Embed Size (px)
Citation preview

1
1
Introduction toMolecular Biology
OUTLINE OF TOPICS
1.1 Intellectual FoundationTwo studies performed in the 1860s provided the intellectual
underpinning for molecular biology.
1.2 Genotypes and PhenotypesEach gene is responsible for the synthesis of a single
polypeptide.
1.3 Nucleic AcidsNucleic acids are linear chains of nucleotides.
1.4 DNA Structure and FunctionTransformation experiments led to the discovery that DNA is
the hereditary material.Chemical experiments also supported the hypothesis that DNA
is the hereditary material.The blender experiment demonstrated that DNA is the genetic
material in bacterial viruses.
RNA serves as the hereditary material in some viruses.Rosalind Franklin and Maurice Wilkins obtained x-ray diffrac-
tion patterns of extended DNA fibers. James Watson and Francis Crick proposed that DNA is a double-
stranded helix.The central dogma provides the theoretical framework for
molecular biology.Recombinant DNA technology allows us to study complex
biological systems. A great deal of molecular biology information is available on
the Internet.
Suggested Reading
Classic Papers
Photo courtesy of James Gathany / CDC
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 1
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

T he term molecular biology first appeared in a report preparedfor the Rockefeller Foundation in 1938 by Warren Weaver,then director of the Foundation’s Natural Sciences Division.
Weaver coined the term to describe a research approach in whichphysics and chemistry would be used to address fundamental biolog-ical problems. Weaver proposed that the Rockefeller Foundationfund research efforts to seek molecular explanations for biologicalprocesses. His proposal was remarkably farsighted, especially whenconsidering that many of his contemporaries believed that living cellspossessed a vital force that could not be explained by chemical orphysical laws that govern the inanimate world. In fact, some physi-cists entered the field of biology in the hope that they might discovernew physical laws.
At the time of Weaver’s report, biology was on the threshold ofmajor changes. Two new disciplines—biochemistry and genetics—had altered the way that biologists think about living systems. Bio-chemists had delivered a major blow to the vital force theory bydemonstrating that cell-free extracts can perform many of the samefunctions as intact cells. Geneticists established that the functionaland physical unit of heredity is the gene. However, they did not knowhow the hereditary information was stored in the gene, how the genewas replicated so that it could be transmitted to the next generation,or how the information stored in the gene determined a specific phys-ical trait such as eye color.
Neither biochemistry nor genetics had the power to solve theseproblems on its own. In fact, it took an interdisciplinary effort involv-ing specialists in many fields of the life sciences, including biochem-istry, biophysics, chemistry, x-ray crystallography, developmentalbiology, genetics, immunology, microbiology, and virology, to solvethe hereditary problem. This interdisciplinary effort resulted in thecreation of a new discipline, molecular biology, which seeks to ex-plain genetic phenomena in chemical and physical terms.
1.1 Intellectual Foundation
Two studies performed in the 1860s provided the intel-
lectual underpinning for molecular biology.
The earliest intellectual roots of molecular biology can be tracedback to the work of two investigators in the 1860s. No connectionwas apparent between the experiments performed by the two inves-tigators for more than 75 years, but when the connection was finallymade, the result was the birth of molecular biology and the beginningof a scientific revolution that continues today. Mendel’s Three Laws of InheritanceThe work of the first investigator, Gregor Mendel, an Austrian monkand botanist, is familiar to all biology students and so will only besummarized briefly here. Mendel discovered three basic laws of in-
2 INTRODUCTION
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 2
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

heritance by studying the way in which simple physical traits arepassed on from one generation of pea plants to the next. For conven-ience, Mendel’s laws of inheritance will be described using two mod-ern biological terms, gene for a unit of heredity and chromosome fora structure bearing several linked genes.
1. The law of independent assortment — Specific physical traitssuch as plant size and color are inherited independently ofone another. Mendel was fortunate to have selected physicaltraits that were determined by genes that were on differentchromosomes.
2. The law of independent segregation — A specific gene mayexist in alternate forms called alleles. An organism inheritsone allele for each trait from each parent. The two alleles,which may be the same or different, segregate (or separate) ingerm cells (sperm or egg) and combine again during repro-duction so that each parent transmits one allele to each off-spring.
3. The law of dominance — For each physical trait, one alleleis dominant so that the physical trait that it specifies appearsin a definite 3:1 ratio. The alternative form is recessive. InMendel’s peas, tallness was dominant and shortness reces-sive. Therefore, three times as many pea plants were tall aswere short. Today we know that there are exceptions to thelaw of dominance. Sometimes neither allele is dominant. Forinstance, a plant that inherits a gene for a red flower and agene for a white flower may produce a pink flower.
Unfortunately, scientists failed to recognize the significance ofMendel’s work during his lifetime. His paper remained obscure untilabout 1900 when scientists rediscovered Mendel’s laws of inheri-tance, giving birth to the science of genetics. Miescher and DNAThe second investigator, the Swiss physician Friedrich Miescher, per-formed experiments that led to the discovery of deoxyribonucleicacid (DNA), which we, of course, now know is the hereditary mate-rial. Miescher did not set out to discover the hereditary material butinstead was interested in studying cell nuclei from white blood cells,which he collected from pus discharges on discarded bandages thathad been used to cover infected wounds. Miescher used a combina-tion of protease (enzymes that hydrolyze proteins) digestion and sol-vent extraction to disrupt and fractionate the white blood cells. Onefraction, which he called nuclein, contained an acidic material withunusually high phosphorus content. Miescher later found thatsalmon sperm cells, which have remarkably large cell nuclei, are alsoan excellent source of nuclein. In 1889, Miescher’s student, RichardAltmann, separated nuclein into protein and a substance with a veryhigh phosphorous content that he named nucleic acid. Because of itshigh phosphorus content, investigators initially thought that nucleicacids might serve as storehouses for cellular phosphorus.
CHAPTER 1 Introduction to Molecular Biology 3
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 3
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

1.2 Genotypes and Phenotypes
Each gene is responsible for the synthesis of a single
polypeptide.
Mendel’s experiments showed that the genetic makeup of an organ-ism, its genotype, determines the organism’s physical traits, its phe-notype. However, his experiments did not show how genes are ableto determine complex physical traits such as plant color or size.Archibald Garrod, an English physician, was the first to provide anexplanation for the relationship between genotype and phenotype.Garrod uncovered this relationship while studying alkaptonuria, arare inherited human disorder in which the urine of affected individ-uals becomes very dark upon standing due to the accumulation ofhomogentisic acid, a breakdown product of the amino acid tyrosine.Garrod correctly proposed that alkaptonuria results from a recessivegene, which causes a deficiency in the enzyme that normally convertshomogentisic acid into colorless products.
Garrod’s work was generally ignored until the early 1940s, whenthe American geneticists, George Beadle and Edward Tatum redis-covered it while seeking experimental proof for the connection be-tween genes and enzymes. They believed that, if a gene really doesspecify an enzyme, it should be possible to create genetic mutantsthat cannot carry out specific enzymatic reactions. They therefore ex-posed spores of the bread mold Neurospora crassa to x-rays or UVradiation and demonstrated that the mutant molds had a variety ofspecial nutritional needs. Unlike their wild-type parents, the mutantscould not reproduce without having specific amino acids or vitaminsadded to their growth medium. A mutant that requires a specific sup-plement that is not required by the wild-type parent is called an auxo-troph. Genetic analysis revealed that each auxotroph appeared to beblocked at a specific step in the metabolic pathway for the requiredamino acid or vitamin. Furthermore, the auxotrophs accumulatedlarge quantities of the substance formed just prior to the blockedstep. Thus, Beadle and Tatum had replicated in the bread mold thesame type of situation that Garrod had observed in alkaptonuria. Adefective gene caused a defect in a specific enzyme that resulted in theabnormal accumulation of an intermediate in a metabolic pathway.As a result of their work with the N. crassa mutants, Beadle and Tatumproposed the one gene-one enzyme hypothesis, which states that eachgene is responsible for synthesizing a single enzyme. We now knowthat many enzymes are made of more than one type of polypeptidechain and that a single mutation may affect just one of the polypep-tide chains. Hence, the original one gene-one enzyme hypothesis wasmodified to become a one gene-one polypeptide hypothesis. How-ever, as we will see later, even the one gene-one polypeptide hypothe-sis is an oversimplification.
4 INTRODUCTION
H
H O
OHC2
C1
H OHC3
H OHC4
H2OHC5
H
H O
HC2
C1
H OHC3
H OHC4
H2OHC5
Ribose Deoxyribose
FIGURE 1.1 The two sugars present in nucleic
acids. (a) Ribose and (b) deoxyribose eachcontain five carbon atoms and an aldehydegroup and therefore belong to aldopentosefamily of simple sugars. The only differencebetween the two sugars is that ribose has ahydroxyl group at carbon-2 and deoxyriboseas a hydrogen atom at carbon-2.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 4
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
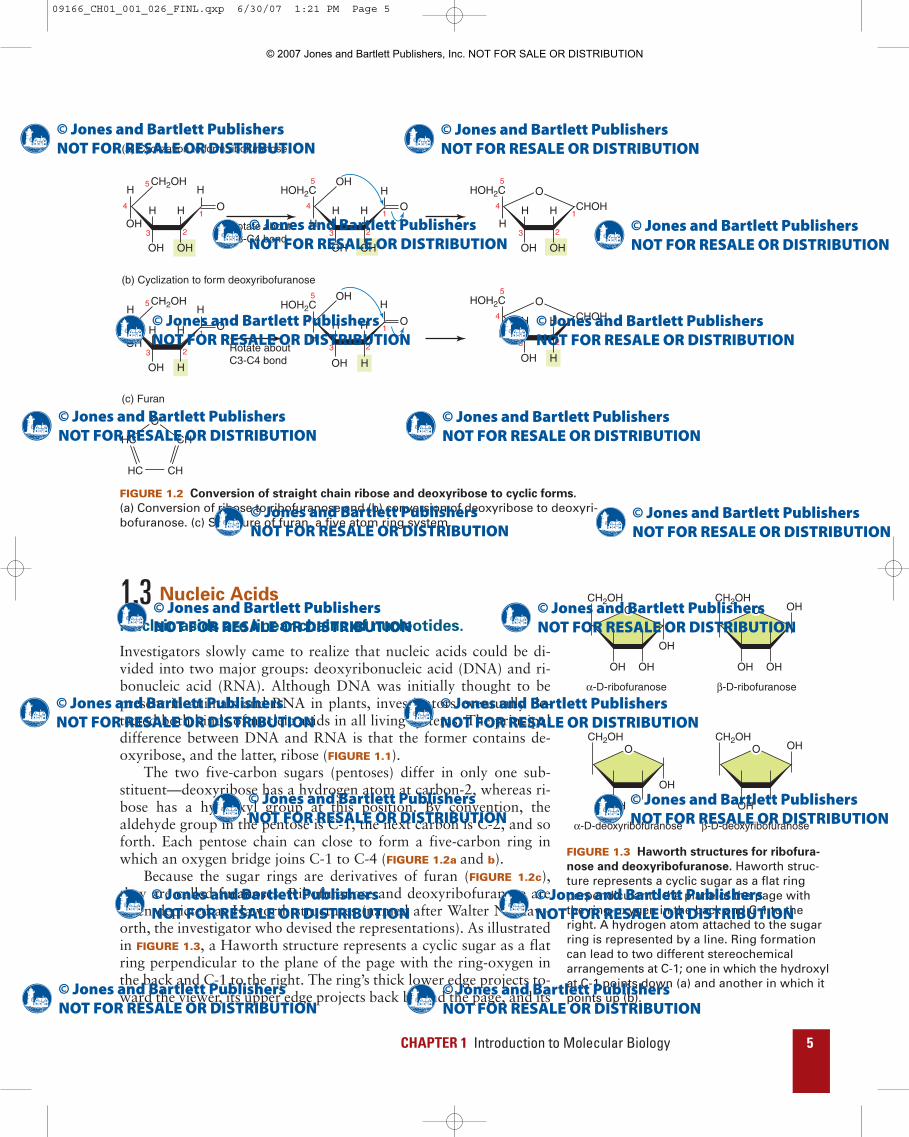
1.3 Nucleic Acids
Nucleic acids are linear chains of nucleotides.
Investigators slowly came to realize that nucleic acids could be di-vided into two major groups: deoxyribonucleic acid (DNA) and ri-bonucleic acid (RNA). Although DNA was initially thought to bepresent in animals and RNA in plants, investigators eventually de-tected both kinds of nucleic acids in all living systems. The principaldifference between DNA and RNA is that the former contains de-oxyribose, and the latter, ribose (FIGURE 1.1).
The two five-carbon sugars (pentoses) differ in only one sub-stituent—deoxyribose has a hydrogen atom at carbon-2, whereas ri-bose has a hydroxyl group at this position. By convention, thealdehyde group in the pentose is C-1, the next carbon is C-2, and soforth. Each pentose chain can close to form a five-carbon ring inwhich an oxygen bridge joins C-1 to C-4 (FIGURE 1.2a and b).
Because the sugar rings are derivatives of furan (FIGURE 1.2c),they are called furanoses. Ribofuranose and deoxyribofuranose areoften depicted as Haworth structures (named after Walter N. Haw-orth, the investigator who devised the representations). As illustratedin FIGURE 1.3, a Haworth structure represents a cyclic sugar as a flatring perpendicular to the plane of the page with the ring-oxygen inthe back and C-1 to the right. The ring’s thick lower edge projects to-ward the viewer, its upper edge projects back behind the page, and its
CHAPTER 1 Introduction to Molecular Biology 5
1
2
CH2OH
OH
OH OH
HH O
HH
3
4
5
1
2
CH2OH
OH
OH H
HH O
HH
3
4
5
1
2
HOH2C
H
OHOH
HH CHOH
3
4
5O
H
1
2
HOH2C
H
OH
HH CHOH
3
4
5O
1
2
HOH2C
H
OH
OH
OH
HH O
H
3
4
5
H
1
2
HOH2C
H
OH
OH
HH O
H
3
4
5
O
HC CH
CHHC
(a) Cyclization to form ribofuranose
(b) Cyclization to form deoxyribofuranose
(c) Furan
Rotate aboutC3-C4 bond
Rotate aboutC3-C4 bond
FIGURE 1.2 Conversion of straight chain ribose and deoxyribose to cyclic forms.
(a) Conversion of ribose to ribofuranose and (b) conversion of deoxyribose to deoxyri-bofuranose. (c) Structure of furan, a five atom ring system.
CH2OH
OHOH
O
OH
CH2OH
OHOH
O OH
CH2OH
OH
O
OH
CH2OH
OH
O OH
α-D-ribofuranose β-D-ribofuranose
α-D-deoxyribofuranose β-D-deoxyribofuranose
FIGURE 1.3 Haworth structures for ribofura-
nose and deoxyribofuranose. Haworth struc-ture represents a cyclic sugar as a flat ringperpendicular to the plane of the page withthe ring-oxygen in the back and C-1 to theright. A hydrogen atom attached to the sugarring is represented by a line. Ring formationcan lead to two different stereochemicalarrangements at C-1; one in which the hydroxylat C-1 points down (a) and another in which itpoints up (b).
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 5
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

