Embed Size (px)
Citation preview

CS532:OperatingSystemsFoundations
Winter2020Prof.KarenL.Karavanic

OperatingSystems:MajorTrends
PSUCS533Prof.KarenL.Karavanic

Outline• TheSingleCoreEra(->2006)
– 0.TheOperatingSystemisHuman– 1.BatchProcessing– 2.MultiProgramming andTimesharing– 3.PersonalComputing&Connectivity
• TheMulticoreEra(2006->)– 5.WhyMulticore?– 6.Manycore
CS532Winter2020 3

CS 532 Winter 20204
The Single Core Era: Early Days■ The First Computer!■ Charles Babbage (1792-1871) and Ada Lovelace: “Analytical
Engine”
■ 1821: Difference Engine No. 1: add, subtract, solve polynomial equations
✦ Required 25,000 precision-crafted parts
◆ Difference Engine No. 2: Simpler version
◆ Analytical Engine: multiplication, division, algebra

CS 532 Winter 20205
The Single Core Era: Early Days
◆ 1990: Science Museum in London builds Difference Engine No. 2 in one year
✦ Cost: $500,000✦ Weight: three tons✦ Size: 11 feet long, 7 feet tall✦ Calculated successive values of seventh-order polynomial
equations containing up to 31 digits✦ Proves Babbage’s design

CS 532 Winter 20206
The Single Core Era: Early Days■ “First Generation” Computing (1940-
50)◆ Goal: compute trajectories for warfare◆ Relays/vacuum tubes (about 20,000)

CS 532 Winter 20207
The Single Core Era: Early Days◆ Programming: plugboards◆ Operating System: none◆ Innovation: punch cards

CS 532 Winter 20208
The Eniac (1946)

CS 532 Winter 20209
The Single Core Era: Early Days
■ “Second Generation” Computing (1950-64)■ Innovation: transistors, mainframes■ Innovation: first compiler (fortran)■ Batch systems■ Programming: Fortran, assembly language■ Innovation: Operating Systems: FMS, IBSYS

CS 532 Winter 202010
The Single Core Era #1: Batch Systems
Early “OS” was human:
◆ Operator carries punch cards to an I/O device◆ Input device reads cards to tape◆ Operator carries tape over to computer◆ Single job runs by reading instructions from tape
and writing output to tape◆ Operator carries tape back to I/O machine which
prints output
■ Cards include instruction to stop to load tape or compiler
■ Switching from one activity to another, loading and saving data were manual, unlike today
CS 532 Winter 202011
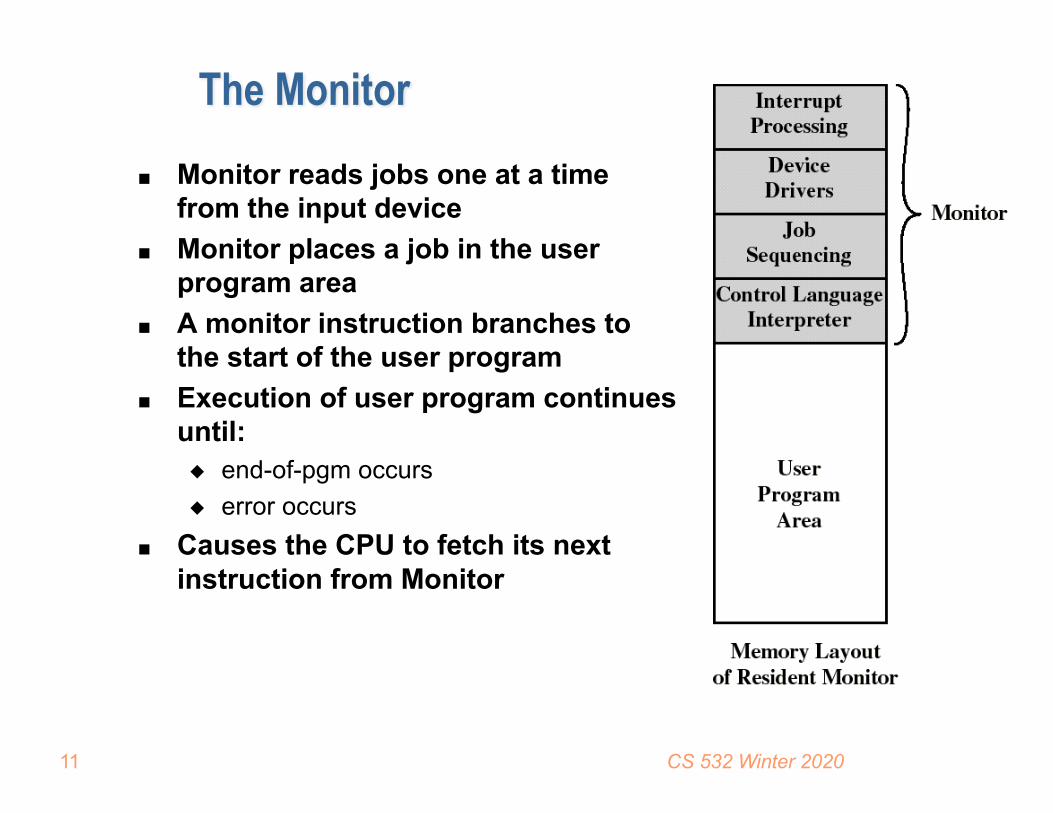
The Monitor■ Monitor reads jobs one at a time
from the input device■ Monitor places a job in the user
program area■ A monitor instruction branches to
the start of the user program■ Execution of user program continues
until:◆ end-of-pgm occurs◆ error occurs
■ Causes the CPU to fetch its next instruction from Monitor

