Embed Size (px)
Citation preview

Data Versioning Systems
Research Proficiency Exam
Ningning Zhu Advisor Tzi-cker Chiueh
Computer Science DepartmentState University Of New York at Stony
BrookFeb 10, 2003

Definitions
Data Object Granularity of Data Object
file, tuple, database table, database logical volume, database, block device
Version of a Data Object A consistent state, a snapshot, a point-in-time image
Data Repository Version Repository

Why need data versioning?
Documentation Versioning Control Human mistakes Malicious attacks Software failure History Study

Data Versioning Vs. Other Techniques
Backup Mirroring Replication Redundancy Perpetual storage

Design Issues
Resource Consumption Storage capacity, CPU Storage bandwidth, network bandwidth
Performance old versions, current object Throughput, latency
Maintenance Effort

Design Options
Who perform ? User, Application, file system, database system, object store,
virtual disks, block-device
Where and what to save? Separate version repository? Full image vs. delta
How? Frequency Scope

Data Versioning Techniques
Save
Represent
Extract

Save: naive approach (1)
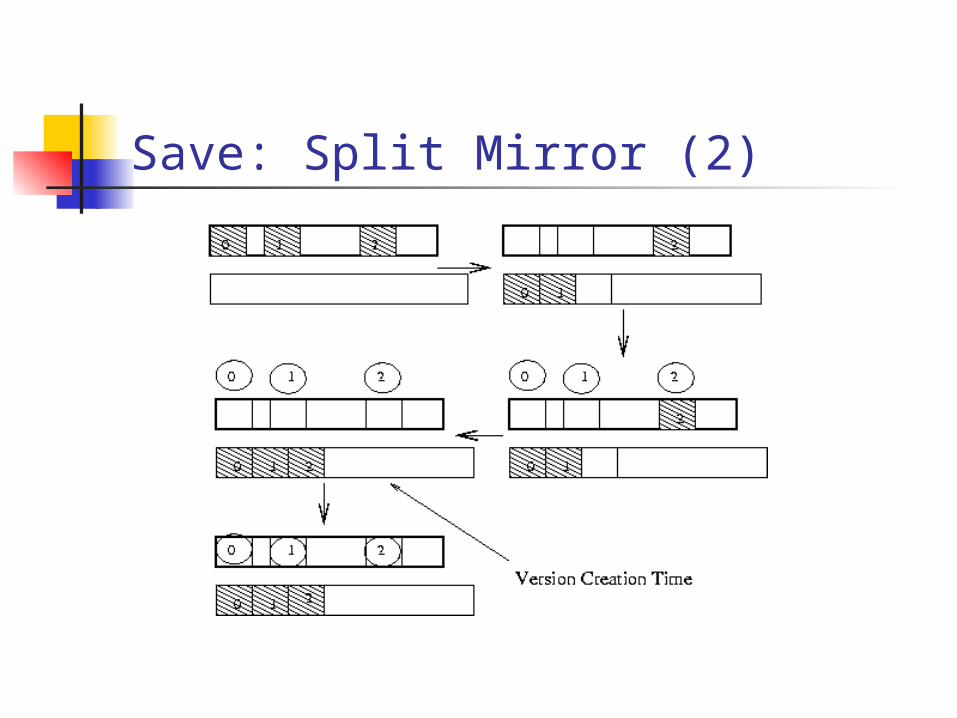
Save: Split Mirror (2)
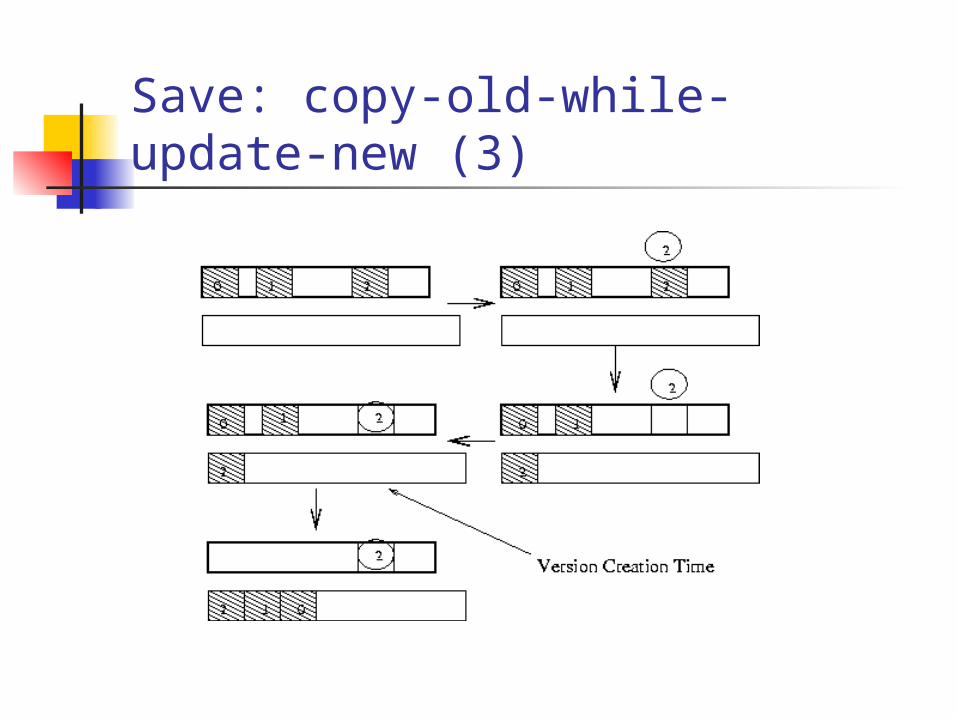
Save: copy-old-while-update-new (3)

