Embed Size (px)
Citation preview

136 Journal of Digital Information Management Volume 16 Number 3 June 2018
Content Based Text Information Search and Retrieval in Document Imagesfor Digital Library
A. Sakila1, S. Vijayarani21Ph. D Research Scholar, Department of Computer Science, Bharathiar UniversityCoimbatore, Tamilnadu, [email protected] Department of Computer Science, Bharathiar UniversityCoimbatore, Tamilnadu, [email protected]
Journal of DigitalInformation Management
Document Processing
Keywords: Document Image, Information Retrieval, OpticalCharacter Recognition, Word spotting, Normalization CrossCorrelation (NCC), Dynamic Time Warping (DTW)
Received: 10 October 2017, Revised 12 December 2017, Ac-cepted 6 January 2018
DOI: 10.6025/jdim/2018/16/3/136-151
1. Introduction
Normally libraries and organizations are still handling largeamount of printed materials such as books, bills, ledgersand questionnaires. They are excessive and voluminous;hence some libraries and organizations are slowly gettingdigitized [23]. Digitalized means paper documents canbe converted into digital form by using digitizationequipment’s like scanners, digital cameras and mobilephones. This document images are used in variousapplications like educational libraries, historical documentanalysis, identification of scripts in different languages,recognize the handwritten images, signature verification,recognizing number plates in traffic signals and so on.
Document image analysis is used to recognize the textand graphics components in images. Two categories ofdocument image analysis can be defined, they are textualprocessing and graphics processing [26]. In textualprocessing, significant components of the documentimages are skew detection, finding columns, paragraphs,text lines and words. Graphics processing deals with the
ABSTRACT: The main objective of this research work isto find the keywords in the captured/scanned printdocument images in the image database. Documentimages are becoming more popular in today’s world andthese are used in paperless offices and digital libraries.Information retrieval from the document images is a verychallenging task. Hence, there is a need for developingsearching strategies to find the required information fromthese document images as per user’s needs, becomesvery essential in nowadays. Traditionally Optical CharacterRecognition (OCR) tools are used for information retrievalfrom the document images, but it’s not an efficient method.Word spotting is an inventive method for searching thedocument images and to retrieve relevant informationwithout any conversion. In this work an algorithm EnhancedDynamic Time Warping was proposed to for findingkeywords from document images, it is based on wordspotting technique. Different matching algorithms are madeavailable for word spotting. Popular algorithms areNormalization Cross Correlation (NCC) and Dynamic TimeWarping (DTW). In this work, we have compared theperformance of these two existing algorithms with theproposed algorithm named as Enhanced Dynamic TimeWarping algorithm (EDTW). Different image formats anddifferent sizes of images are used for experimentation.From the results it is observed that the proposed algorithmhas produced good results than an existing one.
Subject Categories and DescriptorsH.3.3 [Information Search and Retrieval]; H.3.7 [DigitalLibraries]; I.7.5 [Document Capture]: Optical characterrecognition
General Terms: Digital Libraries, Information Retrieval,

Journal of Digital Information Management Volume 16 Number 3 June 2018 137
non-textual line and symbol components like mathematicalsymbols, water marks and company logos. Informationretrieval (IR) from document images has become a growingand challenging problem as compared with digital texts[26]. After converting the documents into digital form, eachand every digitized document is stored in different imageformats and it is very difficult to perform the searchprocess, i.e. to search the particular keyword(s) in thedigitized documents. This situation raises concerns aboutthe development of new techniques and algorithms whichcan able to perform the search and retrieval processefficiently in document images. However informationretrieval is concerned with content based documentbrowsing, indexing and searching from a huge databaseof document images. The text retrieval from documentimages has made significant progress and addressesrelated information processing problems such as topicclustering and information filtering.
Currently, Optical Character Recognition (OCR) tools areused to perform the information retrieval task in a smallerlevel. Optical Character Recognition technique recognizesthe text from the document images and is used to convertscanned image into editable text format [5]. Scannedimages can easily extract that text with the help of differentOCR Tools. Downsides of these tools are that it is verydifficult to extract text because of different font sizes,styles, symbols, dark background and poor quality ofdocument image [5]. Hence, necessitate an alternativeapproach for finding information to the large collections ofdocument image database is needed. An inventive methodto search the document images and retrieve relevantinformation without converting these images is done byusing word spotting techniques which give better resultsthan OCR tools [27].
The remaining portion of this paper is discussed as follows.Related Works are given in Section 2. Section 3 discussesthe proposed method. Section 3 provides the detaileddescription about the document image processing.Section 4 gives the experimental results. Conclusion isgiven in Section 5.
2. Related Works
A. L. Kesidis et.al [1] proposed word spotting structurefor accessing the content of historical machine-printeddocuments, without the use of an optical characterrecognition. The proposed methodology has evaluated thehistorical Modern Greek printed documents which wasavailable during the seventeenth and eighteenth century.Character-based word model makes it possible to performASCII queries, subject to the availability of a set of labeledprototype characters [1] [4]. To improve the efficiency ofaccessing and searching, natural language processingtechniques have been addressed. Searching the documentimages using only a base word-form for locating all thecorresponding inflected word-forms and a synonymdictionary that further facilitates access to the semanticcontext of documents [1] [4].
B. Gatos et.al [4]proposed a word spotting technique forsearching keywords in historical printed documents. Inthis technique, word segmentation step is not required.Synthetic word images are created from keywords, andthese images are compared to all the words in the digitizeddocuments. Their proposed method is based on block-based document image for performing template matchingprocess which satisfied the invariance in terms oftranslation, rotation and scaling. It is required to constrainthe applied matching process only on certain regions ofinterest [11].
