Embed Size (px)
Citation preview

CS480/680: Intro to MLLecture: Deep Neural Networks
Yao-Liang Yu1

Universality: the dark side
• Only proves the existence of such a NN; how to find it is another issue (training of NNs)
• May need exponentially many hidden units
• Increase depth may reduce number of hidden units, significantly
NP-hard
Yao-Liang Yu2

Backprop for NN
f: activation functionJ = L + λΩ: training obj.forward
backwardYao-Liang Yu3

Sigmoid and tanh
Sigmoid• Output range (0,1)• Gradient range (0,1): 𝜎 𝑥 1 − 𝜎 𝑥• Small gradient at saturated regions
Ø x = 0, gradient = 0.25Ø x = 10, gradient = 4.5396e-05Ø x = -10, gradient = 4.5396e-05
Tanh• Output range (-1,1)• Gradient range (0,1): 1 − tanh! 𝑥• Small gradient at saturated regions
Yao-Liang Yu4

Vanishing gradients
• Common weight initialization in (-1, 1)• Denote input of the i-th 𝜎() as 𝑎!
Yao-Liang Yu5

Avoiding vanishing gradients
• Proper initialization of network parameters
• Choose activation functions that do not saturate
• Use Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) architectures.
• …
Yao-Liang Yu6

More activations
• Leaky ReLU
• ELU
f(t) = max{0.1t, t}<latexit sha1_base64="FUs1bv4h7wyPHf9YZJFe8J3H+Gg=">AAAB/3icbVBNS8NAEN3Ur1q/ooIXL4tFqCAlEUEvQtGLxwr2A5pQNttNu3Q3CbsTscQe/CtePCji1b/hzX/jts1Bqw8GHu/NMDMvSATX4DhfVmFhcWl5pbhaWlvf2Nyyt3eaOk4VZQ0ai1i1A6KZ4BFrAAfB2oliRAaCtYLh1cRv3TGleRzdwihhviT9iIecEjBS194LK3CEL7Anyb2XOVUXjjF4465ddqrOFPgvcXNSRjnqXfvT68U0lSwCKojWHddJwM+IAk4FG5e8VLOE0CHps46hEZFM+9n0/jE+NEoPh7EyFQGeqj8nMiK1HsnAdEoCAz3vTcT/vE4K4bmf8ShJgUV0tihMBYYYT8LAPa4YBTEyhFDFza2YDogiFExkJROCO//yX9I8qbomt5vTcu0yj6OI9tEBqiAXnaEaukZ11EAUPaAn9IJerUfr2Xqz3metBSuf2UW/YH18AywBlEQ=</latexit><latexit