Embed Size (px)
Citation preview

Proceedings of the 2021 Conference of the North American Chapter of theAssociation for Computational Linguistics: Human Language Technologies, pages 768–781
June 6–11, 2021. ©2021 Association for Computational Linguistics
768
Human-like informative conversations:Better acknowledgements using conditional mutual information
Ashwin ParanjapeStanford University
Christopher D. ManningStanford University
Abstract
This work aims to build a dialogue agentthat can weave new factual content into con-versations as naturally as humans. We drawinsights from linguistic principles of conver-sational analysis and annotate human-humanconversations from the Switchboard DialogAct Corpus to examine humans strategies foracknowledgement, transition, detail selectionand presentation. When current chatbots(explicitly provided with new factual content)introduce facts into a conversation, theirgenerated responses do not acknowledge theprior turns. This is because models trainedwith two contexts – new factual content andconversational history – generate responsesthat are non-specific w.r.t. one of the contexts,typically the conversational history. We showthat specificity w.r.t. conversational historyis better captured by pointwise conditionalmutual information (pcmih) than by the es-tablished use of pointwise mutual information(pmi). Our proposed method, Fused-PCMI,trades off pmi for pcmih and is preferred byhumans for overall quality over the Max-PMIbaseline 60% of the time. Human evaluatorsalso judge responses with higher pcmih betterat acknowledgement 74% of the time. Theresults demonstrate that systems mimickinghuman conversational traits (in this case ac-knowledgement) improve overall quality andmore broadly illustrate the utility of linguisticprinciples in improving dialogue agents.
1 Introduction
Social chatbots are improving in appeal andare being deployed widely to converse withhumans (Gabriel et al., 2020). Advances in neuralgeneration (Adiwardana et al., 2020; Roller et al.,2020) enable them to handle a wide variety of userturns and to provide fluent bot responses. Peopleexpect their interactions with these dialogue agentsto be similar to real social relationships (Reevesand Nass, 1996). In particular, they expect social
Figure 1: The setting for conversational rephrasing.Conversational history (h) and new factual content(k), two largely independent contexts, are used tosample responses (g1, g2) from a generative model.The samples differ qualitatively. While almost all ofg2 is verbatim from k (in gray), the first sentence in g1(in black) acknowledges using h and bridges to k.
chatbots to both use information that is alreadyknown and separately add new information to theconversation, in line with the given-new contract(Clark and Haviland, 1977).
Neural generation methods for adding new infor-mation (Dinan et al., 2019; Gopalakrishnan et al.,2019; Ghazvininejad et al., 2018; Zhang et al.,2018) measure progress using metrics like “engag-ingness”, “appropriateness” and “informativeness”.But these metrics are too broad and provide littleactionable insight to drive improvements in thesesystems. On the other hand, psycholinguists andsociolinguists have studied human conversations in

769
depth and have identified fine-grained conventions,principles and contracts (Grice, 1975; Clark, 1996;Krauss and Fussell, 1996).
Our first contribution is a linguistic analysisof how human conversations incorporate worldknowledge. We manually annotate conversationsfrom the Switchboard corpus to identify keytraits. In particular, we find that people applyfour kinds of strategies: (1) acknowledgementof each other’s utterances, (2) transition tonew information, (3) appropriate level of detailselection and (4) presentation of factual contentin forms such as opinions or experiences.
To identify deficiencies of the above types inmachine-learned models, we consider a simplifiedtask of conversational rephrasing (Figure 1),in which the factual content to be added is notleft latent but is provided as a text input to themodel (as in Dinan et al. (2019)), along withconversational history. Just as humans do notrecite a fact verbatim in a conversation, we expectthe model to rephrase the factual content by takingconversational context into account. We derivethe data for this task using the Topical Chat dataset(Gopalakrishnan et al., 2019) and fine-tune a largepre-trained language model on it.
Li et al. (2016); Zhang et al. (2020) use max-imum pointwise mutual information (Max-PMI)to filter out bad and unspecific responses sampledfrom a generative language model. However, weobserve that Max-PMI responses lack in acknowl-edgement, an essential human trait. This is becausea generated response that simply copies over thenew factual content while largely ignoring the con-versational history can have high mutual informa-tion (MI) with the overall input.
Our second contribution is a method to selectresponses that exhibit human-like acknowl-edgement. To quantify the amount of informationdrawn from the two contexts of new factualcontent and conversational history, we proposeusing pointwise conditional mutual information(PCMI). We show that responses with a higherPCMI w.r.t conversational history given factualcontent (pcmih) are judged by humans to bebetter at acknowledging prior turns 74% of thetime.1 Then, we use pcmih to identify Max-PMIresponses that lack acknowledgement and findalternative responses (Fused-PCMI) that trade offpmi for pcmih. Despite a lower PMI, human anno-
1Statistically significant with p < 0.05 (Binomial Test).
Figure 2: Examples for Acknowledgement Strategiesfrom Switchboard (parts omitted for brevity).
tators prefer the Fused-PCMI alternative over theMax-PMI response 60% of the time.1 We releaseannotated conversations from the Switchboardcorpus (with guidelines), code for fine-tuning andcalculating scores and human evaluations.2
2 Strategiesfor informative conversations
To understand strategies used by humans whiletalking about factual knowledge, we annotate turnsin human-human conversations. We adopt andextend Herbert Clark’s approach to conversationalanalysis. According to his given-new contract(Clark and Haviland, 1977), the speaker connectstheir utterances with the given information(assumed to be known to the listener) and addsnew information. This builds up common ground(Stalnaker, 2002) between the two participants,defined to be the sum of their mutual, commonor joint knowledge, beliefs and suppositions. Weidentify the following four aspects to the processof adding new information to a conversation.
