Embed Size (px)
Citation preview

Embedded Systems in SiliconTD5102
Data Management (3)SCBD, MAA, and Data Layout
Henk Corporaalhttp://www.ics.ele.tue.nl/~heco/courses/EmbSystems
Technical University Eindhoven
DTI / NUS Singapore
2005/2006

H.C. TD5102 2
Part 3 overview
• Recap on design flow
• Platform dependent steps– SCBD: Storage Cycle Budget Distribution– MAA: Memory Allocation and Assignment– Data layout techniques for RAM– Data layout techniques for Caches
• Results
• Conclusions
Thanks to the IMEC DTSE people

H.C. TD5102 3
Dynamic memory mgmtDynamic memory mgmt
Task concurrency mgmtTask concurrency mgmt
Physical memory mgmtPhysical memory mgmt
Address optimizationAddress optimization
SWSWdesigndesignflowflow
HWHWdesigndesignflowflow
SW/HW co-designSW/HW co-design
Concurrent OO specConcurrent OO spec
Remove OO overheadRemove OO overhead

H.C. TD5102 4
DM stepsC-in
Preprocessing
Dataflow transformations
Loop transformations
Data reuse Memory hierarchy layer assignment
Cycle budget distribution
Memory allocation and assignment
Data layout
C-out
Address optimization

H.C. TD5102 5
Result of Memory hierarchy assignment for cavity detection
L3
L2
L1
N*M
3*1
image_in
M*3
gauss_x gauss_xy comp_edgeimage_out
3*3 1*1 3*3 1*1
N*M
N*M*3 N*M*3 N*M
N*M
0
N*M*3 N*M
N*M*3 N*M*8 N*M*8 N*M*8 N*M*8
M*3 M*3
1MB
SDRAM
16KB
Cache
128 B
RegFile

H.C. TD5102 6
Data-reuse - cavity detection code
for (y=0; y<M+3; ++y) { for (x=0; x<N+2; ++x) { /* first in_pixel initialized */ if (x==0 && y>=1 && y<=M-2)
in_pixels[x%3] = image_in[x][y];
/* copy rest of in_pixel's in row */ if (x>=0 && x<=N-2 && y>=1 && y<=M-2) in_pixels[(x+1)%3]= image_in[x+1][y];
if (x>=1 && x<=N-1-1 && y>=1 && y<=M-2) { gauss_x_tmp=0; for (k=-1; k<=1; ++k) gauss_x_tmp += in_pixels[(x+k)%3]*Gauss[Abs(k)]; gauss_x_lines[x][y%3]= foo(gauss_x_tmp); } else if (x<N && y<M) gauss_x_lines[x][y%3] = 0;
Code after reuse transformation (partly)

Storage Cycle Budget Distribution &Memory Allocation and Assignment
H.C. TD5102 8
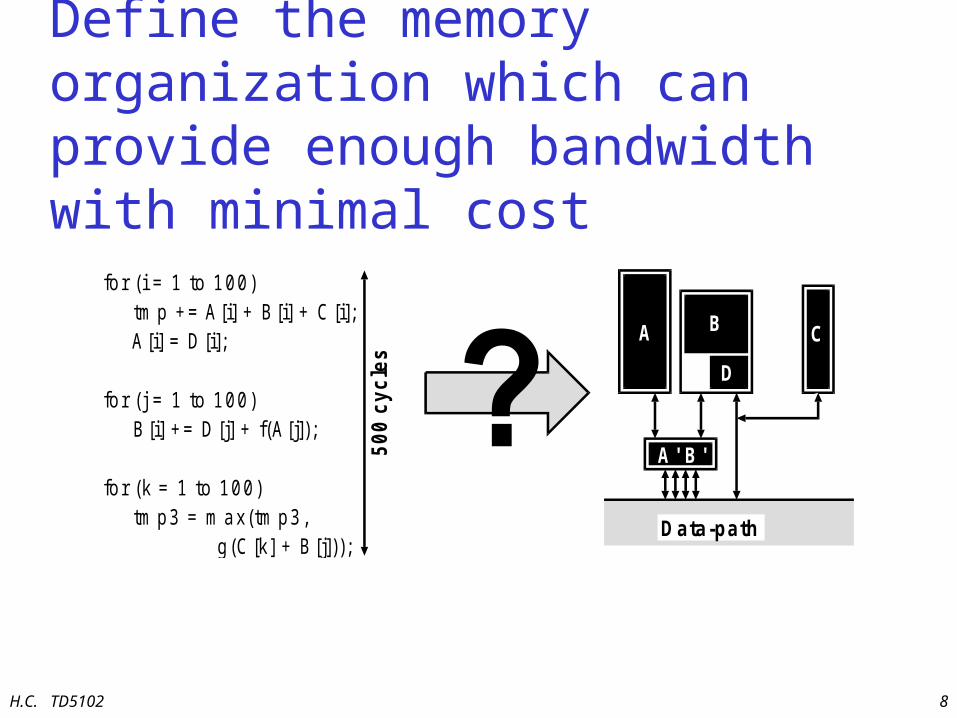
Define the memory organization which can provide enough bandwidth with minimal cost
for (i = 1 to 100) tm p += A [i] + B [i] + C [i]; A [i] = D [i];
for (j = 1 to 100) B [i] += D [j] + f(A [j]);
for (k = 1 to 100) tm p3 = m ax(tm p3, g(C [k] + B [j]));
A B
D
C
A' B'
Data-path
500
cycl
es

