Embed Size (px)
Citation preview

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-34, NO. 9, SEPTEMBER 1985
High-Speed VLSI Multiplication Algorithm with aRedundant Binary Addition Tree
NAOFUMI TAKAGI, MEMBER, IEEE, HIROTO YASUURA, MEMBER, IEEE, AND SHUZO YAJIMA, SENIOR MEMBER, IEEE
Abstract-A high-speed VLSI multiplication algorithm inter-nally using redundant binary representation is proposed. In n bitbinary integer multiplication, n partial products are first gen-erated and then added up pairwise by means of a binary tree ofredundant binary adders. Since parallel addition of two n-digitredundant binary numbers can be performed in a constant timeindependent of n without carry propagation, n bit multiplicationcan be performed in a time proportional to 10g2 n. The com-putation time is almost the same as that by a multiplier with aWallace tree, in which three partial products will be convertedinto two, in contrast to our two-to-one conversion, and is muchshorter than that by an array multiplier for longer operands. Thenumber of computation elements of an n bit multiplier based onthe algorithm is proportional to n2. It is almost the same as thoseof conventional ones. Furthermore, since the multiplier has aregular cellular array structure similar to an array multiplier, itis suitable for VLSI implementation. Thus, the multiplier is excel-lent in both computation speed and regularity in layout. It can beimplemented on a VLSI chip with an area proportional ton2 log2 n. The algorithm can be directly applied to both unsignedand 2's complement binary integer multiplication.
Index Terms -Arithmetic operations, binary integer multi-plication, carry-propagation-free adder, hardware algorithm,high-speed multiplier, redundant binary representation, signed-digit number representation, VLSI.
I. INTRODUCTION
M/[ULTIPLICATION plays important roles in variousdigital systems such as computers, process control-
lers, signal processors, and so on. Designing fast multipliershas long been a great theoretical and practical interest forcomputer scientists and engineers. Various multiplicationalgorithms have been proposed and practically used [1]. Es-pecially, with recent advances of technology of integratedcircuits, many researchers have tried to develop high-speedmultiplication algorithms which are suitable for VLSI imple-mentation (e.g., [2]-[7]). In this paper, we propose a high-speed multiplication algorithm internally using redundantbinary representation [8]. A multiplier based on the algo-rithm can perform n bit multiplication in a time proportionalto log2 n and, further, has a regular cellular array structuresuitable for VLSI implementation.The shift-and-add algorithm is a familiar multiplication
method. Parallel multipliers based on the algorithm, i.e.,array multipliers, have been widely used, and some of them
Manuscript received January 3, 1984; revised February 13, 1985. This workwas supported in part by the Ministry of Education, Science and Culture ofJapan under a Grant in Aid for Science Research.The authors are with the Department of Information Science, Faculty of
Engineering, Kyoto University, Kyoto 606, Japan.
are implemented on commercial LSI chips [2]-[4]. This typeof multiplier has a regular cellular array structure of one typeof basic cell and is very suitable for VLSI implementation.However, it does not operate so fast for longer operandsbecause its computation time is linearly proportional to theword length of operands. In order to achieve high-speedmultiplication, multiplication algorithms using parallelcounters [9], such as the Wallace tree [10], have been pro-posed, and some multipliers based on the algorithms havebeen implemented for practical use. This type of multiplieroperates much faster than an array multiplier for longer oper-ands because its computation time is proportional to the loga-rithm of the word length of operands. It also consists of onetype of basic cell. However, its layout on a VLSI chip be-comes rather complicated, and the area for wires becomeslarger [5]-[7].
It has been one of the challenging problems in these yearsto develop a multiplier which can perform multiplication incomputation time proportional to the logarithm of the wordlength of operands and has a regular cellular array structuresuitable for VLSI implementation. In this paper, we proposea multiplication algorithm for such a multiplier. In the algo-rithm, a redundant binary representation whose each digitcan be 0 or 1 or -1 is used. It is one of the signed-digit (SD)number representations proposed by Avizienis [11]. A multi-plier based on the algorithm is formed by a binary tree ofredundant binary adders. Recently, Vuillemin developed asimilar algorithm, independently [6], [7], in which a carrysave form whose each digit can be 0 or 1 or 2 is used. Bothour algorithm and his achieve high-speed computation and aregular structure. Compared to his algorithm, ours can beapplied to 2's complement binary integer multiplication moreeasily. Since a redundant binary number can be itself eitherpositive or negative, it is easy to handle signed numbers.Based on this fact, we can develop efficient hardware algo-rithms for various other arithmetic operations using the re-dundant binary representation. We have already developedseveral hardware algorithms for division, square rooting,logarithmic function, exponential function, and so on[12], [13]. Avizienis discussed a sequential multiplicationmethod in SD number systems [11]. Atkins implemented aserial-parallel multiplier using a higher-radix SD numberrepresentation in Illiac III [14]. Our algorithm is not merelyan extended version of these algorithms, but makes the bestof parallelism of hardware.
