Embed Size (px)
Citation preview

Independence of Early Speech Processing from Word Meaning
Katherine E. Travis1,8 Matthew K. Leonard8,2, Alexander M. Chan9,6, Christina Torres8,3, Marisa L. Sizemore5, Zhe Qu8,10,Emad Eskandar7, Anders M. Dale1,8,3, Jeffrey L. Elman2,4, Sydney S. Cash9,6 and Eric Halgren1,8,3,4
1Department of Neurosciences, 2Department of Cognitive Science, 3Department of Radiology, 4Kavli Institute for Brain and Mindand 5Joint Doctoral Program in Language and Communication Disorders, San Diego State University/University of California,San Diego, CA 92093, USA 6Department of Neurology and 7Department of Neurosurgery, Massachusetts General Hospital,Boston, MA 02114, USA 8Multimodal Imaging Laboratory, University of California, San Diego, La Jolla, CA 92037, USA 9Harvard-MIT Division of Health Science and Technology, Medical Engineering and Medical Physics, Cambridge, MA 02139, USA10Department of Psychology, Sun Yat-sen University, Guangzhou 510275, China
Address correspondence to Eric Halgren, PhD, Multimodal Imaging Laboratory, University of California, San Diego 8950 Villa La Jolla Dr., SanDiego, CA 92037-0841, USA. Email: [email protected] and Matthew K. Leonard, PhD, Multimodal Imaging Laboratory, University of California,San Diego, 8950 Villa La Jolla Dr., San Diego, CA 92037-0841, USA. Email: [email protected]
K.E.T., M.K.L., and A.M.C. contributed equally to this research.
We combined magnetoencephalography (MEG) with magneticresonance imaging and electrocorticography to separate in anatomyand latency 2 fundamental stages underlying speech comprehen-sion. The first acoustic-phonetic stage is selective for words rela-tive to control stimuli individually matched on acoustic properties. Itbegins ∼60 ms after stimulus onset and is localized to middlesuperior temporal cortex. It was replicated in another experiment,but is strongly dissociated from the response to tones in the samesubjects. Within the same task, semantic priming of the samewords by a related picture modulates cortical processing in abroader network, but this does not begin until ∼217 ms. The earlieronset of acoustic-phonetic processing compared with lexico-semantic modulation was significant in each individual subject. TheMEG source estimates were confirmed with intracranial local fieldpotential and high gamma power responses acquired in 2 additionalsubjects performing the same task. These recordings further ident-ified sites within superior temporal cortex that responded only tothe acoustic-phonetic contrast at short latencies, or the lexico-semantic at long. The independence of the early acoustic-phoneticresponse from semantic context suggests a limited role for lexicalfeedback in early speech perception.
Keywords: ECoG, MEG, N400, speech processing
Introduction
Speech perception can logically be divided into successivestages that convert the acoustic input into a meaningful word.Traditional accounts distinguish several stages: initial acoustic(nonlinguistic), phonetic (linguistic featural), phonemic(language-specific segments) and, finally, word recognition(Frauenfelder and Tyler 1987; Indefrey and Levelt 2004;Samuel 2011). The translation of an acoustic stimulus from asensory-based, nonlinguistic signal into a linguistically rel-evant code presumably requires a neural mechanism thatselects and encodes word-like features from the acousticinput. Once the stimulus is in this pre-lexical form, it can besent to higher level brain areas for word recognition andmeaning integration.
While these stages are generally acknowledged in neuro-cognitive models of speech perception, there is much dis-agreement regarding the role of higher level lexico-semanticinformation during early word-form encoding stages. Inspired
by behavioral evidence for effects of the lexico-semanticcontext on phoneme identification (Samuel 2011), someneurocognitive theories of speech perception posit lexico-semantic feedback to at least the phonemic stage (McClellandand Elman 1986). However, others can account for thesephenomena with a flow of information that is exclusivelybottom-up (Marslen-Wilson 1987; Norris et al. 2000). Thesemodels (and the behavioral data supporting them) provideimportant testable hypotheses to determine whethertop-down effects occur during early word identification orlate post-lexical processing. To date, neural evidence for oragainst feedback processes in speech perception has beenlacking (Fig. 1B), partly because hemodynamic measuressuch as positron emission tomography and functional mag-netic resonance imaging do not have the resolution to separ-ate them temporally, and furthermore they find that all ofthese processes activate overlapping (but not identical) corti-cal locations (Price 2010). Temporal resolution combinedwith sufficient spatial localization thus provides essentialadditional information for untangling the dynamic interactionof the different processes contributing to speech understand-ing, as well as defining the role of feedback from later toearlier stages (Fig. 1B).
We sought to disambiguate various stages involved inspeech processing by using the temporal precision affordedby electromagnetic recording techniques. An analogy may bedrawn with the visual modality, where some evidence sup-ports an area specialized for word-form encoding in the leftposterior fusiform gyrus, peaking at ∼170 ms (McCandlisset al. 2003; Dehaene and Cohen 2011). This activity reflectshow closely the letter string resembles words (Binder et al.2006), and is followed by distributed activation underlyinglexico-semantic associations peaking at ∼400 ms termed theN400 (Kutas and Federmeier 2011), or N400m when recordedwith magnetoencephalography (MEG) (Marinkovic et al.2003). Intracranial recordings find N400 generators in the lefttemporal and posteroventral prefrontal cortex (Halgren et al.1994a, 1994b). These classical language areas also exhibithemodynamic activation during a variety of lexico-semantictasks (Hickok and Poeppel 2007; Price 2010). It is also wellestablished that auditory words evoke N400m activity (VanPetten et al. 1999; Marinkovic et al. 2003; Uusvuori et al.2008), which begins at ∼200 ms after word onset and peakswithin similar distributed left fronto-temporal networks at
© The Author 2012. Published by Oxford University Press. All rights reserved.For Permissions, please e-mail: [email protected]
Cerebral Cortexdoi:10.1093/cercor/bhs228
Cerebral Cortex Advance Access published August 8, 2012 at U
niversity of California, San D
iego on September 30, 2012
http://cercor.oxfordjournals.org/D
ownloaded from

∼400 ms (Van Petten et al. 1999; Marinkovic et al. 2003). Inthe auditory modality, N400 activity is typically preceded byevoked activity in the posterior superior temporal regiontermed the N100 (or M100 in MEG). The N100/M100 is acomposite of different responses (Näätänen and Picton 1987),and several studies have found that basic phonetic/phonemicparameters such as voice onset time can produce effects inthis latency range (Gage et al. 1998, 2002; Frye et al. 2007;Uusvuori et al. 2008). However, it is not known when, duringauditory word recognition, the phonetic and phonemic pro-cessing which eventually leads to word recognition divergesfrom nonspecific acoustic processing. Furthermore, it isunknown whether such processing is influenced by thelexico-semantic contextual manipulations which stronglyinfluence the N400m.
In order to investigate the spatiotemporal characteristics ofneural responses representing successive stages during speechperception, we employed a well-established and validatedneuroimaging technique known as dynamic statistical para-metric mapping (dSPM; Dale et al. 2000) that combines thetemporal sensitivity of MEG with the spatial resolution ofstructural MRI. During MEG recordings, adult subjects listenedto single-syllable auditory words randomly intermixed withunintelligible matched noise-vocoded control sounds withidentical time-varying spectral acoustics in multiple frequencybands (Shannon et al. 1995). The contrast of words versusnoise stimuli was expected to include the neural processesunderlying acoustic-phonetic processing (Davis et al. 2005;Davis and Johnsrude 2007). These stimuli were immediatelypreceded by a picture stimulus that, in some cases, provided asemantic prime. The contrast between words that werepreceded by a semantically congruous versus incongruouspicture was expected to reveal lexico-semantic activityindexed as the N400m response observed using similar(Marinkovic et al. 2003) or identical (Travis et al. 2011) para-digms. We also performed this task using electrocorticography
(ECoG) in 2 patients with semi-chronic subdural electrodes, al-lowing us to validate the timing and spatial localizationinferred from MEG, and to discern distinct sub-centimetercortical organization in posterior superior temporal regionsfor acoustic-phonetic and lexico-semantic processing. Theseresults were also replicated with MEG in a passive listeningtask using single-syllable words spoken by a different speaker.Subjects were also presented with a series of tones at the endof the MEG recording session, in order to distinguish theword-evoked responses from the well-studied M100 com-ponent. While, as described above, the acoustic-phonetic andlexico-semantic stages of speech processing have been exam-ined extensively in separate tasks, to our knowledge, thisstudy is the first to isolate both stages and compare their onsetand interaction within the same task and using the samestimuli.
Methods
SubjectsFor MEG and MRI, 8 healthy right-handed, monolingual English-speaking adults (3 males; 21–29 years) gave informed, writtenconsent, approved by the UCSD Institutional Review Board. For intra-cranial recordings (ECoG), 2 patients undergoing clinical evaluationfor medically intractable epilepsy with intracranial electrodes (PatientA, 29-year-old female, and Patient B, a 32-year-old male) participatedin this study. Intellectual and language functions were in the averageor low average range (Patient A: FSIQ 93, VIQ 85; Patient B: FSIQ 86,VIQ 91). Written informed consent was approved by the Massachu-setts General Hospital IRB.