CS 532 Winter 202012
Batch OS: Hardware Requirements
■ Memory protection◆ Need to protect the monitor code from the user programs
■ Timer◆ prevents a job from monopolizing the system◆ an interrupt occurs when time expires
■ Privileged instructions◆ can be executed only by the monitor◆ an interrupt occurs if a program tries these instructions
■ Interrupts◆ provides flexibility for relinquishing control to and regaining
control from user programs

CS 532 Winter 202013
The Single Core Era #2: Multiprogramming■ Major Innovation: Multiprogramming
◆ three jobs in memory at once

CS 532 Winter 202014
Multiprogrammed Batch Systems: The Insight
■ I/O operations are exceedingly slow (compared to instruction execution)
■ A program containing even a very small number of I/O ops, will spend most of its time waiting for them
■ Hence: poor CPU usage when only one program is present in memory

CS 532 Winter 202015
Multiprogrammed Batch Systems: The Insight
■ If memory can hold several programs, then CPU can switch to another one whenever a program is awaiting for an I/O to complete
■ This is multitasking (multiprogramming)

CS 532 Winter 202016
Multiprogramming (cont’d)
■ Multiprogramming is a virtualization of the single CPU
■ Hardware support:◆ I/O interrupts and (possibly) DMA
✦ in order to execute instructions while I/O device is busy◆ Memory management
✦ several ready-to-run jobs must be kept in memory◆ Memory protection (data and programs)
■ Software support from the OS:◆ Scheduling (which program should run next ? )◆ Resource Management ( contention, request ordering)

CS 532 Winter 2020 17
TheSingleCoreEra#3:Time Sharing Systems (TSS)
• Batch multiprogramming does not support interaction with users
• TSS extends multiprogramming to handle multiple interactive jobs
• Single core Processor’s time is shared among multiple users
• Multiple users simultaneously access the system through terminals– Because of slow human reaction time, a typical user
needs 2 sec of processing time per minute– Then (about) 30 users should be able to share the
same system without noticeable delay in the computer reaction time
• Concurrency: two users try to write to same file

CS 532 Winter 2020 18
TheSingleCoreEra#3:Time Sharing Systems (TSS)
• New OS needs: – Shared File Systems: files must be protected from
unauthorized users (multiple users…)– Improvements needed for the user interface,
connection / networking speeds• Operating Systems: Multics, Unix• Hardware needs: memory capacity
– What if this program doesn’t fit in my memory??– HW/SW Solution: Virtualize the memory– Virtual addresses are used in programs– They are translated to physical addresses at
runtime

CS 532 Winter 2020 19
The Single Core Era #4:Personal Computing & Connectivity (1980-1990s)• Hardware Innovation: [Very] Large Scale
Integration ([V]LSI) • Platform Innovation: microcomputers / PCs• Innovation: GUI (XEROX), X• Innovation: fast networks, internet, WWW,
client/server model, multithreading• Operating Systems: DOS, Windows, Linux

CS 532 Winter 2020 20
The Single Core Era #4:Personal Computing & Connectivity (1980-1990s)• Operating Systems: DOS, Windows, Linux• The POSIX API
– Programmers can write Posix-compliant code and it will run across Unix/Linux systems from different vendors
• OS must support: communication, data exchange, disconnection, battery lifetimes
• Security: servers running 24/7 are vulnerable

