Embed Size (px)
Citation preview

提纲
智能
时代
智能
应用
认知
智能
知识
图谱
2
催生 需要 依赖
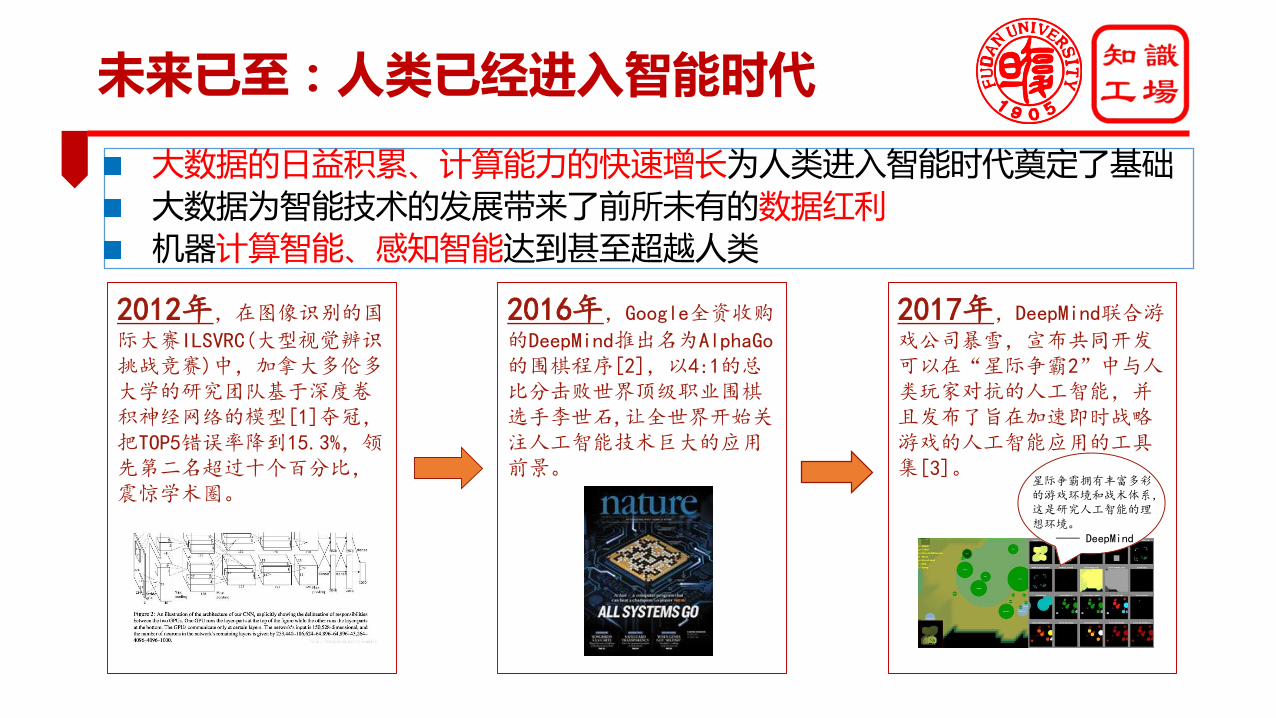
未来已至:人类已经进入智能时代
大数据的日益积累、计算能力的快速增长为人类进入智能时代奠定了基础大数据为智能技术的发展带来了前所未有的数据红利机器计算智能、感知智能达到甚至超越人类
2012年,在图像识别的国
际大赛ILSVRC(大型视觉辨识挑战竞赛)中,加拿大多伦多大学的研究团队基于深度卷积神经网络的模型[1]夺冠,把TOP5错误率降到15.3%,领先第二名超过十个百分比,震惊学术圈。
2016年,Google全资收购
的DeepMind推出名为AlphaGo的围棋程序[2],以4:1的总比分击败世界顶级职业围棋选手李世石,让全世界开始关注人工智能技术巨大的应用前景。
2017年,DeepMind联合游
戏公司暴雪,宣布共同开发可以在“星际争霸2”中与人类玩家对抗的人工智能,并且发布了旨在加速即时战略游戏的人工智能应用的工具集[3]。
星际争霸拥有丰富多彩的游戏环境和战术体系,这是研究人工智能的理想环境。
—— DeepMind

