Embed Size (px)
Citation preview

© 2004 IBM Corporation
IBM Systems Group
IBM Deep Computing Strategy

IBM Systems Group
© 2004 IBM Corporation
IBM’s Deep Computing Strategy
Aggressively evolve the POWER-based Deep Computing product line
Develop advanced systems based on loosely coupled clusters
Deliver supercomputing capability with new access models and financial flexibility
Research and overcome obstacles to parallelism and other revolutionary approaches to supercomputing
Solving Problems More Quickly at Lower Cost

IBM Systems Group
© 2004 IBM Corporation
IBM’s Deep Computing Strategy
Aggressively evolve the POWER-based Deep Computing product line
Develop advanced systems based on loosely coupled clusters
Deliver supercomputing capability with new access models and financial flexibility
Research and overcome obstacles to parallelism and other revolutionary approaches to supercomputing
Solving Problems More Quickly at Lower Cost

IBM Systems Group
© 2004 IBM Corporation
ASCI Purple and Blue Gene/L►The two systems will provide over 460TF
Track record for delivering the world's largest production-quality supercomputers►ASCI Blue (3.9 TF) & ASCI White (12.3 TF)►ASCI Pathforward (Federation 4GB Switch)
DARPA’s HPCS initiative►Awarded $53M in funding for phase 2 of
DARPA’s High Productivity Computing Systems initiative
► IBM PERCS program aimed at bringing sustained multi-petaflop performance and autonomic capabilities to commercial supercomputers
Creating the Future of Deep Computing
IBM Systems Group
© 2004 IBM Corporation
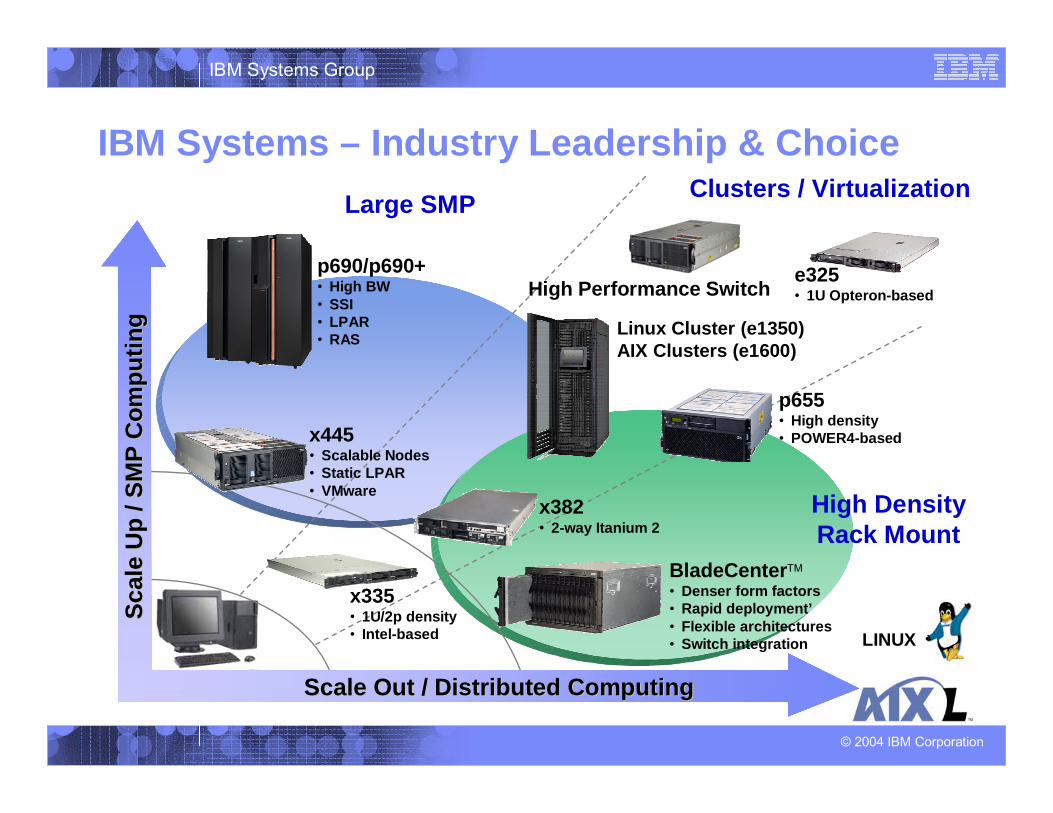
IBM Systems – Industry Leadership & ChoiceClusters / Virtualization