Nikos Vassilopoulos, et.al [15] proposed a classificationfree word spotting system for printed historical documentimage and skipped many of the procedures of a commonword spotting approach. Moreover, it does not includesegmentation, feature extraction, clustering orclassification stages [12]. Instead, it treats the queriesas compact shapes and uses image processingtechniques in order to localize a query in the documentimages [12]. This system was tested on a historicaldocument collection and they obtained good results.
Sayantan Sarkar [20]has proposed a word spotting usingcharacter shape code for handling handwritten Englishdocument images. His proposed work is different fromother word spotting techniques because it implementstwo levels of matching the search query [18] [2]. First oneis based on word size and the next one is based oncharacter shape code of the query. An index database isused to store the word segments which drastically reducethe search time.
Yue Lu, et.al [21] proposed a word spotting techniquewhich is used to search a word portion in document images.Based on this work, one can estimate the relevancybetween the document image word and the user-specifiedword. The present approach has the ability to searchwords in document images, whose portions match withthe user-specified words. The user specified word andthe word image extracted from documents are representedby two feature strings. Inexact string method is used tomeasure the similarity between the two feature strings.This approach has the ability to search words in documentimages, whose portions match with the user-specifiedwords. But this approach cannot handle the italic wordimages due to the inherent shortcoming of the featurestring used to represent the word image.
Partha Pratim Roy, et.al [25] has proposed a wordspotting based information retrieval for medicalprescriptions. A medical prescription is generally dividedinto two parts, a printed letterhead part and a handwrittenpart. To extract the information from document images,first they extracted the printed letterhead portion whichcontains the details about the doctor, i.e. name,qualification, etc and the handwritten part are detectedfrom prescription using Hidden Markov Models (HMMs).An efficient MLP (MultiLayer Perceptron) based Tandemfeature is proposed for improving the performance.

138 Journal of Digital Information Management Volume 16 Number 3 June 2018
K. Zagoris, et.al [30] proposed a novel technique for wordspotting in hand written document images. It uses localproximity search without using any training data. Theyused both segmentation-based word spotting andsegmentation-free word spotting methods. Four historicalhandwritten data sets are used for experiment analysisusing standard evaluation measures. It is found that theproposed algorithm gives better performance than existingword spotting techniques.
Angelos P. Giotis, et.al [29] presented a comprehensivestudy on word spotting technique for various scripts orfonts. They analyzed a various word spotting techniquesfor match the keyword. Described the steps namelypreprocessing, feature extraction, representation andsimilarity measures to retrieve information from thedocument images. Authors also discussed widely useddatasets for word spotting, the state of the art in the mostcommonly used document image databases. Finally theyconclude learning based word spotting technique givesbetter results than learning-free method. Learning-basedmethods without need for manually retrieve to searchingthe text queries.
By analyzing the literature, we come to know that someof the drawbacks of the existing techniques are,it doesnot match different font types, disparate font styles, andvarious font sizes and partially matching keywords. Themain contribution of this research work is to find thekeywords in the captured/scanned print document imagesin the image database using Enhanced DTW technique.
The proposed technique is able to retrieve keywords withdifferent font types, disparate font styles, and various fontsizes and partially matching keywords. Thus drawbacksof the existing techniques are overcome by the proposedtechnique.
3. Proposed Method
In the proposed method, features are preferred to capturethe information of shape using OCR; Shape matching isperformed at the local level with an enhanced DTW. Theproposed system has five steps. They are preprocessing,edge detection, segmentation, optical characterrecognition (OCR) and matching. The architectural viewof the proposed system is depicted in Figure 1.
4. Document Image Processing
4.1 PreprocessingPre-processing is the most important step for documentimage processing and it improves the searching andretrieval process. Paper documents can be converted intodigital form by using digitization equipment. Thisdigitization equipment’s produced some noise likeillumination and low resolution which usually degradedthe quality of the document images [8].Hence documentimages need to be pre-processed so as to improve theeffectiveness of retrieval by reducing extraneous data andnoise [19]. A color image then will be converted to a grayimage before proceeding with the noise removal procedure.
Figure 1. System Architecture
Document image DB
Pre - processing
Edge detection
Segmentation
OCR
Textual Query
Text Rendering
Query Processing
Feature Extraction
Indexed File
Matching Algorithm
Matching Result

Journal of Digital Information Management Volume 16 Number 3 June 2018 139
The de-noised image is then converted to a binary imagewith suitable threshold. This stage involves preparing/cleaning the data set by resolving problems likeindeterminate data, unrelated fields, removal of distantpoints, format conversion, etc. In this research work,average filter, median filter, Gaussian filter, and wienerfilter are used. From the experimental results is foundthat wiener filter gives better results than other filters, itremoves salt and pepper and poison noise in the inputimage. Wiener filter takes less time and it gets high PSNRratio compared with other filters.
4.2 Edge DetectionEdge detection is a significant task in the document imageretrieval; it indicates the process of finding and locatingsharp discontinuation of characters in the documentimages [6]. The main aim of edge detection is to discoverthe information concerning shapes and the reflectance ortransmittance in an image. Some edge detection operatorsare available for extract the edge points in the documentimages. Each operator is designed to be sensitive tocertain types of edges. In this work, the Roberts, Prewitt,Sobel and Canny edge detection techniques are used.For the performance of the experimental results, the CannyEdge detection method provides better results and takesless time and it gets high PSNR ratio than other edgedetection techniques.