智能化升级与转型
增加
收入
降低
成本
提高
效率
安全
保障
4
智能化升级与转型已经成为各行各业的普遍诉求从信息化走向智能化是必然趋势AI+成为AI赋能传统行业的基本模式
战略意义
全方位、深度渗透到各行各业、各个环节
颠覆性影响,重塑行业形态,甚至社会形态

智能化需要机器智能,特别是认知智能
计算智能
• 规则明
确、特
定领域
感知智能
• 语音、
图像、
视频
认知智能
• 理解、
推理、
解释
5
难度价值
随着数据红利消耗殆尽,以深度学习为代表的感知智能遇到天花板认知智能将是未来一段时期内AI发展的焦点,是进一步释放AI产能的关键

认知智能的应用需求
认知智能
精准分析 智慧搜索 智能推荐 智能解释自然人机
交互
深层关系
推理
6
认知智能应用需求广泛多样,需要对传统信息化手段的全面而彻底的革新认知智能:人类脑力解放,机器生产力显著提高

• 精准化数据分析• 舆情分析
• 热点统计
• 军事情报分析
• 商业情报分析
• 精细化数据分析• 酒店评论抽取
• 个性化制造
精准分析
宝强离婚最新动态,DNA结果公布马蓉原形毕露_新闻频道_中华网
深度解析宝宝离婚闹剧事件细说婚姻幸福真谛!_央广网深扒王宝强离婚内幕最大祸根源于谁_百山探索
…..宝宝不知道宝宝的宝宝是不是宝宝亲生的宝宝,宝宝现在担心的是宝宝的宝宝不是宝宝的宝宝如果宝宝的宝宝真的不是宝宝的宝宝那就吓死宝宝了宝宝的宝宝为什么要这样对待宝宝,宝宝很难过,如果宝宝和宝宝的宝宝因为宝宝的宝宝打起来了,你们到底支持宝宝还是宝宝的宝宝!【宝宝心里苦,但是宝宝不说】
军民融合南海掀波陆渔船舰队近逼菲中业岛
意大利华人捐古版中国地图证明钓鱼岛为中国领土
菲律宾相关
日本相关
大数据的精准、精细分析需要智能化技术支撑

智慧搜索
• 精准搜索意图理解• 精准分类、语义理解、个性化
• 复杂多元对象搜索• 表格、文本、图片、视频• 文案、素材、代码、专家
• 多粒度搜索• 篇章级、段落级、语句级
• 跨媒体搜索• 不同媒体数据联合完成搜索任务
8
Search
Search keywords推荐
一切皆可搜索,搜索必达
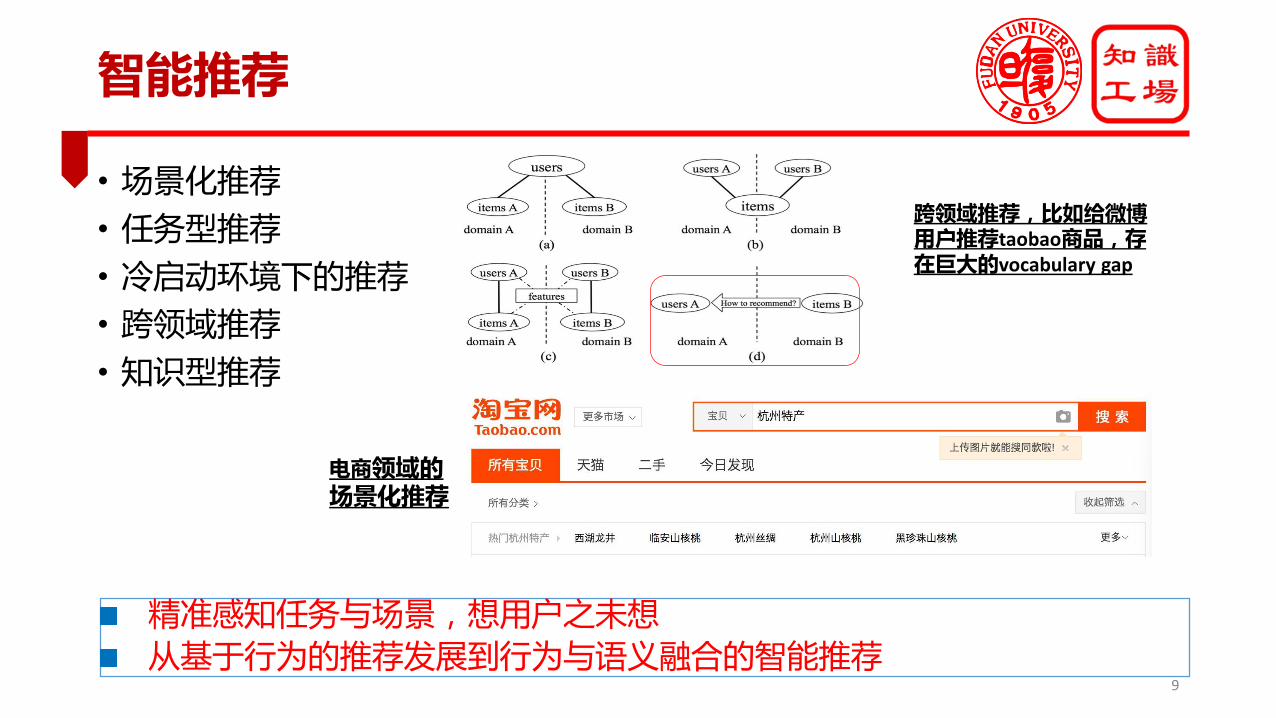
智能推荐
9
• 场景化推荐
• 任务型推荐
• 冷启动环境下的推荐
• 跨领域推荐
• 知识型推荐
精准感知任务与场景,想用户之未想从基于行为的推荐发展到行为与语义融合的智能推荐
跨领域推荐,比如给微博用户推荐taobao商品,存在巨大的vocabulary gap
电商领域的场景化推荐

