Embed Size (px)
Citation preview

Early Scheduling in Parallel State Machine Replication
Eduardo Alchieri1, Fernando Dotti2 and Fernando Pedone31Departamento de Ciencia da Computacao – Universidade de Brasılia, Brazil
2Escola Politecnica – Pontifıcia Universidade Catolica do Rio Grande do Sul, Brazil3Universita della Svizzera italiana (USI), Switzerland
Abstract
State machine replication is standard approach to faulttolerance. One of the key assumptions of state machinereplication is that replicas must execute operations deter-ministically and thus serially. To benefit from multi-coreservers, some techniques allow concurrent execution ofoperations in state machine replication. Invariably, thesetechniques exploit the fact that independent operations(those that do not share any common state or do not up-date shared state) can execute concurrently. A promisingcategory of solutions trades scheduling freedom for sim-plicity. This paper generalizes this category of schedulingsolutions. In doing so, it proposes an automated mecha-nism to schedule operations on worker threads at replicas.We integrate our contributions to a popular state machinereplication framework and experimentally compare the re-sulting system to more classic approaches.
1 Introduction
This paper investigates a new class of scheduling proto-cols for high performance parallel state machine repli-cation. State machine replication (SMR) is a well-established approach to fault tolerance [21, 29]. The ba-sic idea is quite simple: server replicas execute client re-quests deterministically and in the same order. Conse-quently, replicas transition through the same sequence ofstates and produce the same sequence of outputs. Statemachine replication can tolerate a configurable number offaulty replicas. Moreover, application programmers canfocus on the inherent complexity of the application, whileremaining oblivious to the difficulty of handling replicafailures [10]. Not surprisingly, the approach has been suc-cessfully used in many contexts (e.g., [4, 12, 16]).
Modern multi-core servers, however, challenge thestate machine replication model since deterministic ex-ecution of requests often translates into single-threadedreplicas. In search of solutions to this performance limi-tation, a number of techniques have been proposed to al-low multi-threaded execution of requests at replicas (e.g.,
[13, 18, 19, 26]). Techniques that introduce concurrencyin state machine replication build on the observation thatindependent requests can execute concurrently while con-flicting requests must be serialized and executed in thesame order by the replicas. Two requests conflict if theyaccess common state and at least one of them updates thestate, otherwise the requests are independent.
An important aspect in the design of multi-threadedstate machine replication is how to schedule requests forexecution on worker threads. Proposed solutions fall intwo categories. With late scheduling, requests are sched-uled for execution after they are ordered across replicas.Besides the aforementioned requirement on conflictingrequests, there are no further restrictions on scheduling.With early scheduling, part of the scheduling decisionsare made before requests are ordered. After requests areordered, their scheduling must respect these restrictions.
Since late scheduling has fewer restrictions, it allowsmore concurrency than early scheduling. Hence, a natu-ral question is why would one resort to an early schedul-ing algorithm instead of a late scheduling algorithm? Theanswer is that the cost of tracking dependencies amongrequests in late scheduling may outweigh its gains in con-currency. In [20], for example, each replica has a directeddependency graph that stores not-yet-executed requestsand the order in which conflicting requests must be ex-ecuted. A scheduler at the replica delivers requests in or-der and includes them in the dependency graph. Workerthreads remove requests from the graph and execute themrespecting their dependencies. Therefore, scheduler andworkers contend for access to the shared graph.
By restricting concurrency, scheduling can be donemore efficiently. Consider a service based on the typicalreaders-and-writers concurrency model. Scheduling be-comes simpler if reads are scheduled on any one workerthread and writes are scheduled on all worker threads. Toexecute a write, all worker threads must coordinate (e.g.,using a barrier) so that no read is ongoing and only oneworker executes the write. This scheme is more restrictivethan the one using the dependency graph because it doesnot allow concurrent writes, even if they are independent.Previous research has shown that early scheduling can
1
arX
iv:1
805.
0515
2v1
[cs
.DC
] 1
4 M
ay 2
018

outperform late scheduling by a large margin, speciallyin workloads dominated by read requests [24, 26]. Theseworks assume a simple form of early scheduling that fo-cuses on the readers-and-writers concurrency model.
This paper generalizes early scheduling in state ma-chine replication. We follow a three-step approach. First,by using the notion of classes of requests we show howa programmer can express concurrency in an application.In brief, the idea is to group service requests in classesand then specify how classes must be synchronized. Forexample, we can model readers-and-writers with a classof read requests and a class of write requests. The classof write requests conflicts with itself and with the class ofread requests. This ensures that a write is serialized withreads and with other writes. We also consider more elab-orate concurrency models that assume sharded applica-tion state with read and write operations within and acrossshards. These models allow concurrent reads and writes.
Second, we show how one can automatically map re-quest classes to worker threads. The crux of our techniqueis the formulation of the classes-to-threads mapping as anoptimization problem. Mapping classes to threads anddeciding how to synchronize worker threads within andacross classes is a non-trivial problem. One interestingfinding is that it may be advantageous to serialize an in-herently concurrent class (i.e., with read requests only) tocapitalize on more significant gains from increased con-currency in other classes, as we explain in detail in thepaper. Finally, our optimization formulation accounts forskews in the workload.
Third, we have fully implemented our techniques andconducted a number of experiments with different ser-vices and workloads, and compared the performance ofour early scheduling technique to a late scheduling algo-rithm.
The paper continues as follows. Section 2 introducesthe system model and consistency criteria. Section 3 pro-vides some background on parallel approaches to statemachine replication. Section 4 generalizes early schedul-ing. Section 5 describes our optimization model. Sec-tion 6 reports on our experimental evaluation. Section 7surveys related work and Section 8 concludes the paper.
2 System model and consistency
We assume a distributed system composed of intercon-nected processes that communicate by exchanging mes-sages. There is an unbounded set of client processes anda bounded set of replica processes. The system is asyn-chronous: there is no bound on message delays and on rel-ative process speeds. We assume the crash failure modeland exclude arbitrary behavior. A process is correct if itdoes not fail, or faulty otherwise. There are up to f faulty
replicas, out of 2f + 1 replicas.Processes have access to an atomic broadcast commu-
nication abstraction, defined by primitives broadcast(m)and deliver(m), where m is a message. Atomic broad-cast ensures the following properties [9, 14]1:
• Validity: If a correct process broadcasts a messagem, then it eventually delivers m.
• Uniform Agreement: If a process delivers a messagem, then all correct processes eventually deliver m.
• Uniform Integrity: For any message m, every pro-cess delivers m at most once, and only if m was pre-viously broadcast by a process.
• Uniform Total Order: If both processes p and q de-liver messages m and m′, then p delivers m beforem′, if and only if q delivers m before m′.
Our consistency criterion is linearizability. A lineariz-able execution satisfies the following requirements [15]:
• It respects the real-time ordering of operations acrossall clients. There exists a real-time order among anytwo operations if one operation finishes at a clientbefore the other operation starts at a client.
• It respects the semantics of the operations as definedin their sequential execution.
3 BackgroundParallel SMR exploits the fact that strong consistencydoes not always require all operations to be executed inthe same order at all replicas. In this section, we formal-ize this idea and present two categories of SMR systemsthat exploit parallelism.
3.1 The notion of conflictState machine replication determines how service oper-ations must be propagated to and executed by the repli-cas. Typically, (i) every correct replica must receive everyoperation; (ii) no two replicas can disagree on the orderof received and executed operations; and (iii) operationexecution must be deterministic: replicas must reach thesame state and produce the same output upon executingthe same sequence of operations. Even though executingoperations in the same order and serially at replicas is suf-ficient to ensure consistency, it is not always necessary, aswe now explain.
1Atomic broadcast needs additional synchrony assumptions to be im-plemented [6, 10]. These assumptions are not explicitly used by the pro-tocols proposed in this paper.
