Embed Size (px)
Citation preview

Design og implementation af klynge-løsning til biologiskforskning
Skriftligt 2.dels projektDatalogisk Institut Københavns Universitet (DIKU)
Lars G.T. Jørgensen ([email protected]) & Sidsel Jensen ([email protected])
Marts 17, 2003
Resume
Dette projekt omhandler design og implementering af en klynge til brug for biolo-gisk forskning. Projektet er blevet til i samarbejde med Center for Bioinformatik ogZoologisk Museum. Projektet er opdelt i tre faser, den første omhandler udarbejdelsenaf en specifikation af klyngen, den anden fase omhandler inkøb af klyngen og den sid-ste fase omhandler opsætning og evaluering af klyngen. Resultatet af disse tre faser eren 240 maskiners klynge, kaldet “BioCluster” (http://www.biocluster.ku.dk), dersnart er klar til at blive taget i brug. Klyngen vil kunne nedsætte databehandlingstidenfor de to institutter betydeligt og derved fremme deres forskning.

Indhold
1 Indledning 11.1 Organisatorisk setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Motivation for anskaffelse af klynge . . . . . . . . . . . . . . . . . . . . . 21.3 Definition af bioinformatik . . . . . . . . . . . . . . . . . . . . . . . . . . 21.4 Klyngens arbejdsopgaver . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Grundlæggende molekylær biologi 32.1 Biologiske termer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.1.1 Proteiner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32.1.2 Proteinsyntese . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Sekvenssammenligning . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2.1 Parvis og multipel sekvenssammenligning . . . . . . . . . . . . . 52.2.2 Global og lokal sekvenssammenligning . . . . . . . . . . . . . . . 52.2.3 Mellemrumsproblemet . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Phylogenetik . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Analyse 63.1 Programmerne . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3.1.1 Evolutionær matrix . . . . . . . . . . . . . . . . . . . . . . . . . 63.1.2 POY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63.1.3 POY testdatasæt . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.1.4 TNT . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73.1.5 NCBI BLAST . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.1.6 BLAST testdatasæt . . . . . . . . . . . . . . . . . . . . . . . . . 83.1.7 Hidden Markov Models . . . . . . . . . . . . . . . . . . . . . . . 83.1.8 HMM testdatasæt . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Forundersøgelser . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2.1 Testmaskiner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2.2 Malingsværktøjer . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.2.3 Forsøg og resultater . . . . . . . . . . . . . . . . . . . . . . . . . 11
4 Valg af hardware 124.1 Valg af CPU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 124.2 Varmeudvikling og strømforbrug . . . . . . . . . . . . . . . . . . . . . . 134.3 Hukommelsesovervejelser . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.4 Netværksteknologi . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.5 Valg af disk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.6 Valg af server . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154.7 Opsumering over valg af hardware . . . . . . . . . . . . . . . . . . . . . 16
5 Valg af software 175.1 Valg af styresystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.2 Valg af filsystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 175.3 Valg af installationssystem . . . . . . . . . . . . . . . . . . . . . . . . . . 185.4 Jobstyringssoftware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185.5 Biblioteker og applikationer . . . . . . . . . . . . . . . . . . . . . . . . . 19
i

INDHOLD INDHOLD
6 Setup og design af klyngen 206.1 Installationsystemet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206.2 Navngivning af maskiner . . . . . . . . . . . . . . . . . . . . . . . . . . . 226.3 Netværksstrukturen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226.4 De fysiske rammer . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 236.5 Konfiguration af server . . . . . . . . . . . . . . . . . . . . . . . . . . . . 246.6 Det endelig setup . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
7 Test og Evaluering af klyngen 257.1 Fejl og mangler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 257.2 MTBF begrebet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 267.3 Linpack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 277.4 Test af programmerne . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
7.4.1 BLAST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287.4.2 POY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 287.4.3 HMM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297.4.4 Opsummering pa testkørsler . . . . . . . . . . . . . . . . . . . . . 30
8 Konklusion 30
9 Perspektivering 31
10 Litteraturliste 32
A Kørselsudskrifter fra forundersøgelser 34A.1 Testkørsel af POY . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
A.1.1 POY pa testmaskine 3 . . . . . . . . . . . . . . . . . . . . . . . . 34A.1.2 POY pa testmaskine 4 . . . . . . . . . . . . . . . . . . . . . . . . 34A.1.3 POY pa testmaskine 5 . . . . . . . . . . . . . . . . . . . . . . . . 34
A.2 Testkørsel af BLAST . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35A.2.1 BLAST pa testmaskine 3 . . . . . . . . . . . . . . . . . . . . . . 35A.2.2 BLAST pa testmaskine 4 . . . . . . . . . . . . . . . . . . . . . . 35A.2.3 BLAST pa testmaskine 5 . . . . . . . . . . . . . . . . . . . . . . 36
A.3 Testkørsel af HMM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36A.3.1 HMM pa testmaskine 3 . . . . . . . . . . . . . . . . . . . . . . . 36A.3.2 HMM pa testmaskine 4 . . . . . . . . . . . . . . . . . . . . . . . 37A.3.3 HMM pa testmaskine 5 . . . . . . . . . . . . . . . . . . . . . . . 38
B Kravspecifikation pa klyngecomputere 39B.1 Computere . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
C Oversigt over tilbud 41
D Dell tilbud 43
E El tilbud 49
F Kølings tilbud 52
ii

INDHOLD INDHOLD
G Switch tilbud 57
H Linpack konfigurationsfil 63H.1 Vores HPL.dat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63H.2 Horseshoes HPL.dat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
iii

1 INDLEDNING
1 Indledning
Dette er et skriftligt 2.dels projekt, skrevet pa Datalogisk Institut Københavns Univer-sitet (DIKU) i perioden september 2002 - marts 2003. Projektets formal er at analysereet antal programmer specificeret af de involverede forskere fra Center for Bioinformatikog Zoologisk Museum og, udfra disse at designe en klyngecomputer. Herefter er projek-tets formal at implementere den i designfasen skitserede klynge og evaluere de omtalteprogrammers performance pa klyngen. Et delmal er derfor at male klyngens perfor-mance med benchmark programmet Linpack, som benyttes til performance malingerfor TOP500 Supercomputere. Samtidig udvikles et dokumentations website, hvor in-formation om klyngen og dens setup vil kunne forefindes: (http://biocluster.ku.dk/).
Projektet har arbejdet under en deadline, der hed udgangen af ar 2002, for købetaf computerne til klyngen. Projektet er derfor naturligt faldet i 3 faser indenfor denafsatte tid. Hvor fordelingen har været 1/3 tid til analyse og 1/3 tid til design/indkøbog den sidste trediedel til implementering, herunder istandsættelse af serverrum tilklyngen.
Undervejs i projektet var vi i november pa en en-dags studietur til Odense, hvorvi snakkede med Brian Vinther, som er ansvarlig for Syddanske Universitets (SDU)klynge Horseshoe, der er sammenkoblet med en tilsvarende klynge pa Danmarks Tek-niske Universitet (DTU) i Lyngby.
Projektet er undervejs blevet udvidet fra det oprindelige projekt, som kun omhand-lede en klynge til det nyoprettede Center for Bioninformatik, til ogsa at indeholde enklynge til Zoologisk Museum. Zoologisk Museum henvendte sig til Eric Jul i DIKUsDistlab gruppe for at fa hjælp til deres projekt. Vi blev sa naturligt tilkoblet deres klyn-geprojekt, da vores vejleder Jørgen Sværke Hansen snakkede sammen med Eric Jul.Projektet er derfor vokset til dobbelt størrelse, i forhold til hvad vi havde forestillet os.
1.1 Organisatorisk setup
Den klynge, der er tale om i denne rapport, er altsa finanscieret af to selvstændige insti-tutter pa København Universitet: Center for Bioninformatik og Zoologisk Museum. Entrediedel af pengepuljen pa 1,2 million kroner kom fra Center for Bioinformatik og desidste to trediedele kom fra Zoologisk Museum. Det blev ret hurtigt afgjort pa et fællesmøde, at der som minimum skulle laves en fælles indkøbsaftale mellem de to institutter.
Center for Bioinformatik er et lille og helt nyoprettet institut pa København Uni-versitet og bor derfor pt. i nogle lokaler, som er udlant af Zoologisk Institut. I løbet afde næste 2-3 ar, vil der blive bygget et nyt center i universitetsparken , som skal huseuddannelsen. Det var derfor et krav fra starten, at klyngen skulle kunne deles op i toseperate dele, safremt Bioinformatik skulle flytte lokaler. Dette har dog relativt langeudsigter, set i forhold til klyngens formodede levetid, sa det faldt naturligt at spørgeZoologisk Museum, om de havde mulighed for at huse hele klyngen i det serverrum,som de havde afsat til projektet.
1

1 INDLEDNING 1.2 Motivation for anskaffelse af klynge
Zoologisk Museum, havde dog pa det givne tidspunkt ikke et rum, som var indrettettil dette formal. Det blev derfor en del af projektet at fa skabt et serverrum, som kunnehuse klyngen under de rette forudsætninger, sa som pladsforbrug, el og køling. Dettearbejde stod Zoologisk Museums System Administrator Claes Petersen i høj grad forat organisere, og projektet her er blevet til med en stor indsats fra hans side. Vi vilyderligere gerne takke John fra Zoologisk Museum og Ciprian fra GBIF for deres hjælpi projektet.
1.2 Motivation for anskaffelse af klynge
Forskerne pa Zoologisk Museum, anført af Nikolai Sharff, havde et meget stærkt ønskeom en klynge, da de allerede idag benytter sig af en klyngecomputer pa American Mu-seum of National History, som de betaler for. Ved anskaffelsen af deres egen klynge,ville de dermed kunne spare de penge, der la i købet af computertid i USA. Der varderfor ikke nogen tvivl hos Zoologisk Museum om, at de ønskede en klynge, der sa vidtmuligt matchede den klynge, de allerede havde vendt sig til at benytte.
Anders Krogh, centerleder fra Center for Bioinformatik, ønskede ligeledes en klyngeaf forskningshensyn. Klynger er blevet specielt populære indenfor bioninformatik, dade prismæssigt er meget konkurrencedygtige, specielt set i forhold til de traditionellesupercomputere som f.eks. Blade Servers eller Sun Fire familien. 10 ud af 10 af verdenshurtigste computere er idag klynge-computere. Meget forskning indenfor lige præcisbioinformatik bliver dog udført pa desciderede compute farms idag, da de fleste bioin-formatik algoritmer er meget nemme at parallelisere.
1.3 Definition af bioinformatik
Bioinformatik kan defineres pa følgende made: De forskellige matematiske, statistiskeog computerbaserede beregningsmæssige metoder, der stræber mod at løse biologiskeproblemer ved hjælp af DNA og aminosyre sekvenser og den dertil relaterede informa-tion.
Bioinformatik er et relativt nyt forskningsomrade, som blev skabt i 1980’erne, hvorman opdagede, hvad man kunne benytte computere til indenfor det biologiske forsk-ningsomrade. Der er fortsat flere forskellige mader at definere bioinformatik pa. Gene-relt gælder det, at bioinformatik bygger ovenpa den eksisterende viden om biologi.
1.4 Klyngens arbejdsopgaver
Vi ønskede, som noget af det første, pa et møde med forskerne, at fa fastlagt klyngensfremtidige arbejdsopgaver. Vores umiddelbare opgave var nemlig at finde et udsnitaf de applikationer, forskerne ønskede at benytte, som tegnede en profil for klyngensbrug. Disse arbejdsopgaver ville give os nogle kendetegn for de kerneapplikationer, de togrupper af forskere har til fælles. Det viste sig ret hurtigt, at begge grupper hovedsagligtarbejdede med DNA og protein sekvenser. Det kunne f.eks. være at finde relationenmellem to organismer ud fra deres arvemasse.
2

2 GRUNDLÆGGENDE MOLEKYLÆR BIOLOGI
2 Grundlæggende molekylær biologi
Vi vil her kort starte med at introducere lidt grundlæggende molekylær biologisk viden.Denne viden vil gøre det langt nemmere at forsta de programmer, der skal køre paklyngen, men ogsa vise lidt om, hvad det er for nogle forskningsomrader, klyngen skalbenyttes til.
2.1 Biologiske termer
Hver celle i en organisme har nogle fa meget lange DNA (eng. deoxyribonucleic acid)molekyler. DNA er opbygget som en dobbelt- kæde opbygget af simplere molekyler.En enkelt af disse kæder kaldes for en streng. Hvert af de lange DNA molekyler kaldeset kromosom. Hvert kromosom kan indeholde flere forskellige gener. Et gen er kende-tegnet ved at være en sammenhængende klump indefor kromosomet. Mellem genernefindes det man kalder ”ikke-kodende DNA”(eng. junk DNA). Det er fornyligt blevetestimeret, at helt op til 90% af DNA’en i de menneskelige kromosomer bestar af ikke-kodende DNA. Indenfor kromosomet findes derfor desciderede start og stop codon’er,som beskriver hvor vi skal ”læse”fra og hvortil. Dette kaldes en open reading frameforkortet ORF.
DNA er opbygget af nitro-genererede basepar. Der findes fire forskellige baser: Ade-nin, Guanin, Thymin og Cytosin. Disse baser komplementere hinanden. Adenine binderaltid til Thymin og Guanin binder altid til Cytosin. Den sidste base Uracil, der findesi RNA, binder ogsa til Adenin.
Et gen siges at kode for et protein. Proteiner er opbygget af kæder af aminosyrer.Aminosyrer er kroppens mindste byggeblokke. Der findes 20 aminosyrer, som normaltindgar i proteiner i kroppen.
2.1.1 Proteiner
Proteiner er en del af kroppens biologiske proces, tilstedeværelsen eller manglen paet protein kan pavirke kroppen i meget høj grad. Derfor er det uhyre intressant rentforskningsmæssigt at kortlægge, hvilke proteiner der er tilstede, og hvilken funktion dehar.
Da vi alle formodes at afstamme fra den samme forfader, er der meget arvemasse,der stadig er bevaret fra dengang. Hvis to proteiner i to vidt forskellige organismer(men med en fælles stamfader), har den samme funktion, form eller bindingssted, kaldesde for homologer. Det vil sige, at hvis vi kan finde et gen i en anden organisme, dermodsvarer et gen i mennesket, kan vi lige sa vel studere det i den pagældende organismeog dermed forudsige, hvordan det vil pavirke et menneske.
2.1.2 Proteinsyntese
Proteinsyntese er den process i kroppen, der sørger for automatisk at generere de for-skellige proteiner, kroppen har brug for.
3

