Embed Size (px)
Citation preview

Harnessing AI for Speech Reconstruction using Multi-viewSilent Video Feed
Yaman KumarAdobe Systems
Mayank AggarwalNetaji Subhas Institute of Technology
Pratham NawalNetaji Subhas Institute of Technology
Shin’ichi SatohNational Institute of Informatics
Rajiv Ratn ShahIndraprastha Institute of Information
Technology DelhiNew Delhi
Roger ZimmermannNational University of Singapore
ABSTRACTSpeechreading or lipreading is the technique of understanding andgetting phonetic features from a speaker’s visual features such asmovement of lips, face, teeth and tongue. It has a wide range ofmultimedia applications such as in surveillance, Internet telephony,and as an aid to a person with hearing impairments. However, mostof the work in speechreading has been limited to text generationfrom silent videos. Recently, research has started venturing intogenerating (audio) speech from silent video sequences but therehave been no developments thus far in dealing with divergent viewsand poses of a speaker. Thus although, we have multiple camerafeeds for the speech of a user, but we have failed in using thesemultiple video feeds for dealing with the different poses. To thisend, this paper presents the world's first ever multi-view speechreading and reconstruction system. This work encompasses theboundaries of multimedia research by putting forth a model whichleverages silent video feeds from multiple cameras recording thesame subject to generate intelligent speech for a speaker. Initialresults confirm the usefulness of exploiting multiple camera viewsin building an efficient speech reading and reconstruction system. Itfurther shows the optimal placement of cameras which would leadto the maximum intelligibility of speech. Next, it lays out variousinnovative applications for the proposed system focusing on itspotential prodigious impact in not just security arena but in manyother multimedia analytics problems.
KEYWORDSAutomatic Speech Reconstruction; CNN-LSTM models; MultimediaSystems; Lipreading; Speechreading; Speech Reconstruction
MM ’18, October 22–26, 2018, Seoul, Republic of Koreahttps://doi.org/10.1145/3240508.3241911
Figure 1: Domain conjugation andmedia interaction inmul-timedia research
ACM Reference Format:Yaman Kumar, Mayank Aggarwal, Pratham Nawal, Shin’ichi Satoh, RajivRatn Shah, and Roger Zimmermann. 2018. Harnessing AI for Speech Re-construction using Multi-view Silent Video Feed. In 2018 ACM MultimediaConference (MM ’18), October 22–26, 2018, Seoul, Republic of Korea. ACM,New York, NY, USA, 9 pages. https://doi.org/10.1145/3240508.3241911
1 INTRODUCTIONMultimedia as a research topic is more than just a combinationof diverse forms of data [53], i.e., audio, video, text, graphics, etc.Essentially, it is the amalgamation and the interaction among thesedivergent media types that lead to the formation of some extremelychallenging research opportunities such as that of speech readingand reconstruction which are presented in this work [54]. Figure 1introduces the various domains in multimedia research. Tradition-ally, multimedia system have been grouped into text, audio andvideo based information systems. This paper revisits one of themost fundamental problems in multimodality, that of speech read-ing and reconstruction systems. This problem belongs to one ofthose research arenas which are cross domain and exploit the fullbreadth and depth of multimedia research since it involves not justspeechreading but the synchronization of video with lip movementsas well as reconstruction of the audio.
Accepted at ACMMM 2018 Brave New Idea (BNI)
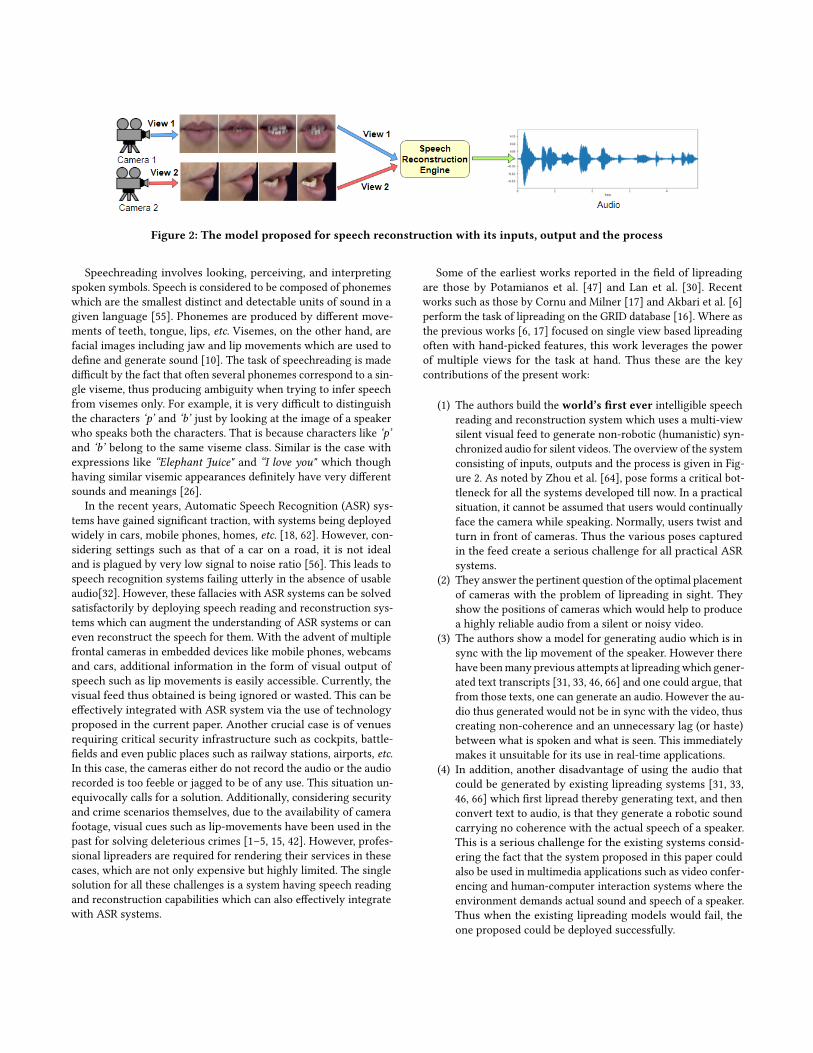
Figure 2: The model proposed for speech reconstruction with its inputs, output and the process
Speechreading involves looking, perceiving, and interpretingspoken symbols. Speech is considered to be composed of phonemeswhich are the smallest distinct and detectable units of sound in agiven language [55]. Phonemes are produced by different move-ments of teeth, tongue, lips, etc. Visemes, on the other hand, arefacial images including jaw and lip movements which are used todefine and generate sound [10]. The task of speechreading is madedifficult by the fact that often several phonemes correspond to a sin-gle viseme, thus producing ambiguity when trying to infer speechfrom visemes only. For example, it is very difficult to distinguishthe characters ‘p’ and ‘b’ just by looking at the image of a speakerwho speaks both the characters. That is because characters like ‘p’and ‘b’ belong to the same viseme class. Similar is the case withexpressions like “Elephant Juice" and “I love you" which thoughhaving similar visemic appearances definitely have very differentsounds and meanings [26].
