Embed Size (px)
Citation preview

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS 1
Variable Latency Speculative Han-Carlson AdderDarjn Esposito, Davide De Caro, Senior Member, IEEE, Ettore Napoli, Nicola Petra, Member, IEEE, and
Antonio Giuseppe Maria Strollo, Senior Member, IEEE
Abstract—Variable latency adders have been recently proposedin literature. A variable latency adder employs speculation: theexact arithmetic function is replaced with an approximated onethat is faster and gives the correct result most of the time, butnot always. The approximated adder is augmented with an errordetection network that asserts an error signal when speculationfails. Speculative variable latency adders have attracted stronginterest thanks to their capability to reduce average delay com-pared to traditional architectures. This paper proposes a novelvariable latency speculative adder based on Han-Carlson par-allel-prefix topology that resulted more effective than variablelatency Kogge-Stone topology. The paper describes the stages inwhich variable latency speculative prefix adders can be subdividedand presents a novel error detection network that reduces errorprobability compared to previous approaches. Several variablelatency speculative adders, for various operand lengths, usingboth Han-Carlson and Kogge-Stone topology, have been synthe-sized using the UMC 65 nm library. Obtained results show thatproposed variable latency Han-Carlson adder outperforms bothpreviously proposed speculative Kogge-Stone architectures andnon-speculative adders, when high-speed is required. It is alsoshown that non-speculative adders remain the best choice whenthe speed constraint is relaxed.Index Terms—Addition, digital arithmetic, parallel-prefix
adders, speculative adders, speculative functional units, variablelatency adders.
I. INTRODUCTION
A DDERS ARE basic functional units in computer arith-metic. Binary adders are used in microprocessor for
addition and subtraction operations as well as for floating pointmultiplication and division. Therefore adders are fundamentalcomponents and improving their performance is one of themajor challenges in digital designs. Theoretical research [1]has established lower bounds on area and delay of -bit adders:the former varies linearly with adder size, the latter has an
behavior.High speed adders are based on well established parallel-
prefix architectures [1], [2], including Brent-Kung [3], Kogge-Stone [4], Sklansky [5], Han-Carlson [6], Ladner-Fischer [7],Knowles [8]. These standard architectures operate with fixedlatency. Better average performances can be achieved by usingvariable latency adders, that have been recently proposed in lit-erature [9]. A variable latency adder employs speculation: theexact arithmetic function is replaced with an approximated onethat is faster and gives the correct result most of the time, butnot always. The approximated adder is augmented with an error
Manuscript received July 23, 2014; revised December 12, 2014 and nulldate;accepted January 29, 2015. This paper was recommended by Associate EditorC. P. Ravikumar.The authors are with the Department of Electrical Engineering and Infor-
mation Technology, University of Napoli “Federico II”, I80125 Naples, Italy(e-mail: [email protected]).Color versions of one or more of the figures in this paper are available online
at http://ieeexplore.ieee.org.Digital Object Identifier 10.1109/TCSI.2015.2403036
detection network that asserts an output signal when speculationfails. In this case (misprediction), another clock cycle is neededto obtain the correct result with the help of a correction stage.Since the addition time is one clock cycle when no error occursand two clock cycles when the speculation fails, the average ad-dition time can be computed as
(1)
where is the clock period and is the error probabilityof the speculative adder.Speculative adders are built upon the observation that the crit-
ical path is rarely activated in traditional adders [9]–[13]. In par-ticular, in traditional adders each output depends on all previousbits, so the most significant output depends on all the inputbits. Instead, in speculative adders each output depends onlyon the previous bits, where goes as [12]–[15].This reflects the fact that a propagate chain longer thanis a very rare event.A first speculative approach to addition was proposed by
Nowick [12] in asynchronous contest, which implements a vari-able latency adder cutting the lowest levels of a Kogge-Stoneadder. In synchronous contest, Verma et al.[13] propose a vari-able latency speculative adder; here the speculative additionis realized in the same way as [12], cutting the lower levelsof a Kogge-Stone adder. A similar approach is employed in[14]. In [15] a variable latency carry-select adder is introduced,where the adder is fragmented in various windows, each onecontaining a Kogge-Stone adder.The Kogge-Stone adder is often used when speed is the pri-
mary concern, since it uses the minimum number of logic levelsand each cell in the adder tree has fanout of 2. This comes at thecost of usingmany propagate-generate cells andmanywires thatmust be routed between stages.In this paper we propose a novel variable latency specula-
tive adder based on Han-Carlson [6] parallel-prefix topology.The Han-Carlson topology uses one more stage than Kogge-Stone adder, while requiring a reduced number of cells and sim-plified wiring. Thus, it can achieve similar speed performancecompared to Kogge-Stone adder, at lower power consumptionand area [16]. We show that a speculative carry tree can beobtained by pruning some intermediate levels of the classicalHan-Carlson topology. The paper presents a rigorous derivationof the error detection network and shows that the error detec-tion network required in speculative Han-Carlson adders is sig-nificantly faster than the one used by speculative Kogge-Stonearchitecture. An extensive set of implementation results for 65nm CMOS technology shows that proposed Han-Carlson vari-able latency adders outperform previously developed variablelatency Kogge-Stone architectures. Compared with traditional,non-speculative, adders, our analysis demonstrates that variablelatency Han-Carlson adders show sensible improvements whenthe highest speed is required; otherwise the burden imposed by
1549-8328 © 2015 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
2 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS
error detection and error correction stages overwhelms any ad-vantage.The paper is organized as follows. In Section II we recall the
basic architecture of parallel-prefix adders. The stages in whichvariable latency speculative prefix adders can be subdivided arepresented in Section III where, after a brief review of Kogge-Stone speculative prefix-processing stage introduced in [12],we present the proposed Han-Carlson speculative topology. De-tailed discussion about the error detection stage is also reportedin this Section. The Section IV presents spatial and timing com-plexity of investigated architectures. Section V shows detailedimplementation and synthesis results of the proposed adders, foroperand size ranging from 32 through 128 bits. Section VI con-cludes the paper with some final remarks.
