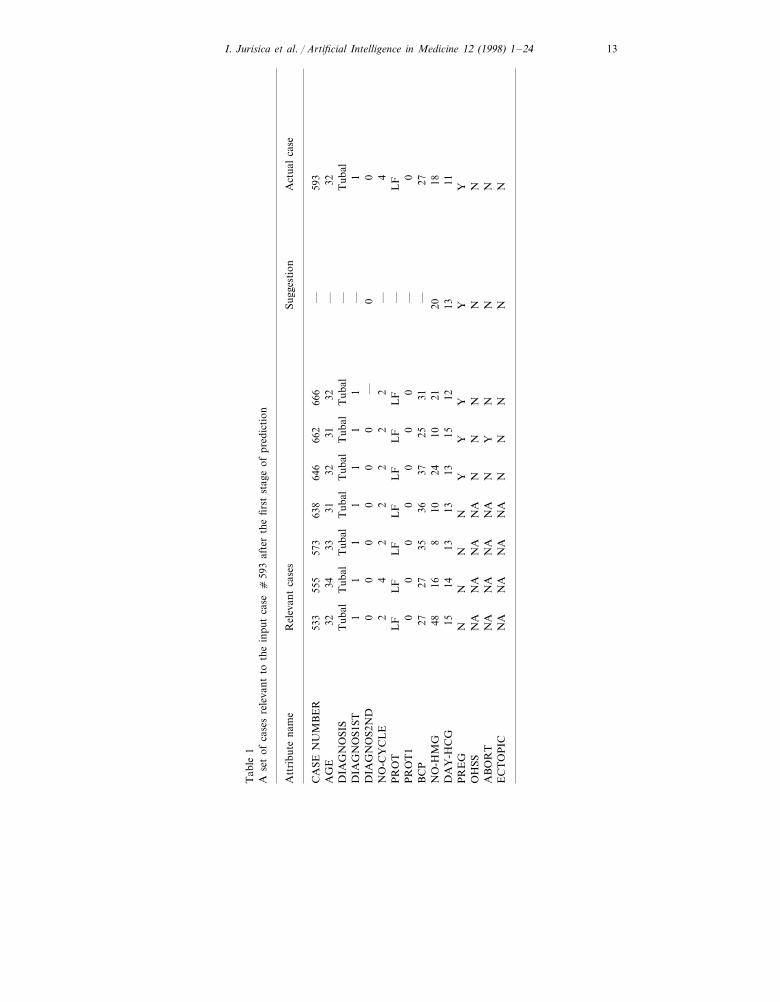
In TA3IVF, a weighted average of attribute values from retrieved cases iscomputed automatically. Retrieved cases are ordered, first according to the class(pregnancy outcome), then according to a relevance measure, giving the mostrelevant cases the highest weight. If not enough cases are retrieved, automaticcontext relaxation is triggered. For example, if only two cases are retrieved andtheir values for DAY–HCG attribute are distant, the system relaxes current contextto retrieve more cases. Then, a cluster of cases with an average value for a predictedattribute is formed to have the highest weight. Remaining retrieved cases have amarginal weight assigned. A weighted average is then computed for the predictedvalues. For example, consider Table 1 and the result of treatment suggestion forattribute NO–HMG. Cases with successful pregnancy (i.e. 646, 662 and 666) areconsidered as positive examples. Since the value of case 662 is about one half thevalue of the other two, the suggested value is computed using the weight of 83% forthe values of cases 646 and 666 and using the weight of 17% for the value of thecase 662.
2.5. Knowledge mining component
Deploying a user-guided knowledge discovery process in TA3 was motivated by:(1) the need to identify salient attributes for use in case-based classification; (2) theneed to structure the case base into clusters of relevant cases for improvingperformance; and (3) the need to find representative values for salient attributes.
Pattern discovery in TA3IVF involves collecting together cases that share some-thing in common. For example, collecting all women that have pregnancy withcomplications and are in their third or fourth cycle. However, pattern identificationalone is not sufficient—patterns also need to be described, i.e. given a set of cases,labeled by class (such as pregnant women), derive an intensional description of theclasses. Although the user can guide the search for patterns, from a statistical pointof view, the process is an exploratory analysis since no hypothesis about what thepatterns may be is posed. Such process of discovery is inherently dynamic and mustoften be performed iteratively.