6 INTRODUCTION
substituents are visualized as being either above or below the plane ofthe ring. A line is used to represent a hydrogen atom attached to thesugar ring. Ring formation can lead to two different stereochemicalarrangements at C-1. One arrangement, the �-anomer, is representedby drawing the hydroxyl group attached to C-1 below the plane ofthe ring and the other, the �-anomer, by drawing it above the planeof the ring. We will see in Chapter 4 that ribofuranose anddeoxyribofuranose actually have puckered rather than planar con-formations. Nevertheless, Haworth structures are convenient repre-sentations for sugar rings when precise three-dimensionalinformation is not required.
1.4 DNA Structure and Function
An early pioneer in the study of nucleic acid chemistry, Phoebus A.Levene found that DNA contains four different kinds of heterocyclicring structures, which are now known simply as bases because theycan act as proton acceptors. Two of the bases, thymine (T) and cyto-sine (C), are derivatives of pyrimidine (FIGURE 1.4a) and the other twoadenine (A) and guanine (G), are derivatives of purine (FIGURE 1.4b).RNA also contains cytosine, adenine, and guanine, but the pyrimi-dine uracil (U) replaces thymine (FIGURE 1.5). The only difference be-tween uracil and thymine is that the latter contains a methyl groupattached to carbon-5. Levene showed that T, C, A, and G combinewith deoxyribose to form a class of compounds called deoxyribonu-cleosides (FIGURE 1.6) and that U, C, A, G combine with ribose toform a related class of compounds called ribonucleosides (FIGURE
1.7). Each base is linked to the pentose ring by a bond that joins a
N
NH
NH2
O 1
2
34
5
6
HNCH3
NH
O
O
1
2
34
5
6
N
N1
2
34
5
6
N
NH
N
N
NH2
1
2
34
5 7
8
9
6N
NH
HN
NH2N
O
1
2
34
57
8
9
6N
NH
N
N
1
2
34
57
8
9
6
Thymine (T)
(b)
Adenine (A)
Purine
Guanine (G)
Cytosine (C)
(a)
Pyrimidine bases
Purine bases
Pyrimidine
FIGURE 1.4 Pyrimidine and purine bases in DNA.
HN
NH
O
O
1
2
34
5
6
Uracil (U)
FIGURE 1.5 Uracil (U).
HNCH3
NO
O
1
1ʹ
2
2ʹ
3
3ʹ
4
4ʹ
5
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
6
CH2OH
OH
O
N
N
N
N
NH2
1
2
34
5 7
8
9
6
CH2OH
OH
O
N
N
HN
NH2N
O
1
2
34
57
8
9
6
CH2OH
OH
O
N
N
NH2
O 1
2
34
5
6
CH2OH
OH
O
Deoxythymidine Deoxycytidine
Deoxyadenosine Deoxyguanosine
FIGURE 1.6 Deoxyribonucleosides.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 6
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
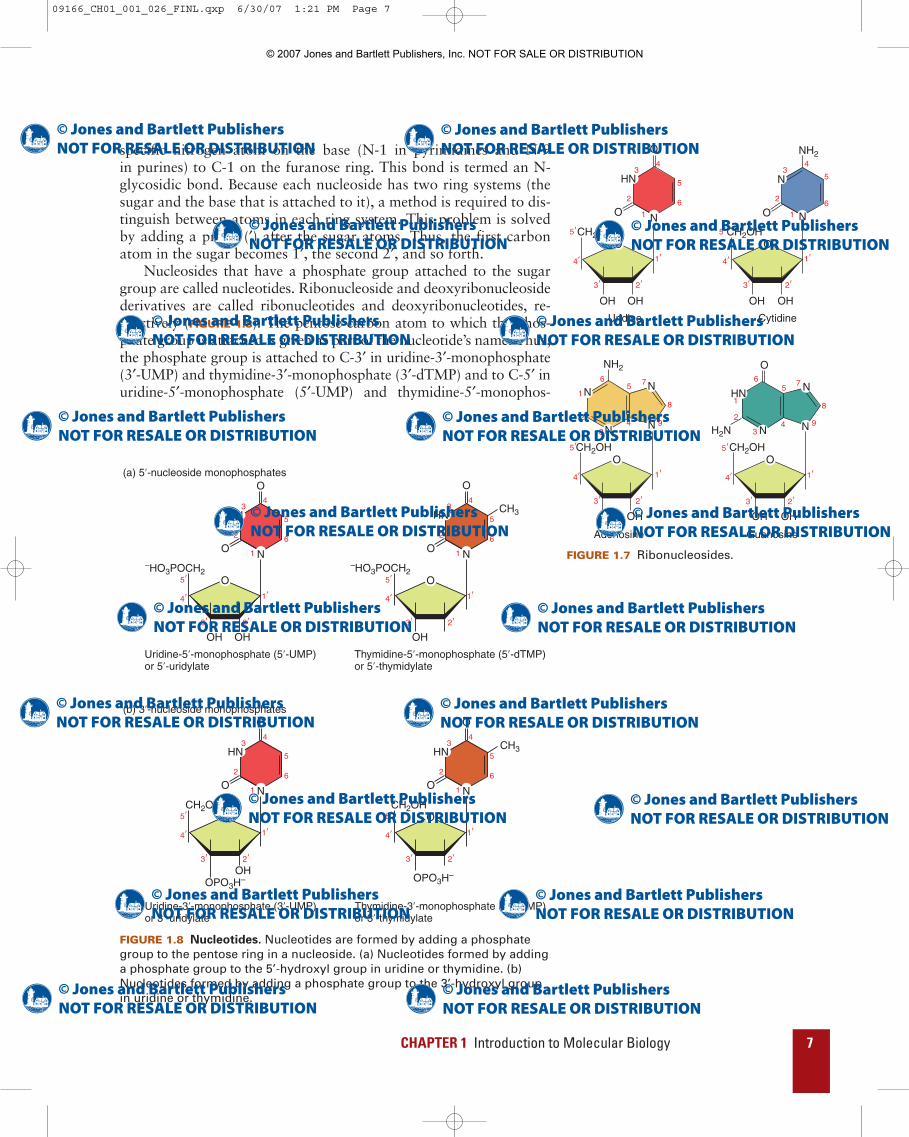
CHAPTER 1 Introduction to Molecular Biology 7
specific nitrogen atom on the base (N-1 in pyrimidines and N-9in purines) to C-1 on the furanose ring. This bond is termed an N-glycosidic bond. Because each nucleoside has two ring systems (thesugar and the base that is attached to it), a method is required to dis-tinguish between atoms in each ring system. This problem is solvedby adding a prime (′) after the sugar atoms. Thus, the first carbonatom in the sugar becomes 1′, the second 2′, and so forth.
Nucleosides that have a phosphate group attached to the sugargroup are called nucleotides. Ribonucleoside and deoxyribonucleosidederivatives are called ribonucleotides and deoxyribonucleotides, re-spectively (FIGURE 1.8). The pentose carbon atom to which the phos-phate group is attached is given as part of the nucleotide’s name. Thus,the phosphate group is attached to C-3′ in uridine-3′-monophosphate(3′-UMP) and thymidine-3′-monophosphate (3′-dTMP) and to C-5′ inuridine-5′-monophosphate (5′-UMP) and thymidine-5′-monophos-
HN
NO
O
1
2
34
5
6
CH2OH
OH OH
O
N
N
N
N
NH2
1
2
34
5 7
8
9
6
CH2OH
OH OH
O
N
N
HN
NH2N
O
1
2
34
57
8
9
6
CH2OH
OH OH
O
N
N
NH2
O 1
2
34
5
6
CH2OH
OH OH
O
Uridine Cytidine
Adenosine Guanosine
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
1ʹ
2ʹ3ʹ
4ʹ
5ʹ
FIGURE 1.7 Ribonucleosides. –HO3POCH2
HNCH3
NO
O
1
2
34
5
6
OH
O
HN
NO 1
2
34
5
6
–HO3POCH2
OH OH
O
O
HNCH3
NO
O
1
2
34
5
6
O
HN
NO 1
2
34
5
6
CH2OH CH2OH
OPO3H– OPO3H–OH
O
O
3ʹ
1ʹ
2ʹ
4ʹ
5ʹ
3ʹ
1ʹ
2ʹ
4ʹ
5ʹ
3ʹ
1ʹ
2ʹ
4ʹ
5ʹ
3ʹ
1ʹ
2ʹ
4ʹ
5ʹ
Uridine-5ʹ-monophosphate (5ʹ-UMP)or 5ʹ-uridylate
Thymidine-5ʹ-monophosphate (5ʹ-dTMP)or 5ʹ-thymidylate
(a) 5ʹ-nucleoside monophosphates
Uridine-3ʹ-monophosphate (3ʹ-UMP)or 3ʹ-uridylate
Thymidine-3ʹ-monophosphate (3ʹ-dTMP)or 3ʹ-thymidylate
(b) 3ʹ-nucleoside monophosphates
FIGURE 1.8 Nucleotides. Nucleotides are formed by adding a phosphategroup to the pentose ring in a nucleoside. (a) Nucleotides formed by addinga phosphate group to the 5’-hydroxyl group in uridine or thymidine. (b)Nucleotides formed by adding a phosphate group to the 3’-hydroxyl groupin uridine or thymidine.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 7
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