II. PRELIMINARIES
A. Prefix AdditionThe binary addition problem can be formulated as fol-
lows: given an -bit augend and an-bit addend generate the -bit sum
. Let us indicate as the carry out of the-th bit. The sum bit and the carry can be computed asfollows:
(2)(3)
In prefix addition we use three stages to compute the sum:pre-processing, prefix-processing and post-processing.In the pre-processing stage the generate and propagate
signal are computed as:
(4)(5)
The condition means that a carry is generated at bit, while the condition means that a carry is propagatedthrough bit .The concept of generate and propagate can be extended to
a block of contiguous bits, from bit to bit (with ) asfollows:
ifotherwise (6)
ifotherwise (7)
where: .The condition means that a carry is generated in the
block , while the condition means that a carryis propagated through the block. Thus, for any bit , the carrycan be expressed as:
(8)
where is the input carry of the -bit adder. In the following,for the sake of simplicity, we assume that , so that (8)simplifies as:
(9)
The block generate and propagate terms are computed inthe prefix-processing stage of the adder. To that purpose, the( , ) couples are expressed with the help of the prefixoperator defined as follows:
Fig. 1. Han-Carlson and Kogge-Stone parallel-prefix topologies. .
(10)
where: . The prefix operator has two importantproperties: it is associative and it is idempotent. These proper-ties are exploited in the prefix-processing stage to speed-up thecomputation.Finally, in the post-processing stage, the sum bit are com-
puted using (8) and:
(11)
B. Han-Carlson and Kogge-Stone Parallel-Prefix AdderTopologiesThe pre-processing and post-processing stages of a prefix
adder involve only simple operations on signals local to eachbit position. Therefore, adder performance mainly depends onprefix-processing stage.Fig. 1 shows Han-Carlson and Kogge-Stone prefix adders
topologies. Here black dots represent the prefix operator (10),while white dots are simple placeholders.Kogge-Stone adder is composed by levels and
present a fanout of two at each level using a large number ofblack cells and many wire tracks. A good trade-off betweenfanout, number of logic levels and number of black cells isgiven by Han-Carlson. The outer rows of the Han-Carlsontopology are Brent-Kung [3] graphs, while the inner rows areKogge-Stone graphs. The Han-Carlson adder in Fig. 1 uses asingle Brent-Kung level at the beginning and at the end of thegraph, and the number of levels is .
III. VARIABLE LATENCY SPECULATIVE PREFIX ADDERS
Variable latency speculative prefix adders can be subdividedin five stages: pre-processing, speculative prefix-processing,post-processing, error detection and error correction. The errorcorrection stage is off the critical path, as it has two clockcycles to obtain the exact sum when speculation fails.

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
ESPOSITO et al.: VARIABLE LATENCY SPECULATIVE HAN-CARLSON ADDER 3
Fig. 2. Kogge-Stone speculative prefix-processing stage. The last row of abit Kogge-Stone adder is pruned, resulting in a speculative prefix-processing
stage with .
A. Pre-Processing
In the pre-processing stage the generate and propagatesignals are computed as in (4), (5).
B. Speculative Prefix-Processing
The speculative prefix-processing stage is one of the maindifferences compared with the standard prefix adders recalledin previous section. Instead of computing all the andrequired in (8) to obtain the exact carry values, only a subset ofblock generate and propagate signals is calculated; in the post-processing stage approximate carry values are obtained fromthis subset. The output of the speculative prefix-processing stagewill also be used in the error detection and in the error correctionstages discussed in the following.The basic assumption behind speculative prefix-processing
stage is that carry signals propagate for no more than bits,with and . This assumption is corrob-orated by the analyses in [13],[17] that demonstrate that havinga propagate chain longer that is a very rare event.1) Kogge-Stone Topology: The Kogge-Stone speculative
prefix-processing stage has been proposed in [12],[13] andcan be obtained by pruning the last levels of a traditionalKogge-Stone adder. In the example shown in Fig. 2, the lastlevel of a bit Kogge-Stone adder is pruned. As it can beobserved, for the length of propagate chains extends for8 bits, resulting in a speculative prefix-processing stage with
.In general, one has , where is the number of
pruned levels; the number of levels of the speculative stage iscorrespondingly reduced from to (assumingthat is a power of two).In general, the computed propagate and generate signals for
the speculative Kogge-Stone architecture are:
(12)
2) Han-Carlson Topology: Han-Carlson adder constitutesa good trade-off between fanout, number of logic levels andnumber of black cells. Because of this, Han-Carlson adder canachieve equal speed performance respect to Kogge-Stone adder,at lower power consumption and area [16]. Therefore it is inter-esting to implement a speculative Han-Carlson adder.Moved by these reasons, we have generated a Han-Carlson
speculative prefix-processing stage by deleting the last rows ofthe Kogge-Stone part of the adder. As an example, the Fig. 3shows the Han-Carlson adder of Fig. 1 in which the two Brent-Kung rows at the beginning and at the end of the graph are un-changed, while the last Kogge-Stone row is pruned. This yieldsa speculative stage with . In general, one has
Fig. 3. Han-Carlson speculative prefix-processing stage. The last Kogge-Stonerow of the bit graph is pruned, resulting in a speculative prefix pro-cessing stage with .
