Embed Size (px)
Citation preview

Graph Indexing: A Frequent Structure-based Approach
Alicia Cosenza
November 26th, 2007

Presentation Outline
IntroductionFrequent FragmentDiscriminative FragmentGindex Experimental Result

Introduction
Graphs are used to model complicated structures such as proteins, circuits, images and XML documents
Current index approach is path based– Example: GraphGrep– Advantages
Paths are easier to handle Index space is predefined :all the path up to maxL length are
selected
– Disadvantages Path is too simple There are too many paths and too many false positives

Introduction
“Can we use a graph structure instead of a a path as the basic index feature?”– gIndex
Indexes only “frequent subgraphs” Creates a smaller index Improves query times

Presentation Outline
IntroductionFrequent FragmentDiscriminative FragmentGindex Experimental Result

Frequent Fragment
Key concept Fragment – small subgraph minsup – minimum support threshold
– A graph is frequent if its support or the number of times it appears in the graph database is greater than minsup
Only frequent fragments will be indexed

Frequent Fragment
low minimum support on small fragments (for effectiveness) – Want to index lots of the small subgraphs
high minimum support on large fragments (for compactness)– Only want to index a large fragment if it appears a lot
Otherwise it will be indexed by the smaller subgraphs
Problem: There could be a lot of frequent fragments!

Presentation Outline
IntroductionFrequent FragmentDiscriminative FragmentGindex Experimental Result

Discriminative Fragment
Definition (Redundant Fragment)– Fragment is redundant with respect to feature
set if
Definition (Discriminative Fragment).– Fragment is discriminative with respect to if
Fragments that are not redundant are called discriminative
xF
x f F f x fD D
x F
x f F f x fD D

Presentation Outline
IntroductionFrequent FragmentDiscriminative FragmentGindex Experimental Result

GIndex - Construction
First generates all frequent fragments while taking out redundant ones
Translates fragments into sequences and holds them in a prefix tree– Each fragment has an id list: the ids of the graphs
containing the fragment – Graph Sequentialization (DFS Code)
Labeled edge is a 5-tuple (I,j,li, l(I,j),lj)
Described in another paper

GIndex - Construction
gIndex Tree– each fragment can be mapped to an edge sequence
(DFS code), insert the edge sequences of discriminative fragments in a prefix tree called the gIndex Tree

GIndex - Construction
gIndex Tree– Implemented using a hash table
Both black and white nodes are included in the table The tree is still an important concept since it determines
what white nodes will be included

GIndex - Search

GIndex - Search
Optimization Apriori Pruning
– If a fragment is not in the gIndex tree, we need not check its super-graphs

GIndex - Search
Verification– After getting the candidate answer set, we have to
verify that the graphs in the set really contain the query graph
perform a subgraph isomorphism test on each graph one by one

GIndex – Maintenance

Presentation Outline
IntroductionFrequent FragmentDiscriminative FragmentGindex Experimental Result