智能解释
10
• 事实解释
• 关系解释
• 过程解释
• 结果解释
解释事实解释机器学习过程
解释是智能的重要体现之一,将是人们对于智能系统的普遍期望
可解释是智能系统决策结果被采信的前提
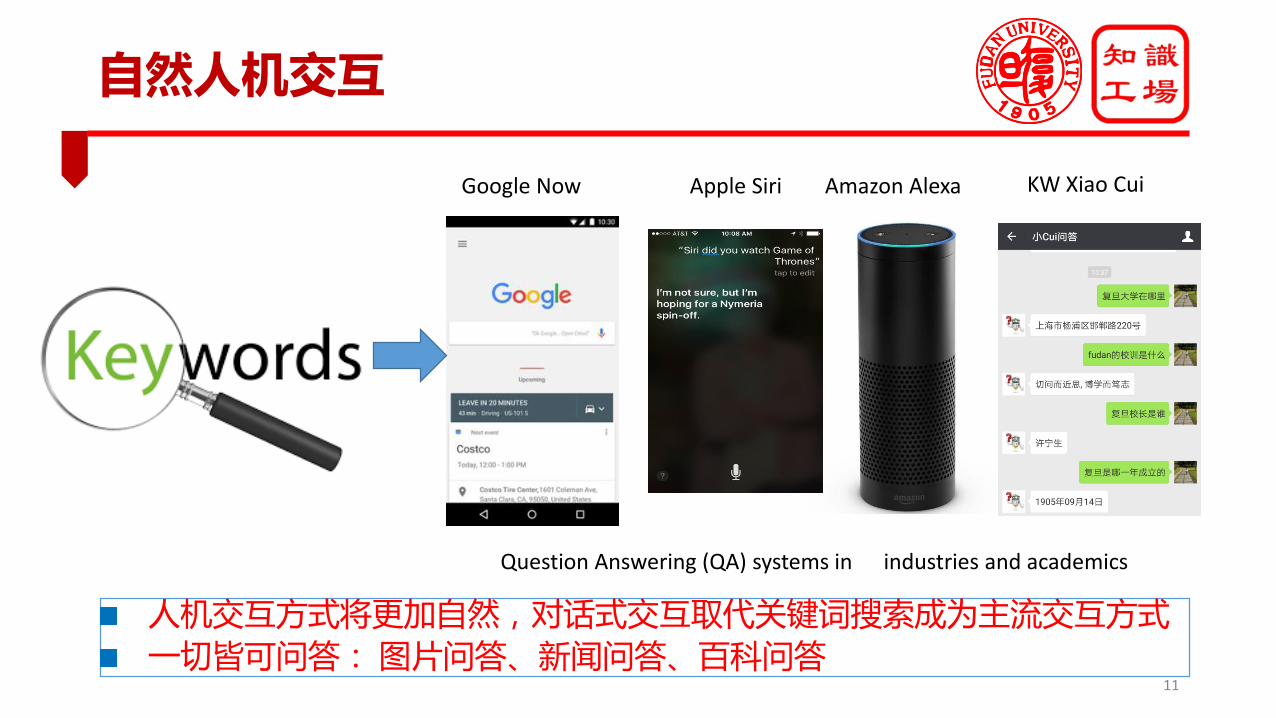
自然人机交互
11
Google Now Apple Siri Amazon Alexa KW Xiao Cui
Question Answering (QA) systems in industries and academics
人机交互方式将更加自然,对话式交互取代关键词搜索成为主流交互方式一切皆可问答:图片问答、新闻问答、百科问答

