Embed Size (px)
Citation preview

1
Fuzzy Empirical Copula for Estimating DataDependence StructureZhaojie Ju a Youlun Xiong b and Honghai Liu a
a Intelligent Systems & Robotics Group, School of Creative Technologies, University of Portsmouth, UKb School of Mechanical Science and Engineering, Huazhong University of Science and Technology, Wuhan China
Fuzzy Empirical Copula, Data Aggregation, Depen-dence Structure.
1. Introduction
The information in the world is becoming more andmore electronic. Due to the improvements in datacollection and storage during the past decades, hugeamounts of data can lead to the problem of infor-mation overload [1] to many researchers in domainssuch as engineering, economics and astronomy. Theincrease of the number of dimensions associated witheach observation and growth of the sampling timepoints are the main reasons of information overload. Inmany cases, datasets contain not only useful messagesbut also considerable trivial and redundant informa-tion both in the dimensions (attributes) and samples.How to remove the redundant information and main-tain the important information is crucial in many ap-plications. Two important methods are normally em-ployed to solve this problem: dimensionality reductionand clustering. The formal reduces trivial attributes,maintaining the number of samples, while the latereliminates the redundant samples without changing thenumber of attributes.There are various traditional and current state of the artdimensionality reduction methods to solve the aboveproblem. Principal Component Analysis (PCA) wasinvented in 1901 by Karl Pearson [2] and is mostlyused for dimensionality reduction in a dataset by re-taining the characteristics of the dataset that con-tribute most to its variance. It keeps lower-order prin-cipal components and ignores higher-order ones. Suchlower-order components often contain the “most im-portant" aspects. Like PCA, Factor analysis (FA) isanother second-order method [3]. FA becomes essen-
tially equivalent to PCA if the “errors" in the FA modelare all assumed to have the same variance. Thesesecond-order methods require classical matrix ma-nipulations and assumption that datasets are realiza-tions from Gaussian distributions. For non-Gaussiandatasets, higher-order dimension reduction methodssuch as Projection Pursuit (PP) [4] and IndependentComponent Analysis (ICA) [5] are introduced. Ad-ditionally, non-linear PCA can also deal with non-Gaussian datasets using non-linear objective functionsto determine the optimal weights in principal [6]. Itsresulting components are still linear combinations ofthe original variables, so it can be regarded as a spe-cial case of ICA. Other non-linear methods such asPrincipal Curves (PC) [7] and Self Organizing Maps(SOM) [8] can be thought to be non-linear ICA [9]in that they replace the linear transformation of ICAwith a real-valued non-linear vector function. Curvi-linear Component Analysis (CCA) is a relatively newnon-linear mapping method, being improved fromSammon’s mapping by Jeanny Heault and Pierre De-martines [10]. It uses a new cost function able tounfold strongly non-linear or even closed structures,which significantly speeds up the calculation and in-teractively helps users control the minimized function.However, more parameters should be considered formost of these high-order and non-linear dimensional-ity reduction methods and their performances stronglydepend on complex adjustments of these parameters,for instance there are three parameters in CCA: theprojection space dimension and the two time decreas-ing parameters.However, dimensionality reduction methods can not beused during estimating data dependence structure, be-cause dependence structure includes all the interrela-tions of the attributes and high-order attributes are not

2
supposed to be ignored. Clustering is the classificationof objects into clusters so that objects from the samecluster are more similar to each other than objects fromdifferent clusters. It can effectively reduce the numberof data samples, so it is suitable for reducing the re-dundant information when estimating data dependencestructure. The most common algorithms include K-means [11], fuzzy C-means [12], and fuzzy C-means-derived clustering approaches such as fuzzy J-means[13] and fuzzy SOM [14], which construct clusterson the basis of pairwise distance between objects, sothat they are incapable of capturing non-linear relation-ships and thereby fail to represent a dataset with non-linear structure. Hierarchical clustering is another im-portant approach but suffers from lack of robustness,non-uniqueness, and inversion problems [15]. Gaus-sian Mixture Model (GMM) is based on the assump-tion that datasets are generated by a mixture of Gaus-sian distributions with certain probability. But this as-sumption is not always satisfied for general datasetseven after various transformations aimed at improvingthe normality of the data distribution [16, 17].Copula is a general way of formulating a multivari-ate distribution with uniform marginal distributions insuch a way that various general types of dependencecan be presented. The copula of a multivariate dis-tribution can be considered as the part describing itsdependence structure as opposed to the behaviour ofeach of its margins [18]. It is a good way of study-ing scale-free measures of dependences among vari-ables and also a good starting point for constructingfamilies of bivariate distributions [19]. Sklar’s theorem[20] elucidates that a multivariate distribution func-tion can be represented by a copula function whichbinds its univariate margins. Further, empirical copu-las were introduced and first studied by Deheuvels in1979 [21,22], which can be used to study the interrela-tions of marginal variables with unknown underlyingdistributions. The copula approach has many advan-tages [23] and has been used widely in finance [24,25]and econometrics [26, 27]. Kolesarova et al. [28] de-fined a new copula called discrete copulas on a gridof the unit square and showed that each discrete cop-ula is naturally associated with a bistochastic matrix.Baets and Meyer [29] also presented a general frame-work for constructing copulas, which extended the di-agonal construction to the orthogonal grid construc-tion. Simultaneously, empirical copula has gained anincreasing amount of attention recently. Dempster etal. [30] constructed an empirical copula for Collat-eralized debt obligation tranche pricing and achieved
a better performance than the dominant base corre-lation approach in pricing non-standard tranches. Maand Sun [31] proposed a Chow-Liu like method basedon a dependence measure via empirical copulas to esti-mate maximum spanning product copula with only bi-variate dependence relations, while Morettin et al. [32]proposed wavelet estimators based on empirical copu-las which can be used for independent, identically dis-tributed time series data.It is evident, however, that the efficiency of empiricalcopula is outstandingly poor though it provides effec-tive performance on data dependence structure estima-tion. It is common that natural datasets are representedby tremendous storage size, and it is impossible to pro-cess them using empirical copula in most cases. In or-der to overcome this problem, we propose an algorithmnamed fuzzy empirical copula which integrates fuzzyclustering with empirical copula. Fuzzy Clustering byLocal Approximation of Memberships (FLAME) [17]is firstly extended into multi-dimensional space, thenthe FLAME+ is utilized to reduce the number of sam-pling data and maintaining the interrelations at thesame time before data dependence structure estima-tion takes over. The remainder of the paper is orga-nized as follows. Section 2 presents copula theory witha focus on dependence structure estimation using em-pirical copula. Section 3 proposes the Fuzzy empir-ical copula algorithm. Section 4 presents the experi-ments whose results demonstrate the effectiveness ofthe proposed fuzzy empirical copula. Concluding re-marks and future work are found in Section 5.
