Embed Size (px)
Citation preview

iDistanceiDistance-- Indexing the Distance-- Indexing the Distance
An Efficient Approach to KNN Indexing
C. Yu, B. C. Ooi, K.-L. Tan, H.V. Jagadish.Indexing the distance: an efficient method to KNN processing, VLDB 2001.

• Similarity queries: Similarity range and KNN queries
• Similarity range query: Given a query point, find all data points within a given distance r to the query point.
•KNN query: Given a query point, find the K nearest neighbours, in distance to the point.
r
Kth NN
Query RequirementQuery Requirement

• SS-tree : R-tree based index structure; use bounding spheres in internal nodes
• Metric-tree : R-tree based, but use metric distance and bounding spheres
• VA-file : use compression via bit strings for sequential filtering of unwanted data points
• Psphere-tree : Two level index structure; use clusters and duplicates data based on sample queries; It is for approximate KNN
• A-tree: R-tree based, but use relative bounding boxes
• Problems: hard to integrate into existing DBMSs
Other MethodsOther Methods

Basic DefinitionBasic Definition• Euclidean distance:
• Relationship between data points:
• Theorem 1: Let q be the query object, and Oi be the reference point for partition i, and p an arbitrary point in partition i. If dist(p, q) <= querydist(q) holds, then it follows that dist(Oi, q) – querydist(q) <= dist(Oi, p) <=dist(Oi,q) + querydist(q).
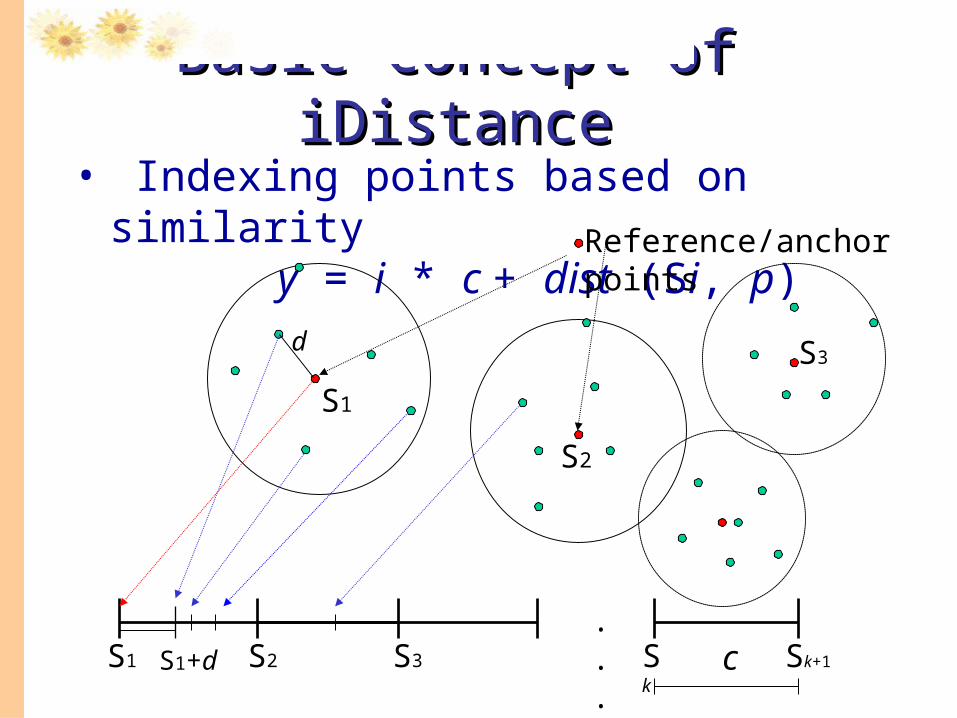
Basic Concept of iDistanceBasic Concept of iDistance
• Indexing points based on similarity y = i * c + dist (Si, p)
S1 S2 S3 Sk Sk+1
Reference/anchor points
S1
S2
S3
. . .
d
S1+d c

• Data points are partitioned into clusters/ partitions.
• For each partition, there is a Reference Point that every data point in the partition makes reference to.
• Data points are indexed based on similarity (metric distance) to such a point using a CLASSICAL B+-tree
• Iterative range queries are used in KNN searching.
iDistanceiDistance
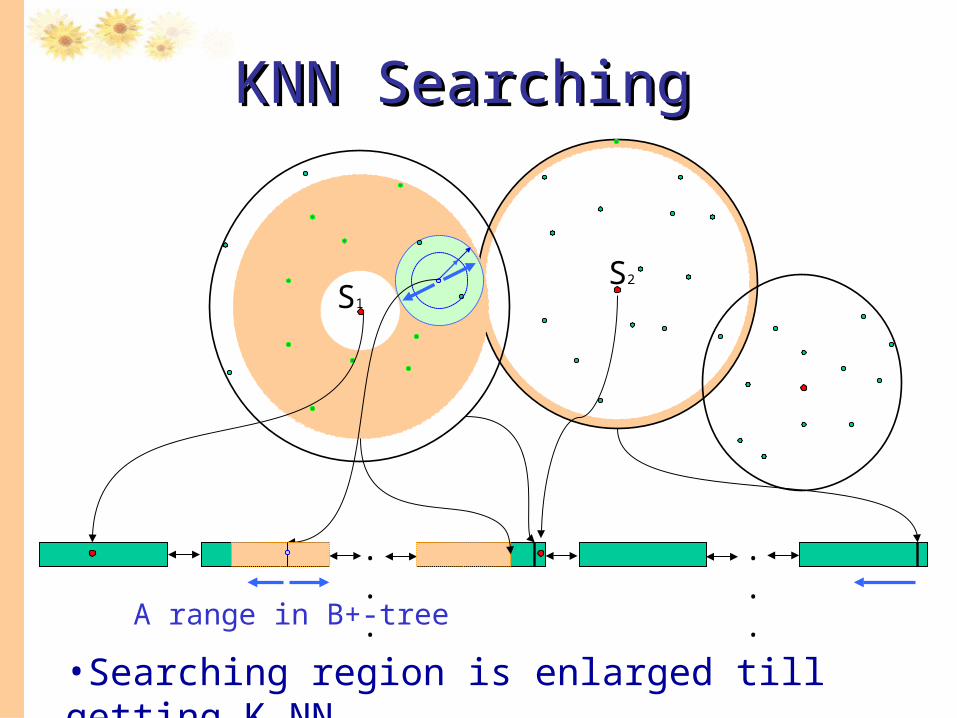
•Searching region is enlarged till getting K NN.
