Embed Size (px)
Citation preview

IN DEGREE PROJECT INFORMATION AND COMMUNICATION TECHNOLOGYSECOND CYCLE 60 CREDITS
STOCKHOLM SWEDEN 2017
FPGA Hardware Acceleration of Inception Style Parameter Reduced Convolution Neural Networks
KALLE NGO
KTH ROYAL INSTITUTE OF TECHNOLOGYSCHOOL OF INFORMATION AND COMMUNICATION TECHNOLOGY
ccopy Kalle Ngo December 2016
Abstract
Some researchers have noted that the growth rate in the number of networkparameters of many recently proposed state-of-the-art CNN topologies is placingunrealistic demands on hardware resources and limits the practical applicationsof Neural Networks This is particularly apparent when considering many of theprojected applications (IoT autonomous vehicles etc) utilize embedded systemswith even greater restrictions on computation and memory bandwidth than thetypical research-class computer cluster that the CNN was designed on
The GoogLeNet CNN in 2014 proposed a new level of organization (ldquoInceptionModulerdquo) that was demonstrated in competition to achieve similarbetter performancewhile using an order of magnitude less network parameters than the othercompeting topologies
This thesis explores the characteristics of the new GoogLeNet inceptionmodules and the implications it presents to current CNN accelerator architecturesA custom FPGA accelerator is proposed to offset the inception modulersquos increasedneed to buffer large intermediate convolution arrays through array partitioning andcascading two convolution operations into a single pipeline pass
A Xilinx Artix-7 FPGA was used to implement architecture where it was ablecontinuously supply data to the 331 utilized DSP blocks (approx half of totalavailable) while using only a quarter of the DDR bandwidth to achieve a peakthroughput of 911 GFLOPS The low utilization of the DDR bandwidth suggeststhat with some optimization the design can be scaled up to better utilize theavailable resources and increase throughput
i
Contents
1 Introduction 111 Problem description 112 Research Objectives 213 Structure thesis 2
2 Background 421 The Perceptron 4
211 Activation Function 522 Artificial Neural Networks 6
221 Multilayer Perceptron 6222 Convolutional Neural Networks 6
23 Convolutional Neural Networks Topology 9231 AlexNet 9232 OverFeat 10233 GoogLeNet 11
3 Related Works 1431 State of Neural Networks Today 1532 Architecture 17
321 Core Processing Element 173211 Time-Division Processing 173212 Matrix Processing 183213 Systolic Array 19
4 Architectural Design 2041 Design Exploration 20
411 GoogLeNet Inception Module 20412 Memory Structure 22413 Data Dependency 24414 Hardware Reuse 25
42 Proposed Architecture 26
ii
CONTENTS iii
421 Data Partitioning 264211 Depth Slicing 264212 Static Width 28
422 Convolution Cascade 30423 Processing Topology 30
5 Implementation and Analysis 32501 Processing Elements 32
5011 Streaming Convolution 335012 Square Convolution 35
502 Accelerator Control 37503 Data Transfer 38
6 Results 4061 Testing Limitations 40
611 Performance 416111 Memory Bandwidth 416112 Floating Point Throughput 42
612 Efficiency 43
7 Conclusions 4471 Conclusion 4472 Future work 44
Bibliography 46
A Vivado Reports 52
List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

ccopy Kalle Ngo December 2016
Abstract
Some researchers have noted that the growth rate in the number of networkparameters of many recently proposed state-of-the-art CNN topologies is placingunrealistic demands on hardware resources and limits the practical applicationsof Neural Networks This is particularly apparent when considering many of theprojected applications (IoT autonomous vehicles etc) utilize embedded systemswith even greater restrictions on computation and memory bandwidth than thetypical research-class computer cluster that the CNN was designed on
The GoogLeNet CNN in 2014 proposed a new level of organization (ldquoInceptionModulerdquo) that was demonstrated in competition to achieve similarbetter performancewhile using an order of magnitude less network parameters than the othercompeting topologies
This thesis explores the characteristics of the new GoogLeNet inceptionmodules and the implications it presents to current CNN accelerator architecturesA custom FPGA accelerator is proposed to offset the inception modulersquos increasedneed to buffer large intermediate convolution arrays through array partitioning andcascading two convolution operations into a single pipeline pass
A Xilinx Artix-7 FPGA was used to implement architecture where it was ablecontinuously supply data to the 331 utilized DSP blocks (approx half of totalavailable) while using only a quarter of the DDR bandwidth to achieve a peakthroughput of 911 GFLOPS The low utilization of the DDR bandwidth suggeststhat with some optimization the design can be scaled up to better utilize theavailable resources and increase throughput
i
Contents
1 Introduction 111 Problem description 112 Research Objectives 213 Structure thesis 2
2 Background 421 The Perceptron 4
211 Activation Function 522 Artificial Neural Networks 6
221 Multilayer Perceptron 6222 Convolutional Neural Networks 6
23 Convolutional Neural Networks Topology 9231 AlexNet 9232 OverFeat 10233 GoogLeNet 11
3 Related Works 1431 State of Neural Networks Today 1532 Architecture 17
321 Core Processing Element 173211 Time-Division Processing 173212 Matrix Processing 183213 Systolic Array 19
4 Architectural Design 2041 Design Exploration 20
411 GoogLeNet Inception Module 20412 Memory Structure 22413 Data Dependency 24414 Hardware Reuse 25
42 Proposed Architecture 26
ii
CONTENTS iii
421 Data Partitioning 264211 Depth Slicing 264212 Static Width 28
422 Convolution Cascade 30423 Processing Topology 30
5 Implementation and Analysis 32501 Processing Elements 32
5011 Streaming Convolution 335012 Square Convolution 35
502 Accelerator Control 37503 Data Transfer 38
6 Results 4061 Testing Limitations 40
611 Performance 416111 Memory Bandwidth 416112 Floating Point Throughput 42
612 Efficiency 43
7 Conclusions 4471 Conclusion 4472 Future work 44
Bibliography 46
A Vivado Reports 52
List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Abstract
Some researchers have noted that the growth rate in the number of networkparameters of many recently proposed state-of-the-art CNN topologies is placingunrealistic demands on hardware resources and limits the practical applicationsof Neural Networks This is particularly apparent when considering many of theprojected applications (IoT autonomous vehicles etc) utilize embedded systemswith even greater restrictions on computation and memory bandwidth than thetypical research-class computer cluster that the CNN was designed on
The GoogLeNet CNN in 2014 proposed a new level of organization (ldquoInceptionModulerdquo) that was demonstrated in competition to achieve similarbetter performancewhile using an order of magnitude less network parameters than the othercompeting topologies
This thesis explores the characteristics of the new GoogLeNet inceptionmodules and the implications it presents to current CNN accelerator architecturesA custom FPGA accelerator is proposed to offset the inception modulersquos increasedneed to buffer large intermediate convolution arrays through array partitioning andcascading two convolution operations into a single pipeline pass
A Xilinx Artix-7 FPGA was used to implement architecture where it was ablecontinuously supply data to the 331 utilized DSP blocks (approx half of totalavailable) while using only a quarter of the DDR bandwidth to achieve a peakthroughput of 911 GFLOPS The low utilization of the DDR bandwidth suggeststhat with some optimization the design can be scaled up to better utilize theavailable resources and increase throughput
i
Contents
1 Introduction 111 Problem description 112 Research Objectives 213 Structure thesis 2
2 Background 421 The Perceptron 4
211 Activation Function 522 Artificial Neural Networks 6
221 Multilayer Perceptron 6222 Convolutional Neural Networks 6
23 Convolutional Neural Networks Topology 9231 AlexNet 9232 OverFeat 10233 GoogLeNet 11
3 Related Works 1431 State of Neural Networks Today 1532 Architecture 17
321 Core Processing Element 173211 Time-Division Processing 173212 Matrix Processing 183213 Systolic Array 19
4 Architectural Design 2041 Design Exploration 20
411 GoogLeNet Inception Module 20412 Memory Structure 22413 Data Dependency 24414 Hardware Reuse 25
42 Proposed Architecture 26
ii
CONTENTS iii
421 Data Partitioning 264211 Depth Slicing 264212 Static Width 28
422 Convolution Cascade 30423 Processing Topology 30
5 Implementation and Analysis 32501 Processing Elements 32
5011 Streaming Convolution 335012 Square Convolution 35
502 Accelerator Control 37503 Data Transfer 38
6 Results 4061 Testing Limitations 40
611 Performance 416111 Memory Bandwidth 416112 Floating Point Throughput 42
612 Efficiency 43
7 Conclusions 4471 Conclusion 4472 Future work 44
Bibliography 46
A Vivado Reports 52
List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Contents
1 Introduction 111 Problem description 112 Research Objectives 213 Structure thesis 2
2 Background 421 The Perceptron 4
211 Activation Function 522 Artificial Neural Networks 6
221 Multilayer Perceptron 6222 Convolutional Neural Networks 6
23 Convolutional Neural Networks Topology 9231 AlexNet 9232 OverFeat 10233 GoogLeNet 11
3 Related Works 1431 State of Neural Networks Today 1532 Architecture 17
321 Core Processing Element 173211 Time-Division Processing 173212 Matrix Processing 183213 Systolic Array 19
4 Architectural Design 2041 Design Exploration 20
411 GoogLeNet Inception Module 20412 Memory Structure 22413 Data Dependency 24414 Hardware Reuse 25
42 Proposed Architecture 26
ii
CONTENTS iii
421 Data Partitioning 264211 Depth Slicing 264212 Static Width 28
422 Convolution Cascade 30423 Processing Topology 30
5 Implementation and Analysis 32501 Processing Elements 32
5011 Streaming Convolution 335012 Square Convolution 35
502 Accelerator Control 37503 Data Transfer 38
6 Results 4061 Testing Limitations 40
611 Performance 416111 Memory Bandwidth 416112 Floating Point Throughput 42
612 Efficiency 43
7 Conclusions 4471 Conclusion 4472 Future work 44
Bibliography 46
A Vivado Reports 52
List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

CONTENTS iii
421 Data Partitioning 264211 Depth Slicing 264212 Static Width 28
422 Convolution Cascade 30423 Processing Topology 30
5 Implementation and Analysis 32501 Processing Elements 32
5011 Streaming Convolution 335012 Square Convolution 35
502 Accelerator Control 37503 Data Transfer 38
6 Results 4061 Testing Limitations 40
611 Performance 416111 Memory Bandwidth 416112 Floating Point Throughput 42
612 Efficiency 43
7 Conclusions 4471 Conclusion 4472 Future work 44
Bibliography 46
A Vivado Reports 52
List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

List of Figures
21 Mathematical Model of a Neuron 422 Multi-Layer Perceptrion 623 Example CNN Network 724 Convolution 825 CNN downsampling with MaxPooling and stride 2 826 Convolution Filter Kernels [1] 927 AlexNet Topology from [1] Image cropping found on original 1028 GoogLeNet Topology from [2] 11210 Inception Module 12
31 Common Inner-production structures 1732 Example Systolic Array [3] 19
41 Modular Topology 2042 Inception Module 2143 Network Parameters of Inception Modules 2344 Next stage is delayed until output array is complete (blue layer) 2445 Partitioned sub-array requires neighboring elements to complete
convolution 2946 Streaming Convolution Array Access Pattern 3047 Conceptual Parallel Processing Element Layout 31
51 Processing Element Architecture 3252 Utilization Report Multiply Unit (HLS Version) 3453 Utilization Report Accumulator Unit (HLS Version) 3454 Convolution Buffer Array 3555 Shift Register Buffer 3656 Utilization Report 5x5 Convolution with two core molecules 3757 Hardware Accelerator System View 38
A1 Power Estimation 52A2 Test System Utilization 53
iv
LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

LIST OF FIGURES v
A3 Test System Utilization 53A4 Implementation Topology 54
List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

List of Tables
21 Common Activation Functions 5
41 GoogleNet Network Topology [2] 2142 Array Memory Usage 2243 Partitioning 3 New Static Array Sizes 28
61 Pipeline Latency for different DDR access patterns 4162 Measured Throughput 42
vi
Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 1
Introduction
Conventional computers have demonstrated near undisputed superiority over thehuman brain in highly structured logic tasks and mathematical computationIntrinsically digital logicrsquos dependence on rigid rules and absolute order limitsitrsquos ability to interpret information from an analog world The Artificial NeuralNetwork (ANN) in contrast to modern computers excel in non-absolute domainssuch as pattern recognition classification and interpretation of incomplete data
The capability of a particular ANN although dependent on many factors canbe fundamentally simplified to be a proportional relationship to the networkrsquoscomplexity (network nodes and connections) Consequently as complexityincreases training (liken to programming the computer) of ANNs suffer fromthe ldquoCurse of Dimensionalityrdquo the time to derive the network weights by iterativeexploration exhibits a factorial time complexity O(n) and can quickly exceed theage of the known universe (even with small networks) Modern research emphasishas been largely concentrated on learning algorithm development and networktopology design
Current applications of neural network have largely been academic withrelatively limited real world implementations such as character recognition inpostal centres medical diagnosis and image processingrecognition by searchengines Most of these real world neural network implementations are utilizedin specialized industrial installations adapting computer graphics processors ornetworked cloud computing
11 Problem descriptionThe current technological advance towards smart context aware systems andautonomous vehicles only accelerates the transition of ANN from researchsupercomputers to applications in embedded systems and further emphasizes the
1
12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

