Embed Size (px)
Citation preview

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
1
IINNTTRROODDUUCCCCIIOONN AA LLAA GGEENNEETTIICCAA CCUUAANNTTIITTAATTIIVVAA
presentación en clases
I. INTRODUCCION
Preguntas específicas que intenta responder la genética cuantitativa 1. ¿Como medir el efecto genético en uno o más caracteres? 2. ¿Como interactúa el efecto genético con el ambiente? ¿...y el tiempo? 3. ¿Como seleccionar aquellos efectos genéticos de interés? 4. ¿Cómo seleccionar para más de un carácter?
Objetivo practico de la genética cuantitativa - Mostrar como el grado de parecido entre distintas clases de parientes puede predecir el
resultado de la reproducción selectiva, e indicar el mejor método de selección.
¿A que se debe las diferencias observables entre árboles?
Es el resultado de : 1. Las diferencias en el ambiente 2. Las diferencias genéticas 3. Las Interacciones entre ambas

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
2
¿Cuales son las fuerzas dan forma a la variación genética? 1. Mutaciones (Incrementan la variación) 2. Flujo génico (Incrementan la variación) 3. Selección natural (Reduce la variación) 4. Deriva genética (Reduce la variación) Nota : 1,2 y 3 son procesos sistemáticos, mientras que 4 es un proceso no sistemático
¿Como se expresa la variación entre árboles? - En forma continua:
1. La masa forestal “ESCONDE” una variación que es el producto de generaciones de interacciones entre individuos con las presiones de selección debido al ambiente y el entorno inmediato de cada uno de ellos.
2. Los árboles difieren de incontables formas, la mayor parte de ellas es un asunto de grado y raramente presentan distinciones claramente definidas”
- Ejemplos de variación continua: altura, diámetro, longitud de las fibras y traqueadas;
densidad básica; etc. - El estudio de la variación continua depende de la medición más que la enumeración. - Los caracteres que muestran una variación continua se denominan caracteres cuantitativos o
métricos. - Los caracteres cuantitativos son estudiados por la genética de poblaciones, biométrica o
cuantitativa.
¿Como se Produce la Variación Continua? Mediante la: 1. Segregación de muchos genes que afectan al carácter y la 2. Sobreposición de la “VERDADERA” variación continua producida por causas no genéticas.

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
3
¿Qué tipos de dominancia genética existen? - Asumamos un locus autonómico, controlado por dos alelos (A1 y A2) - Tenemos tres tipos de dominancia, dependiendo de donde se ubique el valor genotípico
asociado a cada genotipo. - Ejemplos posibles de dominancia son: A2A2 A1A2 A1A1 | | | No Dominancia a (a+b)/2 b A2A2 A1A1 A1A2 | Sobredominancia a (a+b)/2 b A2A2 A1A1 A1A2 | Dominancia Completa a b
¿Qué es importante recordar? - A mayor número de genes (en diferentes loci) que controlan un carácter (segregan), y sus efectos disminuyen, habrá más clases en las mediciones del carácter. Esto implica, diferencias más pequeñas entre ellas”
¿Que tipos de genes podemos encontrar? 1. Gen Mayor = Su efecto causa discontinuidad identificable 2. Gen Menor = Su efecto no es lo suficientemente grande para causar discontinuidad.

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
4
Dos conceptos claves de los caracteres métricos 1. Parecido entre parientes: a mayor parentesco de dos individuos, mayor parecido entre ellos.
Aquí no debemos olvidar que el grado de parecido varia con el carácter. 2. Depresión endogámica, producida por la endogamia (cruzamiento entre individuos
emparentados) tiende a reducir el nivel medio de todos los caracteres relacionados (estrechamente) con la aptitud.
Luego,... No olvidar - Así como algunos caracteres muestran mayor parecido que otros, algunos caracteres
responderán mejor a la selección que otros.
¿En relación a un carácter métrico, qué podemos observar de una población? 1. Promedios 2. Varianzas 3. Covarianzas
Además - La subdivisión natural de una población en familias permite fragmentar, particionar, analizar
la varianza en componentes que forman la base de la medición del grado de parecido entre parientes.
Principales propiedades de los genes que deben ser considerados en el análisis cuantitativo 1. Grado de dominancia 2. Modo de combinación de los efectos génicos en los diferentes loci 3. Pleitropía 4. Ligamiento 5. Aptitud bajo selección natural

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
5
II. CONSTITUCION GENOTIPICA DE UNA POBLACION
¿Como describirla? - Comencemos con la situación más simple. Especificando los genotipos y cuantificando el
número de individuos que existen por cada uno. Ejemplo: 1. Un Locus autosómico A; 2. 2 alelos: A1, A2; 3. Sin Dominancia 4. Posibles genotipos : A1A1, A1A2, y A2A2. - La constitución genética puede ser descrita por las frecuencias genotípicas (proporción o
porcentaje de individuos que pertenecen a cada genotipo). - Hay que recordar que los genes llevados en una población tienen continuidad de generación
en generación, pero los genotipos no. - La constitución genética (en términos de genes) también se describe a través de frecuencias
génicas. Ejemplo:
Genotipos
A1A1
A1A2
A2A2
TOTAL
Número de individuos
30
60
10
100
Frecuencias genotípicas
0.3
0.6
0.1
1.0
Número de genes observados
A1
60
60
--
120
A2
-- 60
20
80
TOTAL
200

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
6
- Luego, las frecuencias génicas son: fA1 = 120 / 200 = 0.6 fA2 = 80 / 200 = 0.4 - En forma general (algebráica)
Genotipos
A1A1
A1A2
A2A2
TOTAL
Número de individuos
A
B
C
N
Frecuencias genotípicas
A/N
B/N
C/N
1.0
Número de genes observados
A1
2A
B
--
2A + B
A2
--
B
2C
2C + B
TOTAL
2N
- Luego, las frecuencias génicas son: fA1= p = (2A + B) / 2N = A/N + ½B/N fA2= q = (2C + B) / 2N = C/N + ½B/N

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
7
¿Qué es el equilibrio Hardy- Weinberg? - En una población grande (PANMITICA), con apareamiento aleatorio, las frecuencias génicas
y genotípicas permanecen constantes de generación en generación, en ausencia de migración, mutación y selección, y las frecuencias genotípicas están determinadas por las frecuencias génicas.
Demostración: a) Generación parental - En la generación parental, tenemos inicialmente los siguientes genotipos y sus frecuencias
genotípicas y génicas Genes Genotipos A1 A2 A1A1 A1A2 A2A2 Frecuencias p q P H Q (b) Apareamiento aleatorio entre individuos. Esto implica: Unión aleatoria entre gametos. Esto es equivalente a decir que la probabilidad de obtener un individuo A1A1 es igual a la probabilidad del suceso: - un alelo A1 es sacado al azar de la población de gametos y un nuevo alelo A1 también es
sacado al azar de la misma población. Entonces, la probabilidad de obtener un individuo A1A1 es P(A1∩A1). A su vez, la probabilidad de obtener un individuo A1A2 es P(A1∩A2), etc.
- Luego, las frecuencias genotípicas en los cigotos equivale al producto de frecuencias de los
tipos gaméticos que se unen para producirlos.