In the recent years, Automatic Speech Recognition (ASR) sys-tems have gained significant traction, with systems being deployedwidely in cars, mobile phones, homes, etc. [18, 62]. However, con-sidering settings such as that of a car on a road, it is not idealand is plagued by very low signal to noise ratio [56]. This leads tospeech recognition systems failing utterly in the absence of usableaudio[32]. However, these fallacies with ASR systems can be solvedsatisfactorily by deploying speech reading and reconstruction sys-tems which can augment the understanding of ASR systems or caneven reconstruct the speech for them. With the advent of multiplefrontal cameras in embedded devices like mobile phones, webcamsand cars, additional information in the form of visual output ofspeech such as lip movements is easily accessible. Currently, thevisual feed thus obtained is being ignored or wasted. This can beeffectively integrated with ASR system via the use of technologyproposed in the current paper. Another crucial case is of venuesrequiring critical security infrastructure such as cockpits, battle-fields and even public places such as railway stations, airports, etc.In this case, the cameras either do not record the audio or the audiorecorded is too feeble or jagged to be of any use. This situation un-equivocally calls for a solution. Additionally, considering securityand crime scenarios themselves, due to the availability of camerafootage, visual cues such as lip-movements have been used in thepast for solving deleterious crimes [1–5, 15, 42]. However, profes-sional lipreaders are required for rendering their services in thesecases, which are not only expensive but highly limited. The singlesolution for all these challenges is a system having speech readingand reconstruction capabilities which can also effectively integratewith ASR systems.
Some of the earliest works reported in the field of lipreadingare those by Potamianos et al. [47] and Lan et al. [30]. Recentworks such as those by Cornu and Milner [17] and Akbari et al. [6]perform the task of lipreading on the GRID database [16]. Where asthe previous works [6, 17] focused on single view based lipreadingoften with hand-picked features, this work leverages the powerof multiple views for the task at hand. Thus these are the keycontributions of the present work:
(1) The authors build the world’s first ever intelligible speechreading and reconstruction system which uses a multi-viewsilent visual feed to generate non-robotic (humanistic) syn-chronized audio for silent videos. The overview of the systemconsisting of inputs, outputs and the process is given in Fig-ure 2. As noted by Zhou et al. [64], pose forms a critical bot-tleneck for all the systems developed till now. In a practicalsituation, it cannot be assumed that users would continuallyface the camera while speaking. Normally, users twist andturn in front of cameras. Thus the various poses capturedin the feed create a serious challenge for all practical ASRsystems.
(2) They answer the pertinent question of the optimal placementof cameras with the problem of lipreading in sight. Theyshow the positions of cameras which would help to producea highly reliable audio from a silent or noisy video.
(3) The authors show a model for generating audio which is insync with the lip movement of the speaker. However therehave beenmany previous attempts at lipreadingwhich gener-ated text transcripts [31, 33, 46, 66] and one could argue, thatfrom those texts, one can generate an audio. However the au-dio thus generated would not be in sync with the video, thuscreating non-coherence and an unnecessary lag (or haste)between what is spoken and what is seen. This immediatelymakes it unsuitable for its use in real-time applications.
(4) In addition, another disadvantage of using the audio thatcould be generated by existing lipreading systems [31, 33,46, 66] which first lipread thereby generating text, and thenconvert text to audio, is that they generate a robotic soundcarrying no coherence with the actual speech of a speaker.This is a serious challenge for the existing systems consid-ering the fact that the system proposed in this paper couldalso be used in multimedia applications such as video confer-encing and human-computer interaction systems where theenvironment demands actual sound and speech of a speaker.Thus when the existing lipreading models would fail, theone proposed could be deployed successfully.

Figure 3: Training of the speech reading and reconstructionmodel. Input to themodel is silent video feed and the actual audioof the speech
(5) Additionally and most importantly, the existing lipreadingsystems are text based systems, which are highly dependenton language and vocabulary. If language and vocabulary arechanged, they fail utterly. A talk between bilingual speak-ers cannot be understood by the existing systems. Here theauthors propose a system which is not only vocabulary butlanguage independent too. They have not used any languagespecific feature in this implementation thus making the sys-tem independent of any and all languages.