8 INTRODUCTION
phate (5′-dTMP). As indicated in Table 1.1, nucleoside monophosphateshave two alternative names. For example, cytidine-5′-monophosphate(5′-CMP) is also known as 5′-cytidylate.
Levene also suggested that neighboring deoxyribonucleosides inDNA are joined to one another by 5′ to 3′ (5′→3′) phosphodiesterbridges. Unfortunately, Levene is remembered more for a hypothesisthat he proposed that turned out to be wrong than for all his impor-tant contributions to the field of nucleic acid chemistry. To place Lev-ene’s hypothesis in context, it is important to note that the analyticaltools available to him were quite poor. Therefore, not surprisingly,Levene based his idea about DNA structure on the incorrect assump-tion that T, C, A, and G are present in DNA in equimolar concentra-tions. He therefore proposed that DNA has a tetranucleotidestructure (FIGURE 1.9). This hypothetical structure became untenablein the 1930s when the Swedish researchers Torbjörn Caspersson andEinar Hammersten showed that DNA has a very high molecularmass and therefore must be a very large molecule or macromolecule.
Nevertheless, scientists continued to accept the idea that DNAcontains a repeating sequence of the four nucleotides. They weretherefore forced to look elsewhere for a molecule that could carry ge-netic information because DNA, which they mistakenly thought hada repetitive and monotonous nucleotide sequence, seemed an unlikelycandidate to carry much information. Proteins seemed to be muchbetter candidates for the genetic material. Although little was knownabout protein structure in the early part of the twentieth century,
Base Sugar Nucleoside 5’-MononucleotideUracil (U) ribose uridine Uridine-5’-monophosphate or
5’-uridylate (5’-UMP)Cytosine (C) ribose cytidine Cytidine-5’-monophosphate or
5’-cytidylate (5’-CMP)Adenine (A) ribose adenosine Adenosine-5’-monophosphate
or 5’-adenylate (5’-AMP)Guanine (G) ribose guanosine Guanosine-5’-monophosphate
or 5’-guanylate (5’-GMP)Thymine (T) deoxyribose deoxythymidine1 Deoxythymidine-5’-monophos-
phate or 5’-deoxythymidylate(5’-dTMP)1
Cytosine (C) deoxyribose deoxycytidine Deoxycytidine-5’-monophos-phate or 5’-deoxycytidylate (5’-dCMP)
Adenine (A) deoxyribose deoxyadenosine Deoxyadenosine-5’-monophosphate or 5’-deoxyadenylate (5’-dAMP)
Guanine (G) deoxyribose deoxyguanosine Deoxyguanosine-5’-monophosphate or 5’-deoxyguanylate (5’-dGMP)
1Deoxythymidine and deoxythymidine-5’-monophosphate are also called thymidine andthymidine-5’-monophosphate, respectively. When thymine is attached to ribose, thenucleoside is called ribothymidine and the nucleotide is called ribothymidylate. Thisnomenclature convention follows from the fact that thymine is most frequently attachedto deoxyribose.
TABLE 1.1 Bases, Nucleosides, and Nucleotides
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 8
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