Figure 2. Input image
Figure 3. Line Segmentation
Figure 4. Word Line Segmentation
4.3 SegmentationSegmentation is necessary for document images, itconverts the text into lines, words and characters, andthis is needed for performing optical character recognitionbased word spotting [24]. The main aim of imagesegmentation is the domain-independent partition of theimage into a set of regions. This work has used threesegmentation techniques to find the keyword in documentimages, they are line segmentation, word segmentationand character segmentation [10]. Each line in thedocument images may not be perfectly horizontal; theywill not have so much of skew that there is no interlinegap [9]. Hence the lines are aligned horizontally usingline segmentation. With our observation, in order to doline segmentation in run-length compressed document,obtaining Horizontal Projection Profile is sufficient,provided that the document is skew free [16]. Aftersegmenting, text documents are split into lines, carryingout word and character is segmented [13]. The wordsegmentation is used to separate the text region into theunit of lines and then finally into words [14]. Words arethen split into characters using character segmentation.In the character segmentation, each character in thedocument image is shown in the bounding box. Figure 2gives the input document image. Figure 3 shows the linesegmented image. Figure 4 presents words are extractedfrom segmented line. Figure 5 displays charactersegmentation from segment word.

140 Journal of Digital Information Management Volume 16 Number 3 June 2018
Figure 5. Character Line Segmentation
4.4 Optical Character Recognition (OCR)Optical Character Recognition (OCR) technique is usedfor text recognition in document images. Both OCR andWord spotting techniques are applied in this research work,to find the keywords accurately. Segmented characterimages are binarized into an array of 15 × 15, where blackpixel representing 1 and white space representing 0, givenin Figure 6. The binary format of each character iscompared with the existing template. Binary format isdivided into 5 tracks and each track subdivided into 8sectors. Figure 7 shows the tracks and sectorsrepresentation.
Figure 6. 15 X 15 Matrix
Figure 7. Representations of Tracks and Sectors
In the center of the matrix, there will be 1’s in each inter-
section of sector and track. The track - sector matrix isgenerated and matched with existing templates; it haseach track-sector intersection value. If all the matrix val-ues are found to match with the template value, the char-acters are identified in the document images. After identi-fying the character it will be stored in the indexed docu-ments. This indexed document is the input for EnhancedDTW, which is used to find the keyword in document im-age in different font case (upper and lower case), fontstyle (bold, italic, underline), font size (10-24) and varietyof fonts (Arial, Book Antiqua, Calibri, Century, Garamond,High Tower Text, Times New Roman, etc...). Table 1 givesOCR Template Values for Alphabets
4.5 Matching AlgorithmThe main task of matching algorithm is to compare thequery features with the indexed features of the word imagesthat are present in the document images [28]. In thissection the proposed Enhanced Dynamic Time Warping(EDTW) technique was discussed with example. Also theexisting techniques Normalized Cross Correlation (NCC)and Dynamic Time Warping (DTW) are illustrated. Theperformance of the proposed work is compared with theseexisting techniques.
4.5.1 Normalized Cross Correlation (NCC)Normalized cross correlation (NCC) computes thesimilarity of two word images by aligning them againsteach other and then normalizing the result by the standarddeviation of their features [3]. The concept of normalizedcorrelation was developed to combat the effect of differentillumination levels on image [2]. NCC computes thesimilarity between two word images if the length differenceof the aligned features is less than the fixed threshold, itcontinues the process, until the aligned features fulfill thespecified condition. The NCC value is confined in the rangebetween -1 and 1. The fixed threshold value is the featurelength difference of the compared word images at eachalignment. Based on the intensive experimentation modethis value is selected.
Table 1. OCR Template Values for Alphabets

Journal of Digital Information Management Volume 16 Number 3 June 2018 141
Where mean I1 and mean I2 refer to the mean and I1 andI2 refer to the standard deviation of the compared wordimages. A given feature vectors of word images: = h1, h2...hNand I = i1, hi2...iN, Where and are maximum feature lengths.If the difference between each feature of the word imageis greater than the threshold, then compute the normal-ized cross correlation, otherwise the same process isrepeated.
4.5.2 Dynamic Time Warping (DTW)Dynamic Time Warping (DTW) matching algorithm is usedto compute a distance between two time sequences [7].For a given two sequences, it finds the matching distance
by computing the optimal alignment between the samplepoints [20]. The alignment is optimal in the sense that itminimizes a cumulative distance measure consisting of“local” distances between aligned samples [14]. Theprocedure is called Time Warping because it warps thetime axes of the two time series in such a way thatcorresponding samples appear at the same location on acommon time axis [17].
The DTW-distance between two time series x1...xm andy1...yN is D(M, N) which calculate in a dynamic programmingapproach using
(1)
(2)
Sim (I1, I2) =Σm
i=0 Σ (xi − meanI1) ∗ (xj − meanI2)j=0n
δI1* δI2

142 Journal of Digital Information Management Volume 16 Number 3 June 2018
The particular choice of recurrence equation and “local”distance function d(xi, yi) varies with the application. Usingthe given three values D(i,j − 1), D(i − 1, j) and D(i − 1, j) inthe calculation of D(i, j) realizes a local continuity constraintwhich ensures smooth time warping [7]. DTW offers amore flexible way to compensate for these variations thanlinear scaling, in the matching algorithm, image columnsare aligned and compared using DTW [20].
where k is used to refer to the k-th dimension of xi and yj.With this distance measure, it calculates the matchingdistance between two word images by comparing theirfeatures using DTW [22].
4.5.3 Enhanced Dynamic Time Warping (EDTW)This research work has enhanced the existing DynamicTime Warping algorithm, which is used to compute thesimilarity between two words in the document image. Theperformance is based on a DTW matching algorithm, bycomputing the optimal alignment “ between the two points.An enhanced DTW algorithm is used to search thekeyword in addition to find partial words in the documentimages. For partial matching we use C be a coefficientfunction defined as
Where p is a keyword matching against the next relevantwords in the document image.