Acknowledgement strategies According toClark and Brennan (1991), the listener pro-vides positive evidence for grounding. Weclassify all mentions of prior context into variousacknowledgement strategies.
Transition strategies According to Sacks andJefferson (1995), topical changes happen step
2https://github.com/AshwinParanjape/human-like-informative-conversations

770
Figure 3: Examples for popular Transition Strategiesfrom Switchboard (parts omitted for brevity).
by step, connecting the given, stated informationto new information. We annotate the semanticjustifications for topical changes as differenttransition strategies.
Detail selection strategies According to Isaacsand Clark (1987), speakers in a conversationinevitably know varying amounts of informationabout the discussion topic and must assess eachother’s expertise to accommodate their differences.We posit that each speaker applies detail selectionstrategies to select the right level of detail to bepresented.
Presentation strategies According to Smithand Clark (1993), presentation of responsesis guided by two social goals – exchange ofinformation and self-presentation. While we do notconsider social goals in this work, we hypothesize
that people talk about factual information innon-factual forms (e.g., opinions, experiences,recommendations) which we classify as variouspresentation strategies.
2.1 Analysis of strategies
Dataset We annotate part of the The SwitchboardDialog Act Corpus (Stolcke et al., 2000), an exten-sion of the Switchboard Telephone Speech Corpus(Godfrey et al., 1992) with turn-level dialog-acttags. The corpus was created by pairing speakersacross the US over telephone and introducing atopic for discussion. This dataset is uniquely usefulbecause as a speech dataset, it is more intimate andrealistic than text-based conversations betweenstrangers. We annotate conversations on socialtopics which might include specific knowledge(like Books, Vacations, etc.) but leave out onesabout subjective or personal experiences.
Specific knowledge We define specific knowledgeas knowledge that can be “looked up” but isn’twidely known (as opposed to general knowledgethat everybody is expected to know and experi-ential knowledge that can only be derived fromembodied experiences). In this work, we areinterested only in specific knowledge becauseit serves as a source of new information in aconversation that is hard for a language modelto learn implicitly but is likely available as textthat can be supplied to the system. Out of 408annotated turns, 111 (27%) incorporate specificknowledge and account for 56% of the tokens.
Next, we analyze various strategies employedin turns containing specific knowledge:
Acknowledgement Strategies In 70% of theturns, the speaker acknowledges the prior turncorroborating Clark and Brennan (1991). Threemain strategies (Figure 2): agreement (or dis-agreement), shared experiences (or differingexperience) and backchanneling account for 60%of the turns (Figure 4). In certain cases, explicitacknowledgement isn’t necessary. For example,the answer to a question demonstrates groundingand serves as an implicit acknowledgement. Theseare categorized as N/A.
Transition Strategies At the beginning of aconversation, the participants use the discussiontheme to pick a topic (various transition strategiesare shown in Figure 3). The decision to stay on thetopic or to transition to a new one is an implicitform of negotiation and depends on the interest

771
None
Sharedexperience
Agreement
BackchannelN/AOther
29%26%
18%15%7%
5%
Acknowledgement
ElaborateSelf
ElaborateOther
Commonality
DifferencesDiscussion
ThemeNone
32%
22%21%
7%13%
5%
Transition0 50
ExperienceOpinionAnswer
QuestionOthers
Fact. Stat.
53%34%
16%9%7%
25%
Presentation
Figure 4: Distribution of acknowledgement, transition and presentation strategies
and ability of both speakers to participate. Nearlyhalf the time, people elaborate upon the currenttopic (Figure 4). With a supportive listener, theymight elaborate upon their own prior utterance(self-elaboration). Or they might signal interestin continuing the topic by elaborating the otherspeaker’s utterance (other-elaboration). However,in a quarter of the turns, a participant loses interestor both participants run out of material. In thatcase, they transition to a new topic, implicitlyjustified by commonalities or differences with thecurrent topic. If all else fails, they fall back to thediscussion theme to pick a new topic.
Detail-selection strategies People probe theother speaker’s knowledge about an entity beforediving into details. As a probing mechanism,people introduce an entity without any details(introduce-entity) 50% of the time. Depending onthe response, details are laid out 66% of the time.Note that a turn can have both labels, i.e., it canintroduce an entity for the first time or it can havedetails of one entity while also introducing anotherentity. Interestingly, in 7% of turns, an entity’sname is omitted but some details are presented, cre-ating an opening for the other speaker to chime in.
Presentation strategies A single utterance canhave multiple modes of presentation. A factual(objective) statement of specific knowledge isuncommon (25%) in comparison with a subjectiverendering in the form of an experience (53%)or an opinion (34%) (Figure 4). The othercommon modes of presentation are questions(9%) and answers (16%), which often occuras adjacency pairs. We also found a few otheruncommon modes (7%) such as recommendationsor hypotheses based on specific knowledge.
2.2 Implications for dialogue agents
The four aspects – acknowledgement, transition,detail selection and presentation – are essentialingredients and indicative of quality conversation.
They provide us with finer-grained questionsamenable to human evaluation: “How doesthe agent acknowledge?”, “Was it a smoothtransition?”, “Does the utterance contain theright level of detail?”, and “Was the informationpresented as experience or an opinion?”.