(6) In light of the current work, the authors discuss severalclosely associated and allied tasks such as augmentation ofaudio in movies, helping people with and without hearingdisabilities to understand speech. These applications cangreatly benefit from building a speech reading and recon-struction system like the one proposed in Figure 2.
The rest of the paper is organized on these lines: Section 2presents the previous work in this domain. Section 3 discussesthe approach followed, overall methodology and models used bythe authors in designing the system. Section 4 shows the resultsfor the experiments carried out. In Section 5, the authors notethe possible futuristic application areas which can greatly benefitfrom the current work. Finally, Section 6 concludes the paper whilepresenting the work intended to be undertaken in the future.
2 RELATEDWORKThe documentation for lipreading spans centuries with some of theearliest works being reported in the 17th century [12]. It mentionsthat useful information can be extracted from facial movements of aspeaker. Several psychological studies have demonstrated that lowerlevel additional information helps in hearing [19, 20]. Experimentsand research studies have shown that people with [11, 35] and
without [59] hearing impairment use visual cues for understandingand augmenting the understanding of what a speaker is trying tosay. As noted by Chen and Rao [13], skilled lip-readers perform thetask by looking at the configuration and movement of tongue, lipsand teeth.
One of the first audio-visual recognition systems was developedby Petajan [44] in which the camera was used to capture the mouthimages which were later thresholded into black and white. Binaryimages thus obtained were analyzed to derive open mouth area,height, perimeter, etc, which were later used for recognition. Tra-ditionally, lipreading has been considered as a classification taskwhere either words or phrases are identified and selected from alimited lexicon. Some of the earliest works using this were those byNgiam et al. [37], Noda et al. [38], Petridis and Pantic [45]. Authorsin those works used hand-picked features used with a combinationof deep learning models followed by classifiers. Several end-to-end deep learning models have also been developed which relyon a combination of convolutional and recurrent neural networks[8, 14, 61].
Many have previously ventured into taking the tasks of lipread-ing for digits only, with some of the notable works being Chen andRao [13], Pachoud et al. [41], Sui et al. [58]. However these systems,since being very specific face a lack of generality.
In their work, Cornu and Milner [17] used hand-engineeredfeatures to reconstruct audio from video, using a deep-learningnetwork. This method then was modified by Ephrat et al. [21] whoused CNN over the entire face of the speaker. Both of these worksused Linear Predictive Coding (LPC) [22] coefficients for modelingaudio features.
As noted in Section 1, it is impractical to assume that speak-ers would be still and continuously facing a camera in a singularpose for their full speech, which is the common unsaid, unwritten

Figure 4: CNN-LSTM based architecture used for speech reading and reconstruction
assumption of almost all the previous works mentioned. This se-riously impedes their lipreading model’s ability when the subjectturns to a new pose. Thus camera view and pose can drastically af-fect the model’s accuracy in predicting and deciphering the speech.Thus with regards to taking pose into consideration, there havebeen three common approaches thus far:
(1) Many authors have used non-frontal views to extract posedependent features and then used them for building ASR.For instance, Iwano et al. [25] used profile views and thencalculated optical flow for each image. In their work, Luceyand Potamianos [33] showed that using a profile view wasinferior to using a frontal view when results were derivedusing their ASR pipeline. However, Kumar et al. [28] usedtheir geometric pose dependent features and other hand-extracted features to recognize the isolated words, henceshowing that results from profile views were better thanfrontal views.
(2) Some research projects have used pose dependent featuresand transformed them into pose independent features, theneventually using them for classification. For instance, Luceyand Potamianos [33] and Lucey et al. [34] transformed posedependent features from an unwanted camera view to thewanted one. However, the results showed that the perfor-mance was substantially worse when compared to the samepose views. In thework by Lan et al. [29], it was inferred fromthe experiments on the derived pose dependent features that30◦ (degrees) (from the frontal view) was the optimal viewfor the task of lipreading. Then the features were projectedto the optimal view which was then tested on other views.Extracting features from pose dependent features, though itseems to be a viable approach, suffers from a grave lack ofdata for the large number of possible views. Pose indepen-dent features based systems being view-blind, suffer from ahuge drop of accuracy and performance [64].
(3) To the best of the authors’ knowledge, there have been onlyfour previous works who have attempted to build multi-viewlipreading systems generating text from silent/noisy videofeeds. Lucey and Potamianos [33] used discrete cosine trans-form based features subsequently fed to a Hidden MarkovModel as input to generate text for the speech. They showedthat a two view system outperformed a single view system.Lee et al. [31] used various CNN-LSTM based architecturesto generate text from speech. They tested the combination ofall the five views which were subsequently found out to beworse than all the single views. Zimmermann et al. [66] usedPrincipal Component Analysis along with a LSTM and HMMbased architecture on OuluVS2 to obtain speech transcripts.They too showed that combining all views led to worse per-formance. Finally, Petridis et al. [46] used CNN-LSTM basednetworks to predict text from video sequences on OuluVS2dataset. The accuracy they obtained was close to 96% usingmultiple views. It is worth noting that none of the said workshave ventured into the task of producing audio from a silentvideo and as noted in Section 1, thus seriously curtailingthe deployment of these systems in real time multimediabased applications which require sync with videos and theoriginal human voice. Additionally, usage of these systemscreates language and vocabulary training dependencies onthe model.
3 METHODOLOGYThe literature survey suggests that researchers have spent great ef-forts and time to find the visual features associated with lips, mouthand teeth to map facial features to speech. The authors in this paperbypass that requirement by employing a Convolutional Neural Net-work (CNN) based deep learning model. A high level view of thesystem is shown in Figure 4. It takes feeds from multiple camerasand then produces the audio corresponding to the images obtained.