A range in B+-tree
KNN SearchingKNN Searching
...
S1
S2
...
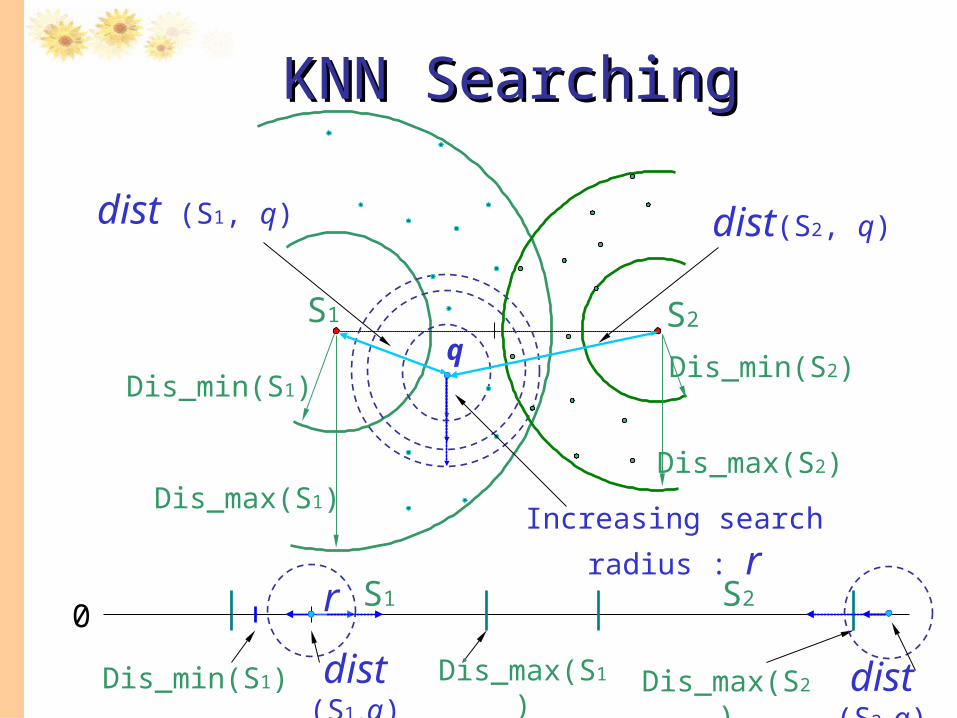
dist (S1, q)
S2S1
Increasing search radius : r
Dis_min(S1)
Dis_max(S1)
q
S1 S20
dist(S2, q)
Dis_max(S2)
Dis_min(S2)
Dis_min(S1) Dis_max(S1) Dis_max(S2)
r
dist (S1,q) dist (S2,q)
KNN SearchingKNN Searching
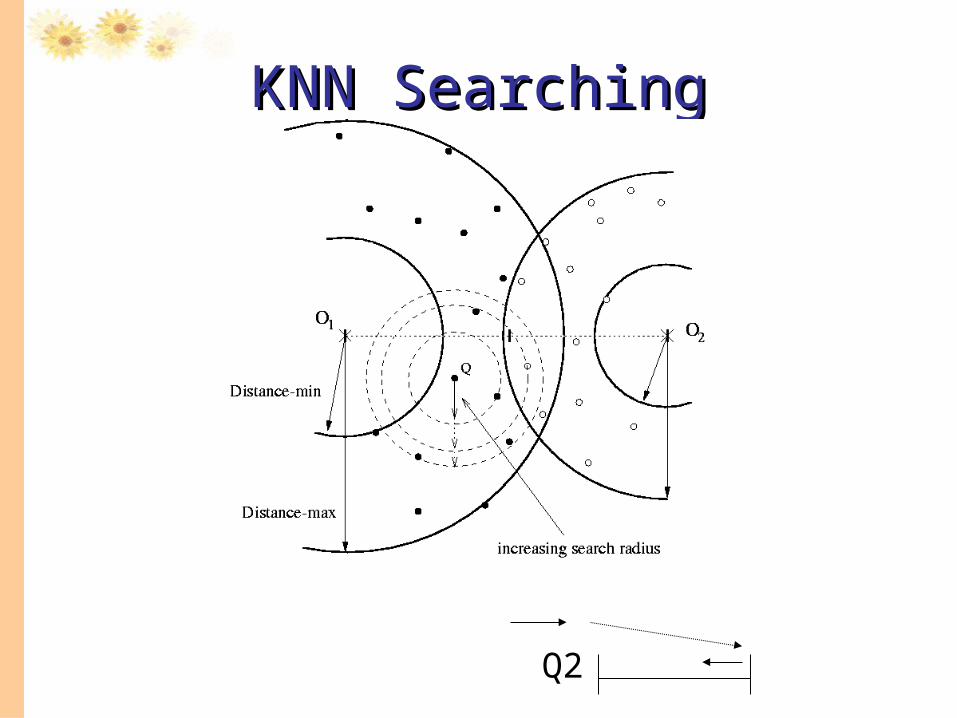
KNN SearchingKNN Searching
Q2
dist (S, q)
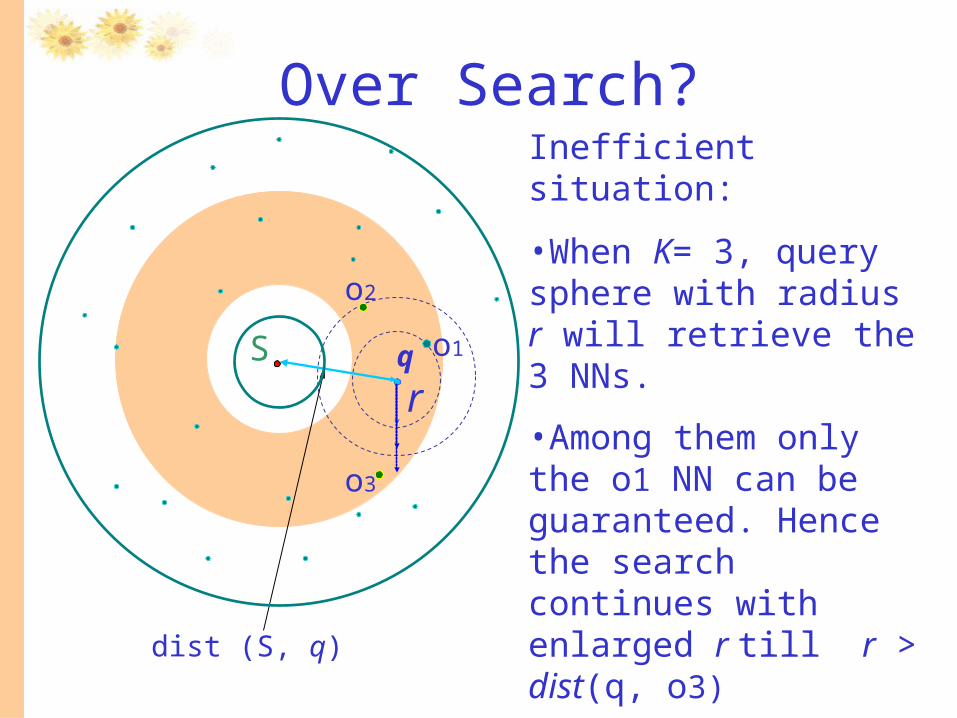
Inefficient situation:
•When K= 3, query sphere with radius r will retrieve the 3 NNs.