, where is the number of pruned levels; the numberof levels of the speculative Han-Carlson stage reduces from
to (assuming that is a power oftwo).As it can be observed in Fig. 3, the length of the propagate
chains is only for , while forthe propagate chain length is .
In general, the computed propagate and generate signals forthe speculative Han-Carlson architecture are:
(13)
As it will be apparent in the following, having the propagatelengths equal to for half of the outputs greatly simplifiesthe error detection.
C. Post-ProcessingIn the post-processing stage we firstly compute the approx-
imate carries, , and then use them to obtain the approximatesum bits as follows:
(14)
Similarly to (9), the approximate carries are obtained as thegenerate signals available in the last level of the prefix-pro-cessing stage. We have:
for:otherwise
(15)and:
for:for: oddfor: even
(16)
D. Error DetectionThe conditions in which at least one of the approximate car-
ries is wrong (misprediction) are signaled by the error detectionstage. In case of misprediction, an error signal is asserted byerror detection stage and the output of the post-processing stageis discarded. The error correction stage will give the correct sumin the next clock period.1) Kogge-Stone: The error condition for carry can be ob-
tained from (9),(15) and using the properties of propagate gen-erate signals as:
for:otherwise (17)
Thus, the error signal can be expressed as:

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
4 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS
Fig. 4. The nodes of the prefix-processing stage, whose outputs are needed tocompute the error signal, are named “checking nodes” and are highlighted asbig hatched dots, for the topologies in Fig. 2–3.
(18)
where the symbol represents the logical OR.It is important to note that (18) is a necessary and sufficient
error condition that requires the calculation of . Unfor-tunately, these terms are actually not computed by the specula-tive prefix-processing stage (avoiding the computation of theseterms is the key idea of speculative adders). Thus, in previouspapers,(18) is replaced by the following looser relation:
(19)
The last equation is a necessary-only error condition. Byusing (19), the error signal can be triggered even in absenceof actual misprediction. While this does not harm the correctoperation of the speculative adder, having an high rate of such“false positive” errors degrades the average addition time (1).In this paper, instead, we rewrite the necessary and sufficientcondition (18) in a form that does not require theterms. To that purpose, let us consider the last two terms of theOR in (18), with index and :
(20)
One has:
(21)
Substituting (21) in (20), the terms with index andof (18) can be simplified as:
(22)
Similar simplifications can be realized by considering in (18)the terms and and so on. Finally one obtains:
(23)
Let us consider, as an example, the prefix-processing stage inFig. 2. The error signal (23) is given by:
(24)
2) Han-Carlson: The error condition for carry can be ob-tained from (9), (16) as:
for:oddeven
(25)
The error signal can be written as:
(26)It can easily be seen that in (26) the terms in the second OR
are implied by the terms in the first OR. Let us consider, forinstance, the first two terms of the OR (assuming that is even).We have:
(27)
Thus, we can write:
(28)
The last equation can be simplified, following an approachsimilar to previous subsection. Let us consider the last two termsof the OR in (28), with index and (assuming thatis even):
(29)
One has:
(30)Substituting (30) in (29), the terms with index and
of (28) can be simplified as:
(31)
Similar simplifications can be realized by considering in (28)the terms and and so on. Finally one obtains:
(32)
Let us consider, as an example, the prefix-processing stage inFig. 3. The error signal (32) is given by:
(33)
By comparing (23) and (32), it can easily be seen that thenumber of terms to be OR-ed to obtain the error signal is halvedin the Han-Carlson topology, compared to Kogge-Stone.We name “checking nodes” the nodes of the prefix-processing
stage, whose outputs are needed to compute the error signal.The checking nodes for both the Kogge-Stone example of Fig. 2and the Han-Carlson example of Fig. 3 are highlighted as bighatched dots in Fig. 4.As it can be observed, in Kogge-Stone some of the checking
cells are at the last level of the graph; their output signals areavailable after three black cells delay. In Han-Carlson the crit-ical checking cells are in the second last level of the graph andare also available after three black cells delay, in spite of thelarger number of levels of the Han-Carlson prefix-processingstage.