TheSingleCoreEra#5:TheMemoryHierarchy
• Whyhaveahierarchy ofmemory?• Howdoesitwork?
CS532Winter2020 21

Carnegie Mellon
22
Metric 1980 1985 1990 1995 2000 2005 2010 2010:1980
$/MB 8,000 880 100 30 1 0.1 0.06 130,000access (ns) 375 200 100 70 60 50 40 9typical size (MB) 0.064 0.256 4 16 64 2,000 8,000 125,000
StorageTrends
DRAM
SRAM
Metric 1980 1985 1990 1995 2000 2005 2010 2010:1980
$/MB 500 100 8 0.30 0.01 0.005 0.0003 1,600,000access (ms) 87 75 28 10 8 4 3 29typical size (MB) 1 10 160 1,000 20,000 160,000 1,500,0001,500,000
Disk
Metric 1980 1985 1990 1995 2000 2005 2010 2010:1980
$/MB 19,200 2,900 320 256 100 75 60 320access (ns) 300 150 35 15 3 2 1.5 200

Carnegie Mellon
23
TheCPU-MemoryGapThe gap between DRAM, disk, and CPU speeds.
0.0
0.1
1.0
10.0
100.0
1,000.0
10,000.0
100,000.0
1,000,000.0
10,000,000.0
100,000,000.0
1980 1985 1990 1995 2000 2003 2005 2010
ns
Year
Disk seek timeFlash SSD access timeDRAM access timeSRAM access timeCPU cycle timeEffective CPU cycle time
Disk
DRAM
CPU
SSD

Carnegie Mellon
24
LocalitytotheRescue!
ThekeytobridgingthisCPU-Memorygapisafundamentalpropertyofcomputerprogramsknownaslocality

Carnegie Mellon
25
Locality¢ PrincipleofLocality: Programstendtousedataand
instructionswithaddressesnearorequaltothosetheyhaveusedrecently
¢ Temporallocality:§ Recentlyreferenceditemsarelikely
tobereferencedagaininthenearfuture
¢ Spatiallocality:§ Itemswithnearbyaddressestend
tobereferencedclosetogetherintime

Carnegie Mellon
26
LocalityExample
¢ Datareferences§ Referencearrayelementsinsuccession
(stride-1referencepattern).§ Referencevariablesum eachiteration.
¢ Instructionreferences§ Referenceinstructionsinsequence.§ Cyclethroughlooprepeatedly.
sum = 0;for (i = 0; i < n; i++)
sum += a[i];return sum;
SpatiallocalityTemporallocality
SpatiallocalityTemporallocality

Carnegie Mellon
27
MemoryHierarchies¢ Somefundamentalandenduringpropertiesofhardware
andsoftware:§ Faststoragetechnologiescostmoreperbyte,havelesscapacity,
andrequiremorepower(heat!).§ ThegapbetweenCPUandmainmemoryspeediswidening.§ Well-writtenprogramstendtoexhibitgoodlocality.
¢ Thesefundamentalpropertiescomplementeachotherbeautifully.
¢ Theysuggestanapproachfororganizingmemoryandstoragesystemsknownasamemoryhierarchy.

Carnegie Mellon
28
AnExampleMemoryHierarchy
Registers
L1cache(SRAM)
Mainmemory(DRAM)
Localsecondarystorage(localdisks)
Larger,slower,cheaperperbyte
Remotesecondarystorage(tapes,distributedfilesystems,Webservers)
Localdisksholdfilesretrievedfromdisksonremotenetworkservers
Mainmemoryholdsdiskblocksretrievedfromlocaldisks
L2cache(SRAM)
L1cacheholdscachelinesretrievedfromL2cache
CPUregistersholdwordsretrievedfromL1cache
L2cacheholdscachelinesretrievedfrommainmemory
L0:
L1:
L2:
L3:
L4:
L5:
Smaller,faster,costlierperbyte

TheSingleCoreEra:OtherAdvances– Mobile devices
• Innovation: Fast Pervasive wireless and cellular• Innovation: Power Management
– Embedded Systems• Is your car on the internet? Your toaster?
– Open Source• Accessibility of OS, rate of upgrades to OS
– Virtualization: including HW support– Cloud Computing
• One server farm consumes as much power as a small U.S. city
CS 532 Winter 2020 29

