Embed Size (px)
Citation preview

Copula-Based Nonparametric Tests for PositiveQuadrant Dependence Allowing for Arbitrary
Marginal Distributions.
James Philip Martin∗
National University of Singapore
October 2021
Abstract
Positive quadrant dependence (PQD) is a common relationship between economic vari-ables. Existing tests of PQD require all the marginal distributions to be continuously (ordiscretely) distributed. This is often very restrictive in practice because many economicrelationships involve both continuous and discrete variables. In this paper, we extendcopula-based tests for PQD based on the multilinear empirical copula to a general settingthat allows for arbitrary marginal distributions. We provide conditions for validity andconsistency of a Kolmogorov-Smirnov (KS) type test and a Cramer–von Mises (CvM) typetest with critical values determined by a multiplier bootstrap. In an empirical application,we use our tests to investigate the dependence between intergenerational wages.
Keywords: Positive Quadrant Dependence; Multilinear Empirical Copula Process; Boot-strap
JEL Codes: C12; C35..
1

1 Introduction
This paper adds to the literature by creating a copula-based test for positive quadrant
dependence (PQD) that allows for non-continuous marginal distributions. The concept
of PQD was introduced by Lehmann (1966). In an intuitive sense, two random variables
are positively quadrant dependent if they are more likely to be simultaneously high or
simultaneously low than if they were independent. An understanding of the presence of
PQD is vital in finance, risk management, and insurance (Denuit et al. 2004; Denuit
and Scaillet, 2004; Hua 2017). For instance, in a portfolio management setting, holding
two independent assets would entail different risks than owning two that exhibit PQD.
Therefore, calculating the value at risk while assuming independently distributed assets
is problematic. Additional uses of PQD, is a new test for maximal tail dependence intro-
duced by Sun et al. (2020) that requires the assumption of PQD, and there are theoretical
results connecting PQD and correlation bounds (Caperaa and Genest,1993).
When all the marginal distributions are continuous, having positive quadrant dependence
of two random variables is equivalent to an inequality condition involving the copula (see
Nelsen, 2006). In the continuous marginal setting, this equivalence can be used to create
robust tests of PQD (Denuit and Scaillet, 2004; Scaillet, 2005; Gijbels et al. 2010). These
tests are all based on some functional of the empirical copula process. This process’s
asymptotics under different assumptions on the marginals and in other spaces have been
examined widely (Fermanian et al., 2004; Segers, 2012). However, the weakest assump-
tion for weak convergence of the empirical copula process that we have been able to find
is from Segers (2012), which requires that the copula’s partial derivatives exist and are
2

continuous on (0, 1)2. This assumption does not hold at the jump points of the marginal
distribution functions in the non-continuous setting. Therefore, copula-style analysis with
non-continuous marginal distributions requires an alternative approach. One approach
that we follow uses the multilinear copula. Under the assumption that the derivatives of
the multilinear copula exist and are continuous on an open set, the convergence of this
process was is initially shown in Genest et al. (2014) in a setting that allows for count
data marginals, and it was then extended in Genest et al. (2017) to a more general setting.
Significantly for our analysis, Neslehova (2004) proves that, in general, PQD is equiv-
alent to an inequality restriction involving the multilinear empirical copula. However,
Neslehova (2004) neither considers a test using this equivalence nor discusses any of the
asymptotic issues involved when using the multilinear empirical copula process. Our pa-
per proposes a test based on some functional of the multilinear empirical copula process
that look similar to the continuous Kolomogrov–Smirnov statistic in Scaillet (2005) and
the Cramer–von Mises (CvM) style statistic in Gijbels et al. (2010). However, we have to
address the specific issues involved with the multilinear empirical copula process, mostly
because this process may not converge everywhere. Thus far, applying the multilinear
empirical copula process has been used only to create a robust test for independence, as
in Genest et al. (2019). However, under the null of independence, the process converges
on [0, 1]2, so the test for independence that they propose does need not take into account
the additional complications involved with the process not converging everywhere. In our
proofs, we must address that the process only converges on only a subset of [0, 1]2 in most
situations with discrete marginals.
3

Additionally, we must use the continuity of the multilinear emperical copula process to
show that although this process converges on only a subset of [0,1], our test is also consis-
tent against alternatives that violate PQD on the set where it dose not converge. This is
a very subtle but important issue as although it may seem logical that this methodology
could for instance be used in a similar way to adapt the tests of symmetry from Genest
et al, (2012), it may not actually possible to do this extension or at least it will need a
different method of proving consistency 1.
The validity of the CvM-style statistic in the multilinear empirical copula setting is
proved in Genest et al. (2019). In this paper, we need to address additional theoret-
ical issues and make assumptions that are necessary for a KS-style statistic to be valid
in the discrete marginal setting, which, to the best of our knowledge, has not been used
before in the literature. We find that a slightly weaker condition is acceptable when us-
ing the KS-style statistic. For non-copula-based tests in the continuous setting, Tang et
al. (2019) introduce an empirical likelihood-based test, and Denuit and Scaillet (2004)
present stochastic-dominance-inspired testing methods. For the case where both marginal
distributions are discrete, Bartolucci et al. (2001) develop a likelihood-based test based
on contingency tables. Unlike the existing methods, the method proposed in our paper
allows for a mix of continuous and discrete marginal distributions.
The limiting distribution of the test statistic is complex and unknown in practice. There-
1This is discussed further in Appendix C
4