In this paper, we are concerned with n bit binary integermultiplication. In the algorithm,, we first convert the multi-
0018-9340/85/0900-0789$01.00 C 1985 IEEE
789

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-34, NO. 9, SEPTEMBER 1985
plicand and the multiplier into equivalent redundant binaryintegers and then generate n n-digit partial products repre-sented in the redundant binary representation. These com-putations can be performed in a constant time independent ofn. Next, we add up the partial products pairwise by means ofa binary tree of redundant binary adders and obtain the prod-uct represented in the redundant binary representation. Sinceaddition of two numbers in the redundant binary numbersystem can be carried out in a constant time independent ofthe word length of operands [1], [11], the additions are per-formed in a time proportional to log2 n. Finally, we convertthe product into binary representation. This conversion canbe performed in a time proportional to log2 n by means of anordinary carry-look-ahead adder (CLA) [11. Thus, n bit mul-tiplication can be performed in a computation time ofO(log n). The algorithm can be directly applied to both un-signed and 2's complement binary integer multiplication.The number of computation elements which make up an n bitmultiplier based on the algorithm is proportional to n2. Sincethe multiplier is formed by a binary tree of redundant binaryadders, it has a regular cellular array structure, and therefore,it is suitable for VLSI implementation. The chip area of itbecomes O(n2 lbg n).The extended Booth's algorithm [10], [15] can be effectively
applied to the multiplier for reducing the computation timeand the amount of hardware. According to our evaluation,using four-input NOR/OR gates as computation elements, themultiplier is as fast as a multiplier with Wallace tree, andmuch faster than a standard array multiplier for longer oper-ands. For example, it is about four times faster for 32 bitmultiplication, and about seven times faster for the 64 bitone, compared to standard array multipliers. The numbers ofcomputation elements of the three types of multipliers arealmost the same. Furthermore, since our multiplier has aregular cellular array structure similar to array multipliers, itslayout is simpler than those of multipliers with a Wallacetree. Thus, our multiplier is excellent in both computationspeed and regularity in layout. A 16 bit multiplier basedon the algorithm has recently been implemented on an LSIchip [16].
In the next section, we will describe some preliminarieson n bit binary integer multiplication and the computationmodel. In Section III, we will be concerned with redundantbinary representation. The high-speed multiplication algo-rithm for VLSI will be proposed in Section IV. In Section V,we will consider the implementation of a multiplier based onthe algorithm. Section VI will appear as a conclusion.
II. PRELIMINARIES
A. n-Bit Binary Integer Multiplication
We are concerned with the multiplication of two n bitunsigned binary integers and that of two n bit 2's complementbinary integers. For simplicity of explanation in the follow-ing, although n can be any positive integer, we assume thatn is the kth power of 2 where k is a positive integer. An n bitunsigned binary integer [xn I ... x0]2 (xi E {0, I}) has thevalue i" x x 2'. The product of two n bit unsigned binary
integers is a 2n bit unsigned binary integer. An n bit 2'scomplement binary integer [xn_ x,-2 . xO]: (xi E {0, 1}) hasthe value -xnI x 2-' + Sin x 2'. Although-2"- canalso be represented in n bit 2's complement binary integernotation, we are not concerned with it. The product of two nbit 2's complement binary integers is a (2n - 1) bit 2's com-plement binary integer.
B. Computation Model
We will be concerned with implementation of a multiplieras a combinational circuit. A combinational circuit is a logiccircuit which is constructed from given computation ele-ments (logic gates) and has no feedback loop in it. We assumethat fan-in (in-degree) of each computation element is re-stricted in a certain constant, but fan-out (out-degree) is notrestricted. For simplicity in evaluation, we assume that allcomputation elements have the same delay, but wires have nodelay. According to these assumptions, the computation timeon a combinational circuit is linearly proportional to thedepth of it. The depth of a combinational circuit is the numberof computation elements on the longest path, i.e., the paththat has the most computation elements, in it. We estimatethe complexity of a combinational circuit by its depth andgate count. The gate count (the size) of a combinationalcircuit is the number of computation elements in it.We also consider implementation of a circuit on a VLSI
chip. The layout rules of a circuit are as follows [ 17]. 1) Eachcomputation element occupies at least a certain constant area,and each wire which connects computation elements has atleast a certain constant width. 2) No computation elementoverlaps other computation elements or wires. 3) At most acertain constant number of wires can overlap (or intersect)each other at any point on a chip. We define the area of acircuit by the area of the minimum rectangular region on aplane including the layout of the circuit.
III. REDUNDANT BINARY REPRESENTATION
A. Redundant Binary Representation
The redundant binary representation utilized in this paperis one of the SD representations proposed by Avizienis [ 11] .It has a fixed radix 2 and a digit set {T, 0, 1} where 1 denotes-1. An n-digit redundant binary integer Y= [Y,-*I*YO]SD2(yi E {1, 0, 1}) has the value Yi02yi x 2'. It is similar to an
unsigned binary integer except that y, can be 1.The redundant binary representation allows the existence
of redundancy. There are several ways to represent aninteger in the redundant binary representation. For example,[O101]5D2, [O111]D2, [1101]SD2, [111]SD2, and [101 1TSD2 allrepresent "5." (However, "O" is uniquely represented.) Ow-ing to the redundancy, we can perform carry-propagation-free addition, and therefore, parallel addition of two redun-dant binary numbers can be performed in a constant timeindependent of the word length of operands, as will be men-tioned in the next subsection.The negation of a redundant binary number is directly
derived by changing the signs of all nonzero digits in thenumber. Since this computation can be performed in parallel
790

TAKAGI et al.: HIGH-SPEED VLSI MULTIPLICATION ALGORITHM
for all digits, it requires a constant computation time indepen-dent of the word length of the number.
B. Carry-Propagation-Free Addition
Carry-propagation-free addition is performed in two steps.In the first step, we determine the intermediate carry ci(E {1, 0, 1}) and the intermediate sum digit si (E {T, 0, 1}) ateach position, satisfying the equation xi + yi = 2ci + si,where xi and yi are the augend and addend digits, re-spectively. In the second step, we obtain the sum digitzi (E {1, 0, 1}) at each position by adding the intermediatesum digit si and the intermediate carry ci-I from the next-lower-order position, without generating a carry.