These four aspects are also more actionable thanthe evaluation metrics used in prior work. Theycan inspire new techniques that are purposefullybuilt to emulate these strategies. For instance,transitions can be improved with purpose-builtinformation retrieval methods that use common-alities and differences to choose a new topic. Toimprove detail-selection, an agent could keep trackof user knowledge and pragmatically select theright level of detail. Moreover, in their datasets,Dinan et al. (2019) and Gopalakrishnan et al.(2019) asked people to reply using knowledgesnippets, but that can lead to factual statementsdominating the presentation strategies. We hopethat newer datasets either suggest ways to reducethis bias or not provide knowledge snippets tohumans in the first place but instead post factomatch utterances to knowledge snippets.
In the rest of the paper, we focus on generatingresponses with better acknowledgements. This isbecause current neural generation methods performpoorly in this regard when compared with theother aspects. They fail to acknowledge prior turnsand even when they do, the acknowledgementsare shallow and generic (e.g., backchannel). Wehypothesize that the bottleneck is not the modelingcapacity, but rather our inability to extract acknowl-edgements. The responses are not specific w.r.t.conversational context, a prerequisite for richeracknowledgements (e.g., shared experiences).We show that selecting responses specific to con-versational context improves acknowledgementsand overall quality. More broadly, we are able todemonstrate the utility of our linguistic analysisin evaluating and improving a dialogue agent.

772
3 A method for richer acknowledgements
Current neural generation methods typically offershort and formulaic phrases as acknowledgements:“That’s interesting”, “I like that”, “Yeah, I agree”.Such phrases are appropriate almost everywhereand convey little positive evidence for understand-ing or grounding. The training corpus, on the otherhand, contains richer acknowledgements, whichgenerated responses should be able to emulate.
We assume that the representational capacity ofcurrent neural models is sufficient and that out ofall the sampled responses, some do indeed containa richer form of acknowledgement. We posit thatnon-existent or poor sample selection strategies areto blame and that without a good sample selectionstrategy, improvements to the dataset, model ortoken-wise sampling methods are unlikely to help.
We hypothesize that responses that are morespecific to conversational history provide betterevidence for understanding and hence containricher acknowledgements. As a baseline sampleselection strategy, we first consider maximumpointwise mutual information (Max-PMI) (as usedby Zhang et al. (2020)) between the generatedresponse and the conversational contexts (i.e., newfactual content and conversational history). How-ever, this is insufficient because it is an imprecisemeasure of specificity w.r.t. conversational history.Instead, we use pointwise conditional mutualinformation (PCMI) to maintain specificity withindividual contexts and propose a combinationof PMI and PCMI scores to select overall betterquality responses than Max-PMI.Conversational rephrasing The choice of newfactual content is a confounding factor for analysis.Hence, we define a simplified task, conversationalrephrasing, where content is provided as an input.Thus, conversational rephrasing is a generationtask where conversational history (h) and newfactual content (k) are given as inputs and aresponse (g) is generated as the output (Figure 1).We expect the generation g to paraphrase the newfactual content k in a conversational manner byutilizing the conversational history h.Base generator We fix the sequence-to-sequencemodel and token-wise sampling method andvary the sample selection strategy. The model istrained to take h and k as input and to generateg as the output with the language modelling loss,i.e., we minimize the token-wise negative loglikelihood. During generation, tokens are sampled
Response pmi(g;h,k) pmi(g;h) pcmihg1 87 18 14g2 150 18 4
Table 1: Measures of mutual information for generatedresponses from Figure 1. g2 largely copies k, has highpmi(g; h,k) and would be chosen by Max-PMI. g1’sfirst sentence acknowledges using h and bridges tok; it would be chosen by Fused-PCMI on the basis ofpcmih. pmi(g; h) cannot differentiate the two.
autoregressively from left-to-right. While samplingeach token, the probability distribution is truncatedusing nucleus sampling (Holtzman et al., 2020) butthe truncation is kept to a minimum with a highvalue of p for top-p sampling. Multiple diversecandidates are sampled from the base generatorand now the best candidate needs to be selected.PMI for overall specificity Li et al. (2016) sug-gest selecting the response with maximum PMI(referred to as MMI in their work) to maintainspecificity and get rid of bland or low-quality sam-ples. Pointwise Mutual Information (PMI) betweentwo events (x, y) is a measure of change in theprobability of one event x, given another event y:pmi(x; y) ≡ log p(x|y)
p(x) . We use pmi to determinethe increase in likelihood of g, given h and k.
pmi(g; h,k) = logp(g|h,k)
p(g)
A candidate generation g with higher PMI is morelikely given the two contexts h and k than other-wise and is therefore considered more specific tothe contexts. A low PMI value for a candidateresponse implies non-specificity to either contextproviding a clear signal for discarding it. A highPMI is necessary but not sufficient for a candidateto be specific to both the contexts simultaneously,since mutual information could come from eithercontext. For example, g2 (Figure 1) merely copiesk but gets a high PMI score (Table 1). Whereasg1 acknowledges prior turn and uses k but gets alower PMI score.PCMI for contextual specificity PointwiseConditional Mutual Information (PCMI) considersa third variable (z) and removes information due toz from pmi(x; y, z) to keep only the informationuniquely attributable to y.
pcmi(x; y|z) = pmi(x; y, z)− pmi(x; z)
We propose using pcmi for contextual speci-ficity, i.e., pcmih = pcmi(g; h|k) for specificity
773
0.0
0.5
1.0pr
obp(g|h, k)p(g|h)p(g|k)p(g)
0
5
pmi pmi(g;h, k)
pmi(g;h)pmi(g; k)
That ’s
cool
, Iw
onde
r ifth
ose
nam
esw
ill be inm
any of
Shak
espe
are ’s
work
sth
at are
perf
orm
edto
day .