fore, to calculate the test’s critical values, we propose using bootstrapping (Efron, 1982).
The bootstrapping methodology we propose is to utilize the multiplier-type method in-
troduced in Genest et al. (2017).
There are many possible applications of this methodology. For instance, there are many
instances where variables of interest are partially continuous and have mass points. A
notable example is the income distribution, which has significant mass points that appear
below tax-level jumps (Le Maire and Schjerning, 2013; Bastani and Selin, 2014; Devereux
et al., 2014). In this paper, we revisit a dataset that has been examined using methods
that require continuous marginals. The issue is that there are a large number of 0’s in
the data, which are normally deleted. However, if one may expect PQD to be violated, it
should be in the left tail of the distribution if policies targeting the lowest income families
are effective.
The rest of the paper is organized as follows. In Section 2, we introduce the techni-
cal details and definitions used in the paper. In section 3, we propose the test statistics
and prove their suitability and outline bootstrapping methods that could possibly be used
in calculating critical values. Section 4 displays some simulation results of the tests apply-
ing in which bootstrapping has been applied. Section 5 gives an application of the tests
to intergenerational mobility. Finally, we provide brief concluding remarks in Section 6.
All proofs can be found in the Appendix.
5

2 Basic Setup
Let H be a bivariate distribution function with marginals X and Y , with cdf’s FX and
FY , respectively. We assume that our data {(X i, Y i)}ni=1 are from n i.i.d. draws from
these distributions. Let FX,n, FY,n, and Hn denote the empirical distribution functions for
X, Y , and H, respectively. Our results rely strongly on the work of Genest et al. (2017)
and we keep the notations consistent with that paper where possible.
Definition 2.1. We say that H exhibits PQD if and only if for all (x, y) ∈ R,
P(X ≤ x, Y ≤ y) ≥ P(X ≤ x)P(Y ≤ y) (1)
In the two-dimensional setting, Sklar’s theorem (Nelsen, 2006) states that there exists a
copula C : [0, 1]2 → [0, 1] satisfying C(FX(x1), FY (x2)) = H(x1, x2) for all x1, x2 ∈ R.
This copula is unique on the range of the marginals [range(FX), range(FY )]. Therefore,
when the marginals are both continuous, the copula C is unique on [0, 1]2. In that case,
most nonparametric analysis is undertaken using the empirical copula Cn:
Cn(u1, u2) =1
n
n∑i=1
1(FX,n(X i) ≤ u1, FY,n(Y i) ≤ u2
), (u1, u2) ∈ [0, 1]2.
Cn was introduced by Deheuvels (1979).2 Under the assumption that all marginals are
continuous and the copula is regular,3 the empirical copula process Cn =√n(Cn − C)
is shown to converge to a tight Brownian process in l∞([0, 1]2) (Fermanian et al., 2004).
2In the continuous marginal setting, there is an alternative popular estimator from Ruschendorf(1976).
3A copula is said to be regular if its partial derivatives exist and are continuous on [0,1]2.
6

However, if both the marginals are not all continuous, this process will no longer converge.
The literature on the use of nonparametric estimators for copulas with discrete marginals
has grown significantly in recent years (see Genest and Neslehova (2007) and Faugeras
(2017) for some background). The approach we follow in this paper is based on the pro-
cess known as the multilinear extension copula (also called the checkerboard copula or
the Maltese copula), which is the copula obtained by multilinearly interpolating between
the unique points guaranteed by Skylar’s theorem. We estimate this multilinear extension
copula obtained by empirical interpolation.
First, we need to introduce some definitions and notation. For a generic distribution
function G, we denote the left limit of G at a point x by G(x−) and the jump at a point
x by ∆G(x) = G(x)−G(x−).
Definition 2.2. For two independent uniform random variables U1, U2 that are also in-
dependent of X and Y define U = FX(X−)+U1∆FX(X) and V = FY (Y−)+U2∆FY
F (Y ).
Then the multilinear extension copula C for a distribution H is the distribution function
for the pair of random variables (U , V ).
This following result is proved in Section 5.3 of Neslehova (2004), links the multilinear em-
pirical copula with PQD. In the continuous setting, there is a similar inequality involving
the true unique copula C.
Lemma 2.1. For any distribution function H and for all u, v ∈ [0, 1],
H exhibits PQD if and only if C (u, v) ≥ uv
7

In the setting where marginal distributions are not continuous, Lemma 2.1 enables us to
create tests based on violations of PQD. Our test is based on a nonparametric estimator
of this multilinear extension copula process that has been examined in Genest et al.
(2017,2019). An alternative approach could use Definition 2.2 as an alternative way
to estimate this process, by adding uniform random variables to the original sample.
However, this has shown to have asymptotically larger variance in Genest et al. (2017)
and additionally two researchers will get different values for the test statistic on the same
data set which is undesirable. Therefore, we will focus on the estimator introduced in
Genest et al. (2014,2017) and applied in the test for independence by Genest et al. (2019).
We first have to define a functional before defining the nonparametric estimator. Let G
be a generic distribution function, and let
λG(u) =
u−G{G−1(u)−}
∆G{G−1(u)} if ∆G{G−1(u)} > 0
1 Otherwise
Then for any x ∈ R and u ∈ [0, 1],
VG(x, u) = λG(u)1(x ≤ G−1(u)) + (1− λG(u))1(x < G−1(u))
Using this, we can now define an empirical multilinear copula estimator,
Cn(u1, u2) =1
n
n∑i=1
VFX,n(X i, u1)VFY,n
(Y i, u2)
This nonparametric estimator for the multilinear copula process can be found in Schweizer
and Sklar (1959) and Moore and Spruill (1975). For the case where both marginals
8

