Embed Size (px)
Citation preview

Changing Engines in Midstream: A Java StreamComputational Model for Big Data Processing
Xueyuan Su, Garret Swart, Brian Goetz,Brian Oliver, Paul Sandoz
Oracle Corporation
VLDB’14September 1st - 5th, 2014
1 Xueyuan Su etc. DistributableStream for Big Data Processing

Xueyuan SuGarret Swart
Brian GoetzPaul Sandoz
Brian Oliver
2 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Motivation
3 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Big Data Space
Many data sources!Many compute engines!
Many tools to learn, use, and maintain!
4 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Usability
Simple computational model.Friendly programming interface.
School kids can process Big Data!
Daddy's Hadoop app will take over
the world!
Cool!I hope to do the same in Java 101.
Alice Bob
5 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Portability
A single API supported over multiple engines.Reuse applications developed for old engines.Leverage the investment in past development.
They also want your Hadoop app on Spark.
Sure... Maybe in 6 months?
Manager Developer
Customers
6 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Query Federation
Various data processing requirements.Varied engine capabilities.
Price, data locality, and resource availability.
BIGDATA
7 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Proposal
A Java streamcomputational model
and interfacefor Big Data processing
8 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Challenges We Try to AddressClarifications
Clarifications
Q: Why Java?
A: User friendliness, big user base, broad adoption in Hadoopecosystem (with other JVM-based languages), ...
Q: Why not SQL?
A: We certainly love SQL – but not all Java programmers useSQL, less natural to implement certain applications in adeclarative language, one can build a SQL compiler on top, ...
Q: Yet another data-parallel MPP system?
A: No. A clean computational model and API for federatingdifferent MPP systems both between and within a query.
9 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
DistributableStream
10 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Take-Home Message
DistributableStreamis an abstraction that supports
generic, distributed and federatedqueries on top of an extensible
set of compute engines.
11 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Concise Yet Expressive
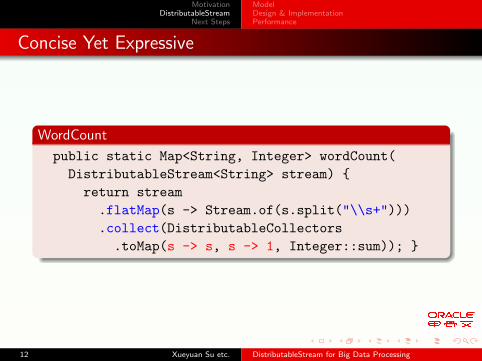
WordCount
public static Map<String, Integer> wordCount(
DistributableStream<String> stream) {
return stream
.flatMap(s -> Stream.of(s.split("\\s+")))
.collect(DistributableCollectors
.toMap(s -> s, s -> 1, Integer::sum)); }
12 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
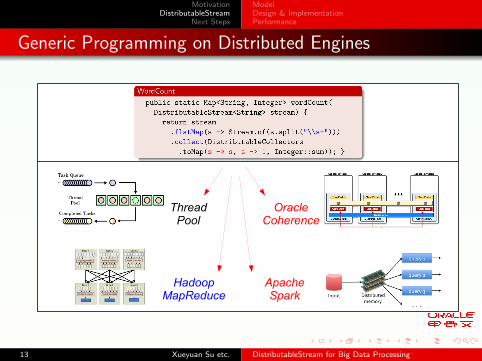
Generic Programming on Distributed Engines
ThreadPool
Hadoop MapReduce
Apache Spark
Oracle Coherence
13 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
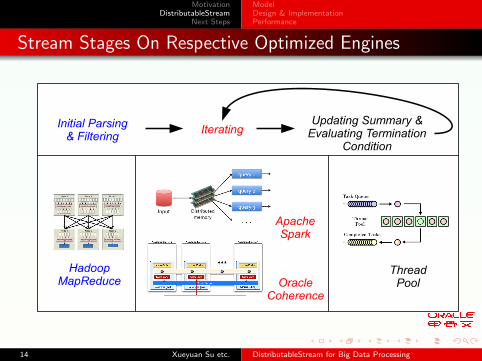
Stream Stages On Respective Optimized Engines
ThreadPool
Hadoop MapReduce
Apache Spark
Oracle Coherence
Initial Parsing & Filtering
IteratingUpdating Summary &
Evaluating Termination Condition
14 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Model
15 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
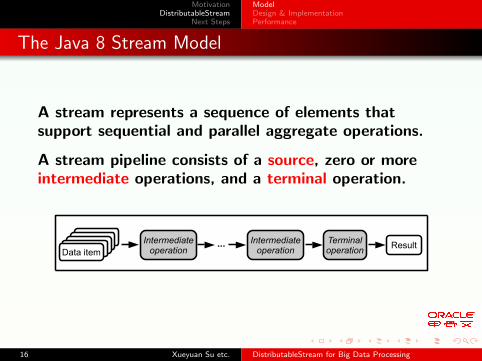
The Java 8 Stream Model
A stream represents a sequence of elements thatsupport sequential and parallel aggregate operations.
