Embed Size (px)
Citation preview

1
STATISTISKA INSTITUTIONEN
Uppsala Universitet
Examensarbete C
Författare: Martin M Eriksson och Viktor Gunnarsson
Handledare: Daniel Preve
HT-10
Finns det ett samband mellan koldioxidutsläpp och ekonomisk tillväxt?
En kointegrationsanalys av BNP och koldioxidutsläpp i Sverige under åren 1860-2000

2
Sammanfattning Enligt Grossman och Krueger, finns det ett samband mellan BNP och utsläpp där utsläppen
följer en inverterad U-kurva, en så kallad Kuznetskurva. För att undersöka om detta
påstående stämmer har historiska data över BNP och koldioxidutsläpp inhämtats från
perioden 1860-2000. Syftet med denna uppsats är att med hjälp av kointegrationsanalys
undersöka om det finns någon form av samband mellan dessa serier. För att kunna göra
detta har villkoren för kointegration redogjorts och undersökts för dessa serier.
Resultaten i undersökningen visar att empiriska stöd har erhållits för den hypotetiska
Kuznetskurvan. Däremot hittades inte empiriska indikationer för ett linjärt, monotont
växande samband. Slutsatsen utifrån detta är att Sverige precis har passerat brytpunkten
och att man, åtminstone i nuläget, har brutit sambandet mellan ekonomisk tillväxt och
ökade koldioxidutsläpp.
Nyckelord: Kointegration, Stationäritet, Regression, Kuznetskurva, BNP, Koldioxidutsläpp
According to Grossman and Kreguer, there exists a relationship between environmental
pollution and national income. This relation should follow an inverted U-curve, a so called
Kuznets curve. To investigate whether this hypothesis is correct, historical data for Swedish
GDP and carbon dioxide emissions has been collected for the years of 1860-2000. With
cointegration analysis as a tool this paper will investigate if there exists any connection
between the two variables. To complete the task the criteria to be able to use cointegration
analysis has been discussed.
The results show that Kuznet’s model may hold and better accounts for the relation between
carbon dioxide emissions and GDP than a linear increasing model does. The conclusion
therefore is that Sweden might have passed the tipping point where carbon dioxide
emissions no longer increases with economic growth.

3
Innehållsförteckning
Sammanfattning ......................................................................................................................... 2
1 Inledning .................................................................................................................................. 5
1.1 Bakgrund ........................................................................................................................... 5
1.2 Syfte .................................................................................................................................. 6
1.3 Metod ............................................................................................................................... 6
1.4 Tidigare forskning ............................................................................................................. 7
2 Data ......................................................................................................................................... 8
2.1 Koldioxidutsläpp ............................................................................................................... 8
2.2 BNP ................................................................................................................................... 9
3 Teori ....................................................................................................................................... 11
3.1 Inledning ......................................................................................................................... 11
3.2 Spuriös korrelation/regression ....................................................................................... 11
3.3 Stationäritet .................................................................................................................... 12
3.4 Enhetsrot ........................................................................................................................ 13
3.5 Stationäritetstest ............................................................................................................ 13
3.5.1 Dickey-Fuller test (DF-test) ...................................................................................... 14
3.5.2 Augmented Dickey-Fuller test ................................................................................. 16
3.5.3 Svagheter med Dickey-Fullers test .......................................................................... 16
3.5.4 KPSS test ................................................................................................................... 17
3.5.5 Hannan-Quinn informationskriterium ..................................................................... 18
3.6 Kointegration .................................................................................................................. 18
3.6.1 Engle-Granger test för icke kointegration ............................................................... 20
3.7 Kuznetskurvan ................................................................................................................ 21
4 Resultat .................................................................................................................................. 22
4.1 Spuriös regression .......................................................................................................... 22
4.2 Stationäritet & enhetsrottest ......................................................................................... 22
4.2.1 Logaritmerad koldioxiddata ..................................................................................... 23
4.2.2 Logaritmerad differentierad koldioxiddata ............................................................. 25

4
4.2.3 Logaritmerad BNP data ............................................................................................ 27
4.2.4 Logaritmerad differentierad BNP data .................................................................... 29
4.3 Engle-Grangers test för icke kointegration .................................................................... 31
5 Analys .................................................................................................................................... 35
6 Förslag till vidare forskning ................................................................................................... 41
7 Slutsats .................................................................................................................................. 41
Referenser ................................................................................................................................ 42
Appendix ................................................................................................................................... 44
Kvadrerad BNP per capita ................................................................................................. 44
Logaritmerad koldioxid per capita .................................................................................... 45
Logaritmerad BNP per capita ............................................................................................ 49
Differentierad logaritmerad koldioxid per capita ............................................................. 52
Differentierad logaritmerad BNP per capita ..................................................................... 55
Enders testprocedur ............................................................................................................. 59
Spuriös regression ................................................................................................................ 60
Engle-Granger test för icke-kointegration ............................................................................ 61
Modell med linjär trend .................................................................................................... 61
Kuznet’s ekvation .............................................................................................................. 62
Dickey-Fuller kritiska värden ............................................................................................. 64
Kritiska värden för modell val ........................................................................................... 64
Engle-Granger kritiska värden........................................................................................... 65
Kritiska värden för justerad testprocedur......................................................................... 65

5
1 Inledning
1.1 Bakgrund
I början av 1990-talet framförde Grossman och Krueger teorin om miljökuznetskurvan (the
environmental Kuznets curve, EKC). Denna teori byggde på att miljöförstöringar under en
uppbyggnadsfas blev värre med en ökad inkomst per capita. Detta samband skulle sedan
plana ut och vända, likt en inverterad U-kurva, med ökad inkomst/capita (Perman & Stern
1999, s.7).
Teorin blev snabbt antagen som en viktig del i IMF och världsbankens arbete, där ekonomisk
tillväxt argumenterades ha en i framtiden god effekt på inte bara levnadsstandarden utan
även miljön (Shafik & Bandyopadhyay 1992, s.21). Detta ledde till vida debatt huruvida
teorin kunde finna stöd i verkligheten och diverse modeller utarbetades för att testa för en
EKC
För att styrka alternativt förkasta det tänkta sambandet använde sig vissa av enkel
regression vilket ifall tidsserierna inte är stationära kan ge ekonometriska problem med
felaktiga slutsatser som följd, något som Yule redan år 1926 generellt påvisat. Regressionen
kunde då mycket möjligt utgöra ett rent nonsenssamband, en så kallad spuriös regression
där samband påvisats av en hög förklaringsgrad trots att variablerna i realiteten är
orelaterade. År 1987 publicerade Engle och Granger en formell procedur för att testa om
spuriösitet är ett problem. Detta var kointegrationsanalysens födelse där det empiriskt
kunde testas huruvida sambandet mellan två variabler var statistiskt giltig (Paterson 2000,
s.324-329).
I denna uppsats kommer det med hjälp av kointegrationsanalys utredas huruvida en
Kuznetskurva kan skönjas när sambandet mellan svenska koldioxidutsläpp samt svenskt BNP
granskas för åren 1860-2000. Det kommer även granskas huruvida koldioxidutsläpp och BNP
istället har en linjär långsiktig jämviktsrelation.
De resultat som eventuellt kan styrkas efter denna uppsats är genomförd kan vara relevanta
för både miljövetare och nationalekonomer. Om dessa tidsserier visar på att det finns en
långsiktig jämviktsrelation kan signifikanta förändringar i utsläpp om förändringar i BNP har
inträffat förutspås, detta bör vara av intresse för miljövetare som då kan sätta in

6
förebyggande aktioner före koldioxidutsläppen har hunnit öka. Även det omvända, vilket är
intressant för nationalekonomer, där en förändring i utsläpp kommer leda till en förändring i
BNP kan vara av intresse då stödpaket eller investeringar kan föregå den aktuella
förändringen.
1.2 Syfte
I uppsatsen ska frågan huruvida svenska koldioxidutsläpp samt svenskt BNP per capita följer
någon långsiktig gemensam relation för åren 1860-2000 undersökas. Mer specifikt ska ett
eventuellt Kuznets-samband med kvadratisk trend testas Detta kompletteras även med test
för kointegration med en linjär relation. Som medel för att nå målet kommer tidsserierna att
statistiskt granskas med hjälp av kointegrationsanalys, och villkoren som krävs för denna typ
av analys också att redogöras för. Uppsatsen ämnar alltså med hjälp av kointegrationsanalys
söka svar på om det föreligger någon långsiktig jämviktsrelation mellan koldioxidutsläpp och
ekonomisk tillväxt.
1.3 Metod
För att besvara frågan huruvida det föreligger en långsiktig jämviktsrelation mellan
koldioxidutsläpp och BNP per capita kommer två tidsserier att analyseras. Analysen kommer
att baseras på den inom ekonometrin relativt nya kointegrationsanalysen.
För att kunna utföra undersökningen har befintlig data hämtats från tillförlitliga källor,
redovisade i nästa avsnitt, då egen insamling av data ligger utanför uppsatsens ram. Detta
data set har sedan behandlats i det statistiska mjukvarupaketet Eviews. Eviews är ett
program som främst används för att utföra tidsserieorienterad ekonometrisk analys. Utöver
detta program har även Excel använts för att kunna överföra tidsserierna till Eviews.
Inhämtningen av teori har skett från erkända författare inom kointegrationsanalys och
forskare som tidigare har undersökt Kuznetssambandet.
För att dra slutsatser har de resultat som erhållits från data jämförts med den teori som
använts och tolkats.

7
1.4 Tidigare forskning
Åtskilliga studier har utförts för att utröna huruvida sambandet mellan miljöutsläpp och
inkomst följer det teoretiserade Kuznetssambandet eller om någon annan relation bättre
beskriver den inbördes relationen.
De flesta såsom Cole, Rayner & Bates (1997), Galeottia, Lanzab & Paulic (2006) och Stern &
Common (2001) har främst använt sig av paneldata där en kortare tidsperiod för flera länder
har granskats och dessa sedan integrerats i en sambandsekvation. Detta resonemang bygger
på att försöka hitta en universal vektor som oberoende av var landet befinner sig i
utvecklingskurvan så ska dess utveckling kunna förutsägas med hjälp av andra länders
positioner. Detta skulle ge en väldigt starkt indikation för EKC men är också väldigt
svårverifierbart.
Resultaten i Cole, Rayner & Bates (1997) indikerar en EKC för luftburna lokala föroreningar.
Dock förkastas EKC till förmån för en monotont växande kurva för globala utsläpp såsom
koldioxid. I Stern & Common (2001) så undersöks svaveldioxid och en EKC verifieras för
OECD-länder, dock när alla länder inkluderas visas sambandet vara monotont växande. I
Galeottia, Lanzab & Paulic (2006) granskas koldioxid samt huruvida olika data set (för samma
land) ger samma resultat. De finner att data verkar ge samma resultat, dock verifieras en EKC
främst i OECD-länder.
Hursomhelst så ämnar denna uppsats testa EKC för svenska koldioxidutsläpp i Sverige och då
behöver inte denna universella vektor anpassas. Studier har gjorts även för detta, bland
annat föreslår Perman & Stern (1999) en modell som används i denna uppsats. Denna form
används mer sällan vilket torde kunna bero på att tidsserierna oftast inte sträcker sig över
ett tillräckligt långt tidsintervall.
Denna uppsats använder ovanligt långa tidsserier vilka förhoppningsvis kan täcka det
eventuella EKC-sambandet från industrialismens vagga till dagens it-samhälle, detta skulle
därmed bli ett intressant specialfall.

8
2 Data
2.1 Koldioxidutsläpp
Tidserien för koldioxidutsläpp i Sverige är hämtad från Carbon dioxide information analysis
center, CDIAC, och finns skattad från och med år 1834 med ett estimat per år fram till år
2000. Tidsserien baseras på estimat över förbränningen av fossila bränslen,
cementproduktion samt gas flaring, vilket är då man eldar upp överbliven gas vid borrande
efter olja, där skattningarna före år 1950 baseras på energidata (Mitchell, 1992) och därefter
på FN:s statistiska årsboks energidata (FN, 2009). Dessa har CDIAC sedan med hjälp av
metoden i Marland & Rotty (1984) omvandlat till hur stora koldioxidutsläpp varje
förbrukningsnivå motsvaras av (http://cdiac.ornl.gov/ftp/trends/emissions/swe.dat). Värt att
notera är att förbränning av fossila bränslen, cementproduktion samt gas flaring utgör den
största delen av de antropogena orsakerna till utsläpp av koldioxid men att källor såsom
avskogning inte är försumbara (Brandt & Gröndahl 2000, s.34-35).
Tabell 2.1.1 Deskriptiv statistik för koldioxidutsläpp per capita Variabel Medel Median Min Max Std.dev Skevhet Kurtosis JB
CO2/cap 1032,98 716,27 53,61 3132,30 855,56 0,758 2,446 0,000
I tabell 2.1.1 redovisas deskriptiv statistik över koldioxid serien. Denna serie ser ut att vara
positivt skev då medianens värde är lägre än medelvärdet vilket leder till en lång svans till
höger i fördelningen. Detta påstående bekräftas då man ser skevhets mått som är positivt.
Kurtosis statistikan indikerar att det inte föreligger en normal distribution då den då hade
varit nära tre. För att formellt testa om något är normalfördelat kan Jarque-Beras
normalitetstest användas. Teststatistikan bygger på kurtosiskoeffeicienten som under
normalfördelningen är tre, skevhetskoefficienten som bör vara noll samt stickprovets
storlek. Nollhypotesen säger att data är normalfördelat, så om denna förkastas kan inte
normalitet antas (Guajarati & Porter s132-134). Detta styrks av det låga p-värdet (JB) för
Jarque-Beras test för normaltiet.

9
Graf 2.1.1 Koldioxidutsläpp från 1860-2000
I graf 2.1.1 har koldioxidutsläpp per capita, mätt i kg, plottats mot tiden under perioden
1860 till och med 2000. Kurvan ser ut att vara exponentiell och strikt ökande, med chocker
vid de två världskrigen, fram till år 1970 då koldioxidutsläppen generellt avtar till år 2000.
Detta strukturbrott som inleddes 1970 har försökts förklarats på flera olika sätt. Dels fick
olika biobränslen ett uppsving i början av 70-talet. Men än viktigare var att priset på olja
chockhöjdes under de två oljekriserna, detta fick till följd att det i Sverige upprättades en
politisk målsättning att minska beroendet av fossila bränslen. Målsättningen realiserades till
stor del genom byggandet av kärnkraftverk, mellan år 1972 och 1985 byggdes samtliga
Sveriges reaktorer (Larsson, 2008). På senare år har även klimatdebatten gett olika direkta
politiska målsättningar att minska koldioxidutsläppen (Regeringskansliet 2009). I arbetet
kommer denna variabel att refereras till som koldioxidutsläpp.
2.2 BNP
Tidsserien för Sveriges Bruttonationalprodukt (BNP) kommer ursprungligen från Rodney
Edvinssons avhandling Growth, Accumulation and Crisis (2005, s. 327) men har nu hämtats
från densammes hemsida (http://www.historia.se/tablesAtoX.xls). Här har Sveriges BNP
skattats i fasta och löpande priser samt i per capita, tidsserien är baserad på årsdata. I denna
uppsats kommer BNP i fasta priser med referensår 2000 att användas eftersom det justerar
för inflation (Fregert & Jonung 2003, s. 50). För information om hur skattningarna gått till
0
400
800
1,200
1,600
2,000
2,400
2,800
3,200
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
Koldioxid/capita Kg

10
hänvisas till avhandlingen (Edvinsson 2005, s. 51-97) Även Sveriges befolkningsmängd för per
capita beräkningar är hämtad ifrån Edvinssons avhandling.
Tabell 2.2.1 Deskriptiv statistik för BNP per capita
Variabel Medel Median Min Max Std.dev Skevhet Kurtosis JB
BNP/cap 73804,51 43991,18 11858,22 226926,0 63746,36 0,923 2,393 0,000
I tabell 2.2.1 redovisas deskriptiv statistik över BNP serien. Denna deskriptiva statistik är
mycket lik den för koldioxid, där det även här visat på positiv skevhet och att det inte
föreligger en normalfördelning utifrån kurtosis och JB p-värdet.
Graf 2.2.1 BNP för åren 1860-2000 från användningssidan till mottagarpris
(kronor), volymvärde (referensår 2000)
I graf 2.2.1har BNP per capita till fast pris från användningssidan till mottagarpris (kronor),
för åren 1860-2000 plottats mot tiden. Studeras kurvans utseende ser man att den ser ut att
vara ökande, och möjligen exponentiell, med eventuella strukturella brott vid de två
världskrigen samt runt 1990 på grund av valutakrisen (Fregert & Jonung 2003, s. 249-350).
Generellt har dock BNP utvecklingen efter recessionerna åter ökat enligt samma mönster
fram till och med år 2000. I arbetet kommer denna variabel att refereras till som BNP.
0
40,000
80,000
120,000
160,000
200,000
240,000
1875 1900 1925 1950 1975 2000
BNP/Capita SEK

11
3 Teori
3.1 Inledning
I denna teoridel redovisas en genomgång av de delar som används inom
kointegrationsanalysen. Det redogörs för regression och dess eventuella spuriösitet, de
stationäritetstest som kan utföras redovisas och detta sammanfogas sedan i delen om
kointegration och Engle-Grangers procedur för att testa för icke-kointegration.
3.2 Spuriös korrelation/regression
Spuriös korrelation innebär att två variabler visar på ett statistiskt signifikant samband när
en linjär regressionen utförs men att det i verkligheten inte föreligger något sådant
samband, även kallat nonsenssamband. Detta kan inträffa om två icke stationära tidsserier
används i en regression (Gujarati & Porter 2009, s. 748-762). Att en regression eventuellt är
spuriös kan påvisas genom att 𝑅2-värdet är väldigt högt samtidigt som Durbin-Watson testet
för autokorrelation är nära noll. 𝑅2-värdet kan rentav ses som en slumpvariabel när
tidsserierna inte är stationära och t-statistikan är då missvisande (Paterson 2000, s. 324-
328). En tumregel kan vara att om 𝑅2 > d (Durbin-Watson) när y ska förklaras av x så kan
regressionen vara spuriös. (Gujarati & Porter 2009, s748). Tidsserierna behöver då vidare
granskas för att avgöra huruvida den statistiska inferensen från regressionen är giltig. Om
dessa resultat föreligger i data så är en kointegrationsanalys nästa steg i proceduren för att
avgöra om det föreligger ett giltigt statistiskt signifikant samband, mer om detta nedan.

