Embed Size (px)
Citation preview

CompositionalArchitecturesandWordVectorRepresentations
forPPAttachment
YonatanBelinkov,TaoLei,ReginaBarzilay,AmirGloberson
NAACL2015(PublishedatTACL)
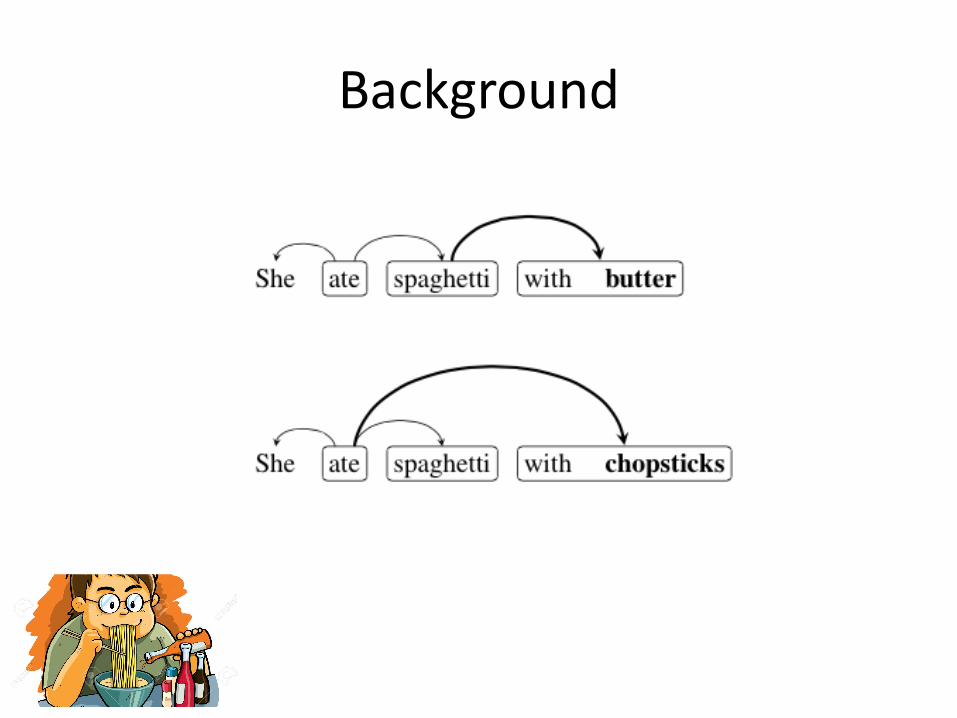
Background

Applications
• PPattachments:majorsourceoferrorsinsyntacticparsing(Kummerfeld etal.2012)
• Syntacticparsing:acoreNLPmodule– Namedentityrecognition–Machinetranslation– Co-referenceresolution
• Relationextraction

HistoricalDevelopment
• ClassicNLPtasksincethe1990s

HistoricalDevelopment
• ClassicNLPtasksincethe1990s• Improvementovertime(Kummerfeld etal.2012)
– 32%errorreductionin15years(sinceCollins1997)

HistoricalDevelopment
• ClassicNLPtasksincethe1990s• Improvementovertime(Kummerfeld etal.2012)
– 32%errorreductionin15years(sinceCollins1997)• But:stillamajorchallengeinparsing– Largestsourceoferrorsacrossarangeofparsers
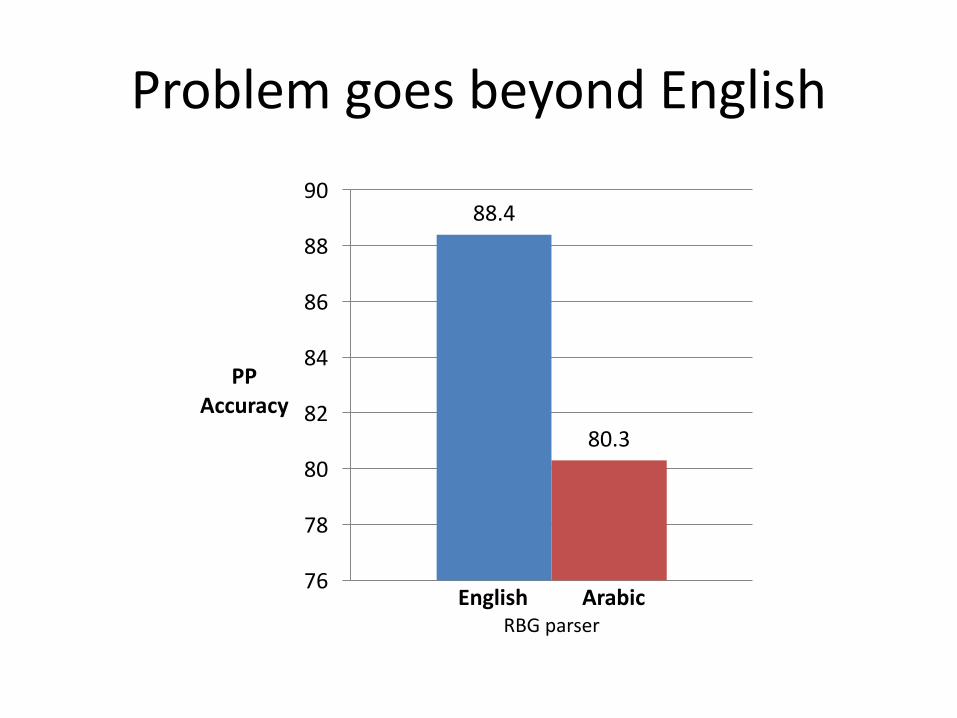
ProblemgoesbeyondEnglish
88.4
80.3
76
78
80
82
84
86
88
90
PPAccuracy
EnglishArabicRBGparser

PreviousWork
• Problemformulation:– Constrainedbinaryclassifiers(Ratnaparkhi 1994;…)– Full-scaleparsersConsideranun-constrainedPPscenario
• Informationsources:– Hand-craftedknowledge(Gamallo etal.2003;…)– Statisticsfromrawtext(Volk2002),wordvectorrepresentations (Šuster 2012;Socheretal.2013)
Combinewordvectorswithotherrepresentations

Setup
• Training:sentences,prepositions(with),children(butter), heads(spaghetti)

Setup
• Training:sentences,prepositions(with),children(butter), heads(spaghetti)
• Testing:– Given:sentences,prepositions,children– Predict:heads
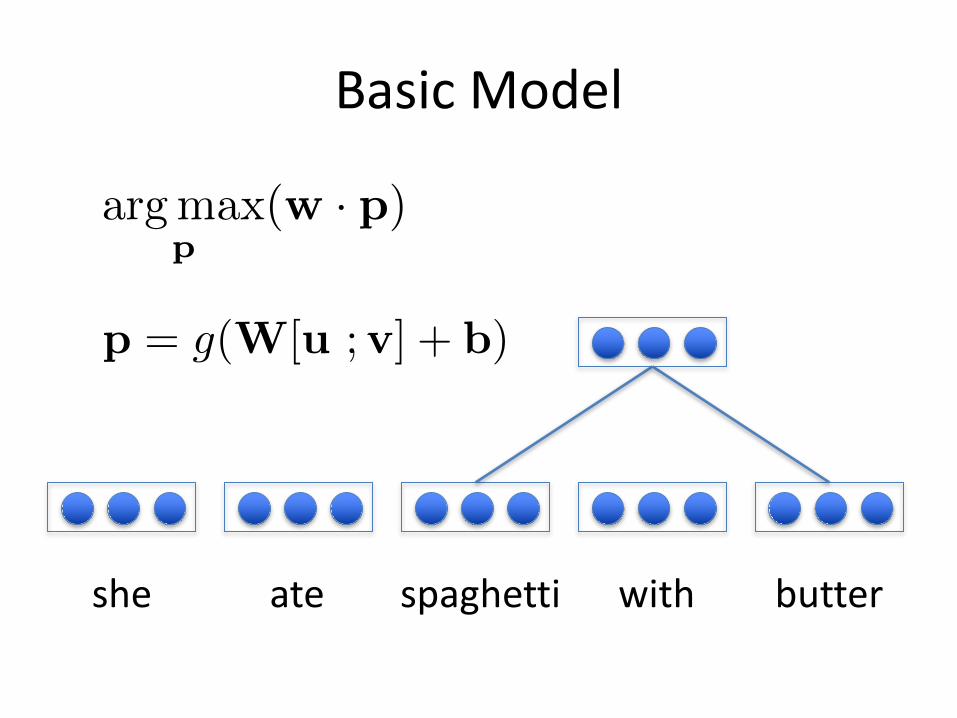
BasicModel
she ate spaghetti with butter
p = g(W[u ;v] + b)
argmax
p(w · p)

