Embed Size (px)
Citation preview

Hardening Functions for Large-Scale
Distributed Computations
Doug SzajdaBarry LawsonJason Owen
1

Large-Scale Distributed Computations
• Easily parallelizable, compute intensive
• Divide into independent tasks to be executed on participant PCs
• Significant results collected by supervisor
• Participants may receive credits – Money, e-cash, ISP fees, fame and glory
2

Examples
• seti@home– Finding Martians
• folding@home– Protein folding
• GIMPS (Entropia)– Mersenne Prime
search
• United Devices, IBM, DOD: Smallpox study
• DNA sequencing• Graphics• Exhaustive
Regression• Genetic Algorithms• Data Mining• Monte Carlo
simulation

The Problem
• Code is executing in untrusted environments– Results may be corrupted either
intentionally or unintentionally– Significant results may be withheld– Cheating : credit for work not
performed

An Obvious Solution
• Assign Tasks Redundantly• Collusion may seem unlikely but…
– Firms solicit participants from groups such as alumni associations and large corporations
• Processor cycles are primary resource
• Some problems can tolerate some bad results

Related Work
• Historical roots in result checking and self-correcting programs
• Golle and Mironov (2001)• Golle and Stubblebine (2001)• Monrose, Wyckoff, Rubin (1999)

Related Work
• Body of literature on protecting mobile agents from malicious hosts– Sander and Tschudin, Vigna, Hohl,
and others
• Syverson (1998)

Adversary
• Assumed to be intelligent– Can decompile, analyze, modify code– Understands task algorithms and
measures used to prevent corruption• Motivation may not be obvious...
– I.e. gaining credits may not be important
– E.g. business competitor• But does not wish to be caught

Our Approach
• Hardening functions– Verb, not adjective
• Does not guarantee resulting computation returns correct results
• Does not prevent an adversary from disrupting a computation
• Significantly increases likelihood that abnormal activity will be detected

The Model
• Computation is evaluation of algorithm f : D -> R for every input value x in D
• Tasks created by partitioning D into subsets Di
• Each task assigned filter function Gi

Two General Classes
• Non-sequential– Computed values of f in task are
independent
• Sequential– Participant given single value x0 and
asked to compute first m elements of sequence xn = f (xn-1)

Hardening Non-sequentials
Plant each task’s data set with values ri such that the following hold:
1. Supervisor knows f(ri) for each i
2. Participant cannot distinguish ri from other data values regardless of number of tasks a participant completes

Hardening Non-sequentials
3. Participants do not know number of ri in data space
4. For some known proportion of ri f(ri) is a significant result
5. Nice but not necessary: Same set of ri can be used for several tasks

Difficulties
• ri are indistinguishable only if they generate truly significant results
• What is indistinguishable in theory may not be in practice– E.g. DES key search: Tasks given
ciphertext C and subset Ki of key space, told to decrypt C with each ki and return any key that generates plausible plaintext

Even Filter Function Can Be Revealing...
• E.g. Traveling Salesperson with five precomputed circuits of length 100, 105, 102, 113, 104– Return any circuit whose length is any
of the above or less than 100– Return the ten best circuits found– Return any circuit with length less
than 120

Optimization Problems
• Designate small proportion of tasks as initial distribution
• Distribute each of these tasks redundantly
• Check returned values — handle non-matches appropriately
• Retain k best results and use them as ringers for remaining tasks

Collusion
• If task in initial distribution is assigned to colluding adversaries, supervisor will initially miss this
• Honest participants not in initial distribution will eventually return results that do not match
• Supervisor can then determine which participants have been dishonest

Size of Initial Distribution• Probability that at least k of n best
results are in proportion p of space is
n
ki
ini p)(1pk
n
n k p prob
50 8 0.25
0.9547
150 5 0.1 0.9967
105 100 0.02
≈1
For 109 inputs,best 105 results are in top 0.01%

Caveat
• Previous figures assume:– n, k much less than size of data space– proportion of incorrect results is small
• Probability should be adjusted to reflect expected number of incorrect results returned in initial distribution

The Good• No precomputing required• Hardening is achieved at fraction of
cost of simple redundancy• Ringers can be used for multiple tasks• Additional good results can be used as
ringers• Collusion resistant since ringers can
be combined in many ways

The Bad
• Assuming tasks require equal time, cost of compute job is at least doubled...
• But, by running multiple projects concurrently, overall throughput rates can be reduced to factor of 1+p times rate of unmodified job
• In some cases, implementation details can give away identities of ringers (or require significant changes to app)

Sequential Computations
• Seeding the data is impractical• Often the validity of returned
results can only be checked by performing the entire task
• Ex: Mersenne Primes– nth Mersenne Number, Mn, is 2n-1