12
3.3 Stationäritet
Då tidsserier ska analyseras är stationäritet ett centralt begrepp. Det finns olika definitioner
av stationäritet, dels en strikt mer teoretisk och en svag. En stokastisk process är strikt
stationär om den simultana fördelningen är densamma för alla tidpunkter samt lagglängder.
En svagt stationär stokastisk process å andra sidan måste uppfylla följande kriterier:
𝐸(𝑌𝑡) = 𝜇 < ∞ 3.3.1
𝑉(𝑌𝑡) = 𝜎2 < ∞ 3.3.2
𝛾𝑘 = 𝐸[(𝑌𝑡 − 𝜇)(𝑌𝑡+𝑘 − 𝜇)] < ∞ 3.3.3
Detta innebär, enligt punkt ett och två, att de två första momenten dvs. medelvärde och
varians är konstanta över tiden. Punkt tre innebär att kovariansen endast beror av laggens
tidsdifferens det vill säga k men inte t i indexeringen (Patterson 2000, s. 67-68). I denna
uppsats kommer den svaga stationäriteten åsyftas när det refereras till stationäritet.
En tidsserie vars rådata inte befinns vara stationär kan ibland bli mer lätthanterlig med hjälp
av transformationer såsom logaritmering, detta görs enligt följande:
𝑌𝑡 = log (𝑌𝑡)
3.3.4
Differentiering av data kan också åstadkomma stationäritet. Detta kan göras genom att
subtrahera tidigare observationer från tidsserien en eller flera gånger. För att erhålla första
differensen av den loggade tidsserien görs följande:
∆𝑌𝑡 = 𝑌𝑡 − 𝑌𝑡−1 3.3.5
En tidsserie kan även vara stationär kring en deterministisk trend, den är då trendstationär.
Begreppet innebär att medelvärde och varians är konstant runt en positiv eller negativ trend
(Patterson 2000, s. 225-227). I detta arbete kommer deterministisk trend åsyftas till då
termen trend används.

13
3.4 Enhetsrot
En icke-stationär tidsserie som differentieras en gång och då blir stationär kallas integrerad
av ordning ett vilket betecknas I(1). På liknande sätt kallas en tidsserie som differentierats d
gånger för att bli stationär, integrerad av ordning d, I(d). Om stationäritet kan påvisas utan
differentiering betecknas serien I(0). En I(1) har en så kallad enhetsrot och varje tidsserie
som kan göras stationär har åtminstone en enhetsrot. Konceptet om enhetsrot kan
illustreras av AR(1) modellen nedan
𝑌𝑡 = 𝜇 + 𝜙1𝑌𝑡−1 + 𝜀𝑡 3.4.1
Som efter omskrivning
𝑌𝑡−𝜙1𝑌𝑡−1 = 𝜇 + 𝜀𝑡 𝑒𝑙𝑙𝑒𝑟 (1−𝜙1𝐿)𝑌𝑡 = 𝜇 + 𝜀𝑡 𝑑ä𝑟 𝐿𝑌𝑡 = 𝑌𝑡−1 3.4.2
Om denna term (1−𝜙1𝐿)𝑌𝑡 divideras med 𝜙1 och sätts till noll så kallas lösningen för L
ekvationens rot. Om L=1 så förekommer en enhetsrot och serien kan alltså göras stationär
via differentiering men är inte stationär i dess nuvarande form. Här förekommer en
enhetsrot om 𝜙1 = 1 och serien är I(1), om däremot 𝜙1 < 1 så är serien stationär I(0). En
serie kan ha flera enhetsrötter och flera differentieringar kan då krävas för stationäritet,
serien är då I(d). En serie kan även, som tidigare nämnts, vara trendstationär och ekvation
3.4.1 behöver då kompletteras med 𝛽𝑡 där t står för tiden och 𝛽 är tidens påverkan.
Tidsserien är då I(0), vilket gör att trendkomponenten ger problem när tidsserierna
tillsammans analyseras i kointegrationsanalysen (Patterson 2000, s. 220-229).
3.5 Stationäritetstest
För att avgöra huruvida tidsserierna är stationära finns några informella metoder. Först kan
plottad data granskas, detta kan ge en känsla för om den innehåller någon trend eller
förändring i varians. Nästa steg i granskningen är att via autokorrelationsfunktionen (ACF)
granska korrelogrammet. Om tidsserien är stationär ska korrelogrammet uppvisa låga
korrelationer mellan laggarna. Om den däremot är icke-stationär uppvisar den en hög
korrelation som mycket sakta avtar. (Gujarati & Porter 2009, s. 748-753)

14
De formella metoderna utgår från sambandet mellan enhetsrötter och stationäritet, därför
kallas testen för enhetssrotstest. I denna kategori ingår bland annat Dickey-Fuller,
augmented Dickey-Fuller samt Kwiatkowski, Phillips, Schmidt och Shin (KPSS) testen.
3.5.1 Dickey-Fuller test (DF-test)
Dickey-Fuller testet används för att testa för en enhetsrot i tidsserien och tillvägagångssättet
kan anta olika utseende beroende på vad tidsserien antas ha för egenskaper. Det första
steget i Dickey-Fuller test proceduren är att differentiera ekvation 3.4.1
För att kunna utföra testet måste regressioner utföras enligt formlerna 3.5.1-3.5.3, där man
har differentierat ekvation 3.4.1 och då får parametern 𝛾 som är 𝜙1 − 1.
∆ 𝑌𝑡 = 𝛾𝑌𝑡−1 + 𝜀𝑡 Ingen trend (𝛽 = 0) samt medelvärde runt noll (𝜇 = 0) 3.5.1
∆𝑌𝑡 = 𝜇 + 𝛾𝑌𝑡−1 + 𝜀𝑡 Ingen trend (𝛽 = 0) samt medelvärde skiljt från noll (𝜇 ≠ 0) 3.5.2
∆ 𝑌𝑡 = 𝜇 + γ𝑌𝑡−1 + 𝛽𝑡 + 𝜀𝑡 Trend (𝛽 ≠ 0) samt medelvärde skiljt från noll (𝜇 ≠ 0) 3.5.3
Parametern av intresse i samtliga regressioner är 𝛾, där det undersöks om den är signifikant
skiljd från noll via ett t-test. Är den det har man en stationär tidsserie och nollhypotesen om
enhetsrot förkastas. Är den inte det accepteras nollhypotesen och det är en icke-stationär
tidsserie.
Om en trend föreligger i den datagenererande processen så ska kritiska värden beräknas
utifrån detta. Om istället endast intercept eller varken intercept eller trend föreligger så ska
kritiska värden istället beräknas utifrån detta. Dessa kritiska värden har beräknats av Dickey-
Fuller genom Monte Carlo simulering (Patterson 2000, s. 225-237).
Innan testen utförs används en variant av DF-testet för att kunna undersöka om
trendkomponent kan bortses från eller ej. En omarbetad föreslagen procedur för test av
förekomst av trendkomponent finns i figur 3.5.1.

15
Figur 3.5.1 Justerad testprocedur
En procedur för test för enhetsrot
Steg1: Estimera Δ𝑌𝑡 = 𝜇 + 𝛾𝑌𝑡−1 + βt + ∑ 𝑎𝑖Δ𝑌𝑡−𝑖 + 𝜀𝑡𝑝𝑖=1
Nej
Ja: Testa
för trendkomponent
Ja
(Enders 2004, s. 260).
De värden som detta test ger kan inte ge grund för ett beslutsfattande utifrån den vanligtvis
använda t-tabellen utan den t-statistiska som beräknas jämförs med de kritiska värden som
DF beräknat och det kan då dras slutsatser om man förkastar de uppställda hypoteserna
eller ej. I detta arbete kommer en approximering att göras där kritiska värden för 100
observationer används och kan ses i Appendix under rubriken Kritiska värden. Då denna
testprocedur utförts vill man även kunna konfirmera sin slutsats gällande enhetsrotens
förekommande i tidsserien. Detta görs genom att använda de regressionsresultat som
formlen 3.5.1 och 3.5.3 har gett och testar dem enligt följande F-test:
𝜙𝑖 = [𝑅𝑆𝑆(𝑟𝑒𝑠𝑡𝑟𝑖𝑐𝑡𝑒𝑑)−𝑅𝑆𝑆(𝑢𝑛𝑟𝑒𝑠𝑡𝑟𝑖𝑐𝑡𝑒𝑑)]/𝑟𝑅𝑆𝑆(𝑢𝑛𝑟𝑒𝑠𝑡𝑟𝑖𝑐𝑡𝑒𝑑)/(𝑇−𝑘)
3.5.4
Där RSS står för residual sum of squares och är den kvadrerade residualsumman, r betyder
antal restriktioner, T är antalet observationer och k är antal parametrar i den mindre
modellen.
Skulle detta test ge ett icke-signifikant resultat, enligt DF-kritiska värden, accepteras
nollhypotesen, att data är genererat av den större modellen och innehåller en enhetsrot.
Är 𝛾 = 0? Dra slutsatsen ingen enhetsrot
Är β = 0 givet att 𝛾 = 0?
Dra slutsatsen att ingen trend föreligger

16
Skulle nollhypotesen förkastas går man vidare och testar 3.5.2 mot 3.5.3 och ser vilken av
dem som har genererat datat.
Efter att ha undersökt vilken av de tre modellerna som är lämplig att anta att tidsserien är
baserad på så undersöker man sin 𝛾 statistika med hjälp av DF-kritiska värden och ser om
den är skild från noll och drar därifrån slutsatsen om serien innehåller en enhetsrot eller
inte. (Gujarati&Porter 2009, s. 893)
3.5.2 Augmented Dickey-Fuller test
Det utökade Dickey-Fuller testet har uppkommit för att kunna utföra Dickey-Fuller testet
trots korrelation mellan feltermerna. Ekvationen som används för ADF-testet ges i ekvation
3.5.5.
Δ𝑌𝑡 = 𝜇 + 𝛾𝑌𝑡−1 + ∑ 𝑎𝑖Δ𝑌𝑡−𝑖 + 𝜀𝑡𝑝𝑖=1 3.5.5
Skillnaden från DF är att laggar har tagits med för korrigeringen för korrelation mellan
feltermer. Hur många laggar som används kan bestämmas av Hannan-Quinn’s
informationskriterium, som är bäst lämpad för stora stickprov, mer om detta i avsnitt 3.5.7.
Precis som i det ursprungliga DF-testet är det parametern 𝛾 som är av intresse och dess t-
värde jämförs med de kritiska värden som Dickey-Fuller har erhållit via Monte Carlo
simulering. Vid ett icke-signifikant resultat accepteras nollhypotesen och man kan inte
förkasta påståendet att serien har en enhetsrot. Vid förkastning av nollhypotesen drar man
slutsatsen att serien är stationär (Patterson, 2000, s. 238-241)
3.5.3 Svagheter med Dickey-Fullers test
Dickey-Fuller testen har ibland kritiserats för att ha låg styrka, vilket innebär att
nollhypotesen för ofta blir accepterad när den egentligen ska förkastas. Det finns ett flertal
orsaker till detta, en av dem är att testets styrka beror på tidsspannet där ett test
innehållande 30 observationer över 30 år har högre styrka än 100 observationer under 100
dagar. En annan orsak är att när koefficienten 𝑌𝑡−1 är nära ett men inte exakt ett så kan
testet visa att den är icke-stationär när så inte är fallet. Även att testet antar att serier är I(1)

17
och inte testar för integrering av högre ordning har framförts som kritik (Gujarati & Porter,
2009, s. 759).
Ett annat problem som redan behandlats och som kan uppstå när DF-testen används är vid
modellspecifikationen. Eftersom alla tre modeller har olika kritiska värden så innebär det, till
exempel, att om modell två används när det egentligen är modell ett som bör användas så
undersöks teststatistikan utifrån felaktiga grunder. Vilket givetvis kan leda till direkt
felaktiga slutsatser.
3.5.4 KPSS test
KPSS Kwiatkowski, Phillips, Schmidt och Shin (1992) testet skiljer sig från övriga test i att
nollhypotesen säger att serien är stationär. KPSS test är tänkt att vara ett komplement till
enhetsrotstest, så som det tidigare nämnda DF-testet.
Teststatistika:
𝐾𝑃𝑆𝑆 = ∁�′𝑉∁�/(𝑛2𝜎�∁∁2 ) 3.5.6
Har nollhypotes och mothypotes då man inkluderat intercept
H0: Tidsserien är stationär
HA: Tidsserien är icke-stationär
Om man istället väljer att inkludera trend och intercept i testets utförande får man
nollhypotesen att tidsserien är stationär kring en trend och samma mothypotes som innan.
Detta innebär även andra förkastelsegränser.
Residualerna ∁�, i 3.5.6, är beräknade utifrån en regression utförd på Y där regressionen
antingen beräknas med endast intercept eller både intercept och trend och 𝜎�∁∁2 beräknas ur
stickprovet som ett viktat medelfel, n är antalet observationer och V är en
multiplikationsmatris baserad på antal observationer (Patterson 2000, s. 268-270). Kritiska
värden för teststatistikan finns rapporterade i D. Kwiatkowski et al. 1992, ”Testing the null
hypothesis of trend stationarity”.