CHAPTER 1 Introduction to Molecular Biology 9
N
NH2
NH2
CH2
CH2
N
N N
N
N
N
HN
O
OO
O
O
O–
O–
P
P
N
N
NH2
O
O
H2C
H2C
O
OO
O
O
O
O
O– P
HNCH3
NO
O
O
O–
PO
O
O
Guanine Cytosine
AdenineThymine
FIGURE 1.9 The tetronucleotide structure proposed by Phoebus A. Levene.
This structure shows the correct connectivity between nucleotides but as-sumes that the structure closes on itself (is circular rather than linear). Al-though wrong, Levene's proposal had a marked influence on the field ofnucleic acid chemistry for many years. Adapted from Klug, W. S., andCummings, M. R. Concepts of Genetics, 2/e. Merrill Publishing Company, 1986.
there did seem to be many kinds of different proteins. Furthermore,proteins, along with DNA, were known to be part of the chromo-somes, distinct structures in the nucleus that had been demonstratedto carry genes. Once DNA had been eliminated as the genetic mate-rial because it seemed to be a “dumb” molecule, investigators focusedon proteins.
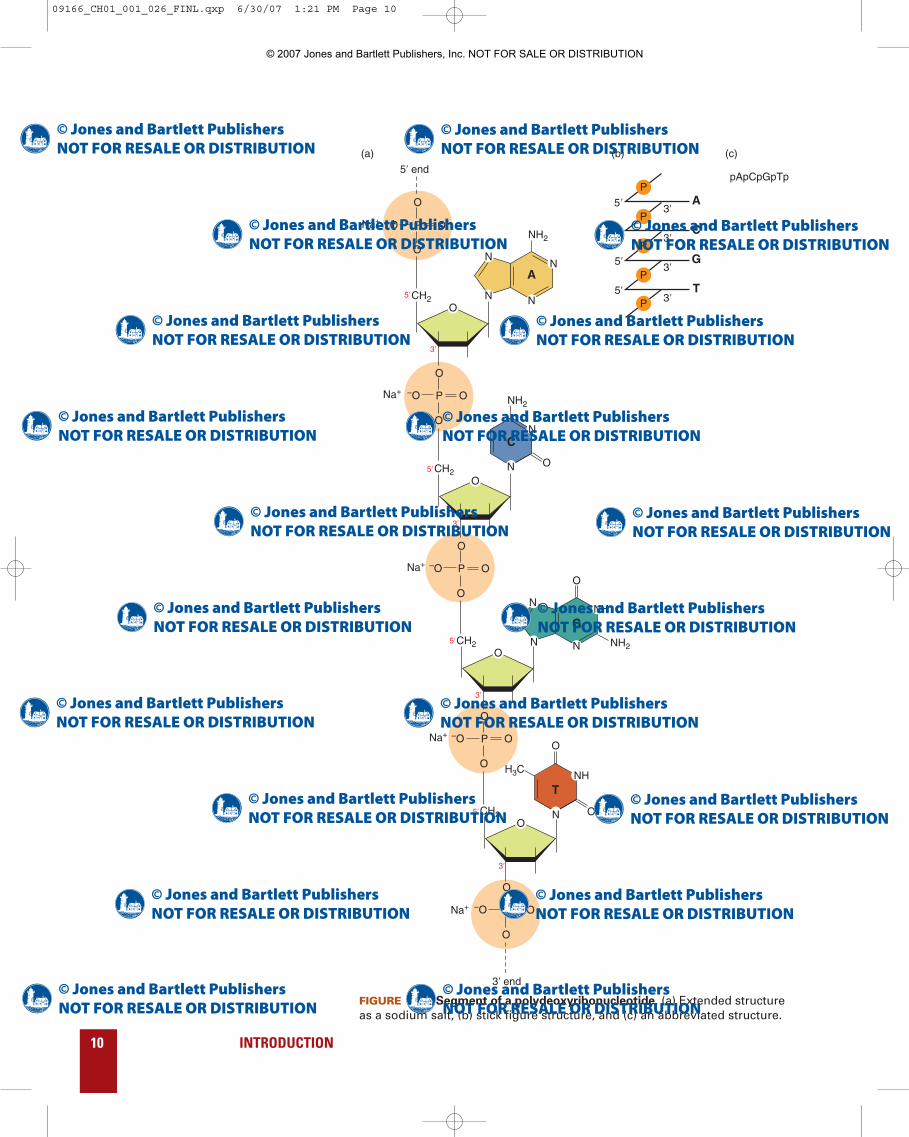
It was not until 1952 that the distinguished British organic chemistLord Alexander Robertus Todd and his associates showed the waythat the various groups in DNA are joined together. These DNA groupsform a long unbranched polymer in which phosphate groups join 5′-and 3′-carbons of neighboring deoxyribonucleosides (FIGURE 1.10a).Thus, each linear DNA chain has a 3′- and a 5′-terminus. This direc-tionality will be very important in future discussions of DNA struc-ture and function. The structure of RNA is very similar to that forDNA (FIGURE 1.11a).
Just three years after the discovery that nucleic acids are linearchains of nucleotides, Frederick Sanger working in England showedthat each kind of polypeptide molecule is a linear chain of aminoacids arranged in a specific order. The amino acid order is responsi-ble for the unique physical and chemical properties of each type ofprotein, including its ability to catalyze specific reactions, protectcells from foreign organisms and substances, transport materials, orsupport the cellular infrastructure. The awareness that DNA mole-
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 9
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
10 INTRODUCTION
N
N
N
N
NH2
CH2O
N
N
NH
N NH2
O
CH2O
N
N
NH2
OCH2O
NH H3C
N O
O
CH2O
5ʹ end
3ʹ end
3ʹ
3ʹ
O
O
O–Na+
Na+
Na+
Na+
Na+
P O
O
O
O– P O
O
O
O– P O
O
O
O– P O
O
O
O– P O
5ʹ
3ʹ
5ʹ
3ʹ
5ʹ
A
A
C
G
T
C
G
T
(a) (b) (c)
5ʹ 3ʹ
3ʹ
3ʹ
3ʹ
P
P
5ʹ
P
5ʹ
P
5ʹ
P
pApCpGpTp
5ʹ
FIGURE 1.10 Segment of a polydeoxyribonucleotide. (a) Extended structureas a sodium salt, (b) stick figure structure, and (c) an abbreviated structure.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 10
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
CHAPTER 1 Introduction to Molecular Biology 11
N
N
N
N
NH2
CH2O
OH
OH
OH
OH
OH
N
N
NH
N NH2
O
CH2O
N
N
NH2
OCH2O
NH
N O
O
CH2O
5ʹ end
3ʹ end
O
O
O–Na+
Na+
Na+
Na+
P O
O
O
O– P O
O
O
O– P O
O
O
O– P O
O
O
O– P O
OH
OH
OH
3ʹ
5ʹ
3ʹ
5ʹ
3ʹ
5ʹ
3ʹ
5ʹ
A
A
C
G
U
C
G
U
(a) (b) (c)
5ʹ 3ʹ
3ʹ
3ʹ
3ʹ
P
P
5ʹ
P
5ʹ
P
5ʹ
P
pApCpGpUp
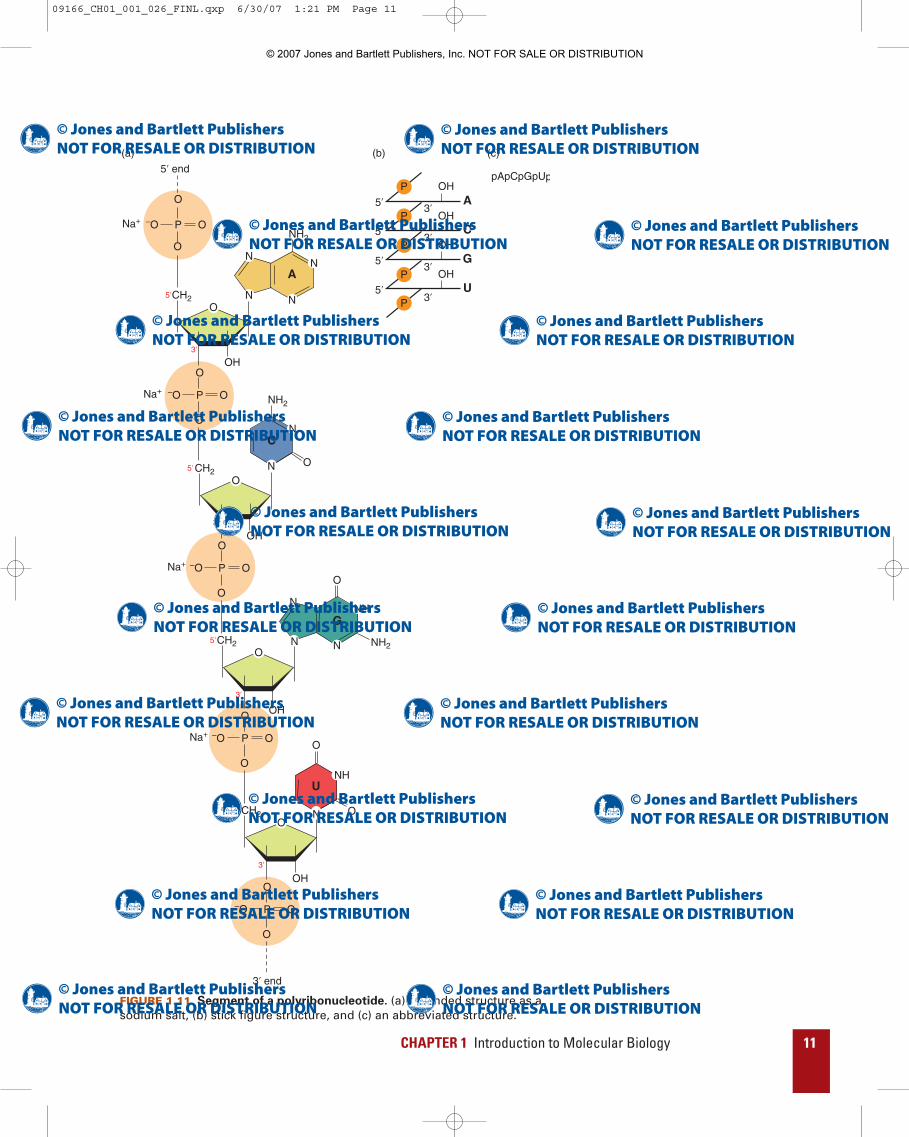
FIGURE 1.11 Segment of a polyribonucleotide. (a) Extended structure as asodium salt, (b) stick figure structure, and (c) an abbreviated structure.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 11
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

cules are made of linear chains of nucleotides and polypeptides aremade of linear chains of amino acids led to the sequence hypothesisthat proposes nucleotide sequences specify amino acid sequences.
Drawing extended structures for DNA and RNA chains requiresconsiderable time and space. It is more convenient to draw stick fig-ure structures, which are adequate representations for many pur-poses (FIGURES 1.10b and 1.11b). The few simple conventions fordrawing stick figure representations for DNA and RNA are as fol-lows: (1) A single horizontal line represents the pentose ring. (2) Theletter A, G, C, U or T, at one end of the horizontal line, represents thepurine or pyrimidine attached to C-1′ of the pentose ring. (3) The let-ter P, connected by short diagonal lines to adjacent horizontal lines,represents the 5′→3′ phosphodiester bond. (4) The symbol OH rep-resents a hydroxyl group. An even simpler method for indicating nu-cleotide sequence is to just write the letters corresponding to thebases (FIGURES 1.10c and 1.11c).
Transformation experiments led to the discovery that
DNA is the hereditary material.
The first hint that genes are made of DNA came from an observationmade in 1928 by Fred Griffith, who was studying Streptococcuspneumoniae, the bacterium responsible for human pneumonia. Thevirulence of this bacterium was known to depend on a surroundingpolysaccharide capsule that protects the bacterium from the body’sdefense systems. This capsule also causes the bacterium to producesmooth-edged (S) colonies on an agar surface. It was known that Sbacteria normally killed mice. Griffith isolated a rough-edged (R)colony mutant, which proved to be both non-encapsulated and non-lethal. He then observed that while either live R or heat-killed S bac-teria are non-lethal, a mixture of the two is lethal (FIGURE 1.12).Furthermore, when bacteria were isolated from a mouse that haddied from such a mixed infection, the bacteria were live S and R.Therefore, the live-R bacteria had somehow either been replaced byor transformed to S bacteria.
Several years later, investigators showed that the mouse itself wasnot needed to mediate this transformation because when a mixturecontaining live R bacteria and heat-killed S bacteria was incubated inculture medium, living S cells were produced. One possible explana-tion for this surprising phenomenon was that the R cells restored theviability of the dead S cells. However, this hypothesis was eliminatedby the observation that living S cells appeared even when the heat-killed S culture in the mixture was replaced by a cell extract preparedfrom broken S cells, which had been freed from both intact cells andthe capsular polysaccharide by centrifugation. Hence, it was con-cluded that the cell extract contained a transforming principle, thenature of which was unknown.
The next development occurred in 1944 when Oswald Avery,Colin MacLeod, and Maclyn McCarty determined the chemical natureof the transforming principle. They did so by isolating DNA from S
12 INTRODUCTION
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 12
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
cells and adding the DNA to live R bacterial cultures (FIGURE 1.13). Af-ter allowing the mixture to incubate for a period of time, they placedsamples on an agar surface and incubated them until colonies ap-peared. Some of the colonies (about 1 in 104) that grew were S type. Toshow that this was a permanent genetic change, Avery and coworkersdispersed many of the newly formed S colonies and placed them on asecond agar surface. The resulting colonies were again S type. If an Rcolony arising from the original mixture was dispersed, only R bacte-ria grew in subsequent generations. Hence, the R colonies retained theR character, whereas the transformed S colonies bred true as S. BecauseS and R colonies differed by a polysaccharide coat around each S bac-terium, Avery and coworkers tested the ability of purified polysac-charide to transform, but observed no transformation. Since theprocedures for isolating DNA then in use produced DNA containingmany impurities, it was necessary to provide evidence that the transfor-mation was actually caused by DNA and not an impurity. This evi-dence was provided by the following four procedures.
1. Chemical analysis of samples containing the transformingprinciple showed that the major component was a deoxyri-bose-containing nucleic acid.
2. Physical measurements showed that the sample contained ahighly viscous substance having the properties of DNA.
3. Incubation with trypsin or chymotrypsin, enzymes that catalyzeprotein hydrolysis, or with ribonuclease (RNase), an enzyme
CHAPTER 1 Introduction to Molecular Biology 13
LivingS cells
LivingR cells
Heat-killedS cells
Living R cells plusheat-killed S cells
Mouse contractspneumonia
Mouse contractspneumonia
Mouse remainshealthy
Mouse remainshealthy
S colonies isolatedfrom tissue of dead mouse
R and S colonies isolatedfrom tissue of dead mouse
R colonies isolatedfrom tissue
No colonies isolatedfrom tissue
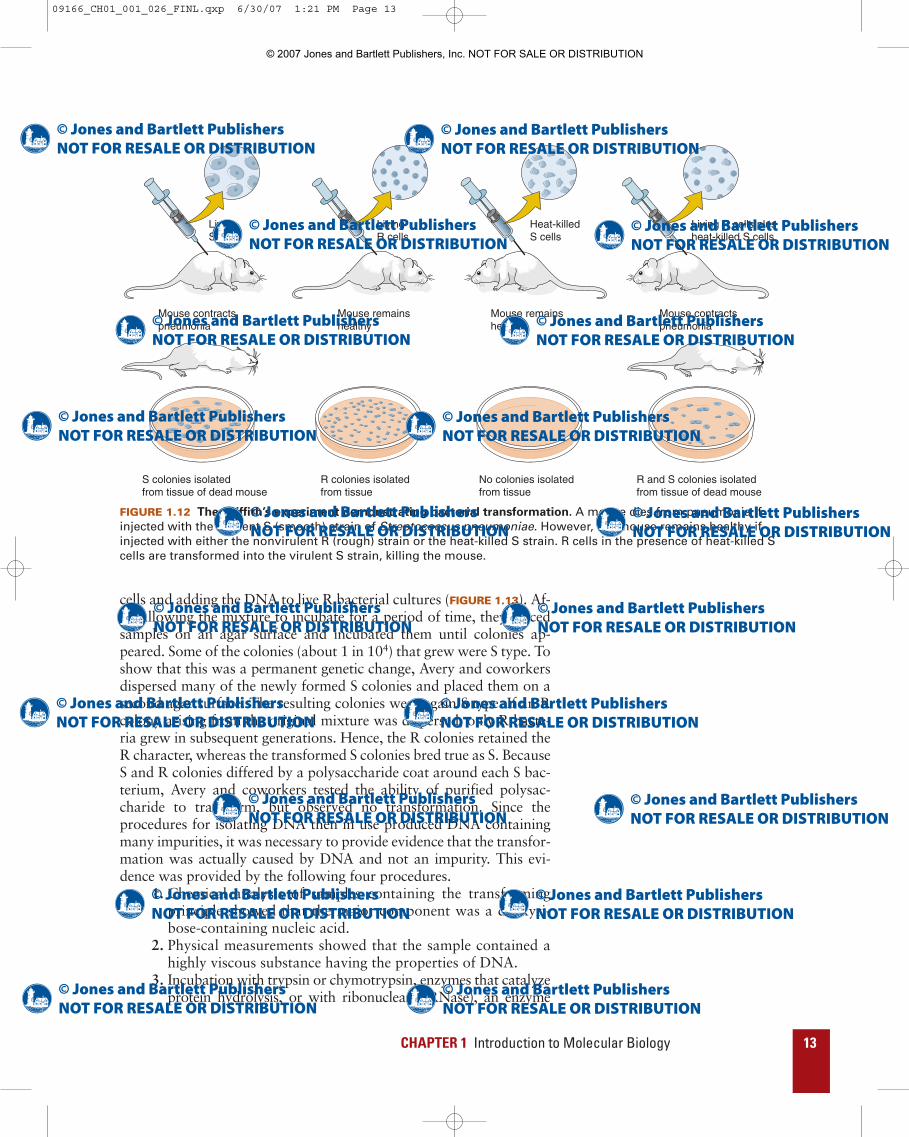
FIGURE 1.12 The Griffith’s experiment demonstrating bacterial transformation. A mouse dies from pneumonia ifinjected with the virulent S (smooth) strain of Streptococcus pneumoniae. However, the mouse remains healthy ifinjected with either the nonvirulent R (rough) strain or the heat-killed S strain. R cells in the presence of heat-killed Scells are transformed into the virulent S strain, killing the mouse.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 13
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