His
wor
ksta
ke...........
acce
nt.
<eos
>
0
5
pcm
i
pcmi(g;h|k)pcmi(g; k|h)
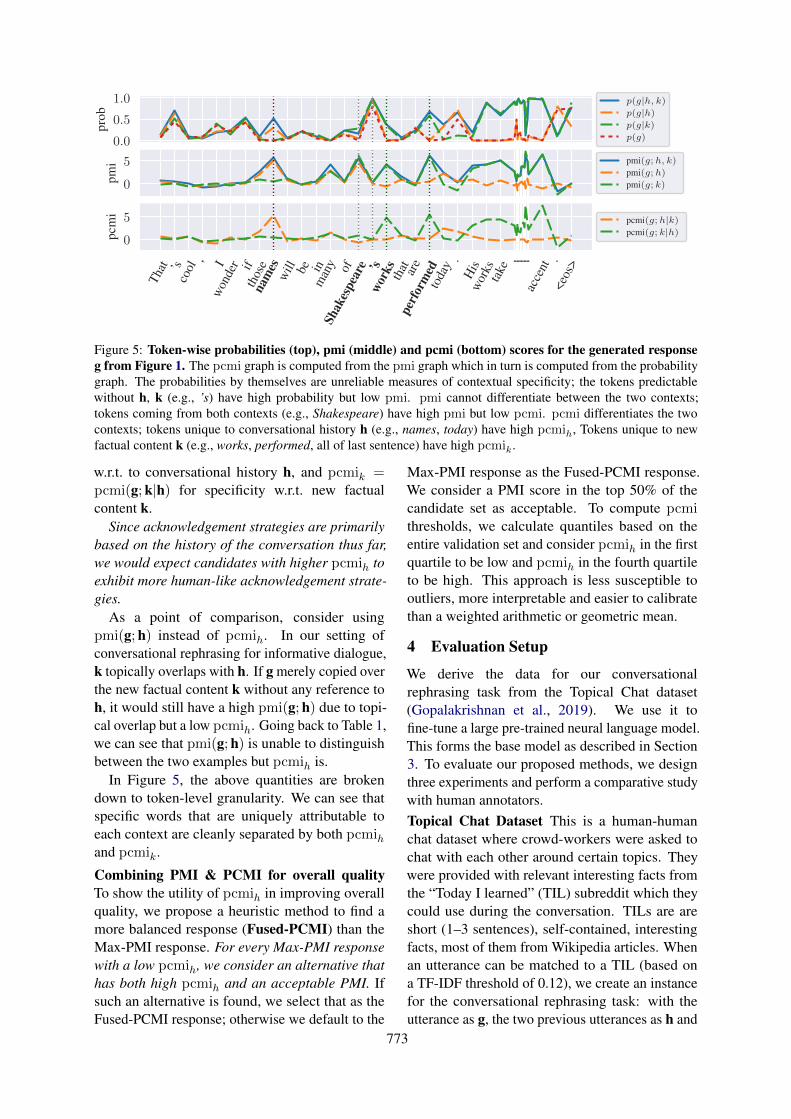
Figure 5: Token-wise probabilities (top), pmi (middle) and pcmi (bottom) scores for the generated responseg from Figure 1. The pcmi graph is computed from the pmi graph which in turn is computed from the probabilitygraph. The probabilities by themselves are unreliable measures of contextual specificity; the tokens predictablewithout h, k (e.g., ’s) have high probability but low pmi. pmi cannot differentiate between the two contexts;tokens coming from both contexts (e.g., Shakespeare) have high pmi but low pcmi. pcmi differentiates the twocontexts; tokens unique to conversational history h (e.g., names, today) have high pcmih, Tokens unique to newfactual content k (e.g., works, performed, all of last sentence) have high pcmik.
w.r.t. to conversational history h, and pcmik =pcmi(g; k|h) for specificity w.r.t. new factualcontent k.
Since acknowledgement strategies are primarilybased on the history of the conversation thus far,we would expect candidates with higher pcmih toexhibit more human-like acknowledgement strate-gies.
As a point of comparison, consider usingpmi(g; h) instead of pcmih. In our setting ofconversational rephrasing for informative dialogue,k topically overlaps with h. If g merely copied overthe new factual content k without any reference toh, it would still have a high pmi(g; h) due to topi-cal overlap but a low pcmih. Going back to Table 1,we can see that pmi(g; h) is unable to distinguishbetween the two examples but pcmih is.
In Figure 5, the above quantities are brokendown to token-level granularity. We can see thatspecific words that are uniquely attributable toeach context are cleanly separated by both pcmihand pcmik.
Combining PMI & PCMI for overall qualityTo show the utility of pcmih in improving overallquality, we propose a heuristic method to find amore balanced response (Fused-PCMI) than theMax-PMI response. For every Max-PMI responsewith a low pcmih, we consider an alternative thathas both high pcmih and an acceptable PMI. Ifsuch an alternative is found, we select that as theFused-PCMI response; otherwise we default to the
Max-PMI response as the Fused-PCMI response.We consider a PMI score in the top 50% of thecandidate set as acceptable. To compute pcmithresholds, we calculate quantiles based on theentire validation set and consider pcmih in the firstquartile to be low and pcmih in the fourth quartileto be high. This approach is less susceptible tooutliers, more interpretable and easier to calibratethan a weighted arithmetic or geometric mean.