are continuous, this multilinear extension was shown in Genest et al. (2017), to be
asymptotically equivalent to Cn.
Assumption 2.1. There exists an open set O such that for all (u, v) ∈ O ∂iC (u, v)
exists and is continuous, where ∂iC (u, v) is the partial derivative of C with respect to
the ith variable.
In practice, this is a very weak assumption, and for most marginals and copulas used
in applications, such a set exists. For instance, this assumption is arbitrarily satisfied
when both of the marginal distributions are discrete (see Genest et al. (2017) for further
discussion). This assumption is weaker than any of the ones used in the continuous
setting, which usually require the derivative to exist and be continuous on (0, 1)2 (Segers,
2012). We note that when any one of the marginal distributions are not fully continuous
the conditions for the convergence of the standard empirical copula mentioned no longer
holds. However, further restrictions on the set O are required for the consistency of our
test, depending on the test statistic used. Note that O depends on the range of the
marginals and the unknown copula; therefore, it is unknown and inestimable in practice.
We give some examples of the set O if X and Y are integer-valued Genest et al (2014)
show that irrespective of C Assumption 2.1 will hold with
O = ∪(i1,i2)∈N2(FX(i1 − 1), FX(i2))× (FY (i1 − 1), FY (i2)),
Genest et al. (2017) gives many more examples. Next we need to make some new as-
sumptions in order to define the limiting distribution.
9

For a distribution H with marginal distributions FX and FY , we define the following
for every subset S of S = {1, 2} and all uj ∈ [0,1]:
λF,S(u1, u2) =∏j∈S
λFj ,S(uj)∏j∈Sc
(1− λFj ,S(uj))
. We finally define,
uF,S =
Fj{F−1j (uj)} if j ∈ S
Fj{F−1j ((uj))−} if j /∈ S
Definition 2.3. The bilinear extension functional F :l∞(rangeF )→ l∞([0, 1]2) is defined
for all g ∈ l∞(rangeF ) and u ∈ [0,1] by
F(g) =∑
S⊆{X,Y }
λF,S(u)g(uF,S).
This allows us to state the convergence result from Genest et al. (2017) which is used
to prove the consistency of our test. For a set K ⊂ [0, 1]2, let C(K) denote the set of
continuous, bounded functions from K → R, and let denote weak convergence in the
Hoffmann - Jørgensen sense (See van der Vaart and Wellner (1996) for details). Weak
convergence in C(O) means weak convergence in C(K) for every compact subset K of O,
with l∞(O) defined analogously. The following lemma is proved as Theorem 1 in Genest et
al. (2017). Then Lemma 2.3 is a simple consequence of this convergence and is analogous
10

to the continuous result of Scallet (2005).
Lemma 2.2. Under Assumption 2.1 we have that
√n(Cn − C ) CC ,
where this convergence takes place in C(O).
With BC = F(BCR ) and BCR a Brownian bridge with covariance kernel, for u,u′ ∈ O
Cov(BCR (u),BCR (u′)
)= C (u ∧ u′)− C (u)C (u′),
where u ∧ u′ is the minimum taken of u and u′, taken componentwise. Then for u ∈ O,
CC can be written as
CC (u) = BCi (u)−2∑q=1
∂qC(u)BC (u(q)),
where u(q) is a vector of ones, except the qth component, which is uq.
In this paper we base our statistics on functionals of the process Dn = uv − Cn(u, v). If
we define D = uv − C (u,v), then Lemma 2.3 is a simple consequence of Lemma 2.2.
Lemma 2.3. Under Assumption 2.1 we have that
√n(Dn −D ) CC .
Where this convergence takes place in C(O) and CC is the same as in defined in Lemma
11

2.2.
3 Proposed Test Statistics
3.1 Test Statistics
Given Lemma 2.1, we can write the null hypothesis (H0) and the alternative (H1) as
follows:
H0 : C (u, v) ≥ uv for all u, v ∈ [0, 1]
H1 : C (u, v) < uv for some u, v ∈ [0, 1].
We base the statistics on measures of violation of the multilinear extension copula Cn
and the independence copula uv. We expect this difference to be negative under the null.
However, unlike the continuous case, where the process converges everywhere, we need to
make assumptions on where the process CCn converges.
Assumption 3.1. (i) There exists an open set O with Lebesgue measure 1 such that
for all (u, v) ∈ O, ∂iC (u, v) exists and is continuous for i = 1, 2. (ii) There exists an
open set O that is dense in [0, 1]2 such that for all (u, v) ∈ O, ∂iC (u, v) exists and is
continuous for i = 1, 2.
Assumption 3.1(i) is the assumption that was given in Genest et al. (2017) to show the
validity of CvM-type statistics. However, Assumption 3.1 (ii) is a slightly weaker con-
12

dition than Assumption 3.1(i). It is introduced in this paper, and under it the KS-type
statistic is show to be valid.
The first test statistic we propose is an extension of the KS-type statistic introduced
in Scaillet (2005). Specifically, it is based on the supremum norm,
Kn =√n supu,v∈[0,1]2
(uv − Cn(u, v)). (2)
We propose another statistic that generalized an CvM-type test statistic, In, in the con-
tinuous case, where it was found to have greater power than the KS-type statistic in the
simulations of Gijbels et al. (2010):
In = n
∫[0,1]2
max(uv − Cn(u, v), 0)2dudv.
Both of the test statistics work by finding a critical value c∗ such that we reject the null
if Dn > c∗, for Dn = In or Dn = Kn.
Proving the validity of our tests has some differences to the tests in the continuous
marginal setting. As our proposed test statistics are applied over the entire set [0, 1]2,
but the multilinear empirical copula process does not converge everywhere in the unit
square, unlike in the continuous case. Hence in order to provide for consistent tests, we
define what it means for a functional to be approximable on a set. We let gRA denote the
restriction of an aribitrary function g : [0, 1]2 → R to a set A ⊂ [0, 1]2. We define a slightly
modified version of approximately than the one used in Genest et al. (2017). We call it
13