(6)
If p = 1 the input keyword which matches the words indocument image, otherwise no matches were found. Hereexample keyword “the” is partially matching in the wordsauthenticate and then is given below.
Features of Proposed EDTWThe proposed algorithm find the keywords in the documentimages. Content available in the document images mayhave, different font types, different Font case, disparatefont styles and various font sizes.
• The proposed algorithm finds the keywords with differentfont types like Arial, Book Antiqua, Calibri, Century,Garamond, High Tower Text, Times New Roman, etc.
• It search the keyword in both upper case and lower case.
• It retrieve keywords even if it appears in disparate fontstyles bold, italic, underline or normal.
d(xi, yj) = Σ (xi,k − yj,k)2d
k=1 (3)
C = Σ Wsks=1 (4)
Where W is a keyword, s is an index of the keyword andk is initializing the index.
p = Cd (xi, yj) (5)

Journal of Digital Information Management Volume 16 Number 3 June 2018 143
• The proposed algorithm finds the keywords with variousfont sizes.
• It finds partial matching keyword.
• It can search multiple keywords.
4.6 Textual Query and Text RenderingWhenever, a user provides a textual query word, the queryword is first rendered. Text rendering converts the user’squery into equivalent word image. i.e. Text query isconverted into query image and this rendering process isdepicted in Figure 8. After rendering the keyword, thekeywords are partially matched in the input documentimage. Figure 9 displays the keyword “idea” which matchesthe OCR database.
Test/TEST/test
Testing/TESTING/testing
Tested/TESTED/tested
Plant/PLANT/plant
Planting/PLANTING/planting
Finger/FINGER/finger
Fingerprint/FINGERPRINT/
fingerprint
Hockey/HOCKEY/hockey
Figure 8. Text Rendering and Partial Matching
Figure 9. Keyword matches in OCR Database
4.7 Query Preprocessing and Feature ExtractionAfter the rendering task, the query image is binarized andits features are extracted based on similarity measurewhich finds similar index terms. Accordingly, if thecomputed similarity values fulfill the minimum thresholdá, document images with index terms are retrieved andranked according to their relevance for the given query.Then the similarity between the query and the word imagein the index file is computed and document images arereturned according to their order of relevance.
5. Experimental Results
This research work is based on word spotting techniquefor finding keywords from document images. To performintensive experimentation, scanned and captureddocument images are used. This research work has usedmore than two hundred different document image formats(JPG, png, bmp and tiff) with different sizes forexperimentation.
Matching AlgorithmThis research work has compared two existing algorithmsnamely Normalized Cross Correlation (NCC), DynamicTime Warping (DTW) and one proposed algorithm namedas Enhanced Dynamic Time Warping (EDTW) algorithm.
TestRendering plant finger HOCKEY
Rendering Rendering Renderingtest plant finger HOCKEY
Idea = I d e a
Bb Cc Dd Ee Ff Gg Hh Ii
Jj
Ss Tt
Kk Ll PpOoNn
WwVv
Mm
Aa
Rr
Xx Yy ZzUu
Experimental results proved that Enhanced Dynamic TimeWarping (EDTW) algorithms finds keywords in documentimages correctly than existing algorithms.
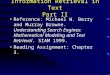
5.1 Accuracy Measure for Matching AlgorithmsThe precision, recall and F-Score measures have beenused to evaluate the performance of the proposed and theexisting techniques. Figure 10 represents the input image.Table 2 shows the performance measures for Normalizedcross correlation, Dynamic time warping and Enhanced
144 Journal of Digital Information Management Volume 16 Number 3 June 2018
Figure 10. Input image
Table 2. Performance Measures for Matching Algorithms
DTW for the input image shown in figure 10.
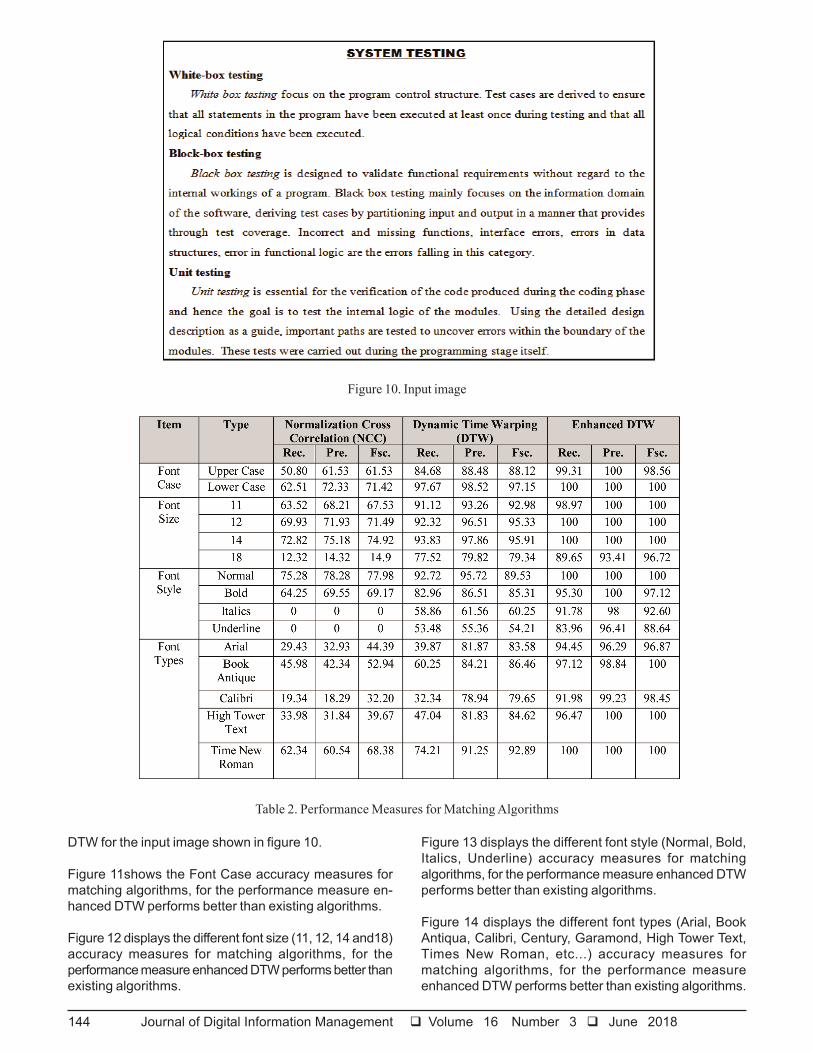
Figure 11shows the Font Case accuracy measures formatching algorithms, for the performance measure en-hanced DTW performs better than existing algorithms.