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
ESPOSITO et al.: VARIABLE LATENCY SPECULATIVE HAN-CARLSON ADDER 5
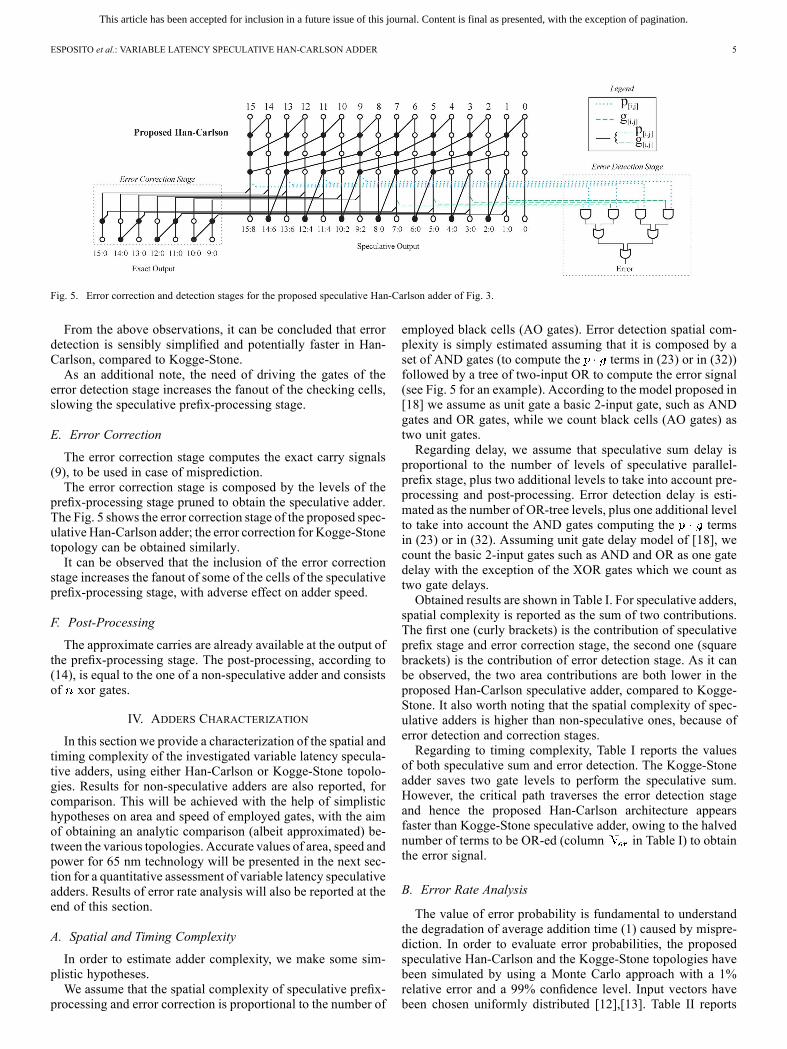
Fig. 5. Error correction and detection stages for the proposed speculative Han-Carlson adder of Fig. 3.
From the above observations, it can be concluded that errordetection is sensibly simplified and potentially faster in Han-Carlson, compared to Kogge-Stone.As an additional note, the need of driving the gates of the
error detection stage increases the fanout of the checking cells,slowing the speculative prefix-processing stage.
E. Error Correction
The error correction stage computes the exact carry signals(9), to be used in case of misprediction.The error correction stage is composed by the levels of the
prefix-processing stage pruned to obtain the speculative adder.The Fig. 5 shows the error correction stage of the proposed spec-ulative Han-Carlson adder; the error correction for Kogge-Stonetopology can be obtained similarly.It can be observed that the inclusion of the error correction
stage increases the fanout of some of the cells of the speculativeprefix-processing stage, with adverse effect on adder speed.
F. Post-Processing
The approximate carries are already available at the output ofthe prefix-processing stage. The post-processing, according to(14), is equal to the one of a non-speculative adder and consistsof xor gates.
IV. ADDERS CHARACTERIZATION
In this section we provide a characterization of the spatial andtiming complexity of the investigated variable latency specula-tive adders, using either Han-Carlson or Kogge-Stone topolo-gies. Results for non-speculative adders are also reported, forcomparison. This will be achieved with the help of simplistichypotheses on area and speed of employed gates, with the aimof obtaining an analytic comparison (albeit approximated) be-tween the various topologies. Accurate values of area, speed andpower for 65 nm technology will be presented in the next sec-tion for a quantitative assessment of variable latency speculativeadders. Results of error rate analysis will also be reported at theend of this section.
