Embed Size (px)
Citation preview

�
�
�
�
講演の概要
• はじめに• 関数最適化問題と実数値 GA
• 個体群分布の発展としての GA の解釈
• ノイズのある関数最適化問題と GA による接近
• 今後の課題と展望
2002 年 12 月 4 日,東京 (2)

�
�
�
�
はじめに
• 遺伝的アルゴリズム– ダーウィンの自然選択説を模した最適化手法.
– 解候補を個体に見立て,個体群を用意.
– 淘汰,複製,交叉,突然変異の繰り返しで計算を進める.
• 目的関数値のみを用いて最適化を進める「直接法」.• 確率的な「大域的」探索法.• 実数値 GA: GA による連続空間での最適化.
2002 年 12 月 4 日,東京 (3)

�
�
�
�
関数最適化問題と実数値 GA
関数最適化問題
連続な探索空間での制約なし最適化問題
minx
f(x)
Subject to a ≤ x ≤ b
x ∈ Rn
何が問題を難しくするのか?
• 目的関数の不連続性,微分不可能性例えばシミュレーションに基づく最適化→ 関数値のみを使う直接法が必要
• 他峰性 → 大域的最適化が必要
2002 年 12 月 4 日,東京 (4)

�
�
�
�
実数値 GA (Real-coded Genetic Algorithms,
RCGA)
• 従来の GA — 解の 2 進表現 (bit-string GA)
– 探索空間の連続性は無視.
– 高精度な探索は困難.
• 実数値 GA (RCGA) — 浮動小数点数表現を利用
– 連続性を考慮した探索オペレータの使用
– 高精度の探索
2002 年 12 月 4 日,東京 (5)
�
�
�
�
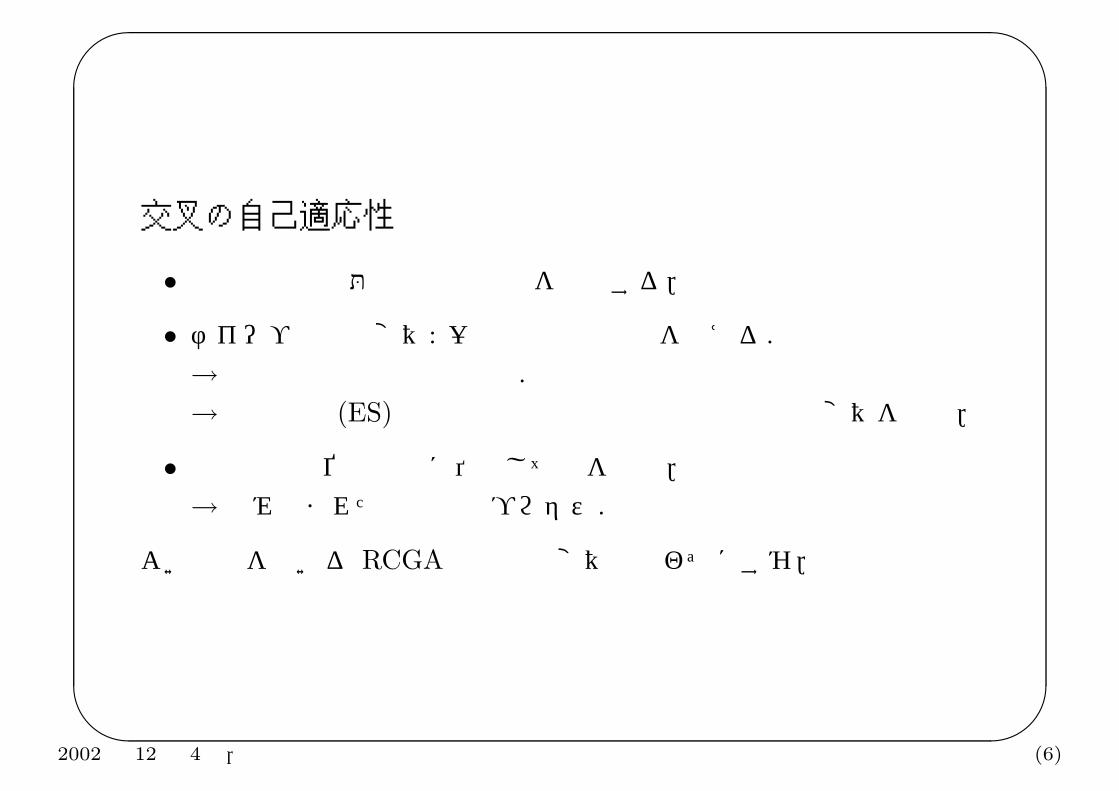
交叉の自己適応性
• 関数最適化問題は高精度の解を要求する.• ナイーブな突然変異: 一定の分散の乱数を加える.→ 高精度な解の探索は困難.→ 進化戦略 (ES) では可調整分散型の自己適応型突然変異を導入.
• 交叉は親の位置関係に依存して子を生成.→ 組み込まれた自己適応プロセス.
よい交叉を用いる RCGA では突然変異は使わずにすむ.
2002 年 12 月 4 日,東京 (6)