Experimental Result
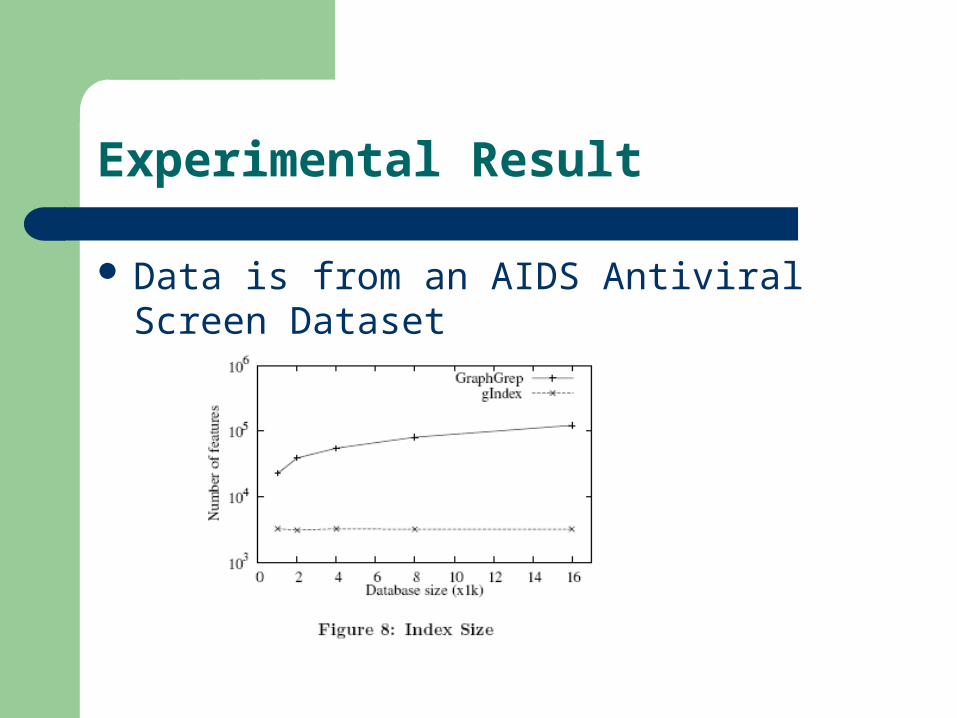
The index size of gIndex is more than 10 times smaller than that of GraphGrep;
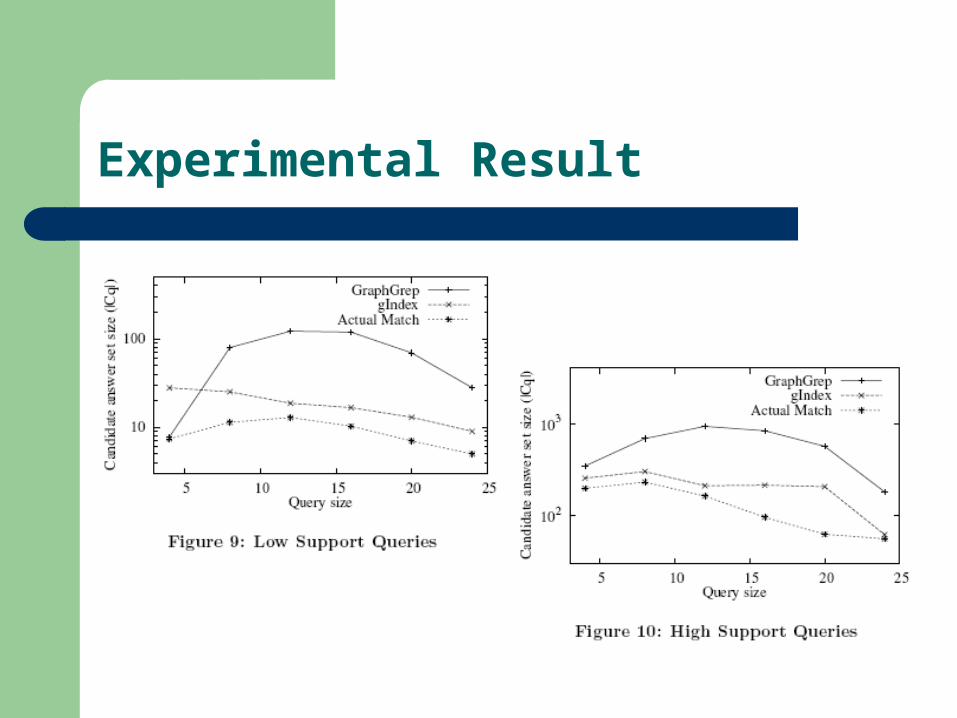
gIndex outperforms GraphGrep by 3 to 10 times in various query loads;
the index returned by the incremental maintenance algorithm is effective: it performs as well as the index computed from scratch provided the data distribution does not change much.
Experimental Result
Data is from an AIDS Antiviral Screen Dataset
Experimental Result

The End





























