Embed Size (px)
Citation preview

CS 7810 Lecture 4
Overview of Steering Algorithms, based on
Dynamic Code Partitioning for Clustered Architectures
R. Canal, J-M. Parcerisa, A. GonzalezUPC-Barcelona
IJPP ’01

Bottlenecks
• Recap from “Complexity-Effective Superscalars”
• Wakeup+Select and Bypass have the longest delays and represent atomic operations
• Pipelining will prevent back-to-back operations
• Increased issue width / window size / wire delays exacerbate the problem (also for the register file and cache)

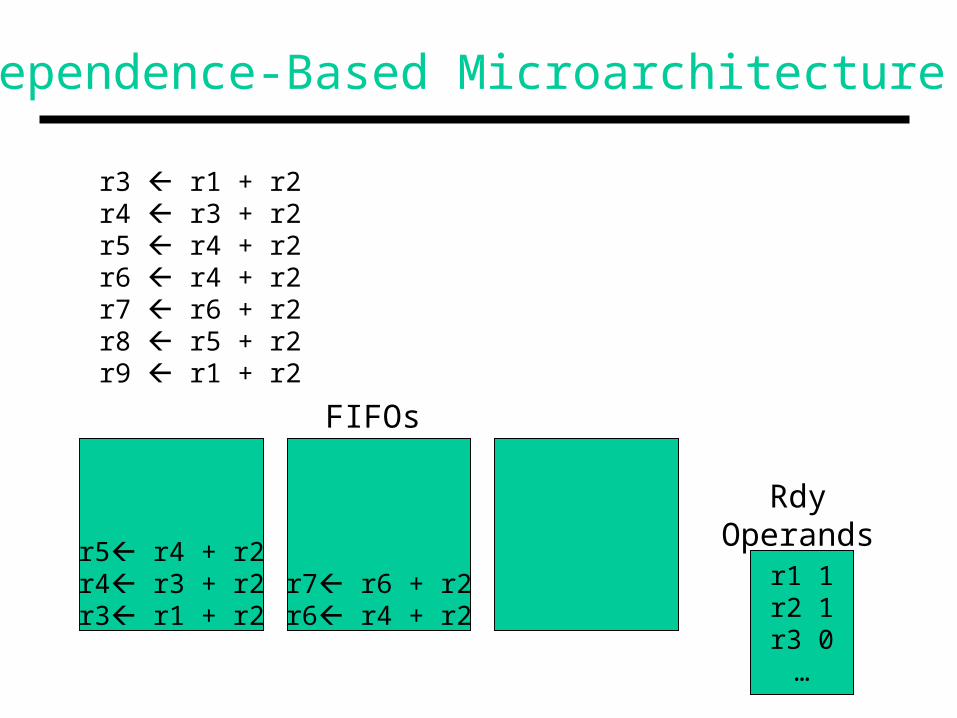
Dependence-Based Microarchitecture
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r3 r1 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r4 r3 + r2r3 r1 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r5 r4 + r2r4 r3 + r2r3 r1 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r5 r4 + r2r4 r3 + r2r3 r1 + r2 r6 r4 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands
Dependence-Based Microarchitecture
r5 r4 + r2r4 r3 + r2r3 r1 + r2
r7 r6 + r2r6 r4 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r8 r5 + r2r5 r4 + r2r4 r3 + r2r3 r1 + r2
r7 r6 + r2r6 r4 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r8 r5 + r2r5 r4 + r2r4 r3 + r2r3 r1 + r2
r7 r6 + r2r6 r4 + r2 r9 r1 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands

Dependence-Based Microarchitecture
r8 r5 + r2r5 r4 + r2r4 r3 + r2r3 r1 + r2
r7 r6 + r2r6 r4 + r2 r9 r1 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 0…
FIFOs
RdyOperands
r1 r2
Dependence-Based Microarchitecture
r8 r5 + r2r5 r4 + r2r4 r3 + r2
r7 r6 + r2r6 r4 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 1…
FIFOs
RdyOperands
r3 r9