Save: keep-old-and-create-new (4)

Represent (1)
Full image Easy to extract, consume more resource
Delta Reference direction reference object Differencing algorithm
Chain of delta and full image

Represent: Chain structure (2)
Forward delta V1, D(1,2), D(2,3), V4, (D4,5), D(5,6), V7
Forward delta with version jumping V1, D(1,2), D(1,3), V4, (D4,5), D(4,6), V7
Reverse delta V1, D(3,2), D(4,3), V4, D(6,5), D(7,6), V7

Represent: differencing algorithm (3)
Insert/Delete (diff) vs. Insert/Copy (bdiff)
Rabin fingerprint Given a sequence of bytes:
SHA-1: Collision free hashing function
MtpptttRFttRF
MtptptptttttRF
tttt
iiiiii mod))((((
mod)()(
))1)1
11
21,...3,2,1
,...3,2,1

XDFS
Drawback of traditional version control
Slow extraction, fragmentation, lack of atomicity support
XDFS A user-level file system with versioning support Separate version labeling with delta compression Effective delta chain Built upon Berkeley DB

Log Structured File System-SpriteLFS
Access assumption: small write Data Structure
Inode Inode map Indirect block Segment summary Segment usage table Superblock (fixed disk location) Checkpoint region (fixed disk location) Directory change log

Research Data Versioning System
File System Elephant Comprehensive Versioning File System
Object-store Self-Secure-Storage-System Oceanstore
Database System Postgres and Fastrek
Storage System Petal and Frangipani

Elephant File System (1)
Retention Policy Keep one
Keep all
Keep safe
Keep landmark (intelligently add landmark)
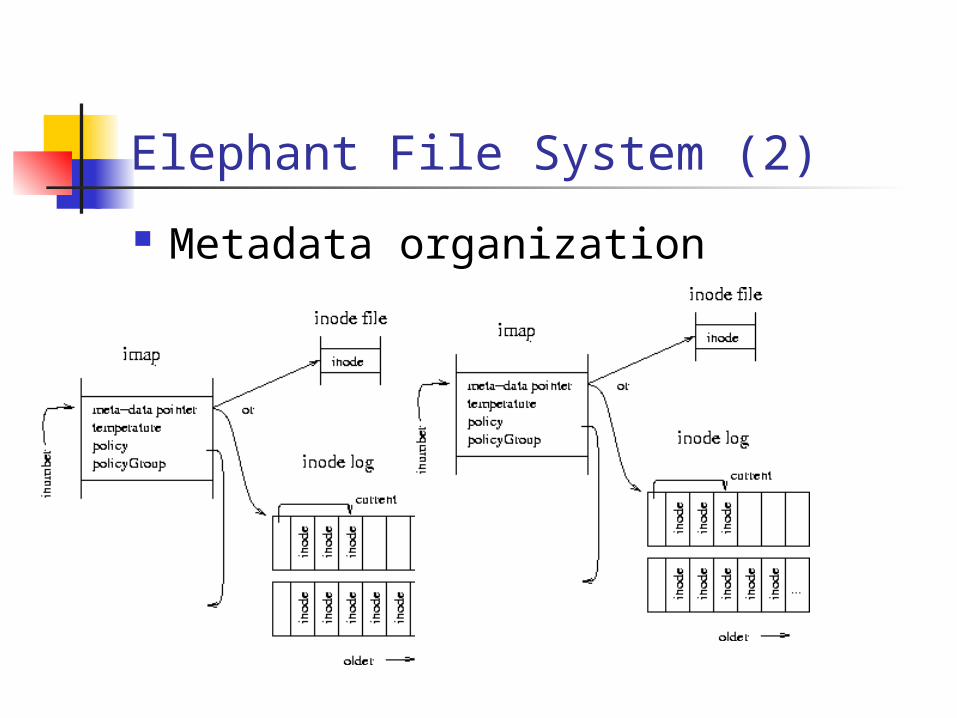
Elephant File System (2)
Metadata organization