BasicModel
• Representwordsasvectors: u,v 2 Rn
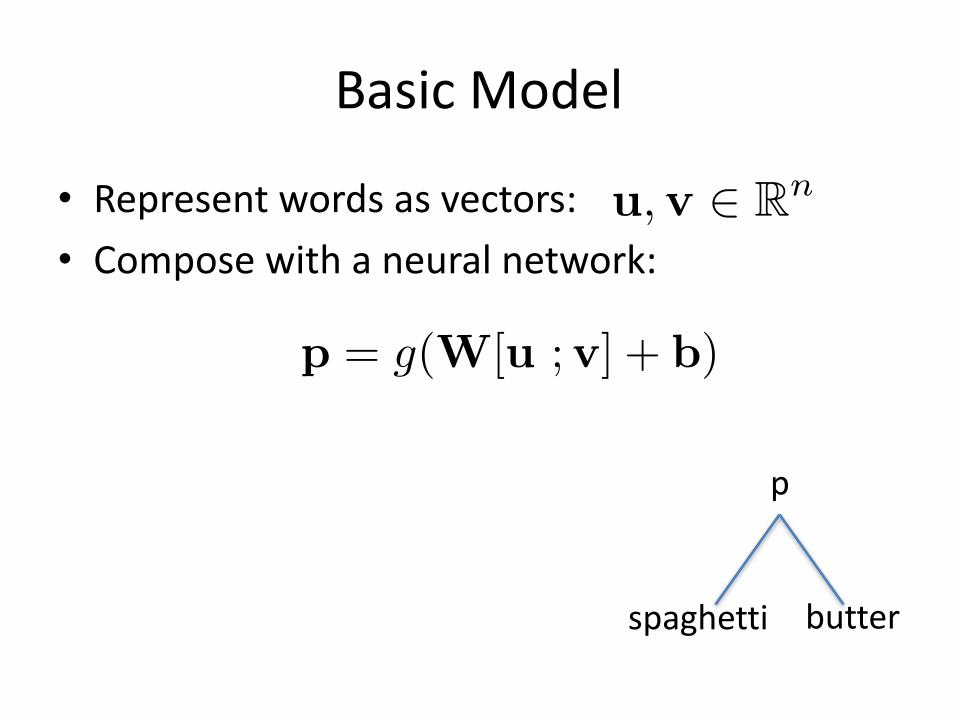
BasicModel
• Representwordsasvectors:• Composewithaneuralnetwork:
u,v 2 Rn
p = g(W[u ;v] + b)
spaghetti butter
p

BasicModel
• Representwordsasvectors:• Composewithaneuralnetwork:
• Scoreparent:
u,v 2 Rn
p = g(W[u ;v] + b)
argmax
p(w · p)
spaghetti butter
p
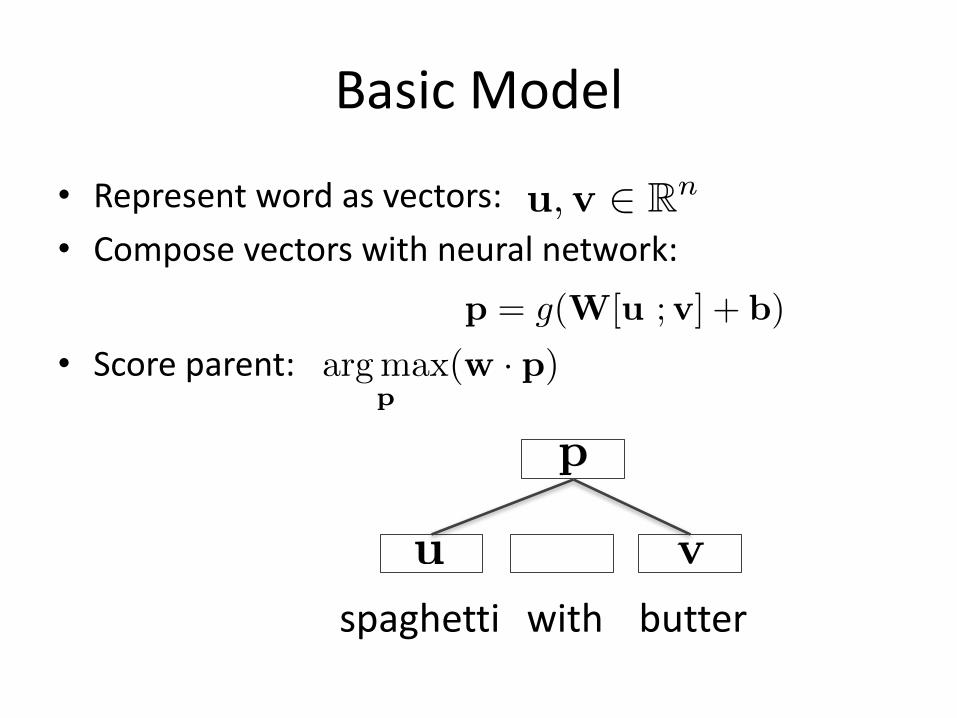
BasicModel
• Representwordasvectors:• Composevectorswithneuralnetwork:
• Scoreparent:
u,v 2 Rn
p = g(W[u ;v] + b)
argmax
p(w · p)
spaghetti with butteru v
p