4 Evaluation Setup
We derive the data for our conversationalrephrasing task from the Topical Chat dataset(Gopalakrishnan et al., 2019). We use it tofine-tune a large pre-trained neural language model.This forms the base model as described in Section3. To evaluate our proposed methods, we designthree experiments and perform a comparative studywith human annotators.Topical Chat Dataset This is a human-humanchat dataset where crowd-workers were asked tochat with each other around certain topics. Theywere provided with relevant interesting facts fromthe “Today I learned” (TIL) subreddit which theycould use during the conversation. TILs are areshort (1–3 sentences), self-contained, interestingfacts, most of them from Wikipedia articles. Whenan utterance can be matched to a TIL (based ona TF-IDF threshold of 0.12), we create an instancefor the conversational rephrasing task: with theutterance as g, the two previous utterances as h and

774
the corresponding TIL as k. We split the instancesinto training, validation and test sets (sizes inSection A.1) such that all utterances related anentity belong to the same set.
Base Model We use the GPT2-medium model(24-layer; 345M params) pretrained on theEnglish WebText dataset (Radford et al., 2019), asimplemented in HuggingFace’s TransferTransfo(Wolf et al., 2019b,a) framework. Fine-tuning isperformed using the language modelling objectiveon the training set with default hyperparametersuntil lowest perplexity is reached on the validationset. During generation, we sample tokens usingnucleus sampling (Holtzman et al., 2020) withp = 0.9 and temperature τ = 0.9 and get candidateresponses. To compute auxiliary probabilities{p(g|h), p(g|k), p(g)} for these candidates, we useseparate ablation models. The ablation models aretrained similar to the base model but after removingrespective contexts from the training inputs.
4.1 Experimental Design
To validate our proposed methods, we do a pairedcomparison (on Amazon Mechanical Turk) wherehuman annotators are shown two prior turnsof conversational history and asked to choosebetween two candidate responses. Annotators areallowed to mark both candidates as nonsensical ifthe responses don’t make sense. In Section A.3,we show the interfaces used to collect annotationsfrom Amazon Mechanical Turk. Each pair ofresponses was compared by three annotators – weconsider a candidate to be better than the otherwhen at least two of them (majority) agree uponit. For each of the following three experiments, wecompare 100 pairs of candidates generated usinginstances from the test set. The null hypothesis(H0) for the three experiments is that there is nodifference between the methods used to generatethe candidates and we hope to reject the nullhypothesis in favor of the alternate hypothesis (H1)at a significance level (α) of 0.05.
Exp 1: PMI and overall quality First, we wantto confirm that high PMI responses are overallbetter quality than randomly chosen candidates(H1). To do so, we first generate 10 responsesfor each instance and compare the responsehaving maximum pmi(g; h,k) (Max-PMI) with arandomly chosen response from the remaining 9.We ask human annotators to pick the overall bettercandidate response.
Exp 2: pcmih and acknowledgement We testif responses having high pcmih provide betteracknowledgement (H1). To do so, we first sample100 responses (larger than previous experiment)and out of all possible pairs keep those with|∆ pcmih | > 15 (larger than population interquar-tile range; Figure 8). To control for the amount ofnew information being added, we pick pairs withclosest values of pcmik (recall that pcmik denotesinformation uniquely attributable to k). Suchselected pairs have Median|∆ pcmik | = 0.42.We ask annotators to pick the response thatprovides better acknowledgement and select anacknowlegement span to support their claim.Exp 3: Fused-PCMI vs. Max-PMI We test ifthe proposed method, Fused-PCMI (that combinesPMI and PCMI) selects better responses thanMax-PMI (H1). For Fused-PCMI, we set low andhigh pcmih thresholds to be 5 and 14 respectivelybased on population quartiles. For instances wherethe Fused-PCMI response is different from theMax-PMI response, we compare the two. We con-sider 10 candidate responses for each test instanceand find that for around 10% of the instancesthe Fused-PCMI candidate is different from theMax-PMI candidate. Human annotators are thenasked to pick the overall better response of the two.
5 Results & Analyses
Based on human annotations, we are able toreject H0 in favor of H1 in all three experiments(Table 2)3: high PMI responses are overallbetter quality than randomly chosen candidates,responses having high pcmih provide betteracknowledgement, and Fused-PCMI selects betterresponses than Max-PMI.
Exp n K p κ
1 87 55 (63%) 0.009 0.182 95 70 (74%) 3e−6 0.483 99 59 (60%) 0.035 0.11
Table 2: Human annotation results. Out of 100instances, majority agreement was reached in ninstances. The majority rejects the null-hypothesis(H0) in favor of the alternate hypothesis (H1) in Kinstances. p denotes the p-value and κ denotes Fliesskappa for Inter-annotator agreement.
While according to Exp 1, high PMI responsesare overall better quality, upon further analysis
3Statistically significant with p < 0.05 (Binomial Test).

775
0% 50% 100%% Contribution of acknowledgement span
pcmikpcmih
pmi(g;h)
Figure 6: Attribution to acknowledgement span. Alarger fraction of pcmih can be attributed to humanannotated acknowledgement spans compared topmi(g;h) and pcmik.
we find that PMI is useful for filtering out badsamples, but not necessarily for selecting betweenthe good samples. When paired with a randomresponse from the top 50% of the candidates(ranked according to their PMI), people preferthe Max-PMI response only 52% of the time(not significant). On the other hand, if therandom response was in the bottom 50%, then theMax-PMI response is preferred 74% of the time.3
In Exp 2, we ask annotators to mark text-spansthat indicate acknowledgement (Table 3). Iftoken-level pcmih is concentrated in these spans,we have further proof that pcmih indicatesacknowledgement. Indeed, in Figure 6, we see thatpcmih is most attributable to the acknowledgementspans, followed by pmi(g;h) and pcmik. Thus,pcmih captures acknowledgements with greaterspecificty than pmi(g;h).