2. Dependence Structure Estimation via EmpiricalCopula
As a general way of formulating a multivariate dis-tribution, copula can be used to study various gen-eral types of dependence between variables. Otherways of formulating multivariate distributions includeconceptually-based approaches in which the real-world meaning of the variables is used to imply whattypes of relationships might occur. In contrast, theapproach via copulas might be considered as beingmore raw, but it does allow much more general typesof dependencies to be included than would usuallybe invoked by a conceptual approach. Nelsen [19]has proven that these measures, such as Kendall’stau, Spearman’s rho and Gini’s gamma, can be re-expressed only in terms of copula. Though their directcalculation may have much less computational cost

3
than when using copulas, copula summarizes all thedependence relations and provides a natural way tostudy and measure dependence between variables instatistics. It is a very important approach since copulaproperties are invariant under strictly increasing trans-formations of the underlying random variables. Spear-man’s rho and Gini’s gamma are considered in thispaper. In this section, we firstly revisit the theoreticalfoundation of copula and empirical copula, then intro-duce the theorem of calculating Spearman’s rho andGini’s gamma using bivariate empirical copula, finallyanalyse the time complexity of the computation.
2.1. Copula
A n-dimensional copula is defined as a multivari-ate joint distribution on the n-dimensional unit cube[0, 1]n such that every marginal distribution is uniformon the interval [0, 1].
Definition 2.1.1. A n-dimensional copula is a functionC from In to I with the following properties [19]:
1. C is grounded, i.e., for every u in In, C(u) = 0 ifat least one coordinate uj = 0, j = 1, · · · , n.
2. If all coordinates of u are 1 except for some uj ,j = 1, · · · , n, thenC(u) = C(1, · · · , 1, uj , 1, · · · , 1) = uj .
3. C n-increasing, i.e., for each hyperrectangleB = ×n
i=1[xi, yi] ⊆ [0, 1]n
Vc(B) =∑
z∈×ni=1{xi,yi}
(−1)N(z)C(z) ≥ 0 (1)
where the N(z) = card{k |zk = xk} . Vc(B) is theso called C-volume of B.
Sklar’s Theorem [20] is central to the theory of copulaand underlies most applications of the copula. It eluci-dates the role that copula plays in the relationship be-tween multivariate distribution functions and their uni-variate margins.
Sklar’s Theorem 2.1.1. Let H be a joint distributionfunction with margins Fi(i = 1, 2, · · · , n). Then thereexists a copula C such that for all xi in R̄,
H(x1, · · · , xn) = C(F1(x1), · · · , Fn(xn)) (2)
where C is a n-dimensional copula, Fi are marginaldistribution function of xi.
If Fi(i = 1, · · · , n) are continuous, C is unique. If Cis a n-dimensional copula and Fi(i = 1, · · · , n) aredistribution functions, then the function H defined byequation 2 is a joint distribution function with marginsFi(i = 1, · · · , n). More details can be seen in [19,23].
2.2. Empirical Copula and Dependence Estimation
The empirical copula is a characterization of the de-pendence function between variables based on obser-vational data using order statistics theory and it canreproduce any pattern found in the observed data. Ifthe marginal distributions are normalized, the empiri-cal copula is the empirical distribution function for thejoint distribution. Priority has been given to bivariateempirical copula due to computational cost. The rea-son is twofold: one is that the interrelation betweenevery two attributes is the basic relationship in mostattributes, and it is practical to use bivariate empiri-cal copula to construct the whole structure of everytwo attributes’ dependence; the second is that the de-pendence structure of dataset X including r attributes
would have(r
2
)= 1
2r(r − 1) bivariate interrelations.
Bivariate empirical copula is given as follows.
Definition 2.2.1. Let {(xk, yk)}nk=1 denote a sampleof size n from a continuous bivariate distribution. Theempirical copula is the function Cn given by
Cn( in ,
jn ) =
card{(x,y):x≤x(i),y≤y(j)}n
(3)
where x(i) and y(j), 1 ≤ i, j ≤ n, denote order statis-tics from the sample [19].The empirical copula frequency cn is given by
cn( in ,
jn ) ={
1n , if (x(i), y(j)) is an element of the sample0, otherwise
(4)
Note that Cn and cn are related via
Cn(i
n,j
n) =
i∑p=1
j∑q=1
cn(p
n,q
n) (5)
Theorem 2.2.1. Let Cn and cn denote, respectively,the empirical copula and the empirical copula fre-quency function for the sample {(xk, yk)}nk=1. If ρ and

4
γ denote, respectively, the sample versions of Spear-man’s rho, and Gini’s gamma [33, 34], then
ρ = 12n2−1
n∑i=1
n∑j=1
[Cn
(in ·
jn
)− i
n ·jn
](6)
and
γ = 2nbn2/2c
{n−1∑i=1
Cn
(in , 1−
in
)−
n∑i=1
[in − Cn
(in ,
in
)]}(7)
Spearman’s rho and Gini’s gamma are two ways ofmeasuring two variables’ association [19]. Accordingto the definition and theorem, we can estimate corre-lations between variables using empirical copula andSpearman’s rho & Gini’s gamma. Suppose the num-ber of objects is n and number of attributes is r. Forr << n, according to the equations 3, 6 and 7, thetime complexity of Spearman’s rho or Gini’s gamma isO(n3).