TheMulticoreEra
• AsinglechipnowhasmorethanoneCPU• Mostsystemstodayaremulticore:
– Servers– PCs/laptops– Yourphone
• Iseverythingmulticore??– Yourtoastermaynotbe
• Software:everythingisparallel• OS:mustmanageacrossCPUs
CS532Winter2020 30

CS532Winter2020 31
TechnologyTrends:MicroprocessorCapacity
2Xtransistors/ChipEvery1.5yearsCalled“Moore’sLaw”
Moore’sLaw
Microprocessorshavebecomesmaller,denser,andmorepowerful.
GordonMoore(co-founderofIntel)predictedin1965thatthetransistordensityofsemiconductorchipswoulddoubleroughlyevery18months.
Slidesource:JackDongarra
CS532Winter2020 32
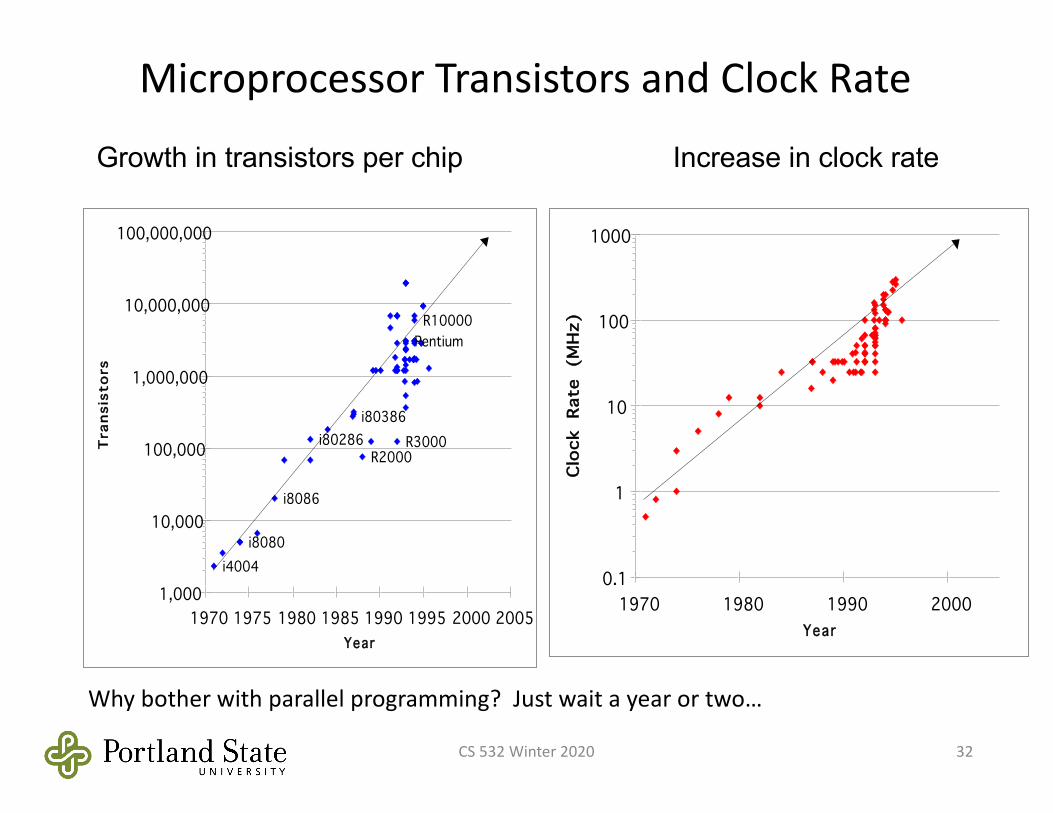
MicroprocessorTransistorsandClockRate
i4004
i80286i80386
i8080
i8086
R3000R2000
R10000Pentium
1,000
10,000
100,000
1,000,000
10,000,000
100,000,000
1970 1975 1980 1985 1990 1995 2000 2005Year
Tra
nsisto
rs
Growth in transistors per chip Increase in clock rate
0.1
1
10
100
1000
1970 1980 1990 2000Year
Clo
ck R
ate
(MH
z)
Whybotherwithparallelprogramming?Justwaitayearortwo…