2 GRUNDLÆGGENDE MOLEKYLÆR BIOLOGI 2.1 Biologiske termer
Figur 1: Overblik over protein syntese processen.
Ved hjælp af et start codon genkender cellemekanismen starten af et givet gen, ogder tages en kopi af genet i form af et RNA molekyle. Den resulterende RNA kaldesfor messenger RNA eller blot mRNA. mRNA’en er fuldstændig identisk med DNA’enbortset fra at basen Thymin (T) bliver erstattet med Uracil (U). Fordi RNA er en-strenget og DNA er dobbelt-strenget, vil den producerede mRNA kun være identisktil den ene af strengene i DNA’en. Denne proces kaldes for transskription.
Selve proteinsyntesen foregar inden i en cellestruktur kaldet ribosomet, som bestaraf rRNA og proteiner. Ribosomets funktion minder om et samleband. Som ”input”tagesdet før omtalte mRNA molekyle, samt en anden form for RNA molekyle kaldet transferRNA eller blot tRNA.
tRNAen er det molekyle, som rent faktisk implementerer den genetiske kode i denprocess, som kaldes translation. tRNAet skaber forbindelsen mellem et givet codon ogden specifikke aminosyre, som codonet koder for. Mens mRNAet passerer igennem ri-bosomet, binder tRNAet til mRNAet med den korrekte aminosyre. Et passende enzymsørger for at katalysere processen, saledes at aminosyren forlader tRNA molekylet ogistedet binder til proteinet. Nar et STOP codon optræder, vil tRNAet ikke associerenogen aminosyrer til mRNAet, og syntesen stopper og mRNAet bliver frigivet og ned-brudt til ribonucleotider af cellemekanismerne i kroppen. Disse genbruger kroppen tilat skabe anden RNA.
4

2 GRUNDLÆGGENDE MOLEKYLÆR BIOLOGI 2.2 Sekvenssammenligning
2.2 Sekvenssammenligning
Sekvensering er den process, hvormed man ønsker at opna information om en givenDNA strengs sammensætning af base-par sekvenser. Et menneskeligt kromosom inde-holder omkring 108 base-par. De største stykker af DNA, som kan sekvenseres i et labo-ratorie er omkring 700 basepar langt. Dette betyder, at der er et hul i størrelsesordenen105 mellem den skala for, hvad der kan sekvenseres og et kromosoms størrelse. Det erderfor uhyre interessant at kunne nedbryde sekvenseringen i mindre dele og undersøgedisse smadele hver for sig for derefter at samle dem til større stykker igen.
Sekvenssammenligning (eng. alignment), er en af de allervigtigste primitiver in-denfor bioinformatik. Det fungerer, som basis for mange andre langt mere kompleksemanipulationer. Groft sagt handler sekvenssammenligning om at afgøre, hvilke dele afen given DNA eller proteinsekvens der er ens og hvilke dele, der ikke er ens.
2.2.1 Parvis og multipel sekvenssammenligning
Da proteiner bliver kodet ud fra arvemassen, kan vi, ved at finde ligheder i den, for-udsige funktionen af et protein. Da DNA og proteiner kan repræsenteres som strenge,kan ligheder mellem deres funktion ofte findes som ligheder i strukturen ([protein]).
En parvis sekvenssammenligning er, som navnet antyder, en sammenligning mellemto sekvenser bestaende af det samme alfabet og typisk nogenlunde samme længde.En multipel sekvenssammenligning er en sammenligning mellem mere end 2 givnesekvenser.
2.2.2 Global og lokal sekvenssammenligning
Bade indenfor parvis, savel som multipel sekvenssammenligning, skelner man mel-lem lokal og global sammenligning. Global sammenligning bestar i at matche to helestrenge imod hinanden og finde den ”bedste”sammenligning. Man kan indsætte ”mel-lemrum”(eng. a gap) i strengene for at de matcher bedre. En lokal sammenligningbestar i at matche to givne del-strenge imod hinanden pa samme made.
2.2.3 Mellemrumsproblemet
En ting, der skal tages højde for i de videnskablige beregninger er muligheden formellemrum i de to givne sekvenser, der skal sammenlignes. Der er forsøgt forskelligetilgangsmader til at løse dette problem. En af maderne, at løse det pa, er at tilføje etmellemrum, som et bogstav til alfabetet, men med en passende straf, sa algoritmenderved tvinges til at prøve at undga dem.
For at finde den ”bedste”sammenligning mellem to strenge, taler man om den ”op-timale”sammenligning. Det kan godt eksistere flere optimale sammenligninger.
I nogle tilfælde snakker man om Træ-sekvenssammenligning (eng. tree alignment).Dette skyldes at man nogle gange arbejder pa et evolutionært træ for den givne sekvens.Træ-sekvenssammenlignings problemet er NP hardt. Det eksisterer en algoritme, som
5

3 ANALYSE 2.3 Phylogenetik
finder den optimale løsning, men denne er eksponentiel i antallet af sekvenser, der skalsammenlignes.
2.3 Phylogenetik
Forskernes fra Zoologisk Museum arbejder bl.a. med evolutionære træer og Phylogene-tik. Phylogenetik er et omrade indenfor biologien, som behandler relationerne mellemforskellige organismer. Det inkluderer kortlæggelsen af disse evalutionære relationer,samt studier af anledningen til disse mønstre. Indenfor dette omrade, taler man omphylogenetiske træer, som bl.a. bygger pa den føromtalte træsekvenssammenligning.
3 Analyse
I det følgende afsnit beskriver vi de applikationer, der skal benyttes pa klyngen, samtundersøger deres virkemade vha. forskellige forundersøgelser.
3.1 Programmerne
Det følgende er en beskrivelse af de 4 programmer, som forskerne helt sikkert kom-mer til at køre pa klyngen. Programmerne POY og TNT skal bruges af forskerne fraZoologisk Museum, mens BLAST og Hidden Markov Models (forkortet HMM’er) skalbruges af Center for Bioinformatik.
POY og TNT er begge programmer, der laver multipel alignment ved brug af entræbaseret model. Dette gør det muligt for forskerne at finde relationer mellem forskel-lige organismers udvikling. BLAST og HMMer foretager begge en databasesøgning,hvor de forsøger at finde sekvenser, der ligner den givne forespørgselssekvens.
3.1.1 Evolutionær matrix
En given sekvens kan ændre sig over tid vha. mutationer. Mutationer i arvemateriale eren naturlig del af evolutionen. Det vil sige, at en base eller en aminosyre over tid ændrestil en lidt anden. Da der ikke er lige stor sandsylighed for, at alle par af aminosyrer ellerbaser kan muteres til hinanden, er der udviklet nogle forskellige matricer, der beskriversandsynligheden for, at en base ændrer sig over tid. Denne matrice efterligner dermedden process, som sker i naturen. Et eksempel pa en sadan matrix er PAM250. Denbeskriver sandsynligheden for mutationer over 250 generationer.
3.1.2 POY
POY er en algoritme udviklet ved American Museum of Natural History af Ward Whe-eler. POY er som nævnt tidligere et program, der benytter sig af træsammenligningertil undersøgelse af phylogenetiske træer. POY benytter en metode, der kaldes “Par-simony” til at opbygge disse træer. Begrebet “Parsimony” kan groft sagt oversættesmed sparsommelighed. Tanken bag metoden er, at afsøge alle træer og for hver træ atberegne prisen for dem. Det billigste træ vil have en lav højde og sa lille en afstand
6

3 ANALYSE 3.1 Programmerne
mellem forældre og barn, som muligt. Den simpleste made at udregne parsimony pa,er som følgende (hvor C er prisen af træet) [binf, pp. 175]:
Initalization:Set C = 0 and k = 2n-1
Recursion:If k is leaf noe:
Set R_k = x^{k}_{u}If k is not a leaf node:
Compute Ri, Rj for the daughter node i, j og k and setR_k = R_i \intersect R_j if the intersection is not empty, or
elseset R_k = R_i \union R_j and increment C
Termination:Minimal cost of tree = C
POY udfører en lidt anden form for multipel alignment. Det gør den, ved at findedet formodede træ, over de angive sekvenser og deres forfædre. Algoritmens frem-gangsmade, er at forsøge at finde fællesmængden mellem de to strenge og ud fra det,at danne en forfader. Hvis fællesmængden er tom, bruges foreningsmængden. Detteforsøges med de forskellige kombinationer, og POY forsøger derved at finde det træmed de fleste og bedste fællesmængder (se [poy]).
3.1.3 POY testdatasæt
Som testdatasæt har vi benyttet “atpa”, der indeholder ca. 438 taxa for det mitochondrion-encodede gen atpA, der encoder α-delenheden af mitochondrial ATP syntese. Der eraltsa tale om et plante-gen.
3.1.4 TNT
Programmet TNT (eng. Tree analysis using New Technology) er udviklet af argen-tineren Pablo Goloboff i 1999, der ogsa har skrevet programmerne Nona (NoName)og PiWe (eng. Parsimony with Implied WEights). Pablo Goloboff besøgte Danmark islutningen af februar i forbindelse med, at han skulle give undervisning pa BotaniskInstitut, og blev saledes den første person, der kom til at køre programmer pa klyngen.Han var blevet kraftigt opfordret til at oversætte sine DOS/Windows programmer tilUNIX, sa de i fremtiden kunne køre pa klyngen. Alle tre programmer: TNT, Nona ogPiWe kan saledes nu køres pa klyngen.
TNT baserer sig pa den samme metode (parsimony) som POY, men sigtet medTNT er kørsler pa meget store datasæt f.eks. 300-500 taxa. TNT benytter sig af ensøgestrategi, der er meget effektiv, som hedder parsimony ratchet. Tanken er, at mangenvægter et tilfældigt sample fra sit datasæt, for derved at komme ud af et lokaltoptimum, og søgningen kan fortsætte “up-hill”. Nar man nar til et nyt optimum, skif-ter algoritmen tilbage til den oprindelige vægtningsstrategi, og søgningen fortsætter.Fordelen ved denne strategi er, at de genvægtede “hill-climbing” cykler, bevarer nogle
7

3 ANALYSE 3.1 Programmerne
af de originale phylogenetiske signaler samtidig med at tiden, der bruges pa trinvisaddition reduceres væsentligt (se [WEBTNT]).
Programmet TNT er desværre fortsat et beta-program, og vi har derfor ikke kunnetkøre programmet pa en tilfredsstillende made indenfor den afsatte tid. F.eks. kræverprogrammet et password udleveret af Pablo Goloboff, for overhovedet at kunne køreog give uddata.
3.1.5 NCBI BLAST
Programmet NCBI BLAST (Basic Local Alignment Search Tool) [BLAST], stammer,som navnet indikierer, fra National Center for Biontechnology Information. BLAST eret af de allermest populære programmer indenfor biologisk forskning for tiden. Pro-grammet er fra 1990, men det har gennemgaet en del ændringer siden da, bl.a. i se-kvenssøgningsdatabasens form. Der findes flere andre implementationer af BLAST endden NCBI distribuerer.
Nar BLAST skal søge i en database med sekvenser, gør den det pa følgende made:
1. Lav en liste over mulige HSP (High Scoring Points) ved at generere strenge, dergiver en høj score ved sammenligninger med søgestrengen.
2. Brug disse HSPer til at søge i databasen vha. en tilstandsmaskine.
3. For alle hits udvid da resultatet, sa det bliver en sa stor match som muligt (vha.en tilstandsmaskine).
Metoden BLAST baserer sig pa de teoretiske resultater beskrevet i [statistics]. Disseresultater beskriver, hvordan det er muligt at, i stedet for at lave en præcis alignmentved hjælp af en sekvens, er det muligt at lave en række andre sekvenser, der giver enhøj score ved sammenligning med sekvensen. Disse kandidater kan derefter bruges til atsøge i databasen og finde sekvenser. De sekvenser, der bliver fundet ved denne søgning,har en høj sandsynlighed for at være dem, der ville findes ved en rigtig kørsel.
3.1.6 BLAST testdatasæt
Som dataset bruger GenBank en database, hvis mal det er at indeholde alle sekvenseri eksistens. Da GenBank distribueres i FASTA formatet, sa skal den først formateresog indekseres til at BLAST kan søge i den. Den oprindelige database er pa ca. 8 Gb,men nar den bliver formateret, fylder den kun ca. 2,6 Gb. Denne database indeholderkun information omkring DNA og RNA sekvenser, da det kun er det vi har valgt atsøge pa. En søgning efter en 700 basers sekvens, tager ca. 1,5 min. Det kan godt være,at det ikke lyder som et overvældende tal, men ofte forekommer det, at man skal søgemed mange forskellige sekvenser i databasen. Efterbehandling af resultaterne fra enBLAST kørsel, tager typisk ogsa lang tid.
3.1.7 Hidden Markov Models
Metoden Hidden Markov Models (herefter forkortet HMM) er ikke unik for biologisksekvenssøgning. Den bliver ogsa brugt i mange andre sammenhænge. Skjulte Markov
8