12 RESEARCH OBJECTIVES 2
need for a capable cost conscious hardware solutionWhile FPGA implementation is ideal due to itrsquos compatibility with the highly
parallel characteristics of ANNs there is always the problem of limited fast on-chip memory necessitating the movement of data across physical chip boundariescausing bandwidth bottlenecks that limit FPGA parallelism
The majority of current solutions are variations that are specifically optimizedfor the limited resources found on embedded systems Even with these optimizationsmany of the current proposed architectures are unable to cope with large datasizes without resorting to using the off-chip storage as the working (Scratch-pad)memory
12 Research ObjectivesThe research objectives pursued in this thesis include
bull Determine the forward-pass resource requirements of a typical ldquoresearchclassrdquo artificial neural network Leading neural network designs will bereferenced from the ILSVRC challenges 1 to ensure an accurate representationsof current state-of-the-art research networks
bull Develop a suitable architecture to meet the computation and memorydemands from the established requirements with modular design to allowfor scaling to implement larger networks
bull Design and test a hardware reference prototype utilizing a Xilinx Artix7FPGA to implement the core CNN processing architecture
13 Structure thesisThis exploration is based in the field of Electronic Systems but spans to includeArtificial neural networks (a field of Machine Learning) with emphasis onexploring hardware solutions for FPGA based embedded systems
Due to the combined research fields this report has been written to includereaders from both disciplines therefore some sections may seem overtly detailedand can be skipped at readerrsquos discretion
bull Chapter 1 describes the problem and its context
1 The ImageNet Large Scale Visual Recognition Challenge (ILSVRC) is an annual event thatevaluates algorithms for object detection and image classification and provides a uniform datasetfor training and evaluation
13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

13 STRUCTURE THESIS 3
bull Chapter 2 provides a simplified background on Artificial Neural Networksand their operations and only covers the depth necessary to understand theproblem under the context of this thesis
bull Chapter 3 contains an exploration of the current state of both fields aswell as architectural solutions commonly applied towards neural networkimplementation
bull Chapter 4 establishes the requirements and is formatted as an ongoingdiscussion in reaching the proposed solution
bull The following 2 chapters involve the physical realization of the principlesdescribed in Chapter 4 and a critical evaluation of the implemented design
bull Chapter 7 offers final conclusions and suggestions on future work anddirection
Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 2
Background
21 The PerceptronThe Neuron is the basic building block of Artificial Neural Networks (ANN) andcan be likened to the logic gate of digital logic circuits First described by FrankRosenblatt in his 1958 paper [4] its design was inspired from the arrangementof neurons found in brain tissue This artificial neuron is often referred to as aPerceptron and consists of one or more inputs a rdquoprocessorrdquo node and an outputThe value of the output is determined by taking the weighted sum of the inputsand evaluating against an activation function
x2 w2 Σ f
Activatefunction
yOutput
x1 w1
x3 w3
Weights
Biasb
Inputs
Figure 21 Mathematical Model of a Neuron
Information incoming to the neuron is multiplied by a weight value that isexclusive to that input and neuron These weighted inputs are then summedtogether along with an optional rdquobiasrdquo value The bias acts as a magnitude offsetfor the summation and regulates the neurons rdquoswitchingrdquo region and sensitivityThe rdquoprogrammingrdquo of an Artificial Neural Network (ANN) structure are the
4
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
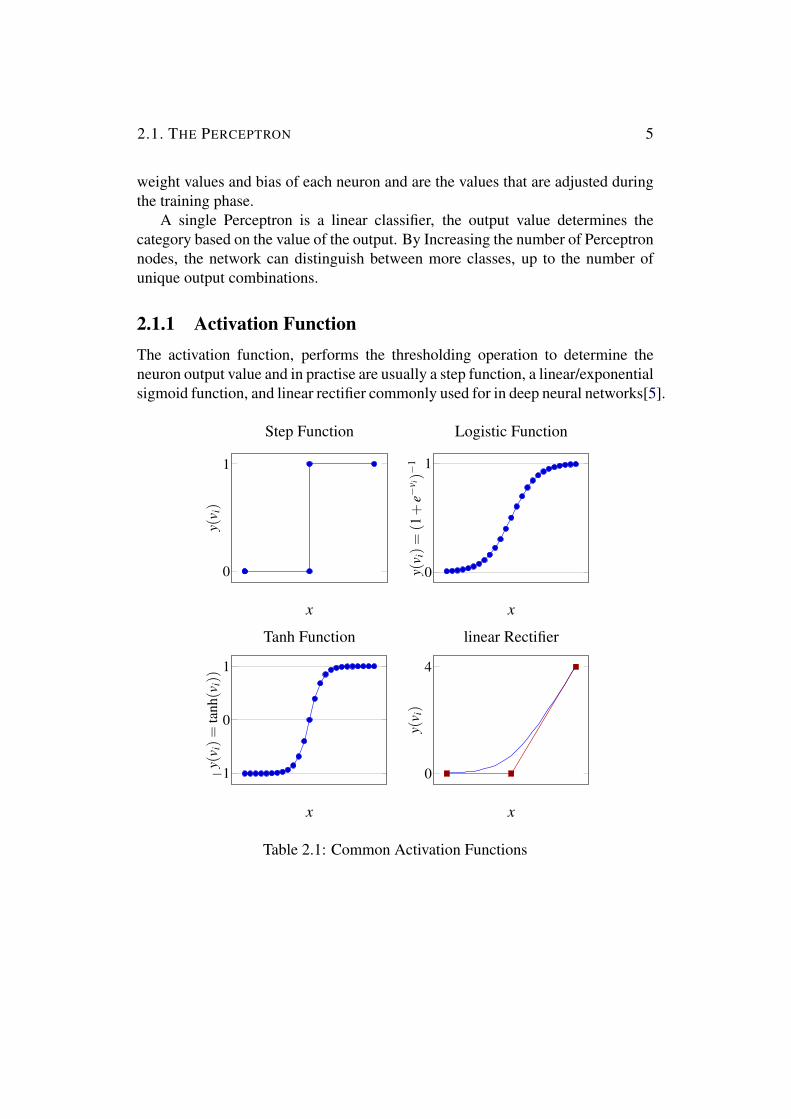
21 THE PERCEPTRON 5
weight values and bias of each neuron and are the values that are adjusted duringthe training phase
A single Perceptron is a linear classifier the output value determines thecategory based on the value of the output By Increasing the number of Perceptronnodes the network can distinguish between more classes up to the number ofunique output combinations
211 Activation FunctionThe activation function performs the thresholding operation to determine theneuron output value and in practise are usually a step function a linearexponentialsigmoid function and linear rectifier commonly used for in deep neural networks[5]
0
1
x
y(v i)
Step Function
0
1
x
y(v i)=(1
+eminus
v i)minus
1
Logistic Function
minus1
0
1
x
y(v i)=
tanh(v
i))
Tanh Function
0
4
x
y(v i)
linear Rectifier
Table 21 Common Activation Functions
22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

22 ARTIFICIAL NEURAL NETWORKS 6
22 Artificial Neural Networks
221 Multilayer PerceptronThe Multilayer Perceptron (MLP) is a modification of the single layer Perceptronto enable classification of non-linearly separable data and commonly referred toas the rdquoFCrdquo (Fully Connected) layer when used in conjunction with other networktopologies MLPs always consists of 2 or more layers where the ldquoHidden Layersrdquorefers to the neurons between the input and output layer
I1
I2
I3
In
H1
Hn
O1
On
Inputlayer
Hiddenlayer
Ouputlayer
Figure 22 Multi-Layer Perceptrion
The MLP is the most basic configuration of the Feed-Forward class of neuralnetworks where the propagation of data only travels from input to the outputlayers during implementation (Recall Phase) This is in contrast to other classessuch as the Recurrent Neural Networks (RNN) with internal states that allow itto exhibit temporal behaviours RNNs are used in applications where events aredistinguished in a serial manner (either by location or time) such as in speech andhandwriting recognition of words or letters
222 Convolutional Neural NetworksLike MLPs Convolutional Neural Network (CNN) belong to the feed-forwardclass of ANNs and are most mainly used for vision applications This networkstructure was motivated from studies of the animal visual cortex where individualneurons were found to be responsive in small over lapping regions of the visual
22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

22 ARTIFICIAL NEURAL NETWORKS 7
Figure 23 Example CNN Network
field in contrast an MLP style structure would require every neuron in the inputlayer to receive information from every pixel of the visual field
CNNs perform rudimentary information extraction by leveraging the spatialstructure found in vision derived data The convolutions serve as preprocessing tofilter and abstract the pixels of visual field into logical ldquofeaturesrdquo that are fractionsof the original data volume This reduction enables far less FC neuron layers toanalyze for recognition and classification
As an analogy in asking a friend over the phone to help identify an object on aphotograph describing the position and colour of every pixel is a poor approachinstead it is more efficient to describe the distinguishing features such as handlebars 2 wheels a seat pedals etc In this way much of the information in thephoto such as sky colour road texture etc are unnecessary for the purpose ofidentifying the bicycle
The 2D Convolution is the core operation that performs the preprocessingabstraction Heavily utilized in the field of signal processing it is an adaptation ofthe mathematical discreet convolution into 2D space The function fundamentallycalculates cross-correlation between 2 matrices and outputs a scalar value thatcorresponds to how similar the input is to the kernel
y[mn] = (b+Kminus1
sumk=1
Lminus1
suml=1
w[k l]x[m+ kn+1]) (21)
The convolution equation 21 where y[mn] is the output matrix map of samedimensions as the input map x m and n are the coordinates of the rdquocenterrdquo pixel ofthe interest region and L K denote the kernel dimensions The convolution kernelrdquoslidesrdquo across the input until the entire image has been traversed as depicted in24a
The convolution kernel values stay constant throughout the frame traversalwith the output map containing correlation values of how strongly a particularinput region displays the kernel feature Each layer of the CNN distinguishmultiple features with independent convolutions each with a distinct kernel Each
22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

22 ARTIFICIAL NEURAL NETWORKS 8
of these convolutions are stored in a unique buffer forming the multiple featuremaps of 23
Input Map
1 2 3 4 5 6
7 81 2 3
7 8
Convolution
Kernel
Output Map
a bc d
ef
g h
(a) Sliding Window Kernel
(ktimesltimes
n)
Convolution
Kernel
Height
Width
nChannels
(b) Three Channel RGB Input Map
Figure 24 Convolution
A common simplification used to learn basic CNN operation is to considerinput image and kernels as two-dimensional arrays but in practice multichannelinputs such as RGB or the combine output feature maps form three-dimensionaldata volumes that utilize similarly three-dimensional convolution kernels Thisenables CNNs to distinguish higher order correlations such as colour and texturesand numerical relations
RGB Input
MapSlid
ing
WindowConvolutio
n
Feature Map
2 1 7 9 5 3
1 6
Pooling
Stride 22 7
1 6
Downsampled
Feature Map
7
Figure 25 CNN downsampling with MaxPooling and stride 2
In most CNN networks such as the fictional 23 it typical for CNN networksto utilize Pooling Layers combined with a stride These Pooling layers combine
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 9
the output of neuron clusters to improve generalization and also perform non-linear down-sampling
The stride dictates the amount of pixels the kernel advances per iteration astride of greater then one results in a dimension reduction of the output by samefactor value Down-sampling is not restricted to only Pooling layers but stride canalso be specified on convolution layers to perform dimensional down-samplingwithout generalizing
There are several pooling functions with MaxPooling being most commona MaxPool function searches for the maximum value in the pooling kernel andsubsequently passes only that value to the output map buffer 25
Figure 26 Convolution Filter Kernels [1]
The convolution Kernels from AlexNet (discussed in Section 231) arevisualized in figure 26 and correspond to the 96 filters of 11x11x3 pixels inthe first layer Patterns found in the visualization are the features each convolutionlooks for in the input image The filters from deeper layers become increasinglyabstract and can not be accurately visualize as they are believed to represent higherorder relationships such as numerical counts orientation etc These combinedfeature maps can be thought of as an extension of the RGB colour channels torepresent higher order features
23 Convolutional Neural Networks Topology
231 AlexNetIn 2012 Krizhevsky et al presented a network design that significantly outperformedthe second runner up in the ILSRC 2012 (top 5 error of 164 compared to runner-up with 258 error) Their paper [1] has since been widely cited by subsequentresearch and has lead the field to shift toward the widespread adaptation andresearch of deep CNN for computer vision tasks [6] Although the topology wassimilar to the pioneering 1989 LeNet [7] AlexNet was much larger and most
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 10
Figure 27 AlexNet Topology from [1]Image cropping found on original
notably featured multiple convolution layers consecutively stacked on top of eachother when other CNN commonly only had 1 convolution layer followed by aPooling layer
The success of their neural network can attributed to several factors but ismainly focused on allowing for the efficient training of deep neural networksThey employed a novel regularization method termed dropout to reduce theoverfitting1 that plagues deep neural network training with finite datasets Thedropout method allowed them to train a large network able to distinguish RGBcolour with a massive 60 million parameters
The AlexNet CNN 27 consists of 8 weight layers with the first 5 beingConvolutional and followed by 3 fully connected classification layersThe splitsfound between the layers were a consequence of the limited memory requiring thenetwork residing on two separate GPUs Training the network with two high-endGTX 580 3GB GPUs took 5 to 6 days with the the GPU memory and the trainingtime limiting the network size
232 OverFeatOverFeat[8] participated in the ILSRC2013 with a CNN network based on theprevious year winner AlexNet This CNN somewhat represents a scaled upderivative with more than double the network weights 125 million compared tothe 60 million of AlexNet
This doubling in network weights pushed the classification error rate downto 142 although it is important to note that this network participated in a newobject localization challenge introduced that year this additional capability mayaffect the performance gains of scaling neural networks
The increased parameters results in 580MB of network weights that must be
1 When a statistical model is excessively complex and describes random errornoise instead of theunderlying relationship Occurs due to iterative network training over a finite dataset
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 11
read during a single forward pass in order to classify a single 221x221 pixel imageframe
For real time video processing ay 30fps this represents a massive computationload with memory bandwidth requirements at 175GBsec just for the networkweights transfer and does not including storage and retrieval of any intermediateresults
233 GoogLeNet
Figure 28 GoogLeNet Topology from [2]
During ILSRC2014 challenge there was a noticeable adaptation towardstopologies belonging to a category dubbed Very Deep Convolutional NeuralNetwork and displayed much higher network layer counts doubling the typicalnumber layers of 2013 These emerging Very Deep networks such as the 2014runner-up VGGNet [9] contained 19 layers but the total neuron connectionsstayed approximately the same as the 8 layer AlexNet This in part due to usingsmaller kernel sizes such as 3x3 and shifting to those resources to constructingthe network deeper
The GoogLeNet network by Szegedy et al[2] introduced a novel approachby integrating several Inception modules together to form a Network-in-Networktopology similarly described in [10] The resulting network consisted of 22 Layerswith the winning top-5 error rate of 666 The significance of their topology isapparent when considering they were able to achieve this accuracy with an orderof magnitude fewer parameters (4M compared to AlexNet with 60M VGGNetwith 143M) resulting in a weight file of only 272MB
The dramatic reduction in parameters is due to the introduction of Inceptionmodules and in part by replacing the fully connected layers with an AveragePoolingto create the output classification
Szegedy et al noted that the recent growth trend of network size came with acorresponding increase in network weight parameters they speculated that if this
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 12
(a) Filter depth optimized for locality (b) Simplified Module
trend continued it could diminish neural networks into a field of purely academiccuriosity Due to their observation they developed GoogLeNet while balancingaccuracy with computational and memory bandwidth
The Inception module from Szegedy et al exploits a tendency for localcorrelations in images By allocating the number of filters accordingly (Figure29a) it is possible to capture a high number of features and cover a larger spatialarea without a dramatic increase in resource utilization[11]
Figure 210 Inception Module
Figure 29b depicts a simplified module where a staggered series of 1x1 3x3and 5x5 convolutions is performed and combined to produce the module outputDue to the depth of the network trivial 5x5 convolutions can be prohibitivelyexpensive when performed on an input with a large number of feature maps[12]
To alleviate this Szegedy et al used 1x1 sized convolutions to reduce thedimensions before the expensive 3x3 and 5x5 filters The 1x1 operations actas a form of compression with a 1x1 convolution kernel that can be trained towork in conjunction with the following 3x3 or 5x5 filter operations This allowGoogLeNet to chain 9 Inception modules in series while maintaining a reasonable15 billion multiply-accumulates for a forward recall pass
The network successfully demonstrated that smaller convolutions of varying
23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