•Among them only the o1 NN can be guaranteed. Hence the search continues with enlarged r till r > dist(q, o3)
S q
r
o2
o1
o3
Over Search?

Stopping CriterionStopping Criterion• Theorem 2: The KNN search algorithm
terminates when K NNs are found and the answers are correct.
Case 1: dist(furthest(KNN’), q) < r
Case 2: dist(furthest(KNN’), q) > r
r
Kth ? In case 2
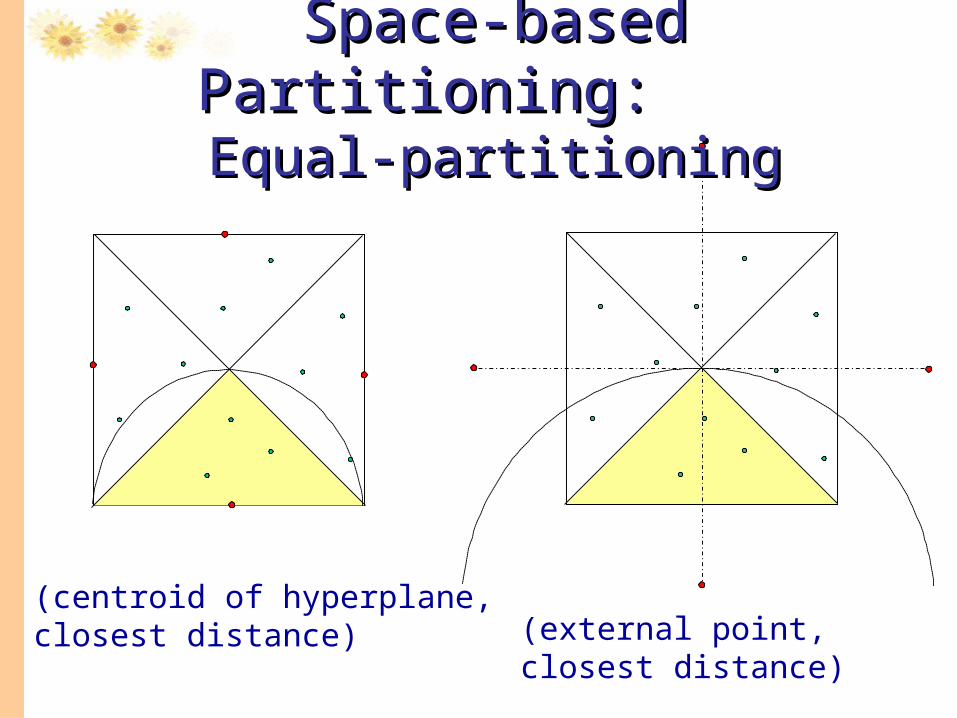
(centroid of hyperplane, closest distance) (external point, closest
distance)
Space-based Partitioning: Space-based Partitioning: Equal-partitioningEqual-partitioning
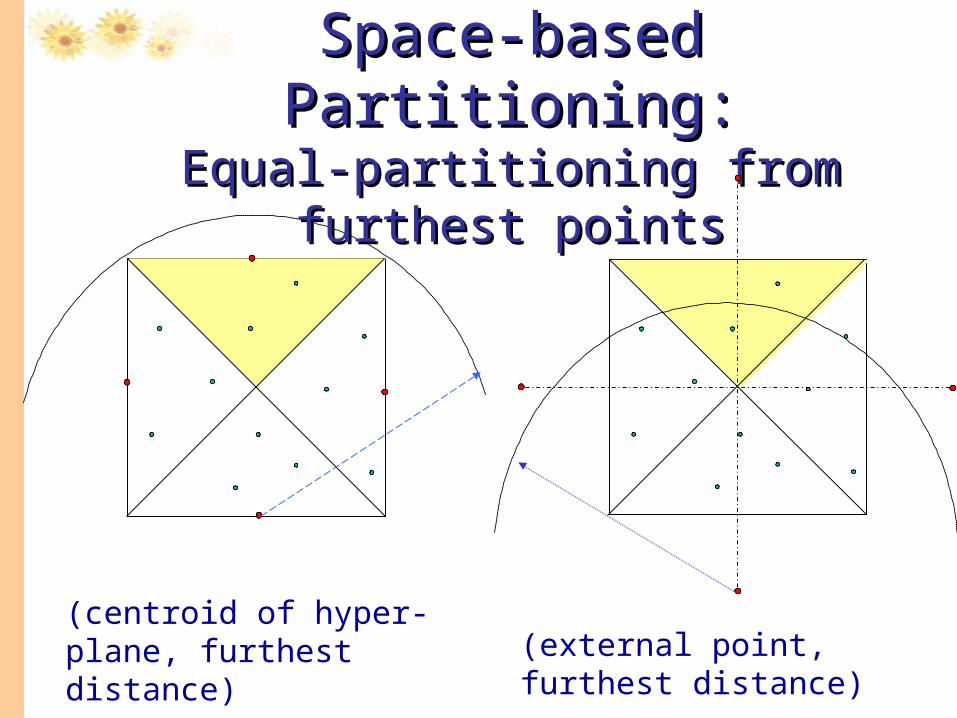
(centroid of hyper-plane, furthest distance)
Space-based Partitioning:Space-based Partitioning:Equal-partitioning from furthest pointsEqual-partitioning from furthest points