H.C. TD5102 9
Lower required performanceby balancing bandwidth
Memory BandwidthRequired
Memory BandwidthRequired
time
time
High
Low
Reduce max. number of loads/store per cycle

H.C. TD5102 10
Data management approach
R(A)
R(A)
R (C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
Flow GraphBalancing
C [i] = f(C [i-1])B [i] = C [i];a = A [i];B [i+1] = B [i+1] + a;d = D [i]+1;A [a] = A [a] + d;D [i] = d
Data-flowAnalysis
1
Cyc
le b
ud
get
= 6
3
2
6
4
5
R(A)
R(A)
R (C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
One of the manypossible schedules

H.C. TD5102 11
Data management approach
R(A)
R(A)
R(C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
A B CD
Memory Allocation &Assignment
Flow GraphBalancing
A B
C D
C [i] = f(C [i-1 ])B [i] = C [i];a = A [i];B [i+1] = B [i+1] + a;d = D [i]+1;A [a] = A [a] + d;D [i] = d
1
3
2
6
4
5
R(A)
R(A)
R(C)
R(D)
W (D)
R(B)
W (B)
W (A)
W (C)
R(C)
W (B)
H.C. TD5102 12
A BB CC DD AA CB
A B
C D
A B CD
FinalSchedule
C onflict G raph A validM em ory C onfiguration
M ax C lique = 3
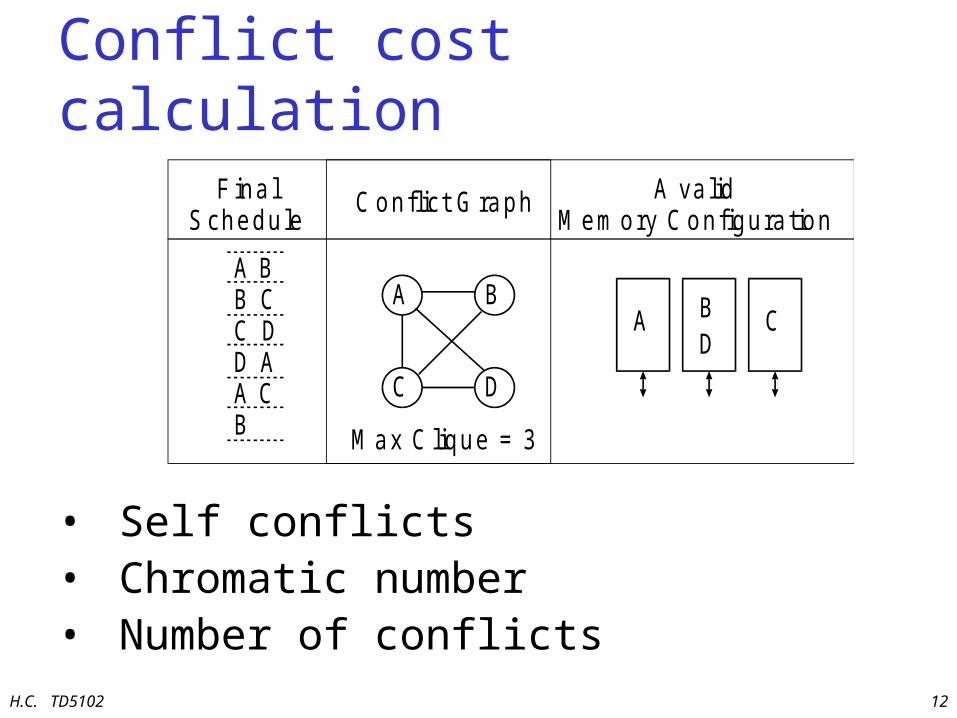
Conflict cost calculation
• Self conflicts• Chromatic number• Number of conflicts