that catalyzes RNA hydrolysis, did not affect transforming activ-ity. Thus, the transforming principle is neither protein nor RNA.
4. Incubation with deoxyribonuclease (DNase), an enzyme thatcatalyzes DNA hydrolysis, inactivated the transforming prin-ciple.
In drawing conclusions from their experiments, Avery, MacLeod,and McCarty avoided stating explicitly that DNA was the hereditarymaterial and concluded at the end of their work only that nucleicacids have “biological specificity, the chemical basis of which is as yetundetermined.” The problem they faced in persuading the scientificcommunity to accept their conclusion was that the hereditary mate-rial had to be a substance capable of enormous variation in order tocontain the information carried by the huge number of genes. How-ever, the tetranucleotide hypothesis seemed incompatible with theidea that DNA could be the sole component of the hereditary mate-rial. Furthermore, the consensus was that genes were made of chro-mosomal protein, an idea that, in the course of a 40-year period, hadlogically evolved from the recognition that protein composition andstructure varied greatly among organisms. For these reasons, thetransformation experiments had little initial impact. Investigatorswho supported the genes-as-protein theory posed two alternative ex-planations for the transformation results. (1) The transforming prin-ciple might not be DNA but rather one of the proteins invariablycontaminating the DNA sample. (2) DNA somehow affected capsuleformation directly by acting in the metabolic pathway for biosynthe-sis of the polysaccharide and permanently altering this pathway. The
14 INTRODUCTION
EncapsulatedS strain Cell-free
extractTransforming principlefrom S strain
Transforming principlefrom S strain
R strain
1. Disrupt cells2. Centrifuge
Mix and spreadon agar plates
Culture containingboth S and R cells
1. Precipitate with ethanol2. Redissolve in water
Preparation of transforming principle from S strain
Addition of transforming principle to R strain
FIGURE 1.13 The Avery, MacLeod, and McCarty transformation experiment.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 14
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

first point should have already been discounted by the original workbecause the experiments showed insensitivity to proteolytic enzymesand sensitivity to DNase. However, since the DNase was not a pureenzyme, the possibility could not be eliminated conclusively.
The transformation experiment was repeated five years later byRollin Hotchkiss with a DNA sample with a protein content that wasonly 0.02%, and it was found that this extensive purification did notreduce the transforming activity. This result supported the view of Av-ery, MacLeod, and McCarty but still did not prove it. The second al-ternative, however, was clearly eliminated—also by Hotchkiss—withan experiment in which he transformed a penicillin-sensitive bacterialstrain to penicillin-resistance. Because penicillin resistance is totallydistinct from the rough-smooth character of the bacterial capsule,this experiment showed that the transforming ability of DNA wasnot limited to capsule synthesis. Interestingly enough, most biologistsstill remained unconvinced that DNA was the genetic material. It wasnot until Erwin Chargaff showed in 1950 that a wide variety ofchemical structures in DNA were possible—thus allowing biologicalspecificity—that this idea was accepted.
Chemical experiments also supported the hypothesis
that DNA is the hereditary material.
The hypothesis of a tetranucleotide structure for DNA arose from thebelief that DNA contained equimolar quantities of adenine, thymine,guanine, and cytosine. This incorrect conclusion arose for two rea-sons. First, in the chemical analysis of DNA, the technique used toseparate the bases before identification did not resolve them verywell, so the quantitative analysis was poor. Second, the DNA ana-lyzed was usually isolated from animals, plants, and yeast in whichthe four bases are present in nearly equimolar concentration, or frombacterial species such as Escherichia coli that also happened to havenearly equimolar base concentrations. Using the DNA from a widevariety of organisms, Chargaff applied new separation and analyticaltechniques and showed that the molar content of bases (generallycalled the base composition) could vary widely. The base composi-tion of DNA from a particular organism is usually expressed as afraction of all bases that are G • C pairs. This fraction called the G +C content can be expressed as follows:
G + C content = ([G] + [C])/[all bases]where the square brackets ([ ]) denote molar concentrations.
Chargaff’s studies also revealed one other remarkable fact aboutDNA base composition. In each of the DNA samples that Chargaffstudied, he found that [A] = [T] and [G] = [C]. Although the signifi-cance of these equalities, known as Chargaff’s rules, was not imme-diately apparent, they would later help to confirm the structure of theDNA molecule.
Base compositions of hundreds of organisms have been deter-mined. Generally speaking, the value of the G + C content is near0.50 for the higher organisms and has a very small range from one
CHAPTER 1 Introduction to Molecular Biology 15
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 15
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

species to the next (0.49–0.51 for the primates). For the lower organ-isms, the value of the G + C content varies widely from one genus toanother. For example, for bacteria the extremes are 0.27 for thegenus Clostridium and 0.76 for the genus Sarcina; E. coli DNA hasthe value 0.50. Thus, it was demonstrated that DNA could have vari-able composition, a primary requirement for the hereditary material.Upon publication of Chargaff’s results, the tetranucleotide hypothe-sis quietly died and the DNA-gene idea began to catch on. Shortly af-terward, workers in several laboratories found that, for a widevariety of organisms, somatic cells have twice the DNA content ofgerm cells, a characteristic to be expected of the genetic material,given the tenets of classical chromosome genetics. Although it couldapply just as well to any component of chromosomes, once this resultwas revealed, objections to the work of Avery, MacLeod, and Mc-Carty were no longer heard, and the hereditary nature of DNA rap-idly became the fashionable idea.
The blender experiment demonstrated that DNA is the
genetic material in bacterial viruses.
An elegant confirmation that DNA is the hereditary material camefrom an experiment performed by Alfred Hershey and Martha Chasein 1952 in which viral replication was studied in the bacterium E.coli. Bacterial viruses are called bacteriophages or phages for short(see Chapter 8 for more information about bacteriophages and otherviruses). The experiment, known as the blender experiment becausea kitchen blender was used as a major piece of apparatus, demon-strated that the DNA injected by a bacteriophage T2 particle into abacterium contains all of the information required to synthesizeprogeny phage particles. A single phage T2 particle consists of DNA(now known to be a single molecule) encased in a protein shell and along protein tail by which it attaches to sensitive bacteria (FIGURE
1.14). Hershey and Chase showed that an attached phage can be tornfrom a bacterial cell wall by violent agitation of the infected cells in akitchen blender. Thus, it was possible to separate an absorbed phagefrom a bacterium and determine the component(s) of the phage thatcould not be shaken free by agitation; presumably, those componentshad been injected into the bacterium.
DNA is the only phosphorus-containing substance in the phageparticle. The proteins of the shell, which contain the amino acids me-thionine and cysteine, have the only sulfur atoms. T2 phage contain-ing radioactive DNA can be prepared by infecting bacteria with T2phage in a growth medium that contains [32P]phosphate as the solesource of phosphorus. If instead the growth medium contains ra-dioactive sulfur as [35S]sulfate, phage containing radioactive proteinsare obtained. When these two kinds of labeled phages are used to in-fect a bacterial host, the phage DNA and the protein molecules canalways be located by their radioactivity. Hershey and Chase usedthese phages to show that 32P but not 35S remains associated with thebacterium.
16 INTRODUCTION
FIGURE 1.14 Bacteriophage T2. (a) Drawingof E. coli phage T2, showing various compo-nents. The DNA, which is confined to the inte-rior of the head, is the only componentlabeled by 32P. Methionine and cysteine in theproteins can be labeled with 35S. (b) An elec-tron micrograph of phage T4, a closely relatedphage. [Electron micrograph courtesy of RobertDuda, University of Pittsburgh.]
(a)
(b)
Protein
DNA
Head(proteinand DNA)
Tail(proteinonly)
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 16
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