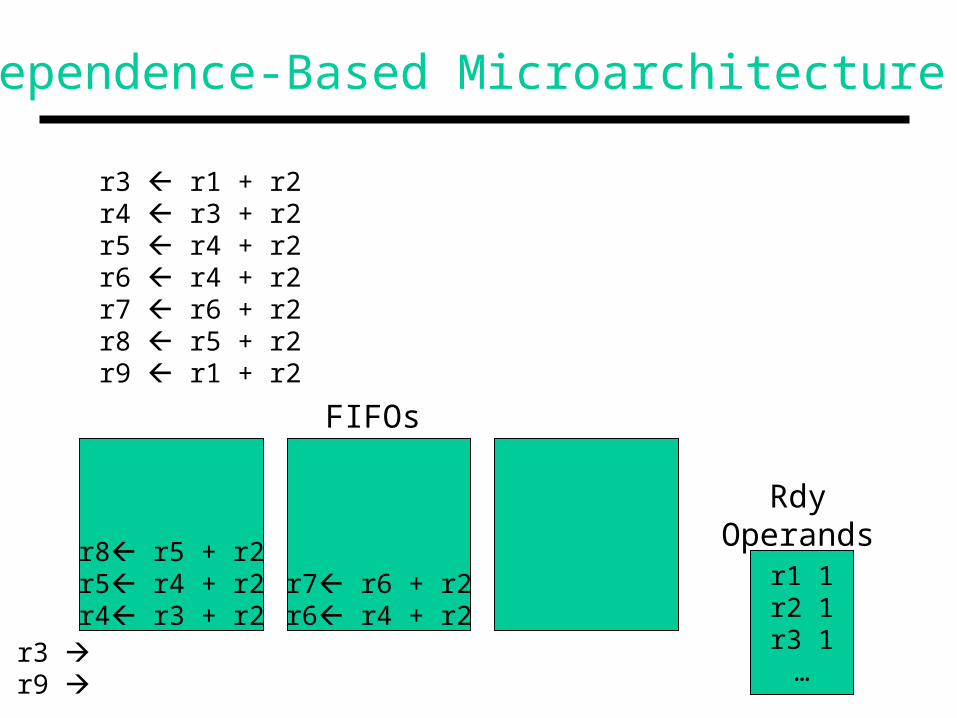
Dependence-Based Microarchitecture
r8 r5 + r2r5 r4 + r2
r7 r6 + r2r6 r4 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 1…
FIFOs
RdyOperands
r4

Dependence-Based Microarchitecture
r8 r5 + r2 r7 r6 + r2
r3 r1 + r2r4 r3 + r2r5 r4 + r2r6 r4 + r2r7 r6 + r2r8 r5 + r2r9 r1 + r2
r1 1r2 1r3 1…
FIFOs
RdyOperands
r5 r6