Tasks
Picture–Word Matching with Noise Control SoundsIn the primary task, an object picture (<5° visual angle) appeared forthe entire 1300 ms trial duration (600–700 ms intertrial interval). Fivehundred milliseconds after picture onset, either a congruously or in-congruously paired word or noise stimulus was presented binaurally(Fig. 1A). Sounds (mean duration = 445 ± 63 ms; range = 304–637 ms;44.1 kHz; normalized to 65 dB average intensity) were presented bi-naurally through plastic tubes fitted with earplugs. Four conditions(250 trials each) were presented in a random order: picture-matchedwords, picture-matched noise, picture-mismatched words, andpicture-mismatched noise. Behavioral responses were recorded pri-marily to ensure that subjects maintained attention during the exper-iment. Participants were instructed to key press when the sound theywere hearing matched the picture being presented. The responsehand alternated between 100 trial blocks. Subjects were not instructedas to the type of sound stimuli (words, noise) that would be playedduring the experiment. Incongruous words differed from the correctword in their initial phonemes (e.g. “ball” presented after a picture ofa dog) so that information necessary for recognition of the mismatchwould be present from word onset. Words were single-syllable nounsrecorded by a female native English speaker. Sensory control stimuliwere generated using a noise-vocoding procedure that matches eachindividual word’s time-varying spectral content (Shannon et al. 1995).Specifically, white noise was band passed and amplitude modulatedto match the acoustic structure of a corresponding word in totalpower in each of 20 equal bands from 50 to 5000 Hz, and the exacttime versus power waveform for 50–247, 248–495, and 496–5000 Hz.This procedure smears across frequencies within the bands men-tioned above, rendering the stimuli unintelligible without significanttraining (Davis et al. 2005). These types of control stimuli have beenused extensively to provide comparisons that isolate acoustic-phoneticprocessing (Scott et al. 2000; Scott and Johnsrude 2003; Davis et al.2005). Following the scanning session, subjects were presented asample of the noise stimuli without the picture context and reported
Figure 1. Experimental design. (A) Trials present words (preceded by a congruousor incongruous picture visible for the duration of the trial) or matched noise controlsound. (B) Comparison of noise and word trials reveals acoustic-phonetic processing;comparison of congruous and incongruous trials reveals modulation of lexico-semantic processing. Feedforward communication of the identified phonemes isrequired for speech comprehension; feedback influences are debated. (C) Corticalcurrents estimated to the posterior superior temporal plane and sulcus distinguishwords from noise beginning at ∼60 ms; the congruity of the preceding picture to theword does not influence the evoked currents until ∼200 ms, and involve a broadernetwork.
2 Independence of Early Speech Processing from Word Meaning • Travis et al.
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

being unable to name the underlying words. Intelligibility of noisestimuli were examined in an additional pilot experiment in whichadult subjects (n = 22) were asked to listen and rate on a scale (1 =low confidence to 7 = high confidence) how well they could under-stand a random series of noise vocoded sounds (n = 200; constructedin the same manner as the main experiment) interspersed with a sub-sample of corresponding words (n = 50). Subjects were instructed thatall stimuli were English words, some of which had been made noisy.Despite these instructions, subjects rated the noise stimuli as mini-mally intelligible; confidence ratings to noise were 2.17 ± 0.54, versus6.72 ± 0.23 for words.
TonesFollowing the picture–word task, subjects listened to 180 1000 Hzbinaural tones at 1 Hz while maintaining fixation. This task was usedto evoke nonlinguistic acoustic processing for comparison with thehypothesized acoustic-phonetic response in the word–noise compari-son. Data from 1 subject were lost due to an equipment malfunction.
Neuroimaging
MEG and MRIThe procedures involved for both the recording and the post-processing of MEG and MRI data have been described previously(Leonard et al. 2010; Travis et al. 2011) and are only briefly describedhere. Two hundred and four planar gradiometer channels and 102magnetometer channels distributed over the scalp were recorded at1000 Hz with minimal filtering (0.1–200 Hz) using an Elekta Neuro-mag Vectorview system. Due to lower signal-to-noise ratio and moreprominent artifacts, magnetometer data were not used; previousstudies have found similar source localizations when gradiometer andmagnetometer data are analyzed with the current methods in cogni-tive tasks using auditory stimuli (Halgren et al. 2011). The MEG datawere epoched from −200 to 800 ms relative to the onset of the audi-tory stimuli, low-pass filtered (50 Hz), and inspected for bad channels(channels with excessive noise, no signal, or unexplained artifacts),which were excluded from all further analyses. Blink artifacts wereremoved using independent component analysis (Delorme andMakeig 2004) by pairing each MEG channel with the electrooculo-gram (EOG) channel and by rejecting the independent componentthat contained the blink. If the MEG evoked by a particular word wasrejected due to an artifact from the word average, then the corre-sponding noise stimulus was removed from the noise average andvice versa. Cortical sources of MEG activity were estimated using alinear minimum-norm approach, noise normalized to a pre-stimulusperiod (Dale et al. 2000; Liu et al. 2002). Candidate cortical dipolesand the boundary element forward solution surfaces were located ineach subject from 3D T1-weighted MRI. Regional time courses wereextracted from regions of interest (ROIs) on the resulting dSPM maps,and were tested for between-condition differences. The average headmovement over the session was 5.3 ± 3.6 mm (2.9 ± 1.1 mm for thepassive listening experiment, Supplementary Fig. S1).
ROI AnalysisSpecific ROI locations were determined by visual inspection of groupaverage dSPM maps without regard to condition and then automati-cally projected to individual brains by aligning the sulcal–gyral pat-terns of their cortical surfaces (Fischl et al. 1999). For the earlyacoustic-phonetic response, ROIs were selected in 2 bilateral regionsexhibiting the largest peak in group average responses to all wordsand noise (90–110 ms; Supplementary Fig. S5). Six additional ROIswere selected in bilateral fronto-temporal regions exhibiting thelargest group average responses to all words during a period whenN400m activity to auditory words is known to occur (200–400 ms;Supplementary Fig. S5). A 20 ms time window surrounding thelargest peak in group average activity to all words and noise (90–110ms) was selected to display and test for early differential acoustic-phonetic activity (Fig. 2, Supplementary Figs S1 and 2). A 50 ms timewindow surrounding the largest peak in group average activity to all
words (250–300 ms) was selected to display and test for the latersemantic priming effects (Fig. 2, Supplementary Fig. S2).
Intracranial MethodsWhile MEG provides whole-brain coverage and allows for bettercross-subject averaging, MEG and EEG source estimation methods(e.g. dSPM) are inherently uncertain because the inverse problem isill-posed. We thus confirmed dSPM results by recording ECoG in 2patients who performed the identical word–noise task as the healthysubjects in the MEG. ECoG was recorded from platinum subduralsurface electrodes spaced 1 cm apart (Adtech Medical, Racine, WI)over left posterior–superior temporal gyrus semi-chronically placed tolocalize the seizure origin and eloquent cortex prior to surgical treat-ment. In one of these subjects, an additional 2 by 16 contact micro-grid (50 μm platinum–iridium wires embedded in, and cut flush withthe silastic sheet, Adtech Medical, Racine, WI) was implanted over thesame area (Fig. 4, Supplementary Fig. S3). Electrodes were localizedby registering the reconstructed cortical surface from preoperativeMRI to the computed tomography performed with the electrodes insitu, resulting in an error of <3 mm (Dykstra et al. 2012). High gammapower (HGP) from 70 to 190 Hz was estimated using wavelets onindividual trials and weighted by frequency (Chan et al. 2011). ECoGrecordings, especially HGP, are primarily sensitive to the tissueimmediately below the recording surface (0.1 mm diameter for micro-grids, 2.2 mm for macrogrids), and the distance between electrodecenters is also small (1 mm for microgrids, 10 mm for macrogrids). Incontrast, analysis of the point-spread function of dSPM (Dale et al.2000; Liu et al. 2002) and the lead-fields of MEG planar gradiometerson the cortical surface (Halgren et al. 2011) suggests that activity in a∼3 cm diameter cortical patch can contribute to an MEG response.Thus, the certainty of spatial localization, as well as the ability toresolve different closely spaced responses, is both greater for ECoGthan MEG. Although patients suffered from long-standing epilepsy,the recorded contacts were many centimeters away from the seizurefocus, and spontaneous EEG from the local cortex appeared normal.
Sensor-Level StatisticsSignificance of responses at single MEG or ECoG sensors in plannedcomparisons between task conditions was tested using randomresampling (Maris and Oostenveld 2007). Individual trials were ran-domly assigned to different conditions, and a t-test was performedacross trials of sensor values (potential in ECoG, or flux gradient inMEG) between the different pseudo-conditions at each latency. Foreach randomization (performed 500 times), the duration of thelongest continuous string of successive latencies with P < 0.05 wassaved to create the distribution under the null hypothesis. The samet-test was then applied to the actual trial assignment, and all signifi-cant strings longer than the 5th longest string from the randomizationwas considered to be significant at P < 0.01 (because 0.01 = 5/500).This statistic does not require correction for multiple comparisons atdifferent latencies (Maris and Oostenveld 2007).
Results
Early differential activity presumably reflecting acoustic-phonetic processes was found by contrasting MEG responsesto words and their matched noise controls. We then isolatedactivity related to lexico-semantic processing by contrastingMEG responses to the same words and task when they werepreceded by a congruous versus incongruous picture. Thetime course and inferred source localization of theseresponses were confirmed and refined with intracranialrecordings in the same task. Comparison of these contrastsrevealed that acoustic-phonetic processes occur prior totop-down lexico-semantic effects, and in partially distinctcortical locations.
The word>noise contrast revealed an MEG response thatpeaked in a left posterosuperior temporal sensor at ∼100 ms
Cerebral Cortex 3
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from
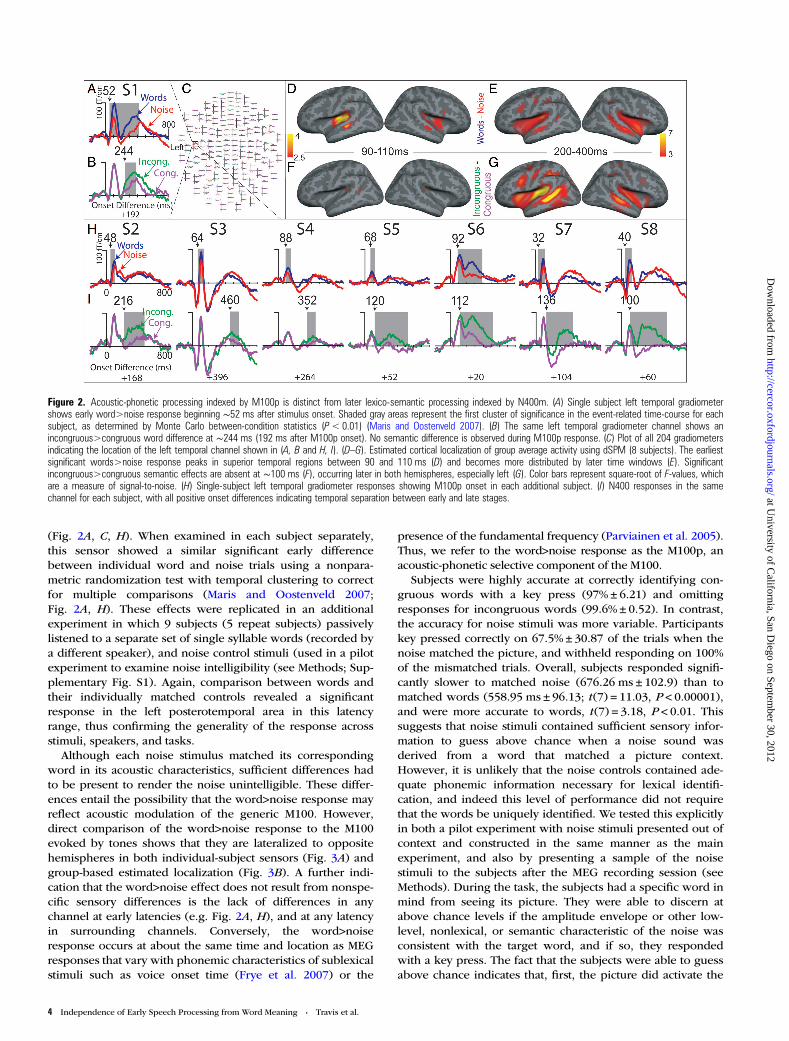
(Fig. 2A, C, H). When examined in each subject separately,this sensor showed a similar significant early differencebetween individual word and noise trials using a nonpara-metric randomization test with temporal clustering to correctfor multiple comparisons (Maris and Oostenveld 2007;Fig. 2A, H). These effects were replicated in an additionalexperiment in which 9 subjects (5 repeat subjects) passivelylistened to a separate set of single syllable words (recorded bya different speaker), and noise control stimuli (used in a pilotexperiment to examine noise intelligibility (see Methods; Sup-plementary Fig. S1). Again, comparison between words andtheir individually matched controls revealed a significantresponse in the left posterotemporal area in this latencyrange, thus confirming the generality of the response acrossstimuli, speakers, and tasks.