Example
Sheatespaghettiwithbutter

Example
• Candidatespaghetti
Sheatespaghetti withbutter

Example
• Candidatespaghetti
Sheatespaghetti withbutter
p1
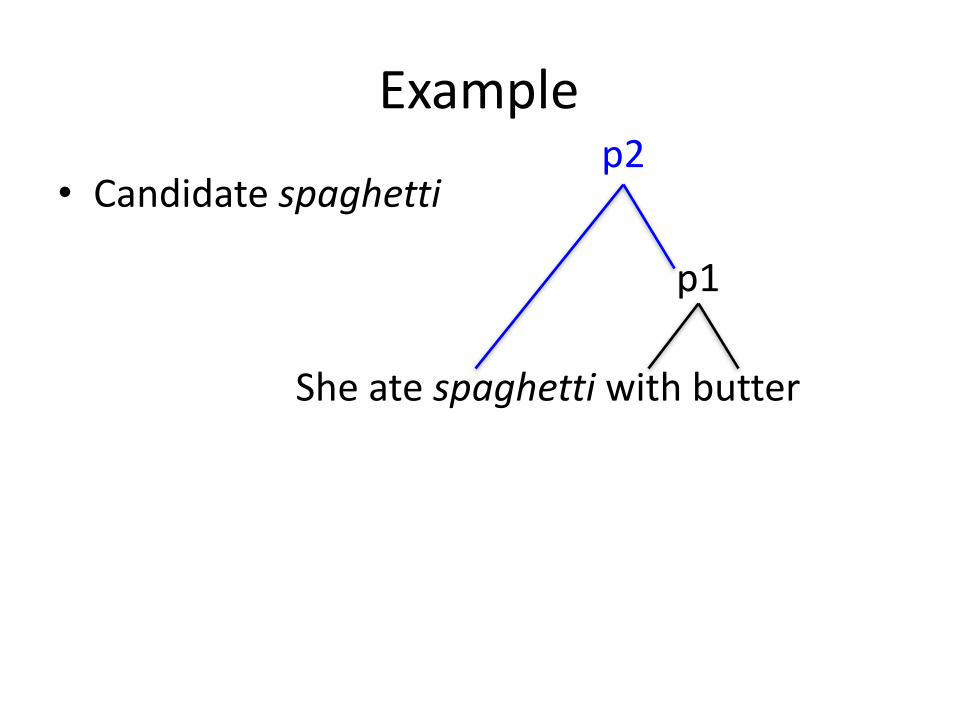
Example
• Candidatespaghetti
Sheatespaghetti withbutter
p1
p2
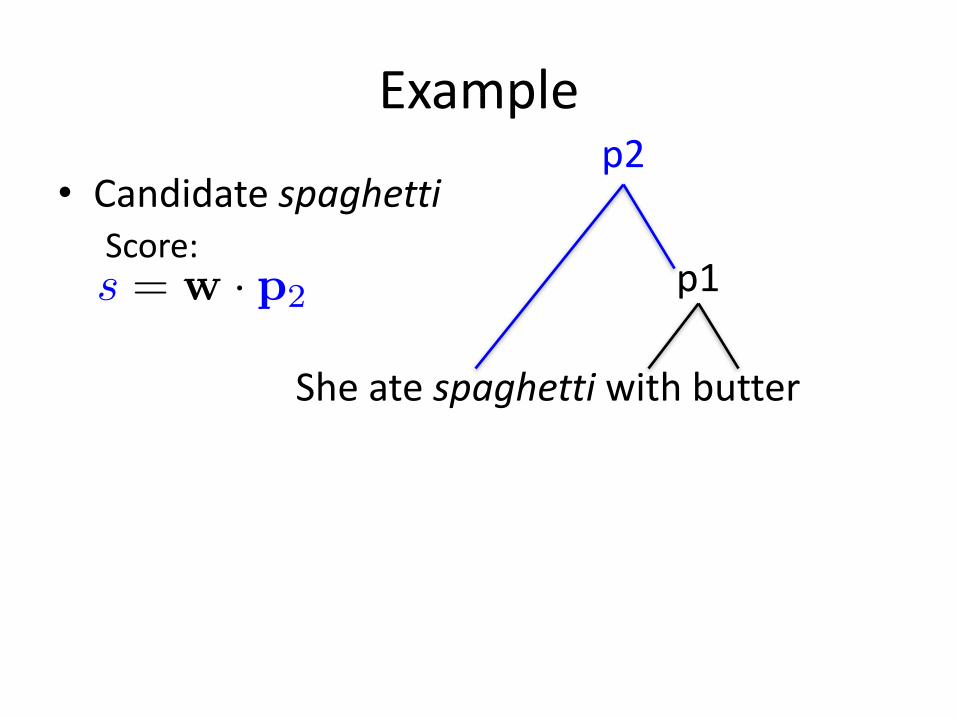
Example
• CandidatespaghettiScore:
Sheatespaghetti withbutter
p1
p2
s = w · p2
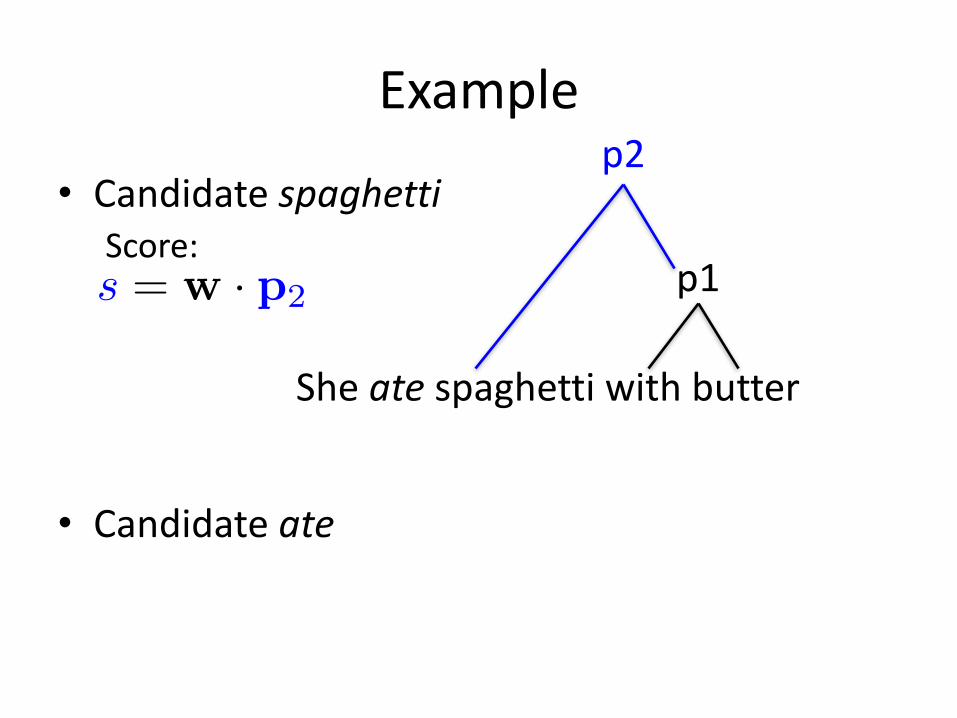
Example
• CandidatespaghettiScore:
• Candidateate
Sheate spaghettiwithbutter
p1
p2
s = w · p2
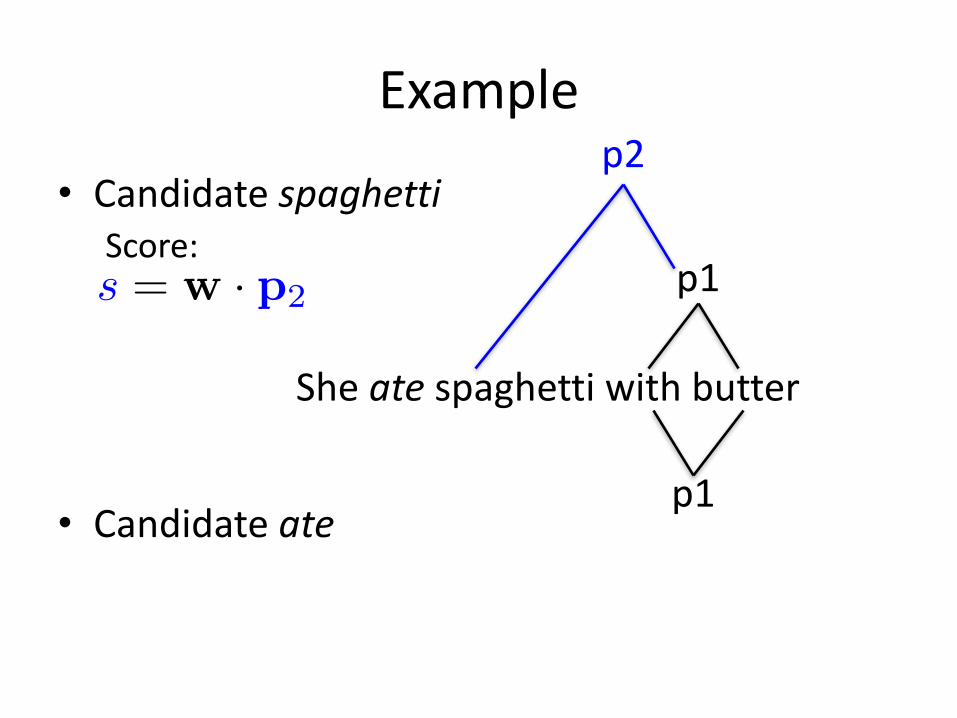