e325• 1U Opteron-based
High DensityRack Mount
Large SMP
Scal
e U
p / S
MP
Com
putin
gSc
ale
Up
/ SM
P C
ompu
ting
x335• 1U/2p density• Intel-based
x445• Scalable Nodes• Static LPAR• VMware
p690/p690+• High BW• SSI• LPAR• RAS
High Performance Switch
x382• 2-way Itanium 2
BladeCenterTM
• Denser form factors• Rapid deployment’• Flexible architectures• Switch integration
Linux Cluster (e1350)AIX Clusters (e1600)
p655• High density• POWER4-based
Scale Out / Distributed ComputingScale Out / Distributed Computing
LINUX

IBM Systems Group
© 2004 IBM Corporation
POWER3POWER3 POWER4POWER4 POWER4+POWER4+
POWER2POWER2
PPC 603ePPC 603e PPC 750PPC 750PPC 750FXPPC 750FX
PPC 970PPC 970
PPC 440GXPPC 440GXPPC 440GPPPC 440GP
PPC 401PPC 401 PPC 405GPPPC 405GP
POWER5POWER5
POWER / PowerPC: The Most Scaleable Architecture
Servers
Desk Top
Games
Embedded
© 2004 IBM Corporation
IBM eServer pSeries IBM Confidential
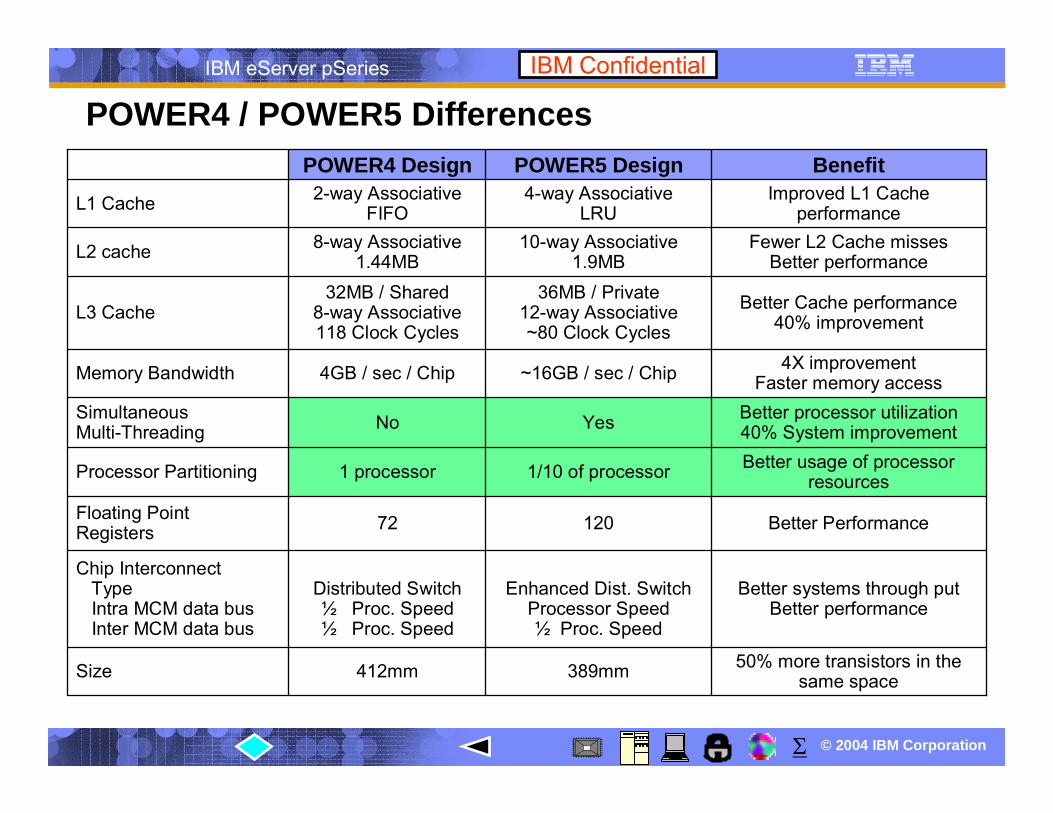
Better Performance12072Floating PointRegisters
389mm
Enhanced Dist. SwitchProcessor Speed½ Proc. Speed
1/10 of processor
Yes
~16GB / sec / Chip
36MB / Private12-way Associative~80 Clock Cycles
10-way Associative1.9MB
4-way AssociativeLRU
POWER5 Design
Better usage of processor resources1 processorProcessor Partitioning
50% more transistors in the same space412mmSize
Better systems through putBetter performance
Distributed Switch½ Proc. Speed½ Proc. Speed
Chip InterconnectTypeIntra MCM data busInter MCM data bus
Better processor utilization40% System improvementNoSimultaneous
Multi-Threading
4X improvementFaster memory access4GB / sec / ChipMemory Bandwidth