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
8
Esto es mejor observado en la siguiente tabla: Gametos femeninos y sus frecuencias
A1 p
A2 q
Gametos Masculinos
A1
p
A1A1 p²
A1A2 pq
y sus frecuencias A2 q A2A1
qp
A2A2 q²
- Entonces, la frecuencia genotípica de los cigotos es: A1A1 A1A2 A2A2 Total p² 2pq q² 1.0 - Luego: p² + 2pq + q² = (p + q)2 = 1
Recordar
Las frecuencias genotípicas dependen sólo de las frecuencias génicas en los progenitores y no de las frecuencias genotípicas parentales. Si y sólo si existe apareamiento al azar. c) Determinación de las frecuencias génicas en la generación F1 - Considerando los siguientes genotipos y sus frecuencias genotípicas en la generación F1: A1A1 A1A2 A2A2 Total p² 2pq q² 1.0

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
9
- Luego, las frecuencias génicas esperadas en la generación F1 son: A1A1 A1A2 A2A2 Total
A1 2p² 2pq - 2p(p + q) = 2p
A2 - 2pq 2q² 2q(p + q) = 2q Σ = 2 - Finalmente, las frecuencias génicas son: fA1= p = 2p/2 = p fA2= q = 2q/2 = q - Es decir, las frecuencias génicas de los alelos A1 y A2 se mantienen de una generación a la
siguiente, cuando hay apareamiento al azar, en ausencia de selección, mutación y migración.
Ejemplo - Las siguientes son las frecuencias genotípicas y génicas observadas:
A1A1 A1A2 A2A2 N Observado P = (30/100) H=(60/100) Q=(10/100) 100 Genes A1 60 60 - 120 A2 - 60 20 80 _______ Total 200 Frecuencias génicas observadas fA1= p = 0.6 fA2= q = 0.4 - Mientras que los siguientes valores son las frecuencias genotípicas y génicas esperadas en
la siguiente generación: A1A1 A1A2 A2A2 Total Frecuencia p² = 0.36 2pq = 0.48 q² = 0.16 1.0 Número 36 48 16 100

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
10
¿Estan en Equilibrio Hardy-Weinberg?
- Para probarlo se debe usar el siguiente estadístico: ∑ ≈−= 21
22 /)( χχ eeoc

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
11
III CONCEPTOS ESTADISTICOS EN LA GENETICA CUANTITATIVA
1. Promedios y efectos medios Recordemos que: 1. La genética cuantitativa esta preocupada de la herencia de las diferencias entre individuos
que son de “grado” más que de tipo. 2. Las diferencias cuantitativas están parcialmente heredadas y dependen de muchos genes
ubicados en distintos loci. Sus efectos son pequeños respecto a otras fuentes de variación. 3. Los métodos de análisis de caracteres métricos iguales basados en el uso de las medias,
varianzas, covarianzas y en la partición de varianzas en componentes debido a la variación ENTRE y DENTRO de familias de individuos con un grado de parentesco en común.
- Una analogía clave para estudiar la herencia de los caracteres cuantitativos consiste en que
los modelos de acción genética son comparables a los modelos lineales. - Por ejemplo, consideremos la siguiente situación: 1. un locus autonómico está controlado por dos alelos A1 y A2. 2. las frecuencias génicas de A1 y A2 son 0.9 y 0.1, respectivamente. 3. luego, las frecuencias genotípicas de los genotipos A1A1, A1A2 y A2A2, en la población,
son 0.81, 0.18 y 0.01, respectivamente. 4. cuando un individuo de la población tiene genotipo A1A1, su valor genotípico (el valor
biométrico aportado directamente por ambos alelos) es 14; 5. mientras que un individuo A1A2 tiene un valor genotípico de 12 y 6. un individuo A2A2 tiene un valor genotípico de 6. - Entonces, la relación entre frecuencias genotípicas y valores genotípicos puede ser
representada por una tabla de doble entrada en que las columnas representan los niveles de
un factor de variación α1, es decir el efecto del alelo proveniente del individuo parental 1,
mientras que las filas representan los niveles de un factor de variación α2, es decir el efecto del alelo proveniente del individuo parental 2.
Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
12
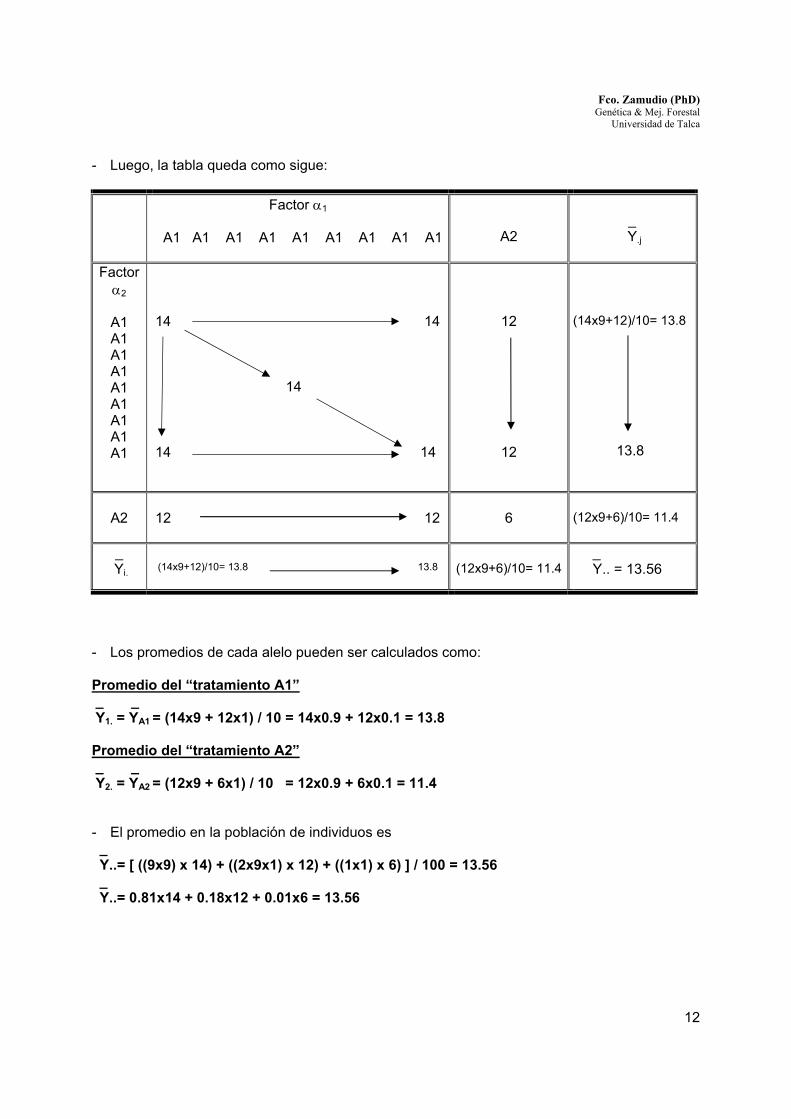
- Luego, la tabla queda como sigue: Factor α1
A1 A1 A1 A1 A1 A1 A1 A1 A1
A2
_
Y.j
Factor α2
A1 A1 A1 A1 A1 A1 A1 A1 A1
14 14 14 14 14
12
12
(14x9+12)/10= 13.8
13.8
A2
12 12
6
(12x9+6)/10= 11.4
_ Yi.
(14x9+12)/10= 13.8 13.8
(12x9+6)/10= 11.4
_ Y.. = 13.56
- Los promedios de cada alelo pueden ser calculados como: Promedio del “tratamiento A1” _ _ Y1. = YA1 = (14x9 + 12x1) / 10 = 14x0.9 + 12x0.1 = 13.8 Promedio del “tratamiento A2” _ _ Y2. = YA2 = (12x9 + 6x1) / 10 = 12x0.9 + 6x0.1 = 11.4 - El promedio en la población de individuos es _ Y..= [ ((9x9) x 14) + ((2x9x1) x 12) + ((1x1) x 6) ] / 100 = 13.56 _ Y..= 0.81x14 + 0.18x12 + 0.01x6 = 13.56