H.C. TD5102 13
Self conflict dual port memory
A CB BA B DC D AC
A
C D
A B CD
A BB CC DD AA CB
A BD
A B
C D
FinalSchedule
C onflict G raph A validM em ory C onfiguration
Self conflict
B C
D ual port m em ory

H.C. TD5102 14
Chromatic number minimum # single port memories
A BA B
C D
A B CD
AC
BD
A B
DCC
FinalSchedule
C onflict G raph A validM em ory C onfiguration
C hrom . N r. = 3
C hrom . N r. = 2
B CC DD AA CB
A BB CC DD AAB C

H.C. TD5102 15
Low number of conflicts large assignment freedom
A BC DA BC DA BC
A B
C D
A BB CC DD AAB C
AC
BD
B
C D
FinalSchedule
Conflict Graph A validMemory Configuration
One solution
Multiple solutions
AC
BD
ACB
D
A

H.C. TD5102 16
time slots
?
R(C)W(B)W(B)R(B)W(A)R(A)R(A)
R(C)W(C)R(D)W(D)
1 2 3 4 5 6
R(A)
R(A)
R(C)
R(D)
W(D)
R(B)
W(B)
W(A)
W(C)
R(C)
W(B)
Conflict Directed Ordering is used for flat graph scheduling
• Reduce intervals until all conflicts known• Driven by cost of conflicts• Constructive algorithm

H.C. TD5102 17
Local optimization is not good for global optimization
A D
A B
C
A B C
B CA
D BC A
A BC D
B
D
A B
C D
A B
C D
A B
C D
D
A C
A B
C
AB D
B DA
A CB D
A CB D
B
D
A B
C D
A B
C D
A B
C D
C
+ +
Local optim ization G lobal optim izationfor (i = 1 to 5) A [i] = A [i] + B [i] +
C [i]+D [i];
for (j = 1 to 5) B [j] = f(A [j]);
tm p += g(C [j]+D [j]);
for (k = 1 to 10)
B [k] = g(D [k], A [k]) tm p2 += B [k],C [k];

H.C. TD5102 18
Budget distribution has large impact on memory cost
for (i = 1 to 100)
A [i] = A [i] + B [i] + C [i];
for (j = 1 to 100)
B [j] = f(A [j]);
for (k = 1 to 100)
C [k] = g(B [j]);
R (A) R (B)
R (C ) W (A)
R (A)
W (B)
R (B) W (C)
R (A) W (B)
R (A) R (B) R (C ) W (A)
200-200-100 200-100-200 100-200-200
A B
C
A B
C
A B
C
R (A) R (B)
R (C ) W (A)
R (B)
W (C )
R (A)
W (B)
R (B)
W (C )
2
2
1
2
2
12
1
2
A B C AB
CA B C
cycle budget = 500 cycles

H.C. TD5102 19
Decreasing basic block length until target cycle budget is met
for (i = 1 to 5) A [i] = A [i] + B [i] +
C [i]+D [i];
for (j = 1 to 5)
B [j] = f(A [j]); D [j] = g(C [j]);
for (k = 1 to 10)
B [k] = g(B [k], A [k]); D [k] = C [k];
5 4
25 20
Target Cycle Budget (75 Cycles)
5 450 40
25 C ycles
Targ
et c
ycle
bud
get (
75 c
ycle
s)
20 C ycles
50 C ycles
4 3
40 30
95 C ycles 90 C ycles
80 C ycles
70 C yles

H.C. TD5102 20
for (i = 1 to 100)
b_tm p = B [i];
A [2*i] = b_tm p + C [i];
A [2*i+1] = b_tm p;
for (j = 1 to 100)
D [j] = f(C [j+100]);
for (i = 1 to 100)
b_tm p = B [i];
A [2*i] = b_tm p + C [i];
A [2*i+1] = b_tm p;
D [i] = f(C [i+100]);
A [i]
C [j]
D [j]
1
2
1
2
Cycle budget: 400 cycles
B[i]
A [i]
C [i] 1 B [i]
A B
C
2 C[i]
3 D [i]
C [i]
A [i]
A [i]
D
A B
C D
BD
CAAB
CD
Obtain more freedom by merging loops
• More scheduling freedom• Extension to different threads

