Embed Size (px)
Citation preview

Concurrent Executions on Relaxed Memory Models
Challenges & Opportunities for Software Model Checking
Rajeev Alur University of Pennsylvania
Joint work with Sebastian Burckhardt and Milo Martin
SPIN Workshop, July 2007
Model Checking Concurrent Software
Multi-threaded Software Shared-memory Multiprocessor
Concurrent Executions
Bugs

Concurrency on Multiprocessors
Output not consistent with any interleaved execution! can be the result of out-of-order stores can be the result of out-of-order loads improves performance
x = 1 y = 1
print y print x
thread 1 thread 2
→ 1 → 0
Initially x = y = 0

Architectures with Weak Memory Models
A modern multiprocessor does not enforce global ordering of all instructions for performance reasons Each processor has pipelined architecture and executes
multiple instructions simultaneously Each processor has a local cache, and loads/stores to local
cache become visible to other processors and shared memory at different times
Lamport (1979): Sequential consistency semantics for correctness of multiprocessor shared memory (like interleaving)
Considered too limiting, and many “relaxations” proposed In theory: TSO, RMO, Relaxed … In practice: Alpha, Intel IA-32, IBM 370, Sun SPARC, PowerPC … Active research area in computer architecture

Programming with Weak Memory Models
Concurrent programming is already hard, shouldn’t the effects of weaker models be hidden from the programmer?
Mostly yes … Safe programming using extensive use of synchronization
primitives Use locks for every access to shared data Compilers use memory fences to enforce ordering
Not always … Non-blocking data structures Highly optimized library code for concurrency Code for lock/unlock instructions
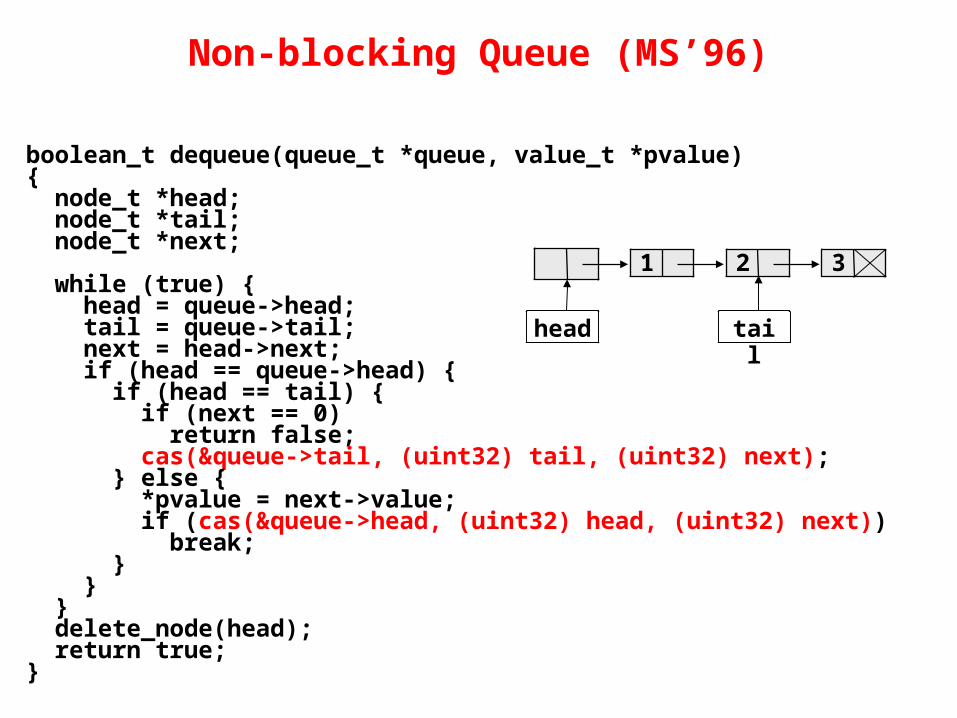
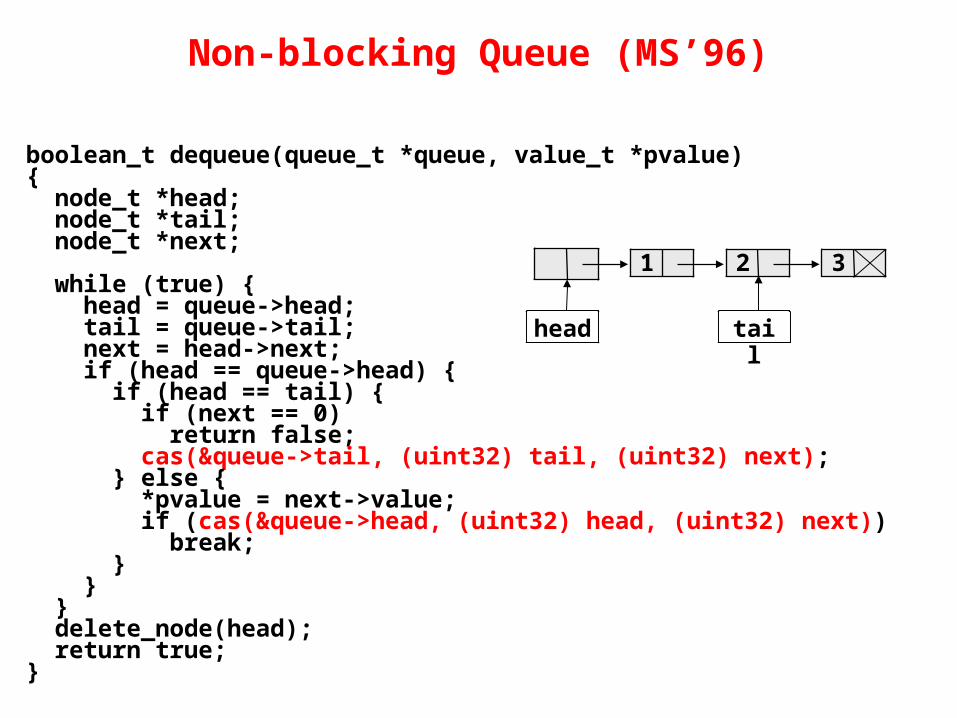
Non-blocking Queue (MS’96)
boolean_t dequeue(queue_t *queue, value_t *pvalue){ node_t *head; node_t *tail; node_t *next;
while (true) { head = queue->head; tail = queue->tail; next = head->next; if (head == queue->head) { if (head == tail) { if (next == 0) return false; cas(&queue->tail, (uint32) tail, (uint32) next); } else { *pvalue = next->value; if (cas(&queue->head, (uint32) head, (uint32) next)) break; } } } delete_node(head); return true;}
1 2 3
head tail