D-approximable, this will be used to emphasise the fact that the domain is important.
As the functional Kn is C-approximable but not l∞-approximable 4.
Definition 3.1. We say that a functional Γ :D→ R is D-approximable on an open set
A ⊂ [0, 1]2 if the following two conditions hold: (i) There exists a functional ΓA:A → R
such that for all g ∈ D,Γ(g) = Γ(gA); (ii) for all M , δ ∈ (0,∞), there exists a compact
set K ⊂ A and a continuous functional ΓK : D(K)→ R such that
supg∈D(A), ||g||≤M
|ΓA(g)− ΓK(gK)| < δ.
In effect, for a functional to be D-approximable it must not be asymptotically affected
by the points where the process does not converge.This allows us to calculate the test
statistics over the all of [0, 1]2 while not knowing the set of convergence. For our functional
to be consistent, We make use of the following result.
Lemma 3.1. (i) Under Assumption 3.1(i), the functional Kn is C-approximable. (ii)
Under Assumption 3.1(ii), In is l∞-approximable.
The Cvm-type test statistics were shown to be consistent under Assumption 3.1(ii) in
Genest et al. (2017), and the proof of Lemma 3.1(i) is given in the Appendix. We then
state a key result similar to Theorem 3 of Genest et al. (2017). However, state this for
l and C approximable functionals. As Cn ∈ C(O), this change makes no difference in
4This is due to the fact that for a dense subsetD of a space A we have that supx∈D f(x) = supx∈A f(x)if f is continuous but not if f is in l∞. There are examples of a dense subset D of a set A and a continuousfunction f such that
∫Df(x)dx 6=
∫Af(x)dx using the Cantor set. Therefore we cannot use In under the
weaker assumption.
14

practice as our test statistic will be continuous. Lemma 3.2 justifies the use of our test
statistic over the all of [0, 1]2.
Lemma 3.2. If C satisfies Assumption 3.1 on some open set O and the functional Γ is
approximable on O then, as n→∞,
Γ(CCn ) ΓO(CC ).
With the convergence taking place in C(O).
This allows us to derive the limiting distribution of our test statistics in Theorem 3.1.
Theorem 3.1. Under Assumption 3.1, and additionally Assumption 3.2(i) for In or
Assumption 3.2(ii) for Kn, we have the following under the null:
In ≤∫
[0,1]
∫[0,1]
max(√n(Dn(u, v)−D(u, v)), 0)2dudv
∫O
max(C (u, v), 0)2dudv
and
Kn ≤ supu,v∈[0,1]
(√n(Dn(u, v)−D(u, v)) sup
u,v∈O(C (u, v)),
where CC is defined as in Lemma 2.2 with the convergence taking place in C(O). Under
the alternative, In and Kn diverge to infinity in probability.
3.2 Critical Values
Because of the complex nature of the asymptotic distribution, an important question is
how to find the critical values for the test statistics as the limiting distribution of the mul-
15

tilinear empirical copula processes. Bootstrap procedures were first introduced in Efron
(1982). In our setting, we use a multiplier bootstrap for this process from Genest et al.
(2017) to calculate the critical values of our test statistics. This bootstrap method was
used to test independence in Genest et al. (2019). However, in the special case of testing
for independence, there is no need to estimate the derivatives. The procedure for the
multiplier bootstrap is outlined as follows.
Procedure 3.1. Multiplier Bootstrap Algorithm
1. Discretize the interval [0,1] into k points u = {ui}ki=1 with uk = 1.
2. Independently of the data, generate random variables ε1b, ..., εnb with mean 0 and
variance 1 and fourth moment at most 3. Then calculate εb = n−1∑n
j=1 εjb for all
ui, uj ∈ u.
3. For all ui, uj ∈ u, calculate
BC ,bn (ui, uj) =
1√n
n∑i=1
(εib − ε)V (X i, ui)V (Y i, uj),
and then calculate
CC ,bn = BC ,b
n (ui, uj)− BC ,bn (ui, uk)∂d1,nC (ui, uj)− BC ,b
n (uk, uj)∂d2,nC (ui, uj).
16

4. Calculate and store
KMn,b = max
ui,uj∈u(CC ,b
n (ui, uj))
IMn,b =1
k2
k∑i=1
k∑j=1
max(CC ,bn (ui, uj), 0)2.
5. Repeat Steps 1 through 4 a large number B of times.
We then compute the p-value for T = In, Kn by pTi,M = B−1∑B
b=1 1(TMnb > Tn). In order
to use this methodology we need to make the following assumption.
Assumption 3.2. (i) The sequence ||BC ,bn || is tight. (ii) For every compact set K ⊂ O,
the derivative estimators ∂i,nC (u, v) must satisfy
||∂i,nC − ∂iC ||Kp→ 0.
The first part of the assumption states that the bootstrap process is tight over the whole
unit square, for the multilinear empirical process this is known to be true under assump-
tion 2.1, however although we expect this to be true for the bootstrap process it is not
yet proved. Under the Assumption 3.2 (i) we give a simple extension of the Theorem 3
in Genest et al (2017) that will be used to prove the consistency of our test.
Lemma 3.4. Under Assumption 3.2 and If C satisfies Assumption 3.1 on some open
set O and the functional Γ is D-approximable on O, then as n→∞,
Γ(CC ,bn ) ΓO(CC ).
17