Example
• CandidatespaghettiScore:
• Candidateate
Sheate spaghettiwithbutter
p1
p2
p1
s = w · p2
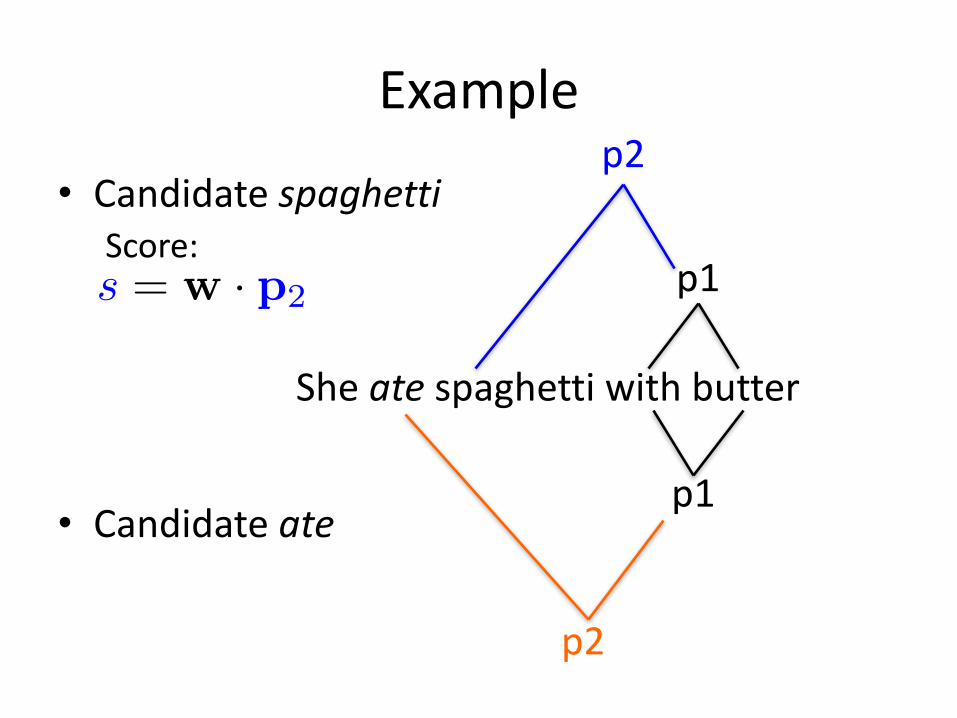
Example
• CandidatespaghettiScore:
• Candidateate
Sheate spaghettiwithbutter
p1
p2
p1
p2
s = w · p2
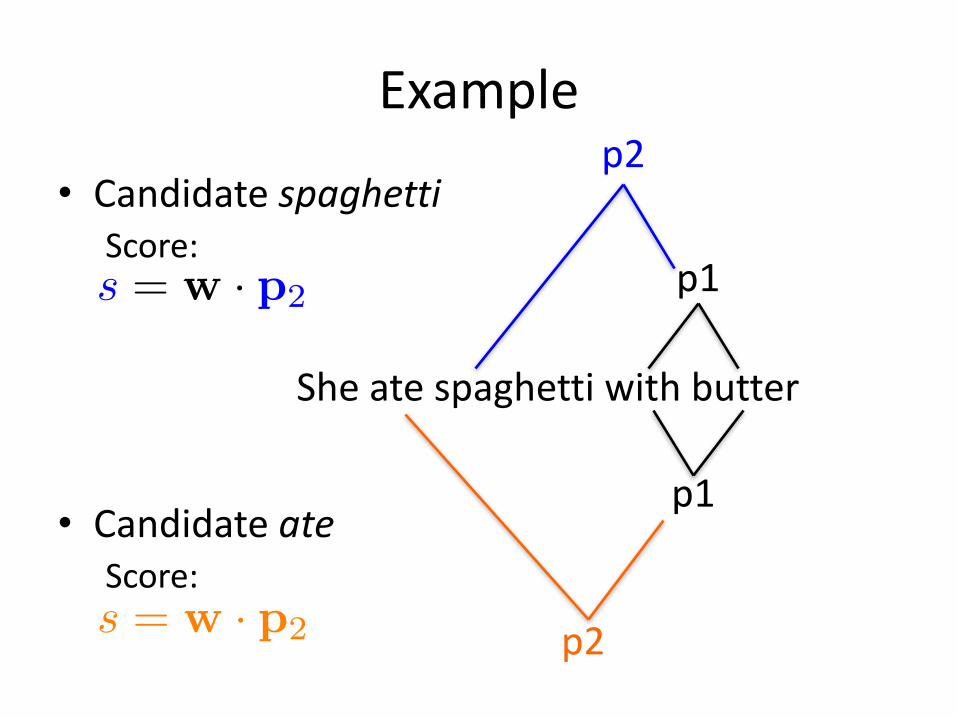
Example
• CandidatespaghettiScore:
• CandidateateScore:
Sheatespaghettiwithbutter
p1
p2
p1
p2
s = w · p2
s = w · p2
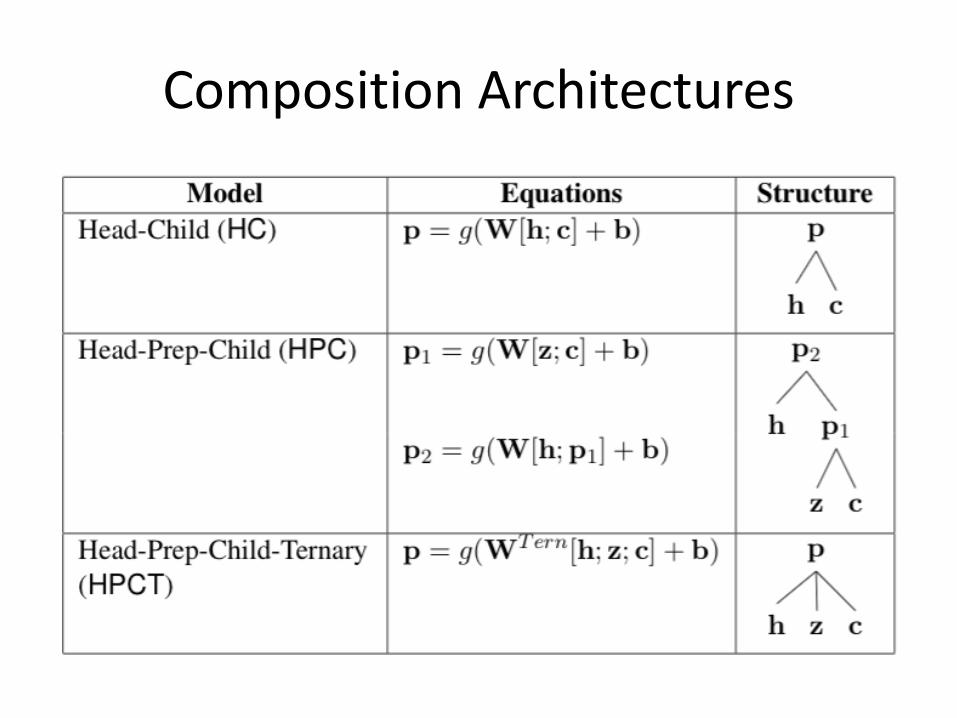
CompositionArchitectures
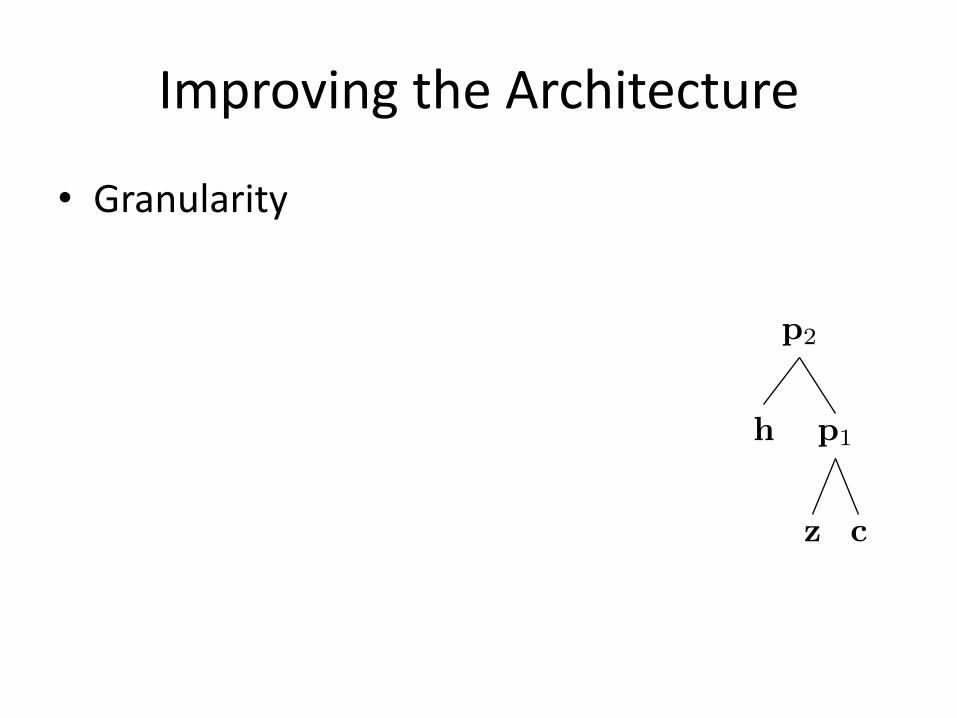
ImprovingtheArchitecture
• Granularity
p2
p1
cz
h

