Embed Size (px)
Citation preview

Grafy i ich reprezentacja

Podstawy
Podstawowe pojęcia:
• Graf G(V,E)– struktura danych składająca się z dwóch zbiorów V i E
• V = [v1…vn]– wierzchołki (vertex)
• E =[e1…em] – krawędzie (edges) E = {(u,v): u,vV}
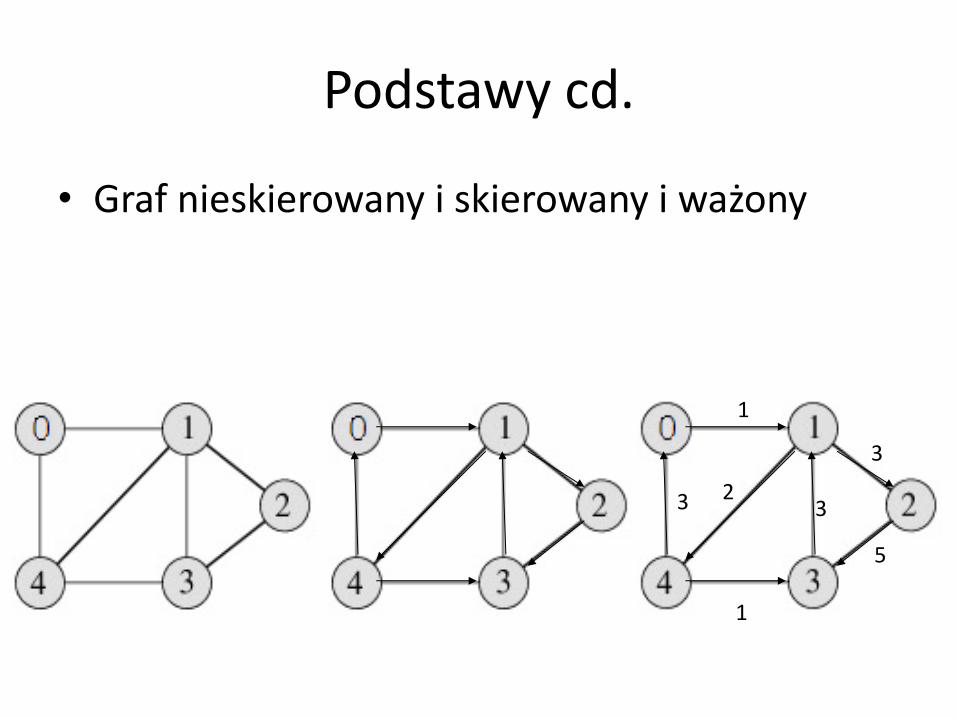
Podstawy cd.
• Graf nieskierowany i skierowany i ważony
1
2 3
3
5
1
3

Podstawowe pojęcia
• Rząd grafu – liczba
wierzchołków w grafie = 5
• Rozmiar grafu – liczba
krawędzi w grafie = 7
• Graf zerowy G(V,E)
V={v1,v2,v3,v4,v5}; E = {}
Podstawowe pojęcia
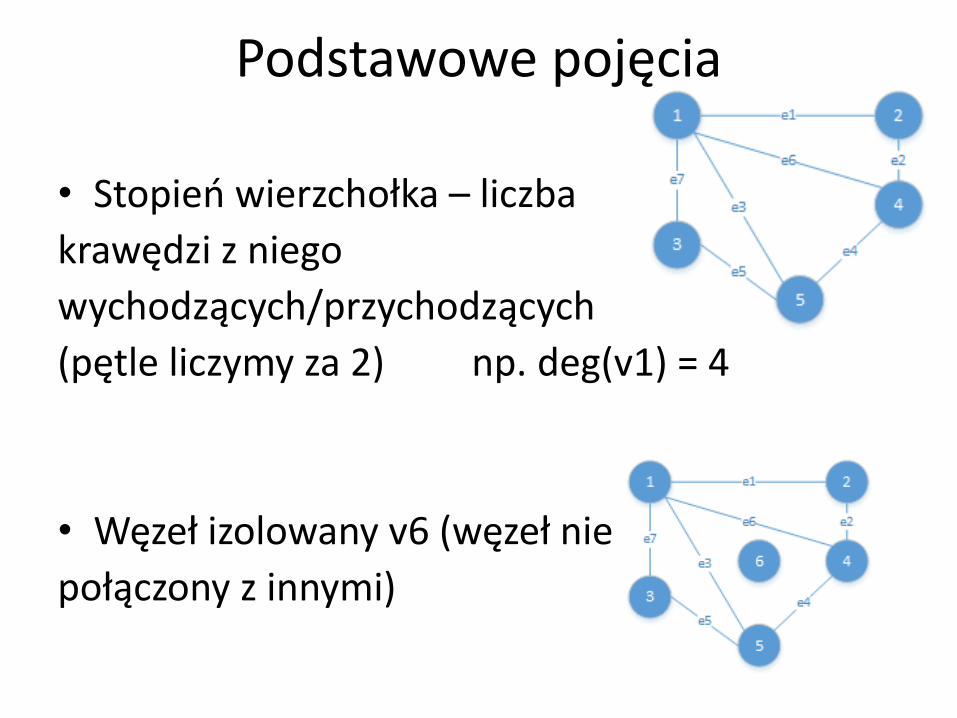
• Stopień wierzchołka – liczba
krawędzi z niego
wychodzących/przychodzących
(pętle liczymy za 2) np. deg(v1) = 4
• Węzeł izolowany v6 (węzeł nie
połączony z innymi)