18
Genom att testa både enhetsrotshypotesen och stationäritetshypotesen kan man urskilja
serier som uppvisar stationäritet och serier som visar på enhetsrot. Utöver de omvända
hypoteserna är den huvudsakliga fördelen med KPSS testet är att det tillåter autokorrelation
i feltermen (Kwiatkowski D. et al., 1992).
3.5.5 Hannan-Quinn informationskriterium
När exempelvis det utökade Dickey-Fuller testet utförs inkluderas vissa laggar för att undvika
felaktig inferens vid autokorrelation. Att välja denna lagglängd kan göras manuellt eller med
hjälp av olika informationskriterier. Enligt Liew (2004) så är Hannan-Quinn det
informationskriterium som bäst väljer antalet laggar när stickprovet är större än 120, vilket i
denna uppsats är fallet.
𝐻𝑄𝐶 = 𝑛 ∗ 𝑙𝑛 �𝑅𝑆𝑆𝑛� 2𝑘 ∗ 𝑙𝑛 𝑙𝑛(𝑛) 3.5.7
Där n står för antalet observationer, RSS är residualernas kvadratsumma från en linjär
regression och k är antalet estimerade parametrar.
3.6 Kointegration
Ett sätt att komma tillrätta med och kunna dra inferens från en regression med två
ickestationära tidserier av samma ordning är att testa om de är kointegrerade, om så är
fallet kommer regressionen inte längre vara spuriös. Men vad innebär kointegration och hur
kan det testas om sådan föreligger?
En linjärkombination av stationära tidsserier är stationär och en linjärkombination av
ickestationära tidsserier är generellt ickestationär. Om linjärkombinationen av två
ickestationära tidsserier istället är stationär sägs serierna vara kointegrerade. Ett sätt att kort
beskriva en kointegrerad serie är, parallellt med tidigare resonemang, via CI(d,b) där d är den
gemensamma integrationsordningen I(d) och b beskriver kointegrationsordningen. I(1)
variabler som via kointegration blir stationära betecknas därmed CI(1,1). (Patterson 2000, s.
69 & 329).

19
Linjärkombinationer av icke stationära tidsserier som eventuellt är kointegrerade kan
illustreras av ekvation 3.6.1 nedan
𝜑1𝑌𝑡 − 𝜑2𝑋𝑡 = 𝜁𝑡 3.6.1
Där 𝜑1 och 𝜑2 är kointegrationskoefficienterna som kan reducera ekvationen till
stationäritet. Ekvation 3.6.1 normaliseras vanligtvis för ena variabeln genom att dividera
ekvationen med dess kointegrationskoefficient, exempelvis 𝜑1. Ekvationerna kan även
uttryckas i vektorform enligt:
(𝜑1 − 𝜑2) �𝑌𝑡𝑋𝑡� = 𝜁𝑡~ 𝐼(0) 3.6.2
Där 𝜁𝑡~ 𝐼(0) indikerar att 𝑌𝑡 och 𝑋𝑡 är kointegrerade. Om tidsserierna är kointegrerade så
implicerar den normaliserade kointegrationskombinationen den giltiga regressionen:
𝑌𝑡 = 𝜑1 + 𝜑2𝑋𝑡 + 𝜉𝑡 𝑑ä𝑟 𝜉𝑡 = 𝜁𝑡 − 𝜑1 3.6.3
Om 𝑌𝑡 och 𝑋𝑡 istället inte är kointegrerade så kommer parametern 𝜑2 i
kointegrationsekvationen 3.6.3 att vara noll. Detta medför att denna ekvation är I(1). Ett
annat alternativ är om någon variabel 𝑧 inte har inkluderats och ekvationen därmed är
underspecificerad. Om 𝑧 är I(1) kommer även slumptermen att vara det, även om 𝑌𝑡 och 𝑋𝑡
är kointegrerade (Patterson 2000, s. 330).
Om variablerna 𝑌𝑡 och 𝑋𝑡 båda är ickestationära I(1) så är alltså generellt en
linjärkombination av dem också I(1). Om de istället tillsammans i
kointegrationskombinationen är I(0) så är de kointegrerade och regression med variablerna
kan utföras med hjälp av OLS. Detta kan mer konkret illustreras med att om 𝑌𝑡 och 𝑋𝑡 delar
en liknande stokastistisk trend så att de på lång sikt följer varandra kan de två I(1)
processerna vara sammanlänkande med en gemensam långsiktig jämvikt. De kommer då att
följa varandra och gå tillbaka till detta långsiktiga jämviktsläge. Regressionen kommer då inte
att vara ett nonsenssamband trots att tecken på ett sådant påvisas (Patterson 2000, s. 328-
330).

20
3.6.1 Engle-Granger test för icke kointegration
Denna procedur kom Engle-Granger på 1987 och kallas ofta EG. Engle-Granger metoden
testar om två eller flera tidsserier av samma integrationsordning inte är kointegrerade.
Första steget är att bestämma tidsseriernas integrationsordning vilket kan göras med de
tidigare nämnda enhetsrottesten. Om serierna är av samma integrationsordning kan man
fortgå med Engle-Grangers test där nästa steg är att granska feltermen, 𝜉𝑡� . I regressionen
nedan som skattas med hjälp av OLS antas ett enkelt linjärt jämviktssamband med intercept
föreligga men även andra samband med modellerande av residualerna, 𝜉𝑡� , kan tänkas:
𝑌𝑡 = 𝜑�1 + 𝜑�2𝑋𝑡 + 𝜉𝑡� 3.6.4
Om 𝜉𝑡�~𝐼(1) i ekvationen ovan så kommer som tidigare påpekats heller inte 𝑌𝑡 och 𝑋𝑡 att
vara kointegrerade. Detta kan exempelvis testas med Dickey-Fuller’s test enligt:
𝜉𝑡 = 𝜑1𝜉𝑡−1 + 𝑢𝑡 3.6.5
Där 𝜑1 = 1 indikerar att serierna inte är kointegrerade. Eller så kan det mer generella ADF-
testet som tidigare beskrivits användas enligt:
Δ𝜉𝑡 = 𝛾𝜉𝑡−1 + ∑ 𝑎𝑖Δ𝜉𝑡−1 + 𝑢𝑡𝑝𝑖=1 3.6.6
Denna ekvation kallas ibland CRADF(p).
Nollhypotesen i båda testen är formulerad som att kointegration inte föreligger, det vill säga
att 𝜑1 = 1, eller 𝛾 = 0, och att serien därmed inte är I(0). Om däremot nollhypotesen
förkastas påvisar Engle-Granger-metoden stöd för altenativhypotesen om att den form av
kointegration som har valts att testa mellan tidsserierna föreligger. Teststatistikans
distribution följer ingen standarddistribution och erhålls därmed, likt tidigare test, via
simulering alternativt via McKinnons hemsida där det finns rapporterade simulerade värden.
Det ska också poängteras att de följande kritiska värdena skiljer sig från tidigare DF-test så
länge koefficienterna 𝜑1 och 𝜑2 är okända och behöver skattas (Patterson 2000, s. 330-
334).

21
3.7 Kuznetskurvan
Den tidigare nämnda teorin om Kuznetskurvan där miljöförstöringar antas öka inledningsvis
under ett lands utvecklingsperiod för att sedan avta när landets ekonomi växt tillräckligt
mycket. För att kunna testa om datat följer det teoretiska Kuznetssambandet finns olika
ekvationer att använda sig utav. En i litteraturen vanligt förekommande är illustrerad i
ekvation 3.7.1.
𝑙𝑛 �𝑈𝑃�𝑡
= 𝛾 + 𝛽1𝑙𝑛 �𝐵𝑁𝑃𝑃�𝑡
+ 𝛽2 �𝑙𝑛 �𝐵𝑁𝑃𝑃��𝑡
2+ 𝜀𝑡 3.7.1
Där U benämner ett kvantifierat mått på miljöförstöring, P är befolkningens storlek och 𝛾 ett
intercept. Den sista variabeln BNP är ett mått på landets inkomst. Denna är även med i
kvadrerad form för att kunna beskriva den inverterade U-kurvan. En deterministisk trend
skulle även kunna inkluderas i modellen ovan om det i data finns stöd för en sådan (Perman
& Stern 1999, s. 12). Om paneldata skulle användas och kurvan skulle generaliseras över
flera olika länder skulle även ett landspecifikt intercept samt indexering behövas, något som
här inte är aktuellt.
För att kunna testa detta tänkta samband för statistisk signifikans används den tidigare
nämnda Engle-Granger metoden. Där första steget är att bestämma de ingående
variablernas integrationsordning. Om alla variabler är integrerade av samma ordning kan
därefter i nästa steg regressionen i ekvation 3.7.1 anpassas. Noterbart är att i
Kuznetsekvationen så består inte längre ekvationen enbart utav linjära variabler, en
kvadrerad BNP term har också inkluderats för att kunna beskriva den tänkta inverterade U-
kurvan.
I sista steget testas modellens residualer i enlighet med ekvation 3.6.6 . Teststatistikans
distribution och därmed de kritiska värdena antas följa samma fördelning som McKinnon har
beräknat kritiska värden för och som tidigare nämnts i del 3.6.1, se
http://www.econ.queensu.ca/faculty/mackinnon/. Ett signifikant resultat skulle innebära att
serien inte har en enhetsrot. I enlighet med tidigare resonemang tolkas detta som att
residualerna är stationära, det går därmed att förkasta att de ingående variablerna inte är
kointegrerade enligt det definierade Kuznetssambandet.

22
4 Resultat
4.1 Spuriös regression
En enkel linjär regression med BNP samt intercept som förklarande variabel till
koldioxidutsläpp utfördes. Förklaringsgraden, 𝑅2, var ca 85 % vilket får anses vara väldigt
högt. Då t-värdet för BNP koefficienten och interceptet granskas visar de sig vara signifikanta
för modellen, vilket är ett positivt tecken för regressionen. Dock är Durbin-Watson
statistikan 0,20 vilket dels indikerar positiv autokorrelation men framförallt så är den
betydligt lägre än förklaringsgraden. Något som tidigare benämnts i teoridelen som en
tumregel för att misstänka att regressionen är spuriös. Då regressionen utfördes enligt
Kuznetssambandet, synligt i ekvation 3.7.1, erhölls än mer tydliga resultat på spuriös
regression, 𝑅2 visade sig vara 93 % och DW-statistikan var 0,45. Regressionsresultaten kan
ses i Appendix under rubriken Spuriös regression. Tidsserierna bör därför var för sig testas
för stationäritet för att kunna gå vidare med kointegrationsanalysen.
4.2 Stationäritet & enhetsrottest
Delen om stationäritet och enhetsrottest inleds, likt teorin förespråkar, med en informell
grafisk tolkning av serierna och dess korrelogram. Detta för att sedan kompletteras med de
formella testerna för stationäritet. För samtliga serier har DF-testet kompletterats med ADF-
testet då granskningen av korrelogramen av residualerna inte gav ett tydligt svar på huruvida
det föreligger autokorrelation mellan feltermerna eller ej. Dessa korrelogram kan beskådas i
Appendix.

23
4.2.1 Logaritmerad koldioxiddata
Graf 4.2.1 Logaritmerade Koldioxidutsläpp från 1860-2000
Då graf 2.1.1 visade att koldioxidutsläpp inte såg ut att uppfylla de tre villkoren för
stationäritet användes ekvation 3.3.4 för att se om en logaritmering av tidsserien kunde leda
till en stationär serie. Resultatet av detta ses i graf 4.2.1 där en stabilare tidsserie erhållits
men stationäritetsvillkoren, gällande konstant medelvärde, varians och kovarians endast
beroende på lagglängd, fortfarande inte ser ut att vara uppfyllda. Detta då grafen visar en
konstant uppåtgående kurva vilket indikerar att det inte finns ett konstant medelvärde i
tidsserien. Då korrelogrammet granskades uppvisade det en inledningsvis hög korrelation
som sakta minskade vilket, enligt teorin, indikerar på att det är en icke-stationär tidsserie.
För att kunna avgöra huruvida denna tidsserie innehåller en trend eller inte utfördes
testproceduren i figur 3.5.1. Detta gav i första steget ett resultat som tydde på en enhetsrot i
tidsserien. Vi gick då vidare för att testa om trendkomponenten hade någon signifikant
inverkan på resultaten. Det visade sig att den inte var signifikant och vi kunde dra slutsatsen
att tidsserien inte verkar innehålla någon trendkomponent. För att ytterligare konfirmera
detta resultat användes ekvation 3.5.4 där vi testade regressionerna 3.5.1 och 3.5.3 mot
varandra, detta gav ett resultat som tyder på enhetsrot och ingen trend. För vidare testande
av dessa resultat har en interceptterm inkluderats då det i grafen kan skådas en
uppåtgående kurva och vi har fastställt att den inte beror på en trend.
3
4
5
6
7
8
9
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
Log Koldioxid/capita Kg

24
Antalet laggar i samtliga test valdes enligt Hannan-Quinn informationskriteriet då det, som
nämnt i teori avsnitt 3.5.7, är det som förutser det mest korrekta antalet laggar vid stora
stickprov.
Efter att ha utfört DF-testet på tidsserien visade detta test att nollhypotesen om förekomst
av enhetsrot inte kan förkastas, därmed kan det inte påvisas att tidsserien är stationär.
Efter att ha utfört ADF-testet så kan nollhypotesen om en enhetsrot inte förkastas och
ytterligare ett resultat stödjer att rådata är icke-stationär.
För att få ytterligare stöd till de tidigare resultaten har även KPSS-testet använts. Som
beskrivet i teoridelen har KPSS-testet omvända hypoteser jämfört med DF- och ADF-testen
och ger alltså ett resultat som ytterligare kan styrka tidigare resultat. I detta fall kan
nollhypotesen om stationäritet förkastas på 5% signifikansnivå och indikationer har funnits
för att denna tidsserie har en enhetsrot och är icke-stationär.
Resultaten från samtliga test och korrelogramet kan skådas i Appendix under logaritmerad
BNP per capita.
25
4.2.2 Logaritmerad differentierad koldioxiddata
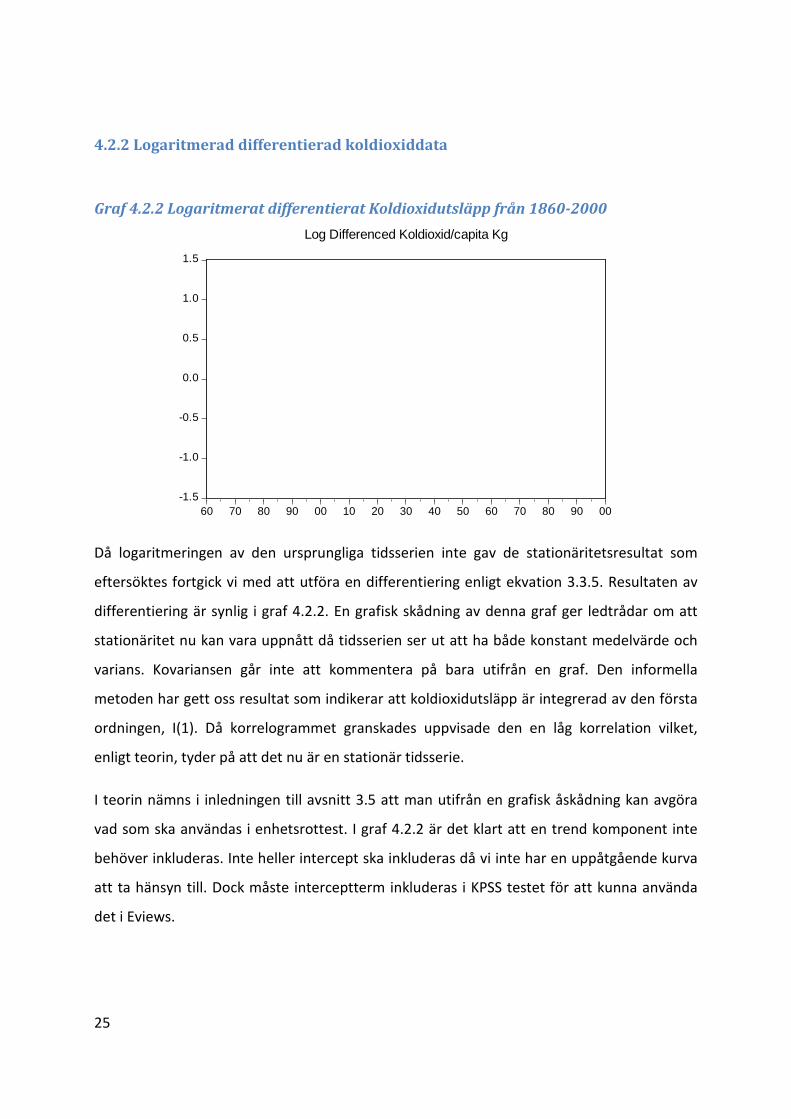
Graf 4.2.2 Logaritmerat differentierat Koldioxidutsläpp från 1860-2000
Då logaritmeringen av den ursprungliga tidsserien inte gav de stationäritetsresultat som
eftersöktes fortgick vi med att utföra en differentiering enligt ekvation 3.3.5. Resultaten av
differentiering är synlig i graf 4.2.2. En grafisk skådning av denna graf ger ledtrådar om att
stationäritet nu kan vara uppnått då tidsserien ser ut att ha både konstant medelvärde och
varians. Kovariansen går inte att kommentera på bara utifrån en graf. Den informella
metoden har gett oss resultat som indikerar att koldioxidutsläpp är integrerad av den första
ordningen, I(1). Då korrelogrammet granskades uppvisade den en låg korrelation vilket,
enligt teorin, tyder på att det nu är en stationär tidsserie.
I teorin nämns i inledningen till avsnitt 3.5 att man utifrån en grafisk åskådning kan avgöra
vad som ska användas i enhetsrottest. I graf 4.2.2 är det klart att en trend komponent inte
behöver inkluderas. Inte heller intercept ska inkluderas då vi inte har en uppåtgående kurva
att ta hänsyn till. Dock måste interceptterm inkluderas i KPSS testet för att kunna använda
det i Eviews.
-1.5
-1.0
-0.5
0.0
0.5
1.0
1.5
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
Log Differenced Koldioxid/capita Kg