In the first step, at each position, we determine ci and si sothat both si and ci_1 are not l's, nor are they l's. When oneof xi and yi is 1 and the other is 0, we determine ci and si asfollows (note that both [Ol]SD2 and [lI]SD2 represent "1").1) If there is a possibility of a 1-carry (a positive carry) fromthe next-lower-order position, we let [c,, s ] be [1 , 1]. 2) Ifthere is a possibility of a 1-carry (a negative carry) from thenext-lower-order position, we let [ci, si] be [0, 1]. 3) If thereis no possibility of a carry from the next-lower-order posi-tion, we may let [c;, si] be either [1, T] or [0, 1]. Similarly,when one of xi and yi is 1 and the other is 0, we let [ci, si ] be[0,1] if there is a possibility of a 1-carry from the next-lower-order position, and let it be [1, 1] if there is a possibility ofa 1-carry. We can know the possibility of a carry from thenext-lower-order position by examining the augend and theaddend digits xi-, and Yi-l at the next-lower-order position.When both xi-1 and yi-l are 1's or one of them is 1 and theother is 0, there is a possibility of a 1-carry. When both ofthem are l's or one of them is I and the other is 0, there is apossibility of a 1-carry. In the other cases, there is no possi-bility of a carry. Therefore, ci and si can be determined byexamining xi, yi, xi-,, and yi- I
When we determine ci and si as stated in the above, nocarry is generated in the addition of si and ci_1 in the secondstep. Thus, each sum digit zi can be computed from xi, Yi,Xi_l, Yi- , xi-2, and Yi-2. Namely, zi depends on only these sixdigits. This fact is the key to the high-speed computation.
Table I shows a computation rule in the first step. Whenone of xi andyi is 1 and the other is 0, we let[c', s1] be [1, 1]or [0, 1] accordingly, as both x-I1 and Yi-l are nonnegative ornot. When one of xi and yi is T and the other is 0, we let it be[0, 1] or [1, 1] accordingly, as both xi-, and Yi-l are non-negative or not. We assume that x.1 and y-1, i.e., the augendand addend digits at the next-lower-order position of the leastsignificant position, are both O's. Fig. 1 shows an example ofcarry-propagation-free addition in accordance with the rule.(Take notice of the computation at the second and the thirdleast significant positions.)
Thus, in the redundant binary number system, carry propa-gation can be eliminated from addition, and therefore, paral-lel addition of two numbers by a combinational circuit isperformed in a constant time independent of the word lengthof operands. Namely, the depth of an n-digit redundant bi-nary adder is a constant independent of n. The gate count ofit is proportional to n.
TABLE ICOMPUTATION RULE FOR THE FIRST STEP IN CARRY-PROPAGATION-FREE
ADDITION
Augend Addend Digits at the next- Intermediate IntermediateType digit digit, lower-order position carry sum digit
(Xi) (yi) (xi~ ii-l)y- (ci) (Si)<1> 1 1 1 0
1 0 Both are nonnegative. 1 T<2>
O 1 Otherwise. 0 1
<3> 0 0
<4>T 1O 1 Both are nonnegative. 0 T
<5> _ -1 0 Otherwise. 1
<6> T 1 1 O
Augend
Addend
Intermediate sum
Intermediate carry
Sum
[E1 0 7 o T 1o ]SD2 ( 87)+ [1 1 T1 o 0 1 |1 SD2 (101)
o 1 o o T J1, o
+ 1 T o 0 10
[ 1T 1 0 0 0 ' 0 00SD2 (188)
Step 1
) Step 2
Fig. 1. Example of cany-propagation-free addition.
The addition method discussed here is an example. Thereare various other carry-propagation-free addition methods inthe redundant binary number system [18].
C. Conversion Between Binary and Redundant BinaryIntegers
An n bit unsigned binary integer [xn_ I ... x0]2 (xi E {0, 1})and an n -digit redundant binary integer [xn I *... XO]SD2 havethe same value 1_oxxi x 2'. Therefore, no computation isrequired to convert an unsigned binary integer into an equiva-lent redundant binary integer, where the equivalence impliesthat they have the same value.An n bit 2's complement binary integer [Xn_lXn2 **... xOhI
(xi E {0, 1}) and an n-digit redundant binary integer[X-lxn-2 ... XO]SD2 have the same value -xn_ x 2?-l +E:i= Xi x 2' where xn-l is 1 or 0 accordingly, as xnI is 1 or 0.Therefore, a conversion of an n bit 2's complement binaryinteger into an equivalent redundant binary integer can beperformed by changing the most significant digit x,, 1 to xn-1The conversion can be clearly performed in a constant timeindependent of n. The number of computation elements re-quired for the conversion is a constant independent of n.A conversion of an n -digit redundant binary integer
Y = [Yn-I.. Yo]SD2 (Yi E {T, 0, 1}) into the equivalent(n + 1) bit 2's complement binary integer X =[XnXn-lXI* Xo (xi E {0, 1}) is performed by subtracting Y-from Y+ where Y+ and Y- are n bit unsigned binary integersformed from the positive digits and the negative digits in Y,respectively. Since Y can be itself either positive or negative,X needs the sign bit x,, at the leftmost position. If Y is guaran-teed to be positive, it can be converted into an n bit un-signed binary integer because xn must be 0. The conversioncan be performed in a computation time proportional tolog2 n by means of a CLA. The number of computationelements of a CLA is proportional to n [19].