Figure 12 displays the different font size (11, 12, 14 and18)accuracy measures for matching algorithms, for theperformance measure enhanced DTW performs better thanexisting algorithms.
Figure 13 displays the different font style (Normal, Bold,Italics, Underline) accuracy measures for matchingalgorithms, for the performance measure enhanced DTWperforms better than existing algorithms.
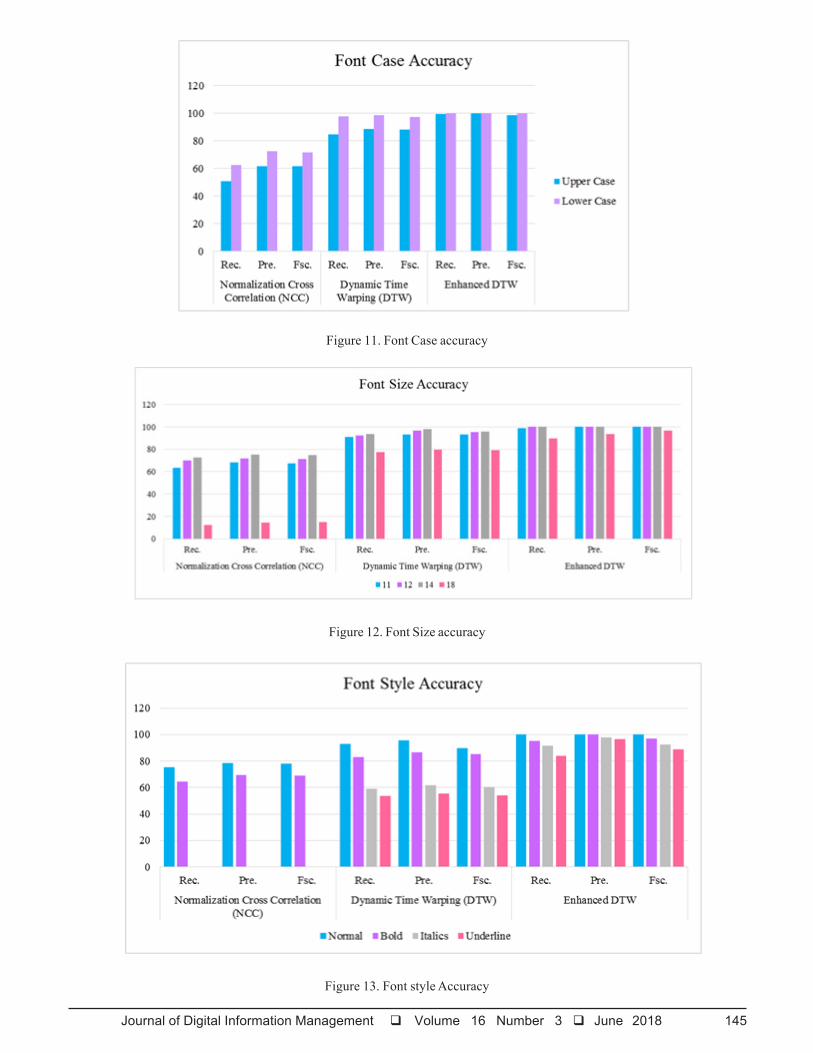
Figure 14 displays the different font types (Arial, BookAntiqua, Calibri, Century, Garamond, High Tower Text,Times New Roman, etc...) accuracy measures formatching algorithms, for the performance measureenhanced DTW performs better than existing algorithms.