sha1_base64="FUs1bv4h7wyPHf9YZJFe8J3H+Gg=">AAAB/3icbVBNS8NAEN3Ur1q/ooIXL4tFqCAlEUEvQtGLxwr2A5pQNttNu3Q3CbsTscQe/CtePCji1b/hzX/jts1Bqw8GHu/NMDMvSATX4DhfVmFhcWl5pbhaWlvf2Nyyt3eaOk4VZQ0ai1i1A6KZ4BFrAAfB2oliRAaCtYLh1cRv3TGleRzdwihhviT9iIecEjBS194LK3CEL7Anyb2XOVUXjjF4465ddqrOFPgvcXNSRjnqXfvT68U0lSwCKojWHddJwM+IAk4FG5e8VLOE0CHps46hEZFM+9n0/jE+NEoPh7EyFQGeqj8nMiK1HsnAdEoCAz3vTcT/vE4K4bmf8ShJgUV0tihMBYYYT8LAPa4YBTEyhFDFza2YDogiFExkJROCO//yX9I8qbomt5vTcu0yj6OI9tEBqiAXnaEaukZ11EAUPaAn9IJerUfr2Xqz3metBSuf2UW/YH18AywBlEQ=</latexit><latexit sha1_base64="FUs1bv4h7wyPHf9YZJFe8J3H+Gg=">AAAB/3icbVBNS8NAEN3Ur1q/ooIXL4tFqCAlEUEvQtGLxwr2A5pQNttNu3Q3CbsTscQe/CtePCji1b/hzX/jts1Bqw8GHu/NMDMvSATX4DhfVmFhcWl5pbhaWlvf2Nyyt3eaOk4VZQ0ai1i1A6KZ4BFrAAfB2oliRAaCtYLh1cRv3TGleRzdwihhviT9iIecEjBS194LK3CEL7Anyb2XOVUXjjF4465ddqrOFPgvcXNSRjnqXfvT68U0lSwCKojWHddJwM+IAk4FG5e8VLOE0CHps46hEZFM+9n0/jE+NEoPh7EyFQGeqj8nMiK1HsnAdEoCAz3vTcT/vE4K4bmf8ShJgUV0tihMBYYYT8LAPa4YBTEyhFDFza2YDogiFExkJROCO//yX9I8qbomt5vTcu0yj6OI9tEBqiAXnaEaukZ11EAUPaAn9IJerUfr2Xqz3metBSuf2UW/YH18AywBlEQ=</latexit><latexit sha1_base64="FUs1bv4h7wyPHf9YZJFe8J3H+Gg=">AAAB/3icbVBNS8NAEN3Ur1q/ooIXL4tFqCAlEUEvQtGLxwr2A5pQNttNu3Q3CbsTscQe/CtePCji1b/hzX/jts1Bqw8GHu/NMDMvSATX4DhfVmFhcWl5pbhaWlvf2Nyyt3eaOk4VZQ0ai1i1A6KZ4BFrAAfB2oliRAaCtYLh1cRv3TGleRzdwihhviT9iIecEjBS194LK3CEL7Anyb2XOVUXjjF4465ddqrOFPgvcXNSRjnqXfvT68U0lSwCKojWHddJwM+IAk4FG5e8VLOE0CHps46hEZFM+9n0/jE+NEoPh7EyFQGeqj8nMiK1HsnAdEoCAz3vTcT/vE4K4bmf8ShJgUV0tihMBYYYT8LAPa4YBTEyhFDFza2YDogiFExkJROCO//yX9I8qbomt5vTcu0yj6OI9tEBqiAXnaEaukZ11EAUPaAn9IJerUfr2Xqz3metBSuf2UW/YH18AywBlEQ=</latexit>
f(t) =
(t, t � 0
↵(et � 1), t 0<latexit sha1_base64="QgsHuOyHfRdrE0PmvFMEClChlc0=">AAACNnicbVBBS9xAGJ1YqzZtNbbHXj5cLLvQLokIeilIe+mloOCqsEmXyeyX3cHJJM58EZawv6qX/o7evPTQUnrtT+hkzUFXHww83vvezHwvLZW0FIY33sqT1adr6xvP/OcvXm5uBduvzmxRGYEDUajCXKTcopIaByRJ4UVpkOepwvP08lPjn1+jsbLQpzQrMcn5RMtMCk5OGgVfsi714APEKU6kroW7ys59egdvgSCe4BWEcezHXJVTDl38SvAeol5rq8b2Y9TjNjgKOmE/XAAekqglHdbieBT8iMeFqHLUJBS3dhiFJSU1NySFwrkfVxZLLi75BIeOap6jTerF2nPYdcoYssK4owkW6t1EzXNrZ3nqJnNOU7vsNeJj3rCi7DCppS4rQi1uH8oqBVRA0yGMpUFBauYIF0a6v4KYcsMFuaZ9V0K0vPJDcrbXj8J+dLLfOfrY1rHB3rAd1mURO2BH7DM7ZgMm2Dd2w36x395376f3x/t7O7ritZnX7B68f/8BN4mnbA==</latexit><latexit