3 ANALYSE 3.2 Forundersøgelser
modeller beskriver en række tilfældige variable og deres indbyrdes relation. Det vil sige,at det er muligt at modellere forskellige mønstre i en sekvens. Træne modellen til atfinde nogle bestemte sekvenser og derefter bruge den til at søge med.
Forskellen mellem BLAST og HMM er, at i BLAST søges i sekvenser, mens man iHMM’er søger i en model. BLAST er derfor god, hvis man allerede har den sekvens,man ønsker at finde, hvorimod HMM’er er en mere generel metode, hvor det ikke gørnogen forskel, om sekvensen indeholder junk DNA.
3.1.8 HMM testdatasæt
Som testdatasæt, har vi faet udleveret 451 sekvenser fra S. Pombe genomet. S. Pombeer en bestemt type gær, der har samme cellestruktur som mennesker. Gær bliver typiskbrugt til biologisk forskning, da det er en encellet struktur, der indeholder en cellekerne,og den er nem at dyrke, samt den er fuldt sekvenseret (hvilket skete i 2002).
3.2 Forundersøgelser
Selv om man kan komme langt ved at se pa forskellige hardware specifikationer, harvi ogsa været nød til at lave nogle konkrete test-kørsler for at identificere, hvordanapplikationerne reagerer i forhold til den valgte hardware.
3.2.1 Testmaskiner
For at udføre vores forsøg brugte vi en række testmaskiner. Modeller og konfigurationerer noget spredt, alt efter hvilke maskiner vi har haft mulighed for at lægge beslag patil testen.
Maskintype CPU RAM Disk1 Intel Celeron 1 GHz 256Mb IDE2 Intel Pentium4 2 GHz 512 Mb IDE3 AMD Athlon XP1700+ 1,5 GHz 512 Mb IDE4 Dual Pentium III 1 GHz 1 Gb SCSI5 Intel Pentium4 2.4GHz 512 Mb IDE
3.2.2 Malingsværktøjer
Vi var nødt til at finde nogle værktøjer, der kunne undersøge, hvordan de forskelligeapplikationer, der skulle køre pa klyngen, opførte sig. De emner, der umiddelbart varinteressante for os at se pa, var hvilke behov applikationerne havde for forskellige fasteressourcer f.eks. CPU, RAM, disk og netværk.
Der findes mange forskellige værktøjer til at undersøge et programs opførsel pa enLinux maskine. De fleste benytter /proc-filsystemet til at læse information fra Linuxkernen, men med disse værktøjer er det ikke muligt at undersøge specfikke hændel-ser pa CPUen. Enten fordi informationen ikke er tilgængelig, eller fordi den ikke kanindhentes hurtigt nok. Derfor har vi set pa kerneudvidelsen Perfctr, der er en del af
9

3 ANALYSE 3.2 Forundersøgelser
Performance API (forkortet PAPI) værktøjerne.
For at undersøge om et program brugte sin hovedvægt pa CPU eller I/O brugte vien kombination af to kommandoer, nemlig time og strace. time kan vise hvormegettid en process bruger i kernen og hvormeget den bruger i brugertilstand. strace opfan-ger alle systemkald, som et program bruger og kan derefter udskrive en opsummering afantallet af de forskellige systemkald. Sa for at undersøge forholdet mellem I/O og CPUforbrug, vil vi bruge time til at undersøge den totale køretid af programmet og stracetil at undersøge hvormeget af tiden, der er blevet brugt pa henholdsvis read og writes.
Perfctr implementerer PAPI grænsefladen, der gør det muligt at undersøge etprogram, ved at tilføje specielle funktionskald. Men det er ogsa muligt at undersøge etprogram uden at ændre i selve programmet. Det var bl.a. en af de ting vi ønskede atbenytte, da vi har valgt at fastholde applikationerne og fremskyde en eventuel forbed-ring af dem til efter klyngen er opsat og kørende.
Programmet, der blev benyttet til at undersøge programmerne var lperfex, derer en videreudvikling af et program, der følger med Perfctr. Lperfex starter enbørneprocess, der kører det program, der skal undersøges, pa en sadan made at denovertager processens processblok. Dette gør at det er muligt, at konfigurere statusre-gistrene i processoren, køre programmet og derefter indsamle de informationer, der erblevet gemt i registrene. Programmet har symbolske konstanter for at definere noglebitmasker, der programmerer registrene til at gemme de ønskede hændelser.
Denne funktionalitet er desvære endnu ikke implementeret pa Pentium 4 proces-soren (forkortet P4). Dette skyldes to ting: P4 har betydelig flere muligheder indbyggetfor selv at indhente status informationer end tidligere processorer, men den er ogsa re-lativt ny. Vi var derfor nødt til at sætte os ind i, hvordan denne mekanisme er lavet,for at kunne programmere den. Vi vil her kort beskrive, hvordan den fungerer.
Hændelsesmalingsmekanismerne i P4 er baseret pa to typer af registre. Den ene typeregister bruges til at konfigurere hvilken type af hændelser (eng. Event Select ControlRegisters), der skal gemmes, mens den anden type benyttes til at konfigurere tællerne(eng. Counter Configuration Control Registers). Hver ESCR og CCCP er en del af engruppe, der modsvarer en del af CPUen.
Perfctr havde ikke understøttelse for konstanter defineret for disse registre, menden havde mulighed for at definere de bitmasker, der skulle gemmes i dem.
Vores mal var derfor at finde den korrekte bitmaske, der ville konfigurere proces-soren til at gemme de hændelser, vi ønskede at undersøge. Et at de emner vi ønskedeat fa klarlagt, var hvorledes applikationerne forholdt sig til maskinernes “Level 2” ca-che. Dette er en af de vigtige forskelle mellem “high-end” CPUer og “desktop” CPUer.Dette kan bl.a. ses pa, at P4 har 512 kb L2 cache, hvorimod en Celeron kun har 128kb L2 cache. Men de to arkitekturer er selvfølgelig ogsa forskellige pa mange andrepunkter end lige cache. Generelt gælder dog, at hvis programmerne ikke kan finde udaf at benytte cache overhovedet, er det er det lige sa hensigtsmæssigt at vælge en
10

3 ANALYSE 3.2 Forundersøgelser
Figur 2: En oversigt over hændelsesmalingslogiken i en P4
Celeron-baseret løsning, som en Pentium4-baseret løsning. Hvis programmerne deri-mod udnytter cachen, er det et argument for at vælge en P4-baseret løsning.
Da vi skulle male P4s cache tog vi udgangspunkt i følgende eksempel af hvordanman maler level 1 cache misses med Perfctr.
perfex -e 0x0003B000/0x12000204@0x8000000C --p4pe=0x01000001 --p4pmv=0x1 some_program
Ud fra [P4Spec, pp. B-37] kan man se, at den eneste forskel mellem at male “level1” og “level 2” misses, er at bit 1 istedet for bit 0 er sat i PEBS ENABLE. Sa parameterenp4pe skal ændres for at male “level 2” misses.
3.2.3 Forsøg og resultater
Vi udførte tre forundersøgelser. En test pa maskine 1 og 2, til identifikation af Ca-che Level2 udnyttelsen, en simpel test pa maskine 2, 3 og 4, vha. top programmet tilidentifikation af RAM forbruget og en test pa maskine 3, 4 og 5 til identifikation afprogrammernes CPU og I/O mønstre.
For at udføre undersøgelsen, installerede vi en alternativ kerne pa maskine 1 og 2.Derefter kørte vi programmet POY og talte antallet af cachelinier, der blev læst indog gangede dette med størrelsen pa cache- linierne. Vores lille forsøg afdækkede, at densamme mænge data blev hentet fra lageret pa begge typer af maskiner. Det vil sige, atapplikationen POY ikke udnytter den større cache, der er tilradighed pa maskine 2.Man skal dog være opmærksom pa at maskine 2 har en langt hurtigere hukommelsesbusend maskine 1.
Resultatet af RAM testen afdækkede, at programmet POY brugte mindre end 256MB RAM, nar det blev kørt. BLAST derimod benytter RAM i forhold til Databasens
11

4 VALG AF HARDWARE
størrelse. Dvs. RAM forbruget er relativt højt, nar man kører BLAST pa en enkeltcomputer, men nar man kører BLAST pa en klynge, deles databasen op i mindre bid-der, der lægges ud pa hver computer. Sa, jo flere knuder BLAST køres pa, jo mindrebliver RAM forbruget.
Den sidste test er lidt sværere at konkludere noget specifikt pa, da programmernefordeler sig over et ret bredt spektrum. POY er mest CPU intensivt, mens BLASTer mest I/O intensivt. Programmet HMM placerer sig i begge ender af spektret, hvortræningsdelen er I/O intensiv, mens selve decodedelen er CPU intensiv. Hvis man skalsige noget generelt, kan man konkludere at vi har behov for begge dele. Der er derforbehov for en velafvejet klynge, hvor der er lige meget fokus pa CPU og I/O.
Resultatet af disse forundersøgelser blev at vi begyndte mere specifikt at formu-lere kravne til hardware, saledes at en kravspecifikation kunne udsendes til forskel-lige PC-leverandører. Pa baggrund af kravspecifikationen kunne vi indhente forskelligecomputertilbud, der nemt kunne sammenlignes.
4 Valg af hardware
De fleste dele i en moderne computer forbedrer idag sin ydelse med et fast tidsinter-val f.eks. far CPUer dobbelt sa mange halvledere hver 18. maned. Et af de vigtigstekrav, nar man designer en klynge, er at finde ud af hvad den billigste hardware er,i forhold til ydelse og de krav, som applikationen stiller til hardwaren pa grund afforældelsesfaktoren.
4.1 Valg af CPU
Ved valg af CPU skulle vi afveje en prioritering mellem strømforbrug, hastighed og pris.De to leverandører af CPUer vi primært sa pa, var AMD og Intel. Hvis man kort skalbeskrive dem, sa har begge leverandører to typer af CPUer. En billig version med min-dre cache og en dyr version med højere ydelse. Hos Intel er de to typer repræsenteretaf Celeron, baseret pa Coppermine (Pentium 3) og Pentium 4, baseret pa NorthwoodII. Hos AMD hedder de to modeller Duron og Athlon. En gennemgaende trend for alleleverandører er, at AMD er billigere per CPU end Intel, men de har desværre ogsa etstørre strømforbrug. AMDs processorer er heller ikke gearet til at overleve en eventueloverophedning, hvorimod Intels CPUer har en indbygget sikkerhedsforanstaltning kal-det speedstep, der sørger for, at processoren clocker ned i hastighed. Dette sikrer, atCPUen ikke brænder sammen.
Grunden til at vi har fokuseret vores interesse pa disse typer af CPUer fra AMDog Intel er, at de fleste alternativer pa ingen made kan forsvares fra et økonomisksynspunkt. Alternativer, sa som AI-64, PowerPC eller Alpha bliver ikke produceret isamme størrelsesorden som IA-32 maskinerne, selv om de pa mange mader har meretiltalende egenskaber. Ydelsen er ikke god nok til at opveje den prisforskel, der fortsater.
12

4 VALG AF HARDWARE 4.2 Varmeudvikling og strømforbrug
Udover forskellige arkitekturer, er der ogsa et valg mellem enkelt- processor ma-skiner eller SMP baserede maskiner. Intels nyeste processor til high-end performancehedder Xeon og benytter sig af en ny teknologi kaldet Hyper Threading. Hyper Thre-ading gør det muligt for en processor at fremsta som 2 processorer. Med en Xeonprocessor er det nemt at bygge SMP maskiner, da man reelt kun vil have behov fordet halve antal processorer i forhold til tidligere tiders SMP løsninger.
Et argument mod SMP maskiner er imidlertid, at CPUerne sidder tætkoblet ogderfor deles om den samme RAM-bus pa bundkortet, og dette kan danne en flaske-hals. Som alle andre nye processorer er prisen ogsa væsentlig højere end for lidt ældreCPUer. [2-4-8] beskriver nogle scenarier, hvor dual maskiner kan være begrænsende isig selv, i forbindelse med visse beregninger, og de er derfor uinteressante ud fra etpris/ydelses synspunkt.
4.2 Varmeudvikling og strømforbrug
Ret hurtigt i forløbet gik det op for os, at to vigtige parametre i forbindelse med designaf klyngen var strømforbrug og køling. Da ingen af os, havde den store erfaring mednogle af disse emner, var vi nød til at arbejde med problemet. At finde det reelle energi-forbrug for en computer var lidt af en udfordring, da de fleste computerfabrikanter blotoplyste maksimum kapaciteten pa strømforsyningen og ikke det reelle forbrug. Vi varderfor nødsaget til at kontakte nogle af leverandørerne, der havde indsendt tilbud, engang til for at fa specificeret dette tal. Et vigtigt faktum var ogsa at de standard tal, deroplyses, normalt inkluderer en skærm tilsluttet computeren. Vores klyngeløsning varbaseret pa ra computerkraft uden skærme. Det viste sig, at standard strømforbrugetfor en computer ligger pa omkring 75 Watt.
Maximum brug 291 BTU/hrMininum brug 127 BTU/hr
Sleep 9 BTU/hrOFF 4 BTU/hr
Figur 3: Varmeudviklingstal for en Dell OptiPlex GX260 maskine
Det var et vigtigt tal, da det kræver ca. samme energi at fjerne den varme, som75 Watt genererer. Disse tal skulle derfor bruges som oplysning til de kølefirmaer, derblev kontaktet for at give tilbud pa en køleløsning. Vi kontaktede 3 firmaer, der spe-cialiserede sig i løsninger af edb-køling, og heraf vente 2 af dem tilbage i tide. Beggedisse firmaer var ude og besigtige serverrummet og afgav tilbud pa baggrund af dette.Der var tre mulige løsningsscenarier:
• Køleenhederne blev placeret inde i rummet
• Køleenhederne blev placeret i et tilstødende tomt lokale
13