Journal of Digital Information Management Volume 16 Number 3 June 2018 145
Figure 11. Font Case accuracy
Figure 12. Font Size accuracy
Figure 13. Font style Accuracy
146 Journal of Digital Information Management Volume 16 Number 3 June 2018
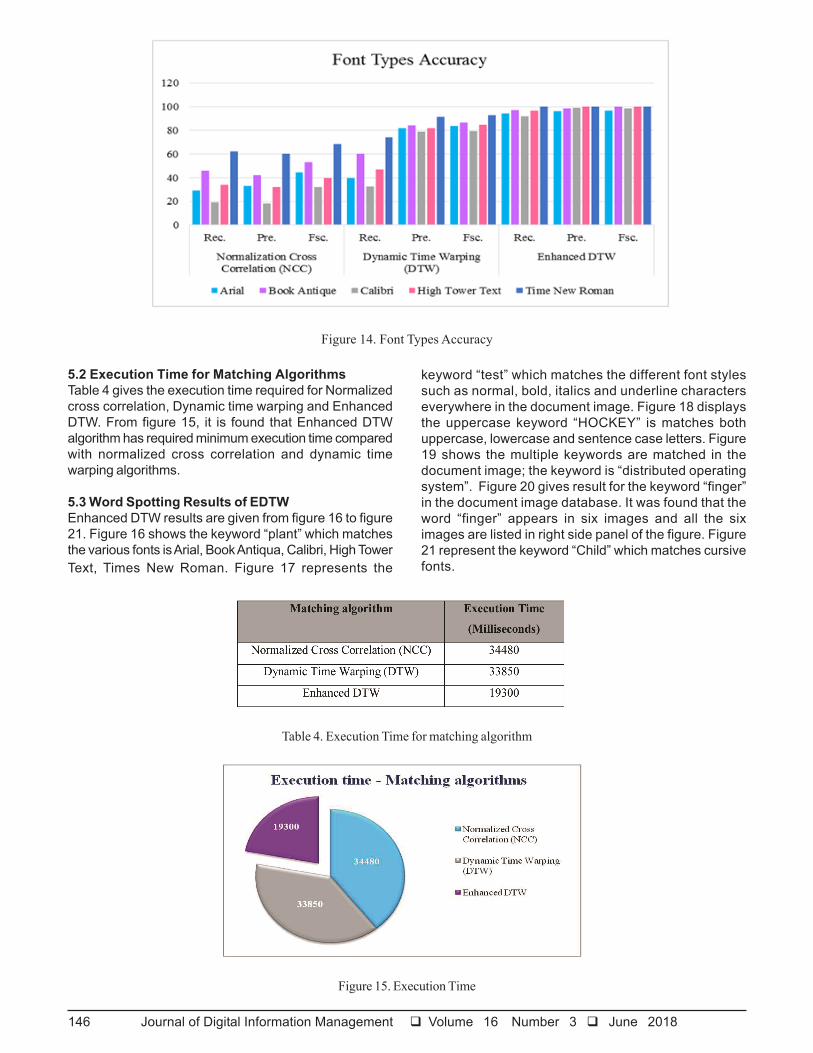
5.2 Execution Time for Matching AlgorithmsTable 4 gives the execution time required for Normalizedcross correlation, Dynamic time warping and EnhancedDTW. From figure 15, it is found that Enhanced DTWalgorithm has required minimum execution time comparedwith normalized cross correlation and dynamic timewarping algorithms.
5.3 Word Spotting Results of EDTWEnhanced DTW results are given from figure 16 to figure21. Figure 16 shows the keyword “plant” which matchesthe various fonts is Arial, Book Antiqua, Calibri, High TowerText, Times New Roman. Figure 17 represents the
Figure 14. Font Types Accuracy
keyword “test” which matches the different font stylessuch as normal, bold, italics and underline characterseverywhere in the document image. Figure 18 displaysthe uppercase keyword “HOCKEY” is matches bothuppercase, lowercase and sentence case letters. Figure19 shows the multiple keywords are matched in thedocument image; the keyword is “distributed operatingsystem”. Figure 20 gives result for the keyword “finger”in the document image database. It was found that theword “finger” appears in six images and all the siximages are listed in right side panel of the figure. Figure21 represent the keyword “Child” which matches cursivefonts.
Table 4. Execution Time for matching algorithm
Figure 15. Execution Time

Journal of Digital Information Management Volume 16 Number 3 June 2018 147
Figure 16. Search result by Enhanced DTW algorithm:Search query “plant”which matches the various fonts is Arial, BookAntiqua, Calibri, High Tower Text, Times New Roman
Figure 17. Search result by Enhanced DTW algorithm: Search query “test” which matches the different font styles such asnormal, bold, italics and underline characters everywhere in the document image