S4: Self-Secure Storage System (1)
Object-store interface Log everything Audit log Efficient metadata logging
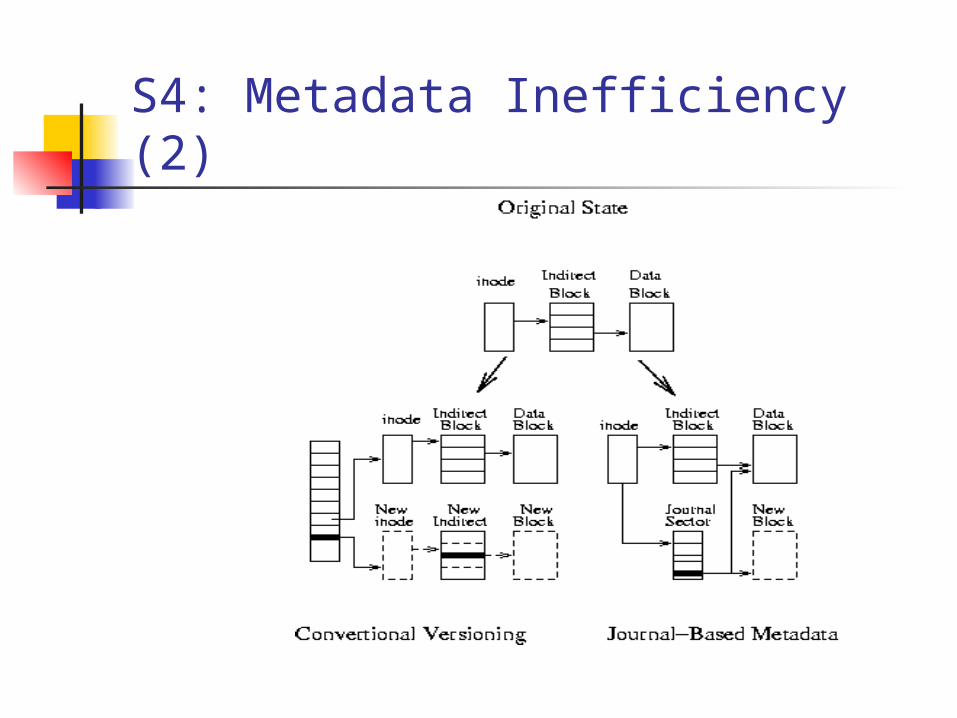
S4: Metadata Inefficiency (2)
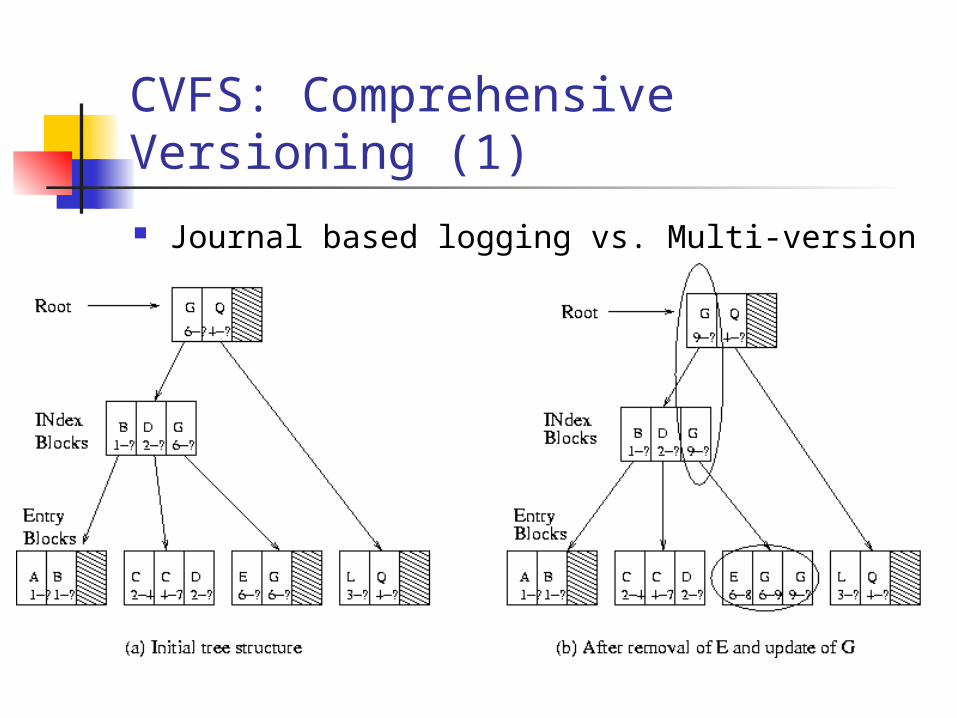
CVFS: Comprehensive Versioning (1)
Journal based logging vs. Multi-version B-tree

