Embed Size (px)
Citation preview

Proyecto Fin de Carrera
Ingeniería de Telecomunicación
Proyecto Fin de Carrera
Ingeniería de Telecomunicación
Separación de mezclas de audio en el dominio tiempo-
frecuencia.
Autor:
Lucas Bernalte Pérez
Tutor:
Sergio Antonio Cruces Álvarez
Profesor titular
Dep. de Teoría de la Señal y Comunicaciones
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2014
Proyecto Fin de Carrera
Ingeniería de Telecomunicación
Separación de mezclas de audio en el dominio
tiempo-frecuencia.
Autor: Lucas Bernalte Pérez
Tutor: Sergio Antonio Cruces Álvarez
Dep. Teoría de la Señal y Comunicaciones
Escuela Técnica Superior de Ingeniería
Universidad de Sevilla
Sevilla, 2014



Proyecto Fin de Carrera: Separación de mezclas de audio en el dominio tiempo-frecuencia.
Autor: Lucas Bernalte Pérez
Tutor: Sergio Antonio Cruces Álvarez
El tribunal nombrado para juzgar el Proyecto arriba indicado, compuesto por los siguientes miembros:
Presidente:
Vocales:
Secretario:
Acuerdan otorgarle la calificación de:
Sevilla, 2014
El Secretario del Tribunal

A mi familia
A mis maestros


vii
Agradecimientos
Este proyecto no hubiera sido posible sin la ayuda de mi tutor Sergio Antonio Cruces Álvarez, de mi
co-tutora Auxiliadora Sarmiento, que ha sido de vital importancia para que entendiera cómo pasar
estos conceptos a MATLAB, a mis padres, que me han apoyado aunque a veces creyera que era más
presión que otra cosa y a muchos amigos motivadores que me han ayudado a pasar por unos baches
durante el tiempo que he estado trabajando en este proyecto. Gracias a todos ellos.
Lucas Bernalte Pérez
Ingeniero de Telecomunicación
Sevilla, 2014

viii
Resumen
La separación de señales de voz o audio, en entornos ruidosos, es una aplicación típica de la teoría de
separación ciega de señales. Se propone realizar un estudio de los métodos de separación de señales
de audio mediante técnicas de enmascaramiento en dominios transformados. La situación a analizar
es la de insuficientes micrófonos, que se caracteriza por la existencia de más sonidos o voces que
micrófonos y, en general, se supone una situación anecoica y la separabilidad de las componentes de
las distintas voces en algún dominio transformado. Estas hipótesis suelen permitir el construir una
máscara adaptada a la señal de voz deseada que, posteriormente, se aplica a cada una de las grabaciones
para estimarla. Aquí se explican conceptos relativos a la separación ciega de fuentes, como otros
métodos de separación, basados en parámetros estadísticos, y en la geometría de la situación.
En este proyecto se propone el estudio de esos métodos para la separación ciega de fuentes, entrando
más en detalle en un algoritmo llamado DUET (Degenerate Unmixing Estimation Technique), el cual
puede separar (teóricamente) cualquier número de fuentes usando solo dos mezclas u observaciones.
Este método es válido cuando ambas fuentes son disjuntas ortogonalmente (W-DO), es decir cuando
la superposición de las transformadas enventanadas de Fourier de las señales en la mezcla son
disjuntas.
Las pruebas realizadas en MATLAB ponen a prueba el número máximo de fuentes que DUET es
capaz de separar, así como la relación señal a ruido de las señales de entrada que permite que estas se
distingan en el histograma, o por el contrario aparezcan como mero ruido. También se estudiará el caso
de una mezcla con instrumentos musicales y voces, y por último una comparación con otro algoritmo
de separación de fuentes, basado en PARAFAC. Para todas estas simulaciones, tomaremos una
medida, para ir comparando objetivamente los resultados. Como veremos en el capítulo
correspondiente a la calidad, la medida que usaremos será la SDR (signal to distorsion ratio).
El código de este algoritmo escrito para su uso en MATLAB, puede encontrarse en el Anexo B.

ix
Abstract
Blind Source Separation of voice or audio signals, in noisy environments, is a typical application of
blind source separation. Here we propose to perform a study of the methods of blind source separation
through masking techniques in time-frequency domain. The situation to analyze is the one that has
insufficient number of microphones, so we have more sounds or voices than microphones, and we also
suppose we have an anechoic situation and separability of voice components in some transformed
domain. These hypothesis usually allow to build a mask adapted to the desired voice signal, which it
is applied to any recording to estimate that voice signal, subsequently. The concepts related to blind
source separation, as well as other methods based on statistic parameters and geometry are here
explained.
This project contains the study of these blind source separation methods, going into greater detail in
DUET algorithm (Degenerate Unmixing Estimation Technique), which is able to separate
(theoretically) any number of sources using only two mixtures or observations (two sensors). This
method is valid when both sources are orthogonally disjoint (W-DO), that is, when the two short time
fourier transforms overlap, they are disjoint.
Tests conducted on MATLAB evaluate the maximum number of sources DUET is able to separate, as
well as the sources signal to noise ratio that allows them to be distinguished in the histogram or not.
The case containing musical instruments and voice as sources is also studied, in addition to a
comparison with another BSS algorithm, PARAFAC based. For all of those simulations, we will be
calculating an objective measure of the quality of the separation. As you will see in the corresponding
chapter, the measurement used is the SDR (signal to distorsion ratio).
Code used containing DUET algorithm written for MATLAB can be found in Annex B.

x

11
Notación
𝑠(𝑡) Señal fuente
𝑠[𝑛] Señal fuente, muestreada
𝑆(𝑓, 𝑡) Transformada localizada o STFT de 𝑠(𝑡)
𝑆(𝑛, 𝑘) Transformada localizada discreta, o STFT discreta
𝑤[𝑛] Ventana, muestreada
𝑥[𝑛] Señal observación, o señal de mezcla muestreada
𝑎𝑖, 𝛿𝑖 Parámetros de atenuación y retardo en el modelo de mezcla.
𝛼𝑖 Parámetro de atenuación simétrica.
�̃�𝑖, 𝛿�̃� Parámetros de atenuación y de retardo estimados
kurt(y) Kurtosis de la variable aleatoria y.
h(Y) Entropía diferencial de la v.a. Y
J(Y) Entropía negativa de la v.a. Y
I(𝑦𝑖 , … , 𝑦𝑖) Información mutua.
𝜃𝑖 Ángulo de llegada de las fuentes
𝑀𝑖(𝑓, 𝑡) Máscara binaria correspondiente a la fuente i.
BSS Blind Source Separation
STFT Short Time Fourier Transform
FBS Método Filter Bank Summation
OLA Método Overlap-Add
CASA Computational Auditory Scene Analysis
PCA Principal Component Analysis
ICA Independent Component Analysis
DUET Degenerate Unmixing Estimation Technique

12
Índice
AGRADECIMIENTOS ............................................................................................................................................................ VII
RESUMEN ........................................................................................................................................................................... VIII
ABSTRACT ..............................................................................................................................................................................IX
NOTACIÓN ............................................................................................................................................................................ 11
ÍNDICE ................................................................................................................................................................................... 12
1 INTRODUCCIÓN ......................................................................................................................................................... 15
1.1 MOTIVACIÓN .................................................................................................................................................................... 15
1.2 OBJETIVOS ........................................................................................................................................................................ 18
1.3 VISIÓN GENERAL ................................................................................................................................................................ 19
2 CONCEPTOS PREVIOS ................................................................................................................................................ 21
2.1 LA SEÑAL DE VOZ. ............................................................................................................................................................... 22
2.2 TRANSFORMADA LOCALIZADA. ............................................................................................................................................. 23
2.2.1 Análisis ................................................................................................................................................................ 23
2.2.2 Síntesis ................................................................................................................................................................. 26
2.2.2.1 Método Filter Bank Summation (FBS).............................................................................................................................. 27
2.2.2.2 Método Overlap-Add (OLA) .............................................................................................................................................. 28
2.3 PROPIEDADES DE LAS SEÑALES DE VOZ. .................................................................................................................................. 30
2.3.1 Propiedad de no-Gaussianidad. ........................................................................................................................ 30
2.3.2 Propiedad de color. ............................................................................................................................................ 31
2.3.3 Propiedad de cuasi-periodicidad. ...................................................................................................................... 32
2.3.4 Propiedad de escasez. ........................................................................................................................................ 33
2.4 MODELOS DE MEZCLA DE VOZ .............................................................................................................................................. 34
2.5 CONCLUSIONES .................................................................................................................................................................. 38
3 EL PROBLEMA DE LA SEPARACIÓN CIEGA DE FUENTES ............................................................................................ 39
3.1 MÉTODOS BASADOS EN ANÁLISIS ESTADÍSTICO. ...................................................................................................................... 43
3.1.1 PCA. Análisis de Componentes Principales. ...................................................................................................... 43
3.1.2 ICA. Análisis de componentes independientes (Independent Component Analysis) ..................................... 44
3.1.2.1 Restricciones en ICA. ......................................................................................................................................................... 44

13
3.1.2.2 Ambigüedades de ICA. ...................................................................................................................................................... 46
3.1.2.3 Blanqueado (Whitening). .................................................................................................................................................. 46
3.1.2.4 Criterios de separación de ICA. ......................................................................................................................................... 48
3.1.2.4.1 Separación mediante la maximización de la no Gaussianidad........................................................................... 48
3.1.2.4.2 Separación mediante la minimización de la información mutua....................................................................... 51
3.1.2.4.3 Separación mediante la máxima verosimilitud. .................................................................................................. 52
3.1.2.4.4 Separación basada en el principio de infomax. ................................................................................................... 53
3.2 MÉTODOS BASADOS EN LA GEOMETRÍA. ................................................................................................................................ 53
3.2.1 DUET. ................................................................................................................................................................... 54
3.2.2 DOA. Por ángulo de llegada (Direction Of Arrival). .......................................................................................... 55
3.3 CONCLUSIONES .................................................................................................................................................................. 56
4 EL ALGORITMO DUET................................................................................................................................................. 57
4.1 ESTIMACIÓN DE PARÁMETROS.............................................................................................................................................. 58
4.2 AGRUPACIÓN DE LAS ESTIMAS .............................................................................................................................................. 60
4.3 CONSTRUCCIÓN DE MÁSCARAS ............................................................................................................................................. 61
4.4 TRANSFORMACIÓN INVERSA A CADA UNA DE LAS COMPONENTES ESTIMADAS ............................................................................. 63
4.5 RESUMEN ......................................................................................................................................................................... 63
5 CALIDAD EN LA SEPARACIÓN .................................................................................................................................... 64
5.1 MEDIDAS OBJETIVAS ........................................................................................................................................................... 65
5.2 MEDIDAS PERCEPTUALES. .................................................................................................................................................... 66
6 SIMULACIONES .......................................................................................................................................................... 68
6.1 NÚMERO DE FUENTES ......................................................................................................................................................... 69
6.2 AÑADIENDO RUIDO GAUSSIANO. .......................................................................................................................................... 73
6.3 INTRODUCIENDO INSTRUMENTOS MUSICALES. ........................................................................................................................ 79
6.4 DISTANCIA MÍNIMA ENTRE FUENTES. ..................................................................................................................................... 84
6.5 SIMULACIÓN CON PARÁMETROS REALISTAS. ........................................................................................................................... 87
6.6 COMPARACIÓN CON OTROS ALGORITMOS. ............................................................................................................................ 90
6.7 CONCLUSIONES .................................................................................................................................................................. 91
7 CONCLUSIONES Y LÍNEAS FUTURAS DE TRABAJO .................................................................................................... 93
7.1 CONCLUSIONES .................................................................................................................................................................. 93
7.2 LÍNEAS FUTURAS ................................................................................................................................................................ 95
ANEXO A. INDETERMINACIÓN EN LA MEZCLA ASOCIADA A LAS VARIABLES GAUSSIANAS. ............................................ 97
ANEXO B. SIMULACIÓN DEL ALGORITMO DUET EN MATLAB. ........................................................................................... 99
REFERENCIAS ...................................................................................................................................................................... 108

14

15
1 INTRODUCCIÓN
“One of our most important faculties is our ability to listen to,
and follow, one speaker in the presence of others. This is such a
common experience that we may take it for granted; we may call it
"the cocktail party problem".”
Colin E. Cherry, 1957 [Cherry57, pág. 280]
1.1 Motivación
n todos los entornos de mezcla, el objetivo de la separación ciega de fuentes (en inglés, Blind
Source Separation, BSS) es el de extraer una o más señales fuente a partir de la mezcla, dejando
a las otras señales fuente como si de ruido no deseado se tratase. Las señales de interés dependen de la
aplicación. Por ejemplo, en el contexto de mejora de audio para teléfonos móviles, la única señal fuente
de interés es el diálogo del usuario del teléfono. Fuentes no deseadas pueden ser las de otras personas
dialogando en el fondo, sonidos ambiente que se pueden producir como ruidos de coches, viento,
lluvia, etc.
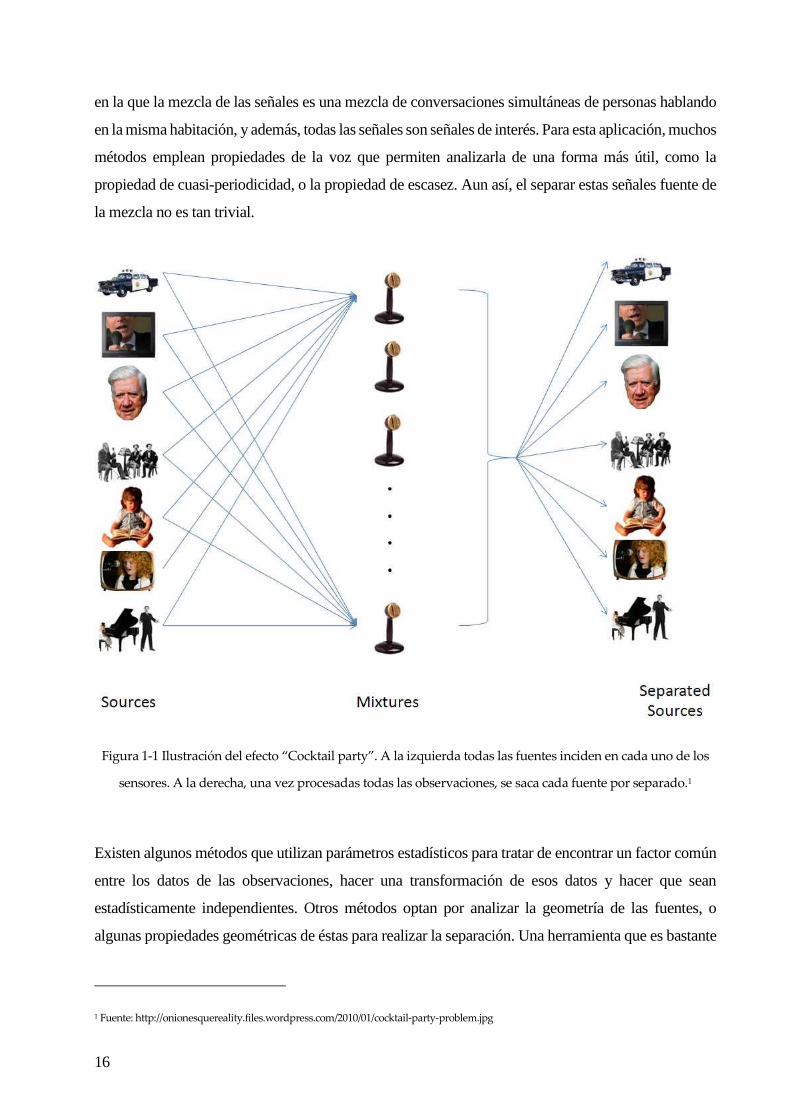
También podemos encontrarnos con el llamado efecto “cocktail-party”, el cual se refiere a la situación
E
16
en la que la mezcla de las señales es una mezcla de conversaciones simultáneas de personas hablando
en la misma habitación, y además, todas las señales son señales de interés. Para esta aplicación, muchos
métodos emplean propiedades de la voz que permiten analizarla de una forma más útil, como la
propiedad de cuasi-periodicidad, o la propiedad de escasez. Aun así, el separar estas señales fuente de
la mezcla no es tan trivial.
Figura 1-1 Ilustración del efecto “Cocktail party”. A la izquierda todas las fuentes inciden en cada uno de los
sensores. A la derecha, una vez procesadas todas las observaciones, se saca cada fuente por separado.1
Existen algunos métodos que utilizan parámetros estadísticos para tratar de encontrar un factor común
entre los datos de las observaciones, hacer una transformación de esos datos y hacer que sean
estadísticamente independientes. Otros métodos optan por analizar la geometría de las fuentes, o
algunas propiedades geométricas de éstas para realizar la separación. Una herramienta que es bastante
1 Fuente: http://onionesquereality.files.wordpress.com/2010/01/cocktail-party-problem.jpg

17
usada por estos métodos es el enmascaramiento. Éstas técnicas consisten en el análisis de los datos,
normalmente en tiempo-frecuencia, y en el uso de la propiedad de escasez de la voz. Después de
realizar una representación de los datos, según la propiedad de escasez, es poco probable que se dé la
superposición de varias fuentes en el mismo punto tiempo-frecuencia. Así, se construyen máscaras
binarias de separación para cada fuente, que recuperan solo aquellos puntos que se interpretan como
que pertenecen a dicha fuente. Entonces el problema de BSS sería determinar qué puntos del espectro
tiempo-frecuencia pertenecen a cada fuente.
Todos estos problemas de separación son muy generales, aunque existe un área de mucho interés, que
es el área que estudia el sistema auditivo humano, de ahí que se estudien casos con solo dos
observaciones. [1] [2]
En la práctica, la separación perfecta de señales es conseguida muy raramente, por ejemplo, porque los
modelos de señal y las suposiciones que hacen los sistemas BSS no se cumplen siempre en situaciones
de la vida real. El nivel de la fuente de interés en cada caso se ve bastante incrementado comparado
con las demás fuentes, pero todavía quedan distorsiones producidas por los filtros aplicados a la fuente
de interés, ruido residual provocado por las demás fuentes y un “gluglú” conocido en inglés como
artifacts, que vienen a ser defectos sonoros. Minimizar algún tipo de distorsión solo puede resultar en
un incremento no deseado de otro tipo de distorsión. Así, una compensación apropiada es buscada
dependiendo de la aplicación, por ejemplo, filtrar la distorsión normalmente degrada la calidad del
reconocimiento de la voz, mientras esos artifacts son bastante molestos para aplicaciones de ayuda a
la escucha.
Si pensamos en el siguiente paso, después de la separación de señales de voz y ya que introduciremos
instrumentos musicales en este proyecto, ¿por qué no separar música? Es decir, a partir de un archivo
de audio de cualquier canción, separar los instrumentos, uno por uno. Esto es una tarea muy
complicada, puesto que las premisas que teníamos para voz ya no se cumplen, además de que en las
mezclas y mastering siempre se aplican efectos, como reverb, que dificultaría aún más la separación
de las fuentes. Aun así, existen compañías que ofrecen estos servicios, mediante un software, aunque,
no con total precisión, como Hit’n’Mix.
También podemos pensar en el cine, donde se graba todo el sonido, aunque lo ideal sería tener las
fuentes por separado. Esto permite tratar las voces independientemente de las demás, ajustar niveles,
e incluso eliminarlas para luego meter doblaje. Este servicio lo ofrecen compañías como Audionamix.
Por supuesto, el reconocimiento de voz es otro campo en el que la separación ciega de fuentes juega
un papel muy importante, ya que necesita de un ambiente libre de ruidos e interferencias. Esto puede

18
ser un estudio directamente relacionado con la fabricación de aparatos que ayudan a la escucha. [3]
También hay estudios relacionados con la separación de grabaciones de música de un solo canal. Éstos
se centran en métodos de separación en los cuales las Fuentes que se van a separar no se conocen de
antemano. En lugar de eso, la separación se realiza utilizando propiedades reales de fuentes de sonido
(continuidad, escasez, repetición en tiempo y frecuencia y armónicos. [4]
Por otro lado, el implantar arrays de sensores cada vez más baratos y con mejores prestaciones debido
a las mejoras en el desarrollo y a la reducción de costes de fabricación es un gran avance, ya que se
pueden implantar arrays de micrófonos fácilmente tanto en un pabellón de deportes y una sala de
conciertos como en vehículos, teléfonos móviles, etc.
También las técnicas BSS se han implantado en algunas aplicaciones biomédicas. Algunos ejemplos
son los análisis de Electroencefalogramas (EEG) [5], Magnetoencefalogramas (MEG),
Electrocardiogramas (ECG) [6] y en Imágenes de Resonancias Magnéticas Funcionales (fMRI). [7]
ICA se usaría para extraer los diferentes artefactos de los datos de las EEGs y MEGs, o para
descomponer campos o potenciales evocados, por ejemplo diferenciando entre respuesta auditiva del
cerebro y potenciales somatosensoriales en el caso de estimulación vibrotáctil.
Ha sido atrayente introducir ICA en el mundo financiero. En situaciones donde se leen muchos datos
paralelamente, como tipos de cambio de moneda, pueden tener factores comunes subyacentes. Ahí
puede intervenir ICA, revelando factores que de otra forma permanecerían ocultos. [8]
1.2 Objetivos
Este proyecto presenta una implementación del problema de separación ciega de dos fuentes teniendo
como referencia dos observaciones. El algoritmo usado es el Degenerate Unmixing Estimations
Technique (DUET) y ha sido implementado en MATLAB. Nos hemos centrado solo en mezclas
sintéticas y sólo de voces.
En este proyecto se propone el estudio de esos métodos para la separación ciega de fuentes, entrando
más en detalle en un algoritmo llamado DUET (Degenerate Unmixing Estimation Technique) el cual
puede separar cualquier número de fuentes usando solo dos mezclas u observaciones. Este método es
válido cuando ambas fuentes son disjuntas ortogonalmente (W-DO), es decir cuando la superposición
de las transformadas enventandas de Fourier de las señales en la mezcla son disjuntas.
Se ha centrado solo en hacer simulaciones de mezclas sintéticas, de voces y algún instrumento musical

19
viendo cuál es el número máximo de fuentes que el algoritmo es capaz de separar. También se
consideran entornos en los que la presencia de ruido es notable, llegando hasta el punto en el que la
relación señal a ruido se hace tan pequeña que es imposible para el algoritmo crear las máscaras que
le permiten separar cada fuente de la mezcla.
Finalmente se propone una comparación con otro algoritmo de separación de fuentes, basado en
PARAFAC. Se han realizado pruebas más escuetas, ya que este algoritmo solo permite simulación de
mezclas determinadas o sobredeterminadas, así que solo se ha comparado en varios entornos el caso
de dos fuentes y dos sensores.
La simulación que se propone de este algoritmo ha sido escrita en MATLAB, cuyo código puede verse
en el Anexo B.
1.3 Visión general
Este proyecto se dividirá en varios capítulos, para hacer frente a distintos contenidos.
En el capítulo 2 se explicarán las herramientas que hacen falta para entender algunos conceptos
explicados más tarde, como pueden ser la naturaleza de la señal de voz, y una visión general de esta,
así como sus propiedades, sin olvidar la transformación que se hace para su análisis, la transformada
localizada o transformada en tiempo-frecuencia, STFT (Short Time Fourier Transform). También se
habla de los diferentes modelos de mezcla que nos podemos encontrar dependiendo de la situación en
la que estemos.
El capítulo 3 recopila los métodos más usados para el problema de la separación ciega de fuentes. Por
un lado tenemos que distinguir entre los que se basan solo en parámetros estadísticos para separar
dichas fuentes, como PCA, que usa la incorrelación, o ICA, que usa la independencia de los
componentes de la señal para tal tarea, y por otro lado, los que se basan en la geometría de la situación.
Estos métodos normalmente se basan en construir unas máscaras binarias para cada fuente,
permitiendo así su separación.
El capítulo 4, explica con detalle el método DUET (Degenerate Unmixing Estimation Technique), que
es un método basado en la geometría. Es de mención especial, ya que es el algoritmo que utilizaremos
en este proyecto en futuras simulaciones.
Antes de comentar dichas simulaciones, el capítulo 5 explica cómo pueden realizarse medidas que
evalúen la calidad que hemos obtenido en la separación. Para ello podemos usar medidas objetivas

20
(son las que utilizaremos) o medidas perceptuales.
El capítulo 6 contiene los datos de las simulaciones realizadas. Las situaciones, números de fuentes,
parámetros de atenuación y retardo, así como los valores que permiten ver la calidad en la separación.
Para ello, haremos simulaciones variando el número de fuentes, modificando su geometría,
introduciendo instrumentos musicales, para al final comparar esos resultados con los obtenidos
mediante otro algoritmo de separación, basado en PARAFAC.
Este proyecto finaliza con el capítulo 7, que explica las aplicaciones de este tipo de estudios y
simulaciones, así como estudios y futuros estudios acerca de este tema, sobre aplicaciones médicas,
aplicaciones de música, o incluso aplicaciones en el mundo de las finanzas.

21
2 CONCEPTOS PREVIOS
“We scarcely know how much of our pleasure and interest in life
comes to us through our eyes until we have to do without them; and
part of that pleasure is that the eyes can choose where to look. But
the ears can't choose where to listen.”
Ursula K. Le Guin
ste capítulo consistirá en introducir algunos términos y conocimientos que iremos aplicando a lo
largo de este proyecto, y con los que tendremos que estar bastante familiarizados, de ahí la
mención especial en un capítulo aparte.
Antes de empezar a desarrollar los métodos que se usan para la separación ciega de fuentes, debemos
saber algunos conceptos que serán necesarios más tarde. También serán necesarios algunos
conocimientos estadísticos básicos que aparecerán según avancemos en el libro, y otros más complejos
que se irán explicando a medida que vayamos desarrollando los distintos métodos.
Básicamente explicaremos qué forma tiene una señal de voz, cómo analizarla y sus propiedades, para
lo cual usaremos la transformada de Fourier enventanada, también llamada transformada localizada o
E

22
conocida por sus siglas en inglés, Short Time Fourier Transform, STFT. Esta transformada es de vital
importancia para la representación de las señales de voz, ya que nos permitirá ver la evolución
frecuencial de las señales a medida que el tiempo avanza. Por supuesto, pasar del dominio del tiempo
al dominio de frecuencia, o mejor dicho, de tiempo-frecuencia, indica que al final tendremos que
antitransformar la señal, es decir, pasar del dominio de tiempo-frecuencia al dominio del tiempo otra
vez. Este método no es tan trivial como la transformada de Fourier, así que veremos dos métodos para
antitransformar: el Filter Bank Summation (FBS) y el método Overlap-Add (OLA) que es el que
usaremos en la simulación en MATLAB.
También estudiaremos los distintos tipos de escenarios que nos podemos encontrar, así como los
modelos de mezcla que se adaptan a estos escenarios.
2.1 La señal de voz.
Las señales de voz son generadas por nuestro aparato fonador, el cual crea un conjunto de sonidos que
forman esa señal acústica. Las señales de voz, como todos los sonidos, pueden representarse como
combinaciones (aunque muy complejas) de senos y cosenos. Esta representación en función del tiempo
también nos dará información acerca de su energía y su tasa de cruces por cero, dos factores que
facilitan su análisis, y dan lugar a muchas aplicaciones, como reconocedores de voz.
Aunque la voz se pueda descomponer en complejas combinaciones de senos y cosenos, es aperiódica.
Pero si miramos muy de cerca, podemos comprobar que cumple una cierta cuasi-periodicidad. En
intervalos pequeños de tiempo (unos 5-20ms) la voz se comporta de una forma casi periódica. Eso
quiere decir que algunas propiedades estadísticas permanecen constantes si solo analizamos esa
ventana. De ahí que el análisis de voz se haga de forma enventanada o localizada.
La frecuencia de pitch o frecuencia fundamental de igual forma nos aporta más información sobre la
señal, concretamente sobre la velocidad a la que vibran las cuerdas vocales al producir los sonidos.
Así, la representación de la voz también la podemos realizar en función de la frecuencia, esto se haría
pasando la señal al dominio frecuencial, mediante la transformada de Fourier o transformada discreta
de Fourier, lo que nos aportaría información sobre la frecuencia fundamental, armónicos y demás
componentes, que se extienden desde los 50Hz hasta pasados los 5KHz.