Podstawowe pojęcia
• Ścieżka lub droga w grafie – uporządkowany zbiór
krawędzi/wierzchołków jaki musimy przebyć aby dotrzeć od wierzchołka początkowego do końcowego
P(v1,v5) = {e1,e2,e4} P(v1,v5) = {v1,v2,v4,v5}
• Cykl – to ścieżka zaczynająca się i kończąca w tym
samym wierzchołku – Cykl prosty – krawędzie / wierzchołki przechodzone są
tylko raz – Cykle Hamiltona – cykl prosty zawierający wszystkie
wierzchołki grafu (brak warunku na krawędzie) – Cykle Eulera – cykl prosty zawierający wszystkie
krawędzie grafu (brak warunku na wierzchołki)
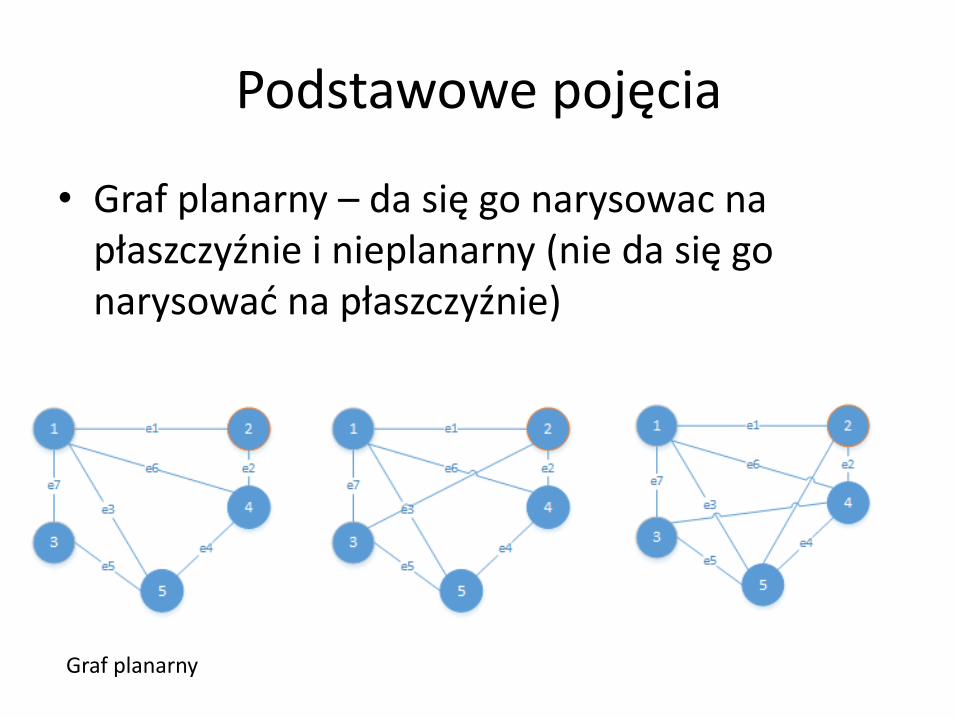
Podstawowe pojęcia
• Graf planarny – da się go narysowac na płaszczyźnie i nieplanarny (nie da się go narysować na płaszczyźnie)
Graf planarny

Podstawowe pojęcia
• Graf pełny – graf w którym pomiędzy każda parą wierzchołków występuje krawędź
Przykład:
• Transpozycja grafu – odwrócenie kierunków krawędzi w grafie
Wykorzystano materiały z: http://eduinf.waw.pl/inf/alg/001_search/0126a.php

Formy reprezentacji grafów
• Lista sąsiedztwa
• Macierz sąsiedztwa
• Macierz incydencji
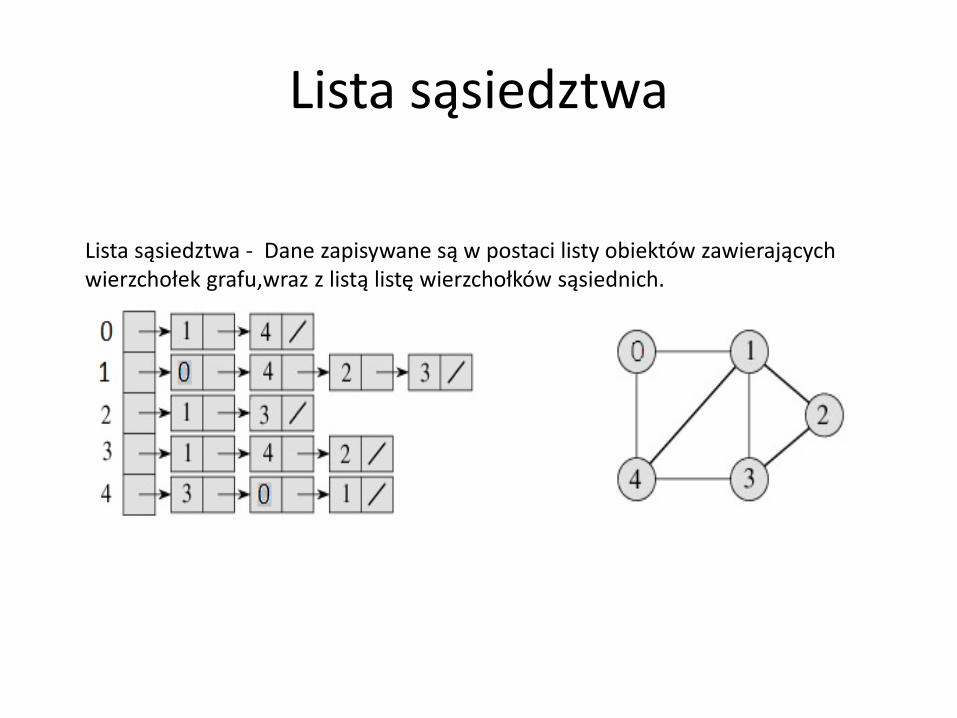
Lista sąsiedztwa
Lista sąsiedztwa - Dane zapisywane są w postaci listy obiektów zawierających wierzchołek grafu,wraz z listą listę wierzchołków sąsiednich.