Better Cache performance40% improvement
32MB / Shared8-way Associative118 Clock Cycles
L3 Cache
Fewer L2 Cache missesBetter performance
8-way Associative1.44MBL2 cache
Improved L1 Cacheperformance
2-way AssociativeFIFOL1 Cache
BenefitPOWER4 Design
POWER4 / POWER5 Differences
© 2004 IBM Corporation
IBM eServer pSeries IBM Confidential
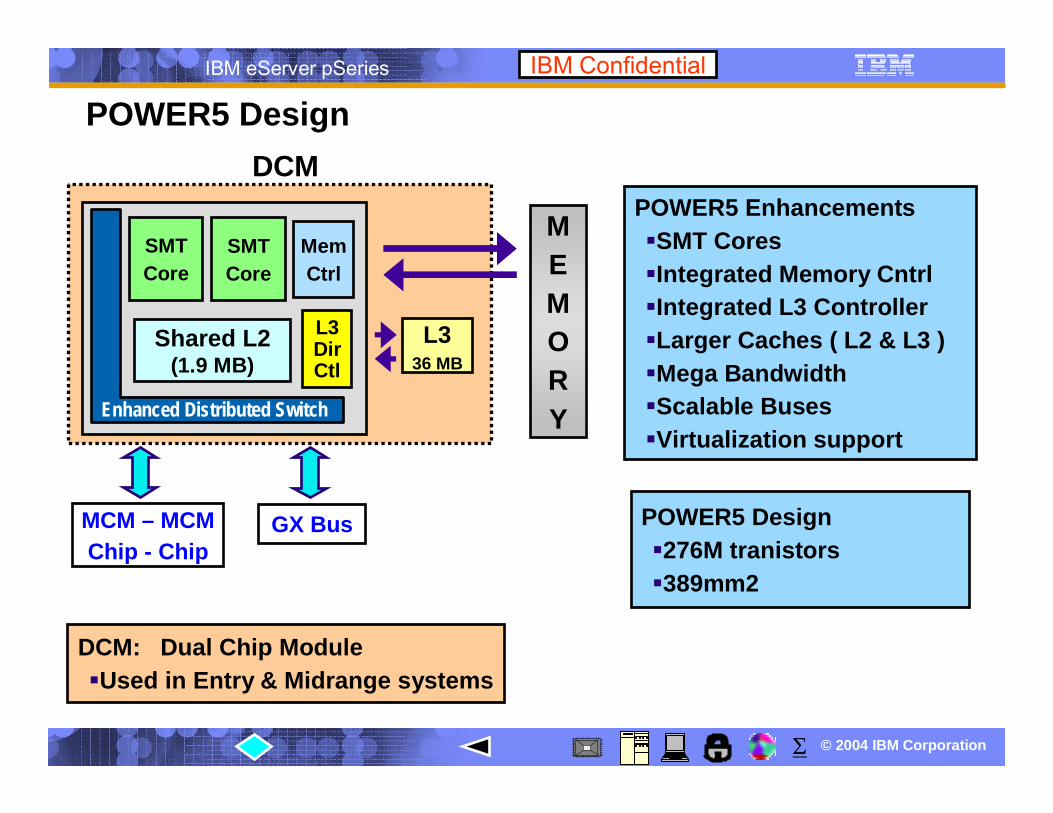
DCMPOWER5 Enhancements
SMT CoresIntegrated Memory CntrlIntegrated L3 ControllerLarger Caches ( L2 & L3 )Mega BandwidthScalable BusesVirtualization support
L336 MB
GX Bus
MEMORY
POWER5 Design276M tranistors389mm2
Enhanced Distributed Switch
Shared L2(1.9 MB)
MemCtrl
L3Dir Ctl
SMTCore
SMTCore
POWER5 Design
DCM: Dual Chip ModuleUsed in Entry & Midrange systems
MCM – MCMChip - Chip
IBM Systems Group
© 2004 IBM Corporation
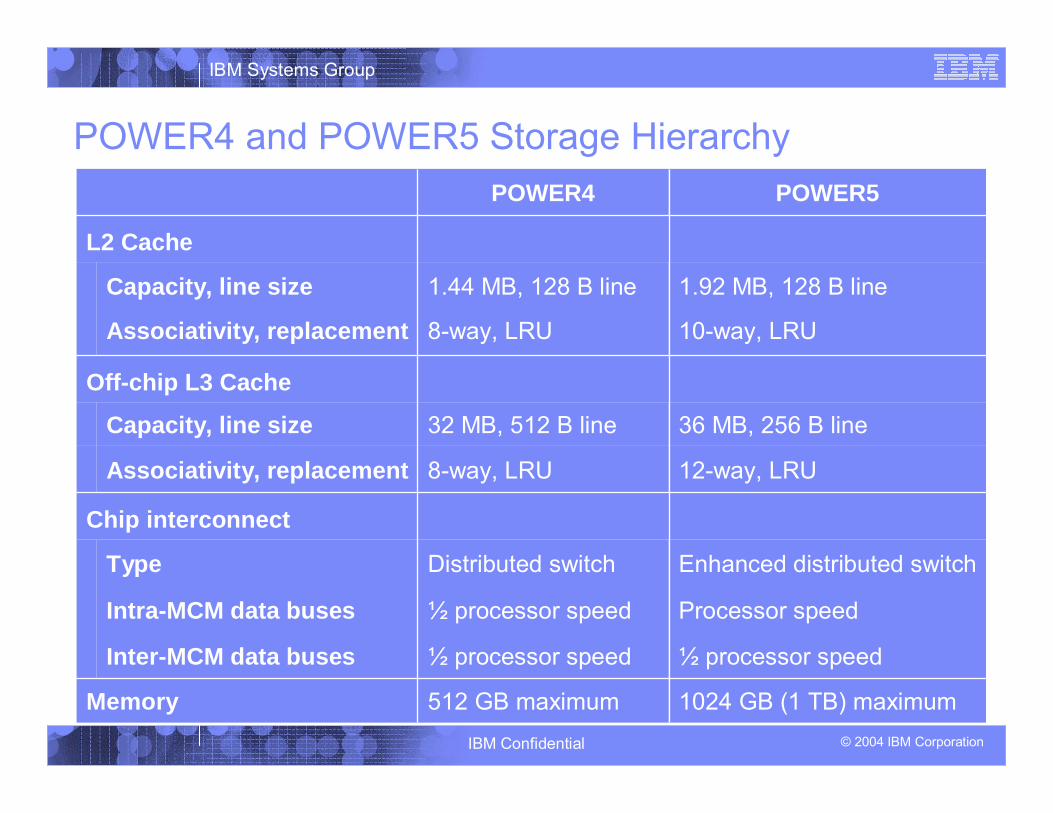
POWER4 and POWER5 Storage Hierarchy
Processor speed½ processor speedIntra-MCM data buses
Type Enhanced distributed switchDistributed switch
10-way, LRU8-way, LRUAssociativity, replacement
1.92 MB, 128 B line1.44 MB, 128 B lineCapacity, line size
1024 GB (1 TB) maximum512 GB maximumMemory
½ processor speed½ processor speedInter-MCM data buses
Chip interconnect
12-way, LRU8-way, LRUAssociativity, replacement
36 MB, 256 B line32 MB, 512 B lineCapacity, line size
Off-chip L3 Cache
L2 Cache
POWER5POWER4
IBM Confidential
IBM Systems Group
© 2004 IBM Corporation
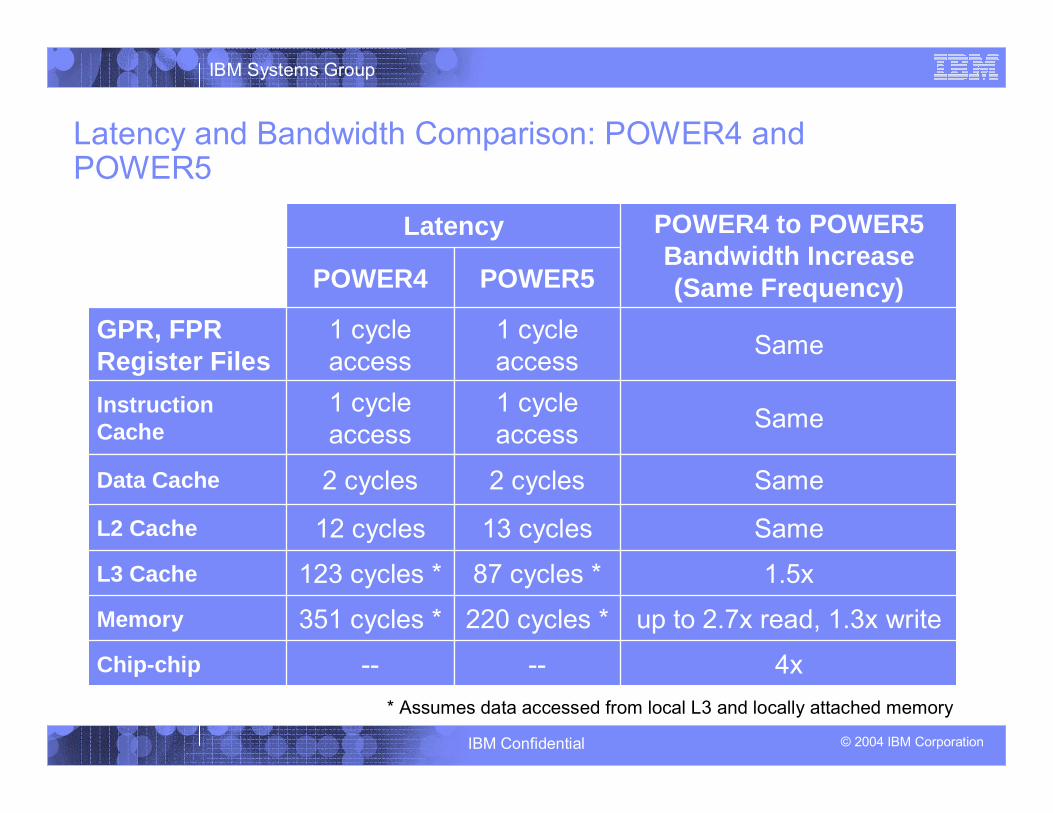
Latency and Bandwidth Comparison: POWER4 and POWER5
4x----Chip-chip
POWER5POWER4
up to 2.7x read, 1.3x write220 cycles *351 cycles *Memory
1.5x87 cycles *123 cycles *L3 Cache
