Embed Size (px)
Citation preview

Chapter 8 Main Memory
Bernard Chen Spring 2007

Objectives
To provide a detailed description of various ways of organizing memory hardware
To discuss various memory-management techniques, including paging and segmentation
To provide a detailed description of the Intel Pentium, which supports both pure segmentation and segmentation with paging

Background
Program must be brought (from disk) into memory and placed within a process for it to be run
Main memory and registers are only storage CPU can access directly
Register access in one CPU clock (or less) Main memory can take many cycles Cache sits between main memory and CPU
registers Protection of memory required to ensure correct
operation

Memory shared by Processes
We first need to make sure that each process has a separate memory space
The BASE register holds the smallest legal physical memory address; the LIMIL register specifies the size of the range

Base and Limit Registers

Base and Limit Registers
The base and limit registers can be loaded only the operating system , which uses a special privileged instruction.
And these instructions can only be executed in kernel mode, which can only achieved by OS

Binding of Instructions and Data to Memory
Binding: A compiler will typically bind the symbolic address To relocatable address (such as “14 bytes from the beginning of the module”)
Address binding of instructions and data to memory addresses can happen at three different stages

Binding of Instructions and Data to Memory
Compile time: If memory location known a priori, absolute code can be generated; must recompile code if starting location changes
Load time: Must generate relocatable code if memory location is not known at compile time
Execution time: Binding delayed until run time if the process can be moved during its execution from one memory segment to another.


Logical vs. Physical Address Space
The concept of a logical address space that is bound to a separate physical address space is central to proper memory management
Logical address–generated by the CPU; also referred to as virtual address
Physical address– addres seen by the memory unit

Logical vs. Physical Address Space
Logical and physical addresses are the same in compile-time and load-time address-binding schemes; logical (virtual) and physical addresses differ in execution-time address-binding scheme
Logical address also refer to a virtual address

Memory-Management Unit (MMU) The run time mapping from virtual to physical
address is done by a hardware device called the memory-management unit, as well as MMU
In MMU scheme, the value in the relocation register is added to every address generated by a user process at the time it is sent to memory
The user program deals with logical addresses; it never sees the real physical addresses

Memory-Management Unit (MMU)

Dynamic Loading If the entire program and all data must
be in physical memory for the process to execute, the size of the process is limited to the size of physical memory
To obtain better memory-space utilization, we can use dynamic loading
Routine is not loaded until it is called

Swapping
A process can swapped temporarily out of memory to a Backing store and then brought back into memory for continued execution.
For example, RR CPU-scheduler, Priority scheduler

Swapping

Swapping Swapping requires a backing store. It must be large enough to store all memory
images for all users, and it must have a direct access to memory
Whenever the CPU scheduler decides to execute a process, it calls the dispatcher
The dispatcher will check whether the next process is in the memory
If not, the dispatcher will swap out a process currently in memory and swaps in the desired process

Swapping We assume that the user process is 10MB, and
the standard hard disk with a transfer rate of 40MB per second, it would take:
10000kb/40000kb per sec = ¼ second = 250 milliseconds
Assume we expect 8 millisecond of delay, each swap will take 258 millisecond. And we need two swaps therefore it takes 516 milliseconds
If we do a RR CPU-scheduler, the time quantum should be more than half second

Contiguous Allocation
Main memory usually into two partitions:
Resident operating system, usually held in low memory with interrupt vector
User processes then held in high memory

Memory Mapping and Protection
Relocation registers used to protect user processes from each other, and from changing operating-system code and data
Base register contains value of smallest physical address
Limit register contains range of logical addresses –each logical address must be less than the limit register
MMU maps logical address dynamically

Memory Mapping and Protection

Memory Allocation
The simplest method for memory allocation is to divide memory into several fix-sized partitions
Initially, all memory is available for user processes and is considered one large block of available memory, a hole.