Although each noise stimulus matched its correspondingword in its acoustic characteristics, sufficient differences hadto be present to render the noise unintelligible. These differ-ences entail the possibility that the word>noise response mayreflect acoustic modulation of the generic M100. However,direct comparison of the word>noise response to the M100evoked by tones shows that they are lateralized to oppositehemispheres in both individual-subject sensors (Fig. 3A) andgroup-based estimated localization (Fig. 3B). A further indi-cation that the word>noise effect does not result from nonspe-cific sensory differences is the lack of differences in anychannel at early latencies (e.g. Fig. 2A, H), and at any latencyin surrounding channels. Conversely, the word>noiseresponse occurs at about the same time and location as MEGresponses that vary with phonemic characteristics of sublexicalstimuli such as voice onset time (Frye et al. 2007) or the
presence of the fundamental frequency (Parviainen et al. 2005).Thus, we refer to the word>noise response as the M100p, anacoustic-phonetic selective component of the M100.
Subjects were highly accurate at correctly identifying con-gruous words with a key press (97% ± 6.21) and omittingresponses for incongruous words (99.6% ± 0.52). In contrast,the accuracy for noise stimuli was more variable. Participantskey pressed correctly on 67.5% ± 30.87 of the trials when thenoise matched the picture, and withheld responding on 100%of the mismatched trials. Overall, subjects responded signifi-cantly slower to matched noise (676.26 ms ± 102.9) than tomatched words (558.95 ms ± 96.13; t(7) = 11.03, P < 0.00001),and were more accurate to words, t(7) = 3.18, P < 0.01. Thissuggests that noise stimuli contained sufficient sensory infor-mation to guess above chance when a noise sound wasderived from a word that matched a picture context.However, it is unlikely that the noise controls contained ade-quate phonemic information necessary for lexical identifi-cation, and indeed this level of performance did not requirethat the words be uniquely identified. We tested this explicitlyin both a pilot experiment with noise stimuli presented out ofcontext and constructed in the same manner as the mainexperiment, and also by presenting a sample of the noisestimuli to the subjects after the MEG recording session (seeMethods). During the task, the subjects had a specific word inmind from seeing its picture. They were able to discern atabove chance levels if the amplitude envelope or other low-level, nonlexical, or semantic characteristic of the noise wasconsistent with the target word, and if so, they respondedwith a key press. The fact that the subjects were able to guessabove chance indicates that, first, the picture did activate the
Figure 2. Acoustic-phonetic processing indexed by M100p is distinct from later lexico-semantic processing indexed by N400m. (A) Single subject left temporal gradiometershows early word>noise response beginning ∼52 ms after stimulus onset. Shaded gray areas represent the first cluster of significance in the event-related time-course for eachsubject, as determined by Monte Carlo between-condition statistics (P< 0.01) (Maris and Oostenveld 2007). (B) The same left temporal gradiometer channel shows anincongruous>congruous word difference at ∼244 ms (192 ms after M100p onset). No semantic difference is observed during M100p response. (C) Plot of all 204 gradiometersindicating the location of the left temporal channel shown in (A, B and H, I). (D–G). Estimated cortical localization of group average activity using dSPM (8 subjects). The earliestsignificant words>noise response peaks in superior temporal regions between 90 and 110 ms (D) and becomes more distributed by later time windows (E). Significantincongruous>congruous semantic effects are absent at ∼100 ms (F), occurring later in both hemispheres, especially left (G). Color bars represent square-root of F-values, whichare a measure of signal-to-noise. (H) Single-subject left temporal gradiometer responses showing M100p onset in each additional subject. (I) N400 responses in the samechannel for each subject, with all positive onset differences indicating temporal separation between early and late stages.
4 Independence of Early Speech Processing from Word Meaning • Travis et al.
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from
desired lexical element, and secondly that the noise stimuliwere sufficiently well matched on their acoustic characteristicsthat they permitted accurate guessing. The fact that the noise
stimuli could not be recognized when presented in isolationshows that they do not adequately activate acoustic-phoneticelements sufficient for word recognition.
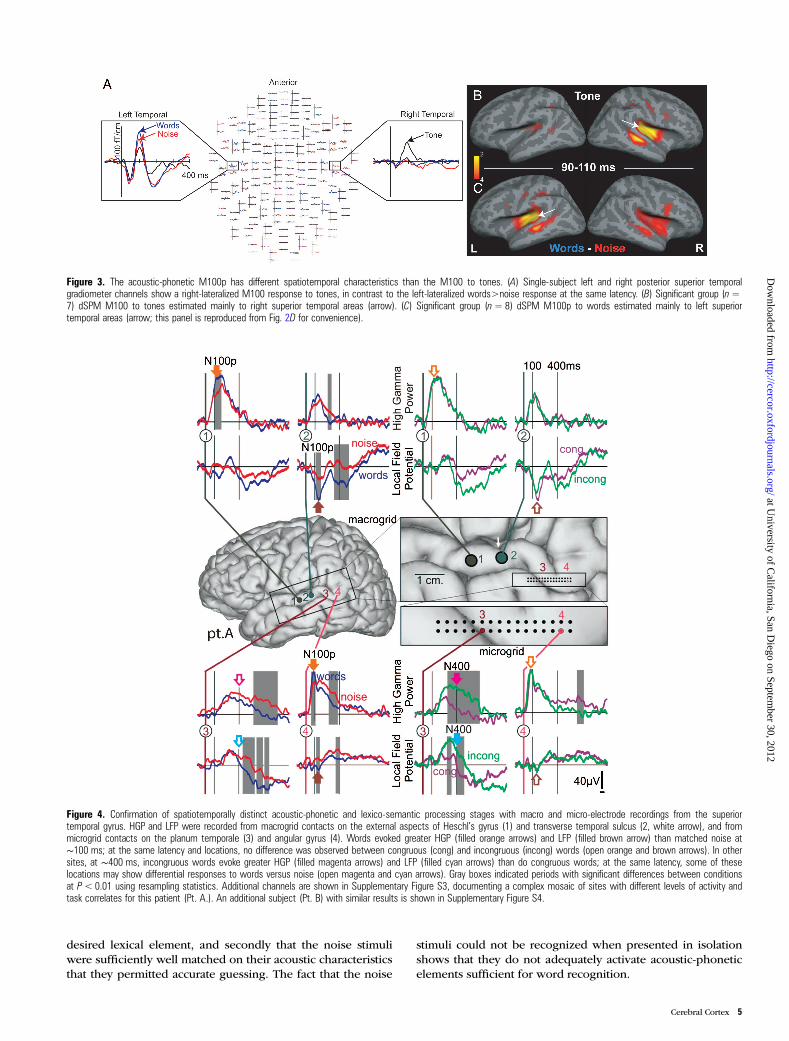
Figure 4. Confirmation of spatiotemporally distinct acoustic-phonetic and lexico-semantic processing stages with macro and micro-electrode recordings from the superiortemporal gyrus. HGP and LFP were recorded from macrogrid contacts on the external aspects of Heschl’s gyrus (1) and transverse temporal sulcus (2, white arrow), and frommicrogrid contacts on the planum temporale (3) and angular gyrus (4). Words evoked greater HGP (filled orange arrows) and LFP (filled brown arrow) than matched noise at∼100 ms; at the same latency and locations, no difference was observed between congruous (cong) and incongruous (incong) words (open orange and brown arrows). In othersites, at ∼400 ms, incongruous words evoke greater HGP (filled magenta arrows) and LFP (filled cyan arrows) than do congruous words; at the same latency, some of theselocations may show differential responses to words versus noise (open magenta and cyan arrows). Gray boxes indicated periods with significant differences between conditionsat P< 0.01 using resampling statistics. Additional channels are shown in Supplementary Figure S3, documenting a complex mosaic of sites with different levels of activity andtask correlates for this patient (Pt. A.). An additional subject (Pt. B) with similar results is shown in Supplementary Figure S4.
Figure 3. The acoustic-phonetic M100p has different spatiotemporal characteristics than the M100 to tones. (A) Single-subject left and right posterior superior temporalgradiometer channels show a right-lateralized M100 response to tones, in contrast to the left-lateralized words>noise response at the same latency. (B) Significant group (n=7) dSPM M100 to tones estimated mainly to right superior temporal areas (arrow). (C) Significant group (n= 8) dSPM M100p to words estimated mainly to left superiortemporal areas (arrow; this panel is reproduced from Fig. 2D for convenience).