H.C. TD5102 21
Memory allocation and assignment

H.C. TD5102 22
Memory Allocation and Assignment Substeps
Array-to-memory Assignment
DC
A
B
Port AssignmentBus Sharing
DC
A
B
Memory Allocation 1 2 3

H.C. TD5102 23
Influence of MAA
• Bitwidth• Address range• Nr. memories• Nr. ports
• Assign arrays to memory • Memory interconnect• Minimize power & Area
Bitwidth
(maximum)Size
Nr. ports (R/W/RW)
MEMORY-1
A
B
Bitwidth
(maximum)Size
Nr. ports (R/W/RW)
MEMORY-N
K
L
1001001110101001
100100111010XXXX
1001XXXXXX
0101110010

H.C. TD5102 24
Trade-offs in the physical memory
Area
Power
Area
Power • Trade off area and power for required bandwidth
A
B
C
DA
C
D
B

H.C. TD5102 25
Example of bus sharing possibilities
R(A) R(B)
R(B) W(A)
W(C) R(A)
R(A) W(B)
W(A) W(B)
W(A) W(C)
m1 m2 m3
A B
X X
C
m1 m2 m3
A BC
m1 m2 m3
A B
X
C

H.C. TD5102 26
Decreasing cycle budget limits freedom and raises cost
Cost
Cycle Budget
A B
C D
C hrom N r=3
Minimum budget Fully sequentialLarge
M any obligatoryC ould be m any
B
C D
A
Lim ited freedom
LowFreeN oneFull freedom
R(A) R(B)
W (A)
W (A)
R(C)
1
2
3
R(A)
R(B)
W (A)
W (A)
R(C)1
2
3
4
5
N eeded bandw idth N r. m em ories
Self conflicts (m ult. port) Assignm ent
A[i] = A[i] + B[i];A[i+1] = C[i];
U nintrestingalternatives

H.C. TD5102 27
MinimumBudget
SequentialBudget
Conflict graph changed,but no impact on assignment
Conflict graph changed,change in assignment
Self conflict,forcing dual port mem.
Resulting Pareto curve for DAB synchro application

H.C. TD5102 28
Example conflict graph for cavity detection

H.C. TD5102 29
MAA result
Power:On-chip area:

H.C. TD5102 30
Data layout
how to put data into memory

H.C. TD5102 31
A
C
?
?
B
MEM1
F
G?
?
H
MEM2
PE
PE
A’B’?
?
CACHE PE
PE
A
B
CACHE
A
C
MEM1
B
F
MEM2
G
H
Memory data layout forcustom and cache architectures
C
A
B
C
B

H.C. TD5102 32
for (i=1; i<5; i++) for (j=0; j<5; j++) a[i][j] = f(a[i-1][j]); i-1
i
j
Window
Intra-array in-place mappingreduces size of one array
aa
time
max nr. of life elements
H.C. TD5102 33
variabledomains
abstractaddresses
realaddresses
aA a
C
A
BaC
aB
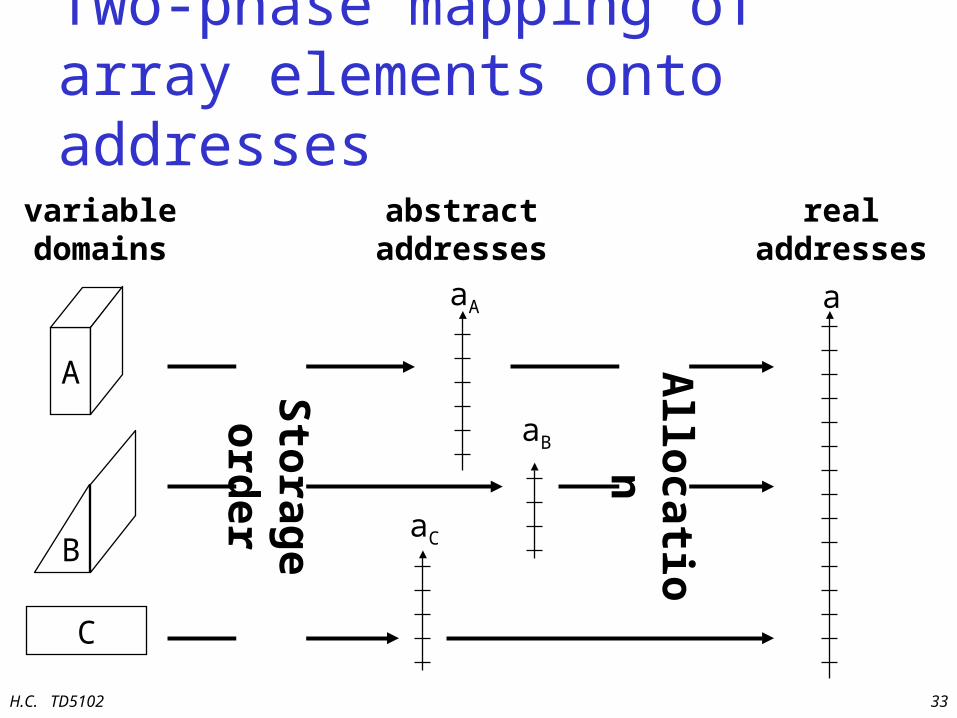
Two-phase mapping of array elements onto addresses
Sto
rage
ord
er
Allo
cation