791

IEEE TRANSACTIONS ON COMPUTERS, VOL. c-34, NO. 9, SEPTEMBER 1985
IV. HIGH-SPEED MULTIPLICATION ALGORITHM FOR VLSI
In ordinary n bit parallel multiplication, n partial productsare first generated and then added up to obtain the product.In our algorithm, we first convert the multiplicand and themultiplier into equivalent redundant binary integers and thengenerate n partial products represented in the redundant bi-nary representation. Next, we add them up pairwise by meansof a binary tree of redundant binary adders and obtain theproduct represented in the redundant binary representation.We represent all intermediate results in the redundant binaryrepresentation and perform all additions in the redundantbinary number system. Finally, we convert the product intobinary representation.The algorithm is as follows.
Multiplication Algorithm(Input)
A and B: a multiplicand and a multiplier, respectively.Both are n bit binary integers. (Eitherunsigned or 2's complement.)
(Output)P: the product of A and B.
(Algorithm)Step 1: Convert the multiplicand A and the multiplier B
into the equivalent redundant binary integers.Step 2: Generate n n -digit partial products P0j,'s
(j = O, 1, n - 1) for n multiplier digits.Let a partial product be zero or the multiplicanditself or the negation of the multiplicand accord-ingly, as the corresponding multiplier digit is 0 or1 or 1.
Step 3: Add up the partial products by means of a binarytree of redundant binary adders and obtain theproduct Pk,o where k is log2 n. Perform allkredun-dant binary additions at each level in the tree inparallel. Namely, perform the additionsPij :=Pi-,, 2j + Pi-1,2+1 in parallel for j :=O, 1, *, n/2 - 1 at ith level (i = 1, 2, * * *, k)where Pij denotes the jth intermediate result atthe ith level in the addition tree.
Step 4: Convert the product Pk,o into the equivalent bi-nary number P. (P is the product.)
In the algorithm, we represent all intermediate results(Pi, j's) in the redundant binary representation, and performall additions in Step 3 in the redundant binary number sys-tem. All additions at each level in the redundant binary addi-tion tree are performed in parallel.As stated in Section III-C, for unsigned binary integers,
the conversion in Step 1 requires no computation. For 2'scomplement binary integers it requires a constant com-putation time independent of n and a constant number ofcomputation elements independent of n.The computation in Step 2 is performed in parallel for all
digits. (Recall the discussion in Section Ill-A.) It requires aconstant computation time independent of n. Since n n-digitpartial products are generated in parallel, the number of com-putation elements required is proportional to n2.
Additions at each level in the tree in Step 3 are performed
A = t1 1 0 1½] (-3)
B = t1 0 1 1½2 (-5)
[I 1 0 1]SD2x CT 0 11
CY
t °10 ]SD> E 1 1 0 0 I
(0 0 0° T SD2 [Q 1iO [ Or 0 O
[1 7 0~~ ~ ~ ~~~~~~ -
.- EQ.. 0
EOQ..LQ 0
0 1 0 0 0 1 SD2
0 1 0 0 0
0 0 0 0 0
0 0 1 1 1
1]2
1J 2
P - 0 0 0 1 1 1 1o2 15)
Fig. 2. Example of 2's complement binary integer multiplication with aredundant binary addition tree.
in parallel. As discussed in Section III-B, addition of tworedundant binary numbers is performed in a constant time.Therefore, the computation at each level in the tree in Step 3is performed in a constant time independent of n. Since thereare log2 n (= k) levels, the computation time for Step 3 isproportional to log2 n. The number of computation elementsrequired is proportional to n2 because n - 1 redundantbinary adders are needed.The conversion in Step 4 is performed in a computation
time proportional to log2 n by means of a CLA, as mentionedin Section Ill-C. The gate count of a CLA is proportional ton [19].
Thus, we conclude that the multiplication algorithm per-forms n bit binary integer multiplication in a time of 0(log n)with 0(n2) computation elements.
This algorithm can be directly applied to both unsigned and2's complement binary integer multiplication.
Fig. 2 illustrates an example of multiplication of 4 bit 2'scomplement binary integers according to the algorithm. Asshown in the figure, because of the carry at the most signifi-cant position in each addition, the product becomes a 9-digitredundant binary integer and is converted into a 10 bit 2'scomplement binary integer. However, on account of thebound of the value of the product, only the seven least signifi-cant bits are needed. Therefore, we do not have to computedigits at some most significant positions in several additions(the digits underlined in the figure). In general, in the case ofn bit unsigned binary integer multiplication, since the prod-uct is composed of 2n bits, we do not have to compute for thedigits whose weight is 22n or more. Similarly, in the case ofn bit 2's complement binary integer multiplication, since theproduct is composed of 2n - 1 bits, we do not have to com-pute for digits whose weight is 22n1- or more.