4 VALG AF HARDWARE 4.3 Hukommelsesovervejelser
• Køleenhederne blev placeret udenfor selve bygningen
Den løsning der blev valgt, benytter sig af det faktum, at der lige ved siden afserverrummet findes et tomt lokale, hvor der tidligere har staet et oliefyr, hvor dervar boret hul i ydervæggen, sa der trækkes frisk luft ind. Køleenhederne er placereti sammenhæng med dette luftindtræk, og der bores hul i væggen tre steder indtilserverrummet, hvor der monteres tre blæsere. To af dem blæser kold luft ind i rummet,mens den sidste suger varm luft ud af rummet. De er fysisk placeret spredt i rummet, saairflowet bliver optimalt. Pa denne made optager køleanlægget ogsa minimal plads i detellers ret pakkede serverrum. Køleløsningen kan køle op til 25kWatt. Dette skulle væreoverdimensioneret i forhold til det reelle forbrug i forhold til klyngen, sa køleanlæggetsmaksimum kapacitet ikke nas fra dag et.
4.3 Hukommelsesovervejelser
Et andet sted, vi var nødt til at træffe nogle valg, var i forbindelse med at fastsættehvilken type RAM og hvilken størrelsesorden af RAM, der var behov for i maskinerne.Der findes flere forskellige konkurrerende RAM typer, primært anført af DDR-SDRAMog RAMBUS RAM (RDRAM). De fleste computere idag leveres idag med DDR RAM,da RAMBUS RAM har problemer med latenstiden og derfor ikke anses for at værehurtig nok.
For at bestemme mængden af RAM, der skulle i klynge computerne, valgte vi atkøre et af de før omtalte performance malingsprogrammer, for at se pa programmernesreelle RAM forbrug. Pa baggrund af disse tests, valgte vi at fa 512 MB RAM i en klodsi hver computer, ikke mindst fordi dette var standard, men ogsa fordi det var mereend en fordobling i forhold til, hvad behovet umiddelbart blev. Ligeledes giver dette,mulighed for en senere udvidelse af RAMen, med en klods mere til 1 GB RAM, hvisdet bliver nødvendigt.
4.4 Netværksteknologi
Nar der skal vælges netværksteknologi for en klynge, er der to grupper at vælge imellem:specielle klyngenetværk med lav latenstid (MyriNet eller SCI) eller standard Ethernet(100 eller 1000 Mbit). Efter at have studeret de udvalgte applikationer, valgte vi udfra et økonomisk og behovssynpunkt at bruge standard Ethernet. Da de fleste andreløsninger, ville have været uhensigstmæssigt dyre, da specialkortene i sig selv, villesvare til halvdelen af prisen for en knude. Derudover, var vi ogsa heldige, idet denleverandør, der endte ud med at have det bedste tilbud, leverede alle maskinerne medindbygget Intel Gigabit Ethernet netkort.
For at lettere kunne installere maskinerne, var det et krav at netkortene undstøttede“Pre-Boot Execution Environment” (PXE) standarden. PXE er en stardard defineretaf Intel i forbindelse med deres “Wired for Management” (WfM) standard. Det mu-liggør at hente en bootloader og kerne over nettet fra en central server. Dette er en storfordel, nar man skal handtere et stort antal maskiner. PXE er egentligt blot en DHCPclient, der kan overføre data.
14

4 VALG AF HARDWARE 4.5 Valg af disk
Udover netværkskortene behøvede vi naturligvis ogsa, en sammenkobling af net-værket. Da vores maskiner har gigabit Ethernet, ville det bedste være at forbinde demmed et rent Gigabit netværk. Men da Gigabit endnu ikke er sa udbredt, at prisen harnaet et niveau, hvor den ikke vil overskygge resten af udgifterne til klyngen, valgte viat benytte kategori 6 kabler, der kan handterer Gigabit, hvis der pa et givet tidspunktblev indkøbt netværksudstyr, der kunne handtere det. Sa den aktuelle struktur er nupa to niveauer med 100 Mbit stackede switche for hver 96 maskiner og et Gigabit up-link til en central gigabit switch.
Der blev indhentet flere forskellige tilbud pa netværksudstyr. Heriblandt HP, Ciscoog Enterasys. Priserne la jævnt fordelt med Cisco i den høje ende og HP i den laveende. Det endelig valg faldt pa udstyret fra Enterasys, som er et spinoff firma af detgamle Cabletron. Den primære grund til at valget faldt pa dette udstyr, var for detførste at det prismæssigt la i mellemgruppen, samt at resten af Zoologisk Museumsnetværksstuktur er opbygget af dette udstyr og for det andet at det blev modtagetpositivt af netværksafdelingen, fordi den administrative byrde blev lettet ved ikke atintroducere andre typer netværksudstyr.
4.5 Valg af disk
Harddiskene i de enkelte knuder skal opfylde to krav: De skal have en relativt høj ydelseog størrelse. De harddiske der som standard findes i de fleste computere idag er IDEdiske. IDE har en god ydelse og en rotationshastighed pa 7200 RPM og en standardstørrelse pa ca. 40-80 Gbyte.
Et alternativ til standard IDE diske havde været en SCSI baseret løsning. SCSI le-veres typisk sammen med serverløsninger, hvorimod IDE leveres sammen med løsningertil sma computere. SCSI standarden giver nem mulighed for at isætte mere end 4 diskei en maskine, og de er typisk ogsa hurtigere end IDE diskene. Et minus er blot, at prisendermed ogsa er højere, samt at de fleste maskiner ikke leveres med en SCSI controller,men kun IDE controller. Prisen bliver derfor en vigtig performance parameter endnuen gang. Vi valgte derfor ikke at udskifte de IDE diske, som fulgte med i computer-tilbuddende. Disse diske er ogsa dækket ind under den generelle 3 ars on-site garanti,sa i tilfælde af fejl pa hardware, vil de blive skiftet uden yderligere omkostninger.
4.6 Valg af server
Der er behov for en server i klyngen, til styring af forskellige administrative opgaver.Det er muligt at koncentrere disse opgaver pa en enkelt server, men det er ogsa muligtat dele funktionerne ud over flere maskiner. De opgaver der umiddelbart skal handtereser:
• Information omkring brugere og forskningsgrupper
• Opbevaring af brugernes data, som de skal bruge pa klyngen
• Software til kørsel og schedulering af programmerne
15

4 VALG AF HARDWARE 4.7 Opsumering over valg af hardware
En af de primære faktorer, der pavirker vores valg af server, er det faktum, atklyngen pa et givet tidspunkt, eventuelt skal opdeles i to. Vi valgte derfor ret hurtigt,at læne os op ad de eksisterende systemer, da dette giver en nem mulighed for atklone serveren over pa en tilfældig knude i tilfælde af deling af klyngen, eller simpelthardware nedbrud. Pa denne made vil hovedswitchen for klyngen, ogsa fungere somsamlingspunkt for det resterende server-netværk.
Derfor, har vi valgt at bruge en af de computere, der skal indga i klyngen, somserver. Serverens hovedopgave bliver bruger-administration og igangsættelse af jobs paklyngen. Tilgengæld har vi valgt at bibeholde filserver-opgaverne pa de to institutterseksisterende afdelings filservere, som er langt bedre rustet til denne opgave, med RAIDsystemer og dertilkoblede backup procedurer.
4.7 Opsumering over valg af hardware
Det endelige valg af klynge computer faldt pa Dell OptiPlex GX260, der er en 2.4GHz Intel baseret computer med 512 MB DDR RAM. Computeren er en Small FormFactor model, der derfor ikke fylder specielt meget. Alle Dell computere leveres medet Intel baseret Gigabit netkort integreret pa bundkortet. Grafikkortet er ogsa et Intelkort, men da vi pa ingen made er interesseret i at benytte grafiske redskaber, havde viingen krav til grafikkortet. Dell OptiPlex computerne er udstyret med en 40 GB IDEdisk og et alm. floppy drev, tilgengæld fulgte der ikke noget cd-rom drev med, da derikke var behov for dette. Dell OptiPlex maskinen er kendetegnet ved, at være megetstøjsvag og har et lavt strømforbrug. Yderligere var denne maskine langt den billigste,af alle de tilbud vi havde modtaget. Den la ca. 1.300 kr under de andre mærker, selvsaml-selv-bambus maskinerne, sa der var ingen tvivl om, hvilken maskine der bedstmatchede vores krav. Det, at prisen var sa lav, betød at der kunne købes mange flerecomputere. Fra et oprindeligt regnskab pa under 200 computere, blev der rad til 241computere, hvilket var væsentligt flere end estimeret i det oprindelige projekt.
Figur 4: Dell OptiPlex GX260 computer
16

5 VALG AF SOFTWARE
5 Valg af software
Men, en klynge bestar jo som bekendt ikke kun af hardware. Det kræver en hel delsoftware. Det følgende afsnit beskæftiger sig, med de forskellige valg indenfor softwarevi traf i forbindelse med etableringen af klyngen. Groft sagt falder de indenfor følgendekategorier:
• Fastlæggelse af styresystem
• Installation og vedligholdelse
• Jobstyring
• Biblioteker og applikationer til kørsel pa klyngen
5.1 Valg af styresystem
Der var flere forskellige muligheder indenfor valg af et styresystem til klyngen. Pri-mært la valget mellem Windows eller UNIX. TNT programmet var før februar manedkun lavet til Windowsplatformen, sa dette var en reel mulighed. Der ville dog ligge enbetydelig udgift i indkøb af licenser til alle maskiner, derfor la det ret hurtigt klartat klyngen skulle køre en form for UNIX som styresystem. Men hvilken UNIX versionvar den bedste? Da vi fortsat skulle tage hensyn til økonomien var det oplagt at be-nytte et gratis open source baseret UNIX styresystem. De to alternativer i betragtningvar henholdsvis FreeBSD og Linux. FreeBSD 4.7 er kendetegnet ved at være en af demest stabile, skalerbare og produktionsmodne opensource operativsystemer. Det harlangt færre fejl end f.eks. Linux 2.4 serien. Problemet var dog at der rent administra-tivt var mere erfaring med Linux hos f.eks. Center for Bioinformatik og de har medfordel benyttet sig af Debian Linux pa deres computerinstallationer. Debian Linux erkendetegnet ved at være relativt konservativt opbygget i forhold til f.eks. Red HatLinux, og har et langt mere modent pakkestyringsystem til installation og vedligehol-delse af software end Red Hats RPM system. Debians pakkesystem er modeleret efterFreeBSDs ”ports-træ”, som er et avanceret pakkesystem som bl.a. checker pakker forafhængigheder og selv henter de afhængige programmer der mangler.
Det endelige valg af styresystem faldt derfor pa Debian Linux, da det var et godtkompromis for alle parter. Men valget blev spcielt truffet ud fra et krav om nemmerevedligeholdelse og support af systemet.
5.2 Valg af filsystem
I sammenhæng med valget af styresystem, skulle der ogsa træffes et valg omkringhvilken type filsystem klyngen skulle køre pa. Et oplagt valg var Linux standard fil-systemet ext3. Havde vi valgt FreeBSD fremfor Debian, ville filsystemet have heddetufs og benyttet softupdates til asynkrone skrivninger til disken. ext3 er kendetegnetved at være et journaliserings filsystem. Af andre kendte journaliserende filsystemerkan nævnes ReiserFS og SGIs xfs. Et journaliseringsfilsystem er kendetegnet ved atoperationer pa disken opbevares midlertidigt i en journal og derefter skrives til disk. I
17

5 VALG AF SOFTWARE 5.3 Valg af installationssystem
tilfælde af et systemnedbrud er der derfor kun behov for at checke indholdet i journal-filen fremfor at køre filesystem check af hele disken (fsck). Dette er specielt gavnligt,nar man arbejder pa store diske, hvad der typisk er standarden idag.
5.3 Valg af installationssystem
For at kunne installere det store antal maskiner er der behov for en nem made at kunneinstallere dem pa. Da alle maskiner har identisk hardware er det nemt at lave et systemtil at geninstallere dem.
Den basale tilgangsmade er at installere en maskine og derefter kopiere installatio-nen ud pa de andre maskiner. For at forenkle denne process findes der en række forskel-lige værktøjer, der er mere eller mindre produktionsmodne. De systemer vi har set paer: Ka-boot, SystemImager og PartImage. Det sidste er ikke et desideret “klonings”-program. Det er kun beregnet til at gemme og gendanne partitioner.
Ka-boot [ka-tools] bestar af en række smaprogrammer. Dels til styring af instal-lationen af maskinerne og dels af nogle sma klientprogrammer, der henter data paklienterne. Det muliggør, at man fra en server kan sige at knude 1 skal replikeres til deandre n-1 knuder. Ka-boot er ogsa open source og understøtter multicast og derigen-nem hurtig installation af et stort antal maskiner.
SystemImager [systemimager] ligner pa mange mader Ka-boot men har et brederefokus, da det ikke kun er designet til klynger.
PartImage [partimage] fungerer i stor udstrækning som Unix kommandoen dd. Dengemmer data fra disken i en fil, som kan komprimeres med gzip eller bzip2. Der ogsamulighed for at hente filerne fra en server.
Vi har valgt at bruge programmet PartImage og nogle ekstra sma programmer, dadet var det, der var nemmest at fa til at fungere. Vi fravalgte Ka-boot, da det var fordarligt dokumenteret og Systemimager, da vi først blev introduceret til det, efter vihavde faet PartImage til at virke.
5.4 Jobstyringssoftware
For at systemet skal kunne køre fornuftigt, skal det være muligt at styre, hvem der kanstarte jobs og hvormeget tid de forskellige jobs bruger, sa en enkelt person ikke kandominere klyngen. De to stykker software, der ansvarlige for at varetage disse opgaver,er et batchsystem og en scheduler. Batchsystemet starter og stopper jobs og schedule-ringssytemet bestemmer hvilke jobs der skal køres i hvilken rækkefølge.
Som batchsystem valgte vi at bruge gratis versionen af “Portable Batch System”(OpenPBS). PBS findes ogsa i en kommerciel udgave kaldet PBSPro, som blandt andetbenyttes pa Odense-klyngen. OpenPBS har defineret et API, sadan at det er muligtat bruge forskellige schedulers. Der følger ogsa en række af forskellige schedulers med.
18

