Embed Size (px)
DESCRIPTION
http://fvalente.zxq.net/presentations/ib_rkl.pdf
Citation preview

KL Realignment for Speaker Diarization withMultiple Feature Streams
Deepu Vijayasenan, Fabio Valente and Herv e Bourlard
Presented By: John Dines
IDIAP Research Institute
Martigny, CH
Interspeech 2009 – p. 1/16

Speaker Diarization
Speaker diarization determines “Who spoke when” inan audio stream
Agglomerative clusteringInitialized with an overdetermined number ofspeaker modelsAt each step, two most similar speaker models aremerged according to a distance criterion
Conventional systems use an ergodic HMMSpeaker model – an HMM state with minimumdurationGaussian Mixture Models for state emissionprobabilities
Interspeech 2009 – p. 2/16
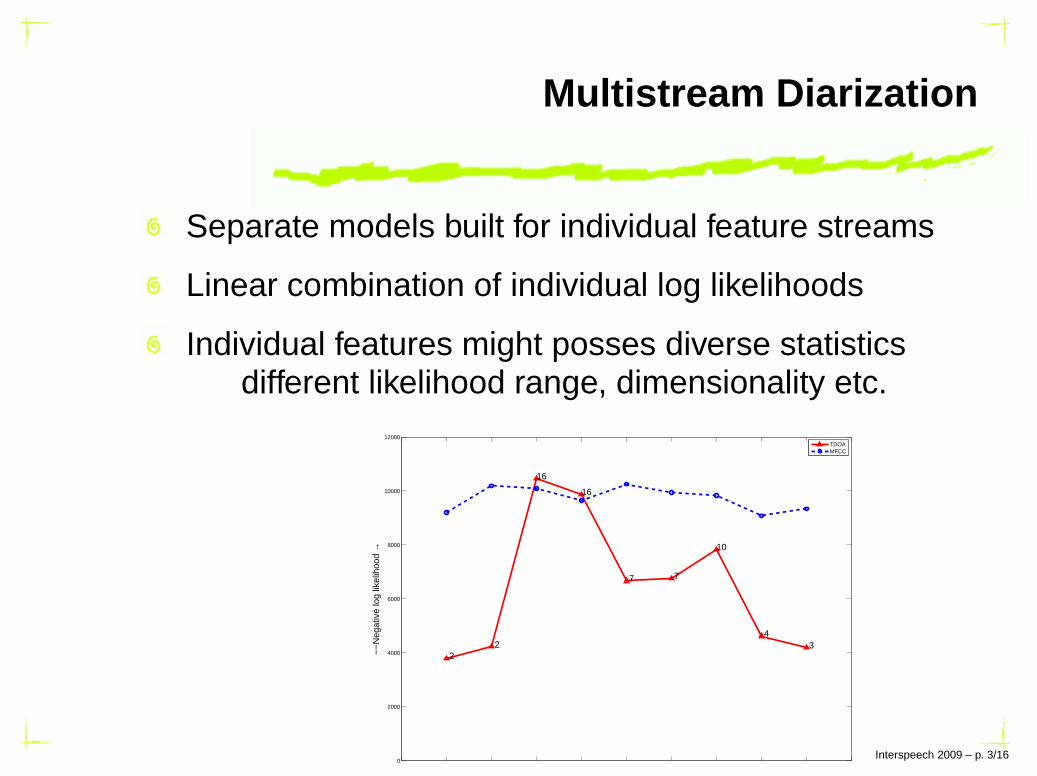
Multistream Diarization
Separate models built for individual feature streams
Linear combination of individual log likelihoods
Individual features might posses diverse statisticsdifferent likelihood range, dimensionality etc.
0
2000
4000
6000
8000
10000
12000
2 2
16
CMU_20050912
16
CMU_20050914
7 7
10
4 3
−−
Neg
ativ
e lo
g lik
elih
ood
→
TDOAMFCC
Interspeech 2009 – p. 3/16

Motivation
The problem of features with diverse statistics isaddressed in an ad-hoc manner
eg: In [Pardo’06] Gaussian components is initializedas one for TDOA and five for MFCC features
We had proposed a non parametric approach basedon Information Bottleneck principle
clustering is based on posteriors of a backgroundGMM model
How to use posterior features for a better multistreamspeaker diarization?
Interspeech 2009 – p. 4/16

Overview
IB Principle
Speaker Diarization using IB
Feature combination
KL Realignment
Interspeech 2009 – p. 5/16

IB Principle
X be a set of elements to cluster into set of clusters Cand Y be set of variables of interest
Assume the conditional distribution p(y|x) is available∀x ∈ X,∀y ∈ Y
IB Principle states that the cluster representation C
should preserve as much information as possible aboutY while minimizing the distortion between C and X.
The objective is to maximizeI(Y,C) − βI(X,C)
Interspeech 2009 – p. 6/16