2

Let R be the set of requests available in a service (i.e.,all the requests that a client can issue). A request can beany deterministic computation involving objects that arepart of the application state. We denote the sets of appli-cation objects that replicas read and write when executingr as r’s readset and writeset, or RS(r) and WS(r), re-spectively. We define the notion of conflicting requests asfollows.
Definition 1 (Request conflict). The conflict relation#R ⊆ R×R among requests is defined as
(ri, rj) ∈ #R iff
RS(ri) ∩WS(rj) 6= ∅
∨WS(ri) ∩RS(rj) 6= ∅
∨WS(ri) ∩WS(rj) 6= ∅
Requests ri and rj conflict if (ri, rj) ∈ #R. We refer
to pairs of requests not in #R as non-conflicting or inde-pendent. Consequently, if two requests are independent(i.e., they do not share any objects or only read shared ob-jects), then the requests can be executed concurrently atreplicas (e.g., by different worker threads at each replica).Concurrent execution of requests raises the issue of howrequests are scheduled for execution on worker threads.We distinguish between two categories of protocols.
3.2 Late schedulingIn this category of protocols, replicas deliver requests intotal order and then a scheduler at each replica assignsrequests to worker threads for execution. The schedulermust respect dependencies between requests. More pre-cisely, if requests ri and rj conflict and ri is deliveredbefore rj , then ri must execute before rj . If ri and rj areindependent, then there are no restrictions on how theyshould be scheduled (e.g., the scheduler can assign eachrequest to a different worker thread).
CBASE [20] is a protocol in this category. In CBASE,a deterministic scheduler (or parallelizer) at each replicadelivers requests in total order and includes them in a de-pendency graph. In the dependency graph, vertices repre-sent delivered but not yet executed requests and directededges represent dependencies between requests. Requestri depends on rj (i.e., ri → rj is an edge in the graph) ifri is delivered after rj , and ri and rj conflict.
The dependency graph is shared with a pool of workerthreads. The worker threads choose requests for execu-tion from the dependency graph respecting their interde-pendencies: a worker thread can execute a request if therequest is not under execution and it does not depend onany requests in the graph. After the worker thread exe-cutes the request, it removes the request from the graphand chooses another one.
3.3 Early schedulingWith early scheduling, a request is assigned to a workerthread (or to a pool of worker threads, from which onethread will execute the request) before it is ordered. Forexample, one could establish that all requests that accessobject x are executed by thread t0 and all requests thataccess object y are executed by thread t1; requests thataccess both objects require threads t0 and t1 to coordi-nate so that only one thread executes the request (we detailthis execution model in the next section). The advantageof early scheduling is that since scheduling decisions aresimple (e.g., there is no dependency graph), the scheduleris less likely to become a performance bottleneck.
Two variants of early scheduling in state machine repli-cation have been proposed. In both cases, clients tag re-quests with the ids of the worker threads that will executethe requests. In [1], a scheduler thread delivers requestsin total order and assigns each request to the worker re-sponsible for the execution of the request. In [24], thereis no scheduler involved; the atomic broadcast primitiveuses the request tag to deliver requests directly to workerthreads at the replicas. Neither proposal explains howclients must tag requests to maximize concurrency.
4 Parallelism with request classesIn this section, we introduce the notion of classes of re-quests and illustrate how they can be used to representconcurrency in three prototypical applications.
4.1 Classes of requestsClasses of requests group requests and their interdepen-dencies. Each class has a descriptor and conflict informa-tion, as defined next.
Definition 2 (Request classes). Recall that R is the setof requests available in a service (c.f. §3.1). Let C ={c1, c2, ..., cnc} be the set of class descriptors, where ncis the number of classes. We define request classes asR = C → P(C) × P(R),2 that is, any class in C mayconflict with any subset of classes in C, and is associatedto a subset of requests in R. Moreover, we introduce therestriction that each request is associated to one and onlyone class.
A request class setR is correct with respect to a requestconflict #R if every conflict in #R is inR:
Definition 3 (Correct request classes). Given a requestconflict relation #R, a request class set R is correct withrespect to #R if for all (ri, rj) ∈ #R, with i 6= j,
2We denote the power set of set S as P(S).
3

it follows that ∃Ci → (CCi, CRi) ∈ R and ∃Cj →(CCj , CRj) ∈ R such that: (a) ri ∈ CRi, (b) rj ∈ CRj ,(c) Cj ∈ CCi, and (d) Ci ∈ CCj .
Intuitively, requests that belong to conflicting classeshave to be serialized according to the total order in-duced by atomic broadcast. Requests that belong to non-conflicting classes can be executed concurrently. Wedifferentiate between two types of conflicts involvingclasses.
• Internal conflicts: We say that class c has internalconflicts if c contains requests that conflict. Requestsin a class with internal conflict must be serialized andexecuted in the same order across replicas. If a classdoes not have internal conflicts, its requests can beprocessed concurrently.
• External conflict: If classes ci and cj , i 6= j, conflict,then requests in ci and cj have to be serialized andexecuted in the same order by the replicas. If ci andcj , i 6= j, do not conflict, then requests in ci and cjcan execute concurrently.
4.2 Applications and request classesWe illustrate request classes with three applications.
• Readers and writers. In this case (Fig. 1 (a)), wehave a class of operations CR that only read the ap-plication state and a class of operations CW that readand update the state. Requests in CR do not conflictwith each other (i.e., no internal conflict) but conflictwith requests in CW . CW also has internal conflicts.
• Sharded state with local readers, local writers, andglobal readers (snapshots). By sharding the servicestate (Fig. 1 (b)), we allow concurrency within andacross shards for operations that only read the state(CR1 and CR2) and concurrency across shards foroperations that read and write the application state(CW1 and CW2). Global reads or snapshots (CS)can execute concurrently with other read operationsbut must be synchronized with write operations.
• Sharded state with local readers and writers andglobal readers and writers. This model (Fig. 1 (c))extends the previous one and allows both read re-quests (CRg) and write requests (CWg) that spanmultiple shards.
4.3 Replica execution modelWe adopt the following replica execution model, whichextends the more restrictive model proposed in [1]:
• All the replicas have n + 1 threads: one schedulerthread and n worker threads.
• Each worker thread (in a replica) has a separate inputqueue and removes requests from the queue in FIFOorder.
• The scheduler delivers requests in total order and dis-patches each request to one or more input queues,according to a mapping of classes to worker threads,which we define below.
• If a request is scheduled to one worker only, then therequest can be processed concurrently with requestsenqueued in other worker threads.
• If two or more worker threads have the same requestr enqueued, it is because r depends on precedingrequests assigned to these workers. Therefore, allworkers involved in r must synchronize before oneworker, among the ones involved, executes r.
The mapping of classes to threads must respect all in-terdependencies between classes. Intuitively, (a) if a classhas internal conflicts, then the synchronization mode ofthe class must be sequential; and (b) if two classes con-flict, then they must be assigned to at least one thread incommon. The mapping of classes to threads is definedbelow and detailed in §4.4.
Definition 4 (Classes to threads, CtoT). If T ={t0, .., tn−1} is the set of worker thread identifiers at areplica, where n is the number of worker threads, T ={Seq, Cnc} is the synchronization mode of the class (i.e.,sequential or concurrent), and C is the set of class namesas in Def. 2, then CtoT = C → T × P(T ).
Algorithms 1 and 2 present the execution model for thescheduler and worker threads, respectively.