sha1_base64="QgsHuOyHfRdrE0PmvFMEClChlc0=">AAACNnicbVBBS9xAGJ1YqzZtNbbHXj5cLLvQLokIeilIe+mloOCqsEmXyeyX3cHJJM58EZawv6qX/o7evPTQUnrtT+hkzUFXHww83vvezHwvLZW0FIY33sqT1adr6xvP/OcvXm5uBduvzmxRGYEDUajCXKTcopIaByRJ4UVpkOepwvP08lPjn1+jsbLQpzQrMcn5RMtMCk5OGgVfsi714APEKU6kroW7ys59egdvgSCe4BWEcezHXJVTDl38SvAeol5rq8b2Y9TjNjgKOmE/XAAekqglHdbieBT8iMeFqHLUJBS3dhiFJSU1NySFwrkfVxZLLi75BIeOap6jTerF2nPYdcoYssK4owkW6t1EzXNrZ3nqJnNOU7vsNeJj3rCi7DCppS4rQi1uH8oqBVRA0yGMpUFBauYIF0a6v4KYcsMFuaZ9V0K0vPJDcrbXj8J+dLLfOfrY1rHB3rAd1mURO2BH7DM7ZgMm2Dd2w36x395376f3x/t7O7ritZnX7B68f/8BN4mnbA==</latexit><latexit sha1_base64="QgsHuOyHfRdrE0PmvFMEClChlc0=">AAACNnicbVBBS9xAGJ1YqzZtNbbHXj5cLLvQLokIeilIe+mloOCqsEmXyeyX3cHJJM58EZawv6qX/o7evPTQUnrtT+hkzUFXHww83vvezHwvLZW0FIY33sqT1adr6xvP/OcvXm5uBduvzmxRGYEDUajCXKTcopIaByRJ4UVpkOepwvP08lPjn1+jsbLQpzQrMcn5RMtMCk5OGgVfsi714APEKU6kroW7ys59egdvgSCe4BWEcezHXJVTDl38SvAeol5rq8b2Y9TjNjgKOmE/XAAekqglHdbieBT8iMeFqHLUJBS3dhiFJSU1NySFwrkfVxZLLi75BIeOap6jTerF2nPYdcoYssK4owkW6t1EzXNrZ3nqJnNOU7vsNeJj3rCi7DCppS4rQi1uH8oqBVRA0yGMpUFBauYIF0a6v4KYcsMFuaZ9V0K0vPJDcrbXj8J+dLLfOfrY1rHB3rAd1mURO2BH7DM7ZgMm2Dd2w36x395376f3x/t7O7ritZnX7B68f/8BN4mnbA==</latexit><latexit sha1_base64="QgsHuOyHfRdrE0PmvFMEClChlc0=">AAACNnicbVBBS9xAGJ1YqzZtNbbHXj5cLLvQLokIeilIe+mloOCqsEmXyeyX3cHJJM58EZawv6qX/o7evPTQUnrtT+hkzUFXHww83vvezHwvLZW0FIY33sqT1adr6xvP/OcvXm5uBduvzmxRGYEDUajCXKTcopIaByRJ4UVpkOepwvP08lPjn1+jsbLQpzQrMcn5RMtMCk5OGgVfsi714APEKU6kroW7ys59egdvgSCe4BWEcezHXJVTDl38SvAeol5rq8b2Y9TjNjgKOmE/XAAekqglHdbieBT8iMeFqHLUJBS3dhiFJSU1NySFwrkfVxZLLi75BIeOap6jTerF2nPYdcoYssK4owkW6t1EzXNrZ3nqJnNOU7vsNeJj3rCi7DCppS4rQi1uH8oqBVRA0yGMpUFBauYIF0a6v4KYcsMFuaZ9V0K0vPJDcrbXj8J+dLLfOfrY1rHB3rAd1mURO2BH7DM7ZgMm2Dd2w36x395376f3x/t7O7ritZnX7B68f/8BN4mnbA==</latexit>
Yao-Liang Yu7