Lista sąsiedztwa
Lista sąsiedztwa - Dane zapisywane są w postaci listy obiektów zawierających wierzchołek grafu,wraz z listą listę wierzchołków sąsiednich.
Jak zapisać graf skierowany?
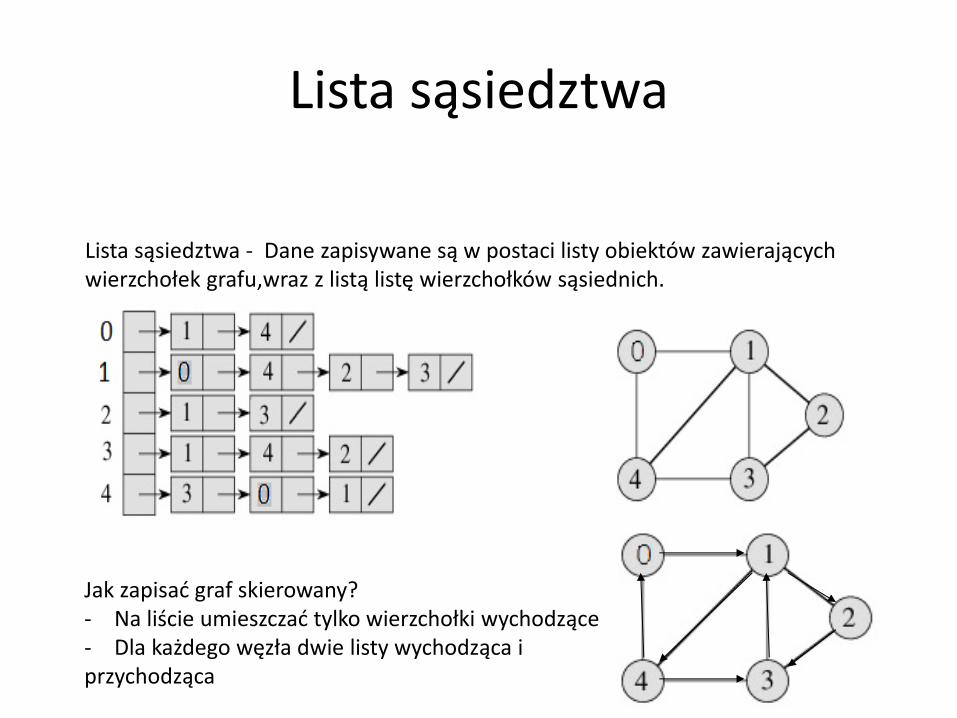
Lista sąsiedztwa
Lista sąsiedztwa - Dane zapisywane są w postaci listy obiektów zawierających wierzchołek grafu,wraz z listą listę wierzchołków sąsiednich.
Jak zapisać graf skierowany? - Na liście umieszczać tylko wierzchołki wychodzące - Dla każdego węzła dwie listy wychodząca i przychodząca
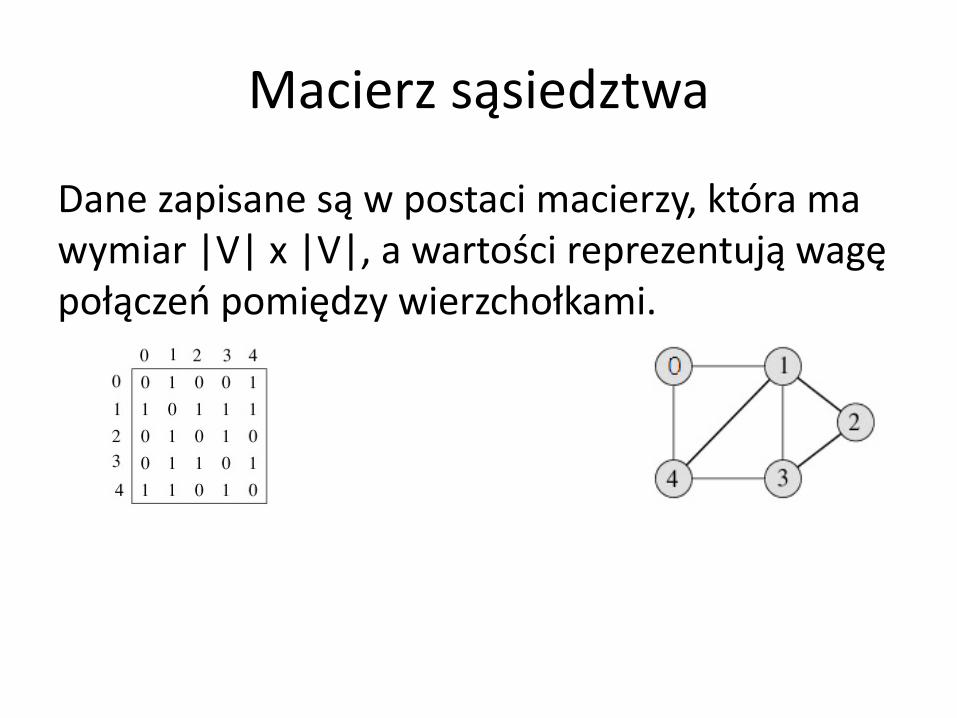
Macierz sąsiedztwa
Dane zapisane są w postaci macierzy, która ma wymiar |V| x |V|, a wartości reprezentują wagę połączeń pomiędzy wierzchołkami.

Macierz sąsiedztwa
Dane zapisane są w postaci macierzy, która ma wymiar |V| x |V|, a wartości reprezentują wagę połączeń pomiędzy wierzchołkami.
Jak zapisać graf skierowany?

Macierz sąsiedztwa
Dane zapisane są w postaci macierzy, która ma wymiar |V| x |V|, a wartości reprezentują wagę połączeń pomiędzy wierzchołkami.
Jak zapisać graf skierowany? Wprowadzić tylko te wiersze które są wychodzące
0 1 2 3 4
0 1
1 1 1
2 1
3 1
4 1 1
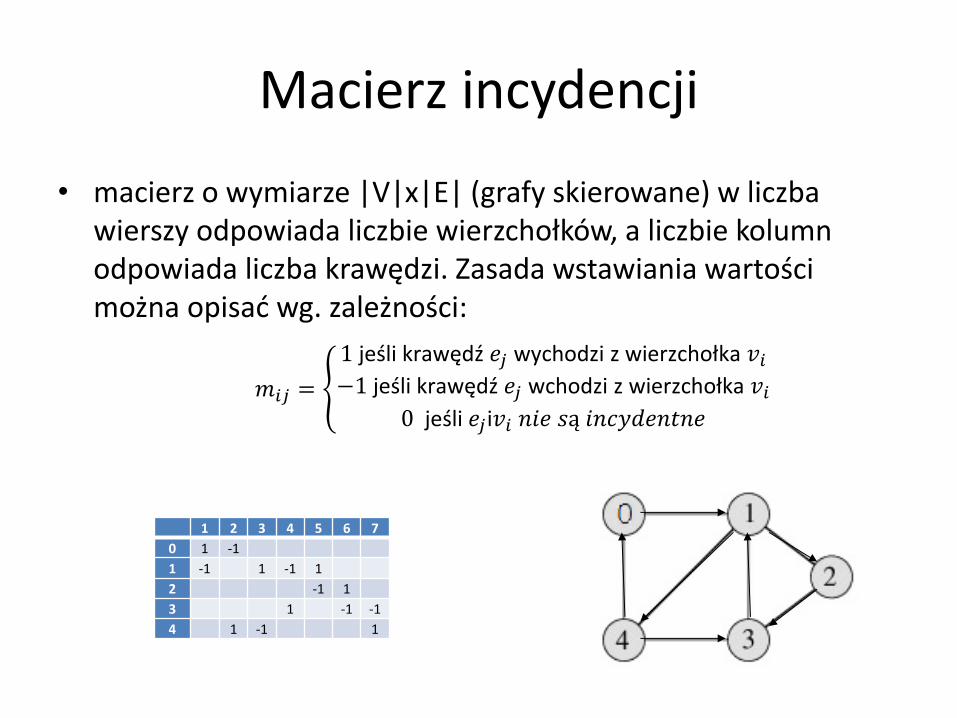
Macierz incydencji
• macierz o wymiarze |V|x|E| (grafy skierowane) w liczba wierszy odpowiada liczbie wierzchołków, a liczbie kolumn odpowiada liczba krawędzi. Zasada wstawiania wartości można opisać wg. zależności:
𝑚𝑖𝑗 =
1 jeśli krawędź 𝑒𝑗 wychodzi z wierzchołka 𝑣𝑖−1 jeśli krawędź 𝑒𝑗 wchodzi z wierzchołka 𝑣𝑖
0 jeśli 𝑒𝑗i𝑣𝑖 𝑛𝑖𝑒 𝑠ą 𝑖𝑛𝑐𝑦𝑑𝑒𝑛𝑡𝑛𝑒
1 2 3 4 5 6 7
0 1 -1
1 -1 1 -1 1
2 -1 1
3 1 -1 -1
4 1 -1 1