IB Optimization
IB criterion is optimized by an agglomerative approachInitialized with |X| clustersIteratively merge the clusters that result in theminimum loss in the objective functionA stopping criterion based on Normalized Mutualinformation determines the number of clusters(Threshold on I(Y,C)
I(Y,X))
Interspeech 2009 – p. 7/16

IB based Speaker Diarization
Components of a background GMM used as relevancevariables
Realignment used to smooth spkr boundaries of IBsystem output
������������������������������������������������
������������������������������������������������
��������������������
��������������������
aIB Realign
p(y|x)
(background GMM)
Y
X(audio features)
Diarization
Output
Interspeech 2009 – p. 8/16

Feature Combination
Individual Posterior streams are combined to get asingle posterior stream. ie., p(y|x) =
∑i p(y|x,MFi
)P iF ,
whereMFi
– background GMM for feature Fi
P iF – prior probability of the stream Fi
Uses only posterior features – problems in combininglikelihoods are eliminated
����������������������������
������������������
������
���������������������
���������������������
����������������
����
���������
���������
������������
Y
X
p(y|x)
Y
X
p(y|x)
aIB RealignDiarization
Output
Interspeech 2009 – p. 9/16
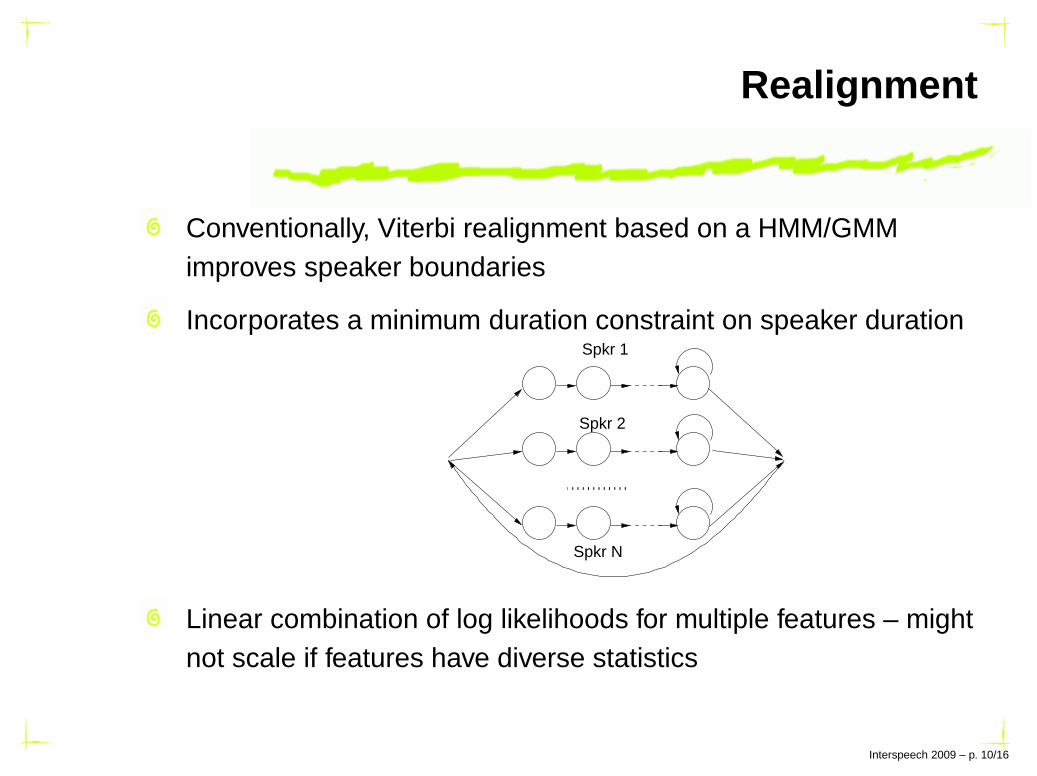
Realignment
Conventionally, Viterbi realignment based on a HMM/GMMimproves speaker boundaries
Incorporates a minimum duration constraint on speaker duration
Spkr N
Spkr 2
Spkr 1
Linear combination of log likelihoods for multiple features – mightnot scale if features have diverse statistics
Interspeech 2009 – p. 10/16

KL based Realignment
Maximization of the mutual information in IB is equivalent tominimization of:
arg minc
∑
t
KL(p(Y |xt)||p(Y |ct))
p(Y |xt) – postr distrbn of relevance variables in a framep(Y |ct) – postr distrbn of relevance variables of a cluster
In order to incorporate the minimum duration constraint, weextend this objective function as :
arg minc
∑
t
[KL(p(Y |xt)||p(Y |ct)) − log(actct+1)]
acicj– transition probability from cluster ci to cj
Interspeech 2009 – p. 11/16