H.C. TD5102 34
a2
a1
a=3a1+a2
a=3(1-a1)+a2
a=3a1+(2-a2)
a=3(1-a1)+(2-a2)
a=2a2+a1
a=2a2+(1-a1) a=2(2-a2)+(1-a1)
a=2(2-a2)+a1
aa=???
memory addressvariable domain
Exploration of storage ordersfor 2-dimensional array
? ?? ? ? ?

H.C. TD5102 35
Chosen storage orderdetermines window size
for (i=1; i<5; i++) for (j=0; j<5; j++) a[i][j] = f(a[i-1][j]);
row-major ordering: a=5i+j
for (i=1; i<5; i++) for (j=0; j<5; j++) a[5*i+j] = f(a[5*i+j-5]);
column-major: a=5j+i
for (i=1; i<5; i++) for (j=0; j<5; j++) a[5*j+i] = f(a[5*j+i-1]);
Highest live address:
Lowest live address:
5*i+j
5*i+j-5
5*4+i-1
5*0+i-1
Difference + 1= Window: 6 21

H.C. TD5102 36
A
B
C
D
E
xx CAa abstrrealx
Memory Size
Static allocation:no in-place mapping
E
aE
C
aC
A
aA
D
aD
BaB

H.C. TD5102 37
C
Memory Size
A
D
B
E
xxx CWmodAa abstrrealx
Static, windowed
C
Memory Size
A
DB
E
Dynamic, windowed
Windowed Allocation:intra-array in-place mapping

H.C. TD5102 38
xx CAa abstrrealx
Dynamic allocation:inter-array in-place mapping
E
aE
C
aC
A
aA
D
aD
BaB
A B
C
D
EMemory
Size

H.C. TD5102 39
A
BC
ED
A C
ED
BMemory
Size
WmodCASa abstrrealxxxx
Dynamic, common window
Dynamic allocation strategy with common window

H.C. TD5102 40
Before:
bit8 B[10][20];bit6 A[30];for(x=0;x<10;++x) for (y=0;y<20;++y) … = A[3*x-y]; B[x][y] = …;
After:
bit8 memory[334];bit8* B =(bit8*)&memory[134];bit6* A =(bit6*)&memory[120];for(x=0;x<10;++x) for (y=0;y<20;++y) … = A[3*x-y]; B[(x*20+y*2)%78] = …;
Expressing memory data layoutin source code
Example: array of 10x20 elements
A: offset 120, no windowB: storage order [20, 2], offset 134, window 78

H.C. TD5102 41
int x[W], y[W];for (i1=0; i1 < W; i1++) x[i1] = getInput();for (i2=0; i2 < W; i2++) { sum = 0; for (di2=-N; di2 <=N; di2++) { sum += c[N+di2] * x[wrap(i2+di2,W)]; } y[i2] = sum;}for (i3=0; i3 < W; i3++) putOutput(y[i3]);
Example of memory data layoutfor storage size reduction

H.C. TD5102 42
i1=0 i1=W-1 i2=0 i2=W-1 i3=0 i3=W-1i2=N
x[0]
x[N]
x[W-1]
y[W-1]
x[]
y[]
y[0]
y[N]
W+W
Occupied address-time domainof x[] and y[]

H.C. TD5102 43
int mem1[N+W];for (i1=0; i1 < W; i1++) mem1[N+i1] = getInput();for (i2=0; i2 < W; i2++) { sum = 0; for (di2=-N; di2 <=N; di2++) { sum += c[N+di2] * mem1[N+wrap(i2+di2,W)]; } mem1[i2] = sum;}for (i3=0; i3 < W; i3++) putOutput(mem1[i3]);
Optimized source codeafter memory data layout

