Embed Size (px)
Citation preview

Fast Functional Simulation with a Dynamic Language
Craig S. Steele, Exogi LLC, USAJP Bonn, Exogi LLC, USA
Fast Functional Simulation with a Dynamic Language
Craig S. Steele, Exogi LLC, USAJP Bonn, Exogi LLC, USA

2
HPEC 2012
Fast Functional Simulation with a Dynamic Language
Craig S. Steele and JP Bonn
Exogi LLCLas Vegas, NV, USA

3
Presentation Outline
• Motivation for Fast Functional Simulator– Programmable Components
• Static versus Dynamic Simulators– Dynamic Binary Translation
• Lua Scripting Language
• Dynamic Language Tracing JIT compilers
• Instruction Pipeline in Software
• Simulating Heterogeneous Devices

4
Motivation for Fast Functional Sim
• Larger systems (including SoCs, FPGAs)– Many programmable components– Non-programmable have functional spec
• Lower-level simulations slow, getting slower
• Waterfall (or over-the-wall) HW/SW flow– Software is late from the start, unintegrated– Fast functional sim enables SW developers
• Future resilient systems need autonomic SW

5
Static vs. Dynamic ISS
• Fetch-decode-execute iterative interpreter– 10+ MIPS– SW analog of a non-pipelined CPU
• Pre-decode binary instructions
• Convert each instruction to “C” function call
• Compile C function call to native code
• Do more of the above at runtime
• Support JIT and self-modifying code

6
Dynamic Binary Translation
• Dynamic Binary Translator (DBT) does it all
• QEMU (Quick EMUlator) Fabrice Ballard
• Hundreds rather than tens of simulated MIPS– Basic blocks (BBs), not single instructions
• Can be used for whole-system simulation– Mainly PC-oriented virtual machines– Also some embedded non-PC systems– Support for several instruction sets

7
Code Generation DSL
• Model target instruction set with “micro-ops”
• Tiny Code Generator (TCG)– Second Generation DSL
• Another app-specific language to remember– Each instruction set is a different port– Supportive user community is tiny
• Simulator code is very different from TCG– New device may need new TCG micro-ops– Code differs for prog & non-prog devices

8
Static vs. Dynamic Languages
• Static Languages: C / C++– Variables have a type– Compiler detects type mismatches– Compiled separately from execution
• Optimize lots of possible paths
• Dynamic Languages– Data is typed, variable can hold any datum– Type is detected at runtime– “Scripting” languages are often interpreted

9
Lua Language
• Small, multi-paradigm “scripting” language
• Supports a functional programming style– First-class functions & closures
• Small conceptual and resource footprint– Well under 300KB memory footprint
• Good embeddability and portability
• Good interface to C

10
Lua Language Quirks
• Only composite data type is table– Associative array– Supports both integer and hashed keys
• Limited native data types
• “Number” type: double or dual double/integer– Dynamic type inference/specialization
• No standardized class-based object system– Many object systems, may not intermix
• Tables & closures reduce centrality of classes

11
LuaJIT Compiler
• Tracing Just-in-Time compilers– Excellent for dynamic languages– Data types can be observed at runtime– Optimization and specialization of types
• Source compiled to register-based bytecode
• Fast assembly-coded interpreter for tracing
• “Hot code” chunks optimized to native binary
• Excellent C Foreign-Function Interface (FFI)

12
C One-Instr. Fetch-Execute Loopfor (int i=0; i < nIters; i++) {
#if TRACE
printf("%08d| PC = 0x%08X\n", i, node->curPC);
if (node->curPC == pausePC)
pauseCount++;
#endif
uint32_t deltaPC = sfp((void *)di, (void *)node);
node->curPC = node->nextPC;
di = virtual_icache_entry(node->nextPC,node);
sfp = di->fPtr;
node->nextPC += deltaPC;
}

13
Lua One-BB Fetch-Execute Loop
for i = 1, n_BBs do
-- 140 MOps vs 572 MOps with single-entry cache
if cur_pc ~= next_pc then -- avoid table lookup if no change
cur_pc = next_pc
cur_instr = loc_imem[cur_pc]
end
next_pc = cur_instr(cpu)
end

14
Closures as Object Substitutes 1-- Generated generic code for all “xor” instructions
-- Anonymous function is a “factory” for XOR/XORI instr. instances
-- When factory function is called,
function arguments are persistently bound to values
return
function(seq_instr,seq_pc,br_pc,cpu,op_fcns,store_RX,valA,valB)
local result = op_fcns.lm32_alu_fcn_xor(valA,valB)
return
store_RX(seq_instr,seq_pc,br_pc,cpu,result)
end

15
Closures as Object Substitutes 2-- Generated generic code for all “bge” branch instructions
-- Anonymous function is a “factory” for BGE/BGEU instr. instances
-- When factory function is called,
function arguments are persistently bound to values
return
function(seq_instr,seq_pc,br_pc,cpu,op_fcns,select_pc,valA,valB)
local result = op_fcns.lm32_cond_fcn_bge(valA,valB)
local next_pc = select_pc(seq_pc,br_pc,result)
return next_pc -- Dynamic return types: (integer | function ref)
end

16
Tail-Call Optimization
• Where does “TCOSim” name come from?
• TC: if last statement in a function is a fcn call
• A tail call is a GOTO for functional languages
• Tail-call Optimization (TCO)– Recursion without a stack
• Multiple functions can be optimized as one
• LuaJIT tracing compiler optimizes calls away
• Functions are organizational, not executable