�
�
�
�
RCGA の交叉演算子
• 成分ごとの継承.– 一点交叉,多点交叉,一様交叉
• 親ベクトルの線形結合– 平均保存交叉,算術的交叉,線形交叉
— 親の中点,内分点を子とする.
– UNDX, UNDX-m: 親ベクトルの内挿,外挿.
• 成分ごとの線形結合– ブレンド交叉 (BLX-α)
2002 年 12 月 4 日,東京 (7)

�
�
�
�
Parent 1
Parent 2
One Point, Multi-Point, Uniform
Averge
α
α
α
α1
1
x2
x 1
One Point, Multi-Point, Unifrom
Blend (BLX- )α
RCGA のための交叉
2002 年 12 月 4 日,東京 (8)

�
�
�
�
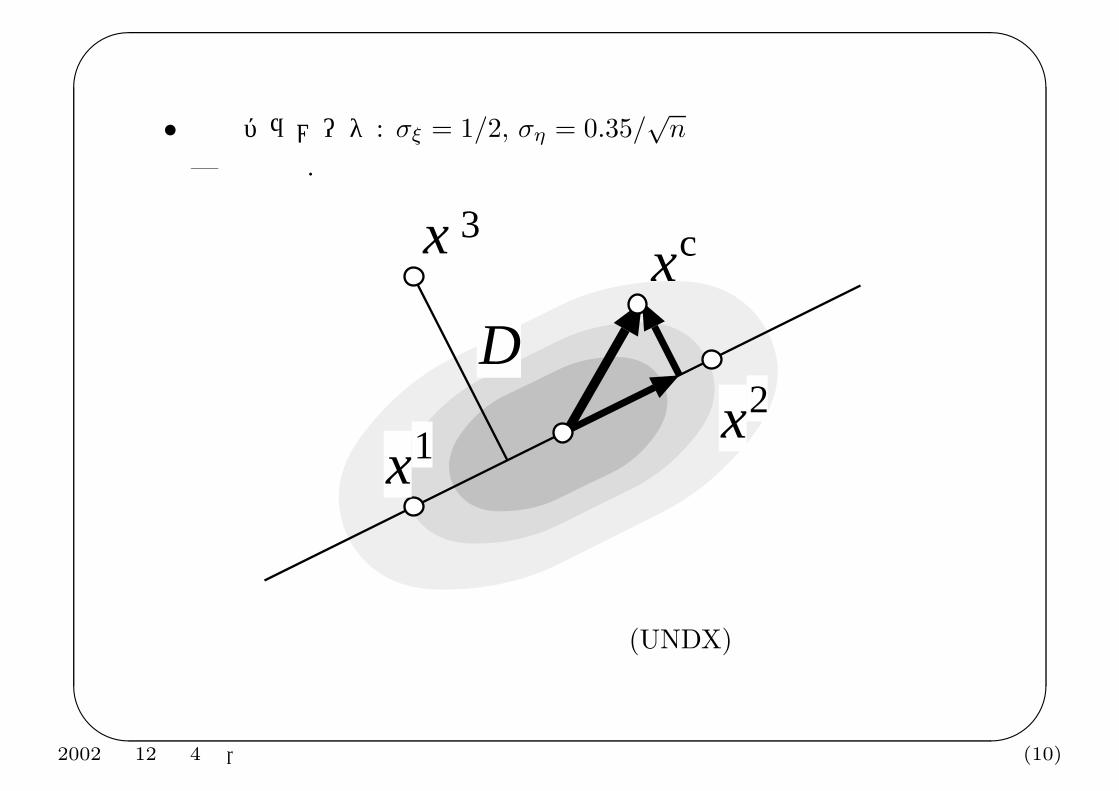
単峰性正規分布交叉 (UNDX)
— Unimodal Normal Distribution Crossover (Ono らが提案 (1997))
• 3 つの親を抽出 x1, x2, x3
• xp = (x1 + x2)/2: 2 との親の中点
• d = x1 − x2: 2 つの親の差ベクトル
• 主探索直線 (PSL): x1 と x2 を通る直線
• D: 第 3 の親 x3 から PSL までの直線の距離.
• 子の生成
xc = xp + ξd + D
n−1∑i=1
ηiei, ξ ∼ N(0, σ2ξ ), ηi ∼ N(0, σ2
η)
ei: PSL に直交する部分空間の正規直交基底
2002 年 12 月 4 日,東京 (9)
�
�
�
�
• 推奨パラメータ: σξ = 1/2, ση = 0.35/√
n
— 経験値.
x
x1
3
Dx2
xc
単峰性正規分布交叉 (UNDX)
2002 年 12 月 4 日,東京 (10)