(external point, furthest distance)

• Using external point to reduce searching area
Effect of Reference Points on Effect of Reference Points on Query SpaceQuery Space
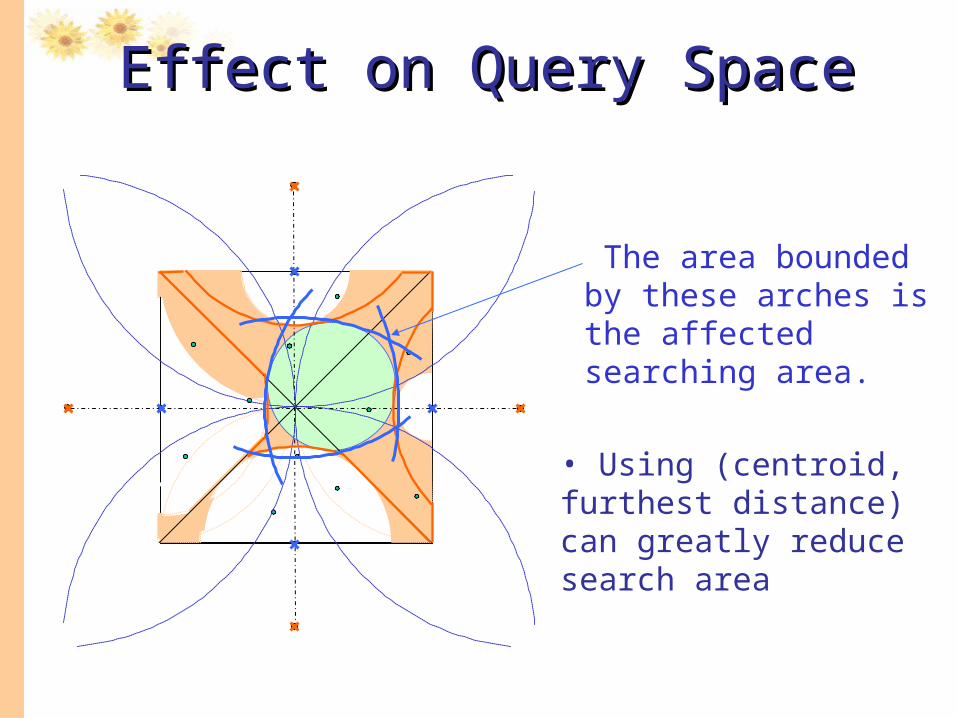
• Using (centroid, furthest distance) can greatly reduce search area
The area bounded by these arches is the affected searching area.
Effect on Query SpaceEffect on Query Space
0.67 1.0
0.31
0.20
0.70
0
1.0
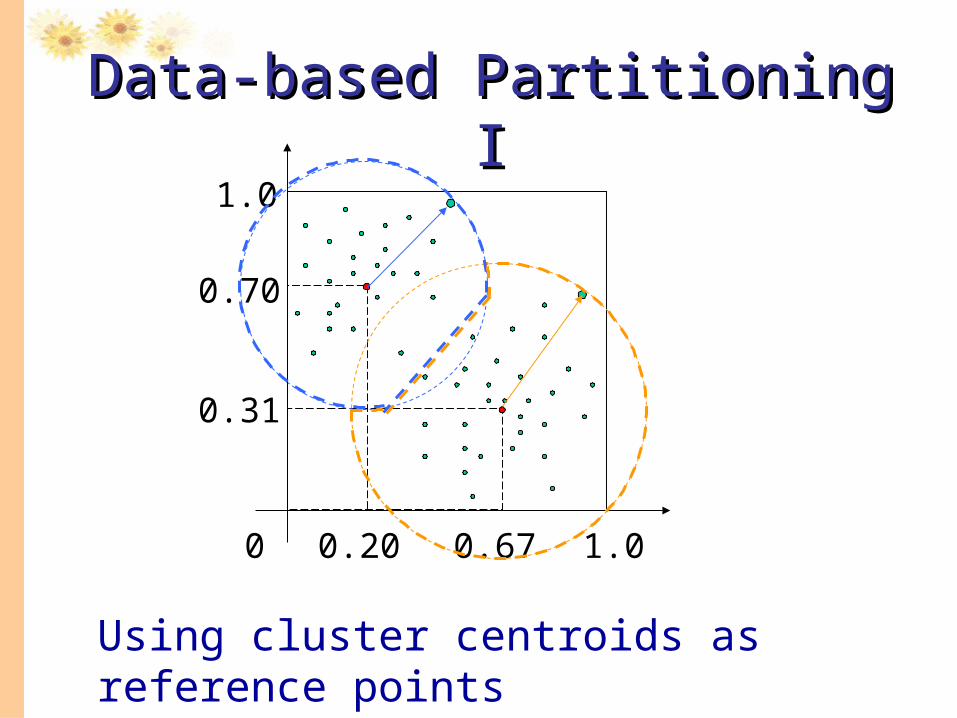
Using cluster centroids as reference points
Data-based Partitioning IData-based Partitioning I
0.67 1.0
0.31
0.20
0.70
0
1.0
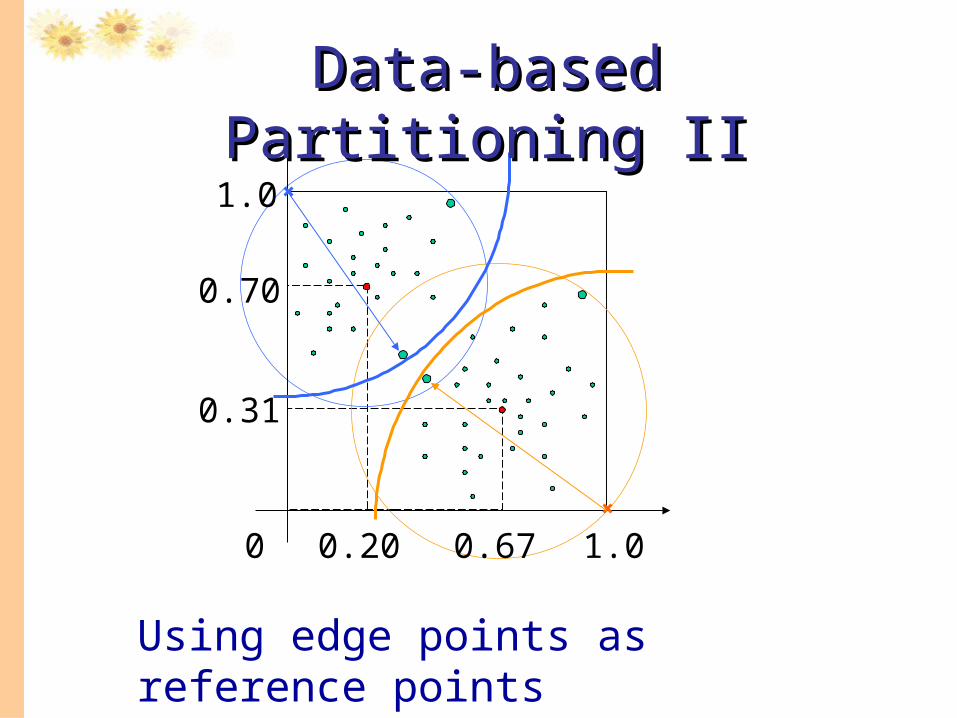
Using edge points as reference points