A stream pipeline consists of a source, zero or moreintermediate operations, and a terminal operation.
Data itemIntermediateoperation
ResultIntermediateoperation
Terminaloperation
...
16 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
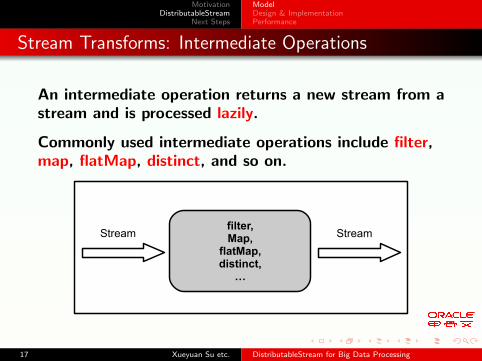
Stream Transforms: Intermediate Operations
An intermediate operation returns a new stream from astream and is processed lazily.
Commonly used intermediate operations include filter,map, flatMap, distinct, and so on.
Stream Streamfilter,Map,
flatMap,distinct,…
17 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Terminal Operations
A terminal operation triggers the traversal of dataitems and consumes the stream.
Two commonly used terminal operations are reduceand collect.
StreamResult
reduce,collect,...
18 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Collectors
Collect method usually works with a Collector.
A Collector is defined by a Supplier, an Accumulator, aCombiner, and an optional Finisher.
Data item
Container
Accumulator
Supplier Container
AccumulatorData item
Supplier
Combiner
Container
ContainerContainer
ContainerCombiner
Container
Finisher
Result
19 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
We extend the Streammodel to allow the use of
distributed enginesfor processing
distributed data sets.
20 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Design & Implementation
21 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
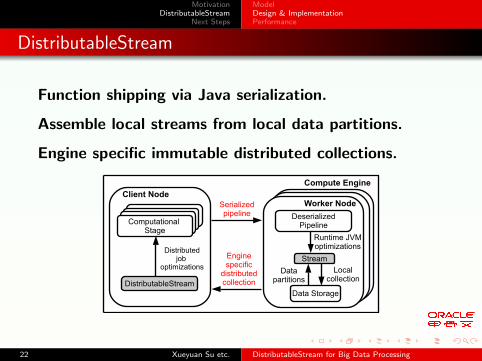
DistributableStream
Function shipping via Java serialization.
Assemble local streams from local data partitions.
Engine specific immutable distributed collections.
Compute Engine Client Node
Distributedjob
optimizations
Serializedpipeline
DistributableStream
Worker Node
Computational Stage
DeserializedPipeline
Stream
Data Storage
Runtime JVMoptimizations
Localcollection
Enginespecific
distributedcollection
Datapartitions
22 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
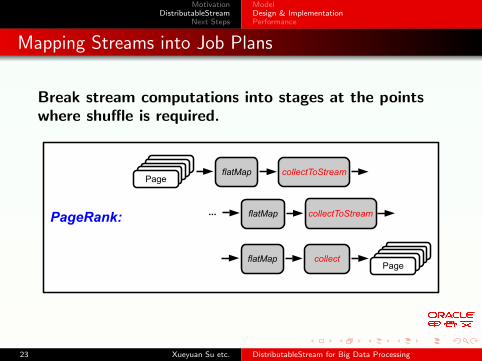
Mapping Streams into Job Plans
Break stream computations into stages at the pointswhere shuffle is required.
PageflatMap collectToStream
flatMap collectToStream
flatMap collectPage
...PageRank:
23 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Engine Interface
Engine interface for separating low-level details fromthe computational model and negotiating data/statemovement between engines.
Each compute engine needs to implement the Engineinterface.
Engine parameters are configured in the engineconfiguration object.