Właściwości
Lista sąsiedztwa Macierz sąsiedztwa Macierz incydencji
Przechowywanie grafu O(|V|+|E|) O(|V|2) O(|V||E|)
Dodanie wierzchołka O(1) O(|V|2) O(|V||E|)
Dodanie krawędzi O(1) O(1) O(|V||E|)
Usunięcie wierzchołka O(|E|) O(|V|2) O(|V||E|)
Usunięcie krawędzi O(|E|) O(1) O(|V||E|)
Zapytanie: czy wierzchołki x i y
są sąsiadujące O(|V|) O(1) O(|V||E|)

Metody przeszukiwania

Co to jest przeszukiwanie
• Przeszukiwanie polega na odnajdywaniu rozwiązania w dyskretnej przestrzeni rozwiązań.
• Dualizm problemu -> reprezentacja problemu w postaci grafu (znalezienie w grafie określonego rozwiązania - węzła) lub reprezentacja problemu w postaci pary: <stan,możliwe zmiany stanu> i poszukiwanie określonego stanu docelowego – UWAGA: Czasami reprezentacja problemu w postaci grafu może
prowadzić do bardzo dużych grafów.
• Przykładowe zastosowania: – gry w szachy, – warcaby, – Przesuwanka, – Problem komiwojażera – Odnajdywanie najkrótszej dorgi itp – itp

Definicja problemu
Trzy elementy potrzebne do zdefiniowania problemu:
1. Baza danych: fakty, stany, możliwości, opis sytuacji.
2. Możliwe operacje: zmieniają stan bazy danych.
3. Strategia kontrolna: start, koniec i kolejność operacji.
• Ciąg operacji tworzy sekwencję działań, od stanu początkowego do stanu końcowego (celu).
• Z każdą operacją związany jest pewien koszt.
• W procesie szukania należy dążyć do minimalizacji całkowitych kosztów.
Źródło W. Duch wykład AI

Pojęcia
• Przeszukiwanie kompletne/zupelne – algorytm przeszukiwania jest kompletny jeśli gwarantuje odnalezienie rozwiązania w grafie, o ile takie rozwiązanie istnieje
• Algorytm przeszukiwania niekompletny – jeśli nie gwarantuje odnalezienie rozwiązania
• Optymalność rozwiązania – odnalezione jest najprostsze rozwiązanie (np. znalezione rozwiązanie w przesuwance gwarantuje minimalna ilość kroków - przesunięć)

Typy metod przeszukiwania
• Przeszukiwanie ślepe – gdy nie mamy żadnej wiedzy/oceny jakości znalezionego rozwiązania
• Przeszukiwanie heurystyczne – gdy potrafimy jakoś ocenić proces przeszukiwania

Przeszukiwanie ślepe
Gdy koszt ruchu zawsze taki sam (graf nie ważony)
• Przeszukiwanie wszerz
• Przeszukiwanie w głąb
• Przeszukiwanie iteracyjnie pogłębianie
• Przeszukiwanie dwukierunkowe
Gdy graf ważony lub różna waga ruchu to:
• Algorytm Dijkstra (wagi dodatnie)
• Algorytm Bellmana-Forda (możliwość występowania wag ujemnych)

Algorytm wszerz

Przeszukiwanie wszerz
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie wszerz
1. Zainicjuj kolejkę Queue
2. Queue <- stan początkowy
3. While ((S <- Queue.Head) != null){
1. If S == rozwiązanie Then koniec
2. For ((C <- S.Children) & C != Visited)
1. Queue <- C
}

Przeszukiwanie wszerz
• Właściwości:
– Zupełność: tak - jeśli skończona liczba krawędzi b (b – max. Liczba rozgałęzień drzewa przeszukiwań)
– Złożoność czasowa: O(bd+1) – wykładnicza względem głębokości d (d-głębokość rozwiązania o najmniejszym koszcie)
– Złożoność pamięciowa: O(bd+1) – przechowuje każdy węzeł w pamięci
– Optymalność: tak – jeśli koszty przejść są równe
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Żródło: http://wazniak.mimuw.edu.pl/index.php?title=Sztuczna_inteligencja/

Algorytm w głąb

Przeszukiwanie w głąb
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie w głąb
1. Zainicjuj Stos
2. Stos <- stan początkowy
3. While ((S <- Stos.tail) != null){
1. If S == rozwiązanie Then koniec
2. For ((C <- S.Children) & C != Visited)
1. Stos <- C
}