�
�
�
�
UNDX の多親拡張 (UNDX-m)
アルゴリズム
1. m + 1 個の親x1, ...,xm+1 をランダムに選ぶ.
2. p = 1m+1
∑i xi: 親の平均値.di = xi − p (i = 1, · · · ,m): xi と p
の差ベクトル.
3. もう一つの親 xm+2 をランダムに選ぶ.
4. D をdm+2 = xm+2 − p のd1, · · · ,dm に直交する成分の大きさ.
5. e1, . . . ,en−m をd1, · · · ,dm に直交する部分空間の正規直交基底.
6. 子を生成 xc:
xc = p +m∑
k=1
wkdk +n−m∑k=1
vkDek
2002 年 12 月 4 日,東京 (11)

�
�
�
�
ここで wk ∼ N(0, σ2ξ ), vk ∼ N(0, σ2
η) は正規乱数,σξ and ση はパラメータ.
(b) UNDX-m(a) UNDX
x3 x2
x1
x3 x2
x1
UNDX-m の推奨パラメータ
σξ =1√m, ση =
β0√n − m
, β0 = 0.35
2002 年 12 月 4 日,東京 (12)

�
�
�
�
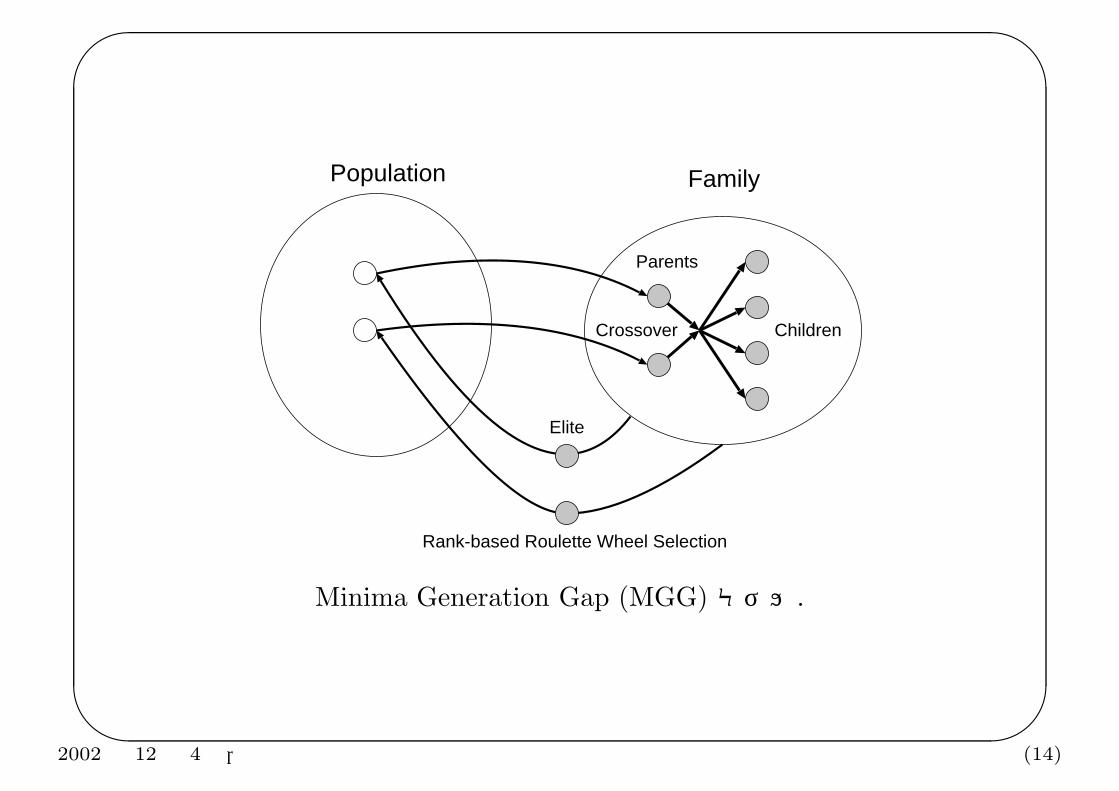
選択/世代交代モデル
大域的探索 — 弱い選択圧での探索
Minimal Generation Gap (MGG) モデル (Satoh et al., 1997)
1. 親 x1 と x2 をランダムに選ぶ.
2. 親 x1, x2 に交叉を c 回適用して子 y1, · · · ,yc を得る.
3. 親と子の和集合を家族 F とする.
4. z1 を家族 F で最良の目的関数値を持つ個体とする.
5. z2 を F から目的関数値のランキングで重みつけしてランダムに選んだ個体とする.
6. 解集団の x1, x2 をz1, z2 で入れ換える.
2002 年 12 月 4 日,東京 (13)
�
�
�
�
Parents
ChildrenCrossover
FamilyPopulation
Elite
Rank-based Roulette Wheel Selection
Minima Generation Gap (MGG) モデル.
2002 年 12 月 4 日,東京 (14)