5 VALG AF SOFTWARE 5.5 Biblioteker og applikationer
Den simpleste er en ren FIFO (eng. First In First Out) scheduler.
Figur 5: OpenPBS og Mauis udførsels af et job
OpenPBS kan deles op, saledes at opgaverne fordeles pa tre typer af maskiner:“frontends”, “servers” og “execution hosts”. En PBS server har defineret en rækkerkøer, hvori jobbene kan tilføjes. Dette kan gøres fra en “frontend” maskine, der bru-ger kommandoen qsub (1), der ogsa kan bruges til at angive hvilke ressourcer et jobskal bruge. Dette kan f.eks. være 8 maskiner. PBS informerer Maui om, at den harmodtaget jobbet (2), som melder tilbage nar jobbet skal startes (3). Nar PBS starterjobbet reserverer den det antal maskiner, der skal bruges og sender kørselsfilen ud tilden første af maskinerne (4). Herfra bliver kørslen udført af den lokale “pbs mom”,der fortæller programmet hvilke maskiner den har tilgængelig, sa den kan brede sig tildem. Nar programmet er kørt færdig bliver uddata fra det sendt til serveren (6), somgemmer det i en fil med jobnummeret pa frontend knuden (7).
En anden scheduler, der ogsa understøttes i PBS API er Maui [Maui]. Da klygensejere en en større konstallation af personer og for senere at kunne handtere mulighedenfor at sælge processortid, valgte vi at bruge Maui scheduleren. Maui har mange mulig-heder for at beskrive hvordan en klynge ma anvendes og bliver brugt i sammenhængmed OpenPBS i mange store systemer, sa den er meget velafprøvet og det er nemt atimplementere forskellige klynge-styrings politikker.
5.5 Biblioteker og applikationer
Da vi ikke kun var ansvarlige for at fa klyngen op og køre, men ogsa for at fa deforskellige programmer til at køre, var vi nød til at undersøge hvad det stillede for kravtil softwaren, installeret pa maskinerne. Vi kan naturligvis ikke forudsige alle typer
19

6 SETUP OG DESIGN AF KLYNGEN
af programmer, der skal installeres pa klyngen, men vi kan undersøge, hvad der skalbruges, sadan at en geninstallering af klyngen ikke er nødvendig i den kommende tid. Vihar pa dette grundlag valgt, at installere de mest almindelige biblioteker for parallelleprogrammer nemlig PVM (eng. Parallel Virtual Machine) og MPICH (eng. MessagePassing Interface Channel). Biblioteket PVM benyttes af programmerne POY og TNT,mens bl.a. Performance testningsprogrammet Linpack benytter MPICH biblioteket tilsine kørsler. Programmerne BLAST og HMM’er er pinligt parallelle og benytter sigderfor ikke af nogen biblioteker.
6 Setup og design af klyngen
Efter at have faet leveret maskinerne, lavede vi en lille testklynge med tre maskiner.I denne fik vi fastlagt hvordan maskinernes BIOS skulle konfigureres og hvordan viskulle sammensætte vores installationssystem. Udover at fa installationssystemet ogjobstyringsystemet til at virke, var der ogsa mange praktiske ting, der skulle ordnes iforbindelse med opsætning af klyngen. De to største var køling og strøm.
6.1 Installationsystemet
Da alle maskiner har PXE og er ens, er det muligt at fuldt ud automatisere installa-tionen, med følgende trin:
1. Først sender serveren en wake-on-lan pakke til maskinerne, der starter dem.
2. Derefter starter PXE med at sende en DHCP forespørgsel ud.
3. Nar DHCP serveren modtager en forspørgsel sender den en IP konfiguration til-bage til klienten og yderligere information omkring PXE: Hvor den skal hente sinbootloader fra og hvad den hedder.
4. Nar klienten har modtaget denne information bruges TFTP (ogsa en del af PXE)til at hente bootloaderen over nettet.
5. Bootloaderen bruger PXE til at hente en konfigurationsfil, der indeholder infor-mation om hvilken kerne, der er tilgængelig og hvilke parametre den skal bruge.Formatet minder meget om det mest almindelige for bootloadere til Linux.
6. Derefter henter den kernen, der er blevet defineret som standard, eller indtastetaf brugeren.
7. Derefter starter kernen, som den havde normalt ville gøre.
8. Nar kernen er startet, er det muligt at fa IP konfigurationen fra PXE sa rootfilsystemet kan monteres pa NFS.
9. Efter at kernen har startet init fra root filsystemet køres et almindeligt filsystem
10. Derefter køres sfdisk med en inddata-fil og partitionerer harddisken.
11. Herefter gendanner PartImage data til disken.
12. Maskinen genstartes og er herefter klar til brug.
20

6 SETUP OG DESIGN AF KLYNGEN 6.1 Installationsystemet
Figur 6: Opstartsprocessen for en maskine.
PXE Linux gør det muligt for os, at definere pa serveren hvilken kerne maskinerneskal starte med. Pa denne made kan vi vælge om maskinerne skal starte lokalt padisk eller via NFS. Vi kan ogsa vælge hvilken NFS export det skal være, sa vi kan faforskellig opførsel fra maskinerne f.eks. en fuld installation eller bare en opgradering.Partioneringen af diskene giver ogsa, en vis frihed til at vælge hvormeget af systemetman vil opdatere. Maden vi har opdelt filsystemet pa er:
dell utility fat16 hda1/boot 128 MB hda2 ext3/ 1 GB hda3 ext3swap 2 GB hda5 (Logisk) ext3/usr 4 GB hda6 (Logisk) ext3/var 2 GB hda7 (Logisk) ext3/tmp 512 MB hda8 (Logisk) ext3/scratch resten (30 GB) hda9 (Logisk) ext3
Hvor tanken er at /scratch partitionen, skal fungere som midlertidigt lagringsstedaf resultater, nar programmerne kører pa klyngen.
Denne made at installere pa, kan give problemer, da alle maskiner samtidig forsøgerat læse fra serveren. Det betyder, at serverens disk bliver overbelastet. Det er netopdette problem, som Ka-boot programmet forsøger at løse. Men da vi første gang skulleinstallere alle maskinerne skulle vi ogsa indsamle samtlige MAC adresser og fysiskmærke maskinerne, sa det blev ikke sa stort et problem for serveren, da vi fysisk kuninstallerede en maskine ad gangen. Det kan eventuelt i fremtiden blive nødvendigt, at
21

6 SETUP OG DESIGN AF KLYNGEN 6.2 Navngivning af maskiner
bruge et system som Ka-boot, eller noget lignende hvis man ønsker en lavere installa-tionstid.
Vi har siden da reinstalleret styresystemet pa knuderne et par gange, og har i denforbindelse kunne se, at det rent faktisk giver problemer med installationstiden, daserveren bliver overbelastet. Installationstiden gar fra at vare 5 min, per maskine, til atvare ca. 15 min, per maskine. Det ma dog forventes, at reinstallation af alle maskinerpa en gang, bliver en sjældenhed nar først klyngen gar i produktion.
6.2 Navngivning af maskiner
For at kunne identificere hvilke maskiner, der sidder pa hvilken switch og for at kunnefinde en maskine hvis den gar ned, var vi nød til at bruge en systematisk tilgang tilat navngive maskinerne. Efter rad fra Odense valgte vi at give maskinerne IP adresserefter hvilken switch de sad placeret pa og vi associerer derfor IP adresser med maskinerved hjælp af MAC adresser i DHCP filen. Alle maskiner har derfor et IP nummer, derer kendetegnet ved : 192.168.switchnr.portnr. Yderligere har vi ogsa fysisk mærketalle maskiner med labels, sa de er nemme at finde. Alle maskiner er navngivet sa dehedder bionode<nummer>, hvor nummeret er et løbenummer fra 1 op til 238.
6.3 Netværksstrukturen
Klyngen er fysisk placeret pa det undernetværk, der i daglig tale bliver kaldt forAKIZCI under KU. AKIZCI bestar af AKI (August Krogh Instituttet), ZI (Zoolo-gisk Institut), ZM (Zoologisk Museum) og IFI (Institut For Idræt).
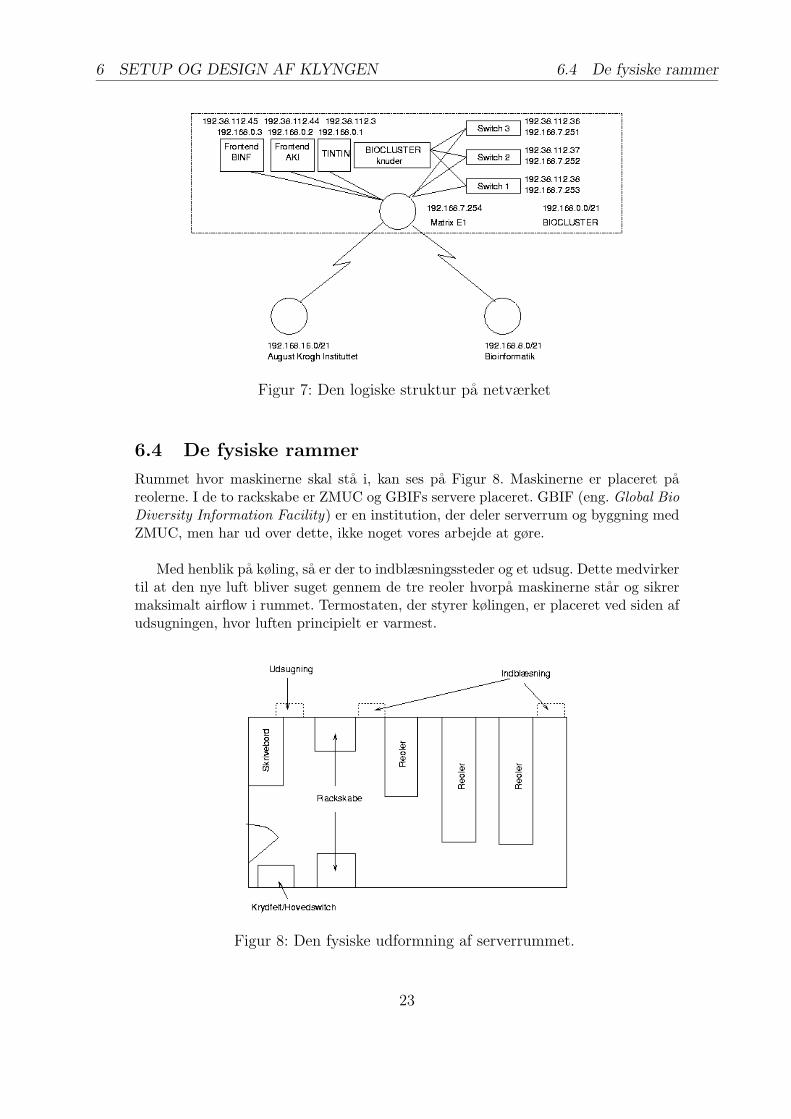
BINF (Bioinformatik-centret) sidder, midlertidigt tilknyttet AKIZCI nettet og ønskersig en stor netværksforbindelse til klyngen, sa den kan udnyttes optimalt. Der er dognogle problemer i den nuværende netværksstruktur. For tiden har BINF f.eks. en fi-rewall der laver NAT (eng. Network Address Translation) ud mod resten af AKIZCI.Dette er gjort for ikke at benytte for mange eksterne IP numre, pa et ellers interntnet. Dvs. at internt bruger BINF de samme lokale IP adresser som klyngen bruger.Dette har besværliggjort netværksopsætningen af NAT og routning mellem institut-terne. Løsningen blev, at der blevet lavet en “class-less” routning mellem de 3 net(BINF, AKI og bioclusteret) og BINF far begrænset sine lokale IP adresser til et lidtmindre range.
Et yderligere problem, er at det er den samme router, der skal styre NAT ud modomverden, som router ind mod lokalnettet. Dette gjorde, at det ikke var muligt atna ud pa internettet fra klyngemaskinerne. Dette gør, at forbindelser ud fra klyngenkommer til at ga gennem BINF, nar der fysisk bliver lavet en fiber-forbindelse mellemBINF og klyngen. Den fiber-forbindelse, som kan ses pa Figur 7 eksisterer altsa ikkept.
22
6 SETUP OG DESIGN AF KLYNGEN 6.4 De fysiske rammer
Figur 7: Den logiske struktur pa netværket
6.4 De fysiske rammer
Rummet hvor maskinerne skal sta i, kan ses pa Figur 8. Maskinerne er placeret pareolerne. I de to rackskabe er ZMUC og GBIFs servere placeret. GBIF (eng. Global BioDiversity Information Facility) er en institution, der deler serverrum og byggning medZMUC, men har ud over dette, ikke noget vores arbejde at gøre.
Med henblik pa køling, sa er der to indblæsningssteder og et udsug. Dette medvirkertil at den nye luft bliver suget gennem de tre reoler hvorpa maskinerne star og sikrermaksimalt airflow i rummet. Termostaten, der styrer kølingen, er placeret ved siden afudsugningen, hvor luften principielt er varmest.
Figur 8: Den fysiske udformning af serverrummet.
23

6 SETUP OG DESIGN AF KLYNGEN 6.5 Konfiguration af server
I forbindelse med klargøringen af rummet til serverrum, er el-installationen blevetopgraderet til at kunne klare de mange maskiner. Dette fremgar ikke af oversigtstegnin-gen, men el-installationen var en betydelig udgift pa budgettet. Den nye el-installationkrævede en udvidelse af den eksisterende el-tavle, oprettelse af nye grupper samt etab-lering af UPS-strøm til bl.a. fiber-hovedswitchen. Installationen af el og køling harværet den proces, der har taget længst tid i klargøringen af serverrummet.
6.5 Konfiguration af server
Som tidligere nævnt, sa valgte vi at bruge en af maskinerne, som server, sa den var nem,at erstatte ved eventuelle fejl. Det der adskiller serverens konfiguration, fra knuderneskonfiguration er følgende programmer:
• DHCP-server
• TFTP-server
• Navneserver (DNS)
• Filserver (NFS)
• NIS-server
• Jobstyringsserver (OpenPBS)
• Køstyringsserver (Maui)
DHCP, DNS og TFTP delen benyttes i sammenhæng med installationsystemet.Filserver delen, benyttes til at eksportere folks hjemmekataloger rundt pa klyngen, sade altid fysisk kun er placeret et sted, nemlig pa serveren. Men de er til enhver tidtilgængelige fra f.eks. frontend maskinerne. De tre sidste programmer: NIS, OpenPBSog Maui er alle tre relateret til jobstyring pa klyngen. Det var nødvendigt at installereNIS, for at OpenPBS kunne validere brugere pa tværs af knuder, da brugerne kun eroprettet pa serveren, men ikke pa knuderne.
server_state = Idle
scheduling = False
total_jobs = 2
state_count = Transit:0 Queued:0 Held:0 Waiting:0 Running:2 Exiting:0
managers = [email protected],[email protected],
default_queue = dque
log_events = 511
mail_from = adm
resources_assigned.nodect = 48
scheduler_iteration = 600
pbs_version = OpenPBS_2.3.16
Figur 9: OpenPBS serverens konfiguration
Vi benyttede os af [pbsinstall] , som vejledning til hvordan vi skulle konfigurereOpenPBS og Maui, sa det fungerede korrekt sammen. Bade OpenPBS og Maui erglimrende dokumenteret, sa det var intet problem, at konfigurere disse programmer.Vores konfiguration kan ses som Figur 9. Der er pt. kun en nkelt jobkø kaldet dque(eng. default queue) tilgængelig.
24