24 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Configuring Engine Parameters
MapReduceEngine
25 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
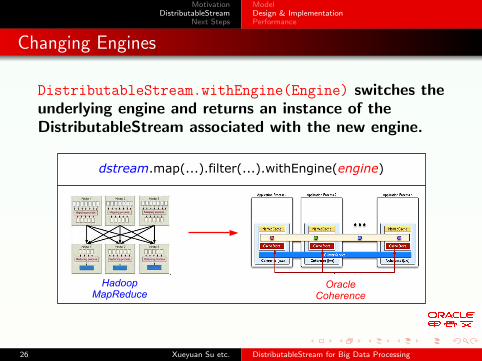
Changing Engines
DistributableStream.withEngine(Engine) switches theunderlying engine and returns an instance of theDistributableStream associated with the new engine.
Hadoop MapReduce
Oracle Coherence
dstream.map(...).filter(...).withEngine(engine)
26 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
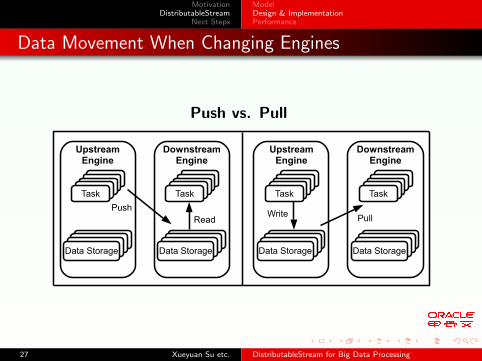
Data Movement When Changing Engines
Push vs. Pull
UpstreamEngine
Push
Task
Data Storage
DownstreamEngine
Task
Data Storage
Read
UpstreamEngine
Task
Data Storage
DownstreamEngine
Task
Data Storage
Write Pull
27 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Push
Push is the default option.
Upstream engine writes to downstream storage.
UpstreamEngine
Push
Task
Data Storage
DownstreamEngine
Task
Data Storage
Read
28 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Pull
Pull is usually used when upstream engine cannot writeto downstream storage.
When upstream engine is in memory, pulling from itsaves disk access costs.
UpstreamEngine
Task
Data Storage
DownstreamEngine
Task
Data Storage
Write Pull
29 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Special Pull: Short-Circuiting
Short-circuiting enables downstream engine to pull fromupstream storage without running tasks there.
Use case: Hadoop InputFormat → Coherencein-memory cache, similar to HadoopRDD in Spark.
UpstreamEngine
Task
Data Storage
DownstreamEngine
Task
Data Storage
Pull
30 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Example Applications
WordCount
Distributed Reservoir Sampling
PageRank
K-Means Clustering
Refer to the paper for actual code
31 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Performance
32 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Environment
Oracle Big Data Appliance (BDA):- Each node has:
- 2 × eight-core Intel Xeon processors.- 64GB memory.- 12 × 4TB 7200RPM disks.- InfiniBand interconnections.
- Cloudera Hadoop CDH 5.0.2.- Oracle Coherence 12.1.2.- Java SE 8u5.- Recompile Hadoop and Coherence source code
with JDK8, install JRE8.
33 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Overhead?
34 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Stream vs. Native Implementations
WordCount implemented with DistributableStreamand native Hadoop.
Input: 45GB Wikipedia dumps.
Writable and Java immutable types for comparison.
35 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
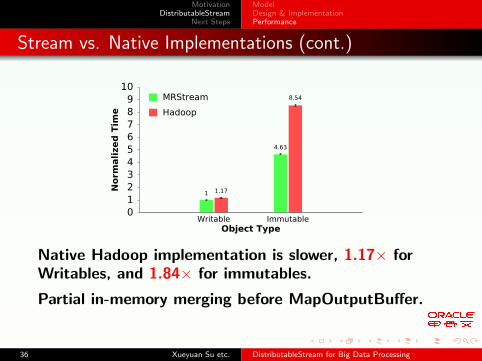
Stream vs. Native Implementations (cont.)
0 1 2 3 4 5 6 7 8 9
10
Writable Immutable
Norm
alized
Tim
e
Object Type
MRStream
Hadoop
1
4.63
1.17
8.54
Native Hadoop implementation is slower, 1.17× forWritables, and 1.84× for immutables.
Partial in-memory merging before MapOutputBuffer.
36 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Why Federation?
37 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
Hadoop MR vs. Coherence as Engine for Iterations
K-means implemented with DistributableStream.
Input: 45GB raw data representing one billion vertices.
Hadoop MR for parsing raw input, {Hadoop MR,Coherence} for iterations, Local SMP for updatingcentroids and evaluating termination condition.
Most disk IOs are avoided during the job execution bycaching the input data and all intermediate results inthe OS cache.