23 CONVOLUTIONAL NEURAL NETWORKS TOPOLOGY 13
sizes are able to differentiate features just as well as a typical single largecontiguous filter but with the benefit of significantly reducing the necessarynetwork weight parameters This reduction of parameters does come at a costdue to the multiple stages of back-to-back convolutions the network topologyproduces many large intermediate arrays that consume buffer space and will to beinvestigated to determine if the reduced parameters translates to a total reductionin requirements
Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 3
Related Works
Many earlier proposed systems were faced with the challenges of limited FPGAsgate capacities and lead to a compromise in arithmetic precision[13] or in thecase of [14] required 30 Xilinx XC3090 FPGAs to implement the relativelysmall (by todayrsquos standards) MLP network To make matters worse the mostdirect known method of improving neural network performance is to simplyincrease network size [2] consequently even with the modern increased capacityof FPGAs specialized DSP blocks and runtime reconfiguration there will alwaysbe an unbridgeable divide between theoretical network design and realizablecapacity
The most straightforward CNN implementation with ideal performance is tosimply map every neuron and connection directly onto the FPGA This wouldbe prohibitively expensive and realistically infeasible for nearly any modernlarge artificial neural networks The finite density of FPGAs have lead tosolutions that break down the neural network into smaller manageable portionsfor computations
While this divide-and-conquer methodology provides greater functional densityit comes at a cost by storing the unused network portions off chip memorybandwidth is fast becoming the limiting factor unable to keep up with the rawcomputation power of modern FPGAs
The majority of CNN solutions take inspiration from the SIMD vectorprocessors of the GPUs commonly used for ANN development Leveraging theGPU architectural reliance on program counter and instruction issues in order toemulate any ANN by breaking the topology down to an ambiguous massive seriesof floating point calculations
Sankaradas et al [15] employed this principle on a Xilinx Virtex5 to builda general purpose FPGA CNN accelerator with a custom pipeline optimizedfor floating point multiply accumulate Their prototype was tested to under-perform the theoretical potential by a large margin (337 vs 115 GMACs) and
14
31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

31 STATE OF NEURAL NETWORKS TODAY 15
was attributed to the bottleneck in data access to off-chip memory A similarconclusion is found by [16] where a custom pipeline ANN (requiring researchers3 man years to complete) is compared to an IP derived vector coprocessor Theyfound both processors to yield similar performance when memory becomes thebottleneck
CNNs characteristically exhibit deterministic data access patterns by exploitingthis property with loop optimization techniques[17] and careful cache design[18]it is possible to maximize data reuse and reduce off-chip transfers In the paper[19] Zang et al evaluates these techniques along with Loop nest optimizationusing the polytope method1 using the roofline model[21] to address the issue offinding an efficient balance of the above optimizations to improve performanceand reduce FPGA area
Although their prototype posted high throughput it was still memory boundto 6162 GFLPOS of their calculated 100 GFLOPS computational roof Alsothe choice to only use layer 1-5 (out of 8) of their test network[1] creates anartificially high CTC ratio (computation to communication) by explicitly avoidingthe communication intensive MLP classifier (layers 6 to 8) Similar testing of onlylayers 1-5 was also observed in [22] but author describes the platform as a CNNaccelerator implying the fully connected layers would be processed by the hostThe prototype of [19] also displayed 50 BRAM utilization indicating that theaddition of DMA pre-fetching capabilities such as [23] and [24] could potentiallyhelp to reduce overall congestion during periods of peak memory access
A similar result is presented in [25] despite using a much smaller networkmemory bandwidth was also found as the limiting factor in their attempt to bringCNN to a more mobile platform Jin et al notes the current lack of mobileplatforms capable of applying CNN and many of the proposed CNN hardwareprocessing solutions were actually PC accelerators that relied on a PCI connectionwith the host computer Although their solution was also a co-processor it wasa single chip FPGA solution designed around the ARM core of the Xilinx Zynq-7000 and a stark contrast to the other proposals that utilized expensive high endFPGAs
31 State of Neural Networks TodayIn order to derive the resource reference for an embedded platform targeted atcurrent ldquostate of the artrdquo neural networks it is prudent to first determine whatcriteria would allow a neural network to claim such a credited title As Neuralnetworks are an actively researched field there are countless variations and factors
1 a formal mathematical framework for extracting legal loop transformation described by [20]
31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

31 STATE OF NEURAL NETWORKS TODAY 16
that make a fair comparative evaluation of performance difficultEven when networks of duplicate topology and learning methodology are
trained for an identical task the performance will differ depending on thetraining data Organized events such as ImageNet Large Scale Visual RecognitionChallenge (ILSVRC) and PASCAL Visual Object Classes Recognition Challenge(PASCAL VOC) provide a reliable performance evaluation by providing aconsistent training and test dataset ILSVRC is an annually held challenge ofaccuracy in object classification localization and detection for still images (Videointroduced for 2015) A fully annotated training dataset of 12 Million images isreleased prior (approx 3 months) to the submission deadline The images arecollected from the internet and are hand labeled with the presence or absence of1000 object categories
It is important to note that these events are oriented towards the areaof Machine Learning research a subfield of computational science thereforepublications from the participant teams are primarily focused on discussionsinvolving training algorithm methodology and network topology Consequentlylittle concern is placed on evaluating computational effort or data utilization andnot usually directly discussed in the papers (with the notable exception of [2])Therefore requirements stated in this section was derived through analysis of thepublished network topologies
The computation cost estimation used here are related to the Connections-per-second (CPS) metric described in [26] where a multiply and accumulateoperation count as a single connection The sum of the multiply-accumulates of asingle forward pass should proportionally reflect the total computational effort ofa network topology because of the overwhelming prevalence of the convolutionoperator The fully connected layer neurons are conceptually identical to 1x1convolutions and as such are included in the effort calculation
In an analysis of the ILSVRC (2010 to 2014) [6] provides an examination ofimprovements and current state of the art in computer vision In 2012 a massiveleap in accuracy was observed in object classification by the AlexNet deep CNN[1] this marked a paradigm shift towards CNN as the dominating neural networkfor computer vision
In relating the performance of neural networks against humans in objectclassification Russakovsky et al finds that the current (2014) best modelGoogLeNet only slightly under-performs (16) against humans in objectrecognition although the study notes that due to the length and repetitivenessof the tests human performance could be improved if significant effort anddetermination
32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

32 ARCHITECTURE 17
32 Architecture
321 Core Processing ElementIn [27] Hu et al states that among the many challenges of implementing ANNsmapping of the algorithm to achieve higher computation power is particularlycritical due to the sheer frequency of inner-product calculations These structuresform the core of the processing element and can be fundamentally broken downinto two ways chain-configuration and tree-configuration but in large scaleimplementations a combination of both is common
(a) Chain Configuration [27] (b) Tree Configuration [27]
Figure 31 Common Inner-production structures
These fundamental computation structures must be shared between neuronsdue to finite logic density[28] Many solutions have been published and acomparative evaluation between the complete proposed system is difficult asvarying test hardware and optimizations that are specific to the chosen test CNNmay skew the results for a particular computation structure Therefore theproposals will be categorized by the processing methodology in order to betterunderstand the distinguishing characteristics
3211 Time-Division Processing
The basic solution for calculating the inner-product of the convolution operationfollows a form of time-division-multiplexing as stated by [29] where all the inputsof an individual neuron share a single multiply-accumulate (MACC) processingelement such as in [30] These structures utilize a repeated loop where the inputsare multiplied by the weight and added to a running sum upon completion of theloop the neuronrsquos weighted sum is passed to the activation function which in turnrecords the result into the output feature map buffer
The strengths of this method include the flexibility to accommodate anysize convolution kernel by simply increasing loop iterations low logic countfine grained control and increased ldquogeneral-purposerdquo compatibility While inter-neuron (between different neurons) parallelism can be simply exploited by
32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

32 ARCHITECTURE 18
replicating the processing units by definition this method is not able to exploitthe intra-neuron parallelism inherit in Convolutional Neural Networks
Adaptations utilizing vector processing cores follow this ideology in order tolocalize data and reduce data transfer between cores A scalable custom pipelinevariation is presented in [24] and [31] along with a memory network that allowsindividual data streaming to each core This removes the need for the controller toexplicitly manage the cores and allows for simpler scaling of processing elements
3212 Matrix Processing
Most platforms exhibit a variation of the above to exploit the intra-neuronparallelism by instantiating processing elements consisting of NxN convolutionMACC units such as in [32] [25] [33] The NxN convolution is usually equal toor greater than the largest network filter kernel size Inefficiencies are unavoidableduring layers where convolution kernel is less then NxN due to the unusedmultiplication units
The energy and utilization penalty for instantiating arbitrarily large processingelements usually confine this design to implementations where network topologyis known before hardware design When a neural network is created specificallyto satisfy these limitation this arrangement can be very efficient in terms ofperformance per watt as demonstrated by [33] (using fixed point notation)
Bypassing the fixed kernel size limitation is possible with additional computationoverhead as in [32] a CNN coprocessor accelerator that utilizes the host pre-processing to decompose larger kernels into NxN convolution
FPGA runtime reconfigurability has been leveraged to adapt the convolutionkernel size to the specific needs of each layer This adaptable architecture isdemonstrated in both [34] and [35] with the latter paper observing a resultingspeed up of 12x to 35x over the fixed architecture In the paper the total computetime for a forward pass is listed but there was no discussion on the impact ofreconfiguration time vs compute time
While runtime reconfiguration may improve efficiency and density limitationsit also places additional periodic load on the memory subsystem with possiblyto coincide with the ANN data access patterns further aggravating the limitedmemory bandwidth Multiplexing the FPGA layout also requires that theproductive compute time is sufficiently longer then the reconfiguration time inorder overcome the overhead of reconfiguration Guccione et al [36] provides arelationship of the break-even point M = R (N-1) where R is time (in cycles) toperform reconfiguration and N is total compute time between reconfiguration
32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