Next, we state Theorem 3.2, which proves the validity of our tests.
Theorem 3.2. Under Assumptions 3.1 and 3.2 additionally, Let α ∈ (0, 12). Finally,
under Assumption 3.1(i) for Kn, and Assumption 3.1(ii) for In and using the rule that we
reject if pTiK < α for T = In or Kn,we have the following:
limn→∞
P(reject H0) ≤ α If H0 is true
limn→∞
P(reject H0) = 1 If H0 is false
4 Simulation Study
nTest Statistic Kn InMarginal dist. P1 P20 P1G P20G G P1 P20 P1G P20G G
50 0.030 0.037 0.050 0.047 0.033 0.033 0.027 0.023 0.037 0.050100 0.027 0.033 0.047 0.020 0.030 0.027 0.013 0.027 0.023 0.033200 0.033 0.056 0.030 0.040 0.057 0.023 0.037 0.020 0.037 0.037
Table 4.1: (Size of PQD test) The table reports the size of the PQD test using the KS-type and Cvm-type statistics when the critical values are obtained from the multiplerbootstrap. The data were generated under the null from the independence copula withvarying marginals. The nominal level is fixed at α = 0.05.
In this section, we display the results of a simulation study using the two test statistics.
First, we generate a sample {xi}ni=1 of size n ∈ {50, 100, 200}. To generate this sample,
we fix the copula to be the Gaussian copula with ρ ∈ {0,−0.21,−0.31,−0.41}. These
are the parameter values used in the simulation study of the PQD test in Scaillet (2005).
18

The case with ρ = 0 corresponds to the independence case (i.e., under the null), whereas
those with a negative value of ρ are under the alternative. Note, however, that as the
marginals are not continuous, this no longer coincides with Kendall’s τ . We use six dif-
ferent combinations of marginals to test a wide range of marginal dependence structures:
1. F = G for Poisson random variables with mean 1. This is a situation with many
ties in the data.
2. F = G for Poisson random variables with mean 20.
3. F = Poisson with mean 1 and G =normal. This is the situation where one marginal
is continuous and the other is discrete.
4. F = Poisson with mean 20 and G =normal.
5. F = G is Gaussian distributed with mean 0 and variance 1. We also see how the
test performs in the continuous setting.
We denote these marginal combinations by P1, P20, P1-G, P20-G, and G respectively.
After generating this sample, we calculate the test statistics In and Kn. Then we boot-
strap the test statistics using the multiplier bootstrap,5 as introduced for the discrete
settings in Genest et al. (2017) and the classical bootstrap with replacement. To calcu-
late the critical values, we use B = 1000 bootstrap replications. Finally, we record the
result of the test and then repeat this process 1000 times.
5We apply the simple derivative estimator
∂di,nC (u, v) =C (u+ 1(i = 1)h, v + 1(i = 2)) + C (u− 1(i = 1)h, v − 1(i = 2))
2h
with h = 1√n, as suggested in Genest et al. (2017)
19

In Table 4.1, we display the simulated size of the tests with data generated from the inde-
pendence copula. The first five columns present the results of the KS-type test statistic.
These show that for all sample sizes and marginal combinations, the multiplier bootstrap
performs well in regard to maintaining the nominal sizes. However, the results for the
KS test imply that the test is slightly conservative. The final five columns show the size
of the Cvm-based test statistic. For all the sample sizes, the test is slightly conservative.
Although there is a range of different marginal structures that affect the limits as in Gen-
est et al. (2019), we find that the size of the test is not very strongly influenced by the
type of marginal distributions examined.
Finally, we examine the power of the test under different marginals in Table 4.2. This
table displays the rejection rates in our study, where we vary both the marginal distribu-
tions and the parameter of the Gaussian copula with ρ ∈ {−0.21,−0.31,−0.41}. In line
with the results for size, we find that for Sn the power is higher at every sample size and
ρ. The results indicate that the CvM–type test statistic is more powerful. To make sure
these results are not sensitive to the use of the normal copula, we repeated the simulations
using the Frank copula which can be found in Appendix B. The Frank copula is a popular
copula that exhibits negative quadrant dependence for some parameter values.
20

ρ n MethodKn In
P1 P20 P1G P20G G P1 P20 P1G P20G G
−0.2150 0.433 0.453 0.443 0.510 0.530 0.570 0.573 0.553 0.637 0.637100 0.657 0.753 0.687 0.420 0.690 0.780 0.873 0.807 0.903 0.777200 0.913 0.950 0.957 0.937 0.867 0.970 0.990 0.990 0.997 1.000
−0.3150 0.780 0.757 0.817 0.813 0.787 0.853 0.877 0.907 0.910 0.887100 0.943 0.980 0.940 0.987 0.953 0.987 1.000 0.980 0.993 0.990200 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
−0.4150 0.950 0.960 0.953 0.963 0.963 0.987 0.987 0.987 0.993 0.987100 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000200 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
Table 4.2: (Power of PQD test ) The table reports the power of the Positive quadrantdependence test using the KS and CvM-type test statistics, when the critical values areobtained from the multiplier bootstrap. With the data generated from a Gaussian copulawith parameters ρ = {−0.21,−0.31,−0.41} The nominal level is fixed at α = 0.05.
5 Application
5.1 Intergenerational mobility
This section illustrates application of the process to an example from the Intergenerational
mobility literature. This topic is vital to understanding the current allocation of wealth.
In recent work, Chetty et al. (2014) found a variation in the coefficient of the rank–rank
regression of father and son incomes across different states in the United States. One
issue that is discussed is the fact that there were many ties and zeros in the data. The
methodology introduced here is suitable in this setting as this method is robust to the
presence of ties.
We use the data from the Panel Study of Income Dynamics (PSID), which is studied
in Minicozzi (2003) where they show the importance of taking censoring into account.
21