7 TEST OG EVALUERING AF KLYNGEN 6.6 Det endelig setup
6.6 Det endelig setup
Figur 10: Billeder af klyngen.
Det endelige biocluster klynge setup, bestar af 241 Dell OptiPlex GX260 maskiner,der alle kører Debian Linux. Hver hylde i en reol indeholder 12 computere. Der er taget4 computere fra til specielle roller. En er taget fra som server (tintin), en er taget frasom failover, hvis tintin fejler (dupont) og to maskiner er taget fra, til at fungere somfrontend maskiner for henholdsvis Zoologisk Museum og Center for Bioinformatik.Resten af maskinerne fungerer som bionoder. Pa figur 10 kan ses to billeder af detendelige klynge setup, som det ser ud idag.
7 Test og Evaluering af klyngen
I det følgende afsnit beskæftiger vi os med klyngens generelle performance, dels vedkørsler af programmet inpack, dels ved kørsler af de biologiske programmer. Biocluste-ret har det sidste stykke tid desværre, været ramt af hardware fejl, der har besværlig-gjort vores testmuligheder. Derfor er tuningen af klyngen, endnu ikke helt pa plads.
7.1 Fejl og mangler
Vi opdagede allerede ret tidligt, at vores fiber-hovedswitch havde et problem, da denefter en dag i drift gik ned. Problemet blev afhjulet af en netværkskonsulent og her-efter virkede den korrekt i 14 dage. I løbet af projektets sidste uge, gik den ned igenog denne gang i en sa udefinerbar tilstand, at den skulle skiftes under garantien. Enerstatning blev bestilt i Irland, men blev af uvisse arsager forsinket sa væsentligt at
25

7 TEST OG EVALUERING AF KLYNGEN 7.2 MTBF begrebet
den først kommer til Danmark omkring d. 18/3, hvilket er efter afleveringsfristen fordenne opgave.
Da dette er hovedswitchen, der binder hele netværket sammen, havde vi ingen mu-lighed for at kører nogle tests pa klyngen pa mere end 96 maskiner, uden den. Vi lantederfor midlertidigt en Dell gigabit-switch af DIKUs Distlab gruppe saledes at maski-nerne kunne snakke sammen internt, men der var ingen forbindelse til noget eksterntnet. Det lykkedes os ogsa at lane en fiber-switch af GBIF, saledes at vi fik eksternnetforbindelse indtil vores egen fiber-switch kommer retur.
Undervejs i vores tests gik det op for os, at der var et eller andet galt med netværket,da vi fik nogle meget mystiske resultater retur fra vores kørsler. Ved brug af program-met Netperf kunne vi se, at der kun var 46 Mbit forbindelse mellem to maskiner, derfysisk sad pa den samme stackede switch. Endnu værre stod det til med forbindelsenfra tintin til knuderne, her var hastigheden helt nede pa 2 Mbit. Det viste sig, at overhalvdelen af knuderne stod til at køre 100Mbit half duplex istedet for 100Mbit fullduplex. Kun de øverste af de stackede switche var konfigureret korrekt til 100Mbit fullduplex, resten stod til autonegotiate. Da fejlen først var fundet og identificeret, tog detikke lang tid at udbedre, men vi brugte næsten en hel uge pa at finde frem til dennefejl, og vi matte smide samtlige testkørselsresultater, fra før fejlen blev rettet ud, dade ikke gav nogen mening.
Efter fejlen blev rettet kørte vi Netperf programmet igen og kunne nu se at allemaskinerne havde en bandbredde pa ca. 96 Mbit til serveren, hvilket er væsentligttættere pa de forventede 100 Mbit.
Sidst, men ikke mindst, skal det siges at kølingen i rummet blev endeligt tilsluttettirsdag d. 11/3. Det var saledes ikke muligt at have alle maskiner tændt pa en gang,før dette tidspunkt, da rummet blev meget varmt og det ikke er specielt sundt formaskinerne. Kølingen naede ogsa at ga i stykker en enkelt gang siden d. 11/3, menblev dog ordnet allerede dagen efter. Tre maskiner er muligvis brændt af den nat,kølingen stoppede.
7.2 MTBF begrebet
Termen MTBF (eng. Mean Time Between Failure) beskriver komponenternes for-modede levetid. Lige meget hvor gode vores programmer er, har hardware en forventetlevetid. Hvis programmerne ikke implementerer en form for checkpointing, kan detvære relevant at give den enkelte programkørsel yderligere kørsels-timer, hvis en ellerflere af knuderne er gaet ned under kørslen. Dette kan OpenPBS garantere os - men vikan ikke garantere os mod fejlene. Der er dog ofte stor forskel mellem den teoretiskeog den faktiske fejlrate. Erfaringer fra Odense viser, at hvor de burde have et nedbrudper dag, har de istedet typisk et nedbrud per 3 dage. Nedenstaende graf er taget fraBrian Vinther (SDU) (se Figur 11).
Teoretisk set burde vores klynge have nedbrud ca. hver 33 time. Vi kender desværreendnu ikke de reelle tal. Vi vil dog anbefale, at der placeres en logbog sammen med
26

7 TEST OG EVALUERING AF KLYNGEN 7.3 Linpack
Figur 11: Graf over Mean Time Between Failure.
klyngen, hvor evt. systemnedbrud noteres samt servicepapirer placeres, sa man efter3 - 6 mdr. har mulighed for at bedømme den reelle nedetid af klyngen og fastsættepassende ekstra tid til folks kørsler efter dette.
7.3 Linpack
For at sammenligne vores klynge med andre eksisterende klynger har vi udført en kørselmed performancemalingsprogrammet Linpack. Da alle maskinerne teoretisk set skullekunne udføre 2 flydende tals operationer per clockcykel sa burde klyngen principieltkunne udføre ca. 1152 Giga FLOPS.
Det problem som Linpack forsøger at løse, er n ligninger med n ubekendte. Deting man kan justere pa i Linpack er hvor stort et n (N) man vil bruge og hvor storblokstørrelse (NB) man vil bruge til at opdele problemet. Man kan yderligere defineregeometrien af det logiske “grid” som maskinerne bliver placeret i (P og Q).
Ud fra de vejledninger vi har læst omkring Linpack, har vi fundet ud af, at n skalvære: 80% af RAM (512*0,8) divideret med størrelsen af et dobbelt flydende talordganget med antallet af computere. Dette giver os et tal pa ca. 100.000.
Det største resultat det er lykkedes os at fa til at køre er 80.000 pa 182 maskiner.
T/V N NB P Q Time GflopsW11R2C4 80000 60 13 14 6801.26 5.019e+01
Et resultat pa 50 Gigaflops, ma siges at være meget langt fra vores teoretiske mal.Vi har forsøgt at lokalisere kilden til dette skæve tal, men har svært ved trænge ind tilkernen af problemet. Vi ved derfor ikke om det skyldes en fejl i vores MPI installation,eller om det skyldes fejl i valg af parametre til Linpack.
Vi har korresponderet med Brian Vinther fra Odense, og bl.a. faet udleveret deresLinpack konfigurationsfil. Den lignede i høj grad vores egen (se H). Brian anbefalede
27

7 TEST OG EVALUERING AF KLYNGEN 7.4 Test af programmerne
dog brug af MPI-LAM biblioteket istedet for MPICH biblioteket som vi indtil nu harbenyttet os af. Det kan tænkes, at dette kan give langt bedre performance.
7.4 Test af programmerne
I det følgende afsnit vil vi forklare, hvordan vi har kørt de forskellige biologiske pro-grammer, samt vise de forskellige programmers performance pa klyngen.
7.4.1 BLAST
I den nuværende version af BLAST, som vi bruger, er den almindeligste strategi for atdistribuere arbejde, at dele databasen op i flere sma dele, som kører med den sammeforespørgeselssekvens pa mange maskiner. Vi har kørt BLAST pa 4 og 8 maskiner. Ti-derne er vist i Figure 12. Tiderne maler kun selve databasesøgningen og ikke overførslenaf data.
For at undersøge BLAST kørte programmet med følgende parametre:
formatdb -v $volume_size -p F -o T -i $DB_BASE
blastall -p blastn -d $dbname -i tempfasta
Hvor volume size er databasestørrelsen divideret med antallet af knuder. Og dbnameer navnet pa de enkelte dele af databasen.
Antal maskiner Tider per maskine (sek) Gennemsnitlig tid
4 273, 283, 289, 292 284,258 251, 267, 267, 269, 270, 273, 277, 278 269
Figur 12: Køretider af BLAST
Som det kan ses af figur 12, opnar vi en lille speedup, ved at køre BLAST pa dob-belt sa mange maskiner. Kørselstiden formindskes kun en lille smule, ved halvering afdatabasen. Dette tyder pa et stort opstartsoverhead ved søgning i databasen med kunen forespørgslessekvens. Dette tyder pa, at vores paralleliseringsstrategi for databasener uegnet til at køre pa en klynge, i sin nuværende form. Det kan skyldes at voresscenario er urealistisk.
Grunden til at vi ikke har faet kørt BLAST pa flere maskiner, skyldes problemermed programmet til formateringen af databasen (formatdb). Den splittede ikke data-basen, som forventet. Dette problem vil forhabentlig blive løst af en person med størreforstaelse for BLAST programmet, end os.
7.4.2 POY
POY er den eneste af applikationerne hvor vi har fundet tidligere littaratur omkringprogrammets opførsel pa en klynge [parapoy]. POY har to forskellige metoder til atkøre pa en klynge. Den ene kaldes for “parallel” og den anden kaldes for “multi”. I denførste samarbejder alle knuder om det samme træ, hvor den i den anden arbejder pa
28

7 TEST OG EVALUERING AF KLYNGEN 7.4 Test af programmerne
forskellige træer. Dette gør at “multi” skalerer bedre end “parallel”, da en af maderneat køre “multi” pa er udtømmende søgning, sa burde den fungere rigtig godt pa enklynge. Da vi ikke kunne afgøre hvilke parametre, der passede bedst til vores datasæt,valgte vi at bruge defaultværdier for alle parametre.
For at undersøge POY kørte vi programmet med følgende parametere:
poy -verbose -parallel -molecularmatrix /home/lars/poy/fn221
/home/lars/poy/atpa
Figur 13: Kørsler og Speedup for POY.
POY er det program, hvor det er lykkedes os at fa de fleste resultater og programmetafvikler betydeligt hurtigere i parallel. Men vores kørsler ligger dog langt fra de tæt paideelle køretider bseskrevet i [parapoy].
7.4.3 HMM
Strategien, der bliver brugt for at udnytte parallel computerkraft med HMMer, er atman laver parallel krydsvalidering. Dvs. at man deler sit datasæt op i n dele hvor(n-1)/n bliver brugt til træning og den sidste 1/n bliver brugt til at kontrollere atmodellen er korrekt. Nar vi kørte HMM’er i parallelversionen, kørte vi træningsdelenog dekodningsdelen pa sammen maskine.
For undersøge HMM kørte vi programmet med følgende parametere:
cat data/pombe.lab.1 data/pombe.lab.2 data/pombe.lab.3 data/pombe.lab.4 | ./trainanhmm
runs/pombe55/ml.0 -modelfile models/pombe00c.imod -f setup/mlstd.ini > runs/pombe55/ml.0.out
cat data/pombe.lab.0 | ./decodeanhmm runs/pombe55/ml.0.bsmod -N1
-pp -ps -pl > runs/pombe55/ml.0.pred
cat data/pombe.lab.1 data/pombe.lab.2 data/pombe.lab.3 data/pombe.lab.4 | ./trainanhmm
runs/pombe55/chmm.0 -modelfile runs/pombe55/ml.0.bsmod -f setup/chmmstd.ini > runs/pombe55/chmm.0.out
cat data/pombe.lab.0 | ./decodeanhmm runs/pombe55/chmm.0.bsmod -N1
-pp -ps -pl > runs/pombe55/chmm.0.pred
cat data/pombe.lab.0 data/pombe.lab.2 data/pombe.lab.3 data/pombe.lab.4 | ./trainanhmm
runs/pombe55/ml.1 -modelfile models/pombe00c.imod -f setup/mlstd.ini > runs/pombe55/ml.1.out
cat data/pombe.lab.1 | ./decodeanhmm runs/pombe55/ml.1.bsmod -N1
-pp -ps -pl > runs/pombe55/ml.1.pred
29