Cerebral Cortex 5
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

In order to investigate whether top-down lexico-semanticinformation can modulate this initial acoustic-phonetic pro-cessing, we compared the early MEG response to words whenits meaning had been preactivated with a congruous pictureversus the response to the same word when it was precededby an incongruous (control) picture. As expected, this con-trast revealed a distributed left fronto-temporal incongruous>congruous difference peaking at ∼400 ms, i.e. a typicalN400m associated with lexical access and semantic integration(Fig 2B, F, G, I). We examined the response in the left postero-temporal MEG sensor where the maximal M100p to the samewords was recorded in the same task using a Monte Carlorandom effects resampling statistic to identify the onset of thedifference between the 2 conditions (Maris and Oostenvelt2007). Critically, this difference did not begin until ∼150 msafter the beginning of the word>noise difference. Across thegroup, we found that word>noise differences onset signifi-cantly earlier (average onset 61 ± 22 ms) than incongruous>congruous semantic priming effects (average onset 217 ± 130ms; t(7) = −3.51 P < 0.01). Examination of individual subjectresponses in this same left temporal sensor further confirmedthat M100p activity consistently occurred prior to the onset ofsemantic priming effects for all participants, despite relativelylarge variability in the onset of the later response (Fig 2A, B, H,I). Post hoc analyses of the M100p time window revealed thatthe early semantic responses (<120 ms; Fig. 2I) observed in 2subjects (Supplementary Figs S6 and 8) were likely driven bystrategic differences in how these subjects performed theexperimental task.
Additional post hoc power analyses were performed to de-termine whether a semantic effect might be present immedi-ately after the onset of the M100p response, but was notdetected due to the lack of power. We found that the effectsize (comparing congruous versus incongruous words) wasextremely small (Cohen’s d = 0.05) from this same channelwhich showed a strong word versus noise effect, measuredduring the first 20 ms after the onset of the M100p responsein each subject (i.e. on average from 61 to 81 ms after stimu-lus onset; see Fig. 2A, B, H, I). In contrast, a much largereffect size was obtained for M100p responses during thissame time (Cohen’s d = 0.91). Conversely, a large semanticeffect size was clearly observed both at 50 ms following theonset of semantic effects in each subject (i.e. on average from217 to 267 ms after stimulus onset; Cohen’s d = 0.93), as wellas during the 250–300 ms time window when semantic effectswere a priori predicted to occur (Cohen’s d = 1.33). Thus, thetime surrounding the onset of the M100p (∼60–80 ms) is notaffected by lexico-semantic context, which only begins toexert its influences later. Together, both group and individualsubject analyses suggest that the acoustic-phonetic processesindexed by the M100p are initially independent of thesemantic processes indexed by the N400m.
The cortical sources of these responses were estimatedwith dSPM in each subject, and then averaged across subjectson the cortical surface (Dale et al. 2000). The cortical distri-bution for words versus noise during the time of the M100p(90–110 ms) concentrated mainly on superior temporalregions, especially on the left (Fig. 2D, E, SupplementaryFigs. S1 and 2). No significant differences to incongruousversus congruous words were observed at this time, but werepresent during later windows (200–400 ms; Fig. 2F, G) in theleft inferior frontal, insular, ventral temporal, and posterior
superior temporal regions. Right hemispheric activity wasconcentrated mainly within insular and superior temporalregions (Fig. 2G). Such differences are consistent in their taskcorrelates, timing, and left temporal distribution with previousdSPM estimates of N400m activity using similar (Marinkovicet al. 2003) or identical paradigms (Travis et al. 2011; Leonardet al. 2012). Random effects tests of dSPM values in corticalregions of interest generally confirmed these maps for boththe early acoustic-phonetic response in superior temporalregions and the lexico-semantic effect in more widespreadareas (Supplementary Fig. S2). Specifically, the regions selec-ted to test for M100p responses from 90 to 110 ms exhibitedactivity that was significantly greater to words than noise inleft superior temporal sulcus (STS) F(1,7) = 13.50, P < 0.01,right STS (F(1,7) = 13.12, P < 0.01), and left planum temporale(PT) (F(1,7) = 12.37, P < 0.01). Only from 250 to 300 ms whenlexico-semantic effects were predicted to occur did theseareas (left PT (t(7) = 2.43, P < 0.046; with trends in left STS (t(7) = 2.12, P < 0.072 and right STS (t(7) = 2.30, P < 0.055) andother left temporal areas selected a priori to test for latersemantic effects (anterior inferior temporal sulcus (t(7) = 2.37,P < 0.05), posterior STS (t(7) = 2.02, P < 0.083, trend) showsignificantly greater responses to incongruous versuscongruous words.
Due to their limited spatial resolution, these MEG resultsare ambiguous as to whether the same locations that performacoustic-phonetic processing at short latencies also participatein lexico-semantic processing at longer latencies. On the onehand, the cortical locations estimated with dSPM as showingan early word>noise effect (Fig. 2D) are a subset of the areasshowing a late incongruous>congruous effect (Fig. 2G). Thisoverlap is almost complete within the left posterior sTg,suggesting that top-down semantic influences may be ubiqui-tous at longer latencies in areas participating in acoustic-phonetic processing at short latencies. However, it remainspossible that small areas within the sTg are specialized forearly acoustic-phonetic processing, and adjacent small areasare devoted to late lexico-semantic processing, but theirprojections to the MEG sensors are too overlapping to beresolved. In order to test for this possibility, we turned to thehigh spatial resolution afforded by recordings in the sametask made directly from the cortical surface (ECoG). Intracra-nial recordings also allow HGP to be recorded in addition tolocal field potentials (LFPs; Jerbi et al. 2009). To determinethe timing and locations of the onset of the M100p and N400effects, we used the same Monte Carlo resampling statisticdescribed above for the MEG data.
Clear evidence was found for a partial spatial segregationof sites in left posterior sTg responding to words>noise atshort latencies, versus incongruous>congruous words at longlatencies (Fig. 4, Supplementary Figs S3 and 4). For example,in Figure 4, cortex underlying contact 4 generates words>noise HGP and LFP responses in the 80–120 ms range(orange and brown arrows), but no late incongruous>congru-ous LFP difference until after 600 ms, following the behavioralresponse. In contrast, the cortex underlying contact 3 (∼1 cmanterior to contact 4) responds to incongruous>congruouswords with LFP and HGP starting at ∼200 ms, but does notshow a words>noise effect until after 400 ms. Contact 2, 1 cmanterior to contact 3, shows both the early acoustic-phoneticand late lexico-semantic effects, in LFP but not HGP. Contact1, 1 cm anterior to contact 2, shows the early acoustic-
6 Independence of Early Speech Processing from Word Meaning • Travis et al.
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from
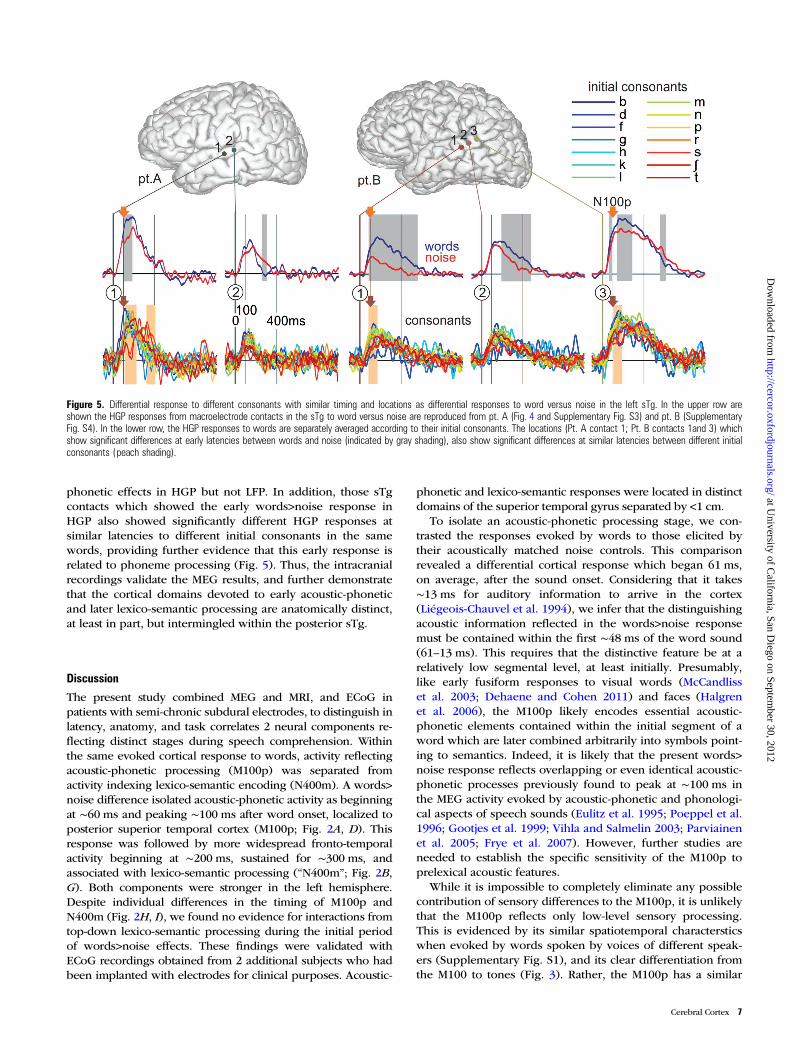
phonetic effects in HGP but not LFP. In addition, those sTgcontacts which showed the early words>noise response inHGP also showed significantly different HGP responses atsimilar latencies to different initial consonants in the samewords, providing further evidence that this early response isrelated to phoneme processing (Fig. 5). Thus, the intracranialrecordings validate the MEG results, and further demonstratethat the cortical domains devoted to early acoustic-phoneticand later lexico-semantic processing are anatomically distinct,at least in part, but intermingled within the posterior sTg.
Discussion
The present study combined MEG and MRI, and ECoG inpatients with semi-chronic subdural electrodes, to distinguish inlatency, anatomy, and task correlates 2 neural components re-flecting distinct stages during speech comprehension. Withinthe same evoked cortical response to words, activity reflectingacoustic-phonetic processing (M100p) was separated fromactivity indexing lexico-semantic encoding (N400m). A words>noise difference isolated acoustic-phonetic activity as beginningat ∼60 ms and peaking ∼100 ms after word onset, localized toposterior superior temporal cortex (M100p; Fig. 2A, D). Thisresponse was followed by more widespread fronto-temporalactivity beginning at ∼200 ms, sustained for ∼300 ms, andassociated with lexico-semantic processing (“N400m”; Fig. 2B,G). Both components were stronger in the left hemisphere.Despite individual differences in the timing of M100p andN400m (Fig. 2H, I), we found no evidence for interactions fromtop-down lexico-semantic processing during the initial periodof words>noise effects. These findings were validated withECoG recordings obtained from 2 additional subjects who hadbeen implanted with electrodes for clinical purposes. Acoustic-
phonetic and lexico-semantic responses were located in distinctdomains of the superior temporal gyrus separated by <1 cm.