�
�
�
�
数値実験
テスト関数
• 20-次元 回転 Rastrigin 関数: 非分離,多峰性の関数.
fRot−Rastrigin(x) = fRastrigin(Ax), −5.12 ≤ xi ≤ 5.12, 1 ≤ i ≤ n
fRastrigin(y) = 200 +20∑
i=1
[y2i − 10 cos(2πyi)]
ここで A は回転変換.
• 20-次元 悪スケール Rosenbrock 関数: 高度に非分離.
fIS−Rosenbrock(x) =20∑
i=2
[100(x1 − (ixi)2)2 + (ixi − 1)2],
−2.048/i ≤ xi ≤ 2.048/i, 1 ≤ i ≤ 20
2002 年 12 月 4 日,東京 (15)

�
�
�
�
Rastrigin
-4-2
02
4-4
-2
0
2
4
0
10
20
30
40
50
60
70
80
Rosenbrock
-2
-1.5
-1
-0.5
0
0.5
1
1.5
2-2
-1.5-1
-0.50
0.51
1.52
0
200
400
600
800
1000
Rastrigin 関数 Rosenbrock 関数
2002 年 12 月 4 日,東京 (16)

�
�
�
�
数値実験 — 設定
• 世代交代モデル: MGG
• 集団サイズ: 300
• 生成子個体: 200/generation.
• 交叉: BLX-0.5, UNDX, UNDX-4
2002 年 12 月 4 日,東京 (17)

�
�
�
�
数値実験 — 結果
BLX-α UNDX UNDX-4
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
回転 Rastrigin 関数
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
1e-10
1e-08
1e-06
0.0001
0.01
1
100
10000
1e+6 2e+6 3e+6 4e+6 5e+6 6e+6
OB
JEC
TIV
E
EVALUATION
悪スケール Rosenbrock 関数
2002 年 12 月 4 日,東京 (18)