Same13 cycles12 cyclesL2 Cache
Same2 cycles2 cyclesData Cache
Same1 cycle access
1 cycle access
Instruction Cache
Same1 cycle access
1 cycle access
GPR, FPR Register Files
POWER4 to POWER5 Bandwidth Increase(Same Frequency)
Latency
* Assumes data accessed from local L3 and locally attached memory
IBM Confidential

IBM Systems Group
© 2004 IBM Corporation
Simultaneous Multi-Threading in POWER5
Each chip appears as a 4-way SMP to softwareProcessor resources optimized for enhanced SMT performanceSoftware controlled thread priorityDynamic feedback of runtime behavior to adjust priorityDynamic switching between single and multithreaded mode
FX0
FX1
FP0
FP1
LS0
LS1
BRX
CRL
Simultaneous Multi-Threading
Thread 0 active Thread 1 active

© 2004 IBM Corporation
IBM eServer pSeries IBM Confidential
SF4 Entry SystemDeskside 4U rack chassis
Rack: 19" x 26"
3Media Bays
OptionalInternal RAID
YesRedundant Cooling
FeatureRedundant Power
40Dynamic LPAR
Yes / 8RIO2 Drawers
Dual Ports10/100/1000Integrated Ethernet
Dual Ultra 320Integrated SCSI5 / 4 slots (Hot Plug)I/O Expansion
8 DASD (Hot Plug)DASD / Bays
Deskside / 4U ( 19” rack )Packaging
1GB – 64GBMemory36MB L3 Cache
1 , 2, 4 – wayPOWER5Architecture
SF4POWER5 SF4

© 2004 IBM Corporation
IBM eServer pSeries IBM Confidential
ML4 Entry SystemDeskside 4U rack chassis
Rack: 19" x 26"
3 (Base System)Media Bays
OptionalInternal RAID
YesRedundant Cooling
YesRedundant Power
40 (Base System)Dynamic LPAR
Yes / 8 (Base System)RIO2 Drawers
Dual Ports10/100/1000
(Base System)Integrated Ethernet
Dual Ultra 320 (Base System)Integrated SCSI
6/5 slots (Hot Plug)I/O Expansion
6 DASD (Base system)DASD / Bays