Przeszukiwanie w głąb
• Właściwości
– Zupełność: tak (jeśli przestrzeń skończona, w szczególności gdy skończona głebokość)
– Złożoność czasowa: O(bm) – wykładnicza m-liczba wierzchołków, dobra metoda jeśli gęste rozwiązania
– Złożoność pamięciowa: O(bm) – liniowa
– Optymalność: nie – znalezione rozwiązanie nie koniecznie jest optymalne
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Żródło: http://wazniak.mimuw.edu.pl/index.php?title=Sztuczna_inteligencja/

Algorytm iteracyjne pogłębianie

Przeszukiwanie iteracyjne pogłębianie
• Przeszukiwanie ograniczone wgłąb ale stopniowo zwiększamy głębokość
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie iteracyjne pogłębianie
• Właściwości
– Zupełność: tak
– Złożoność czasowa: O(bd)
– Złożoność pamięciowa: O(bd)
– Optymalność: tak – jeśli równy koszt przejść
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie dwukierunkowe

Przeszukiwanie dwukierunkowe
• Do zastosowań jeśli znamy start i rozwiązanie a szukamy ścieżki prowadzącej do rozwiązania
• Równolegle szukanie od startu i od rozwiązania

Przeszukiwanie dwukierunkowe
• Właściwości
– Zupełność: tak (jeśli szukanie wszerz)
– Złożoność czasowa: O(bd/2)
– Złożoność pamięciowa: O(bd/2)
– Optymalność: tak – jeśli szukanie wszerz
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Żródło: http://wazniak.mimuw.edu.pl/index.php?title=Sztuczna_inteligencja/

Algorytm Dijkstry

Poszukiwanie najkrótszej ścieżki
• Gdy graf nie ważony lub koszt ruchu zawsze taki sam to algorytm w szerz
• Przeszukiwanie grafu ważonego -> Algorytm Dijkstry

Algorytm Dijkstry
• Szukanie najkrótszej ścieżki w grafie • W rzeczywistości algorytm zwraca odległość od
wybranego wierzchołka do wszystkich wierzchołków
• Uwaga: założenie nieujemnych wag!!! • Dla ujemnych ścieżek – algorytm Bellmana-Forda
(założenie brak ujemnych cykli) • Złożoność obliczeniowa:
– Naiwna implementacja O(|V|2) – Z wykorzystaniem kolejki priorytetowej
O(|E|+|V|log|V|)

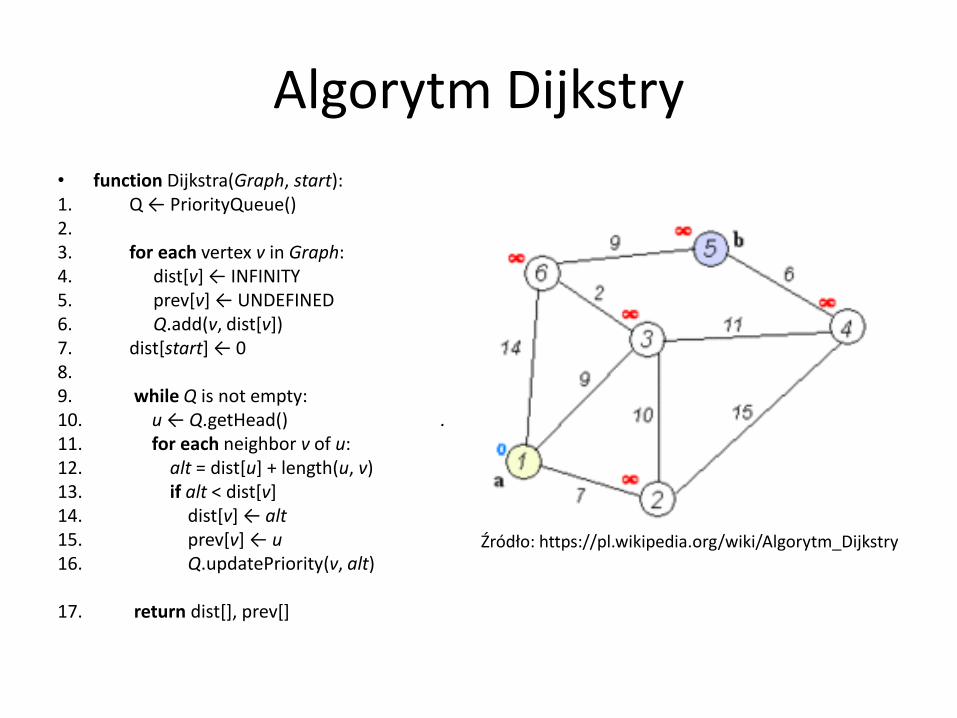
Algorytm Dijkstry
• function Dijkstra(Graph, start): 1. Q ← PriorityQueue() // Inicjalizuj kolejkę priorytetową
2. for each vertex v in Graph: 3. dist[v] ← INFINITY // Nieznana odległość od startu do v 4. prev[v] ← UNDEFINED // Poprzednik v 5. Q.add(v, dist[v]) 6. dist[start] ← 0 // Inicjalizacja 7. 8. while Q is not empty: // Główna pętla 9. u ← Q. getHead() // Usuń I zwróć najbliższy wierzch. 10. for each neighbor v of u: // Dla sąsiadów u 11. alt = dist[u] + length(u, v) 12. if alt < dist[v] 13. dist[v] ← alt 14. prev[v] ← u 15. Q.updatePriority(v, alt)
16. return dist[], prev[]
Algorytm Dijkstry
• function Dijkstra(Graph, start): 1. Q ← PriorityQueue() 2. 3. for each vertex v in Graph: 4. dist[v] ← INFINITY 5. prev[v] ← UNDEFINED 6. Q.add(v, dist[v]) 7. dist[start] ← 0 8. 9. while Q is not empty: 10. u ← Q.getHead() . 11. for each neighbor v of u: 12. alt = dist[u] + length(u, v) 13. if alt < dist[v] 14. dist[v] ← alt 15. prev[v] ← u 16. Q.updatePriority(v, alt)
17. return dist[], prev[]
Źródło: https://pl.wikipedia.org/wiki/Algorytm_Dijkstry

Algorytm Dijkstry
• function Dijkstra(Graph, start): 1. Q ← PriorityQueue() 2. 3. for each vertex v in Graph: 4. dist[v] ← INFINITY 5. prev[v] ← UNDEFINED 6. Q.add(v, dist[v]) 7. dist[start] ← 0 8. 9. while Q is not empty: 10. u ← Q.getHead() . 11. for each neighbor v of u: 12. alt = dist[u] + length(u, v) 13. if alt < dist[v] 14. dist[v] ← alt 15. prev[v] ← u 16. Q.updatePriority(v, alt)
17. return dist[], prev[]