�
�
�
�
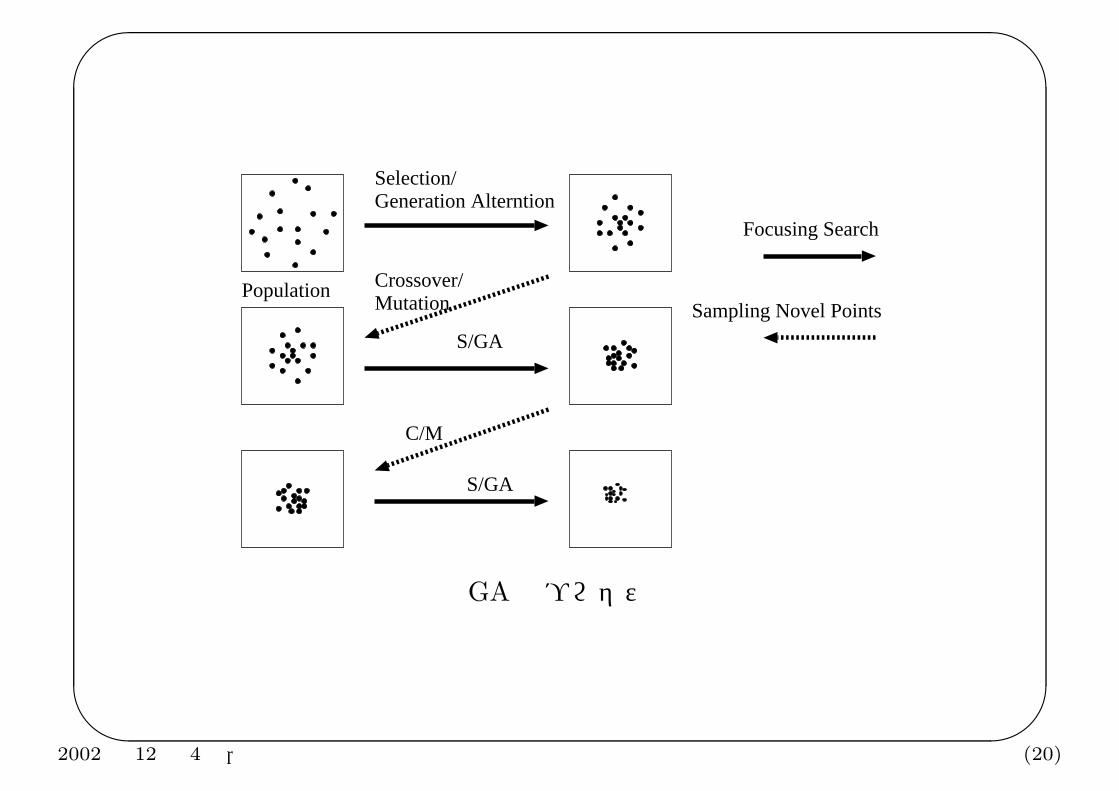
個体群分布の発展としての GA の解釈
GA における機能分担
• 探索によって得た良い解に関する情報 — 解集団が担う.
• 選択 — 良くない解を淘汰して探索を重点化.
• 交叉 — 解集団の情報を用いて新たな探索点をサンプリングする.
2002 年 12 月 4 日,東京 (19)
�
�
�
�
Selection/Generation Alterntion
Crossover/Mutation
S/GA
C/M
S/GA
Population
Focusing Search
Sampling Novel Points
GA のプロセス
2002 年 12 月 4 日,東京 (20)

�
�
�
�
実数値 GA の理論解析
— Qi et al. 1994, Nomura 1997, Kita et al. 1999.
• 解集団を分布関数 (PDF)で表現
– 親と子の PDF: p(x), pc(x)
• 探索空間の連続性:分布関数の平均や分散などの統計量で議論できる.
– 平均値ベクトル
x̄i =∫
xip(x)dx
– 共分散マトリクス
γij =∫
(xi − x̄i)(xj − x̄j)p(x)dx
2002 年 12 月 4 日,東京 (21)

�
�
�
�
• 交叉を分布関数の変換オペレータだと考える
crossover : p(x) �→ pc(x)
• 交叉による PDF や統計量の親子間での変化を計算する.
2002 年 12 月 4 日,東京 (22)

�
�
�
�
平均値に関する定理 : 一点,多点,平均交叉,BLX-α, UNDX は平均値を保存する.
一様交叉での共分散行列に関する定理 :相関の喪失
γcij =
0.5γij if i �= j
γij if i = j
平均交叉での共分散行列に関する定理 :分布の縮小
γcij = 0.5γij
UNDXでの共分散行列に関する定理 :UNDX は共分散行列をよく保存する.
2002 年 12 月 4 日,東京 (23)

�
�
�
�
理論解析の含意
• 成分ごとの交叉による共分散の低下→ 非分離な関数の最適化が困難.
• 内挿的交叉による分散の低下→ 解集団の内部へのサンプリングの偏り
→ 解集団全域での探索の不足
• 推奨値での UNDX における分散,共分散のよい保存性.
→ 高い探索性能に関する合理的な説明.
2002 年 12 月 4 日,東京 (24)

�
�
�
�
実数値 GA の交叉の設計指針
指針 0 (分布の保存) :
交叉は解集団の分布を保存すべきである.
— もし交叉で生成される子の分布が
• 親のそれより狭ければ不十分な探索.• 親のそれより広ければ無駄な探索.
— 任意の分布の保存は不可能→ 指針 1 に緩和.
(a) Parent Population (b) Too Narrow (d) Too Wide(c) Appropriate
Crossover
2002 年 12 月 4 日,東京 (25)

�
�
�
�
実数値 GA の交叉の設計指針
指針 1: 統計量の保存 交叉による生成される子の分布は平均値ベクトルや共分散行列などの統計量をよく保存すべきである.
指針 2: Diversity of Offsprings 指針 1 の拘束条件下で多様な子を生成する.べきである.多様性の測度:例えばエントロピー.
指針 3: ロバスト性の強化
• 指針 1, 2 は理想的な選択・世代交代を想定.
• 時には失敗して望ましい探索域を解集団が示さなくなる.• GA による探索をロバストにするには分布を指針 1, 2 に示されたものより広げる必要がある.
• 指針 1, 2 は基準点を与え,指針 3 は調整の方向を与える.
指針に基づく交叉の設計:UNDX-m はこれらの指針に基づいてUNDXを多親拡張したもの.
2002 年 12 月 4 日,東京 (26)