Software Model Checking for Concurrent Code on Multiprocessors
Why?: Real bugs in real code
Opportunities 10s—100s lines of low-level library C code Hard to design and verify -> buggy Effects of weak memory models, fences …
Challenges Lots of behaviors possible: high level of concurrency How to formalize and reason about weak memory models?

Talk Outline
Motivation
Relaxed Memory Models
CheckFence: Analysis tool for Concurrent Data Types

Hierarchy of Abstractions
Programs (multi-threaded) -- Synchronization primitives: locks, atomic
blocks -- Library primitives (e.g. shared queues)
Assembly code -- Synchronization primitives: compare&swap, LL/SC -- Loads/stores from shared memory
Hardware -- multiple processors -- write buffers, caches, communication bus …
Language level memory model
Architecture level memory model

Shared Memory Consistency Models
Specifies restrictions on what values a read from shared memory can return
Program Order: x <p y if x and y are instructions belonging to the same thread and x appears before y
Sequential Consistency (Lamport 79): There exists a global order < of all accesses such that < is consistent with the program order <p
Each read returns value of most recent, according to <, write to the same location (or initial value, if no such write exists)
Clean abstraction for programmers, but high implementation cost

Effect of Memory Model
Ensures mutual exclusion if architecture supports SC memory
Most architectures do not enforce ordering of accesses to different memory locations
Does not ensure mutual exclusion under weaker models
Ordering can be enforced using “fence” instructions Insert MEMBAR between lines 1 and 2 to ensure mutual
exclusion
1. flag1 = 1;2. if (flag2 == 0)
crit. sect.
1. flag2 = 1;2. if (flag1 == 0)
crit. sect.
thread 1 thread 2
Initially flag1 = flag2 = 0

Relaxed Memory Models
A large variety of models exist; a good starting point:Shared Memory Consistency Models: A tutorial IEEE Computer 96, Adve & Gharachorloo
How to relax memory order requirement? Operations of same thread to different locations need not be
globally ordered
How to relax write atomicity requirement? Read may return value of a write not yet globally visible
Uniprocessor semantics preserved
Typically defined in architecture manuals (e.g. SPARC manual)

Unusual Effects of Memory Models
Possible on TSO/SPARC Write to A propagated only to local reads to A Reads to flags can occur before writes to flags
Not allowed on IBM 370 Read of A on a processor waits till write to A is complete
flag1 = 1; A = 1; reg1 = A; reg2 = flag2;
thread 1 thread 2
Initially A = flag1 = flag2 = 0
flag2 = 1; A = 2; reg3 = A; reg4 = flag1;
Result reg1 = 1; reg3 = 2; reg2 = reg4 = 0
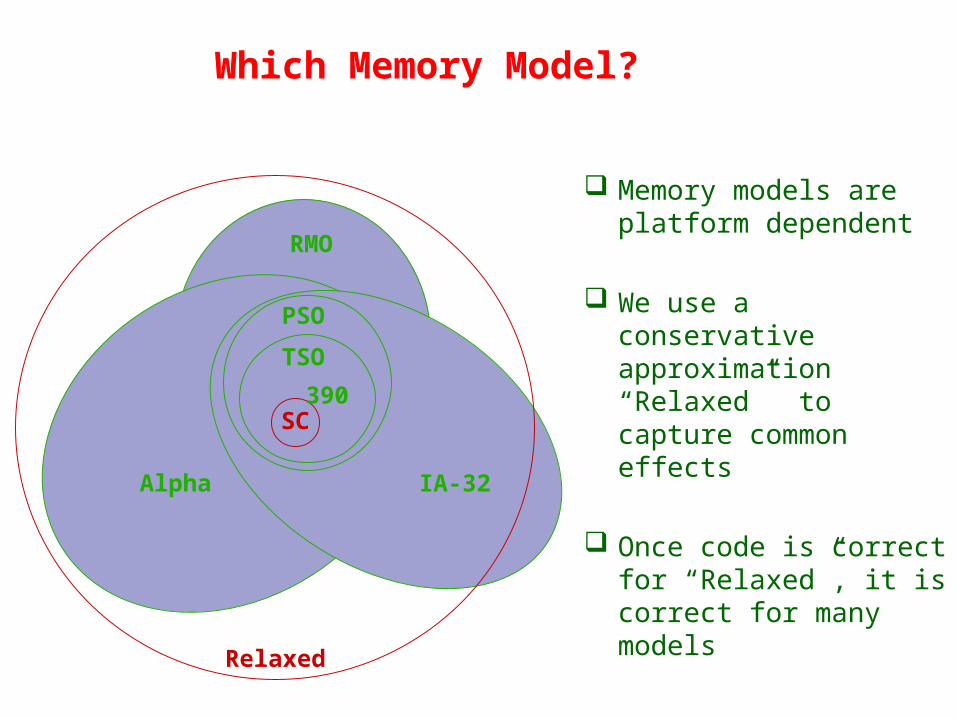
Which Memory Model?
Memory models are platform dependent
We use a conservative approximation “Relaxed” to capture common effects
Once code is correct for “Relaxed”, it is correct for many models
TSO
PSO
IA-32Alpha
Relaxed
RMO
390SC