Given a speaker’s images, a CNN-LSTM based network automat-ically learns the optimal features required for reconstructing theaudio signal.
This model has the advantage of not depending on a particularsegmentation of the input feed into words or letters or even phrasesand sentences. It uses “natural supervision” to learn a predictiontarget from a natural signal of theworld [40]. A large enough datasetcan train this network successfully to predict out-of-vocabularywords (OOVs).
3.1 Audio FeaturesMany techniques such as sinusoidal models, vocoders, etc, havebeen employed for speech reconstruction [36, 57]. One could alsowork directly with spectrograms but as per the experiments carriedout by the authors, the quality of the audio reconstruction obtainedfrom it is poor. Results obtained from those experiments are notpresented in this work due to their inferior quality. Raw audiowaves cannot be used due to a lack of suitable loss function. Theauthors in this work have chosen Linear Predictive Coding (LPC) forrepresenting the audio speech [22]. LPC is a technique to representthe compressed spectral envelope of speech using a linear predictivemodel. It produces high-quality speech using low bit-rate. The orderP of LPC was varied and chosen so as to get the best quality speech.Line Spectrum Pairs (LSPs) [24] can represent LPC coefficientsin a robustly quantized manner. Thus LSPs prove to be useful atrepresenting LCP for the task at hand. The current audio pipelinehas the advantage of modeling other parts of human speech suchas emotion, prosody, etc.
3.2 Training the ModelThe proposed system is shown in the Figure 4. It consists of aCNN-LSTM based architecture. While CNN layers extract the vi-sual features from images, LSTM layers are used for taking intoconsideration the time dependence of speech (both video and au-dio). Finally dense layers are then connected to LSTM layers whichproduce audio corresponding to the sequence of images.
As shown in the Figure 3, for training of the model, the systemrequires multiple views of the same subject speaking somethingand the corresponding audio. The images are preprocessed in or-der to obtain better features from the images. The preprocessinginvolved converting the images to gray-scale, resizing them andthen applying Contrast Limited Adaptive Histogram Equalization(CLAHE) [51]. The obtained images are then fed to the CNN-LSTMbased network.
The output of the CNN-LSTM architecture is the audio corre-sponding to the video given. It is processed according to the tech-nique mentioned in Section 3.1.
Although the goal is to map a single video frame Ii to a singleaudio vector Si , due to instantaneous lip and mouth movements,it would be inefficient for the system to do so. Thus the systemmaps a sequence of images to a part of the corresponding audiovector. It serves as a temporal neighborhood for the Ii image andhas a corresponding Si audio vector. The sequence length of imageswas taken as a hyper-parameter and was optimized to get the bestquality sound. Thus the timesteps parameter of LSTM was obtainedas 5 images. In other words, the model considered 5 previous frames
Table 1: Results for the proposed model. V1, V2, V3, V4, V5represent the single views mapping to 0◦, 30◦, 45◦, 60◦ and90◦ respectively. V1_2 means the combination of 0◦ and 30◦and V1_4 represents the combination of 0◦ and 60◦. Resultsshown are PESQ values for two speakers- Speaker 1 (Male)and Speaker 10 (Female)
View Speaker 1 Speaker 10V1 1.7674 1.7812V2 1.7255 1.7129V3 1.6161 1.6012V4 1.4962 1.5312V5 1.4284 1.4453V1_2 1.9683 1.9978V1_4 1.8636 1.9463
to be the temporal dependency of a frame while constructing thespeech. The network was then trained on a combination of meansquared and correlation based error loss metric.
4 EVALUATION4.1 Database UsedIn the current work, the authors use the OuluVS2 database [7].OuluVS2 is a multi-view audio-visual database. It consists of 53speakers with five different views spanning between frontal andprofile views. The talking speed was not regulated and dependedon the speaker. The database consists of three different types ofdata:
(1) Ten short English phrases such as "Good-Bye" and "Hello".These phrases were also present in OuluVS [63] databasewhich was extensively used in various studies [39, 43, 49, 50,65].
(2) Ten random digit sequences uttered by 53 speakers.(3) Ten randomly chosen TIMIT sentences. [67]A variety of speaker appearance types were considered in the
dataset with most of them being of the following types: European,Chinese, Arabian, African and Indian/Pakistani. Cameras recordedthese subjects from 5 different angles: 0◦, 30◦, 45◦, 60◦ and 90◦.Thus this database serves well for this work. The database consistsof speech which ranges from digits to commonly used phrases andTIMIT sentences [67]. The speakers have different ethnic appear-ances and importantly, were recorded from 5 different views, thusforming the base for our subsequent analysis.
4.2 Evaluation Metric usedIn this work, Perceptual Evaluation of Speech Quality (PESQ) [52] istaken as the metric used to evaluate the quality and intelligibility ofthe speech. While there are many choices for evaluation of speechquality, the authors have chosen this since it corresponds well tothe perceived audio quality [23], in addition to the system’s lossfunction. Among all the measures such as PSQM [9] and PEAQ[60], PESQ has been recommended by ITU-T for speech qualityassessment of 3.2 kHz codecs [48]. PESQ compares two audios oneof them being original and the other one being generated by thesystem. The PESQ system first level aligns the two audios, then afterpassing them through filters, time aligns them, passes them through

Table 2: Average PESQ results after comparing original au-dio with the audio obtained as explained in Section 3.1. Re-sults are for the two speakers- Speaker 1 (Male) and Speaker10 (Female)
Speakers PESQSpeaker 1 2.5291Speaker 10 2.6255
an auditory transform and finally extracts two distortion param-eters. These distortion parameters are the difference between thetransform of the two signals. Finally after aggregating the signalsin frequency and time, they are mapped to a mean opinion score. APESQ score ranges from -0.5 to 4.5 with 4.5 being the score for highquality reconstruction of the original audio. Previous works suchas Ephrat et al. [21] and Akbari et al. [6] also use this measure.