3. Fuzzy Empirical Copula
In this section Fuzzy clustering by Local Approxima-tion of Memberships (FLAME) is extended first interms of dimension and distance functions, then is in-tegrated into empirical copula to enhance its compu-tational efficiency. FLAME was proposed to clusterDNA microarraydata [17]. It defines clusters in the rel-atively dense regions of a dataset and performs clus-ter assignment solely based on the neighbourhood re-lationships among objects. One of the FLAME algo-rithm features is that the memberships of neighbouringobjects in the fuzzy membership space are set accord-ing to the neighbourhood relationships among neigh-bouring objects in the feature space. FLAME has beenextended in terms of dimension and distance func-tion (i.e., FLAME+), which still consists of three mainsteps of FLAME algorithm: initialization, approxima-tion and assignment.
3.1. Initialization
The first step, initialization, is to classify three typesof objects: Cluster Supporting Object (CSO), clusteroutliers and the rest which are named Normal Points(NPs).
Let X be a r-dimensional dataset with n objects. Ther-dimensional distance between two instances is
dp(x, y) = (r∑
i=1
|xi − yi|p)(1/p) (8)
where x, y ∈ X; 1 ≤ p ≤ ∞; d1 is the Manhattandistance, d2 is the familiar Euclidean distance, and d∞corresponds to the maximum distance in any dimen-sion. Then the similarity of these two objects is calcu-lated as:
sxy = 1dp(x,y) (9)
Similarity is the degree of resemblance between two ormore objects. There are different ways to calculate thesimilarity. Since “the density of each object is calcu-lated as one over the average distance to the k-nearestneighbors" in the FLAME clustering algorithm [17], tomake the relation between similarity and density moredirect and simple, we choose Eq. 9 to calculate the sim-ilarity in the paper.The K-Nearest Neighbours (KNNs) for each object aredefined as the k objects (k ≤ n) with the k highestsimilarity. The density of object x with KNNs can beobtained
Denp(x) = k∑y∈knn(x)
dp(x,y) (10)
where knn(x) stands for the set of KNNs of the objectx.Subsequently, the set of CSOs is defined as the set ofobjects with local maximum density, i.e., with a den-sity higher than that of every object in their KNNs. Thehigher k is, the less CSOs will be identified, then lessclusters will be generated. A density threshold needsdefining to find possible cluster outliers, so objectswith densities below the threshold are defined as pos-sible outliers.Each object x is associated with a membership vectorp(x), in which each element pi(x) indicates the mem-bership degree of x in cluster i
p(x) = (p1(x), ..., pm(x)), (11)
where 0 ≤ pi(x) ≤ 1;∑m
i=1 pi(x) = 1; m is the totalnumber of CSOs and the outlier cluster, i.e.,m = c+1where c is the number of CSOs; Each element of mem-bership vector takes value between 0 and 1, indicatinghow much percentage an object belonging to a cluster,or being an outlier.

5
Based on the density estimation, each CSO is assignedwith fixed and full membership to itself to representone cluster, for example p(x) = (0, 1, ...0) indicatesthat object x is the second CSO . Each outlier is as-signed with fixed and full membership to the outliergroup, p(x) = (0, · · · , 0, 1), and the NP is assignedwith equal memberships to all clusters and the outliergroup, p(x) = (1/m, · · · , 1/m).
3.2. Approximation
The second step is named local/neighbourhood ap-proximation of fuzzy memberships, in which eachNP’s fuzzy membership is updated by a linear combi-nation of the fuzzy memberships of its KNNs, whileCSOs and outliers maintain the fixed and full member-ships to themselves respectively.The weights defining how much each neighbour willcontribute to approximation of the fuzzy membershipof that neighbour are estimated in equation 12, basedon the fact that the neighbours that have higher simi-larities must have higher weights.
wxy =sxy∑
z∈knn(x)
sxz (12)
where y ∈ knn(x). The membership vector of eachNP is approximated according to equation 13, min-imizing the overall difference between membershipvectors and their approximations.
pt+1(x) =∑
y∈knn(x)wxyp
t(y) (13)
The overall local/neighbourhood approximation erroris calculated by:
E({p}) =∑x∈X
∥∥∥∥∥p(x)−∑
y∈knn(x)wxyp(y)
∥∥∥∥∥2
(14)
The iteration of equation 13 breaks under the conditionthat E({p}) is less than a predetermined threshold.
3.3. Assignment
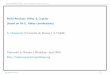
Finally, it is to assign each object to the cluster basedon its fuzzy membership. Usually, one cluster containsthe objects that have higher membership degrees in thiscluster than other clusters.An example of FLAME+ is provided in Fig. 1, wherea dataset with 600 objects is randomly generated from
a 3 dimensional distribution. FLAME+ is applied tothis dataset and three groups of objects are clustered asoutliers, CSOs and NPs.
−4 −2 0 2 4 6−5
0
5
10
−4
−2
0
2
4
6
Colormap of the clusters
Fig. 1. Clustering random 3D Euclidean positions using FLAME+.The star points in black are the centres of the clusters (CSO); pointslabeled with triangles are the outliers; the colour range of NPs rep-resents their membership degrees.