Formalization of Relaxed
A set of addresses V set of valuesX set of memory accesses S are stores L are loadsa(x) memory address of x v(x) value loaded or stored by x
<p is a partial order over X (program order)
Correctness wrt Relaxed demands existence of a total order < over X s.t.
For a load l in L, define the following set of stores that are “visible to l”:
S(l) = { s in S | a(s) = a(l) and (s < l or s <p l ) }
1. If x <p y and a(x) = a(y) and y in S, then x < y2. For l in L and s in S(l), always either v(l) = v(s) or there exists another store s’ in
S(l) such that s < s’

Talk Outline
Motivation
Relaxed memory models
CheckFence: Analysis tool for Concurrent Data Types

concurrency libraries with lock-free synchronization
... are simple, fast, and safe to use concurrent versions of queues, sets, maps, etc.
more concurrency, less waiting
fewer deadlocks
... are notoriously hard to design and verify tricky interleavings routinely escape reasoning and testing
exposed to relaxed memory models
code needs to contain memory fences for correct operation!
CheckFence Focus
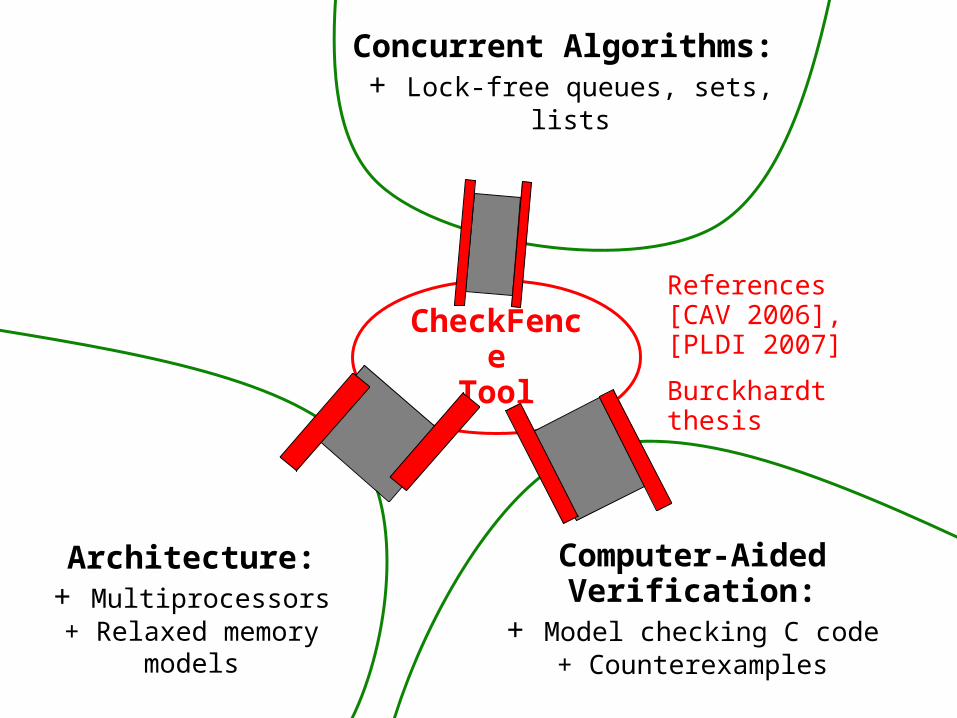
Architecture:+ Multiprocessors
+ Relaxed memory models
Concurrent Algorithms:+ Lock-free queues, sets, lists
Computer-Aided Verification:
+ Model checking C code+ Counterexamples
CheckFence
Tool
References[CAV 2006], [PLDI 2007]
Burckhardt thesis

Non-blocking Queue
The implementation
optimized: no locks. not race-free exposed to memory model
The client program
on multiple processors calls operations
....
... enqueue(1)
... enqueue(2)
....
.... ....
Processor 1
....
...
...a = dequeue()b = dequeue()
Processor 2
void enqueue(int val) { ...}
int dequeue() { ... }
Non-blocking Queue (MS’96)
boolean_t dequeue(queue_t *queue, value_t *pvalue){ node_t *head; node_t *tail; node_t *next;
while (true) { head = queue->head; tail = queue->tail; next = head->next; if (head == queue->head) { if (head == tail) { if (next == 0) return false; cas(&queue->tail, (uint32) tail, (uint32) next); } else { *pvalue = next->value; if (cas(&queue->head, (uint32) head, (uint32) next)) break; } } } delete_node(head); return true;}
1 2 3
head tail