The authors would like to note that using the audio pipeline asexplained in Section 3.1, the audio constructed was compared tothe original audio and the results obtained are shown in Table 2.
4.3 ResultsTable 1 contains the results obtained using the speech reconstruc-tion model used. It shows both the single view and multi-viewresults for speaker 1 (a male) and speaker 10 (a female) of OuluVS2.The speakers 1 and 10 have been chosen randomly, and not becauseof some specific strategy. One of them, i.e., speaker 1 is a male andthe other one, i.e., speaker 10 is a female, thus demonstrating theresults for both the sexes. Due to the paucity of space, only thebest results among multiple views are shown in the table. View 1corresponds 0◦, view 2 to 30◦, view 3 to 45◦, view 4 to 60◦ and view5 to 90◦. As shown by the table, views 1 and 4 and views 1 and 2outperform other multiple as well as single views.
For the male speaker, the combination of views 1 and 2 showsan improvement of approximately 26% over view 1 and 33% overview 2 individually while the combination of views 1 and 4 showsan improvement of 12.5% over view 1 and 80% over view 4. Forthe female speaker, the combination of views 1 and 2 shows animprovement of approximately 27% over view 1 and 40% over view2 individually while the combination of views 1 and 4 shows animprovement of 21% over view 1 and 80% over view 4. This is a verysignificant improvement considering the fact that the cost of includ-ing already available information (in terms of multiple video feeds)into the model is negligible where as the gains are outstanding.These preliminary results show that the model performs equallywell for male as well as female speakers.
Thus considering the task of placement of cameras, the modelwould perform best if the angle between the two cameras is in therange of 30◦ to 60◦. This would give the maximum intelligibility ofspeech and can help immensely in the reconstruction of speech.
5 DISCUSSION AND APPLICATIONS OFLIPREADING SYSTEMS
As illustrated in Figure 5, there are a host of applications for thecurrent multi-view lipreading system:
• Lipreading in general and multi view lipreading in particularcan be used to augment the understanding of what a personsays. It is highly useful for hearing impaired [11, 35] people.Thus a major use case of the multi-view lipreading systemwould be hearing impaired people who would largely benefitwith accurate text of what the speaker is speaking.
• People who have full hearing capabilities [59] can employthis system in their day-to-day lives. For instance, as noted by[13], listeners face trouble comprehending the audio speechwhen either the speaker has a foreign accent or even whenthe speaker is unfamiliar to the listener. This problem canbe solved using multi-view lipreading. Ultimately, the audiosignals of foreign or accented speakers might be differentbut the lip-movements required for producing the standardalphabet are the same. Thus while the video sequence wouldbe from the foreign speaker and would remain the same butthe audio could be changed. The audio used in the trainingof the system can be replaced by an audio which is familiarto the listener, thus while the words would be of the foreignspeaker the sound would be of a familiar person thus makingidea exchange much more efficient.
• One of the major deployment opportunities of the multi-view lipreading are crowded places whose security is ofgrave concern to the public at large. Huge amounts of money,manpower and systems are rightly deployed in recording,listening, surveilling, patrolling and in general protectionand security related activities. At crowded public places likerailway stations, airports, road intersections, stadiums, audi-toriums, etc. it becomes imperative for the authorities to lookfor and keep a watch on unwanted elements. For this, CCTVand camera footage become a vital source of informationof their movements. The speech-reconstruction system pro-posed in this paper, if deployed, with multiple camera feedscan become an indispensable tool in the hands of authorities.
• The other major use case for the system proposed is movies.Movies, whether in the format of entertainment or for educa-tional purposes such as in MOOCs (Massively Open OnlineCourses) can reap the benefits of this system. Often multiplecameras record the subject in a movie simultaneously out ofwhich a single view is then shown to the viewers. Wheneverthe speech of a subject is non-audible or non-decipherable,the viewers are left wondering what the speaker said. At thispoint of time, such an approach is not only highly inefficientbut wasteful too. The feed from multiple cameras can easilybe used to augment the speech and the sound of the speaker.
• Highly noisy environments such as those of parties or festi-val celebrations serve as another area of deployment of thesystem proposed. Multiple cameras recording the subjectcan inform the listener of the speech in real time.
• With the advent ofmobile devices andmultiple front camerasthat come along with them, applications like video confer-encing have seen a tremendous rise in their user-base. Theauthors think of these as a great platform for the employ-ment of the system proposed due to the near perfect camerafeed, most of which contains only the speaker’s face. Dueto bad reception, it is often the case that audio becomesjagged. Thus the speech reconstruction system proposed

Figure 5: Applications ofmulti-view lipreading. The applica-tions shown are (starting from the top-left in clockwise or-der) in noisy environments such as parties, at public placessuch as road intersections, for enhancing security infras-tructure such as by making use of multiple camera at air-ports, in augmenting audio of MOOCs, in correcting audioin video conferencing applications and in movies
can reinforce the speech of the speaker using the video feedavailable.
• One of the very worthwhile applications of the system pro-posed is in the medical field. It can be a boon for people withcerebral palsy. Cerebral palsy is a condition which makes ithard to move certain parts of the body. The pathology alsoaffects the communication skills of the patient. In the USalone, it affects 764,000 people [27]. The system proposedcan greatly affect the lives of people suffering with cere-bral palsy in a very positive way. The system deployed on acamera can detect their lip movements and then constructaudio for those movements. The system, for this applicationwould be trained on audio taken from a healthy speaker andvideo sequences from the patient. The lip sequences thuslearned from the patient would be mapped onto the audio ofa healthy person, thus giving him a new voice. This wouldimmensely help the patient in communicating effectivelywith the world.