Pros and Cons
• Wakeup and select over a subset of issue queue entries (only FIFO heads)
• Under-utilization as FIFOs do not get filled (causes about 5% IPC loss) – but it is not hard to increase their sizes
• You still need an operand-rdy table
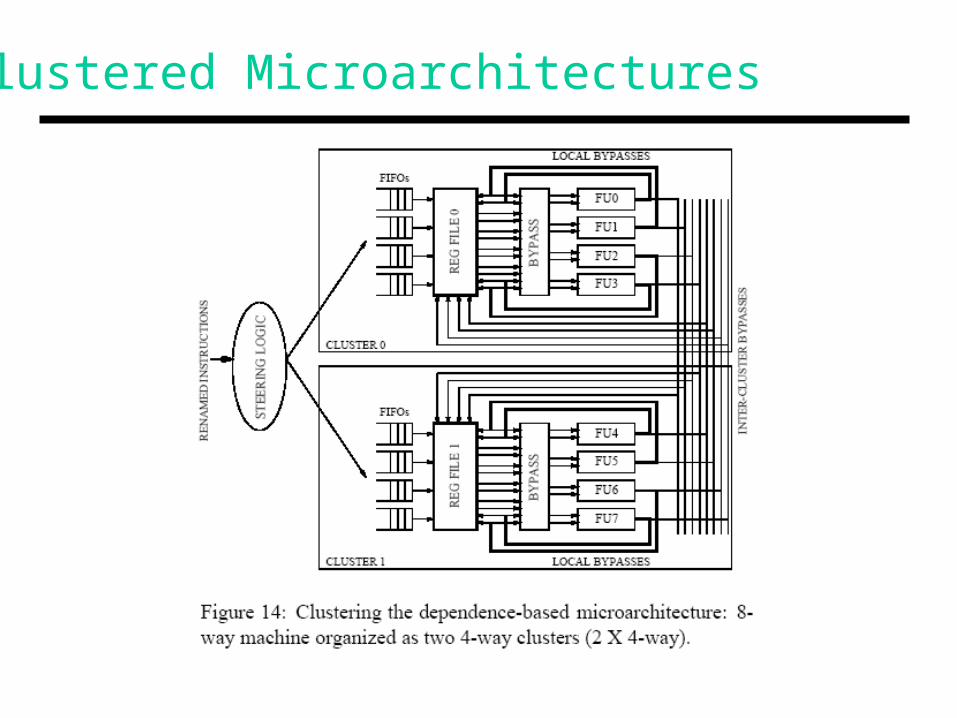
Clustered Microarchitectures

Clustered Microarchitectures
• Simplifies wakeup+select and bypassing
• Dependence-based, hence most communication is local
• Low porting requirements on register file, issue queue
• IPC loss of 6.3%, but a clock speed improvement

Clustered Microarchitectures
• Two primary motivations: hard to design 8-way machines in future technologies the FP cluster is idle most of the time
• Advantages: Few entries, few ports low delays fast clocks, simple pipelines Every instruction is not penalized for wire delays Potential for large windows and high ILP Design and verification costs do not scale up (?)

Dependences
• During rename, steer dependent instructions to the same cluster
• However, we do not know about converging chains (can have workarounds – traces/compilers)
• If the assigned cluster is full, do we stall or go elsewhere? – not clarified in the paper
r1 r2 + r3 cl-1r4 r1 + r2 cl-1r5 r6 + r7 cl-2r8 r5 + r1 ?

Load Imbalance
• All instructions in 1 cluster zero communication, but zero utilization of other resources
• Six ready instructions in cl-1 and two in cl-2 more contention and wasted issue slots
• Ready instructions in each should be equal – however, instruction readiness happens long after instruction steering