CS532Winter2020 33
Limit#1:Powerdensity
400480088080
8085
8086
286 386486
Pentium®P6
1
10
100
1000
10000
1970 1980 1990 2000 2010Year
PowerDen
sity(W
/cm
2 )
HotPlate
NuclearReactor
RocketNozzle
Sun’sSurface
Source:PatrickGelsinger,Intelâ
Scalingclockspeed(businessasusual)willnotwork
Cansoonputmoretransistorsonachipthancanaffordtoturnon.-- Patterson‘07

CS532Winter2020 34
ParallelismSavesPower• Exploitexplicitparallelismforreducingpower
Power = C * V2 * F Performance = Cores * F
Capacitance Voltage Frequency
• Usingadditionalcores– Increasedensity(=moretransistors=morecapacitance)– Canincreasecores(2x)andperformance(2x)– Orincreasecores(2x),butdecreasefrequency(1/2):sameperformanceat¼thepower
Power = 2C * V2 * F Performance = 2Cores * FPower = 2C * V2/4 * F/2 Performance = 2Cores * F/2Power = (C * V2 * F)/4 Performance = (Cores * F)*1
• Additionalbenefits– Small/simplecoresàmorepredictableperformance

CS532Winter2020 35
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
25%/year
52%/year
??%/year
Limit#2:HiddenParallelismTappedOut
• VAX:25%/year1978to1986
• RISC+x86:52%/year1986to2002
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, 2006
Applicationperformancewasincreasingby52%peryearasmeasuredbytheSpecIntbenchmarkshere
• ½ due to transistor density• ½ due to architecture
changes, e.g., Instruction Level Parallelism (ILP)

CS532Winter2020 36
Limit#2:HiddenParallelismTappedOut
• Superscalar(SS)designswerethestateoftheart;manyformsofparallelismnotvisibletoprogrammer– multipleinstructionissue– dynamicscheduling:hardwarediscoversparallelism
betweeninstructions– speculativeexecution:lookpastpredictedbranches– non-blockingcaches:multipleoutstandingmemoryops
• Unfortunately,thesesourceshavebeenusedup

37
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Per
form
ance
(vs.
VA
X-1
1/78
0)
25%/year
52%/year
??%/year
UniprocessorPerformance(SPECint)Today
• VAX :25%/year1978to1986• RISC+x86:52%/year1986to2002• RISC+x86:??%/year2002topresent
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach, 4th edition, 2006
Þ Seachangeinchipdesign:multiple“cores” orprocessorsperchip
3X
2xevery5years?
CS532Winter2020
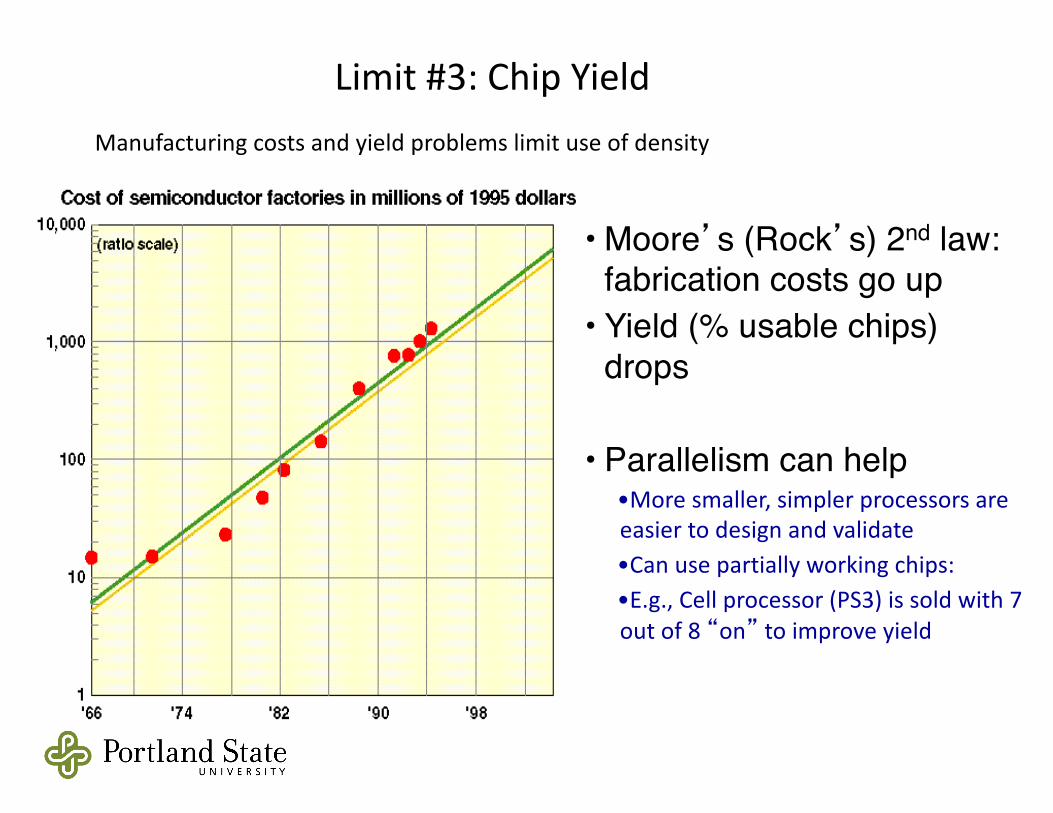
Limit#3:ChipYield
• Moore’s (Rock’s) 2nd law: fabrication costs go up
• Yield (% usable chips) drops
• Parallelism can help•Moresmaller,simplerprocessorsareeasiertodesignandvalidate•Canusepartiallyworkingchips:•E.g.,Cellprocessor(PS3)issoldwith7outof8“on” toimproveyield
Manufacturingcostsandyieldproblemslimituseofdensity