32 ARCHITECTURE 19
Figure 32 Example Systolic Array [3]
3213 Systolic Array
The name of systolic arrays comes from the likeness of the dataflow pattern tothe systolic contraction phase of a beating heart a wave like propagation througha homogeneous array of processing elements The architecture is organized suchthat each processing element only performs a single predefined function thenrepeats after passing the output to the next node in the array This eliminates theneed to store and coordinate data transfer between processing elements resultingin reduced on-chip memory utilization
These characteristics are confirmed by several studies [37] where also acomparison against his earlier dynamically reconfigurable CNN implementation[38] found that the systolic array was significantly faster (5x) with less memoryaccesses while utilizing the same silicon area
The trade off to this approach comes from the fixed nature of the systolic arrayand constrains the convolution operation to the instantiated dimensions while alsolimiting the number of concurrent convolutions implementable this is due to thearea costs of the inherently large granularity requiring a complete structure forproper function
A proposal for rdquoSuper-Systolicrdquo architecture in [39] and [40] describes abit-level systolic convolution purported to utilize FPGA resources with greaterefficiency and increased performance Results from implementations shows asignificant reduction in FPGA slice utilization requiring about a third of theresource of a conventional word level systolic array uses While this is a largereduction of resources the kernel depth limitation still remains and will need tobe investigated to determine the suitable architecture for implementing very largenetworks
Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 4
Architectural Design
41 Design Exploration
411 GoogLeNet Inception ModuleThe GoogLeNet Neural Network is derived from an emerging class of ldquoNetworkin Networkrdquo type topologies The network entered into the ImageNet challengecomprises of 9 rdquoInception Modulesrdquo where each contain several differentlysized convolution and maxpool operations that are organized over two internallayers The utilization of smaller 1x1 convolutions as a form of abstraction pre-processing allows the more expensive 3x35x5 convolutions to require less filtersto extract the desired information and the major contributing factor of reducingthe required network parameters by a factor of 12 (as compared to AlexNet) TheGoogLeNet development team also attempted to keep the computational budgetat 15 billion multiply-adds approximately similar to AlexNet
Figure 41 Modular Topology
20
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
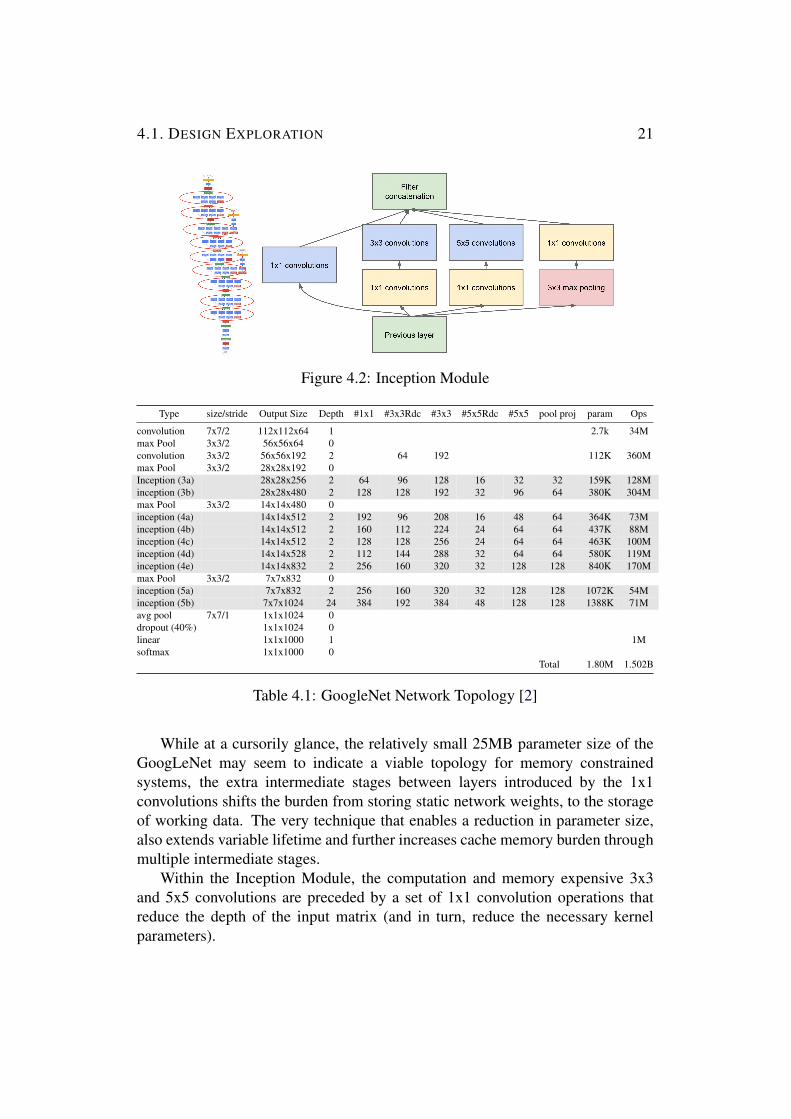
41 DESIGN EXPLORATION 21
Figure 42 Inception Module
Type sizestride Output Size Depth 1x1 3x3Rdc 3x3 5x5Rdc 5x5 pool proj param Ops
convolution 7x72 112x112x64 1 27k 34Mmax Pool 3x32 56x56x64 0convolution 3x32 56x56x192 2 64 192 112K 360Mmax Pool 3x32 28x28x192 0Inception (3a) 28x28x256 2 64 96 128 16 32 32 159K 128Minception (3b) 28x28x480 2 128 128 192 32 96 64 380K 304Mmax Pool 3x32 14x14x480 0inception (4a) 14x14x512 2 192 96 208 16 48 64 364K 73Minception (4b) 14x14x512 2 160 112 224 24 64 64 437K 88Minception (4c) 14x14x512 2 128 128 256 24 64 64 463K 100Minception (4d) 14x14x528 2 112 144 288 32 64 64 580K 119Minception (4e) 14x14x832 2 256 160 320 32 128 128 840K 170Mmax Pool 3x32 7x7x832 0inception (5a) 7x7x832 2 256 160 320 32 128 128 1072K 54Minception (5b) 7x7x1024 24 384 192 384 48 128 128 1388K 71Mavg pool 7x71 1x1x1024 0dropout (40) 1x1x1024 0linear 1x1x1000 1 1Msoftmax 1x1x1000 0
Total 180M 1502B
Table 41 GoogleNet Network Topology [2]
While at a cursorily glance the relatively small 25MB parameter size of theGoogLeNet may seem to indicate a viable topology for memory constrainedsystems the extra intermediate stages between layers introduced by the 1x1convolutions shifts the burden from storing static network weights to the storageof working data The very technique that enables a reduction in parameter sizealso extends variable lifetime and further increases cache memory burden throughmultiple intermediate stages
Within the Inception Module the computation and memory expensive 3x3and 5x5 convolutions are preceded by a set of 1x1 convolution operations thatreduce the depth of the input matrix (and in turn reduce the necessary kernelparameters)
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
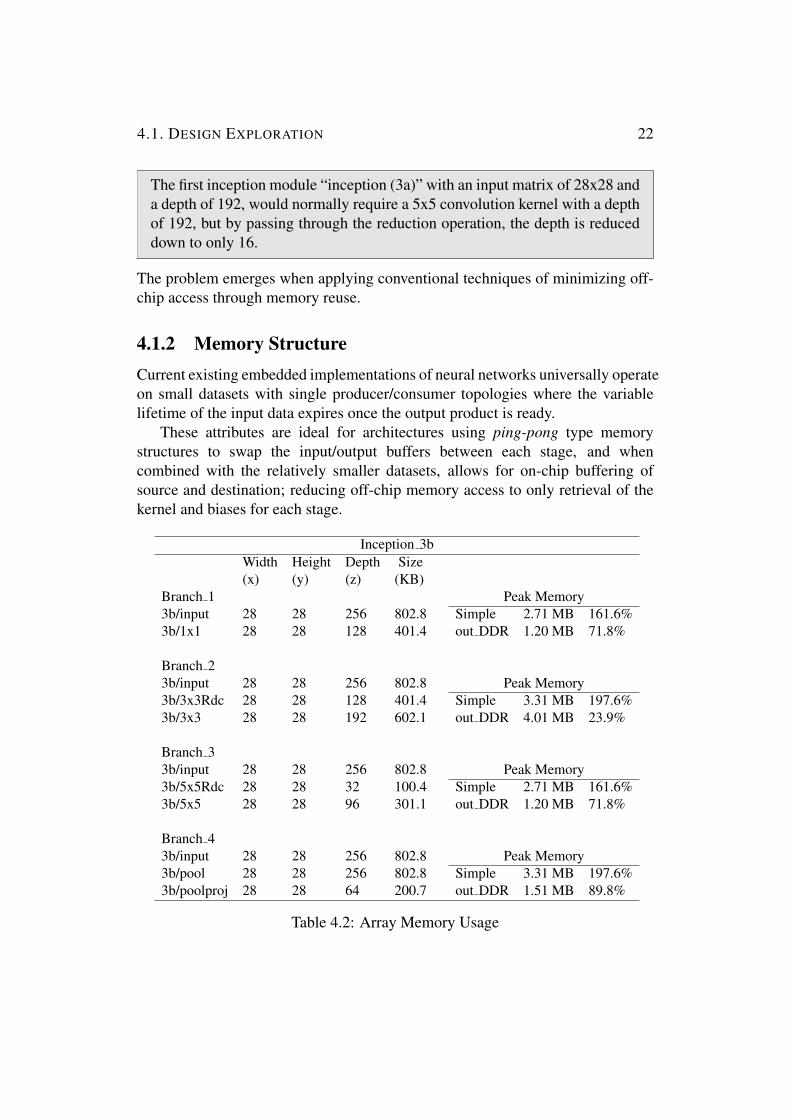
41 DESIGN EXPLORATION 22
The first inception module ldquoinception (3a)rdquo with an input matrix of 28x28 anda depth of 192 would normally require a 5x5 convolution kernel with a depthof 192 but by passing through the reduction operation the depth is reduceddown to only 16
The problem emerges when applying conventional techniques of minimizing off-chip access through memory reuse
412 Memory StructureCurrent existing embedded implementations of neural networks universally operateon small datasets with single producerconsumer topologies where the variablelifetime of the input data expires once the output product is ready
These attributes are ideal for architectures using ping-pong type memorystructures to swap the inputoutput buffers between each stage and whencombined with the relatively smaller datasets allows for on-chip buffering ofsource and destination reducing off-chip memory access to only retrieval of thekernel and biases for each stage
Inception 3bWidth Height Depth Size(x) (y) (z) (KB)
Branch 1 Peak Memory3binput 28 28 256 8028 Simple 271 MB 16163b1x1 28 28 128 4014 out DDR 120 MB 718
Branch 23binput 28 28 256 8028 Peak Memory3b3x3Rdc 28 28 128 4014 Simple 331 MB 19763b3x3 28 28 192 6021 out DDR 401 MB 239
Branch 33binput 28 28 256 8028 Peak Memory3b5x5Rdc 28 28 32 1004 Simple 271 MB 16163b5x5 28 28 96 3011 out DDR 120 MB 718
Branch 43binput 28 28 256 8028 Peak Memory3bpool 28 28 256 8028 Simple 331 MB 19763bpoolproj 28 28 64 2007 out DDR 151 MB 898
Table 42 Array Memory Usage
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
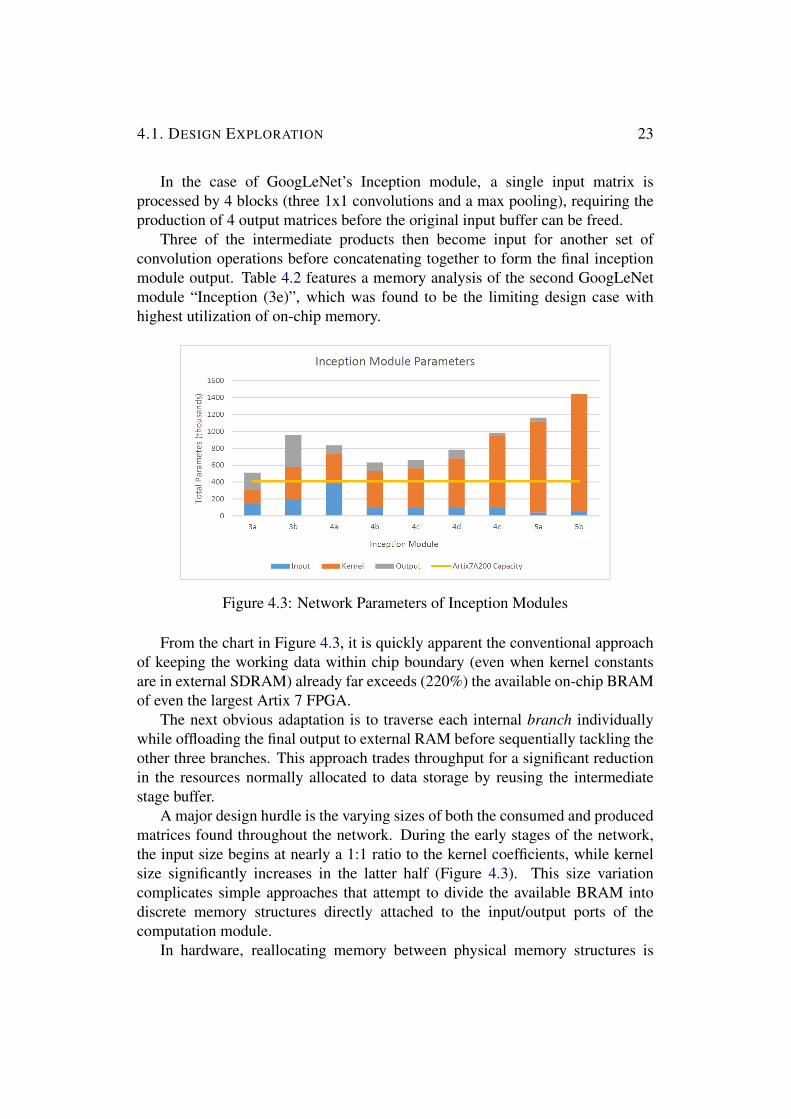
41 DESIGN EXPLORATION 23
In the case of GoogLeNetrsquos Inception module a single input matrix isprocessed by 4 blocks (three 1x1 convolutions and a max pooling) requiring theproduction of 4 output matrices before the original input buffer can be freed
Three of the intermediate products then become input for another set ofconvolution operations before concatenating together to form the final inceptionmodule output Table 42 features a memory analysis of the second GoogLeNetmodule ldquoInception (3e)rdquo which was found to be the limiting design case withhighest utilization of on-chip memory
Figure 43 Network Parameters of Inception Modules
From the chart in Figure 43 it is quickly apparent the conventional approachof keeping the working data within chip boundary (even when kernel constantsare in external SDRAM) already far exceeds (220) the available on-chip BRAMof even the largest Artix 7 FPGA
The next obvious adaptation is to traverse each internal branch individuallywhile offloading the final output to external RAM before sequentially tackling theother three branches This approach trades throughput for a significant reductionin the resources normally allocated to data storage by reusing the intermediatestage buffer
A major design hurdle is the varying sizes of both the consumed and producedmatrices found throughout the network During the early stages of the networkthe input size begins at nearly a 11 ratio to the kernel coefficients while kernelsize significantly increases in the latter half (Figure 43) This size variationcomplicates simple approaches that attempt to divide the available BRAM intodiscrete memory structures directly attached to the inputoutput ports of thecomputation module
In hardware reallocating memory between physical memory structures is
41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

41 DESIGN EXPLORATION 24
not a trivial affair since it requires advanced techniques such as runtimereconfiguration Although it may be tempting to follow a software inspiredapproach to implement dynamic memory allocation by using registers to storelsquovirtualrsquo buffer array offsets to address a location in a single large contiguousaddress space (as suggested by a colleague) From a hardware perspective thiswould require combining the entire BRAM resource into a single structure Thiswill certainly result in poor concurrency due to the large quantity of data (possiblythe entire computational payload) will be constrained behind the BRAMrsquos dualport interface
Optionally by carefully partitioning the data array to ensure all concurrentlyaccessed elements are placed in separate BRAM interfaces and using multiplexersto handle the addressing it is possible to increase the number of access ports toa single address space when the data access pattern is predictable such as mostmatrix array accesses Application of this technique must be used in moderationas it became apparent that due to large width MUXs required to select a particularBRAM structure cause massive congestion during place and route
413 Data Dependency
3times3times2
KConvolution
Figure 44 Next stage is delayed until output array is complete (blue layer)
The dependency between (back to back) convolution operators limits thenext convolution stage to begin only after last activation map 1 is written to theoutput array This is depicted in Figure 44 where each output element (ball)requires calculation with the entire input depth covered by the kernel (left Array)Consequently the last feature filter (Blue) needs to complete itrsquos convolution (bluelayer) before passing the output array to the next convolution stage to begin
1 Activation Map is the convolution output resulting from a single kernel filter and with a depthof 1 (lengthtimeswidthtimes1)
41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