CHAPTER 1 Introduction to Molecular Biology 17
35S-Labeled phage particles were adsorbed to bacteria for a fewminutes. The bacteria were separated from unadsorbed phage andphage fragments by centrifuging the mixture and collecting the sedi-ment (the pellet), which consisted of the phage-bacterium complexes.These complexes were resuspended in aqueous solutions and blended.The suspension was again centrifuged, and the pellet (consisting al-most entirely of bacteria) and the supernatant were collected. It wasfound that 80% of the radioactive sulfur was in the supernatant and20% was in the pellet. The 20% of the 35S that remained associatedwith the bacteria was shown many years later to consist mostly ofphage tail fragments that adhered too tightly to the bacterial surfaceto be removed by the blending. A very different result was observedwhen the phage population was labeled with radioactive phosphate.In this case, 70% of the 32P remained associated with the bacteria inthe pellet after blending and only 30% was in the supernatant. Of theradioactivity in the supernatant, roughly one third could be accountedfor by breakage of the bacteria during the blending. (The remainderwas shown some years later to be a result of defective phage particlesthat could not inject their DNA.) When the pellet material was resus-pended in growth medium and reincubated, it was found to be capa-ble of phage production. Thus, the ability of a bacterium to synthesizeprogeny phage is associated with transfer of 32P, and hence of DNA,from parental phage to the bacteria.
Another series of experiments (FIGURE 1.15), known as transferexperiments, supported the interpretation that genetic material con-tains 32P but not 35S. In these experiments, progeny phage were iso-lated, after blending, from cells that had been infected with either 35S-or 32P-containing phage and the progeny were then assayed for ra-dioactivity. The idea was that some parental genetic material shouldbe found in the progeny. No 35S but about half of the injected 32P wastransferred to the progeny. This result indicated that although 35Smight be residually associated with the phage-infected bacteria, itwas not part of the phage genetic material. The interpretation (nowknown to be correct) of the transfer of only half of the 32P was thatprogeny DNA is selected at random for packaging into protein coatsand that all progeny DNA is not successfully packaged.
RNA serves as the hereditary material in some viruses.
The transformation and blender experiments settled once and for allthe question of the chemical identity of the genetic material. The ab-solute generality of the conclusion remained in question, though, be-cause several plant and animal viruses were known to containsingle-stranded RNA and no DNA. These particles became under-standable shortly afterward as the role of RNA in the flow of infor-mation from gene to protein became clear. That is, DNA storesgenetic information for protein synthesis and the pathway fromDNA to protein always requires the synthesis of an RNA intermedi-ate, which is copied from a DNA template. Thus, a virus that lacksDNA utilizes the base sequence of RNA both for storage of informa-
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 17
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
18 INTRODUCTION
Infection withnonradioactive T2 phage
Infection withnonradioactive T2 phage
E. coli cells grownin 32P-containing medium (labels DNA)
E. coli cells grownin 35S-containing medium (labels protein)
Phage reproduction; cell lysis releases DNA-labeled progeny phage
Phage reproduction;cell lysis releases protein-labeled progeny phage
DNA-labeled phage used to infect nonradioactive cells
Protein-labeled phage used to infect nonradioactive cells
Infected cell Infected cell
Phage reproduction; cell lysisreleases progeny phage that contain some 32P-labeled DNAfrom the parental phage DNA
Phage reproduction; cell lysis releases progeny phage that contain almost no 35S-labeled protein
After infection, part of phageremaining attached to cells isremoved by violent agitationin a kitchen blender
After infection, part of phageremaining attached to cells isremoved by violent agitationin a kitchen blender
Infectinglabeled DNA
Infectingnonlabeled DNA
(a) (b)
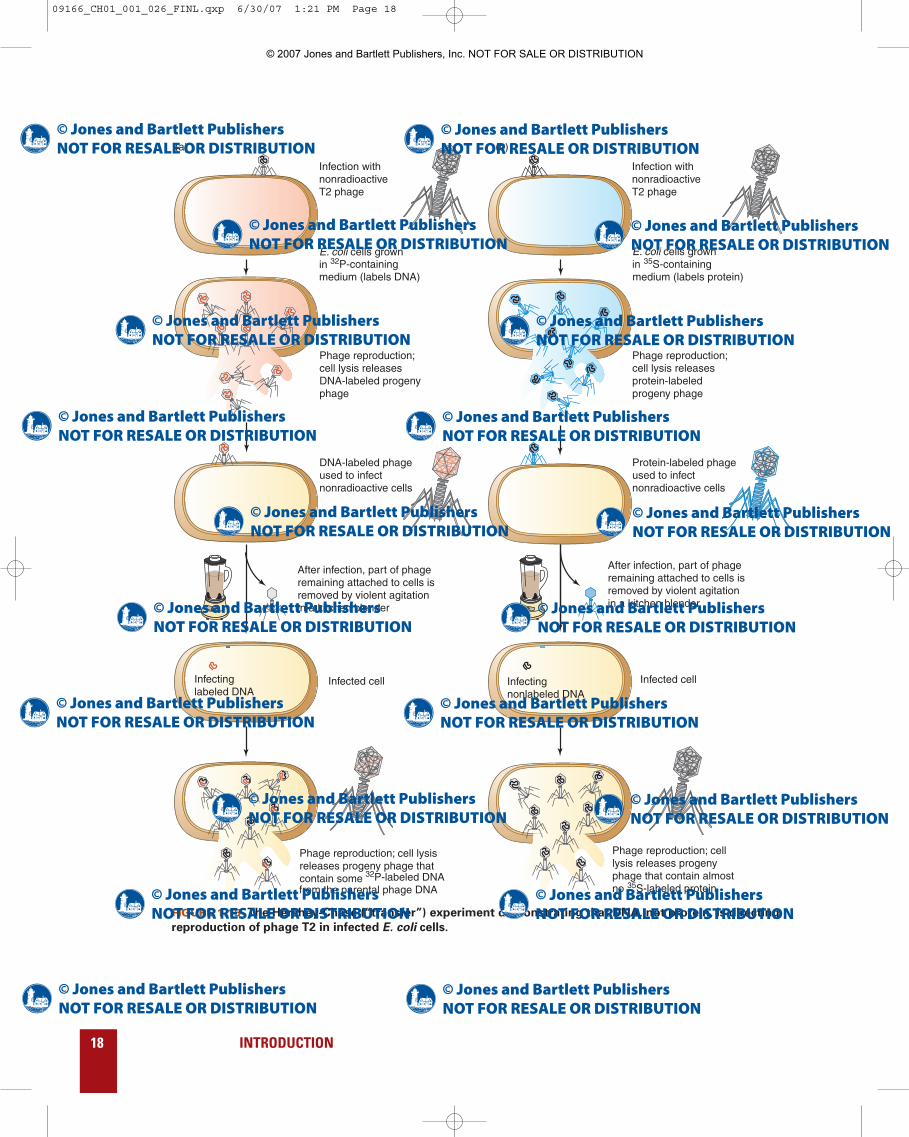
FIGURE 1.15 The Hershey-Chase (“transfer”) experiment demonstrating that DNA, not protein, is directing
reproduction of phage T2 in infected E. coli cells.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 18
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

tion and as a template from which the amino acid sequence of pro-teins can be obtained. RNA does not serve these two functions as ef-ficiently as the DNA→RNA system, but it does work.
Rosalind Franklin and Maurice Wilkins obtained x-ray
diffraction patterns of extended DNA fibers.
At the same time that chemists were attempting to learn somethingabout the composition of DNA, crystallographers were trying to ob-tain a three-dimensional image of the molecule. Rosalind Franklin andMaurice Wilkins obtained some excellent x-ray diffraction patterns ofextended DNA fibers in the early 1950s (FIGURE 1.16). One might pre-dict that all the x-ray diffraction patterns would look alike, but thiswas not the case. DNA structure and, therefore, x-ray diffraction pat-terns depend on several variables. One of the most important of theseis the relative humidity of the chamber in which DNA fibers are placed.
Two types of DNA structure are of particular interest. B-DNA isstable at a relative humidity of about 92%. A-DNA appears as the rel-ative humidity falls to about 75%. Crystallographers did not knowwhether A-DNA or B-DNA is present in the living cell. Partly for thisreason, Wilkins turned his attention toward taking x-ray diffractionpictures of DNA in sperm cells. Franklin focused her attention on x-ray diffraction patterns of A-DNA because they appeared to providemore detail. She believed that careful analyses of the detailed patternswould eventually lead to the solution of DNA’s structure.
James Watson and Francis Crick proposed that DNA is a
double-stranded helix.
The American biologist, James D. Watson, and the English crystallog-rapher, Francis Crick, working together in England, took a differentapproach to determining DNA’s structure. They tried to obtain asmuch information as they could from the x-ray diffraction patternsand then to build a model consistent with this information.
The term model has a special meaning to scientists. A model is ahypothesis or tentative explanation of the way a system works, usu-ally including the components, interactions, and sequences of events.A successful model suggests additional experiments and allows inves-tigators to make predictions that can be tested in the laboratory. Ifpredictions do not agree with experimental results, the model mustbe considered incorrect in its current form and modified. A modelcannot be proved to be correct merely by showing that it makes acorrect prediction. However, if it makes many correct predictions, itis probably nearly, if not completely, correct.
Watson and Crick focused their attention on Franklin’s x-ray dif-fraction patterns of B-DNA. This pattern indicated that B-DNA hasa helical structure, a diameter of approximately 2.0 nm, and a repeatdistance of 0.34 nm. Their model would have to account for thesestructural features. Watson and Crick still had to work out the num-ber of DNA chains in a DNA molecule, the location of the bases, andthe position of the phosphate and deoxyribose groups. The density of
CHAPTER 1 Introduction to Molecular Biology 19
A-form DNA
B-form DNA
FIGURE 1.16 X-ray diffraction patterns of the
A and B forms of the sodium salt of DNA.
Reproduced from Franklin, R. E., and Gosling,R.G., Acta Crystallographica 6 (1953): 673–677.Photos courtesy of International Union ofCrystallography.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 19
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