�
�
�
�
ノイズのある関数最適化問題と GA による接近
背景
• ノイズが含まれている目的関数の最適化:工学的応用– 実機実験を通じての最適化,
– 乱数を用いたシミュレーションを通じての最適化,
• 計算機の小型化,低価格化,高性能化によりニーズが拡大— 実験の自動化,大規模なシミュレーションの高速な実行
• GA の適用可能性
– 目的関数値のみを用いるという直接法
– 選択と複製による最適化はノイズに強い
• 実応用での解評価回数の制限 — より効果的なアルゴリズムが求められる.
2002 年 12 月 4 日,東京 (27)

�
�
�
�
問題の定式化
以下ではノイズの含まれた最適化問題として次のようなものを考える:
minx∈R
〈F (x)〉,
F (x) = f(x) + δ
ここで
• R は連続な探索領域,
• f と F は真の目的関数とその観測値である.
• δ は平均が 0 の加法的なノイズであり,
• 〈〉 は δ に関する期待値.
2002 年 12 月 4 日,東京 (28)

�
�
�
�
探索履歴を用いた適応度の推定
• 従来手法:同じ解候補について複数回,目的関数を評価して,その平均値を用いる.→ 解の評価回数が増大,実応用には不適当.
• 提案手法:解候補や目的関数の観測値を履歴として保存し,適応度の推定に利用.
– 探索履歴を利用した適応度の推定:適応度関数のモデルが必要.
– パラメータ数の少ないモデルが望ましい.
• 適応度の確率モデル:適応度の真の値 f は
– 推定する点での真の値のまわりに正規分布に従って分布.
– 分散は推定しようと点からの距離に比例して増加する成分と
– 重畳するノイズに相当する定数分
2002 年 12 月 4 日,東京 (29)

�
�
�
�
• モデルに基づく探索点における目的関数の推定値 (最尤法)— 探索履歴中の目的関数値の加重平均:
f̃(x) =
H∑l=1
F (hl)k′dl + 1
H∑l=1
1k′dl + 1
=
F (x) +H∑
l=2
1k′dl + 1
F (hl)
1 +H∑
l=2
1k′dl + 1
(1)
ここでx :目的関数値を推定しようとする探索点.H = {hl} :探索した点の集合であり,hl :探索履歴 H 中の個体で x からの距離は dl.k′ :パラメータ.
• 加重平均:外挿的な探索では探索の停滞を招く.目的関数のサンプル値が十分に良い場合は推定値ではなくサンプル値を用いて選択を進める.
2002 年 12 月 4 日,東京 (30)

�
�
�
�
MFEGAのアルゴリズム
探索履歴を利用する GA (Memory-based Fitness Estimation GA,MFEGA) のプロトタイプアルゴリズム:
1. M 個の初期個体 x1, ...,xM をランダムに生成する.
2. 評価回数のカウンタを初期化:e = 0. 最大評価回数を E とする.
3. 探索履歴を空にする:H = ∅.4. 個体群から親個体 xp1, xp2 をランダムに選び家族個体
y1 = xp1,y2 = xp2 とする.
5. 親個体 y1, y2 に交叉を適用して C 個の子個体y2+i, i = 1, 2, · · · , C を生成する.
6. 家族個体について目的関数の観測値 F (yi), i = 1, · · · , C + 2 を得る.
2002 年 12 月 4 日,東京 (31)

�
�
�
�
7. e = e + C + 2.
8. 観測した目的関数値を家族個体とともに履歴 H に加える:H = H ∪ {(yi, F (yi))|i = 1, ..., C + 2}.
9. 最小の観測値を持つ個体 hmin を履歴 H から選ぶ.
10. パラメータ k′ を hmin を用い最尤法 (数値計算)で決定する.
11. 家族個体について目的関数の推定値 f̃(yi) を求める.
12. 家族個体中の最良観測値からある程度以上悪い観測値を持つ個体を除外し,残りを Y Accept とする.
13. Y Accept 中で目的関数の推定値 f̃(yi) の最良のものを持つ 2 個体で親個体xp1, xp2入れ換える.
14. もし e ≤ E なら Step 4. へ,そうでなければ終了.
2002 年 12 月 4 日,東京 (32)