41 DESIGN EXPLORATION 25
To pipeline multiple convolution stages in a single accelerator pass normallythe entire output product of a prior stage must be available Therefore it has beencommon among all recently reviewed works to process only one network layer at atime to full completion before tackling the next while using the external memoryto assemble the individual activation maps to form the output array for the nextpass through the accelerator This type of architecture benefits from simpler datatraffic and management of a large number of concurrent matrix multipliers
Unfortunately adapting this flow for large modern deep layered networks suchas GoogLeNet leading to poor throughput due to several compounding factorsand cumulates in poor data reuse and massive amounts of data transfer acrossthe chip boundary to external memory almost degrading to a situation where theexternal SDRAM acts as an accelerator based on external scratchpad memory
A contributing factor is a larger number of layers found in deep networksnaturally leads to greater total latency from increased input array loads fromexternal memory but the largest impact comes from the tendency of modernnetwork topologies to incorporate multiple back to back convolution operations ina single layermodule and extremely large datasets that further delay the startingof the next convolution stage
To produce a single slice W timesH (A coloured layer from Figure 44) of theoutput arrayrsquos depth n (n=4 for Figure 44) the entire input array must bereferenced n times by a single operation block Without the capacity to completelystore the input array amounts to a transfer of the same input data for everyActivation map to be calculated
The first Inception module has an input array of 28times 28times 256 totalling803KB (32bit float) and needs be entirety referenced by a convolutionoperation to produce a single Activation Map of 28times28times1 This operationis repeated for each of the 128 Feature Maps (Kernels) stacking the outputActivation Map to eventually produce the output array of 28times28times128 Thistotals approx 102MB of kernel reads and when considering this output arrayis only 1 of 6 convolution operators within a single Inception module whichin turn is only 1 of 9 inception modules it is not surprising that workingdirectly off SDRAM is detremental to performance
414 Hardware ReuseThe performance of GoogLeNet (specifically network-within-network topologies)accelerator will largely depend on finding an efficient manner to split theoperations while balancing concurrency data reuse and on-chip cache space
A prerequisite to extractingleveraging parallelism through hardware designinvolves careful analysis of the algorithm to determine a pattern of data execution
42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 26
that meets the FPGA resources budget while enabling the largest portion ofcomputational work to be completed in a single loop iteration
The limited FPGA resources requires thoughtful allocation to accelerate onlystructures of high utilization ideally the derived execution pattern needs to begeneral enough such that a single instantiation of the CNN Accelerator can bereused for all 9 inception modules of the network
Typically this generalization is achieved through a trivial application of a loopcounter and limiting concurrency to operations within single slice of the inputarray depth (LxWx1) Therefore by setting the loop control register variouscalculation depths can be handled
A consequence of this method prevents the chaining of multiple operators withvarying depths (loop iterations) without resorting to intermediate data buffersAnother factor complicating hardware reuse the module and the internal operatorsmust also be compatible accross 4 different input array widths in addition to thevariable depth
The variation along all three input dimensions would conventionally indicatethe only suitable elements for concurrent processing are the fixed exit conditionsof the inner most two loops of the typical convolution (Listing 41) and can bethough as to represent a slice of the convolution kernel (NxNx1) Subsequentlyfollowing through with these methods of large intermediate buffers and loops theanalysis will begin to lead back to the extreamly poor performance architecturediscussed in section 413
42 Proposed Architecture
421 Data Partitioning4211 Depth Slicing
When dealing with large datasets and limited on-chip cache the emphasize shiftstowards finding a suitable pattern of memory access that is simple (to reduce statelogic) repeatable and compatible with the DDR rowbank access limitations Thefollowing proposed partition method tackles the aforementioned complicationsof hardwaredata reuse varying inputconvolution sizes and also proposed is amethod of chaining convolution operators for increased throughput per acceleratorpass
Current implementations fundamentally retain the ldquohierarchyrdquo defined by thenetwork layers and operational blocks This adherence simplifies the design ofCNN dataflow architectures and additionally guarantees the logical correctnessof itrsquos implementation but in this case becomes an unnecessary limitation whenscaled up to research class neural networks
42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 27
Due to the scope and complexity of dissolving the abstraction boundaries thatinherently preserve the temporal sequences of all dependencies and time-costs ofRTL development it becomes necessary to have the ability to evaluate the logicalcorrectness of developing algorithm before RTL entry
Through leveraging known Loop optimization techniques it should be possibleto ensure the functional correctness of the new modified processing flow if
bull Original pseudocode description of function + Legal loop transformations
bull Results in the pseudocode of modified (partitioned) function
Listing 41 represents a typical square kSizetimeskSize Convolution and will beused in the following section to provide clarity to the proposed data manipulations
1 for(feat=0 feat lt numKerns feat++)2 for(chnl=0 chnl lt kSizeZ chnl++)3 for(row=0 row lt dSizeY row++)4 for(col=0 col lt dSizeX col++)5 for(i=0 i lt kSize i++)6 for(j=0 j lt kSize j++)7 out_Map[feat][row][col]+=inArr[chnl][row+i][col+j]
kernel[feat][chnl][i][j]8
Listing 41 2D Convolution Pseudocode
By partitioning the large input matrices (and their respective kernels) acrossthe depth dimension to produce kSizeZN block slices of dSizeX times dSizeY timesNwhere N is selected to prioritize fitting the full input width and height dimensionsof the input array This results in a flow where every kSizeZN iteration of loop 2(line 2) of Listing 51 only requires data available within chip boundaries Thisworks by reducing the variable size and lifetime to N shifting the requirement offull array depth for loop processing and replacing with the less resource intensiverequirement of shared access to the output array
This technique allows a large input array to be quickly convoluted in smallerportions while only requiring per-element summation to assemble the completedoutput array
1 for(feat=0 feat lt numKerns feat++)2 for(partn=0 partn lt kSizeZN partn ++)3 for(chnl=0 chnl lt N chnl++)4 for(row=0 row lt dSizeY row++)5 for(col=0 col lt dSizeX col++)6 for(i=0 i lt kSize i++)7 for(j=0 j lt kSize j++)8 out_Map[feat][row][col]+=inArr[chnl+(partnN)][row+i][
col+j]kernel[feat][chnl+(partnN)][i][j]
42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 28
9
Listing 42 Partitioned 2D Convolution
This principle will be combined with Stream processing (Section 422)to produce partially convoluted data blocks feeding the (3x35x5) convolutionoperators This combination will functionally enabling full input depthprocessing by leveraging a unique characteristic inherent in 1x1 convulsions
4212 Static Width
To enable efficient optimization and enable reusing of a single hardware structurefor the different inception module the variable loop exit conditions must be madestatic or reordered such that the variable bounds are at the top of the nestedloop structure Then with loop bounds known at synthesis time (and no datadependencies) it becomes possible to ldquounrollrdquo the inner loops and schedule theiterations for concurrent execution
Fixing the convolution kernel to 5x5 was done for the prototype implementationto further reduce the design to a single square convolution operator Using a 5x5convolution operator to perform a 3x3 can be simply performed by centering the3x3 kernel and setting the boarder elements to zero With this optimization the3x3 Convolution operator essentially becomes free as the 5x5 structure is requiredirrespective of the 3x3 operation
Module Original Partitioned Size
Inception (3a) 28x28x256 (256N)28x28xNinception (3b) 28x28x480 (480N)28x28xN
inception (4a) 14x14x512 (512N)14x14xNinception (4b) 14x14x512 (512N)14x14xNinception (4c) 14x14x512 (512N)14x14xNinception (4d) 14x14x528 (528N)14x14xNinception (4e) 14x14x832 (832N)14x14xN
inception (5a) 7x7x832 (832N)7x7xNinception (5b) 7x7x1024 (1024N)7x7xN
Table 43 Partitioning 3 New Static Array Sizes
Employing only the above partitioning optimizations still results in 3 arrayssizes serving to complicate further optimizations by requiring either looping of
42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 29
small parallel structures or separate structures to enable compatibility To enablehardware pipelining of Line 4amp5 in Listing 51 without further optimization thevariable loop limits controlling the width and height would necessitate either
bull A single many stage (high latency) pipeline designed for the largest controlvariable(s) (2828) with multiplier zero filling and stage pass-through toforce compatibility with the other 2 input sizes
bull Three separate pipelines each specialized for their respective input size
Both options induce enormously poor allocation of resources therefore byfixing these loop variables to a static value resources (such as DSP FP multiplier)can be better concentrated to increase simultaneous multiplications and reducetotal overall loop iterations The logical choice for the fixed width is arrays of7x7xN as the other 2 sizes can be implemented with multiple 7x7xN structuresin parallel
P3
P1
P4
P2
(a) Input array split into 4 Partitions
P3
P1
P4
P2
(b) Kernel at edge of partition boundary
Figure 45 Partitioned sub-array requires neighboring elements to completeconvolution
Splitting the input to convolution operator can not be performed throughsimple truncation without violating the boundary condition of the mathematicaloperator When depicted as a sliding window the region surrounding the outputelement is weighted and summed therefore when the window reaches an artificialboundary produced by the partitioning method the values of the extra elements(ie 2 elements for 5x5 kernel) in the next partition must also be made available tothe operator (Figure 54)
To provide the ability to correctly rearrange the elements for convolutionbuffer a control state machine must recognize which partition it is currently
42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 30
responsible for and either pad the extra elements with zeros as in when a ldquotruerdquoboundary exists or populating with elements from the neighbouring partition
422 Convolution CascadeThe Inception module utilizes 1x1 convolutions to perform a depth reductionbefore the main 3x3 or 5x5 convolution Utilizing kernels width of only one thisenables the combination of stream processing and data reordering for convolutionto be performed without additional on-chip memory utilization (beyond kernelstorage)
1times1timesn
Convolution Kernels
Input Arrayofdepth n
f numof
Filter Kernels
Multiply
AccumulateBuffer
Figure 46 Streaming Convolution Array Access Pattern
Significantly these characteristics will be heavily exploited to bypass theinnate data-dependencies of cascading 2 convolution stages and allow the secondstage begin before the completion of the first
By interweaving the computation of the different feature filters and traversingldquodepth before breadthrdquo through the input array the output data will be produced inan order that (combined with above partitioning methods) allows a smaller partialblock to be processed by the second stage This is possible because this smallerblock is actually identical to the kSizeZN partitioned block therefore requiringonly a summation of the final output blocks to produce the full convolution output
423 Processing TopologyThe above principles are combined to produce a modular Processing Elementwhere a streaming input removes the need for large input buffering with the on
42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

42 PROPOSED ARCHITECTURE 31
chip memory This in turn enables multiple processing elements to handle aparallel pipelined computation of single (1x1) and square (3x35x5) Convolutionssuch as those of the GoogleLeNet Inception modules (Figure 47)
StreamInfrom DMA
Partial Convolution PEs
Split
conv0
conv1
convn
Concat
StreamOutto DMA
Figure 47 Conceptual Parallel Processing Element Layout
Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 5
Implementation and Analysis
501 Processing ElementsEach Processing Element contain a pipelined architecture containing a streamingconvolution unit an intermediate Array Block Buffer followed by the largerrdquosquarerdquo convolution operator
Figure 51 Processing Element Architecture
The intermediate Array Block Buffer serves to convert from the dataflowdomain of single data wordcycle (of the 1x1 convoluter) into an array datapacket for variable cycle computation (controlflow) of the square convolutionoperator This combination architecture maximizes data reuse by enabling registercontrol of the numKerns variable (Line 1 in Listing reflstlisting) Control ofthis register is necessary because of the ratio of 1x1 to 3x3 (or 1x1 to 5x5)varies between different inception modules without this control some inceptionmodules branches will require some of the DDR bandwidth to re-access inputvalues to compute the unfinished 3x3 or 5x5 feature kernels
Since Majority (5 of 9) of the Inception module uses 14times14 as the input arraysize the processing element was implemented with 2 convolution modules with aninput array size of 7times7 that share a single buffer control state machine and operatesimilar to a SIMD architecture but on a higher (convolution module) level
32
33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