26
För att testa om stationäritet har uppnåtts efter en differentiering av serien har i första
steget DF-testet använts. Detta test visar att nollhypotesen om en enhetsrot förkastas och
man har funnit indikationer för att serien inte längre innehåller en enhetsrot.
Då ADF-testet utfördes på den logaritmerade differentierade BNP serien så ger den ett
resultat som överensstämmer med DF-testets förkastande av nollhypotesen. ADF testet ger
ett signifikant resultat och man kan förkasta nollhypotesen om enhetsrot och dra slutsatsen
att stationäritet föreligger.
Som i tidigare fall har KPSS-testet använts för att ytterligare ge styrka åt tidigare resultat. I
detta fall är en acceptering av nollhypotesen önskvärt och det är det resultatet har visat.
Efter de tre testen har resultaten lett till att vi har dragit slutsatsen att tidsserien
logaritmerad koldioxid är stationär efter en differentiering, alltså en I(1) process. Dessa
resultat och korrelogram kan ses i Appendix under rubriken differentierad logaritmerad
koldioxid per capita.
Tabell 4.2.1 Koldioxid per capita Variabel Medel Median Min Max Std.dev Skevhet Kurtosis JB
CO2/cap 1032,98 716,27 53,61 3132,30 855,56 0,758 2,446 0,000
LogCO2/cap 6,472 6,574 3,982 8,050 1,100 -0,542 2,291 0,007
Logd(CO2/cap) 0,0240 0,0257 -1,0168 1,3269 0,2048 0,2348 20,3119 0,000
I tabell 4.2.1 redovisas deskriptiv statistik över de transformerade serierna av koldioxid och
JB p-värdet visar att datat inte är normalfördelat.

27
4.2.3 Logaritmerad BNP data
Graf 4.2.3 Logaritmerad BNP från 1860-2000
Då tidsserien för BNP per capita i graf 2.2.1 logaritmerades så såg inte heller den ut att
uppfylla villkoren för stationäritet. Serien, som kan ses i graf 4.2.3, blev betydligt mycket mer
linjär men med en tydlig positiv trend som i sig motsäger villkoret om konstant medelvärde.
Då korrelogrammet granskades uppvisade den en inledningsvis hög korrelation som saktade
minskade vilket, enligt teorin, tyder på att det är en icke-stationär tidsserie.
För att kunna avgöra huruvida denna tidsserie innehåller en trend eller inte så utfördes
samma testprocedur som för den logaritmerade koldioxidserien, enligt figur 3.5.1. Detta gav
resultat som ledde till samma slutsatser, serien innehåller en enhetsrot men ingen
trendkomponent. Även i detta test konfirmerades resultatet med ett F-test mellan ekvation
3.5.1 och 3.5.3 och vid jämförande av detta framräknade värde med DF-kritiska värde så ger
det ett resultat som ytterligare indikerar att serien innehåller enhetsrot och inte innehåller
trend. Resultat och kritiska värden för detta test finns rapporterat i Appendix. För vidare
testande av dessa resultat har en interceptterm inkluderats då det i grafen kan skådas en
uppåtgående kurva och vi har fastställt att den inte beror på en trend.
Återigen har antal laggar i samtliga test valts enligt Hannan-Quinn´s informationskriterium av
tidigare nämnda anledningar. Efter att ha utfört DF-testet på tidsserien logaritmerad BNP
9.2
9.6
10.0
10.4
10.8
11.2
11.6
12.0
12.4
1875 1900 1925 1950 1975 2000
Log BNP/Capita SEK

28
visade detta test att nollhypotesen om icke-stationäritet inte kan förkastas och det kan inte
visas att tidsserien är stationär. Efter att ha utfört ADF-testet, där nollhypotesen är att serien
innehåller en enhetsrot; så kan nollhypotesen om en enhetsrot inte förkastas och ytterligare
ett resultat stödjer alltså att den logaritmerade BNP-serien är icke-stationär.
Även KPSS-testet användes och i detta fall kan nollhypotesen om stationäritet förkastas på
5% signifikansnivå vilket indikerar att denna tidsserie har en enhetsrot och är icke-stationär.
Sammanfattningsvis visar resultaten att tidsserien BNP är icke-stationär och innehåller en
enhetsrot. I nästa avsnitt testas om en differentiering kan åstadkomma stationäritet.
Resultaten från samtliga test och korrelogramet kan ses i Appendix under rubriken
Logaritmerad BNP per capita.

29
4.2.4 Logaritmerad differentierad BNP data
Graf 4.2.4 Logaritmerad differentierad BNP från 1860-2000
I graf 4.2.4 har den logaritmerade serien även differentierats en gång. Den ser då ut att
uppvisa drag såsom konstant medelvärde och varians vilket skulle kunna implicera att
tidsserien är stationär efter differentiering, I(1). Då korrelogrammet granskades uppvisade
den en låg korrelation vilket, enligt teorin, tyder på att det nu är en stationär tidsserie.
I graf 4.2.4 är det klart att en trend komponent inte ska inkluderas. Inte heller intercept ska
inkluderas då vi inte har en uppåtgående kurva att ta hänsyn till. Dock måste interceptterm
inkluderas i Eviews procedur för KPSS testet för att kunna använda det.
För att testa om stationäritet har uppnåtts efter en differentiering av serien har i första
steget DF-testet använts. Detta test visar att nollhypotesen om en enhetsrot förkastas och
resultatet tyder på att den differentierade BNP serien är stationär.
Då ADF-testet utfördes på den logaritmerade differentierade BNP serien så ger den ett
resultat som överensstämmer med DF-testets förkastande av nollhypotesen. ADF testet ger
ett signifikant resultat och man kan förkasta nollhypotesen om enhetsrot och dra slutsatsen
att stationäritet föreligger. Som i tidigare fall har KPSS-testet använts för att ytterligare ge
-.20
-.15
-.10
-.05
.00
.05
.10
.15
.20
1875 1900 1925 1950 1975 2000
Log Differenced BNP/Capita SEK

30
styrka åt tidigare resultat. I detta fall är en acceptering av nollhypotesen önskvärt, vilket
också är det som har erhållits.
Efter att tre test utförts har samtliga resultat visat att tidsserien logaritmerad BNP är
stationär efter en differentiering, alltså en I(1) process. Även den serie som kommer
användas till Kuznetssambandet, kvadrerad BNP, har efter testande visat resultat som leder
till slutsatsen att det också är en I(1) process. Resultaten av testen av denna serie redovisas i
Appendix under rubriken Kvadrerad BNP per capita.
Resultaten från samtliga test och korrelogramet kan ses i Appendix under rubriken
differentierad logaritmerad BNP per capita.
Tabell 4.2.2 BNP per capita Variabel Medel Median Min Max Std.dev Skevhet Kurtosis JB
BNP/Cap 73804,51 43991,18 11858,22 226926,0 63746,36 0,923 2,393 0,000
LN(Bnp/cap) 10,822 10,692 9,381 12,332 0,899 0,178 1,697 0,005
(Ln(BNP/cap)d 0,020 0,024 -0,150 0,160 0,040 -0,994 7,436 0,000
I tabell 4.2.2 redovisas deskriptiv statistik över de transformerade serierna av koldioxid och
JB p-värdet visar att datat inte är normalfördelat.

31
4.3 Engle-Grangers test för icke kointegration
Då de båda tidsserierna, efter de test som har utförts, visat sig vara I(1), stationära efter en
differentiering, betyder det att det villkor som nämns i 3.6.1 är uppfyllt och man kan fortgå
med Engle-Grangers test för icke kointegration. Det vi ämnar testa för i denna sektion är om
det föreligger någon långsiktig jämviktsrelation mellan koldioxidutsläpp och BNP. Först
testas ett linjärt kointegrationssamband, därefter testas även det kvadrerade sambandet
som har som syfte att illustrera det eventuella Kuznets-sambandet.
För att testa om ett linjärt samband i kointegrationsekvationen föreligger mellan
koldioxidutsläpp och BNP användes regressionen i 3.6.4 med skillnaden att tidsserierna
logaritmerats enligt tidigare forskning.
Graf 4.3.1 Residualer från regression med intercept och linjär trend
I figur 4.3.1 ovan har residualerna från denna regression plottats, de visar inga tecken på att
innehålla någon trend, däremot fluktuerar residualerna en del.
Dessa residualer testades sedan för enhetsrot med hjälp av ADF-testet i ekvation 3.6.6.
Dessa testresultat används sedan för att jämföras med Mckinnons kritiska värden för test av
kointegration. Då trend inte ansågs förekomma efter den grafiska skådningen exkluderades
den från testfunktionen. Resultatet visar på att residualerna inte har enhetsrot enligt Dickey-
Fuller kritiska värden. Detta betyder dock inte att indikationer för kointegration har funnits
då det är olika kritiska värden för test av enhetsrot och test för kointegration. Vi kan inte
-1.6
-1.2
-0.8
-0.4
0.0
0.4
0.8
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
RESIDINTBNP

32
förkasta nollhypotesen om icke-kointegration. Testresultaten finns redovisade i Appendix
under rubriken Modell med linjär trend.
Detta innebär att vi inte har funnit stöd för att dessa serier kointegrerar enligt ett linjärt
samband men att regressionens residualer är stationära enligt ADF-testet.
Graf 4.3.2 Linjär regression med faktiska och anpassade värden
I graf 4.3.2 skådas de linjära regressionsresultaten där den röda linjen visar de faktiska
värdena och den gröna visar de anpassade. Den faktiska regressionen visar på en konstant
uppåtgående kurva, med två chocker, fram till och med ca år 1975 då kurvan avtar och
istället ser ut att påbörja nedåtgående trend.
Även det tänkta Kuznetssambandet, enligt ekvation 3.7.1, med en kvadrerad BNP term som
tillägg till ovan nämnda regression testades för kointegration. Denna kvadrerade BNP term
har testats för att bekräfta att den är I(1) för att kunna fortgå med kointegrationsanalysen.
Testresultaten visade entydigt att kvadrerad BNP är I(1). Resultaten av dessa test kan ses i
Appendix.
3
4
5
6
7
8
9
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
Fitted Actual

33
Graf 4.3.3 Residualer från linjär och kvadratisk modell
I Graf 4.3.3 ovan har residualerna från Kuznets-regressionen, med den kvadrerade BNP-
termen inkluderad, plottats. De visar inte heller här några tecken på att innehålla någon
trend, och de fluktuerar runt lägre värden än i den linjära modellen.
Residualerna testades för enhetsrot med hjälp av det utökade Dickey-Fuller testet i ekvation
3.6.6. Då trend inte verkade vara ett problem exkluderades den även här från
testfunktionen. Resultatet visar på att man kan förkasta nollhypotesen om enhetsrot och vi
har funnit stöd för att serien inte innehåller en enhetsrot då man jämför med McKinnons
kritiska värden. Testresultaten finns redovisade i Appendix.
I och med dessa resultat kan vi förkasta nollhypotesen om att koldioxidutsläpp och BNP inte
kointegrerar och vi har funnit stöd för att dessa serier kointegrerar enligt ett kvadrerat
samband som illustrerar det tänka Kuznetssambandet.
-2.0
-1.5
-1.0
-0.5
0.0
0.5
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
RESIDINTBNPBNP2

34
Graf 4.3.4 Kvadrerad regression
I graf 4.3.4 kan resultaten från den kvadrerade regressionen ses där den gröna linjen
representerar den anpassade regressionen och den röda är de faktiska värdena. Här ser
man, i enlighet med graf 4.3.2, en uppåtgående kurva fram till och med ca 1975 där den
upphöjda BNP termen i regressionen ser ut att ta över och påbörja en sväng nedåt och då
visa det tänkta inverterade U:et som eftersöks. Dock skulle en längre tidsserie behövas för
att se vart detta samband leder, det går inte att dra definitiva slutsatser om framtiden
utifrån endast detta.
3
4
5
6
7
8
9
60 70 80 90 00 10 20 30 40 50 60 70 80 90 00
FITTED ACTUAL

35
5 Analys Resultatet av den genomförda Engle-Granger proceduren gav ett resultat som möjliggjorde
att man kunde förkasta att koldioxidutsläpp och BNP inte var kointegrerade enligt ett
kvadratiskt samband. Detta betyder att stöd erhållits för att dessa båda serier följer varandra
enligt en långsiktig jämviktsrelation i likhet med den av Kreugmann & Grossman framlagda
teorin om miljökuznetskurvan. En relation som vid en första granskning kunde tyckas vara
spuriös men efter den genomgångna Engle-Granger istället befanns giltig. I och med detta
kan det på annat än spekulativ basis bestämmas vilket samband som bäst representerar de
två tidsseriernas inbördes relation, Kuznetssambandet verkar bättre representera
sambandet mellan svenska koldioxidutsläpp och svensk BNP än vad ett linjärt samband gör.
Detta kan vid en första tanke verka som ett något konstigt resultat med tanke på hur
graferna 4.3.2 samt 4.3.4 ser ut men även med tanke på resultat från tidigare studier som
ofta påvisat ett monotont ökande samband. Trots detta torde dock några relativt rimliga,
alternativa förklaringar kunna ges till att ett monotont växande samband inte kan styrkas
samt att den inverterade U-kurvan inte riktigt tagit form men ändå kan styrkas.
Denna uppsats finner alltså stöd för att koldioxid och BNP följer Kuznetsekvationen. Dock är
troligtvis tidpunkten när trenden vänder allt för nära nutid för att fullt kunna åskådliggöra
den tänkta inverterade U-kurvan. Tidsperioden med avtagande koldioxidutsläpp består av
endast en femtedel av tidsserien och utgör därmed helt enkelt en så liten del av den totala
perioden att nedgången i koldioxid ännu inte riktigt fått full effekt. Vi tror att om samma
undersökning utförs år 2050, med samma utveckling som idag och med de senaste trettio
årens utveckling i åtanke, så skulle sambandet tydligare kunna skådas grafiskt och avsevärt
skilja sig från det monotont växande sambandet. Denna tanke borde vara rimlig med tanke
på dagens fokus på att reducera koldioxidutsläppen från samhället.
Dock kan inte alternativa synsätt negligeras. Ett annat alternativ är att sambandet i själva
verket är monotont växande med temporär nedgång under de senaste 30 åren. Detta går
inte att utesluta men känns samtidigt en aning långsökt då minskningen av koldioxidutsläpp
de senaste trettio åren skett successivt. Den utlösande faktorn var säkerligen att oljan blev
dyrare i och med oljekrisen men sedan stadgades det snarare som ett långsiktigt politiskt
mål att minska oljeberoendet och därmed koldioxidutsläppen. Detta implementerades i ett