�
�
�
�
MFEGA のマルチカーエレベータ制御への応用
MFEGA の応用例 — マルチカーエレベータの運行制御ルール最適化
マルチカーエレベータ (以下,MCE):
• 1つのエレベータシャフト内に複数のカゴを持つエレベータ.
• リニアモータ技術の進歩により技術的に可能.• 追い越しができないことから,運行制御上の制約が厳しい.• 従来のエレベータの制御のノウハウはそのままでは使えない.
MCE の制御ルール最適化:
• カゴの呼びへの割り当て:カゴの状態を示す属性 (11変数)の加重和で決定.
• 加重値 (11 変数のうち規格化した 1 つを除いた 10 個):最適化すべき決定変数.
2002 年 12 月 4 日,東京 (33)
�
�
�
�
• 評価関数値:乗客を乱数で発生させたエレベータのシミュレーションにより平均待ち時間などを計測して使用.
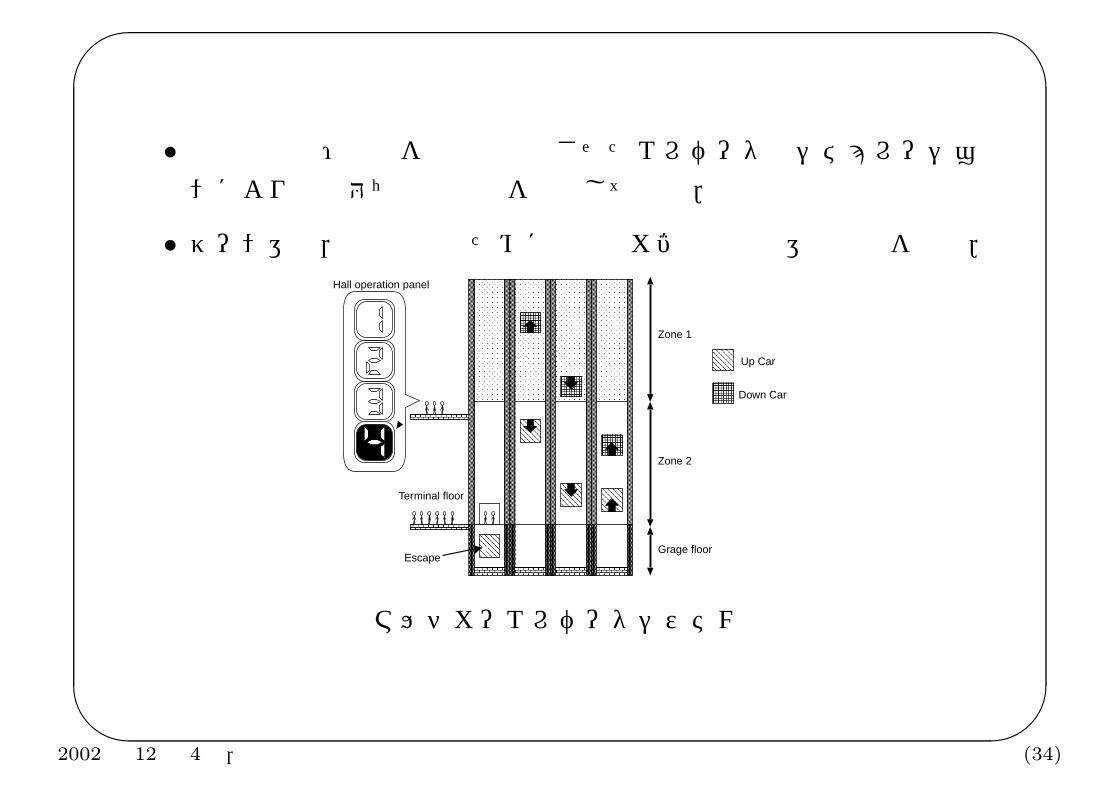
• ゾーン運転,衝突防止のために上下のカゴの同方向運転制約を導入.
Zone 1
Zone 2
Grage floor
Terminal floor
Down Car
Escape
Hall operation panel
Up Car
マルチカーエレベータシステム
2002 年 12 月 4 日,東京 (34)

�
�
�
�
MCE システムの諸元
階床数 30 シャフト数 6 カゴ数/シャフト 2
基準階 1 下方階ゾーン 2-15 上方階ゾーン 16-30
交通密度 2700 人/時
MCE 制御の最適化に使用した GA のパラメータ
世代数 G = 200 個体群 P = 30 初期領域 [−1.0, 1.0]10
(E = 1400) サイズ
生成子個体 C = 5 交叉 UNDX 突然変異 なし
MCE のシミュレーション
• 1 回には PentiumIII800MHz/JDK1.3/Linux で約 50 秒を要し,
• GA の実行に 20 時間ほどかかる.
2002 年 12 月 4 日,東京 (35)