Accurately calculating the entire time complexity ofFLAME+ is very challenging in that each iteration oflocal/neighbourhood approximation depends on the er-ror threshold. However, it is necessary to analyse thecomplexity of the first step of the algorithm. Supposethe number of objects is n, number of attributes is r, itsCSOs’ number is c and number of nearest neighboursis k. For r << n and k << n, the time complexity ofthe initialization is O(n2). An empirical study of thetime complexity of FLAME+ compared with other al-gorithms is performed to illustrate that FLAME+ hassignificant computational advantage over hierarchicalclustering, fuzzy C-means and fuzzy SOM, an excep-tion is K-means [17]. In section 4, FLAME+ and K-means are compared in the context of fuzzy empiricalcopula.We aim at developing an algorithm which can effi-ciently reduce the computational cost of empirical cop-ula by filtering out redundant information in the sam-ple. In addition, this algorithm should also be capa-ble of dealing with arbitrary-distributed datasets in or-der to inherit the main advantage of empirical copulafor data structure estimation. FLAME algorithm is se-lected for this purpose in that it not only fulfills theabove requirements but also possesses the merit of fewparameters, i.e., the number of nearest neighbours andthe value of the outlier’s threshold.It is evident that samples with higher densities aremore reliable when used to represent whole samplesin such a way that the main feature of the whole sam-

6
ple is maintained. The FLAME algorithms have the ca-pability of identifying those “special" sampling pointsbased on the objects’ density analysis. The “special"points are represented by the CSOs with the highestdensities in all clusters. Therefore, the fuzzy empiricalcopula algorithm is proposed for achieving the follow-ing: high dimension FLAME algorithm is employed toidentify characteristic feature points, and dependencestructure, on the other hand, it is estimated via empiri-cal copula.Let X be r-dimensional dataset with n objects:
X =
x11 · · · x1n.... . .
...xr1 · · · xrn
so the ith object is represented by the ith columnin matrix X: xi = [x1i, x2i, · · · , xri]T and the jthattribute of X is defined as the jth row: x(j) =[xj1, xj2, · · · , xjn]. The dependence structure in thispaper is defined as the whole structure of every twoattributes’ dependence which can be calculated by bi-variate empirical copula, because the interrelation be-tween every two attributes is the most basic relation-ship in several attributes. Given interrelations betweenevery two attributes, relations of three or more at-tributes would be derived from their dependence struc-
ture which would have(r
2
)= 1
2r(r−1) interrelations
(r is the number of attributes).In fuzzy empirical copula, firstly FLAME+ reducesthe samples from n objects to c CSOs, and then empir-ical copula analyses the dependence of every two at-tributes in the derived CSO matrix. The first step canbe considered as the operation on the column and thelater on the row. For ideal performance of the proposedalgorithm, one of outputs of FLAME+, CSOs, is com-puted leading to efficient computation. That is to saywe only have to implement the first step in the FLAMEalgorithm which has less time complexity than em-pirical copula and only one parameter, the number ofneighbours, is required since the threshold works onlyfor outliers. The Spearman’s rho and Gini’s gamma ofthe CSOs would be
ρ(u, v) = 12c2−1
c∑i=1
c∑j=1
[C
(uv)c
(ic ,
jc
)− i
c ·jc
](15)
and
γ(u, v) =2n
bn2/2c
{c−1∑i=1
C(uv)c
(i
c, 1− i
c
)−
c∑i=1
[i
c− C(uv)
c
(i
c,i
c
)]}(16)
where u ∈ [1, · · · , r) and v ∈ (u, · · · , r]; C(uv)c is the
bivariate empirical copula of the uth and vth attributeswith c objects, and C(uv)
c = C(vu)c .
The optimization is designed to automatically iden-tify the optimized number of neighbours with accept-able errors. The number of nearest neighbours is in-creased by one at every step during the optimizationuntil proper number of neighbours is identified. Theoptimization stops when the overall error of Spear-man’s rho or Ginis gamma in equation is under the pre-set error threshold. The pseudo-code of fuzzy empir-ical copula is presented in algorithmic form 1 and its‘EmpSG’ function is in algorithm form 2.
4. Experiment and Discussions
Experiments are conducted in this section, and resultsand discussions are provided for evaluating the effec-tiveness and efficiency of fuzzy empirical copula. Af-ter a brief explanation of the datasets, empirical copulaand fuzzy empirical copula are employed respectivelyto estimate the dependence structures of the datasets.The section is concluded with the roles that clusteringalgorithms play in fuzzy empirical copula.
4.1. Data
Abalone [35] and yeast [36] datasets from UCI ma-chine learning repository [37] were selected to evalu-ate the proposed algorithm in this paper. The abalonedataset was used to predict the age of abalone fromthe physical measurements such as weight and length,and it is not a trivial task to get their ages by count-ing the number of rings in their bodies through a mi-croscope. 4177 abalone are sampled with 9 attributesin this dataset. Fig. 2 shows interrelations of length,diameter, whole weight and shell weight. This datasetcould be regarded as 9 dimensional data with 4177samples in which some measurements are intrinsicallyinterrelated. The yeast dataset was constructed for pre-dicting the cellular localization sites of proteins. It

7
Algorithm 1 Fuzzy Empirical Copula algorithmRequire: X = {x1, x2, ..., xn} {X is a r dimensional