To isolate an acoustic-phonetic processing stage, we con-trasted the responses evoked by words to those elicited bytheir acoustically matched noise controls. This comparisonrevealed a differential cortical response which began 61 ms,on average, after the sound onset. Considering that it takes∼13 ms for auditory information to arrive in the cortex(Liégeois-Chauvel et al. 1994), we infer that the distinguishingacoustic information reflected in the words>noise responsemust be contained within the first ∼48 ms of the word sound(61–13 ms). This requires that the distinctive feature be at arelatively low segmental level, at least initially. Presumably,like early fusiform responses to visual words (McCandlisset al. 2003; Dehaene and Cohen 2011) and faces (Halgrenet al. 2006), the M100p likely encodes essential acoustic-phonetic elements contained within the initial segment of aword which are later combined arbitrarily into symbols point-ing to semantics. Indeed, it is likely that the present words>noise response reflects overlapping or even identical acoustic-phonetic processes previously found to peak at ∼100 ms inthe MEG activity evoked by acoustic-phonetic and phonologi-cal aspects of speech sounds (Eulitz et al. 1995; Poeppel et al.1996; Gootjes et al. 1999; Vihla and Salmelin 2003; Parviainenet al. 2005; Frye et al. 2007). However, further studies areneeded to establish the specific sensitivity of the M100p toprelexical acoustic features.
While it is impossible to completely eliminate any possiblecontribution of sensory differences to the M100p, it is unlikelythat the M100p reflects only low-level sensory processing.This is evidenced by its similar spatiotemporal charactersticswhen evoked by words spoken by voices of different speak-ers (Supplementary Fig. S1), and its clear differentiation fromthe M100 to tones (Fig. 3). Rather, the M100p has a similar
Figure 5. Differential response to different consonants with similar timing and locations as differential responses to word versus noise in the left sTg. In the upper row areshown the HGP responses from macroelectrode contacts in the sTg to word versus noise are reproduced from pt. A (Fig. 4 and Supplementary Fig. S3) and pt. B (SupplementaryFig. S4). In the lower row, the HGP responses to words are separately averaged according to their initial consonants. The locations (Pt. A contact 1; Pt. B contacts 1and 3) whichshow significant differences at early latencies between words and noise (indicated by gray shading), also show significant differences at similar latencies between different initialconsonants (peach shading).
Cerebral Cortex 7
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

latency and anatomical location to previously identifiedacoustic-phonetic responses in MEG (see above), hemo-dynamic studies, and intracranial recordings (reviewedbelow). Further evidence that the words>noise differencereflects processing at the acoustic-phonetic level was obtainedfrom intracranial HGP recordings: ECoG contacts that re-sponded differentially to words>noise also responded differ-entially at a similar latency to different initial consonants(Fig. 5). Unlike MEG and LFP, where a larger response mayresult from either inhibition or excitation of the generatingneurons, HGP reflects integrated high-frequency synapticactivity and/or action potentials (Crone et al. 2011), and ishighly correlated with the BOLD response (Ojemann et al.2010). Thus, even if there is some contribution of sensorydifferences to the M100p, these considerations indicate thatits major generators are early phonetic selective synapticactivity that performs the acoustic-phonetic encoding whichultimately leads to lexical identification and semantic inte-gration. However, it is important that future studies continueto characterize the specific perceptual attributes responsiblefor evoking the M100p response by employing a variety ofacoustic controls.
The ability of some subjects to rapidly shadow a recordedpassage (Marslen-Wilson 1975), and the priming effects onvisual words when presented at different points in an audi-tory passage (Zwitserlood 1989), both suggest that somelexico-semantic information becomes available at ∼150 msafter word onset, in reasonably good agreement with theaverage 217 ms latency of the lexico-semantic effects reportedhere. By ∼200 ms when semantic effects are seen, enough ofthe word has been presented so that it is possible to predicthow it might be completed. Specifically, our results are con-sistent with several lexical processing models that have pro-posed that at least the initial syllable of a word (∼150 ms)must be analyzed before contact is initiated with the lexicon(Frauenfelder and Tyler 1987; Marslen-Wilson 1987; Norriset al. 2000). However, it is long before the acoustic stimuluscontains enough information to definitively and uniquelyidentify the word. Thus, lexico-semantic modulation observedhere likely reflects the multiple lexical possibilities consistentwith the initial ∼204 ms (=217− 13) of the stimulus, as pre-dicted by some models of speech understanding (Marslen-Wilson 1987; Norris et al. 2000).
While it is possible to infer from previous M/EEG andECoG studies when acoustic-phonetic and lexico-semanticstages may occur during speech comprehension, to ourknowledge, our study is the first to directly compare theirrelative spatial and temporal characteristics within the sametask, subjects, and using the same word stimuli. Indeed, ourevidence for the timing and anatomy of acoustic-phonetic andlexico-semantic effects is consistent with both neurophysiolo-gical and hemodynamic activity associated with these proces-sing stages studied in separate tasks. Here, the localization ofearly words>noise effects estimated from MEG and ECoG tothe posterior and middle levels of the superior temporal gyrusand sulcus correspond closely to the areas showing hemody-namic activation associated with prelexical processing(Hickok and Poeppel 2007; Price 2010). Similarly, the localiz-ation of later incongruous>congruous word effects estimatedfrom MEG correspond to those found with hemodynamicmethods to be active during lexico-semantic processing,reflecting a hypothesized ventral and anterior pathway for
speech recognition (Hickok and Poeppel 2007; Binder et al.2009). Both words>noise and incongruous>congruous MEGdifferences are bilateral with left predominance, consistentwith hemodynamic activations (Hickok and Poeppel 2007;Binder et al. 2009; Price 2010).
The timing and sources of acoustic-phonetic effects seenhere are also consistent with previous studies that have foundthat LFP and HGP in the left posterior sTg distinguishbetween different phonemes at ∼100 ms latency (Chang et al.2010; Steinschneider et al. 2011) and between words andnoise at ∼120 ms (Canolty et al. 2007). However, these studiesdid not determine whether this activity is sensitive totop-down lexico-semantic influences. Conversely, repetition-modulated N400-like activity has been recorded in this regionwith LFP (Halgren et al. 1994a) and HGP (McDonald et al.2010), at a latency of ∼240–300 ms, but the sensitivity ofthese areas to acoustic-phonetic processing was not deter-mined. The onset of lexico-semantic effects in the currentstudy is consistent with previous N400 recordings that do notobserve semantic priming effects until ∼200 ms post-stimuluseven when the initial phoneme of an auditory word presentedin a sentential context is mismatched to the predicted com-pletion of a congruous sentence (Van Petten et al. 1999). Thetiming of lexico-semantic effects seen here is also compatiblewith the latency from word onset of MEG activity associatedwith lexical (Pulvermuller et al. 2001) and semantic (Pulver-muller et al. 2005) processing isolated during a mismatchnegativity paradigm. Taken together, the present findingsprovide strong evidence, within the same task and subjects,for distinct stages of auditory word processing, representingearly acoustic-phonetic versus later lexico-semantic speechprocessing, and distinguished by their latency, location, andtask correlates.
To summarize, our study demonstrates that, on average,the first ∼150 ms of acoustic-phonetic activity is unaffected bythe presence of a strong lexico-semantic context. This revealsa stage in processing where language-relevant properties ofthe speech signal have been identified (this is usually con-sidered the acoustic-phonetic stage), but which is unaffectedby top-down influences from context-driven lexico-semanticrepresentations. The present data do not rule out the potentialfor interactions between prelexical and lexico-semantic pro-cesses at longer latencies (Figs 2 and 4, Supplementary Fig.S3), which may support the effects of lexico-semantic contexton phoneme identification (Samuel 2011). Statistical corre-lations found between MEG activity estimated to the supra-marginal gyrus and the posterior superior temporal gyrusindicate that top-down influences may occur during the timeperiod from 160 to 220 ms following word onset (Gow et al.2008). However, the current results indicate that initial proces-sing of the word is not affected by lexico-semantic infor-mation. The present findings establish the neural basis for anacoustic-phonetic level of processing that can be studiedusing lexical stimuli, and provide a strong physiological con-straint on the role of top-down projections in computationalmodels of speech processing (McClelland and Elman 1986).
Supplementary MaterialSupplementary material can be found at: http://www.cercor.oxfordjournals.org/.
8 Independence of Early Speech Processing from Word Meaning • Travis et al.
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

NotesThe authors thank J. Sherfey and D. Hagler for their generous techni-cal support and M. Borzello and J. Naftulin for assisting in data collec-tion. Conflict of Interest: None declared.
Funding
This study was supported by the Kavli Institute for Brain andMind, NIH R01 NS018741, and NSF BCS-0924539. K.E.T. andM.K.L. have been supported by NIH pre-doctoral traininggrants DC000041 and MH020002 and the Chancellor’s Colla-boratories Award, UCSD. J.L. Evans supported the develop-ment of stimuli with funding from NIH R01-DC005650.
Authors’ Contributions
K.E.T., M.K.L., M.S., and E.H. designed the experiments. K.E.T, M.K.L., and C.T. were responsible for all neuroimagingprocedures and data analysis of MEG data. A.M.C. was respon-sible intracranial data analysis. E.E. was responsible for gridimplantations. M.S. and Q.Z. assisted with the development ofexperimental stimuli. K.E.T., M.K.L., C.T., E.H., and J.L.E.prepared figures and wrote the paper. E.H., S.S.C., and J.L.E.supervised all aspects of the work.
ReferencesBinder J, Medler D, Westbury C, Liebenthal E, Buchanan L. 2006.
Tuning of the human left fusiform gyrus to sublexical ortho-graphic structure. Neuroimage. 33:739–748.
Binder JR, Desai RH, Graves WW, Conant LL. 2009. Where is the se-mantic system? A critical review and meta-analysis of 120 func-tional neuroimaging studies. Cereb Cortex. 120:2767–2796.
Canolty RT, Soltani M, Dalal SS, Edwards E, Dronkers NF, NagarajanSS, Kirsch HE, Barbaro NM, Knight RT. 2007. Spatiotemporal dy-namics of word processing in the human brain. Front Neurosci.1:185–196.