A. Spatial and Timing Complexity
In order to estimate adder complexity, we make some sim-plistic hypotheses.We assume that the spatial complexity of speculative prefix-
processing and error correction is proportional to the number of
employed black cells (AO gates). Error detection spatial com-plexity is simply estimated assuming that it is composed by aset of AND gates (to compute the terms in (23) or in (32))followed by a tree of two-input OR to compute the error signal(see Fig. 5 for an example). According to the model proposed in[18] we assume as unit gate a basic 2-input gate, such as ANDgates and OR gates, while we count black cells (AO gates) astwo unit gates.Regarding delay, we assume that speculative sum delay is
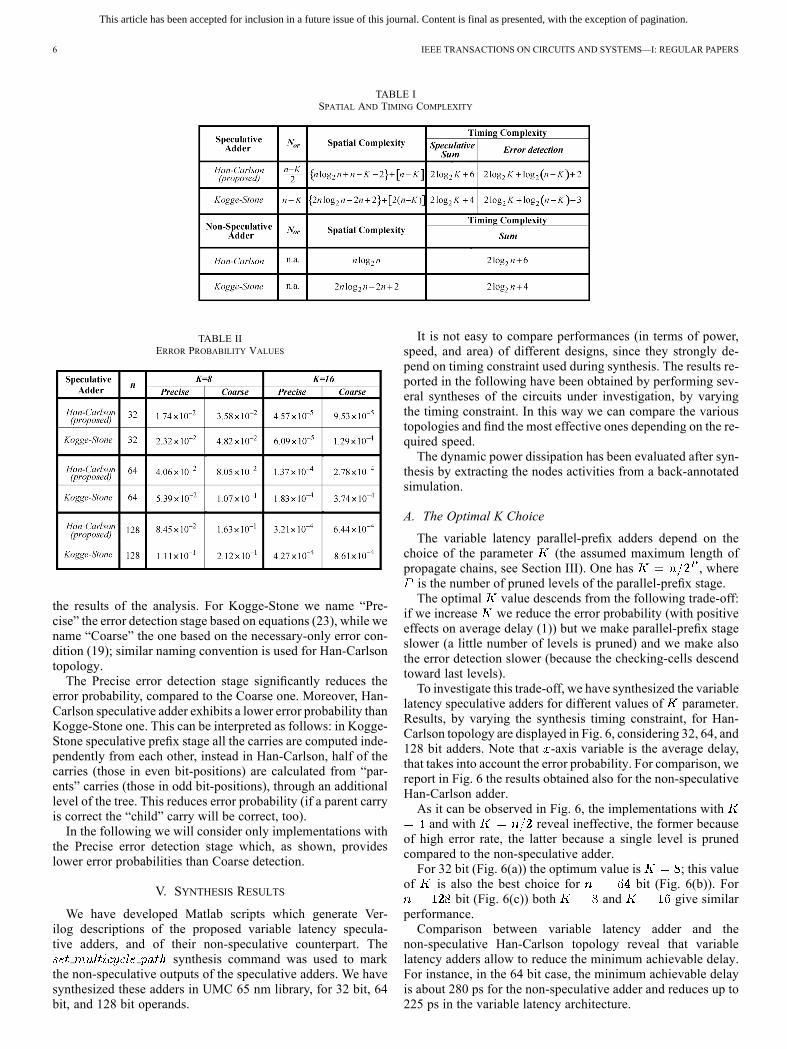
proportional to the number of levels of speculative parallel-prefix stage, plus two additional levels to take into account pre-processing and post-processing. Error detection delay is esti-mated as the number of OR-tree levels, plus one additional levelto take into account the AND gates computing the termsin (23) or in (32). Assuming unit gate delay model of [18], wecount the basic 2-input gates such as AND and OR as one gatedelay with the exception of the XOR gates which we count astwo gate delays.Obtained results are shown in Table I. For speculative adders,
spatial complexity is reported as the sum of two contributions.The first one (curly brackets) is the contribution of speculativeprefix stage and error correction stage, the second one (squarebrackets) is the contribution of error detection stage. As it canbe observed, the two area contributions are both lower in theproposed Han-Carlson speculative adder, compared to Kogge-Stone. It also worth noting that the spatial complexity of spec-ulative adders is higher than non-speculative ones, because oferror detection and correction stages.Regarding to timing complexity, Table I reports the values
of both speculative sum and error detection. The Kogge-Stoneadder saves two gate levels to perform the speculative sum.However, the critical path traverses the error detection stageand hence the proposed Han-Carlson architecture appearsfaster than Kogge-Stone speculative adder, owing to the halvednumber of terms to be OR-ed (column in Table I) to obtainthe error signal.
B. Error Rate Analysis
The value of error probability is fundamental to understandthe degradation of average addition time (1) caused by mispre-diction. In order to evaluate error probabilities, the proposedspeculative Han-Carlson and the Kogge-Stone topologies havebeen simulated by using a Monte Carlo approach with a 1%relative error and a 99% confidence level. Input vectors havebeen chosen uniformly distributed [12],[13]. Table II reports
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
6 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS
TABLE ISPATIAL AND TIMING COMPLEXITY
TABLE IIERROR PROBABILITY VALUES
the results of the analysis. For Kogge-Stone we name “Pre-cise” the error detection stage based on equations (23), while wename “Coarse” the one based on the necessary-only error con-dition (19); similar naming convention is used for Han-Carlsontopology.The Precise error detection stage significantly reduces the
error probability, compared to the Coarse one. Moreover, Han-Carlson speculative adder exhibits a lower error probability thanKogge-Stone one. This can be interpreted as follows: in Kogge-Stone speculative prefix stage all the carries are computed inde-pendently from each other, instead in Han-Carlson, half of thecarries (those in even bit-positions) are calculated from “par-ents” carries (those in odd bit-positions), through an additionallevel of the tree. This reduces error probability (if a parent carryis correct the “child” carry will be correct, too).In the following we will consider only implementations with
the Precise error detection stage which, as shown, provideslower error probabilities than Coarse detection.
V. SYNTHESIS RESULTS
We have developed Matlab scripts which generate Ver-ilog descriptions of the proposed variable latency specula-tive adders, and of their non-speculative counterpart. The
synthesis command was used to markthe non-speculative outputs of the speculative adders. We havesynthesized these adders in UMC 65 nm library, for 32 bit, 64bit, and 128 bit operands.
It is not easy to compare performances (in terms of power,speed, and area) of different designs, since they strongly de-pend on timing constraint used during synthesis. The results re-ported in the following have been obtained by performing sev-eral syntheses of the circuits under investigation, by varyingthe timing constraint. In this way we can compare the varioustopologies and find the most effective ones depending on the re-quired speed.The dynamic power dissipation has been evaluated after syn-
thesis by extracting the nodes activities from a back-annotatedsimulation.