Algorithm 1 Scheduler.1: variables:2: queues[0, ..., n− 1]← ∅ // one queue per worker thread3: on deliver(req):4: if req.class.smode = Seq then // if execution is sequential5: ∀t ∈ CtoT (req.classId) // for each conflicting thread6: queues[t].fifoPut(req) // synchronize to exec req7: else // else assign req to one thread in round-robin8: queues[next(CtoT (req.classId))].fifoPut(req)
Whenever a request is delivered by the atomic broad-cast protocol, the scheduler (Algorithm 1) assigns it toone or more worker threads. If a class is sequential, thenall threads associated with the class receive the requestto synchronize the execution (lines 4–6). Otherwise, re-quests are associated to a unique thread (line 7–8), fol-lowing a round-robin policy (function next).
4

CR
CW
CR1
CW1
CR2
CW2
CS
CR1
CW1
CR2
CW2
CRg
CWg
(a) (b) (c)
Figure 1: Classes of requests for three applications: (a) readers (CR) and writers (CW ); (b) sharded with local readers(CR1 and CR2), local writers (CW1 and CW2), and global snapshots (CS); and (c) sharded with local readers andwriters (CR1, CR2, CW1 and CW2), and global readers and writers CRg and CWg. Edges in the graphs representexternal conflicts between classes; loops represent internal conflicts.
Algorithm 2 Worker threads.1: variables:2: myId← id ∈ {0, ..., n− 1} // thread id, out of n threads3: queue[myId]← ∅ // the queue with requests for this thread4: barrier[C] // one barrier per request class5: while true do6: req ← queue.fifoGet() // wait until a request is available7: if req.class.smode = Seq then // sequential execution:8: if myId = min(CtoT (req.classId)) then // smallest id:9: barrier[req.classId].await() // wait for signal
10: exec(req) // execute request11: barrier[req.classId].await() // resume workers12: else13: barrier[req.classId].await() // signal worker14: barrier[req.classId].await() // wait execution15: else // concurrent execution:16: exec(req) // execute the request
Each worker thread (Algorithm 2) takes one request ata time from its queue in FIFO order (line 6) and thenproceeds depending on the synchronization mode of theclass. If the class is sequential, then the thread synchro-nizes with the other threads in the class using barriers be-fore the request is executed (lines 8–14). In the case ofa sequential class, only one thread executes the request.If the class is concurrent, then the thread simply executesthe request (lines 15–16).
4.4 Mapping classes to worker threadsAssuming the execution model described in the previoussection, the mapping of classes to worker threads mustsatisfy the following rules:
• R.1: Every class is associated with at least oneworker thread. This is an obvious requirement,needed to ensure that requests in every class areeventually executed.
• R.2: If a class has internal conflicts, then it mustbe sequential. In this case, all workers associated tothe class must be synchronized so that each requestis executed by one worker in the same order acrossreplicas. Associating multiple workers to a sequen-tial class does not help performance, but it inducesimportant synchronization across classes.
• R.3: If two classes conflict, at least one of them mustbe sequential. Requirement R.2 may help decidewhich class, between two conflicting classes, mustbe sequential.
• R.4: If classes c1 and c2 conflict, c1 is sequential,and c2 is concurrent, then the set of workers asso-ciated to c2 must be included in the set of workersassociated to c1. This requirement ensures that re-quests in c1 are serialized with requests in c2.
• R.5: If classes c1 and c2 conflict and both c1 andc2 are sequential, it suffices that c1 and c2 have atleast one worker in common. The common workerensures that requests in the classes are serialized.
The previous rules ensure linearizable executions, thecorrectness proofs are in Appendix A.
5 Optimizing scheduling
In this section, we formulate the problem of mapping aclass of requests to a set of worker threads. The mappingassumes the execution model described in §4.3 and satis-fies the rules presented in §4.4.
5

5.1 The optimization modelThe mapping of threads to classes is shaped as an opti-mization problem that must produce a solution that sat-isfies a number of constraints and is optimized for a fewconditions (see Algorithm 3).
Input and output (lines 1–8). The input is the requestclasses definition, a set of available worker threads, theconflicts among classes, and the relative weight of classes.
• The set of classes C = {c1, .., cnc}, as in Def. 2.
• The set of worker threads T = {t0, .., tnt−1} thatwill be mapped to classes.
• The class conflict relation # ⊆ C × C, derivedfrom R in Def. 3, where (c1, c2) ∈ # iff (c1 →(cset, rset)) ∈ R and c2 ∈ cset.
• The weight of classes W ⊆ C×R, used to representthe work imposed by each class. We assign weightsto classes based on the frequency of requests in theclass in the workload. (If such information is notavailable, we assume equal weight to all classes.)
The optimization of this model has as output the map-ping of worker threads to classes and the choice ofwhether a class is sequential or concurrent.
• The mapping uses ⊆ C × T of worker threads toclasses; where uses(c, t) means that worker thread tis mapped to class c.
• The synchronization mode of each class, either se-quential or concurrent.
Constraints (lines 15–20). The output of the optimizermust follow the set of restrictions R.1–R.5, as defined in§4.4.
Objective function (lines 21–26). The restrictions im-posed by the constraints may be satisfied by several as-sociations of threads to classes. Among those, we aim atsolutions that minimize the “cost of execution”, as definedbelow.
• O.1: Minimize threads in sequential classes andmaximize threads in concurrent classes. We accountfor this by penalizing sequential classes proportion-ally to the number of threads assigned to the class(O.1a), and rewarding (i.e., negative cost) concur-rent classes proportionally to the number of threadsassigned to the class (O.1b). In both cases, we alsotake into account the weight of the class with respectto other classes with the same synchronization mode.
• O.2: Assign threads to concurrent classes in pro-portion to their relative weight. More concretely,we minimize the difference between the normalizedweight of each concurrent class c (i.e., w[c]/wc)and the number of threads assigned to c relativeto the total number of threads (i.e., |{∀t ∈ T :uses[c, t]}|/nt).
• O.3: Minimize unnecessary synchronization amongsequential classes. We penalize solutions that in-troduce common threads in independent sequentialclasses. Since the classes are sequential, a singlethread in common would make the classes mutuallyexclusive. Moreover, we give this objective higherpriority than the others.
Algorithm 3 Optimization model.1: input:2: set C // set of request classes3: set T // set of worker threads4: #{Ci, Cj} ∈ {0, 1} // #[ci, cj ] = 1 : ci and cj conflict5: w{C} ∈ R // weight of each class6: output:7: uses{C, T} ∈ {0, 1} // uses[c,t] = 1 : class c uses thread t
8: Seq{C} ∈ {0, 1} // Seq(c) = 1 : c is sequential9: auxiliary definitions:
10: nc = |C| // number of classes11: nt = |T | // number of worker threads12: Cnc{C} = ¬Seq{C} ∈ {0, 1} // Cnc(c)=1:c is concurrent13: wc =
∑∀c∈C : Cnc[c] w[c] // weights of concurrent classes
14: ws =∑
∀c∈C : Seq[c] w[c] // weights of sequential classes
15: constraints:16: ∀c ∈ C :
∨∀t∈T uses(c, t) // R.1
17: ∀c ∈ C : #[c1, c1]⇒ Seq[c1] // R.2
18: ∀c1, c2 ∈ C : #[c1, c2]⇒ Seq[c1] ∨ Seq[c2] // R.3
19: ∀c1, c2 ∈ C, t ∈ T :#[c1, c2] ∧ Seq[c1] ∧ Cnc[c2] ∧ uses[c2, t]⇒ uses[c1, t]
// R.4
20: ∀c1, c2 ∈ C : #[c1, c2] ∧ Seq[c1] ∧ Seq[c2]⇒∃t ∈ T : uses[c1, t] ∧ uses[c2, t] // R.5
21: objective:22: minimize cost:
23: +∑
∀t∈T, ∀c∈C :Seq[c] uses[c, t]× w[c] /ws // O.1a
24: −∑
∀t∈T, ∀c∈C :Cnc[c] uses[c, t]× w[c] /wc // O.1b
25: +∑
∀c∈C :Cnc[c] |w[c]/wc− (|{∀t ∈ T : uses[c, t]}|/nt)|// O.2
26: +∑
∀c1,c2∈C :Seq[c1]∧Seq[c2]∧¬#[c1,c2]
|{∀t ∈ T : uses[c1, t] ∧ uses[c2, t]}| × nt× nc // O.3
We described the optimization problem in the AMPLlanguage [11] and solved it with the KNitro solver [5].The problem description in AMPL is roughly similar toAlgorithm 3.