ImprovingtheArchitecture
• Granularity– Differentmatricesfordifferentcompositions
p1 = g(Wbottom[z; c] + bbottom)
p2 = g(Wtop[h;p1] + btop)p2
p1
cz
h

ImprovingtheArchitecture
• Granularity– Differentmatricesfordifferentcompositions
– Distance-dependentmatrices
p1 = g(Wbottom[z; c] + bbottom)
p2 = g(Wtop[h;p1] + btop)
p2 = g(Wd[h;p1] + bd)
p2
p1
cz
h

ImprovingtheArchitecture
• Granularity– Differentmatricesfordifferentcompositions
– Distance-dependentmatrices
• Context– Concatenatevectorsforneighbors
p1 = g(Wbottom[z; c] + bbottom)
p2 = g(Wtop[h;p1] + btop)
p2 = g(Wd[h;p1] + bd)
p2
p1
cz
h

Training
• Givenacorpusofpairsofsentencesandattachments,{x(i),y(i)},minimize:

Training
• Givenacorpusofpairsofsentencesandattachments,{x(i),y(i)},minimize:
• Optimization:AdaGrad (Duchi etal.2011)
• Regularization:Dropout(Hintonetal.2012)

AdaGrad
• Adaptivegradientdescent(Duchi etal.2011)
• Updateforparameterθi attimet+1:
✓t+1,i = ✓t,i �⌘qPt
t0=1 g2t0,i
gt,i

AdaGrad
• Guaranteesasymptoticallysub-linearregret:
• Where:– θ* istheoptimalparameterset– f istheobjectivefunction
R(T ) =TX
t=1
[ft(✓t)� ft(✓⇤)]

Dropout
• Regularizationforneuralnetworks(Hintonetal.2012)
• Randomlydropoutunitsfromeachlayer:
• r = randomBernoullivariablew/parameterρ• Intesting,scalematrices:
p̃ = p� r
W̃ = ⇢W

WordVectorRepresentations
• Initialwordvectors:– Trainedfromrawtexts– Skip-grammodel(Mikolov etal.2013)
– Similarwordshavesimilarvectors

Skip-gramModel
• ForacorpuswithT wordsw1,…,wT,maximize:
• where:
• - input/outputofneuralnetwork• Withsomeadditionalapproximations
1
T
TX
t=1
X
�cjc,j 6=0
log p(wt+j |wt)
p(wt+j |wt) =exp(v0Twt+j
vwt)
PWw=1 exp(v
0Tw vwt)
vw, v0w

AlternativeRepresentations
• Relearnvectorsduringtraining– Backpropagate errorsfromsuperviseddata

AlternativeRepresentations
• Relearnvectorsduringtraining– Backpropagate errorsfromsuperviseddata
• Enrichvectorswithexternalresources–WordNet,VerbNet,POS