8 KONKLUSION
Vores kørselstider for HMM’er findes i Figur 14. Da der ikke er nogen kommunika-tion mellem processerne undervejs, tager den parallel kørsel, samme tid som den længstkørende process er om at blive færdig. De resultater vi har faet fra HMM’er modsvarerdet vi havde forventet, da HMM’er har en meget lav grad af granularitet. Grunden til,at vi ikke har faet kørt flere kørsler med HMM’er, der ellers ser meget lovende ud, erat det var det sidste program vi kom til at køre tests pa og vi desværre derfor ikkehavde nok tid til yderligere kørsler.
Antal maskiner Tider per maskine (sek) “Wallclock” tid
1 11983 119833 1367, 9245, 1367 9245
Figur 14: Køretider pa krysvalidering af HMM
7.4.4 Opsummering pa testkørsler
Vores testkørsler viser, at programmerne afvikler hurtigere pa klyngen end de villehave gjort serielt pa en enkelt maskine. Vi har desværre ikke haft tid til at udføreevalueringen i sadan grad, som vi gerne ville. Dette skyldes dels at det har taget osbetydeligt længere tid at fa programmerne køre pa klyngen end først antaget, og delsde allerede omtalte problemer relateret til opsætningen af netværket.
8 Konklusion
Vores formal med dette projekt var at analysere, designe og implementere en klyn-geløsning til biologisk forskning. Vi har evalueret de applikationer, som forskerne ønskerat benytte pa klyngen og vi har malt klyngens performance med programmet Linpack.Vi har i høj grad naet, det vi havde sat os for, pa trods af at projektet er blevet dobbeltsa stort, som oprindeligt antaget.
Hvis man ser pa de tværfaglige aspekter i opgaven, har udvidelsen af projektetikke kun øget antallet af applikationer, der skulle evalueres, det har ogsa betydet envæsentlig forøgelse i antallet af involverede personer. Dette har betydet, at der opstodet langt større behov for kommunikation og videns-udveksling pa tværs i gruppen endførst antaget. Det har i den grad kompliceret beslutningsprocessen undervejs i projek-tet. Det er vores holdning, at det ville have været hensigtsmæssigt med en tilknyttetprojektleder, der kunne koordinere projektet og følge op pa problemer. En person, somhavde været hævet over de organisatoriske strukturer, da projektet har baret præg afforvirring omkring ansvarsomrader og mangel pa koordinerende møder.
Rent økonomisk har projektet nydt godt af at vores arbejdskraft har været næ-stengratis for de tilknyttede institutter. Hvis man havde valgt at benytte en eksternkonsulent ville en større del af projektets budget være gaet til afløning. Men selv ved atgøre dette, ville projektet næppe have fungeret bedre, da en stor del af forsinkelserne
30

9 PERSPEKTIVERING
skyldtes etableringen af serverrummet, der tog meget længere tid, end først antaget(3-4 maneder).
Pa trods af alle disse forhindringer, er vi nu i en situation, hvor vi vurderer atklyngen kan tages rigtigt i brug indenfor kort tid. Der er fortsat et par udestaender,f.eks. mangler vi fortsat at dokumentere de daglige procedurer for brugen af klyngenog der er behov for yderligere tuning af opsætningen. Vi mener dog, at de valg dertruffet, har givet den bedst ydende klynge, set i forhold til prisen. Dette baserer vi delspa vores evaluering af programmerne, dels pa at Horseshoe klyngen i Odense fornylig,er blevet udvidet med maskiner af samme model, som vores.
9 Perspektivering
Det skriftlige projekt er nu afsluttet, men klyngen er endnu ikke taget i daglige drift.I den kommenende tid, vil der derfor komme en hel række af ekstra opgaver i rela-tion til klyngen. Første skridt bliver at fa genetableret den rigtige fiber-hovedswitch,sa klyngen kan fungere korrekt. Herefter skal der arbejdes pa tuningen af klyngen, saforskerne kan fa den optimale ydelse ud af maskinerne inden den officielle ibrugtagningaf den. Forskerne har store forhabninger til klyngen og der arbejdes bl.a. pa en presse-meddelelse, der skal informere offentligheden om dens eksistens.
To af vores egne udestaender bestar i, at fa etableret et dokumentations web-site (http://biocluster.ku.dk/), hvor forskerne kan fa svar pa de mest almindeligespørgsmal i forbindelse med klyngen. Yderligere er vi blevet bedt om at holde enKlynge introduktions-dag for forskerne, sa de kan komme godt igang med at benytteklyngen. Allerede nu, star forskerne pa Zoologisk Museum, med 3 nye programmer, deønsker at prøve af pa klyngen. Det drejer sig om: Nona, PiWe og Mr. Bayes, der allearbejder med at løse phylogeni problemer.
Pa lidt længere sigt, skal der implementeres en mere udvidet brug af de forskelligebrugs-politikker i OpenPBS og Maui, sa opsætningen garantere at ingen monopolisererklyngen i længere tid. En anden ting vi ønsker at se pa, er en forbdring af applika-tionerne, sa de er bedre egnet til klyngekørler. Et eksempel er en MPI version afprogrammet BLAST, der fornylig er blevet frigivet, og vil være værd at undersøgeperformance pa.
Der er ogsa tale om at blive koblet pa det danske Grid computing initiativ. GridComputing initiativet er et forsøg pa, at koble alle de danske forsknings klyngecompu-tere sammen til en stor løstkoblet klynge, til støtte for dansk forskning.
31

10 LITTERATURLISTE
10 Litteraturliste
Websider
[diskless] NFS Root Mini HOWTO“http://www.ibiblio.org/pub/Linux/docs/HOWTO/mini/other-formats/html single/NFS-R/”
[Maui] Maui Scheduler“http://supercluster.org/”
[OpenPBS] OpenPBS Administrators Guide“http://www.openpbs.org/UserArea/Download/v2.3 admin.pdf”
[SYSLINUX] About SysLinux Project“http://syslinux.zytor.com/”
[pvm] Parallel Virtual Machine“http://www.csm.ornl.gov/pvm/pvm home.html”
[Dellbenchmark] Rizwan Ali et al.“Evaluating High-Performance Computing Clusters Using Benchmarks”“http://www.dell.com/powersolutions”
[Freshmeat] Linux Clustering Software“http://freshmeat.net/articles/view/458”
[bioinf] Bioinformatics“http://bioinformatics.org/”
[ka-tools] Ka Tools“http://ka-tools.sf.net”
[systemimager] SystemImager“http://www.systemimager.org”
[partimage] PartImage“http://www.partimage.org”
[pbsinstall] OpenPBS Install Notes“http://epp.ph.unimelb.edu.au/epp/grid/globus/openpbs.shtml”
Artikler
[PVMMPI] G. A. Geist et al.“PVM and MPI: a comparison of Features” Artikel, pp. 1-16, 1996.
[POYexplo] Gonzalo Giribet“Exploring the Behavior of POY, a Program for Direct Optimization of MolecularData” Cladistics 17, pp. 60-70, 2001.
[MOSIX] Ammon Barak et al.“The MOSIX Multicomputer Operating System for High Performance Cluster Compu-ting” Artikel, pp. 1-14, 199x.
[BEOWULF] Donald J. Becker et al.“Beowulf: A Parallel Workstation for Scientific Computation” Artikel, pp. 1-4, 1995.
32

10 LITTERATURLISTE
[Bioinformatics] O. Trelles“On the Parallelisation of Bioinformatic Applications” Briefings in Bioinformatics vol.2, nr. 2, pp. 181-194, May 2001.
[BLAST] Stephen F. Altschul et. al“Basic Local Aligment Search Tool” Journal of Molecular Biology vol. 215, pp. 403-410,1990.
[statistics] Samuel Karlin and Stephen F. Altschul“Methods for assessing the statistical significance of molecular sequence features byusing general scoring schemes” Procedings of National Academic Science of USA, vol87, pp. 2264-2268, March 1990 Evolution.
[protein] William R. Pearson“Protein sequence comparision and Protein evolution” Tutorial ISMB200, October2001.
[P4Perf] Brinkley Sprunt“Pentium 4 Performance-Monitoring Features” IEEE Micro no. 4, pp. 72-82, 2002.
[P4Spec] Intel“Intel Pentium 4 Processor Performance Metrics” Intel r© Pentium r© 4 Processor Op-timization Reference Manual, Appendix B, 2002.
[2-4-8] B. Vinter, O. Anshus, T. Larsen, J. Bjørndalen“Using Two-, Four- and Eight-Way Multiprocessors as Cluster Components” Proce-dings of Communicating Process Architectures, CPA, 2001
[binf] R. Durbin, et. al“Biological sequence analysis - Probabilistic models of proteins and nucleic acids”,Camb. press 1998
[parapoy] Daniel A. Janies and Ward C. Wheeler“Efficiency of Parallel Direct Optimization”, Cladistics 17, S71-S82, 2001
[tnt] Pablo A. Goloboff“Analyzing Large Data Sets in Reasonable Times: Solutions for Composite Optima”,Cladistics 15, 415-428, 1999
[poy] Ward Wheeler“Optimization Alignment: The end of multiple sequence alignment in phylogenetics”,Cladistics 12, 1-9, 1996
Algoritmer
[WEBPOY] POY“ftp://ftp.amnh.org/pub/molecular/poy”
[WEBBLAST] BLAST“http://www.ncbi.nlm.nih.gov/BLAST/”
[WEBTNT] TNT“http://www.cladistics.com/webtnt.html”
33

A KØRSELSUDSKRIFTER FRA FORUNDERSØGELSER
A Kørselsudskrifter fra forundersøgelser
A.1 Testkørsel af POY
A.1.1 POY pa testmaskine 3Process took 56 seconds
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
85.62 0.016646 151 110 write
6.29 0.001222 53 23 old_mmap
5.63 0.001095 1 759 brk
0.70 0.000137 7 19 read
0.44 0.000085 28 3 munmap
0.38 0.000073 6 12 1 open
0.34 0.000066 7 9 3 stat64
0.27 0.000052 52 1 readlink
0.11 0.000021 2 11 close
0.06 0.000011 4 3 mprotect
0.04 0.000008 8 1 1 access
0.04 0.000008 1 7 fcntl64
0.03 0.000006 2 4 fstat64
0.03 0.000005 2 3 time
0.02 0.000003 3 1 uname
0.01 0.000002 2 1 rt_sigaction
0.01 0.000001 1 1 sigaltstack
------ ----------- ----------- --------- --------- ----------------
100.00 0.019441 968 5 total
real 0m55.944s
user 0m55.080s
sys 0m0.100s
A.1.2 POY pa testmaskine 4Process took 97 seconds
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
46.01 0.005206 3 1517 brk
41.29 0.004672 42 110 write
4.30 0.000486 21 23 old_mmap
2.41 0.000273 14 19 read
1.85 0.000209 70 3 munmap
1.12 0.000127 11 12 1 open
1.03 0.000117 13 9 3 stat64
0.59 0.000067 67 1 readlink
0.43 0.000049 4 11 close
0.34 0.000038 5 7 fcntl64
0.21 0.000024 8 3 time
0.16 0.000018 6 3 mprotect
0.10 0.000011 3 4 fstat64
0.05 0.000006 6 1 uname
0.04 0.000005 5 1 rt_sigaction
0.04 0.000004 4 1 sigaltstack
0.02 0.000002 2 1 1 semget
------ ----------- ----------- --------- --------- ----------------
100.00 0.011314 1726 5 total
real 1m36.354s
user 1m36.130s
sys 0m0.290s
A.1.3 POY pa testmaskine 5Process took 38 seconds
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
88.36 0.013040 119 110 write
7.96 0.001175 2 741 brk
1.18 0.000174 8 23 old_mmap
0.72 0.000106 6 19 read
0.37 0.000055 6 9 3 stat64
0.37 0.000054 5 12 1 open
0.35 0.000052 17 3 munmap
0.24 0.000036 36 1 readlink
0.14 0.000021 7 3 time
0.14 0.000020 2 11 close
0.05 0.000008 1 7 fcntl64
0.05 0.000007 2 3 mprotect
0.03 0.000004 1 4 fstat64
0.01 0.000002 2 1 uname
0.01 0.000002 2 1 rt_sigaction
0.01 0.000002 2 1 sigaltstack
34

A KØRSELSUDSKRIFTER FRA FORUNDERSØGELSER A.2 Testkørsel af BLAST
------ ----------- ----------- --------- --------- ----------------
100.00 0.014758 949 4 total
real 0m38.617s
user 0m38.570s
sys 0m0.030s
A.2 Testkørsel af BLAST
A.2.1 BLAST pa testmaskine 3execve("/usr/bin/blastall", ["blastall", "-p", "blastn", "-d", "nt",
"-i", "tempfasta"], [/* 19 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
67.79 0.188344 727 259 read
15.66 0.043508 71 616 write
12.03 0.033418 234 143 munmap
3.21 0.008917 811 11 3 mmap2
0.43 0.001208 3 406 _llseek
0.32 0.000883 6 159 old_mmap
0.20 0.000549 4 151 brk
0.10 0.000288 7 39 8 open
0.08 0.000210 5 39 12 stat64
0.03 0.000095 2 50 time
0.03 0.000091 3 32 close
0.02 0.000044 44 1 clone
0.02 0.000044 2 19 fstat64
0.01 0.000034 4 8 mprotect
0.01 0.000034 9 4 4 rt_sigsuspend
0.01 0.000031 31 1 pipe
0.01 0.000023 23 1 socket
0.01 0.000019 19 1 1 connect
0.00 0.000011 3 4 rt_sigaction
0.00 0.000010 3 4 4 sigreturn
0.00 0.000010 2 6 rt_sigprocmask
0.00 0.000008 4 2 uname
0.00 0.000008 8 1 getcwd
0.00 0.000007 7 1 1 access
0.00 0.000007 7 1 wait4
0.00 0.000006 6 1 _sysctl
0.00 0.000004 2 2 fcntl64
0.00 0.000002 2 1 getpid
0.00 0.000002 2 1 setrlimit
0.00 0.000002 2 1 getrlimit
0.00 0.000002 2 1 getuid32
------ ----------- ----------- --------- --------- ----------------
100.00 0.277819 1966 33 total
real 2m32.498s
user 0m30.530s
sys 0m5.880s
A.2.2 BLAST pa testmaskine 4execve("/usr/bin/blastall", ["blastall", "-p", "blastn", "-d", "nt",
"-i", "tempfasta"], [/* 14 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
56.77 0.314240 1204 261 read
26.38 0.146003 237 616 write
15.60 0.086341 600 144 munmap
0.41 0.002256 6 406 _llseek
0.25 0.001394 5 283 brk
0.22 0.001244 8 160 old_mmap
0.08 0.000468 11 43 11 open
0.06 0.000337 9 39 12 stat64
0.06 0.000323 81 4 4 rt_sigsuspend
0.04 0.000200 18 11 3 mmap2
0.04 0.000194 4 50 time
0.03 0.000169 5 33 close
0.02 0.000090 5 20 fstat64
0.01 0.000044 6 8 mprotect
0.01 0.000032 32 1 1 connect
0.01 0.000030 30 1 socket
0.00 0.000025 6 4 4 sigreturn
0.00 0.000022 22 1 pipe
0.00 0.000013 13 1 clone
0.00 0.000013 7 2 uname
0.00 0.000011 2 6 rt_sigprocmask
0.00 0.000010 10 1 wait4
0.00 0.000010 3 3 rt_sigaction
0.00 0.000009 9 1 getcwd
0.00 0.000008 8 1 _sysctl
0.00 0.000006 3 2 fcntl64
35