6

6 Experimental evaluationIn order to compare the performance of the two schedul-ing methods for parallel state machine replication, we im-plemented the CBASE late scheduler [20] and the earlyscheduling technique proposed in this paper and con-ducted several experiments.
6.1 EnvironmentWe implemented both early and late scheduling in BFT-SMART [2]. BFT-SMART can be configured to use pro-tocols optimized to tolerate crash failures only or Byzan-tine failures. In all the experiments, we configured BFT-SMART to tolerate crash failures. BFT-SMART was de-veloped in Java and its atomic broadcast protocol executesa sequence of consensus instances, where each instanceorders a batch of requests. To further improve the per-formance of the BFT-SMART ordering protocol, we im-plemented interfaces to enable clients to send a batch ofrequests inside the same message.
In late scheduling, scheduler and workers synchronizeaccess to the graph using a lock on the entire graph, assuggested in [20]. As a consequence, the performance oflate scheduling is impacted by the size of the dependencygraph since scheduler and workers traverse the graph toinclude and remove edges (dependencies), respectively.Providing efficient concurrent access to a graph is an openproblem [17, 28]. In the experiments, we carefully config-ured the size of the dependency graph so that late schedul-ing produces its best performance in our setup: at most 50entries in the graph for workloads with writes only and150 entries otherwise.
The experimental environment was configured with9 machines connected in a 1Gbps switched network.The software installed on the machines was CentOSLinux 7.2.1511 and a 64-bit Java virtual machine version1.8.0 131. BFT-SMART was configured with 3 replicashosted in separate machines (Dell PowerEdge R815 nodesequipped with four 16-core AMD Opteron 6366HE pro-cessors running at 1,8 GHz and 128 GB of RAM) to toler-ate up to 1 replica crash, while up to 200 clients were dis-tributed uniformly across another 4 machines (HP SE1102nodes equipped with two quad-core Intel Xeon L5420processors running at 2.5 GHz and 8 GB of RAM).
6.2 ApplicationThe application consists of a set of linked lists. Each liststored integers and represented one shard (partition). Forsingle-shard reads and writes, we support operations toverify if a list contains some entry and to add an itemto a list: contains(i) returns true if i is in the list, oth-erwise returns false; add(i) includes i in the list and re-
turns true if i is not in the list, otherwise returns false.Parameter i in these operations was a randomly chosenposition in the list. For multi-shard reads and writes, weimplemented operations containsAll and addAll to exe-cute the respective operations involving all shards. Listswere initialized with 1, 1k and 10k entries at each replica,representing operations with light, moderate, and heavyexecution costs, respectively.
6.3 Goals of the evaluationThe main goal of our experimental evaluation is to com-pare the two scheduling techniques and identify in whichconfigurations one outperforms the other. We considera parameter space containing (a) two prototypical appli-cations with one or more shards, single-shard and multi-shard read and write operations (i.e., cases 1 and 3 pre-sented in Fig. 1); (b) three execution costs, comprisinglight, moderate and heavy operations; and (c) uniform andskewed workloads (i.e., the three cases depicted in Fig. 4).We evaluated the throughput of the system at the serversand the latency perceived by the clients, a warm-up phasepreceded each experiment.
6.4 Single-sharded systemsThe first set of experiments considers reads and writesin a single shard. Fig. 2 shows the throughput presentedby each scheduling approach for different execution costsand number of workers threads, considering two work-loads: a workload with read operations only and a mixedworkload composed of 15% of writes and 85% of readsuniformly distributed among clients.
Considering the read operations only workload(Figs. 2(a), 2(b) and 2(c)), in general the early sched-uler presented more than twice the performance of the latescheduler. The late scheduler uses one data structure (de-pendency graph) that is accessed by the scheduler to in-sert requests and by the workers to remove requests, lead-ing to contention. The shared dependency graph rapidlybecomes a bottleneck and performance does not increasewith additional workers. Another important aspect isthat the late scheduler presented similar performance forall execution costs, indicating that its performance wasbounded by the synchronization and contention in the de-pendency graph and not by the time the workers spent toexecute a request.
Following a different approach, the early scheduleremploys one data structure (queue) per worker. Con-sequently, workers do not content with one another, al-though the scheduler and each worker share a data struc-ture. For each execution cost the system reached peakthroughput with a different number of threads: for light,moderate and heavy requests it was necessary 8, 10 and
7

10 50
100
150
200
250
300
350
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(a) Read - Light
10 50
100
150
200
250
300
350
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(b) Read - Moderate
10 50
100
150
200
250
300
350
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(c) Read - Heavy
10
20
30
40
50
60
70
80
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(d) Mixed - Light
10
20
30
40
50
60
70
80
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(e) Mixed - Moderate
10
20
30
40
50
60
70
80
1 2 4 6 8 10 12 14 16 18 20 22 24
Thro
ughp
ut (k
ops/
sec)
Number of Workers
earlylate
(f) Mixed - Heavy
Figure 2: Throughput in readers-and-writers service (single shard) for different workloads and execution costs.
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90
Late
ncy
(ms)
Throughput (kops/sec)
early, read, 2 workersearly, write, 2 workers
late, read, 8 workerslate, write, 8 workers
(a) Mixed - Light
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90
Late
ncy
(ms)
Throughput (kops/sec)
early, read, 2 workersearly, write, 2 workers
late, read, 8 workerslate, write, 8 workers
(b) Mixed - Moderate
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90
Late
ncy
(ms)
Throughput (kops/sec)
early, read, 4 workersearly, write, 4 workerslate, read, 14 workerslate, write, 14 workers
(c) Mixed - Heavy
Figure 3: Latency in readers-and-writers service (single shard) for a mixed workload and different execution cost.
22 workers, respectively. Early scheduling largely out-performs late scheduling since in the former there is nosynchronization among workers.
A final remark about these experiments is that afterthe peak throughput is reached, increasing the numberof workers hampers performance. Considering the earlyscheduler, this happens for the following reason. Afterexecuting a request, a worker thread checks its queue forrequests and if no request is found it blocks until one isavailable. As the number of threads increases, there arefewer requests enqueued per worker, which finds its queueempty more often. Considering a run of the experimentwith light execution cost (Fig. 2(a)), 201.543 system callsto sleep (block) are executed when the system is config-ured with 8 workers (an average of 25.192 system callsper worker) and 31.016.088 such calls are executed in the
configuration with 24 workers (an average of 1.292.337system calls per worker). Although presenting a lowerimpact, this phenomenon also occur in the late scheduler.
Figs. 2(d), 2(e) and 2(f) show throughput results for themixed workload. For each execution cost, Fig. 3 alsoshows latency versus throughput results for the threadconfiguration that presented the best performance in eachscheduling approach. The early scheduler technique againpresented the best peak throughput, which was achievedwith 2, 2 and 4 workers for light, moderante and heavy op-erations costs, respectively. This configuration representsan equilibrium between the synchronization needed to ex-ecute writes and the number of workers available to exe-cute parallel reads. Reads and writes have similar latencybecause they have similar execution costs and the syn-chronization of writes impacts the performance of reads
8

ordered after a write.In workloads with predominance of write operations,
sequential execution presents best performance [1, 24].For example, considering a workload with only write op-erations of moderante costs, the early scheduling pre-sented a throughput of 53 Kops/sec with 1 worker thatdropped down to 24 kops/sec with 2 workers. Noticethis is the worst case for this approach, where all workersneed to synchronize for each request execution. The latescheduling presented a throughput of 31 Kops/sec with 1worker and 23 kops/sec with 2 workers. For an interme-diary workload composed of 50% of reads and 50% ofwrites, the early scheduling presented a throughput of 55kops/sec with 1 worker and 41 kops/sec with 2 workers.The late scheduling presented a throughput of 39 Kops/secwith 1 worker and 36 kops/sec with 2 workers.