dataset with n objects and r << n}Require: [ρall, γall] {the Spearman’s rho and Gini’s
gamma of the original data X}1: for all i such that 1 ≤ i ≤ n do2: for all j such that 1 ≤ j ≤ n do3: d2(xi, xj) ← eqution8 {calculate the Eu-
clidean distance between two objects usingequation 8}
4: end for5: end for6: K = 0 {K is the number of nearest neighbours
under consideration}7: repeat8: K = K + 19: for all i such that 1 ≤ i ≤ n do
10: Den2(xi)← equation10 {get the density ofevery object}
11: end for12: c = 0 {the number of CSOs}13: for all i such that 1 ≤ i ≤ n do14: if Den2(xi) ≥ max(Den2(yi)) where yi ∈
knn(xi) then15: c = c+ 116: CSOc ← xi {get CSOs which have the
local maximum densities}17: end if18: end for19: for all u such that 1 ≤ u ≤ r do20: for all v such that (u+ 1) ≤ v ≤ r do21: [ρ(u, v), γ(u, v)] ←
EmpSG(CSO(u), CSO(v)) {CSO(i)is the ith attribution of CSO, EmpSG isa function to calculate the data’s Spear-man’s rho and Gini’s gamma as showedin algorithm 2, ρr×r is the matrix ofSpearman’s rho and γr×r is the matrix ofGini’s gamma}
22: end for23: end for24: error = ‖[ρall, γall]− [ρr×r, γr×r]‖ {take the
Euclidean distance of the ρ and γ as the overallerror}
25: until error ≥ threshold {threshold is thethreshold of overall error decided according to theoriginal dataset}
Algorithm 2 Function of EmpSG for Spearman’s rhoand Gini’s gammaRequire: CSO(u), CSO(v) {two attributes in CSO}Ensure: SP,GI {Spearman’s rho and Gini’s gamma
of above two attributes}1: x = CSO(u); y = CSO(v) {x and y are two
vectors with c elememts}2: x′ = sort(x); y′ = sort(y) {x′ and y′ are the
order statistics of x and y}3: for all i such that 1 ≤ i ≤ c do4: for all j such that 1 ≤ j ≤ c do5: num← 0 {initialization}6: for all t such that 1 ≤ t ≤ c do7: if x(t) ≤ x′(i) and y(t) ≤ y′(j) then8: num← num+ 19: end if
10: end for11: EC(i, j)← num/c12: end for13: end for14: SP ← 0 {the return value of Spearman’s rho}15: GI ← 0 {the return value of Gini’s gamma}16: for all i such that 1 ≤ i ≤ c do17: for all j such that 1 ≤ j ≤ c do18: SP ← SP + EC(i, j)− (j ∗ i)/(c ∗ c)19: end for20: if i 6= b then21: GI ← GI + EC(i, c− i)− i/c+ EC(i, i)22: end if23: end for24: SP ← SP ∗ 12/(c ∗ c− 1)25: GI ← 2 ∗ c/(c ∗ c/2) ∗ (GI − 1 + EC(c, c))26: return SP and GI
contains 1484 instances with 8 attributes for each in-stance. Both of these two datasets contain strong non-linear dependences between attributes. Priority hereinis given to the sampling density and the interrelationsamong attributes. Supposing one dataset contains s at-
tributes, its dependence structure includes(s
2
)inter-
relations of every two attributes among this dataset,which means the abalone and yeast datasets have twodependence structures of 36 and 28 interrelations to beanalysed respectively.
4.2. Dependence Structure Estimation via EmpiricalCopula
Spearman’s rhos and Gini’s gammas are calculated ac-cording to equations 6 and 7 via empirical copula using

8
0 0.5 10
0.5
1
0 0.5 10
2
4
0 0.5 10
1
2
0 0.5 10
0.5
1
0 0.5 10
2
4
0 0.5 10
1
2
0 2 40
0.5
1
0 2 40
0.5
1
0 2 40
1
2
0 1 20
0.5
1
0 1 20
0.5
1
0 1 20
2
4
Fig. 2. The interrelations of length, diameter, whole weight and shellweight of abalone dataset
the two above datasets. The results of abalone’s depen-dences of 36 correlations for 9 attributes are listed inthe Fig. 3, and yeast dataset of 28 correlations for 8 at-tributes in the Fig. 4. The whole computation time forabalone is 27226 seconds, which is unrealistic for re-lated applications. On the other hand, though the yeastdataset has fewer instances its computational time isstill high, at 2813 seconds. It should be noted that it hasto carefully handle the tradeoff between efficiency andaccuracy of fuzzy empirical copula. The more near-est neighbours are considered (e.g., Fig.3), the fewerCSOs will appear, the more efficient the algorithm is.It also, however, leads to larger error.
0 5 10 15 20 25 30 35 40−0.5
0
0.5
1
Gin
is g
am
ma
Abalone dataset
36 bivariate interrelations
0 5 10 15 20 25 30 35 40−0.5
0
0.5
1
Spearm
ans r
ho
Abalone dataset
36 bivariate interrelations
Fig. 3. The result of dependences of 36 correlations of the originalabalone dataset
4.3. Dependence Structure Estimation via FuzzyEmpirical Copula
The proposed fuzzy empirical copula is employed inthis section to reduce computation time for depen-dence structure analysis of these two datasets. Themore nearest neighbours are considered, the fewerCSOs will appear. It indicates that the calculation of
0 5 10 15 20 25 30−0.5
0
0.5
1
Spearm
ans r
ho
28 bivariate interrelations
Yeast dataset
0 5 10 15 20 25 30−0.2
0
0.2
0.4
0.6
Gin
is g
am
ma
28 bivariate interrelations
Yeast dataset
Fig. 4. The result of dependences of 28 correlations of the originalyeast dataset
fuzzy empirical copula will be more efficient at thecost of lower accuracy. The proposed fuzzy empiricalcopula has the ability to identify the proper number ofnearest neighbours which guarantees the fast compu-tation with the overall error under the preset threshold.The threshold for Spearman’s rho from equation 15 ispredefined as,
threshold = p×(s
2
)= ps(s−1)
2 (17)
where(s
2
)is the number of interrelations, combining
2 attributes out of s attributes; p is the average errorpercentage for each interrelation. Different thresholdresults in different computational time, and p is definedto take a value in the range from 0.5% to 1% accordingto the different features of datasets. From the aboveresults of the two datasets using empirical copula, pis predefined as 0.6% and 1% for abalone and yeastdatasets respectively, which indicates that abalone andyeast datasets have the thresholds of 0.228 and 0.28.