H.C. TD5102 44
i1=0 i1=W-1 i2=0 i2=W-1 i3=0 i3=W-1i2=N
mem1[0]
mem1[N]
mem1[W-1]x[]
y[]
mem1[W+N-1]
N+W
Optimized OAT domainafter memory data layout

H.C. TD5102 45
In-place mapping for cavity detection example• Input image is partly consumed by the time
first results for output image are ready
index
time
Image_in
time
address
Image
time
index
Image_out

H.C. TD5102 46
In-place - cavity detection code
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image_out[x-5][y-3] = …; /* code removed */
… = image_in[x+1][y]; }}
for (y=0; y<=M+3; ++y) { for (x=0; x<N+5; ++x) { image[x-5][y-3] = …; /* code removed */
… = image [x+1][y]; }}

H.C. TD5102 47
Cavity detection summary
0
100
200
300
400
500
600
accesses size cycles
Overall result:
• Local accesses reduced by factor 3
• Memory size reduced by factor 5
• Power reduced by factor 5
• System bus load reduced by factor 12
• Performance worsened by factor 6

H.C. TD5102 48
Data layout for caches• Caches are hardware controled• Therefore: no explicit copy coded needed !• What can we do ?

H.C. TD5102 49
p-k-m mk
tag index address byte address
tagdata
Hit?
mainmemory
CPU
2k lines
p-k-m2m bytes
Cache line / BlockCache principles

H.C. TD5102 50
Cache Architecture Fundamentals
• Block placement – Where in the cache will a new block be placed?
• Block identification– How is a block found in the cache?
• Block replacement policy– Which block is evicted from the cache?
• Updating policy– How is a block written from cache to memory?

H.C. TD5102 51
CacheCache0011
77
2233445566
22334455
0011
6677......
0011223344556677
Fully associative Fully associative (one-to-many)(one-to-many)
Anywhere in cacheAnywhere in cache
Anywhere in cacheAnywhere in cache
Here only!Here only!
0011223344556677
Direct mapped Direct mapped (one-to-one)(one-to-one)
Here only!Here only!
MemoryMemory00112233445566778899
101011111212131314141515
Mapping?Mapping?
......
Block placement policies

H.C. TD5102 52
Direct mapped cache
20 10
Byteoffset
Valid Tag DataIndex
0
1
2
1021
1022
1023
Tag
Index
Hit Data
20 32
31 30 13 12 1 1 2 1 0Address (bit positions)

H.C. TD5102 53
• Taking advantage of spatial locality:
Direct mapped cache: larger blocks
Address (showing bit positions)
16 12 Byteoffset
V Tag Data
Hit Data
16 32
4Kentries
16 bits 128 bits
Mux
32 32 32
2
32
Block offsetIndex
Tag
31 16 15 4 32 1 0
Address (bit positions)

H.C. TD5102 54
• Increasing the block size tends to decrease miss rate:
Performance
1 KB
8 KB
16 KB
64 KB
256 KB
256
40%
35%
30%
25%
20%
15%
10%
5%
0%
Mis
s ra
te
64164
Block size (bytes)

H.C. TD5102 55
4-way associative cacheAddress
22 8
V TagIndex
0
1
2
253
254255
Data V Tag Data V Tag Data V Tag Data
3222
4-to-1 multiplexor
Hit Data
123891011123031 0

H.C. TD5102 56
Performance
0%
3%
6%
9%
12%
15%
Eight-wayFour-wayTwo-wayOne-way
1 KB
2 KB
4 KB
8 KB
Mis
s ra
te
Associativity 16 KB
32 KB
64 KB
128 KB
1 KB
2 KB
8 KB

H.C. TD5102 57
Cache FundamentalsThe “Three C's”• Compulsory Misses
– 1st access to a block: never in the cache
• Capacity Misses– Cache cannot contain all the blocks
– Blocks are discarded and retrieved later
– Avoided by increasing cache size
• Conflict Misses– Too many blocks mapped to same set
– Avoided by increasing associativity

H.C. TD5102 58
for(i=0; i<10; i++) A[i] = f(B[i]);
Cache(@ i=2)
A[0]B[1]
B[2]
B[0]
A[1]
A[2]------
• B[3], A[3] required• B[3] never loaded before
loaded into cache• A[3] never loaded before
allocates new line
Cache(@ i=3)
Compulsory miss example