Metody heurystyczne

Metody heurystyczne
W odróżnieniu od szukania ślepego wykorzystujemy wiedzę o przeszukiwanej przestrzeni oceniając znalezione rozwiązania
Problem metod ślepych - eksplozja kombinatoryczna liczby możliwych stanów
Szukanie heurystyczne wykorzystuje informacje, które poprawiają efektywność procesu szukania.
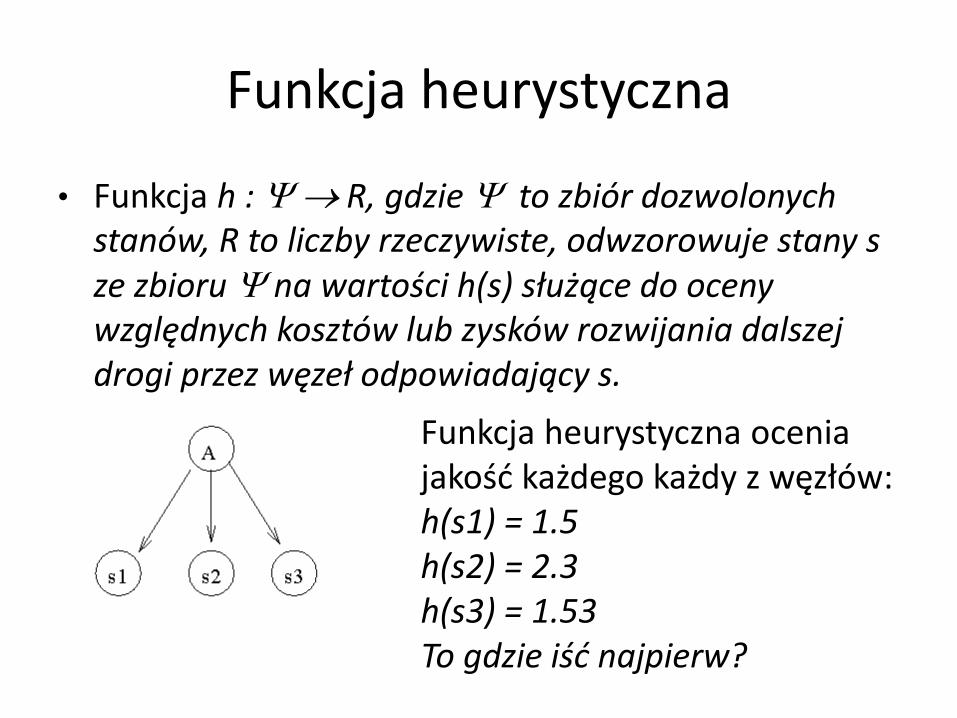
Funkcja heurystyczna
• Funkcja h : R, gdzie to zbiór dozwolonych stanów, R to liczby rzeczywiste, odwzorowuje stany s ze zbioru na wartości h(s) służące do oceny względnych kosztów lub zysków rozwijania dalszej drogi przez węzeł odpowiadający s.
Funkcja heurystyczna ocenia jakość każdego każdy z węzłów: h(s1) = 1.5 h(s2) = 2.3 h(s3) = 1.53 To gdzie iść najpierw?

Metody heurystyuczne
• Pierwszy najlepszy
– Przeszukiwanie zachłanne
– Przeszukiwanie A*
– inne
• Iteracyjne poprawianie
– Algorytm wspinaczki
– Algorytmy genetyczne
– inne

Przeszukiwanie zachłanne

Przeszukiwanie zachłanne
• Algorytm przeszukiwania, w którym zachłannie rozwija się każde rozwiązanie prognozujące lokalnie na danym etapie najlepsze rozwiązanie cząstkowe.
• Przykład: problem komiwojażera – każdorazowo odwiedzamy najbliższe nieodwiedzone miasto.