4.3.1. Abalone datasetUnder the overall error threshold of 0.228 for Spear-man’s rho, fuzzy empirical copula with 12 nearestneighbours has the lowest computation time. Thanks tothe FLAME+’s density sampling, when the number ofnearest neighbours is 12, the number of data instancesis reduced to 100 from 4177 depicted in Fig. 5. The 36interrelations of the 9 attributes of these 100 CSOs areestimated as shown in red line in Fig. 6, where the bluelines are results generated from empirical copula. It il-lustrates that fuzzy empirical copula with 12 nearestneighbours does not cause unacceptable error to Spear-man’s rho and Gini’s gamma compared to empirical

9
copula. However, the computation time of fuzzy em-pirical copula algorithm is 68 seconds, which is only0.25 percent of the computational time conducted byempirical copula algorithm.
0 0.5 10
0.5
1
0 0.5 10
2
4
0 0.5 10
1
2
0 0.5 10
0.5
1
0 0.5 10
2
4
0 0.5 10
1
2
0 2 40
0.5
1
0 2 40
0.5
1
0 2 40
1
2
0 1 20
0.5
1
0 1 20
0.5
1
0 1 20
2
4
Fig. 5. Result of sampled abalone data using12-neighbour-FLAME+
0 5 10 15 20 25 30 35 40−0.5
0
0.5
1
Spearm
ans r
ho
Abalone dataset
36 bivariate interrelations
0 5 10 15 20 25 30 35 40−0.5
0
0.5
1
Gin
is g
am
ma
Abalone dataset
36 bivariate interrelations
Fig. 6. Comparison of Spearman’s rhos and Gini’s gammas. Bluelines are the correlations of Empirical Copula algorithm while redlines are of Fuzzy Empirical Copula algorithm
In order to have a better understanding of the perfor-mance of fuzzy empirical copula, Fig. 7 displays thechange of CSO’s number with the growing number ofnearest neighbours from 1 to 20. It shows that the num-bers of abalone’s CSOs drops exponentially with thegrowth of the number of nearest neighbours. With thegrowing nearest neighbours, Fig. 8 shows the overallerror changes of Spearmans rho and Ginis gamma andFig. 9 presents the time change. The error threshold lo-cates the place between 12 and 13 nearest neighbours.Given a threshold, the error and the computational timecan easily be decided from Figs. 8 and 9.
0 5 10 15 200
200
400
600
800
1000
1200
1400
1600Abalone dataset
NO. of neighbors
Num
ber
of S
am
plin
g P
oin
ts
Fig. 7. The relationship between number of nearest neighbours andnumber of abalone’s CSOs
0 5 10 15 200
0.1
0.2
0.3
0.4
X: 12Y: 0.1754
Errors of Abalone dataset
NO. of neighbors
Gin
is g
am
ma
0 5 10 15 200
0.1
0.2
0.3
0.4
X: 12Y: 0.1506
Errors of Abalone dataset
NO. of neighbors
Spearm
ans r
ho X: 0
Y: 0.228
X: 13Y: 0.2309
Fig. 8. Change of overall errors of Spearman’s rhos and Gini’s gam-mas with the growth of number of nearest neighbours in FLAME+
Fig. 9. Change of time costed by Fuzzy Empirical Copula with thegrowth of number of nearest neighbours in FLAME+
4.3.2. Yeast datasetSimilar data processing in above section was employedon yeast dataset. If the threshold of Spearman’s rhooverall error is set to be 0.28, 2 nearest neighbourswould make the estimation perform well because ofthe relatively small error which is under the threshold

10
and fast computation. The result with 2 nearest neigh-bours is shown in red in Fig. 10, compared with theresult in blue from Empirical Copula, which demon-strates that the dependence structure of yeast datasetis maintained. The errors are only 0.28 for Spearman’srho and 0.24 for Gini’s gamma in Fig. 10, and compu-tation time is 26.3 seconds which is only 0.93 percentof the time cost by Empirical Copula.
0 5 10 15 20 25 30−0.5
0
0.5
1
Spearm
ans r
ho
Yeast dataset
28 bivariate interrelations
0 5 10 15 20 25 30−0.5
0
0.5
Gin
is g
am
ma
Yeast dataset
28 bivariate interrelations
Fig. 10. Comparison of Spearman’s rhos and Gini’s gammas. Bluelines are the correlations of Empirical Copula algorithm while redlines are of Fuzzy Empirical Copula algorithm
The number of yeast’s CSOs also drops exponentiallywith the growth of the number of nearest neighboursfrom 1 to 20 shown in Fig. 11. Fig. 12 shows thechanges of errors of Spearman’s rho and Gini’s gammagrows with the number of nearest neighbours, whileFig. 13 displays the changes of cost time.
0 5 10 15 200
100
200
300
400
500
600
700
800Yeast dataset
NO. of neighbors
Num
ber
of S
am
plin
g P
oin
ts
Fig. 11. The relationship between number of nearest neighbours andnumber of yeast’s CSOs
However, for 5 or more nearest neighbours, the numberof sampling data is reduced to less than 70 instances inFig. 11, which are so few that the result becomes unac-ceptable with huge errors since the sampling data cannot cover the main feature area of the whole dataset.
