Embed Size (px)
Citation preview

How Should We Assess the Fit of Rasch-Type Models?
Approximating the Power of Goodness-of-fit Statistics in Categorical Data Analysis
Alberto Maydeu-OlivaresRosa Montano

OutlineIntroductionRasch-Type Models for Binary DataRationale of Goodness-of-Fit Statistics
◦Full Picture◦M2, R1 and R2
Estimating the PowerEmpirical Comparison of R1, R2 and M2Numerical ExamplesDiscussion and Conclusion

IntroductionTwo properties of Rasch-Type models
◦ Sufficient statistics◦ Specific objectivity
Estimation methods◦ Specific for Rasch-Type models (CML)◦ General procedures (MML via EM)
Goodness-of-fit testing procedures◦ Specific to Rasch-Type models◦ General to IRT or multivariate discrete data
models

IntroductionCompare the performance of certain
goodness-of-fit statistics to test Rasch-Type models in MML via EM◦ Binary data◦ 1PL (random effects)
R1 and R2 for 1PLM2 for multivariate discrete data

Rasch model and 1PL
Fixed effects◦ The distribution of ability is not specified
Random effects◦ Specify a standard normal distribution for
ability◦ The less restrictive definition of specific
objectivity still hold
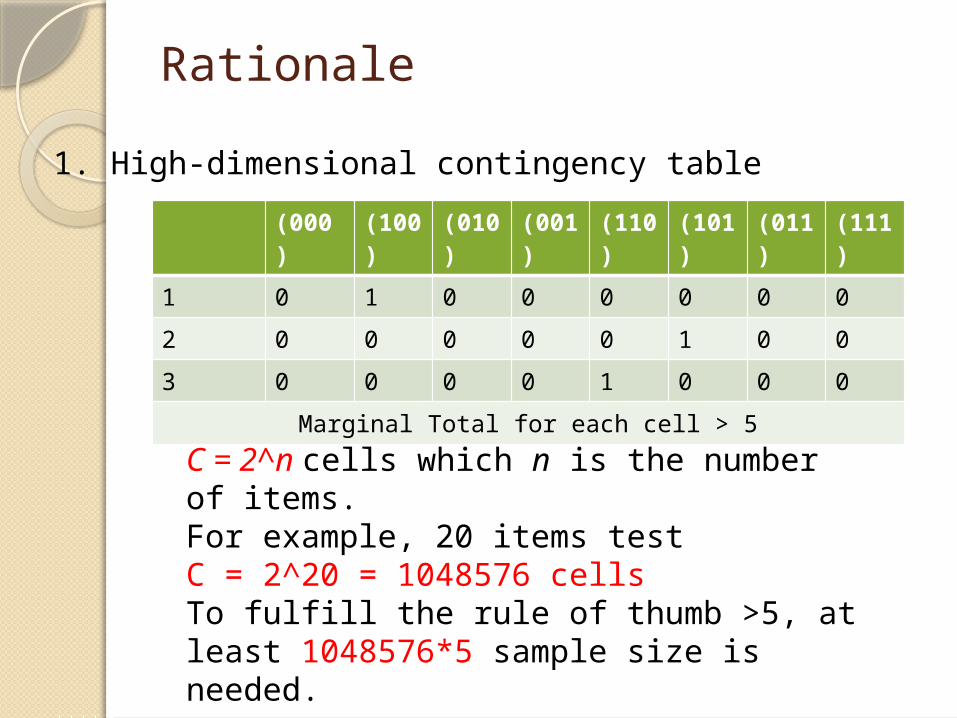
Rationale
(000)
(100)
(010)
(001)
(110)
(101)
(011)
(111)
1 0 1 0 0 0 0 0 0
2 0 0 0 0 0 1 0 0
3 0 0 0 0 1 0 0 0
Marginal Total for each cell > 5
1. High-dimensional contingency table
C = 2^n cells which n is the number of items.For example, 20 items testC = 2^20 = 1048576 cellsTo fulfill the rule of thumb >5, at least 1048576*5 sample size is needed.
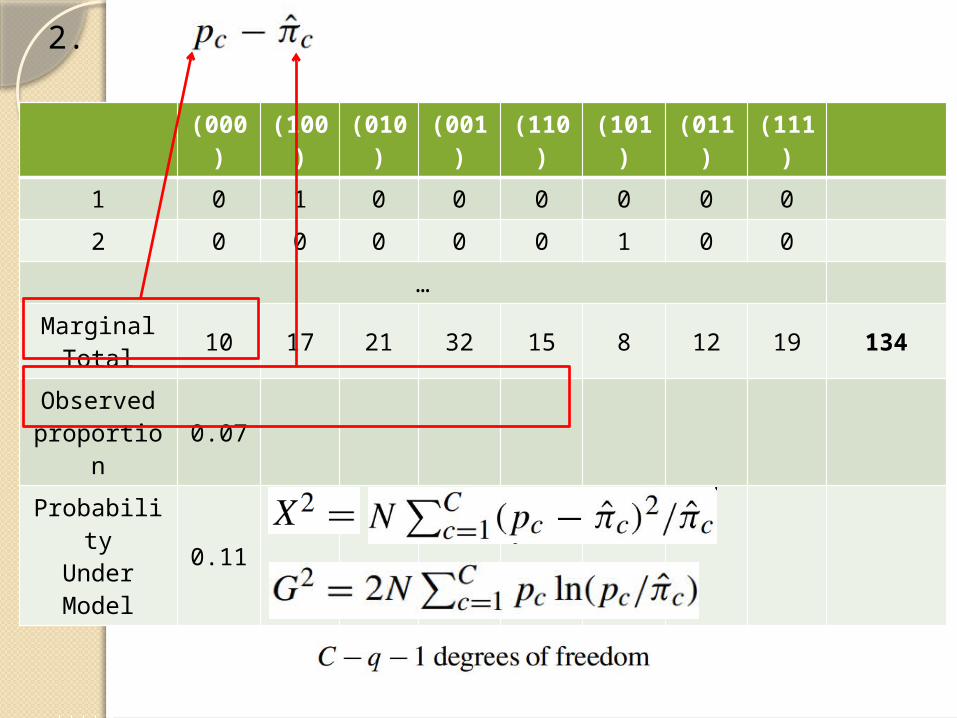
(000)
(100)
(010)
(001)
(110)
(101)
(011)
(111)
1 0 1 0 0 0 0 0 0
2 0 0 0 0 0 1 0 0
…
Marginal Total 10 17 21 32 15 8 12 19 134
Observed proportion 0.07
ProbabilityUnder Model
0.11
2.