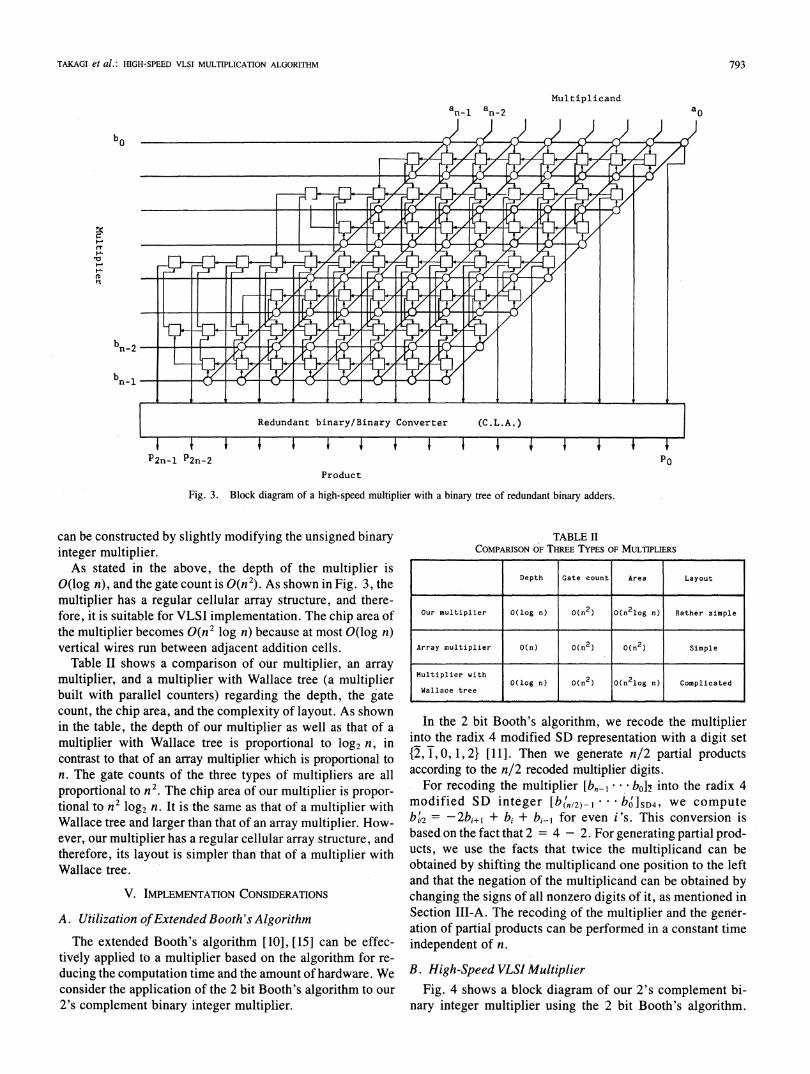
Fig. 3 shows a block diagram of an unsigned binary integermultiplier based on the algorithm. 0 denotes a partial prod-uct generation cell, and each horizontal row of O's forms apartial product generator. FL denotes a redundant binary addi-tion cell, and each horizontal row of R's forms a redundantbinary adder, i.e., a carry-propagation-free adder. The re-dundant binary/binary converter is a modification of a CLAand is implemented easily by Unger's method [19]. A 2'scomplement binary integer multiplier based on the algorithm
792
TAKAGI et al.: HIGH-SPEED VLSI MULTIPLICATION ALGORITHM
Multiplicand
rrl
H.
P2n-l P2n-2 P0Product
Fig. 3. Block diagram of a high-speed multiplier with a binary tree of redundant binary adders.
can be constructed by slightly modifying the unsigned binaryinteger multiplier.As stated in the above, the depth of the multiplier is
0(log n), and the gate count is 0(n2). As shown in Fig. 3, themultiplier has a regular cellular array structure, and there-fore, it is suitable for VLSI implementation. The chip area ofthe multiplier becomes 0(n2 log n) because at most 0(log n)vertical wires run between adjacent addition cells.
Table II shows a comparison of our multiplier, an array
multiplier, and a multiplier with Wallace tree (a multiplierbuilt with parallel counters) regarding the depth, the gatecount, the chip area, and the complexity of layout. As shownin the table, the depth of our multiplier as well as that of a
multiplier with Wallace tree is proportional to log2 n, in
contrast to that of an array multiplier which is proportional ton. The gate counts of the three types of multipliers are allproportional to n2. The chip area of our multiplier is propor-
tional to n2 log2 n. It is the same as that of a multiplier withWallace tree and larger than that of an array multiplier. How-ever, our multiplier has a regular cellular array structure, andtherefore, its layout is simpler than that of a multiplier withWallace tree.
V. IMPLEMENTATION CONSIDERATIONS
A. Utilization ofExtended Booth's Algorithm
The extended Booth's algorithm [10], [15] can be effec-tively applied to a multiplier based on the algorithm for re-
ducing the computation time and the amount of hardware. Weconsider the application of the 2 bit Booth's algorithm to our
2's complement binary integer multiplier.
TABLE IICOMPARISON OF THREE TYPES OF MULTIPLIERS
Depth Gate count Area Layout
Our multiplier O(log n) O(n2) o(n2log n) Rather simple
Array multiplier 0(n) O(n2) 0(n2) Simple
Multiplier with 2 20(log n) O(n ) O(n log n) Complicated
Wallace tree
In the 2 bit Booth's algorithm, we recode the multiplierinto the radix 4 modified SD representation with a digit set{2,1,0,1,2} [11]. Then we generate n/2 partial productsaccording to the n/2 recoded multiplier digits.
For recoding the multiplier [b_1 *1.* bo]7 into the radix 4modified SD integer [b',2) l* D4, we computebi,2= - 2bi+1 + bi + bi_1 for even i's. This conversion isbased on the fact that 2 = 4 - 2. For generating partial prod-ucts, we use the facts that twice the multiplicand can beobtained by shifting the multiplicand one position to the leftand that the negation of the multiplicand can be obtained bychanging the signs of all nonzero digits of it, as mentioned inSection III-A. The recoding of the multiplier and the gener-ation of partial products can be performed in a constant timeindependent of n.