ReLU, Leaky ReLU, and ELU
ReLU• Computationally efficient• Gradient = 1 when x> 0• Gradient = 0 when x<0 (cannot update parameter)
Ø Initialize ReLU units with slightly positive values, e.g., 0.01Ø Try other activation functions, e.g., Leaky ReLU
Leaky ReLU• Computationally efficient• Constant gradient for both x>0 and x<0
ELU• Small gradient at negative saturation region
Yao-Liang Yu8

Tips
• Sigmoid and tanh functions are sometimes avoided due to the vanishing/exploding gradients
• Use ReLU as a default choice
• Explore other activation functions, e.g., Leaky ReLUand ELU, if ReLU results in dead hidden units
Yao-Liang Yu9

Overfitting and regularization
• High capacity increases risk of overfittingØ # of parameters is often larger than # of data
• Regularization: modification we make to a learning algorithm that is intended to reduce its generalization error but not its training error
Ø Parameter norm penalties (e.g., L1 and L2 norms)Ø BaggingØ DropoutØ Data augmentationØ Early stoppingØ…
Yao-Liang Yu10

Dropout
For each training example keep hidden units with probability 𝑝.• A different and random network for each training example• A smaller network with less capacity
e.g., let p = 0.5 for all hidden layers
delete ingoing and outgoing links for eliminated hidden units
Yao-Liang Yu11

Implementation
Consider implementing dropout in layer 1.
• Denote output of layer 1 as h with dimension 4*1• Generate a 4*1 vector d with elements 0 or 1 indicating whether units are kept or not• Update h by multiplying h and d element-wise• Update h by h/p (“inverted dropout’’)
Yao-Liang Yu12

Inverted dropout
Motivation: keep the mean value of output unchanged
Example: Consider 𝒉(") in the previous slide. 𝒉(") is used as the input to layer 2. Let 𝑝 = 0.8.
𝒛($) = 𝑾($)𝒉(") + 𝒃($)
• 20% of hidden units in layer 1 are eliminated• Without “inverted dropout’’, the mean of 𝑧($) would be decreased by 20% roughly
Yao-Liang Yu13

Prediction
Training• Use (“inverted’’) dropout for each training example
Prediction• Usually do not use dropout • If “inverted dropout’’ is used in training, no further scaling is needed in testing
Yao-Liang Yu14

Why does it work?
Intuition: Since each hidden unit can disappear with some probability, the network cannot rely on any particular units and have to spread out the weightsà similar to L2 regularization
Another interpretation: Dropout is training a large ensemble of models sharing parameters
Yao-Liang Yu15

Hyperparameter 𝑝
𝑝: probability of keeping units
How to design 𝑝?• Keep 𝑝 the same for all layers• Or, design 𝑝 for each layer: set a lower 𝑝 for overfitting layers, i.e., layers with a large number of units• Can also design 𝑝 for the input, but usually set 𝑝 = 1 or very close to 1
Yao-Liang Yu16