When order r = 2, Mr -> M2M2 used the univariate and bivariate
informationThe degree of freedom is It is statistics of choice for testing IRT models
3. Limited information approach (M2)
Pooling cells of the contingency table

Degree of freedom is n(n-2)Specific to the monotone increasing and
parallel item response functions assumptions
3. Limited information approach (R1 and R2)
Degree of freedom is (n(n-2)+2)/2Specific to the unidimensionality assumption

Estimating the Asymptotic Power RateUnder the sequence of local
alternatives◦The noncentrality parameter of a chi-
square distribution can be calculated given the df for M2, R1 and R2
The Kullback-Leibler discrepancy function can be used◦The minimizer of DKL is the same as
the maximizer of the maximum likelihood function between a “true” model and a null model

Study 1: Accuracy of p-values under correct model
df = Mean; df = ½ Var Another Study by Montano (2009), M2 is better than
R1 and the discrepancies between the empirical and asymptotic rate were not large.
Group the sum scores ->

The degree of freedom is also adjustAn iterative procedureWhen appropriate score ranges are used, the
empirical rejection rate of R1 should be closely match the theoretical rejection rates.
This should be also done in R2
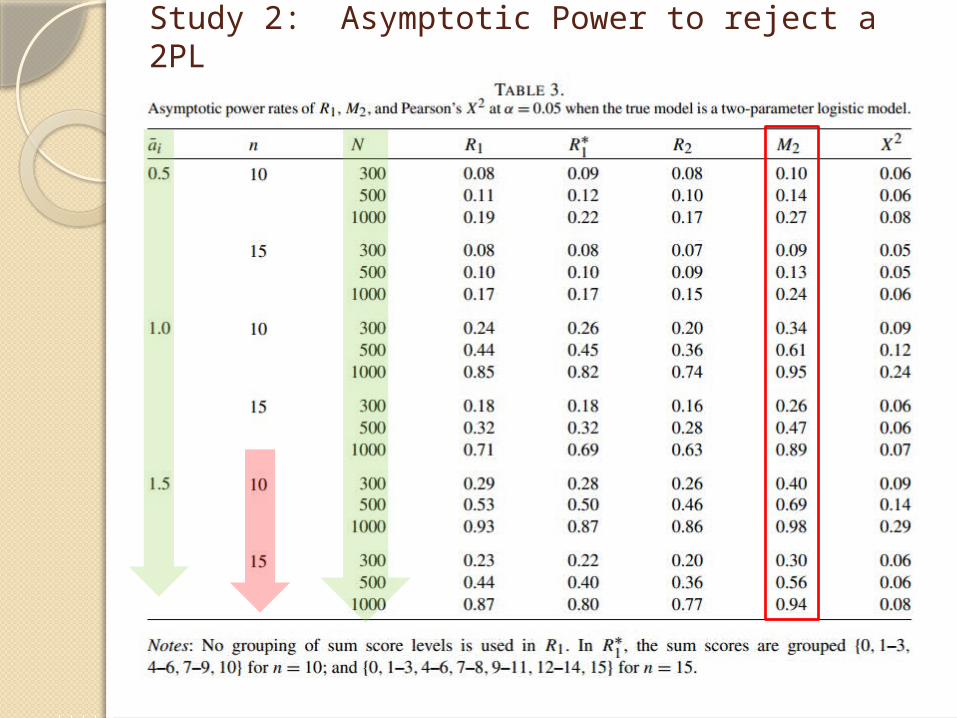
Study 2: Asymptotic Power to reject a 2PL