6.5 Optimizing multi-sharded systemsWe now evaluate our optimization model. We considerthe generalized sharded service depicted in Fig. 1(c) with2 shards, 4 worker threads, and three workloads, as de-scribed below. For each workload, Fig. 4 shows the result-ing proportion of local reads, local writes, global reads,and global writes.
• Workload 1: Balanced load. This workload is com-posed by 85% of reads and 15% of writes, fromwhich 95% are single-shard (local), equally dis-tributed between the two shards, and 5% are multi-shard (global).
• Workload 2: Skewed load, shard 1 receives more re-quests than shard 2. Similar to Workload 1, but lo-cal requests are unbalanced with 67% to shard 1 and33% to shard 2.
• Workload 3: Skewed load, shard 1 receives morewrites and fewer reads than shard 2. Similar toWorkload 1, but local requests are unbalanced with67% of writes and 33% of reads to shard 1, and 33%of writes and 67% of reads to shard 2.
Fig. 4 shows the results produced by the optimizer foreach workload and by a naive assignment of threads. Inthe naive assignment, we first configure read-only classesto be concurrent and assign workers more or less propor-tionally to the percentage of commands in the workload.We then assign workers to write classes to ensure the cor-rectness of the model.
For all workloads, our optimization model establishesthat reads and writes in shards 1 and 2 use disjoint setsof threads, and threads are distributed in proportion tothe class weights. Since single-shard reads are concur-rent but conflict with writes in the shard, the single-shard
write class has all threads associated to the respectiveread class. Multi-shard writes must be synchronized withall other operations, therefore all threads are assigned tomulti-shard writes. According to the conflict definition,multi-shard reads are concurrent. Nevertheless, the opti-mizer sets the class CRg as sequential. The reason is thatsince CRg conflicts with CW1 and CW2, if CRg is con-figured as concurrent all threads assigned to CRg wouldhave to be included in CW1 and CW2. Doing so wouldsynchronize CW1 and CW2 since their threads would notbe disjoint. A more efficient solution is to define CRg assequential and assign to it one thread from CW1 and onethread from CW2. As a result, multi-shard reads synchro-nize with local-shard writes, but local writes to differentshards can execute concurrently.
CR1 CR2
CRg
CWg
CW2CW1
Seq : t0..t4
Workload 1
CR1 CW1 CR2 CW2 CRg CWg
0.4 0.075 0.4 0.075 0.04 0.01
0.53 0.1 0.27 0.05 0.04 0.01Workload 2
Seq : t0..t4
Seq : t0, t3Seq : t0, t2
balanced
skewed
Workload 1
Workload 2
Workload 3 skewed 0.27 0.1 0.53 0.05 0.04 0.01
Seq : t0..t4Seq : t0..t4 Workload 3
Naive
Cnc : t0, t2Seq : t0, t1
Cnc : t3Cnc : t2, t3
Cnc : t2, t3Cnc : t1, t2, t3
Seq : t3Seq : t2, t3
Seq : t0, t2, t3Seq : t1, t2, t3
Cnc : t0, t1, t2Cnc : t0, t1
Cnc : t0, t1Cnc : t0
Seq : t0, t1, t2Seq : t0, t1
Seq : t0, t1, t2Seq : t0
Figure 4: Thread assignment in sharded application.
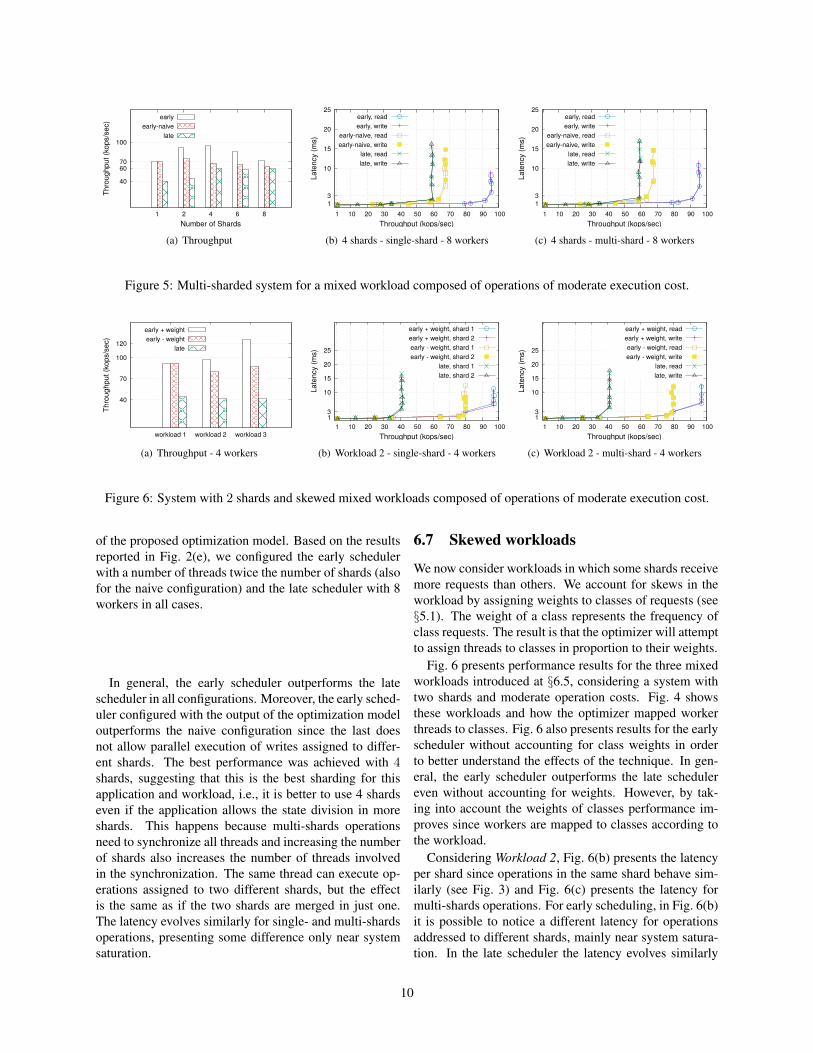
6.6 Multi-sharded systemsThe first set of experiments showed that the early sched-uler outperforms the late scheduler in a single-shardedsystem. A natural question is whether this is also truefor a multi-sharded system since the early scheduler stati-cally allocates workers to shards while the late schedulerallocates workers to shards dynamically. Fig. 5 answersthis question positively and shows the advantage of earlyscheduling over late scheduling for a mixed workload insystems with 1, 2, 4, 6 and 8 shards and moderate opera-tion costs. The workload is similar to the balanced Work-load 1 introduced at §6.5, extrapolated for systems withmore shards, i.e., the single-shard operations are equallydistributed among all shards. Moreover, operations areuniformly distributed among the clients.