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
13
- El modelo lineal análogo asociado a este ejemplo es:
ijjiijij gy δαα ++== donde: gij = yij = valor genotípico, αi = efecto del i-ésimo alelo αj = efecto del j-ésimo alelo δij= efecto de dominancia entre los alelos i y j - Este modelo tiene los siguientes estimadores mínimo-cuadráticos:
)()()( •••••••••••• +−−+−+−+= YYYyYYYYYy jiijjiij
donde: _ _ _ Yi. = promedio del i-ésimo alelo. Puede ser YA1 o YA2 _ Y.. = promedio poblacional. De otra forma: Genotipos A1A1 A1A2 A2A2 Valor genotípico (Yij) 14 12 6 Me= (14+6)/2=10 Yij – Me a = +4 d = +2 -a = -4 Frec.genotípica 0.81 0.18 0.01 Frecuencias génicas: pA1 = 0.9 qA2 = 0.1

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
14
Tabla de frecuencias y valores genotípicos
A1 (p = 0.9)
A2
(q = 0.1)
A1 (p = 0.9)
p2 = 0.81 14
pq = 0.09 12
A2 (q = 0.1) qp = 0.09
12
q2 = 0.01 6
p2 + pq = 0.9 = p q2 + pq = 0.1 = q
Valor medio del gen _ _ Yi. = YA1 = 14 x (81/90) + 12 x (9/90) = 14 x 0.9 + 12 x 0.1 = 13.8 _ _ Yi. = YA1 = (14 x p2 + 12 x pq) / p = 14 x p + 12 x q _ _ Yj. = YA2 = 12 x (9/10) + 6 x (1/10) = 12 x 0.9 + 6 x 0.1 = 11.4 _ _ Yj. = YA2 = (12 x pq + 6 x q2 ) / q = 12 x p + 6 x q
Efecto medio del gen - Efecto medio de los “factores” involucrados o “efecto medio del gen” puede ser calculado
como sigue Para: _ _ A1: α1 = (YA1 – Y..) = 13.8 - 13.56 = 0.24 _ _ A2: α2 = (YA2 – Y..) = 11.4 - 13.56 = -2.16

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
15
Efecto de sustitución del gen - El efecto de sustitución del gen es: α = α1 - α2 = 0.24 + 2.16 = 2.4
2. Valor reproductivo - Cuando un solo locus esta bajo consideración, se pude aplicar el siguiente modelo genético
lineal
ijjiijg δαα ++= donde:
αi + αj = Valor reproductivo dij = Desviación de dominancia
Valor reproductivo = valor de un individuo juzgado por el valor promedio de su progenie. - Desde un punto de vista estadístico, dij (desvío de dominancia) es una interacción entre
alelos, dentro de un locus. Entonces:
ijjiijg δαα ++=
G = A + D Donde: G = valor genotípico; A = valor reproductivo = efecto (genético) aditivo D = efecto de dominancia
Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
16
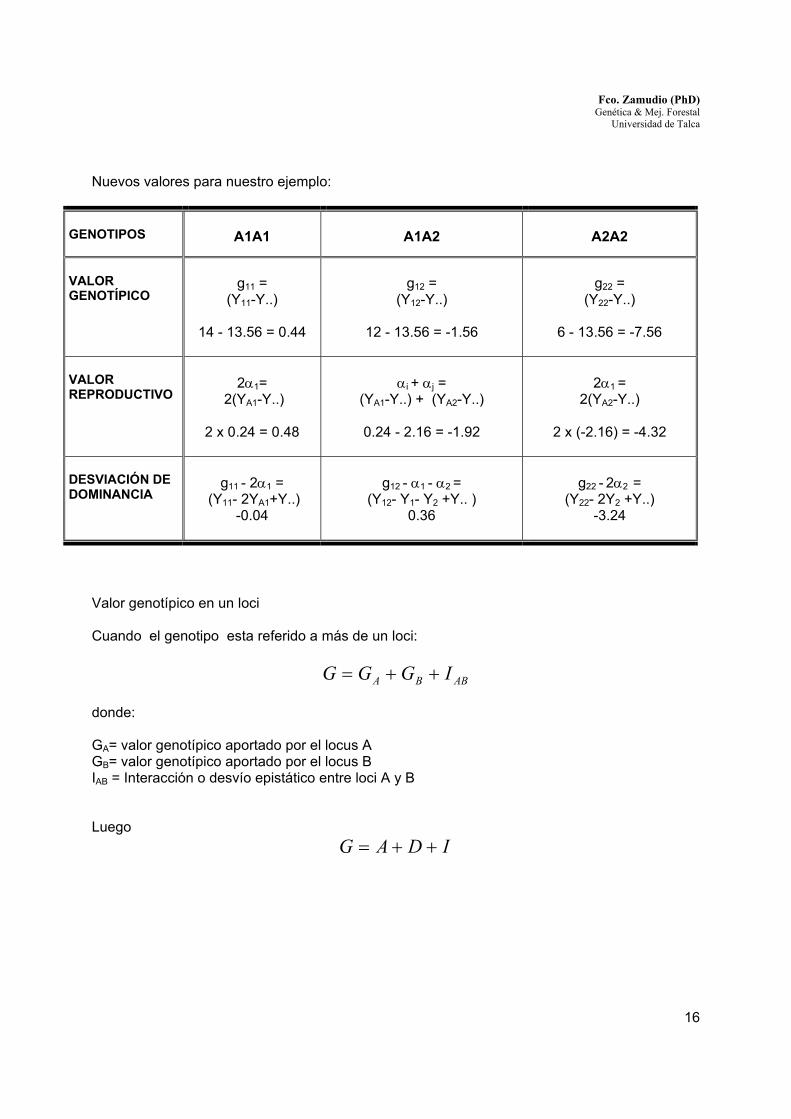
Nuevos valores para nuestro ejemplo:
GENOTIPOS
A1A1
A1A2
A2A2
VALOR GENOTÍPICO
g11 =
(Y11-Y..)
14 - 13.56 = 0.44
g12 =
(Y12-Y..)
12 - 13.56 = -1.56
g22 =
(Y22-Y..)
6 - 13.56 = -7.56
VALOR REPRODUCTIVO
2α1=
2(YA1-Y..)
2 x 0.24 = 0.48
αi + αj =
(YA1-Y..) + (YA2-Y..)
0.24 - 2.16 = -1.92
2α1 =
2(YA2-Y..)
2 x (-2.16) = -4.32
DESVIACIÓN DE DOMINANCIA
g11 - 2α1 =
(Y11- 2YA1+Y..) -0.04
g12 - α1 - α2 =
(Y12- Y1- Y2 +Y.. ) 0.36
g22 - 2α2 =
(Y22- 2Y2 +Y..) -3.24
Valor genotípico en un loci Cuando el genotipo esta referido a más de un loci:
ABBA IGGG ++= donde: GA= valor genotípico aportado por el locus A GB= valor genotípico aportado por el locus B IAB = Interacción o desvío epistático entre loci A y B Luego
IDAG ++=