33
5011 Streaming Convolution
On every cyclethe streaming convoluter is able to accept a new 32bit float value(initiation interval = 1) perform 16 multiplications and pass the results to theaccumulate block through a 512bit wide (1632bit) FIFO implemented withXilinx Shift-Register-Logic This ensures the greatest possible throughput (tomatch DMA) to avoid any foreseeable bottlenecks due to the serial communicationand high inputlow reuse data nature
In Figure 51 separating the Multiply and Accumulate blocks was notnecessary and was only performed to simplify pipeline development and remainconceptually identical to a single pipelined Multiply-Accumulate unit
The three cycle latency of the Xilinx DSP48E Floating point multiply can berdquohiddenrdquo by staggering the use over three sets of 16 DSP multipliers effectivelyreducing the initiation interval to 1 cycle Unfortunately if the same method wasused to create a single cycle (initiation interval) pipelined accumulate operationwould require a staggering 112 DSP units due to the approximately seven cycledelay1 for floating point addition
By describing the above Multiply-accumulate unit to Vivado HLS it wasable to was able to achieve the same initiation interval with only 32 DSP48Eunits (Figure 53) This lead to the exploration and eventual adaptation of theVivado HLS generated multiply unit as well although DSP utilization remainedthe same (48timesDSP48E Slices) it only required 339 and 332 less FF andLUTs (respectively) than the initial design
The one-third reduction in LUT and FF utilization was eventually tracedback (in part) to clevercomplex utilization of the dedicated DSP interconnectresources[41] to pass values between stages instead of general FPGA fabric 2
1 Xilinx DSP User guide[41] describes advanced topologies that can reduce this delay at the costof more DSP resource utilization 2 The operation of the DSP48 Slice is extremely complex withmultiple modes of operation and case-specific optimization techniques due to time restrictionsexhaustive analysis is beyond the scope of this thesis
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
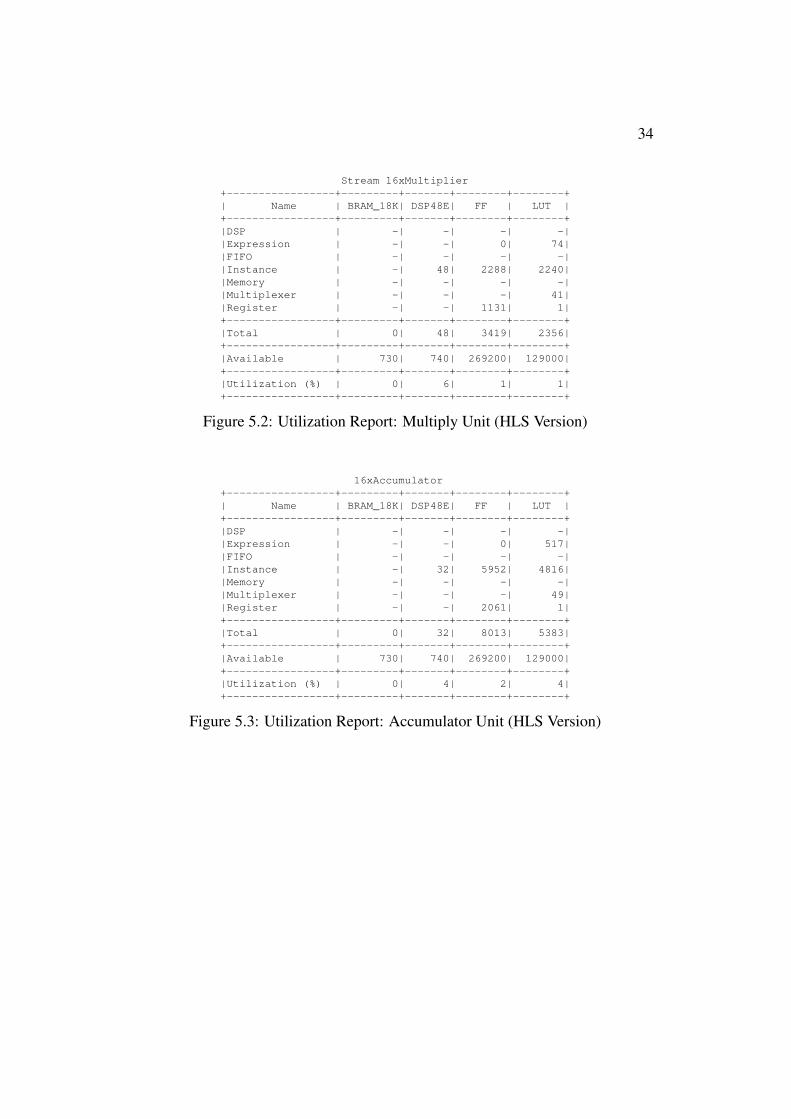
34
Stream 16xMultiplier+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 74||FIFO | -| -| -| -||Instance | -| 48| 2288| 2240||Memory | -| -| -| -||Multiplexer | -| -| -| 41||Register | -| -| 1131| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 48| 3419| 2356|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 6| 1| 1|+-----------------+---------+-------+--------+--------+
Figure 52 Utilization Report Multiply Unit (HLS Version)
16xAccumulator+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 517||FIFO | -| -| -| -||Instance | -| 32| 5952| 4816||Memory | -| -| -| -||Multiplexer | -| -| -| 49||Register | -| -| 2061| 1|+-----------------+---------+-------+--------+--------+|Total | 0| 32| 8013| 5383|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 0| 4| 2| 4|+-----------------+---------+-------+--------+--------+
Figure 53 Utilization Report Accumulator Unit (HLS Version)
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
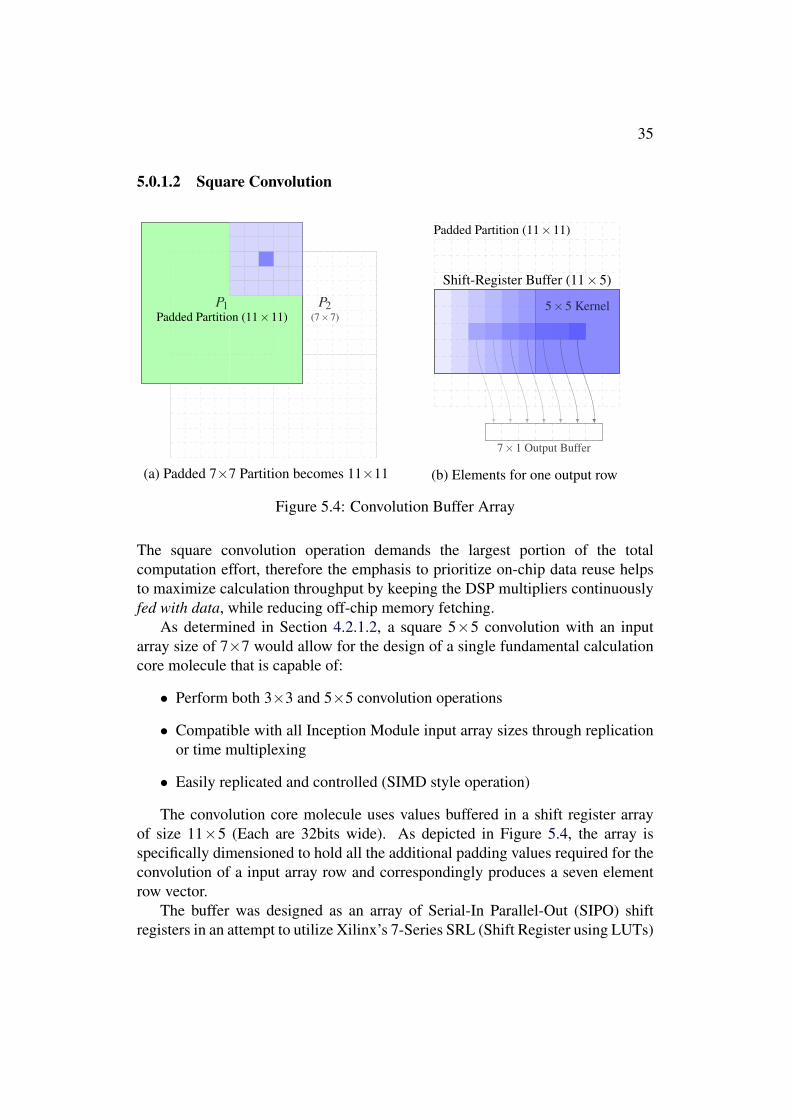
35
5012 Square Convolution
P1 P2Padded Partition (11times11)(7times7) (7times7)
(a) Padded 7times7 Partition becomes 11times11
Padded Partition (11times11)
Shift-Register Buffer (11times5)
7times1 Output Buffer
5times5 Kernel
(b) Elements for one output row
Figure 54 Convolution Buffer Array
The square convolution operation demands the largest portion of the totalcomputation effort therefore the emphasis to prioritize on-chip data reuse helpsto maximize calculation throughput by keeping the DSP multipliers continuouslyfed with data while reducing off-chip memory fetching
As determined in Section 4212 a square 5times5 convolution with an inputarray size of 7times7 would allow for the design of a single fundamental calculationcore molecule that is capable of
bull Perform both 3times3 and 5times5 convolution operations
bull Compatible with all Inception Module input array sizes through replicationor time multiplexing
bull Easily replicated and controlled (SIMD style operation)
The convolution core molecule uses values buffered in a shift register arrayof size 11times5 (Each are 32bits wide) As depicted in Figure 54 the array isspecifically dimensioned to hold all the additional padding values required for theconvolution of a input array row and correspondingly produces a seven elementrow vector
The buffer was designed as an array of Serial-In Parallel-Out (SIPO) shiftregisters in an attempt to utilize Xilinxrsquos 7-Series SRL (Shift Register using LUTs)
36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

36
Input ArrayShift Register Buffer
(11times5)ShiftUp
Shift Out
Shift Row In
Figure 55 Shift Register Buffer
optimization[42] to reduce FPGA flip-flop utilization but current attempts couldnot get the Vivado HLS tool to recognize the SRL optimization
A shift register topology is ideal because after performing the seven convolutionoperations corresponding to a horizontal row only eleven new elements 1 need tobe shifted into the buffer in order to restart the row convolution (Figure 55) The5times5 kernel constants are held in a set of 25 registers as they are constantly reusedfor the entire 7times7 frame before the next set of 25 constants are required Thisshifting window pattern reuses 44 of the 55 buffer elements to vastly reduce non-buffer memory accesses while maintaining a simple symmetric control flow toallow SIMD operation
The core molecule operates synchronously and without need for inter-modulecommunication because each internal buffer array is already padded with theneighboring partition elements This was achieved with simple mux logic thatsends overlapping data to each module during the bufferrsquos shift-in read stageThe intention of using mux logic was to allow for the dynamic allocation of theprocessing modules into two different operating modes for better efficiency overa range of Inception module attributes
The currently implemented operating mode allows multiple computation coremolecules to be rdquoStichedrdquo together by loading with identical kernel coefficientsand overlapping padding to handle larger input array sizes (ie 2 modules for14times14 and 4 modules for 28times28) The anticipated drawback of this mode isreduced efficiency during the later stages of the GoogLenet where partitioningis not required because the raw input size drops to 7times7 this creates a situationwhere it is beneficial to allocate the molecules to each tackle a different set kernel1 a padded 7times7 row becomes eleven elements wide
37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

37
filters and consequently they will require identical (non-padded) data insteadDue to limited time and heavy resource utilization of the unoptimized shift
register array the convolution module was limited to 2 concurrent computationcore instances operating in rdquoStichedrdquo mode1 This 2 core configuration willbe utilized for testing and is reflected in the utilization and performance resultspresented in this chapter
+-----------------+---------+-------+--------+--------+| Name | BRAM_18K| DSP48E| FF | LUT |+-----------------+---------+-------+--------+--------+|DSP | -| -| -| -||Expression | -| -| 0| 1182||FIFO | -| -| -| -||Instance | -| 251| 28471| 27768||Memory | 22| -| 4544| 5952||Multiplexer | -| -| -| 15994||Register | -| -| 31209| 5|+-----------------+---------+-------+--------+--------+|Total | 22| 251| 64224| 50901|+-----------------+---------+-------+--------+--------+|Available | 730| 740| 269200| 129000|+-----------------+---------+-------+--------+--------+|Utilization () | 3| 33| 23| 39|+-----------------+---------+-------+--------+--------+
Figure 56 Utilization Report 5x5 Convolution with two core molecules
502 Accelerator ControlThe proposed accelerator was originally conceived for stand alone operationwith minimal control oversight and therefore contain all the data manipulationcontrol states within the processing element module The control interface of theaccelerator are a series of values describing the topology of the network in whichthe accelerator will calculate and set internal registers for the necessary loops anditerations This interface was intended to allow a small topology descriptor headerfile to be provided along with the network weights on portable media such as anSDcard
Due to time limitations the topology header read module remains unfinishedIn its current implementation the control registers are memory mapped andexposed onto an AXI-Lite bus for hardware accelerator operation as defined inthis thesis
For simplicity a Xilinx Microblaze microprocessor was used to initiate thetopology control registers in the accelerator through the use of the followingcontrol data structure1 For up to 14times14 input size
38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

38
Figure 57 Hardware Accelerator System View
1 enum ConvTypeCONV_ONE = 0 CONV_THREE CONV_FIVE23 struct cmd4 5 ConvType mode6 short in_dimen Input Array Depth=width7 short in_depth Input Array Depth8 short K_1x1_feat of Feature Filters 1x19 short K_5x5_depth of Feature Filters 3x3 or 5x5
1011 u32 K_1x1_addr DDR_offset first 1x1 Kernel12 u32 B_1x1_addr DDR_offset first 1x1 Bias Vector13 u32 K_5x5_addr DDR_offset first 3x35x5 Kernel14 u32 B_5x5_addr DDR_offset first 3x35x5 Bias Vector15 u32 out_addr DDR_offset Output Array16 short stride Convolution stride for downsampling17 short batches of 3x35x5 Feature Maps = numKerns18
Listing 51 Accelerator Control
503 Data TransferIn order to efficiently stream data to the acceleratorrsquos 1x1 convolution blocksa Xilinx AXI DMA controller was elected over the simpler option of usinga Microblaze processing core to directly regulate data transfers The use ofa processing core would enable simpler control over the ordering and flow ofdata to the accelerator by directly interfacing to the processor pipeline through
39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

