Embed Size (px)
Citation preview

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 1/23
Developing Kernels: Part 2Algorithm Considerations, Multi-Kernel Programs and Optimization
Steven Gratton, Institute of Astronomy

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 2/23
• Want to break the problem up into multiple steps, each of which could
do with a large number of blocks and threads within blocks thrown at it
• How do we synchronize between steps?
• Remember __syncthreads() only works within a block…
• Key point:
the global memory persists on the gpu after a kernel finishes, and a new
kernel isn’t start until pending memory writes complete

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 3/23
Global Synchronization
• So, enforce global synchronization by stopping one kernel and starting
another one!
• A bit drastic, but it works!
• O(10^-5 s) kernel launch overhead
• Shared memory is erased
• No problem as long as you don’t have to do it too often!

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 4/23
So, we’ll need something like…
__global__ topleft(,);
__global__ strip(,);
__global__ therest(,);
for (n=0;n<SZ;n++) {
topleft<<<,>>>(n,);
strip<<<,>>>(n,);
therest<<<,>>>(n,);
}

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 5/23
Only worry about/optimize what matters!
• For us, therest<<<,>>>() is what matters
• As long as we don’t do anything silly, the other two basically just have to
work and no more

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 6/23
So, what can we do?
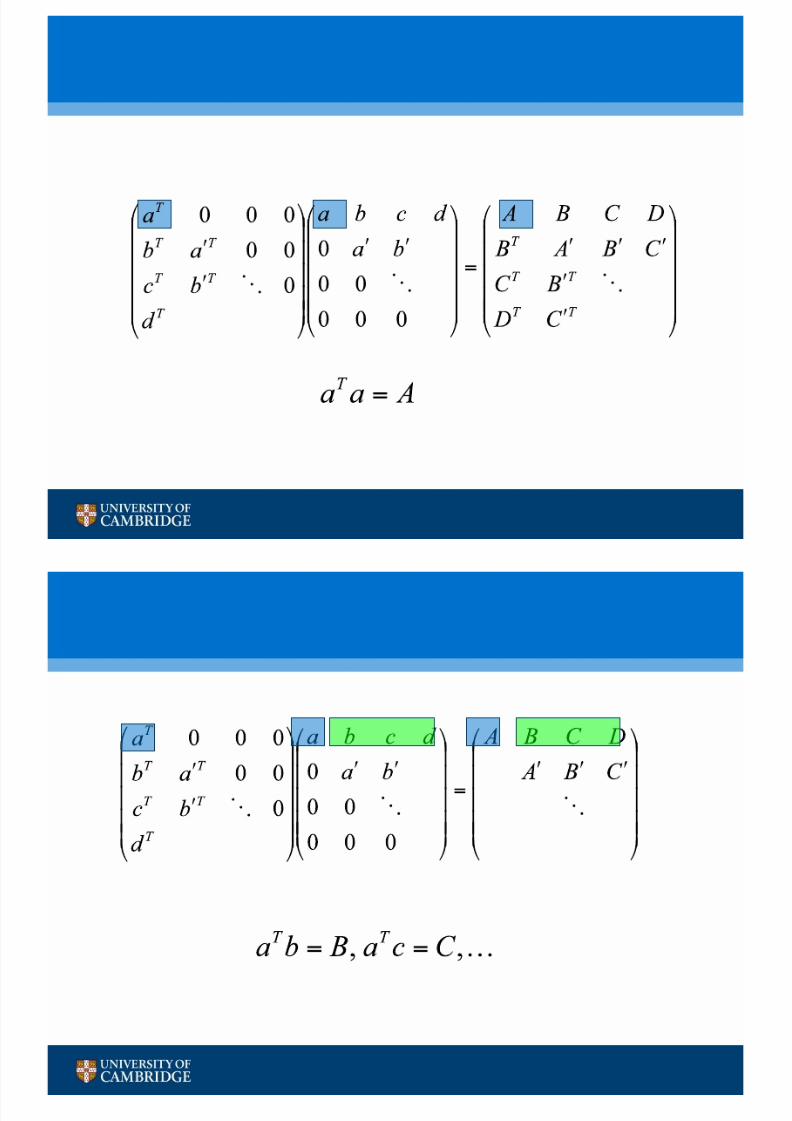
• Matrix suggests a tiled approach, each thread doing one element.
• Keeping our thread blocks square for simplicity, a natural choice is
16x16 (more on this later), so we’ll need a
dim3 Db(16,16);
Nb. 16x16=8x32, so no incomplete warps!
• But a problem is now that we have to subtract a vector times its
transpose
• Vectors are a bit unnatural when dealing with 16x16 tiles!
• Can we improve our algorithm?
7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 7/23
Now treat our elements as tiles!