CVFS: Comprehensive Versioning (2)
Journal-based vs. Multi-version B-tree
Assumptions about metadata access
Optimizations: Cleaner: pointers in version repository Both forward delta and reverse delta Checkpointing and clustering Bounded old version access by forcing checkpoint

Oceanstore: decentralized storage
A global-scale persistent storage A deep archival system Data Entity is identified by
<A-GUID, V-GUID>
Internal data structure is similar to S4.
Use B+ tree for object block indexing

Postgres:a multi-version database(1)
Versioning support “Save” of a version in the database context Optimized towards “extract”
Database Structure and Operation Tables made up of tuples First and secondary indices Transaction log: <TID, operation> Update Delete + Insert

Postgres: record structure (2)
Extra fields for versioning: OID : record ID, shared by versions of this
record Xmin : TID of the inserting transaction Tmin : Commit time of Xmin Xmax : TID of the deleting transaction Tmax : Commit time of Xmax PTR : forward pointer from old new
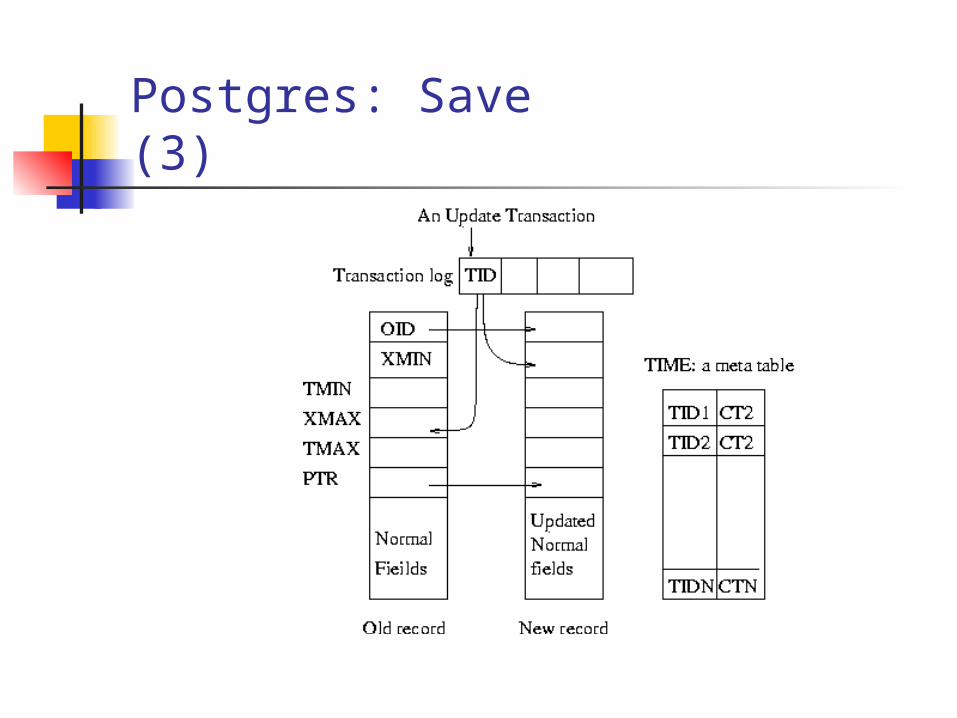
Postgres: Save (3)