AlternativeRepresentations
• Relearnvectorsduringtraining– Backpropagate errorsfromsuperviseddata
• Enrichvectorswithexternalresources–WordNet,VerbNet,POS
• Exploitsyntacticcontext– Dependency-basedwordvectors
(Bansal etal.2014,LevyandGoldberg2014)
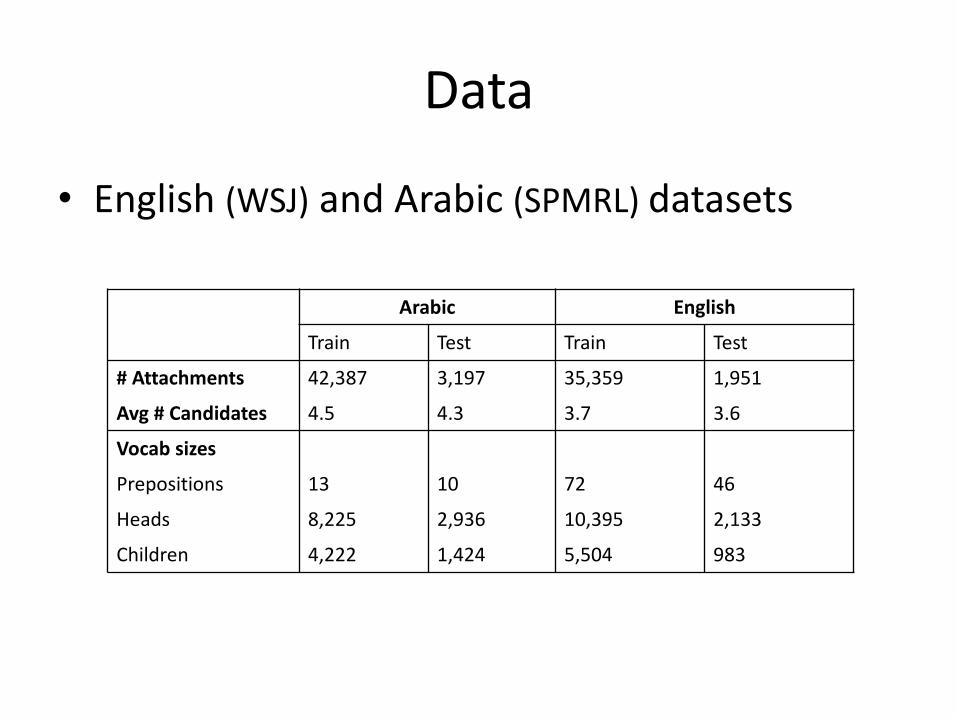
Data
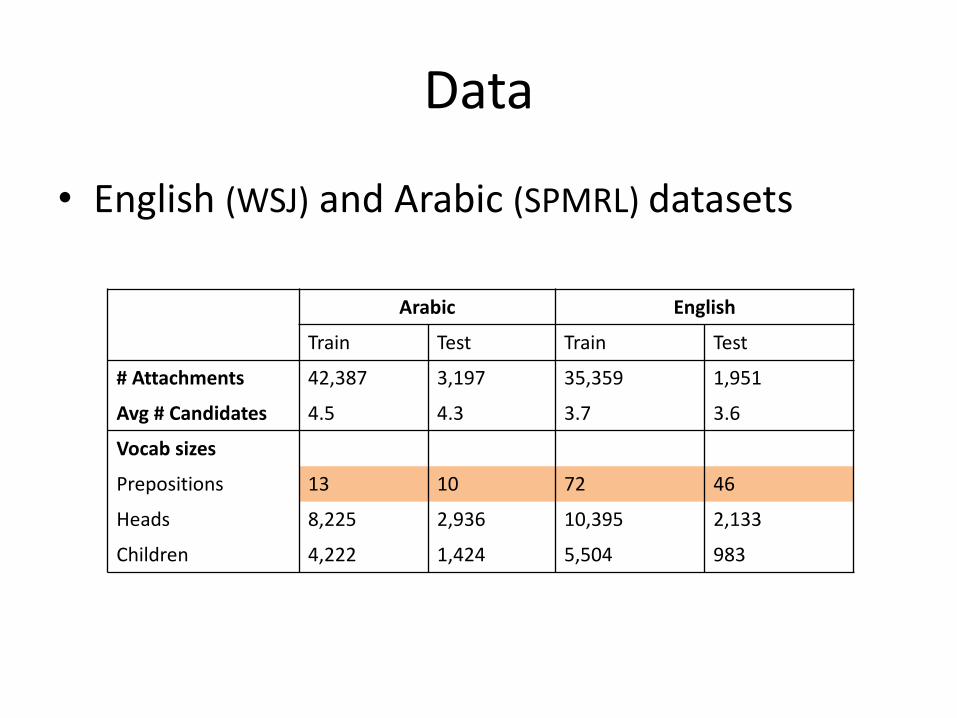
• English(WSJ) andArabic(SPMRL)datasets
Arabic English
Train Test Train Test
#Attachments 42,387 3,197 35,359 1,951
Avg #Candidates 4.5 4.3 3.7 3.6
Vocabsizes
Prepositions 13 10 72 46
Heads 8,225 2,936 10,395 2,133
Children 4,222 1,424 5,504 983
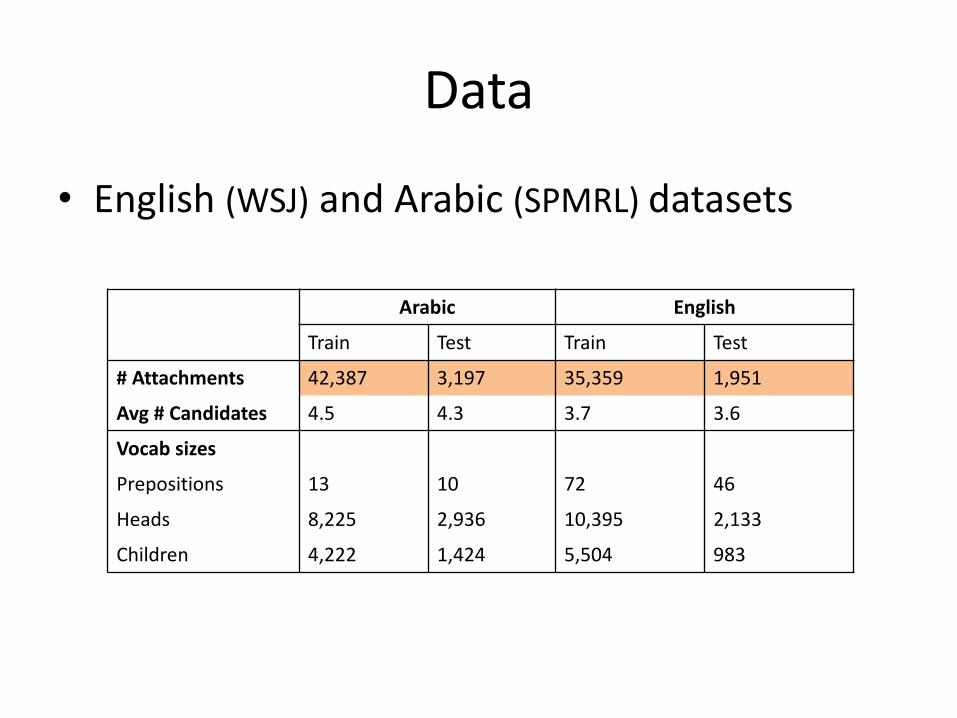
Data
• English(WSJ) andArabic(SPMRL)datasets
Arabic English
Train Test Train Test
#Attachments 42,387 3,197 35,359 1,951
Avg #Candidates 4.5 4.3 3.7 3.6
Vocabsizes
Prepositions 13 10 72 46
Heads 8,225 2,936 10,395 2,133
Children 4,222 1,424 5,504 983
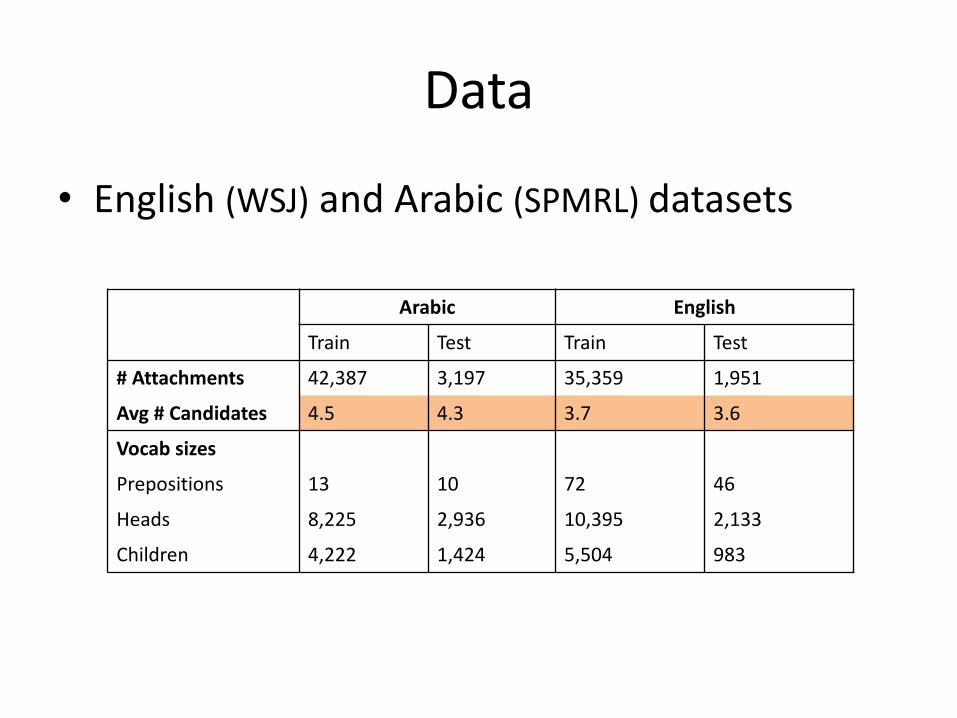
Data
• English(WSJ) andArabic(SPMRL)datasets
Arabic English
Train Test Train Test
#Attachments 42,387 3,197 35,359 1,951
Avg #Candidates 4.5 4.3 3.7 3.6
Vocabsizes
Prepositions 13 10 72 46
Heads 8,225 2,936 10,395 2,133
Children 4,222 1,424 5,504 983
Data
• English(WSJ) andArabic(SPMRL)datasets
Arabic English
Train Test Train Test
#Attachments 42,387 3,197 35,359 1,951
Avg #Candidates 4.5 4.3 3.7 3.6
Vocabsizes
Prepositions 13 10 72 46
Heads 8,225 2,936 10,395 2,133
Children 4,222 1,424 5,504 983

Baselines
• Closestcandidate• SVM

Baselines
• Closestcandidate• SVM• Parsers–Malt(Niveretal.2006)–MST(McDonaldetal.2005)– Turbo(Martinsetal.2010,2013)– RBG(Leietal.2014)– RNN(Socheretal.2013)– Charniak-RS(McCloskyetal.2006)

Results(PPattachment)
System Arabic English
Simplebaselines
Closestcandidate 62.7 81.7
SVM 77.5 85.9