Fig. 5 also presents results for the naive threads assign-ment in the early scheduler in order to assess the impact
9
40
60 70
100
1 2 4 6 8
Thro
ughp
ut (k
ops/
sec)
Number of Shards
earlyearly-naive
late
(a) Throughput
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90 100
Late
ncy
(ms)
Throughput (kops/sec)
early, readearly, write
early-naive, readearly-naive, write
late, readlate, write
(b) 4 shards - single-shard - 8 workers
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90 100
Late
ncy
(ms)
Throughput (kops/sec)
early, readearly, write
early-naive, readearly-naive, write
late, readlate, write
(c) 4 shards - multi-shard - 8 workers
Figure 5: Multi-sharded system for a mixed workload composed of operations of moderate execution cost.
40
70
100
120
workload 1 workload 2 workload 3
Thro
ughp
ut (k
ops/
sec)
early + weightearly - weight
late
(a) Throughput - 4 workers
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90 100
Late
ncy
(ms)
Throughput (kops/sec)
early + weight, shard 1early + weight, shard 2early - weight, shard 1early - weight, shard 2
late, shard 1late, shard 2
(b) Workload 2 - single-shard - 4 workers
1 3
10
15
20
25
1 10 20 30 40 50 60 70 80 90 100
Late
ncy
(ms)
Throughput (kops/sec)
early + weight, readearly + weight, writeearly - weight, readearly - weight, write
late, readlate, write
(c) Workload 2 - multi-shard - 4 workers
Figure 6: System with 2 shards and skewed mixed workloads composed of operations of moderate execution cost.
of the proposed optimization model. Based on the resultsreported in Fig. 2(e), we configured the early schedulerwith a number of threads twice the number of shards (alsofor the naive configuration) and the late scheduler with 8workers in all cases.
In general, the early scheduler outperforms the latescheduler in all configurations. Moreover, the early sched-uler configured with the output of the optimization modeloutperforms the naive configuration since the last doesnot allow parallel execution of writes assigned to differ-ent shards. The best performance was achieved with 4shards, suggesting that this is the best sharding for thisapplication and workload, i.e., it is better to use 4 shardseven if the application allows the state division in moreshards. This happens because multi-shards operationsneed to synchronize all threads and increasing the numberof shards also increases the number of threads involvedin the synchronization. The same thread can execute op-erations assigned to two different shards, but the effectis the same as if the two shards are merged in just one.The latency evolves similarly for single- and multi-shardsoperations, presenting some difference only near systemsaturation.
6.7 Skewed workloads
We now consider workloads in which some shards receivemore requests than others. We account for skews in theworkload by assigning weights to classes of requests (see§5.1). The weight of a class represents the frequency ofclass requests. The result is that the optimizer will attemptto assign threads to classes in proportion to their weights.
Fig. 6 presents performance results for the three mixedworkloads introduced at §6.5, considering a system withtwo shards and moderate operation costs. Fig. 4 showsthese workloads and how the optimizer mapped workerthreads to classes. Fig. 6 also presents results for the earlyscheduler without accounting for class weights in orderto better understand the effects of the technique. In gen-eral, the early scheduler outperforms the late schedulereven without accounting for weights. However, by tak-ing into account the weights of classes performance im-proves since workers are mapped to classes according tothe workload.
Considering Workload 2, Fig. 6(b) presents the latencyper shard since operations in the same shard behave sim-ilarly (see Fig. 3) and Fig. 6(c) presents the latency formulti-shards operations. For early scheduling, in Fig. 6(b)it is possible to notice a different latency for operationsaddressed to different shards, mainly near system satura-tion. In the late scheduler the latency evolves similarly
10

for both shards since the dependency graph becomes fullof operations addressed to shard 1 also impacting the per-formance of operations in shard 2. Increasing the sizeof the dependency graph does not help since (1) largergraphs have more overhead due to the addition and re-moval of requests in the graph (e.g., for a graph with 500entries, the write throughput is approximately 7 kops/sec)and (2) given enough time and requests, the graph willbecome full of such requests anyway. This is a seriousdrawback of late scheduling: given enough requests, theoverall performance is bounded by operations with worstperformance.
Building on the observation above, we conducted anadditional experiment in a system with 4 workers, where50 clients read from shard 1 and another 50 clients write inshard 2. While early scheduler used one thread for shard2 and the others for shard 1, executing 179 kops/sec, thelate scheduler achieved only 22 kops/sec.
6.8 Lessons learnedThis section presents a few observations about the exper-imental evaluation.
1. Early scheduling outperforms late scheduling. De-spite the fact that early scheduling is more restrictivethan late scheduling, it delivers superior performancein almost all cases we considered. This happens fortwo reasons: (1) the early scheduler can make simpleand fast decisions, and (2) by using one data struc-ture per worker thread, worker threads do not con-tent of a single data structure, as with late schedul-ing. As we could notice, in high throughput systemsthere is room to discuss the tradeoff of fast versusaccurate runtime decisions. Although CBASE doesnot hinder the concurrency level (since the depen-dencies followed are the needed and sufficient onesgiven by service semantics), better throughput re-sults can be achieved with a solution trading concur-rency for fast runtime decision. The main reason forthis is related to contention due to the graph struc-ture but it is also relevant to observe that since thenumber of threads (cores) for an application is typi-cally bounded in concrete implementations, adoptingstrategies that limit the achievable concurrency levelmay still not hinder the concurrency level in concretesettings.
2. Choosing the right data structures is fundamental toperformance. Since all requests must go through thesame data structure, the performance of late sched-uler is bounded by requests with worst performance.The early scheduler uses a queue per worker anddoes not force workers to synchronize in the pres-ence of independent requests. Moreover, requests of
one class do not impact performance of requests inother classes.
3. The number of workers matters for performance, butnot equally for the two scheduling techniques. Forboth schedulers, the ideal number of worker threadsdepends on the application and workload. However,the performance impact caused by the number ofworkers is lower in the late than in the early sched-uler. This observation suggests that both schedulingtechniques can benefit from a reconfiguration proto-col [1] to adapt the number of workers on-the-fly.
4. Class to thread assignment needs information aboutall classes. A local view of related classes was notsufficient to reach good (in terms of the optimiza-tion objective) assignments. The naive thread assign-ment shows this. While it may seem acceptable toconfigure concurrent classes distributing threads pro-portionally to their demands and then assure that se-quential classes synchronize with the other classes asneeded, it has been observed that analysing the wholeconflict relation could be worthy to consider a classas sequential (even it could be concurrent) to avoidfurther inducing synchronization with other classes.Whether this assignment problem can be partitioned(according to the class conflict topology) is still to beanalysed.
7 Related Work
This paper is at the intersection of two areas of research:scheduling and state machine replication.
7.1 Scheduling
The area of scheduling has been active for severaldecades, with a rich body of contributions. According to[23], one classification of scheduling algorithms regards apriori knowledge of the complete instance (i.e., set of jobsto schedule): while with offline algorithms scheduling de-cisions are made based on the knowledge of the entire in-put instance that is to be scheduled, with online algorithmsscheduling decisions are taken while jobs arrive. Onlinescheduling may be further considered stochastic or deter-ministic. The first arises when problem variables such asthe release times of jobs and their processing times are as-sumed from known distributions. Processing times mayalso be correlated or independent. Deterministic schedul-ing does not consider such information. Several algo-rithms of interest are called nonclairvoyant in the sensethat further information about the behavior of jobs (suchas their processing times) are not known even upon their
11

arrival (but only after completion). Another known classi-fication is whether the scheduling is real-time or not. Theprimary concern of real-time scheduling is to meet harddeadline application constraints, that have to be clearlystated, while non-real-time have no such constraints.