39
16 dedicated 32bit AXI-Stream links While an enticing interface optionearly exploration on the feasibility for applications involving large datasets andfrequent constant retrieval from external memory quickly saturated the 32bitwidth bus limitation of the Microblaze lsquo Neural networks intrinsically place alarge emphasis tasks based on retrieving pre-calculated values (network weights)consequently nearly every value to be forwarded to the accelerator from theMicroblaze pipeline must therefore arrive externally through the data bus
Employing a DMA controller over a processing core in directing data flownot only frees the core for other duties outside the occasional DMA instructionissue but also avoids the throughput costs of the pre-requisite register load fromexternal memory prior to transmitting on the pipeline stream links Additionallythe DMA readwrite bus can be expanded up to 1024 bit width far beyond thelimitation of the Microblaze This attribute is profound even in platforms withseemingly ldquolowrdquo DDR widths such as the 16bit DDR width on the developmentboard used for this study (Diligent Nexys Video)
Assuming a data burst from the same row and bank of the SDRAM operatingat DDR frequency equivalence of 800MHz the 16bit width at DDR transfersa 32bit word every 2 DDR data beats With the memory controller and designlogic frequency at one fourth (100MHz) of the memory and under ideal burstcondition can generate up to 128 bits of data for every processing cycle
Out of the three Xilinx DMA IPs the AXI DMA core is the only controllerthat supports vectored IO by enabling the Scatter-Gather (SG) engine whilemore FPGA resource intensive this feature is vital for efficiently facilitating thepatterned memory access described earlier in Section 422 for the streaming 1x1Convolution
The Scatter-Gather engine itself enables logic that through the instantiationof a control structure consisting of a linked-list of ldquoBuffer Descriptorsrdquo supportsthe collection (Gather) of data from multiple buffers and writing to a stream or inthe reverse writing portions of the incoming stream to multiple buffers (Scatter)Essentially it can be thought of as a fifo list of register commands that can beconstructed by the processor and passed to hardware for execution with eachdescriptor able to specify a unique address offset and transfer length
Combining the SG engine with Multichannel mode adds three new descriptorfields to describe a simple 2D memory access patterns With the HSIZE parameterdefining the length in bytes of each burst a STRIDE field to express the offset andVSIZE dictating the iterations This capability is idea for tasks featuring numerousrepetitions of non-sequential single word transfers followed by a fixed offseta common pattern in two-dimensional array accesses Without these featuresenabled the processing core will be continuously interrupted to prepare DMAcommands with burst lengths of only 4 bytes
Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 6
Results
The original intention was to instantiate and test 2 Processing Elements but LUTutilization including the support framework (DMA DDR Memory controllerMicroblaze etc) pushed beyond the available resources in the Xilinx Artix7A200to 120 utilization
It should be noted that during the design of the square convolution kernelbuffer that as a matter of convenience it was implemented with the samecapabilities as the Input Array Buffer including several expensive large widthMUX logic to perform line shifting (not required for the Kernel buffer) Althoughchanging the kernel buffers to only use simple registers would save someresources the savings would not be significant enough to vastly reduce theutilization and Place amp Route may still fail timing due to congestion
Additionally if 2 processing elements were used for testing the utilizationwould leave no room for the Xilinx Debug core to gather results Therefore in thefollowing sections only a single processing element set up as a 14times14 input sizewill be used (Technically two 7times7 Convolution units working in unison)
61 Testing LimitationsAs a consequence of limited time the MaxPool operator in the Inception moduleremains incomplete and therefore excludes complete evaluation of the acceleratorover the entire GoogLeNet network topology The exclusion of MaxPoolcapabilities is actually not uncommon in convolution accelerator designs due tothe low calculation (purely comparative) nature of the MaxPool procedure andmay be more resource efficient to implement with the microblaze
40
61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

61 TESTING LIMITATIONS 41
Access Pattern Cycles
Frame Skipping 238289Sequential (Test Case) 37290Rotated Array (Impl Design) 37663
Table 61 Pipeline Latency for different DDR access patterns
611 Performance6111 Memory Bandwidth
Under initial testing it was observed that the data stream from DMA toAccelerator was unable to sustain transfer of a new 32bit value per clock cyclebeyond the first 6 vectors containing 192 floating point values This pattern isconsistent with an empty DMA buffer induced by inefficient non sequential readsfrom DDR memory this was confirmed by temporarily modifying the DMAaccess pattern (HSIZE VSIZE STRIDE) and observing the results
The difference between sequential and non-sequential is approx 6 cycle perword and is in line with the DDR memory timing cycles [43] of 11-11-11 (RCT-RP-CL) indicating that the latency between reads on different rows requires 33cycles (TRP + TRCD + CL)
By factoring in the fabric to memory controller clock ratio of 14 (18 DDRequivalence) gives a latency of approx 4 cycles between transfers (5 cycles percompleted word transfer) which confirms that the delays observed are due tonon-sequential reads1 that require SDRAM rows to be opened and closed for eachword
Considering that the processing pipeline has been designed to accept newvalues every cycle this latency severely under utilizes the resources allocatedto the acceleratorThis poor performance from non-sequential DDR reads wasanticipated during design and can resolved by simply rdquorotatingrdquo the storage arraysuch that depth becomes width resulting in sequential reads to produce the DMAstream
The slight increase in cycles from the modified rotated array as compared tothe earlier artificial test scenario are due to the periodic kernel buffering accessThese memory reads were sequential before rotating the storage pattern but haveminimal negative impact due to the high data reuse greatly reduces the frequencyof kernel loads The extra latency cycles can be completely eliminated if therotated storage pattern was only applied to the inputoutput arrays but due to timerestrictions was not implemented in the test architecture1 The approx 1 cycle difference between measured and calculated (Table 61) is due to includingsquare convolution stage cycles
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
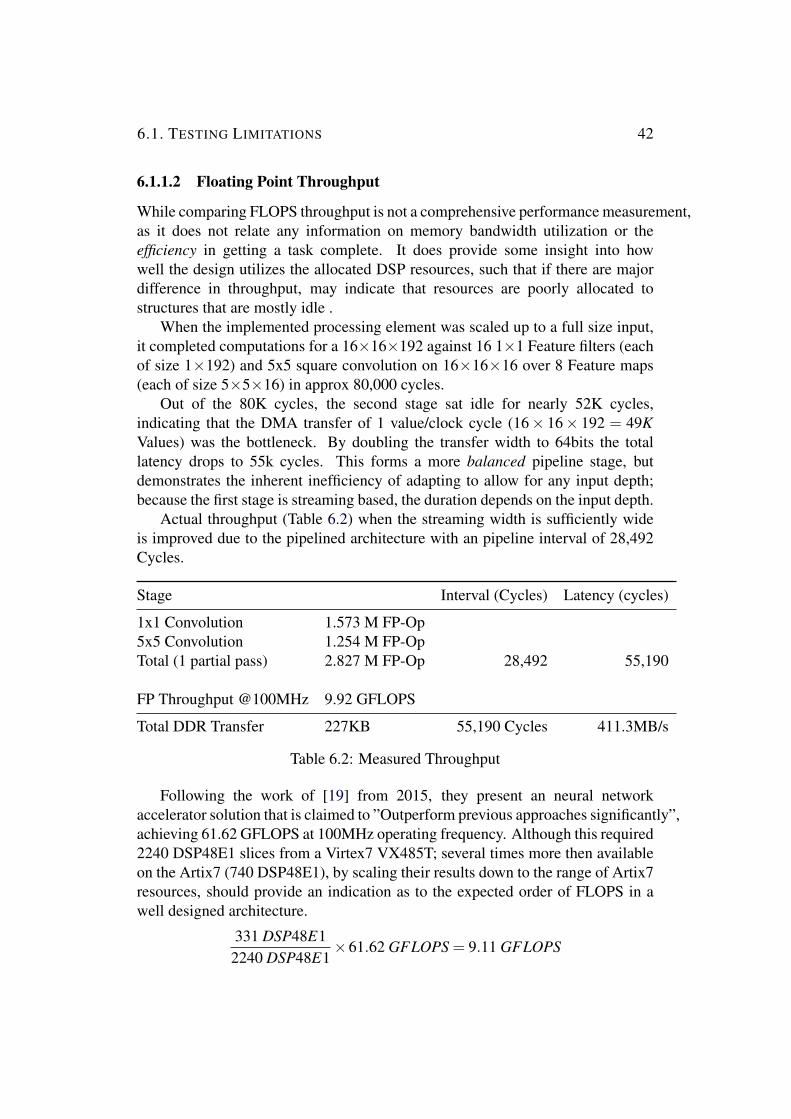
61 TESTING LIMITATIONS 42
6112 Floating Point Throughput
While comparing FLOPS throughput is not a comprehensive performance measurementas it does not relate any information on memory bandwidth utilization or theefficiency in getting a task complete It does provide some insight into howwell the design utilizes the allocated DSP resources such that if there are majordifference in throughput may indicate that resources are poorly allocated tostructures that are mostly idle
When the implemented processing element was scaled up to a full size inputit completed computations for a 16times16times192 against 16 1times1 Feature filters (eachof size 1times192) and 5x5 square convolution on 16times16times16 over 8 Feature maps(each of size 5times5times16) in approx 80000 cycles
Out of the 80K cycles the second stage sat idle for nearly 52K cyclesindicating that the DMA transfer of 1 valueclock cycle (16times 16times 192 = 49KValues) was the bottleneck By doubling the transfer width to 64bits the totallatency drops to 55k cycles This forms a more balanced pipeline stage butdemonstrates the inherent inefficiency of adapting to allow for any input depthbecause the first stage is streaming based the duration depends on the input depth
Actual throughput (Table 62) when the streaming width is sufficiently wideis improved due to the pipelined architecture with an pipeline interval of 28492Cycles
Stage Interval (Cycles) Latency (cycles)
1x1 Convolution 1573 M FP-Op5x5 Convolution 1254 M FP-OpTotal (1 partial pass) 2827 M FP-Op 28492 55190
FP Throughput 100MHz 992 GFLOPS
Total DDR Transfer 227KB 55190 Cycles 4113MBs
Table 62 Measured Throughput
Following the work of [19] from 2015 they present an neural networkaccelerator solution that is claimed to rdquoOutperform previous approaches significantlyrdquoachieving 6162 GFLOPS at 100MHz operating frequency Although this required2240 DSP48E1 slices from a Virtex7 VX485T several times more then availableon the Artix7 (740 DSP48E1) by scaling their results down to the range of Artix7resources should provide an indication as to the expected order of FLOPS in awell designed architecture
331 DSP48E12240 DSP48E1
times6162 GFLOPS = 911 GFLOPS
61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

61 TESTING LIMITATIONS 43
The architecture in this paper achieved 992 GFLOPS using 331 DSP slicesthis is comparable (slightly greater) to the scaled 911 GFLOPS expected froma comparable FPGA implementation of [19] where the emphasis was placed onmemory optimizations to maximize DSP loading (minimize DSP Idling waitingfor data) This comparative result indicates that the proposed solution in thisthesis is effective in continuously providing data to the computation units
In itrsquos current prototype configuration (including the support framework) thedesign only uses 485 of the 365 Block RAM tiles (133 utilization) Thisleaves room to alleviate memory access contentions between the DMA and theconvolution block buffers that may arise when the number of processing elementsare increased By allocating more memory to the kernel buffers there will be areduction in reads issued by the convolution block
612 EfficiencyThe major benefit of this architecture is that it enables the piece-wise processingof very large network datasets while decreasing the mass of data crossing onoffchip boundary by serializing two normally conflicting operations in a single pass
Additionally this architecture also incorporates the ability to separate thesecond stage square convolution from the first stage streaming operator in orderto reuse the intermediate buffered values for the next set of 3x35x5 feature filterkernels re-fetching values for every set of filter kernels as would be required fora typical rdquosingle production single consumerrdquo dataflow architecture
The throughput efficiency of the architecture is inherently related to the inputdepth where if an Inception module was specified to have an input array ofsignificant depth may cause the second square convolution stage to sit idle forshort periods This is unavoidable due to the variable inputoutput sizes foundthroughout GoogLeNet If the network sizes were set to a fixed ratio (as is typicalfor adapting ANN to embedded systems) then peak efficiency can be guaranteedfor every layer in the network This modification would reduce the usability ofaccelerator to implementing only specially adapted network topologies (typicallimitation of embedded ANNs)
From Table 62 it is also evident that there is still lots of utilized externalDDR memory bandwidth able to accommodate an increase to 64 bit width DMAtransfers By doubling the words per DMA transfers and instantiating two first-stage streaming multiply accumulate units would allow the accelerator to handlenetwork topologies with high depth inputs This is a viable modification becausethe first stage only requires a fraction of the DSP units as the second squareconvolution stage (80 vs 251 respectively)
Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Chapter 7
Conclusions
71 ConclusionAs noted by Szegedy et al [2] the recent trend of increasingly greater numberof network parameters to improve performance is endangering Neural Networksto a realm of rdquopurely academic curiosityrdquo their method was demonstrated inILSRC2014 to not only better all other entries in top 5 accuracy but achievedthis with an order of magnitude less network parameters While their methodvastly reduced weight parameters it also introduced new attributes requiring theexploration of new architectures and optimizations for efficient implementation
This architecture proposed in this thesis presents a series of techniques thatcombine to enable FPGA based embedded platforms to leverage the new advancesin Convolutional Neural Network topologies Specifically networks that relyon similar principles (proven effective in GoogLeNet) of using smaller (1x1)convolutions as a form of dimensional reductionabstraction before the larger mainconvolution operation
From a product development standpoint it still remains to be seen whetherspecially designed hardware structures such as the architecture proposed here (inthis thesis) or those in the literature study (Section 3) can scale and compete inperformance against a new emerging class of GPU (vector processing) acceleratedembedded platforms such as the NVIDIA Jetson [44] that benefit from theenormous memory bandwidth of GDDR that an ASIC implementation enables(GDDR5 operates at bus frequencies up to 7GHz)
72 Future workThe logical next step is to complement the processing element with a MaxPooloperator capability this would complete the pipeline for use as an inception
44
72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

72 FUTURE WORK 45
module accelerator usable in real applicationsBalancing of latency between the two convolution stages should be expanded
to account for all the inception module input depths the current single cycleinitiation interval of the streaming convolution may be relaxed (and resourcessaved) if it is determined that the second stage convolution across all input rangesnever completes before X number of cycles where X then can be used to calculateagainst the largest expected stream convolution size to find the minimum initiationinterval required before a bottleneck forms
Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Bibliography
[1] A Krizhevsky I Sulskever and G E Hinton ldquoImageNet Classification withDeep Convolutional Neural Networksrdquo Advances in Neural Information andProcessing Systems (NIPS) pp 1ndash9 2012
[2] C Szegedy W Liu Y Jia P Sermanet S Reed D Anguelov D ErhanV Vanhoucke and A Rabinovich ldquoGoing Deeper with ConvolutionsrdquoarXiv preprint arXiv14094842 pp 1ndash12 2014 [Online] Availablehttparxivorgabs14094842v1
[3] D Strenski C Kulkarni J Cappello and P Sundararajan ldquoLatestFPGAs show big gains in floating point performancerdquo 2012 [Online]Available httpwwwhpcwirecom20120416latest fpgas show big gains in floating point performance
[4] F Rosenblatt and F Rosenblatt ldquoThe Perceptron A Probabilistic Model forInformation Storage and Organization in The Brainrdquo PSYCHOLOGICALREVIEW pp 65mdash-386 1958 [Online] Available httpciteseerxistpsueduviewdocsummarydoi=10115883775
[5] X Glorot A Bordes and Y Bengio ldquoDeep Sparse Rectifier NeuralNetworksrdquo Aistats vol 15 pp 315ndash323 2011
[6] O Russakovsky J Deng H Su J Krause S Satheesh S Ma Z HuangA Karpathy A Khosla M Bernstein A C Berg and L Fei-FeildquoImageNet Large Scale Visual Recognition Challengerdquo InternationalJournal of Computer Vision vol 115 no 3 pp 211ndash252 2015 [Online]Available httpdxdoiorg101007s11263-015-0816-y
[7] Y LeCun B Boser J S Denker D Henderson R E Howard W Hubbardand L D Jackel ldquoBackpropagation Applied to Handwritten Zip CodeRecognitionrdquo Neural Computation vol 1 no 4 pp 541ndash551 dec 1989[Online] Available httpwwwmitpressjournalsorgdoiabs101162neco198914541
46
BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