KL based Realignment II
Can be solved using a EM algorithm, and thus canperform realignment based on posterior features
The re-estimation formula becomesp(y|ci) = 1
p(ci)
∑xt:xt∈ci
p(y|xt)p(xt)
Linear combination of the posteriors can be used incase of multistream diarization
No additional computational effort with additionalfeatures
Interspeech 2009 – p. 12/16

Evaluation
Evaluation performed on RT06 Nist Evaluation data forMeeting Diarization Task
Since same speech/no-speech referencesegmentation is used speaker error is used as theevaluation measure
Explored the combination of MFCC and TDOA features
Individual feature weights are empirically determinedfrom a development dataset
estimated weights are ( (PMFC , PDEL) = (0.7, 0.3)as compared to (0.9, 0.1) in likelihood basedcombination
Interspeech 2009 – p. 13/16
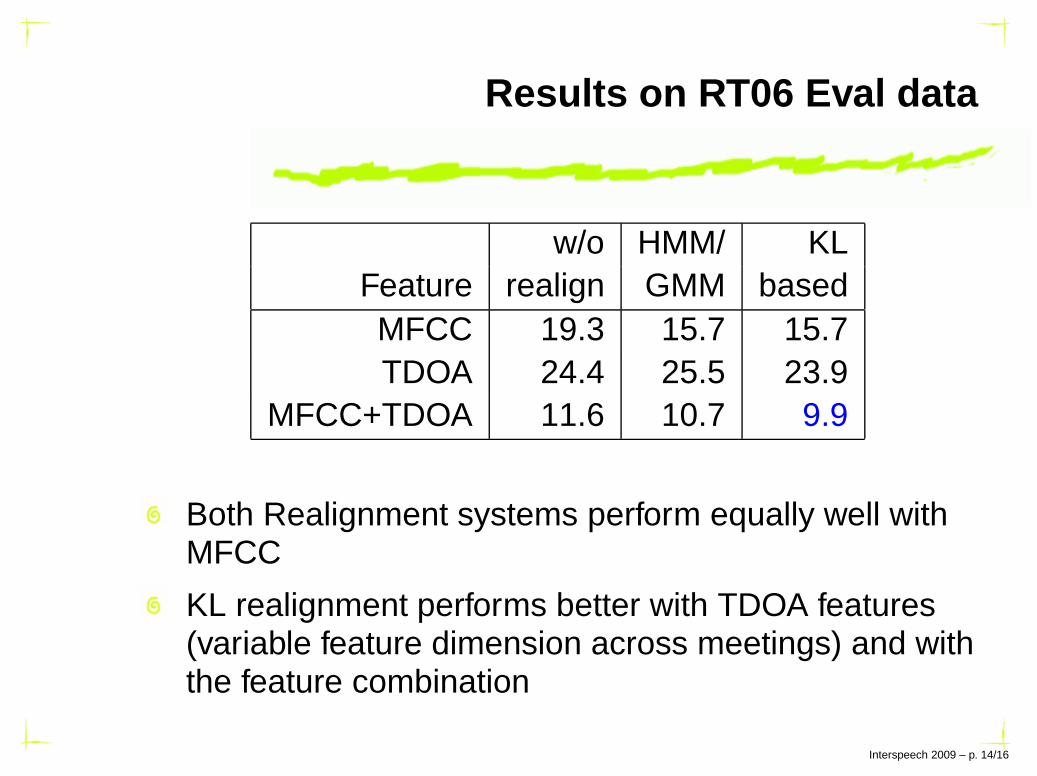
Results on RT06 Eval data
w/o HMM/ KLFeature realign GMM basedMFCC 19.3 15.7 15.7TDOA 24.4 25.5 23.9
MFCC+TDOA 11.6 10.7 9.9
Both Realignment systems perform equally well withMFCC
KL realignment performs better with TDOA features(variable feature dimension across meetings) and withthe feature combination
Interspeech 2009 – p. 14/16

Conclusions
Proposed a KL divergence based realignment schemethat operates only on the a set of posterior features
The system provides same performance asconventional HMM/GMM when tested on a singlefeature stream (MFCC)
The KL based realignment system performs better(9.9%) than conventional HMM/GMM realignment(10.7%) when tested on multiple feature stream(MFCC+TDOA)
The system currently being extended to more featurestreams and initial results shows improvement inperformance
Interspeech 2009 – p. 15/16

T HANKYOU
Interspeech 2009 – p. 16/16





