4U ( 19” rack )Packaging
1GB – 64GB (Base System)Memory*
36MB L3 Cache
2 / 4 – way Base System4 – way Secondary Systems
POWER5Architecture
ML4POWER5 ML4
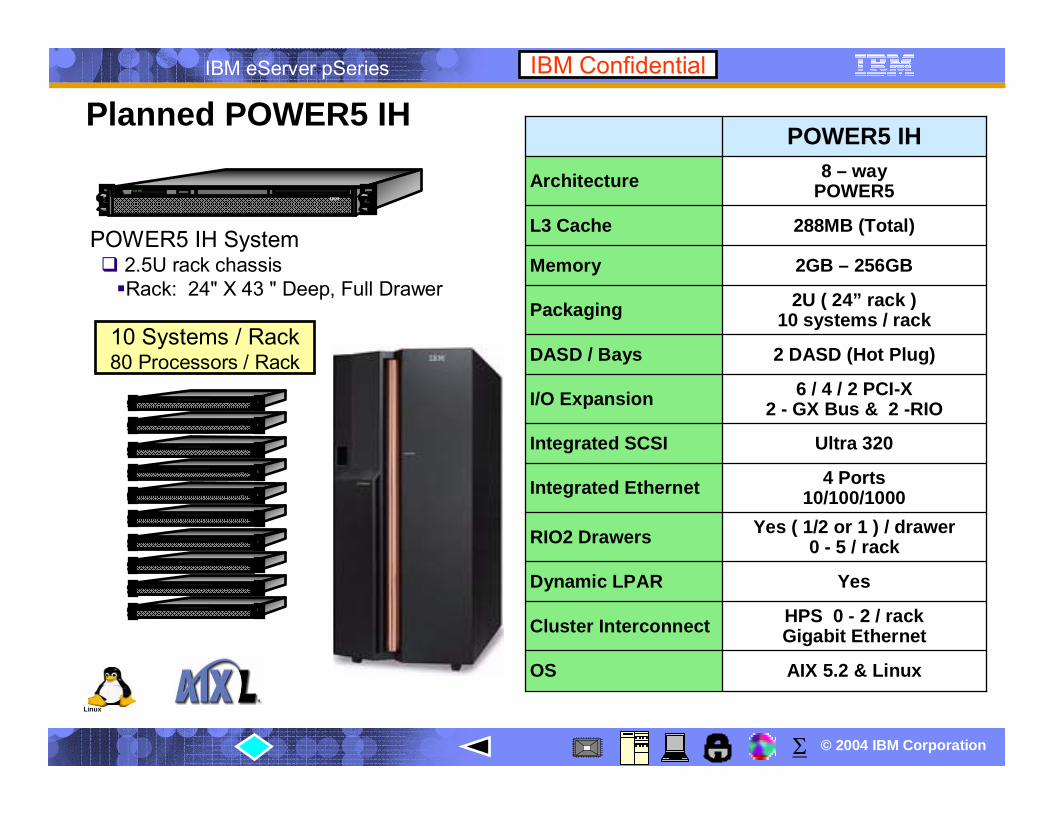
© 2004 IBM Corporation
IBM eServer pSeries IBM Confidential
POWER5 IH System2.5U rack chassisRack: 24" X 43 " Deep, Full Drawer
IBM
H C R U 6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
IBM
H C R U6
10 Systems / Rack80 Processors / Rack
AIX 5.2 & LinuxOS
HPS 0 - 2 / rackGigabit EthernetCluster Interconnect
YesDynamic LPAR
Yes ( 1/2 or 1 ) / drawer0 - 5 / rackRIO2 Drawers
4 Ports10/100/1000Integrated Ethernet
Ultra 320Integrated SCSI
6 / 4 / 2 PCI-X2 - GX Bus & 2 -RIOI/O Expansion
2 DASD (Hot Plug)DASD / Bays
2U ( 24” rack )10 systems / rackPackaging
2GB – 256GBMemory
288MB (Total)L3 Cache
8 – wayPOWER5Architecture
POWER5 IH
Linux
Planned POWER5 IH

IBM Systems Group
© 2004 IBM Corporation
POWER5 Improves HPC Performance
Higher Sustained-to-Peak FLOPS ratio compared to POWER4Dedicated memory busReduction in L3 and memory latency
Integrated memory controller
Increased rename resources allows higher instruction level parallelism in compute intensive applicationsFast barrier synchronization operationEnhanced data prefetch mechanism

IBM Research
BlueGene/L © 2003 IBM Corporation
BlueGene/L system architecture

IBM Research
BlueGene/L | System Software Overview © 2003 IBM Corporation
BlueGene/L fundamentals
A large number of nodes (65,536)Low-power (20W) nodes for densityHigh floating-point performanceSystem-on-a-chip technology
Nodes interconnected as 64x32x32 three-dimensional torus