H.C. TD5102 59
Capacity miss example
B[3]B[0]A[0]
i=0B[3]B[0]A[0]B[4]B[1]A[1]
i=1A[2]B[0]A[0]B[4]B[1]A[1]B[5]B[2]
i=2A[2]B[6]B[3]A[3]B[1]A[1]B[5]B[2]
i=3A[2]B[6]B[3]A[3]B[7]B[4]A[4]B[2]
i=4B[5]A[5]B[3]A[3]B[7]B[4]A[4]B[8]
i=5B[5]A[5]B[9]B[6]A[6]B[4]A[4]B[8]
i=6
for(i=0; i<N; i++) A[i] = B[i+3]+B[i];
B[5]A[5]B[9]B[6]A[6]B[10]B[7]A[7]
i=7
• 11 compulsory misses (+8 write misses)
• 5 capacity misses
Cache size: 8 blocks of 1 wordFully associative

H.C. TD5102 60
Cache (@ i=0)
1234567
B[0][j]
A[0]/B[0][j]0
for(j=0; j<10; j++) for(i=0; i<4; i++) A[i] = A[i]+B[i][j];
A[0]0A[1]1A[2]
B[3][9]
7
10
31
B[3][0]B[0][1]
A[3]234 B[0][0]
B[1][0]
B[1][1]
B[2][0]56
11
B[2][1]B[3][1]
12
B[0][2]B[1][2]1
3 B[2][2]B[3][2]
89
1415
01
7
2
7
23456
345
01
67
B[0][3] 0...
Memoryaddress
Cacheaddress
j=even
A[0] multiply loaded
A[i] multiple x read
-> A[0] flushed in favor B[0][j] -> Miss j=odd
Conflict miss example
H.C. TD5102 61
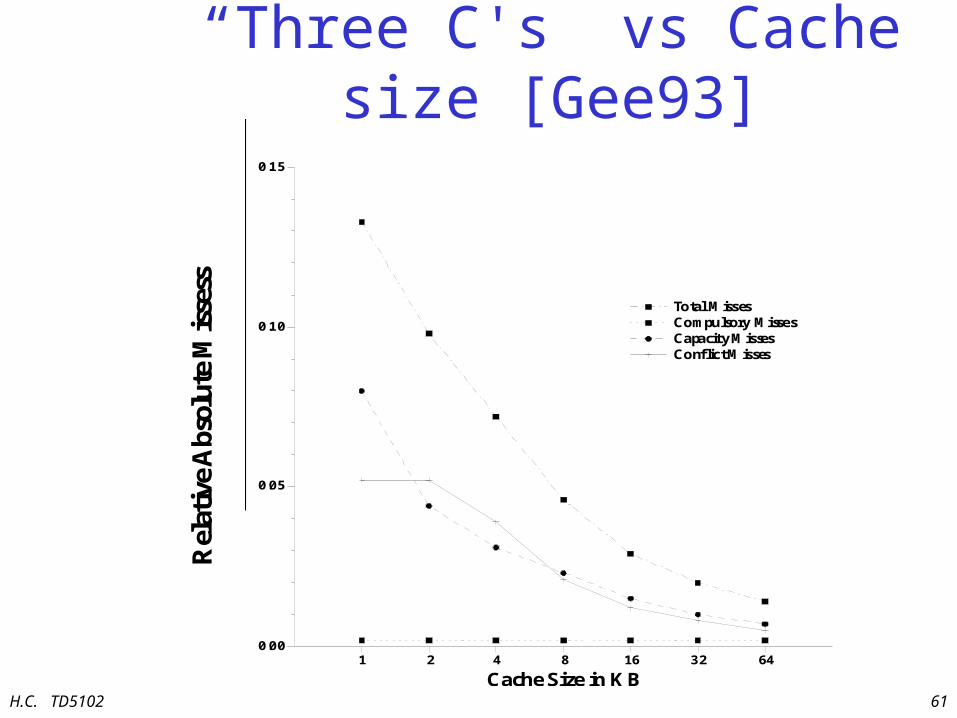
“Three C's” vs Cache size [Gee93]
1 2 4 8 16 32 64
Cache Size in KB
0.00
0.05
0.10
0.15
Total Misses Compulsory Misses Capacity MissesConflict Misses
Rel
ativ
e A
bsol
ute
Mis
sess