The Strategy
• Share the work of computing N tasks among K participants
• K > N is very small proportion of total number of participants in computation
• Assume:– Each task requires roughly m iterations– K/N < 2, else simple redundancy is
cheaper

The Algorithm
1. Divide tasks into S segments, each containing roughly J = m/S iterations
2. Each participant in group is given an initial value and computes first J iterations using this value
3. When J iterations complete, results returned to supervisor

The Algorithm
4. Supervisor checks correctness of redundantly assigned subtasks
5. Supervisor permutes N values and assigns these values to K participants as initial value for next segment
6. Repeat until all S segments completed

The Numbers
• If K/N < 2, each task assigned to no more than two participants, and adversary cheats in L (of S) segments, then in absence of collusion
L
KK2N
1P(nabbed)
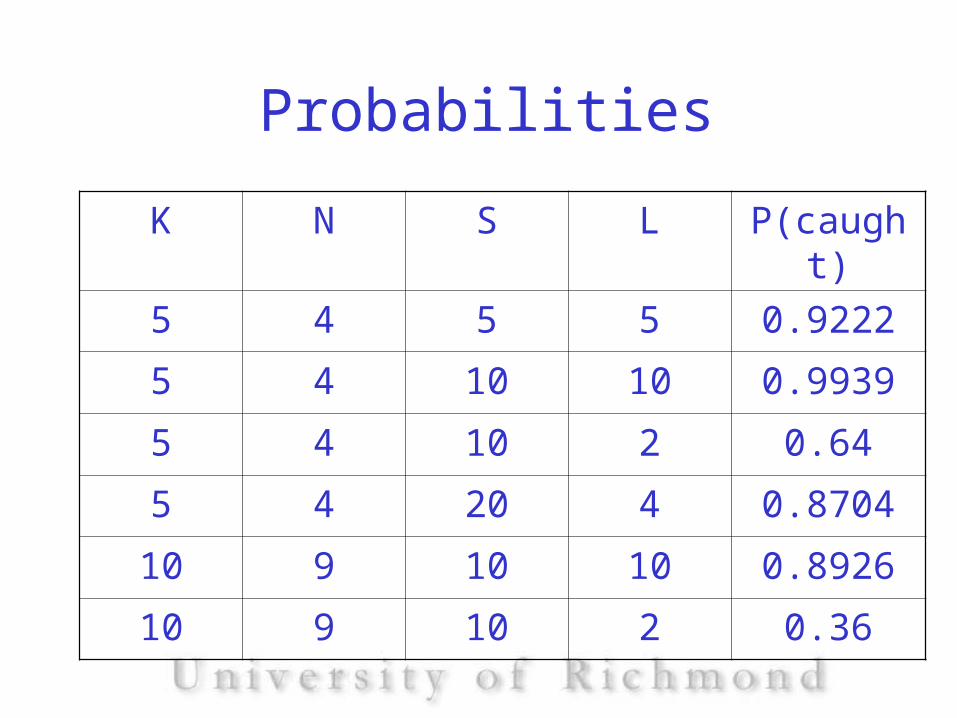
Probabilities
K N S L P(caught)
5 4 5 5 0.9222
5 4 10 10 0.9939
5 4 10 2 0.64
5 4 20 4 0.8704
10 9 10 10 0.8926
10 9 10 2 0.36

Redundancy vs. P values
P 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
K/N 1.05
1.11
1.18
1.25
1.33
1.43
1.54
1.67
1.82
2.0
P 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0
K/N 1.03
1.06
1.09
1.13
1.17
1.23
1.29
1.38
1.52
2.0
L = 1
L = 2

Advantages
• Far fewer task compute cycles than simple redundancy
• Values need not be precomputed• Method is relatively collusion resistant
(unless supervisor picks an entire group of colluding participants)
• Method is tunable• Can also be applied to non-sequential case

Disadvantages
• Increased coordination and communication costs for supervisor
• Need for synchronization increases time cost of job– Dial-up connectivity– Sporadic task execution (owners using
PCs)

Disadvantages
• Strategy does not protect well against adversary who cheats once
• Cheating damage can be magnified – Propagation of undetected incorrect
results

Conclusions• Presented two strategies for hardening
distributed metacomputations• Non-sequential: Seed data with ringers• Sequential: Share N tasks among K > N
participants• Small increase in average execution time
of modified task• Overall computing costs significantly less
than redundantly assigning every task





























![WŁAŚCIWOŚCI RETENCYJNE ZIELONYCH DACHÓW ...[Szajda i in. 2008, Szajda i Pęczkowski 2010, Burszta-Adamiak i in. 2014]. Jedną z form zrównoważonych systemów pozwalających na](https://img.pdfslide.net/doc/110x75/60d0d7623a3c99342b4aebff/waciwoci-retencyjne-zielonych-dachw-szajda-i-in-2008-szajda-i-pczkowski.jpg)