I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 13
Tab
le1
Ase
tof
case
sre
leva
ntto
the
inpu
tca
sec
593
afte
rth
efir
stst
age
ofpr
edic
tion
Att
ribu
tena
me
Rel
evan
tca
ses
Sugg
esti
onA
ctua
lca
se
533
646
662
666
—59
355
557
3C
ASE
NU
MB
ER
638
3132
—32
32A
GE
3133
3432
Tub
alT
ubal
—T
ubal
DIA
GN
OSI
ST
ubal
Tub
alT
ubal
Tub
alT
ubal
11
—1
11
1D
IAG
NO
S1ST
11
00
0—
00
00
0D
IAG
NO
S2N
D2
22
2—
44
22
NO
-CY
CL
EL
FL
F—
LF
LF
PR
OT
LF
LF
LF
LF
00
00
—0
PR
OT
10
00
2531
—27
3727
BC
P36
3527
2448
1021
2018
168
10N
O-H
MG
1315
1512
1311
1413
13D
AY
-HC
GY
YY
YY
PR
EG
NN
NN
NA
NN
NN
NO
HSS
NA
NA
NA
YN
NN
NN
AA
BO
RT
NA
NA
NA
EC
TO
PIC
NN
AN
NN
NA
NA
NA
N

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2414
TA3IVF also allows for organizing case representation to support flexible retrievalusing context reduction, which can be used during problem solving for improvingprediction accuracy and scalability. Moreover, new relationships among attributescan be discovered and the case base can be structured into semantically meaningfulclusters of cases. The context discovery function maps a set of cases and a case baseonto a context that guarantees the relevance of cases. Since there are severalpossible contexts, the system supports controlled-discovery, i.e. a user-specifiedcoverage T is used as a termination criteria for the learning algorithm. T specifiesthe percentage of cases that must be relevant in order to accept a particular context.The task for the context discovery function is to find the minimal context whichsatisfies the given threshold T. The context discovery function uses the retrievalfunction to determine how many of the selected cases match the current context. Ifat least T% of cases match the context for a particular attribute, then the attributeis set aside, since the criteria for it are satisfied, and further relaxation of constraintson context would only increase the coverage. If less than T% of the cases match thecontext for a particular attribute then the attribute needs to be value-relaxed, i.e.another value from remaining cases will be added to it. The process is repeated untilall attributes satisfy the user-specified threshold T and the returned context isguaranteed to satisfy it. It should be noted that only one pass over cases in a casebase is necessary. Value relaxation is improved by not only including specificvalues, but also by using generalization hierarchies. The algorithm that implementscontext discovery, presented below, uses factor analysis [22] and is similar to theCDP algorithm [23].
Factor analysis is a statistical technique used to identify a small number offactors that can be used to represent relationships among sets of interrelatedvariables. Once cases can be described by their characteristic features, the case baseis dynamically organized into particular clusters. If there is a high variability ofvalues for a particular attribute, then the attribute is not a good predictor for agiven class. Low variability of attribute values suggests a predictive feature. Whenall attributes are processed, the system groups similar attributes into categories, i.e.predictive attributes are separated from attributes unsuitable for prediction. Thistechnique is simple enough that it scales up for large case bases, yet it allows forimproved reasoning as will be shown in the next section.
In TA3IVF, the user poses a focused query, such as ‘What have the pregnantwomen in common?’ and the system finds a context which makes a given class ofcases similar. Thus, TA3IVF finds salient attributes and values for these attributes,i.e. a generalized interpretation of a given set of cases. This process is user-directed,interactive and possibly iterative. The user specifies the query which constrains thesearch space and the threshold T, which represents the certainty factor. The initialquery is evaluated to produce a subset of the case base (e.g. find cases wherePREG :Y and ABORTION :N). Then, cases within the selected group are analyzedto produce a case interpretation that guarantees the coverage T (e.g. at least T% ofcases have protocol PROT1:1, 2). The result is confirmed by an alternative query(e.g. for cases where PREG :Y and ABORTION :Y determine PROT1:1, 2).

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 15
3. TA3IVF performance evaluation
Evaluating the performance of a medical decision-support system is usuallyperformed by comparing the system’s answer to the physician’s recommendation[24]. Another possibility is to evaluate the system’s performance by removing testexamples from a case base and determining their values or their classification(‘leave-one-out’ method). This approach allows for an objective evaluation since theactual value can be compared and a deviation expressed.
When assessing a system’s performance, measure of precision/recall or accuracy/coverage are usually used. Since determining relevancy of retrieved cases usingrecall and precision measures is usually subjective, we have used a leave-one-outevaluation method and measured accuracy—the ratio between correct and incor-rect classifications. Case-based classification is based on an assumption that similarcases are classified similarly. So if the system retrieves strictly relevant cases thenclassification based on this knowledge would be more accurate. Thus, accuracy alsomeasures the quality of the retrieval function and the capability of the adaptationalgorithm. The retrieval function ensures high precision and recall while theadaptation algorithm ensures the proper answer from the given set of relevantcases. If the system’s classification achieves 100% accuracy, it means that the systemis able to retrieve only relevant cases (assuming that the problem is not trivial).
