Embed Size (px)
Citation preview

Efficient Scheduling of Scientific Workflows using Hot Metadata in a
Multisite Cloud
Ji Liu1,2,3, Luis Pineda1,2,4, Esther Pacitti1,2,3, Alexandru Costan4, Patrick Valduriez1,2,3, Gabriel Antoniu1 and Marta Mattoso5
1 Inria, 2 Microsoft-Inria Joint Centre,
3 LIRMM and University of Monpellier, France 4 IRISA / INSA Rennes
5 COPPE, UFRJ, Rio de Janeiro, Brazil

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

3
Introduction
• Scientific workflow (SWf) • Scientific applications are modeled as SWfs • Consists of a set of jobs and data dependencies • Scientific Workflow Management System (SWfMS)
• Tool to model, develop and run SWfs • Data-intensive SWf execution
• E.g.: Execution time (3 seconds) and time (1.5 seconds) to transfer intersite data for a task
• SWfs handle millions of files, beyond the capability of a single cloud site • Big data -> big set of small data • Datasets are often geo-distributed
• Environment: multisite cloud • One cloud operator • Multiple cloud sites • Data distribution

4
Metadata
• Captures traces of data and SWf execution • Task metadata: command, parameters, start and end time, status,
execution site etc. • E.g., Input data (In1.fits + In2.fits); Output data (Out1.jpeg); Execution @ Site 1; Start time: 13:05:12; End time:
13:05:13
• File metadata: name, size, location, replica • In1.fits: 2,1MB, @ Site 1; In2.fits: 2.1 MB, @ Site 2; Out1.jpeg: 2,3MB @ Site 3, @ Site 2 etc.
• Why is this important? • Useful for execution, e.g. a global view of data location for
data transfer • To help understand results produced by complex SWfs
• Access frequency • Hot metadata: frequently accessed during execution
• Task metadata & file metadata • Cold metadata: otherwise

5
Multisite SWf Scheduling
Montage SWf *
* http://montage.ipac.caltech.edu/docs/gridtools.html
S1
S2
S3
D D D D • The process of scheduling the tasks of each job to different sites in order to reduce execution time
• Assumptions • Distributed input data at
multiple sites • Transferring inter-site data
takes much time • Intermediate data • Metadata

6
Metadata Becomes a Bottleneck
• Current centralized management is an issue • Too many pieces of small data
• E.g. CyberShake SWf, 800K tasks, 80K input files, 200TB of data
• Long latency networks prevail in multisite cloud environments
• Problem • How to improve performance for metadata management
in order to reduce SWf execution time? • How to adapt decentralized handling [Pineda-Morales et al.
CLUSTER 2015] ?
• How to couple the metadata management with scheduling approaches [Liu et al. TLDKS 2017] ?

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

8
Related Work • Metadata management
• Centralized approaches: • The metadata is handled by a centralized registries
• E.g. Pegasus, Swift or Chiron • Low performance because of concurrency or high I/O pressure
• Distributed approaches: • Distributed Hash Table (DHT) based metadata distribution for files • No support for the whole SWf execution or geographically distributed multisite
clouds • Hybrid approaches
• DHT + centralized • No distinction between hot and cold metadata • No support for multisite clouds
• Multisite scheduling • OLB (Opportunistic Load Balancing) randomly selects a site for a task • MCT (Minimum Completion Time) schedules a task to the site that can
finish the execution first • DIM (Data-Intensive Multisite task scheduling) schedules a set of tasks
with consideration of inter-site data transfer and load balancing • No support from distributed metadata

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

10
Hot Metadata
• We focus on two types of hot metadata • Task metadata
• The metadata for the execution of tasks
• File metadata • The metadata for data transfer
• How to identify hot metadata • Empirical choice • User tags or dynamic selection (future work)
Montage SWf execution

11
Design Principles
• Two-Layer multisite SWf Management • Intra-site layer is a site composed of several nodes • Inter-site layer coordinates through a master/slave
architecture
• Adaptive placement for metadata • Cold metadata is stored locally and synchronized during the
execution of the job • Hot metadata is handled according to different strategies
• Eventual consistency for high-latency communications • The latency between two cloud site is high • The system is guaranteed to be eventually consistent with a
reasonable delay due to high latency propagation

12
Architecture
• A filtering component in each master node • Cold metadata are locally cached
and propagated asynchronously • Hot metadata is handled with
high priority with different strategies
Site 3 Site 2
M S
Metadata Store Shared File System
M Master node S Slave node
SFS
…
M M
Site 1 S
SFS
S
SFS …
S
SFS …
S
S
• Two-level multisite execution • Inter-site
• Communication and synchronization among master nodes
• Every master node holds a metadata store
• Intra-site • Master/slave scheme • All nodes are connected to a shared
file system • Metadata updates are propagated to
other sites through the master node
Site X M
S
Filter
<META>
Selector Site Y
M
Master Site
M
M S Metadata Store
Master Node
Slave Node

13
Hot Metadata Management Strategies • Centralized
• All the hot metadata is stored at a centralized site • Local storage without replication (LOC)
• Every hot metadata entry is stored at the site where it has been created
• Hashed without replication (DHT) • Hot metadata is queried and updated following the
principle of a distributed hash table • Hashed with local replication (REP)
• Combination of LOC and LOC • The data is stored at the local site and a hashed site
Centralized LOC DHT REP

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

15
DMM-Chiron
• Decentralized-Metadata Multisite (DMM) • Based on Multisite Chiron
• Scheduling in two phases • Multisite (OLB, MCT or DIM) • Single site (FAF)
• File Management • Multisite -> P2P • Single site -> Shared FS
• Multisite coordination • Task execution in each node • Control message through a message queue
Textual UI
Job Manager
Multisite Scheduler
Single Site Scheduler
Task Executor
Shared File System Multisite File Transfer
Multisite Message Communication
Metadata Manager