深层关系发现/推理
12
Why baoqiang select Qizhun Zhang as his lawyer? Why A invests B?
隐式关系发现、深层关系推理将成为智能的主要体现之一
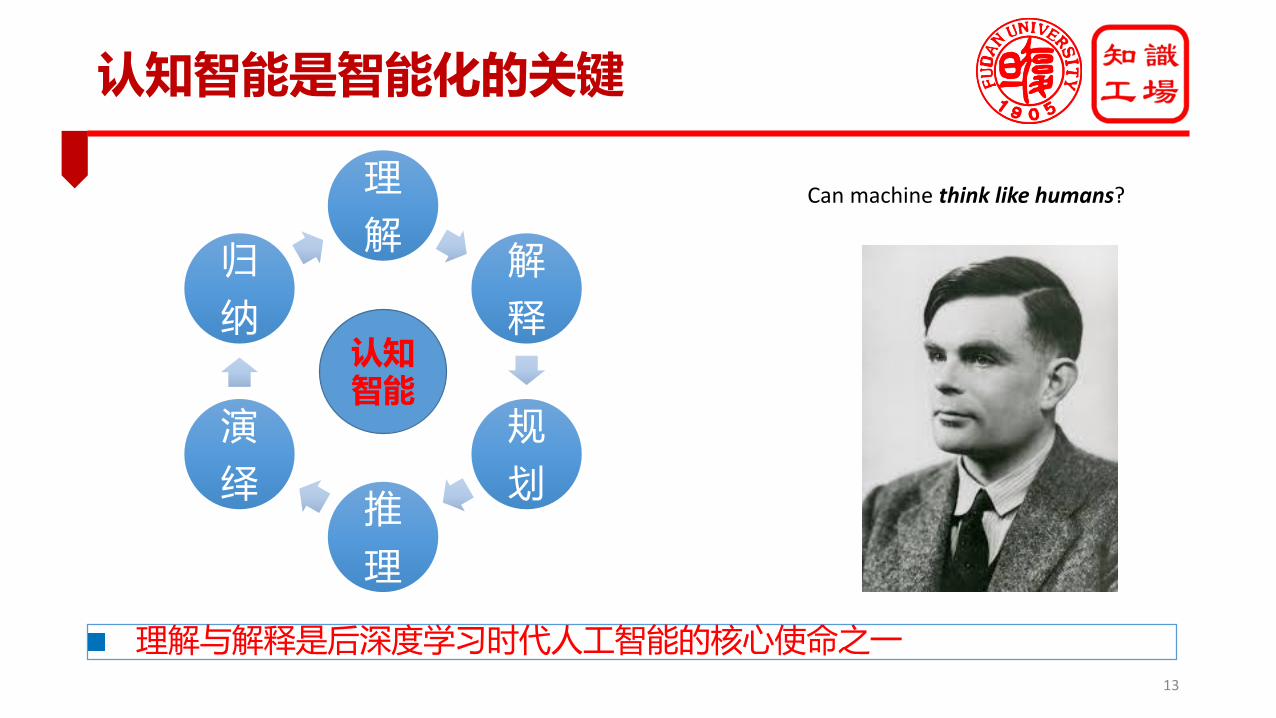
认知智能是智能化的关键
理
解解
释
规
划推
理
演
绎
归
纳
13
Can machine think like humans?
认知智能
理解与解释是后深度学习时代人工智能的核心使命之一