Postgres: Represent & Extract (4)
Full image + forward delta SQL query with TIME parameter Build indices using R-tree for ops:
Contained in , overlap with
Secondary indices When a delta record is inserted, if secondary indices
need to be changed, an full image need to be constructed

Postgres: Frequency of extraction (5)
No archive Timestamp never filled in
Light archive Extract time from TIME meta table
Heavy archive First use, extract time from TIME metadata, then fill
the field Later use, directly from data record

Postgres: Hardware Assumption (6)
Another level of archival storage WORM (optical disks)
Optimizations: Indexing Accessing method Query plan Combine indexing at magnetic disks and archival
storage

Fastrek: application of versioning
Built on top of Postgres Tracking read operation Tracking write operation
Tmin, Tmax
Data dependency analysis Fast and intelligent repair

Petal and Frangipani
Petal: a distributed storage supports virtual disk snapshot <virtual disk id, off> -> <physical disk id, off> <virtual disk id, epoch, off> -> <physical disk id,
off>
Frangipani: A distributed file system built on top of Petal Versioning by creating virtual disks snapshot Coarse granularity: mainly for back purpose

Commercial Data Versioning Systems
Network Appliance IBM EMC

Network Appliance: WAFL
Network Appliance Customized for NFS and RAID
Automatic checkpointing Utilize NVRAM:
fast recovery
Good performance: update batching, least blocking upon versioning
Easy extraction: .snapshot directory

WAFL: system layout

WAFL:Limited Versioning

Network Appliance: SnapMirror
Built upon WAFL Synchronous Mirroring Semi-synchronous Mirroring Asynchronous Mirroring
15 minutes interval, save 50% of update
SnapMirror: Get block information from blockmap Schedule mirroring at block-device level

IBM (Flash Copy ESS)
A block-device mirroring system Copy-old-while-update-new Use ESS cache and fast write to
mask write latency Use bitmap to keep track each
block of old version and new version

EMC (TimeFinder)
Split mirror Implementation

Proposal:
Non-point-in-time versioning What is the most valuable state?
Operation-based journaling Natural metadata journaling efficiency
Design Transparent mirroring and versioning Primary site non-journaling, mirror site journaling against intrusion, mistake Applied to network file server

Repairable File Service: architecture

Represent: operation-based
Delta: NFS packets Journal: Reverse delta chain
No checkpointing overhead A chain of 2 months will cost <$100
Efficiency metadata journaling 100-200 bytes for inode, directory update One hash table entry for indirect block update

Save: a hybrid approach
Data block update Copy-old-create-new
Metadata update: Naïve: Read old, write old, update new Variation of Naïve: Guess old,write old, update-new Variation of Naïve: Get old, write old, update-new

User Level Journaling File System

System Layout

Extract: intelligent and fast repair
Dependency logging Dependency analysis Fast Repair
Fast extract of most valuable state of a data system
Drawback: Poor performance for other extract specification

Conclusion (1)
Hardware technology -> DV possible Capacity Random access storage CPU time
Penalty of data loss -> DV a necessity
Data loss System down time
DV technology: Journaling, B+, differencing algorithm

Conclusion (2)
DV at application level DV at file system/database level DV at storage system/block device
level A combined and flexible solution to
satisfy all DV requirement at low cost.

Future Trend (1)
Comprehensive versioning Perpetual versioning High performance versioning
Comparable to non-versioning system
Intrusion oriented versioning Testing new untrusted application Reduce system maintenance cost
Semantic extraction

Future Trend (2)
In decentralized storage system, integrate and separate DV with
Replication Redundancy Mirroring Encryption
Avoid similar functionality being implemented at by multiple modules





