BIBLIOGRAPHY 47
[8] P Sermanet D Eigen X Zhang M Mathieu R Fergus and Y LeCunldquoOverFeat Integrated Recognition Localization and Detection usingConvolutional Networksrdquo pp 1ndash16 dec 2013 [Online] Availablehttparxivorgabs13126229
[9] K Simonyan and A Zisserman ldquoVery deep convolutional networks forlarge-scale image recognitionrdquo Iclr pp 1ndash14 2015 [Online] Availablehttparxivorgabs14091556
[10] M Lin Q Chen and S Yan ldquoNetwork In Networkrdquo arXiv preprint p 102013 [Online] Available httparxivorgabs13124400
[11] C Szegedy V Vanhoucke S Ioffe J Shlens and Z Wojna ldquoRethinkingthe Inception Architecture for Computer Visionrdquo arXiv preprint 2015[Online] Available httparxivorgabs151200567
[12] C Szegedy S Ioffe and V Vanhoucke ldquoInception-v4 Inception-ResNetand the Impact of Residual Connections on Learningrdquo feb 2016 [Online]Available httparxivorgabs160207261
[13] J Cloutier E Cosatto S Pigeon F Boyer and P Simard ldquoVIP an FPGA-based processor for image processing and neuralnnetworksrdquo Proceedingsof Fifth International Conference on Microelectronics for Neural Networkspp 330ndash336 1996
[14] C E Cox and W E Blanz ldquoGanglion-a fast hardware implementation ofrdquoIEEE Journal of Solid-State Circuits vol 27 no 3 pp 288 ndash 299 1991
[15] M Sankaradas V Jakkula S Cadambi S Chakradhar I DurdanovicE Cosatto and H Graf ldquoA Massively Parallel Coprocessor forConvolutional Neural Networksrdquo 2009 20th IEEE International Conferenceon Application-specific Systems Architectures and Processors pp 53ndash602009
[16] M Naylor P J Fox A T Markettos and S W Moore ldquoManaging theFPGA memory wall Custom computing or vector processingrdquo 2013 23rdInternational Conference on Field Programmable Logic and ApplicationsFPL 2013 - Proceedings 2013
[17] M Peemen B Mesman and H Corporaal ldquoOptimal Iteration Schedulingfor Intra- and Inter- Tile Reuse in Nested Loop Acceleratorsrdquo PhDdissertation 2013
BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

BIBLIOGRAPHY 48
[18] M Peemen A A A Setio B Mesman and H Corporaal ldquoMemory-centricaccelerator design for Convolutional Neural Networksrdquo in 2013 IEEE 31stInternational Conference on Computer Design (ICCD) IEEE oct 2013pp 13ndash19 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=6657019
[19] C Zhang P Li G Sun Y Guan B Xiao and J Cong ldquoOptimizingFPGA-based Accelerator Design for Deep Convolutional Neural NetworksrdquoProceedings of the 2015 ACMSIGDA International Symposium on Field-Programmable Gate Arrays - FPGA rsquo15 pp 161ndash170 2015 [Online]Available httpdlacmorgcitationcfmid=2689060
[20] S Verdoolaege and T Grosser ldquoPolyhedral Extraction Toolrdquo SecondInternational Workshop on Polyhedral Compilation Techniques (IMPACT)2012
[21] S Williams A Waterman and D Patterson ldquoRoofline An InsightfulVisual Performance Model for Floating-Point Programs and MulticoreArchitecturesrdquo EECS Department University of California BerkeleyTech Reports UCBEECS-2008-134 vol 52 no 4 pp 65mdash-762008 [Online] Available httpwwweecsberkeleyeduPubsTechRpts2008EECS-2008-134html
[22] M Motamedi P Gysel V Akella and S Ghiasi ldquoDesign spaceexploration of FPGA-based Deep Convolutional Neural Networksrdquo in2016 21st Asia and South Pacific Design Automation Conference(ASP-DAC) IEEE jan 2016 pp 575ndash580 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7428073
[23] C Farabet Y Lecun K Kavukcuoglu E Culurciello B MartiniP Akselrod S Talay M Bilenko and J Langford ldquoLarge-Scale FPGA-based Convolutional Networks Chapter in Machine Learning on Very LargeData Setsrdquo Machine Learning on Very Large Data Sets pp 1ndash26 2011
[24] C Farabet B Martini P Akselrod S Talay Y LeCun and E CulurcielloldquoHardware accelerated convolutional neural networks for synthetic visionsystemsrdquo Proceedings of 2010 IEEE International Symposium on Circuitsand Systems pp 257ndash260 2010 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=5537908$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5537908
[25] J Jin and V Gokhale ldquoAn efficient implementation of deep convolutionalneural networks on a mobile coprocessorrdquo Circuits and Systems pp
BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

BIBLIOGRAPHY 49
133ndash136 2014 [Online] Available httpieeexploreieeeorgxplsabs alljsparnumber=6908370
[26] C S Lindsey and T Lindblad ldquoSurvey of neural network hardwarerdquoS K Rogers and D W Ruck Eds vol 2492 apr 1995 pp 1194ndash1205[Online] Available httpproceedingsspiedigitallibraryorgproceedingaspxarticleid=1001095
[27] H H H Hu J H J Huang J X J Xing and W W W Wang ldquoKey Issuesof FPGA Implementation of Neural Networksrdquo 2008 Second InternationalSymposium on Intelligent Information Technology Application vol 3 pp259ndash263 2008
[28] J Misra and I Saha ldquoArtificial neural networks in hardware A survey oftwo decades of progressrdquo Neurocomputing vol 74 no 1-3 pp 239ndash2552010 [Online] Available httpdxdoiorg101016jneucom201003021
[29] R Gadea J Cerda F Ballester and A Mocholi ldquoArtificial NeuralNetwork Implementation on a single FPGA of a Pipelined On- LineBackpropagationrdquo ISSS rsquo00 Proceedings of the 13th internationalsymposium on System synthesis pp 225ndash230 2000
[30] N Izeboudjen A Farah S Titri and H Boumeridja ldquoDigitalimplementation of artificial neural networks From VHDL descriptionto FPGA implementationrdquo in Engineering Applications of Bio-InspiredArtificial Neural Networks 1999 vol 7 no 11 pp 139ndash148 [Online]Available httplinkspringercom101007BFb0100480
[31] C Farabet C Poulet and Y LeCun ldquoAn FPGA-based stream processor forembedded real-time vision with convolutional networksrdquo 2009 IEEE 12thInternational Conference on Computer Vision Workshops ICCV Workshops2009 pp 878ndash885 2009
[32] C Farabet C Poulet J Y Han and Y LeCun ldquoCNP An FPGA-based processor for Convolutional Networksrdquo in 2009 InternationalConference on Field Programmable Logic and Applications vol 1no 1 IEEE aug 2009 pp 32ndash37 [Online] Available httpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=5272559
[33] B Ahn ldquoReal-time video object recognition using convolutional neuralnetworkrdquo 2015 International Joint Conference on Neural Networks(IJCNN) pp 1ndash7 2015 [Online] Available httpieeexploreieeeorgxplarticleDetailsjsparnumber=7280718$delimiterrdquo026E30F$nhttpieeexploreieeeorglpdocsepic03wrapperhtmarnumber=7280718
BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

BIBLIOGRAPHY 50
[34] L Bengtsson A Linde T Nordstrom B Svensson and M TavenikuldquoThe REMAP reconfigurable architecture A retrospectiverdquo FPGAImplementations of Neural Networks pp 325ndash360 2006
[35] S Chakradhar M Sankaradas V Jakkula and S Cadambi ldquoAdynamically configurable coprocessor for convolutional neural networksrdquoACM SIGARCH Computer Architecture News vol 38 no 3 p 247 2010
[36] S A Guccione and M J Gonzalez ldquoClassificationand performance of reconfigurable architecturesrdquo inInternational Conference on Field Programmable Logic andApplications (FPL) 1995 vol 975 pp 439ndash448 [Online]Available httpwwwspringerlinkcomindex735w56752142g024pdfhttplinkspringercom1010073-540-60294-1 138
[37] S A Dawwd ldquoThe multi 2D systolic design and implementation ofConvolutional Neural Networksrdquo Proceedings of the IEEE InternationalConference on Electronics Circuits and Systems pp 221ndash224 2013
[38] S A Dawwd and B S Mahmood ldquoA reconfigurable interconnectedfilter for face recognition based on convolution neural networkrdquo 2009 4thInternational Design and Test Workshop IDT 2009 pp 1ndash6 2009
[39] J-J Lee and G Y Song ldquoSuper-systolic array for 2D convolutionrdquo IEEERegion 10 Annual International Conference ProceedingsTENCON 2007
[40] J-J Lee and G-Y Song ldquoImplementation of the super-systolicarray for convolutionrdquo vol 4 pp 491ndash494 2003 [Online]Available httpieeexploreieeeorgezproxyhplhpcomielx585042687801195065pdftp=amparnumber=1195065ampisnumber=26878$delimiterrdquo026E30F$nhttpieeexploreieeeorgezproxyhplhpcomxplsabs alljsparnumber=1195065
[41] Xilinx UG479 7 Series DSP48E1 Slice Xilinx 2014 [Online]Available httpwwwxilinxcomsupportdocumentationuser guidesug479 7Series DSP48E1pdf
[42] mdashmdash ldquoug474 - 7 Series FPGAs Configurable Logic Blockrdquo vol 474pp 1ndash72 2014 [Online] Available httpswwwxilinxcomsupportdocumentationuser guidesug474 7Series CLBpdf
[43] Micron ldquoMT41K256M16 DDR3L SDRAM Datasheetrdquo pp 1ndash2162011 [Online] Available httpswwwmicroncompartsdramddr3-sdrammt41k256m16ha-125
BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

BIBLIOGRAPHY 51
[44] N Corporation ldquoNVIDIA Jetson Embedded Platformrdquo2016 [Online] Available httpsdevelopernvidiacomembeddedmeet-jetson-embedded-platform
Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

Appendix A
Vivado Reports
Figure A1 Power Estimation
52
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
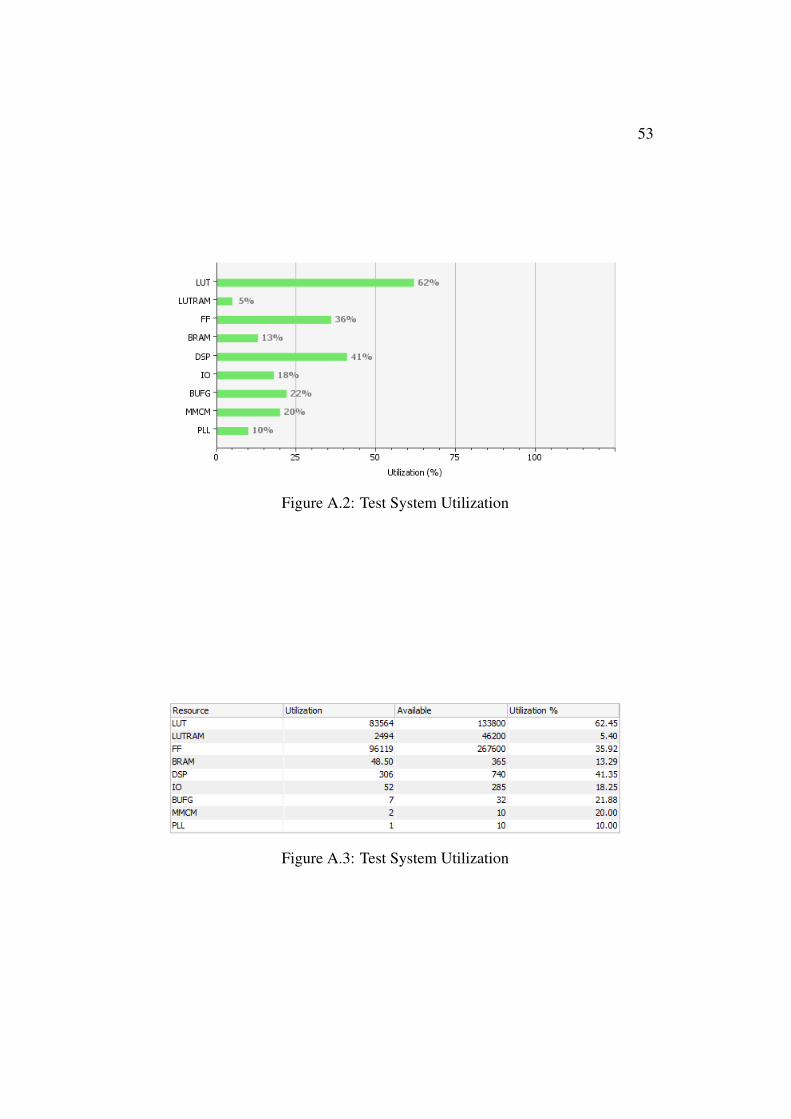
53
Figure A2 Test System Utilization
Figure A3 Test System Utilization
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse
54
Figure A4 Implementation Topology
ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

ccopy Kalle Ngo December 2016
TRITA -ICT-EX-2016188
wwwkthse

TRITA -ICT-EX-2016188
wwwkthse





