23
2.2 Transformada localizada.
Analizando señales de voz con la transformada discreta de Fourier encontramos el problema de que
no puede mostrar cambios en el espectro de frecuencias a medida que el tiempo varía. En contraste la
transformada en tiempo-frecuencia o transformada localizada, la cual usaremos para analizar las
señales de voz, en inglés Short Time Fourier Transform (STFT) consiste en una transformada de
Fourier para cada instante de tiempo.
En señales de voz, no tiene sentido hacer la Transformada de Fourier, puesto que es no estacionaria, y
obtendremos una superposición de comportamientos. Esta transformada nueva se basa en el
enventanado de la señal, puesto que la voz es cuasi-estacionaria en intervalos cortos de tiempo (10-
30ms) [9].
Dividiremos el estudio de esta transformada en dos partes, análisis, donde veremos dicha
transformación y las diferentes definiciones o formas de verla, y síntesis, donde partiendo de la
transformada, vamos a antitransformar para volver al dominio del tiempo.
2.2.1 Análisis
Empezaremos por la definición. La STFT de una señal muestreada 𝑠[𝑛] será:
𝑆(𝑛, 𝜔) = ∑ 𝑠[𝑚]𝑤[𝑛 − 𝑚]𝑒−𝑗𝜔𝑚
∞
𝑚=−∞
(2.1)
La STFT discreta puede obtenerse de la STFT por la siguiente relación:
𝑆(𝑛, 𝑘) = 𝑆(𝑛, 𝜔)|𝜔 =
2𝜋
𝑁𝑘 (2.2)
Básicamente la STFT discreta es una STFT donde se ha sampleado con un intervalo de muestreo de
frecuencia de 2𝜋
𝑁. Nos referimos a 𝑁 como el factor de muestreo.
Siendo 𝑤[𝑛] la ventana utilizada (en nuestro caso utilizaremos Hamming porque evita la distorsión en
la forma y envolvente del espectro de la señal de la voz enventanada).
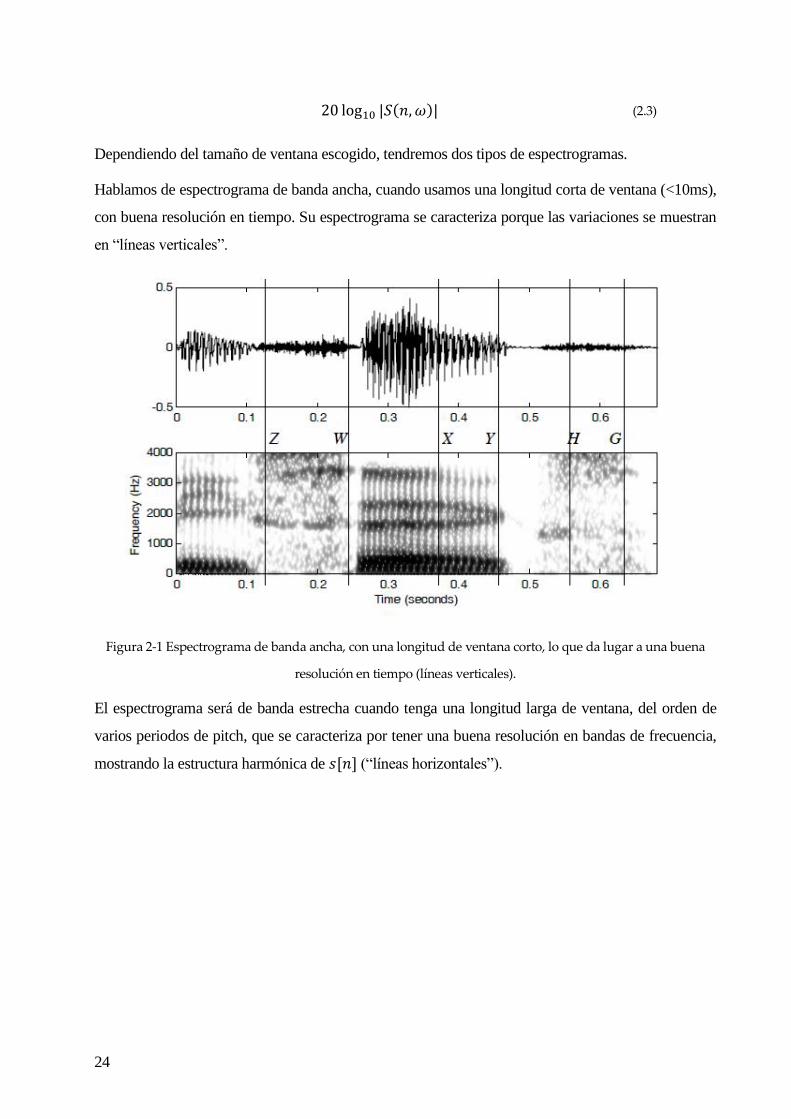
Si analizamos el espectrograma de la transformada localizada,
24
20 log10 |𝑆(𝑛, 𝜔)| (2.3)
Dependiendo del tamaño de ventana escogido, tendremos dos tipos de espectrogramas.
Hablamos de espectrograma de banda ancha, cuando usamos una longitud corta de ventana (<10ms),
con buena resolución en tiempo. Su espectrograma se caracteriza porque las variaciones se muestran
en “líneas verticales”.
Figura 2-1 Espectrograma de banda ancha, con una longitud de ventana corto, lo que da lugar a una buena
resolución en tiempo (líneas verticales).
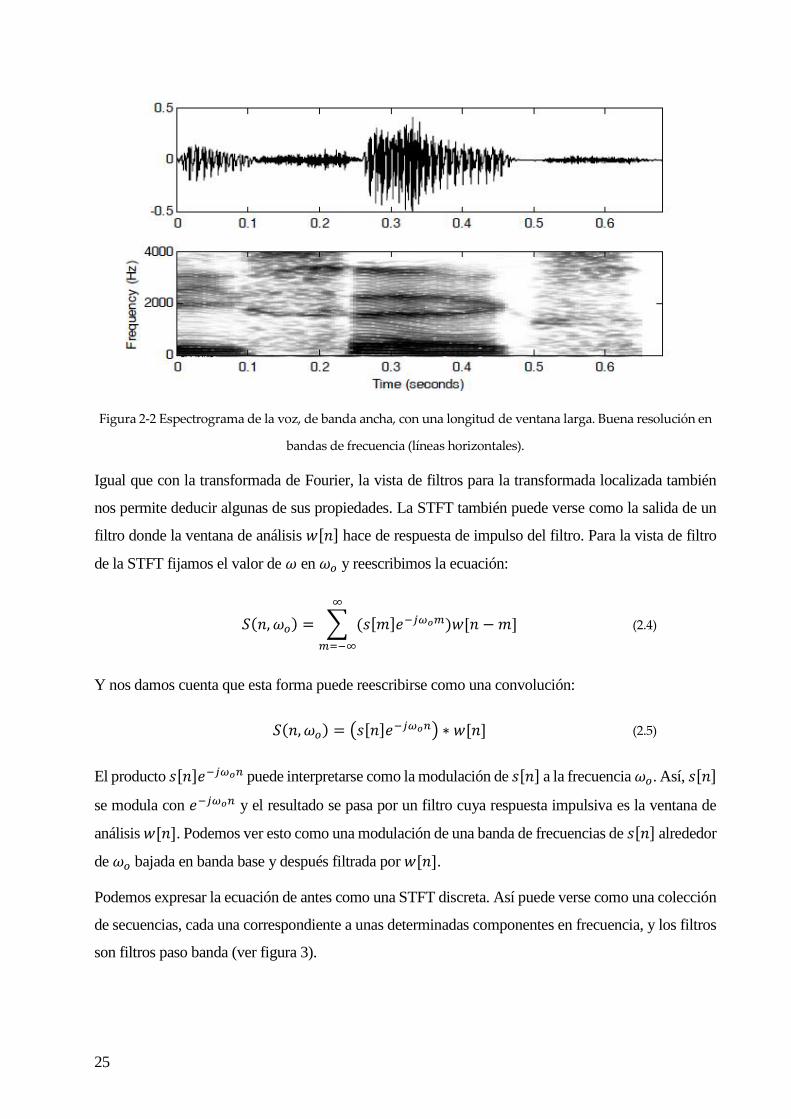
El espectrograma será de banda estrecha cuando tenga una longitud larga de ventana, del orden de
varios periodos de pitch, que se caracteriza por tener una buena resolución en bandas de frecuencia,
mostrando la estructura harmónica de 𝑠[𝑛] (“líneas horizontales”).
25
Figura 2-2 Espectrograma de la voz, de banda ancha, con una longitud de ventana larga. Buena resolución en
bandas de frecuencia (líneas horizontales).
Igual que con la transformada de Fourier, la vista de filtros para la transformada localizada también
nos permite deducir algunas de sus propiedades. La STFT también puede verse como la salida de un
filtro donde la ventana de análisis 𝑤[𝑛] hace de respuesta de impulso del filtro. Para la vista de filtro
de la STFT fijamos el valor de 𝜔 en 𝜔𝑜 y reescribimos la ecuación:
𝑆(𝑛, 𝜔𝑜) = ∑ (𝑠[𝑚]𝑒−𝑗𝜔𝑜𝑚)𝑤[𝑛 − 𝑚]
∞
𝑚=−∞
(2.4)
Y nos damos cuenta que esta forma puede reescribirse como una convolución:
𝑆(𝑛, 𝜔𝑜) = (𝑠[𝑛]𝑒−𝑗𝜔𝑜𝑛) ∗ 𝑤[𝑛] (2.5)
El producto 𝑠[𝑛]𝑒−𝑗𝜔𝑜𝑛 puede interpretarse como la modulación de 𝑠[𝑛] a la frecuencia 𝜔𝑜. Así, 𝑠[𝑛]
se modula con 𝑒−𝑗𝜔𝑜𝑛 y el resultado se pasa por un filtro cuya respuesta impulsiva es la ventana de
análisis 𝑤[𝑛]. Podemos ver esto como una modulación de una banda de frecuencias de 𝑠[𝑛] alrededor
de 𝜔𝑜 bajada en banda base y después filtrada por 𝑤[𝑛].
Podemos expresar la ecuación de antes como una STFT discreta. Así puede verse como una colección
de secuencias, cada una correspondiente a unas determinadas componentes en frecuencia, y los filtros
son filtros paso banda (ver figura 3).

26
Figura 2-3 Vista esquemática de la transformada STFT como una modulación más una serie de filtros paso
banda.
2.2.2 Síntesis
Ahora consideremos el problema de obtener la secuencia a partir de la STFT discreta tal y como la
vimos en el análisis. Para este proceso de síntesis debemos mirar, aunque es invertible siempre, algunas
condiciones en los ratios de muestreo.
Si para cada 𝑛 tomamos la transformada inversa de Fourier de la correspondiente frecuencia,
obtenemos la secuencia de 𝑓𝑛[𝑚]. Si la evaluamos en 𝑚 = 𝑛, obtenemos el valor 𝑥[𝑛]𝑤[0].
Asumiendo que 𝑤[0] ≠ 0 podemos dividir por 𝑤[0] para recuperar 𝑥[𝑛]. Así tenemos la ecuación:
𝑥[𝑛] =1
2𝜋𝑤[0]∫ 𝑋(𝑛, 𝜔)𝑒𝑗𝜔𝑛𝑑𝜔
𝜋
−𝜋
(2.6)
En contraste con la STFT, la STFT discreta no siempre es invertible, por ejemplo, puede darse el caso
de que escojamos un intervalo de muestreo mayor que el ancho de banda de la ventana. En este caso
habrá componentes de 𝑥[𝑛] que no pasan por ninguno de los filtros de la STFT discreta. Podrían tener

27
valores arbitrarios y aun así obtendríamos la misma STFT discreta. Por esto podemos decir que no
puede ser invertible.
Seleccionando valores apropiados de ventana y de muestreo la transformada STFT discreta es
invertible. A continuación se explican dos métodos que pueden hacer la síntesis de una STFT discreta
para recuperar la señal original 𝑥[𝑛].
2.2.2.1 Método Filter Bank Summation (FBS)
En la interpretación basada en filtros de la STFT discreta, ésta, es el resultado de unas salidas de unos
filtros. En este método, las salidas de cada uno de esos filtros se modula con una exponencial compleja,
y todo eso se suma en cada instante de tiempo para obtener la muestra en tiempo de la secuencia
original. Así tenemos la ecuación:
𝑦[𝑛] =1
𝑁𝑤[0]∑ 𝑋(𝑛, 𝑘)𝑒
𝑗2𝜋𝑁
𝑛𝑘
𝑁−1
𝑘=0
(2.7)
Ahora deduciremos las condiciones para que la secuencia 𝑦[𝑛] sea igual a la original 𝑥[𝑛]. Si
sustituimos 𝑋(𝑛, 𝑘) en la ecuación por la STFT discreta de 𝑥[𝑛] tenemos que:
𝑦[𝑛] =1
𝑁𝑤[0]∑ [∑ 𝑥[𝑚]𝑤[𝑛 − 𝑚]𝑒
−𝑗2𝜋𝑁
𝑚𝑘
∞
−∞
] 𝑒𝑗2𝜋
𝑁𝑛𝑘
𝑁−1
𝑘=0
(2.8)
Usando la interpretación basada en filtros de la STFT se puede ver como una convolución, y podemos
reescribirla así:
𝑦[𝑛] =1
𝑁𝑤[0]𝑥[𝑛] ∗ ∑ 𝑤[𝑛]𝑒
𝑗2𝜋𝑁
𝑛𝑘
𝑁−1
𝑘=0
(2.9)
Sacando 𝑤[𝑛] del sumatorio y reescribiendo el sumatorio de las exponenciales como un tren de deltas
de periodo 𝑁:
𝑦[𝑛] =
1
𝑤[0]𝑥[𝑛] ∗ 𝑤[𝑛] ∑ 𝛿[𝑛 − 𝑟𝑁]
∞
−∞
(2.10)
Después de esto, si deseamos que 𝑦[𝑛] = 𝑥[𝑛], entonces el producto de 𝑤[𝑛] y el tren de deltas debe
reducirse a 𝑤[0]𝛿[𝑛].

28
𝑤[𝑛] ∑ 𝛿[𝑛 − 𝑟𝑁]
∞
−∞
= 𝑤[0]𝛿[𝑛] (2.11)
Esto se cumple para toda ventana de análisis cuya longitud 𝑁𝑤 sea menor o igual al número de filtros
de análisis, 𝑁. Si hacemos la transformada de Fourier en ambos miembros de la igualdad anterior,
obtenemos:
∑ 𝑊 (𝜔 −2𝜋
𝑁𝑘) = 𝑁𝑤[0]
𝑁−1
𝑘=0
(2.12)
Esto básicamente quiere decir que la respuesta en frecuencia de todos los filtros debe ser una constante
para todo el ancho de banda.
2.2.2.2 Método Overlap-Add (OLA)
Para este método, no veremos la STFT como un conjunto de filtros. Lo que haremos será tomar la
transformada DFT inversa para cada instante de tiempo en la STFT, y luego hacemos que se solapen
y las vamos sumando, de ahí el nombre. Este método elimina la ventana de análisis para recuperar la
secuencia original. La explicación es que la redundancia con el solapado quitan el efecto del
enventanado. La relación entre la secuencia y su transformada STFT sería:
𝑥[𝑛] =
1
2𝜋𝑊[0]∫ ∑ 𝑋(𝑝, 𝜔)𝑒𝑗𝜔𝑝𝑑𝜔
∞
𝑝=−∞
𝜋
−𝜋
(2.13)
Donde:
𝑊[0] = ∑ 𝑤[𝑛]
∞
𝑛=−∞
(2.14)
Así, la relación de síntesis puede ser igual que la que teníamos antes, con una STFT discreta:
𝑦[𝑛] =1
𝑊[0]∑ [
1
𝑁∑ 𝑋(𝑝, 𝑘)𝑒
𝑗2𝜋𝑁
𝑛𝑘
𝑁−1
𝑘=0
]
∞
𝑝=−∞
(2.15)

29
El término entre corchetes es simplemente la transformada inversa, que para cada 𝑝 nos devuelve:
𝑓𝑝[𝑛] = 𝑥[𝑛]𝑤[𝑝 − 𝑛] (2.16)
Mientras que la longitud de la transformada 𝑁 sea mayor que la longitud de ventana 𝑁𝑤 no habrá
aliasing. Reescribimos la ecuación anterior:
𝑦[𝑛] =
1
𝑊[0]∑ 𝑥[𝑛]𝑤[𝑝 − 𝑛]
∞
𝑝=−∞
(2.17)
Que sacando el 𝑥[𝑛] fuera del sumatorio, vemos que 𝑦[𝑛] = 𝑥[𝑛] solo si se cumple:
∑ 𝑤[𝑝 − 𝑛] = 𝑊(0)
∞
𝑝=−∞
(2.18)
Que observamos que siempre es cierto porque la suma de los valores de una secuencia debe ser siempre
igual al primer valor de su transformada de Fourier. Además, si la STFT discreta ha sido diezmada en
tiempo por un factor 𝐿 puede mostrarse como:
∑ 𝑤[𝑝𝐿 − 𝑛] =
𝑊(0)
𝐿
∞
𝑝=−∞
(2.19)
Así 𝑥[𝑛] puede sintetizarse usando la relación:
𝑥[𝑛] =𝐿
𝑊[0]∑ [
1
𝑁∑ 𝑋(𝑝𝐿, 𝑘)𝑒
𝑗2𝜋𝑁
𝑛𝑘
𝑁−1
𝑘=0
]
∞
𝑝=−∞
(2.20)
Que se cumplirá para cualquier tamaño de ancho de banda de la ventana de análisis siempre que su
máxima frecuencia sea menor que 2𝜋
𝐿. A continuación se muestra una figura comparativa de los dos
métodos.

30
Figura 2-4 Comparativa de los métodos de síntesis explicados. A la izquierda el método FBS (Filter Bank
Summation) el cual ve la señal como la salida de unos filtros. A la derecha el método OLA (Overlap-Add) el
cual antitransforma la señal, para cada instante de tiempo.
2.3 Propiedades de las señales de voz.
2.3.1 Propiedad de no-Gaussianidad.
Las funciones de densidad de probabilidad de la voz no siguen un modelo gaussiano, son mucho más
abruptas y con largas colas. Esta propiedad es imprescindible para métodos estadísticos como ICA,
que veremos en el capítulo 3, ya que este método se basa en la independencia estadística de las señales.
Si queremos aproximar la función de densidad de probabilidad de las señales de voz, podemos
modelarla como una distribución Laplaciana, que seguiría una distribución super-gaussiana.
𝑝𝑋(𝑥) ∝ 𝐾𝑒−(𝛼|𝑥|𝜏) 0 < 𝜏 < 1 (2.21)
En la Figura 2-5 vemos la comparación, con ambas distribuciones normalizadas, siendo la distribución
Laplaciana la de la línea continua y la gaussiana la discontinua.
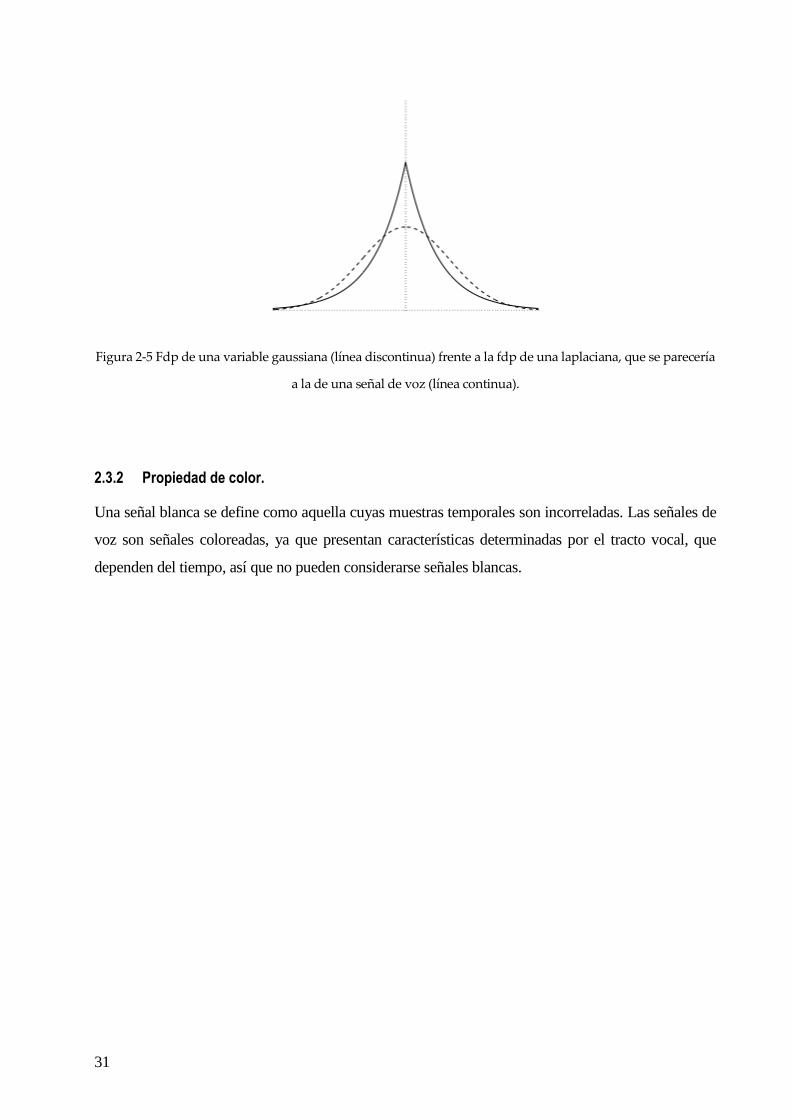
31
Figura 2-5 Fdp de una variable gaussiana (línea discontinua) frente a la fdp de una laplaciana, que se parecería
a la de una señal de voz (línea continua).
2.3.2 Propiedad de color.
Una señal blanca se define como aquella cuyas muestras temporales son incorreladas. Las señales de
voz son señales coloreadas, ya que presentan características determinadas por el tracto vocal, que
dependen del tiempo, así que no pueden considerarse señales blancas.
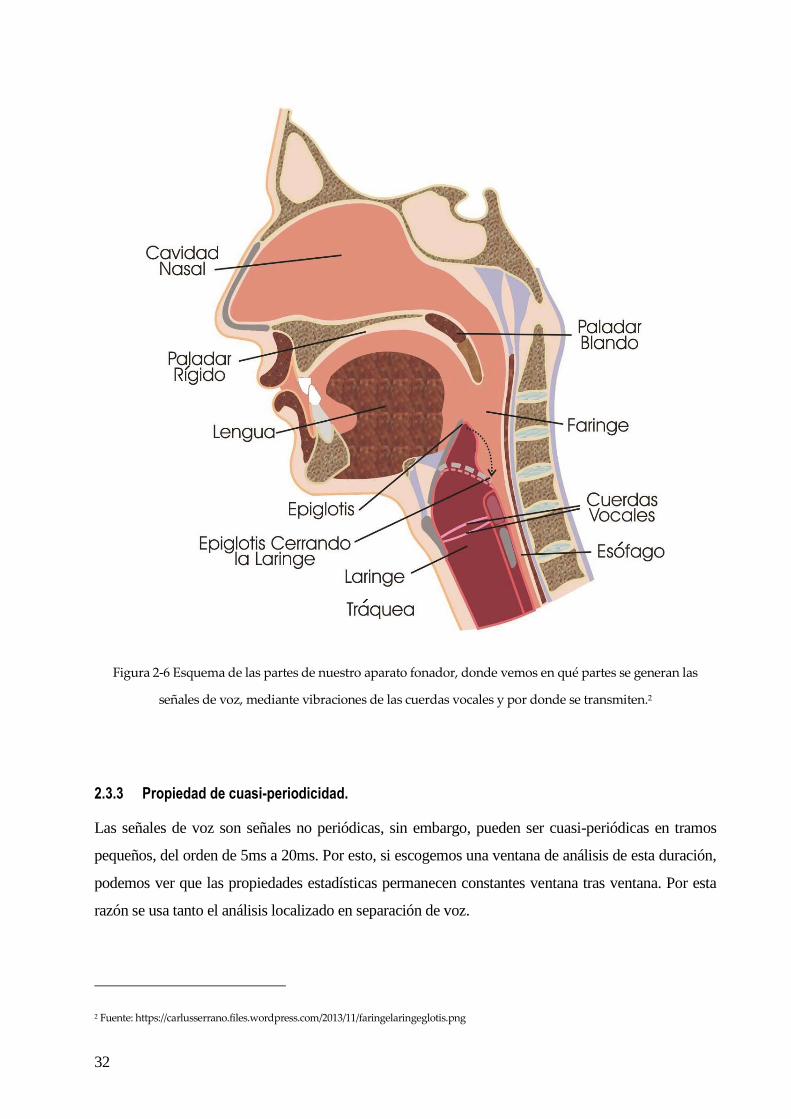
32
Figura 2-6 Esquema de las partes de nuestro aparato fonador, donde vemos en qué partes se generan las
señales de voz, mediante vibraciones de las cuerdas vocales y por donde se transmiten.2
2.3.3 Propiedad de cuasi-periodicidad.
Las señales de voz son señales no periódicas, sin embargo, pueden ser cuasi-periódicas en tramos
pequeños, del orden de 5ms a 20ms. Por esto, si escogemos una ventana de análisis de esta duración,
podemos ver que las propiedades estadísticas permanecen constantes ventana tras ventana. Por esta
razón se usa tanto el análisis localizado en separación de voz.
2 Fuente: https://carlusserrano.files.wordpress.com/2013/11/faringelaringeglotis.png
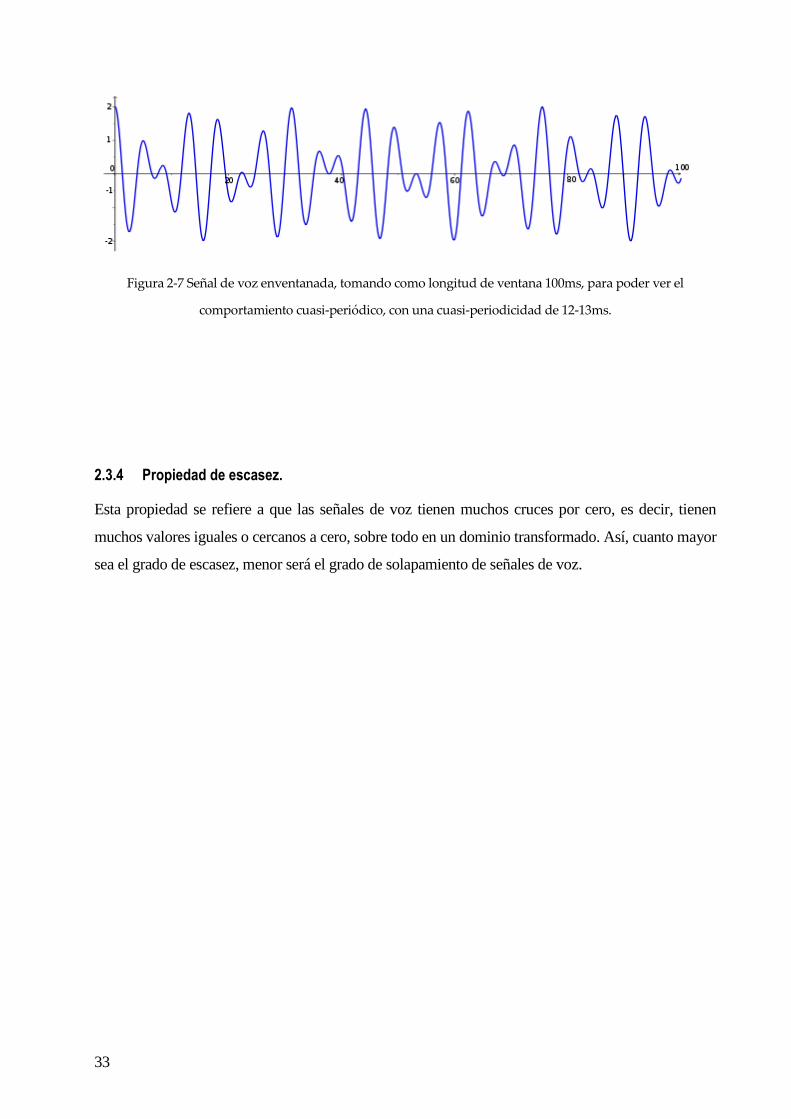
33
Figura 2-7 Señal de voz enventanada, tomando como longitud de ventana 100ms, para poder ver el
comportamiento cuasi-periódico, con una cuasi-periodicidad de 12-13ms.
2.3.4 Propiedad de escasez.
Esta propiedad se refiere a que las señales de voz tienen muchos cruces por cero, es decir, tienen
muchos valores iguales o cercanos a cero, sobre todo en un dominio transformado. Así, cuanto mayor
sea el grado de escasez, menor será el grado de solapamiento de señales de voz.
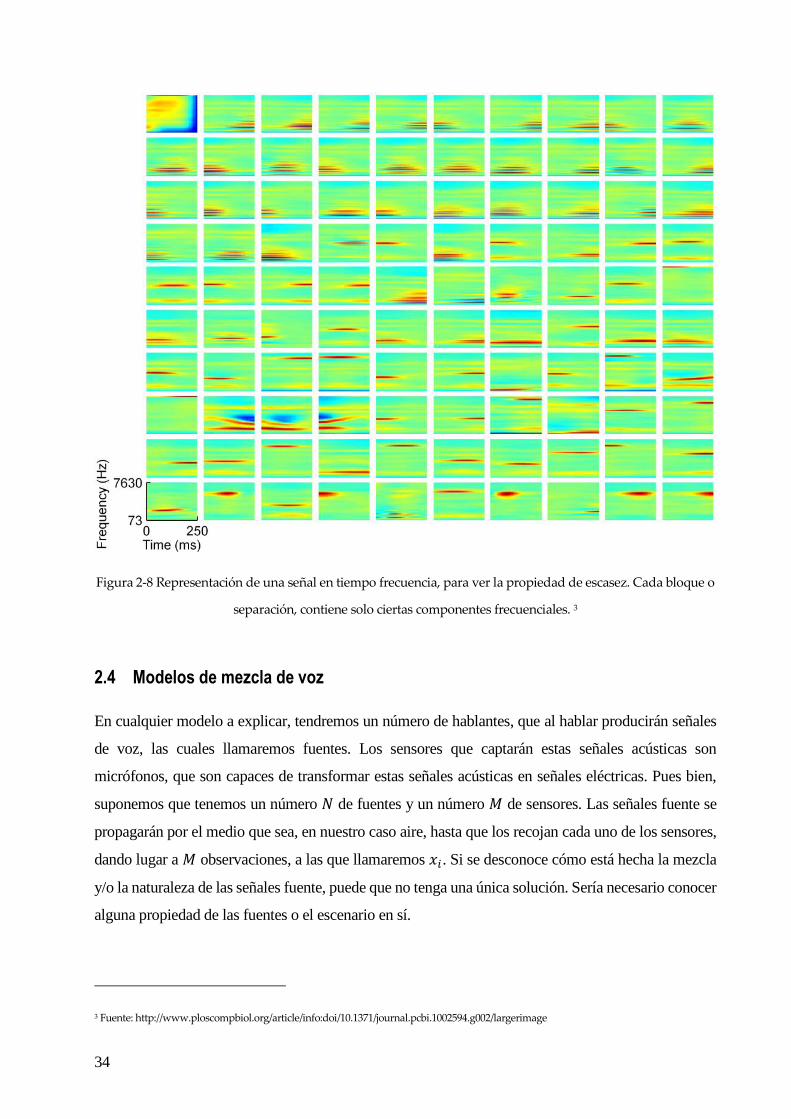
34
Figura 2-8 Representación de una señal en tiempo frecuencia, para ver la propiedad de escasez. Cada bloque o
separación, contiene solo ciertas componentes frecuenciales. 3
2.4 Modelos de mezcla de voz
En cualquier modelo a explicar, tendremos un número de hablantes, que al hablar producirán señales
de voz, las cuales llamaremos fuentes. Los sensores que captarán estas señales acústicas son
micrófonos, que son capaces de transformar estas señales acústicas en señales eléctricas. Pues bien,
suponemos que tenemos un número 𝑁 de fuentes y un número 𝑀 de sensores. Las señales fuente se
propagarán por el medio que sea, en nuestro caso aire, hasta que los recojan cada uno de los sensores,
dando lugar a 𝑀 observaciones, a las que llamaremos 𝑥𝑖. Si se desconoce cómo está hecha la mezcla
y/o la naturaleza de las señales fuente, puede que no tenga una única solución. Sería necesario conocer
alguna propiedad de las fuentes o el escenario en sí.
3 Fuente: http://www.ploscompbiol.org/article/info:doi/10.1371/journal.pcbi.1002594.g002/largerimage
35
El fenómeno de la reverberación puede estar presente, interfiriendo de forma que las incidencias en los
sensores no provendrían sólo de las fuentes, sino también de las múltiples reflexiones de esas ondas
sonoras en muros y demás presentes en el entorno. Para caracterizar este entorno existe lo que se
denomina función de transferencia acústica, es decir la respuesta impulsiva desde las fuentes hasta los
sensores [9].
Esta respuesta impulsiva se compone de tres partes, un primer pico, el correspondiente al camino
directo entre la fuente y el micrófono, seguido de unos picos más pequeños correspondientes a las
reflexiones tempranas y una cola decreciente debido a los demás ecos producidos por la reverberación.
La posición de las reflexiones tempranas puede saberse si sabemos la geometría de la habitación. La
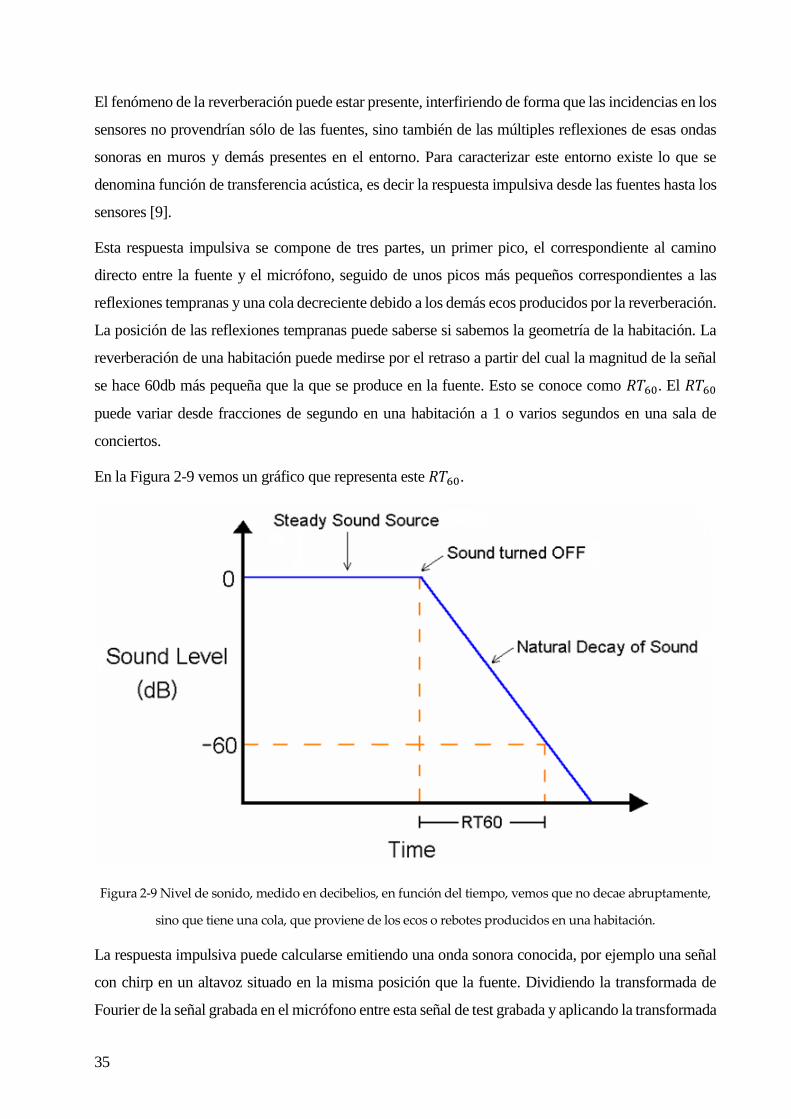
reverberación de una habitación puede medirse por el retraso a partir del cual la magnitud de la señal
se hace 60db más pequeña que la que se produce en la fuente. Esto se conoce como 𝑅𝑇60. El 𝑅𝑇60
puede variar desde fracciones de segundo en una habitación a 1 o varios segundos en una sala de
conciertos.
En la Figura 2-9 vemos un gráfico que representa este 𝑅𝑇60.
Figura 2-9 Nivel de sonido, medido en decibelios, en función del tiempo, vemos que no decae abruptamente,
sino que tiene una cola, que proviene de los ecos o rebotes producidos en una habitación.
La respuesta impulsiva puede calcularse emitiendo una onda sonora conocida, por ejemplo una señal
con chirp en un altavoz situado en la misma posición que la fuente. Dividiendo la transformada de
Fourier de la señal grabada en el micrófono entre esta señal de test grabada y aplicando la transformada