Correctness Condition
Data type implementations must appear sequentially consistent to the client program:
the observed argument and return values must be consistent with some
interleaved, atomic execution of the operations.
enqueue(1)dequeue() -> 2
enqueue(2)dequeue() -> 1
enqueue(1)enqueue(2)dequeue() -> 1
dequeue() -> 2
Observation Witness Interleaving

thread 1
enqueue(X)
thread 2
dequeue() → Y
How To Bound Executions
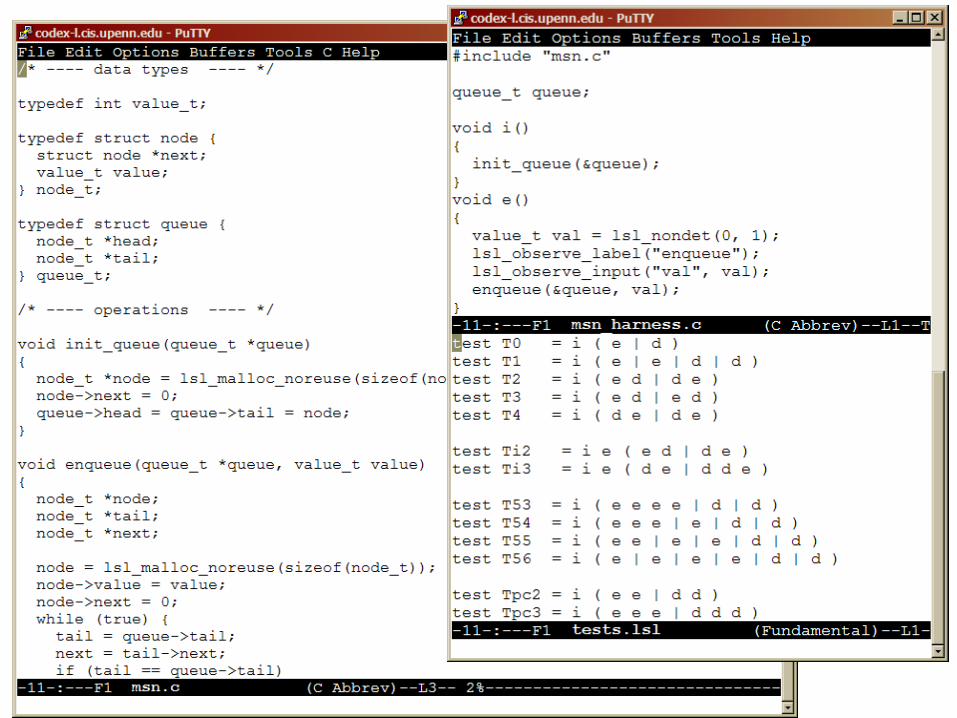
Verify individual “symbolic tests” finite number of concurrent threads finite number of operations/thread nondeterministic input values
Example
User creates suite of tests of increasing size