38 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
ModelDesign & ImplementationPerformance
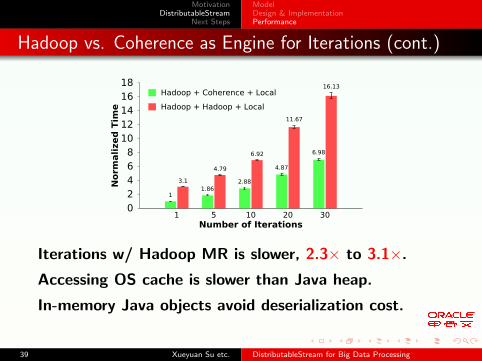
Hadoop vs. Coherence as Engine for Iterations (cont.)
0 2 4 6 8
10 12 14 16 18
1 5 10 20 30
Norm
alized
Tim
e
Number of Iterations
Hadoop + Coherence + Local
Hadoop + Hadoop + Local
11.86
2.88
4.87
6.98
3.1
4.79
6.92
11.67
16.13
Iterations w/ Hadoop MR is slower, 2.3× to 3.1×.
Accessing OS cache is slower than Java heap.
In-memory Java objects avoid deserialization cost.
39 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Next?
40 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Short Term
More Data Sources,such as Databases.
More Compute Engines,such as Apache Spark and Tez.
41 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Long Term
Job Planner and Optimizer,for automatical engine assignment.
Job Progress Monitor,for fault tolerance across engines.
Java JIT Optimization,for low-level JVM tuning.
API Extension,for supporting DAGs.
42 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Development Community
We need your help!
A JSR (Java Specification Request).
An OpenJDK project.
43 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Take-Home Message
DistributableStreamis an abstraction that supports
generic, distributed and federatedqueries on top of an extensible
set of compute engines.
You are welcome to make contributions!
44 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Thank You!
Questions?
45 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Backup Slides
46 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
LocalStream
A wrapper DistributableStream implementation thatwraps a Java 8 Stream inside.
Operations are delegated to the wrapped Stream.
47 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
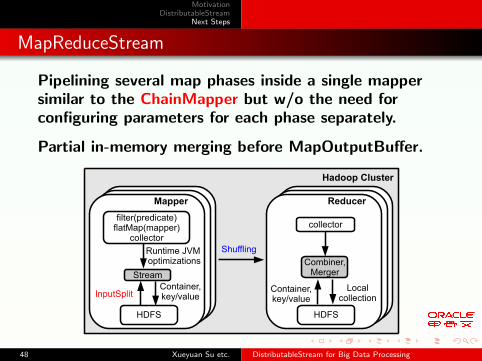
MapReduceStream
Pipelining several map phases inside a single mappersimilar to the ChainMapper but w/o the need forconfiguring parameters for each phase separately.
Partial in-memory merging before MapOutputBuffer.
Hadoop Cluster
Reducer
collector
Combiner,Merger
HDFS
Localcollection
Shuffling
Container,key/value
Mapper
filter(predicate)flatMap(mapper)
collector
Stream
HDFS
Runtime JVM optimizations
Container,key/valueInputSplit
48 Xueyuan Su etc. DistributableStream for Big Data Processing
MotivationDistributableStream
Next Steps
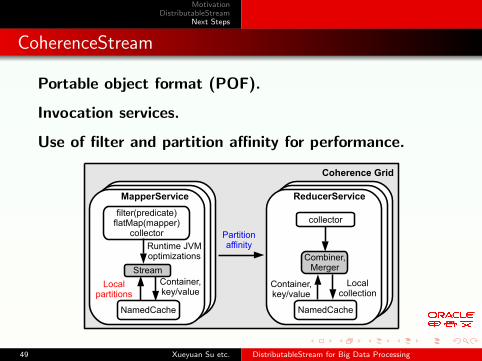
CoherenceStream
Portable object format (POF).
Invocation services.
Use of filter and partition affinity for performance.
Coherence Grid
ReducerService
collector
Combiner,Merger
NamedCache
Localcollection
Partitionaffinity
Container,key/value
MapperService
filter(predicate)flatMap(mapper)
collector
Stream
NamedCache
Runtime JVMoptimizations
Container,key/value
Localpartitions
49 Xueyuan Su etc. DistributableStream for Big Data Processing

MotivationDistributableStream
Next Steps
Creation of DistributableStreams
By Engine instance methods over a persistent enginespecific data set, e.g.,MapReduceEngine.valueStream(conf)
From an Engine specific distributed collection, e.g.,coherenceDistMap.entryStream()
Use the result ofDistributableStream.collectToStream(collector)
50 Xueyuan Su etc. DistributableStream for Big Data Processing





