TA3IVF ’s performance is evaluated on two common tasks performed by IVFphysicians: prediction and discovery. Prediction is performed in two stages: suggest-ing hormonal therapy for a given patient and predicting pregnancy outcome. First,given initial information about the patient (first eight attributes), the task is to findsimilar patients from the case base and make a suggestion of how to treat thecurrent patient to increase the probability of a successful pregnancy. This includesfinding all relevant cases, and considering retrieved cases with pregnancy assuccessful examples and retrieved cases without pregnancy as negative cases. Anadaptation process uses this information to predict the remaining attributes in thecurrent case, namely the day of human chorionic gonadotrophin administration(DAY–HCG) and the number of ampoules of human menopausal gonadotrophin(NO–HMG). Second, after the initial treatment is completed, additional attributesare available (next 31 attributes). The task is then to predict the outcome of thewhole treatment, i.e. to predict the values for pregnancy (PREG), abortion(ABORT), ectopic pregnancy (ECTOPIC) and ovarian hyper stimulation syndrome(OHSS) attributes (see Table 2). The prediction task can also be considered as anoptimization problem: for a given patient minimize the amount of hormonaltherapy required.
Disco6ery is used to find regularities in the case base by using knowledge miningtechniques, and to suggest missing data. The physician has no particular case inmind, however, (s)he may consider the whole case base or only certain cases.Knowledge mining in TA3IVF involves finding a context in which a particular groupof cases is considered similar. The user has the ability to specify a threshold, whichcontrols the quality and the quantity of discovered information. Discovery task canbe regarded as an induction process, namely as a process of inducing the usefulcontext representation or an inductive process of structuring the case base.
I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2416
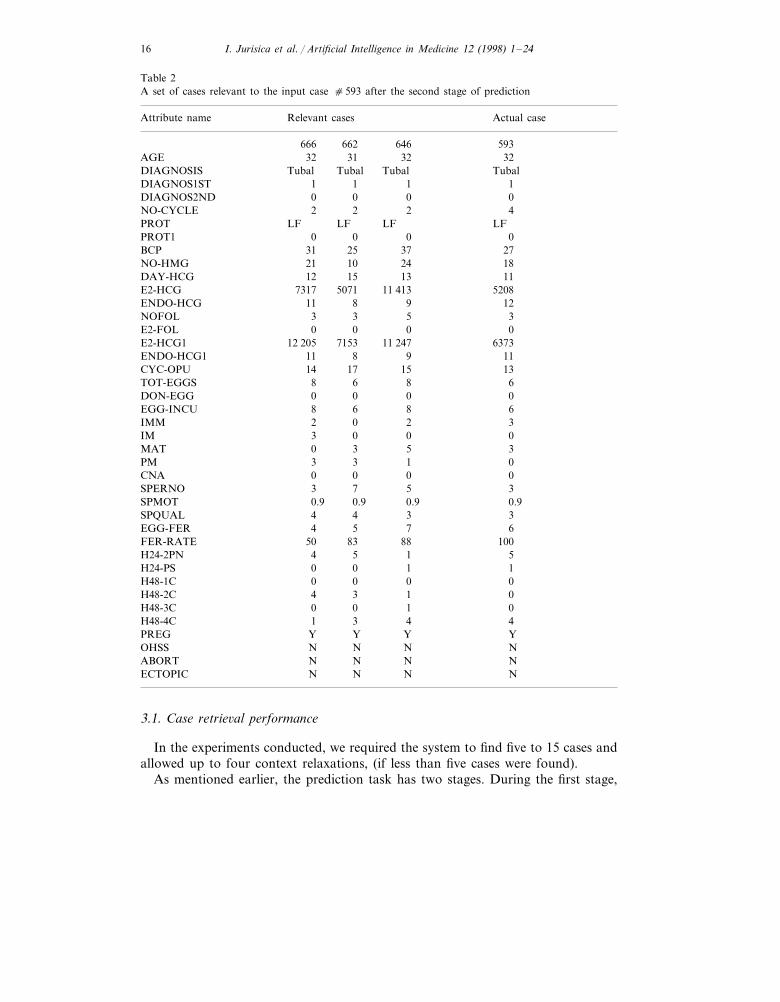
Table 2A set of cases relevant to the input case c593 after the second stage of prediction
Actual caseAttribute name Relevant cases
646666 5936623232AGE 3132
TubalDIAGNOSIS Tubal TubalTubal1DIAGNOS1ST 1 1 10 0DIAGNOS2ND 00
2 2 4NO-CYCLE 2LFPROT LF LF LF
0 0PROT1 0037BCP 31 272524NO-HMG 21 10 1813 11DAY-HCG 1512
5071 11 413 5208E2-HCG 73179ENDO-HCG 11 8 125 3NOFOL 33
0 0 0E2-FOL 011 247E2-HCG1 12 205 7153 6373
9 11ENDO-HCG1 81117 15 13CYC-OPU 14
8TOT-EGGS 8 6 60 0DON-EGG 00
6 8EGG-INCU 6832IMM 02
0IM 3 0 05MAT 0 3 31 0PM 330CNA 0 0 05SPERNO 3 7 30.9 0.9SPMOT 0.90.9
4 3 3SPQUAL 47EGG-FER 4 5 6
88 100FER-RATE 83505H24-2PN 4 5 1
1H24-PS 0 0 10 0H48-1C 00
3 1 0H48-2C 41H48-3C 0 0 04 4H48-4C 31
Y YPREG YYNOHSS N N NN NABORT NN
N NECTOPIC NN
3.1. Case retrie6al performance
In the experiments conducted, we required the system to find five to 15 cases andallowed up to four context relaxations, (if less than five cases were found).
As mentioned earlier, the prediction task has two stages. During the first stage,

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 17