Data augmentation
The best way to improve generalization is to have moretraining data. But often, data is limited.
One solution: create fake data, e.g., transform input Example: object recognition (classification)• Horizontal/vertical flip• Rotation• Stretching• …
Yao-Liang Yu17
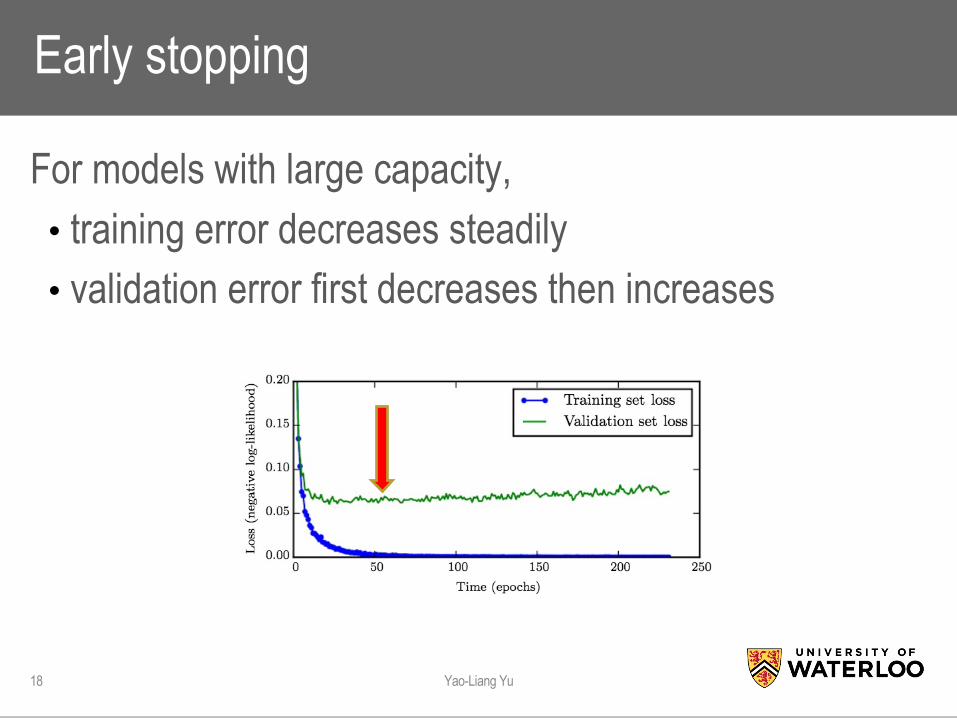
Early stopping
For models with large capacity, • training error decreases steadily • validation error first decreases then increases
Yao-Liang Yu18

Batch normalization (BN)
Use BN for each dimension in hidden layers, either before activation function or after
𝑧(#)either apply BN to 𝑧(#) or ℎ(#)
𝛾 and 𝛽 are optimization variables; not hyperparameters
h(3) = f3(W(3)h(2) + b(3))
Yao-Liang Yu19

Why BN? (1)
Consider applying BN to 𝑧 (i.e., before activation)• 𝑧 : mean 𝛽, variance 𝛾$• Robust to parameter changes in previous layers• Independent learning of each layer
Without BN, layer 2 depends on output of layer 1 hence params of layer 1With BN, mean and variance of 𝑧(") unchanged
apply BN
Yao-Liang Yu20

Why BN? (2)
Assume the orders of features in hidden layers are significantly different
• E.g., feature 1: 1; feature 2: 103 ; feature 3: 10-3
• With BN, features are of similar scale• Speed up learning
Yao-Liang Yu21

Why BN? (3)
BN has a slight regularization effect (not intended)
• Each mini-batch is scaled by the mean/variance computed on that mini-batch• This adds some noise to z and to each layer’s activations
Yao-Liang Yu22

Optimization
Problem of SGD: slow convergence
SGD + momentum
• Accumulate an exponentially decaying moving average of past gradients• Hyperparameter 𝛼 determines how quickly the contributions of previous
gradients exponentially decay (𝛼 = 0.9 usually works well)
g O✓
1
m
mX
i=1
L(f(x(i);✓), y(i))
!
v ↵v + (1� ↵)g
✓ ✓ � ✏v
exponentially weighted averages
Yao-Liang Yu23