36
inversa.
Los diferentes entornos que podemos encontrarnos se ajustarán a unos modelos de mezcla. De esta
forma, tendremos:
Entornos donde el camino desde la fuente al sensor no sigue solo el camino directo, sino
que se producen reverberaciones. Estas mezclas se llaman convolutivas.
Entornos anecoicos, es decir, ambientes donde no se produce ninguna reverberación. Al no
haber presencia de esas reverberaciones, nos referiremos a que nuestra mezcla es no
convolutiva o instantánea.
Además, las mezclas pueden ser variantes o invariantes con el tiempo, con presencia de
ruido aditivo o sin él.
Dependiendo del número de fuentes y de sensores, el modelo será sobredeterminado (más
sensores que fuentes), determinado (igual número de ambos), o indeterminado (más
fuentes que sensores).
El modelo de mezcla que usaremos será el de un entorno anecoico, es decir, una mezcla instantánea.
Además tampoco consideramos que haya presencia de ruido aditivo en la mezcla.
Matemáticamente, si llamamos 𝑠𝑖 a las señales fuente, podemos escribir este modelo de mezcla
(instantánea y sin ruido aditivo) de la siguiente forma:
𝑋𝑘(𝑡) = ∑ 𝑎𝑘,𝑖𝑆𝑖(𝑡 − 𝑑𝑘,𝑖)
𝑛
𝑖=1
𝑘 = 1, … , 𝑚 (2.22)
O en forma matricial,
𝒙𝑖 = 𝑨𝒔𝑖 (2.23)
En la Figura 2-10 vemos dos hablantes, dos sensores y cómo se produce el efecto “cocktail party”.

37
Figura 2-10 Efecto “cocktail-party” donde dos fuentes, 𝑠1 y 𝑠2, se mezclan dando lugar a dos señales de mezcla
u observaciones, 𝑥1 y 𝑥2, con unos coeficientes de mezcla, 𝑎𝑖𝑗 .
Donde 𝑨 sería la matriz de mezcla.
En un sistema con 3 fuentes y 3 sensores, podríamos tener:
𝑥1(𝑡) = 𝑎11𝑠1(𝑡) + 𝑎12𝑠2(𝑡) + 𝑎13𝑠3(𝑡)
𝑥2(𝑡) = 𝑎21𝑠1(𝑡) + 𝑎22𝑠2(𝑡) + 𝑎23𝑠3(𝑡)
𝑥3(𝑡) = 𝑎31𝑠1(𝑡) + 𝑎32𝑠2(𝑡) + 𝑎33𝑠3(𝑡)
(2.24)
Ésta representa una transformación, que podrá contemplar atenuación, retraso, etc. 𝑎𝑘,𝑖 y 𝛿𝑘,𝑖 serían la
atenuación y retrasos asociados con el camino desde la i-ésima fuente al k-ésimo sensor. Para
simplificar, haremos que 𝑎1,𝑖 = 1 y 𝛿1,𝑖 = 0 para 𝑗 = 1, … , 𝑁.
Vamos a considerar ahora el modelo que se usa en este proyecto, que consta de dos señales fuente y
dos sensores. Renombramos así, 𝑎2,𝑖 como 𝑎𝑖 y 𝛿2,𝑖 como 𝛿𝑖.

38
Podemos reescribir el modelo matemático:
[X1(t, 𝜔)X2(t, 𝜔)
] = [1 … 1
𝑎1𝑒−𝑗𝜔𝛿1 … 𝑎𝑁𝑒−𝑗𝜔𝛿𝑁] [
S1(𝑡, 𝜔)…
S𝑁(𝑡, 𝜔)] (2.25)
2.5 Conclusiones
Ya sabemos cómo es una señal de voz, sabemos de su comportamiento cuasi-periódico, y cómo éste
nos permite un análisis con muchas más aplicaciones, ya que durante un periodo corto de tiempo, la
voz mantiene propiedades constantes, permitiéndonos así realizar el análisis de la señal, usando
ventanas.
Para este análisis enventanado, hacemos uso de la transformada localizada, la cual pasa al dominio de
frecuencia la señal ventana tras ventana, pudiendo verse en una representación el comportamiento que
tiene la señal frecuencialmente, en función del tiempo. Una vez tenemos la transformada en tiempo-
frecuencia, hay distintos métodos para volver al dominio del tiempo, el FBS, que tiene una visión
basada en filtros, y el OLA, que realiza la transformada inversa para cada instante de tiempo.
También conocemos otras propiedades de la voz que son interesantes para futuros análisis como la
propiedad de no-Gaussianidad o la propiedad de escasez, muy útil en separación ciega de fuentes.
La voz tampoco será una señal aislada siempre, ya que puede verse en diferentes entornos, los cuales
se modelan mediante modelos de mezcla de voz, que pueden ser instantáneas o convolutivas,
invariantes o no en el tiempo, sobredeterminados (más sensores que fuentes), determinados (igual
número de ambos) o indeterminados (más fuentes que sensores).
A continuación se presentan diferentes métodos para la separación ciega de fuentes, que usarán las
herramientas explicadas en este capítulo, de ahí la importancia de tener un capítulo aparte con algunos
conocimientos necesarios para abordar el problema que se presenta en este proyecto.

39
3 EL PROBLEMA DE LA SEPARACIÓN CIEGA DE
FUENTES
The adjective ‘blind’ stresses the fact that i) the source signals
are not observed and ii) no information is available about the
mixture.
Jean-François Cardoso, 1998
a separación ciega de fuentes, en inglés Blind Source Separation (BSS) se refiere al problema de
recuperar dos o más fuentes de una mezcla de fuentes indeterminadas, utilizando determinadas
propiedades de las mismas. Este problema abarca muchos campos, desde procesado de imágenes,
ingeniería biomédica, procesado de audio, etc. Cuando se refiere a señales de voz, esto también se
conoce como el efecto “cocktail party”, que es el que se produce cuando una persona puede focalizar
su atención en una sola conversación, en una habitación en la que hay más de una conversación al
mismo tiempo.
Hay numerosas posibilidades en el entorno en el que se pueden observar estas señales de voz, así que
dependerá de factores como el número de sensores, el número de señales fuente, si el entorno de
grabación es cerrado o por el contrario hay presencia de ruido, reverberaciones, etcétera. Cuando las
fuentes, los sensores y el canal son invariantes con el tiempo, el modelo puede ser modelado como una
L

40
convolución de las fuentes por unos filtros de mezcla.
Todo esto es configurado en lo que hemos llamado modelo de mezcla, así diferentes entornos darán
lugar a distintos modelos de mezcla. Este problema también podrá pasarse al dominio en tiempo-
frecuencia, usando la transformada localizada, el cual nos ayudará bastante al permitir aproximar el
modelo de convolución mencionado anteriormente por un conjunto de mezclas instantáneas. Es decir,
estudiaremos algoritmos en los que el problema se solucionará en el dominio tiempo-frecuencia, y
algoritmos que no convierten las señales fuente a ningún otro dominio, aunque buscan parámetros y
factores en común entre sus componentes mediante un análisis estadístico.
El primero que hizo referencia al problema “Cocktail party” y le puso dicho nombre fue Colin Cherry
en 1953, un británico que quiso describir la capacidad del cerebro humano para filtrar una conversación
de entre muchas otras simultáneas. Todavía no se sabe muy bien en profundidad cómo realiza nuestro
cerebro esta tarea de filtrar distintas voces de entre una conversación. Para que se dé este fenómeno
son necesarios ambos oídos (dos sensores). Así, el cerebro humano es capaz de filtrar esa conversación
de entre todas las que hay a la vez, pero esto traducido en procesamiento digital de señales, es algo más
complicado.
Existen distintas soluciones al problema, algunas basadas en métodos estadísticos, métodos de
conformación de haz, otras en técnicas de enmascaramiento y otras basadas en la percepción humana
de la escena auditiva, que consisten en un análisis computacional (CASA, Computational Auditory
Scene Analysis). Estos métodos matemáticos suelen hacer suposiciones sobre las fuentes para
simplificar los cálculos. Los métodos de conformación de haz solo podrán considerarse métodos ciegos
cuando se desconoce la posición de las fuentes.
La mayoría de los sistemas CASA están modelados sobre las fases que se conocen sobre cómo
funciona nuestro sistema auditivo. Analizan las variaciones de la presión en el aire que son generadas
por las distintas voces. También intervienen las diferentes características de las voces de los hablantes:
periodo de pitch, velocidad, acentos, etc. Además, nuestro oído también predice secuencias de palabras
debido a la redundancia del lenguaje. Todo esto para recuperar la información de esa mezcla que
obtenemos. Bregman [10] fue el primero que presentó una respuesta coherente a cómo recuperar la
información de las fuentes a partir del análisis de estas mezclas.

41
Figura 3-1 Diagrama de bloques de un sistema CASA.
Su trabajo explicaba que los que escuchan lo hacen en un proceso de dos fases. En la primera, la mezcla
acústica se descompone en elementos. Un elemento puede ser considerado una mínima parte de la
escena auditiva que describe un evento acústico determinado. Un conjunto de éstos pueden formar una
estructura que podemos llamar flujo. En la Figura 3-1 podemos ver el diagrama de bloques completo
de un sistema CASA.
En los términos de Bregman, el tracto vocal del hablante es la fuente acústica, mientras que la
representación mental de la voz del hablante es ese flujo de datos. Pueden considerarse grupos en los
que los componentes acústicos o armónicos se solapan en frecuencia, y aquellos que usan rangos de
frecuencia distintos que no se solapan entre ellos. También, para que el oído distinga a los diferentes
hablantes, interviene el periodo de pitch. En muchos sistemas CASA algo importante son las máscaras
tiempo-frecuencia. Estas máscaras binarias permiten diferenciar si una parte de este espectro tiempo-
frecuencia está dominada por una fuente u otra. Weintraub [11] fue el primero que usó este método en
un sistema CASA, algo que después fue adoptado por muchos otros trabajos. El uso de máscaras está
motivado por el oído humano, que enmascara sonidos débiles cuando hay otros más fuertes.
Las soluciones basadas en métodos estadísticos, se centran en alguna propiedad de las fuentes. El
Análisis de Componentes Independientes (ICA) descompone las observaciones recogidas por los
sensores en componentes independientes. Este método se basa en el principio de que las fuentes son
estadísticamente independientes y no gaussianas. La separación se consigue con estadísticos de alto
orden, basados otra vez en la independencia mutua de las fuentes. Uno de los algoritmos ICA más
conocidos es el FastICA. [12].
Los métodos de conformación de haz (Figura 3-2) son aquellos que extraen una señal teniendo un
array de micrófonos. El array de sensores recoge muestras espaciales de ondas propagándose, que son
procesadas por el formador de haz o beamformer. Así estima cómo llega la señal desde una
determinada dirección en presencia de ruido y otras señales interferentes. Esto se hace mediante filtros
espaciales para separar las señales que tienen un rango de frecuencias que se solapan pero
originalmente provienen de diferentes localizaciones espaciales.

42
Figura 3-2 Ejemplo de beamforming con 3 sensores, vemos señales que llegan a dichos sensores, su ángulo de
llegada y la distancia entre sensores.4
Este proyecto propone centrarse exclusivamente en señales de voz, así que el problema que
veremos en los siguientes capítulos será cómo extraer las diferentes voces que hay en una
mezcla, previamente obtenida del resultado de la grabación de las voces por varios micrófonos
en un determinado entorno, aunque lo que haremos para las simulaciones será una mezcla
sintética en el dominio tiempo-frecuencia.
A continuación se detallan los métodos más usados para separación ciega de fuentes.
4 Fuente: http://dsp.stackexchange.com/questions/7825/difference-between-conventional-and-adaptive-beamformers

43
3.1 Métodos basados en análisis estadístico.
Ahora que hemos visto en qué consiste el problema de separación ciega de fuentes y los modelos de
mezcla que nos podemos encontrar, vamos a ver el análisis estadístico. Concretamente, al estudiar ICA
(Análisis de Componentes Independientes) veremos que el primer paso consistirá en buscar una
representación en la que los componentes sean estadísticamente independientes, ya que sobre esto se
basará la separación. En la práctica no podremos hacer esto con total exactitud, así que tendremos una
representación que nos permita tener los componentes “lo más independientes” posible.
3.1.1 PCA. Análisis de Componentes Principales.
El Análisis de Componentes Principales, conocido por sus siglas en inglés, PCA (Principal Component
Analysis), y la transformación de Karhunen-Loève son técnicas clásicas usadas en el análisis de datos,
extracción de parámetros, o compresión de estos, derivados del trabajo de Pearson [13].
El objetivo es, dado un conjunto de medidas, encontrar un conjunto menor de variables con menos
redundancia, que nos dé la mejor representación posible. Esto está relacionado como podemos ver con
el análisis de componentes independientes. Sin embargo, en PCA, la redundancia se mide por las
correlaciones entre los componentes, mientras en ICA se usa un concepto mucho más rico de la
independencia. Además, ICA no le da tanta importancia a la reducción del número de variables. Usar
solo la correlación en PCA tiene la ventaja de que el análisis puede basarse en estadísticos de segundo
orden solamente.
Partimos desde un vector aleatorio 𝒙 con 𝑛 elementos, y muestras 𝒙(1), … , 𝒙(𝑇). No se hace ninguna
suposición sobre la fdp, siempre que los estadísticos de primer y segundo orden sean conocidos o
puedan ser estimados desde las muestras. Es esencial que los elementos tengan correlación entre ellos,
en el caso de que los elementos sean independientes, PCA no puede hacer nada. Este vector, PCA lo
transforma a otro vector 𝒚 mediante una matriz 𝑾 de 𝑚 elementos, 𝑚 < 𝑛, para quitar esa
redundancia.
𝒚 = 𝑾𝒙 (3.1)
Así se obtiene una nueva representación de los elementos, ya incorrelados. También, decir que ahora
la autocorrelación de 𝒚 es la matriz identidad, debido a esta incorrelación.
Esto se hace encontrando un sistema de coordenadas ortogonal de forma que los elementos del vector

44
𝒙 sean ahora incorrelados. Al mismo tiempo, las varianzas de las proyecciones del vector 𝒙 en las
nuevas coordenadas son maximizadas, de forma que en el nuevo sistema, las varianzas tienen una
progresión decreciente. Básicamente, esta transformación lineal consiste en una rotación del espacio
de los datos originales.
Si queremos conectar PCA con ICA, PCA puede ser un buen preprocesado de los datos para ICA.
También puede usarse para eliminar ruido aditivo y reducir la dimensión de las observaciones en
mezclas sobredeterminadas.
3.1.2 ICA. Análisis de componentes independientes (Independent Component Analysis)
Recordemos el modelo de mezcla presentado en (2.23). Teniendo esto en mente, podemos definir ICA
como lo siguiente: encontrar una transformación lineal dada por una matriz 𝑨, compuesta por unos
coeficientes reales para que se cumpla:
𝑥𝑖 = 𝑎𝑖,1𝑠1 + 𝑎𝑖,2𝑠2 + ⋯ + 𝑎𝑖,𝑛𝑠𝑛, ∀𝑖 = 1, … , 𝑛 (3.2)
En cada observación.
Los componentes independientes 𝑠𝑗 (algunas veces abreviacos como ICs) son variables latentes. Esto
significa que no pueden ser observadas directamente. También los coeficientes 𝑎𝑖,𝑗 de la matriz 𝑨 son
desconocidos. Lo único que observamos son las variables 𝑥𝑖, así que tendremos que estimar los dos
coeficientes anteriores sólo con las variables 𝑥𝑖.
Esta es la definición más básica, y para estar seguros que este modelo puede ser estimado tendremos
que tomar algunas restricciones y suposiciones.
3.1.2.1 Restricciones en ICA.
Los componentes independientes (ICs) se asumen estadísticamente independientes.
Este es el principio sobre el que se basa ICA. Sorprendentemente, no hace falta asumir mucho más
para que sea estimado el modelo explicado anteriormente. Por eso ICA es un método muy potente para
aplicaciones en muchas áreas.
Básicamente variables aleatorias 𝑦1, 𝑦2, … , 𝑦𝑛 son independientes si la información en 𝑦𝑖 no da
ninguna información sobre 𝑦𝑗, con 𝑖 ≠ 𝑗. También podemos definir la independencia estadística

45
mediante la función densidad de probabilidad. Si 𝑝(𝑦1, 𝑦2, … , 𝑦𝑛) es la función densidad de
probabilidad conjunta, y 𝑝𝑖(𝑦𝑖) la función densidad de probabilidad marginal, cuando solo
consideramos 𝑦𝑖, entonces decimos que los 𝑦1, 𝑦2, … , 𝑦𝑛 son estadísticamente independientes si y solo
si la función densidad de probabilidad conjunta es factorizable de esta forma:
𝑝(𝑦1, 𝑦2, … , 𝑦𝑛) = 𝑝1(𝑦1)𝑝2(𝑦2) … 𝑝𝑛(𝑦𝑛) (3.3)
Los componentes independientes deben tener distribuciones no gaussianas.
ICA es imposible de ejecutar si las variables observadas tienen distribuciones gaussianas. Podemos
ver una explicación matemática en el Anexo A. Recordar que en el modelo nosotros no asumimos
conocer la forma de esta distribución.
Podría darse el caso de que solo uno de los componentes fuera gaussiano. El modelo funcionaría
perfectamente, estimando todos los componentes no gaussianos. Los componentes gaussianos no
pueden ser separadas como tal, solo estimaría combinaciones lineales de éstas. Si solo hay un
componente que es gaussiano, no tendría ninguna otra variable con la que pueda combinarse y podría
separarse perfectamente.
Por simplicidad, asumimos que la matriz de mezcla desconocida es cuadrada.
En otras palabras, el número de componentes independientes es igual al número de observaciones.
Esta suposición la hacemos porque simplifica mucho los cálculos. Una vez estimada la matriz 𝐴,
podemos calcular su inversa, 𝐵 para así obtener los componentes independientes de forma muy simple:
𝒔 = 𝑩𝒙 (3.4)
Así que también asumimos que la matriz de mezcla es invertible. Si este no es el caso, podemos
encontrar partes redundantes que pueden ser omitidas, en cuyo caso, la matriz de mezcla ya no sería
cuadrada, y tendríamos el caso en el que el número de observaciones no es igual al número de
componentes independientes.
Con estas tres suposiciones (o como mínimo con las dos primeras) el modelo de ICA es identificable,
en el sentido de que tanto la matriz de mezcla como los componentes independientes pueden ser
estimados, aunque en este proyecto no demostraremos la validez del modelo de ICA.