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/
Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
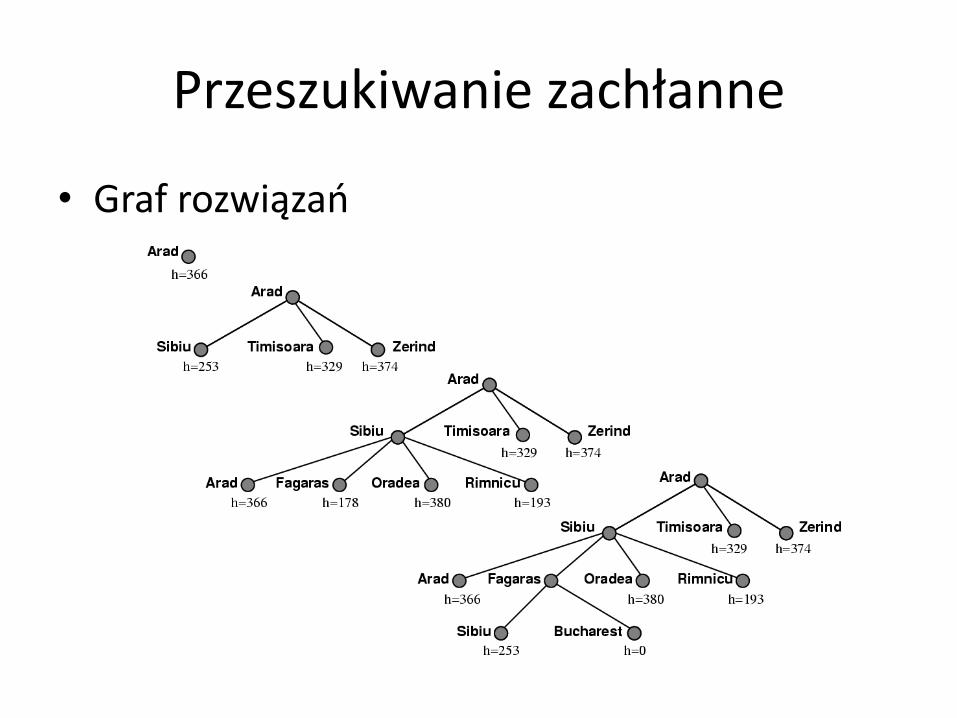
Przeszukiwanie zachłanne
• Graf rozwiązań
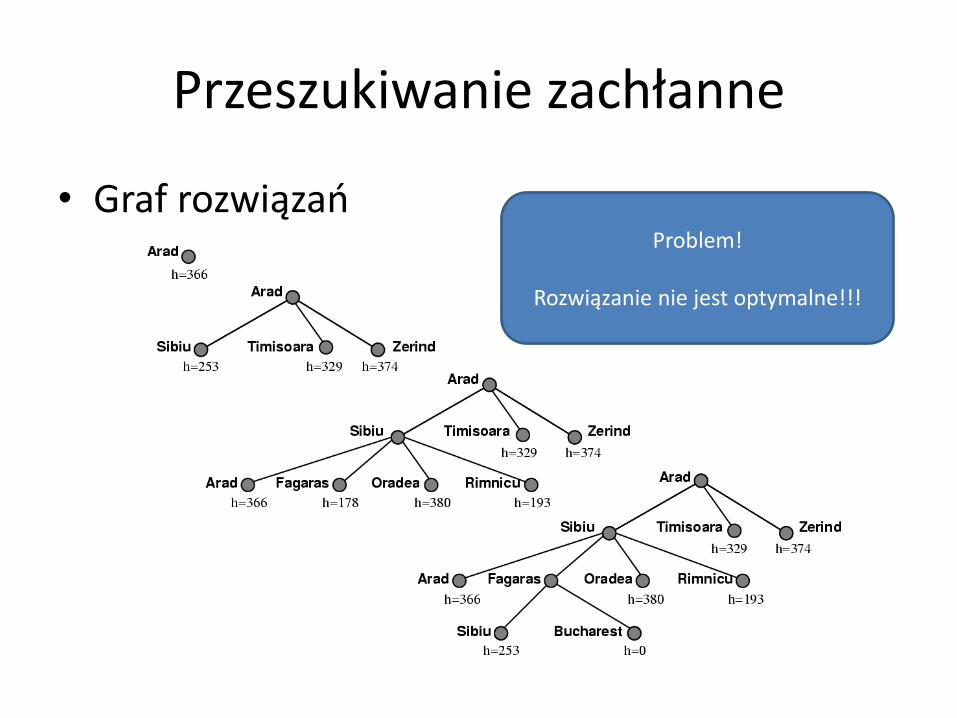
Przeszukiwanie zachłanne
• Graf rozwiązań
Problem!
Rozwiązanie nie jest optymalne!!!

Przeszukiwanie zachłanne
• Właściwości
– Zupełność: nie
– Złożoność czasowa: zależna od heurystyki
– Złożoność pamięciowa: zależna od heurystyki
– Optymalność: nie
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Algorytm A*

Przeszukiwanie A*
• Podobne do przeszukiwania zachłannego ale zmodyfikowana (rozszerzona) heurystyka:
f(n) = h(n) + g(n)
• h(n) – koszt dotarcia do celu
• g(n) – koszt dotarcia od startu do danego węzła
f(n) – unika stanów do których ponieśliśmy duży koszt dotarcia

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Przeszukiwanie zachłanne Funkcja heurystyczna: h(n) odległość w linii prostej z miasta n do Bukaresztu. Zadanie: znaleźć optymalną trasę z Arad do Bukaresztu
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Algorytm A*
G – graf; start – węzeł startowy; koniec – węzeł końcowy; Q <- kolejka protorytetowa C <- lista węzłów do odwiedzonych (clesedSet) M <- mapa gdzie kluczem jest dany węzeł, a wartością para (rodzic, odległosc) Q.add(start,heurystyka(start,koniec)) M.put(start,[prev=null, dist=0]) while ( !isempty(Q) ) u <- Q.head() if (u == koniec) break; C.add(u); //dodanie węzła u do closedSet for (v = u.Neighbors()){//Iterujemy po sąsiadach węzła u if (C.contains(v)){ //jeśli v już odwiedzony (jest w closedSet) continue;} distU = M.get(u).dist; //odczytanie odległości od u do startu tmpDist = distU + G(u,v); //wyznaczenie nowej odległości G(u,v) to waga krawędzi pomiędzy u i v if (!Q.contains(v)) //Jeśli kolejka nie zawiera v Q.add(v,tmpDist + heurystyka(v,koniec)); M.put(v,[prev = u, dist = tmpDist]) else distV = M.get(v).dist if (tmpDist < distV) M.put(v,[prev = u, dist = tmpDist]) Q.update(v,tmpDist + heurystyka(v,koniec));

Typowe heurystyki
• Dla podróżowania wykorzystujemy odległość Euklidesa od mety do danego węzła (jak w problemie Rumunii)
• W labiryncie dobrą heurystyka jest odległość Manhattan pomiędzy danym stanem a układem końcowym – Metryka Manhattan
d(x,y) = 𝑥𝑖 − 𝑦𝑖𝑛𝑖=1
• W układance dobrą heurystyką jest liczba niepasujących pól (liczba klocków które są w niewłaściwym położeniu) lub suma odległość Manhattan dla każdego pola tj. gdzie dany klocek się znajduje a gdzie powinien znajdować

Przeszukiwanie A*
• Właściwości
– Zupełność: tak jeśli heurystyka dopuszczalna
– Złożoność czasowa: zależy od heurystyki
– Złożoność pamięciowa: zależy od heurystyki
– Optymalność: tak – choć zależy od heurystyki
Żródło: Arkadiusz Wojna, http://www.mimuw.edu.pl/~awojna/SID/

Iteracyjne poprawianie i metody losowe

Algorytmy optymalizacji Algorytmy gradientowe
• Sposób działania:
• Dobre jeśli funkcja celu jest wypukła

Algorytmy optymalizacji Algorytmy gradientowe – problemy
• Problem braku wypukłości funkcji – punkty siodłowe
• Problem przeskoczenia optimum
• Problem optimów lokalnych i punktu startu
Punkt siodłowy, gradient = 0

Algorytmy losowe Algorytm wspinaczki
• Schemat algorytmu
• Funkcja Tweak
Szukamy takiej modyfikacji S która poprawia wynik funkcji celu
Losowo modyfikujemy każdą ze składowych
wektora V, ale zapewniamy by V był w okreslonym przedziale