17
Pipelined Instruction Definition
Example: 3-operand RISC ALU instruction class
local function lm32_build_RR_format_instr(format,instr) …
local load_valB = lm32_load_RZ[instr[4]] …
return load_valB(seq_instr,
seq_pc,cpu,lm32_ops,store_val,alu_op,load_valA) …return
load_valA (seq_instr, … …
return alu_op(seq_instr, … …
return seq_instr(cpu)
Example: Helper ALU operation shared by XOR/XORI
local function lm32_alu_fcn_xor(x,y)
local result = bit_bxor(x + y)
return result
end

18
Basic Block Instruction Fusion
• Non-branching instructions end with tail call
return seq_instr(cpu)
• Branch instructions return new PClm32_operation_builder_string["BI"] = [[
return function(seq_instr,
seq_pc,br_pc,cpu,op_fcns,select_pc,valA,valB)
local result = op_fcns.lm32_cond_fcn_%s(valA,valB)
local next_pc = select_pc(seq_pc,br_pc,result)
return next_pc
end
]]
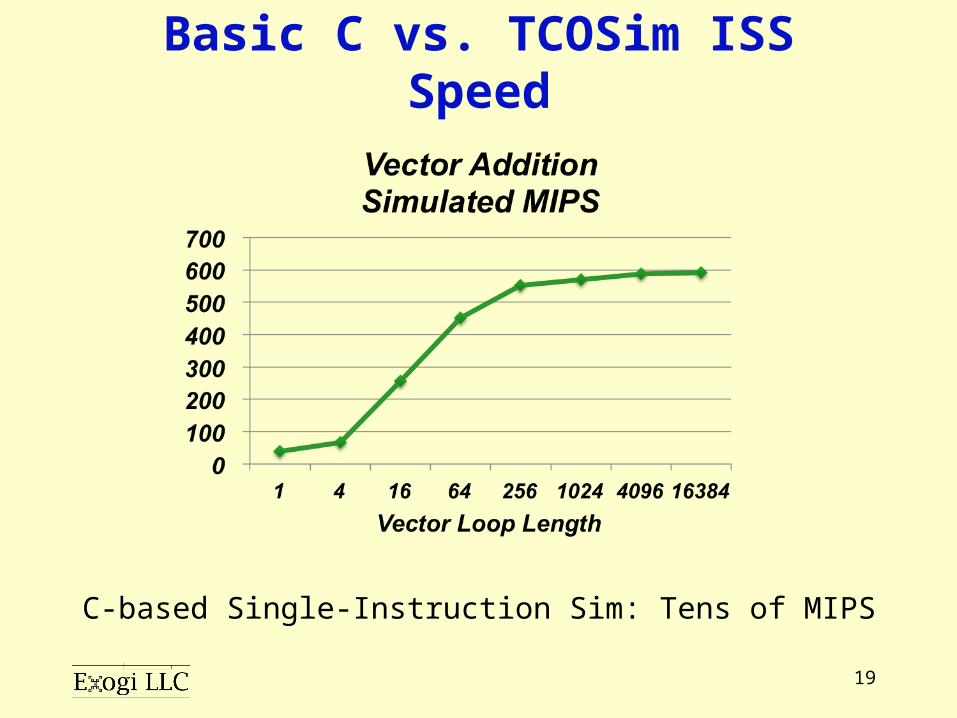
19
Basic C vs. TCOSim ISS Speed
C-based Single-Instruction Sim: Tens of MIPS

20
Simulating Heterogeneous Devices
• Simulator calls a chain of instructions– Basic block, ending with branch– Device/CPU is a parameter
• CPU or other programmed HW• With HDL design, most HW is a program
• Devices can be intermixed in BB chain– Multiple CPU HW threads (or hetero CPUs)– DMA devices– Event polling devices, e.g., interrupt control

21
Future Directions
• Integrate gdb debug server– Compile existing C server code for target– Run gdb server as “virtual” thread on sim– Should be fairly portable to real HW
• Support external events, e.g., interrupts
①Interleave polling instruction blocks
②Asynchronous callback to inner loop
• Multi-threaded simulation host support
• Self-host LuaJIT compiler within sim target

22
Conclusion
• Lua: small dynamic scripting language– Easy dynamic-code-creating programs– Fast edit-run-expletive cycle– Can be fast with a tracing JIT compiler
• Surprisingly good fit for functional simulation
• Loose typing good for heterogenous devices
• Conventional coding, not exotic ISS DSL
• Small enough and fast enough to go meta

23
Meta-Meta
http://xkcd.com/917/

25
Caching in Lua
• Lua has one primitive composite data type
• Table is associative array– Almost any data type can be used as index– Integers are optimized like C arrays– Other index types are used for hashtable– Tables are both arrays and hashtables
• Meta-tables allow custom index operations
• Using one table to cache another is very easy

26
A Use Case of Caching in Lua
• Instruction-memory decoding can be either– Static: binary available at start, unchanging– Dynamic: binary is JITed or self-modifying
• Step 0 – Get binary encoded instruction
• Step 1 – Decode to table, e.g., {"add”,1,0,21}
• Step 2 – Build instruction as stack of Lua fcns
• Step 3 – Link instructions into basic blocks
• Step 4 – Locate BBs at absolute addresses
• Every step can be cached and “on demand”






