Easy to build large systems, as each node connects only to six nearest neighbors – full routing in hardwareBisection bandwidth per node is proportional to n2/n3
Auxiliary networks for I/O and global operations
Applications consist of multiple processes with message passing
Strictly one process/nodeMinimum OS involvement and overhead
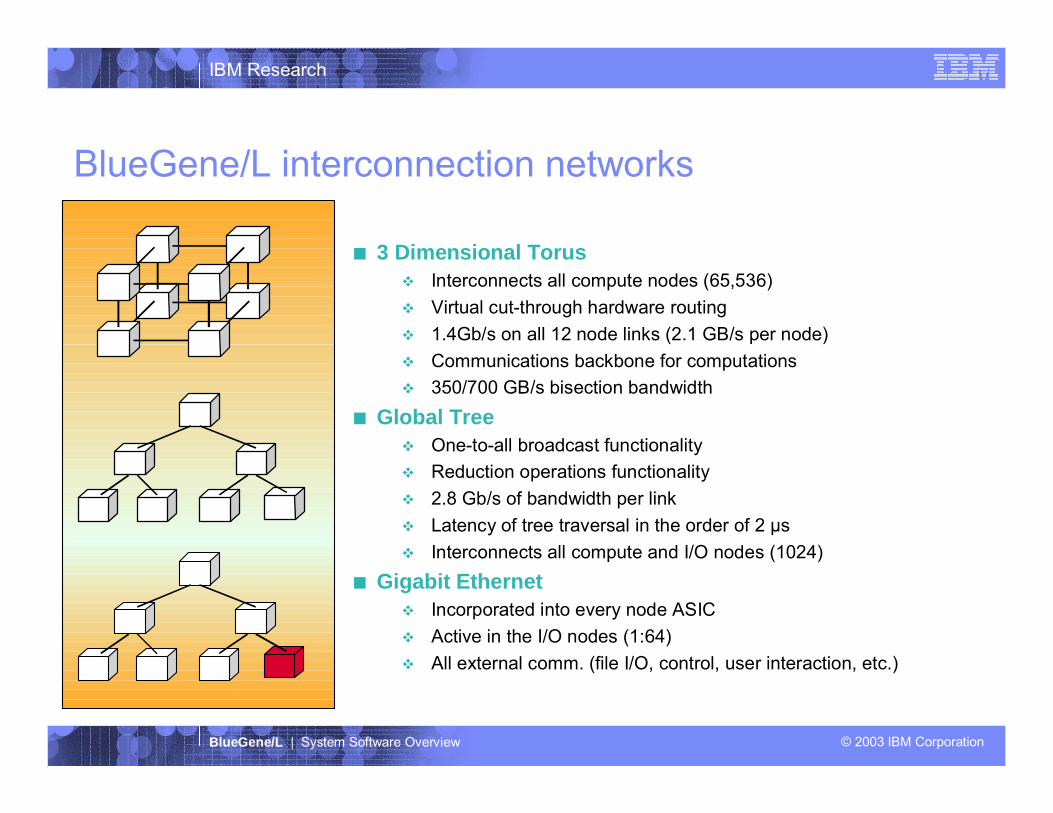
IBM Research
BlueGene/L | System Software Overview © 2003 IBM Corporation
BlueGene/L interconnection networks
3 Dimensional TorusInterconnects all compute nodes (65,536)Virtual cut-through hardware routing1.4Gb/s on all 12 node links (2.1 GB/s per node)Communications backbone for computations350/700 GB/s bisection bandwidth
Global TreeOne-to-all broadcast functionalityReduction operations functionality2.8 Gb/s of bandwidth per linkLatency of tree traversal in the order of 2 µsInterconnects all compute and I/O nodes (1024)
Gigabit EthernetIncorporated into every node ASICActive in the I/O nodes (1:64)All external comm. (file I/O, control, user interaction, etc.)
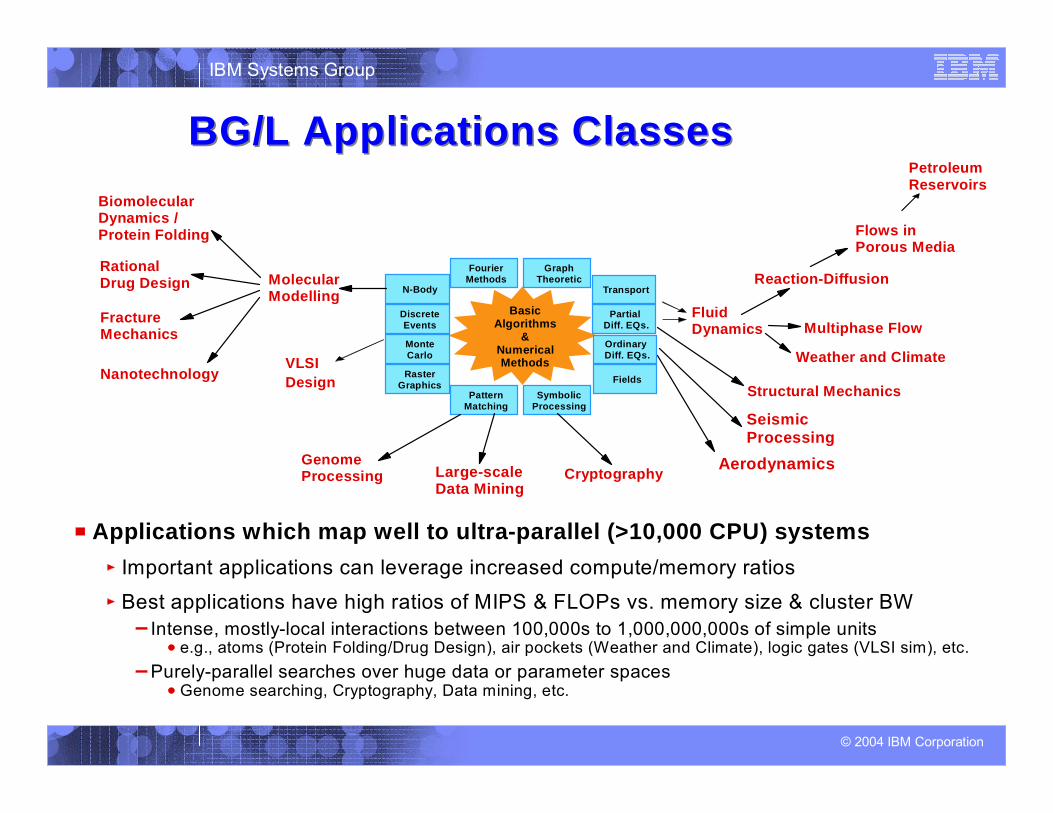
IBM Systems Group
© 2004 IBM Corporation
Applications which map well to ultra-parallel (>10,000 CPU) systemsImportant applications can leverage increased compute/memory ratios
Best applications have high ratios of MIPS & FLOPs vs. memory size & cluster BWIntense, mostly-local interactions between 100,000s to 1,000,000,000s of simple units
e.g., atoms (Protein Folding/Drug Design), air pockets (Weather and Climate), logic gates (VLSI sim), etc.Purely-parallel searches over huge data or parameter spaces
Genome searching, Cryptography, Data mining, etc.