148 Journal of Digital Information Management Volume 16 Number 3 June 2018
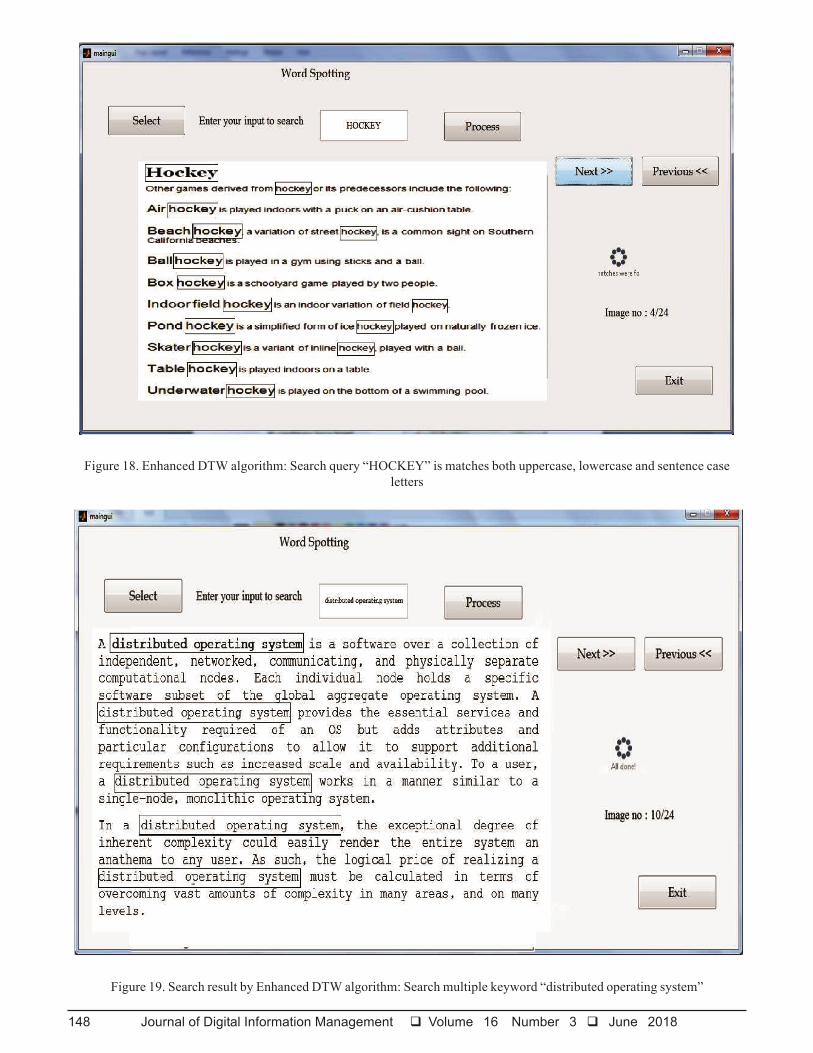
Figure 18. Enhanced DTW algorithm: Search query “HOCKEY” is matches both uppercase, lowercase and sentence caseletters
Figure 19. Search result by Enhanced DTW algorithm: Search multiple keyword “distributed operating system”
Journal of Digital Information Management Volume 16 Number 3 June 2018 149
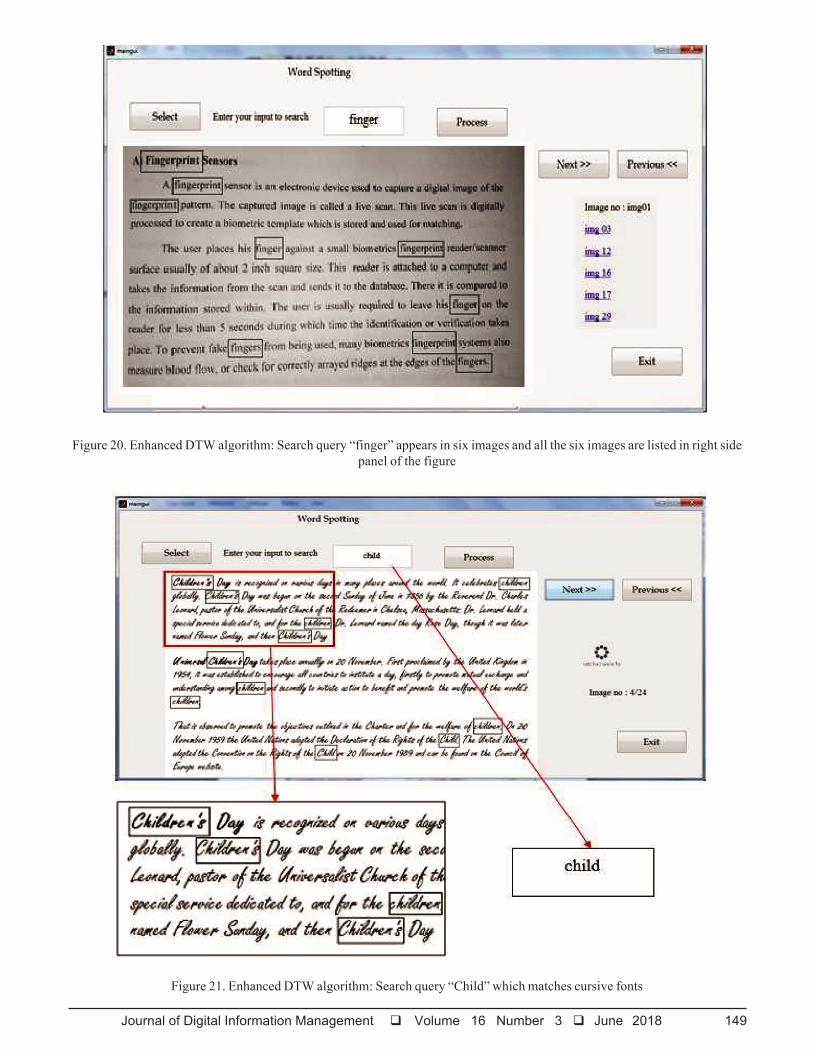
Figure 20. Enhanced DTW algorithm: Search query “finger” appears in six images and all the six images are listed in right sidepanel of the figure
Figure 21. Enhanced DTW algorithm: Search query “Child” which matches cursive fonts

150 Journal of Digital Information Management Volume 16 Number 3 June 2018
6. Conclusion and Future Work
In this research work Enhanced DTW matching algorithmis proposed for finding user specified keyword in thedocument images. It is compared with Dynamic timewarping (DTW) and Normalized Cross-Correlation (NCC).Based on the experimental results, it is found that theEnhanced DTW is better than existing algorithms; itsupports different font size and styles. The proposedalgorithm handles word variants and different font types,font sizes, font styles and partial match’s keyword in thescanned document images. In addition, the enhancedDTW searches multiple keywords in the given documentimage. In future, this research work will be extended forhandling large amount of quality and non-quality documentimages.
Reference
[1] Kesidis, A. L., Galiotou, E., Gatos, B., Pratikakis, I.(2010). A word spotting framework for historical machine-printed documents, IJDAR, Springer-Verlag,
[2] Lawrence Spitz, A. (1995). Character Shape Code forword spotting in document images, D. Dori and A.Bruckstein, eds., World Scientific, Singapore.
[3] Aldali., Nureddin, Ali. F., Jungang, Miao. (2015).Comparisons between BGI and Wiener Filter Method InResolution Enhancement of Simulated Image,Proceedings of 44th IRF International Conference, 29th(November), Pune, India.