Exponentially weighted averages
Let
total weight: 1 − 𝛼% (close to 1 if t is large)
Yao-Liang Yu24
vt = ↵vt�1 + (1� ↵)gt; ↵ = 0.9
<latexit sha1_base64="ySpkCCTxoNIT+szNpgMgPfW9N4I=">AAADIHicbZJNb9QwEIad8FXCR7dw5GKxQiqgrpIKWhBUqsSFY5HYbqXNKrIdJ7HqOCGeLF1Z+Slc+CtcOIAQ3ODX4OxuFdowUpQ37zNjjyempRQafP+34165eu36jY2b3q3bd+5uDrbuHeuirhgfs0IW1Qklmkuh+BgESH5SVpzkVPIJPX3T8smcV1oU6j0sSj7LSapEIhgBa0Vbzl6o+EdW5DlRsQnpWWPCnEBGE3PWNN5FOOngpAezDmY9OO/gvAfTDqY9GNOO0h6FjAOxCbSQsV7k9mXCldd4Xkh5KpQhUqTqia2k8wjwAQ6JLDOC208DO0GDn+LtYGflPrbdRPAKhx9qEp9nHmB/9NILud3xfC0vGgz9kb8M3BfBWgzROo6iwa8wLlidcwVMEq2ngV/CzJAKBJPcdldrXhJ2SlI+tVKRnOuZWf7gBj+yToyTorKPArx0/60wJNft8W1mOyp9mbXm/9i0huTFzAhV1sAVW22U1BJDgdvbgmNRcQZyYQVhlbC9YpaRijCwd6odQnD5yH1xvDsKno2ev9sdHr5ej2MDPUAP0TYK0D46RG/RERoj5nxyvjjfnO/uZ/er+8P9uUp1nXXNfXQh3D9/AaynBes=</latexit>
v100 = 0.1g100 + 0.1 ⇤ 0.9g99 + 0.1 ⇤ 0.92g98 + · · ·+ 0.1 ⇤ 0.999g1
<latexit sha1_base64="HBPEBnfCgT2GIAIRDb+VlUVCvl0=">AAADQ3icbZLPi9QwFMfTrj/W+mt2PXoJDoKsMLSDy+6AwoIXjys4OyvTcUjStA2bJqVJxx1C/zcv/gPe/Ae8eFDEq2A6rXR264OmL9/Pe3nJ4+GcM6V9/6vj7ty4eev27h3v7r37Dx4O9vbPlCwLQqdEclmcY6QoZ4JONdOcnucFRRnmdIYvXtd8tqKFYlK80+ucLjKUCBYzgrSVlnvO+1DQj0RmGRKRCfFlZcIM6RTH5rKqvKtw1sFZD6YdTHtw1cFVDyYdTHowwh3FPapTqpENwJJHap3ZnwkbrfK8ENOECYM4S8SBzcSrpQl8v4KvoD8KbN12+7zeHthlstEmk23pw7gRjyto1ZBEUqttXIc3R9kK1F7qXzlvORj6I39jsO8ErTMErZ0uB1/CSJIyo0ITjpSaB36uFwYVmhFO7fGlojkiFyihc+sKlFG1MJsZqOBTq0QwloX9hIYbdTvDoEzVHbKRdTfVdVaL/2PzUsfHC8NEXmoqSFMoLjnUEtYDBSNWUKL52jqIFMzeFZIUFYhoO3Z1E4LrT+47Z+NR8GJ0+HY8PHnZtmMXPAZPwDMQgCNwAt6AUzAFxPnkfHN+OD/dz+5395f7uwl1nTbnEbhi7p+/HigOJA==</latexit>

Illustration
Contour of loss function• red: SGD + momentum• black: SGD
Yao-Liang Yu25

RMSProp (root mean square propagation)
• Greater progress in the more gently sloped directions • One of the go-to optimization methods for deep learning
discard history from extreme past
Yao-Liang Yu26

Adam (adaptive moments)
A variant combining of RMSProp and momentum
both 1st and 2nd moments included
when t is large, the effect of bias correction is small
Yao-Liang Yu27

Learning rate
SGD, SGD+Momentum, AdaGrad, RMSProp, Adam all have learning rate as a hyperparameter. àReduce learning rate over time!
• Step decaye.g., decrease learning rate by halving every few epochs
• Exponential decay
• 1/t decay t: iteration number
Yao-Liang Yu28

Illustration
Yao-Liang Yu29

Questions?
Yao-Liang Yu30





