A. The Optimal K Choice
The variable latency parallel-prefix adders depend on thechoice of the parameter (the assumed maximum length ofpropagate chains, see Section III). One has , whereis the number of pruned levels of the parallel-prefix stage.The optimal value descends from the following trade-off:
if we increase we reduce the error probability (with positiveeffects on average delay (1)) but we make parallel-prefix stageslower (a little number of levels is pruned) and we make alsothe error detection slower (because the checking-cells descendtoward last levels).To investigate this trade-off, we have synthesized the variable
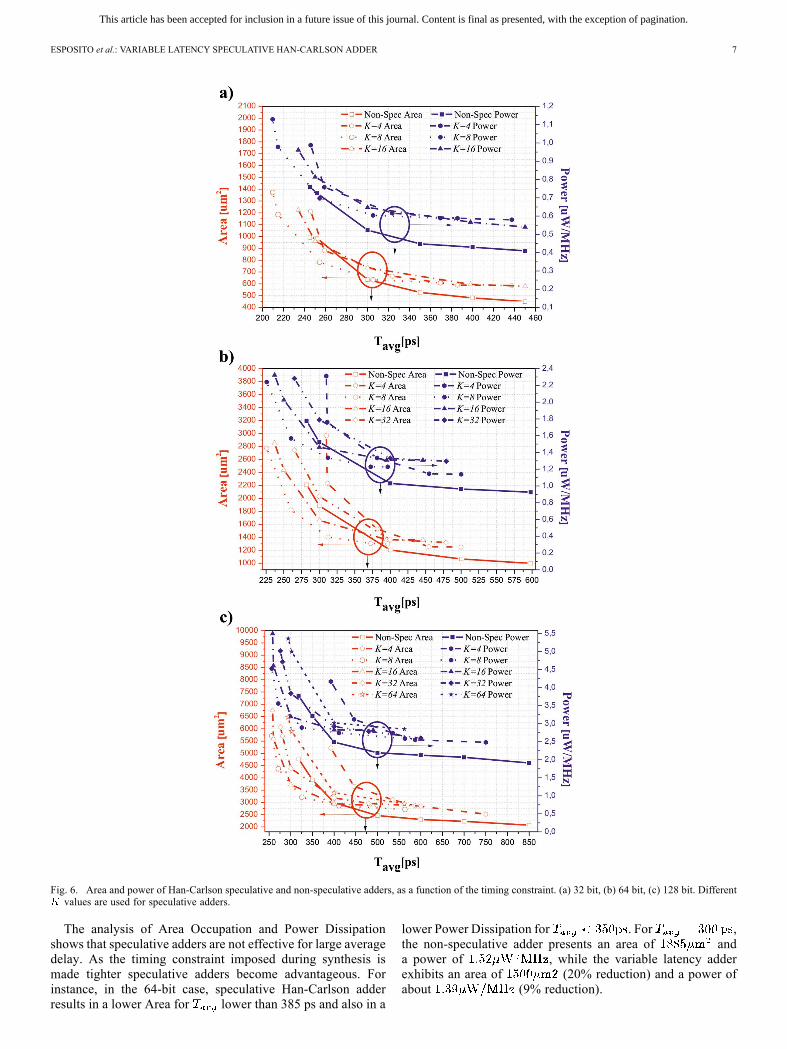
latency speculative adders for different values of parameter.Results, by varying the synthesis timing constraint, for Han-Carlson topology are displayed in Fig. 6, considering 32, 64, and128 bit adders. Note that -axis variable is the average delay,that takes into account the error probability. For comparison, wereport in Fig. 6 the results obtained also for the non-speculativeHan-Carlson adder.As it can be observed in Fig. 6, the implementations withand with reveal ineffective, the former because
of high error rate, the latter because a single level is prunedcompared to the non-speculative adder.For 32 bit (Fig. 6(a)) the optimum value is ; this value
of is also the best choice for bit (Fig. 6(b)). Forbit (Fig. 6(c)) both and give similar
performance.Comparison between variable latency adder and the
non-speculative Han-Carlson topology reveal that variablelatency adders allow to reduce the minimum achievable delay.For instance, in the 64 bit case, the minimum achievable delayis about 280 ps for the non-speculative adder and reduces up to225 ps in the variable latency architecture.
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
ESPOSITO et al.: VARIABLE LATENCY SPECULATIVE HAN-CARLSON ADDER 7
Fig. 6. Area and power of Han-Carlson speculative and non-speculative adders, as a function of the timing constraint. (a) 32 bit, (b) 64 bit, (c) 128 bit. Differentvalues are used for speculative adders.
The analysis of Area Occupation and Power Dissipationshows that speculative adders are not effective for large averagedelay. As the timing constraint imposed during synthesis ismade tighter speculative adders become advantageous. Forinstance, in the 64-bit case, speculative Han-Carlson adderresults in a lower Area for lower than 385 ps and also in a
lower Power Dissipation for . For ,the non-speculative adder presents an area of anda power of , while the variable latency adderexhibits an area of (20% reduction) and a power ofabout (9% reduction).