Why symbolic test programs?
1) Make everything finite State is unbounded (dynamic memory allocation)
... is bounded for individual test Checking sequential consistency is undecidable (AMP 96)
... is decidable for individual test
2) Gives us finite instruction sequence to work with State space too large for interleaved system model
.... can directly encode value flow between instructions Memory model specified by axioms
.... can directly encode ordering axioms on instructions
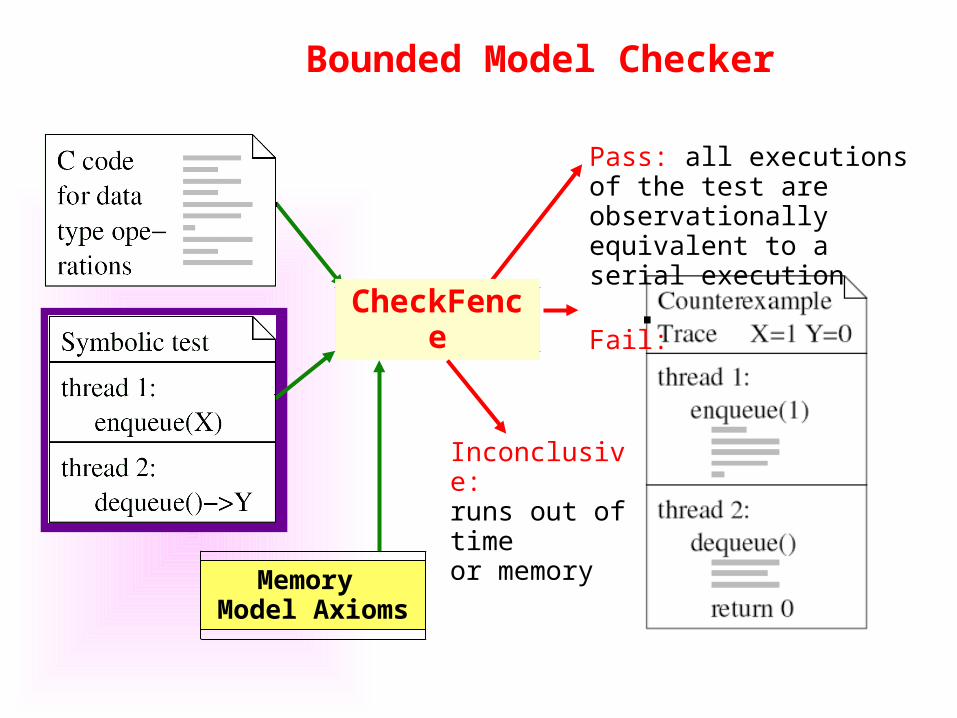
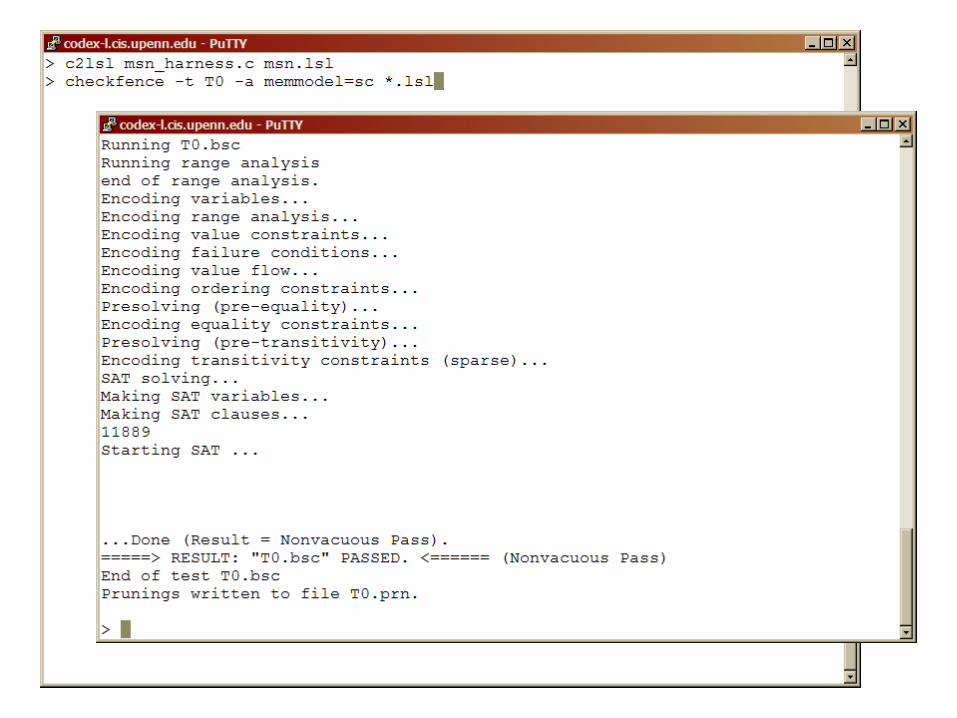
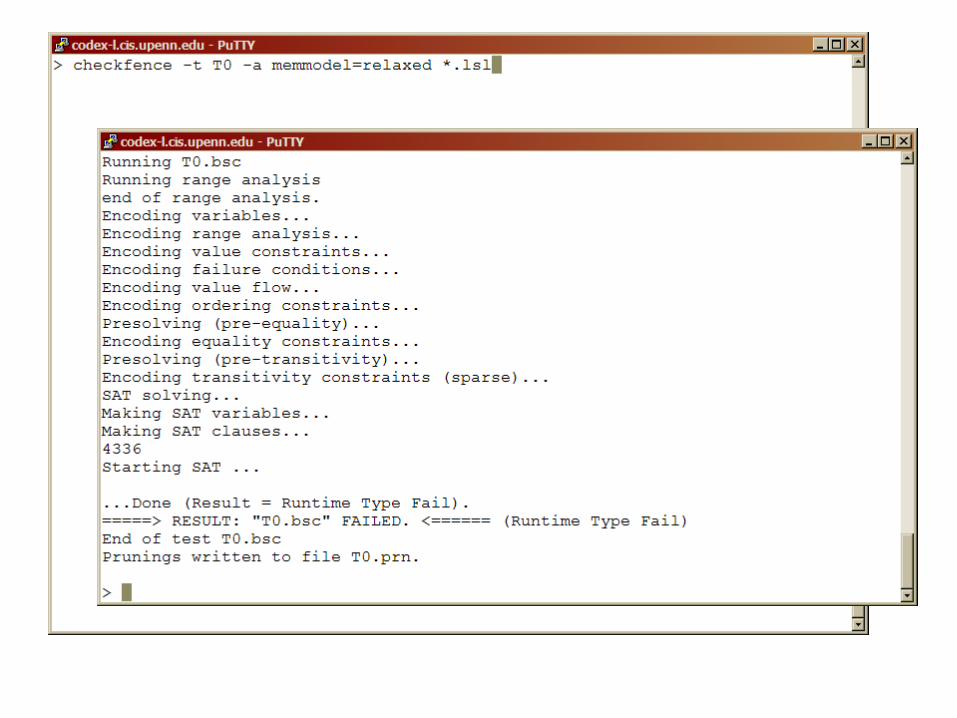
Bounded Model Checker
Pass: all executions of the test are observationally equivalent to a serial execution
Fail:CheckFence
Memory Model Axioms
Inconclusive: runs out of time or memory
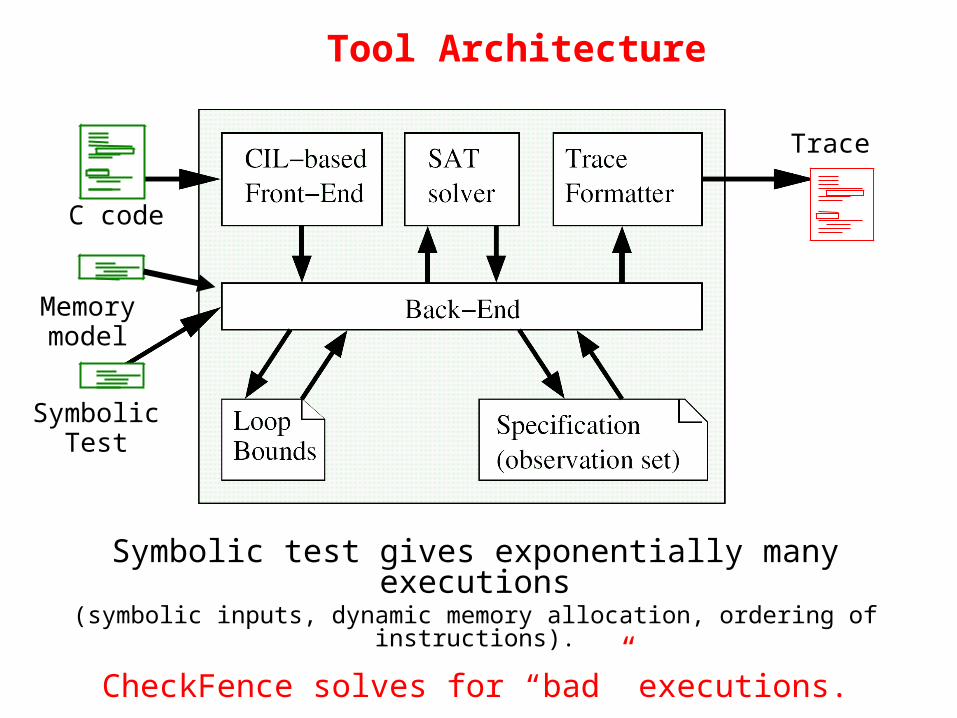
Tool Architecture
C code
Symbolic Test
Trace
Symbolic test gives exponentially many executions(symbolic inputs, dynamic memory allocation, ordering of instructions).
CheckFence solves for “bad” executions.
Memory model
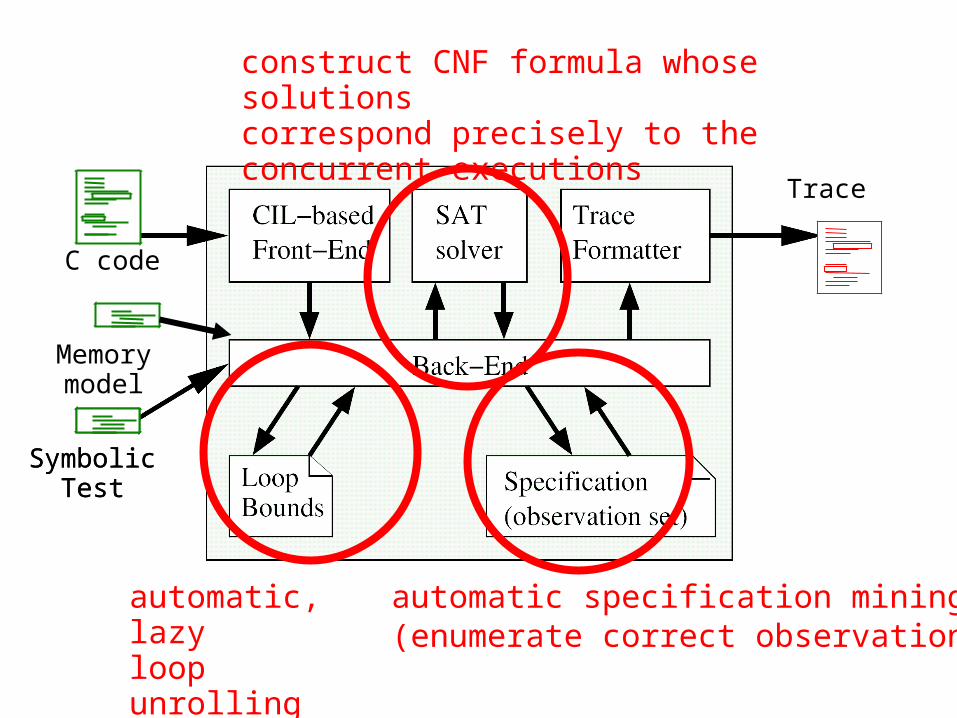
C code
Symbolic Test
Trace
Symbolic Test
automatic, lazyloop unrolling
automatic specification mining(enumerate correct observations)
construct CNF formula whose solutions correspond precisely to the concurrent executions
Memory model