• A very interesting application of this system could be silentvideos (both movies and documentaries) recorded in 19thand 20th centuries. Lipreading followed by speech recon-struction performed on these videos could potentially intro-duce audio in these movies. This could revive a new waveof interest in these movies.
• A highly contemporary application of this system could bevarious gaming systems which depend on human computerinteraction. Human interaction in the form of speech can beaugmented and enhanced using this system.
6 CONCLUSIONS AND FUTUREWORKThe paper presented a model for generating intelligent speechleveraging silent feeds from multiple cameras at different angles. Italso showed the optimal placement of cameras which would lead tothe maximum intelligibility of the speech. To the best of the authors’knowledge, this is the first ever model built for doing so. The authors’finally laid out some potential industrial and academic applicationswhich could benefit tremendously from the proposed system. The
model was evaluated on a multi-view multi-speaker audio-visualdatabase, OuluVS2, for its testing and training purposes.
The short term future goal for this work is to use more viewsfor the task of speech reading and reconstruction. In the presentwork, the authors presented preliminary results which proved theconcept that speech reconstruction could be made better if one canleverage the power of multiple views. The authors in this work usedjust two views for this purpose, but they intend to carry forwardthe task of speech reading and reconstruction for more number ofviews. Additionally, they also look forward to extend the model forwords which are out of the limited lexicon of OuluVS2. This is acrucial task in light of the various potential applications presentedin Section 5.
The long term aims and objectives in this research arena are im-mense. Before being able to actually commercialize speech readingand reconstruction systems, the research has to improve these sys-tems drastically. Currently all the research is conducted on speakersin laboratory conditions with ample lighting facilities. In the realworld, this is not always the case and the lighting is often poor anddiffused. Practical lipreading and speech reconstruction systemshave to overcome these hitches. They need to be useful in not justroom and lab environments but at real places like airports andrailway stations. In addition, for these models to be deployed oncamera chips, they need to be smaller in size. Currently not onlyare the systems’ size huge but the processing power required totrain and test is colossal when compared with the processing powerof camera chips. This is a serious hindrance for the deployment ofthese immensely helpful systems at a large scale.
ACKNOWLEDGMENTSThis research was supported in part by the National Natural ScienceFoundation of China under Grant no. 61472266 and by the NationalUniversity of Singapore (Suzhou) Research Institute, 377 Lin QuanStreet, Suzhou Industrial Park, Jiang Su, People’s Republic of China,215123.
We gratefully acknowledge the support of NVIDIA Corporationwith the donation of a Titan Xp GPU used for this research
REFERENCES[1] 2005. Frontline Scotland reveals new evidence in Arlene Fraser murder case.
(2005). http://www.bbc.co.uk/pressoffice/pressreleases/stories/2005/10_october/19/fraser.shtml
[2] 2012. John Terry cleared of racism against Anton Ferdinand. (2012). http://www.bbc.com/news/uk-england-london-18827915
[3] 2012. John Terry defence ’improbable, implausible and contrived’. (2012). https://www.bbc.com/sport/football/19842795
[4] 2018. . https://www.judiciary.gov.uk/judgments/r-v-john-terry-judgment/[5] 2018. Nine jailed over Euro 11m stolen goods. (2018). http://news.bbc.co.uk/2/
hi/uk_news/england/2806155.stm[6] Hassan Akbari, Himani Arora, Liangliang Cao, and Nima Mesgarani. 2017.
Lip2AudSpec: Speech reconstruction from silent lip movements video. arXivpreprint arXiv:1710.09798 (2017).
[7] Iryna Anina, Ziheng Zhou, Guoying Zhao, and Matti Pietikäinen. 2015. OuluVS2:A multi-view audiovisual database for non-rigid mouth motion analysis. In Auto-matic Face and Gesture Recognition (FG), 2015 11th IEEE International Conferenceand Workshops on,, Vol. 1. IEEE, 1–5.
[8] Yannis M Assael, Brendan Shillingford, Shimon Whiteson, and Nando de Freitas.2016. LipNet: end-to-end sentence-level lipreading. (2016).
[9] John G Beerends and Jan A Stemerdink. 1994. A perceptual speech-qualitymeasure based on a psychoacoustic sound representation. Journal of the AudioEngineering Society 42, 3 (1994), 115–123.
[10] Christian Benoit, Tahar Lallouache, Tayeb Mohamadi, and Christian Abry. 1992.A set of French visemes for visual speech synthesis. , 485–501 pages.

[11] Lynne E Bernstein, Marilyn E Demorest, and Paula E Tucker. 1998. What makesa good speechreader? First you have to find one. Hearing by eye II: Advances inthe psychology of speechreading and auditory-visual speech (1998), 211–227.
[12] John Bulwer. 1648. Philocopus, or the Deaf and Dumbe Mans Friend. Humphreyand Moseley.
[13] Tsuhan Chen and Ram R Rao. 1998. Audio-visual integration in multimodalcommunication. In IEEE 86, 5 (1998), 837–852.
[14] Joon Son Chung and Andrew Zisserman. 2016. Lip reading in the wild. In AsianConference on Computer Vision. Springer, 87–103.
[15] David Conn. 2003. John Terry judgment: Main findings of the FAś regula-tory commission. (2003). https://www.theguardian.com/football/2012/oct/05/john-terry-judgment-commission
[16] Martin Cooke, Jon Barker, Stuart Cunningham, and Xu Shao. 2006. An audio-visual corpus for speech perception and automatic speech recognition. TheJournal of the Acoustical Society of America 120, 5 (2006), 2421–2424.