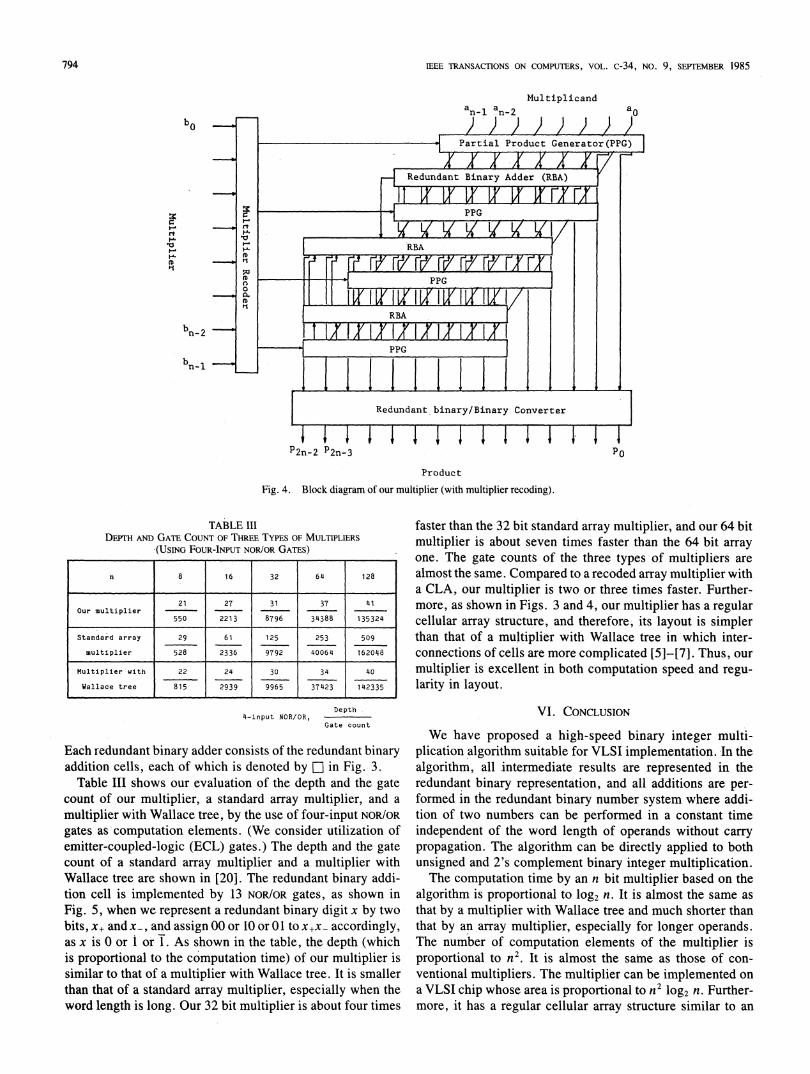
B. High-Speed VLSI MultiplierFig. 4 shows a block diagram of our 2's complement bi-
nary integer multiplier using the 2 bit Booth's algorithm.
793
IEEE TRANSACTIONS ON COMPUTERS, VOL. c-34, NO. 9, SEPTEMBER 1985
an-l an-2) )n)Multiplicand
a0
I)Partial Product Generator (PPG)J
Redundant Binary Adder (RBA) -rPI 1U' 11 11 v1t-LrC
PPG
z -1. 1. 1.
RBA
I IF £r/ f rrvvZ7PI IRBA
r1VI%I%I,flPPG XI%~~~PPG
Redundant binary/Binary Converter
I,
P2n-2 P2n-3
Product
Fig. 4. Block diagram of our multiplier (with multiplier recoding).
TABLE IIIDEPTH AND GATE COUNT OF THREE TYPES OF MULTIPLIERS
(USING FOUR-INPUT NOR/OR GATES)
n | 8 16 32 64 128
21 27 31 37 41Our multiplier
550 2213 8796 34388 135324
Standard array 29 61 125 253 509
multiplier 528 2336 9792 40064 162048
Multiplier with 22 28 30 34 40
Wallace tree 815 2939 9965 37423 142335
Depth4-input NOR/OR,
Gate count
Each redundant binary adder consists of the redundant binaryaddition cells, each of which is denoted by el in Fig. 3.Table III shows our evaluation of the depth and the gate
count of our multiplier, a standard array multiplier, and a
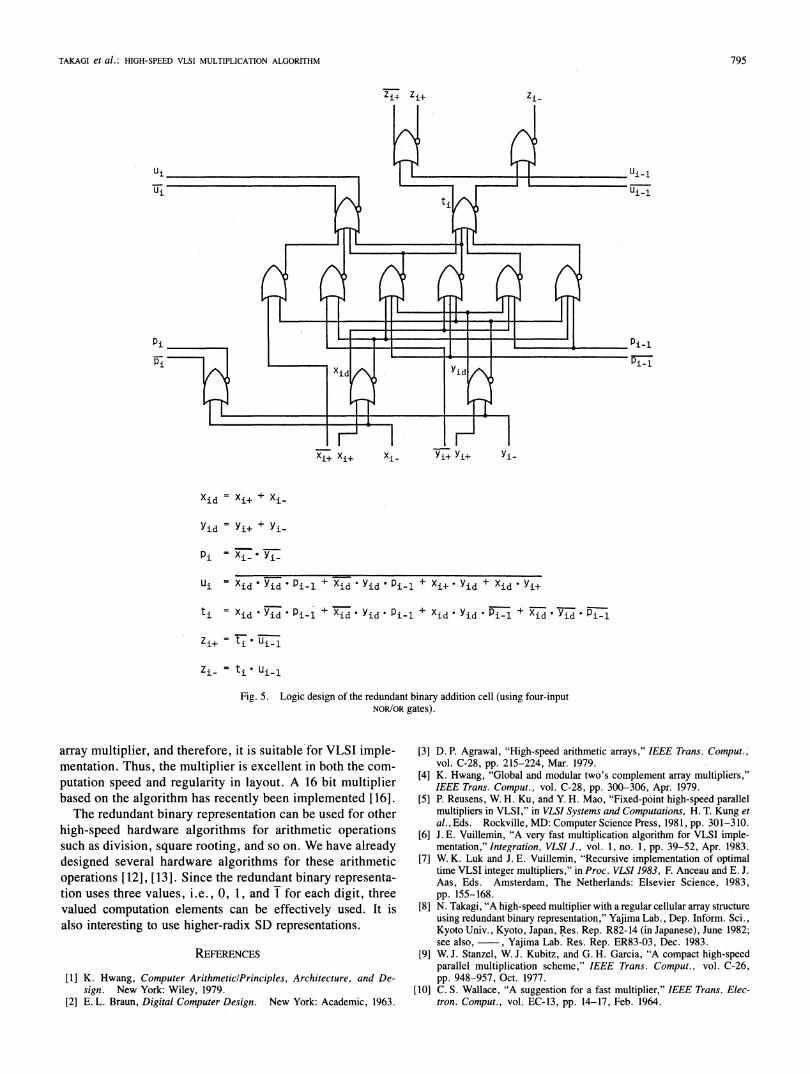
multiplier with Wallace tree, by the use of four-input NOR/ORgates as-computation elements. (We consider utilization ofemitter-coupled-logic (ECL) gates.) The depth and the gatecount of a standard array multiplier and a multiplier withWallace tree are shown in [20]. The redundant binary addi-tion cell is implemented by 13 NOR/OR gates, as shown inFig. 5, when we represent a redundant binary digit x by twobits, x+ andx_, and assign 00 or 10 or 01 to x+x accordingly,as x is 0 or 1 or 1. As shown in the table, the depth (whichis proportional to the computation time) of our multiplier is
similar to that of a multiplier with Wallace tree. It is smallerthan that of a standard array multiplier, especially when theword length is long. Our 32 bit multiplier is about four times
faster than the 32 bit standard array multiplier, and our 64 bitmultiplier is about seven times faster than the 64 bit array
one. The gate counts of the three types of multipliers are
almost the same. Compared to a recoded array multiplier witha CLA, our multiplier is two or three times faster. Further-more, as shown in Figs. 3 and 4, our multiplier has a regularcellular array structure, and therefore, its layout is simplerthan that of a multiplier with Wallace tree in which inter-connections of cells are more complicated [5]-[7]. Thus, our
multiplier is excellent in both computation speed and regu-
larity in layout.
VI. CONCLUSION