Data-based Partitioning IIData-based Partitioning II
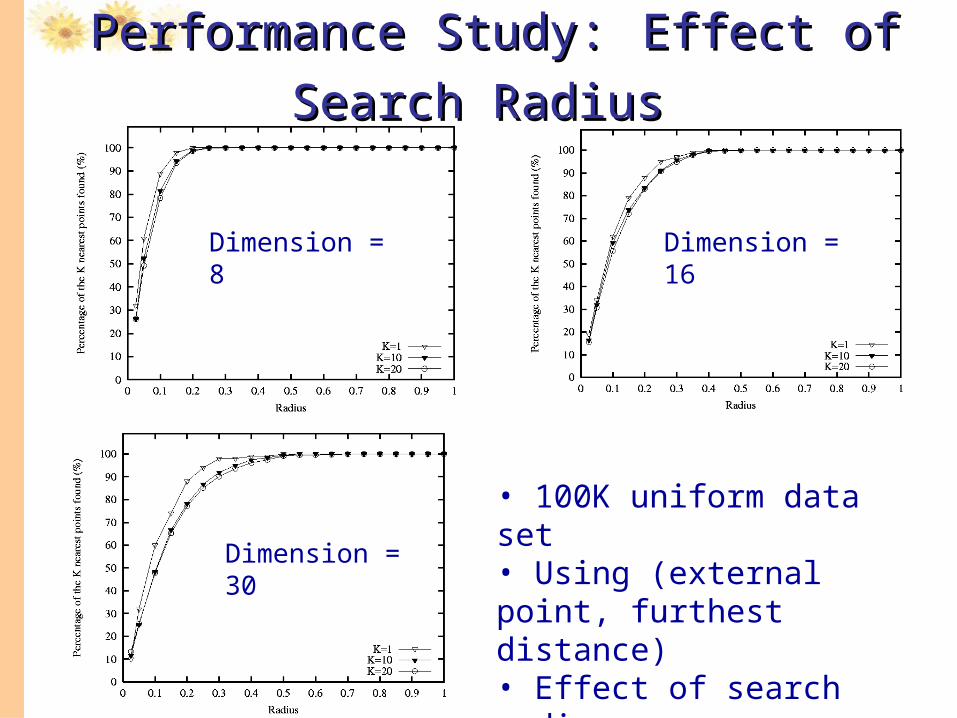
• 100K uniform data set• Using (external point, furthest distance)• Effect of search radius on query accuracy
Dimension = 8 Dimension = 16
Dimension = 30
Performance Study:Performance Study: Effect of Search RadiusEffect of Search Radius
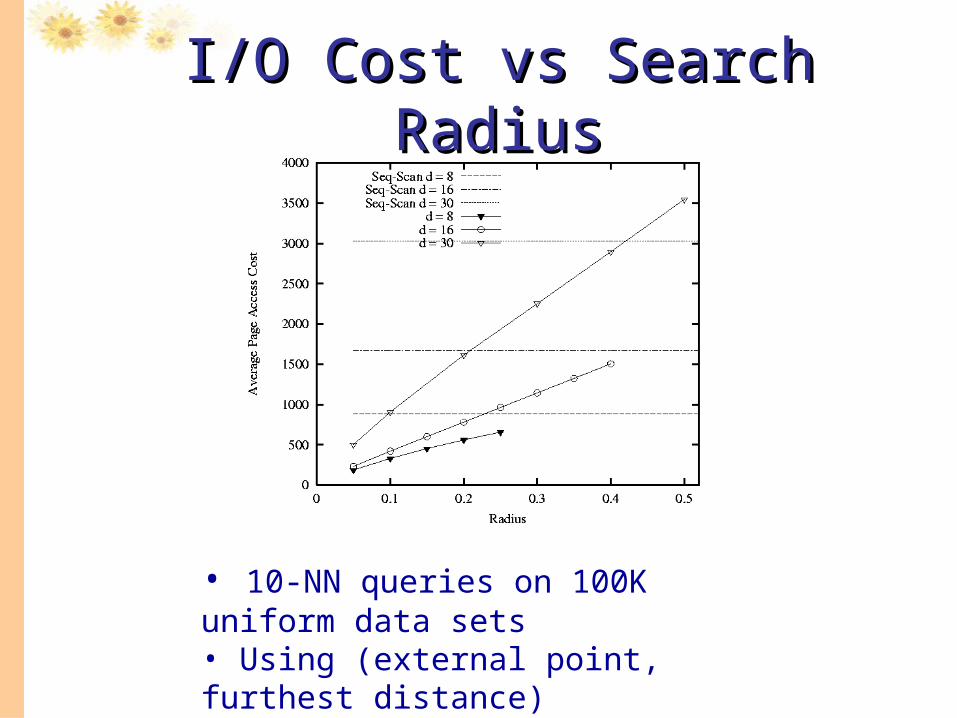
• 10-NN queries on 100K uniform data sets • Using (external point, furthest distance)• Effect of search radius on query cost
I/O Cost vs Search RadiusI/O Cost vs Search Radius
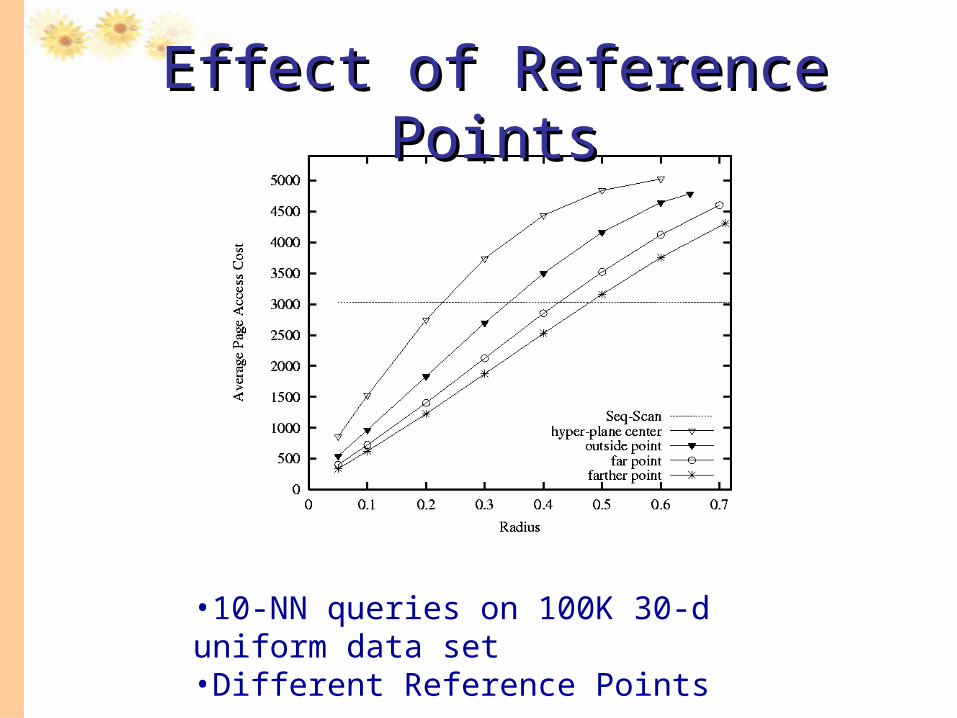
•10-NN queries on 100K 30-d uniform data set •Different Reference Points
Effect of Reference PointsEffect of Reference Points
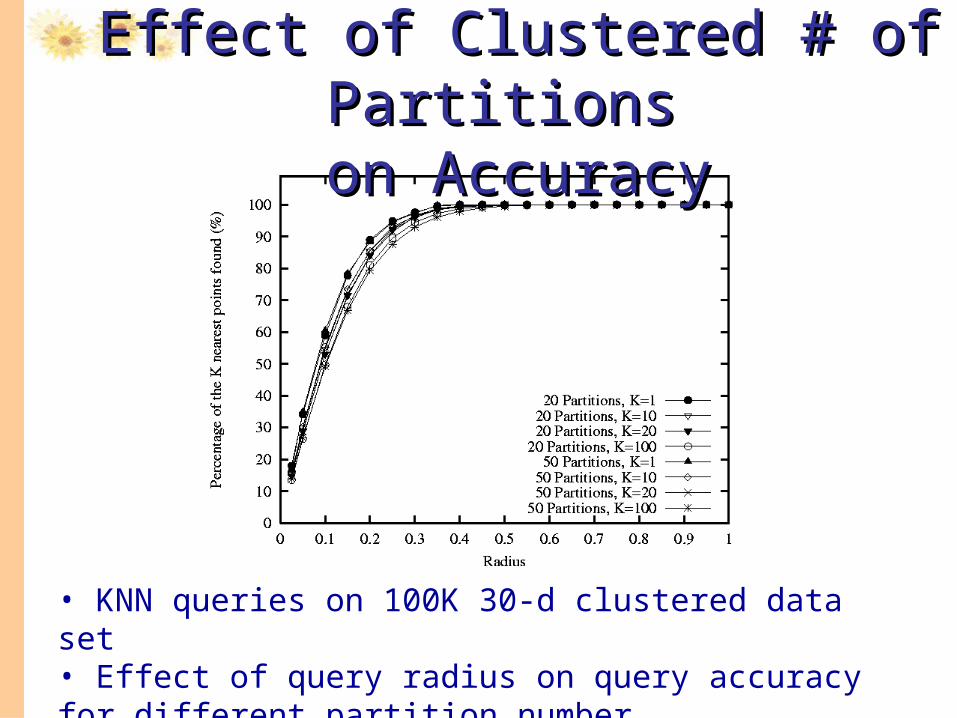