36
första steg med hjälp av kärnkraftens utbyggnad men har senare gått vidare till mer specifika
koldioxidreducerande åtgärder. Att koldioxidutsläpp per capita inom Sveriges gränser åter
skulle öka finns ingen direkt anledning idag att anta. Sverige vill minska den, har minskat den
och så kommer det mest troligt att fortgå med dagens klimatdebatt i åtanke. Detta skulle
innebära att den monotont växande kurvan varit den gällande men då koldioxidutsläppen
minskat de senaste åren generar att en monotont växande kurva inte kan styrkas.
Ett lite alternativt spekulativt synsätt, dock inte heller orimligt, skulle vara att
koldioxidutsläppen som har sin grund inom Sveriges gränser följer Kuznetssambandet men
att svenskarnas sammanlagda koldioxidutsläpp, om man räknar till vad vi konsumerar,
fortfarande är monotont växande. Där vi med ökad inkomst per capita gått till en annan fas i
utvecklingen. En fas där den svenska arbetskraften inte längre främst sysselsätter sig inom
tillverkningsindustrin utan snarare inom olika tjänstesektorer som inte släpper ut lika mycket
föroreningar. Detta skulle kunna vara ett argument för att Kuznetssambandet bör testas
med paneldata för många länder när det som i detta fall gäller föroreningar som är globala i
sin natur.
Stöd har alltså funnits för att koldioxid och BNP serierna följer varandra i en långsiktig
jämviktsrelation där orsak-verkan modeller dem emellan inte utgörs av en nonsensrelation.
En förespråkare för att Sverige är ett energieffektivt, miljövänligt föregångarland kan välja
att dra slutsatser utifrån sambandet som visades i graf 4.3.4 och hävda att Sverige kan
fortsätta växa ekonomiskt utan att ytterligare öka sitt bidrag till växthuseffekten utan
snarare minska det. Detta argument kan hävdas med statistiskt signifikanta indikationer då
resultaten visar att koldioxid och BNP kointegrerar enligt det tänka Kuznetssambandet.
Denne förespråkare har därmed ett relativt starkt stöd för sitt resonemang.
Den lite mer negative skulle kanske åberopa det linjära sambandet i graf 4.3.2 och hävda att
de senaste trettio åren endast är en tillfällig sänkning i utsläppsnivån på grund av
kärnkraftverk som inte håller för evigt. Denne skulle även kunna hävda att
koldioxidutsläppen inom Sveriges gränser minskat men att det i dagens globaliserade värld
inte på grund av detta kan fastställas att svenskarnas koldioxidutsläpp per capita reellt
minskat sett till vår konsumtion. Ändå skillnaden skulle då utgöras av att smutsig
tillverkningsindustri flyttat utomlands utan att svenskarna för den skull slutat konsumera

37
varorna som den tillverkar. Dessa åsikter blir dock lättare att bemöta då man, i denna
uppsats, inte kunnat visa att koldioxid och BNP kointegrerar enligt ett linjärt samband. Dock
återstår det spekulativa argumentet om den smutsiga industrins utflyttning som varken kan
förkastas eller styrkas med det aktuella datamaterialet. Det skulle potentiellt kunna besvaras
med något mått där allt svenskarna konsumerar mäts i koldioxidekvivalenter men som sagt
inte med hjälp av utsläppsdata för Sverige.
Poängteras bör även göras att koldioxidutsläpp utgör en form av miljöförstöring orsakad av
människan. Denna uppsats visar på sambandet mellan koldioxidutsläpp med grund i Sverige
och svenskarnas inkomst. Kuznetssambandet är en generell hypotes för vitt skilda
miljöförstöringar såsom avskogning i Amazonas, partikelutsläpp på Kungsgatan samt buller i
närheten av en järnväg. Uppsatsen är på intet sätt en generell validering av
Kuznetssambandet utan visar som tidigare nämnts endast på sambandet mellan
logaritmerade värden för koldioxidutsläpp och BNP i Sverige för åren 1860-2000 och inget
annat.
Det bör nämnas att studien, likt de flesta, har en del svaga punkter där siffrorna bör
separeras från deras matematiska betydelse och snarare granskas utifrån de bakomliggande
antagandena och premisserna. Därför kommer nedan svagheterna att granskas med ett par
kritiska glasögon på.
Då detta är en studie, till mångt och mycket, baserad på estimerade tidsserier måste en viss
försiktighet gentemot resultaten iakttas. Det måste alltid kommas ihåg att ett estimat ger
ytterligare felkällor och att estimera koldioxidutsläpp med hjälp av i sin tur skattad
energianvändning på 1800-talet inte direkt görs lättvindigt och exakt. De tidiga estimaten för
koldioxid ansågs inte vara tillräckligt tillförlitliga och uppvisade stor varians då en differens
utförts på de logaritmerade värdena, detta gjorde att serierna som tidigare nämnts
trunkerats till år 1860. En trunkering som ger i sig tudelade konsekvenser. Den kan både
anses ge stabilare resultat, då osäkra äldre estimat eliminerats men den begränsar även
tidshorisonten och därmed också antalet observationer vilket gör inferens samt prognoser
osäkrare.

38
Ytterligare en källa till att iaktta försiktighet vid tolkande av de resultat som denna
undersökning visat är att samtliga källor till koldioxidutsläpp inte är inkluderande utan
endast baserad på estimat över förbränningen av fossila bränslen, cementproduktion samt
gas flaring. Detta exkluderande av koldioxidkällor kan leda till en tidsserie som inte
representerar de korrekta koldioxidutsläppen på ett riktigt vis.
Utöver dessa tveksamheter som är helt relaterade till tidsserieestimatens kvalitet kan
enhetsrottestens tillförlitlighet, som i teorin nämnts, diskuteras. De olika Dickey-Fuller-
testen har ju kritiserats för sin svaga styrka där de alltför ofta accepterar en falsk nollhypotes
om enhetsrot, bl.a. om koefficienten som testas är nära noll. Detta skulle för denna uppsats
främst kunna innebära problem i steget där de logaritmerade tidsserierna testas för
enhetsrot. Ett felaktigt accepterande av nollhypotesen skulle då innebära att stationäritet
utesluts trots att serien är stationär. Om detta skulle vara fallet för en av koldioxidutsläpp
och BNP-serierna så skulle kriterierna för att utföra Engle-Granger-proceduren inte vara
uppfyllda och därmed skulle kointegration vara en statistiskt ogiltig metod. Problemet är inte
lika aktuellt för de differentierade serierna då nollhypotesen om enhetsrot här konsekvent
förkastades. Även kointegrationstesten utförs med hjälp av enhetsrottest vilket även gör
dem potentiellt känsliga och man skulle kunna argumentera för att det möjligen föreligger
kointegration enligt en linjär relation mellan BNP och koldioxid men att testet har lett till en
felaktig acceptering av nollhypotesen om icke-kointegration.
Denna brist i uppsatsen kan inte ignoreras men förutsättningar för hög styrka samt riktiga
slutsatser borde trots allt vara goda, detta dels då tidsserierna baseras på årsdata för en lång
tidsserie vilket generellt ska ge högre styrka än för exempelvis dagsdata. Dock har ett par av
de testade koefficienterna visat sig vara nära noll vilket drar ner styrkan av testen, denna
skillnad är dock högst marginell. Detta bör vägas upp av det faktum att resultaten från KPSS-
testen rakt igenom styrker Dickey-Fuller testens resultat
Generellt för alla test som ingår i kointegrationsanalysen är att de följer komplicerade
asymptotiska fördelningar och erhålls via Monte Carlo simlulering. Dessutom antar
sannolikhetsfördelningen, som tidigare nämnts, olika former beroende på vilka termer som
inkluderas, antalet laggar och observationer. Detta medför att olika kritiska värden erhålls
för olika testfunktioner. Då det i denna uppsats utförts approximationer för de kritiska

39
värdena baserade på framräknade tabeller men för annat antal observationer innebär detta
en potentiell felkälla. Detta skulle kunna innebära att något test felaktigt förkastar eller
missar att förkasta en nollhypotes. Dock är skillnaden i förkastelseområde försumbar så att
detta inte bedöms vara fallet i denna uppsats.
Av den möjliga faunan av enhetsrottest finns, som illustrerats ovan, ett flertal alternativ
samt specifikationer att botanisera i och än fler som inte redogjorts för. Valet av vilket som
skall användas beror helt enkelt på tidsseriens karaktär. Om man i Dickey-Fuller testet kan
anta att dess felterm är identiskt oberoende likafördelad så används den enklast, annars är
ADF-testet mer lämpligt. KPSS med sina omvända hypoteser ger ett starkare stöd och är
därmed ett bra komplement. Dessutom måste det, med tanke på tidsseriens utseende,
avgöras huruvida en term som tar en eventuell tidstrend i beaktande bör inkluderas, samt
om denna trend kan sägas vara stokastisk eller determinstisk. Alla dessa beslut bör och har
noga underbyggts men procedurdjungeln är snårig och inte alltid helt lättframkomlig. Det
bör även nämnas att de två strukturbrotten som ser ut att föreligga i dataserien över
koldioxid kan påverka resultaten av enhetsrotstesten och kan ge upphov till falsk enhetsrot,
med en mycket långsamt avtagande autokorrelation. Detta leder i så fall till resultat som
påvisar enhetsrot när data i själva verket inte innehåller enhetsrot. Det finns enhetsrottest
som tar hänsyn till strukturbrott men i detta arbete har dessa valts att exkluderas då det
ligger utanför arbetets ram.
Trots dessa eventuella felkällor visar resultaten i denna uppsats att indikationer har funnits
för att koldioxidutsläpp och BNP i Sverige följer en långsiktig jämviktsrelation enligt
Kuznetskurvan. Detta är en statistiskt signifikant indikation med hög säkerhet då samtliga
stationäritet/enhetsrottest som använts för att testa serierna har uppvisat entydiga resultat.
Detta i sig möjliggjorde fortgåendet med en kointegrationsanalys. Den procedur som
föreslagits av Engle-Granger ansågs vara mest lämplig för detta arbete och är även den
metod som främst används av forskare inom området. Med hjälp av denna
kointegrationsanalys har vi lyckats finna en långsiktig jämviktsrelation. När arbetet
påbörjades ansåg vi att det monotont växande sambandet är det mest troliga då vi
konsumerar mer och mer vilket vi trodde leder till ökade utsläpp trots den senaste tidens
debatt om energieffektivisering. Detta visade sig vara ett felaktigt antagande då vi inte

40
kunde finna stöd för att det monotont växande sambandet var statistiskt signifikant.
Däremot, efter granskande av graf 4.3.4, har Sverige inte hunnit tillräckligt långt i sin
energieffektivisering för att påbörja den andra delen av utvecklingen, där vi ser ökad BNP
samtidigt som koldioxidutsläppen minskar. Man kan beskriva läget Sverige befinner sig i nu
som en brytpunkt och förhoppningsvis följer de närmsta årens utveckling den tänkta, och i
detta arbete indikerade, Kuznetssambandet.

41
6 Förslag till vidare forskning Med utgångspunkt i studiens resultat och slutsatser presenteras här ett antal förslag på hur
vidare forskning inom ämnet skulle kunna utföras.
• Ett förslag till vidare forskning med tät anknytning till denna uppsats är att utföra
prognoser på perioden 2001-2010, som data är tillgänglig för, och använda sig utav
Kuznetssambandet för att se hur bra den representerar data och utifrån det vidare
analysera Sveriges fortsatta energieffektiviserande.
• Man skulle, med mer tid, kunna sammanställa mer fullständiga data för samtliga
koldioxidutsläpp och med detta data set utföra samma testprocedur och därmed
undersöka om uteslutandet av källor till koldioxidutsläpp inverkat signifikant på de
resultat som visats. Alternativt göra samma projekt för metan eller andra
växthusgaser.
• Ett annat tillvägagångssätt skulle kunna vara att addera ytterligare variabler, såsom
temperatur och konsumtion, att lägga till i modellen och testa detta för
kointegration.
7 Slutsats Uppsatsens syfte var att undersöka om någon långsiktig jämviktsrelation mellan BNP och
koldioxidutsläpp per capita förelåg under perioden 1860-2000 i Sverige. Resultatet visar på
förekomsten av jämviktsrelation enligt Kuznetssambandet.

42
Referenser
Tryckta källor
Brandt N. & Gröndahl F. ”Miljöeffekter – kompendium I miljöskydd, del 4”. 2000, 4:e upplagan, Kungliga tekniska högskolan. Norstedts. Stockholm
Bates J. M., Cole M.A. & Rayner A.J. “The environmental Kuznets curve: an empirical analysis, Environment and Development Economics”. 1997, 2:4:401-416 Cambridge University Press
Edvinsson R. “Growth, Accumulation, Crisis : With New Macroeconomic Data for Sweden 1800-2000 ”. Acta Universitatis Stockholmiensis; 2005. Stockholm Studies in Economic History, 41
Enders, W. ”Applied econometric time series”. 2004, Second edition, Wiley
Fregert, K & Jonung, L. ”Makroekonomi – Teori, politik & institutioner”. 2003. 1:a upplagan. Studentlitteratur. Lund.
Galeottia M., Lanzab A. & Paulic F. “Reassessing the environmental Kuznets curve for CO2 emissions: A robustness exercise”. Ecological Economics. Volume 57, Issue 1, 15 April 2006, P. 152-163
Guajarati N. & Porter C. “Basic econometrics”. 2009, McGraw-Hill. International fifth edition. New York.
Kwiatkowski D., Phillips P.C.B., Schmidt P. & Shin Y. “Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series have a unit root?”. Journal of Econometrics Volume 54, Issues 1-3, October-December 1992, P. 159-178
Liew V.K. ”Which lag length criteria should we employ?”. Economics Bulletin, Volume 3, Issue 33, Year 2004, P.1-9
Marland, G., & R.M. Rotty. “Carbon dioxide emissions from fossil fuels: A procedure for estimation and results for 1950-82 ”. 1984, Tellus 36(B):P. 232-61.
Mitchell, B.R.” International Historical Statistics: Europe 1750-1988 ”. 1992, Stockton Press, New York, United States. p. 465-485.
Patterson, Kerry. ”An introduction to applied econometrics: a time series approach” 2000, Palgrave Macmillan, First edition. New York.

43
Regeringskansliet: Näringsdepartementet & Miljödepartementet .”Klimat- och energipolitik för en hållbar framtid”. Promemoria 2009-03-11
Shafik, N & Bandyopadhyay S. “Economic growth and environmental quality : time series and cross-country evidence”. The world bank, Policy research working paper nr 904. 1992. Washington.
Stern D.I.& Common M.S. “Is there an environmental Kuznets curve for sulphur?”, Journal of Environmental Economics and Management 14, 2001, P. 162–178
United Nations. 2007 “Energy Statistics Yearbook”. United Nations Department for Economic and Social Information and Policy Analysis, Statistics Division, New York.
Perman, R. & Stern, D. I. “The Environmental Kuznets Curve: Implications of Non-stationarity”. Working paper in ecological economics. 1999. Canberra
Elektroniska källor Edvinsson R.” Historisk data over BNP och befolkning”. http://www.historia.se/tablesAtoX.xls 03-11-10
Carbon Dioxide Information Analysis Center data (2) och metod för skattning (1) av koldioxidutsläpp
http://cdiac.ornl.gov/trends/emis/overview_2007.html 02-11-10
http://cdiac.ornl.gov/ftp/trends/emissions/swe.dat 02-11-10
Mckinnon J., hemsida
http://www.econ.queensu.ca/faculty/mackinnon/ 07-11-10
Larsson, F. ”Sverige bröt trenden på 70-talet” http://www.ekonomifakta.se/sv/Artiklar/2008/Januari/Sverige-brot-trenden-pa-70-talet/ 10-11-10

44
Appendix
Kvadrerad BNP per capita Null Hypothesis: LOGBNPCAPPOW has a unit root Exogenous: Constant Lag Length: 0 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic 0.809918 0.9939
Test critical values: 1% level -3.477487 5% level -2.882127 10% level -2.577827 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGBNPCAPPOW) Method: Least Squares Date: 12/02/10 Time: 12:48 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGBNPCAPPOW(-1) 0.002935 0.003623 0.809918 0.4194
C 0.096404 0.432132 0.223090 0.8238 R-squared 0.004731 Mean dependent var 0.441741
Adjusted R-squared -0.002481 S.D. dependent var 0.830154 S.E. of regression 0.831183 Akaike info criterion 2.482250 Sum squared resid 95.33947 Schwarz criterion 2.524273 Log likelihood -171.7575 Hannan-Quinn criter. 2.499327 F-statistic 0.655968 Durbin-Watson stat 2.092010 Prob(F-statistic) 0.419382
Null Hypothesis: D(LOGBNPCAPPOW) has a unit root Exogenous: Constant Lag Length: 0 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -12.21001 0.0000
Test critical values: 1% level -3.477835 5% level -2.882279 10% level -2.577908 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGBNPCAPPOW,2) Method: Least Squares Date: 12/02/10 Time: 12:48 Sample (adjusted): 1862 2000