46
3.1.2.2 Ambigüedades de ICA.
En el modelo presentado en (2.23) vemos que las siguientes ambigüedades pueden aparecer:
No podemos determinar la energía de los componentes independientes
La razón es que al ser 𝑨 y 𝒔 desconocidos, cualquier escalar, 𝛼𝑖, que multiplique a una de las fuentes
puede ser cancelado dividiendo la columna correspondiente 𝑎𝑖 de 𝐴 por el mismo escalar.
𝑥 = ∑(
1
𝛼𝑖𝑎𝑖)(𝑠𝑖𝛼𝑖)
𝑖
(3.5)
Como consecuencia, para normalizar estos resultados, ICA asume que cada componente independiente
tiene varianza 1: 𝐸{𝑠𝑖2} = 1. Así, la matriz 𝑨 estará adaptada a la solución. Esto todavía deja pendiente
la ambigüedad del signo: podríamos multiplicar un componente independiente por −1 sin que afectara
al modelo. Esto, afortunadamente, es insignificante en la mayoría de los casos.
No podemos determinar el orden de los componentes independientes.
La razón es que al ser 𝑨 y 𝒔 desconocidos como dijimos anteriormente, podríamos cambiar el orden
de los términos en la suma en (4.1) y decir que cualquiera de esos componentes independientes es el
primero. Formalmente, una matriz de permutación 𝑷 y su inversa pueden ser introducidas en el modelo
de esta forma: 𝒙 = 𝑨𝑷−𝟏𝑷𝒔. Los elementos de 𝑷𝒔 son los componentes independientes originales,
pero en otro orden. La matriz 𝑨𝑷−𝟏 es una nueva matriz de mezcla desconocida para ser resuelta por
ICA.
3.1.2.3 Blanqueado (Whitening).
Dadas unas variables aleatorias, una tarea sencilla es transformarlas linealmente a variables
incorreladas. Por lo tanto, es tentador intentar estimar los componentes independientes con este
método, llamado blanqueado, y que es implementado por técnicas como PCA, como ya vimos
anteriormente. También veremos que aunque esto es así, el blanqueado es una herramienta muy útil
para el preprocesado de datos en ICA.
El blanqueado de un vector de media cero, llamémoslo y, significa hacer sus componentes incorreladas
y sus varianzas igual a la unidad. En otras palabras, la matriz de covarianza (y la matriz de correlación)
de y es la matriz identidad:

47
𝐸{𝒚𝒚𝑇} = 1 (3.6)
En consecuencia, el blanqueado significa que transformamos linealmente el vector observación
multiplicándolo linealmente por una matriz V.
𝒛 = 𝑽𝒙 (3.7)
Y obtenemos un nuevo vector 𝒛 que ya está blanqueado. Esta transformación siempre es posible de
hacer y existen varios métodos para el blanqueado como por ejemplo la descomposición en EVD de
la matriz de covarianza.
𝐸{𝒙𝒙𝑇} = 𝑬𝑫𝑬𝑇 (3.8)
Donde 𝑬 es la matriz ortogonal de autovectores de 𝐸{𝒙𝒙𝑇} y 𝑫 es la matriz diagonal de sus
autovalores, 𝑫 = 𝑑𝑖𝑎𝑔(𝑑1, … , 𝑑𝑛). Así, la operación de blanqueado puede hacerse mediante la
siguiente matriz 𝑽:
𝑽 = 𝑬𝑫1/2𝑬𝑇 (3.9)
Aquí podemos ver el antes (Figura 3-3) y el después (Figura 3-4) del blanqueado, y podemos observar
que es simplemente una transformación ortogonal.
No se debe pensar que con esta operación resolvemos ICA, ya que esto se basa en la incorrelación, que
es más débil que la independencia estadística, así que no es suficiente para la estimación del modelo.
Aunque también hay que decir que el blanqueado aporta a los componentes independientes una
Figura 3-3
Figura 3-4

48
transformación ortogonal, muy importante para el preprocesado, ya que la nueva matriz de mezcla
�̃� = 𝑽𝑨 es ortogonal. Esto puede verse de la siguiente forma:
𝐸{𝒛𝒛𝑇} = �̃�𝐸{𝒔𝒔𝑇}�̃�𝑇 = �̃��̃�𝑇 = 𝑰 (3.10)
Así, podemos decir a groso modo que el blanqueado solamente resuelve la mitad del problema de ICA.
3.1.2.4 Criterios de separación de ICA.
Una vez que hemos preprocesado los datos, para determinar la separación de fuentes en ICA, es
necesario el uso de las llamadas funciones contrastes, o contrastes, que son capaces de medir y
cuantificar la independencia estadística de las señales estimadas. Esta estimación vendrá dada por una
maximización o minimización de dichas funciones. En separación de señales, Comon [Comon94a]
introdujo y presentó estas funciones contrastes.
Los criterios de separación son bastantes, aquí estudiaremos con un poco de detalle los más conocidos:
separación mediante estadísticos de orden superior, mediante la maximización de la no Gaussianidad,
mediante la minimización de la información mutua, mediante la máxima verosimilitud y según el
principio de infomax.
3.1.2.4.1 Separación mediante la maximización de la no Gaussianidad.
La no Gaussianidad es de bastante importancia en la estimación de ICA. Sin esta propiedad, la
estimación no es posible, como podemos ver en el Anexo1, por tanto no es ninguna sorpresa que la
propiedad sea usada para la estimación de ICA.
Podemos empezar la maximización de la no Gaussianidad por el teorema central del límite.
Este teorema indica que, en condiciones muy generales, si 𝑆𝑛 es la suma de n variables
aleatorias independientes, entonces la función de distribución de 𝑆𝑛 “se aproxima bien” a una
distribución gaussiana (también llamada distribución normal, curva de Gauss o campana de Gauss).
Así pues, el teorema asegura que esto ocurre cuando la suma de estas variables aleatorias e
independientes es lo suficientemente grande. Por tanto, la mezcla tendrá una distribución más parecida
a la Gaussiana que las fuentes.
Como alternativas en la medición de la no gaussianidad, introduciremos el cumulante de cuarto orden

49
llamado kurtosis. Usando kurtosis, derivamos algoritmos e introducimos una cantidad de información
llamada entropía negativa como una medida alternativa de la no gaussianidad.
Kurtosis.
Es el nombre que se le da al cumulante de cuarto orden de una variable aleatoria. La kurtosis de 𝑦, que
se escribe como 𝑘𝑢𝑟𝑡(𝑦) se define como:
𝑘𝑢𝑟𝑡(𝑦) = 𝐸{𝑦4} − 3(𝐸{𝑦2})2 (3.11)
También asumimos que todas las variables aleatorias aquí tienen media 0. En el caso general, la
definición de kurtosis es algo más compleja. Para simplificar las cosas, podemos asumir que 𝑦 ha sido
normalizada para que su varianza sea 1. Así la parte derecha se simplifica como: 𝐸{𝑦4} − 3. Esto
muestra que esta definición simplificada de la kurtosis no es más que una versión normalizada del
cuarto momento 𝐸{𝑦4}. Para una 𝑦 gaussiana, el cuarto momento es 3(𝐸{𝑦2})2. Así, la kurtosis sería
0 para cualquier variable aleatoria gaussiana. Para todas las demás no gaussianas (aunque no el 100%)
la kurtosis será positiva o negativa.
Las variables aleatorias cuya kurtosis es negativa se llaman subgaussianas, y aquellas cuya kurtosis es
positiva son llamadas supergaussianas. Estas últimas tienen una función densidad de probabilidad
picuda y con largas colas, parecidas a la Laplaciana, cuya fdp viene dada por:
𝑝(𝑦) =
1
√2 exp (√2|𝑦|) (3.12)
Por el contrario, las subgaussianas tienen una función plana, como lo sería por ejemplo la distribución
uniforme, cuya fdp normalizada vendría dada por:
𝑝(𝑦) = {
1
2√3, 𝑠𝑖 |𝑦| ≤ √3
0, 𝑒𝑛 𝑜𝑡𝑟𝑜 𝑐𝑎𝑠𝑜
(3.13)
Típicamente la no gaussianidad se mide por el valor absoluto del kurtosis. La raíz de la kurtosis también
puede usarse. Hay algunas variables aleatorias no gaussianas que tienen kurtosis cero, pero
normalmente no será el caso.
Por las propiedades de la kurtosis, deducimos que la maximización del valor absoluto de las kurtosis
es una función contraste:

50
𝜓𝐾𝑢𝑟𝑡(𝒀) = ∑ |𝑘𝑢𝑟𝑡(𝑌𝑖)|
𝑁
𝑖=1
(3.14)
La estimación de la kurtosis se puede calcular fácilmente computacionalmente. Sin embargo, es una
medida poco robusta de la no Gaussianidad, debido a que la estimación a partir de un conjunto de
muestras es sensible a los outliers.
Entropía negativa.
Para empezar debemos explicar primero el concepto de entropía diferencial de una variable aleatoria.
Este concepto está relacionado con la cantidad de información que nos da la variable al observarla.
Así, a mayor aleatoriedad, mayor entropía. La definimos como:
ℎ(𝒀) = − ∫ 𝑝𝒀
𝑌
(𝒚) log 𝑝𝒀 (𝒚)𝑑𝒚 (3.15)
La entropía negativa de una variable aleatoria Gaussiana será 0, y tendrá siempre valores positivos
para otros tipos de variables aleatorias, así tenemos una medida fiable de la no Gaussianidad. La
escribimos como 𝐽 y la definimos así:
𝐽(𝒀) = ℎ(𝒀𝐺𝑎𝑢𝑠𝑠) − ℎ(𝒀) (3.16)
Donde 𝒀𝐺𝑎𝑢𝑠𝑠 es una variable aleatoria Gaussiana con la misma matriz de covarianza que Y.
Esta medida implica calcular la función de densidad de probabilidad de la v.a., por lo que se ve a simple
vista que tiene alto coste computacional. Aun así, es un estimador óptimo de la no Gaussianidad. En
la práctica, para evitar ese alto coste computacional se utilizan distintas aproximaciones. Una
aproximación clásica para el cálculo de la entropía negativa es:
𝐽(𝑦) ≈
1
12𝐸[𝑦3]2 +
1
48𝑘𝑢𝑟𝑡(𝑦)2 (3.17)
Esta aproximación implica el cálculo de una kurtosis, lo cual puede ser no demasiado robusto. Hay
otras aproximaciones más robustas [Hyvärinen99], basadas en el principio de la máxima entropía.
Podemos reemplazar esas funciones 𝑦3 e 𝑦4 por otras funciones 𝐺𝑖, donde 𝑖 es un índice no una
potencia. Así, usaremos funciones no cuadráticas 𝐺1 y 𝐺2, escogiendo 𝐺1 una función impar y 𝐺2 par.
Sustituyendo en la ecuación anterior, quedaría así:

51
𝐽(𝑦) ≈ 𝑘1(𝐸{𝐺1(𝑦)})2 + 𝑘2(𝐸{𝐺2(𝑦)} − 𝐸{𝐺2(𝑦𝐺𝑎𝑢𝑠𝑠)})2 (3.18)
En el caso de que usemos solo una función no cuadrática 𝐺, la aproximación se convierte en:
𝐽(𝑦) ∝ [𝐸{𝐺(𝑦)} − 𝐸{𝐺(𝑦𝐺𝑎𝑢𝑠𝑠)}]2 (3.19)
Esto es una generalización en donde si tomamos 𝐺(𝑦) = 𝑦4 obtenemos una aproximación basada en
la kurtosis. Pero el objetivo es escoger 𝐺 de forma inteligente para obtener mejores aproximaciones.
Funciones que proporcionan mejores aproximaciones son:
𝐺1(𝑦) =
1
𝑎1log cosh 𝑎1𝑦 (3.20)
𝐺2(𝑦) = −exp (−
𝑦2
2) (3.21)
Donde 1 ≤ 𝑎1 ≤ 2 es una constante, que normalmente toma el valor 1.
Así tendremos una representación de una “distancia” entre la función de probabilidad de la variable
aleatoria y de la función de probabilidad gaussiana. Esto es medible mediante la divergencia de
Kullback-Leiber (K-L), medida clásica de divergencia entre dos fdp. Esta divergencia solo es 0 si las
dos funciones son iguales, en el resto de los casos, es positiva. La definimos como:
𝐷𝑓𝑌(𝑦)||𝑔𝑌(𝑦) ≡ ∫ 𝑓𝑌(𝑦) log(𝑓𝑌(𝑦)
𝑔𝑌(𝑦)
∞
−∞
)𝑑𝑦 (3.22)
Así, la entropía negativa en términos de la divergencia K-L será:
𝐽(𝑌) = 𝐷𝑝𝑌||𝑝𝑌𝐺𝑎𝑢𝑠𝑠 (3.23)
3.1.2.4.2 Separación mediante la minimización de la información mutua.
La motivación de estudiar este enfoque es debido a que en muchos casos no es demasiado realista
asumir que todos los datos siguen el modelo ICA perfectamente. Por tanto, necesitamos otro
planteamiento que no haga suposiciones acerca de los datos. Querremos tener una medida de propósito
general de la dependencia de los componentes de un vector aleatorio. Usando esta medida, podemos
definir ICA como una descomposición lineal que minimiza esta medida.

52
La información mutua 𝐼 es positiva, y solo será nula en el caso de que el vector aleatorio tenga sus
componentes estadísticamente independientes. Por tanto esta minimización de la información mutua
conduce a la independencia estadística de las mismas. La función sería la siguiente, donde 𝐻 representa
la entropía:
𝐼(𝑦1,𝑦2, … , 𝑦𝑚) = ∑ 𝐻(𝑦𝑖) − 𝐻(𝒚)
𝑚
𝑖=1
(3.24)
3.1.2.4.3 Separación mediante la máxima verosimilitud.
Otro método para estimar el modelo de análisis de componentes independientes es la estimación
mediante máxima verosimilitud (ML, Maximum Likelihood). Este método es un método fundamental
en la estadística, y veremos cómo aplicarlo para la estimación de ICA [14]. Tiene una conexión con el
principio de maximización de la información en una red neuronal (Infomax).
No es difícil obtener la verosimilitud en el modelo ICA libre de ruidos. Se basa en el uso de la densidad
de una transformación lineal, así la densidad 𝑝𝑥(x) del vector de mezcla 𝒙 = 𝑨𝒔 es:
𝑝𝑥(𝐱) = |det 𝐁|𝑝𝑠(𝐬) = | det 𝐁 | ∏ 𝑝𝑖( 𝑠𝑖 )
i
(3.25)
Donde 𝑩 = 𝑨−1, y 𝑝𝑖 denota la densidad de los componentes independientes. Y esta sería la fdp que
tendríamos que maximizar.
Asumimos que tenemos un número 𝑇 de observaciones de 𝒙, entonces la verosimilitud puede
obtenerse como el producto de esta densidad evaluada en los 𝑇 puntos. A esta función de verosimilitud
la llamaremos 𝐿(𝑩), y además se suele ver siempre como el logaritmo de la verosimilitud, ya que es
algebraicamente más simple. Esto no supone ninguna diferencia, ya que el máximo del logaritmo se
obtiene en el mismo punto que el máximo de la función verosimilitud.
1
𝑇log 𝐿(𝑩) = 𝐸{∑ log 𝑝𝑖(𝒃𝑖
𝑇𝒙)} + log | det 𝑩 |
𝑛
𝑖=1
(3.26)
Para realizar estos cálculos de forma práctica, necesitamos de un algoritmo que realice la maximización
numérica de la verosimilitud. Pueden ser algoritmos de gradiente como el algoritmo de Bell-
Sejnowski, el algoritmo natural del gradiente, o FastICA.

53
3.1.2.4.4 Separación basada en el principio de infomax.
Una estimación de ICA que está muy directamente relacionada con la maximización de la
verosimilitud es el principio de infomax. Este principio se basa en maximizar la entropía de salida o
flujo de información, de una red neuronal no lineal. Bell-Sejnowski que ya mencionamos
anteriormente, estudiaron este principio y resolvieron la separación ciega de fuentes mediante este
criterio.
Si llamamos 𝑥 a la entrada de la red neuronal, las salidas serán de la forma 𝑦𝑖 = 𝜙𝑖(𝒃𝑖𝑇𝒙) + 𝒏 donde
𝜙𝑖 son funciones escalares no lineales, así que para maximizar la entropía de las salidas, tendremos
que maximizar:
𝐻(𝒚) = 𝐻(𝜙1(𝒃1𝑇𝒙), … , 𝜙𝑛(𝒃𝑛
𝑇𝒙)) (3.27)
Esto tiene sentido solo si hay algúna pérdida de información en la transmisión (de ahí el vector 𝒏
anteriormente). Puede demostrarse que la no presencia de ruido en la red, hace que la maximización
de esta función de información mutua sea equivalente a la maximización de la entropía de salida.
3.2 Métodos basados en la geometría.
Hay otro tipo de métodos que no necesitan de parámetros estadísticos. Se basan más bien en la
geometría de las fuentes y ser capaces de determinar su localización. Una vez determinada, son capaces
de distinguir las direcciones de llegada de las fuentes, o medir retrasos para ser capaces de construir
máscaras binarias de separación.
Las técnicas de “masking” normalmente siempre usan la transformada en tiempo-frecuencia, debido a
que la distribución de las componentes de las señales es mucho más adecuada. Es más común que usen
la transformada STFT aunque la transformada discreta del coseno modificado (MDCT) u otras
transformadas también se han empleado en estos métodos.
Estos algoritmos generalmente dependen de unos factores:
-La existencia de una transformación invertible 𝑇 que transforme las señales a un dominio en
el que tengan una representación disasociada.
-Encontrar funciones F y G que aporten los términos para etiquetar las distintas fuentes en el

54
dominio transformado.
Un apunte es que en la descripción requerimos de F y G para proporcionar los exactos parámetros de
mezcla. Aunque esto es lo deseado ya que los parámetros de mezcla darían las etiquetas perfectas y
pueden ser usados para otros propósitos (averiguar la dirección de llegada por ejemplo), no es necesario
para el algoritmo de recuperación de las señales. Con alguna función que etiquete en el dominio
transformado sería suficiente. En resumidas cuentas, es mucho más importante el primer factor
(transformación 𝑇 invertible).
Hay ejemplos en varios documentos que usan este tipo de métodos con diferentes opciones de 𝑇 para
distintos modelos de mezcla (anecoico e instantáneo). La hipótesis general que se toma es que para un
determinado instante de tiempo, al menos una fuente no es cero. En muchos de estos documentos la
transformada localizada de Fourier (short-time Fourier transform) es usada como transformación 𝑇.
Esto satisface la condición debido a la escasez en su representación de las señales de voz. Para
argumentar esto se puede consultar “On the approximate W-disjoint orthogonality of speech” de S.
Rickard y O. Yilmaz. Sin embargo, en un estudio de M. Zibulevsky y B. A. Pearlmutter se escoge 𝑇
dependiendo de la clase de interés de la señal. En “Clustering approach to square and nonsquare blind
source separation” de M. Van Hulle el algoritmo usa clustering para la separación de fuentes,
agrupando los clústeres de los puntos en el espacio (𝑇𝑥1, 𝑇𝑥2). Mientras, otros estudios como “Sound
source segregation base don estimating incident angle of each frequency component of input signals
acquired by multiple microphones” de M. Aoki, M. Okamoto, S. Aoki y más autores, usan una
estrategia de etiquetado para estimar los parámetros de mezcla, creando así máscaras binarias en el
dominio transformado correspondiendo a cada fuente.
3.2.1 DUET.
DUET (Degenerate Unmixing Estimation Technique), es un método de separación ciega de fuentes,
el cual puede separar cualquier número de fuentes con tan solo dos observaciones. Este método solo
es válido cuando estas observaciones cumplen una serie de requisitos, como que las transformadas en
tiempo-frecuencia de las fuentes no se solapen. Como ya hemos visto, la voz cumple perfectamente
esta característica, ya que como vemos en su propiedad de escasez, es poco probable que dos voces se
solapen en el mismo punto tiempo-frecuencia. Para mezclas anecoicas de fuentes, el método permite
estimar los parámetros de mezcla extrayendo pares atenuación-retraso y haciendo un clustering de
éstos. Ésta técnica funciona incluso para mezclas indeterminadas.

55
En el capítulo siguiente, entraremos mucho más en detalle, además de proponer un código DUET para
MATLAB, el cual se incluye en el Anexo B, y realizar varias simulaciones y comparaciones que
veremos en el capítulo 6.
3.2.2 DOA. Por ángulo de llegada (Direction Of Arrival).
Hay técnicas de enmascaramiento que se basan en que las voces llegan a los sensores desde distintos
ángulos, y así construyen las máscaras. Estas técnicas se llaman por sus siglas en inglés DOA,
Direction Of Arrival.
Podemos suponer la hipótesis de campo lejano para las fuentes, así que pueden considerarse como
ondas planas que alcanzan los sensores en caminos paralelos. Para ver el retardo, trazamos una línea
que une a los dos sensores. Tomamos como referencia uno de ellos, y el ángulo que forma la fuente 𝑖
con la perpendicular a la línea trazada entre los dos sensores, sería el ángulo de llegada 𝜃𝑖. Así podemos
escribir el retardo relativo 𝛿𝑖 al otro sensor mediante la siguiente expresión:
𝛿𝑖 =
𝑑 sin 𝜃𝑖
𝑐 (3.28)
Donde 𝑐 es la velocidad de propagación del frente de ondas, en este caso, la velocidad de propagación
del sonido, 𝑐 = 331.5 + 0.6𝑇𝑐 donde 𝑇𝑐 es la temperatura en grados Celsius.
Así las señales que incidan con distinto 𝜃𝑖, o DOA, llegarán con distinto retardo relativo en el modelo
de mezcla.
El retardo estimado en cada punto en tiempo-frecuencia, puede calcularse para así poder construir una
máscara que sirva para separar las señales originales. Si llamamos 𝑋𝑖(𝑓, 𝑡) a la transformada STFT de
la observación 𝑖, para un caso con dos sensores tendremos:
𝛿𝑖 =
−1
2𝜋𝑓< (
𝑋2(𝑓, 𝑡)
𝑋1(𝑓, 𝑡)) (3.29)

56
3.3 Conclusiones
La separación ciega de fuentes puede hacerse por varios métodos, los cuales permiten varios
algoritmos como solución al problema. Hemos visto aquellos que necesitan de parámetros estadísticos
para encontrar algún factor en común entre los datos observados y aquellos que se basan en la
geometría de la situación para ver la localización de las fuentes y así poder distinguirlas.
PCA, una herramienta muy útil para el preprocesado de datos a usar con ICA, puede parecer igual que
el blanqueado, pero hay una diferencia. El blanqueado de datos solo utiliza una transformación
ortogonal, mientras que PCA hace esta transformación ortogonal, y además maximiza la varianza.
ICA es una herramienta muy potente y compleja, hemos visto cuáles son los criterios de separación,
aunque para entrar mucho más en detalle, como estudiar los algoritmos que lo resuelven, es muy
recomendable el libro “Independent Component Analysis” de Aapo Hyvärinen, Juha Karhunen, y
Erkki Oja, que podemos encontrar en las referencias de este proyecto [15]. Como es de esperar, tiene
muchas aplicaciones, no sólo en el ámbito de señales de voz, como ya veremos en el capítulo 7.
Entre los métodos que utilizan “masking” hemos visto DUET, el cual es el punto clave de este
proyecto, que veremos con profundidad en el capítulo siguiente y del que se hará un modelo
matemático sobre el cual se simularán distintas situaciones para probar su efectividad.
El método que usa la dirección de llegada, DOA, que se basa solo y exclusivamente en la geometría
de la situación y la posición de las fuentes y de los sensores, también construye máscaras, al igual que
DUET.

57
4 EL ALGORITMO DUET
There appears to be something magical about blind signal
processing; we are estimating the original source signals without
knowing the parameters of mixing and/or filtering processes. It is
difficult to imagine that one can estimate this at all
Andrzej Cichocki, 2002
a hemos visto anteriormente cuál era el objetivo de la separación ciega de fuentes y los distintos
entornos que nos podemos encontrar. Si miramos el modelo de mezcla, cuando el número de
fuentes es mayor que el número de mezclas, el problema resultante es que la matriz de mezcla no se
puede invertir para recuperar las señales. Pero, si podemos obtener una representación de las fuentes
en la que estas estén claramente diferenciadas, es posible obtener las señales originales. Determinar
esa partición desde una sola mezcla no es determinado, pero añadiendo una segunda mezcla podemos
describir el método para particionar el espacio y crear las máscaras para poder separar las fuentes.
El algoritmo DUET es capaz de separar N señales de voz a partir de dos observaciones y siguiendo un
modelo de mezcla anecoico.
Y

58
Las fuentes deben ser ortogonalmente disjuntas (W-DO, W-disjoint orthogonal). Esto significa que
para una función W el producto de las fuentes es 0, es decir, solo una fuente está activa en cada
momento. Usaremos siempre la transformada en tiempo-frecuencia (STFT), así podemos decir que la
hipótesis que tomamos es:
𝑆1(𝑓, 𝑡)S2(𝑓, 𝑡) = 0, ∀𝜏, 𝜔 (4.1)
Entonces, cuando las fuentes son W-DO, al menos una está activa en un determinado punto tiempo-
frecuencia; esto es, para un (𝑓, 𝑡) determinado en el que 𝑋1(𝑓, 𝑡) ≠ 0, existe una 𝑗 tal que 𝑆𝑗(𝑓, 𝑡) ≠
0 y 𝑆𝑘(𝑓, 𝑡) = 0 para 𝑗 ≠ 𝑘.
Desafortunadamente, esto no se satisface para señales de voz simultáneas porque la representación en
tiempo-frecuencia de las señales de voz rara vez es cero. Sin embargo, la propiedad de escasez nos
dice que con un porcentaje pequeño de los coeficientes en tiempo-frecuencia captamos un porcentaje
muy alto de toda su energía, además, es muy improbable que los coeficientes coincidan, por lo que 𝑠1
y 𝑠2 serán aproximadamente W-DO.
En la práctica es suficiente que 𝑆1(𝑓, 𝑡)S2(𝑓, 𝑡) sea pequeño con una alta probabilidad [16].
4.1 Estimación de parámetros
Recordemos el modelo de mezcla matricial definido en (2.25).
Vamos a introducir estas nuevas definiciones, si asumimos la condición explicada anteriormente, que
solo una fuente está activa en un determinado momento:
X1(𝑓, 𝑡) = S𝑖(𝑓, 𝑡)
X2(𝑓, 𝑡) = S𝑖(𝑓, 𝑡)𝑎𝑖𝑒−𝑗𝜔𝛿𝑖
(4.2)
Es posible obtener los parámetros 𝑎 y 𝛿 correspondiente a los términos de amplitud y fase a partir de
la diferencia de amplitud y fase en las representaciones en tiempo-frecuencia de las observaciones.
Estos parámetros son distintos para cada punto tiempo-frecuencia, así que nos dirán la fuente que está
activa en cada momento. Por tanto el algoritmo DUET tiene como condición:
(𝑎𝑖 ≠ 𝑎𝑗) 𝑜 (𝛿𝑖 ≠ 𝛿𝑗) ∀𝑖 ≠ 𝑗 (4.3)

59
El ratio 𝑋1(𝜔)
𝑋2(𝜔), que llamaremos a partir de ahora 𝑅21 es un ratio STFT y los parámetros que derivan de
él son los que llamamos estimadores.
Las estimas 𝑎 y 𝛿 i-ésimas se pueden obtener con las siguientes relaciones:
�̃�𝑖 = |
X2(𝜔)
X1(𝜔)| (4.4)
𝛿𝑖 = −
1
𝜔𝐼𝑚 (
X1(𝜔)
X2(𝜔)) (4.5)
La separación de los micrófonos también debe cumplir una condición, para evitar una ambigüedad de
fase en la estima de los retardos [17].
𝑑 ≤𝑐
2𝑓𝑚 (4.6)
Donde 𝑓𝑚 es la frecuencia máxima presente en las fuentes. Es normal que esta frecuencia sea en torno
a 4KHz para señales de voz, lo que nos da una distancia máxima entre sensores de 4,3cm.
Si esta distancia entre los micrófonos se cumple, no habrá ambigüedad en la fase, y por tanto:
|𝜔𝛿𝑖| ≤ 𝜋 (4.7)
En la práctica, estos estimadores locales no se corresponderán exactamente con los valores teóricos,
ya que las hipótesis normalmente no se cumplirán de forma estricta.
Otro apunte es que en vez de usar el parámetro de atenuación tal cual, haremos uso de la atenuación
simétrica, definida como:
𝛼𝑗 = 𝑎𝑗 −
1
𝑎𝑗 (4.8)
Cuya estima local, por consiguiente es:
�̃�𝑗 = |
𝑋2(𝜔)
X1(𝜔)| − |
X1(𝜔)
X2(𝜔)| (4.9)
La atenuación simétrica presenta la propiedad de que si la señal fuente 𝑗 tiene mayor potencia en el

60
sensor de referencia que en el otro sensor entonces 𝛼𝑗 < 0, mientras que si tiene mayor potencia en el
otro sensor entonces 𝛼𝑗 > 0.
DUET, en teoría puede determinar todos los estimadores 𝑎𝑖 y 𝛿𝑖 detectando N clústers en un
histograma de amplitud y retraso definido por las ecuaciones anteriores. Así puede obtener
estimadores de las fuentes de una mezcla solo seleccionando los correspondientes valores de tiempo-
frecuencia y transformarlos otra vez al dominio del tiempo.
DUET en teoría puede obtener y sintetizar hasta 5 fuentes distintas a partir de dos observaciones, pero
estos estimadores tienen ya un ruido considerable, o artifacts. Éstos aumentan a medida que el número
de fuentes aumenta. La condición de W-DO puede que sea demasiado fuerte, y aunque
aproximadamente sea correcta, no se satisfaga del todo en la realidad, de ahí esos artifacts. Muchas
soluciones BSS se basan en el caso par, de N número de fuentes y N observaciones, simplemente en
ortogonalidad estadística.
4.2 Agrupación de las estimas
Una vez tenemos las estimas de atenuación y fase, llega la etapa en la que tenemos que diferenciarlas
en N grupos, cada uno correspondiente a una fuente. Asumimos que los parámetros de mezcla 𝑎 y 𝛿
están suficientemente separados, y que las estimas se agrupan en torno a ellos. Usaremos un histograma
bidimensional para representarlas y clasificarlas, que debido a lo explicado anteriormente presentará
N picos, cada uno correspondiente a una fuente, y la localización de estos picos (�̃�𝑗 , 𝛿𝑗), 𝑗 = 1, … , 𝑁
proporcionará una estimación de los parámetros de mezcla.
Matemáticamente construimos el histograma bidimensional ponderado con la siguiente fórmula:
𝐻(𝛼, 𝛿) = ∬ |X1(𝑓, 𝑡)X2(𝑓, 𝑡)|𝑝
(𝑓,𝑡)𝜖𝐼(𝛼,𝛿)
𝑓𝑞𝑑𝑓𝑑𝑡 (4.10)
Donde 𝐼(𝛼, 𝛿) es el conjunto de puntos que contribuyen a la formación del histograma:
𝐼(𝛼, 𝛿) = {(𝑓, 𝑡): |�̃�(𝑓, 𝑡) − 𝛼| < ∆𝛼, |𝛿(𝑓, 𝑡) − 𝛿| < ∆𝛿} (4.11)
Donde ∆𝛼 y ∆𝛿 son parámetros de resolución.
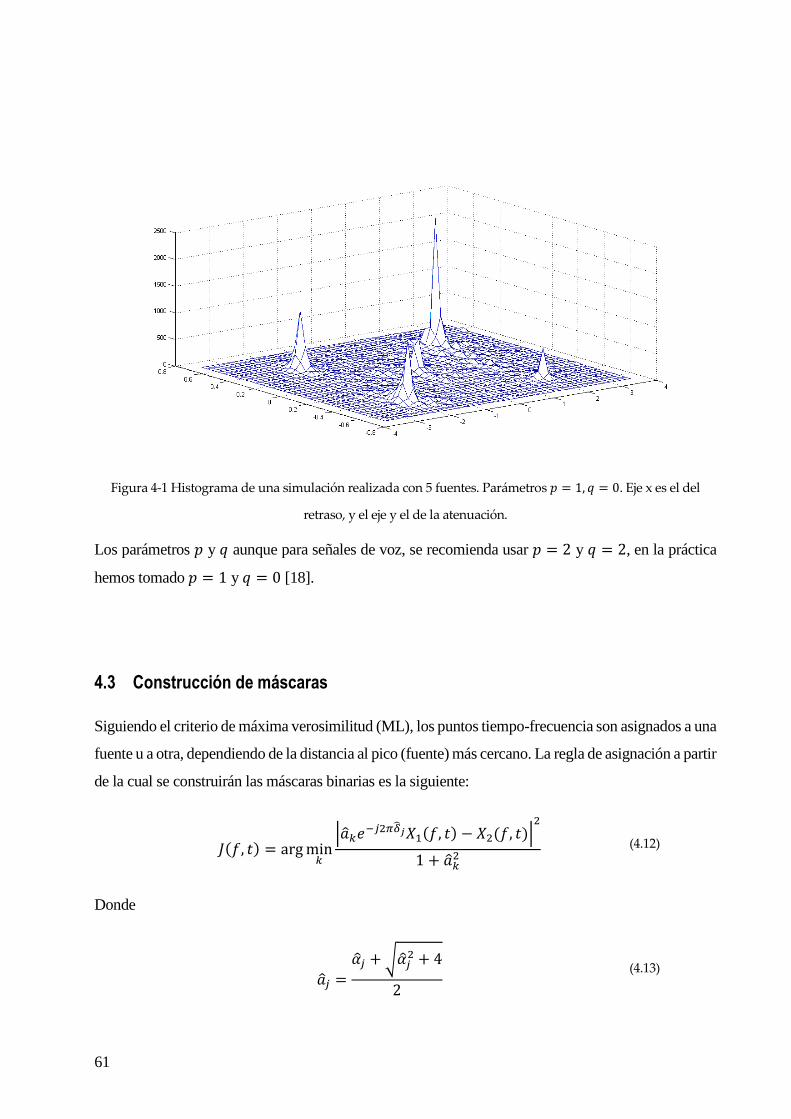
61
Figura 4-1 Histograma de una simulación realizada con 5 fuentes. Parámetros 𝑝 = 1, 𝑞 = 0. Eje x es el del
retraso, y el eje y el de la atenuación.
Los parámetros 𝑝 y 𝑞 aunque para señales de voz, se recomienda usar 𝑝 = 2 y 𝑞 = 2, en la práctica
hemos tomado 𝑝 = 1 y 𝑞 = 0 [18].
4.3 Construcción de máscaras
Siguiendo el criterio de máxima verosimilitud (ML), los puntos tiempo-frecuencia son asignados a una
fuente u a otra, dependiendo de la distancia al pico (fuente) más cercano. La regla de asignación a partir
de la cual se construirán las máscaras binarias es la siguiente:
𝐽(𝑓, 𝑡) = arg min𝑘
|�̂�𝑘𝑒−𝑗2𝜋�̂�𝑗𝑋1(𝑓, 𝑡) − 𝑋2(𝑓, 𝑡)|2
1 + �̂�𝑘2 (4.12)
Donde
�̂�𝑗 =
�̂�𝑗 + √�̂�𝑗2 + 4
2
(4.13)