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
17
donde: G = valor genotípico A = valor aditivo D= efecto de dominancia I = efecto de interacción epistática - Entonces, el modelo lineal que representa los efectos aditivos y de dominancia puede ser
extendido al caso de loci múltiples. - La partición del modelo lineal es “análoga” a la partición ortogonal de la suma de cuadrados
de un análisis de varianza. Es decir: Locus A: Linear (aditivo) Cuadrático(Dominancia) Locus B: Linear (aditivo) Cuadrático (Dominancia) Locus AxB:
Linear x linear (aditivo A x aditivo B) Linear x cuadrático (aditivo Ax dominancia B) Cuadrático x linear ( dominancia A x aditivo B) Cuadrático x cuadrático (dominancia A x dominancia B)
Modelo (genético) lineal para el caso de 2 loci
++++++++++= )()()()( jliljkikklijlkjiijkly αβαβαβαβγδββαα
ijklijlijkjklikl δγβδβδαγαγ ++++ )( o bien:
∑∑∑∑∑≠≠≠
++++=´
´´
´´
´ii
iiii
iiii
iii
ii
i DDADAADAG

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
18
donde: Ai = efecto aditivo del i-ésimo loci Di = efecto de dominancia del i-ésimo loci AAii´ = efecto de interacción aditivo-aditivo entre loci i y i´ ADii´ = efecto de interacción aditivo-dominante entre loci i y i´ DDii´ = efecto de interacción domiante-dominante entre loci i y i´
3. Varianzas - Se define varianza como:
2))(()( yyyVar εε −=
además: GxEEGP ++=
EIDAP +++= )(
entonces:
VEVIVDVAVEVGVP +++=+= con los supuestos: COV(G,E) = 0 ; GxE = 0
Caso de 1 locus y dos alelos
ijjiijij Yyg δαα ++=−= )(
))((2)()()( 222ijjiijjiijjiVG δααεδεααεδααε ++++=++=
y
)(2)()()( 222jijiji ααεαεαεααε ++=+
Debido a que existe apareamiento al azar:
0))(( =+ ijji δααε y 0)( =jiααε

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
19
Luego:
22 )()(2 ijiVG δεαε += o bien
VDVAVG += - En nuestro ejemplo:
ε(αi )2 = (0.24)2 x 0.9 + (-2.16)2 x 0.1 = 0.052 + 0.467 = α1
2 p + α22 q = 0.519
ε(dij)2 = (-0.04)2 x 0.81 + (0.36)2 x 0.18 + (-3.24)2 x 0.01
VD = d11
2 p2 + d122 2pq + d22
2 q2 = 0.13 VG = 2 x 0.519 + 0.13 VG = 1.038 + 0.13 = 1.168 VG = VA + VD

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
20
4. Parentesco o coascendencia y consanguinidad - El grado de parentesco entre parientes: 1. Puede ser determinado directamente de la población (conociendo el pedigrí). 2. Entrega un medio de estimación de la VA - Recordar: Entender las causas del parecido entre parientes es “fundamental” para el estudio
práctico de un carácter métrico y su aplicación al mejoramiento genético.
Definición del parentesco y consanguinidad en términos de probabilidades Condiciones para definir el coeficiente de parentesco: - Supongamos que un locus autosomico A , y dos alelos X e Y. - X e Y son iguales “en estado”, si X e Y son fundamentalmente indistinguibles. - X e Y son idénticos por descendencia (IPD) si: 1. X es una copia de Y 2. Y es una copia de X 3. X e Y son copias del mismo gen ancestral Recordar: “copia” = duplicación meíotica - Si X e Y son alelos aleatoriamente seleccionados del Locus A y de dos individuos X e Y,
luego el coeficiente de parentesco o consanguinidad se define como :
rXY =P (X ≡Y) Donde (≡) significa idéntico por descendencia (IDP)

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
21
Derivación de Parentesco para distintos linajes El coeficiente de parentesco para individuos autosómicos diploides puede ser derivado aplicando las reglas simples de probabilidades. Consideremos el siguiente pedigrí: padre madre padre madre
A(a1,a2) B(b1,b2) C(c1,c2) D(d1,d2) a b c d X(a,b) Y(c,d) x y
Z(z1,z2) Sean x e y, alelos de locus A, muestreados “al azar” de X e Y. Luego, el parentesco entre X e Y es:
);;();;();;();;( dbdybxPcbcybxPdadyaxPcacyaxPrxy ≡==+≡==+≡==+≡=== Si: P(x=a) = P(x=b) = P(y=c) =P(y=d) = ½ entonces:
( )[ ])()()()(¼ dbPcbPdaPcaPrxy ≡+≡+≡+≡=
o
( )[ ]BDBCADACxy rrrrr +++= ¼ Recordar: El coeficiente de parentesco (rxy), de consanguinidad o de ascendencia es la probabilidad que un gen “al azar” de X sea IPD con un gen al azar de Y.