Memory Allocation

Dynamic storage allocation problem When a process arrives and needs
memory, the system searches the set for a hole that is large enough for it.
If it is too large, the space divided into two parts. One part is allocate for the process and another part is freed to the set of holes
When the process terminate, the space is placed back in the set of holes
If the space is not big enough, the process wait or next available process comes in

Dynamic Storage-Allocation Problem How to satisfy a request of size n from a
list of free holes First-fit: Allocate the first hole that is
big enough Best-fit: Allocate the smallest hole that
is big enough; must search entire list, unless ordered by size (Produces the smallest leftover hole)
Worst-fit: Allocate the largest hole; must also search entire list (Produces the largest leftover hole)

Fragmentation All strategies for memory allocation suffer
from external fragmentation external fragmentation: as process are
loaded and removed from memory, the free memory space is broken into little pieces
External fragmentation exists when there is enough total memory space to satisfy the request, but available spaces are not contiguous

Fragmentation Statistical analysis of first fit even
with some optimization, given N allocated blocks, another 0.5N blocks will be lost to fragmentation.
That is one-third of memory may be unusable!
This property is known as the 50-percent rule

Fragmentation
If the hole is the size of 20,000 bytes, suppose that next process requests 19,000 bytes. 1,000 bytes are lose
This is called internal fragmentation- memory that is internal to a partition but is nor being used

Fragmentation Possible solution to external-fragmentation
problem is to permit the logical address space of the process to be noncontiguous
Thus, allowing a process to be allocated physical memory wherever the space is available
Two complementary techniques achieves this solution: paging(8.4) segmentation (8.6) combined (8.7)

8.4 paging Paging is a memory-management
scheme that permits the physical address space of a process to be non-contiguous.
The basic method for implementation involves breaking physical memory into fixed-sized blocks called FRAMES and break logical memory into blocks of the same size called PAGES

Paging
Every address generated by the CPU is divided into two parts: Page number (p) and Page offset (d)
The page number is used as an index into a Page Table

Paging
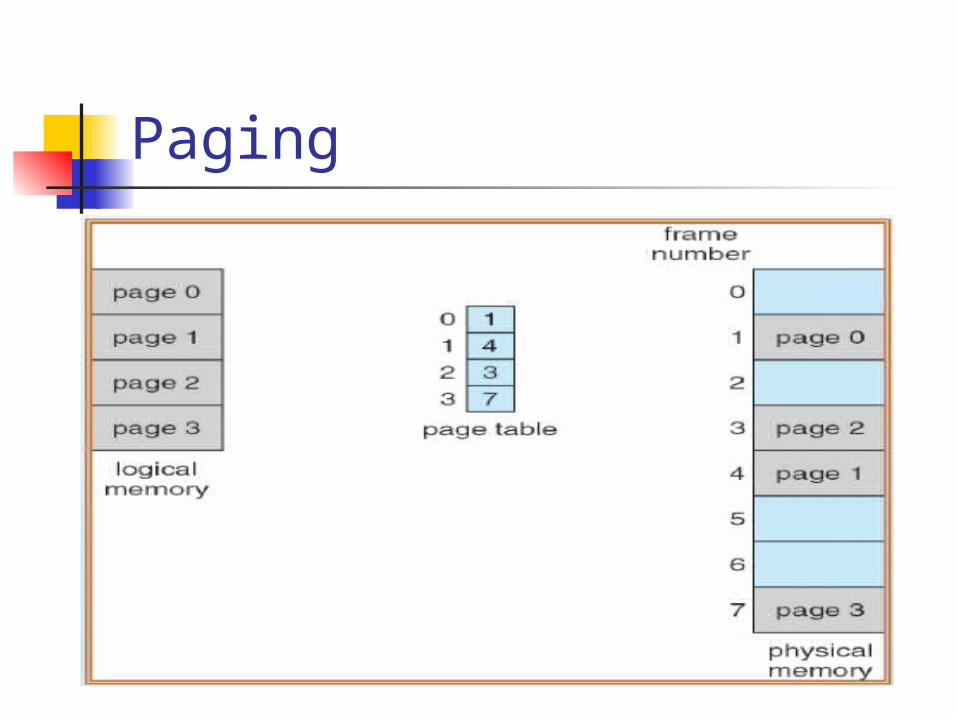
Paging

Paging The page size is defined by the hardware The size of a page is typically a power of
2, varying between 512 bytes and 16MB per page
Reason: If the size of logical address is 2^m and page size is 2^n, then the high-order
m-n bits of a logical address designate the page number