Chan AM, Baker JM, Eskandar E, Schomer D, Ulbert I, Marinkovic K,SS C, Halgren E. 2011. First-pass selectivity for semantic categoriesin human anteroventral temporal lobe. J Neurosci. 49:18119–181129.
Chang EF, Rieger JW, Johnson K, Berger MS, Barbaro NM, Knight RT.2010. Categorical speech representation in human superior tem-poral gyrus. Nat Neurosci. 13:1428–1432.
Crone NE, Korzeniewska A, Franaszczuk PJ. 2011. Cortical gammaresponses: searching high and low. Int J Psychophysiol. 79:9–15.
Dale AM, Liu AK, Fischl BR, Buckner RL, Belliveau JW, Lewine JD,Halgren E. 2000. Dynamic statistical parametric mapping: combin-ing fMRI and MEG for high-resolution imaging of cortical activity.Neuron. 26:55–67.
Davis M, Johnsrude I. 2007. Hearing speech sounds: top-down influ-ences on the interface between audition and speech perception.Hear Res. 229:132–147.
Davis MH, Johnsrude IS, Hervais-Adelman A, Taylor K, McGettigan C.2005. Lexical information drives perceptual learning of distortedspeech: evidence from the comprehension of noise-vocoded sen-tences. J Exp Psychol Gen. 134:222–241.
Dehaene S, Cohen L. 2011. The unique role of the visual word formarea in reading. Trends Cogn Sci. (Regul Ed) 15:254–262.
Delorme A, Makeig S. 2004. EEGLAB: an open source toolbox foranalysis of single-trial EEG dynamics including independent com-ponent analysis. J Neurosci Methods. 134:9–21.
Dykstra A, Chan A, Quinn B, Zepeda R, Keller C, Cormier J, Madsen J,Eskandar E, Cash SS. 2012. Individualized localization and corticalsurface-based registration of intracranial electrodes. Neuroimage59:3563–3570.
Eulitz C, Diesch E, Pantev C, Hampson S, Elbert T. 1995. Magneticand electric brain activity evoked by the processing of tone andvowel stimuli. J Neurosci. 15:2748–2755.
Fischl B, Sereno MI, Dale AM. 1999. Cortical surface-based analaysisII: Inflation, flattening and a surface-based coordinate system.Neuroimage. 9:195–207.
Frauenfelder UH, Tyler LK. 1987. The process of spoken word recog-nition: An introduction. Cognition. 25:1–20.
Frye RE, Fisher JM, Coty A, Zarella M, Liederman J, Halgren E. 2007.Linear coding of voice onset time. J Cogn Neurosci. 19:1476–1487.
Gage N, Poeppel D, Roberts TPL, Hickok G. 1998. Auditory evokedM100 reflects onset acoustics of speech sounds. Brain Res. 814:236–239.
Gage NM, Roberts TPL, Hickok G. 2002. Hemispheric asymmetries inauditory evoked neuromagnetic fields in response to place ofarticulation contrasts. Cogn Brain Res. 14:303–306.
Gootjes L, Raij T, Salmelin R, Hari R. 1999. Left-hemisphere domi-nance for processing of vowels: A whole-scalp neuromagneticstudy. Neuroreport. 10:2987–2991.
Gow DW, Jr., Segawa JA, Ahlfors SP, Lin FH. 2008. Lexical influenceson speech perception: A Granger causality analysis of MEG andEEG source estimates. Neuroimage. 43:614–623.
Halgren E, Baudena P, Heit G, Clarke J. 1994a. Spatio-temporal stagesin face and word processing. I. Depth-recorded potentials in thehuman occipital, temporal and parietal lobes. J Physiol. (Paris)88:1–50.
Halgren E, Baudena P, Heit G, Clarke M. 1994b. Spatio-temporalstages in face and word processing. II: Depth-recorded potentialsin the human frontal and Rolandic cortices. J Physiol (Paris)88:51–80.
Halgren E, Sherfey J, Irimia A, Dale AM, Marinkovic K. 2011. Sequen-tial temporo-fronto-temporal activation during monitoring of theauditory environment for temporal patterns. Hum Brain Mapp.32:1260–1276.
Halgren E, Wang C, Schomer D, Knake S, Marinkovic K, Wu J, UlbertI. 2006. Processing stages underlying word recognition in theanteroventral temporal lobe. Neuroimage. 30:1401–1413.
Hickok G, Poeppel D. 2007. The cortical organization of speech pro-cessing. Nat Rev Neurosci. 8:393–402.
Indefrey P, Levelt W. 2004. The spatial and temporal signatures ofword production components. Cognition. 92:101–144.
Jerbi K, Ossandón T, Hamamé CM, Senova S, Dalal SS, Jung J, MinottiL, Bertrand O, Berthoz A, Kahane P et al. 2009. Task-relatedgamma-band dynamics from an intracerebral perspective: Reviewand implications for surface EEG and MEG. Hum Brain Mapp30:1758–1771.
Kutas M, Federmeier KD. 2011. Thirty years and counting: findingmeaning in the N400 component of the event-related brain poten-tial (ERP). Annu Rev Psychol 62:621–647.
Leonard MK, Brown TT, Travis KE, Gharapetian L, Hagler DJ, DaleAM, Elman JL, Halgren E. 2010. Spatiotemporal dynamics of bilin-gual word processing. Neuroimage. 49:3286–3294.
Leonard MK, Ferjan Ramirez N, Torres C, Travis KE, Hatrak M,Mayberry RI, Halgren E. 2012. Signed words in the congenitallydeaf evoke typical late lexico-semantic responses with no earlyvisual responses in left superior temporal cortex. J Neurosci.32:9700–9705.
Liégeois-Chauvel C, Musolino A, Badier JM, Marquis P, Chauvel P.1994. Evoked potentials recorded from the auditory cortex inman: Evaluation and topography of the middle latency com-ponents. Electroencephalogr Clin Neurophysiol. 92:204–214.
Liu AK, Dale AM, Belliveau JW. 2002. Monte Carlo simulation studiesof EEG and MEG localization accuracy. Hum Brain Mapp16:47–62.
Marinkovic K, Dhond R, Dale A, Glessner M. 2003. Spatiotemporaldynamics of modality-specific and supramodal word processing.Neuron 38:487–497.
Maris E, Oostenveld R. 2007. Nonparametric statistical testing ofEEG- and MEG-data. J Neurosci Methods. 164:177–190.
Marslen-Wilson W. 1975. Sentence perception as an interactiveparallel process. Science. 189:226–228.
Cerebral Cortex 9
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

Marslen-Wilson WD. 1987. Functional parallelism in spokenword-recognition. Cognition. 25:71–102.
McCandliss BD, Cohen L, Dehaene S. 2003. The visual word formarea: Expertise for reading in the fusiform gyrus. Trends Cogn Sci.(Regul Ed) 7:293–299.
McClelland JL, Elman JL. 1986. The TRACE model of speech percep-tion* 1. Cognit Psychol 18:1–86.
McDonald CR, Thesen T, Carlson C, Blumberg M, Girard HM, Trong-netrpunya A, Sherfey JS, Devinsky O, Kuzniecky R, Dolye WKet al. 2010. Multimodal imaging of repetition priming: Using fMRI,MEG, and intracranial EEG to reveal spatiotemporal profiles ofword processing. Neuroimage 53:707–717.
Näätänen R, Picton T. 1987. The N1 wave of the human electric andmagnetic response to sound: A review and an analysis of the com-ponent structure. Psychophysiol. 24:375–425.
Norris D, McQueen JM, Cutler A. 2000. Merging information inspeech recognition: Feedback is never necessary. Behav Brain Sci.23:299–325.
Ojemann GA, Corina DP, Corrigan N, Schoenfield-McNeill J, Poliakov A,Zamora L, Zanos S. 2010. Neuronal correlates of functional magneticresonance imaging in human temporal cortex. Brain. 133:46–59.
Parviainen T, Helenius P, Salmelin R. 2005. Cortical differentiation ofspeech and nonspeech sounds at 100 ms: Implications for dyslex-ia. Cereb Cortex. 15:1054–1063.
Poeppel D, Yellin E, Phillips C, Roberts TP, Rowley HA, Wexler K,Marantz A. 1996. Task-induced asymmetry of the auditory evokedM100 neuromagnetic field elicited by speech sounds. Brain ResCogn Brain Res. 4:231–242.
Price C. 2010. The anatomy of language: A review of 100 fMRI studiespublished in 2009. Ann N Y Acad Sci. 1191:62–88.
Pulvermuller F, Kujala T, Shtyrov Y, Simola J, Tiitinen H, Alku P, AlhoK, Martinkauppi S, Ilmoniemi RJ, Naatanen R. 2001. Memory
traces for words as revealed by the mismatch negativity. Neuro-image. 14:607–616.
Pulvermuller F, Shtyrov Y, Ilmoniemi R. 2005. Brain signatures ofmeaning access in action word recognition. J Cogn Neurosci.17:884–892.
Samuel AG. 2011. Speech perception. Annu Rev Psychol. 62:49–72.Scott SK, Blank CC, Rosen S, Wise RJS. 2000. Identification of a
pathway for intelligible speech in the left temporal lobe. Brain123:2400–2406.
Scott SK, Johnsrude I. 2003. The neuroanatomical and functionalorganization of speech perception. Trends Neurosci. 26:100–107.
Shannon RV, Zeng FG, Kamath V, Wygonski J, Ekelid M. 1995. Speechrecognition with primarily temporal cues. Science. 270:303–304.
Steinschneider M, Nourski KV, Kawasaki H, Oya H, Brugge JF,Howard MA. 2011. Intracranial study of speech-elicited activity onthe human posterolateral superior temporal gyrus. Cereb Cortex.21:2332–2347.
Travis KE, Leonard MK, Brown TT, Hagler DJ, Curran M, Dale AM,Elman JL, Halgren E. 2011. Spatiotemporal neural dynamics ofword understanding in 12- to 18-month-old-infants. Cereb Cortex.8:1832–1839.
Uusvuori J, Parviainen T, Inkinen M, Salmelin R. 2008. Spatiotemporalinteraction between sound form and meaning during spokenword perception. Cereb Cortex. 18:456–466.
Van Petten C, Coulson S, Rubin S, Plante E, Parks M. 1999. Timecourse of word identification and semantic integration in spokenlanguage. J Exp Psychol. 25:394–417.