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
8 IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS—I: REGULAR PAPERS
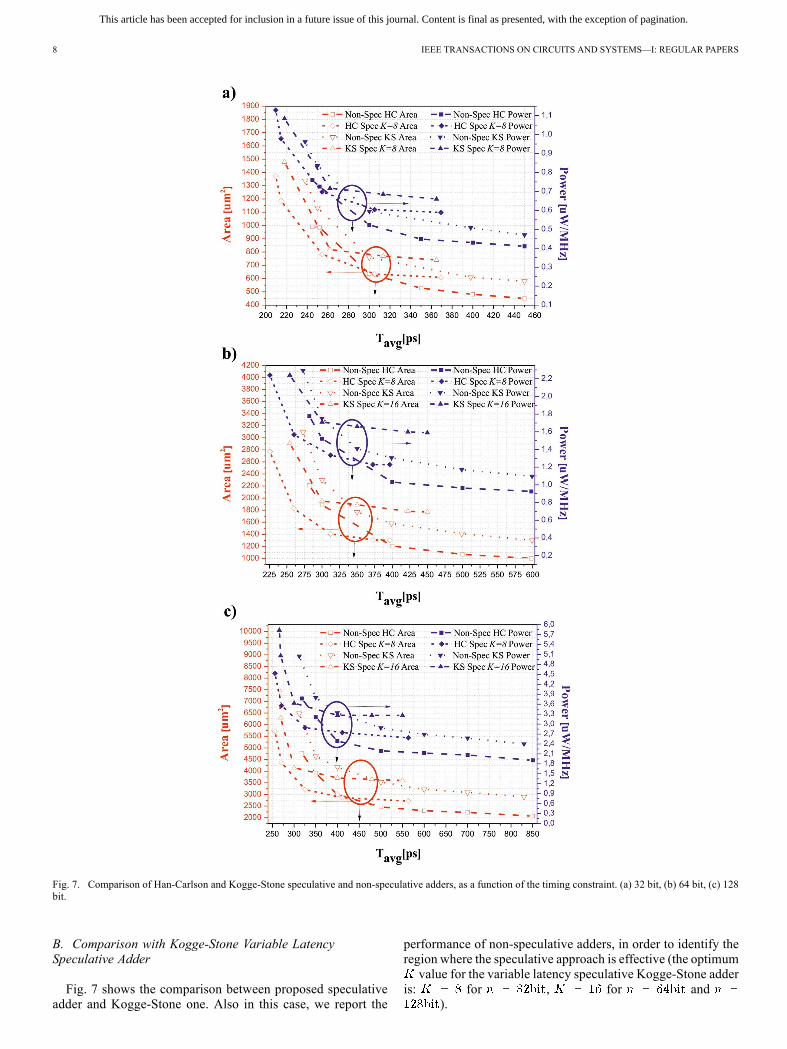
Fig. 7. Comparison of Han-Carlson and Kogge-Stone speculative and non-speculative adders, as a function of the timing constraint. (a) 32 bit, (b) 64 bit, (c) 128bit.
B. Comparison with Kogge-Stone Variable LatencySpeculative Adder
Fig. 7 shows the comparison between proposed speculativeadder and Kogge-Stone one. Also in this case, we report the
performance of non-speculative adders, in order to identify theregion where the speculative approach is effective (the optimum
value for the variable latency speculative Kogge-Stone adderis: for , for and
).

This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
ESPOSITO et al.: VARIABLE LATENCY SPECULATIVE HAN-CARLSON ADDER 9
The proposed variable latency Han-Carlson adder outper-forms the speculative Kogge-Stone architecture in all theconsidered cases, confirming the trend highlighted in Table I.As an example, focusing on 64-bit adders, for lower than
350 ps, the proposed Han-Carlson speculative adder is the bestchoice in terms of silicon area and power consumption. More-over, it allows to reduce the minimum achievable to 225ps, with a 18% improvement respect to Kogge-Stone non-spec-ulative adder and a 11% improvement respect to Kogge-Stonespeculative adder. For , proposed speculativeadders offer 45% area reduction and 35% power saving com-pared to Kogge-Stone non-speculative adder.
VI. CONCLUSIONIn this paper a novel variable latency Han-Carlson parallel-
prefix speculative adder for high-speed application is proposed.A new, more accurate, error detection network is introduced,which allows reducing the error probability compared to the pre-vious approaches.An extensive set of implementation results for 65 nm
CMOS technology shows that proposed Han-Carlson variablelatency adders outperforms previously developed variablelatency Kogge-Stone architectures. Compared with traditional,non-speculative, adders, our analysis demonstrates that variablelatency Han-Carlson adders show sensible improvements whenthe highest speed is required; otherwise the burden imposedby error detection and error correction stages overwhelms anyadvantage. Additional work is required to extend the specu-lative approach to other parallel-prefix architectures, such asBrent-Kung, Ladner-Fisher, and Knowles.
REFERENCES[1] I. Koren, Computer Arithmetic Algorithms. Natick, MA, USA: A K
Peters, 2002.[2] R. Zimmermann, “Binary adder architectures for cell-based VLSI and
their synthesis,” Ph.D. thesis, Swiss Federal Institute of Technology,(ETH) Zurich, Zurich, Switzerland, 1998, Hartung-Gorre Verlag.
[3] R. P. Brent and H. T. Kung, “A regular layout for parallel adders,”IEEE Trans. Comput., vol. C-31, no. 3, pp. 260–264, Mar. 1982.
[4] P. M. Kogge and H. S. Stone, “A parallel algorithm for the efficientsolution of a general class of recurrence equations,” IEEE Trans.Comput., vol. C-22, no. 8, pp. 786–793, Aug. 1973.
[5] J. Sklansky, “Conditional-sum addition logic,” IRE Trans. Electron.Comput., vol. EC-9, pp. 226–231, Jun. 1960.