Results(PPattachment)
System Arabic English
Simplebaselines
Closestcandidate 62.7 81.7
SVM 77.5 85.9
Parsers
Malt 75.4 79.7
MST 76.7 86.8
Turbo 76.7 88.3
RBG 80.3 88.4
RNN 68.9 85.1
Charniak-RS 80.8 88.6
Results(PPattachment)
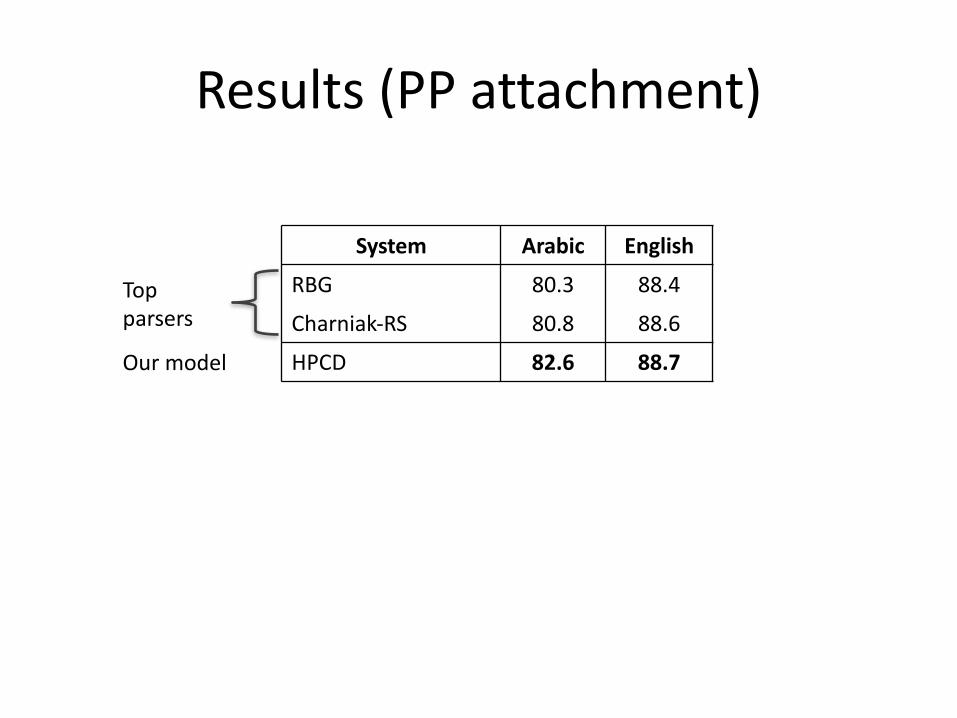
System Arabic English
Topparsers
RBG 80.3 88.4
Charniak-RS 80.8 88.6
Our model HPCD 82.6 88.7
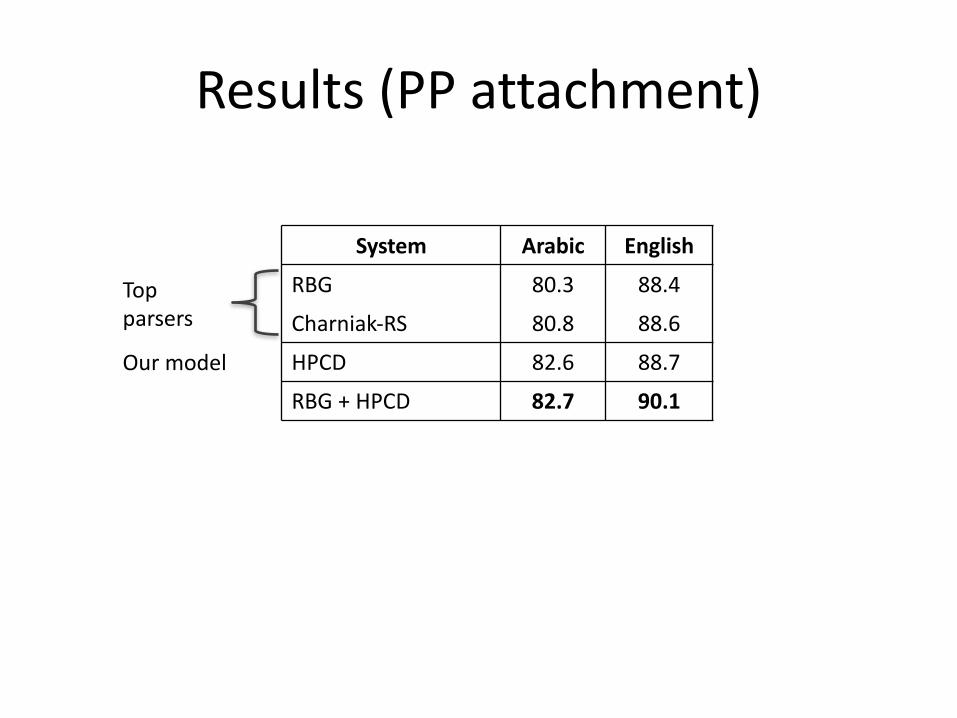
Results(PPattachment)
System Arabic English
Topparsers
RBG 80.3 88.4
Charniak-RS 80.8 88.6
Our model HPCD 82.6 88.7
RBG+HPCD 82.7 90.1

Results(parsing)
• AddPPpredictionstoastate-of-the-artparser
• Binaryfeatureforeachpredictedattachment
System Arabic EnglishRBG 87.70 93.96
RBG+predictedPP 87.95 94.05