45
Included observations: 139 after adjustments Variable Coefficient Std. Error t-Statistic Prob. D(LOGBNPCAPPOW(-1)) -1.041589 0.085306 -12.21001 0.0000
C 0.464476 0.079980 5.807401 0.0000 R-squared 0.521120 Mean dependent var 0.008267
Adjusted R-squared 0.517625 S.D. dependent var 1.200421 S.E. of regression 0.833732 Akaike info criterion 2.488474 Sum squared resid 95.22985 Schwarz criterion 2.530696 Log likelihood -170.9489 Hannan-Quinn criter. 2.505632 F-statistic 149.0843 Durbin-Watson stat 1.992349 Prob(F-statistic) 0.000000
Logaritmerad koldioxid per capita Date: 12/03/10 Time: 13:19 Sample: 1860 2000 Included observations: 141
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|******* .|******* 1 0.962 0.962 133.30 0.000
.|******* .|* | 2 0.934 0.118 259.92 0.000 .|******* .|. | 3 0.907 0.016 380.22 0.000 .|******| .|. | 4 0.883 0.023 494.93 0.000 .|******| *|. | 5 0.851 -0.100 602.33 0.000 .|******| .|. | 6 0.820 -0.036 702.71 0.000 .|******| .|* | 7 0.796 0.080 798.02 0.000 .|******| .|. | 8 0.770 -0.020 887.89 0.000 .|***** | .|. | 9 0.746 0.020 972.89 0.000 .|***** | *|. | 10 0.717 -0.069 1052.0 0.000 .|***** | .|. | 11 0.692 0.003 1126.3 0.000 .|***** | .|. | 12 0.669 0.027 1196.3 0.000 .|***** | .|. | 13 0.646 -0.009 1261.9 0.000 .|**** | .|. | 14 0.622 -0.005 1323.4 0.000 .|**** | .|. | 15 0.598 -0.023 1380.6 0.000 .|**** | .|. | 16 0.577 0.006 1434.3 0.000 .|**** | .|. | 17 0.557 0.023 1484.8 0.000 .|**** | .|. | 18 0.535 -0.033 1531.7 0.000 .|**** | .|. | 19 0.516 0.029 1575.7 0.000 .|**** | *|. | 20 0.492 -0.087 1616.0 0.000 .|*** | .|. | 21 0.471 0.009 1653.3 0.000 .|*** | .|. | 22 0.449 -0.004 1687.5 0.000 .|*** | .|. | 23 0.432 0.044 1719.5 0.000 .|*** | .|. | 24 0.412 -0.033 1748.7 0.000 .|*** | *|. | 25 0.384 -0.128 1774.4 0.000 .|*** | .|. | 26 0.362 0.022 1797.4 0.000 .|** | .|. | 27 0.339 -0.016 1817.8 0.000 .|** | .|. | 28 0.315 -0.035 1835.5 0.000 .|** | .|. | 29 0.287 -0.041 1850.3 0.000 .|** | .|. | 30 0.266 0.052 1863.2 0.000 .|** | .|. | 31 0.246 -0.005 1874.3 0.000 .|** | .|. | 32 0.227 0.011 1883.8 0.000 .|* | .|. | 33 0.209 0.015 1892.0 0.000 .|* | .|. | 34 0.190 -0.024 1898.8 0.000 .|* | .|. | 35 0.173 -0.008 1904.5 0.000

46
.|* | .|. | 36 0.158 0.016 1909.3 0.000 .|* | .|. | 37 0.141 -0.029 1913.1 0.000 .|* | .|. | 38 0.129 0.061 1916.4 0.000 .|* | .|. | 39 0.116 -0.011 1919.0 0.000 .|* | .|. | 40 0.105 -0.002 1921.3 0.000 .|* | .|. | 41 0.091 -0.039 1922.9 0.000 .|* | .|. | 42 0.078 -0.013 1924.2 0.000 .|. | .|. | 43 0.066 0.003 1925.1 0.000 .|. | .|. | 44 0.055 0.022 1925.7 0.000 .|. | .|. | 45 0.043 -0.023 1926.1 0.000 .|. | .|. | 46 0.033 0.019 1926.3 0.000 .|. | .|. | 47 0.026 0.018 1926.5 0.000 .|. | .|. | 48 0.022 0.065 1926.6 0.000 .|. | .|. | 49 0.015 -0.041 1926.6 0.000 .|. | .|. | 50 0.008 -0.012 1926.6 0.000
Residualkorrelation
Date: 12/06/10 Time: 11:06 Sample: 1860 2000 Included observations: 140
Autocorrelation Partial Correlation AC PAC Q-Stat Prob **|. | **|. | 1 -0.209 -0.209 6.2228 0.013
.|. | *|. | 2 -0.045 -0.093 6.5167 0.038 *|. | *|. | 3 -0.084 -0.119 7.5302 0.057 .|* | .|* | 4 0.195 0.154 13.070 0.011 .|. | .|* | 5 0.008 0.077 13.078 0.023 **|. | **|. | 6 -0.230 -0.212 20.935 0.002 .|. | .|. | 7 0.014 -0.055 20.966 0.004 .|. | *|. | 8 -0.014 -0.083 20.996 0.007 .|* | .|. | 9 0.080 0.018 21.976 0.009 .|. | .|* | 10 -0.029 0.075 22.102 0.015 *|. | .|. | 11 -0.067 -0.050 22.792 0.019 .|. | .|. | 12 0.069 0.019 23.537 0.024 .|. | .|. | 13 -0.021 -0.041 23.608 0.035 .|. | .|. | 14 0.032 -0.015 23.772 0.049 .|. | .|. | 15 -0.022 0.040 23.848 0.068 .|. | .|. | 16 -0.015 -0.020 23.882 0.092 .|. | .|. | 17 0.069 0.060 24.641 0.103 *|. | *|. | 18 -0.187 -0.182 30.354 0.034 .|* | .|. | 19 0.131 0.043 33.156 0.023 .|. | .|. | 20 -0.026 0.034 33.270 0.032 .|. | *|. | 21 -0.024 -0.071 33.368 0.042 *|. | .|. | 22 -0.078 -0.031 34.398 0.045 .|* | .|. | 23 0.084 0.053 35.606 0.045 .|** | .|* | 24 0.236 0.210 45.164 0.006 *|. | .|. | 25 -0.143 0.005 48.677 0.003 .|. | .|. | 26 0.016 0.015 48.722 0.004 .|. | .|. | 27 0.002 0.011 48.723 0.006 .|* | .|* | 28 0.165 0.076 53.578 0.003 *|. | *|. | 29 -0.182 -0.126 59.478 0.001 .|. | .|. | 30 -0.035 0.038 59.698 0.001 .|. | .|. | 31 0.003 -0.018 59.700 0.001 .|. | *|. | 32 -0.032 -0.100 59.886 0.002 .|. | .|. | 33 0.033 0.027 60.085 0.003 .|. | .|. | 34 -0.055 -0.005 60.654 0.003

47
.|. | .|. | 35 -0.021 -0.044 60.739 0.004 .|. | .|. | 36 0.056 0.016 61.348 0.005
Dependent Variable: LOGKOLDIOXKGCAPD Method: Least Squares Date: 12/06/10 Time: 10:37 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.240787 0.102065 2.359155 0.0197
LOGKOLDIOXKGCAP(-1) -0.033532 0.015563 -2.154563 0.0329 R-squared 0.032544 Mean dependent var 0.023984
Adjusted R-squared 0.025533 S.D. dependent var 0.204774 S.E. of regression 0.202143 Akaike info criterion -0.345499 Sum squared resid 5.638936 Schwarz criterion -0.303475 Log likelihood 26.18490 Hannan-Quinn criter. -0.328421 F-statistic 4.642143 Durbin-Watson stat 2.414184 Prob(F-statistic) 0.032932
Null Hypothesis: LOGKOLDIOXKGCAP has a unit root Exogenous: None Lag Length: 1 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic 1.254711 0.9463
Test critical values: 1% level -2.581705 5% level -1.943140 10% level -1.615189 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGKOLDIOXKGCAP) Method: Least Squares Date: 12/02/10 Time: 12:49 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGKOLDIOXKGCAP(-1) 0.003285 0.002618 1.254711 0.2117
D(LOGKOLDIOXKGCAP(-1)) -0.208525 0.083470 -2.498206 0.0137
R-squared 0.038266 Mean dependent var 0.022458
Adjusted R-squared 0.031246 S.D. dependent var 0.204714 S.E. of regression 0.201491 Akaike info criterion -0.351863 Sum squared resid 5.561995 Schwarz criterion -0.309640

48
Log likelihood 26.45447 Hannan-Quinn criter. -0.334705 Durbin-Watson stat 2.040673
Null Hypothesis: LOGCO2_KGCAP is stationary Exogenous: Constant Bandwidth: 9 (Newey-West automatic) using Bartlett kernel
LM-Stat. Kwiatkowski-Phillips-Schmidt-Shin test statistic 1.365016
Asymptotic critical values*: 1% level 0.739000 5% level 0.463000 10% level 0.347000 *Kwiatkowski-Phillips-Schmidt-Shin (1992, Table 1) Residual variance (no correction) 1.201823
HAC corrected variance (Bartlett kernel) 10.81400
KPSS Test Equation Dependent Variable: LOGCO2_KGCAP Method: Least Squares Date: 12/02/10 Time: 12:52 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C -0.436062 0.092652 -4.706439 0.0000 R-squared 0.000000 Mean dependent var -0.436062
Adjusted R-squared 0.000000 S.D. dependent var 1.100185 S.E. of regression 1.100185 Akaike info criterion 3.035901 Sum squared resid 169.4570 Schwarz criterion 3.056814 Log likelihood -213.0310 Hannan-Quinn criter. 3.044399 Durbin-Watson stat 0.034871

49
Logaritmerad BNP per capita Date: 12/03/10 Time: 13:19 Sample: 1860 2000 Included observations: 141
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|******* .|******* 1 0.981 0.981 138.58 0.000
.|******* .|. | 2 0.962 -0.009 272.79 0.000 .|******* .|. | 3 0.942 -0.027 402.50 0.000 .|******* .|. | 4 0.923 0.009 527.95 0.000 .|******* .|. | 5 0.904 -0.013 649.14 0.000 .|******| .|. | 6 0.885 -0.003 766.21 0.000 .|******| .|. | 7 0.866 -0.020 879.08 0.000 .|******| .|. | 8 0.847 -0.011 987.81 0.000 .|******| *|. | 9 0.825 -0.072 1091.9 0.000 .|******| .|. | 10 0.804 -0.003 1191.4 0.000 .|******| .|. | 11 0.784 0.021 1286.7 0.000 .|******| .|. | 12 0.764 -0.015 1377.9 0.000 .|***** | .|. | 13 0.744 -0.010 1465.1 0.000 .|***** | .|. | 14 0.724 -0.014 1548.3 0.000 .|***** | .|. | 15 0.703 -0.020 1627.4 0.000 .|***** | .|. | 16 0.683 -0.011 1702.6 0.000 .|***** | .|. | 17 0.663 -0.001 1774.0 0.000 .|***** | .|. | 18 0.642 -0.016 1841.7 0.000 .|**** | .|. | 19 0.622 -0.024 1905.6 0.000 .|**** | .|. | 20 0.602 -0.003 1965.9 0.000 .|**** | .|. | 21 0.580 -0.038 2022.5 0.000 .|**** | .|. | 22 0.559 -0.013 2075.5 0.000 .|**** | .|. | 23 0.538 -0.010 2125.0 0.000 .|**** | .|. | 24 0.517 -0.013 2171.0 0.000 .|**** | .|. | 25 0.495 -0.035 2213.7 0.000 .|*** | .|. | 26 0.473 -0.016 2252.9 0.000 .|*** | .|. | 27 0.451 -0.022 2288.9 0.000 .|*** | .|. | 28 0.429 -0.023 2321.7 0.000 .|*** | .|. | 29 0.407 0.000 2351.5 0.000 .|*** | .|. | 30 0.385 -0.017 2378.3 0.000 .|*** | .|. | 31 0.362 -0.020 2402.4 0.000 .|** | .|. | 32 0.340 -0.017 2423.8 0.000 .|** | .|. | 33 0.319 0.003 2442.8 0.000 .|** | .|. | 34 0.298 0.000 2459.5 0.000 .|** | .|. | 35 0.277 -0.021 2474.1 0.000 .|** | .|. | 36 0.256 -0.013 2486.7 0.000 .|** | .|. | 37 0.235 -0.013 2497.4 0.000 .|** | .|. | 38 0.215 0.002 2506.4 0.000 .|* | .|. | 39 0.196 0.008 2514.0 0.000 .|* | .|. | 40 0.177 0.001 2520.3 0.000 .|* | .|. | 41 0.159 -0.019 2525.4 0.000 .|* | .|. | 42 0.140 -0.014 2529.4 0.000 .|* | .|. | 43 0.122 -0.001 2532.5 0.000 .|* | .|. | 44 0.105 -0.009 2534.8 0.000 .|* | .|. | 45 0.087 -0.008 2536.4 0.000 .|. | .|. | 46 0.070 -0.013 2537.4 0.000 .|. | .|. | 47 0.054 0.003 2538.1 0.000 .|. | .|. | 48 0.039 0.019 2538.4 0.000 .|. | .|. | 49 0.023 -0.015 2538.5 0.000 .|. | .|. | 50 0.008 -0.026 2538.5 0.000

50
Residualkorrelation Date: 12/06/10 Time: 11:03 Sample: 1860 2000 Included observations: 139
Autocorrelation Partial Correlation AC PAC Q-Stat Prob **|. | **|. | 1 -0.210 -0.210 6.2888 0.012
.|. | *|. | 2 -0.059 -0.108 6.7906 0.034 .|. | .|. | 3 -0.023 -0.063 6.8680 0.076 .|* | .|* | 4 0.114 0.093 8.7453 0.068 *|. | *|. | 5 -0.188 -0.157 13.893 0.016 .|. | .|. | 6 0.072 0.015 14.659 0.023 .|. | .|. | 7 0.025 0.022 14.749 0.039 *|. | *|. | 8 -0.157 -0.174 18.413 0.018 .|* | .|* | 9 0.131 0.114 21.010 0.013 .|. | .|. | 10 -0.018 -0.036 21.058 0.021 .|. | .|. | 11 -0.058 -0.058 21.566 0.028 .|. | .|. | 12 0.033 0.065 21.739 0.041 .|. | .|. | 13 0.051 -0.028 22.147 0.053 .|. | .|. | 14 -0.010 0.066 22.161 0.075 .|. | .|. | 15 -0.041 -0.030 22.428 0.097 .|* | .|. | 16 0.086 0.028 23.601 0.099 .|. | .|. | 17 -0.052 0.027 24.043 0.118 *|. | *|. | 18 -0.079 -0.127 25.042 0.124 .|. | .|. | 19 0.026 0.010 25.155 0.156 .|. | .|. | 20 0.034 0.019 25.345 0.189 .|. | .|. | 21 -0.025 -0.015 25.444 0.228 *|. | *|. | 22 -0.131 -0.128 28.333 0.165 .|** | .|* | 23 0.223 0.152 36.754 0.034 .|. | .|. | 24 -0.037 0.044 36.985 0.044 .|. | .|. | 25 -0.034 -0.039 37.180 0.056 .|. | .|. | 26 -0.022 -0.008 37.265 0.071 .|. | .|. | 27 0.042 -0.026 37.576 0.085 .|. | .|* | 28 0.031 0.116 37.747 0.103 *|. | *|. | 29 -0.149 -0.191 41.691 0.060 .|. | .|. | 30 0.031 -0.052 41.866 0.073 .|. | .|* | 31 -0.008 0.095 41.877 0.092 .|. | .|. | 32 0.059 -0.046 42.519 0.101 *|. | .|. | 33 -0.091 -0.042 44.054 0.095 .|. | .|. | 34 0.069 0.044 44.940 0.099 .|. | .|. | 35 -0.012 -0.001 44.966 0.121 .|. | .|. | 36 0.013 0.020 44.998 0.145
Dependent Variable: LOGBNP_CAP_AFPD Method: Least Squares Date: 12/06/10 Time: 10:36 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.004992 0.041535 0.120191 0.9045
LOGBNP_CAP_AFP(-1) 0.001410 0.003829 0.368189 0.7133