We have proposed a high-speed binary integer multi-plication algorithm suitable for VLSI implementation. In thealgorithm, all intermediate results are represented in theredundant binary representation, and all additions are per-
formed in the redundant binary number system where addi-tion of two numbers can be performed in a constant timeindependent of the word length of operands without carry
propagation. The algorithm can be directly applied to bothunsigned and 2's complement binary integer multiplication.The computation time by an n bit multiplier based on the
algorithm is proportional to log2 n. It is almost the same as
that by a multiplier with Wallace tree and much shorter thanthat by an array multiplier, especially for longer operands.The number of computation elements of the multiplier isproportional to n2. It is almost the same as those of con-
ventional multipliers. The multiplier can be implemented on
a VLSI chip whose area is proportional to n2 log2 n. Further-more, it has a regular cellular array structure similar to an
FrtH.
la'1-
tiHoF&00x4{Dki
rt
J.'-
bn-1
I I I I I I I I I 1 pIPO
I
794
TAKAGI et al.: HIGH-SPEED VLSI MULTIPLICATION ALGORITHM
Xid = Xi + Xi_
Yid Yi+ + yi-
Pi Xi- .Yi-
Ui Xid *Yid * Pi-.1+ Xid Yid * Pi- 1+ Xi+ Yid + Xid * Yi+
t Xid. YidP 1 +XidYid * Pi-1 + Xid * Yid Pi-1 +Rid * d
Zi+ = IT. ui-i
Zi- = ti * Ui-i
Fig. 5. Logic design of the redundant binary addition cell (using four-inputNOR/OR gates).
array multiplier, and therefore, it is suitable for VLSI imple-mentation. Thus, the multiplier is excellent in both the com-putation speed and regularity in layout. A 16 bit multiplierbased on the algorithm has recently been implemented [16].The redundant binary representation can be used for other
high-speed hardware algorithms for arithmetic operationssuch as division, square rooting, and so on. We have alreadydesigned several hardware algorithms for these arithmeticoperations [12], [13]. Since the redundant binary representa-tion uses three values, i.e., 0, 1, and T for each digit, threevalued computation elements can be effectively used. It isalso interesting to use higher-radix SD representations.
REFERENCES
[1] K. Hwang, Computer Arithmetic/Principles, Architecture, and De-sign. New York: Wiley, 1979.
[2] E. L. Braun, Digital Computer Design. New York: Academic, 1963.
[3] D. P. Agrawal, "High-speed arithmetic arrays," IEEE Trans. Comput.,vol. C-28, pp. 215-224, Mar. 1979.
[4] K. Hwang, "Global and modular two's complement array multipliers,"IEEE Trans. Comput., vol. C-28, pp. 300-306, Apr. 1979.
[5] P. Reusens, W. H. Ku, and Y. H. Mao, "Fixed-point high-speed parallelmultipliers in VLSI," in VLSI Systems and Computations, H. T. Kung etal., Eds. Rockville, MD: Computer Science Press, 1981, pp. 301-3 10.