the first eight (out of 55) attributes are known. The system’s task is to predictthe preferred treatment (attributes NO–HMG, DAY–HCG) in order to have asuccessful pregnancy, e.g. pregnancy, no OHSS, no abortion and no ectopicpregnancy. The second stage begins after a patient finishes the treatment andembryos are ready to transfer, when the task is to predict the success rate fromcases similar in the first 39 attributes. To evaluate the retrieval process, weselected case 593 randomly as a target case and used the system to predictattribute values during the two stages. Fig. 2 shows the context we selected inorder to find relevant cases. Attributes NO–HMG, DAY–HCG, PREG, OHSS,ABORT, ECTOPIC illustrate the results of retrieval.
Table 1 lists all relevant cases after the first stage of prediction. Consideringthe retrieved cases, the adaptation algorithm predicts values for the remainingattributes, including the treatment outcome. Since the main goal is to have apregnancy, the system favors the values suggested by cases 646, 662 and 666.Thus, the suggested amount of hormonal stimulation to be received (NO–HMG)is 18 (average value from cases 646, 662, 666). Similarly, the suggested day fortriggering the ovulation (DAY–HCG) is 13. If we look at the values of targetcase 593, the prediction error is small. Considering all cases, there is a predictedchance of 43% for pregnancy and 29% for pregnancy without complications. Thenext stage will give us a better comparison between cases selected during the firststage.
For the second part of the prediction experiment, we extended a context tocover the first 39 attributes. After restricting the context, only three relevantcases were located (see Table 2). Using these cases, the system predicted a 100%chance of pregnancy and 33% chance of abortion.
To evaluate prediction accuracy statistically, we conducted a series of tests,similar to examples presented above. In order to guarantee objectivity of results,we used ‘leave-one-out’ testing method and conducted a series of random evalua-tions with 95% confidence intervals. The performance evaluation process wasperformed by repeating the following steps: (1) select a random case and use it asa query-by-example; (2) retrieve relevant cases and order them according tosimilarity and the pregnancy outcome, considering pregnant patients as positiveexamples and other patients as negative examples; (3) compute an average valuefor the hormonal therapy from positive examples.
Results presented in Table 3 cover the first stage of prediction, i.e. predictingthe hormonal therapy. Prediction accuracy was obtained as an average valueover 20 random trials with a 95% confidence level.
During the process of predicting the pregnancy outcome, the system achievedaccuracy of 60.6%, as an average value over 20 random trials. The accuracy ofpredicting pregnancy outcome was increased to 71.2% when 15 additional attributesare used, namely a series of estrogen (E2) values. This result is important to notice,since it suggests that the knowledge about IVF (and other complex domains aswell) evolves over time. Cost of retrieval for three context transformations inlogarithmic scale using IVF and other domains is presented in Fig. 5. �CB�—case

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2418
Table 3Accuracy of predicting hormonal therapy
Average absolute error Relative errorPredicted attribute
3.291.98 0.1590.09NO–HMG0.0790.040.990.558DAY–HCG
Average and absolute errors between suggested and actual values for the treatment, namely day ofhuman chorionic gonadotrophin administration (DAY–HCG) and the number of ampoules of humanmenopausal gonadotrophin (NO–HMG). Statistical results with 95% confidence level.
base size, cost—CPU time. S/I—standard/incremental approach to context trans-formation: G—generalization, R—reduction.