Algorytm wspinaczki a funkcja Tweak
• Splot Gaussowski –
Dodajemy niedużo szumu w okolicy poprzedniego rezultatu, przy czym szum ma rozkład Gaussa
Rozkład Gaussa w zależności od parametru . Im mniejsza
wartość tym mniejszy rozrzut punktów

Algorytmy losowe Przeszukiwanie losowe
• Przeszukiwanie losowe sprawdza różne losowe rozwiązania i wybiera najlepsze rozwiązanie
Uwaga często dobrze działa!!! Tylko trzeba dostatecznie dużo próbkować

Algorytm symulowanego wyżarzania
• Algorytm można opisać schematem
Idea: akceptacja gorszych rozwiązań jeśli spełniona
zależność.
Jak t = 0 to mamy algorytm
wspinaczki
Tą zależność liczymy gdy Quality(S) > Quality(R)
Bo stosujemy gdy pierwszy warunek jest niespełnony, czyli R jest gorszym rozwiązaniem niż S
Prawdopodobieństwo akceptacji gorszego rozwiązania

Algorytmy genetyczne
• Inspirowane procesami ewolucyjnymi, • Idea działania jak wyżej ale zamiast jednego losowego przypadku mamy
całą populację • Pojęcia:
– Genotyp – reprezentacja numeryczna przestrzeni stanów – określa sposób kodowani informacji (może być binarny, całkowito liczbowy, rzeczywisty)
– Fenotyp – reprezentacja odpowiadająca rzeczywistości np. w problemie komiwojażera przekształcamy Gentoyp w postaci ciągu liczb całkowitych na odpowiadające im miasta
– chromosom - pojedynczy osobnik populacji – pojedynczy stan/węzeł zakodowany w postaci binarnej, (w algorytmach ewolucyjnych nie koniecznie reprezentacja binarna)
– Populacja – zbiór jednocześnie rozpatrywanych węzłów - osobników – Potomstwo – Populacja powstała na podstawie poprzedniej populacji – Generacja – określona, któraś z kolei populacja
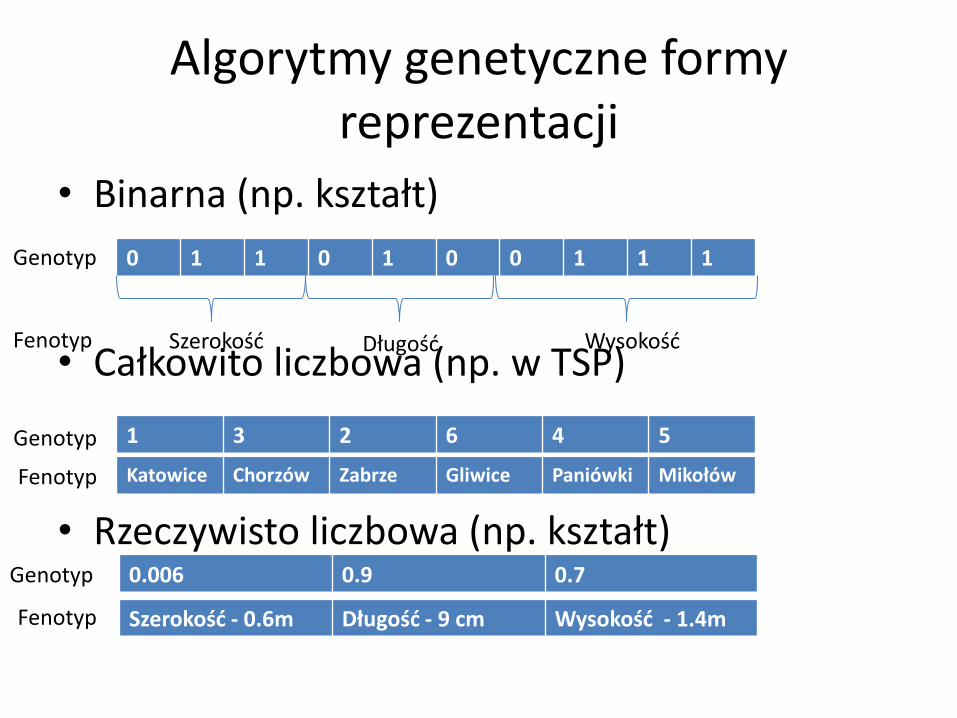
Algorytmy genetyczne formy reprezentacji
• Binarna (np. kształt)
• Całkowito liczbowa (np. w TSP)
• Rzeczywisto liczbowa (np. kształt)
0 1 1 0 1 0 0 1 1 1 Genotyp
Fenotyp Szerokość Długość Wysokość
Genotyp 1 3 2 6 4 5
Fenotyp Katowice Chorzów Zabrze Gliwice Paniówki Mikołów
0.006 0.9 0.7 Genotyp
Fenotyp Szerokość - 0.6m Długość - 9 cm Wysokość - 1.4m

Algorytmy genetyczne operatory
Operatory • Mutacja – odpowiednik wcześniej opisywanej
operacji Tweak • Krzyżowanie – nowy operator – korzystając z kilku
losowych rozwiązań, miesza je ze sobą • Selekcja – wybór losowy osobników jednakże
zależny od poziomu ich dopasowania
UWAGA Dobór operatorów to sposób dostosowania algorytmu do określonego problemu

Algorytmy genetyczne Krzyżowanie i mutacja dla reprezentacji binarnej
• Krzyżowanie – wymiana informacji pomiędzy dwoma osobnikami
• Mutacja –zmiana stanu jednego z bitów na losowej pozycji - małe prawdopodobieństwo zajścia zdarzenia

Algorytmy genetyczne Selekcja
• Metoda proporcjonalna – prawdopodobieństwo wylosowania proporcjonalne do poziomu dopasowania
• Metoda turniejowa – prawdopodobieństwo wylosowania zależne od poziomu dopasowania (na zasadzie rankingu)
Uwaga problem skalowania funkcji celu
Rozwiązanie zależne od rankingu, a nie od wartości
funkcji celu. Bardzo często sotsowane

Algorytmy genetyczne
Źródło: http://www.chemia.uj.edu.pl/~sulka/ais/012.html

Algorytmy genetyczne
• Sposób schemat
Inicjalizacja
Wybór najlepszego rozwiązania
Generowanie nowego pokolenia
Wybór rodziców zgodnie z algorytmami selekcji
Krzyżowanie osobników
Mutacja i dodanie do listy rozwiązań

Koniec





