To understand the mechanism behind theimprovement in Exp 3, we look at the distributionof samples w.r.t. pcmik and pcmih in Figure 7.We observe that Max-PMI responses heavily skewthe distribution towards higher pcmik, whereasFused-PCMI responses show a more balancedimprovement along both pcmih and pcmik. Fused-PCMI increases both pcmih and pcmik (medianscross 75% quartiles), indicating that the responsesare simultaneously specific to both h and k.
6 Discussion
We show that samples with higher pcmih pro-vide better acknowledgement and Fused-PCMIimproves overall quality compared to Max-PMI.Thus, by improving acknowledgements – anaspect we identified during our analysis of humanstrategies – we were able to improve overall quality.This demonstrates the utility of linguistic analysisfor finding interpretable and actionable metrics.
While we show that our learnings apply to in-formative dialogue which adds factual knowledge(Dinan et al., 2019; Parthasarathi and Pineau,
0 5 10 15 20
pcmih
0
20
40
60
80
100
pcm
i k
All candidates Max. PMI Fused-PCMI
Figure 7: Bivariate Kernel Density Estimate plot Allcandidates, Max-PMI responses and Fused-PCMIresponses. Bivariate kernel density estimate plot w.r.t.pcmik and pcmih at levels 0.5 and 0.75. We see thatFused-PCMI responses compared with Max-PMI tradeoff little pcmik for a large relative gain in pcmih. SeeFigure 8 in Section A.2 for univariate box plots.
2018; Gopalakrishnan et al., 2019), we expect itto generalize to any dialog setting that adds newcontent, e.g., experiences (Ghazvininejad et al.,2018) and personas (Zhang et al., 2018). Anydual-context language generation task where thetwo contexts are asymmetric in their informationcontent can potentially benefit from PCMI.
There is scope for improvement: Max-PMIstill selects better responses than Fused-PCMI in40% of the instances. This could be because it iseasy for the model to copy over k and generate ahigh PMI response that is also fluent and accurate.Fused-PCMI encourages synthesis of acknowledge-ment using h and abstraction over k and it couldtherefore be prone to disfluencies and inaccuracies.We hope that orthogonal modeling improvements(Meng et al., 2020) reduce such effects.
A cause for concern with the human evaluationis low inter-annotator agreement for Exp 1 and 3where we ask them to pick responses with “overallbetter quality and suitability”. However, qualitymeasurements are inherently subjective; peoplediffer in the importance they place on differentaspects such as engagement, informativeness,fluency etc., as corroborated by prior work (Finchand Choi, 2020) that shows low Cohen’s kappa(0.13, 0.22) for overall quality judgements. Inthis work, diverse expectations from multipleannotators are captured yet subsequently averagedinto “overall quality”. We leave it to futurework to find finer-grained metrics that have highinter-annotator agreement and derive empiricalweights to combine them into “overall quality”.
In this work, we looked at acknowledgementsand their impact on quality in isolation, but in a real

776
Previous Utterance High pcmih candidate
No I did not! Han Solo was apparently also an imperiallieutenant before meeting up with Chewbacca.
that is very interesting and I wonder if he was one of thefirst or the first one to meet Chewba. I was just readingthat George Lucas originally intended Han to be a green alien
I did not. That sounds interesting. Much like the "tip of thehat" originates from Knights raising their visors.
Yes, that sounds like a very cool tradition. I wonderhow they enforced that law, it sounds as ridiculous as theprohibition of wearing a hat in 1912, that was a law thatwould prevent the use of hat pins by suffragettes.
Yeah. When Apollo 11 was preparing for their voyage, theyhad discussion as to whether they should plant a United Na-tions flag instead of a US flag. If I planted a UN flar and some-one asked me "whose flag is that?" I would answer, mine. . .
lol, no kidding. I wonder if they are still discussing theissue with the moon? I can’t believe the moon is movingaway from us at about the rate that your nails grow. Thatseems really slow to me.
Table 3: Human annotated spans of text that indicate acknowledgement (in bold) in candidate responses withhigher pcmih from Exp 2.
Previous Utterance Max-PMI candidate Fused-PCMI candidate1 I live in the southwest USA desert.
Not much in the way of water hereeither, but we’ve got some nice arti-ficial pools. What kind of swimmingdid you do?
There is a type of competitiveswimming where the athlete has theirhands and legs bound, and swims likea dolphin. I have never heard thatbefore. It seems fishy to me. I’m notsure I can swim like that.
I went competitively but was havinga tough time. I liked that kind ofcompetition where the swimmer canswim with their hands bound.
2 It is interesting. It’s also interestingthat they are trying to plan a Marscolonization project that will befunded by a reality show, I really wantto see that!
A satellite was lost on Mars becauseof the use of the Imperial system andNASA used the metric system.
Sounds like a weird reality show. I’mgoing to look it up. A satellite waslost on Mars because it was used byNASA using the metric system.
3 Yeah I definitely like clothes. I thinkit’s interesting how many uses hatshave, like for protection, ceremonialreasons, religious reasons, safety, andfashion.
Did you know that until 1998, Britishpoliticians had to wear a top hat ifmaking a point of order in the houseof commons?
In 1998, British politicians wererequired to wear a top hat if makinga point of order in the house ofcommons. I guess that’s kind ofmessed up and counterproductive.