[6] J. E. Vuillemin, "A very fast multiplication algorithm for VLSI imple-mentation," Integration, VLSI J., vol. 1, no. 1, pp. 39-52, Apr. 1983.
[7] W. K. Luk and J. E. Vuillemin, "Recursive implementation of optimaltime VLSI integer multipliers," in Proc. VLSI 1983, F. Anceau and E. J.Aas, Eds. Amsterdam, The Netherlands: Elsevier Science, 1983,pp. 155-168.
[8] N. Takagi, "A high-speed multiplier with a regular cellular array structureusing redundant binary representation," Yajima Lab., Dep. Inform. Sci.,Kyoto Univ., Kyoto, Japan, Res. Rep. R82-14 (in Japanese), June 1982;see also, , Yajima Lab. Res. Rep. ER83-03, Dec. 1983.
[9] W. J. Stanzel, W. J. Kubitz, and G. H. Garcia, "A compact high-speedparallel multiplication scheme," IEEE Trans. Comput., vol. C-26,pp. 948-957, Oct. 1977.
[10] C. S. Wallace, "A suggestion for a fast multiplier," IEEE Trans. Elec-tron. Comput., vol. EC-13, pp. 14-17, Feb. 1964.
795

MIEEE TRANSACTIONS ON COMPUTERS, VOL. C-34, NO. 9, SEPTEMBER 1985
[11] A. Avizienis, "Signed-digit number representations for fast parallel arith-metic," IRE Trans. Electron. Comput., vol. EC-10, pp. 389-400, Sept.1961.
[12] N. Takagi, "VLSI-oriented hardware algorithms for arithmetic operationsand data manipulations," Masters thesis, Dep. Inform. Sci., KyotoUniv., Kyoto, Japan, Feb. 1983.
[13] N. Takagi and S. Yajima, "Hardware algorithms for logarithmic andexponential functions using redundant binary representation," Tech.Group Automata Lang. IECE Japan, Rep. AL83-70 (in Japanese),Feb. 1984.
[14] D. E. Atkins, "Design of the arithmetic units of Illiac III: Use of redun-dancy and higher radix methods," IEEE Trans. Comput., vol. C-19,pp. 720-733, Aug. 1970.
[15] S. Waser, "High-speed monolithic multipliers for real-time digital signalprocessing," IEEE Comput., vol. 11, pp. 19-29, Oct. 1978.
[16] Y. Harata, Y. Nakamura, H. Nagase, M. Takigawa, and N. Takagi,"High speed multiplier LSI using a redundant binary adder tree," in Proc.IEEE ICCD'84, Oct. 1984.
[17] R. P. Brent and H. T. Kung, "The area-time complexity of binary multi-plication," J. ACM, vol. 28, pp. 521-534, July 1981.
[18] C. Y. Chow and J. E. Robertson, "Logical design of a redundant binaryadder," in Proc. 4th Symp. Comput. Arithmetic, pp. 109-115,Oct. 1978.
[19] S. Unger, "Tree realization of iterative circuit," IEEE Trans. Comput.,vol. C-26, pp. 365-383, Apr. 1977.
[20] H. Miyata, H. Yasuura, and S. Yajima, "A high-speed multiplier usingextended Booth's algorithm and Wallace tree," Trans. IECE Japan (inJapanese), vol. J65-D, no. 6, pp. 807-808, June 1982.
Naofumi Takagi (S'82-M'84) was born in Osaka,Japan, in 1959. He received the B.E. and M.E.degrees in information science from Kyoto Univer-sity, Kyoto, Japan, in 1981 and 1983, respectively.He is an Instructor at the Department of Informa-
tion Science, Faculty of Engineering, Kyoto Univer-sity. His current interests include design and analysisof hardware algorithms, computer arithmetic, com-puter architecture, and CAD/DA for VLSI logicdesign.
Mr. Takagi received the IEEE Centennial Medaland the Outstanding Paper Award of the IEEE International Conference onComputer Design 1984.
Hiroto Yasuura (M'81) was born in Fukuoka,-Japan, in 1953. He received the B.E., M.E., andPh.D. degrees in information science from KyotoUniversity, Kyoto, Japan, in 1976, 1978, and 1983,respectively.He is now an Instructor in the Department of In-
formation Science, Faculty of Engineering, KyotoUniversity. His current interests include design andanalysis of hardware algorithms, the complexity the-ory of parallel computation, and CAD/DA for VLSIlogic design. Since 1982 he has been a member of
the Working Group WG.5 (Basic Theory) of the Institute of New GenerationComputer Technology (ICOT).
Dr. Yasuura is a member of the Editorial Board of the Journal of theInformation Processing Society of Japan.
Shuzo Yajima (M'66-SM'76) was born in Tak-arazuka, Japan, on December 6, 1933. He receivedthe B.E., M.E., and Ph.D. degrees in electrical en-gineering from Kyoto University, Kyoto, Japan, in1956, 1958, and 1964, respectively.He developed Kyoto University's first digital
computer, KDC-I, in 1960. In 1961 he joined thefaculty of Kyoto University. Since 1971 he has beena Professor in the Department of Information Sci-ence, Faculty of Engineering, Kyoto University, en-gaged in research and education in logic circuits,
switching, and automata theory.Dr. Yajima was a Trustee of the Institute of Electronics and Communication
Engineers of Japan and Chairman of the Technical Committee on Automata andLanguages of the Institute. He served on the Board of Directors of the Informa-tion Processing Society of Japan.
796





