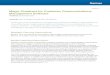
(a) (X ,Y ) (b) (X,Y)
Figure 1: The left panel is a scatter plot of the integrally transformed father and sonincomes while breaking the ties at random. The right panel shows a scatter plot of theraw data.
We focus on two variables: wage of the son at 28 (X) and the predicated wage of the
father (Y ). In previous studies of this topic by Lee et al. (2009), Delgado and Escanciano
(2012), and Seo (2018), their methods required continuous marginal assumptions. How-
ever, there is a large amount of discreteness in the data. The total size of the data set
is n = 616. Nevertheless, there are only 488 unique entries for the son’s income and 477
unique values for the father’s predicted income. It may as first sight seem obvious that we
would expect to see positive dependence. However, as PQD is a global condition if there
was upward mobility in the lower tail of the distribution, due to government intervention
we would not expect to see PQD.
To begin our analysis, we look at Figure 1. The right panel shows the bivariate plot
of the data (X, Y ), while the left panel shows a random sample from the multilinear
22

copula. 6. As can be seen in the figure, the raw data are very skewed by the outliers.
The raw data appear to show a positive relationship, but this is not clear. The left panel
shows the positive dependence more clearly, and it also indicates a large amount of tail
dependence, with groupings in the upper-right and lower-left corners. We calculate the
test statistics (0,−0.0218), with corresponding p-value of (1). This allows us to conclude
that there is very strong evidence of PQD. This would suggests that when do analysis
you should not rule out a Copula the exhibits PQD when modeling this relationship.
6 Conclusion
In this paper, we took steps to developing a nonparametric copula-based test without the
stringent continuous marginal assumptions. Here we have extended the tests for PQD
from Scaillet (2005) and Gijbels et al. (2010). However, according to results discussed
in this paper, the KS-type can be used in future tests in which the multilinear empirical
copula is applied.
There are currently no results on the convergence of the multilinear copula process under
different mixing conditions conditions. When such results become available, it will be easy
to extend this test for PQD without the continuous assumption to the time-series case.
Here we have focused on PQD, which is a two-dimensional concept. However, there is an
extension of the multilinear empirical copula to d dimensions (see Genest et al. (2017)).
This would allow us to test for some higher dimensional objects, as discussed at the end
of Scallet (2005).
6((X ,Y )) was created by integrally transforming the data and breaking the ties at random.
23

References
Bartolucci, F., Forcina, A., & Dardanoni, V. (2001). Positive quadrant depen-
dence and marginal modeling in two-way tables with ordered margins. Journal of the
American Statistical Association, 96(456), 1497–1505.
Bastani, S., & Selin, H. (2014). Bunching and non-bunching at kink points of the
Swedish tax schedule. Journal of Public Economics, 109, 36–49.
Caperaa, P., & Genest, C. (1993). Spearman’s ρ is larger than Kendall’s τ for
positively dependent random variables. Journal of Nonparametric Statistics, 2(2), 183–
194
Chetty, R., Hendren, N., Kline, P., & Saez, E. (2014). Where is the land of
opportunity? The geography of intergenerational mobility in the United States. The
Quarterly Journal of Economics, 129(4), 1553–1623.
Deheuvels, P. (1979). La fonction de dependance empirique et ses proprietes: Un test
non parametrique d’independance. Academie Royale de Belgique, Bulletin de la Classe
des Sciences (5), 65, 274–292.
Delgado, M. A., & Escanciano, J. C. (2012). Distribution-free tests of stochastic
monotonicity. Journal of Econometrics, 170(1), 68–75.
Denuit, M., Dhaene, J., & Ribas, C. (2004). Does positive dependence between
individual risks increase stop-loss premiums?. Insurance: Mathematics and Economics,
28(3), 305–308.
24

Denuit, M., & Scaillet, O. (2004). Nonparametric tests for positive quadrant de-
pendence. Journal of Financial Econometrics, 2(3), 422–450.
Devereux, M. P., Liu, L., & Loretz, S. (2014). The elasticity of corporate taxable
income: New evidence from UK tax records. American Economic Journal: Economic
Policy, 6(2), 19–53.
Efron, B. (1982). The jackknife, the bootstrap and other resampling plans. Society for
Industrial and Applied Mathematics.
Faugeras, O. P. (2017). Inference for copula modeling of discrete data: A cautionary
tale and some facts. Dependence Modeling, 5(1), 121–132.
Fermanian, J.-D., Radulovic, D., & Wegkamp, M. (2004). Weak convergence of
empirical copula processes. Bernoulli, 10, 847–860.
Genest, C., Neslehova, J. (2007). A primer on copulas for count data. ASTIN
Bulletin: The Journal of the IAA, 37(2), 475–515.
Genest, C., Neslehova, J.G., & Remillard, B. (2014). On the empirical multi-
linear copula process for count data. Bernoulli, 20(3), 1344–1371.
Genest, C., Neslehova, J.G., & Remillard, B. (2017). Asymptotic behavior of
the empirical multilinear copula process under broad conditions. Bernoulli. Journal of
Multivariate Analysis, 159, 82–110.
Genest, C., Neslehova, J. G., Remillard, B. & Murphy, O. A. (2019). Testing
for independence in arbitrary distributions. Biometrika, 106, 47–68.
25