• KNN queries on 100K 30-d clustered data set • Effect of query radius on query accuracy for different partition number
Effect of Clustered # of Partitions Effect of Clustered # of Partitions on Accuracyon Accuracy

• 10-NN queries on 100K 30-d clustered data set • Effect of # of partitions on I/O and CPU Costs
Effect of # of Partitions Effect of # of Partitions on I/O and CPU Coston I/O and CPU Cost
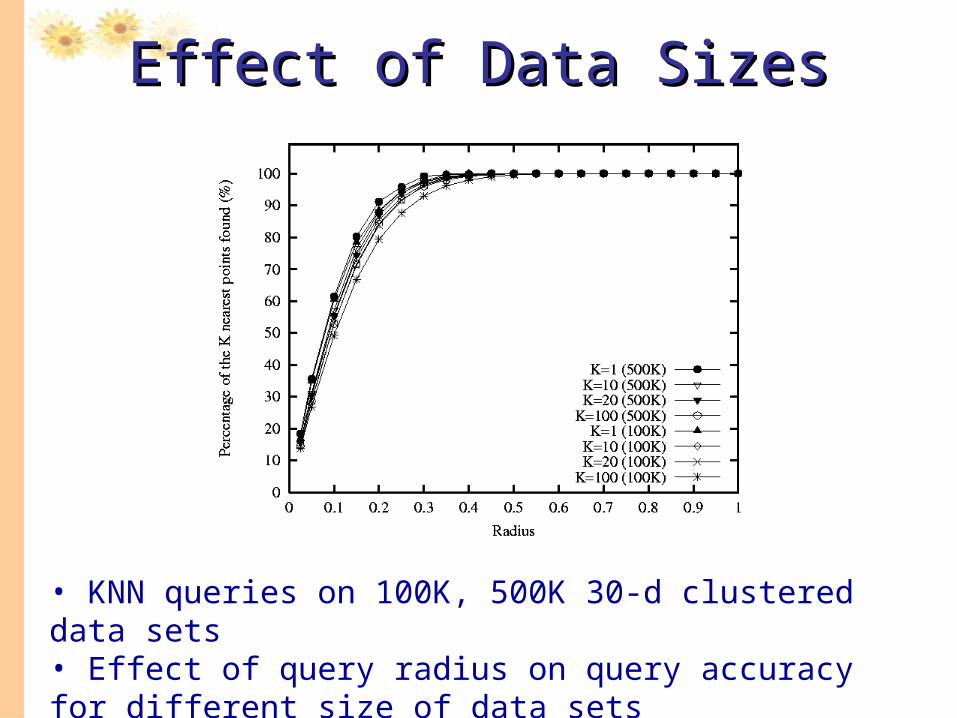
• KNN queries on 100K, 500K 30-d clustered data sets • Effect of query radius on query accuracy for different size of data sets
Effect of Data SizesEffect of Data Sizes
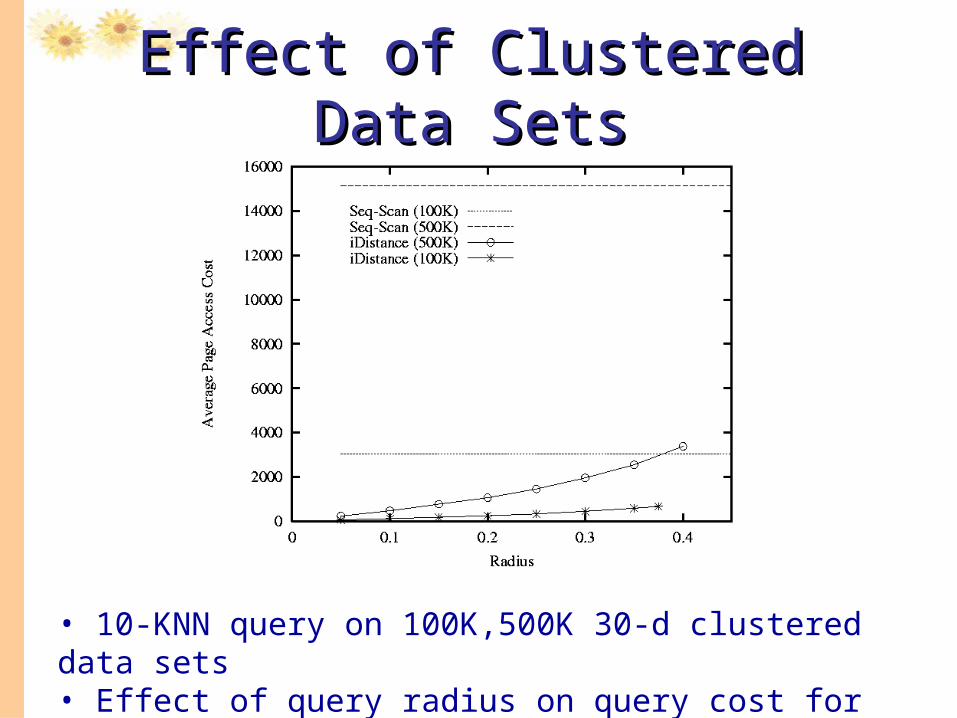