Study 3: Empirical Power to reject a 2PL
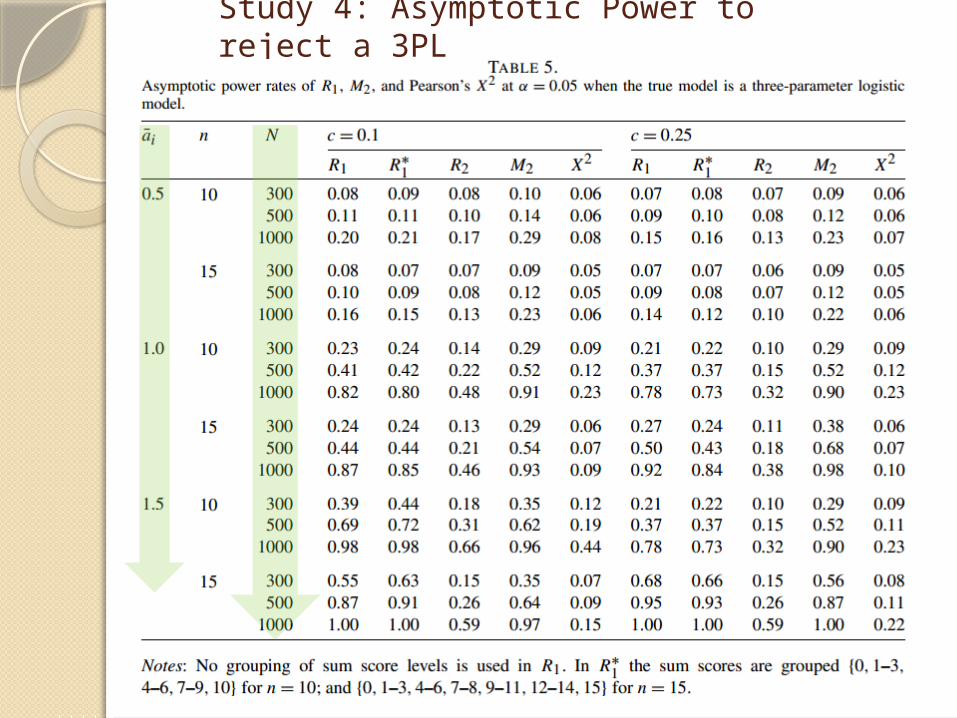
Study 4: Asymptotic Power to reject a 3PL
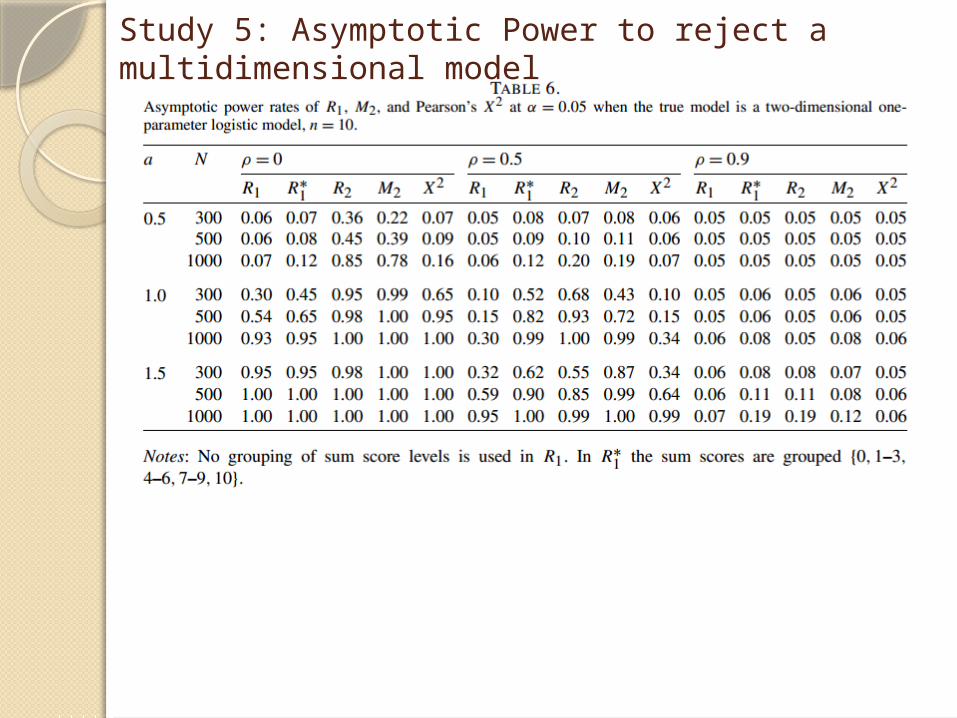
Study 5: Asymptotic Power to reject a multidimensional model
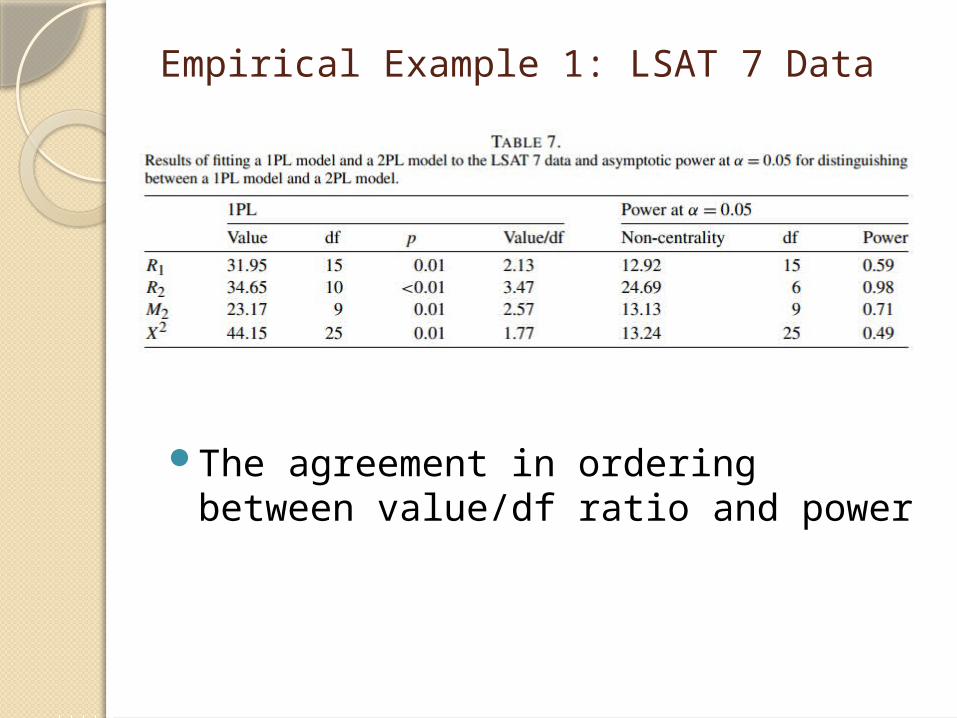
Empirical Example 1: LSAT 7 Data
The agreement in ordering between value/df ratio and power