62
Las máscaras binarias, correspondientes a cada fuente, las definimos como:
𝑀𝑖(𝑓, 𝑡) = {
1, 𝑠𝑖 𝐽(𝑓, 𝑡) = 𝑖 0, 𝑒𝑛 𝑜𝑡𝑟𝑜 𝑐𝑎𝑠𝑜
(4.14)
Para recuperar las señales, está claro que debemos multiplicar la observación por la máscara binaria
correspondiente a la fuente:
S𝑗(𝑓, 𝑡) = 𝑀𝑗(𝑓, 𝑡)X1(𝑓, 𝑡), ∀𝑓, 𝑡 (4.15)
Una propiedad está clara si miramos esas dos definiciones:
𝑀𝑗(𝑓, 𝑡)𝑀𝑘(𝑓, 𝑡) = 0, ∀(𝑓, 𝑡) 𝑠𝑖 𝑗 ≠ 𝑘 (4.16)
Figura 4-2 Imagen de una máscara binaria. Se aprecia que sigue la misma forma que seguiría un
espectrograma de la voz.
Estas máscaras pueden aplicarse sobre la observación de referencia para estimar la representación en
tiempo-frecuencia de cada una de las fuentes:
𝑌𝑖(𝑓, 𝑡) = 𝑀𝑖(𝑓, 𝑡)𝑋1(𝑓, 𝑡) (4.17)
O bien realizar una estimación de máxima verosimilitud (ML) de la fuente en la forma

63
𝑌𝑖(𝑓, 𝑡) = 𝑀𝑖(𝑓, 𝑡) (
𝑋1(𝑓, 𝑡) + �̂�𝑗𝑒−𝑗2𝜋𝑓�̂�𝑗𝑋2(𝑓, 𝑡)
1 + �̂�𝑗2 ) (4.18)
4.4 Transformación inversa a cada una de las componentes estimadas
Una vez tenemos las 𝑌𝑖(𝑓, 𝑡) desde 𝑖 = 1, … , 𝑁 debemos aplicar la transformación inversa para
calcular las 𝑁 señales estimadas.
El método usado para esta labor en la simulación en MATLAB ha sido el explicado en el apartado
2.2.2.2 de este documento, el método Overlap-Add.
4.5 Resumen
El algoritmo DUET lo podemos resumir en los siguientes pasos:
1. Construir representaciones en tiempo-frecuencia 𝑋1(𝑓, 𝑡) y 𝑋2(𝑓, 𝑡) a partir de las
observaciones 𝑥1(𝑡) y 𝑥2(𝑡).
2. Para cada punto tiempo-frecuencia no nulo, calcular las estimas de atenuación y retardo: �̃�𝑗 , 𝛿𝑗.
3. Agrupar los puntos (�̃�𝑗, 𝛿𝑗) mediante un histograma bidimensional en 𝑁 grupos.
4. Generación de las máscaras binarias para cada fuente.
5. Multiplicar cada máscara por la representación en tiempo-frecuencia de la observación para
obtener las fuentes separadas.
6. Reconstrucción en el dominio del tiempo de las fuentes.

64
5 CALIDAD EN LA SEPARACIÓN
The fundamental problem of communication is that of
reproducing at one point either exactly or approximately a
message selected at another point.
Claude Shannon, 1948
ara evaluar los sistemas BSS podemos tomar como norma principal, que se asume que o bien las
señales originales, o bien sus contribuciones a la mezcla están disponibles como referencia. Por
norma general, muchos de estos métodos fueron diseñados para evaluar diferentes aplicaciones, y
después han sido adaptados para evaluar la calidad de la separación, así que no podemos decir que hay
un método mejor que otro de evaluar la calidad.
Asumiendo que las fuentes las tenemos como referencia, una forma natural de evaluar un sistema BSS
de audio sería preguntar directamente a una serie de sujetos, y que escuchen y evalúen la calidad y la
inteligibilidad de cada fuente estimada comparada con la de referencia. Esto hace posible determinar
si las distorsiones entre las dos señales son audibles y cómo de mal las distorsiones son percibidas.
P

65
Esta aproximación es relevante si las señales fuente estimadas van a ser escuchadas en la aplicación
considerada. Por ejemplo, si la señal extraída va a ser utilizada como señal de entrada en otra aplicación
de procesamiento de señal, la calidad del sistema BSS podría ser medida por el rendimiento de todo el
sistema en general. Si se usan los sistemas BSS para reconocimiento de voz, el word error rate (WER)
de todo el sistema puede ser comparado con el que se obtendría con la señal original.
5.1 Medidas objetivas
En un contexto de desarrollo, estos sistemas de medición específicos para cada aplicación tienen poco
sentido. Tiene mucho más sentido reemplazarlos por algo más genérico, para que sea fácilmente
computable e interpretable. Así, estos parámetros de medida se definen descomponiendo cada fuente
estimada como la suma de un término correspondiente a la señal de referencia y uno o más términos
relativos a distorsiones. La importancia relativa de estos términos se mide en diferencias de energía,
expresada en decibelios (dB). La medida más directa es el signal-to-distorsion ratio (SDR) que mide
la distorsión en general. El signal-to-interference ratio (SIR) evalúa el rechazo de las otras fuentes de
interés. Más general, podemos tener el signal-to-noise ratio (SNR) que evalúa el rechazo de las fuentes
no deseadas, y el signal-to-artifacts ratio (SAR) que al evaluar la distorsión también evalúa esos
artifacts producidos.
El estudio de Vincent propone descomponer la señal estimada �̂�𝑗 y compararla con la fuente original
𝑠𝑗. Esto no determina el problema de la permutación, así que si es necesario, se ejecutaría el método
para cada una de las fuentes existentes, hasta dar con el mejor resultado, que provendría de la fuente
con la que se corresponde la señal estimada.
El método consiste en dos pasos, primero descomponer la señal, como ya hemos dicho, en varias
partes:
�̂�𝑗 = 𝑠𝑡𝑎𝑟𝑔𝑒𝑡 + 𝑒𝑖𝑛𝑡𝑒𝑟𝑓 + 𝑒𝑛𝑜𝑖𝑠𝑒 + 𝑒𝑎𝑟𝑡𝑖𝑓 (5.1)
Donde 𝑠𝑡𝑎𝑟𝑔𝑒𝑡 = 𝑓(𝑠𝑗) es una versión de 𝑠𝑗 modificada por una distorsión, y 𝑒𝑖𝑛𝑡𝑒𝑟𝑓, 𝑒𝑛𝑜𝑖𝑠𝑒 y 𝑒𝑎𝑟𝑡𝑖𝑓
son respectivamente, los términos correspondientes a las interferencias, ruido y artifacts.
El segundo paso sería hacer los cálculos para ver cuánta cantidad de estos términos hay en la señal
completa. Se haría multiplicando las fuentes con sus coeficientes de mezcla por una matriz
correspondiente a una transformación lineal, y una vez tenemos el resultado, la obtención de las

66
componentes se harían mediante descomposiciones ortogonales.
Después, una vez que tenemos las componentes, podemos ver los cálculos numéricos para los
medidores de calidad:
𝑆𝐷𝑅 = 10 log
‖𝑠𝑡𝑎𝑟𝑔𝑒𝑡‖2
‖𝑒𝑖𝑛𝑡𝑒𝑟𝑓 + 𝑒𝑛𝑜𝑖𝑠𝑒 + 𝑒𝑎𝑟𝑡𝑖𝑓‖2 (5.2)
𝑆𝐼𝑅 = 10 log
‖𝑠𝑡𝑎𝑟𝑔𝑒𝑡‖2
‖𝑒𝑖𝑛𝑡𝑒𝑟𝑓‖2 (5.3)
𝑆𝑁𝑅 = 10 log
‖𝑠𝑡𝑎𝑟𝑔𝑒𝑡 + 𝑒𝑖𝑛𝑡𝑒𝑟𝑓‖2
‖𝑒𝑛𝑜𝑖𝑠𝑒‖2 (5.4)
𝑆𝐴𝑅 = 10 log
‖𝑠𝑡𝑎𝑟𝑔𝑒𝑡 + 𝑒𝑖𝑛𝑡𝑒𝑟𝑓 + 𝑒𝑛𝑜𝑖𝑠𝑒‖2
‖𝑒𝑎𝑟𝑡𝑖𝑓‖2 (5.5)
Estas medidas provienen de la definición del Signal to Noise Ratio, con algunas modificaciones. Para
fuentes estimadas por filtros linealmente invariantes al tiempo, no tendríamos artifacts, con lo cual:
𝑆𝐴𝑅 = +∞, y 𝑆𝐷𝑅 ≈ 𝑆𝐼𝑅.
A pesar de esto, para tener una medida más efectiva, también deberíamos incluir el intervalo de tiempo
en el que se hace la medición, puesto que ésta puede variar con el tiempo, por ejemplo, en el número
de fuentes que hablan simultáneamente, etc.
5.2 Medidas perceptuales.
Últimamente se han introducido medidas para la calidad de los sistemas BSS basadas en el
funcionamiento del sistema auditivo. La más importante y a destacar es la evaluación de la calidad
vocal por percepción, PESQ.
PESQ es el estándar de la ITU-T para medir la calidad de voz en las redes de comunicación.
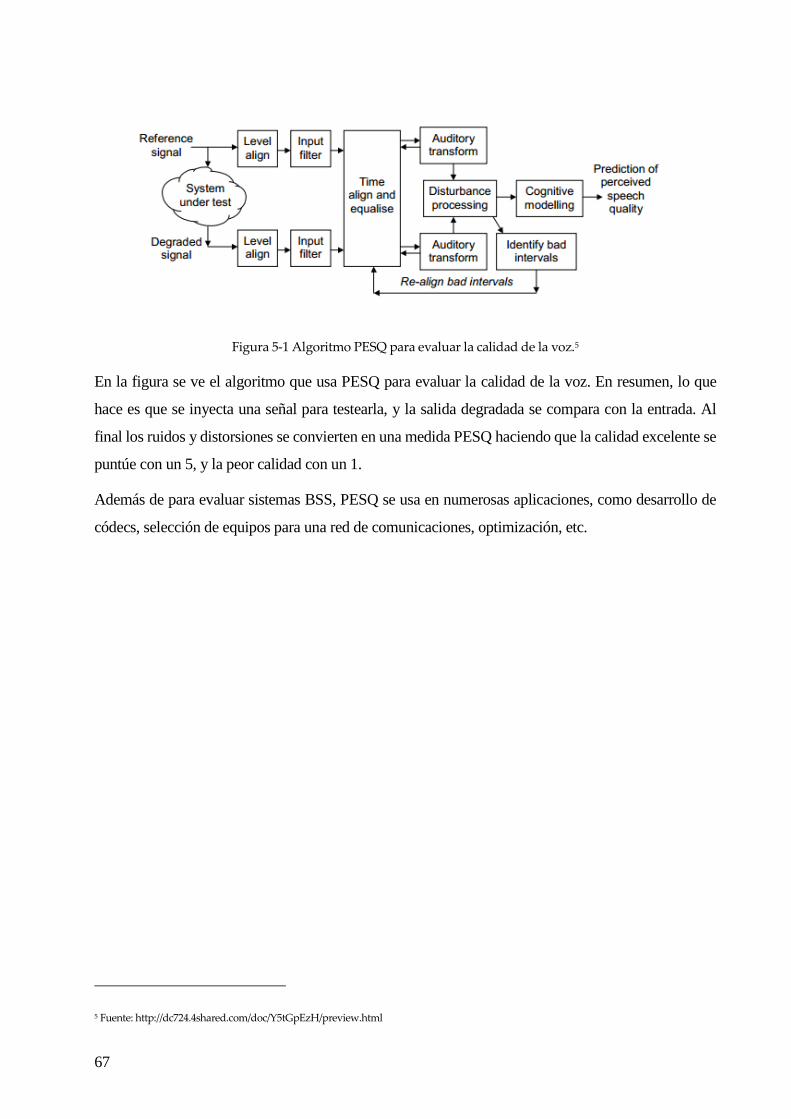
67
Figura 5-1 Algoritmo PESQ para evaluar la calidad de la voz.5
En la figura se ve el algoritmo que usa PESQ para evaluar la calidad de la voz. En resumen, lo que
hace es que se inyecta una señal para testearla, y la salida degradada se compara con la entrada. Al
final los ruidos y distorsiones se convierten en una medida PESQ haciendo que la calidad excelente se
puntúe con un 5, y la peor calidad con un 1.
Además de para evaluar sistemas BSS, PESQ se usa en numerosas aplicaciones, como desarrollo de
códecs, selección de equipos para una red de comunicaciones, optimización, etc.
5 Fuente: http://dc724.4shared.com/doc/Y5tGpEzH/preview.html

68
6 SIMULACIONES
Theory can give a complete description of the operation of the
frequency convertor, either in time language, or in frequency
language, or in the more general representacion discussed in
previous communications, but it does not enable us to draw
conclusions on the quality of the reproduction..
Dennis Gabor, 1944
l propósito de este proyecto no era otro que el de simular varios entornos para comprobar la
eficacia de DUET. Así, en este capítulo se presentan las medidas y experimentos realizados para
la separación ciega de fuentes.
En todas ellas haremos medidas para comparar la calidad de la separación, utilizando el modelo
explicado en el capítulo anterior, calculando las SDR, SIR y SAR, aunque lo que se espera de
estimaciones hechas con filtros linealmente invariables con el tiempo, es que al descomponer la señal,
la parte correspondiente a artifacts sea ≈ 0 y así: 𝑆𝐴𝑅 = +∞, y 𝑆𝐷𝑅 ≈ 𝑆𝐼𝑅. Utilizaremos esta última
medida para comparar las distintas simulaciones que van a hacerse con DUET. Para todas ellas, se
propondrán dos sensores, es decir dos micrófonos, con lo cual partiremos siempre de dos
observaciones.
E
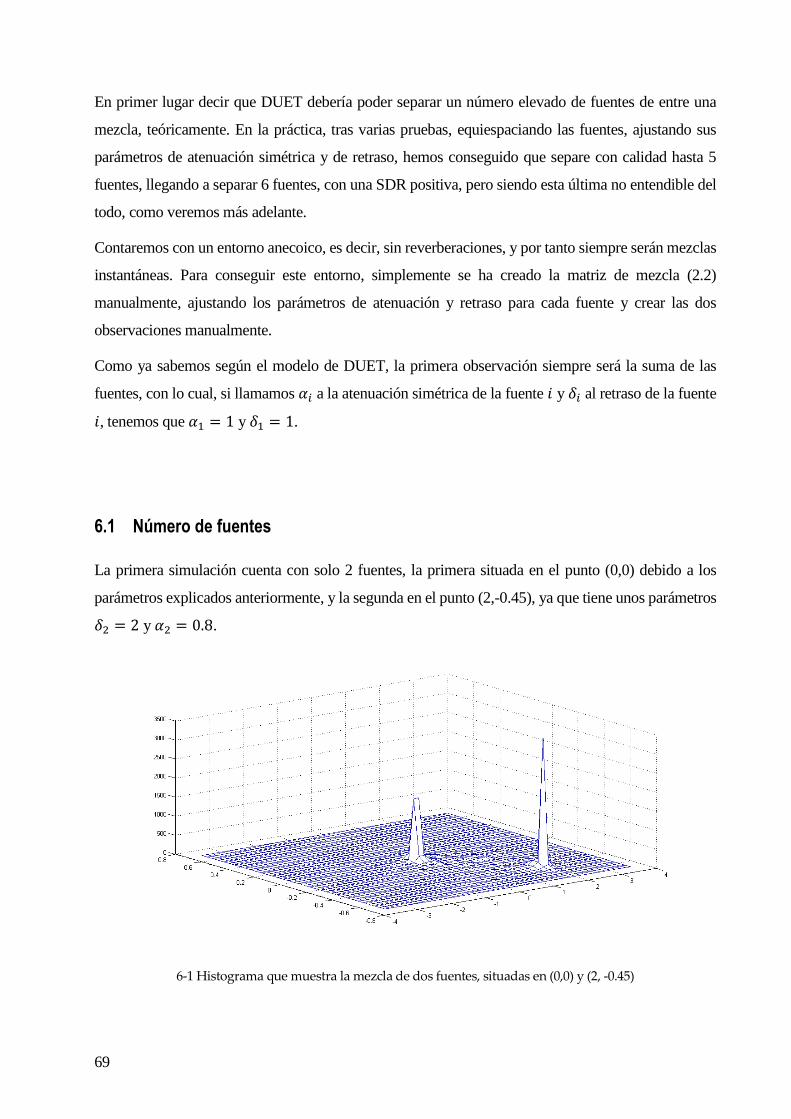
69
En primer lugar decir que DUET debería poder separar un número elevado de fuentes de entre una
mezcla, teóricamente. En la práctica, tras varias pruebas, equiespaciando las fuentes, ajustando sus
parámetros de atenuación simétrica y de retraso, hemos conseguido que separe con calidad hasta 5
fuentes, llegando a separar 6 fuentes, con una SDR positiva, pero siendo esta última no entendible del
todo, como veremos más adelante.
Contaremos con un entorno anecoico, es decir, sin reverberaciones, y por tanto siempre serán mezclas
instantáneas. Para conseguir este entorno, simplemente se ha creado la matriz de mezcla (2.2)
manualmente, ajustando los parámetros de atenuación y retraso para cada fuente y crear las dos
observaciones manualmente.
Como ya sabemos según el modelo de DUET, la primera observación siempre será la suma de las
fuentes, con lo cual, si llamamos 𝛼𝑖 a la atenuación simétrica de la fuente 𝑖 y 𝛿𝑖 al retraso de la fuente
𝑖, tenemos que 𝛼1 = 1 y 𝛿1 = 1.
6.1 Número de fuentes
La primera simulación cuenta con solo 2 fuentes, la primera situada en el punto (0,0) debido a los
parámetros explicados anteriormente, y la segunda en el punto (2,-0.45), ya que tiene unos parámetros
𝛿2 = 2 y 𝛼2 = 0.8.
6-1 Histograma que muestra la mezcla de dos fuentes, situadas en (0,0) y (2, -0.45)
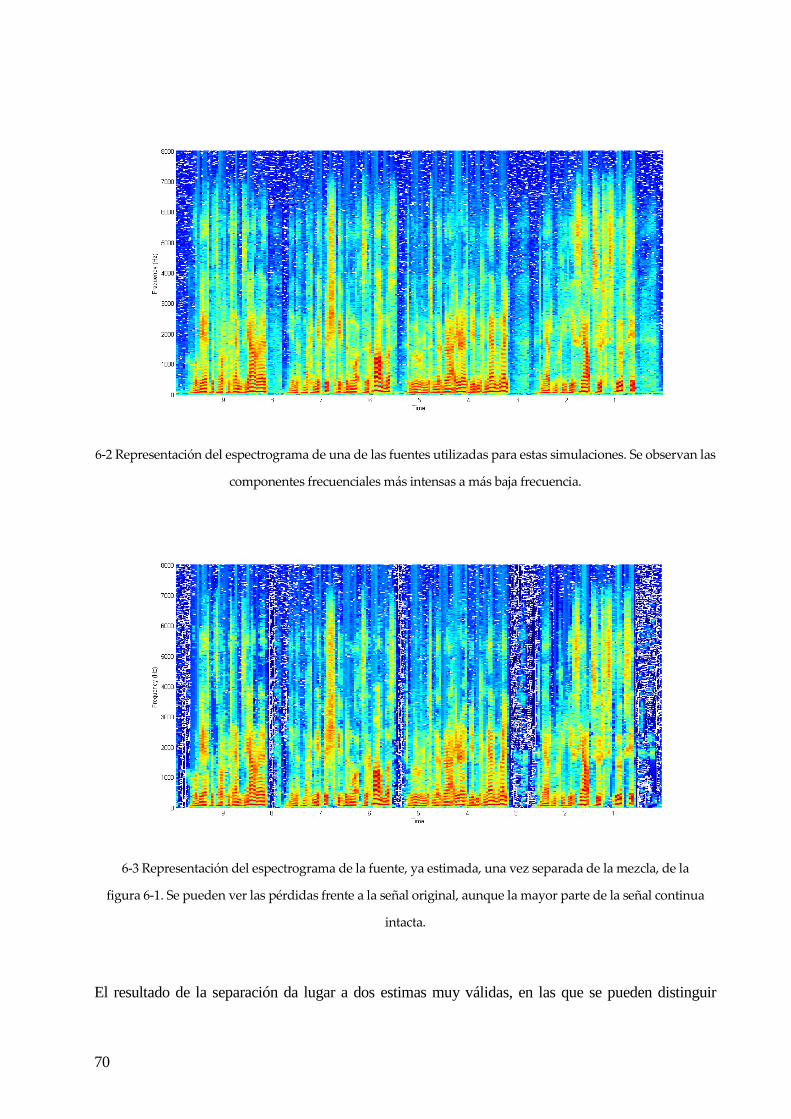
70
6-2 Representación del espectrograma de una de las fuentes utilizadas para estas simulaciones. Se observan las
componentes frecuenciales más intensas a más baja frecuencia.
6-3 Representación del espectrograma de la fuente, ya estimada, una vez separada de la mezcla, de la
figura 6-1. Se pueden ver las pérdidas frente a la señal original, aunque la mayor parte de la señal continua
intacta.
El resultado de la separación da lugar a dos estimas muy válidas, en las que se pueden distinguir
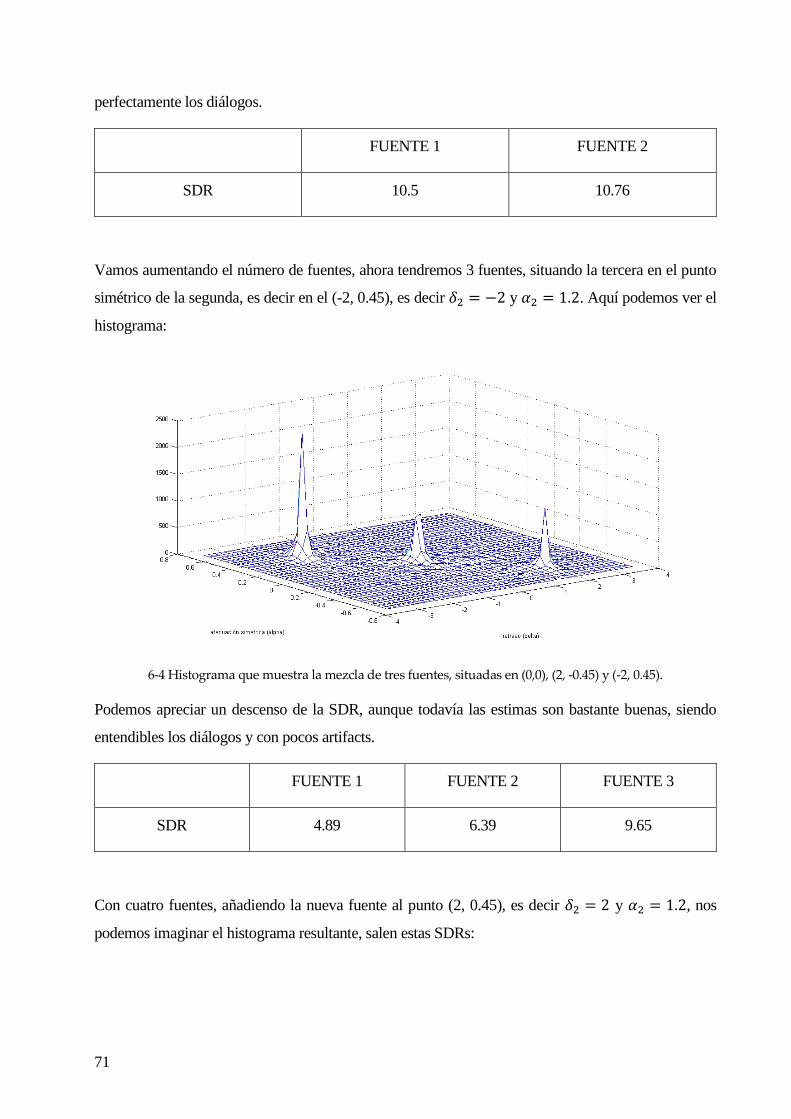
71
perfectamente los diálogos.
FUENTE 1 FUENTE 2
SDR 10.5 10.76
Vamos aumentando el número de fuentes, ahora tendremos 3 fuentes, situando la tercera en el punto
simétrico de la segunda, es decir en el (-2, 0.45), es decir 𝛿2 = −2 y 𝛼2 = 1.2. Aquí podemos ver el
histograma:
6-4 Histograma que muestra la mezcla de tres fuentes, situadas en (0,0), (2, -0.45) y (-2, 0.45).
Podemos apreciar un descenso de la SDR, aunque todavía las estimas son bastante buenas, siendo
entendibles los diálogos y con pocos artifacts.
FUENTE 1 FUENTE 2 FUENTE 3
SDR 4.89 6.39 9.65
Con cuatro fuentes, añadiendo la nueva fuente al punto (2, 0.45), es decir 𝛿2 = 2 y 𝛼2 = 1.2, nos
podemos imaginar el histograma resultante, salen estas SDRs:

72
FUENTE 1 FUENTE 2 FUENTE 3 FUENTE 4
SDR 3.19 4.42 7.93 8.22
Con cinco fuentes, situando la quinta en el punto simétrico de la cuarta, (-2,-0.45):
FUENTE 1 FUENTE 2 FUENTE 3 FUENTE 4 FUENTE 5
SDR 1.58 3.39 6.94 6.87 7.4
Ahora la sexta fuente la situamos con los siguientes parámetros, 𝛿2 = 2 y 𝛼2 = 1, es decir en el punto
(2,0).
6-5 Máscaras binarias de separación, para cada una de las cuatro fuentes presentes en una mezcla.