Paging

Paging Example

Paging When we use a paging scheme, we
have no external fragmentation: ANY free frame can be allocated to a process that needs it.
However, we may have internal fragmentation
For example: if a page size is 2048 bytes, a process of 72766 bytes would need 35 pages plus 1086 bytes

Paging
If the process requires n pages, at least n frames are required
The first page of the process is loaded into the first frame listed on free-frame list, and the frame number is put into page table
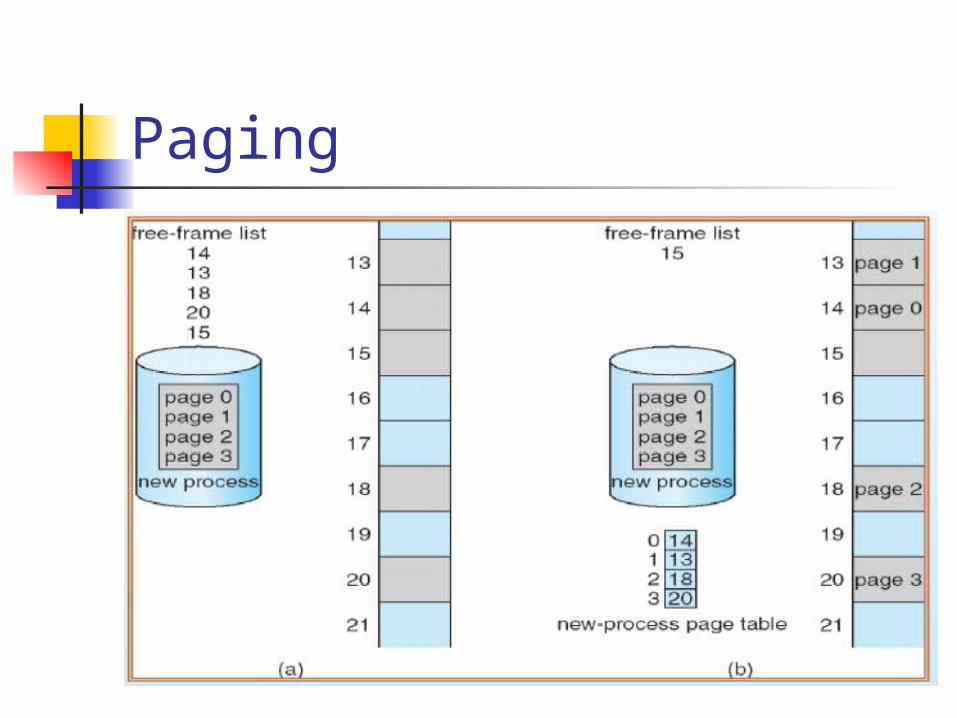
Paging

Hardware Support on Paging To implement paging, the simplest
method is to implement the page table as a set of registers
However, the size of register is limited and the size of page table is usually large
Therefore, the page table is kept in main memory

Hardware Support on Paging If we want to access location I, we must
first index into page table, this requires one memory access
With this scheme, TWO memory access are needed to access a byte
The standard solution is to use a special, small, fast cache, called Translation look-aside buffer (TLB) or associative memory

TLB

TLB If the page number is not in the TLB
(TLB miss) a memory reference to the page table must be made.
In addition, we add the page number and frame number into TLB
If the TLB already full, the OS have to must select one for replacement
Some TLBs allow entries to be wire down, meaning that they cannot be removed from the TLB, for example kernel codes