A KØRSELSUDSKRIFTER FRA FORUNDERSØGELSER A.3 Testkørsel af HMM
0.00 0.000004 4 1 getrlimit
0.00 0.000003 3 1 setrlimit
0.00 0.000003 3 1 1 semget
0.00 0.000002 2 1 getpid
0.00 0.000002 2 1 getuid32
------ ----------- ----------- --------- --------- ----------------
100.00 0.553506 2107 36 total
real 2m11.028s
user 0m52.030s
sys 0m6.010s
A.2.3 BLAST pa testmaskine 5% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
50.92 0.020468 1365 15 munmap
22.16 0.008905 85 105 write
20.08 0.008071 577 14 read
2.73 0.001099 34 32 12 stat64
1.14 0.000457 16 28 8 open
0.84 0.000339 339 1 poll
0.45 0.000180 6 28 old_mmap
0.28 0.000111 22 5 1 mmap2
0.26 0.000105 2 50 time
0.19 0.000075 4 20 brk
0.16 0.000064 3 22 close
0.09 0.000036 9 4 4 rt_sigsuspend
0.08 0.000034 2 14 fstat64
0.08 0.000032 16 2 socket
0.07 0.000027 4 7 mprotect
0.06 0.000026 26 1 clone
0.06 0.000023 23 1 pipe
0.05 0.000022 22 1 sendto
0.04 0.000016 16 1 1 connect
0.03 0.000014 2 6 rt_sigprocmask
0.03 0.000012 12 1 readv
0.03 0.000011 3 4 uname
0.02 0.000009 2 4 4 sigreturn
0.02 0.000007 2 3 rt_sigaction
0.02 0.000007 2 3 fcntl64
0.01 0.000006 6 1 wait4
0.01 0.000006 6 1 _sysctl
0.01 0.000005 5 1 recvfrom
0.01 0.000005 5 1 setsockopt
0.01 0.000004 4 1 1 bind
0.01 0.000003 2 2 getpid
0.01 0.000003 3 1 ioctl
0.01 0.000003 3 1 _llseek
0.00 0.000002 2 1 setrlimit
0.00 0.000002 2 1 gettimeofday
0.00 0.000002 2 1 getrlimit
0.00 0.000002 2 1 getuid32
------ ----------- ----------- --------- --------- ----------------
100.00 0.040193 385 31 total
real 1m2.291s
user 0m0.840s
sys 0m2.470s
A.3 Testkørsel af HMM
A.3.1 HMM pa testmaskine 3train:
execve("./trainanhmm", ["./trainanhmm", "runs/pombe55/ml.0", "-modelfile",
"models/pombe00c.imod", "-f", "setup/mlstd.ini"], [/* 18 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
62.21 0.300519 63 4801 write
21.28 0.102785 2 58228 brk
15.53 0.075032 17 4495 read
0.60 0.002894 107 27 2 open
0.19 0.000908 7 130 munmap
0.10 0.000475 3 139 old_mmap
0.06 0.000295 12 24 close
0.02 0.000109 4 27 fstat64
0.01 0.000045 5 10 time
0.00 0.000007 7 1 1 access
0.00 0.000006 3 2 mprotect
0.00 0.000005 3 2 2 ioctl
0.00 0.000003 3 1 uname
0.00 0.000002 2 1 getpid
------ ----------- ----------- --------- --------- ----------------
36

A KØRSELSUDSKRIFTER FRA FORUNDERSØGELSER A.3 Testkørsel af HMM
100.00 0.483085 67888 5 total
real 27m55.494s
user 27m48.070s
sys 0m4.380s
decode:
execve("./decodeanhmm", ["./decodeanhmm", "runs/pombe55/ml.0.bsmod",
"-N1", "-pp", "-ps", "-pl"], [/* 18 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
79.76 0.095187 49 1946 write
18.75 0.022371 20 1133 read
0.93 0.001109 4 286 brk
0.22 0.000265 8 33 munmap
0.15 0.000180 4 41 old_mmap
0.13 0.000154 19 8 1 open
0.02 0.000022 22 1 time
0.01 0.000016 3 6 close
0.01 0.000015 2 9 fstat64
0.01 0.000006 6 1 1 access
0.01 0.000006 3 2 mprotect
0.00 0.000005 3 2 2 ioctl
0.00 0.000003 3 1 uname
------ ----------- ----------- --------- --------- ----------------
100.00 0.119339 3469 4 total
real 8m1.041s
user 7m58.220s
sys 0m1.070s
A.3.2 HMM pa testmaskine 4train:
execve("/net/bin/trainanhmm", ["trainanhmm", "runs/pombe55/ml.0", "-modelfile",
"models/pombe00c.imod", "-f", "setup/mlstd.ini"], [/* 14 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
75.69 0.656769 6 116463 brk
9.30 0.080734 18 4497 read
7.53 0.065337 2722 24 close
5.07 0.043992 9 4801 write
1.94 0.016831 623 27 2 open
0.25 0.002206 17 130 munmap
0.12 0.001076 8 139 old_mmap
0.05 0.000473 18 27 fstat64
0.03 0.000243 24 10 time
0.00 0.000014 7 2 mprotect
0.00 0.000010 5 2 2 ioctl
0.00 0.000010 10 1 uname
0.00 0.000003 3 1 getpid
0.00 0.000003 3 1 1 semget
------ ----------- ----------- --------- --------- ----------------
100.00 0.867701 126125 5 total
real 38m46.153s
user 38m33.880s
sys 0m5.310s
decode:
execve("/net/bin/decodeanhmm", ["decodeanhmm", "runs/pombe55/ml.0.bsmod",
"-N1", "-pp", "-ps", "-pl"], [/* 14 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
51.96 0.082697 73 1133 read
44.49 0.070817 36 1946 write
2.97 0.004726 9 553 brk
0.25 0.000403 12 33 munmap
0.18 0.000280 7 41 old_mmap
0.09 0.000141 18 8 1 open
0.02 0.000038 4 9 fstat64
0.02 0.000026 4 6 close
0.01 0.000013 7 2 mprotect
0.01 0.000010 5 2 2 ioctl
0.01 0.000009 9 1 uname
0.00 0.000002 2 1 time
0.00 0.000001 1 1 1 semget
------ ----------- ----------- --------- --------- ----------------
100.00 0.159163 3736 4 total
real 10m6.720s
user 10m4.600s
sys 0m0.680s
37

A KØRSELSUDSKRIFTER FRA FORUNDERSØGELSER A.3 Testkørsel af HMM
A.3.3 HMM pa testmaskine 5train:
execve("./trainanhmm", ["./trainanhmm", "runs/pombe55/ml.0", "-modelfile",
"models/pombe00c.imod", "-f", "setup/mlstd.ini"], [/* 13 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
45.78 0.117158 2 58111 brk
33.53 0.085809 18 4801 write
19.78 0.050631 11 4495 read
0.39 0.001004 37 27 2 open
0.27 0.000694 5 130 munmap
0.17 0.000444 3 139 old_mmap
0.02 0.000059 2 24 close
0.02 0.000058 2 27 fstat64
0.01 0.000034 3 10 time
0.00 0.000006 3 2 mprotect
0.00 0.000004 2 2 2 ioctl
0.00 0.000003 3 1 uname
0.00 0.000002 2 1 getpid
------ ----------- ----------- --------- --------- ----------------
100.00 0.255906 67770 4 total
real 16m53.451s
user 16m52.010s
sys 0m1.070s
decode:
execve("./trainanhmm", ["./trainanhmm", "runs/pombe55/ml.0", "-modelfile",
"models/pombe00c.imod", "-f", "setup/mlstd.ini"], [/* 13 vars */]) = 0
% time seconds usecs/call calls errors syscall
------ ----------- ----------- --------- --------- ----------------
45.78 0.117158 2 58111 brk
33.53 0.085809 18 4801 write
19.78 0.050631 11 4495 read
0.39 0.001004 37 27 2 open
0.27 0.000694 5 130 munmap
0.17 0.000444 3 139 old_mmap
0.02 0.000059 2 24 close
0.02 0.000058 2 27 fstat64
0.01 0.000034 3 10 time
0.00 0.000006 3 2 mprotect
0.00 0.000004 2 2 2 ioctl
0.00 0.000003 3 1 uname
0.00 0.000002 2 1 getpid
------ ----------- ----------- --------- --------- ----------------
100.00 0.255906 67770 4 total
real 6m8.785s
user 6m7.700s
sys 0m0.140s
38

B KRAVSPECIFIKATION PA KLYNGECOMPUTERE
B Kravspecifikation pa klyngecomputere
Vedlagt findes en kravspecifikation pa en computerkonfiguration som skal benyttes tilen klyngecomputer. Vi ønsker et tilbud der i størst mulig grad imødekommer vores krav.
B.1 Computere
Vi skal bruge en pris pa to computere dels en Pentium 4 og dels en Celeron. Da viendnu ikke har fastsat vores krav til L2 cache.
Vi ønsker ikke tilbud pa AMD processorer.
Del KravCPU Pentium 4 (2.4 GHz gerne med tilbud pa 400 og 533 MHz front side bus) eller
Celeron (2 GHz Northwood).Disk ≥ 40 Gb (7200 RPM med lav varmeudvikling)
Netkort 100 Mbit Fast Ethernet (skal fungere med Linux)Bios Bios indstilling skal kunne gemmes til og gendannes fra diskette
Hukommelse 512 Mb DDR (i en klods eller et bundkort med fire “slots”)Bundkort Med PXE (netkort/grafikkort/etc onboard)Kabinet Small form faktor (gerne A-Open) eller noget lignende
Netværk
Maskinerne skal sammenkoples med to niveauer af switche.
Del KravFørste niveau switche 100 Mbit Fast Ethernet (gerne 48 porte) med en 1Gb port.Anden niveau switch En 1Gb switch (gerne modulær).
Levering
Da vi skal bruge i omegnen af 200 af disse computere vil vi gerne vide om de kan leveresinden udgangen af aret.
Tilbud skal sendes til:Claes PetersenSystem Administrator
Zoological MuseumAdministration DepartmentUniversitetsparken 15DK-2100 Copenhagen ØDenmark
Tel: +45 3532 1112Mobil: +45 2875 1112
39

C OVERSIGT OVER TILBUD
C Oversigt over tilbud
41

C OVERSIGT OVER TILBUD
Fyld
42

D DELL TILBUD
D Dell tilbud
43

D DELL TILBUD
Fyld
44

D DELL TILBUD
Fyld
45

D DELL TILBUD
Fyld
46

D DELL TILBUD
Fyld
47

D DELL TILBUD
Fyld
48

E EL TILBUD
E El tilbud
49

E EL TILBUD
Fyld
50

E EL TILBUD
Fyld
51

F KØLINGS TILBUD
F Kølings tilbud
52

F KØLINGS TILBUD
Fyld
53

F KØLINGS TILBUD
Fyld
54

F KØLINGS TILBUD
Fyld
55

F KØLINGS TILBUD
Fyld
56

G SWITCH TILBUD
G Switch tilbud
57

G SWITCH TILBUD
Fyld
58

G SWITCH TILBUD
Fyld
59

G SWITCH TILBUD
Fyld
60

G SWITCH TILBUD
Fyld
61

G SWITCH TILBUD
Fyld
62

H LINPACK KONFIGURATIONSFIL
H Linpack konfigurationsfil
H.1 Vores HPL.dat
HPLinpack benchmark input fileInnovative Computing Laboratory, University of TennesseeHPL.big output file name (if any)1 device out (6=stdout,7=stderr,file)3 # of problems sizes (N)80000 90000 100000 Ns3 # of NBs64 128 256 NBs2 # of process grids (P x Q)13 14 Ps14 13 Qs16.0 threshold1 # of panel fact1 PFACTs (0=left, 1=Crout, 2=Right)1 # of recursive stopping criterium4 NBMINs (>= 1)1 # of panels in recursion2 NDIVs1 # of recursive panel fact.2 RFACTs (0=left, 1=Crout, 2=Right)1 # of broadcast1 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)1 # of lookahead depth1 DEPTHs (>=0)2 SWAP (0=bin-exch,1=long,2=mix)60 swapping threshold0 L1 in (0=transposed,1=no-transposed) form0 U in (0=transposed,1=no-transposed) form1 Equilibration (0=no,1=yes)8 memory alignment in double (> 0)
H.2 Horseshoes HPL.dat
HPLinpack benchmark input fileInnovative Computing Laboratory, University of TennesseeHPL.out output file name (if any)1 device out (6=stdout,7=stderr,file)3 # of problems sizes (N)61440 122880 245760 Ns3 # of NBs64 128 256 NBs4 # of process grids (P x Q)8 16 32 64 Ps
63

H LINPACK KONFIGURATIONSFIL H.2 Horseshoes HPL.dat
64 32 16 8 Qs16.0 threshold3 # of panel fact0 1 2 PFACTs (0=left, 1=Crout, 2=Right)2 # of recursive stopping criterium3 4 NBMINs (>= 1)1 # of panels in recursion4 NDIVs1 # of recursive panel fact.1 RFACTs (0=left, 1=Crout, 2=Right)3 # of broadcast0 1 4 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)3 # of lookahead depth2 4 8 DEPTHs (>=0)2 SWAP (0=bin-exch,1=long,2=mix)64 swapping threshold (64)1 L1 in (0=transposed,1=no-transposed) form1 U in (0=transposed,1=no-transposed) form1 Equilibration (0=no,1=yes)16 memory alignment in double (> 0)
64






