51
R-squared 0.000981 Mean dependent var 0.020234
Adjusted R-squared -0.006258 S.D. dependent var 0.040167 S.E. of regression 0.040292 Akaike info criterion -3.571139 Sum squared resid 0.224037 Schwarz criterion -3.529115 Log likelihood 251.9797 Hannan-Quinn criter. -3.554061 F-statistic 0.135563 Durbin-Watson stat 2.136104 Prob(F-statistic) 0.713297
Null Hypothesis: LOGBNP_CAP_AFP has a unit root Exogenous: None Lag Length: 0 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic 5.973177 1.0000
Test critical values: 1% level -2.581584 5% level -1.943123 10% level -1.615200 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGBNP_CAP_AFP) Method: Least Squares Date: 12/02/10 Time: 12:53 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGBNP_CAP_AFP(-1) 0.001868 0.000313 5.973177 0.0000 R-squared 0.000877 Mean dependent var 0.020234
Adjusted R-squared 0.000877 S.D. dependent var 0.040167 S.E. of regression 0.040149 Akaike info criterion -3.585320 Sum squared resid 0.224060 Schwarz criterion -3.564308 Log likelihood 251.9724 Hannan-Quinn criter. -3.576781 Durbin-Watson stat 2.136857
Null Hypothesis: LOGBNP_CAP_AFP is stationary Exogenous: Constant Bandwidth: 10 (Newey-West automatic) using Bartlett kernel
LM-Stat. Kwiatkowski-Phillips-Schmidt-Shin test statistic 1.373907
Asymptotic critical values*: 1% level 0.739000 5% level 0.463000 10% level 0.347000 *Kwiatkowski-Phillips-Schmidt-Shin (1992, Table 1) Residual variance (no correction) 0.801643

52
HAC corrected variance (Bartlett kernel) 8.202691
KPSS Test Equation Dependent Variable: LOGBNP_CAP_AFP Method: Least Squares Date: 12/02/10 Time: 12:53 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C 10.82201 0.075670 143.0149 0.0000 R-squared 0.000000 Mean dependent var 10.82201
Adjusted R-squared 0.000000 S.D. dependent var 0.898537 S.E. of regression 0.898537 Akaike info criterion 2.630970 Sum squared resid 113.0317 Schwarz criterion 2.651883 Log likelihood -184.4834 Hannan-Quinn criter. 2.639468 Durbin-Watson stat 0.002491
Differentierad logaritmerad koldioxid per capita Date: 12/03/10 Time: 13:20 Sample: 1860 2000 Included observations: 140
Autocorrelation Partial Correlation AC PAC Q-Stat Prob **|. | **|. | 1 -0.212 -0.212 6.4251 0.011
.|. | *|. | 2 -0.048 -0.097 6.7525 0.034 *|. | *|. | 3 -0.085 -0.123 7.7961 0.050 .|* | .|* | 4 0.194 0.151 13.282 0.010 .|. | .|* | 5 0.008 0.077 13.290 0.021 **|. | **|. | 6 -0.229 -0.210 21.103 0.002 .|. | .|. | 7 0.018 -0.052 21.149 0.004 .|. | *|. | 8 -0.013 -0.081 21.173 0.007 .|* | .|. | 9 0.085 0.023 22.263 0.008 .|. | .|* | 10 -0.026 0.080 22.368 0.013 .|. | .|. | 11 -0.065 -0.045 23.013 0.018 .|. | .|. | 12 0.070 0.022 23.770 0.022 .|. | .|. | 13 -0.020 -0.038 23.835 0.033 .|. | .|. | 14 0.033 -0.012 24.009 0.046 .|. | .|. | 15 -0.023 0.042 24.092 0.064 .|. | .|. | 16 -0.015 -0.019 24.129 0.087 .|. | .|. | 17 0.068 0.061 24.875 0.098 *|. | *|. | 18 -0.185 -0.179 30.455 0.033 .|* | .|. | 19 0.133 0.047 33.369 0.022 .|. | .|. | 20 -0.027 0.036 33.487 0.030 .|. | *|. | 21 -0.024 -0.070 33.586 0.040 *|. | .|. | 22 -0.079 -0.033 34.649 0.042 .|* | .|. | 23 0.083 0.048 35.824 0.043 .|** | .|* | 24 0.234 0.208 45.230 0.005 *|. | .|. | 25 -0.145 0.006 48.840 0.003 .|. | .|. | 26 0.015 0.016 48.882 0.004 .|. | .|. | 27 0.002 0.013 48.883 0.006

53
.|* | .|* | 28 0.164 0.075 53.677 0.002 *|. | *|. | 29 -0.184 -0.129 59.757 0.001 .|. | .|. | 30 -0.037 0.032 60.009 0.001 .|. | .|. | 31 0.001 -0.026 60.009 0.001 .|. | *|. | 32 -0.033 -0.106 60.210 0.002 .|. | .|. | 33 0.033 0.021 60.407 0.002 .|. | .|. | 34 -0.057 -0.011 61.008 0.003 .|. | .|. | 35 -0.021 -0.049 61.095 0.004 .|. | .|. | 36 0.056 0.012 61.703 0.005 *|. | *|. | 37 -0.096 -0.138 63.470 0.004 .|. | .|. | 38 0.040 -0.025 63.777 0.005 .|. | .|* | 39 0.024 0.086 63.894 0.007 .|* | .|* | 40 0.096 0.077 65.725 0.006 *|. | .|. | 41 -0.067 0.015 66.636 0.007 .|. | .|. | 42 -0.015 0.031 66.679 0.009 .|. | *|. | 43 0.008 -0.117 66.691 0.012 .|. | .|. | 44 0.015 0.007 66.736 0.015 .|. | .|. | 45 -0.039 -0.007 67.047 0.018 .|. | .|. | 46 -0.058 0.032 67.750 0.020 .|. | *|. | 47 -0.020 -0.146 67.831 0.025 .|* | .|. | 48 0.088 0.022 69.501 0.023 .|. | .|. | 49 -0.054 -0.029 70.147 0.025 .|* | .|* | 50 0.088 0.076 71.864 0.023
Residualkorrelation Date: 12/06/10 Time: 11:09 Sample: 1860 2000 Included observations: 139
Autocorrelation Partial Correlation AC PAC Q-Stat Prob .|. | .|. | 1 -0.036 -0.036 0.1853 0.667
*|. | *|. | 2 -0.112 -0.114 1.9896 0.370 .|. | *|. | 3 -0.063 -0.073 2.5619 0.464 .|* | .|* | 4 0.196 0.181 8.1316 0.087 .|. | .|. | 5 0.001 0.002 8.1318 0.149 **|. | **|. | 6 -0.242 -0.218 16.778 0.010 .|. | .|. | 7 -0.035 -0.030 16.964 0.018 .|. | *|. | 8 0.012 -0.067 16.984 0.030 .|* | .|. | 9 0.079 0.046 17.921 0.036 .|. | .|. | 10 -0.027 0.057 18.034 0.054 *|. | .|. | 11 -0.068 -0.059 18.740 0.066 .|. | .|. | 12 0.059 0.022 19.268 0.082 .|. | .|. | 13 -0.002 -0.048 19.269 0.115 .|. | .|. | 14 0.021 -0.001 19.338 0.152 .|. | .|. | 15 -0.024 0.032 19.427 0.195 .|. | .|. | 16 -0.008 -0.018 19.438 0.247 .|. | .|. | 17 0.040 0.033 19.701 0.290 *|. | *|. | 18 -0.159 -0.174 23.797 0.162 .|* | .|* | 19 0.094 0.080 25.233 0.153 .|. | .|. | 20 -0.006 0.003 25.239 0.192 .|. | *|. | 21 -0.053 -0.088 25.701 0.218 *|. | .|. | 22 -0.075 -0.014 26.652 0.225 .|* | .|* | 23 0.121 0.095 29.109 0.177 .|** | .|* | 24 0.242 0.193 39.084 0.027 *|. | .|. | 25 -0.105 -0.029 40.972 0.023 .|. | .|. | 26 -0.012 0.026 40.996 0.031 .|. | .|. | 27 0.036 0.012 41.222 0.039

54
.|* | .|. | 28 0.137 0.041 44.533 0.025 *|. | *|. | 29 -0.175 -0.136 50.015 0.009 *|. | .|. | 30 -0.080 0.049 51.169 0.009 .|. | .|. | 31 -0.012 -0.052 51.196 0.013 .|. | *|. | 32 -0.028 -0.094 51.339 0.016 .|. | .|. | 33 0.014 0.036 51.378 0.022 .|. | .|. | 34 -0.059 -0.028 52.038 0.025 .|. | .|. | 35 -0.023 -0.039 52.139 0.031 .|. | .|. | 36 0.035 -0.015 52.369 0.038
Dependent Variable: D(LOGKOLDIOXKGCAPD) Method: Least Squares Date: 12/06/10 Time: 10:42 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGKOLDIOXKGCAPD(-1) -1.196220 0.083064 -14.40115 0.0000 R-squared 0.600441 Mean dependent var -0.001866
Adjusted R-squared 0.600441 S.D. dependent var 0.319423 S.E. of regression 0.201910 Akaike info criterion -0.354826 Sum squared resid 5.625910 Schwarz criterion -0.333714 Log likelihood 25.66039 Hannan-Quinn criter. -0.346247 Durbin-Watson stat 2.033420
Null Hypothesis: LOGKOLDIOXKGCAPD has a unit root Exogenous: None Lag Length: 0 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -14.40115 0.0000
Test critical values: 1% level -2.581705 5% level -1.943140 10% level -1.615189 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGKOLDIOXKGCAPD) Method: Least Squares Date: 12/02/10 Time: 12:56 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.

55
LOGKOLDIOXKGCAPD(-1) -1.196220 0.083064 -14.40115 0.0000 R-squared 0.600441 Mean dependent var -0.001866
Adjusted R-squared 0.600441 S.D. dependent var 0.319423 S.E. of regression 0.201910 Akaike info criterion -0.354826 Sum squared resid 5.625910 Schwarz criterion -0.333714 Log likelihood 25.66039 Hannan-Quinn criter. -0.346247 Durbin-Watson stat 2.033420
Null Hypothesis: LOGKOLDIOXKGCAPD is stationary Exogenous: Constant Bandwidth: 4 (Newey-West automatic) using Bartlett kernel
LM-Stat. Kwiatkowski-Phillips-Schmidt-Shin test statistic 0.233326
Asymptotic critical values*: 1% level 0.739000 5% level 0.463000 10% level 0.347000 *Kwiatkowski-Phillips-Schmidt-Shin (1992, Table 1) Residual variance (no correction) 0.041633
HAC corrected variance (Bartlett kernel) 0.025534
KPSS Test Equation Dependent Variable: LOGKOLDIOXKGCAPD Method: Least Squares Date: 12/02/10 Time: 12:56 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.023984 0.017307 1.385839 0.1680 R-squared 0.000000 Mean dependent var 0.023984
Adjusted R-squared 0.000000 S.D. dependent var 0.204774 S.E. of regression 0.204774 Akaike info criterion -0.326699 Sum squared resid 5.828622 Schwarz criterion -0.305687 Log likelihood 23.86893 Hannan-Quinn criter. -0.318160 Durbin-Watson stat 2.415802
Differentierad logaritmerad BNP per capita Date: 12/03/10 Time: 13:18 Sample: 1860 2000 Included observations: 140
Autocorrelation Partial Correlation AC PAC Q-Stat Prob *|. | *|. | 1 -0.068 -0.068 0.6674 0.414

56
*|. | *|. | 2 -0.081 -0.086 1.6200 0.445 .|. | .|. | 3 -0.022 -0.034 1.6900 0.639 .|* | .|* | 4 0.087 0.077 2.8017 0.592 *|. | *|. | 5 -0.164 -0.160 6.7689 0.238 .|. | .|. | 6 0.053 0.046 7.1899 0.304 .|. | .|. | 7 0.032 0.017 7.3469 0.394 *|. | *|. | 8 -0.155 -0.168 10.985 0.203 .|* | .|* | 9 0.093 0.117 12.299 0.197 .|. | .|. | 10 -0.010 -0.065 12.316 0.264 .|. | .|. | 11 -0.056 -0.049 12.800 0.307 .|. | .|* | 12 0.034 0.078 12.984 0.370 .|. | .|. | 13 0.062 -0.026 13.587 0.404 .|. | .|. | 14 -0.006 0.061 13.592 0.481 .|. | .|. | 15 -0.035 -0.030 13.792 0.541 .|* | .|. | 16 0.081 0.031 14.832 0.537 .|. | .|. | 17 -0.050 0.008 15.237 0.578 *|. | *|. | 18 -0.089 -0.123 16.526 0.556 .|. | .|. | 19 0.027 0.035 16.648 0.614 .|. | .|. | 20 0.033 0.015 16.828 0.664 .|. | .|. | 21 -0.031 -0.027 16.990 0.712 *|. | *|. | 22 -0.114 -0.100 19.178 0.634 .|* | .|* | 23 0.213 0.180 26.878 0.261 .|. | .|. | 24 -0.011 0.015 26.900 0.309 .|. | .|. | 25 -0.034 -0.036 27.099 0.351 .|. | .|. | 26 -0.017 0.003 27.149 0.402 .|. | .|. | 27 0.039 -0.016 27.421 0.441 .|. | .|* | 28 0.021 0.095 27.502 0.491 *|. | **|. | 29 -0.150 -0.208 31.508 0.342 .|. | .|. | 30 0.016 -0.009 31.553 0.389 .|. | .|* | 31 -0.004 0.094 31.556 0.438 .|. | .|. | 32 0.046 -0.065 31.953 0.469 *|. | .|. | 33 -0.075 -0.019 33.005 0.467 .|. | .|. | 34 0.057 0.052 33.619 0.486 .|. | .|. | 35 -0.000 -0.012 33.619 0.535 .|. | .|. | 36 0.026 0.042 33.744 0.576 .|* | .|. | 37 0.100 0.056 35.685 0.531 *|. | *|. | 38 -0.136 -0.121 39.269 0.413 .|. | .|. | 39 -0.001 0.021 39.269 0.458 .|* | .|* | 40 0.132 0.107 42.728 0.355 .|. | .|* | 41 0.069 0.083 43.677 0.358 *|. | *|. | 42 -0.162 -0.071 48.991 0.213 .|* | .|. | 43 0.080 0.013 50.302 0.207 .|. | *|. | 44 -0.047 -0.072 50.751 0.225 *|. | .|. | 45 -0.135 -0.017 54.546 0.156 .|. | *|. | 46 0.015 -0.090 54.593 0.180 *|. | **|. | 47 -0.103 -0.239 56.865 0.153 *|. | *|. | 48 -0.153 -0.091 61.911 0.086 .|. | .|. | 49 0.056 0.034 62.590 0.092 .|. | .|. | 50 0.069 -0.039 63.627 0.093