Load Imbalance Metrics
• Metrics: Instrs in each cluster Unissued instrs that could have issued elsewhere (note latency between steer & issue)
• The second metric does not help much
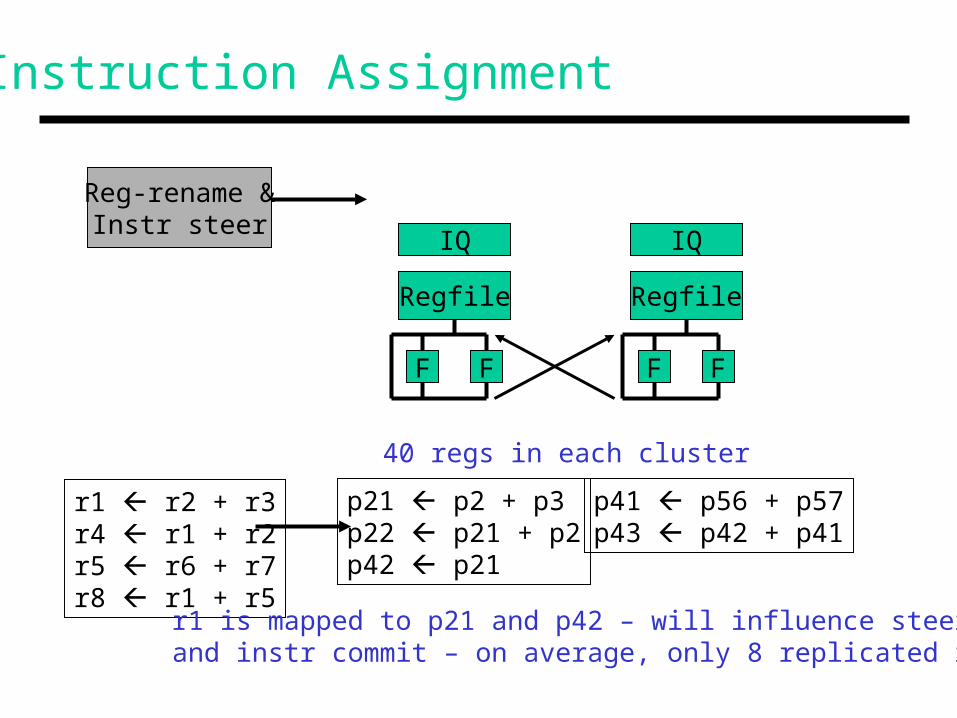
Instruction Assignment
Reg-rename &Instr steer
IQ
Regfile
F F
IQ
Regfile
F F
r1 r2 + r3r4 r1 + r2r5 r6 + r7r8 r1 + r5
p21 p2 + p3p22 p21 + p2p42 p21
p41 p56 + p57p43 p42 + p41
40 regs in each cluster
r1 is mapped to p21 and p42 – will influence steering and instr commit – on average, only 8 replicated regs

Assignment by the Compiler
• ISA modification
• Less accurate notion of load
• Depends on good branch prediction, memory dependence prediction, cache miss prediction, contention modeling, etc.
• Dynamic mechanisms can add pipeline stages

Steering Heuristics
• Simple Register Mapping Based Steering (Simple-RMBS): if communication cannot be avoided, pick a random cluster
• Balanced-RMBS: if communication cannot be avoided, pick the less-loaded cluster
• Advanced-RMBS: if significant imbalance, pick the less-loaded cluster, else use Balanced-RMBS
• Modulo-steering: assignment alternates between clusters

Results
• Modulo steering: too much communication
• Balanced and Simple RMBS do well (27 and 22% better than the base) – less than 3 comms per 100 instructions (a single bus is enough) – assuming zero comm-cost isolates effect of workload imbalance
• Advanced RMBS performs 35% better than base
• The max possible improvement (UB model) is 44%

Other Results
• Scheduling constraints limit improvements for FP programs
• The compiler can do better than what Fig.10 indicates
• Palacharla algorithm doesn’t do as well – no load considerations and few FIFOs more communication

Optimizations
• Information on converging chains (slices)
• First-fit and Mod-N
• Identify critical source operands
• Interconnect-sensitive steering
• Stalls in dispatch

Future Trends
• Increased wire delays and more transistors each cluster is smaller more clusters latency across clusters is higher
• Load imbalance and communication become worse – the best heuristic/threshold will depend on the assumed model/latency
• Data cache access time increases

Dynamic Cluster Allocation
• At some point, using more clusters can increase communication costs and worsen performance
• More clusters larger windows/FUs more ILP more communication penalties
• Steering heuristic should take degree of ILP into account (ISCA ’03)

Other Recent Papers
• Hierarchical interconnect designs – Aggarwal and Franklin
• Distributed data caches – UPC
• Power-efficiency of clustered designs – Zyuban and Kogge
• TRIPS processor – UT-Austin (compiler mapping)

Important Problems
L1D L1D
L1DL1D
L2 L2
FE
FE
FE
FE
• Cluster allocation to threads• Design of interconnects• Latency tolerance• Exploiting heterogeneity• 3D design• Power efficiency and temperature• Branch fan-out

Next Week’s Paper
• “The Optimal Logic Depth per Pipeline Stage is 6 to 8 FO4 Inverter Delays”, UT-Austin/Compaq, ISCA’02

Title
• Bullet





