14
知识图谱是实现认知智能的关键技术,是实现机器认知智能的使能器(Enabler)

知识图谱
• Knowledge Graph is a large scale semantic network• Consisting of entities/concepts as well as the semantic relationships among them
15
http://knowledgeworks.cn/cndbpedia/search知识图谱富含实体、概念、属性、关系等信息,使得机器理解与解释成为可能

知识图谱的广义内涵
• 知识图谱作为一种语义网络,是大数据时代知识表示的重要方式之一
• 知识图谱作为一种技术体系,是大数据时代知识工程的代表性进展
16

从“小”知识到“大”知识
17
Small knowledge+ big data= big knowledge
知识图谱引领知识工程复兴
Ontology,Frame
Logic rules
Bayesian network
Decision tree
Big Knowledge
• 传统知识工程,专家构建,代价高昂,规模有限;知识边界易于突破,难以适应大数据时代开放应用到规模化需求
• 大规模开放应用需要“大”知识(大规模知识库)

基于知识图谱的认知智能
• 机器理解数据的本质:建立从数据到知识库中实体、概念、关系的映射
• 机器解释现象的本质:利用知识库中实体、概念、关系解释现象的过程
18
2013年的金球奖得主C罗
为什么C
罗那么牛?

机器语言理解需要背景知识
Language is complicated• Ambiguous, contextual and implicit• Seemingly infinite number of ways to express the same meaning
Language understanding is difficult• Grounded only in human cognition• Needs significant background knowledge

• Language understanding of machines needs knowledge bases
• Large scale
• Semantically rich
• Friendly structure
• High quality
• Traditional knowledge representations can not satisfy these requirements, but KG can
• Ontology• Semantic network/frame• Texts
知识图谱使能(Enable)机器语言认知
NLP+KB= NLU, NLP=Natural language processing, NLU=natural language understanding

The roadmap of knowledge-guided NLP
21
Knowledge Base
Knowledge-guided NLP(Knowledge extraction)
More Powerful Models
BiggerBetterKB
Corpora
NLU(Close the semantic gap)

Example: Using concepts to understand a natural language?
• Representation: concept based templates.• Questions are asking about entities. The semantic of the question is reflected by its
corresponding concept.
• Advantage: Interpretable, user-controllable
• Learn templates from QA corpus, instead of manfully construction.
How many people are there in Shanghai?
Shanghai 2420万Population
How many people are there in Beijing?
Beijing 2172万Population
How many people are there in $City?
Conceptualization By Probase
Learn from QA Corpora and KB
Wanyun Cui, Yanghua Xiao*, Haixun Wang, Yangqiu Song, Seung-won Hwang, Wei Wang, KBQA: Learning Question Answering over QA Corpora and Knowledge Bases, (VLDB 2017)

知识图谱使能可解释人工智能
23
鲨鱼为什么那么可怕?因为它们是食肉动物
鸟儿为何能够飞翔?因为它们有翅膀
鹿晗关晓彤最近为何刷屏?因为关晓彤是鹿晗女朋友
概念
属性
关系
解释取决于人类认知的基本框架;概念、属性、关系是认知的基石
“Concepts are the glue that holds our mental world together”
--Gregory Murphy

24
Example 1: Explainable entity recommendation using taxonomy
Problem:Given a set of entities, can we understand its concept and recommend a most related entity?
Applications:E-commerce: if users are searching samsung s6, and iPhone 6, what should we recommend and why?
Yi Zhang, et al, Entity suggestion with conceptual explanation, (IJCAI 2017)Taxonomy

Basic Idea:
Ming Dbpedia, using properties to explain a category
Model:
Mining Defining Features from DBpeida
25
Example 2: Explain a Concept/Category using Properties
Problem:How do we understand a concept/category?
Example:How to understand “Bachelor”=> (Sex=man, Marriage status=unmarried)
Bo Xu, et al, Learning Defining Features for Categories. (IJCAI 2016)
Solution Framework

知识引导将成为解决问题的主要方式
26
Knowledge Guided
Data Driven
张三把李四打了,他进医院了
张三把李四打了,他进监狱了
• “数据驱动”利用统计模式解决问题
• 单纯依赖统计模式难以有效解决很多实际问题