3.2. Knowledge mining performance
Knowledge mining in TA3IVF is user-directed, i.e. the user specifies an initialcontext and a threshold T to constrain the search space. If no attributes arepreselected in the context, then the function considers cases with all attributes. Thesearch space can be further constrained by specifying only a subset of the wholecase base, as opposed to using the whole case base. Thus, the criteria allows us tospecify what part of a case base to use and context allows us to specify whichattributes to consider. The discovery function suggests contexts for specific tasks.Considering the IVF case base, we can use TA3IVF to determine which attributesare likely to be good predictors for pregnancy. This is done by considering caseswhere the patient is pregnant and specifying a query to analyze selected (or all)attributes. The derived context can be learned and used later for case baseclassification and for retrieval.
Table 4 shows partial results of knowledge mining on the set of pregnant patientswithout abortion. The first column displays the initial context, selected from thefirst case in the set. The second column shows a modified context that satisfies thethreshold T]50%. Attribute values that achieve high coverage with minimumconstraints are likely to be good predictors for pregnancy. Attributes with lowercoverage and/or high variance in constraints cannot be successfully used forpredicting pregnancy. As illustrated, some value constraints were reduced to definea stronger pattern5 (DIAGNOSIS1), some remained unchanged (PROT) and somewere changed, since the initial value did not satisfied any of the selected cases(PROT1). The coverage gives us the level of uncertainty for a particular attribute.It should be noted that the algorithm also confirms the result by consideringalternative queries, such as pregnant patients with abortion. This is necessarybecause PROT1: 0 for all pregnant women without abortion could also mean that
5 A stronger pattern is an attribute constraint that satisfies the coverage tbreshold and has minimalvariance.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 19
Table 4Context discovery function
Discovered contextAttribute name Initial context Change type
51%: tubal Stronger pattern82%: vendo, tubalDIAGNOSIS62%: 1DIAGNOSIS1 79%: 1–4 Stronger pattern
No change72%: 072%: 0DIAGNOSIS2Coverage increaseNO–CYCLE 37%: 1 79%: 1–2No changePROT 89%: LF 89%: LF
100%: 0PROT1 0%: 1 New constraint65%: 20–30 No change65%: 20–30BCP62%: 14–18, 24–37NO–HMG No change62%: 14–18, 24–37
New constraint55%: 12–1313%: 14–15DAY–HCGShifted constraintENDO–HCG 20%: 8–10 65%: 9–11New constraintCYC–OPU 13%: 16–17 55%: 14–15
Initial and final (discovered) contexts for the class of pregnant patients. Initial context may remainunchanged if values for a given attribute satisfy coverage constraint, new constraint may be created ifold values are completely off, constraint may be shifted to increase the coverage or the constraint maybe shrinked to make it stronger.
all patients had PROT1: 0, even patients with abortion. Only then could the resultbe selected as a good predictor. Using an alternative query showed that pregnantwomen with abortion had PROT1: 1 in 66% of the cases. Other similar results havebeen obtained during a physician’s interaction with the system. Previously describedclassification accuracy, obtained by TA3IVF, serves as an evaluation of the knowl-edge discovery used in the system.
4. Discussion
4.1. Related research
There is substantial research effort in the knowledge mining [10] and case-basedreasoning [3] communities. An extensive literature overview in these domains isbeyond the scope of this paper. We shall concentrate on research relevant tomedicine.
Several studies have been concerned with trying to find the predictive power ofparticular information from IVF patient’s record [25–28]. However, only a limited(and fixed) number of attributes have been considered and their significanceassessed in predicting pregnancy outcome. In contrast, the knowledge mining partof TA3IVF allows for finding combinations of attributes, suitable for suggestinghormonal therapy and predicting pregnancy outcome.
Soo et al. [29] present a case-based concept formation model D-UNIMEM. Thesystem is applied to discover clinical implications from a Percutaneous Translumi-nal Coronary Angioplasty database. First, a feature-disjunction is used as the earlystage of concept formation. Second, an index-conjunction is used for placing only

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2420
relevant instances into clusters. Similar to our work, case interpretations grouprelevant cases together, but the granularity and flexibility of discovered knowl-edge is different. The case interpretation in TA3IVF can be used during predictionand can be further relaxed/constrained using the discovered knowledge.