FIGURE 1.17 The figure in the 1953 paper byWatson and Crick in Nature that shows theirdouble helix model for DNA for the first time.Reproduced from Watson, J. D., and Crick, F. H. C., Nature 171 (1953): 737–738.
DNA seemed to be consistent with one, two, or three chains per mol-ecule. Watson and Crick tried to build a two-chain model with hy-drogen bonds (weak electrostatic attractions; see Chapter 2) holdingthe bases together. They were unsuccessful until Jerry Donohue sug-gested that they use the keto tautomeric forms of T and G in theirmodels. At first, Watson tried to link two purines together and twopyrimidines together in what he called a “like-with-like” model. Adramatic turning point occurred in 1953 when Watson realized thatadenine forms hydrogen bonds with thymine and guanine forms hy-drogen bonds with cytosine. Watson describes this turning point inhis book, The Double Helix:
“When I got to our still empty office the following morning,I quickly cleared away the paper from my desk top so thatI would have a large, flat surface on which to form pairs ofbases held together by hydrogen bonds. Though I initiallywent back to my like-with-like prejudices, I saw all toowell that they led nowhere. When Jerry [Donohue] came inI looked up, saw that it was not Francis [Crick], and beganshifting the bases in and out of various other pairing possi-bilities. Suddenly I became aware that an adenine-thyminepair held together by two hydrogen bonds was identical inshape to a guanine-cytosine base pair held together by atleast two hydrogen bonds. All the hydrogen bonds seemedto form naturally; no fudging was required to make thetwo types of base pairs identical in shape.”
With the realization that adenine-thymine and cytosine-guanine basepairs have the same width, Watson and Crick were quickly able toconstruct a double helix model of DNA that fit Franklin’s x-ray dif-fraction data (FIGURE 1.17).The key features of the Watson-Crick Model for B-DNA are as follows:
1. Two polydeoxyribonucleotide strands twist about each otherto form a double helix.
2. Phosphate and deoxyribose groups form a backbone on theoutside of the helix.
3. Purine and pyrimidine base pairs stack inside the helix andform planes perpendicular to the helix axis and the deoxyri-bose groups.
4. The helix diameter is 2.0 nm (or 20 Å). 5. Adjacent base pairs are separated by an average distance of
0.34 nm (or 3.4 Å) along the helix axis. The structure repeatsitself after about ten base pairs, or about once every 3.4 nm(or 34 Å) along the helix axis.
6. Adenine always pairs with thymine and guanine with cyto-sine. The original model showed two hydrogen bonds stabi-lizing each kind of base pair. Although this was an accuratedescription for A-T base pairs, later work showed that G-Cbase pairs are stabilized by three hydrogen bonds (FIGURE
1.18). (These base pairing relationships explained Chargaff’sobservation that the molar ratios of adenine to thymine andguanine to cytosine are one.)
20 INTRODUCTION
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 20
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

7. The two strands are antiparallel, which means that thestrands run in opposite directions. That is, one strand runs3′→5′ in one direction while the other strand runs 5′→3′ inthe same direction. Because the strands are antiparallel, aconvention is needed for stating the sequence of bases of asingle chain. The convention is to write a sequence with the5′-P terminus at the left; for example, ATC denotes the trinu-cleotide 5′-ATC-3′. This is also often written as pApTpC,again using the conventions that the left side of each base isthe 5′-terminus of the nucleotide and that a phosphodiestergroup is represented by a p between two capital letters.
8. A major and a minor groove wind about the cylindrical outerhelical face. The two grooves are of about equal depth but themajor groove is much wider than the minor groove.
The Watson-Crick Model indicates that when the nucleotide sequenceof one strand is known, the sequence of the complementary strandcan be predicted, providing the theoretical framework needed to un-derstand the fidelity of gene replication. Each strand serves as a moldor template for the synthesis of the complementary strand (FIGURE
1.19). Watson and Crick ended their short paper announcing the dou-ble helix model with the following sentence that must be one of thegreatest understatements in the scientific literature: “It has not es-caped our notice that the specific pairing we have postulated im-mediately suggests a possible copying mechanism for the geneticmaterial.” The double helix showed how establishing a chemicalstructure can be used to understand biological function and to makepredictions that guide new research.
Structure-function relationships remain a central theme of mo-lecular biology. We will see, time and again, throughout this bookhow knowledge of structure helps us to understand function andleads us to new insights. Biological structures are sometimes quite
CHAPTER 1 Introduction to Molecular Biology 21
N H
H3C
N
O
O
N
O
N
Deoxyribose
N
H N
N
N
N
NH
H
H
H
N
NH
H
O
A
Deoxyribose
N
N
N
N N
O
O
O
O
Adenine
Thymine
Guanine
Cytosine
Deoxyribose
Deoxyribose
FIGURE 1.18 Base pairs in DNA.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 21
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
complex and difficult to study. However, it is worth the effort tostudy the structures because the reward for doing so is so great. TheWatson-Crick Model also serves as a powerful example of the funda-mental principles that help to define molecular biology as a disci-pline. (1) The same physical and chemical laws apply to living systemsand inanimate objects. (2) The same biological principles tend to ap-ply to all organisms. (3) Biological structure and function are inti-mately related. The Watson-Crick Model provided an excellentstarting point for the challenging job of elucidating the chemical ba-sis of heredity.
22 INTRODUCTION
Parent duplex
Daughterduplex
Replicastrands
Templatestrands
A
T
T
A
A
G C
C G
C G
T A
C G
C G
T A
A T
C G
A T
T
T A
T
T
A
A
G C
C G
C
T AC G
C G
A T
T A
T
T
A
A
G CC G
G
T A
C G
C G
A TT A
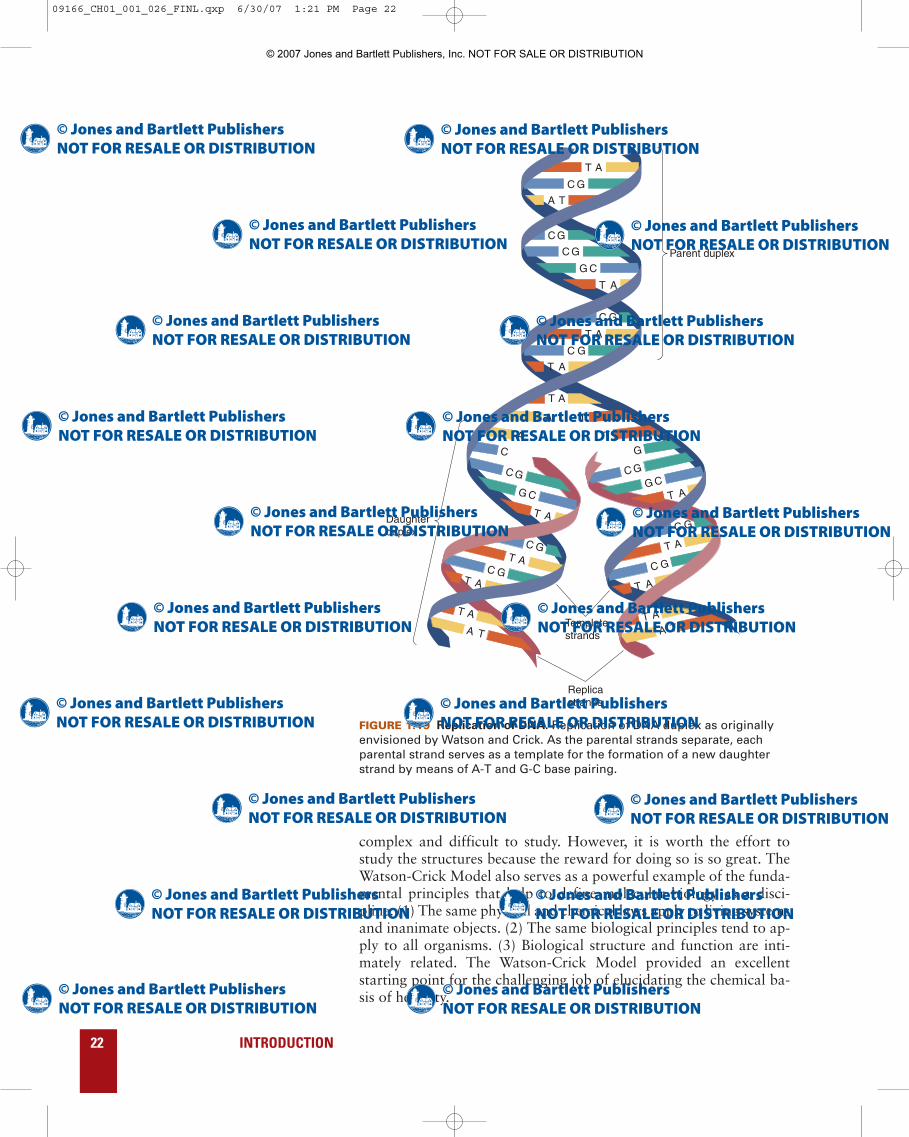
FIGURE 1.19 Replication of DNA. Replication of DNA duplex as originallyenvisioned by Watson and Crick. As the parental strands separate, eachparental strand serves as a template for the formation of a new daughterstrand by means of A-T and G-C base pairing.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 22
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