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
22
Coeficiente de Endogamia (F) Sea Z una progenie de X e Y, luego podemos definir el coeficiente de consanguinidad como la probabilidad que los dos alelos transportados por el individuo Z sean IPD:
( )21 zzPFz ≡=
);;();;();;();;( 21212121 dbdzbzPcbczbzPdadzazPcaczazPFz ≡==+≡==+≡==+≡===
( )[ ])()()()(¼ dbPcbPdaPcaPFz ≡+≡+≡+≡= Luego, la probabilidad que los dos genes de un individuo sean I.P.D. es
xyz rF = Recordar: El coeficiente de endogamia de un individuo es igual al coeficiente de parentesco entre los padres
Caso especial: parentesco de un individuo consigo mismo Un caso especial de parentesco es el de un individuo consigo mismo. Es decir, se realiza un muestreo al azar de un gen “con reemplazo” desde el Individuo X
( )´xxPrxx ≡=
);´;();´;();´;();´;( bbbxbxPabaxbxPbabxaxPaaaxaxPrxx ≡==+≡==+≡==+≡===
( )[ ])()()()(¼ bbPabPbaPaaPrxx ≡+≡+≡+≡=
( )[ ]1)()(1¼ +≡+≡+= abPbaPrxx
( )[ ]xxx Fr += 1½

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
23
Estimación del coeficiente de parentesco para casos relevantes Hermanos completos (full sibs)
A(a1a2) B(b1b2) A(a1a2) B(b1b2) a b a’ b’
X(ab) Y(a’b’)
( ; ;́ ´) ( ; ;́ ´) ( ; ;́ ´) ( ; ;́ ´)xyr P x a y a a a P x a y b a b P x b y a b a P x b y b b b= = = ≡ + = = ≡ + = = ≡ + = = ≡
( )[ ]¼ ( ´) ( ´) ( ´) ( ´)xyr P a a P a b P b a P b b= ≡ + ≡ + ≡ + ≡
( )[ ]¼ 2xy AA AB BBr r r r= + +
( ) ( ) ( )¼ ½ 1 ½ 1 2xy A B ABr F F r= + + + +
( ) ( )¼ 1 ½ 2xy A B ABr F F r= + + + Si no existe endogamia, ni consanguinidad entre los individuos A y B, entonces FA= FB = rAB = 0 y
14xyr =

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
24
Medio hermanos (half-sibs) A(a1a2) B(b1b2) C(c1c2)
a b b’ c
X(ab) Y(b’c)
( ; ´; ´) ( ; ; ) ( ; ´; ´) ( ; ; )xyr P x a y b a b P x a y c a c P x b y b b b P x b y c b c= = = ≡ + = = ≡ + = = ≡ + = = ≡
( )[ ]¼ ( ´) ( ) ( ´) ( )xyr P a b P a c P b b P b c= ≡ + ≡ + ≡ + ≡
( )[ ]¼xy AB AC BB BCr r r r r= + + +
( ) ( )¼ ½ 1xy AB AC B BCr r r F r= + + + + Si no existe endogamia, ni consanguinidad entre los individuos A, B y C, entonces
rAB =rAC= FB =rBC = 0 y
18xyr =

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
25
Probabilidad de simultaneidad Otra importante probabilidad es la probabilidad que ambos alelos en X sean IPD con ambos alelos de Y. Esto puede ser representado en forma gráfica como:
A(a1a2) B(b1b2) C(c1c2) D(d1d2)
a b c d
X(ab) Y(cd)
( ) ( ), ,xyU P a c b d P a d b c= ≡ ≡ + ≡ ≡
( ) ( )) ( ) (xyU P a c P b d P a d P b c= ≡ ≡ + ≡ ≡ xy AC BD AD BCU r r r r= +
Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
26
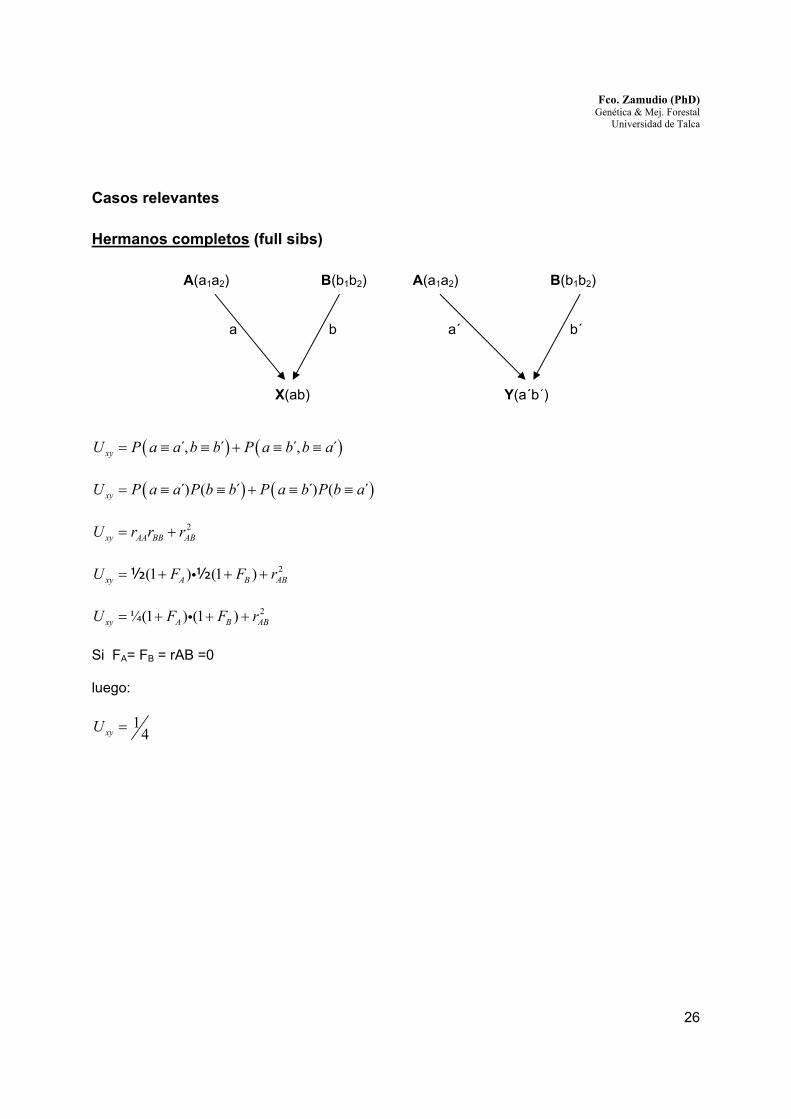
Casos relevantes
Hermanos completos (full sibs)
A(a1a2) B(b1b2) A(a1a2) B(b1b2)
a b a´ b´
X(ab) Y(a´b´)
( ) ( ),́ ´ ,́ ´xyU P a a b b P a b b a= ≡ ≡ + ≡ ≡
( ) ( ))́ ( ´ )́ ( ´xyU P a a P b b P a b P b a= ≡ ≡ + ≡ ≡
2xy AA BB ABU r r r= +
2(1 ) (1 )xy A B ABU F F r= + + +i½ ½
2¼(1 ) (1 )xy A B ABU F F r= + + +i
Si FA= FB = rAB =0 luego:
14xyU =
Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
27
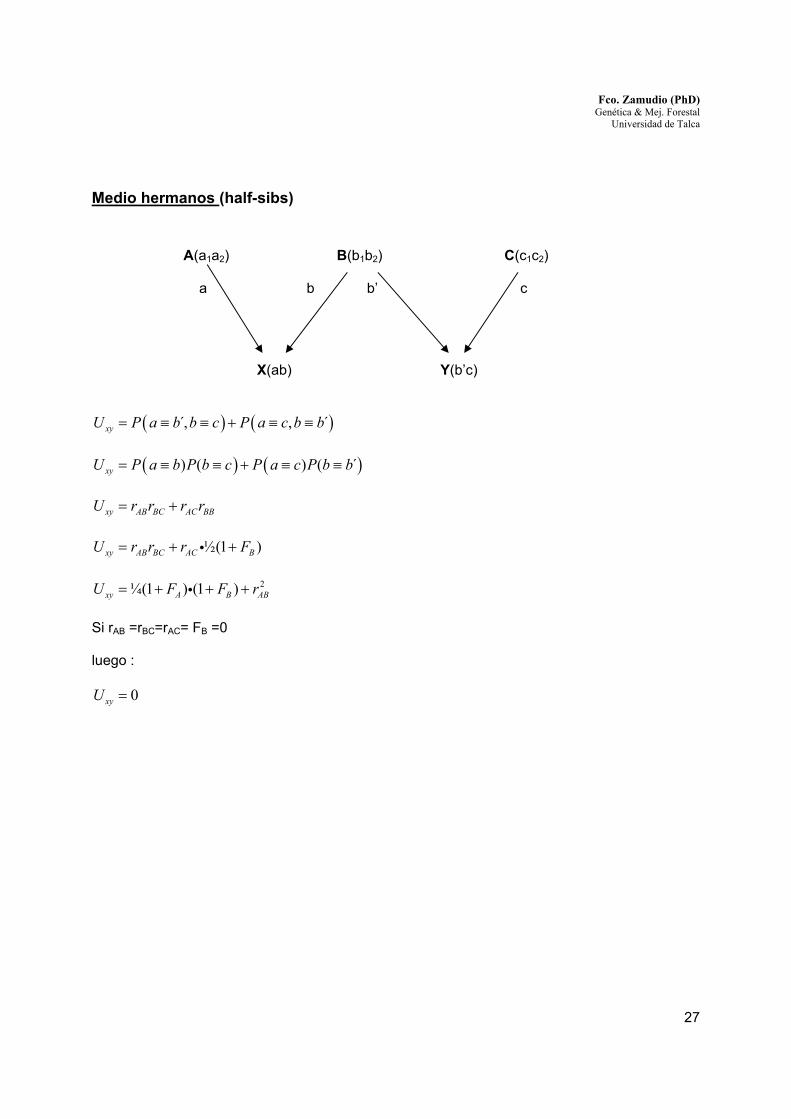
Medio hermanos (half-sibs)
A(a1a2) B(b1b2) C(c1c2)
a b b’ c
X(ab) Y(b’c)
( ) ( ),́ , ´xyU P a b b c P a c b b= ≡ ≡ + ≡ ≡
( ) ( )) ( ) ( ´xyU P a b P b c P a c P b b= ≡ ≡ + ≡ ≡ xy AB BC AC BBU r r r r= +
½(1 )xy AB BC AC BU r r r F= + +i
2¼(1 ) (1 )xy A B ABU F F r= + + +i
Si rAB =rBC=rAC= FB =0 luego :
0xyU =