MacRad is a diagnostic system for radiology that uses a multilevel queryformulation for retrieving relevant cases, supports browsing and template match-ing [30]. The system is similar to TA3IVF in its use of search criteria. SCINA is areasoning system for the interpretation of myocardial perfusion scintigrams [31].It utilizes case-based reasoning techniques to derive a computer-based imageinterpretation program, using a case library of 150 cases. Similar to TA3IVF,SCINA uses query-by-example, but our system implements context transforma-tion and also allows for automatic query relaxation and restriction. PROTOS[32] is a medical case-based system applied in the domain of a hearing disordersdiagnosis. In this domain, many of the diagnoses manifest themselves in similarways and only subtle variations differentiate them. By using feedback from theuser, PROTOS learns these subtle differences. In contrast, TA3IVF allows forautomatic discovery of case interpretations.
CONIR [33] is an intelligent retrieval system for hospital information systemsin the domain of patient discharge summaries on coronary illness. CONIR’ssimilarity to our work is in the use of conceptual context information to allowfor flexible retrieval.
4.2. Conclusions
Medicine is an obvious domain for applying case-based reasoning techniques.Cases were used in medical practice and education even before a case-basedparadigm was proposed in computer science. The medical student is trained atthe theoretical level but is also presented some important, prototypical cases. Inthe medical practice, a doctor’s competence increases with experience, i.e. withthe number of solved cases. Many times, seeing two patients as similar medicalcases and applying knowledge gained from one to the other can save valuableresources (e.g. some unnecessary tests) and still provide professional help. Casesare an effective way of acquiring and storing knowledge and can be effectivelyused during problem solving. Positive cases are used to suggest preferred hor-monal treatment, while negative cases are used to avoid unsuccessful practices.
Case-based reasoning, as a technology, has been successfully applied in manydifferent domains. However, every domain poses individual constraints and prob-lems and thus the performance of one system evaluated in one domain is not aguarantee for the same performance in another domain. The TA3IVF system canbe used as an advisor to the physician during clinical work as well as duringresearch, to help in determining which information is relevant for reasoning in aparticular situation and to retrieve all such relevant information. This processalso helps in standardizing the reasoning process. The knowledge mining part ofTA3IVF allows for better knowledge organization by finding a suitable structure

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 21
for its representation. In addition, the knowledge mining algorithm may help inidentifying important attributes to be used as predictors and may also identifycases that look similar, yet have different outcomes (characterize domains withlow informativeness). Finding low informativeness for a particular domain maytrigger a search for other descriptors and thus supports case representation evolu-tion. Our experience supports this fact, since including a series of E2 levelsimproved accuracy of prediction.
We believe that systems similar to TA3IVF may improve health care, by mak-ing information more accessible in remote places where the doctor’s experience islimited by the number of patients. In addition, by minimizing the amount ofhormones prescribed, the system optimizes the cost of treatment. Providing addi-tional information in the form of positive and negative cases, a patient can assessprocedure risks before paying for expensive treatment.
The novel approach to relevance assessment presented in this paper is the basison the TA3IVF system. Its main advantage is the added semantic meaning torelevance and thus to retrieval and explanation of the inference process. TA3IVF
implements meaningful clustering that improves access time and makes knowl-edge visualization easier. Using a user-oriented knowledge mining enables con-trolling precision, recall and coverage. Information retrieval systems are generallyoptimized for achieving either high recall and moderate precision or vice versa.However, the goal of the decision-support system, such as TA3IVF, is to havehigh accuracy and thus both high precision and recall. TA3IVFs use of context-based retrieval allows for achieving both high precision and recall. TA3IVF de-ploys an improved nearest-neighbor algorithm. Namely, the algorithm is extendedby using: (1) more powerful knowledge representation; (2) explicit context; (3)machine-learning-assisted knowledge organization; and (4) inherently incrementalimplementation of retrieval algorithm. It has been shown that this allows forimproved system performance [2,12,21,34], for flexibility during problem solving[35] and for a more comprehensible presentation of complex information. Pre-sented results support the claim that the reasoning accuracy is improved due toan enhanced nearest-neighbor algorithm. In addition, incremental context manip-ulation improves performance when compared with the naive approach. Perfor-mance improvement is increased when the case base size is substantial, cases havemany attributes and/or several subsequent context transformations are required.