Vihla M, Salmelin R. 2003. Hemispheric balance in processing at-tended and non-attended vowels and complex tones. Cogn BrainRes. 16:167–173.
Zwitserlood P. 1989. The locus of the effects of sentential-semanticcontext in spoken-word processing* 1. Cognition. 32:25–64.
10 Independence of Early Speech Processing from Word Meaning • Travis et al.
at University of C
alifornia, San Diego on Septem
ber 30, 2012http://cercor.oxfordjournals.org/
Dow
nloaded from

1
Supplementary Materials Supplementary Reference Edwards E, Soltani M, Kim W, Dalal SS, Nagarajan SS, Berger MS, Knight RT. 2009. Comparison of time-frequency responses and the event-related potential to auditory speech stimuli in human cortex. J Neurophysiol. 102:377-386.
2
Supplementary Figures and Legends
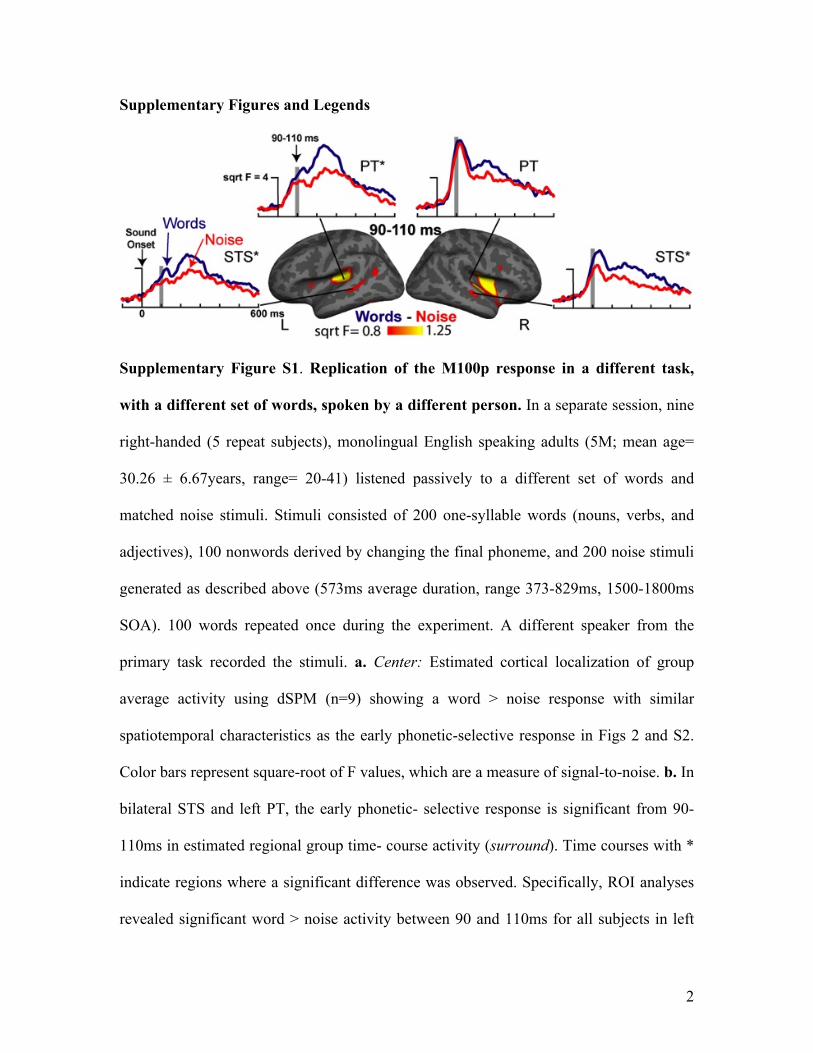
Supplementary Figure S1. Replication of the M100p response in a different task,
with a different set of words, spoken by a different person. In a separate session, nine
right-handed (5 repeat subjects), monolingual English speaking adults (5M; mean age=
30.26 ± 6.67years, range= 20-41) listened passively to a different set of words and
matched noise stimuli. Stimuli consisted of 200 one-syllable words (nouns, verbs, and
adjectives), 100 nonwords derived by changing the final phoneme, and 200 noise stimuli
generated as described above (573ms average duration, range 373-829ms, 1500-1800ms
SOA). 100 words repeated once during the experiment. A different speaker from the
primary task recorded the stimuli. a. Center: Estimated cortical localization of group
average activity using dSPM (n=9) showing a word > noise response with similar
spatiotemporal characteristics as the early phonetic-selective response in Figs 2 and S2.
Color bars represent square-root of F values, which are a measure of signal-to-noise. b. In
bilateral STS and left PT, the early phonetic- selective response is significant from 90-
110ms in estimated regional group time- course activity (surround). Time courses with *
indicate regions where a significant difference was observed. Specifically, ROI analyses
revealed significant word > noise activity between 90 and 110ms for all subjects in left

3
planum temporale (t(8)=2.23, p<0.05), and left (t(8)=2.54, p<0.03) and right (t(8)= 2.64,
p<0.03) superior temporal sulci.
4
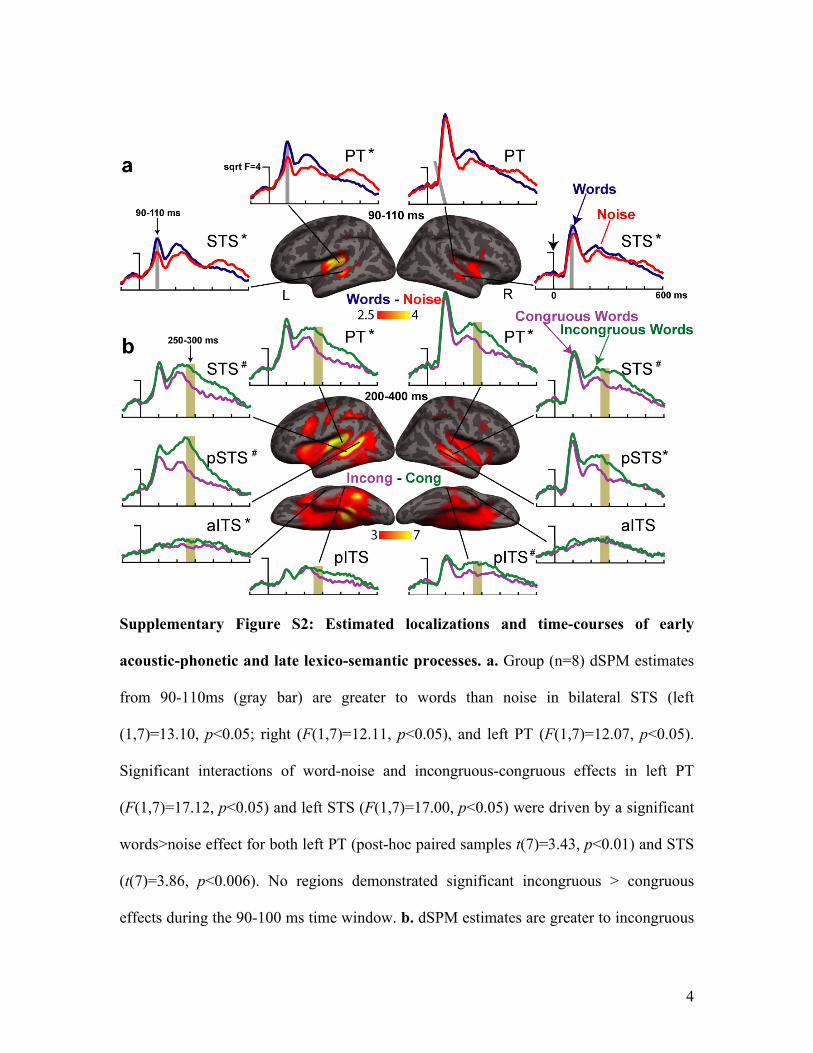
Supplementary Figure S2: Estimated localizations and time-courses of early
acoustic-phonetic and late lexico-semantic processes. a. Group (n=8) dSPM estimates
from 90-110ms (gray bar) are greater to words than noise in bilateral STS (left
(1,7)=13.10, p<0.05; right (F(1,7)=12.11, p<0.05), and left PT (F(1,7)=12.07, p<0.05).
Significant interactions of word-noise and incongruous-congruous effects in left PT
(F(1,7)=17.12, p<0.05) and left STS (F(1,7)=17.00, p<0.05) were driven by a significant
words>noise effect for both left PT (post-hoc paired samples t(7)=3.43, p<0.01) and STS
(t(7)=3.86, p<0.006). No regions demonstrated significant incongruous > congruous
effects during the 90-100 ms time window. b. dSPM estimates are greater to incongruous

5
than congruous words from 250-300ms (tan bar) in left PT (t(7)=2.46, p<0.044), and
aITS (t(7)=2.61, p<0.035), with trends in the mSTS (t(7)=2.16, p<0.068) and pSTS
(t(7)=1.97, p<0.089). In the right hemisphere, effects were obtained for PT (t(7)=2.40,
p<0.048), pSTS (t(7)=2.74, p<0.029) and pITS (t(7)=2.32, p<0.053), with a trend in STS
(t(7)=2.24, p<0.060). Regions of Interest (ROIs: Supplementary Materials, fig. 3): STS =
superior temporal sulcus, PT = planum temporale, p = posterior, a = anterior, ITS =
inferior temporal sulcus. *=p<0.05; #=trend.