BasicAlgorithms
&NumericalMethods
PetroleumReservoirs
MolecularModelling
BiomolecularDynamics / Protein Folding
RationalDrug Design
Nanotechnology
FractureMechanics
Flows in Porous Media
FluidDynamics
Reaction-Diffusion
Multiphase Flow
Weather and Climate
Structural Mechanics
Seismic Processing
Aerodynamics
VLSIDesign
GenomeProcessing Large-scale
Data MiningCryptography
SymbolicProcessing
Pattern Matching
RasterGraphics
MonteCarlo
DiscreteEvents
N-Body
FourierMethods
GraphTheoretic
Transport
Partial Diff. EQs.
Ordinary Diff. EQs.
Fields
BG/L Applications ClassesBG/L Applications Classes
IBM Systems Group
Project Three Rivers | IBM Confidential | © 2004 IBM Corporation
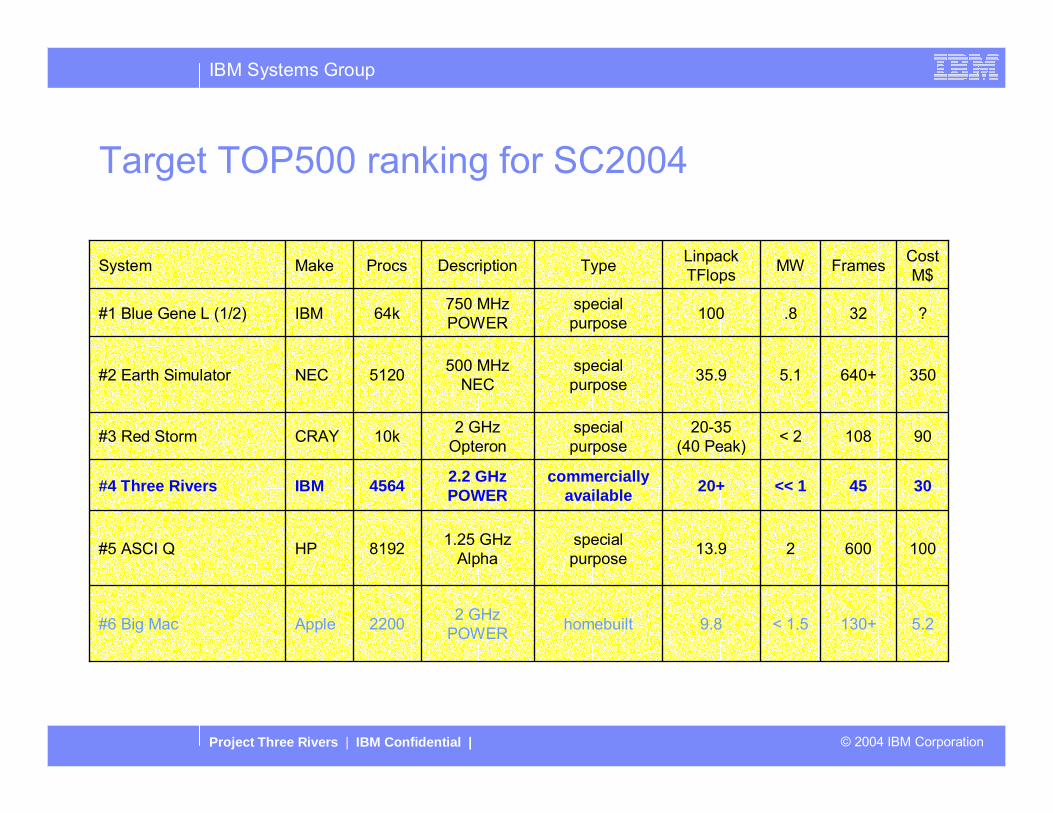
Target TOP500 ranking for SC2004
100600213.9specialpurpose
1.25 GHzAlpha8192HP#5 ASCI Q
5.2130+< 1.59.8homebuilt2 GHzPOWER2200Apple#6 Big Mac
3045<< 120+commerciallyavailable
2.2 GHzPOWER4564IBM#4 Three Rivers
90108< 220-35(40 Peak)
specialpurpose
2 GHzOpteron10kCRAY#3 Red Storm
350640+5.135.9specialpurpose
500 MHzNEC5120NEC#2 Earth Simulator
?32.8100specialpurpose
750 MHzPOWER64k IBM#1 Blue Gene L (1/2)
CostM$FramesMWLinpack
TFlopsTypeDescriptionProcsMakeSystem

IBM Systems Group
Project Three Rivers | IBM Confidential | © 2004 IBM Corporation
Major Three Rivers Innovative TechnologiesIBM 970 POWER processor
Industry leading 64-bit commodity processor
IBM Blade Center IntegrationRecord cluster densityImproved cluster operating efficiency (power, space, cooling)
Advanced semiconductor technology (CMOS10S)Record price/performance in HPC workloadsRecord system throughput
New dense Myrinet interconnect and new MPI software (MX)Significant reduction in switching hardwareFaster parallel processing
Enterprise scale-out FAStT IBM StorageImproved subsystem cost and reliability
Network root file systemImproved node reliabilityReduced installation and maintenance costs