Example 1: Use Concepts for Chinese Entity Linking
• Entity linking: P(e|C), • where C is context and e is candidate entity
• Basic idea: using concepts (t) in knowledge base
𝑃 𝑒𝑖 𝐶 = 𝑡 𝑃(𝑒𝑖|𝑡) × 𝑃(𝑡|𝐶)
Typicality of an entity within a concept
The probability to observe an entity of t given context C
李娜(中国女子网球名将):人物、体育人物、运动员、名将
李娜(流行歌手、佛门女弟子):人物、演员、歌手、弟子
** Entity Annotation API
Our Method
Precision 56.7% 86.1%
Recall 67.8% 84.5%
F1 61.7% 85.3%

Example 2: Using knowledge to prevent semantic drift in pattern based IE
• Pattern based bootstrapping is popular
• Problem: semantic drift• <China isA country> =>• ‘occupation of $’, =>• ‘occupation of Planet earth’=>• <Planet Earch isA coutntry>
• Principles: no bad patterns, only wrong applications
• Our idea• Run a pattern on the text for an appropriate
entity• Using knowledge to guide the execution of the
learned pattern• 95%+ accuracy
<复旦大学 - 简称 - 复旦><复旦大学 - 创始人 - 马相伯>……

知识将显著增强机器学习能力
• 降低机器学习模型的大样本依赖,提高学习的经济性
• 提高机器学习模型对于先验知识的利用效率
• 增强机器学习模型与先验知识的一致性
29
机器学习模型
数据 结果
传统机器智能 基于知识的机器智能
机器学习模型
数据 结果知识库
知识增强的机器学
习
知识 知识
知识
专家系统数据 结果
传统专家系统
知识
ML+KB= ML2