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
28
5. Covarianza entre parientes
- Recordemos que la genética cuantitativa descansa en el parecido entre parientes para estimar la varianza genética.
- El método de Malècot (1948) es el más adecuado para derivar las covarianzas entre
parientes, el cual está basado en las causas del parecido entre parientes. - Supuestos del análisis: 1. población en equilibrio Hardy-Weinberg; 2. existe un cruzamiento aleatorio entre individuos y 3. la selección, mutación, interacción GxE y epistasis están ausentes. - Entonces, asumamos: (1) un locus autonómico y (2) 2 individuos Y1 Y2, no emparentados, sin
endogamia. - Luego, los valores genotípicos pueden representarse como
1 1 1 1 1m p m pY α α δ= + +
2 2 2 2 2m p m pY α α δ= + +
- La covarianza entre individuos emparentados puede definirse como:
1 2 1 2( , ) ( )Cov Y Y Y Yε= ⋅
1 2 1 1 1 1 2 2 2 2( , ) ( )( )m p m p m p m pCov Y Y ε α α δ α α δ= + + + +
1 2 1 2 1 2 1 2 1 2 1 1 2 2( , ) ( ) ( ) ( ) ( ) ( )m m m p p m p p m p m pCov Y Y ε α α ε α α ε α α ε α α ε δ δ= ⋅ + ⋅ + ⋅ + ⋅ + ⋅ - Además, podemos asumir que:
( ) ( ) 0mi mjpj pi mjpjε α δ ε α δ⋅ = ⋅ =
- Luego:
[ ] [ ]2 21 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2( , ) ( ) ( ) ( ) ( ) ( ) ( ) ( , ) ( , )i ijCov Y Y P m m P m p P p m P p p P m m p p P m p p mε α ε δ= ≡ + ≡ + ≡ + ≡ + ≡ ≡ + ≡ ≡
2 2
1 2 1 2 1 2( , ) ( ) 4 ( )i Y Y ij Y YCov Y Y r Uε α ε δ= ⋅ + ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
29
Pero:
22 ( )iVA ε α= ⋅ y 2( )iVD ε δ= Por lo tanto:
1 2 1 2 1 2( , ) ½ 4 Y Y Y YCov Y Y VA r VD U= ⋅ ⋅ + ⋅ o
1 2 1 2 1 2( , ) 2 Y Y Y YCov Y Y r VA U VD= ⋅ + ⋅
Casos relevantes
Hermanos completos (full sibs)
14xyr = y 1
4xyU =
Luego:
1 2( , ) ½ ¼Cov Y Y VA VD= ⋅ + ⋅
Medio hermanos (half-sibs)
18xyr = y 0xyU =
Luego:
1 2( , ) ¼Cov Y Y VA= ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
30
IV ESTIMACIÓN DE PARAMETROS GENETICOS EN ENSAYOS GENETICOS
- Si los individuos de distintos grupos son genéticamente idénticos, la variación dentro de grupos sería puramente ambiental, y la variación entre grupos sería puramente genética.
- La máxima contribución de la varianza genética a la variación total implica que los
individuos son aleatoriamente seleccionados y los efectos ambientales minimizados.
- Entre ambos extremos, se puede señalar que la variación depende del tipo de parentesco entre los individuos.
- En ambientes similares, los individuos cercanamente emparentados son generalmente
menos variables entre ellos que aquellos individuos no emparentados. Esto se debe a que sus genes derivan de una población restringida, es decir existe una correlación entre sus efectos génicos.
1. CORRELACIÓN INTRACLASE
La correlación entre individuos emparentados puede definirse en términos de los componentes “causales” de la variación genética:
VG VA VD VI= + +
donde: VG, VA, VD y VI son las varianzas genética, aditiva, de dominancia y epistática., respectivamente. Pero la correlación entre parientes se puede definir en términos de “varianzas” familiares estimadas directamente de ensayos genéticos. Es decir: Variación Fenotípica = función de componentes causales = función de componentes observables
Si se agrupan los individuos de acuerdo a familias y se realiza un ANDEVA, entonces se puede particionar la variación total observada en dos componentes:
1. entre grupos y 2. dentro de grupos