thread 1
enqueue(X); enqueue(Y)
thread 2
dequeue() → Z
Specification Mining
Possible Operation-level Interleavings
enqueue(X)
enqueue(Y)
dequeue() -> Z
enqueue(X)
dequeue() -> Z
enqueue(Y)
dequeue() -> Z
enqueue(X)
enqueue(Y)
For each interleaving, obtain symbolic constraint by encoding corresponding executions in SAT solverSpec is disjunction of all possibilities:
Spec: (Z=X) | (Z=null)
To find bugs, check satisfiability of Phi & ~ Specwhere Phi encodes all possible concurrent executions
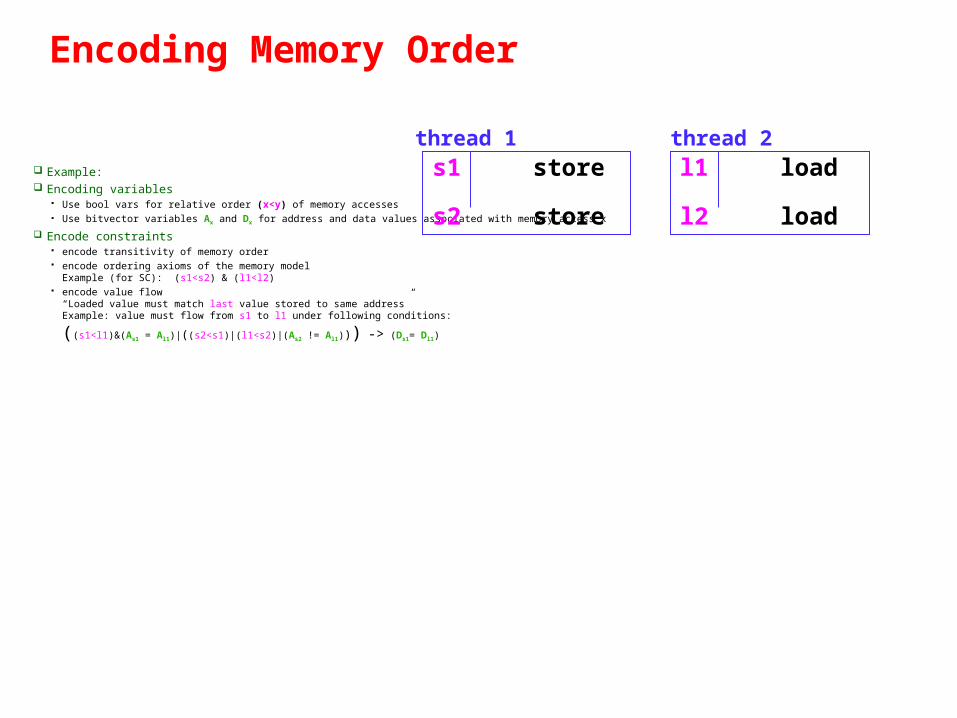
Encoding Memory Order
Example: Encoding variables
Use bool vars for relative order (x<y) of memory accesses Use bitvector variables Ax and Dx for address and data values associated with memory access x
Encode constraints encode transitivity of memory order encode ordering axioms of the memory model
Example (for SC): (s1<s2) & (l1<l2) encode value flow
“Loaded value must match last value stored to same address”Example: value must flow from s1 to l1 under following conditions:
((s1<l1)&(As1 = Al1)|((s2<s1)|(l1<s2)|(As2 != Al1))) -> (Ds1= Dl1)
s1 store s2 store
l1 load l2 load
thread 1 thread 2
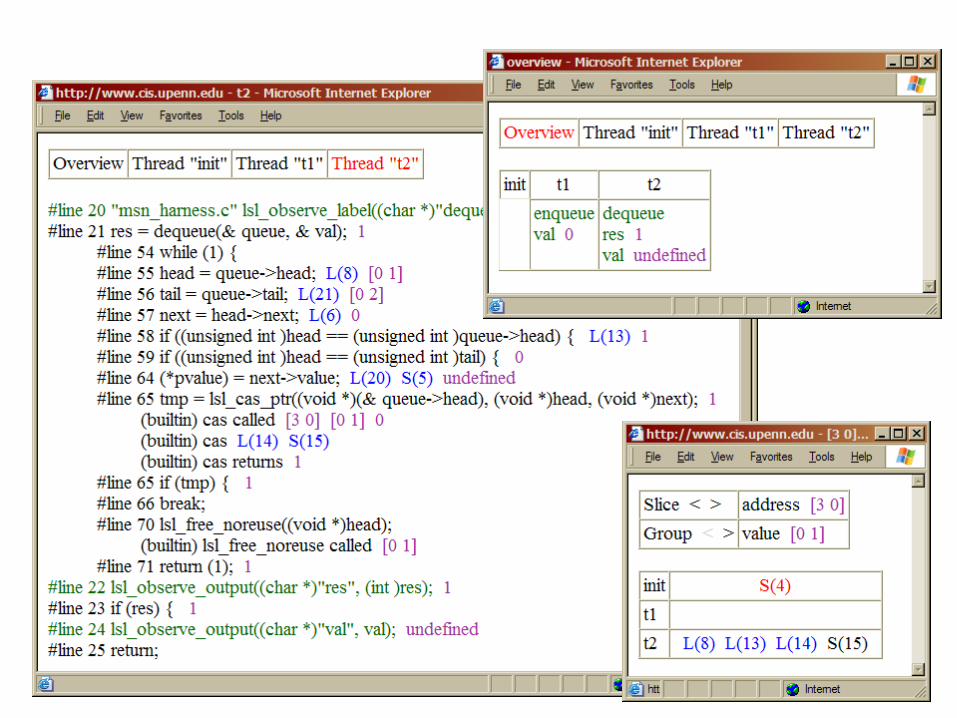