Data layout may reduce cache misses

H.C. TD5102 63
Example 1: Capacity & Compulsory miss reduction
B[3]B[0]A[0]
i=0B[3]B[0]A[0]B[4]B[1]A[1]
i=1A[2]B[0]A[0]B[4]B[1]A[1]B[5]B[2]
i=2A[2]B[6]B[3]A[3]B[1]A[1]B[5]B[2]
i=3A[2]B[6]B[3]A[3]B[7]B[4]A[4]B[2]
i=4B[5]A[5]B[3]A[3]B[7]B[4]A[4]B[8]
i=5B[5]A[5]B[9]B[6]A[6]B[4]A[4]B[8]
i=6
for(i=0; i<N; i++) A[i] = B[i+3]+B[i];
B[5]A[5]B[9]B[6]A[6]B[10]B[7]A[7]
i=7
• 11 compulsory misses (+8 write misses)
• 5 capacity misses

H.C. TD5102 64
#Words
B[]
i60
CacheMemory
Main Memory
(16 words) (16 words)
AB[new]
Fit data in cache within-place mapping
A[]
15Detailed Analysis:
max=15 words
12
for(i=0; i<12; i++) A[i] = B[i+3]+B[i];Traditional
Analysis:max=27 words

H.C. TD5102 65
Remove capacity / compulsory misses with in-place mapping
AB[3]AB[0]
i=0AB[3]AB[0]AB[4]AB[1]
i=1AB[3]AB[0]AB[4]AB[1]AB[5]AB[2]
i=2AB[3]AB[0]AB[4]AB[1]AB[5]AB[2]AB[6]
i=3AB[3]AB[0]AB[4]AB[1]AB[5]AB[2]AB[6]AB[7]
i=4AB[3]AB[8]AB[4]AB[1]AB[5]AB[2]AB[6]AB[7]
i=5AB[3]AB[8]AB[4]AB[9]AB[5]AB[2]AB[6]AB[7]
i=6
for(i=0; i<N; i++) AB[i] = AB[i+3]+AB[i];
AB[7]AB[8]AB[4]AB[9]AB[5]AB[10]AB[6]AB[7]
i=7
• 11 compulsory misses
• 5 cache hits (+8 write hits)

H.C. TD5102 66
Cache (@ i=0)
1234567
B[0][j]
A[0]/B[0][j]0
for(j=0; j<10; j++) for(i=0; i<4; i++) A[i] = A[i]+B[i][j];
A[0]0A[1]1A[2]
B[3][9]
7
10
31
B[3][0]B[0][1]
A[3]234 B[0][0]
B[1][0]
B[1][1]
B[2][0]56
11
B[2][1]B[3][1]
12
B[0][2]B[1][2]1
3 B[2][2]B[3][2]
89
1415
01
7
2
7
23456
345
01
67
B[0][3] 0...
Memoryaddress
Cacheaddress
j=even
A[0] multiply loaded
A[i] multiple x read
-> A[0] flushed in favor B[0][j] -> Miss j=odd
Example 2: Conflict miss reduction

H.C. TD5102 67
for(j=0; j<10; j++)for(j=0; j<10; j++) for(i=0; i<4; i++)for(i=0; i<4; i++) A[i] = A[i]+B[i][j];A[i] = A[i]+B[i][j];
A[0]A[0]00A[1]A[1]11A[2]A[2]
B[3][9]B[3][9]
77
1122
3311
B[3][0]B[3][0]
B[0][1]B[0][1]
Main MemoryMain Memory
A[3]A[3]223344 B[0][0]B[0][0]
B[1][0]B[1][0]
B[1][1]B[1][1]
B[2][0]B[2][0]5566
1133
Leave gapLeave gap
B[2][1]B[2][1]B[3][1]B[3][1]
Leave gapLeave gapB[0][2]B[0][2]
0011
77
44
77
2233445566
556677
11441155
1188
44......
......
......
11223344556677
B[0][j]B[0][j]
A[0]A[0]00
A[0] A[0] multiply multiply loadedloaded
A[i] multiple A[i] multiple xx read read
No No conflictconflict
Cache Cache (@ i=0)(@ i=0)
j=anyj=any
© imec 2001
Avoid conflict miss withmain memory data layout

H.C. TD5102 68
0
2
4
6
8
10
12
14
16
512Bytes 1KB 2KB
Cache Size
Mis
s R
ate
(%
) Initial - DirectMapped
Data Layout Org -Direct Mapped
Initial - Fully Assoc
Data Layout Organization forDirect Mapped Caches

H.C. TD5102 69
Conclusion on Data Management
• In multi-media applications exploring data transfer and storage issues should be done at source code level
• DMM method– Reducing number of external memory accesses
– Reducing external memory size
– Trade-offs between internal memory complexity and speed
– Platform independent high-level transformations
– Platform dependent transformations exploit platform characteristics (efficient use of memory, cache, …)
– Substantial energy reduction





