57
Residualkorrelation Date: 12/06/10 Time: 11:06 Sample: 1860 2000 Included observations: 139
Autocorrelation Partial Correlation AC PAC Q-Stat Prob **|. | **|. | 1 -0.210 -0.210 6.2888 0.012
.|. | *|. | 2 -0.059 -0.108 6.7906 0.034 .|. | .|. | 3 -0.023 -0.063 6.8680 0.076 .|* | .|* | 4 0.114 0.093 8.7453 0.068 *|. | *|. | 5 -0.188 -0.157 13.893 0.016 .|. | .|. | 6 0.072 0.015 14.659 0.023 .|. | .|. | 7 0.025 0.022 14.749 0.039 *|. | *|. | 8 -0.157 -0.174 18.413 0.018 .|* | .|* | 9 0.131 0.114 21.010 0.013 .|. | .|. | 10 -0.018 -0.036 21.058 0.021 .|. | .|. | 11 -0.058 -0.058 21.566 0.028 .|. | .|. | 12 0.033 0.065 21.739 0.041 .|. | .|. | 13 0.051 -0.028 22.147 0.053 .|. | .|. | 14 -0.010 0.066 22.161 0.075 .|. | .|. | 15 -0.041 -0.030 22.428 0.097 .|* | .|. | 16 0.086 0.028 23.601 0.099 .|. | .|. | 17 -0.052 0.027 24.043 0.118 *|. | *|. | 18 -0.079 -0.127 25.042 0.124 .|. | .|. | 19 0.026 0.010 25.155 0.156 .|. | .|. | 20 0.034 0.019 25.345 0.189 .|. | .|. | 21 -0.025 -0.015 25.444 0.228 *|. | *|. | 22 -0.131 -0.128 28.333 0.165 .|** | .|* | 23 0.223 0.152 36.754 0.034 .|. | .|. | 24 -0.037 0.044 36.985 0.044 .|. | .|. | 25 -0.034 -0.039 37.180 0.056 .|. | .|. | 26 -0.022 -0.008 37.265 0.071 .|. | .|. | 27 0.042 -0.026 37.576 0.085 .|. | .|* | 28 0.031 0.116 37.747 0.103 *|. | *|. | 29 -0.149 -0.191 41.691 0.060 .|. | .|. | 30 0.031 -0.052 41.866 0.073 .|. | .|* | 31 -0.008 0.095 41.877 0.092 .|. | .|. | 32 0.059 -0.046 42.519 0.101 *|. | .|. | 33 -0.091 -0.042 44.054 0.095 .|. | .|. | 34 0.069 0.044 44.940 0.099 .|. | .|. | 35 -0.012 -0.001 44.966 0.121 .|. | .|. | 36 0.013 0.020 44.998 0.145
Dependent Variable: D(LOGBNP_CAP_AFPD) Method: Least Squares Date: 12/06/10 Time: 10:41 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGBNP_CAP_AFPD(-1) -0.850690 0.084391 -10.08032 0.0000

58
R-squared 0.424050 Mean dependent var 0.000352 Adjusted R-squared 0.424050 S.D. dependent var 0.058846 S.E. of regression 0.044659 Akaike info criterion -3.372346 Sum squared resid 0.275233 Schwarz criterion -3.351235 Log likelihood 235.3780 Hannan-Quinn criter. -3.363767 Durbin-Watson stat 2.020174
Null Hypothesis: LOGBNP_CAP_AFPD has a unit root Exogenous: None Lag Length: 3 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -3.441784 0.0007
Test critical values: 1% level -2.582076 5% level -1.943193 10% level -1.615157 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(LOGBNP_CAP_AFPD) Method: Least Squares Date: 12/02/10 Time: 12:57 Sample (adjusted): 1865 2000 Included observations: 136 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. LOGBNP_CAP_AFPD(-1) -0.464630 0.134997 -3.441784 0.0008
D(LOGBNP_CAP_AFPD(-1)) -0.447545 0.128554 -3.481370 0.0007 D(LOGBNP_CAP_AFPD(-2)) -0.357667 0.111311 -3.213224 0.0016 D(LOGBNP_CAP_AFPD(-3)) -0.226836 0.083396 -2.719980 0.0074
R-squared 0.470608 Mean dependent var 0.000135
Adjusted R-squared 0.458576 S.D. dependent var 0.057948 S.E. of regression 0.042639 Akaike info criterion -3.443110 Sum squared resid 0.239990 Schwarz criterion -3.357444 Log likelihood 238.1315 Hannan-Quinn criter. -3.408298 Durbin-Watson stat 1.987672
Null Hypothesis: LOGBNP_CAP_AFPD is stationary Exogenous: Constant Bandwidth: 1 (Newey-West automatic) using Bartlett kernel
LM-Stat. Kwiatkowski-Phillips-Schmidt-Shin test statistic 0.117133
Asymptotic critical values*: 1% level 0.739000 5% level 0.463000 10% level 0.347000 *Kwiatkowski-Phillips-Schmidt-Shin (1992, Table 1)

59
Residual variance (no correction) 0.001602 HAC corrected variance (Bartlett kernel) 0.001492
KPSS Test Equation Dependent Variable: LOGBNP_CAP_AFPD Method: Least Squares Date: 12/02/10 Time: 12:57 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.020234 0.003395 5.960343 0.0000 R-squared 0.000000 Mean dependent var 0.020234
Adjusted R-squared 0.000000 S.D. dependent var 0.040167 S.E. of regression 0.040167 Akaike info criterion -3.584442 Sum squared resid 0.224257 Schwarz criterion -3.563431 Log likelihood 251.9110 Hannan-Quinn criter. -3.575904 Durbin-Watson stat 2.131010
Enders testprocedur Dependent Variable: LOGKOLDIOXKGCAPD Method: Least Squares Date: 12/01/10 Time: 09:47 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. C 0.467909 0.183004 2.556824 0.0117
T 0.001827 0.001169 1.562574 0.1205 LOGKOLDIOXKGCAP(-1) -0.094262 0.043187 -2.182655 0.0308
LOGKOLDIOXKGCAPD(-1) -0.173770 0.085211 -2.039279 0.0434 R-squared 0.089237 Mean dependent var 0.022458
Adjusted R-squared 0.068998 S.D. dependent var 0.204714 S.E. of regression 0.197526 Akaike info criterion -0.377541 Sum squared resid 5.267215 Schwarz criterion -0.293096 Log likelihood 30.23911 Hannan-Quinn criter. -0.343225 F-statistic 4.409112 Durbin-Watson stat 2.020086 Prob(F-statistic) 0.005420
Dependent Variable: LOGBNP_CAP_AFPD Method: Least Squares Date: 12/01/10 Time: 09:53 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob.

60
C 0.731440 0.284582 2.570227 0.0112 T 0.001836 0.000714 2.569722 0.0113
LOGBNP_CAP_AFP(-1) -0.081416 0.032411 -2.512004 0.0132 LOGBNP_CAP_AFPD(-1) -0.038345 0.084838 -0.451982 0.6520
R-squared 0.051882 Mean dependent var 0.020450
Adjusted R-squared 0.030813 S.D. dependent var 0.040230 S.E. of regression 0.039605 Akaike info criterion -3.591348 Sum squared resid 0.211759 Schwarz criterion -3.506903 Log likelihood 253.5987 Hannan-Quinn criter. -3.557032 F-statistic 2.462446 Durbin-Watson stat 1.984468 Prob(F-statistic) 0.065243
Spuriös regression
Dependent Variable: LOGKOLDIOXKGCAP Method: Least Squares Date: 11/30/10 Time: 13:48 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C -5.756254 0.434448 -13.24957 0.0000
LOGBNP_CAP_AFP 1.129915 0.040008 28.24208 0.0000 R-squared 0.851593 Mean dependent var 6.471693
Adjusted R-squared 0.850526 S.D. dependent var 1.100185 S.E. of regression 0.425353 Akaike info criterion 1.142287 Sum squared resid 25.14856 Schwarz criterion 1.184113 Log likelihood -78.53121 Hannan-Quinn criter. 1.159283 F-statistic 797.6152 Durbin-Watson stat 0.200561 Prob(F-statistic) 0.000000
Dependent Variable: LOGKOLDIOXKGCAP Method: Least Squares Date: 11/29/10 Time: 17:01 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. LOGBNP_CAP_AFP 0.601628 0.004945 121.6735 0.0000 R-squared 0.664162 Mean dependent var 6.471693
Adjusted R-squared 0.664162 S.D. dependent var 1.100185 S.E. of regression 0.637574 Akaike info criterion 1.944775 Sum squared resid 56.91014 Schwarz criterion 1.965688 Log likelihood -136.1066 Hannan-Quinn criter. 1.953273 Durbin-Watson stat 0.094165
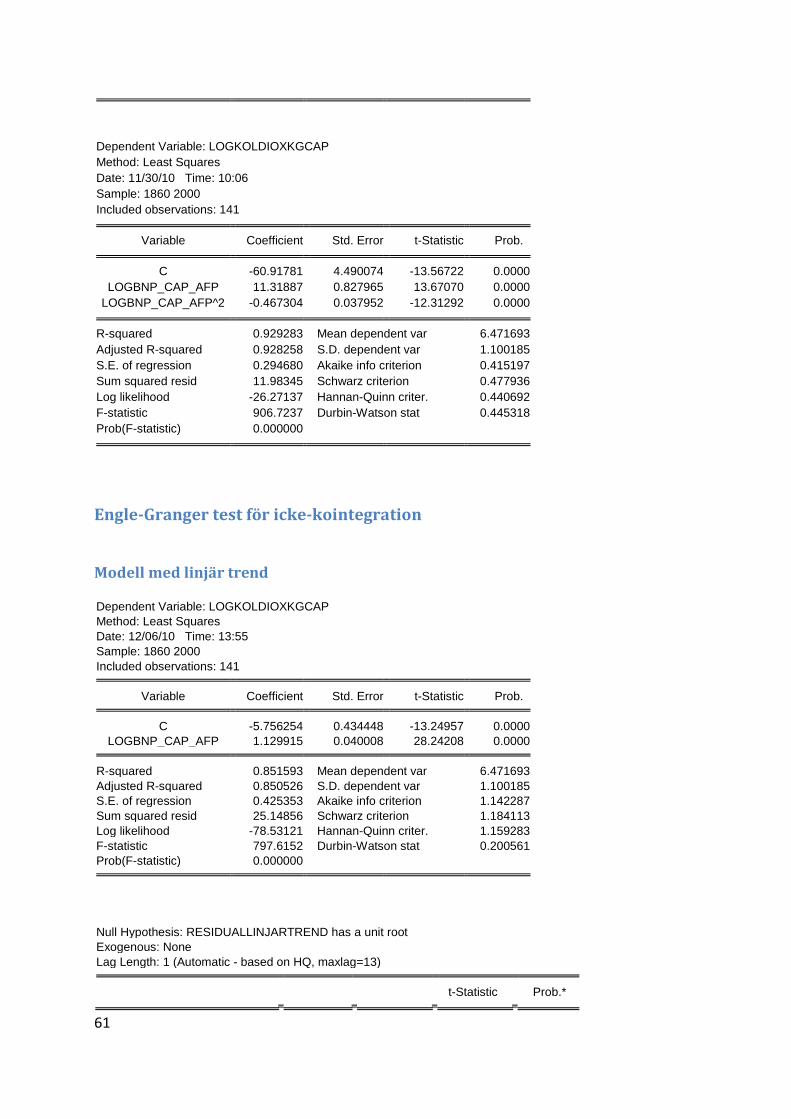
61
Dependent Variable: LOGKOLDIOXKGCAP Method: Least Squares Date: 11/30/10 Time: 10:06 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C -60.91781 4.490074 -13.56722 0.0000
LOGBNP_CAP_AFP 11.31887 0.827965 13.67070 0.0000 LOGBNP_CAP_AFP^2 -0.467304 0.037952 -12.31292 0.0000
R-squared 0.929283 Mean dependent var 6.471693
Adjusted R-squared 0.928258 S.D. dependent var 1.100185 S.E. of regression 0.294680 Akaike info criterion 0.415197 Sum squared resid 11.98345 Schwarz criterion 0.477936 Log likelihood -26.27137 Hannan-Quinn criter. 0.440692 F-statistic 906.7237 Durbin-Watson stat 0.445318 Prob(F-statistic) 0.000000
Engle-Granger test för icke-kointegration
Modell med linjär trend Dependent Variable: LOGKOLDIOXKGCAP Method: Least Squares Date: 12/06/10 Time: 13:55 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C -5.756254 0.434448 -13.24957 0.0000
LOGBNP_CAP_AFP 1.129915 0.040008 28.24208 0.0000 R-squared 0.851593 Mean dependent var 6.471693
Adjusted R-squared 0.850526 S.D. dependent var 1.100185 S.E. of regression 0.425353 Akaike info criterion 1.142287 Sum squared resid 25.14856 Schwarz criterion 1.184113 Log likelihood -78.53121 Hannan-Quinn criter. 1.159283 F-statistic 797.6152 Durbin-Watson stat 0.200561 Prob(F-statistic) 0.000000
Null Hypothesis: RESIDUALLINJARTREND has a unit root Exogenous: None Lag Length: 1 (Automatic - based on HQ, maxlag=13)
t-Statistic Prob.*

62
Augmented Dickey-Fuller test statistic -2.177658 0.0288 Test critical values: 1% level -2.581705
5% level -1.943140 10% level -1.615189 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(RESIDUALLINJARTREND) Method: Least Squares Date: 12/06/10 Time: 14:32 Sample (adjusted): 1862 2000 Included observations: 139 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. RESIDUALLINJARTREND(-1) -0.083884 0.038520 -2.177658 0.0311
D(RESIDUALLINJARTREND(-1)) -0.194901 0.083102 -2.345322 0.0204 R-squared 0.086761 Mean dependent var -0.000649
Adjusted R-squared 0.080095 S.D. dependent var 0.190016 S.E. of regression 0.182248 Akaike info criterion -0.552615 Sum squared resid 4.550353 Schwarz criterion -0.510392 Log likelihood 40.40674 Hannan-Quinn criter. -0.535457 Durbin-Watson stat 2.029541
Kuznet’s ekvation
Dependent Variable: LOGKOLDIOXKGCAP Method: Least Squares Date: 12/06/10 Time: 13:57 Sample: 1860 2000 Included observations: 141
Variable Coefficient Std. Error t-Statistic Prob. C -60.91781 4.490074 -13.56722 0.0000
LOGBNP_CAP_AFP 11.31887 0.827965 13.67070 0.0000 LOGBNP_CAP_AFP^2 -0.467304 0.037952 -12.31292 0.0000
R-squared 0.929283 Mean dependent var 6.471693
Adjusted R-squared 0.928258 S.D. dependent var 1.100185 S.E. of regression 0.294680 Akaike info criterion 0.415197 Sum squared resid 11.98345 Schwarz criterion 0.477936 Log likelihood -26.27137 Hannan-Quinn criter. 0.440692 F-statistic 906.7237 Durbin-Watson stat 0.445318 Prob(F-statistic) 0.000000
Null Hypothesis: RESIDKUZNETS has a unit root Exogenous: None Lag Length: 0 (Automatic - based on HQ, maxlag=13)

63
t-Statistic Prob.* Augmented Dickey-Fuller test statistic -4.309710 0.0000
Test critical values: 1% level -2.581584 5% level -1.943123 10% level -1.615200 *MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation Dependent Variable: D(RESIDKUZNETS) Method: Least Squares Date: 12/06/10 Time: 14:31 Sample (adjusted): 1861 2000 Included observations: 140 after adjustments
Variable Coefficient Std. Error t-Statistic Prob. RESIDKUZNETS(-1) -0.229757 0.053312 -4.309710 0.0000 R-squared 0.117828 Mean dependent var 0.001390
Adjusted R-squared 0.117828 S.D. dependent var 0.195933 S.E. of regression 0.184028 Akaike info criterion -0.540339 Sum squared resid 4.707425 Schwarz criterion -0.519327 Log likelihood 38.82371 Hannan-Quinn criter. -0.531800 Durbin-Watson stat 2.232098

64
Dickey-Fuller kritiska värden
LogKoldioxid t=100 t=200 Intercept=0,25 -2,393 -2,156
LogBnp t=100 t=200 Intercept=0 -2,897 -2,878
Dlogkoldioxid t=100 t=200 Utan intercept -1,945 -1,938
Dlogbnp t=100 t=200 Utan intercept -1,945 -1,938
Kvadreradlogbnp t=100 t=200 Intercept=0,1 -2,807 -2,717
DKvadreradlogbnp t=100 t=200 Intercept=0,5 -2,018 -1,888
Källa: Patterson 2000 s.232
Kritiska värden för modell val
F-test av modellval för logbnp enligt ekvation 3.5.4
Inkluderat RSS T k F-värde Kritiskt värde none 0,22406 140 1
t=100 t=200
intercept&trend 0,212156 140 3 3,843511 6,606 6,397
F-test av modellval för logkoldioxid enligt ekvation 3.5.4
Inkluderat RSS T k F-värde Kritiskt värde none 5,561995 139 1
t=100 t=200
intercept&trend 5,267215 139 3 3,805624 6,606 6,397 Källa för kritiska värden: Patterson 2000, s.234

65
Engle-Granger kritiska värden
Tabell med kritiska värden:
Obs Krit. värde intercept utan trend intercept, trend och kvadratisk trend 139 -3,3805 -3,8025 Källa: http://www.econ.queensu.ca/faculty/mackinnon/
Kritiska värden för justerad testprocedur
Är 𝛾 = 0? T=100 Kritiskt värde -3,45
Är β= 0? T=100 Kritiskt värde 2,79 Källa: Enders 2004, s.223