ContributionofModelComponents
• Wordrepresentations– Relearningwordvectors– Enrichingwordvectors– Usingsyntacticwordvectors
• Compositionarchitectures
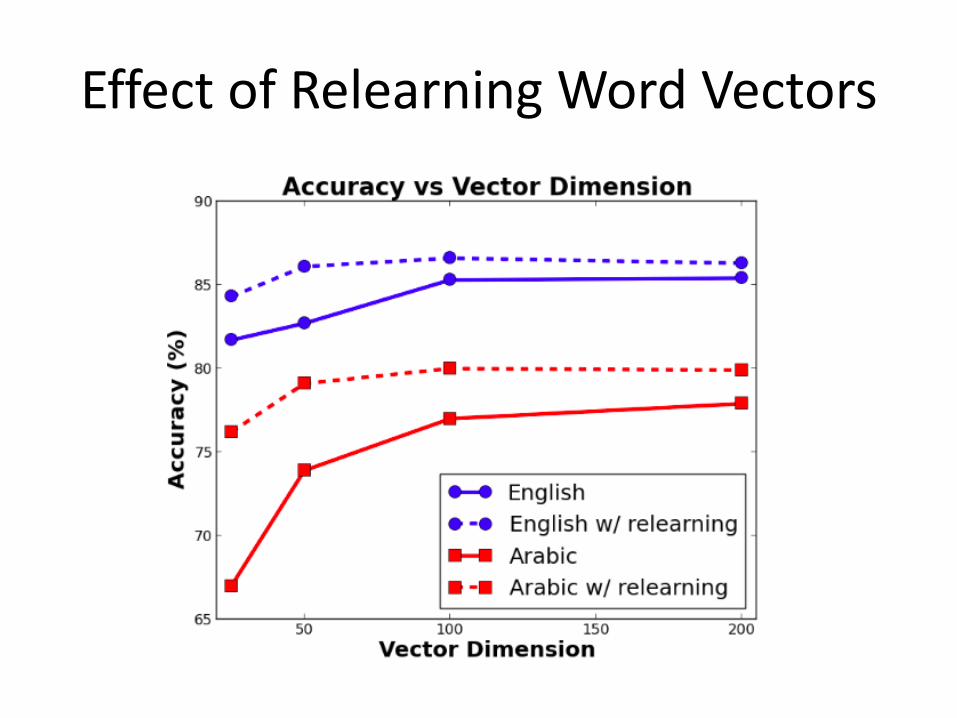
EffectofRelearningWordVectors
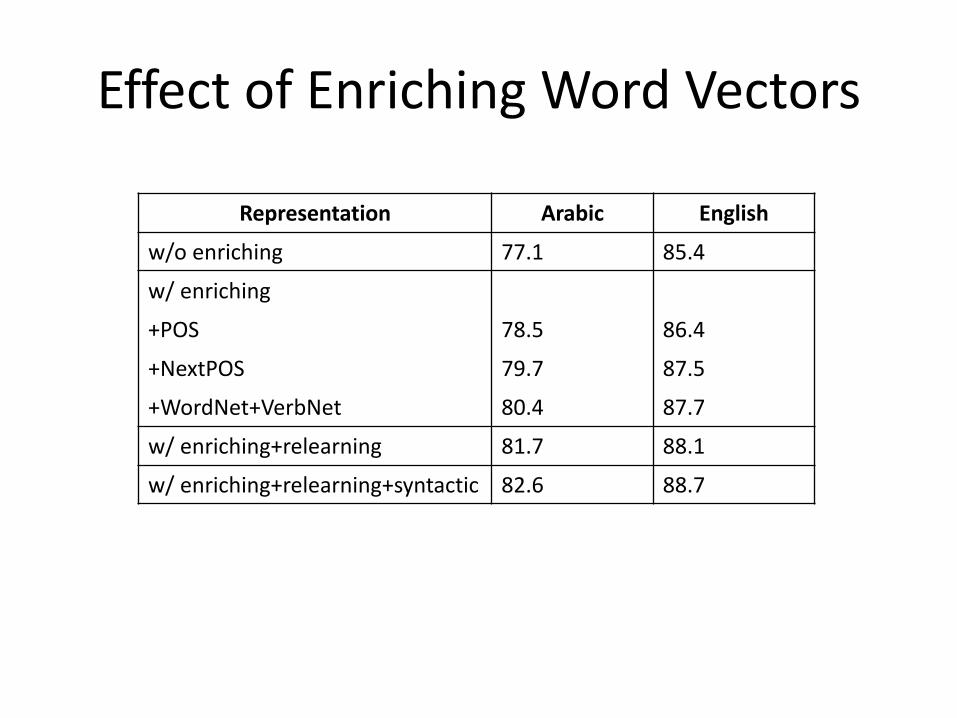
EffectofEnrichingWordVectors
Representation Arabic English
w/oenriching 77.1 85.4
w/enriching
+POS 78.5 86.4
+NextPOS 79.7 87.5
+WordNet+VerbNet 80.4 87.7
w/enriching+relearning 81.7 88.1
w/enriching+relearning+syntactic 82.6 88.7
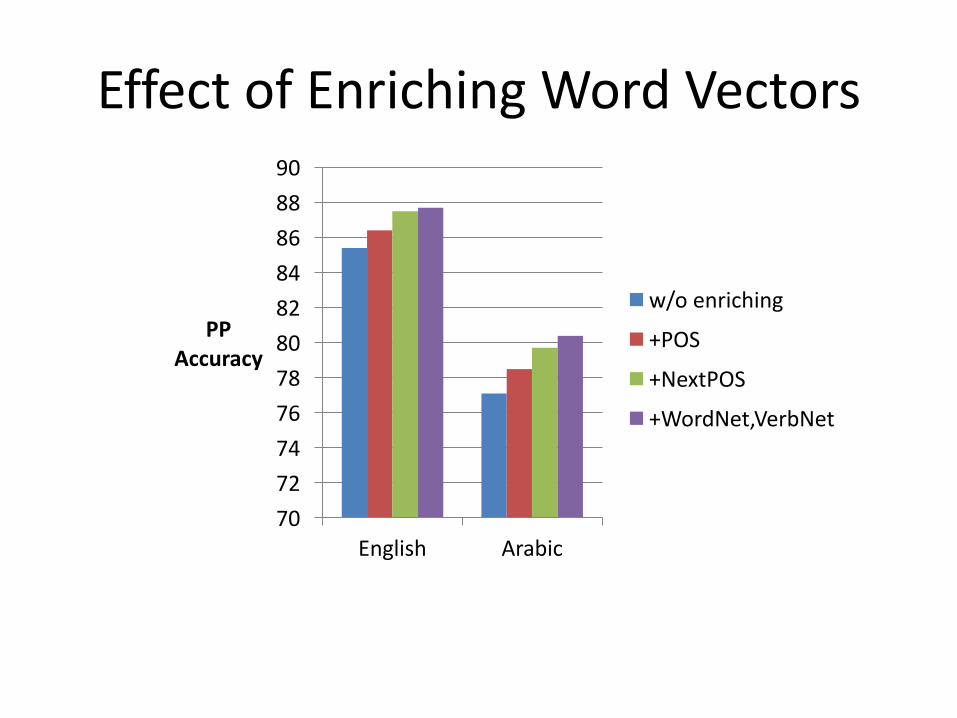
EffectofEnrichingWordVectors
7072747678808284868890
English Arabic
PPAccuracy
w/oenriching
+POS
+NextPOS
+WordNet,VerbNet
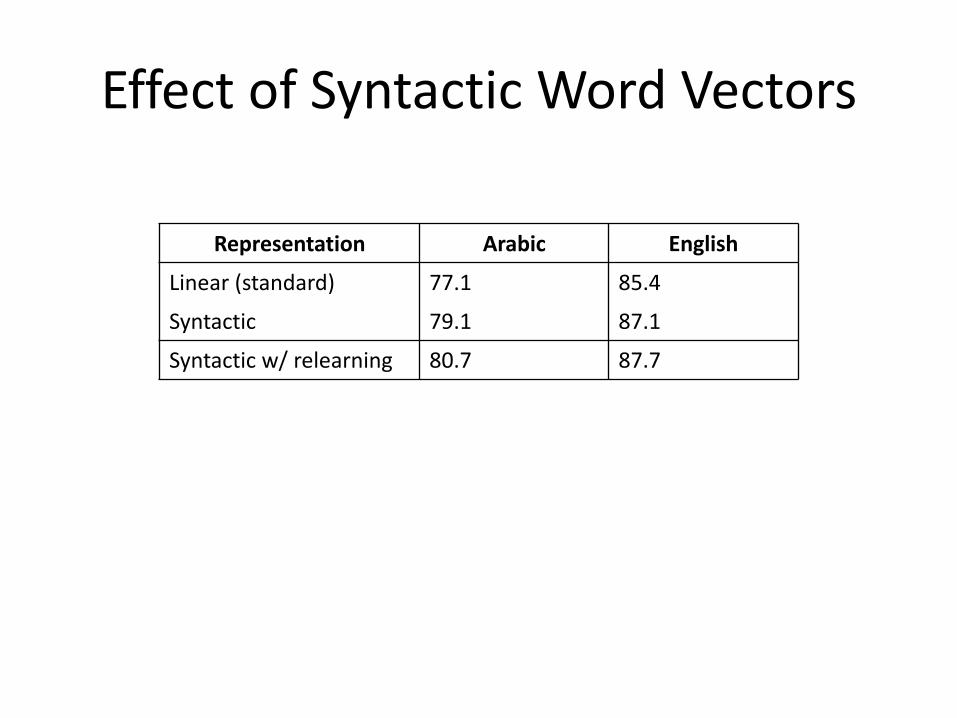
EffectofSyntacticWordVectors
Representation Arabic English
Linear (standard) 77.1 85.4
Syntactic 79.1 87.1
Syntacticw/relearning 80.7 87.7
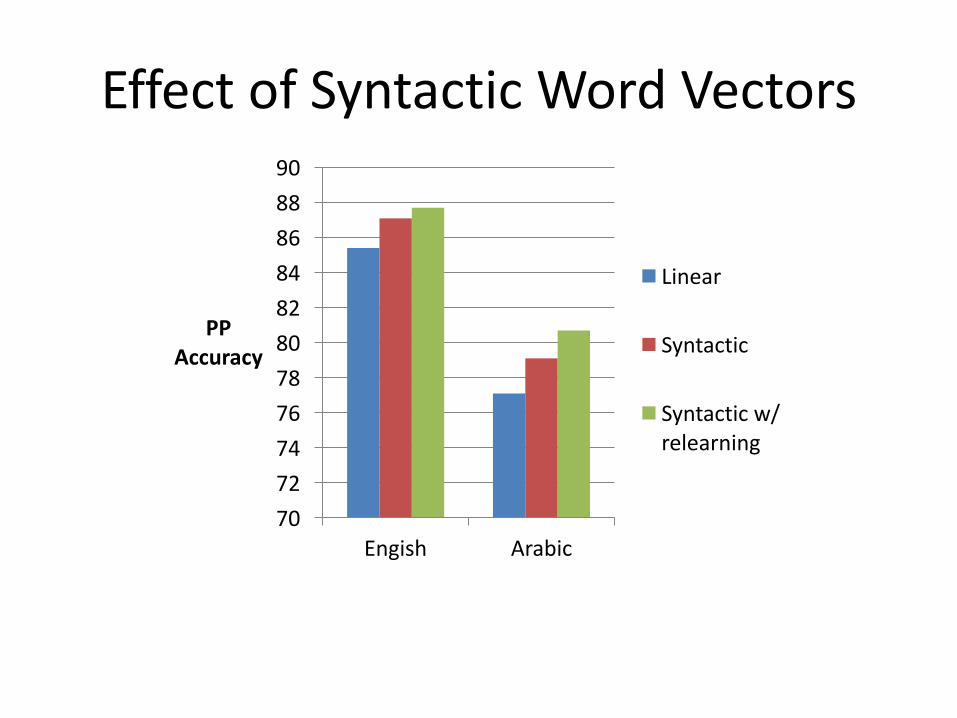
EffectofSyntacticWordVectors
7072747678808284868890
Engish Arabic
PPAccuracy
Linear
Syntactic
Syntacticw/relearning

EffectofCompositionArchitectures

Contributions
• DevelopacompositionalneuralnetworkmodeldedicatedforPPattachment
• Exploreutilityofdifferentwordvectorrepresentations
• Improveperformanceofastate-of-the-artparser
• Codeanddata:http://groups.csail.mit.edu/rbg/code/pp





