73
FUENTE 1 FUENTE 2 FUENTE 3 FUENTE 4 FUENTE 5 FUENTE 6
SDR 0.6 2.35 6.04 5.25 6.90 2.15
Como era de esperar y podemos ver en las 4 simulaciones, la SDR de las fuentes va disminuyendo a
medida que introducimos nuevas fuentes en la mezcla. Para esta última simulación, la fuente 1 es la
que presenta una SDR menor, aunque podemos escuchar con baja calidad el diálogo presente en dicha
fuente, el audio está lleno de artifacts que degradan esa calidad, haciéndola, por momentos, casi
ininteligible.
La siguiente simulación propuesta, con 7 fuentes, presenta ya en algunas estimas una SDR negativa.
Puesto que ya con 6 fuentes, a veces algunas estimas se hacen ininteligibles, con 7 fuentes esto se ve
intensificado. La mayoría de ellas están repletas de artifacts que hacen que no se distinga la fuente
extraída.
FUENTE
1
FUENTE
2
FUENTE
3
FUENTE
4
FUENTE
5
FUENTE
6
FUENTE
7
SDR -1.29 1.62 3.41 4.48 4.66 1.58 -0.68
6.2 Añadiendo ruido gaussiano.
Una vez hemos visto que DUET es capaz de separar varias fuentes de la mezcla sintética (un máximo
de 6 fuentes mostrando una SDR positiva), probaremos a ver hasta qué nivel de ruido es capaz de
aguantar para distintos números de fuentes presentes en la mezcla. Para añadir este ruido blanco a la
señal haremos uso de la función “randn” de Matlab, la cual permite genera una secuencia de números
aleatorios con una distribución uniforme. En esta propuesta, hemos partido de un valor alto de SNR
(35 dB) para luego ir disminuyéndolo. Aquí solo pondremos un ejemplo de histograma con ruido
blanco gaussiano añadido y el caso límite para cada simulación con un número de fuentes distinta.
Como es de esperar, si introducimos una relación señal a ruido alta, el resultado será muy parecido al
que obtendríamos sin introducir ruido alguno. Empezaremos por dos fuentes.
El valor más bajo de la SNR que todavía nos permite identificar a las fuentes en el histograma es en
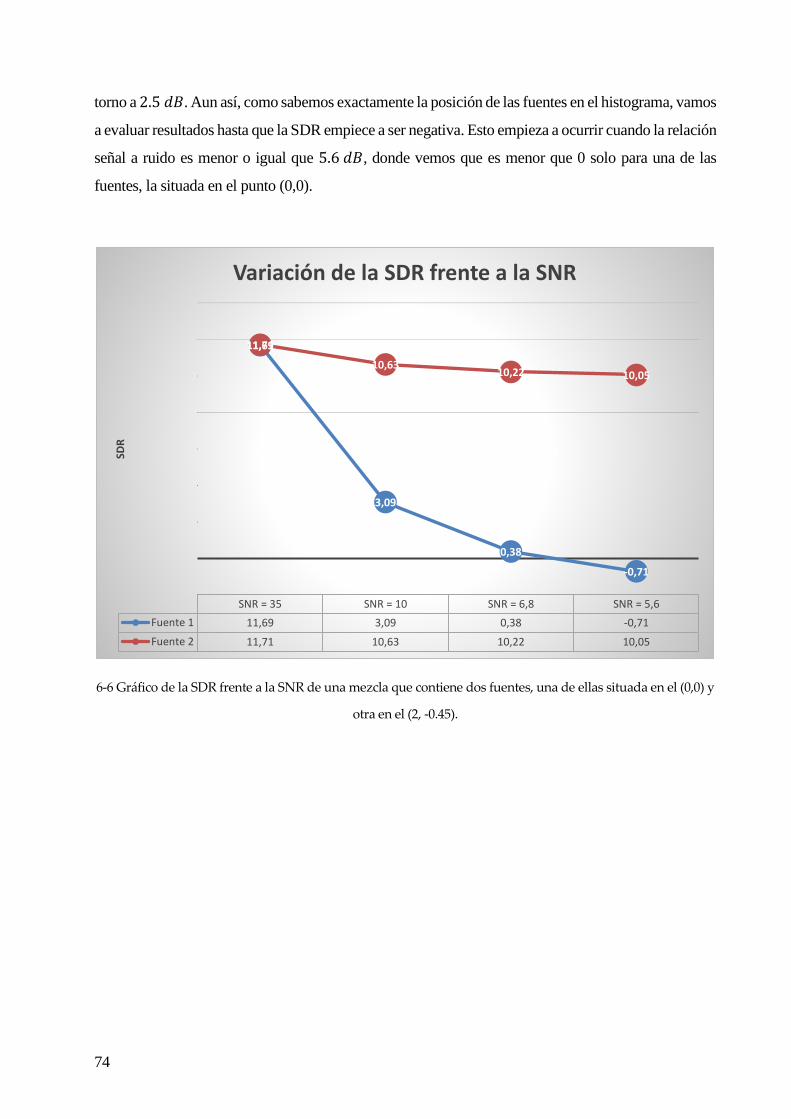
74
torno a 2.5 𝑑𝐵. Aun así, como sabemos exactamente la posición de las fuentes en el histograma, vamos
a evaluar resultados hasta que la SDR empiece a ser negativa. Esto empieza a ocurrir cuando la relación
señal a ruido es menor o igual que 5.6 𝑑𝐵, donde vemos que es menor que 0 solo para una de las
fuentes, la situada en el punto (0,0).
6-6 Gráfico de la SDR frente a la SNR de una mezcla que contiene dos fuentes, una de ellas situada en el (0,0) y
otra en el (2, -0.45).
SNR = 35 SNR = 10 SNR = 6,8 SNR = 5,6
Fuente 1 11,69 3,09 0,38 -0,71
Fuente 2 11,71 10,63 10,22 10,05
11,69
3,09
0,38
-0,71
11,71
10,6310,22 10,05
SDR
Variación de la SDR frente a la SNR
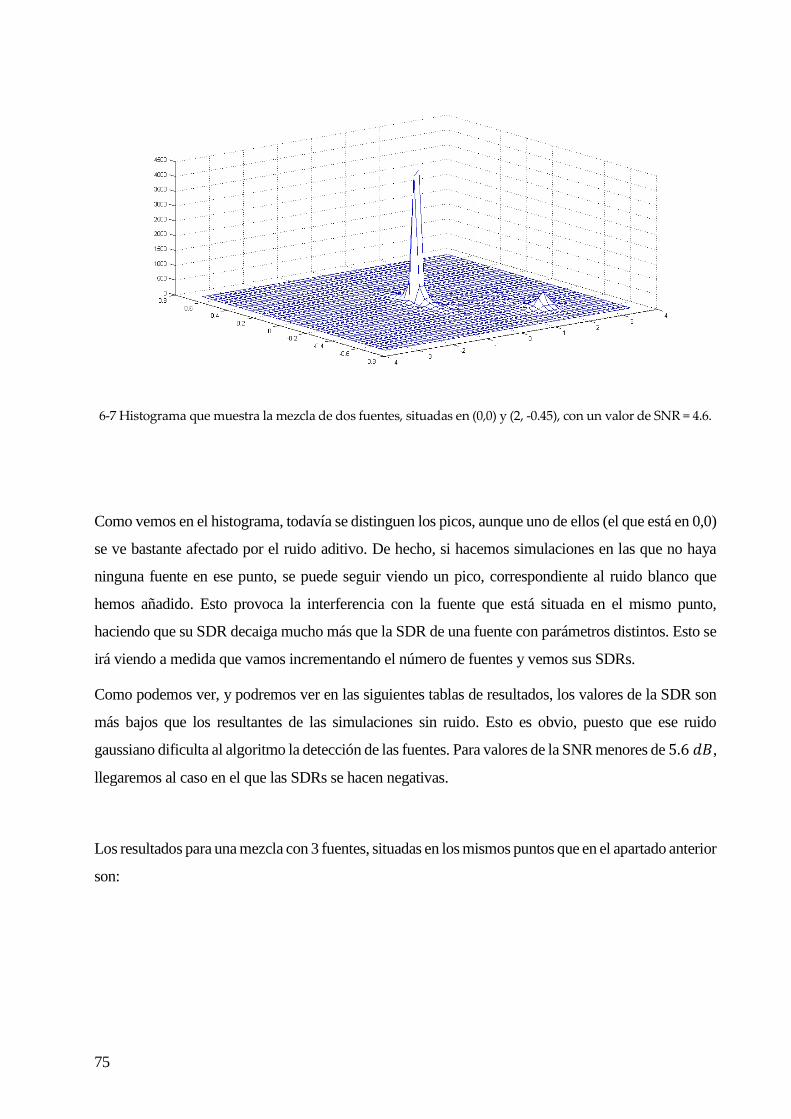
75
6-7 Histograma que muestra la mezcla de dos fuentes, situadas en (0,0) y (2, -0.45), con un valor de SNR = 4.6.
Como vemos en el histograma, todavía se distinguen los picos, aunque uno de ellos (el que está en 0,0)
se ve bastante afectado por el ruido aditivo. De hecho, si hacemos simulaciones en las que no haya
ninguna fuente en ese punto, se puede seguir viendo un pico, correspondiente al ruido blanco que
hemos añadido. Esto provoca la interferencia con la fuente que está situada en el mismo punto,
haciendo que su SDR decaiga mucho más que la SDR de una fuente con parámetros distintos. Esto se
irá viendo a medida que vamos incrementando el número de fuentes y vemos sus SDRs.
Como podemos ver, y podremos ver en las siguientes tablas de resultados, los valores de la SDR son
más bajos que los resultantes de las simulaciones sin ruido. Esto es obvio, puesto que ese ruido
gaussiano dificulta al algoritmo la detección de las fuentes. Para valores de la SNR menores de 5.6 𝑑𝐵,
llegaremos al caso en el que las SDRs se hacen negativas.
Los resultados para una mezcla con 3 fuentes, situadas en los mismos puntos que en el apartado anterior
son:
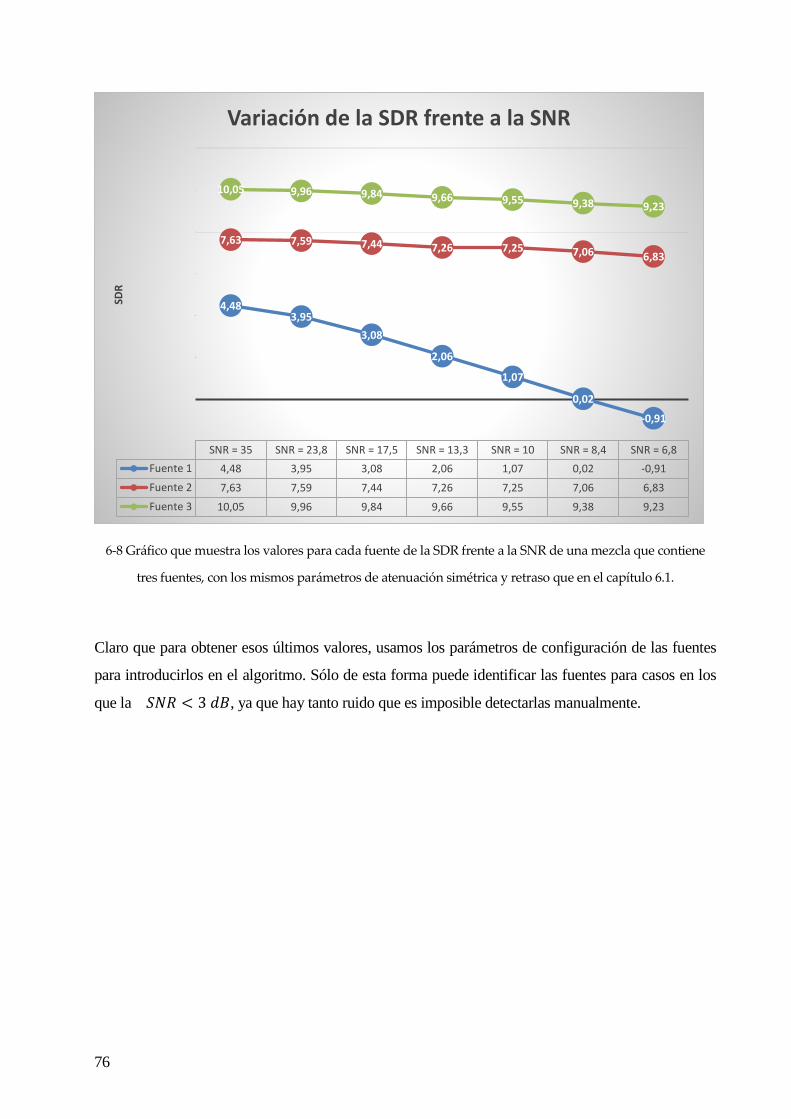
76
6-8 Gráfico que muestra los valores para cada fuente de la SDR frente a la SNR de una mezcla que contiene
tres fuentes, con los mismos parámetros de atenuación simétrica y retraso que en el capítulo 6.1.
Claro que para obtener esos últimos valores, usamos los parámetros de configuración de las fuentes
para introducirlos en el algoritmo. Sólo de esta forma puede identificar las fuentes para casos en los
que la 𝑆𝑁𝑅 < 3 𝑑𝐵, ya que hay tanto ruido que es imposible detectarlas manualmente.
SNR = 35 SNR = 23,8 SNR = 17,5 SNR = 13,3 SNR = 10 SNR = 8,4 SNR = 6,8
Fuente 1 4,48 3,95 3,08 2,06 1,07 0,02 -0,91
Fuente 2 7,63 7,59 7,44 7,26 7,25 7,06 6,83
Fuente 3 10,05 9,96 9,84 9,66 9,55 9,38 9,23
4,483,95
3,08
2,06
1,07
0,02
-0,91
7,63 7,59 7,44 7,26 7,25 7,06 6,83
10,05 9,96 9,84 9,66 9,55 9,38 9,23
SDR
Variación de la SDR frente a la SNR
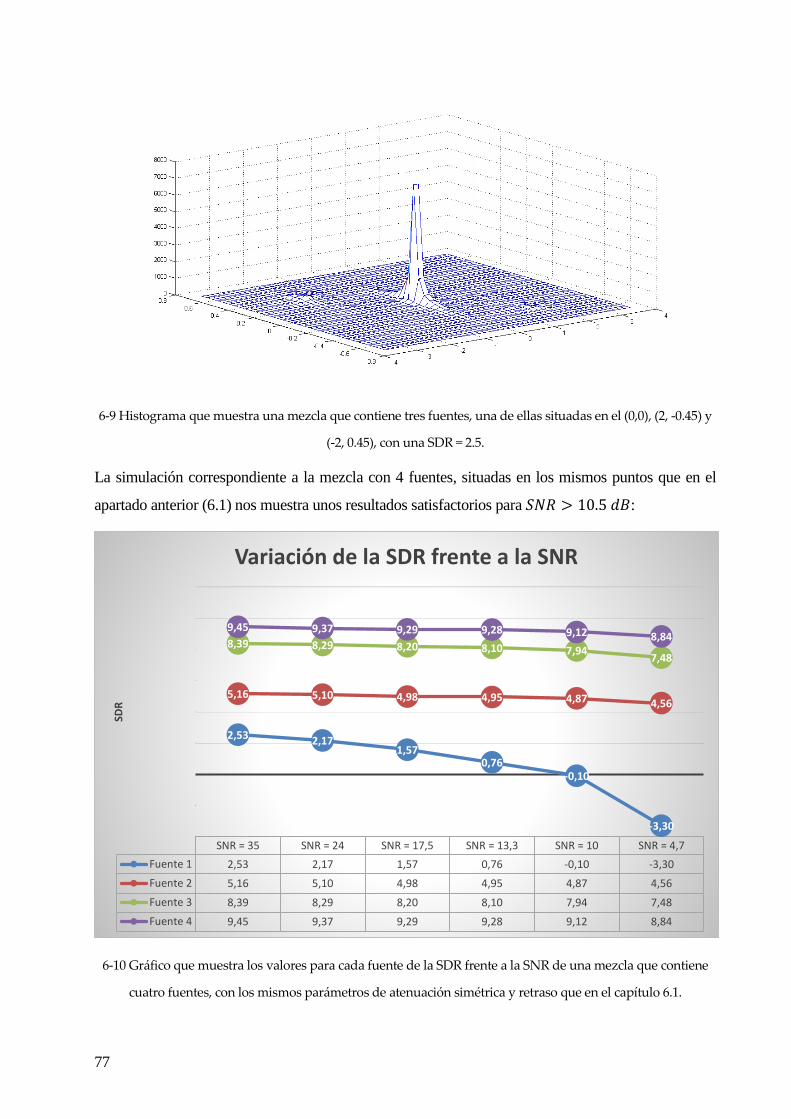
77
6-9 Histograma que muestra una mezcla que contiene tres fuentes, una de ellas situadas en el (0,0), (2, -0.45) y
(-2, 0.45), con una SDR = 2.5.
La simulación correspondiente a la mezcla con 4 fuentes, situadas en los mismos puntos que en el
apartado anterior (6.1) nos muestra unos resultados satisfactorios para 𝑆𝑁𝑅 > 10.5 𝑑𝐵:
6-10 Gráfico que muestra los valores para cada fuente de la SDR frente a la SNR de una mezcla que contiene
cuatro fuentes, con los mismos parámetros de atenuación simétrica y retraso que en el capítulo 6.1.
SNR = 35 SNR = 24 SNR = 17,5 SNR = 13,3 SNR = 10 SNR = 4,7
Fuente 1 2,53 2,17 1,57 0,76 -0,10 -3,30
Fuente 2 5,16 5,10 4,98 4,95 4,87 4,56
Fuente 3 8,39 8,29 8,20 8,10 7,94 7,48
Fuente 4 9,45 9,37 9,29 9,28 9,12 8,84
2,53 2,171,57
0,76-0,10
-3,30
5,16 5,10 4,98 4,95 4,87 4,56
8,39 8,29 8,20 8,10 7,947,48
9,45 9,37 9,29 9,28 9,12 8,84
SDR
Variación de la SDR frente a la SNR
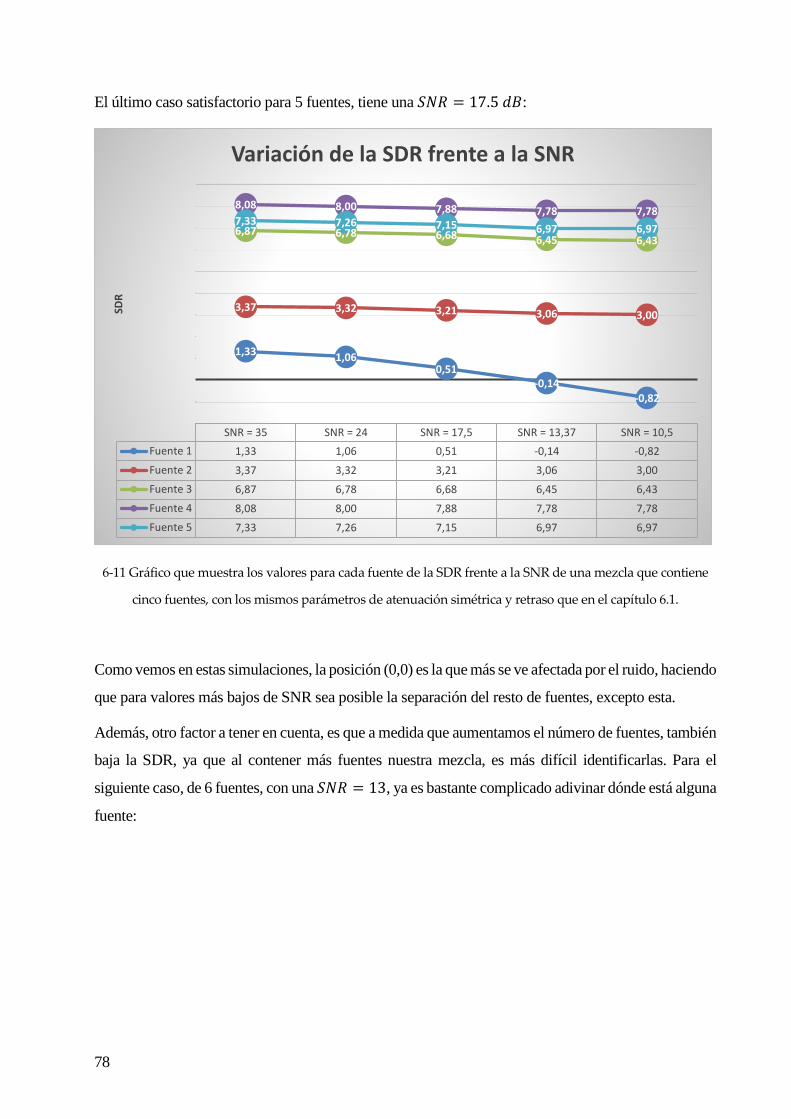
78
El último caso satisfactorio para 5 fuentes, tiene una 𝑆𝑁𝑅 = 17.5 𝑑𝐵:
6-11 Gráfico que muestra los valores para cada fuente de la SDR frente a la SNR de una mezcla que contiene
cinco fuentes, con los mismos parámetros de atenuación simétrica y retraso que en el capítulo 6.1.
Como vemos en estas simulaciones, la posición (0,0) es la que más se ve afectada por el ruido, haciendo
que para valores más bajos de SNR sea posible la separación del resto de fuentes, excepto esta.
Además, otro factor a tener en cuenta, es que a medida que aumentamos el número de fuentes, también
baja la SDR, ya que al contener más fuentes nuestra mezcla, es más difícil identificarlas. Para el
siguiente caso, de 6 fuentes, con una 𝑆𝑁𝑅 = 13, ya es bastante complicado adivinar dónde está alguna
fuente:
SNR = 35 SNR = 24 SNR = 17,5 SNR = 13,37 SNR = 10,5
Fuente 1 1,33 1,06 0,51 -0,14 -0,82
Fuente 2 3,37 3,32 3,21 3,06 3,00
Fuente 3 6,87 6,78 6,68 6,45 6,43
Fuente 4 8,08 8,00 7,88 7,78 7,78
Fuente 5 7,33 7,26 7,15 6,97 6,97
1,33 1,060,51
-0,14-0,82
3,37 3,32 3,21 3,06 3,00
6,87 6,78 6,68 6,45 6,43
8,08 8,00 7,88 7,78 7,787,33 7,26 7,15 6,97 6,97
SDR
Variación de la SDR frente a la SNR
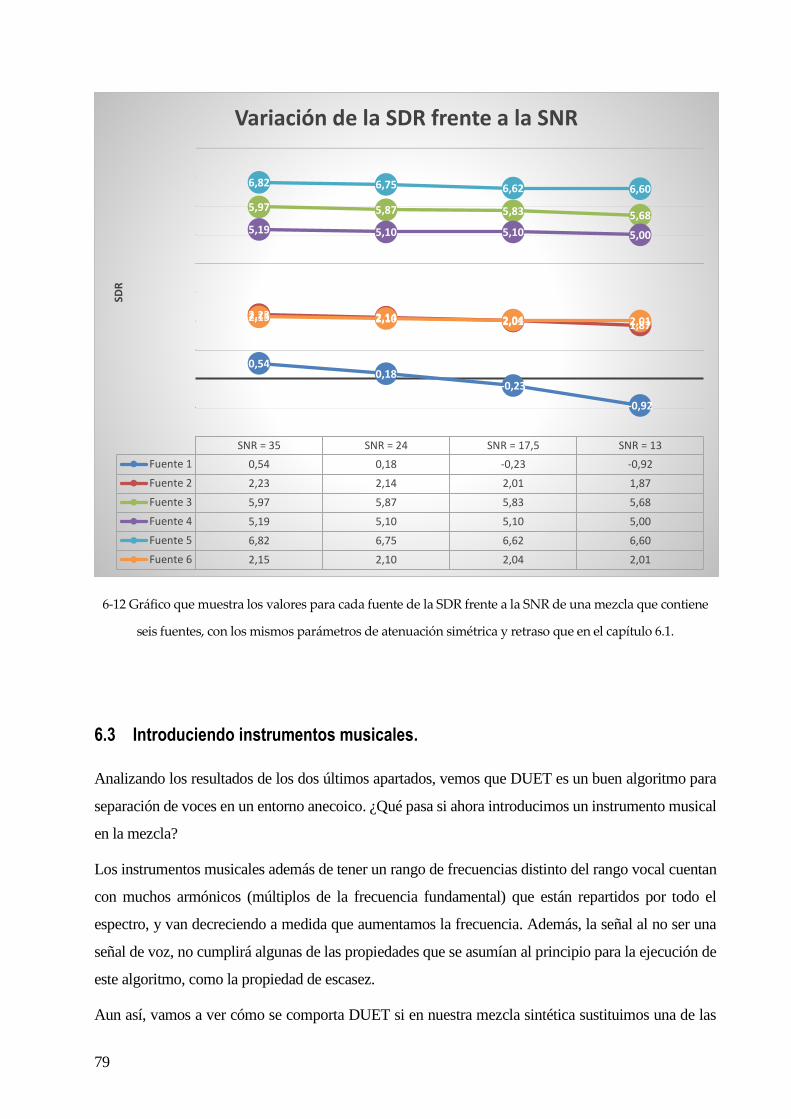
79
6-12 Gráfico que muestra los valores para cada fuente de la SDR frente a la SNR de una mezcla que contiene
seis fuentes, con los mismos parámetros de atenuación simétrica y retraso que en el capítulo 6.1.
6.3 Introduciendo instrumentos musicales.
Analizando los resultados de los dos últimos apartados, vemos que DUET es un buen algoritmo para
separación de voces en un entorno anecoico. ¿Qué pasa si ahora introducimos un instrumento musical
en la mezcla?
Los instrumentos musicales además de tener un rango de frecuencias distinto del rango vocal cuentan
con muchos armónicos (múltiplos de la frecuencia fundamental) que están repartidos por todo el
espectro, y van decreciendo a medida que aumentamos la frecuencia. Además, la señal al no ser una
señal de voz, no cumplirá algunas de las propiedades que se asumían al principio para la ejecución de
este algoritmo, como la propiedad de escasez.
Aun así, vamos a ver cómo se comporta DUET si en nuestra mezcla sintética sustituimos una de las
SNR = 35 SNR = 24 SNR = 17,5 SNR = 13
Fuente 1 0,54 0,18 -0,23 -0,92
Fuente 2 2,23 2,14 2,01 1,87
Fuente 3 5,97 5,87 5,83 5,68
Fuente 4 5,19 5,10 5,10 5,00
Fuente 5 6,82 6,75 6,62 6,60
Fuente 6 2,15 2,10 2,04 2,01
0,540,18
-0,23
-0,92
2,23 2,14 2,01 1,87
5,97 5,87 5,83 5,685,19 5,10 5,10 5,00
6,82 6,75 6,62 6,60
2,15 2,10 2,04 2,01
SDR
Variación de la SDR frente a la SNR
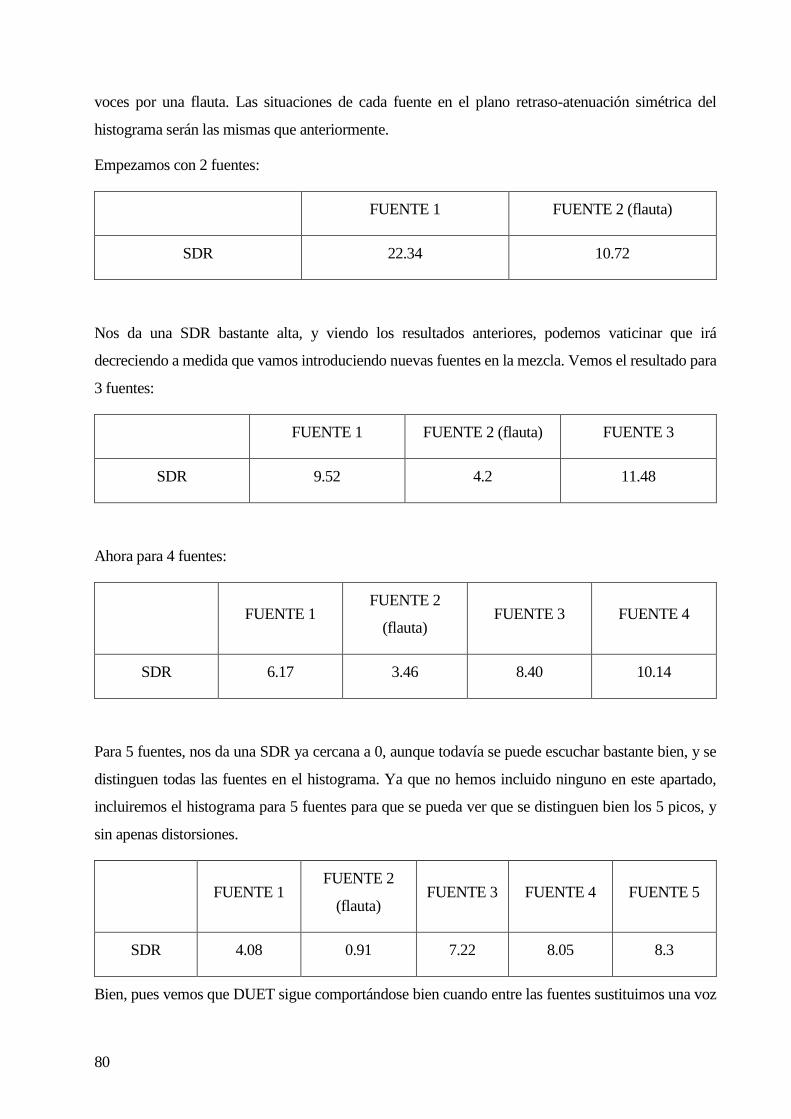
80
voces por una flauta. Las situaciones de cada fuente en el plano retraso-atenuación simétrica del
histograma serán las mismas que anteriormente.
Empezamos con 2 fuentes:
FUENTE 1 FUENTE 2 (flauta)
SDR 22.34 10.72
Nos da una SDR bastante alta, y viendo los resultados anteriores, podemos vaticinar que irá
decreciendo a medida que vamos introduciendo nuevas fuentes en la mezcla. Vemos el resultado para
3 fuentes:
FUENTE 1 FUENTE 2 (flauta) FUENTE 3
SDR 9.52 4.2 11.48
Ahora para 4 fuentes:
FUENTE 1 FUENTE 2
(flauta) FUENTE 3 FUENTE 4
SDR 6.17 3.46 8.40 10.14
Para 5 fuentes, nos da una SDR ya cercana a 0, aunque todavía se puede escuchar bastante bien, y se
distinguen todas las fuentes en el histograma. Ya que no hemos incluido ninguno en este apartado,
incluiremos el histograma para 5 fuentes para que se pueda ver que se distinguen bien los 5 picos, y
sin apenas distorsiones.
FUENTE 1 FUENTE 2
(flauta) FUENTE 3 FUENTE 4 FUENTE 5
SDR 4.08 0.91 7.22 8.05 8.3
Bien, pues vemos que DUET sigue comportándose bien cuando entre las fuentes sustituimos una voz
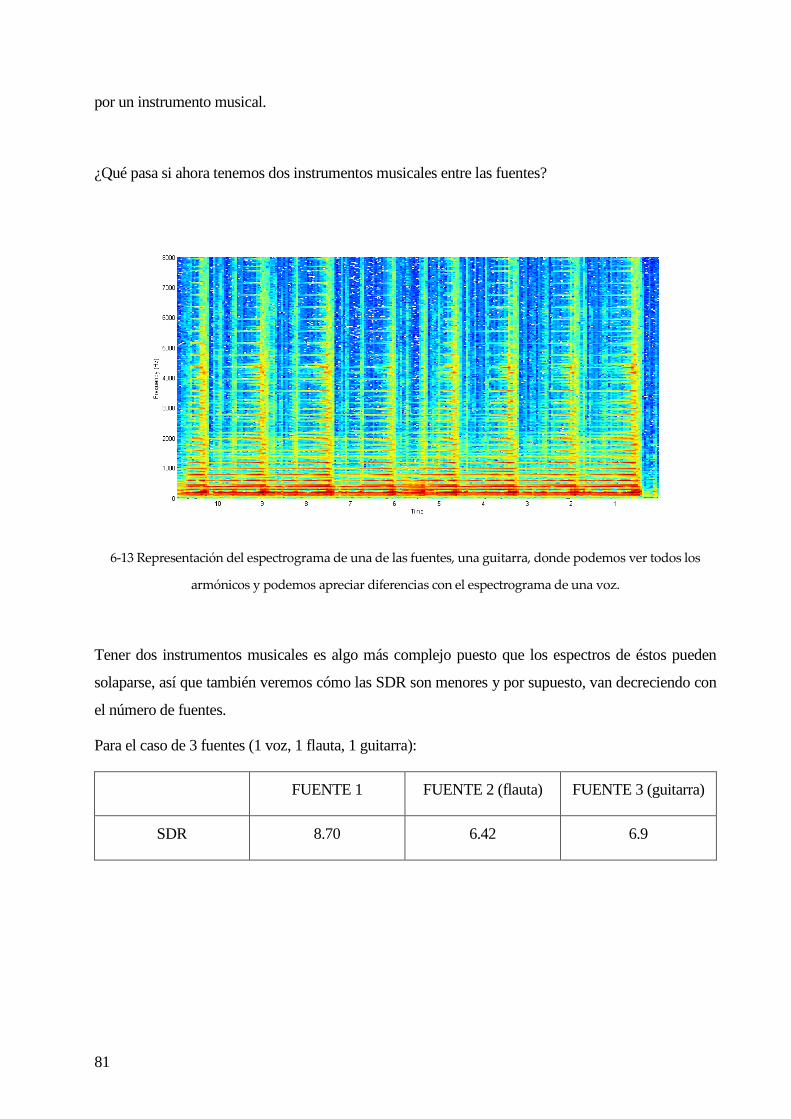
81
por un instrumento musical.
¿Qué pasa si ahora tenemos dos instrumentos musicales entre las fuentes?
6-13 Representación del espectrograma de una de las fuentes, una guitarra, donde podemos ver todos los
armónicos y podemos apreciar diferencias con el espectrograma de una voz.
Tener dos instrumentos musicales es algo más complejo puesto que los espectros de éstos pueden
solaparse, así que también veremos cómo las SDR son menores y por supuesto, van decreciendo con
el número de fuentes.
Para el caso de 3 fuentes (1 voz, 1 flauta, 1 guitarra):
FUENTE 1 FUENTE 2 (flauta) FUENTE 3 (guitarra)
SDR 8.70 6.42 6.9
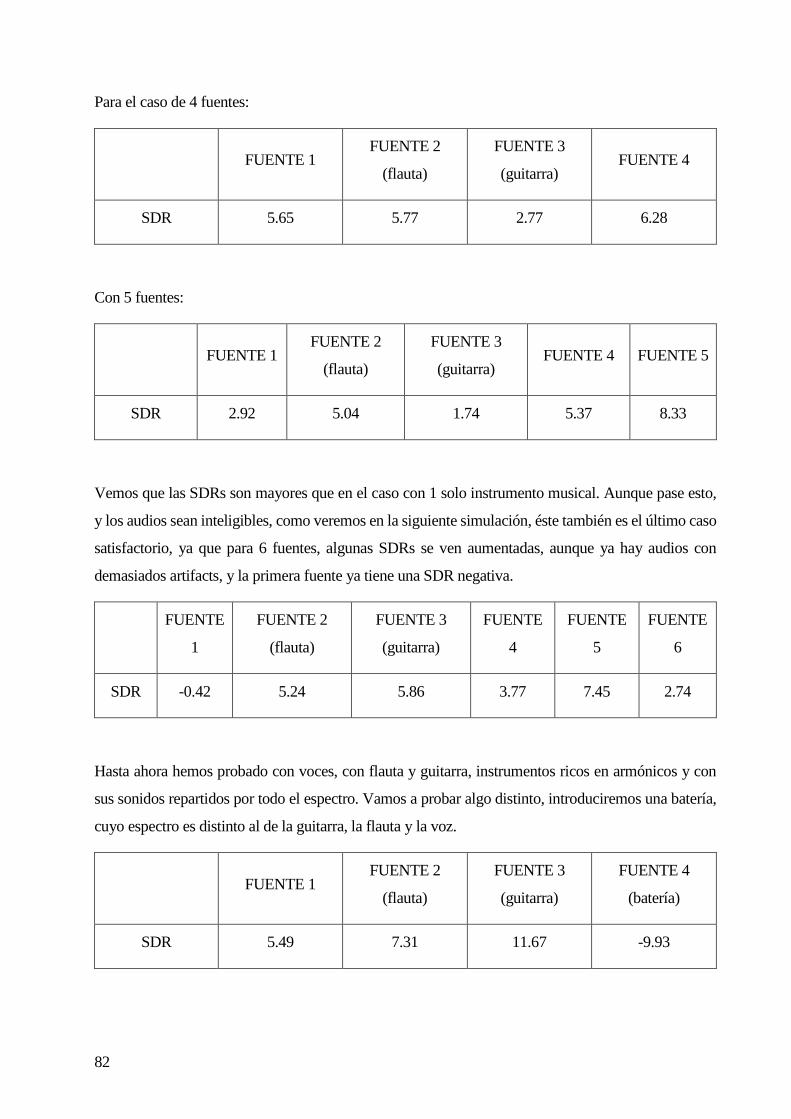
82
Para el caso de 4 fuentes:
FUENTE 1 FUENTE 2
(flauta)
FUENTE 3
(guitarra) FUENTE 4
SDR 5.65 5.77 2.77 6.28
Con 5 fuentes:
FUENTE 1 FUENTE 2
(flauta)
FUENTE 3
(guitarra) FUENTE 4 FUENTE 5
SDR 2.92 5.04 1.74 5.37 8.33
Vemos que las SDRs son mayores que en el caso con 1 solo instrumento musical. Aunque pase esto,
y los audios sean inteligibles, como veremos en la siguiente simulación, éste también es el último caso
satisfactorio, ya que para 6 fuentes, algunas SDRs se ven aumentadas, aunque ya hay audios con
demasiados artifacts, y la primera fuente ya tiene una SDR negativa.
FUENTE
1
FUENTE 2
(flauta)
FUENTE 3
(guitarra)
FUENTE
4
FUENTE
5
FUENTE
6
SDR -0.42 5.24 5.86 3.77 7.45 2.74
Hasta ahora hemos probado con voces, con flauta y guitarra, instrumentos ricos en armónicos y con
sus sonidos repartidos por todo el espectro. Vamos a probar algo distinto, introduciremos una batería,
cuyo espectro es distinto al de la guitarra, la flauta y la voz.
FUENTE 1 FUENTE 2
(flauta)
FUENTE 3
(guitarra)
FUENTE 4
(batería)
SDR 5.49 7.31 11.67 -9.93
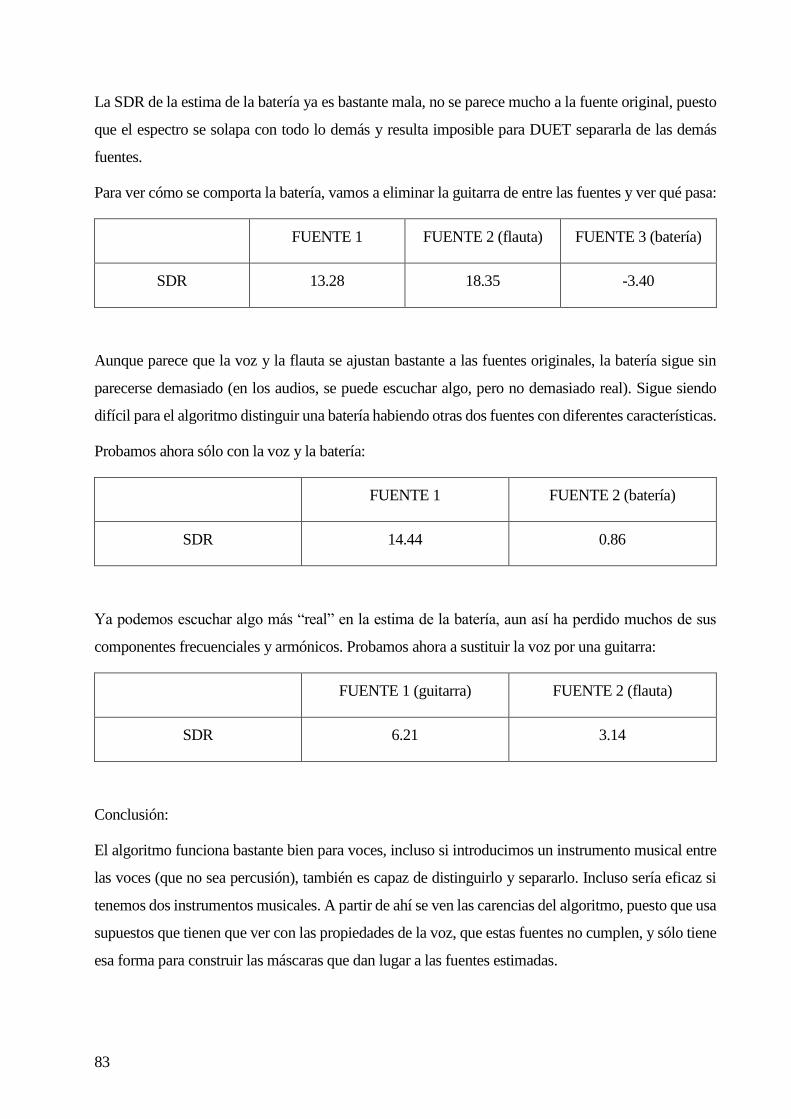
83
La SDR de la estima de la batería ya es bastante mala, no se parece mucho a la fuente original, puesto
que el espectro se solapa con todo lo demás y resulta imposible para DUET separarla de las demás
fuentes.
Para ver cómo se comporta la batería, vamos a eliminar la guitarra de entre las fuentes y ver qué pasa:
FUENTE 1 FUENTE 2 (flauta) FUENTE 3 (batería)
SDR 13.28 18.35 -3.40
Aunque parece que la voz y la flauta se ajustan bastante a las fuentes originales, la batería sigue sin
parecerse demasiado (en los audios, se puede escuchar algo, pero no demasiado real). Sigue siendo
difícil para el algoritmo distinguir una batería habiendo otras dos fuentes con diferentes características.
Probamos ahora sólo con la voz y la batería:
FUENTE 1 FUENTE 2 (batería)
SDR 14.44 0.86
Ya podemos escuchar algo más “real” en la estima de la batería, aun así ha perdido muchos de sus
componentes frecuenciales y armónicos. Probamos ahora a sustituir la voz por una guitarra:
FUENTE 1 (guitarra) FUENTE 2 (flauta)
SDR 6.21 3.14
Conclusión:
El algoritmo funciona bastante bien para voces, incluso si introducimos un instrumento musical entre
las voces (que no sea percusión), también es capaz de distinguirlo y separarlo. Incluso sería eficaz si
tenemos dos instrumentos musicales. A partir de ahí se ven las carencias del algoritmo, puesto que usa
supuestos que tienen que ver con las propiedades de la voz, que estas fuentes no cumplen, y sólo tiene
esa forma para construir las máscaras que dan lugar a las fuentes estimadas.