CS532Winter2020 39
Limit#4:SpeedofLight(Fundamental)
• Considerthe1Tflop/ssequentialmachine:– Datamusttravelsomedistance,r,togetfrommemorytoCPU.
– Toget1dataelementpercycle,thismeans1012 timespersecondatthespeedoflight,c=3x108 m/s.Thusr<c/1012=0.3mm.
• Nowput1Tbyteofstorageina0.3mmx0.3mmarea:– Eachbitoccupiesabout1squareAngstrom,orthesizeofasmallatom.
• Nochoicebutparallelism
r=0.3mm1Tflop/s,1Tbytesequentialmachine

CS532Winter2020 40
Thus,theMulticoreEra• Chipdensityis
continuingincrease~2xevery2years*– Clockspeedisnot– Numberof
processorcoresmaydoubleinstead
• Thereislittleornohiddenparallelism(ILP)tobefound
• Parallelismmustbeexposedtoandmanagedbysoftware
Source:Intel,Microsoft(Sutter)andStanford(Olukotun,Hammond)

Carnegie Mellon
41
IntelCorei7CacheHierarchy
Regs
L1 d-cache
L1 i-cache
L2 unified cache
Core 0
Regs
L1 d-cache
L1 i-cache
L2 unified cache
Core 3
…
L3 unified cache(shared by all cores)
Main memory
Processor packageL1i-cacheandd-cache:
32KB,8-way,Access:4cycles
L2unifiedcache:256KB,8-way,Access:11cycles
L3unifiedcache:8MB,16-way,Access:30-40cycles
Blocksize:64bytesforallcaches.

WhatisManycore ?
• Whatifweuseallofthetransisters onachipforasmanycoresaswecanfit??
• Beyondtheedgeofnumberofcoresincommon“multicore”architectures
• Dividinglineisnotclearlydefined• Activeresearch,nowinembedded&clusters• Examples:
– NVIDIAFermiGraphicsProcessingUnit(GPU)• Firstmodel:32“CUDAcores”perSM,16SMs
– (SM=“streamingmultiprocessor”)• K20model:2496CUDAcores,peak3.52Tflops
CS532Winter2020 42

Ex:NVIDIAFermi
CS532Winter2020 43

WhatisManycore ?
• Examples(cont’d)– IntelXeonPhicoprocessorandKnightsLanding
• Upto61coreseach– Example:Tianhe-2Supercomputer(China)
• 32,000multicoreCPUs• 48,000coprocessors (“accelerators”)• peak33.86PetaFLOPS
– Example:SummitSupercomputer(U.S.)• IBMPower9processors• acceleratedwithNVIDIAVoltaGPUs• Total#cores:2,414,592
CS532Winter2020 44

Acknowledgments
• Thispresentationincludesmaterialsandideasdevelopedbyothers:– 15-213:IntroductiontoComputerSystems,2010
• RandyBryantandDaveO’Hallaron
– JackDongarra,UniversityofTennessee– KathyYelick,UC-Berkeley– AndrewS.Tanenbaum,ModernOperatingSystems
– Remzi andAndreaC.Arpaci-Dusseau,OperatingSystems:ThreeEasyPieces
CS532Winter2020 45





