In this context, our scheduling problem can be clas-sified as online, deterministic (non-stochastic), and non-realtime. Moreover, our scheduling problem imposes de-pendencies among jobs that have to be respected. Thisaspect has also been regarded in the scheduling literature,where we can find early discussions on how to processjobs whose interdependencies assume the topology of adirected acyclic graph, which is also the case here. How-ever, as far as we could survey, there is no discussionin the scheduling literature on the costs or techniques todetect and represent dependencies among jobs (i.e., thejob dependency graph is typically given). Also, there isno discussion on synchronization costs to enforce job de-pendencies upon execution. While this is valid to severalscheduling problems, these aspects matter when schedul-ing computational jobs. This is important in our work, aswell as in related work in the area of parallel approaches tostate machine replication. In modern computational sys-tems, due to high throughput and concurrency, the over-head to manage dependencies gains in importance andmay become a bottleneck in the system.
7.2 State machine replication
State machine replication (SMR) is a well studied andcentral approach to the provision of fault-tolerant ser-vices. As current and emerging applications require bothhigh availability and performance, the seminal, sequentialdesign of SMR is challenged in a number of ways.
The sequential execution approach is followed by mostSMR systems to ensure deterministic execution and thusreplica consistency, but creates an important bottleneckfor applications with increasing throughput demands. Theproliferation of multi-core systems also calls for new de-signs to allow concurrent execution. As it has been earlyobserved [29], independent requests can be executed con-currently in SMR. Moreover, previous works have shownthat many workloads are dominated by independent re-quests, which justifies strategies for concurrent requestexecution (e.g., [3, 22, 8, 20, 24, 25]). As we briefly sur-vey existing proposals, we observe that they differ in thestrategy and architecture to detect and handle conflicts onthe request processing path.
In [20], the authors present CBASE, a parallel SMRwhere replicas are augmented with a deterministic sched-uler. Based on application semantics, the scheduler serial-izes the execution of conflicting requests according to thedelivery order and dispatches non-conflicting requests tobe processed in parallel by a pool of worker threads. Con-
flict detection is done at the replica side, based on pair-wise comparison of requests in different levels of detail.Requests are then organized in a dependency graph andprocessed as soon as possible (i.e., whenever dependen-cies have been executed). CBASE is an example of latescheduling and studied in detail in the previous sections.
While CBASE centralizes the conflict detection andhandling at the scheduler, after ordering and before ex-ecuting requests, a distinct approach is followed byRex [13] and CRANE [7], which add complexity to theexecution phase. Instead of processing conflict infor-mation to allow concurrent execution of independent re-quests, and synchronize conflicting requests, both Rexand CRANE solve the non-determinism due to concur-rency during request execution. Rex logs dependenciesamong requests during execution, based on shared vari-ables locked by each request. This creates a trace of de-pendencies which is proposed for agreement with otherfollower replicas. After agreement replicas replay the ex-ecution restricted to the trace of the first executing server.CRANE [7] implements a parallel SMR and solves non-determinism first by relying on Paxos and then enforcingdeterministic logical times across replicas that combinedwith deterministic multi-threading [27] allow to determin-istically order requests consistently among replicas.
While CBASE handles conflicts before execution, Rexand CRANE during execution, Eve [19] handles conflictsafter execution. According to this approach, replicas opti-mistically execute requests as they arrive and check afterexecution if consistency is violated. In such case, syn-chronization measures are taken to circumvent this prob-lem. In Eve replicas speculatively execute batched com-mands in parallel. After the execution of a batch, the ver-ification stage checks the validity of replica’s state. If toomany replicas diverge, replicas roll back to the last veri-fied state and re-execute the commands sequentially.
In Storyboard [18], a forecasting mechanism predictsthe same ordered sequence of locks across replicas. Whileforecasts are correct, requests can be executed in parallel.If the forecast made by the predictor does not match theexecution path of a request, then the replica has to estab-lish a deterministic execution order in cooperation withthe other replicas.
P-SMR [24] avoids a central parallelizer or scheduler,to keep request execution free from additional overheadand without need for a posteriori checking of the exe-cution. This is achieved by mapping requests to differ-ent multicast groups. Non-conflicting requests are sentthrough different multiple multicast groups that partiallyorder requests across replicas. Requests are delivered bymultiple worker threads according to the multicast group.This approach imposes a choice of destination group atthe client side, based on request information which is ap-plication specific. Non-conflicting requests can be sent to
12

distinct groups, while conflicting ones are sent to the samegroup(s). At replica side each worker thread is associatedto a multicast group and processes requests as they arrive.
More than proposing a strategy for parallel SMR, ourapproach formalizes an abstraction to represent classes ofconflicts among requests. This abstraction allows to ex-press the conflict semantics of an application with sim-ple and common elements. Nodes are classes, edgesare conflicts and requests are grouped in disjoint classes.This representation of conflicts and their interdependen-cies could be used in other contexts. For example, inCBASE [20] to improve the request conflict checking orin P-SMR [24] to help the decision at client side of whichmulticast group to use.
8 ConclusionsThis paper reports on our efforts to increase the per-formance of parallel state machine replication through ascheduling approach that simplifies the work done by thescheduler. The main idea is that by assigning requests to aworker thread (or a set of them) prior to their ordering, thescheduler is less likely to become a performance bottle-neck. This work also proposed an optimization model forefficiently mapping of request classes to worker threads.A comprehensive set of experiments showed that earlyscheduling improves the overall system performance.
It is important to observe that the early scheduler doesnot provide the best degree of concurrency, but since deci-sions are simple and fast it outperforms other approachesthat need a more complex processing to allow more par-allelism in the execution. The existence (or not) of anoptimization model that combines early scheduling andunrestricted concurrency is an open problem.
References[1] E. Alchieri, F. Dotti, O. M. Mendizabal, and F. Pe-
done. Reconfiguring parallel state machine replica-tion. In Symposium on Reliable Distributed Systems,2017.
[2] A. Bessani, J. Sousa, and E. Alchieri. State ma-chine replication for the masses with BFT-SMaRt.In IEEE/IFIP International Conference on Depend-able Systems and Networks, 2014.
[3] C. E. Bezerra, F. Pedone, and R. V. Renesse. Scal-able state-machine replication. In IEEE/IFIP In-ternational Conference on Dependable Systems andNetworks, 2014.
[4] M. Burrows. The chubby lock service for looselycoupled distributed systems. In Proceedings of the
7th Symposium on Operating Systems Design andImplementation, 2006.
[5] R. H. Byrd, J. Nocedal, and R. A. Waltz. Knitro:An integrated package for nonlinear optimization.In Large Scale Nonlinear Optimization, 2006, pages35–59. Springer Verlag, 2006.
[6] T. D. Chandra and S. Toueg. Unreliable failure de-tectors for reliable distributed systems. Journal ofACM, 43(2):225–267, 1996.
[7] H. Cui, R. Gu, C. Liu, T. Chen, and J. Yang. Paxosmade transparent. In ACM Symposium on OperatingSystems Principles, 2015.
[8] D. da Silva Boger, J. da Silva Fraga, and E. Alchieri.Reconfigurable scalable state machine replication.In Latin-American Symposium on Dependable Com-puting, 2016.
[9] X. Defago, A. Schiper, and P. Urban. Total orderbroadcast and multicast algorithms: Taxonomy andsurvey. ACM Computing Surveys, 36(4):372–421,Dec. 2004.
[10] M. J. Fischer, N. A. Lynch, and M. S. Paterson. Im-possibility of distributed consensus with one faultyprocess. Journal of the ACM, 32(2):374–382, Apr.1985.
[11] R. Fourer, D. Gay, and B. Kernighan. AMPL:A Modeling Language for Mathematical Program-ming. Scientific Press, 1993.
[12] L. Glendenning, I. Beschastnikh, A. Krishnamurthy,and T. Anderson. Scalable consistency in scatter. InProceedings of the Twenty-Third ACM Symposiumon Operating Systems Principles, 2011.
[13] Z. Guo, C. Hong, M. Yang, L. Zhou, L. Zhuang, andD. Zhou. Rex: Replication at the speed of multi-core. In European Conference on Computer Sys-tems, 2014.