[6] T. Han and D. A. Carlson, “Fast area-efficient VLSI adders,” in Proc.IEEE 8th Symp. Comput. Arith. (ARITH), May 18–21, 1987, pp. 49–56.
[7] R. E. Ladner and M. J. Fischer, “Parallel prefix computation,” J. ACM,vol. 27, no. 4, pp. 831–838, Oct. 1980.
[8] S. Knowles, “A Family of Adders,” in Proc. 14th IEEE Symp. Comput.Arith., Vail, CO, USA, Jun. 2001, pp. 277–281.
[9] S.-L. Lu, “Speeding up processing with approximation circuits,” Com-puter, vol. 37, no. 3, pp. 67–73, Mar. 2004.
[10] T. Liu and S.-L. Lu, “Performance improvement with circuit-levelspeculation,” in Proc. 33rd Annu. IEEE/ACM Int. Symp. Microarchit.(MICRO-33), 2000, pp. 348–355.
[11] N. Zhu, W.-L. Goh, and K.-S. Yeo, “An enhanced low-power high-speed Adder For Error-Tolerant application,” in Proc. 2009 12th Int.Symp. Integr. Circuits (ISIC '09), Dec. 14–16, 2009, pp. 69–72.
[12] S. M. Nowick, “Design of a low-latency asynchronous adder usingspeculative completion,” IEE Proc. Comput. Digit. Tech., vol. 143, no.5, pp. 301–307, Sep. 1996.
[13] A. K. Verma, P. Brisk, and P. Ienne, “Variable Latency SpeculativeAddition: A New Paradigm for Arithmetic Circuit Design,” in Proc.Design, Autom., Test Eur. (DATE '08), Mar. 2008, pp. 1250–1255.
[14] A. Cilardo, “A new speculative addition architecture suitable for two'scomplement operations,” in Proc. Design, Autom., Test Eur. Conf.Exhib. (DATE '09), Apr. 2009, pp. 664–669.
[15] K. Du, P. Varman, and K. Mohanram, “High performance reliable vari-able latency carry select addition,” in Proc. Design, Autom., Test Eur.Conf. Exhib. (DATE '12), Mar. 2012, pp. 1257–1262.
[16] S. K. Mathew, R. K. Krishnamurthy, M. A. Anders, R. Rios, K. R.Mistry, and K. Soumyanath, “Sub-500-ps 64-b ALUs in 0.18- m SOI/bulk CMOS: Design and scaling trends,” IEEE J. Solid-State Circuits,vol. 36, no. 11, pp. 1636–1646, Nov. 2001.
[17] B. Parhami, Computer Arithmetic: Algorithms and Hardware De-sign. New York: Oxford Univ. Press, 2000.
[18] A. Tyagi, “A reduced-area scheme for carry-select adders,” IEEETrans. Comput., vol. 42, no. 10, pp. 1163–1170, Oct. 1993.
Darjn Espositowas born in 1989 in Naples, Italy. Hereceived the M.S. degree (with honors) in electronicengineering from the University of Naples “FedericoII,” in 2013, where he is currently working toward thePh.D. degree. His research interests include designof digital VLSI circuits, with particular emphasis onspeculative functional units.
Davide De Caro (M'05–SM'09) received the M.S.degree in electronic engineering with honors, in July1999, and the Ph.D. degree in electronic engineeringand computer science, in February 2003, both fromthe University of Naples “Federico II”, Italy.He has worked in the area of digital integrated
VLSI circuit design for the last fourteen years. SinceMarch 2003 he is a Researcher at the Department ofElectrical Engineering and Information Technology.Dr. De Caro is author of more than 50 technicalpapers in international journals and refereed inter-
national conferences.
Ettore Napoli was born in Italy in 1971. He receivedthe Electronic engineering degree with honors in1995; the Ph.D. degree in electronic engineering in1999, and the Physics degree with honors in 2009.He has been an Associate Professor, University ofNapoli, Italy, since 2005.He was a Research Associate at the Engineering
Dept. of the University of Cambridge, U.K., in 2004.His scientific interests include modeling and designof power semiconductor devices and VLSI circuit de-sign. Prof. Napoli is author or coauthor of more than
100 papers published in international journals and conferences.
Nicola Petra (M'05) received the Laurea degreeand the Ph.D. degree from the University of Napoli“Federico II,” Italy, in 2002 and 2007 respectively.His research interests include design of digital VLSIcircuits for telecommunications and high-perfor-mance arithmetic circuits. He is now working asa Researcher at the Department of Electronics andTelecommunications Engineering of the Universityof Napoli “Federico II.” He has authored or coau-thored more than 30 papers on scientific journals andinternational conferences.
Antonio Giuseppe Maria Strollo (M'05–SM'06) re-ceived the Laurea degree (cum laude) and the Ph.D.degree in electronic engineering from the Universityof Napoli Federico II, Italy. From 2002 he is fullprofessor at the same University. He has publishedmore than 110 papers on international journalsand conferences. His current research interests aredesign and analysis of VLSI circuits. From 2009to 2012 he served as Associate Editor of the IEEETRANSACTIONS ON CIRCUITS AND SYSTEMS—PARTI: REGULAR PAPERS; currently he is Associate Editor
of Integration, the VLSI Journal.




