[17] Thomas Le Cornu and Ben Milner. 2015. Reconstructing intelligible audio speechfrom visual speech features. In Sixteenth Annual Conference of the InternationalSpeech Communication Association.
[18] John R. Allen Darrell M. West. 2018. How artificial intelligenceis transforming the world. https://www.brookings.edu/research/how-artificial-intelligence-is-transforming-the-world/
[19] Marilyn E Demorest and Lynne E Bernstein. 1991. Computational explorationsof speechreading. Journal of the Academy of Rehabilitative Audiology (1991).
[20] Barbara Ed Dodd and Ruth Ed Campbell. 1987. Hearing by eye: The psychology oflip-reading. Lawrence Erlbaum Associates, Inc.
[21] Ariel Ephrat, Tavi Halperin, and Shmuel Peleg. 2017. Improved speech reconstruc-tion from silent video. In ICCV 2017Workshop on Computer Vision for Audio-VisualMedia.
[22] Gunnar Fant. 2012. Acoustic theory of speech production: with calculations basedon X-ray studies of Russian articulations. Vol. 2. Walter de Gruyter.
[23] Rainer Huber and Birger Kollmeier. 2006. PEMO-QâĂŤa newmethod for objectiveaudio quality assessment using a model of auditory perception. IEEE Transactionson audio, speech, and language processing 14, 6 (2006), 1902–1911.
[24] Fumitada Itakura. 1975. Line spectrum representation of linear predictor coeffi-cients of speech signals. The Journal of the Acoustical Society of America 57, S1(1975), S35–S35.
[25] Koji Iwano, Tomoaki Yoshinaga, Satoshi Tamura, and Sadaoki Furui. 2007. Audio-visual speech recognition using lip information extracted from side-face images.EURASIP Journal on Audio, Speech, and Music Processing 2007, 1 (2007), 4–4.
[26] Dawid Jachimski, Andrzej Czyzewski, and Tomasz Ciszewski. 2017. A compara-tive study of English viseme recognition methods and algorithms. MultimediaTools and Applications (2017), 1–38.
[27] Karen W Krigger. 2006. Cerebral palsy: an overview. American family physician73, 1 (2006).
[28] Kshitiz Kumar, Tsuhan Chen, and Richard M Stern. 2007. Profile view lip reading.In IEEE International Conference on Acoustics, Speech and Signal Processing, 2007.ICASSP 2007., Vol. 4. IEEE, IV–429.
[29] Yuxuan Lan, Barry-John Theobald, and Richard Harvey. 2012. View independentcomputer lip-reading. In IEEE International Conference on Multimedia and Expo.IEEE, 432–437.
[30] Yuxuan Lan, Barry-John Theobald, Richard Harvey, Eng-Jon Ong, and RichardBowden. 2010. Improving visual features for lip-reading. In Auditory-VisualSpeech Processing 2010.
[31] Daehyun Lee, Jongmin Lee, and Kee-Eung Kim. 2016. Multi-view automatic lip-reading using neural network. In Asian Conference on Computer Vision. Springer,290–302.
[32] Jinyu Li, Li Deng, Reinhold Haeb-Umbach, and Yifan Gong. 2015. Robust Auto-matic Speech Recognition: A Bridge to Practical Applications. Academic Press.
[33] Patrick Lucey and Gerasimos Potamianos. 2006. Lipreading using profile versusfrontal views. In IEEE Workshop on Multimedia Signal Processing. IEEE, 24–28.
[34] Patrick J Lucey, Sridha Sridharan, and David B Dean. 2008. Continuous pose-invariant lipreading. (2008).
[35] Marc Marschark, Dominique LePoutre, and Linda Bement. 1998. Mouth move-ment and signed communication. Hove, United Kingdom: Psychology Press Ltd.Publishers.
[36] Robert McAulay and Thomas Quatieri. 1986. Speech analysis/synthesis based ona sinusoidal representation. IEEE Transactions on Acoustics, Speech, and SignalProcessing 34, 4 (1986), 744–754.
[37] Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and An-drewYNg. 2011. Multimodal deep learning. In Proceedings of the 28th internationalconference on machine learning (ICML-11). 689–696.
[38] Kuniaki Noda, Yuki Yamaguchi, Kazuhiro Nakadai, Hiroshi G Okuno, and TetsuyaOgata. 2015. Audio-visual speech recognition using deep learning. AppliedIntelligence 42, 4 (2015), 722–737.
[39] Eng-Jon Ong and Richard Bowden. 2011. Learning sequential patterns for lipread-ing. In BMVC 2011-Proceedings of the British Machine Vision Conference 2011. TheBritish Machine Vision Association and Society for Pattern Recognition.
[40] Andrew Owens, Phillip Isola, Josh McDermott, Antonio Torralba, Edward HAdelson, and William T Freeman. 2016. Visually indicated sounds. In Proceedingsof the IEEE Conference on Computer Vision and Pattern Recognition. 2405–2413.
[41] Samuel Pachoud, Shaogang Gong, and Andrea Cavallaro. 2008. Macro-cuboidbased probabilistic matching for lip-reading digits. In IEEE Conference on Com-puter Vision and Pattern Recognition. IEEE, 1–8.
[42] Alasdair Palmer. 2003. Lip reader saw Fraserś incriminating conver-sations. (2003). https://www.telegraph.co.uk/news/uknews/1420816/Lip-reader-saw-Frasers-incriminating-conversations.html
[43] Yuru Pei, Tae-Kyun Kim, and Hongbin Zha. 2013. Unsupervised random forestmanifold alignment for lipreading. In IEEE International Conference on ComputerVision. IEEE, 129–136.