6
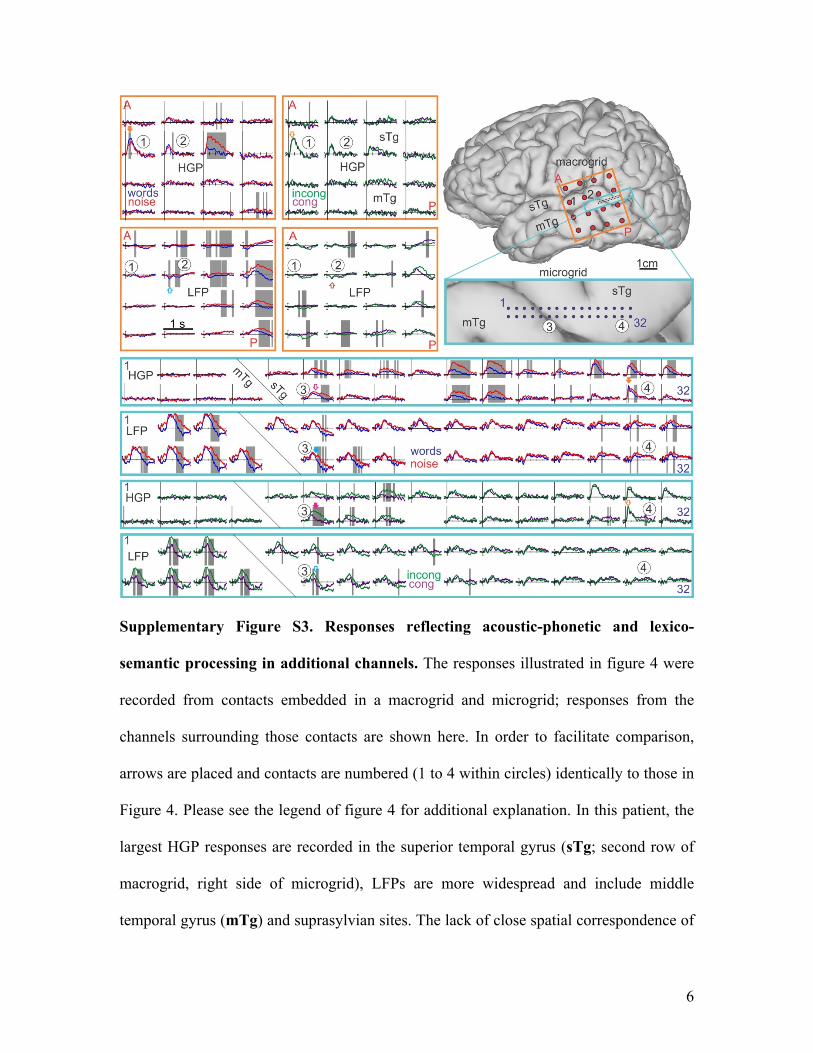
Supplementary Figure S3. Responses reflecting acoustic-phonetic and lexico-
semantic processing in additional channels. The responses illustrated in figure 4 were
recorded from contacts embedded in a macrogrid and microgrid; responses from the
channels surrounding those contacts are shown here. In order to facilitate comparison,
arrows are placed and contacts are numbered (1 to 4 within circles) identically to those in
Figure 4. Please see the legend of figure 4 for additional explanation. In this patient, the
largest HGP responses are recorded in the superior temporal gyrus (sTg; second row of
macrogrid, right side of microgrid), LFPs are more widespread and include middle
temporal gyrus (mTg) and suprasylvian sites. The lack of close spatial correspondence of

7
HGP versus LFP responses has previously been reported (Edwards et al., 2009;
McDonald et al., 2010). Further studies in more subjects are needed to determine the
anatomical distribution of these responses. Pt. A.
8
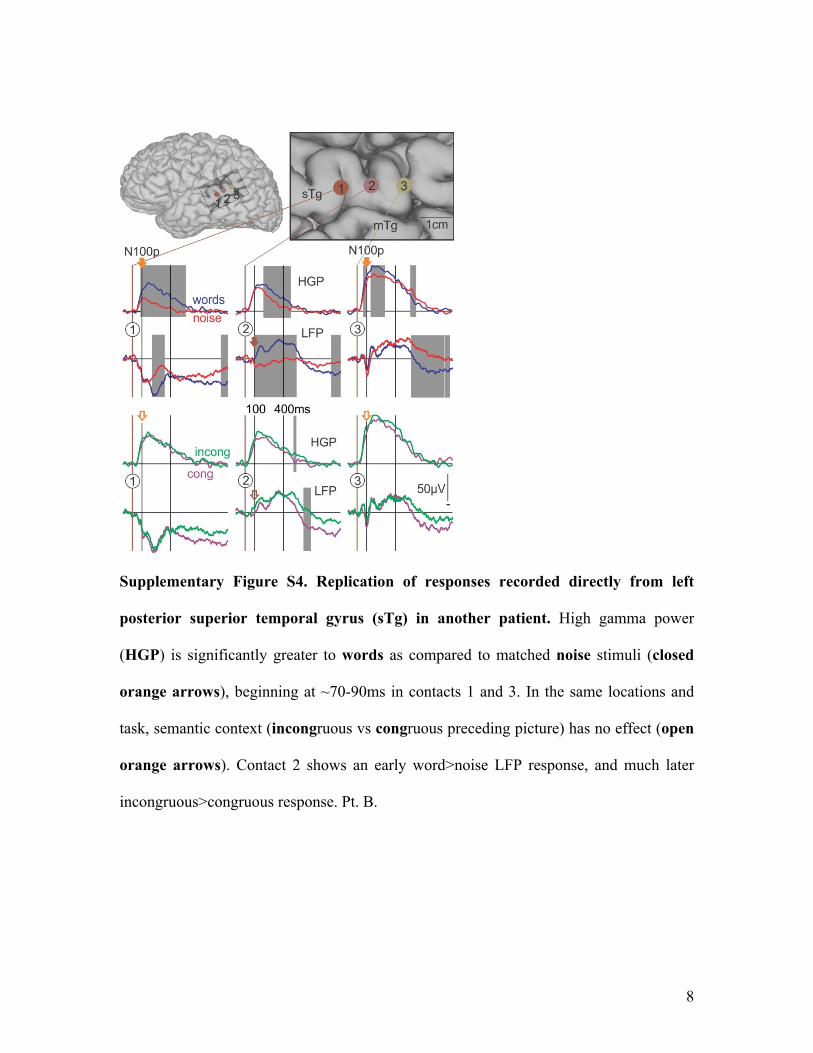
Supplementary Figure S4. Replication of responses recorded directly from left
posterior superior temporal gyrus (sTg) in another patient. High gamma power
(HGP) is significantly greater to words as compared to matched noise stimuli (closed
orange arrows), beginning at ~70-90ms in contacts 1 and 3. In the same locations and
task, semantic context (incongruous vs congruous preceding picture) has no effect (open
orange arrows). Contact 2 shows an early word>noise LFP response, and much later
incongruous>congruous response. Pt. B.
9
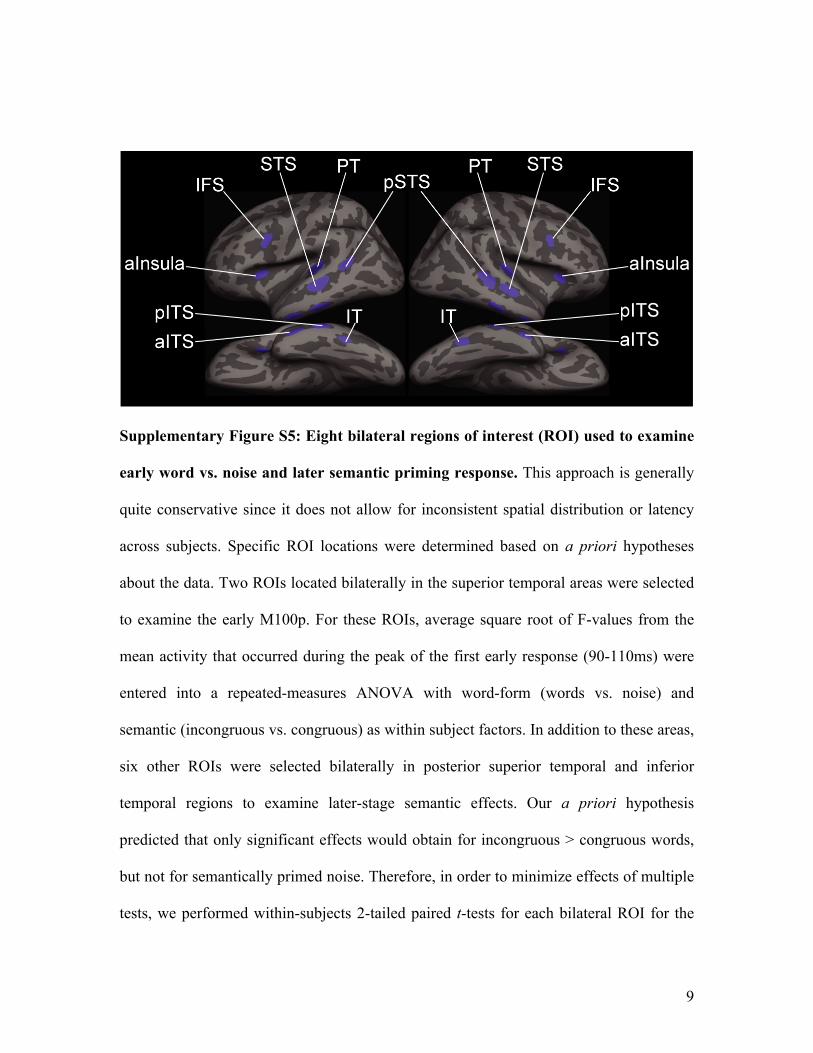
Supplementary Figure S5: Eight bilateral regions of interest (ROI) used to examine
early word vs. noise and later semantic priming response. This approach is generally
quite conservative since it does not allow for inconsistent spatial distribution or latency
across subjects. Specific ROI locations were determined based on a priori hypotheses
about the data. Two ROIs located bilaterally in the superior temporal areas were selected
to examine the early M100p. For these ROIs, average square root of F-values from the
mean activity that occurred during the peak of the first early response (90-110ms) were
entered into a repeated-measures ANOVA with word-form (words vs. noise) and
semantic (incongruous vs. congruous) as within subject factors. In addition to these areas,
six other ROIs were selected bilaterally in posterior superior temporal and inferior
temporal regions to examine later-stage semantic effects. Our a priori hypothesis
predicted that only significant effects would obtain for incongruous > congruous words,
but not for semantically primed noise. Therefore, in order to minimize effects of multiple
tests, we performed within-subjects 2-tailed paired t-tests for each bilateral ROI for the

10
mean activity occurring only to mismatched and matched words obtained from the 50ms
(250-300ms) time window between 200-400ms. To test the task- and stimulus specificity
of early words and noise differences, ROI analyses were also performed on estimated
activity to words and noise presented during the passive listening task. Within-subjects 2-
tailed, paired t-tests were performed on the mean activity to words and noise conditions
that occurred between (90-110ms) in the two bilateral superior temporal ROIs. IFS =
Inferior frontal sulcus; STS = Superior temporal sulcus; PT = Planum temporale; p =
posterior; a = anterior; ITS = Inferior temporal sulcus; IT = Inferotemporal.





