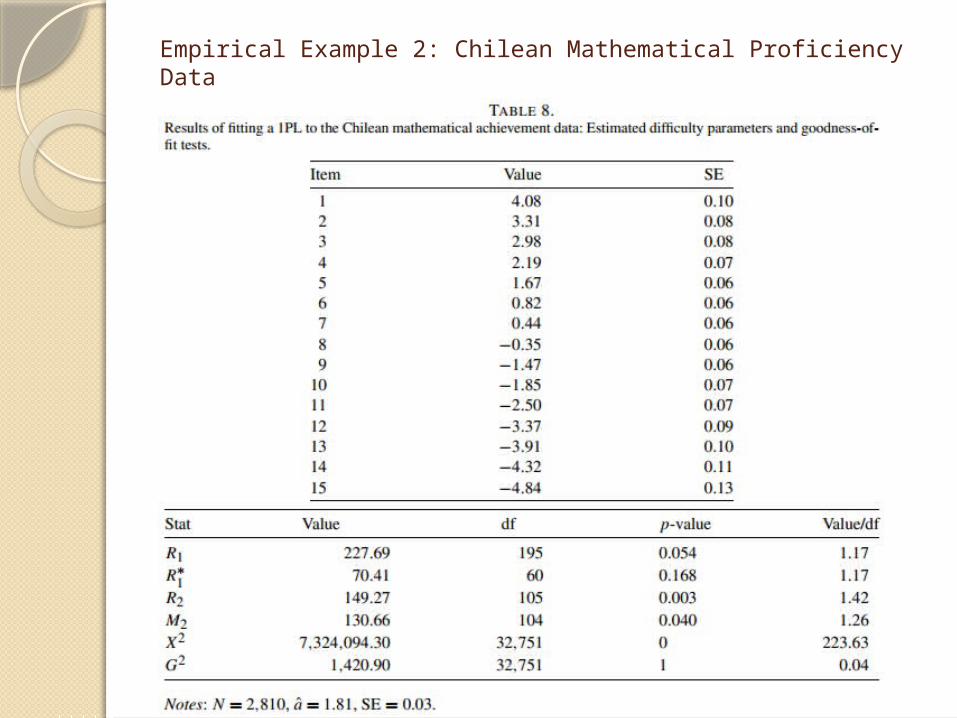
Empirical Example 2: Chilean Mathematical Proficiency Data

Discussion and ConclusionsGenerally, M2 is more powerful
than R1, R2.That is, the R1 and R2 which
developed specific to Rasch-type models is not superior than the general M2





