[44] Eric David Petajan. 1984. Automatic lipreading to enhance speech recognition(speech reading). (1984).
[45] Stavros Petridis and Maja Pantic. 2016. Deep complementary bottleneck featuresfor visual speech recognition. In IEEE Transactions on Acoustics, Speech, and SignalProcessing. IEEE, 2304–2308.
[46] Stavros Petridis, Yujiang Wang, Zuwei Li, and Maja Pantic. 2017. End-to-EndMulti-View Lipreading. arXiv preprint arXiv:1709.00443 (2017).
[47] Gerasimos Potamianos, Chalapathy Neti, Juergen Luettin, and Iain Matthews.2004. Audio-visual automatic speech recognition: An overview. Issues in visualand audio-visual speech processing 22 (2004), 23.
[48] ITU-T Recommendation. 2001. Perceptual evaluation of speech quality (PESQ):An objective method for end-to-end speech quality assessment of narrow-bandtelephone networks and speech codecs. Rec. ITU-T P. 862 (2001).
[49] Ahmed Rekik, Achraf Ben-Hamadou, and Walid Mahdi. 2014. A new visualspeech recognition approach for RGB-D cameras. In International ConferenceImage Analysis and Recognition. Springer, 21–28.
[50] Ahmed Rekik, Achraf Ben-Hamadou, and Walid Mahdi. 2015. Unified system forvisual speech recognition and speaker identification. In International Conferenceon Advanced Concepts for Intelligent Vision Systems. Springer, 381–390.
[51] Ali M Reza. 2004. Realization of the contrast limited adaptive histogram equaliza-tion (CLAHE) for real-time image enhancement. Journal of VLSI signal processingsystems for signal, image and video technology 38, 1 (2004), 35–44.
[52] Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. 2001.Perceptual evaluation of speech quality (PESQ)-a new method for speech qualityassessment of telephone networks and codecs. In IEEE Transactions on Acoustics,Speech, and Signal Processing, Vol. 2. IEEE, 749–752.
[53] Rajiv Shah and Roger Zimmermann. 2017. Multimodal analysis of user-generatedmultimedia content. Springer.
[54] Rajiv Ratn Shah, Yi Yu, and Roger Zimmermann. 2014. Advisor: Personalizedvideo soundtrack recommendation by late fusion with heuristic rankings. InProceedings of the 22nd ACM international conference on Multimedia. ACM, 607–616.
[55] Sally E Shaywitz. 1996. Dyslexia. Scientific American 275, 5 (1996), 98–104.[56] Rita Singh, Richard M Stern, and Bhiksha Raj. 2002. Signal and feature compensa-
tion methods for robust speech recognition. Noise reduction in speech applications7 (2002), 219.
[57] Yannis Stylianou. 2001. Applying the harmonic plus noise model in concatenativespeech synthesis. IEEE Transactions on speech and audio processing 9, 1 (2001),21–29.
[58] Chao Sui, Mohammed Bennamoun, and Roberto Togneri. 2015. Listening withyour eyes: Towards a practical visual speech recognition system using deep boltz-mann machines. In Proceedings of the IEEE International Conference on ComputerVision. 154–162.
[59] Quentin Summerfield. 1992. Lipreading and audio-visual speech perception. Phil.Trans. R. Soc. Lond. B 335, 1273 (1992), 71–78.
[60] Thilo Thiede, William C Treurniet, Roland Bitto, Christian Schmidmer, ThomasSporer, John G Beerends, and Catherine Colomes. 2000. PEAQ-The ITU standardfor objective measurement of perceived audio quality. Journal of the AudioEngineering Society 48, 1/2 (2000), 3–29.
[61] Michael Wand, Jan Koutník, and Jürgen Schmidhuber. 2016. Lipreading withlong short-term memory. In IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), 2016. IEEE, 6115–6119.
[62] Business Wire. 2018. European $1.66 Billion Speech and Voice Recog-nition Market Analysis 2016-2018 Forecast to 2025 - Key Players areMicrosoft, Nuance Comms, and iFlytek - ResearchAndMarkets.com.https://www.businesswire.com/news/home/20180417005875/en/European-1.66-Billion-Speech-Voice-Recognition-Market
[63] Guoying Zhao, Mark Barnard, and Matti Pietikainen. 2009. Lipreading withlocal spatiotemporal descriptors. IEEE Transactions on Multimedia 11, 7 (2009),1254–1265.
[64] Ziheng Zhou, Guoying Zhao, Xiaopeng Hong, and Matti Pietikäinen. 2014. Areview of recent advances in visual speech decoding. Image and vision computing32, 9 (2014), 590–605.
[65] Ziheng Zhou, Guoying Zhao, and Matti Pietikäinen. 2011. Towards a practicallipreading system. In IEEE International Conference on Computer Vision. IEEE,137–144.

[66] Marina Zimmermann, Mostafa Mehdipour Ghazi, Hazım Kemal Ekenel, andJean-Philippe Thiran. 2016. Visual speech recognition using PCA networks andLSTMs in a tandem GMM-HMM system. In Asian Conference on Computer Vision.Springer, 264–276.
[67] Victor Zue, Stephanie Seneff, and JamesGlass. 1990. Speech database developmentat MIT: TIMIT and beyond. Speech Communication 9, 4 (1990), 351–356.


















![Improved Speech Reconstruction from Silent Videosynthesis using predicted spectrogram magnitude, including Tacotron (Wang et al.) [43] for speech synthesis, and the baseline model](https://img.pdfslide.net/doc/110x75/5ea3ce25fda4e52d8c1de6a1/improved-speech-reconstruction-from-silent-synthesis-using-predicted-spectrogram.jpg)