4 Yeah it’s super funny that he had a rapbattle in the lunchroom. Seems likesomething straight out of a movie!
Ha, I agree. Speaking of rappers, didyou know that "California Gurls" wasactually a West Coast vs East Coastanswer song to Alicia Keys and JayZ’s "Empire State of Mind"
Yeah, and how about the fact that theCalifornia Gurls song was actually awest coast vs east coast answer songto a pair of famous rappers. That issurprising
5 im not surprised. rats are quite clever,and i guess if scientists understandthe rat brain, then they can wire upthe interface. cool.
It’s amazing how they can be cleverand change forms. I like how they cannow Debrate a chicken with surgicalprecision.
Robots can also debone chicken withprecision. I guess that would helpavoid chicken pogis.
Table 4: Illustrative samples of selected responses used in Exp 3. For samples 1,2 and 3 people preferFused-PCMI and for samples 4 and 5 they prefer Max-PMI. Factual content copied largely verbatim by the modelis in gray. Specifically, the Fused-PCMI candidate in 1 answers the question (Max-PMI does not) and in 3 refersback to contradict utility of hats.
system, the performance of the model also dependson other factors like user compliance and theretrieval model. In practice, we think the interplaybetween the four linguistic aspects is critical andneeds to be explored. For instance, preliminaryexperiments with live conversations and an off-the-shelf retriever suggested that a bad choice of kwith tenuous connections to h can make synthesisharder and lead to lower quality Fused-PCMIresponses. Better retrieval models (Ren et al.,2020) that make use of transition strategies todetermine k can lead to better acknowledgements.
In this work, we identified salient aspects of
human-human informative conversations and founddeficiencies in current neural dialogue systems.We proposed a PCMI-based selection strategythat selected responses with acknowledgementsand higher overall quality. We hope that our workprovides actionable insights and metrics for futurework and more generally inspires the use of linguis-tic literature for grounding conversational research.
7 Acknowledgements
We are grateful to Amelia Hardy, Nandita Bhaskhar,Omar Khattab, Kaitlyn Zhou, Abigail See, otherStanford NLP group members and the anonymous

777
reviewers for helpful comments. This research isfunded in part by Samsung Electronics Co., Ltd.and in part by DARPA CwC under ARO primecontract no. W911NF-15-1-0462. This articlesolely reflects the opinions and conclusions of itsauthors. Christopher Manning is a CIFAR Fellow.
ReferencesDaniel Adiwardana, Minh-Thang Luong, David R So,
Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang,Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu,et al. 2020. Towards a human-like open-domainchatbot. arXiv preprint arXiv:2001.09977.
Herbert H. Clark. 1996. Using Language. ‘Using’Linguistic Books. Cambridge University Press.
Herbert H Clark and Susan E Brennan. 1991. Ground-ing in communication. In L. B. Resnick, J. M.Levine, and S. D. Teasley, editors, Perspectives onsocially shared cognition, pages 127–149. AmericanPsychological Association.
Herbert H Clark and S Haviland. 1977. Comprehen-sion and the given-new contract. In Roy O Freedle,editor, Discourse production and comprehension,pages 1–40. Lawrence Erelbaum Associates,Hillsdale, NJ.
Emily Dinan, Stephen Roller, Kurt Shuster, AngelaFan, Michael Auli, and Jason Weston. 2019. Wizardof Wikipedia: Knowledge-powered conversationalagents. In International Conference on LearningRepresentations.
Sarah E. Finch and Jinho D. Choi. 2020. Towardsunified dialogue system evaluation: A comprehen-sive analysis of current evaluation protocols. InProceedings of the 21th Annual Meeting of theSpecial Interest Group on Discourse and Dialogue,pages 236–245, 1st virtual meeting. Association forComputational Linguistics.
Raefer Gabriel, Yang Liu, Anna Gottardi, MihailEric, Anju Khatri, Anjali Chadha, Qinlang Chen,Behnam Hedayatnia, Pankaj Rajan, Ali Binici,Shui Hu, Karthik Gopalakrishnan, SeokhwanKim, Lauren Stubel, Arindam Mandal, and DilekHakkani-Tür. 2020. Further advances in opendomain dialog systems in the third alexa prizesocialbot grand challenge. Alexa Prize Proceedings.
Marjan Ghazvininejad, Chris Brockett, Ming-WeiChang, Bill Dolan, Jianfeng Gao, Wen-tau Yih,and Michel Galley. 2018. A knowledge-groundedneural conversation model. In Thirty-Second AAAIConference on Artificial Intelligence.
J. J. Godfrey, E. C. Holliman, and J. McDaniel. 1992.Switchboard: telephone speech corpus for researchand development. In ICASSP-92: 1992 IEEEInternational Conference on Acoustics, Speech, andSignal Processing, volume 1, pages 517–520 vol.1.
Karthik Gopalakrishnan, Behnam Hedayatnia, Qin-lang Chen, Anna Gottardi, Sanjeev Kwatra, AnuVenkatesh, Raefer Gabriel, and Dilek Hakkani-Tür. 2019. Topical-Chat: Towards Knowledge-Grounded Open-Domain Conversations. In Proc.Interspeech 2019, pages 1891–1895.
Herbert P Grice. 1975. Logic and conversation. InPeter Cole and Jerry L. Morgan, editors, Speechacts, pages 41–58. Brill.
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes,and Yejin Choi. 2020. The curious case of neuraltext degeneration. In International Conference onLearning Representations.
Ellen A Isaacs and Herbert H Clark. 1987. Referencesin conversation between experts and novices. Jour-nal of experimental psychology: general, 116(1):26.