84
6.4 Distancia mínima entre fuentes.
Hasta ahora hemos equiespaciado las fuentes lo mejor que hemos podido para evaluarlas con claridad,
eliminando el posible problema de solapamiento de las fuentes en el histograma. Esto se produciría si
tuvieran unos valores de atenuación simétrica y retraso muy parecidos.
Pues bien, simulando con solo dos fuentes, y acercándolas, vemos que en realidad no influye
demasiado, puesto que se distinguen bien los dos picos a medida que se van acercando, y las SDRs
apenas se ven alteradas.
Igual que antes, tendremos la fuente 1 en el punto (0,0), con 𝛿1 = 0 y 𝛼1 = 1. Vamos a ir variando
los parámetros de la fuente 2.
¿Qué pasa si variamos la atenuación simétrica?
SDRs
FUENTE 1 FUENTE 2
𝛅𝟐 = 𝟎 y 𝛂𝟐 = 𝟎. 𝟖 11.83 11.85
𝛅𝟐 = 𝟎 y 𝛂𝟐 = 𝟎. 𝟖𝟓 11.78 11.81
𝛅𝟐 = 𝟎 y 𝛂𝟐 = 𝟎. 𝟗 11.73 11.93
𝛅𝟐 = 𝟎 y 𝛂𝟐 = 𝟎. 𝟗𝟓 11.68 12.04
𝛅𝟐 = 𝟎 y 𝛂𝟐 = 𝟎. 𝟗𝟕 11.61 12.06
Las SDRs apenas se ven afectadas a medida que vamos reduciendo la distancia entre las fuentes. Pero
veamos los histogramas:
Para el caso en el que 𝛼2 = 0.95 todavía se distinguen los dos picos, con lo cual, como tenemos que
introducir las fuentes manualmente, podemos conseguir esas SDRs que teníamos en la tabla anterior.
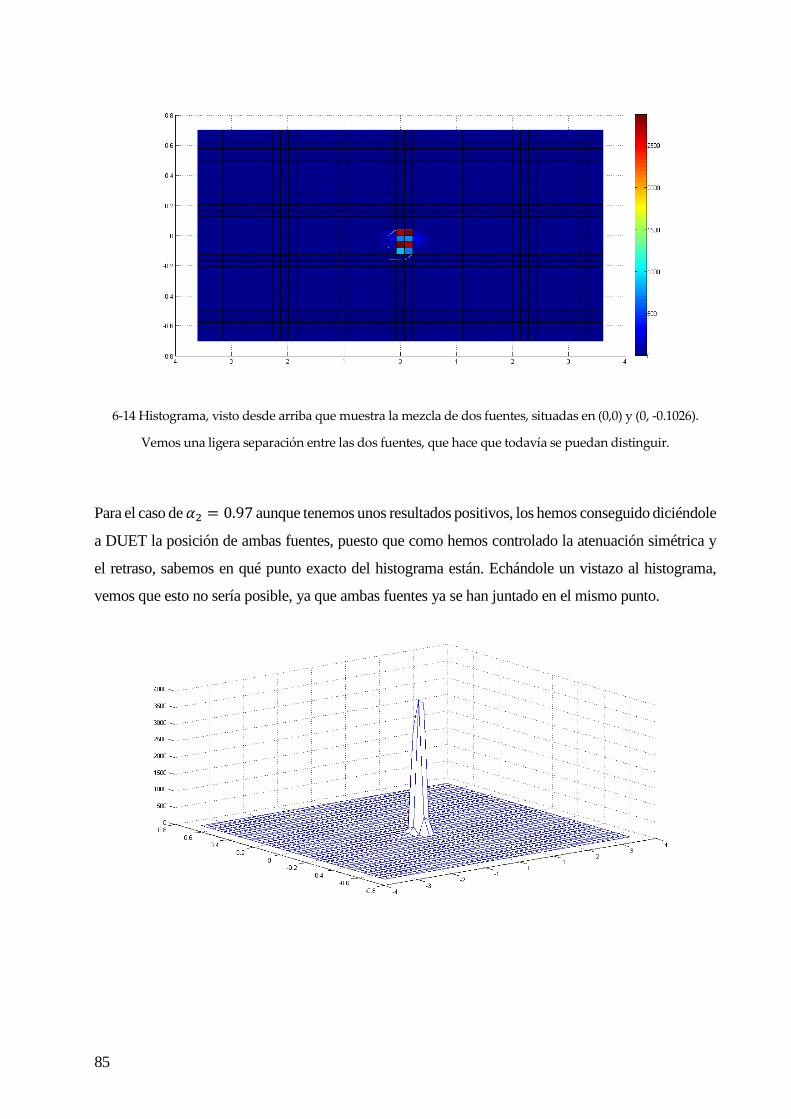
85
6-14 Histograma, visto desde arriba que muestra la mezcla de dos fuentes, situadas en (0,0) y (0, -0.1026).
Vemos una ligera separación entre las dos fuentes, que hace que todavía se puedan distinguir.
Para el caso de 𝛼2 = 0.97 aunque tenemos unos resultados positivos, los hemos conseguido diciéndole
a DUET la posición de ambas fuentes, puesto que como hemos controlado la atenuación simétrica y
el retraso, sabemos en qué punto exacto del histograma están. Echándole un vistazo al histograma,
vemos que esto no sería posible, ya que ambas fuentes ya se han juntado en el mismo punto.
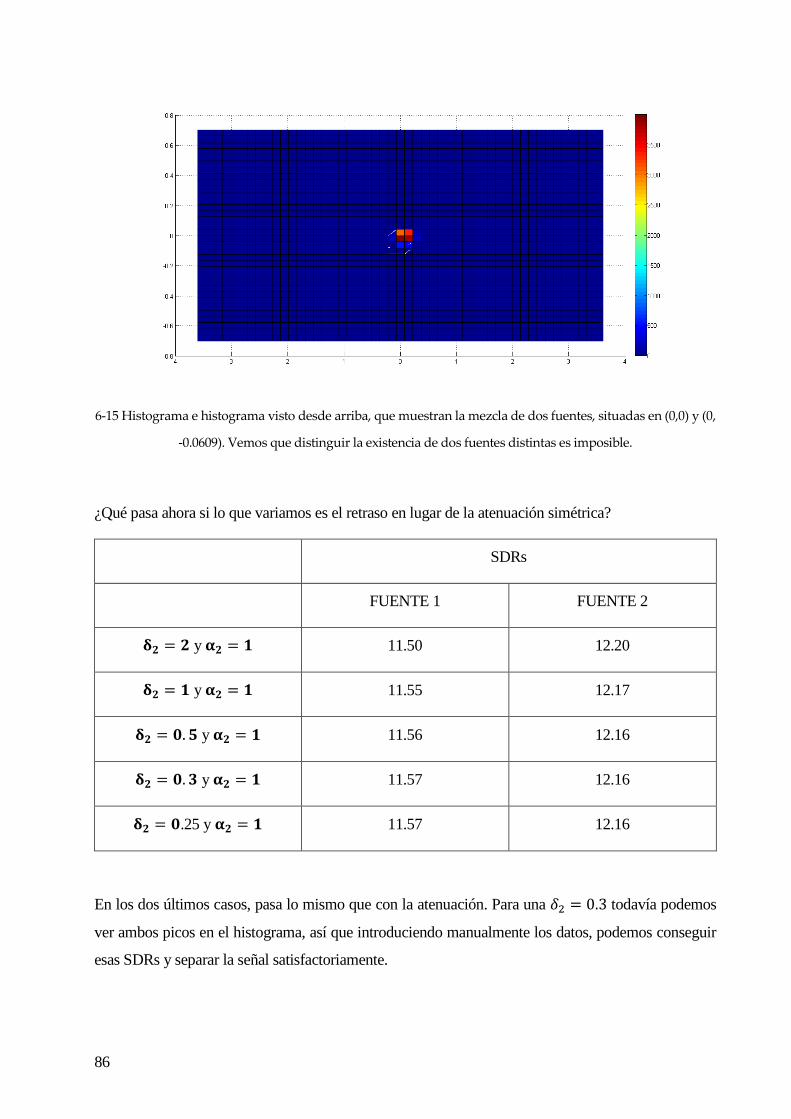
86
6-15 Histograma e histograma visto desde arriba, que muestran la mezcla de dos fuentes, situadas en (0,0) y (0,
-0.0609). Vemos que distinguir la existencia de dos fuentes distintas es imposible.
¿Qué pasa ahora si lo que variamos es el retraso en lugar de la atenuación simétrica?
SDRs
FUENTE 1 FUENTE 2
𝛅𝟐 = 𝟐 y 𝛂𝟐 = 𝟏 11.50 12.20
𝛅𝟐 = 𝟏 y 𝛂𝟐 = 𝟏 11.55 12.17
𝛅𝟐 = 𝟎. 𝟓 y 𝛂𝟐 = 𝟏 11.56 12.16
𝛅𝟐 = 𝟎. 𝟑 y 𝛂𝟐 = 𝟏 11.57 12.16
𝛅𝟐 = 𝟎.25 y 𝛂𝟐 = 𝟏 11.57 12.16
En los dos últimos casos, pasa lo mismo que con la atenuación. Para una 𝛿2 = 0.3 todavía podemos
ver ambos picos en el histograma, así que introduciendo manualmente los datos, podemos conseguir
esas SDRs y separar la señal satisfactoriamente.
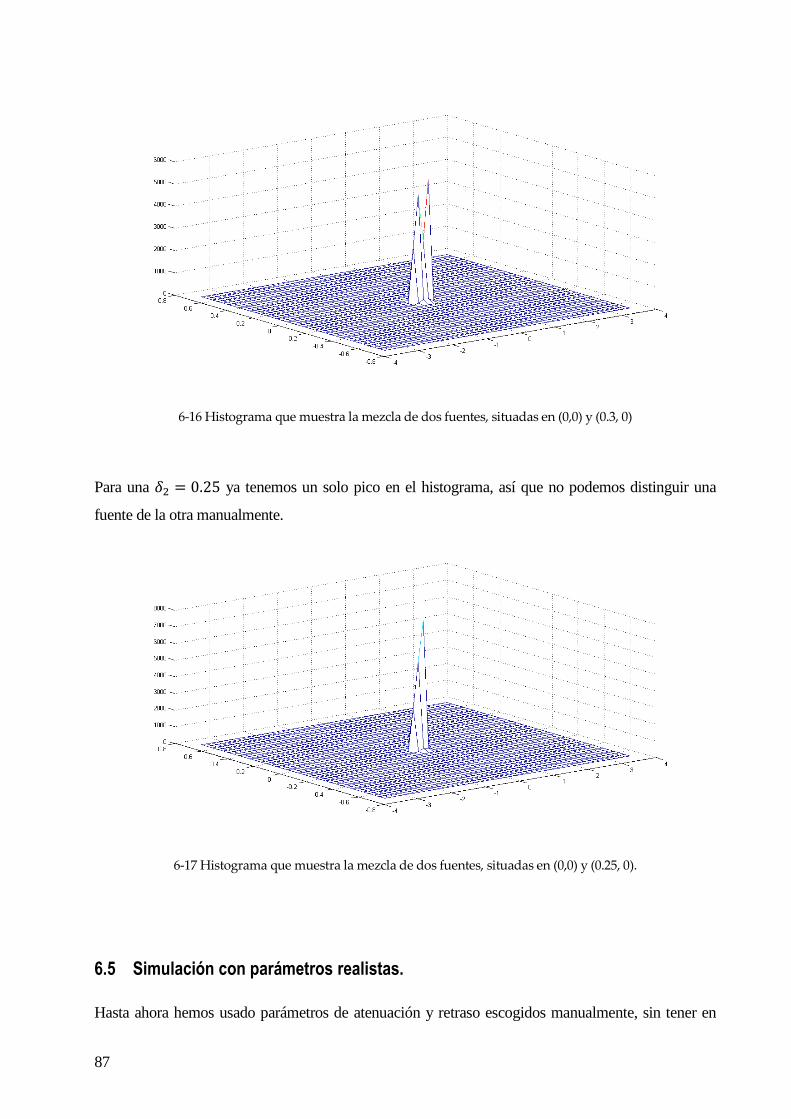
87
6-16 Histograma que muestra la mezcla de dos fuentes, situadas en (0,0) y (0.3, 0)
Para una 𝛿2 = 0.25 ya tenemos un solo pico en el histograma, así que no podemos distinguir una
fuente de la otra manualmente.
6-17 Histograma que muestra la mezcla de dos fuentes, situadas en (0,0) y (0.25, 0).
6.5 Simulación con parámetros realistas.
Hasta ahora hemos usado parámetros de atenuación y retraso escogidos manualmente, sin tener en