• 10-KNN query on 100K,500K 30-d clustered data sets • Effect of query radius on query cost for different size of data set
Effect of Clustered Data SetsEffect of Clustered Data Sets
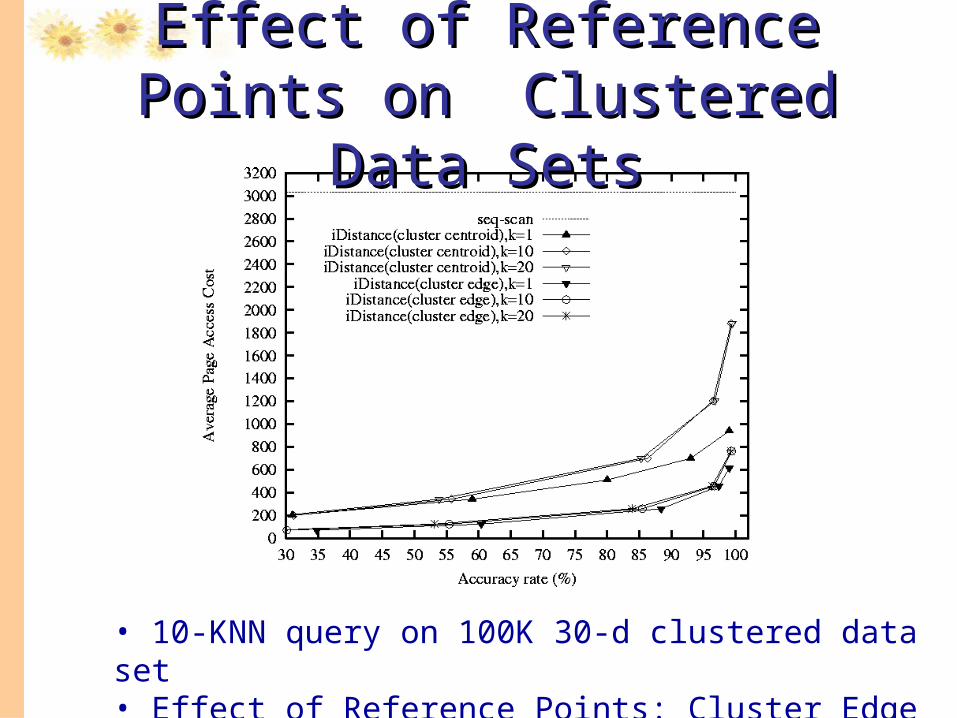
• 10-KNN query on 100K 30-d clustered data set • Effect of Reference Points: Cluster Edge vs Cluster Centroid
Effect of Reference Points on Effect of Reference Points on Clustered Data SetsClustered Data Sets

• 10-KNN query on 100K,500K 30-d clustered data sets • Query cost for variant query accuracy on different size of data set
iDistance ideal for Approximate iDistance ideal for Approximate KNN?KNN?
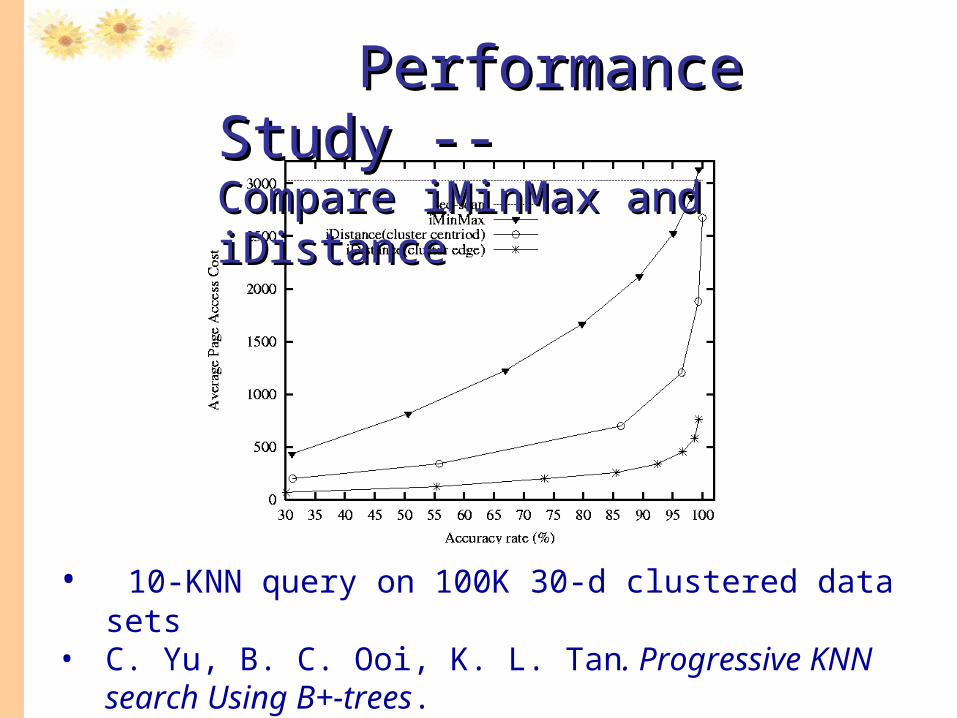
• 10-KNN query on 100K 30-d clustered data sets • C. Yu, B. C. Ooi, K. L. Tan. Progressive KNN search Using
B+-trees.