Example 1: Deep language generation with prior knowledge
Incorporating Complicated Rules in Deep Generative Models, under review
into deep architectures fordiscrim inative tasks such as sen-tim ent analysis and N ER .(G anchev etal.2010) proposeda fram ew ork of using posterior regularization for addingpriori linear constraints into the m odels. (K araletsos, B e-longie,and R atsch 2015)developed a generative m odelw ithsim ilarity know ledge expressed in triplet form at to learnim proved disentangled representations. C om pared to thesew orks, our w ork is novel in 1) adding priori rules intodeep generativem odels;2)accom m odating any com plicatedrules thatspecify w hatisa good resultornot.
M ethodG lobalFram ew ork
Suppose w e have a generative m odelG (z),w hich uses a la-tentvectorz asthe input,and generatesdata sam plesx.H erethe inputz ⇠ pz m ay be a noise input,oran encoding ofacondition,such as the encoded contextvector of the inputsentence in m achine translation.A fterthe training,the out-putdistribution pg ofthe generative m odelG (z)isexpectedto be sim ilarto the realdata distribution pdata.Figure 1 show s our fram ew ork of incorporating com pli-cated priorirules into the generator G .The m ostim portantpartof our fram ew ork is an additional m odel R ,w hich isreferred to as rule discrim inator.W e use R to m odel anycom plicated priorirules.There are tw o m ajorprocedures torun our fram ew ork.The firstprocedure is training the rulediscrim inatorR .Itisa binary classifierthataccepts the fakesam ple generated by G as the input,and its outputis 0 or1 indicating w hether the sam ple is in com pliance w ith therules.The second procedure is using the rule discrim inatorR to guide the data generator G .These tw o procedures areexecuted in turn,and finally the generatorw illconverge to astate generating data in com pliance w ith the rules.N ext,w eelaborate each m ajorcom ponentin ourfram ew ork.
Back propagation
Random noises or encoded contexts
RuleExaminer
If then return 1If then return 0
...
zMany fake
samples
Positive samples
Negative samples
G RP
Back propagation from golden samples
Figure 1:O urfram ew ork
R ulesD iscrim inator RA challenge is,how to letthe m achine understand the pri-orirules.Itis difficultfor m achines to understand the de-scription ofrules.A betterstrategy isdata-driven,i.e.tellingthe m achine w hatsam ples can pass the rules.In general,itis easy to w rite a sim ple program to realize the evaluation.Forexam ple,a program to testw ord-repetition is show n inA lgorithm 1.M any com plicated rules (like Table 1)can bew ritten as a sim ple program .A ctually any rules thatcan beexpressed by a program can be incorporated into deep gen-erative m odels underourfram ew ork.The data to train R com es from the generator G (z).Thegenerated data thatpass the rule exam iner are used as pos-itive sam ples and those not are used as negative sam ples.
A lgorithm 1 W ord repetition exam ination
Input: S :The inputsentence,a w ord array.O utput: A boolean value ofw hetherS hasno w ord-repetition.1: for ifrom 0 to len(S )− 1 do2: for j from i+ 1 to len(S )− 1 do3: ifS [i]= = S [j]and S [i]!= “the”then4: return False5: end if6: end for7: end for8: return True
Table 1:Exam ples ofcom plicated rulesR ules1 Sentences should end w ith‘#’(a specialcharacter).2 Subjectshould appearonce in a sentence.3 N o repeated continuous characters in the sentence.4 Length ofsentence should be m ore than 4 characters.5 The num berofhigh frequency w ords should be lessthanhalfofsentence length.
These positiveand negativesam plesare used to train therulediscrim inatorR .O urrule exam iner(a rule testprogram )canbe treated asa function P (x).P (x)is1 ifx passesthe rules,and P (x) = 0 otherw ise.The loss function to train R is asbelow :
L R = − E x⇠pg [P (x)log(R (x))+ (1− P (x))log(1− R (x))](1)
This version is based on negative log likelihood,w hich isw idely used in binary classification m odels.W e m ightalter-natively use the leastsquare loss:
L R = E x⇠pg [(R (x)− P (x))2] (2)
In the follow ing texts,w e w illfocus on the discussion w henthe loss function is negative log likelihood.C onsidering thegeneratorG ,the loss function w illbe:
L R = − E z⇠pz [P (G (z))log(R (G (z)))
+ (1 − P (G (z)))log(1 − R (G (z)))](3)
Thus,R istrained to approxim ate P .W hile the deep neu-ralnetw ork hasthe greatability to approxim ate any com pli-cated function,R isexpected to havethe sam e behaviorasPsince w e can use sufficientdata generated from G to train R .The largestdifference betw een R and P isthatR isdifferen-tiable,w hich m eans thatw e can use back-propagation (R o-jas 1996) to optim ize G by R .In this w ay,w e incorporaterules specified in P into deep generative m odels G .
U se R to Im prove GW e firstuse G A N ,one ofthe m ostpopulardeep generativem odels,to elaborate how w e train G via R .In our fram e-w ork,therole ofR issim ilarto thediscrim inatorD in gener-ative adversarialnetw orks.W hile the traditionalG A N usesD to train G ,w e use a sim ilar m ethod to train G via R .InG A N ,the lossfunctions ofD and G are:
L D = − (E x⇠pd a ta [log(D (x))]+ E z⇠pz [1− log(D (G (z)))])(4)
在超级验证码中的应用
Demo地址:http://kw.fudan.edu.cn/ddemos/vcode/API地址:http://kw.fudan.edu.cn/apis/supervcode/

Example 2: Long-tailed query term embedding guided by knowledge
• In Deep IR, its hard to train effective word embedding for long tailed query terms
海尔 isA洗衣机品牌XYZ isA洗衣机品牌
……
Knowledge base
海尔洗衣机全自动海尔洗衣机半自动
海尔洗衣机全自动家用 8公斤洗衣机全自动海尔
海尔洗衣机全自动家用滚筒海尔滚筒洗衣机10公斤
全自动洗衣机家用海尔10公斤海尔迷你洗衣机海尔官方旗舰店
Transfer
F1 score increases by24% in the evaluation of similar queries
XYZ洗衣机全自动XYZ洗衣机半自动
XYZ衣机全自动家用 8公斤洗衣机全自动 XYZ
XYZ洗衣机全自动家用滚筒XYZ滚筒洗衣机10公斤
全自动洗衣机家用 XYZ10公斤XYZ迷你洗衣机XYZ官方旗舰店

知识将成为比数据更为重要的资产
• 大数据时代是得“数据者”得天下
• 人工智能时代是得“知识者”得天下
• 经过知识沉淀的机器智能使得知识工作自动化成为可能
• 数据是石油,知识就是石油的萃取物
32
“Knowledge is power in AI”, Edward Feigenbaum
知识加工与石油萃取