Genest, C., Neslehova, J. G., Remillard, B. & Quessy, J. F. (2012). Tests
of symmetry for bivariate copulas. Annals of the Institute of Statistical Mathematics,
64(4), 811–834.
Gijbels, I., Omelka, M., & Sznajder, D. (2010). Positive quadrant dependence
tests for copulas. Canadian Journal of Statistics, 38(4), 555–581.
Hua, L. (2017). On a bivariate copula with both upper and lower full-range tail de-
pendence. Insurance: Mathematics and Economics, 73, 94–104.
Lee, S., Linton, O., & Whang, Y. (2009). Testing for stochastic monotonicity.
Econometrica, 77(2), 585–602.
Lehmann, E. L. (1966). Some concepts of dependence. The Annals of Mathematical
Statistics, 1137–1153.
Le Maire, D., & Schjerning, B. (2013). Tax bunching, income shifting and self-
employment. Journal of Public Economics, 107, 1–18.
Minicozzi, A. L. (2003). Estimation of sons’ intergenerational earnings mobility in the
presence of censoring.. Journal of Applied Econometrics, 18(3), 291–314.
Moore, D. S., & Spruill, M. C. (1975). Unified large-sample theory of general
chi-squared statistics for tests of fit. The Annals of Statistics, 599–616.
Nelsen, R. B. (2006). An Introduction to Copulas, 2nd ed. Springer, New York.
Neslehova (2004). Dependence of Non-Continuous Random Variables. Doctoral dis-
sertation. Universitat Oldenburg, Oldenburg, Germany.
26

Ruschendorf, L. (1976). Asymptotic distributions of multivariate rank order statis-
tics. Annals of Statistics, 4, 912–923.
Scaillet, O. (2005). A Kolmogorov–Smirnov type test for positive quadrant depen-
dence. Canadian Journal of Statistics, 33, 415–427.
Schweizer, B., & Sklar, A. (1974). Operations on distribution functions not deriv-
able from operations on random variables. Studia Mathematica, 52(1), 43–52.
Segers, J. (2012). Asymptotics of empirical copula processes under non-restrictive
smoothness assumptions. Bernoulli, 18, 764–782.
Sklar, A. (1959). Fonctions de repartition a n dimensions et leurs marges. Publications
of the Institute of Statistics of the University of Paris, 8, 229–231.
Seo, J. (2018). Tests of stochastic monotonicity with improved power. Journal of Econo-
metrics, 207(1), 53–70.
Sun, N., Yang, C., Zitikis, R. (2020). A statistical methodology for assessing the
maximal strength of tail dependence. ASTIN Bulletin: The Journal of the IAA, 50(3),
799–825.
Tang, C. F., Wang, D., El Barmi, H., & Tebbs, J. (2019). Testing for positive
quadrant dependence. The American Statistician, 1–15.
van der Vaart, A. W., & Wellner, J. A. (1996). Weak Convergence and Empirical
Processes: With Applications to Statistics, Springer, New York.
27

Appendices
A Proofs of Results
Here we prove the results given in this paper.
Proof of Lemma 3.1
Part (ii) of Lemma 3.1 was proved in Genest et al. (2017). Here we prove part (i). To do
this, we have to show that the two parts of Definition 3.1 hold for the sup norm.
Under Assumption 3.1(i) we can assume that the set A = O is dense. To prove that Kn
satisfies Definition 3.1(i), we note that the supremum of a continuous function on a dense
set is equal to the supremum over the whole space, and so the functional for g ∈ S([0, 1]2)
ΓO(g) = supu,v∈O g(x, y), satisfies definition 3.1(i).
To show that Kn satisfies Definition 3.1(ii), we fix any δ > 0 and M > 0 and, we take
any g ∈ S(A) such that ||g|| < M . We propose the same functional ΓO as in the proof of
part (i). If the supremum is attained at one or more points in O, we define (u1, v1) ∈ O
as one of those points. Otherwise, the supremum is achieved at a limit point say (u2, v2)
of O but is not contained in it. In the first case, we define the compact set A = {u1, u1},
and the difference is trivially zero. In the second case, we define A = (u3, v3) for some
(u3, v3) that is δ∗ close to (u2, u2), we then have
|ΓO(g)− ΓA(g)| = |g(u2, v2)− g(u3, v3)| < δ
28

This is due to the fact that g is ibdi, and so for n large we can make δ∗ as small as we
wish.
Proof of Lemma 3.2
As every function f ∈ C([0, 1]2) implies that f ∈ l∞([0, 1]2), the same proof will hold as
in Genest et al. (2017) as Theorem 3.
Proof of Theorem 3.1
First, we define B((u, v), ε) to be the open ball centered at a point (u, v) with radius ε.
We give the proof of this only for Kn as the proof for In is almost identical. We prove the
distribution under the null first.
Kn = supu,v∈[0,1]
(√nDn) ≤ sup
u,v∈[0,1]
((√n(Dn −D )) + sup
u,v∈[0,1]
(√nD )
≤ supu,v∈[0,1]
((√n(Dn −D )))
The first inequality is due to the triangle inequality for semimetrics, and the second in-
equality is due to the fact that D ≤ 0 under the null. Now as n→∞, applying Lemma
2.3 and Lemma 3.1 gives the first part of the result.
Under the alternative, by Lemma 3.1 there exists a point (u, v) ∈ [0, 1]2 such that
D (u, v) = δ > 0. As D is continuous, there is an ε > 0 that D (u, v) > 0 for such
B((u, v), ε). such that (u, v) ∈ B(([u, v), ε). Now under Assumption 3.1(i) and the fact
that this ball is open, there is some point (u∗, v∗) ∈ B((u, v), ε) such that (u∗, v∗) ∈ O.
29