Performance Study -- Performance Study -- Compare iMinMax and iDistanceCompare iMinMax and iDistance
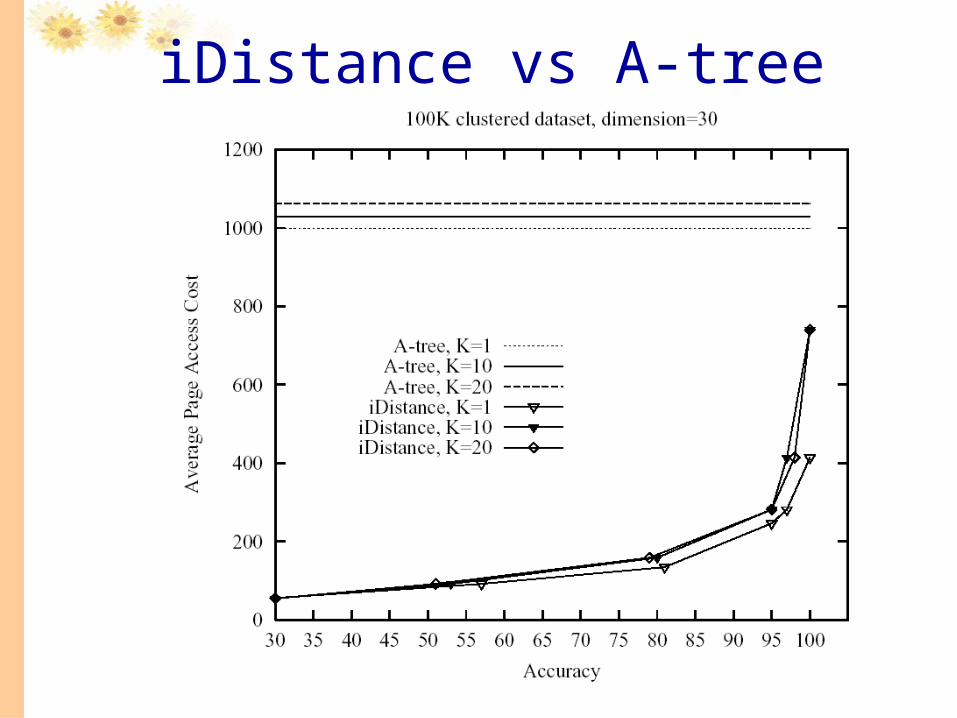
iDistance vs A-tree
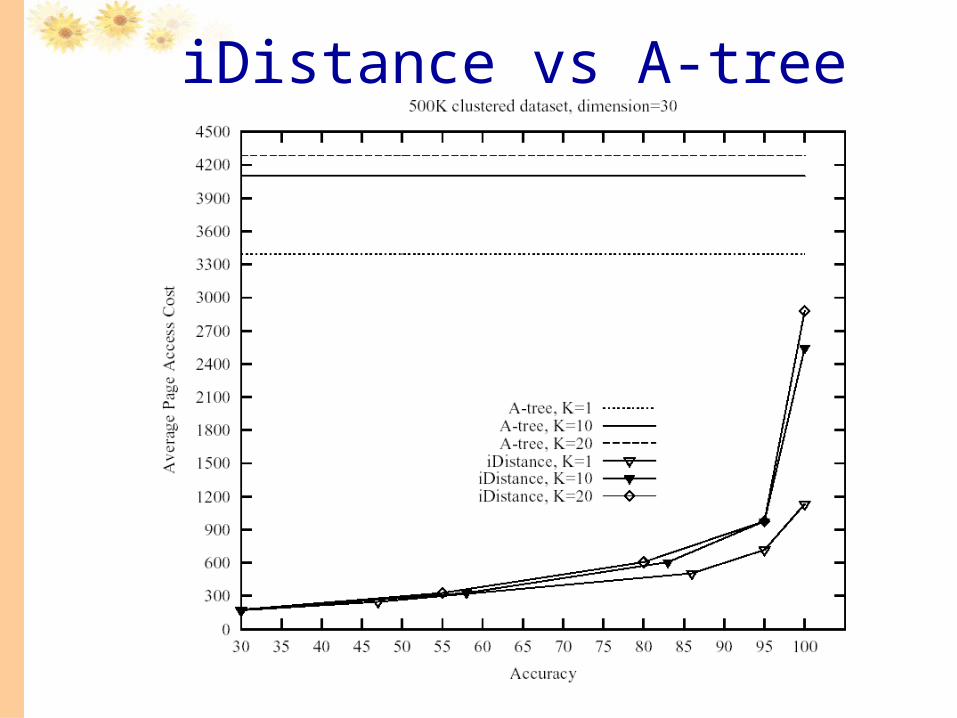
iDistance vs A-tree

Summary of iDistanceSummary of iDistance• iDistance is simple, but efficient• It is a Metric based Index• The index can be integrated to existing
systems easily.



![iDistance: An Adaptive B -tree Based Indexing Method for ...ooibc/todsidistance.pdf · compare iDistance against sequential scan, the M-tree [Ciaccia et al. 1997], the Omni-sequential](https://img.pdfslide.net/doc/110x75/5ffbb69234d11e238d21c548/idistance-an-adaptive-b-tree-based-indexing-method-for-ooibc-compare-idistance.jpg)

