[4] Gatos, Pratikakis, I. (2009). Segmentation-free WordSpotting in Historical Printed Documents, 10thInternational Conference on Document Analysis andRecognition, IEEE 236, p.271-275.
[5] Vijayarani, S., Sakila, A. (2015). PerformanceComparison of OCR Tools, International Journal ofUbiComp (IJU), 6(3) (July)19-30.
[6] Vijayarani, S., Sakila, A. (2016). A PerformanceComparison of Edge Detection Techniques for Printed andHandwritten Document Image, International Journal ofInnovative Research in Computer and CommunicationEngineering, 4(5) (May).
[7] Nagendar, G., Jawahar, C. V. (2015). Efficient WordImage Retrieval using Fast DTW Distance, In: InternationalConference on Document Analysis and Recognition(ICDAR 2015).
[8] Garima, Ashraf, Javed. (2013). An advanced filter forimage enhancement and restoration, International Journalof Innovative Research and Studies (IJIRS), 2 (6) (June).
[9] https://www.researchgate.net/publication/261253745_Extraction_of_Line_Word_Character_Segments_Directly_from_Run_Length_Compressed_Printed_Text_Documents
[10] Yan, Hum., Chai, Eko., Supriyanto., Lai., Wee,Khin. MRI Brain Tumor Image Segmentation using Region-Based Active Contour Model, Latest Trends in AppliedComputational Science.
[11] Cao, Huaigu., Venu, Govindaraju. (2006). Template-free word spotting in low-quality manuscripts, September30, 2006. (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.92.9015&rep=rep1&type=pdf)
[12]Zagoris, Konstrantinos., Ergina., Kavallieratou.,Papamarkos, Nikos. (2010). A Document image retrivalsystem, Engineering Application of Artificial Intelligence,23 (6) (September).
[13] Manish, T., Wanjari, Keshao, D., Kalaskar, Mahendra,P., Dhore. (2015). Document Image Segmentation UsingEdge Detection Method, International Journal of Computer& Mathematical Sciences IJCMS 4 (6) (June).
[14] Mohammed Javed, P., Nagabhusha, Chaudhuri, B.B. Extraction of Line Word Character Segments Directlyfrom Run Length Compressed Printed Text Documents.
[15] Vassilopoulosa, Nikos., ErginaKavallieratoua. (2013).A Classification-free Word-Spotting System”, SPIE-IS&T,Vol. 8658, 86580.
[16] Manmatha, R., Han, Chengfeng., Riseman, E. M.Word Spotting: A New Approach to Indexing Handwriting,In: Proceedings of IEEE Computer Society Conferenceon Computer Vision and Pattern Recognition, CVPR ’96,1996, p. 631 – 637.
[17] Park, Sang Cheol., Son, Hwa Jeong., Jeong, ChangBu., Kim, Soo Hyung. (2005). Keyword Spotting onHangul Document Images Using Two-Level Image-to-ImageMatching, Springer-Verlag Berlin Heidelberg, p. 79 – 81.
[18] Maurya, Samudra Gupt., Chugh, Ritika., Rohit Kumar,Manoj, P, V. (2014). Capital Letter Recognition in NonCursive Handwritten Documents, International Journal ofComputer Science and Information Technologies (IJCSIT),5 (3).
[19] Sarkar, Sayantan. (2013). Word Spotting in CursiveHandwritten Documents using Modified Character ShapeCodes. (http://arxiv.org/ftp/arxiv/papers/1310/1310.6063.pdf)
[20] Toni, M., Rath, Manmath, R. (2002). Word ImageMatching Using Dynamic Time Warping, (January) (http://ciir-publications.cs.umass.edu/pdf/MM-38.pdf
[21] Lu, Yue., Chew Lim Tan. (2002). Word Searching inDocument Images Using Word Portion Matching”, Springerp. 319–328.
[22] Nagendar, G., Jawahar, C. V. Efficient Word ImageRetrieval using Fast DTW Distance Centre for VisualInformation Technology, IIIT Hyderabad.
[23] Vijayarani, S., Sakila, A. (2016). A Survey on Word

Journal of Digital Information Management Volume 16 Number 3 June 2018 151
Spotting Techniques for Document Image Retrieval,International Journal of Engineering Applied Sciences andTechnology, 1 (8).
[24] Mohammed Javed, Nagabhushan, P., Chaudhuri, B.B.Extraction of Line Word Character Segments Directlyfrom Run Length Compressed Printed Text Documents,Research Gate.
[25] Roya, Partha Pratim Bhunia, Ayan Kumar., AyanDas, Dhar, Prithviraj., Pal, Umapada. (2017). Keywordspotting in doctor’s handwriting on medical prescriptions,Expert Systems With Applications, (January).
[26] O’Gorman, Lawrence., Kasturi, Rangachar (2009).Document Image Analysi, IEEE Computer SocietyExecutive Briefings, 2009.
[27] Angelos, P., Giotis, Sfikas, Giorgos., Gatos, Basilis.,Nikou, Christophoros. (2017). A survey of document imageword spotting techniques, Pattern Recognition, 68, 310-332.
[28] Kumar, Gaurav., Govindaraju, Venu., Bayesian. (2017)background models for keyword spotting in handwrittendocuments, Pattern Recognition, 64, 84-91.
[29] Angelos, P., Giotis, Giorgos Sfikas, Basilis Gatos,Christophoros Nikou, (2017). A survey of document imageword spotting techniques, Pattern Recognition, 68, 2017.
[30] Zagoris, K., Pratikakis, I., Gatos, B. (2017).Unsupervised Word Spotting in Historical HandwrittenDocument Images Using Document-Oriented LocalFeatures, IEEE Transactions on Image Processing, 26(8) 4032-4041, (August).