Now we can use that
Kn ≥√nDn((u∗, v∗))
Thus using Lemma 2.3 gives us the second part of the result that Kn →∞ .
Proof of Lemma 3.4
The can be proved in the same way as Theorem 3 in Genest et al (2018). After adding
assumption 3.2 (i) that the bootstrap processes will be tight over the whole space.
Proof of Theorem 3.2
This proof is similar in logic to proving the consistency of the test in Genest et al. (2019),
however different results are required. We define K = supu,v∈O(C ), which is the limit of
the sup-norm test statistic.
Firstly we assume that the null is true. Then by applying Lemmas 3.2 and 3.4, we
conclude that for a bootstrap replication b,
Kbn =
∫[0,1]2
(√n(Cn,b − Cn))
∫O
C := Kb.
Therefore, Kn and {Kbn}Bi=1 jointly converge in C(O) to Kb conditional on the data. We
note that the pB take values only in {0, 1B, . . . , B
B}. Now for any j ∈ {0, . . . , B} consider,
P(pn,b =
j
B
)=
(B
k
)P(K1
n > Kn, ..., Kkn) > Kn, K
k+1n ≤ Kn, ..., K
Bn ≤ Kn).
As all of the variables are continuous and the functionals are approximable as indicated
30

in using the discussiona above, by the continuous mapping theorem gives we have that as
n→∞ this probability converges to
(B
k
)P(K1 > K, ..., Kj > K, Kj+1 ≤ K, ..., KB ≤ Kn) =
1
B + 1.
Thus as n → ∞, we have pn,b → pB =∑B
i=11(Kb>K)
Bin law, where BpB is uniform
on {0, ..., B}. Therefore, for any α ∈ (0, 1), we have that, P(pn,B < α) → (pB < α) =
(dαB−1e+1)B+1
. Now the first part of the theorem is clear, as Sn ≤ Sn and the probability
tends to α as B →∞.
Next, we assume that the alternative is true. From the proof of Theorem 3.1, we have
that Sn → ∞ and the α quantile is finite. These two facts, taken together, give us the
consistency of the test.
31

B Additional Simulation Results
Here we display some additional simulation results regarding the power of the tests under
the Frank copula. We look at the power of the test under all of the marginal structures
used in this paper. We also look at the rejection rate under the Frank copula and with
the parameters fixed such that the theoretical kendall’s τ ∈ {−0.21,−0.31,−0.41} if the
marginals were continuous.
τ n MethodKn In
P1 P20 P1G P20G G P1 P20 P1G P20G G
−0.2150 Multiplier 0.556 0.614 0.603 0.627 0.649 0.675 0.705 0.674 0.685 0.744100 Multiplier 0.755 0.832 0.809 0.817 0.824 0.837 0.914 0.874 0.854 0.895200 Multiplier 0.966 0.981 0.970 0.974 0.980 0.991 0.996 0.991 0.991 0.994
−0.3150 Multiplier 0.842 0.871 0.881 0.871 0.895 0.914 0.931 0.940 0.924 0.950100 Multiplier 0.970 0.987 0.989 0.986 0.990 0.992 0.998 0.998 0.998 0.996200 Multiplier 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
−0.4150 Multiplier 0.973 0.871 0.985 0.978 0.987 0.995 0.998 0.997 0.989 0.997100 Multiplier 0.998 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000200 Multiplier 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000 1.000
Table 4.2: (Power of PQD test) The table reports the power of the positive quadrantdependence test using the KS- and CvM-type test statistics when the critical values areobtained from the multipler bootstrap based. The data were generated generated from aFrank copula. The nominal level is fixed at α = 0.05.
32

C Possible issues when testing for symmetry
It may seem logical that this methodology using the Checkerboard Copula, can be easily
expanded in order to test symmetry. This would be done for instance by plugging in this
empirical checkerboard copula to one of the proposed test statistic of Genest et al (2012),
Tn = supu,v∈[0,1]
√n|(C (u∗, v∗)− C (v∗, u∗))|
A difficulty will appear when we wish to prove that is this test consistent. Specifically that
under the alternative we wish to show the test statistic converges to infinity. Normally we
would take a point (u∗, v∗) such that C (u∗, v∗) 6= C (v∗, u∗). The issue arises if all such
points are not in O. In this paper we use the continuity to show that if we are under the
alternative there must be at least one point in O that is under the alternative condition.
However, in a possible test of symmetry just because for one point C (u∗, v∗) 6= C (v∗, u∗),
it dose not imply (using continuity) that there must be a point such that C (a∗, b∗) 6=
C (b∗, a∗) and (b∗, a∗) ∈ O. So although the test statistic may be bounded bellow by
√n(C (u∗, v∗)) it is not clear if this diverges to infinity as (u∗, v∗) may not be in O. We
are not arguing that it is impossible to construct a test for symmetry using this method,
just that there are some complications that need to be considered when compared with
the continuous setting.
33