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
31
Recordar: Entre grupos = Variación del promedio “verdadero” respecto al promedio total (población) Dentro de grupos = Variación individual respecto al promedio “verdadero” Promedio verdadero = valor esperado de un grupo genético, estimado sin error desde una población muy grande y al azar. Supuestos del ANDEVA: 1. Los efectos familiares son aleatorios: fi ~ (0, σ2
f), es decir son una muestra a azar de una población panmítica;
2. El efecto ambiental es fijo; Luego, el modelo de componentes observables es un modelo lineal mixto Por ejemplo, observemos el modelo más sencillo
ij i ijY f eµ= + + donde: fi = efecto familiar, aleatorio ~ (0, σ2
f); eij = efecto residual, aleatorio ~ (0, σ2
e); ε(yij) = µ Уij ~ (µ, σ2
f +σ2e)
Luego, la varianza fenotípica del modelo de componentes observables es:
2 2 2P f eVP σ σ σ= = +
El análisis de varianza correspondiente al modelo es: ANDEVA Fuente de variación gl CM Ε (CM) Familias
f-1
CMF
2 2e fnσ σ+
Residuo
fn-1
CMR
2eσ

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
32
De acuerdo a los supuestos del modelo, la covarianza entre dos individuos dentro de la i-ésima familia será:
´ ´( , ) ( )( )ij ij i ij i ijCov Y Y f e f eε= + +
2´ ´ ´( , ) ( ) ( ) ( ) ( )ij ij i i ij i ij ij ijCov Y Y f f e f e e eε ε ε ε= + + +
2
´( , )ij ij fCov Y Y σ=
Correlación Intraclase (parecido entre individuos de la misma familia)
´
´
( , )( ) ( )
ij ij
ij ij
Cov Y Yt
Var Y Var Y=
⋅
22
2
ef
ftσσ
σ+
=
Estimadores de varianza (Método de momentos)
2ˆ ;e CMEσ = 2ˆ ( ) / ;f CMF CME nσ = −
Casos relevantes
Hermanos completos (full sibs)
2´
1 1( ) ( , ) 2 4ij ij fCov FS Cov Y Y VA VD σ= = + =
Si: 20 2 fVD VA σ= ⇒ =

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
33
Medio hermanos (half-sibs)
2´
1( ) ( , ) 4ij ij fCov HS Cov Y Y VA σ= = =
y
24 fVA σ=
2. HEREDABILIDAD - es la proporción de la varianza total (VP) atribuible a los efectos promedios de los genes (VA), lo cual determina el parecido entre parientes.
- permite predecir, es decir, mide la confiabilidad del valor fenotípico como una guía al valor reproductivo.
- luego, heredabilidad es el grado de correspondencia entre los valores fenotípico y reproductivo.
Tipos
Heredabilidad en sentido estricto
Para medio hermanos: 2 2
22 2 2
4 4f f
p f e
VAhVP
σ σσ σ σ
= = =+
Para hermanos completos (asumiendo VD=0): 2 2
22 2 2
2 2f f
p f e
VAhVP
σ σσ σ σ
= = =+
Heredabilidad en sentido amplio
VPVGh =2

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
34
Variación Residual Note que en el caso de medio hermanos:
2´
1( ) ( , ) 4ij ij fCov HS Cov Y Y VA σ= = =
2 2f eVP VA VD VE σ σ= + + = +
21
4 eVP VA VD VE VA σ= + + = +
Luego:
2 34e VA VD VEσ = + +
Mientras que para hermanos completos:
2´
1 1( ) ( , ) 2 4ij ij fCov FS Cov Y Y VA VD σ= = + =
2 2f eVP VA VD VE σ σ= + + = +
21 1
2 4 eVP VA VD VE VA VD σ= + + = + +
Luego:
2 312 4e VA VD VEσ = + +

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
35
3. CORRELACIÓN GENÉTICA - Todos los principios descritos para estimar varianzas genéticas y heredabilidad pueden ser aplicados para estimar correlación genética.
- Cuadrados medios y componentes de varianzas son reemplazados por productos cruzados y componentes de covarianza entre pares de caracteres.
- Por ejemplo, sean Xij e Yij dos caracteres X e Y medidos al j-ésimo individuo dentro de la i-ésima familia. Entonces:
ij y yi yijY f eµ= + + ;
ij x xi xijX f eµ= + + ;
donde:
µy y µx = promedio esperado en la población
fyi y fxi = efectos familiares
eyjj y exjj = efectos residuales
Para el caso de medio hermanos (HS):
( ) ( , ) ( )( )ij ij xi xij yi yijCov HS Cov X Y f e f eε= = + +
( ) ( , ) ( )ij ij xi yi fxfyCov HS Cov X Y f fε σ= = ⋅ =
1( ) ( , )4 x y fxfyCov HS Cov A A σ= =
Entonces, la covarianza de efectos aditivos es:
( , ) 4x y fxfyCov A A σ= luego, la expresión de cálculo de correlación genética para medio hermanos es:
2 2
4( , )( ) ( ) 4 4
xfy fxfyx Ygxy
fx fyX Y fx fy
Cov A ArVar A Var A
σ σσ σσ σ
⋅= = =
⋅⋅ ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
36
Para el caso de hermanos completos (FS):
1 1( ) ( , ) ( , ) ( , )2 4xy ij ij x y x y fxfyCov FS Cov X Y Cov A A Cov D D σ= = + =
Asumiendo Cov(Dx; Dy) = 0, entonces, la covarianza de efectos aditivos es:
( , ) 2x y fxfyCov A A σ= luego, la expresión de cálculo de correlación genética para hermanos completos es:
2 2
2( , )( ) ( ) 2 2
xfy fxfyx Ygxy
fx fyX Y fx fy
Cov A ArVar A Var A
σ σσ σσ σ
⋅= = =
⋅⋅ ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
37
4. PREDICCIÓN DE GANANCIA GENÉTICA - De la curva de distribución normal 0 c Se conoce que:
2
21( )2
c
z f c eπ
− = = ⋅
Si S es el diferencial de selección, entonces: µ0 µS S 0SS µ µ= −
0S S z ib
µ µσ σ−
= = =
0SS zbσµ µ= − = ⋅
o bien zS ib
σ σ= ⋅ = ⋅ ,
donde i = diferencial de selección estandarizada.
σ b
z