16
From Single Site to Multisite
• Job manager is responsible for its own tasks • Metadata write
• Cold metadata is locally cached and propagated asynchronously • Hot Metadata is handled according to different strategies
• Metadata read • Send a request to all the master nodes • Process the first non-vide response
• The multisite scheduler is connected to the metadata manager • Hot metadata is exploited by scheduling algorithms, e.g.
data location information for MCT and DIM

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

18
Experiment Setup
• Setup • Three sites with distributed input
data in Azure • West Europe (WEU), North Europe
(NEU) and Central US (CUS) • Coordinator: WEU, participants: NEU
and CUS • Up to 27 A3 VMs (8 CPU cores)
• Chiron implementation: • Azure Service Bus Queue for intersite
message transferring • Java Socket for data transferring
• Use case: Montage • Buzz*
1 2 3 4
5
6 7 8 9
1 2 3 4 5 6
7
8 9 10 11 12 13
Job Dependency
* J. Dias, E. S. Ogasawara, D. de Oliveira, F. Porto, P. Valduriez, and M. Mattoso. Algebraic dataows for big data analysis. In IEEE Int. Conf. on Big Data, pages 150-155, 2013.

19
Execution with OLB
• Up to 28% improvement using local storage (10% for Buzz) • Performance becomes more obvious for big data sets • Because of balanced load and small inter-site hot metadata transfer
• Performance degradation of hashing strategies with big data sets • Geo-distributed execution penalizes remote hot metadata read • Big data transfer with OLB
• Optimization at no cost: same resources as in centralized approach

20
Zoom on Multi-task Jobs (OLB)
• Consistent improvement (up to 20%) in large-scale experiment • Beyond 50% improvement with hashed strategies at smaller scale
• Unexpected peaks in smaller scale execution • We attribute it to the network latency variations • No single strategy fits all jobs

21
Execution with MCT and DIM
• Up to 28.2% improvement using LOC with MCT • Although the improvement of LOC with DIM is not as
obvious as that with OLB, the execution time is the smaller • Since the execution time is already much reduced by DIM • The combination of LOC and DIM can reduce up to 37.5%
compared with the combination of centralized and OLB
(MCT) (DIM)
22
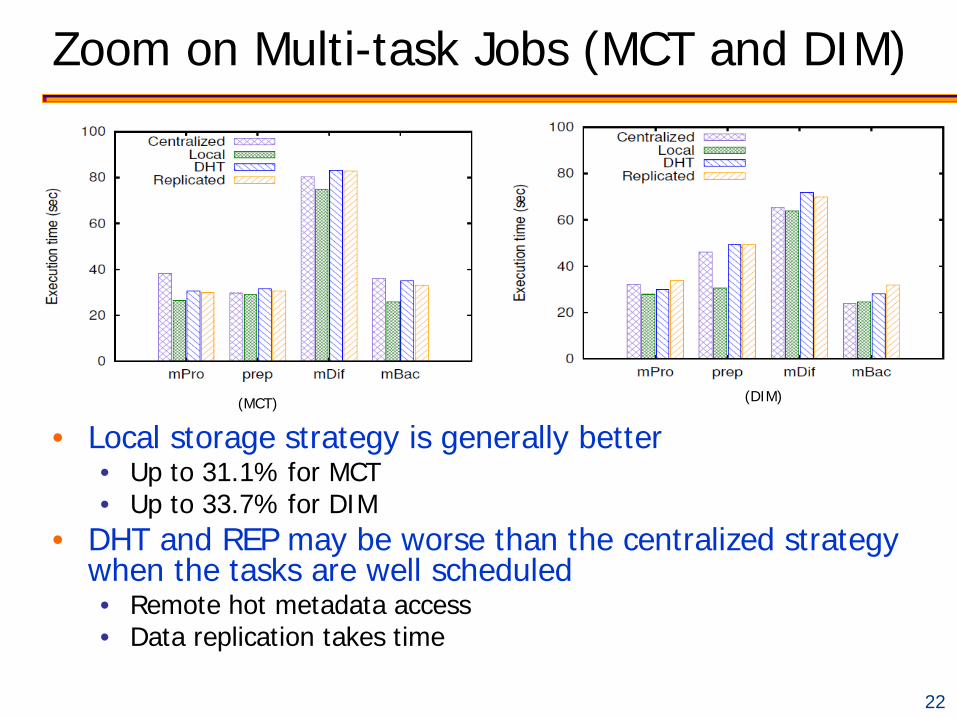
Zoom on Multi-task Jobs (MCT and DIM)
• Local storage strategy is generally better • Up to 31.1% for MCT • Up to 33.7% for DIM
• DHT and REP may be worse than the centralized strategy when the tasks are well scheduled • Remote hot metadata access • Data replication takes time
(MCT) (DIM)

Outline
• Introduction • Related work • Our approach & hot metadata • Implementation: DMM-Chiron • Experimental evaluation • Conclusion

24
Conclusion
• We introduced the concept of hot metadata for SWfs • Frequently accessed metadata, statistically identified • Delayed propagation of cold metadata
• We designed a hybrid model for hot metadata on multisite clouds
• Three distributed hot metadata management strategies: LOC, DHT, REP • Ensure availability of hot metadata • Reduce inter-site latency impact
• Up to beyond 50% improvement for highly-parallel jobs • Compared to centralized solution • No additional cost
• We coupled hot metadata management with scheduling algorithms • Better performance: up to 37.5% (LOC + DIM) compared with
(Centralized + OLB) • Future Work:
• Heterogeneous multisite environments • Dynamic monitoring of the capacity at cloud sites for scheduling






