0 5 10 15 200
0.5
1
1.5
2
X: 2Y: 0.2392
Errors of Yeast dataset
NO. of neighbors
Gin
is g
am
ma
0 5 10 15 200
1
2
3
X: 3Y: 0.3559
Errors of Yeast dataset
NO. of neighbors
Spearm
ans r
ho
X: 2Y: 0.28
Fig. 12. Change of overall errors of Spearman’s rhos and Gini’s gam-mas with the growth of number of nearest neighbours in FLAME+
Fig. 13. Change of time cost by Fuzzy Empirical Copula with thegrowth of number of nearest neighbours in FLAME+
4.4. Comparison of FLAME+ and K-means in FuzzyEmpirical Copula
The reason to choose FLAME+ as the fuzzy clus-tering algorithm instead of other algorithms (e.g., K-menas) in Fuzzy Empirical Copula is on the basisof FLAME+’s four main advantages. First it has theability to capture non-linear relationships and non-globular clusters; secondly it can automatically definethe number of clusters and identify cluster outliers;thirdly, compared with K-means and fuzzy C-means,the centres of FLAME+ are real instances in the orig-inal dataset instead of the centroids of clusters withdifferent traits which probably result in wrong depen-dence measures. Finally, FLAME+ is also capable ofdealing with a free-distributed dataset, which is not al-ways true for algorithms like Gussian Mixture Models.In order to demonstrate the effectiveness of the pro-posed fuzzy empirical copula, we constructed K-means based Empirical Copula which employs theK-means algorithm to cluster the original dataset into

11
numbers of subsets and uses centroids as the newdataset. Both of these two methods were applied to theabalone dataset. The comparison is based on the factthat cluster number of K-means is set to be the sameas the abalone’s CSOs number of FLAME+ as listedin the table 1.Fig. 14 demonstrates the comparison of computationalcost by the proposed fuzzy empirical copula and K-means based empirical copula, where red curves arethe changes of cost time by K-means based EmpiricalCopula while blue curves are by the proposed fuzzyempirical copula. It presents that both of the two algo-rithms achieve almost the same performance in savingthe computational time.
0 5 10 15 200
500
1000
1500
2000
2500
3000
3500
4000
4500
5000Abalone dataset
NO. of neighbors
Tim
e(s
)
FEC
KEC
Fig. 14. Change of time cost when comparing the proposed FuzzyEmpirical Copula (FEC) and K-means based Empirical Copula(KEC)
In Fig. 15, with the decreasing number of clusters,the errors caused by K-means based Empirical Copulafluctuate violently and keep much higher than thoseby proposed fuzzy empirical copula. It illustrates thatFLAME+ outperforms K-means in maintaining thedependence structure though both of them have the al-most same performance in reducing the cost time, andFLAME+ is more suitable to be used in fuzzy empir-ical copula. One reason for the above results is thatFLAME+ is capable in dealing with non-linear rela-tionships while K-means is not. Another reason is thatFLAME+ considers the real objects CSOs which arethe samples in the datasets while K-means considerscentroids which are virtual objects beyond the datasets.Centroids not belonging to the datasets may have dif-ferent traits which probably result in wrong depen-dence measures.
0 5 10 15 200
0.2
0.4
0.6
0.8Errors of Abalone dataset
NO. of neighbors
Gin
is g
am
ma
0 5 10 15 200
0.2
0.4
0.6
0.8Errors of Abalone dataset
NO. of neighbors
Spearm
ans r
ho
FEC
KEC
FEC
KEC
Fig. 15. Changes of overall errors of Spearman’s rhos and Gini’sgammas when comparing the proposed Fuzzy Empirical Copula(FEC) and K-means based Empirical Copula (KEC)
5. Concluding Remarks
Fuzzy empirical copula has been proposed to alleviatethe computational burden of empirical copula. A high-dimensional FLAME+ has been developed to iden-tify the important objects containing the main featuresof the entire dataset, then empirical copula has beenimplemented to estimate the dependence structure ofthe objects. Abalone and yeast datasets from UCI ma-chine learning repository are employed to evaluate theproposed method. The number of nearest neighboursis the tradeoff factor for handling accuracy and effi-ciency of data processing. With the preselected errorthreshold, fuzzy empirical copula has the capabilityof automatically identifying the optimized number ofneighbours, which could be used to fast analyse similardatasets. Additionally nearest neighbours at the rangeof 0 − 20 have been used to demonstrate the overallerror changes of Spearman’s rho and Gini’s gamma,and the change of computational time. The experimen-tal results have shown that fuzzy empirical copula cansubstantially reduce the computation cost while fea-tures of the data are maintained with the preselected er-ror threshold. In addition, we compare FLAME+ withK-means to evaluate the clustering role in fuzzy empir-ical copula and the result has illustrated that FLAME+
outperforms K-means in maintaining the dependencestructure of the datasets.Further work will be concerned with releasing the lim-itation of calculating the true value of original datasetand making the method more applicable.Though Cop-ula has been widely applied to finance problems in thepast decades, some areas such as intelligent robotics,artificial intelligence and automation require empiri-cal copula and its variants being both effective ap-

12
Table 1Number of clusters corresponding to number of nearest neighbors
Neighbors 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Clusters 1574 525 377 287 243 211 185 165 142 128 109 100 94 89 88 81 74 69 67 63
proaches, and practical and efficient algorithms. FuzzyEmpirical Copula has succeeded in overcoming theproblem of computation cost of dependence structureestimation via Empirical Copula. The algorithm willbe evaluated in more real-time or near real-time ap-plications, priority will be given to human hand ges-ture recognition and object manipulation using robotichands [38–40].
References
[1] A. Edmunds and A. Morris. The problem of information over-load in business organisations: a review of the literature. In-ternational Journal of Information Management, 20(1):17–28,2000.
[2] K. Pearson. On lines and planes of closest fit to systems ofpoints in space. Philosophical Magazine, 2(6):559–572, 1901.
[3] K.V. Mardia, J.T. Kent, J.M. Bibby, et al. Multivariate analysis.1979.
[4] J.H. Friedman, S.L.A. Center, and J.W. Tukey. A PRO-JECTION PURSUIT ALGORITHM FOR EXPLORATORYDATA ANALYSIS. The Collected Works of John W. Tukey:Graphics 1965-1985, 1988.
[5] P. Comon et al. Independent component analysis, a new con-cept. Signal Processing, 36(3):287–314, 1994.
[6] J. Karhunen, P. Pajunen, and E. Oja. The nonlinear PCAcriterion in blind source separation: Relations with other ap-proaches. Neurocomputing, 22(1-3):5–20, 1998.
[7] T. Hastie and W. Stuetzle. Principal Curves. Journal of theAmerican Statistical Association, 84(406):502–516, 1989.