总结-1
• 人类社会已经进入智能时代
• 智能时代催生大量智能化应用需求
• 认知智能是实现行业智能化的关键技术
• 知识图谱技术是实现机器认知智能的核心技术• 知识图谱使能机器语言认知• 知识图谱使能可解释人工智能• 知识引导成为问题求解方式之一• 知识将显著增强机器学习能力
33

总结-2
34
定理1: NLP+KB=NLU
定理2: Small knowledge+ big data= big knowledge
定理3: ML+KB= ML2

总结-3
35
知识的沉淀与传承,铸就了人类文明的辉煌,
也将成为机器智能持续提升必经道路。

References
• Yi Zhang, Yanghua Xiao*,Seuongwon Hwang, Haixun Wang, X.Sean Wang, Entity Suggestion with Conceptual Explanation, (IJCAI2017)
• Jiaqing Liang, Sheng Zhang, Yanghua Xiao*, How to Keep a Knowledge Base Synchronized with Its Encyclopedia Source, (IJCAI2017 )
• Bo Xu, Yong Xu, Jiaqing Liang, Chenhao Xie, Bin Liang, Wanyun Cui and Yanghua Xiao*, CN-DBpedia: A Never-Ending Chinese Knowledge Extraction System, (IEA/AIE2017 )
• Jiaqing Liang, Yi Zhang, Yanghua Xiao*, Haixun Wang, Wei Wang, Probase+: Inferring Missing Links in Conceptual Taxonomies, Transactions on Knowledge and Data Engineering (TKDE2017)
• Wanyun Cui, Yanghua Xiao*, Haixun Wang, Yangqiu Song, Seung-won Hwang, Wei Wang, KBQA: Learning Question Answering over QA Corpora and Knowledge Bases, (VLDB 2017)
• Jiaqing Liang, Yi Zhang, Yanghua Xiao*, Haixun Wang, Wei Wang and Pinpin Zhu, On the Transitivity of Hypernym-hyponym Relations in Data-Driven Lexical Taxonomies, (AAAI 2017)
• Jiaqing Liang, Yanghua Xiao*, Yi Zhang, Seung-Won Hwang and Haixun Wang, Graph-based Wrong IsA Relation Detection in a Large-scale Lexical Taxonomy, (AAAI 2017)
• Xiangyan Sun, Yanghua Xiao*, Haixun Wang, Wei Wang, On Conceptual Labeling of a Bag of Words, (IJCAI 2015)
• Xiangyan Sun, Haixun Wang, Yanghua Xiao*, Zhongyuan Wang, Syntactic Parsing of Web Queries, (EMNLP 2016)

References
• Bo Xu, Chenhao Xie, Yi Zhang, Yanghua Xiao*, Haixun Wang and Wei Wang, Learning Defining Features for Categories, (IJCAI 2016)
• Wanyun Cui, Yanghua Xiao*, Wei Wang, KBQA: An Online Template Based Question Answering System over Freebase, (IJCAI 2016)
• Wanyun Cui, Xiyou Zhou, Hangyu Lin,Yanghua Xiao*,Seungwon Hwang,Haixun Wang and Wei Wang, Verb Pattern: A Probabilistic Semantic Representation on Verbs, (AAAI 2016)
• Yi Zhang, Yanghua Xiao*,Seuongwon Hwang, Haixun Wang, X.Sean Wang, Entity Suggestion with Conceptual Expanation, (IJCAI2017 )
• Deqing Yang, Yanghua Xiao*,Yangqiu Song, Wei Wang, Semantic-based Recommendation Across Heterogeneous Domains, (ICDM 2015)
• Deqing Yang, Yanghua Xiao*, Hanghang Tong, Wanyun Cui and Wei Wang, Towards Topic Following in Heterogeneous Information Networks, (ASONAM 2015)
• Xiangyan Sun, Yanghua Xiao*, Haixun Wang, Wei Wang, On Conceptual Labeling of a Bag of Words, (IJCAI 2015)
• Deqing Yang, Yanghua Xiao*, An Integrated Tag Recommendation Algorithm Towards Weibo User Profiling, (DASFAA 2015)
• Deqing Yang, Jingrui He, Huazhen Qin, Yanghua Xiao and Wei Wang, A Graph-based Recommendation across Heterogeneous Domains, (CIKM 2015)
• Jiaqing Liang, Yanghua Xiao, et,al. Tag inference with knowledge graph, (under review), Technique Report of KW@Fudan
37






