System performance during case retrieval can be improved by indexing [36] orknowledge clustering. Indexing is the most predominant way of accessing cases inCBR. It usually relies on a predetermined set of salient features, which are usedfor memory organization. Since indexing may not guarantee 100% accessibility ofcases [30], we have chosen the second approach for the TA3IVF system. Inaddition, clustering allows for flexible retrieval. There are two types of knowledgeclustering—user-based and system-based. The former type is used when there isheuristic knowledge available. Such an approach involves, for example, clusteringpatients into three age categories or clustering patients according to pregnancyoutcome. The latter form of clustering is based on information extracted from

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2422
the knowledge base automatically. Here, the system finds features and corre-sponding values that are good predictors for pregnancy outcome and thus can beused as discrimination factors.
Organizing attributes into categories using knowledge mining reduces the nega-tive effect of irrelevant attributes on the performance. Since appropriate group-ings of attributes improves m–of–n matching [34], context reduction may usediscovered knowledge to select a category for relaxation. In addition to valuehierarchies, the similarity algorithm (and generalization function) can use knowl-edge about the variability of values to decide what values are ‘close’.
We presented an application of the TA3 system as an intelligent decision-sup-port system for IVF practitioners. The main advantages of the TA3IVF systemcan be summarized as follows: (1) computerized knowledge base of patient’srecords; (2) ability to retrieve similar cases even for a partially specified query;(3) ability to suggest treatment which enhances pregnancy rate and minimizescost by predicting the amount of hormonal stimulation to be received and theday for triggering ovulation; (4) ability to predict pregnancy outcome; (5) abilityto use knowledge mining to discover interesting correlations in the case base.Furthermore, after applying the TA3 system to other domains [37,9,12,35,21] weconclude that this novel approach to relevance assessment also has some generaladvantages, including: (1) naturally incremental approach to implementation ofcontext-based retrieval algorithm; (2) flexibility in retrieving relevant informationby allowing context changes; (3) ability to automatically determine suitablematching criteria by using discovery function; (4) ability to retrieve the mostsimilar cases using the efficient retrieval strategies. In the future, we plan toevaluate TA3IVFs classification accuracy and knowledge mining capabilities onnew cases, acquired during clinical work.
References
[1] O.K. Davis, Z. Rosenwaks. In vitro fertilization, in: Reproductive Endocrinology, Surgery, andTechnology, vol. 2, Lippencott-Raven, 1995, pp. 2319–2334.
[2] I. Jurisica, H. Shapiro. A computer model for case-based reasoning in IVF, in: 51st Conf. Am.Soc. for Reproductive Medicine, Seattle, Washington, USA, 1995.
[3] D. Leake (Ed.), Case-Based Reasoning: Experiences, Lessons, and Future Directions, AAAIPress, Menlo Park, CA, 1996.
[4] R.E. Stepp, R.S. Michalski, Conceptual clustering: inventing goal-oriented classifications of struc-tured objects, in: R.S. Michalski, J.G. Carbonell, T.M. Mitchell (Eds.), Machine Learning: AnArtificial Intelligence Approach, Morgan Kaufmann, 1986, pp. 471–498.
[5] J.W. Shavlik, R.J. Mooney, G.G. Towell, Symbolic and neural learning algorithms—an experi-mental comparison, Mach. Learn. 6 (2) (1991) 111–143.
[6] P. Frey, D. Slate, Letter recognition using Holland-style adaptive classifiers, Mach. Learn. 6 (2)(1991).
[7] D. Schuurmans, R. Greiner, Learning to classify incomplete examples, in: Computational Learn-ing Theory and Natural Learning Systems: Addressing Real World Tasks, 1995.
[8] B.W. Porter, E.R. Bareiss, R.C. Holte, Concept learning and heuristic classification in weak-the-ory domains, Artif. Intell. 45 (1990) 229–263.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–24 23
[9] I. Jurisica, J. Glasgow, Case-based classification using similarity-based retrieval, in: 8th IEEE Int.Conf. on Tools with Artificial Intelligence, Toulouse, France, 1996.
[10] U. Fayyad et al., Advances in Knowledge Discovery and Data Mining, AAAI Press, MenloPark, CA, 1996.
[11] J. Mylopoulos, A. Borgida, M. Jarke, M. Koubarakis, Telos: Representing knowledge aboutinformation systems, ACM Trans. Inf. Syst. 8 (4) (1990) 325–362.
[12] I. Jurisica. Inductive learning and case-based reasoning, in: Canadian AI Conference, Workshopon what is inductive learning? Toronto, Canada, May 1996.
[13] P.R. Thagard, K.J. Holyoak, G. Nelson, D. Gotchfeld, Analog retrieval by constraint satisfac-tion, Artif. Intell. 46 (1990) 259–310.