IBM Systems Group
© 2004 IBM Corporation
IBM to receive $53.3M grant...Develop new generation of SupercomputingMulti-petaflop sustained performance by 2010
petaflop = 1 quadrillion calculations / secIBM Research with consortium of 12 leading universities
Univ. of Il, Univ. of New Mexico, etc.Continuation of IBM Technology Leadership
Processors, systems design, etc.IBM proposal: PERCS
Productive, Easy-to-use, Reliable Computing SystemsHighly adaptable systems that configures hardware & software to match application needsRevolutionary chip technologyNew computer architecture
DARPA award ( Defense Advance Research Projects Agency )

IBM Systems Group
© 2004 IBM Corporation
ASCI Purple and Blue Gene/L►The two systems will provide over 460TF
Track record for delivering the world's largest production-quality supercomputers►ASCI Blue (3.9 TF) & ASCI White (12.3 TF)►ASCI Pathforward (Federation 4GB Switch)
DARPA’s HPCS initiative►Awarded $53M in funding for phase 2 of
DARPA’s High Productivity Computing Systems initiative
► IBM PERCS program aimed at bringing sustained multi-petaflop performance and autonomic capabilities to commercial supercomputers
Creating the Future of Deep Computing
IBM Systems Group
© 2004 IBM Corporation
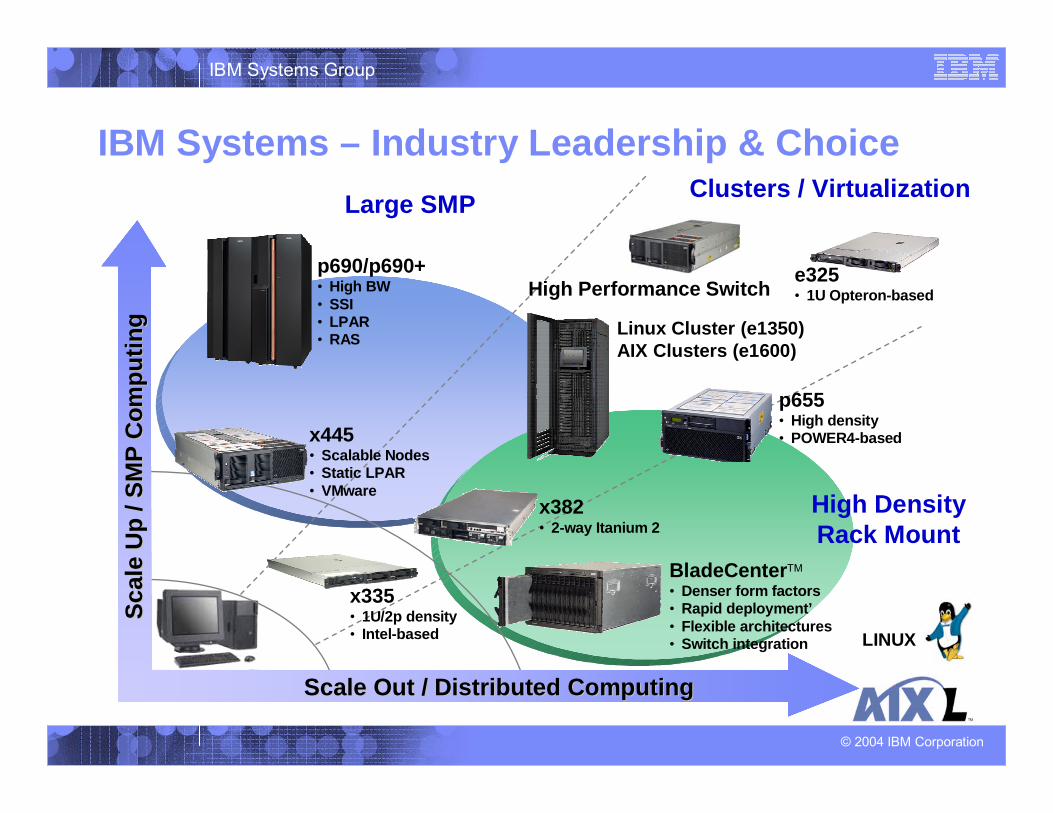
IBM Systems – Industry Leadership & ChoiceClusters / Virtualization
e325• 1U Opteron-based
High DensityRack Mount
Large SMP
Scal
e U
p / S
MP
Com
putin
gSc
ale
Up
/ SM
P C
ompu
ting
x335• 1U/2p density• Intel-based
x445• Scalable Nodes• Static LPAR• VMware
p690/p690+• High BW• SSI• LPAR• RAS
High Performance Switch
x382• 2-way Itanium 2
BladeCenterTM
• Denser form factors• Rapid deployment’• Flexible architectures• Switch integration
Linux Cluster (e1350)AIX Clusters (e1600)
p655• High density• POWER4-based
Scale Out / Distributed ComputingScale Out / Distributed Computing
LINUX





