The central dogma provides the theoretical framework
for molecular biology.
Much of the research in molecular biology in the late 1950s was di-rected toward discovering the mechanisms by which nucleotide se-quences specify amino acid sequences. In a talk given at a 1957symposium, Crick suggested a model for information flow that pro-vides a theoretical framework for molecular biology. The followingexcerpt from Crick’s presentation states the theory known as the cen-tral dogma in a clear and concise fashion.
“In more detail, the transfer of information from nucleicacid to nucleic acid, or from nucleic acid to protein may bepossible, but transfer from protein to protein, or from pro-tein to nucleic acid is impossible. Information means herethe precise determination of sequence, either of bases in nu-cleic acid or of amino acid residues in protein.” Thus, Crick was proposing that genetic information flows from
DNA to DNA (DNA replication), from DNA to RNA (transcrip-tion), and from RNA to polypeptide (translation) (FIGURE 1.20).
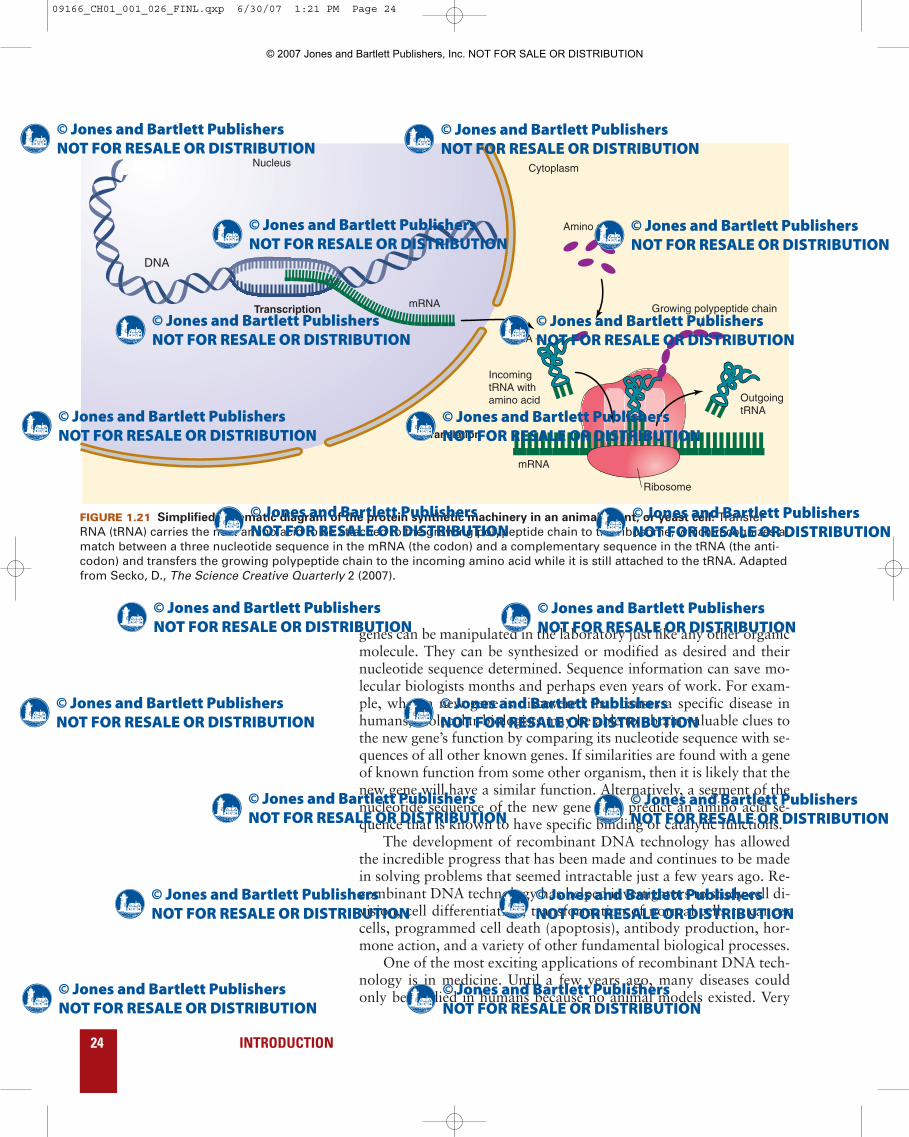
By the mid-1960s, molecular biologists had obtained consider-able experimental support for the central dogma. In particular, theyhad discovered enzymes that catalyze replication and transcriptionand elucidated the pathway for translating nucleotide sequences toamino acid sequences. With some variations in detail, all organismsuse the same basic mechanism to translate information from nucleo-tide sequences to amino acid sequences. Three major components ofthe translation machinery—messenger RNA (mRNA), ribosomes,and transfer RNA (tRNA)—play major roles in this information trans-fer (FIGURE 1.21). Each gene can serve as a template for the synthesisof specific mRNA molecules. Messenger RNA molecules program ri-bosomes (protein synthetic factories) to form specific polypeptides.Transfer RNA molecules carry activated amino acids to programmedribosomes, where under the direction of the mRNA the amino acidsjoin to form a polypeptide chain. The twelve years of extraordinaryscientific progress that followed the discovery of DNA’s structure werecapped by a series of brilliant investigations by Marshal W. Niren-berg and others that culminated in deciphering the genetic code. By1965, investigators could predict a polypeptide chain’s amino acidsequence from a DNA or mRNA molecule’s nucleotide sequence. Re-markably, the genetic code was found to be nearly universal. Eachparticular sequence of three adjacent nucleotides or codon specifiesthe same amino acid in bacteria, plants, and animals. Could one askfor more convincing support for the uniformity of life processes?
Recombinant DNA technology allows us to study com-
plex biological systems.
The second major wave in molecular biology started in the late 1970swith the development of recombinant DNA technology (also knownas genetic engineering). Thanks to recombinant DNA technology,
CHAPTER 1 Introduction to Molecular Biology 23
Transcription
Translation
DNA
mRNA
Ribosome
Polypeptide
Replication
FIGURE 1.20 The “central dogma.” The cen-tral dogma as originally proposed by FrancisCrick postulated information flow from DNAto RNA to protein. The ribosome is an essen-tial part of the translation machinery. Laterstudies demonstrated that information canalso flow from RNA to RNA and from RNA toDNA (reverse transcription).
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 23
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION
genes can be manipulated in the laboratory just like any other organicmolecule. They can be synthesized or modified as desired and theirnucleotide sequence determined. Sequence information can save mo-lecular biologists months and perhaps even years of work. For exam-ple, when a new gene is discovered that causes a specific disease inhumans, molecular biologists may be able to obtain valuable clues tothe new gene’s function by comparing its nucleotide sequence with se-quences of all other known genes. If similarities are found with a geneof known function from some other organism, then it is likely that thenew gene will have a similar function. Alternatively, a segment of thenucleotide sequence of the new gene may predict an amino acid se-quence that is known to have specific binding or catalytic functions.
The development of recombinant DNA technology has allowedthe incredible progress that has been made and continues to be madein solving problems that seemed intractable just a few years ago. Re-combinant DNA technology has helped investigators to study cell di-vision, cell differentiation, transformation of normal cells to cancercells, programmed cell death (apoptosis), antibody production, hor-mone action, and a variety of other fundamental biological processes.
One of the most exciting applications of recombinant DNA tech-nology is in medicine. Until a few years ago, many diseases couldonly be studied in humans because no animal models existed. Very
24 INTRODUCTION
DNA
mRNA Growing polypeptide chain
Incoming tRNA withamino acid
tRNA
Amino acids
Outgoing tRNA
mRNA
Ribosome
Nucleus Cytoplasm
Transcription
Translation
FIGURE 1.21 Simplified schematic diagram of the protein synthetic machinery in an animal, plant, or yeast cell. TransferRNA (tRNA) carries the next amino acid to be attached to the growing polypeptide chain to the ribosome, which recognizes amatch between a three nucleotide sequence in the mRNA (the codon) and a complementary sequence in the tRNA (the anti-codon) and transfers the growing polypeptide chain to the incoming amino acid while it is still attached to the tRNA. Adaptedfrom Secko, D., The Science Creative Quarterly 2 (2007).
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 24
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

CHAPTER 1 Introduction to Molecular Biology 25
little progress was made in studying these diseases because of obviousethical constraints associated with studying human diseases. Once in-vestigators learned how to transfer genes from one species to another,they were able to create animal models for human diseases, thus fa-cilitating study of the diseases. Recombinant DNA technology alsohas led to the production of new drugs to treat diabetes, anemia, car-diovascular disease, and cancer as well as to the development of di-agnostic tools to detect a wide variety of diseases. The list of practicalmedical applications grows longer with each passing day.
Although recombinant DNA technology promises to change ourlives for the better, it also forces us to consider important social, po-litical, ethical, and legal issues. For example, how do we protect theinterests of an individual when DNA analysis reveals that the individ-ual has alleles that are likely to cause a serious physical or mental dis-ease in the future, especially if there is no cure or treatment? Whatimpact will the knowledge have on affected individuals and theirfamilies? Should insurance companies or potential employers haveaccess to the genetic information? If not, how do we limit access toinformation and how do we enforce the limitation? Rapid progress inrecombinant DNA technology also raises troubling ethical issues.Germ line therapy allows new genes to be introduced into fertilizedeggs and thereby alter the genetic characteristics of future genera-tions. This technique has been used to introduce desired traits intoplants and animals but it has not as yet been reported in humans.
An argument can be made for using germ line therapy to correcthuman genetic diseases such as Tay Sachs disease, cystic fibrosis, orHuntington disease so that affected individuals and their families canbe spared the devastating consequences of these diseases. However,we must be very careful about application of germ line therapy to hu-mans because the technique has the power to do great harm. Whowill decide which genetic characteristics are desirable and which areundesirable? Should the technique be used to change physical ap-pearance, intelligence, or personality traits? Should anyone be per-mitted to make such decisions?
A great deal of molecular biology information is avail-
able on the Internet.
Recombinant DNA technology has generated so much informationthat it would be nearly impossible to share all of it in a timely fash-ion with the entire molecular biology community by conventionalmeans such as publishing in professional journals or writing books.Fortunately, there is an alternate method for sharing large quantitiesof rapidly accumulating information that is both quick and efficient.A worldwide network of communication networks, the Internet, al-lows us to gain almost instant access to the information. The Internetalso provides many helpful tutorials and instructive animations. Thistext will include references to helpful Internet sites. However, be-cause the addresses for these Web sites tend to change over time, thistext will refer the reader to a primary site maintained by the publisher.
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 25
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION

Suggested Reading
General
Choudri, S. 2003. The path from nuclein to human genome: a brief history of DNAwith a note on human genome sequencing and its impact on future research in bi-ology. Bull Sci Technol Soc 23, 360–367.
Crick, F. 1988. What Mad Pursuit: A Personal View of Scientific Discovery. NewYork: Basic Books.
Crick, F. 1974. The double helix: a personal view. Nature 248:766–769.Judson, H. F. 1996.The Eighth Day of Creation: Makers of the Revolution in Biol-
ogy. Cold Spring Harbor, NY: Cold Spring Harbor Laboratory.Maddox, B. 2002. Rosalind Franklin: The Dark Lady of DNA. New York: Harper
Collins.McCarty, M. 1985. The Transforming Principle: Discovering that Genes Are Made
of DNA. New York: W.W. Norton.Olby, R. C. 1994. The Path to the Double Helix: The Discovery of DNA. New York:
Dover Publications.Pukkila, P. J. 2001. Molecular biology: the central dogma. Encyclopedia of Life Sci-
ences. pp. 1–5. London, UK: Nature Publishing Co.Sayre, A. 1978. Rosalind Franklin and DNA. New York: W. W. Norton.Stent, G. 1972. Prematurity and uniqueness in scientific discovery. Sci Am 227:84–93.Summers, W. C. 2002. History of molecular biology. Encyclopedia of Life Sciences.
pp. 1–8. London, UK: Nature Publishing Co.Watson, J. D. 1968. The Double Helix: A Personal Account of the Discovery of the
Structure of DNA. New York: Antheneum Books.Wilkins, M. 2003. The Third Man of the Double Helix: The Autobiography of Mau-
rice Wilkins. Oxford, UK: Oxford University Press.
Classic Papers
Avery, O. T., Macleod, C. M., and McCarty, M. 1944. Studies on the chemical na-ture of the substance inducing transformation of pneumococcal types. Inductionof transformation by a deoxyribonucleic acid fraction isolated from Pneumococ-cus type III. J Exp Med 79:137–156.
Beadle, G. W., and Tatum, E., 1941. Genetic control of biochemical reactions inNeurospora. Proc Nat Acad Sci USA 27:499–506.
Hershey A. D., and Chase, M. 1952. Independent functions of viral protein and nu-cleic acid in growth of bacteriophage. J Gen Physiol 36:39–56.
Watson, J. D., and Crick F. H. 1953. Molecular structure of nucleic acids; a structurefor deoxyribose nucleic acid. Nature 171:737–738.
26 INTRODUCTION
09166_CH01_001_026_FINL.qxp 6/30/07 1:21 PM Page 26
© 2007 Jones and Bartlett Publishers, Inc. NOT FOR SALE OR DISTRIBUTION