[8] T. Kohonen. Self-Organizing Maps. Springer, 2001.[9] J. Karhunen. Nonlinear Independent Component Analysis.
ICA: Principles and Practice, pages 113–134, 2001.[10] P. Demartines and J. Herault. Curvilinear component analysis:
a self-organizing neural networkfor nonlinear mapping of datasets. Neural Networks, IEEE Transactions on, 8(1):148–154,1997.
[11] JA Hartigan and MA Wong. A K-means clustering algorithm.JR Stat. Soc. Ser. C-Appl. Stat, 28:100–108, 1979.
[12] JC Dunn. A Fuzzy Relative of the ISODATA Process and ItsUse in Detecting Compact Well-Separated Clusters. Cybernet-ics and Systems, 3(3):32–57, 1973.
[13] N. Belacel, P. Hansen, and N. Mladenovic. Fuzzy J-Means:a new heuristic for fuzzy clustering. Pattern Recognition,35(10):2193–2200, 2002.
[14] P. VUORIMAA. FUZZY SELF-ORGANIZING MAP. Fuzzysets and systems, 66(2):223–231, 1994.
[15] P. Tamayo, D. Slonim, J. Mesirov, Q. Zhu, S. Kitareewan,E. Dmitrovsky, E.S. Lander, and T.R. Golub. Interpreting pat-terns of gene expression with self-organizing maps: Methodsand application to hematopoietic differentiation. Proc. Natl.Acad. Sci. USA, 96:2907–2912, 1999.
[16] KY Yeung, C. Fraley, A. Murua, AE Raftery, and WL Ruzzo.Model-based clustering and data transformations for gene ex-pression data. Bioinformatics, 17(10):977–987, 2001.
[17] L. Fu and E. Medico. FLAME, a novel fuzzy clustering methodfor the analysis of DNA microarray data. BMC Bioinformatics,8:3, 2007.
[18] J.D. FERMANIAN and O. SCAILLET. Nonparametric Esti-mation of Copulas for Time Series. 2003.
[19] R.B. Nelsen. An Introduction to Copulas (Springer Series inStatistics). 2006.
[20] A. Sklar. Fonctions de répartition a n dimensions et leursmarges. Publ Inst Statist Univ Paris, 8:229–231, 1959.
[21] P. Deheuvels. La fonction de dépendance empirique et ses pro-priétés: Un test non paramétrique dŠindépendance. Bulletin delŠAcadémie royale de Belgique: Classe des sciences, 65:274–292, 1979.
[22] P. Deheuvels. A non parametric test for independence. Publ.Inst. Statist. Univ. Paris, 26(2):29–50, 1981.
[23] N. Kolev, U. Anjos, and B.V.M. Mendes. Copulas: A Reviewand Recent Developments. Stochastic Models, 22(4):617–660,2006.
[24] A. Dias and P. Embrechts. Dynamic copula models for mul-tivariate high-frequency data in finance. Manuscript, ETHZurich, 2004.
[25] P. Embrechts, F. Lindskog, and A. McNeil. Modelling de-pendence with copulas and applications to risk management.Handbook of Heavy Tailed Distributions in Finance, 8:329–384, 2003.
[26] P.K. Trivedi and D.M. Zimmer. Copula Modeling: An Intro-duction for Practitioners. Foundations and Trends R© in Econo-metrics, 1(1):1–111, 2006.
[27] L. Hu. Dependence patterns across financial markets: a mixedcopula approach. Applied Financial Economics, 16(10):717–729, 2006.
[28] A. Kolesarova, R. Mesiar, J. Mordelova, and C. Sempi.Discrete Copulas. Fuzzy Systems, IEEE Transactions on,14(5):698–705, 2006.
[29] B. De Baets and H. De Meyer. Orthogonal Grid Construc-tions of Copulas. Fuzzy Systems, IEEE Transactions on,15(6):1053–1062, 2007.
[30] M.A.H. Dempster, E.A. Medova, S.W. Yang, and Judge Busi-ness School (Cambridge University. Empirical Copulas forCDO Tranche Pricing Using Relative Entropy. InternationalJournal of Theoretical and Applied Finance, 10(4):679–701,2007.
[31] J. Ma and Z. Sun. Dependence Structure Estimation via Cop-ula. Arxiv preprint arXiv:0804.4451, 2008.
[32] P.A. Morettin, C.M.C. Toloi, C. Chiann, and J.C.S. de Miranda.Wavelet Smoothed Empirical Copula Estimators. 2008.
[33] W.H. Kruskal. Ordinal measures of association. Journal of theAmerican Statistical Association, 53(284):814–861, 1958.
[34] E.L. Lehmann. Some concepts of dependence. Ann. Math.Statist, 37(1):137–1, 1966.
[35] WJ Nash, TL Sellers, SR Talbot, AJ Cawthorn, and WB Ford.

13
The population biology of abalone (Haliotis species) in Tasma-nia. I. Blacklip abalone (H. rubra) from the north coast and theFurneaux group of islands. Sea Fisheries Division TechnicalReport, 48:1–69, 1994.
[36] P. Horton and K. Nakai. A Probabilistic Classification Systemfor Predicting the Cellular Localization Sites of Proteins. pages109–115, 1996.
[37] A. Asuncion and D.J. Newman. UCI machine learning reposi-tory. 2007.
[38] H. Liu. A Fuzzy Qualitative Framework for Connecting Robot
Qualitative and Quantitative Representations. IEEE Transac-tions on Fuzzy Systems, 16(6):1522–1530, 2008.
[39] H. Liu, D. Brown, and G. Coghill. Fuzzy Qualitative RobotKinematics. IEEE Transactions on Fuzzy Systems, 16(3):808–822, 2008.
[40] Z. Ju, H. Liu, X. Zhu, and Y. Xiong. Dynamic Grasp Recog-nition Using Time Clustering, Gaussian Mixture Models andHidden Markov Models. Advanced Robotics, 23(10):1359–1371, 2009.