[14] T. Gaasterland, Restricting query relaxation through user constraints, in: Proc. Int. Conf. onIntelligent and Cooperative Information Systems, Rotterdam, 1993, pp. 359–366.
[15] T. Kokeny, Constraint satisfaction problems with order-sorted domains, Int. J. Artif. Intell.Tools 4 (1 and 2) (1995) 55–72.
[16] D. Wettschereck, T.G. Dietterich, An experimental comparison of the nearest neighbor andnearest hyperrectangle algorithmns, Mach. Learn. 19 (1) (1995) 5–27.
[17] R. Greiner, AAAI Fall Symp. Series on Relevance, AAAI Press, Menlo Park, CA, 1994.[18] P. Devanbu, B. Ballard, R. Brachman, P. Selfridge. LaSSIE: A knowledge-based software infor-
mation system, in: M. Lowry, R. McCartney (Eds.), Automatic Software Design, AAAI Press,Menlo Park, CA, 1991.
[19] F. Bancilhon, Naive evaluation of recursively defined relations, in: M.L. Brodie, J. Mylopoulos(Eds.), Knowledge Base Management Systems, 1986, pp. 165–178.
[20] L. Bækgaard, L. Mark, Incremental computation of time-varying query expressions, IEEE Trans.Knowledge Data Eng. 7 (4) (1995) 583–589.
[21] I. Jurisica, J. Glasgow, A case-based reasoning approach to learning control, in: 5th Int. Conf.on Data and Knowledge Systems for Manufacturing and Engineering, DKSME-96, Phoenix, AZ,1996.
[22] H. Harman, Modern Factor Analysis, University of Chicago Press, Chicago, 1976.[23] R. Agrawal, T. Imielinski, A. Swami, Database mining: A performance perspective, IEEE Trans.
Knowledge Data Eng. Learn. Discovery Knowledge-Based Databases 5 (1993) 914–925.[24] N. Shahsavar, et al., Evaluation of a knowledge-based decision-support system for ventilator
therapy management, AI Med. 7 (1) (1995) 37–52.[25] M. Bustillo, et al., Serum progesterone and estradiol concentrations in the early diagnosis of
ectopic pregnancy after in vitro fertilization-embryo transfer, Fertil. Steril. 59 (3) (1993) 668–670.[26] B.G. Bateman, L.A. Kolp, Prediction and Management of Persistent Ectopic Pregnancy, ASRM,
Seattle, 1995.[27] C.M. Blacker et al., Predictive Value of Serum Follistatin Levels in Women Undergoing IVF: A
Retrospective Study, ASRM, Seattle, 1995.[28] L. Hoover, et al., Evaluation of a new embryo-grading system to predict pregnancy rates
following in vitro fertilization, Gynecol. Obstet. Invest. 40 (1995) 151–157.[29] V.W. Soo, J.S. Wang, S.P. Wang, Learning and discovery from a clinical database: An incre-
mental concept formation approach, AI Med. 6 (3) (1994) 249–261.[30] R.T. Macura, K.T. Macura, MacRad: radiology image resource with a case-based retrieval
system, in: Proc. ICCBR-95, Sesimbra, Portugal, Springer-Verlag, Berlin, 1995.[31] M. Haddad, SCINA: A CBR system for the interpretation of myocardial perfusion scintigrams,
PhD thesis, Department of Cardiology, University of Vienna, Vienna, 1995.[32] E.R. Bareiss, A unified approach to concept representation, classipcation, and learning, PhD
thesis, Department of Computer Science, University of Texas, 1988.[33] B. Nangle, M.T. Keane, Effective retrieval in hospital information systems: The use of context in
answering queries to patient discharge summaries, AI Med. 6 (3) (1994) 207–227.[34] J. Ortega, On the informativeness of the DNA promoter sequences domain theory, JAIR 2
(1995) 361–367.

I. Jurisica et al. / Artificial Intelligence in Medicine 12 (1998) 1–2424
[35] I. Jurisica, Supporting flexibility. a case-based reasoning approach, in: AAAI Fall Symp. FlexibleComputation in Intelligent Systems: Results, Issues, and Opportunities, Cambridge, MA, 1996.
[36] C.M. Seifert, et al., Case-based learning—predictive features in indexing, Mach. Learn. 16 (1–2)(1994) 37–56.
[37] I. Jurisica, A similarity-based retrieval tool for software repositories, in: The Third Workshop onAI and Software Engineering: Breaking the Mold. IJCAI-95, Montreal, Quebec, 1995.
.