[14] V. Hadzilacos and S. Toueg. Fault-tolerant broad-casts and related problems. In S. Mullender,editor, Distributed Systems, pages 97–145. ACMPress/Addison-Wesley Publishing Co., New York,NY, USA, 1993.
[15] M. Herlihy and J. M. Wing. Linearizability: Acorrectness condition for concurrent objects. ACMTransactions on Programing Languages and Sys-tems, 12(3):463–492, July 1990.
[16] J. D. J. C. Corbett and M. E. et al. Spanner: Google’sglobally distributed database. In Prooceedings of the
13

10th Symposium on Operating Systems Design andImplementation, 2012.
[17] N. D. Kallimanis and E. Kanellou. Wait-Free Con-current Graph Objects with Dynamic Traversals. InOPODIS, 2016.
[18] R. Kapitza, M. Schunter, C. Cachin, K. Stengel,and T. Distler. Storyboard: Optimistic determinis-tic multithreading. In Workshop on Hot Topics inSystem Dependability, 2010.
[19] M. Kapritsos, Y. Wang, V. Quema, A. Clement,L. Alvisi, and M. Dahlin. All about Eve: execute-verify replication for multi-core servers. In Sympo-sium on Operating Systems Design and Implementa-tion, 2012.
[20] R. Kotla and M. Dahlin. High throughput byzan-tine fault tolerance. In IEEE/IFIP Int. Conferenceon Dependable Systems and Networks, 2004.
[21] L. Lamport. Time, clocks, and the ordering of eventsin a distributed system. Communications of theACM, 21(7):558–565, 1978.
[22] L. H. Le, C. E. Bezerra, and F. Pedone. Dynamicscalable state machine replication. In IEEE/IFIP In-ternational Conference on Dependable Systems andNetworks, 2016.
[23] J. Leung, L. Kelly, and J. H. Anderson. Handbook ofScheduling: Algorithms, Models, and PerformanceAnalysis. CRC Press, Inc., Boca Raton, FL, USA,2004.
[24] P. J. Marandi, C. E. Bezerra, and F. Pedone. Rethink-ing state-machine replication for parallelism. InIEEE International Conference on Distributed Com-puting Systems, 2014.
[25] P. J. Marandi and F. Pedone. Optimistic parallelstate-machine replication. In IEEE Int. Symposiumon Reliable Distributed Systems, 2014.
[26] O. M. Mendizabal, R. T. S. Moura, F. L. Dotti, andF. Pedone. Efficient and deterministic scheduling forparallel state machine replication. In IEEE Inter-national Parallel & Distributed Processing Sympo-sium, 2017.
[27] M. Olszewski, J. Ansel, and S. Amarasinghe.Kendo: efficient deterministic multithreading insoftware. ACM Sigplan Notices, 44(3):97–108,2009.
[28] S. Peri, M. Sa, and N. Singhal. Maintaining acyclic-ity of concurrent graphs. CoRR, 2016.
[29] F. B. Schneider. Implementing fault-tolerant serviceusing the state machine aproach: A tutorial. ACMComputing Surveys, 22(4):299–319, Dec. 1990.
A - Appendix - CorrectnessWe argue that any mapping that follows the rules pre-sented in § 4.4 generates correct executions. We substan-tiate our claim with a case analysis, starting with classeswithout external conflicts.
1. Class c has no internal and no external conflicts.Then any request r ∈ c is independent of any otherrequests and can be dispatched to the input queue ofany thread (assigned to c). According to R.1, such athread exists. According to line 6 of Algorithm 2, re-quests are dequeued in FIFO order. Since the class isCnc, lines 15–16 execute the request without furthersynchronizing with other threads.
2. Class c has internal conflicts but no external con-flicts. Then, by rule R.2, request r ∈ c is scheduled tobe executed in all threads associated to c. Accordingto Algorithm 1, requests are enqueued to threads inthe order they are delivered. According to Algorithm2, lines 8–14, these threads synchronize to execute r,i.e., conflicting requests are executed respecting thedelivery order.
Now we consider two conflicting classes.
3. Class c1 has no internal conflicts, but conflicts withc2. In such a case, by rule R.3, one of the classesmust be sequential. Without loss of generality, as-sume c2 is sequential and c1 is concurrent. Since (i)the scheduler handles one request at a time (see Al-gorithm 1, line 3); (ii) it dispatches the request to allthreads of c2 (see lines 5–6); (iii) threads synchro-nize to execute (as already discussed in case 2); and(iv) the threads that implement c1 are contained inthe set of threads that implement c2 (from R.4), itfollows that every request from c1 is executed beforeor after any c2’s request, according to the deliveryorder. Due to the total order of atomic broadcast, allreplicas impose the same order among c1’s and c2’srequests. Notice that this holds even though requestsin c1 are concurrent.
4. Classes c1 and c2 have internal conflicts and conflictwith each other. According to restriction R.5, theseclasses have at least one common thread tx. As inAlgorithm 2, lines 5–14: (i) the input queue of txhas requests from both classes preserving the deliv-ery order; (ii) according to R.2 and lines 7–14, txwill synchronize with all threads implementing c1 to
14

execute c1’s requests and with all threads implement-ing c2 to execute c2’s requests. This implies that tximposes c1’s and c2’s requests to be executed in thereplica sequentially, according to their delivery oder.Due to the total order of atomic broadcast, all repli-cas impose the same order of c1’s and c2’s requests.
Now we generalize to consider a system with an arbi-trary request classes definition. From Def. 2, each requestis associated to one class c only.
Let c be a concurrent class that conflicts with a num-ber of other classes, the mapping imposes that all otherclasses are sequential (R.3) and include c’s threads (R.4).As already discussed in case 3, c’s requests are orderedw.r.t. requests from each of the other classes.
Let c be a sequential class that conflicts with a numberof other classes. The mapping states that each of theseconflicting classes may be both sequential or concurrent(R.3). From cases 3 and 4, requests from different classes,respectively concurrent and sequential, are processed ac-cording to the delivery order w.r.t. c’s requests.
Since (i) the delivery order has no dependency cycles(i.e., a request rn can only depend on previously enqueuedrequests rm, m < n); (ii) the request queue of each of theworker threads preserves this order; and (iii) each threadprocesses its requests sequentially, then request depen-dencies among worker threads is acyclic. With this it isalways possible to find a lowest element that does not de-pend on any other to be executed, and there is no dead-lock.
We now show that any execution of early schedulingensures linearizability. From §2, an execution is lineariz-able if there is a way to reorder the client requests in asequence that (i) respects the semantics of the requests, asdefined in their sequential specifications, and (ii) respectsthe real-time ordering of requests across all clients.
(i.a) Consider two independent requests rx and ry . Theexecution of one does not affect the other and thus theycan be executed in any relative order. As already dis-cussed (cases 1 and 2), either rx and ry belong to asame concurrent class or they belong to different non-conflicting classes. In either case, these requests willbe scheduled to execute without any synchronization be-tween them.
(i.b) Consider two dependent requests rx and ry . Asalready discussed, either rx and ry belong to a same in-ternally conflicting class or they belong to different, con-flicting classes. In any of those, there are common threadsthat synchronize to serialize the execution of the requestsaccording to the order provided by the atomic broadcast.Thus, the execution is sequential and respects the orderprovided by the atomic broadcast across replicas. Sincetheir execution is sequential, their semantics is satisfied.The order across replicas ensures consistent states.
(ii) Concerning the real-time constraints among rx andry , consider rx precedes ry , i.e. rx finishes before rystarts. Since before rx executes it must have been broad-cast, this means that rx was delivered before ry . There-fore the delivery order satisfies the real-time constraintsamong the requests.
15





