Example: Memory Model Bug
Processor 1 links new node into list
Processor 2 reads value at head of list
--> Processor 2 loads uninitialized value
...
3 node->value = 2; ...1 head = node; ...
...
2 value = head->value; ...
Processor 1 reorders the stores! memory accesses happen in order 1 2 3
adding a fence between lines on left side prevents reordering
1 2 3
head
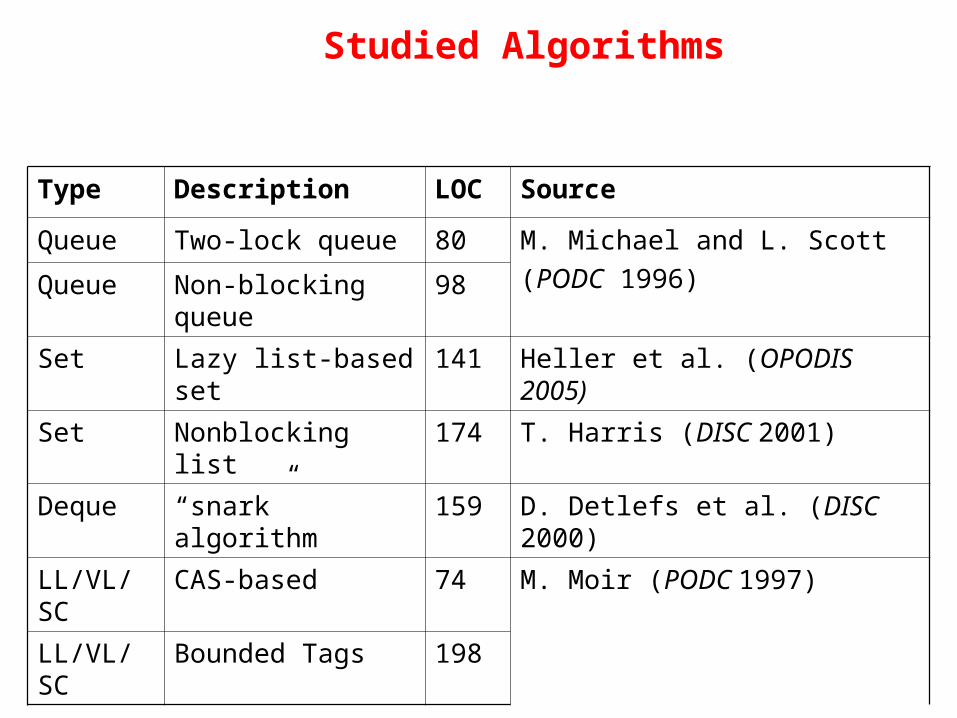
Type Description LOC Source
Queue Two-lock queue 80 M. Michael and L. Scott
(PODC 1996)Queue Non-blocking queue 98
Set Lazy list-based set 141 Heller et al. (OPODIS 2005)
Set Nonblocking list 174 T. Harris (DISC 2001)
Deque “snark” algorithm 159 D. Detlefs et al. (DISC 2000)
LL/VL/SC CAS-based 74 M. Moir (PODC 1997)
LL/VL/SC Bounded Tags 198
Studied Algorithms