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 8/23

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 9/23

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 10/23
• i.e.
• Just another Cholesky factorization, smaller by one tile!

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 11/23
What have we gained?
• (N/16)^3 tiled operations altogether.
• Each of these is now an 16x16 matrix multiply, so 16^3.
• No change in the FLOPs.
• But what about memory?
• If each block can store the tiles it needs in shared memory, then it
only has to do 16x16 loads
• So saves a factor of 16 on the memory!!!

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 12/23
But why 16?
• A “magic number” in CUDA, for many reasons. We’ve already seen
that 16^2 = 32x8
• But here’s another one:
• On existing hardware, memory accesses are grouped by half-warp,
which is 16
• And global memory accesses are optimal (“coalesced ”) if all threads
in a half-warp access consecutive memory locations
Even more important for 1st gen hardware
(Now you can “shuffle” your accesses somewhat)

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 13/23
Sharing memory banks
• Remember, we’re caching the tiles in shared memory!
• Like global memory, shared memory is accessed per half-warp.
• Divided up into banks, currently 16, each a float wide.
• So __shared__float c[16][16]; has one column per bank

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 14/23
• Shared memory is quick if:
• All threads access a different bank
• C[?][tx] is fine
• All threads access the same element in a given bank
• C[ty][3] is fine
• But c[tx][3] is not

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 15/23
• Look at B’, need to load b^T and c
• Fine for the untransposed matrix, we’ll have something like
c[ty][tx]=m[ty][tx];
• but what about the transposed one? We need something like…
b[ty][tx]=m[ty][tx];

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 16/23
• To do the matrix multiply within a block, we’ll need
for (i=0;i<16;i++){
m[ty][tx]=m[ty][tx]-b[i][ty]*c[i][tx];
}
so we’re okay here

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 17/23
Digression: Loop unrolling
#pragma unroll 16
for (i=0;i<16;i++){
m[ty][tx]=m[ty][tx]-b[i][ty]*c[i][tx];
}
replaces the loop with 16 lines of code, saving loop overhead

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 18/23
What if you do have shared memory bank conflicts?
• Typically happen when accessing a 16x16 array columnwise rather than
rowwise
• Consider defining your array “a bit off”:
__shared__float c[16][17];
• Now not only is each element of a row in a different bank, but now each
element of a column is also!
• (just don’t get a half warp to access diagonal elements now…)
• Avoiding conflicts can be tricky if you’re dealing with e.g. doubles

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 19/23
So, let’s have a look through and give it a go!
…see cholesky.cu, transchol.cu, doublechol.cu
(Code available via www.ast.cam.ac.uk/~stg20/cuda/cholesky/)

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 20/23
What goes on “under the hood”?
• nvcc
• splits your .cu code into .c/.cpp code for the host compiler and code
for the device
• Compiles the device code into a virtual assembly language (.ptx)
• This then gets further compiled into proper executable machine code
for your gpu (.cubin)
• Everything then gets put back together and linked with the
appropriate libraries to give you your executable “a.out”

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 21/23
You can take a look:
nvcc –keep …
Looking at the ptx can give you a good idea of what is going on.
Nvidia haven’t disclosed the real ISA, but you can look at the .cubin file
and see some interesting things, like how many registers per thread and
how much shared memory your kernels need – the less of both, the
more blocks per multiprocessor you can run which helps hide memory
latency

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 22/23
Conclusions
• We’ve seen how that GPGPU is all about having many threads run the
same program
• Hardware constraints make this more complicated than it might be
• Seen how we can use multiple kernels if we need global
synchronization
• Choice of algorithm to implement crucial
• Looked at possible optimizations and what goes on beneath the surface

7/30/2019 CUDA_May_09_STG_L4
http://slidepdf.com/reader/full/cudamay09stgl4 23/23
Further issues
• Need 6 warps per multiprocessor to hide any pipelining
• As well as shared memory bank conflicts, you can also have register
bank conflicts. The only advice is to have 64, 128, … threads per block.
• Global memory is partitioned round-robin between channels in 256-byte
chunks. Be careful to avoid all threads only accessing memory that lies
in one channel! Nvidia now recognize this and call it partition camping.
• nvcc -maxrregcount n can sometimes help





