88
cuenta si esos valores se corresponden con cualquier mezcla real que obtengamos de un experimento.
A partir de ahora, haremos simulaciones más realistas, calculando esos parámetros para situaciones
concretas.
Para obtener esos valores, debemos calcular la diferencia de presión sonora. Para ello, vemos que la
presión sonora decae con la distancia a la fuente:
𝑃2(𝑟2, t) =𝑟1
𝑟2∗ 𝑃1(𝑟1, t − τ) (6.1)
Donde 𝑟1 y 𝑟2 son la distancia a la fuente desde cada sensor (1 o 2).
La separación entre sensores para que funcione DUET debe ser muy pequeña, así que la establecemos
en 1 𝑐𝑚.
La diferencia entre los dos puntos que tenemos que calcular, es decir, la atenuación, no será 𝑟1/𝑟2 si
no 𝑟1/(𝑟1 + 𝑑 ∗ sin(𝜃)), siendo 𝑑 la separación entre sensores, y 𝜃 el ángulo de incidencia.
Figura 6-18 Vemos los parámetros que se usan para calcular la atenuación, y la fórmula de la presión sonora,
decayendo con la distancia a la fuente.
d
d sin (𝜃)
𝑃(𝑟2, 𝑡) =𝑟1
𝑟1 + d sin(𝜃)𝑃(𝑟1, 𝑡 − 𝜏)
𝑃(𝑟1, 𝑡)
𝑟2
𝑟1
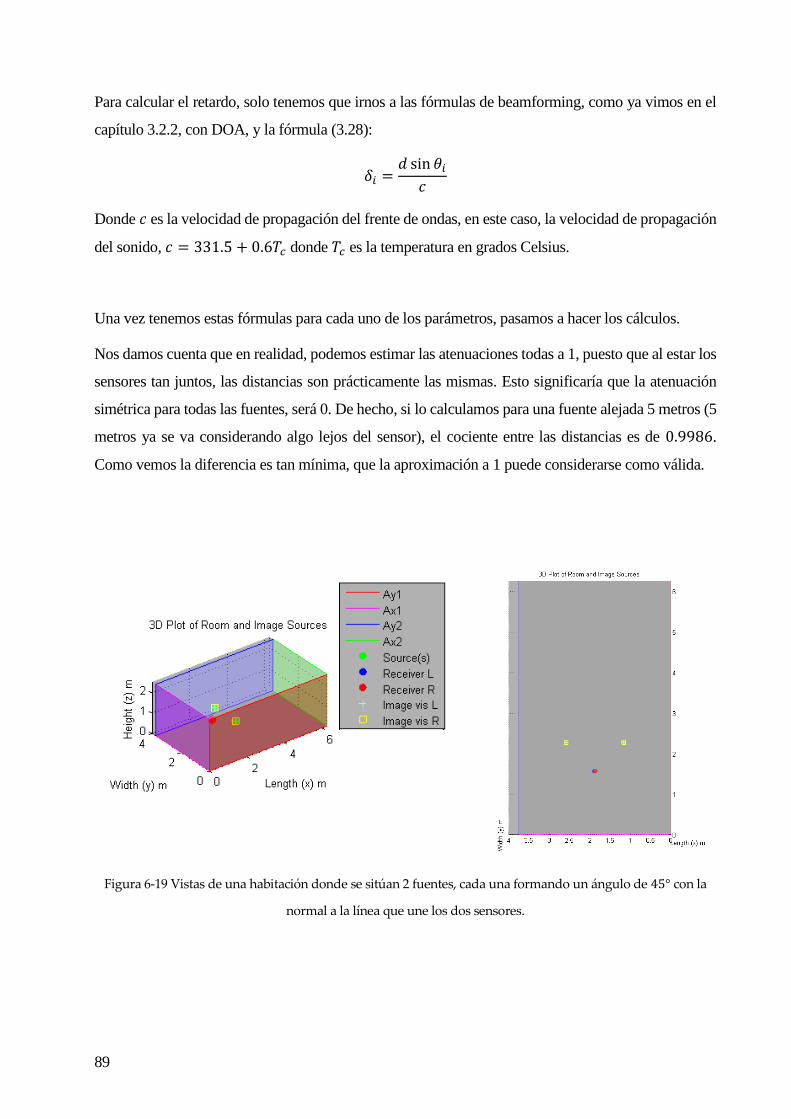
89
Para calcular el retardo, solo tenemos que irnos a las fórmulas de beamforming, como ya vimos en el
capítulo 3.2.2, con DOA, y la fórmula (3.28):
𝛿𝑖 =𝑑 sin 𝜃𝑖
𝑐
Donde 𝑐 es la velocidad de propagación del frente de ondas, en este caso, la velocidad de propagación
del sonido, 𝑐 = 331.5 + 0.6𝑇𝑐 donde 𝑇𝑐 es la temperatura en grados Celsius.
Una vez tenemos estas fórmulas para cada uno de los parámetros, pasamos a hacer los cálculos.
Nos damos cuenta que en realidad, podemos estimar las atenuaciones todas a 1, puesto que al estar los
sensores tan juntos, las distancias son prácticamente las mismas. Esto significaría que la atenuación
simétrica para todas las fuentes, será 0. De hecho, si lo calculamos para una fuente alejada 5 metros (5
metros ya se va considerando algo lejos del sensor), el cociente entre las distancias es de 0.9986.
Como vemos la diferencia es tan mínima, que la aproximación a 1 puede considerarse como válida.
Figura 6-19 Vistas de una habitación donde se sitúan 2 fuentes, cada una formando un ángulo de 45° con la
normal a la línea que une los dos sensores.
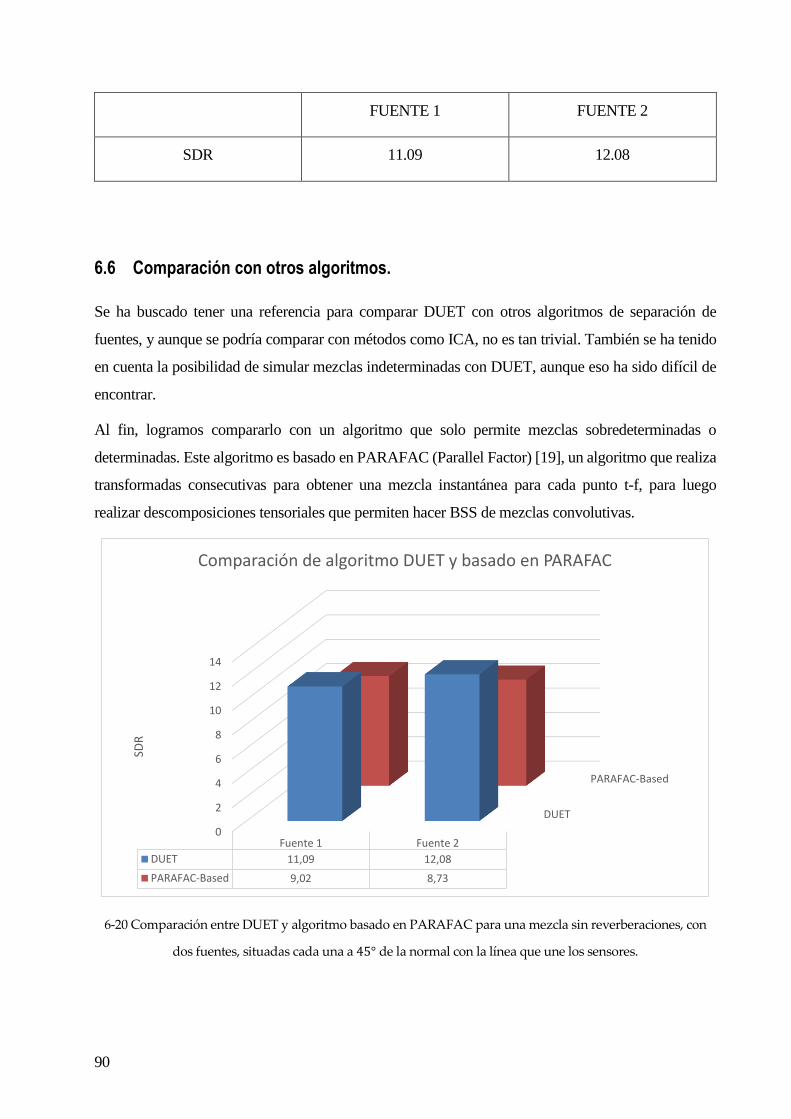
90
FUENTE 1 FUENTE 2
SDR 11.09 12.08
6.6 Comparación con otros algoritmos.
Se ha buscado tener una referencia para comparar DUET con otros algoritmos de separación de
fuentes, y aunque se podría comparar con métodos como ICA, no es tan trivial. También se ha tenido
en cuenta la posibilidad de simular mezclas indeterminadas con DUET, aunque eso ha sido difícil de
encontrar.
Al fin, logramos compararlo con un algoritmo que solo permite mezclas sobredeterminadas o
determinadas. Este algoritmo es basado en PARAFAC (Parallel Factor) [19], un algoritmo que realiza
transformadas consecutivas para obtener una mezcla instantánea para cada punto t-f, para luego
realizar descomposiciones tensoriales que permiten hacer BSS de mezclas convolutivas.
6-20 Comparación entre DUET y algoritmo basado en PARAFAC para una mezcla sin reverberaciones, con
dos fuentes, situadas cada una a 45° de la normal con la línea que une los sensores.
DUET
PARAFAC-Based
0
2
4
6
8
10
12
14
Fuente 1 Fuente 2
DUET 11,09 12,08
PARAFAC-Based 9,02 8,73
SDR
Comparación de algoritmo DUET y basado en PARAFAC
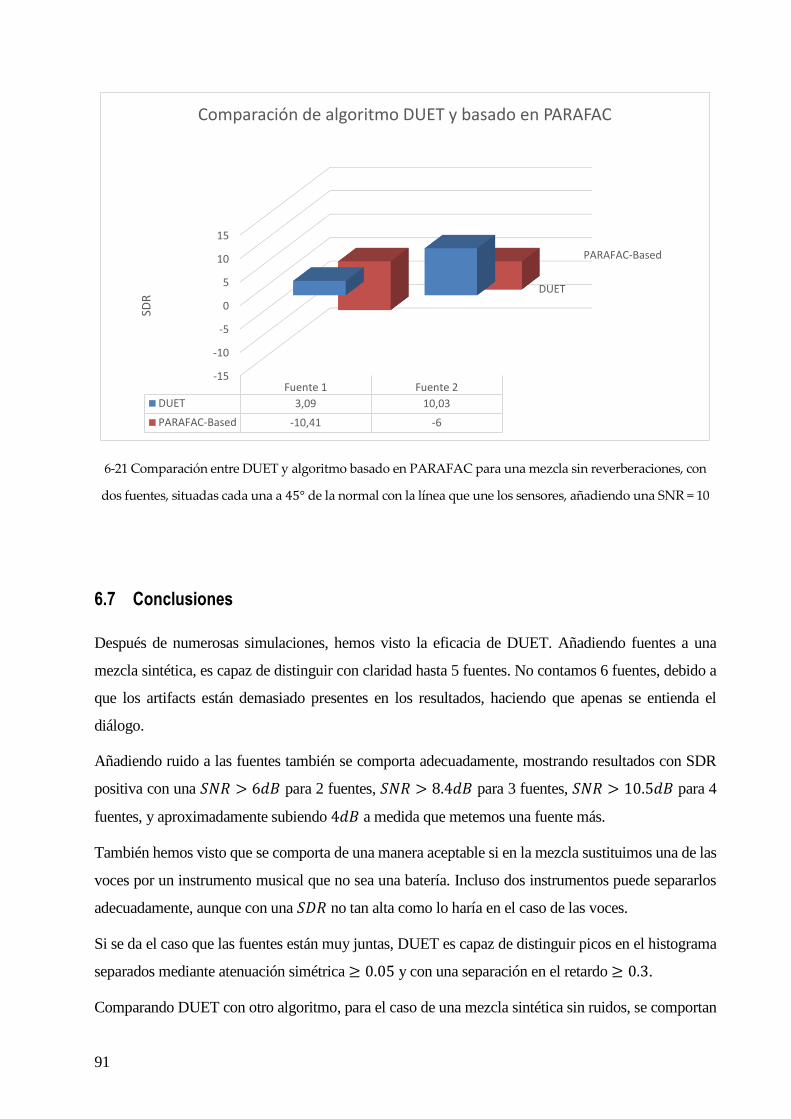
91
6-21 Comparación entre DUET y algoritmo basado en PARAFAC para una mezcla sin reverberaciones, con
dos fuentes, situadas cada una a 45° de la normal con la línea que une los sensores, añadiendo una SNR = 10
6.7 Conclusiones
Después de numerosas simulaciones, hemos visto la eficacia de DUET. Añadiendo fuentes a una
mezcla sintética, es capaz de distinguir con claridad hasta 5 fuentes. No contamos 6 fuentes, debido a
que los artifacts están demasiado presentes en los resultados, haciendo que apenas se entienda el
diálogo.
Añadiendo ruido a las fuentes también se comporta adecuadamente, mostrando resultados con SDR
positiva con una 𝑆𝑁𝑅 > 6𝑑𝐵 para 2 fuentes, 𝑆𝑁𝑅 > 8.4𝑑𝐵 para 3 fuentes, 𝑆𝑁𝑅 > 10.5𝑑𝐵 para 4
fuentes, y aproximadamente subiendo 4𝑑𝐵 a medida que metemos una fuente más.
También hemos visto que se comporta de una manera aceptable si en la mezcla sustituimos una de las
voces por un instrumento musical que no sea una batería. Incluso dos instrumentos puede separarlos
adecuadamente, aunque con una 𝑆𝐷𝑅 no tan alta como lo haría en el caso de las voces.
Si se da el caso que las fuentes están muy juntas, DUET es capaz de distinguir picos en el histograma
separados mediante atenuación simétrica ≥ 0.05 y con una separación en el retardo ≥ 0.3.
Comparando DUET con otro algoritmo, para el caso de una mezcla sintética sin ruidos, se comportan
DUET
PARAFAC-Based
-15
-10
-5
0
5
10
15
Fuente 1 Fuente 2
DUET 3,09 10,03
PARAFAC-Based -10,41 -6
SDR
Comparación de algoritmo DUET y basado en PARAFAC
92
ambos casi de la misma forma, obteniendo DUET mayor valor de 𝑆𝐷𝑅. Para el caso de una mezcla
sintética con ruido, los valores de la 𝑆𝐷𝑅 de DUET son muy válidos, en comparación con los valores
que da el algoritmo basado en PARAFAC, el cual no puede separar las fuentes satisfactoriamente.

93
7 CONCLUSIONES Y LÍNEAS FUTURAS DE
TRABAJO
The fundamental problem of communication is that of
reproducing at one point either exactly or approximately a
message selected at another point.
Claude Shannon, 1948
7.1 Conclusiones
ntes de proponer líneas de trabajo a seguir para complementar lo visto aquí, vamos a recopilar
toda la información que hemos estudiado a lo largo de este libro.
Hemos presentado las propiedades de las señales de voz, su propiedad de color, de escasez, su
comportamiento cuasi-periódico y cómo realizar su análisis. Para ello hemos hecho uso del dominio
tiempo-frecuencia, transformando la señal mediante la STFT, consistente en varias transformadas de
Fourier enventanadas. Para antitransformar y volver al dominio del tiempo hemos visto los dos
métodos más usados para ello, el FBS y el OLA (que luego usaremos para nuestras simulaciones).
A

94
Estas señales de voz son recogidas por dos sensores (micrófonos) así que la señal que llega a ellos
puede verse afectada por el entorno. Así, hemos visto los distintos modelos de mezcla, instantáneas o
convolutivas, sobredeterminadas, indeterminadas, etc.
Una vez tenemos el modelo de mezcla vemos los distintos métodos que existen para el problema de la
BSS. Cuando se trata de señales de voz, es también conocido como el problema “cocktail party” y ha
ido desarrollándose hasta la actualidad. Conocemos métodos basados en CASA (Computational
Auditory Scene Analysis) que se basan en la percepción humana de la escena auditiva, y hacen análisis
matemáticos computacionales. También conocemos métodos que analizan las fuentes para extraer
parámetros estadísticos, o bien basados en la correlación, como PCA, o bien basados en la
independencia de sus componentes o fuentes, como ICA. También se puede usar PCA como
preprocesado de datos antes de usar ICA. Para resolver este último, existen varios criterios de
separación, y aunque no se ha entrado en detalle, algunos algoritmos para su resolución, si se quiere
profundizar en el tema, recomendamos al lector el libro “Independent Component Analysis” [15].
Otros métodos que no usan parámetros estadísticos, se basan en la geometría del entorno de grabación.
Así, tenemos DOA (Direction of Arrival) basado en la dirección de llegada de las fuentes, y DUET
(Degenerate Unmixing Estimation Technique), el algoritmo estudiado en este proyecto. Este método
construye representaciones en tiempo-frecuencia a partir de las observaciones, calcula unos parámetros
para cada uno de los puntos t-f (atenuación y retardo). Esto se consigue haciendo que los sensores que
recogen las observaciones estén muy cerca, lo cual limita un poco el entorno de trabajo de DUET. Por
último, genera máscaras binarias para cada fuente, que luego, al multiplicar dichas máscaras por la
representación en t-f de la observación, obtenemos las fuentes separadas, para luego pasarlas otra vez
al dominio del tiempo.
Antes de proponer las simulaciones y pruebas, decir que solo hemos usado una de las medidas de
calidad para la evaluación de los sistemas BSS. Es una medida objetiva, no perceptual, la SDR (signal
to distorsion ratio) propuesta por Vincent [20]. Con esta medida hemos evaluado pruebas que han
determinado la eficacia de DUET. Todas ellas se han realizado usando una mezcla sintética
(instantánea). En cuanto a número de fuentes a separar, determinamos en 5 el número máximo de
fuentes que separa con claridad, siendo inteligible el contenido del audio. Añadiendo ruido, DUET
aguanta hasta una 𝑆𝑁𝑅 > 6𝑑𝐵 para 2 fuentes, 𝑆𝑁𝑅 > 8.4𝑑𝐵 para 3 fuentes, 𝑆𝑁𝑅 > 10.5𝑑𝐵 para
4 fuentes, y aproximadamente subiendo 4𝑑𝐵 a medida que metemos una fuente más.
También, probando instrumentos musicales no se comporta mal, a excepción de si uno de estos
instrumentos es una batería. Incluso introduciendo dos instrumentos musicales en la mezcla, da

95
resultados positivos, aunque con una SDR no tan alta como lo haría en el caso de las voces, debido a
las diferencias entre sus espectros.
Si comparamos DUET con un algoritmo basado en PARAFAC, un algoritmo que realiza
transformadas consecutivas para obtener una mezcla instantánea para cada punto t-f, para luego
realizar descomposiciones tensoriales, también obtiene resultados satisfactorios. Este algoritmo solo
ha permitido ser usado con mezclas determinadas, así que solo se ha contemplado el caso con dos
fuentes y dos sensores. Para mezclas sin ruidos, se comportan aproximadamente de la misma forma,
aunque si tenemos presencia de ruido en la mezcla, DUET obtiene valores más altos de SDR.
7.2 Líneas futuras
Después de analizar todo lo planteado en este proyecto, así como los resultados de las simulaciones,
sólo cabe decir que DUET, así como las demás técnicas de masking para separación ciega de fuentes
están todavía en desarrollo, y aún falta mucho por implementar.
Ya que en este proyecto se ha hecho hincapié en simulaciones, una buena línea de trabajo estaría ligada
a más pruebas y comparaciones con distintos algoritmos, a ser posible basados en el uso de parámetros
estadísticos, como ICA. El desarrollo de ICA planteará varios problemas, como el problema de la
permutación, un tema del que se han propuesto ya varias soluciones [21].
Con respecto a futuros estudios sobre DUET, la primera idea a mejorar estaría relacionada con el tipo
de mezcla a analizar. Solo se ha probado con mezclas instantáneas, así que un posible estudio sería
mediante mezclas convolutivas.
Para que el entorno de trabajo de DUET sea más amplio, la distancia que separa los sensores podría
ser una arbitraria en vez de ser tan pequeña, que a veces ni sería posible en situaciones reales. Para ello
existen métodos diferenciales, que analizan la diferencia de fase entre ratios t-f adyacentes para estimar
el retraso, y métodos que implican retrasar progresivamente una mezcla con la otra y construir un
histograma para cada uno de esos retrasos [17].
Dentro del algoritmo, introducimos el número de fuentes y su posición manualmente, así que
proponemos una detección automática del número de fuentes y de sus parámetros de atenuación y
retardo, haciendo uso de las observaciones. Es importante resaltar que muchos métodos actuales no
son completamente ciegos. En DUET, introducimos manualmente el número de fuentes y su
atenuación y retardo, así que el sistema ya conoce de antemano algunas características de la mezcla.

96
El algoritmo debería depender en la menor medida posible del sesgo que esta detección automática
supondría, ya que por ejemplo en entornos ruidosos, la mezcla se ve afectada. Para ello sería
conveniente usar algoritmos clásicos de agrupamiento, como k-means [21]. Otra aproximación a este
problema sería la que se propone en [22], que modela el vector de retardos relativos estimados en cada
punto T-F como una mezcla de N Gaussianas generalizadas unidimensionales, GGMM. Para una
mayor documentación sobre este tema, se recomienda al lector leer la tesis doctoral de Auxiliadora
Sarmiento [23] que además de proponer esta solución, contiene simulaciones y contenidos que
complementan este trabajo.

97
ANEXO A. INDETERMINACIÓN EN LA
MEZCLA ASOCIADA A LAS VARIABLES
GAUSSIANAS.
El blanqueado también nos permite ver por qué no se pueden usar más de una señal gaussiana en ICA.
Supongamos que tenemos la función conjunta de probabilidad de dos componentes independientes, 𝑠1
y 𝑠2, y que ésta es gaussiana. Esto significa que la función se expresaría de esta forma:
𝑝(𝑠1,𝑠2) =
1
2𝜋exp (−
𝑠12 + 𝑠2
2
2) =
1
2𝜋exp (−
‖𝑠‖2
2) (0.1)
Ahora asumamos que la matriz de mezla 𝑨 es ortogonal. Por ejemplo, podemos asumir esto debido a
que los datos han sido blanqueados. Usando la fórmula de densidad de una transformación, y sabiendo
que para una matriz ortogonal 𝑨−1 = 𝑨𝑇, tenemos que la función de probabilidad conjunta de las
observaciones 𝑥1 y 𝑥2 es la siguiente:
𝑝(𝑥1,𝑥2) =
1
2𝜋exp (−
‖𝑨𝑇𝒙‖2
2) | det 𝑨𝑇| (0.2)
Debido a la ortogonalidad de 𝑨 tenemos que ‖𝑨𝑇𝒙‖2 = ‖𝒙‖2 y que | det 𝑨𝑇| = 1. Recordar que si
una matriz es ortogonal, su transpuesta también lo es. Sustituyendo en la ecuación anterior, nos queda:
𝑝(𝑥1,𝑥2) =
1
2𝜋exp (−
‖𝒙‖2
2) (0.3)

98
Y vemos que la matriz de mezcla ortogonal no cambia la función de probabilidad conjunta, ya que no
aparece en esta última ecuación. Las distribuciones originales y mezcladas son idénticas. Por
consiguiente, no hay ninguna manera en la que la matriz de mezcla infiera en las mezclas.
Este fenómeno, por el cual no podemos estimar la matriz de mezcla cuando las variables son gaussianas
se debe a la propiedad que dice que variables gaussianas incorreladas conjuntas son necesariamente
independientes. Así, la información de la independencia de los componentes no nos permite avanzar
más de lo que lo hace el blanqueado.
Gráficamente, podemos ver este fenómeno dibujando la distribución de las observaciones ortogonales,
que es de hecho la misma que la distribución de los componentes independientes. La Figura 0-1
muestra que la función densidad de probabilidad es simétrica rotacionalmente. Por lo tanto, no hay
ninguna información sobre las columnas de la matriz de mezcla 𝑨. Por mucho que hagamos una
transformación ortogonal, tendrá el mismo dibujo. Es por esto por lo que 𝑨 no puede ser estimada.
Figura 0-1 Función distribución de dos variables gaussianas independientes. Se comprueba que es imposible
distinguir dos v.a. gaussianas una vez han sido mezcladas.
Luego, en el caso de los componentes indepentientes gaussianos, solo podemos estimar el modelo ICA
hasta el punto de tener una transformación ortogonal. En otras palabras, la matriz 𝑨 no es identificable
para componentes independientes gaussianos. Con estas variables gaussianas, lo único que podemos
hacer es blanquear los datos.

99
ANEXO B. SIMULACIÓN DEL ALGORITMO
DUET EN MATLAB.
% Implementación del Algoritmo DUET para separación ciega de
fuentes
% Lucas Bernalte Pérez
% Proyecto Fin de Carrera. Ingeniería de Telecomunicación.
% Universidad de Sevilla.
% 25/10/2014
%
% Notación:
%
% s1, s2, ... -> señales fuente.
% stf1, stf2, ... -> transformada de fourier de las señales fuente.
% SNR -> Relación señal a ruido de las fuentes (dB).
% FS -> frecuencia de muestreo.

100
% windowsize -> tamaño de la ventana para análisis STFT.
% window -> tipo de ventana usada (en nuestro caso, hamming).
% nfft -> resolución en frecuencia.
% overlap -> número de muestras que se solaparán.
% f -> vector de frecuencias
% fmat -> matriz que contiene el vector de frecuencias repetido en
% columnas, normalizada.
% a1, a2, ... -> atenuaciones que tendrán las fuentes en la mezcla.
% d1, d2, ... -> retrasos que tendrán las fuentes en la mezcla.
% tf1, tf2 -> observaciones (señales recogidas por los micrófonos)
creadas
% mediante la mezcla instantánea.
% att, attsim, delta -> atenuación, atenuación simétrica y retrasos
% estimados.
%% PREPARACIÓN DE FUENTES
% SNR = 37.5;
[s1,FS,NBITS]=wavread('dev1_male3_src_1.wav');
% s1 = awgn(s1,SNR);
[s2,FS,NBITS]=wavread('dev1_male3_src_2.wav');
% s2 = awgn(s2,SNR);

101
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%% CREAR LA MEZCLA INSTANTÁNEA
windowsize = 1024;
window = hamming(windowsize);
nfft=1024;
overlap=0.25*windowsize; %Tiene este valor para que la
antitransformada sea directa.
stf1 = stft(s1, window, overlap, nfft, FS);
stf2 = stft(s2, window, overlap, nfft, FS);
f = (0:size(stf1,1)-1)*FS/nfft;
fmat=repmat(f',1,size(stf1,2));
fmat=fmat/8000*pi;
%parámetros en la mezcla. Según DUET, ponemos a1=1 y d1=1.
a1=1;
d1=1;
a2=0.8;
d2=2; %si tenemos más fuentes podemos seguir, a3, d3, a4, d4, etc.
tf1=stf1+stf2; %Si tenemos más fuentes: +stf3+..., etc
tf2=stf1+a2*exp(-1i.*fmat*d2).*stf2; %Aquí haríamos lo mismo:

102
+a3*exp(-1i.*fmat*d3).*stf3+...;
R21=(tf2)./(tf1);
att=abs(R21);
attsim = att - 1./att; %atenuacionsimetrica
delta = -imag(log(R21))./fmat ;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%% Histograma ponderado
p = 1; q = 0; % powers used to weight histogram
tfweight = (abs(tf1).*abs(tf2)).^p.*abs(fmat).^q ; %weights
maxa = 0.7 ; maxd = 3.6 ; % hist boundaries
abins = 35; dbins = 50; % number o f h i s t bins
%
% %only consider time?freq points yielding estimates in bounds
amask=(abs(attsim)<maxa)&(abs(delta)<maxd) ;
alpha_vec = attsim(amask);
delta_vec = delta(amask);
tfweight = tfweight(amask);
%
% % determine histogram indices
alpha_ind = round(1+(abins-1)*(alpha_vec+maxa)/(2*maxa));
delta_ind = round(1+(dbins-1)*(delta_vec+maxd)/(2*maxd));

103
%
figure(1)
plot(alpha_ind,delta_ind,'.')
xi=linspace(min(alpha_ind),max(alpha_ind),abins);
yi=linspace(min(delta_ind),max(delta_ind),dbins);
xr=interp1(xi,1:numel(xi),alpha_ind,'nearest')';
yr=interp1(yi,1:numel(yi),delta_ind,'nearest')';
Z=accumarray([alpha_ind delta_ind],tfweight,[abins dbins]);
xaxis=linspace(-maxa,maxa,35);
yaxis=linspace(-maxd,maxd,50);
figure(2)
mesh(yaxis,xaxis,Z)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%% Introducir número de fuentes y su posición en el histograma
manualmente
numfuentes = 2;
delta_p = [0 2];
alpha_p = [0 -0.45];
% convert alpha to a
a_p = (alpha_p+sqrt(alpha_p.^2+4))/2;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%

104
%%%%%%%%%%
%% Construccion de máscaras
for i = 1:numfuentes
jft(i,:,:) = (abs(((a_p(i)*exp(-sqrt(-
1)*fmat*delta_p(i))).*tf1)-tf2).^2)/(1+a_p(i)^2);
end
[minimos,iminimos]=min(jft,[],1);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%% Antitransformar
mask=[];
for i = 1:numfuentes
mask=squeeze(iminimos==i);
fuenteest=(tf1+a_p(i)*exp(sqrt(-
1)*fmat*delta_p(i)).*tf2)./(1+a_p(i)^2);
fuenteest=fuenteest.*squeeze(mask);
y = zeros(1, length(s1));
for j = 0:overlap:(overlap*(size(fuenteest, 2)-1))

105
aux = fuenteest(:, 1+j/overlap);
aux = [aux; conj(aux(end-1:-1:2))];
aux = real(ifft(aux));
% overlap, window and add
y((j+1):(j+nfft)) = y((j+1):(j+nfft)) + (aux.*window)';
end
if i==1
salida1=istft(fuenteest,overlap,window,nfft,FS);
[SDR1]=bss_eval_sources(salida1,s1') %poner ; al final si
no se desea mostrar la calidad de la separación de esta fuente.
end
if i==2
salida2=istft(fuenteest,overlap,window,nfft,FS);
[SDR2]=bss_eval_sources(salida2,s2')
end
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%% Si se van a pasar las fuentes estimadas a un archivo wav:

106
wavwrite(salida1,FS,'fuenteestimada1.wav');
wavwrite(salida2,FS,'fuenteestimada2.wav');
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%%%%%%%%%
DUET.m

107
function stft = stft(x, window, h, nfft, fs)
% form the stft matrix
rown = ceil((1+nfft)/2); % calculate the total number
of rows
coln = 1+fix((length(x)-length(window))/h); % calculate the
total number of columns
stft = zeros(rown, coln); % form the stft matrix
j = 1;
% perform STFT
for i=1:h:(length(x)-length(window))
aux = fft(x(i:i+length(window)-1).*window, nfft);
% update the stft matrix
stft(:,j) = aux(1:(rown));
j = j + 1;
end
end
stft.m

108
REFERENCIAS
[1] N. Roman, D. Wang and G. Brown, "Speech segregation based on sound localization," Journal
of the Acoustical Society of America, p. 2236–2252, 2003.
[2] M. Bodden, "Binaural Modeling and Auditory Scene Analysis," IEEE 1995, 1995.
[3] M. Pedersen, Source Separation for Hearing Aid Applications (Thesis), Copenhagen, 2006.
[4] T. Virtanen, Sound Source Separation in Monaural Music Signals, Tampere, 2006.
[5] S. Makeig, A. Bell, T. P. Jung and T. J. Sejnowsk, "Independent component analysis of
electroencephalographic data," MIT Press, 1995, Advances in Neural Information Processing
Systems.
[6] L. De Lathauwer, J. Vandewalle and B. De Moor, in Fetal electrocardiogram extraction by
source subspace separation., Aiguablava, Spain, June 1995., p. pag. 134–8.
[7] A. M. Bronstein, M. M. Bronstein and M. Zibulevsky, Blind Source Separations: Biomedical
applications, 2005.

109
[8] A. D. Back and A. S. Weigend, "A first application of independent component analysis to
extracting structure from stock returns," Int. J. on Neural Systems, p. 8(4):473–484, 1997.
[9] S. Cruces and I. Durán, "Apuntes de tratamiento digital de la voz.," 2009.
[10] A. S. Bregman, Auditory scene analysis, Cambridge, 1990.
[11] M. Weintraub, A theory and computational model of monaural auditory sound, Standford
University, 1985.
[12] A. Hyvärinen and U. Köster, A fastfixed point algorithm for independent component analysis.,
1997.
[13] K. Pearson, "On lines and planes of closestfit to systems of points in space," Philosophical
Magazine, p. 559–572, 1901.
[14] D. Pham, P. Garat and C. Jutten, "Separation of a mixture of independent sources through a
maximum likelihood approach," Signal Processing VI: Theories and Applications, p. 771–774,
1992.
[15] A. Hyvärinen, J. Karhunen and E. Oja, Independent Component Analysis, 2001.
[16] Ö. Yılmaz and S. Rickard, "Blind Separation of Speech Mixtures via Time-Frequency Masking,"
IEEE TRANSACTIONS ON SIGNAL PROCESSING, vol. 52, no. 7, 2004.
[17] S. Rickard, The DUET Blind Source Separation Algorithm.
[18] H. Hawada, S. Makino and L. L.W., "Blind Speech Separation," Springer, 2007.
[19] D. Nion, K. N. Mokios, N. D. Sidiropoulos and A. Potamianos, "Batch and Adaptive
PARAFAC-Based Blind Separation of Convolutive Speech Mixtures," IEEE TRANSACTIONS
ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, vol. 18, no. 6, 2010.
[20] S. Rickard, R. Balan and J. Rosca, "Real-time time-frequency based blind source separation,"
Proc. International Conference on Independent Component Analysis, pp. 651-656, 2001.

110
[21] A. Sarmiento, S. Cruces and I. Durán, "Modelos de mezcla generalizados en separación ciega de
voz mediante enmascaramiento," XXII Symposium Nacional de la Unión Científica
Internacional de Radio (URSI2007), vol. 22, 2007.
[22] A. Sarmiento, Mejoras en la separación ciega de señales de voz mediante técnicas de análisis de
componentes. Tesis Doctoral., Sevilla, 2011.