2 known
1 unknown
regular
bugs
Bounded Tags
CAS-based
fixed “snark”
original “snark”
Nonblocking list
Lazy list-based set
Non-blocking queue
Two-lock queue
Description
Deque
LL/VL/SC
LL/VL/SC
Deque
Set
Set
Queue
Queue
Type
Results
snark algorithm has 2 known bugs lazy list-based set had a unknown bug
(missing initialization; missed by formal correctness proof [CAV 2006] because of hand-translation of pseudocode)
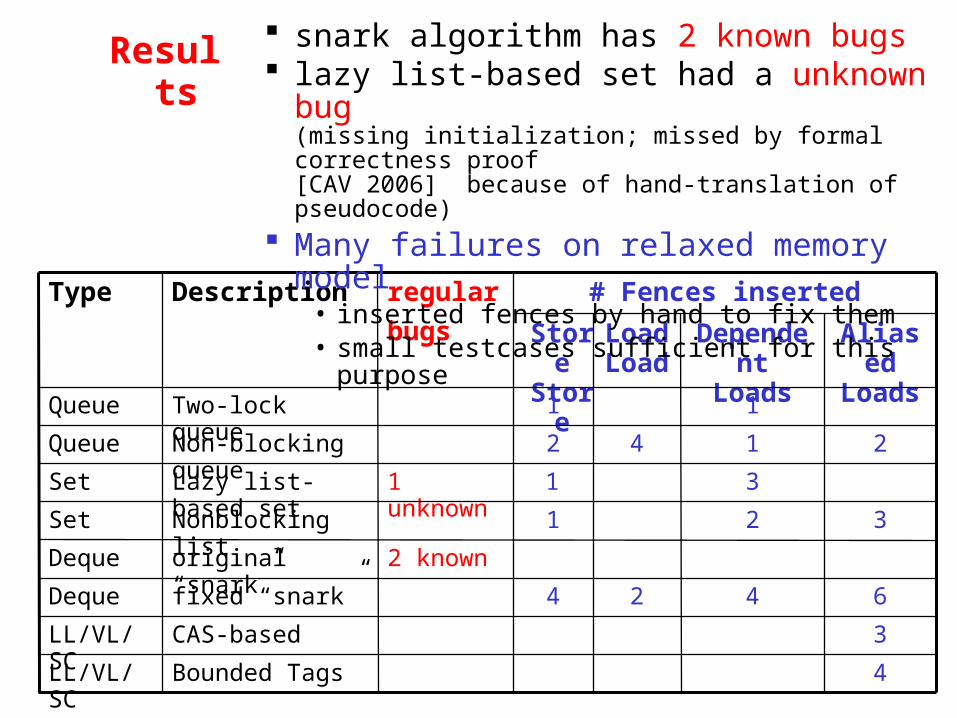
# Fences inserted
2 known
1 unknown
regular
bugs
4
1
1
2
1
StoreStore
2
4
Load Load
4
2
3
1
1
DependentLoads
4
3
6
3
2
AliasedLoads
Bounded Tags
CAS-based
fixed “snark”
original “snark”
Nonblocking list
Lazy list-based set
Non-blocking queue
Two-lock queue
Description
Deque
LL/VL/SC
LL/VL/SC
Deque
Set
Set
Queue
Queue
Type
Results
snark algorithm has 2 known bugs lazy list-based set had a unknown bug
(missing initialization; missed by formal correctness proof [CAV 2006] because of hand-translation of pseudocode)
Many failures on relaxed memory model• inserted fences by hand to fix them• small testcases sufficient for this purpose

Typical Tool Performance
Very efficient on small testcases (< 100 memory accesses)Example (nonblocking queue): T0 = i (e | d) T1 = i (e | e | d | d )- find counterexamples within a few seconds- verify within a few minutes- enough to cover all 9 fences in nonblocking queue
Slows down with increasing number of memory accesses in testExample (snark deque):Dq = pop_l | pop_l | pop_r | pop_r | push_l | push_l | push_r | push_r- has 134 memory accesses (77 loads, 57 stores)- Dq finds second snark bug within ~1 hour
Does not scale past ~300 memory accesses

Conclusions
Software model checking of low-level concurrent software requires encoding of memory models
Challenge for model checking due to high level of concurrency and axiomatic specifications
Opportunity to find bugs in library code that’s hard to design and verify
CheckFence project at Penn SAT-based bounded model checking for concurrent data
types Real bugs in real code with fences

Research Challenges
What’s the best way to verify C code (on relaxed memory models)? SAT-based encoding seems suitable to capture specifications
of memory models, but many opportunities for improvement Can one develop explicit-state methods for these
applications?
Language-level memory models: Can we verify Java concurrency libraries using the new new Java memory model?
Hardware support for transactional memory Current interest in industry and architecture research Can formal verification influence designs/standards?





