TLB The percentage of times that a particular page
number is found in the TLN is called hit ratio If it takes 20 nanosecond to search the TLB
and 100 nanosecond to access memory
If our hit ratio is 80%, the effective memory access time equal:
0.8*(100+20) + 0.2 *(100+100)=140 If our hit ratio is 98%, the effective memory
access time equal: 0.98*(100+20) + 0.02 *(100+100)=122 (detail in CH9)

Memory Protection
Memory protection implemented by associating protection bit with each frame
Valid-invalid bit attached to each entry in the page table:
“valid” indicates that the associated page is in the process’ logical address space, and is thus a legal page
“invalid” indicates that the page is not in the process ’logical address space

Memory Protection
Suppose a system with a 14bit address space (0 to 16383), we have a program that should use only address 0 to 10468. Given a page size of 2KB, we may have the following figure:
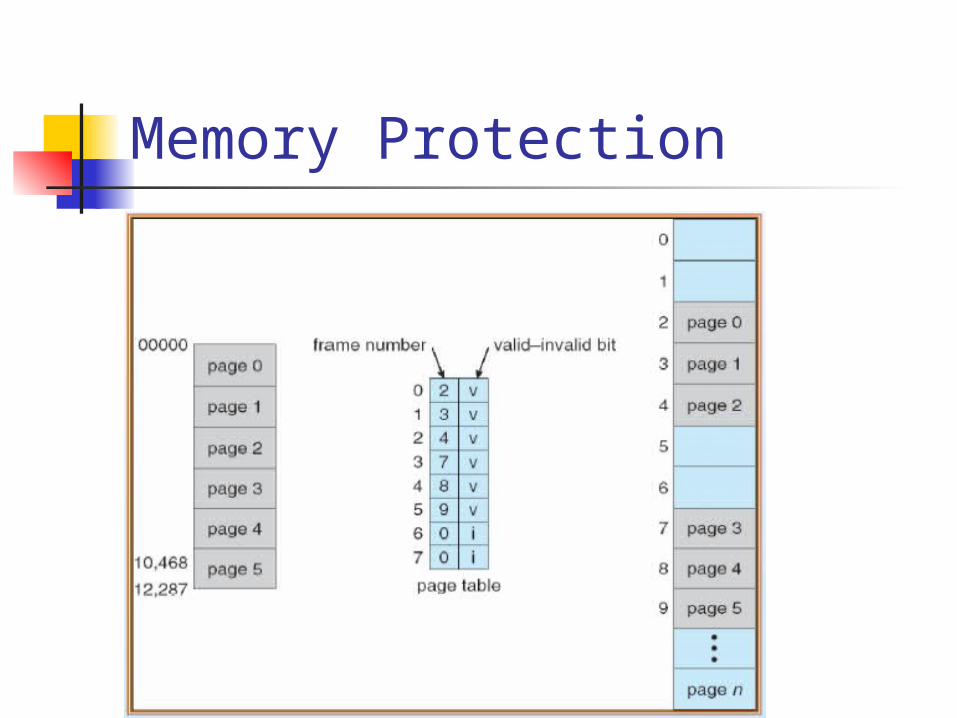
Memory Protection

Memory Protection Any attempt to generate an
address in page 6 or 7 will be invalid
Notice that this scheme allows the program to access 10468 to 12287, this problem is result of the 2KB page size and reflects the internal fragmentation of paging

Shared Pages An advantage of paging is the possible
of sharing common code, especially time-sharing environment
For example a server with 40 user using text editor (with 150k reentrant code and 50k data space)
In next figure, we see three page editor with 50k each. Each process has its own data page

Shared Pages

Shared Pages
In this case, we need only 150k + 40* 50k = 2150 KB
Instead of (150k + 50K)*40 = 8000KB





