�
�
�
�
GA の実行結果
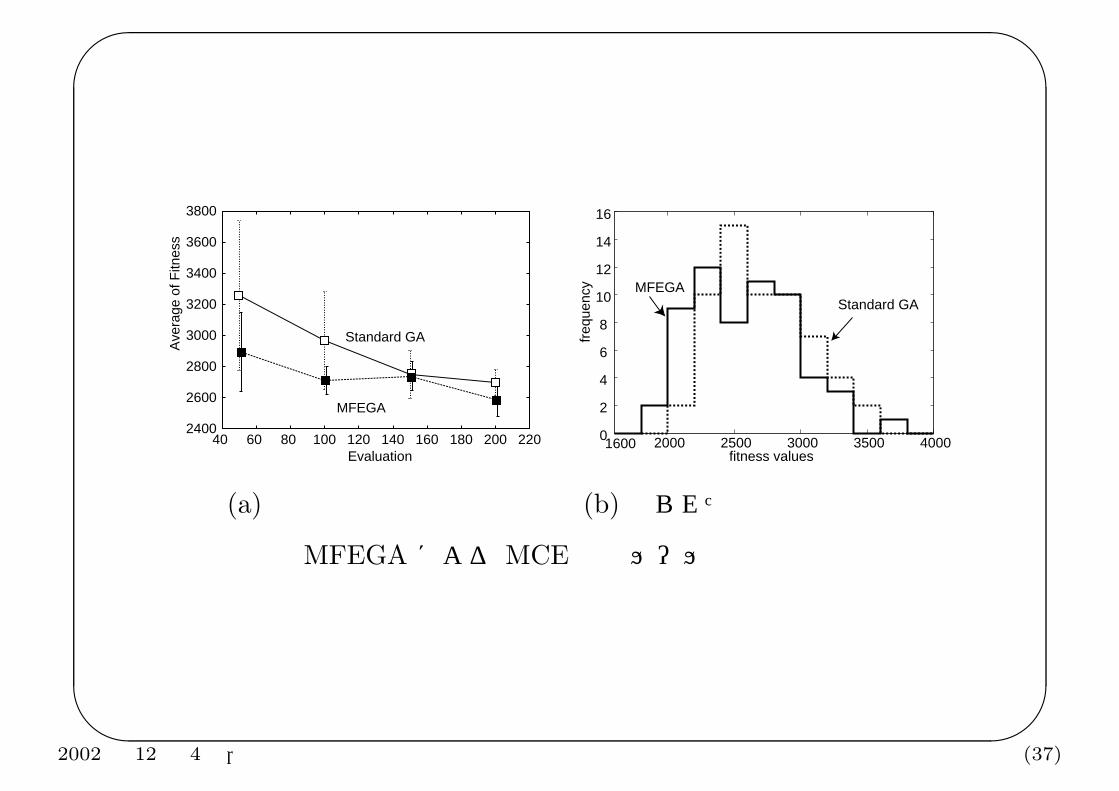
• (a):3 回の GA の試行で得られた最良個体の評価値の改善状況.50 世代ごとに 20 回のシミュレーションを行い,その平均値で目的関数値を評価.— ノイズの影響を考慮しない GA に比べ MFEGA でより良い解がより速く得られている.
• (b):最終的に得られた 3 つの解の合計 60 回のシミュレーションによる評価値の分布である.
• 人手で経験的に調整されたプロトタイプコントローラよりも高い性能を示した.
2002 年 12 月 4 日,東京 (36)
�
�
�
�
2400
2600
2800
3000
3200
3400
3600
3800
40 60 80 100 120 140 160 180 200 220
Ave
rage
of F
itnes
s
Evaluation
Standard GA
MFEGA
0
2
4
6
8
10
12
14
16
20001600 2500 3000 3500 4000
freq
uenc
y
fitness values
MFEGAStandard GA
(a) 評価関数値の発展 (b) 得られた解の評価値の分布
MFEGA による MCE 制御ルールの最適化
2002 年 12 月 4 日,東京 (37)
�
�
�
�
今後の課題と展望
• 実応用面での実数値 GA の有効性の検証.
• 適用可能な問題規模の拡大.• 分布推定型の最適化手法との比較.
– GA: 現個体群と似た分布を持つ個体群を交叉により直接,生成する.
– 分布推定型最適化法:
∗ 現個体群を確率分布でモデル化.∗ モデル化した確率分布に従って新しい解を生成.
– 個体群による探索,選択操作は共通.
2002 年 12 月 4 日,東京 (38)






