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
38
Respuesta esperada a la Selección µ0 µS µ0 µ1 R
Recordar: - El promedio en la subpoblación seleccionada (µs) puede ser estimado por SY . - Además, R = (µ1 - µ0) es estimado por la diferencia entre promedios de población resultante en la generación de selección 1 y la población original (generación 0):
1 0R Y Y= − - A nivel infinitesimal, el valor esperado del cambio en una generación a la siguiente es:
1 0( ) µε µ µ δ− = - A su vez, el cambio en la frecuencia génica (pi) se espera que resulte en un cambio en el promedio en la próxima generación:
pddpµµδ δ= ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
39
- Si la relación entre p (frecuencia génica) e Y (el carácter seleccionado) es linear, sobre un rango de p, desde p0 a (p0 + δp), luego:
0( )p S pyY Yδ β= − ⋅
- Es decir, se espera que el diferencial de selección S = (µS - µ0) resultará en un cambio en la frecuencia génica: δp :
( )p f Sδ =
- En un modelo ij i j ijY g e gxe= + +
- Se cumple:
( , ) ( , )i ij i i j ijCov p Y Cov p g e gxe= + +
( , ) ( )( )i ij i i j ijCov p Y p g e gxeε= + +
( , ) ( )i ij i iCov p Y p gε= ⋅ entonces:
( , ) ( , )i ij i iCov p Y Cov p g= donde pi = frecuencia génica

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
40
Modelo de regresión: pi py ijYδ β= ⋅ 2( )pi py ijQ Yδ β= − ⋅∑
2 ( ) 0pi py ij ijdQ Y Yd
δ ββ= − − ⋅ ⋅ =∑
∑ ∑=∗ 2
ijpyijPi YY βδ
2
( _ ; _ )( _ )
Pi ijpy
ij
Y Cov frecuencia genica valor fenotipicoY Var valor fenotipico
δβ
⋅= =∑∑
0pdGdpµµδ δ∆ = = ⋅
00( )S py
dG Y Ydpµµδ β∆ = = − ⋅ ⋅
0( , )( )
dCov p YG SVar Y dp
µδ∆ = ⋅ ⋅
También se puede demostrar que:
0( , )
( )dCov p Y VA
Var Y dp VPµδ
⋅ =
Finalmente, una expresión de cálculo para la predicción de ganancia genética es:
2 2VAG S S h i h VPVP
∆ = ⋅ = ⋅ = ⋅ ⋅

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
41
ANDEVA
Modelo de efectos aleatorios: bloques completamente aleatorizado ijk i j ij ijkY f B fxB eµ= + + + +
Supuestos
2(0, )ff σ∼ , 2(0, )BB σ∼ , 2(0, )fxBfxB σ∼ , 2(0, )ee σ∼
Estimadores mínimo cuadráticos
... .. ... .. ... . .. .. ... .( ) ( ) ( ) ( )ijk i j ij i j ijk ijY Y Y Y Y Y Y Y Y Y Y Y= + − + − + − − + + −
Suma de cuadrados
2 2 2... ...( )a b n a b n
ijk ijki j k i j kSST Y Y Y abn Y= − = − ⋅∑ ∑ ∑ ∑ ∑ ∑
2 2 2
.. ... .. ...( )a b n ai ii j k i
SSF Y Y bn Y abn Y= − = ⋅ − ⋅∑ ∑ ∑ ∑
2 2 2
.. ... .. ...( )a b n bj ji j k j
SSB Y Y an Y abn Y= − = ⋅ − ⋅∑ ∑ ∑ ∑
2 2 2 2 2
. .. .. ... . .. .. ...( )a b n a b a bij i j ij i ji j k i j i j
SSFxB Y Y Y Y n Y bn Y an Y abn Y= − − + = ⋅ − ⋅ − ⋅ + ⋅∑ ∑ ∑ ∑ ∑ ∑ ∑
2 2 2
. .( )a b n a b n a bijk ij ijk iji j k i j k i j
SSE Y Y Y nY= − = −∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
42
Cuadrados Medios
1SSFCMFa
=−
1SSBCMBb
=−
( 1)( 1)SSFxBCMFxBa b
=− −
( 1)SSECME
ab n=
−
Esperanza de cuadrados medios
2 2ˆ( ) e eCME CMEε σ σ= ⇒ =
2 2 2 ( )ˆ( ) e fxB fxBCMFxB CMECMFxB n
nε σ σ σ −
= + ⇒ =
2 2 2 2 ( )ˆ( ) e fxB B B
CMB CMFxBCMB n anan
ε σ σ σ σ −= + + ⇒ =
2 2 2 2 ( )ˆ( ) e fxB f f
CMF CMFxBCMF n bnbn
ε σ σ σ σ −= + + ⇒ =

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
43
ANCOVA
Modelo de efectos aleatorios: bloques completamente aleatorizado
ijk xi xj xij xijkX f B fxB eµ= + + + + ; ijk yi yj yij yijkY f B fxB eµ= + + + +
Supuestos
2(0, )ff σ∼ , 2(0, )BB σ∼ , 2(0, )fxBfxB σ∼ , 2(0, )ee σ∼
Estimadores mínimo cuadráticos para Y
... .. ... .. ... . .. .. ... .( ) ( ) ( ) ( )ijk i j ij i j ijk ijY Y Y Y Y Y Y Y Y Y Y Y= + − + − + − − + + −
Suma de productos cruzados
... ... ... ...( )( ) ( ) ( )a b n a b nijk ijk ijk ijk ijki j k i j k
SPCT X X Y Y X Y abn X Y= − − = − ⋅∑ ∑ ∑ ∑ ∑ ∑
.. ... .. ... .. .. ... ...( ) ( )a b n ai i i ii j k i
SPCF X X Y Y bn X Y abn X Y= − ⋅ − = ⋅ − ⋅∑ ∑ ∑ ∑
.. ... .. ... .. .. ... ...( )( )a b n bj j j ji j k j
SPCB X X Y Y an X Y abn X Y= − − = ⋅ − ⋅∑ ∑ ∑ ∑
. .. .. ... . .. .. ... . . .. .. .. ... ...( )( )a b n a b a bij i j ij i j ij ij i i j ji j k i j i j
SPCFxB X X X X Y Y Y Y n X Y bn XY an X Y abn X Y= − − + − − + = ⋅ − ⋅ − ⋅ + ⋅∑ ∑ ∑ ∑∑ ∑ ∑
. . . .( )( )a b n a b n a bijk ij ijk ij ijk ijk ij iji j k i j k i j
SPCE X X Y Y X Y nX Y= − − = −∑ ∑ ∑ ∑ ∑ ∑ ∑ ∑

Fco. Zamudio (PhD) Genética & Mej. Forestal
Universidad de Talca
44
Productos Medios
1SPCFPMFa
=−
1SPCBPMBb
=−
( 1)( 1)SPCFxBPMFxBa b
=− −
( 1)SPCEPMEab n
=−
Esperanza de productos cruzados medios
ˆ( ) exey exeyPME PMEε σ σ= ⇒ =
( )ˆ( ) exey fBxfBy fBxfByPMFxB PMEPMFxB n
nε σ σ σ −
= + ⇒ =
( )ˆ( ) exey fBxfBy BxBy BxByPMB PMFxBPMB n an
anε σ σ σ σ −
= + + ⇒ =
( )ˆ( ) exey fBxfBy fxfy fxfyPMF PMFxBPMF n bn
bnε σ σ σ σ −
= + + ⇒ =


























![Glossario Di Genetica [Dispense Genetica Biologia]](https://img.pdfslide.net/doc/110x75/5460bdb1af795949708b53b0/glossario-di-genetica-dispense-genetica-biologia.jpg)