Robert M Krauss and Susan R Fussell. 1996. Socialpsychological models of interpersonal communi-cation. Social psychology: Handbook of basicprinciples, pages 655–701.
Jiwei Li, Michel Galley, Chris Brockett, JianfengGao, and Bill Dolan. 2016. A diversity-promotingobjective function for neural conversation models.In Proceedings of the 2016 Conference of the NorthAmerican Chapter of the Association for Computa-tional Linguistics: Human Language Technologies,pages 110–119, San Diego, California. Associationfor Computational Linguistics.
Chuan Meng, Pengjie Ren, Zhumin Chen, ChristofMonz, Jun Ma, and Maarten de Rijke. 2020. Refnet:A reference-aware network for background basedconversation. In Thirty-Fourth AAAI Conference onArtificial Intelligence.
Prasanna Parthasarathi and Joelle Pineau. 2018. Ex-tending neural generative conversational modelusing external knowledge sources. In Proceedingsof the 2018 Conference on Empirical Methodsin Natural Language Processing, pages 690–695,Brussels, Belgium. Association for ComputationalLinguistics.
Alec Radford, Jeffrey Wu, Rewon Child, David Luan,Dario Amodei, and Ilya Sutskever. 2019. Languagemodels are unsupervised multitask learners.
Byron Reeves and Clifford Nass. 1996. The MediaEquation: How People Treat Computers, Television,and New Media like Real People and Places.Cambridge University Press, USA.
Pengjie Ren, Zhumin Chen, Christof Monz, Jun Ma,and Maarten de Rijke. 2020. Thinking globally,acting locally: Distantly supervised global-to-localknowledge selection for background based con-versation. In Thirty-Fourth AAAI Conference onArtificial Intelligence, volume abs/1908.09528.

778
Stephen Roller, Emily Dinan, Naman Goyal, Da Ju,Mary Williamson, Yinhan Lui, Jing Xu, Myle Ott,Kurt Shuster, Eric M Smith, Y-Lan Boureau, andJason Weson. 2020. Recipes for building an open-domain chatbot. ArXiv preprint arXiv:2004.13637.
Harvey Sacks and Gail Jefferson. 1995. Winter 1971,chapter 12. John Wiley & Sons, Ltd.
Vicki L Smith and Herbert H Clark. 1993. On thecourse of answering questions. Journal of memoryand language, 32(1):25–38.
Robert Stalnaker. 2002. Common ground. Linguisticsand philosophy, 25(5/6):701–721.
Andreas Stolcke, Klaus Ries, Noah Coccaro, ElizabethShriberg, Rebecca Bates, Daniel Jurafsky, PaulTaylor, Rachel Martin, Carol Van Ess-Dykema, andMarie Meteer. 2000. Dialogue act modeling forautomatic tagging and recognition of conversationalspeech. Computational Linguistics, 26(3):339–374.
Thomas Wolf, Lysandre Debut, Victor Sanh, JulienChaumond, Clement Delangue, Anthony Moi, Pier-ric Cistac, Tim Rault, Rémi Louf, Morgan Funtow-icz, Joe Davison, Sam Shleifer, Patrick von Platen,Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu,Teven Le Scao, Sylvain Gugger, Mariama Drame,Quentin Lhoest, and Alexander M. Rush. 2019a.Huggingface’s transformers: State-of-the-art naturallanguage processing. ArXiv, abs/1910.03771.
Thomas Wolf, Victor Sanh, Julien Chaumond, andClement Delangue. 2019b. Transfertransfo: Atransfer learning approach for neural network basedconversational agents. CoRR, abs/1901.08149.
Saizheng Zhang, Emily Dinan, Jack Urbanek, ArthurSzlam, Douwe Kiela, and Jason Weston. 2018.Personalizing dialogue agents: I have a dog, doyou have pets too? In Proceedings of the 56thAnnual Meeting of the Association for Computa-tional Linguistics (Volume 1: Long Papers), pages2204–2213, Melbourne, Australia. Association forComputational Linguistics.
Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen,Chris Brockett, Xiang Gao, Jianfeng Gao, JingjingLiu, and Bill Dolan. 2020. DialoGPT: Large-scalegenerative pre-training for conversational responsegeneration. In ACL, system demonstration.

779
A Appendix
A.1 Model training detailsEach model (main and ablation) was trained ona single NVIDIA Titan Xp GPU for 5 epochsand took approximately 8 hours to train. Thetraining dataset had 51407 instances, validation2491 and test 2728. The Topical Chat dataset andSwitchboard corpus are in English language. Themain model used for response generation had avalidation loss (average negative log liklihood) of2.05 which it reached after 2 epochs.
A.2 Univariate distribution
0
50
100
150
pcm
i k
(a)
0
10
20
pcm
i h
(b)
All candidates Max. PMI Fused-PCMI
Figure 8: Univariate box plots for All candidates,Max-PMI responses and Fused-PCMI responses.(a) is w.r.t. pcmik and (b) w.r.t pcmih. Pink horizontallines indicate 75% quartile for All candidates. Max-PMI responses (orange) have high pcmik (medianabove pink line), but low pcmih. Fused-PCMIresponses (green) show balanced yet high pcmih andpcmik (medians cross pink lines).
A.3 Annotation DetailsWe had 9, 19 and 19 unique annotators for exper-iments 1, 2 and 3 respectively. All three annotatorsagreed in 32/87 instances for experiment 1, 52/87instances for experiment 2 and 32/99 instances forexperiment 3.

780
Figure 9: Annotation interface for Best PMI v/s rest

781
Figure 10: Annotation interface for acknowledgement differences due to pcmih