Embed Size (px)
Citation preview

- 2 -
Innehållsförteckning Innehållsförteckning.......................................................................................................... - 2 -
PAST - Introduktion.............................................................................................................. - 3 - Introduktion....................................................................................................................... - 3 - Hjälpmanual ...................................................................................................................... - 3 - Installation......................................................................................................................... - 3 -
Datahantering ........................................................................................................................ - 4 - Mata in data....................................................................................................................... - 4 - Utökning av antalet rader eller kolumner.......................................................................... - 4 - Markera celler/områden .................................................................................................... - 5 - Flytta rader/kolumner........................................................................................................ - 5 - Kopiera, klippa ut och klistra in ........................................................................................ - 5 - Radering av rader/kolumner.............................................................................................. - 5 - Importering av data ........................................................................................................... - 5 - Sortera data........................................................................................................................ - 5 -
Deskriptiv statistik................................................................................................................. - 6 - Beskrivande mått............................................................................................................... - 6 - Korrelation ........................................................................................................................ - 6 - Allmänt om grafer ............................................................................................................. - 7 - Box-plot............................................................................................................................. - 8 - Spridningsdiagram ............................................................................................................ - 8 - Konfidensintervall och t-test av teoretiskt medelvärde..................................................... - 9 -
Statistisk Inferens ................................................................................................................ - 10 - Allmänt om statistiska test .............................................................................................. - 10 - Parade data ...................................................................................................................... - 10 - Icke-parade data .............................................................................................................. - 11 - Chi2 - test ........................................................................................................................ - 13 - Fishers exakta test ........................................................................................................... - 14 -

- 3 -
PAST - Introduktion
Introduktion PAST– PAlaentological STatistics, ver 1.65 är ett program, skapat av Öyvind Hammer, D.A.T Harper och P.D Ryan, som i första hand är tänkt att används till statistiska tillämpningar inom paleontologin. Eftersom programvaran är mycket lättanvänd, och innehåller de flesta funktioner som behövs för deskriptiv statistik och för att utföra enkla tvågruppsanalyser är PAST även lämpligt för grundläggande epidemiologiska/kliniska studier. Det finns även möjligheter att utföra mer avancerade statistiska analyser i programmet, t ex ANOVA, MANOVA, Principal komponent analys, olika regressionsmodeller, mm. Dessa behandlas dock inte i detta kompendium. Fördelarna med PAST är att det är ett gratisprogram och dessutom mycket lätt att lära. Nackdelarna med programmet berör främst chi-2 och Fishers exakta test, där man först måste aggregera data innan analyserna kan genomföras. Vidare kan chi-2 endast genomföras med 2 x k-tabeller och Fishers exakta endast med 2 x 2-tabeller. Även övrig datahantering avviker i vissa avseenden från andra programvaror såsom SAS, SPSS och STATA. Vi tror dock att PAST är tillräckligt bra för att kunna klara de flesta analyser som kan bli aktuella i ST-projekten.
Hjälpmanual En manual i pdf-format för hur programmet används kan laddas ner från programmets hemsida: http://folk.uio.no/ohammer/past/.
Installation Programmet kan laddas ner gratis från http://folk.uio.no/ohammer/past. Klicka först på Download PAST och därefter Past.exe (executable), ver. 1.65. Spara programmet, t ex på skrivbordet eller i en ny mapp. Installationen sker därefter automatiskt. Dubbelklicka på ikonen (se nedan) som skapats för att starta programmet. Det har rapporterats en del (ej vanliga) problem vid installationen, se i så fall hjälpmanualen för mer information hur man skall gå tillväga.

- 4 -
När programmet öppnas Programmet ser ut som ett Excel-datablad när det öppnas:
Datahantering
Mata in data Om data skall matas in direkt i programmet kan detta endast göras om Edit mode-boxen är ikryssad enligt nedan. Vill vi dessutom namnge våra kolumner (id och age i nedanstående exempel) eller rader måste även Edit labels vara ifylld. Viktigt! Saknade värden (missing values) måste skrivas in som frågetecken (?). Alla funktioner klarar dock inte av att hantera saknade värden, mer om detta senare.
Utökning av antalet rader eller kolumner När programmet startas innehåller arbetsbladet raderna 1 till 99 samt kolumnerna A till Z. Antalet rader eller kolumner kan utökas genom att välja insert more rows… eller insert more columns… i Edit-menyn.

- 5 -
Markera celler/områden När Edit mode–boxen inte är ifylld kan en eller flera celler i arbetsbladet markeras med muspekaren. För att markera en hel rad/kolumn klickar man på rad/kolumn-namnet. Dessutom kan flera rader/kolumner markeras samtidigt genom att hålla shift-knappen nedtryckt. Observera att endast intilliggande rader/kolumner kan markeras.
Flytta rader/kolumner Rader/kolumner kan flyttas genom att klicka på rad/kolumnnamnet och dra det till dess nya position.
Kopiera, klippa ut och klistra in Markerade celler kan på samma sätt som i Excel kopieras, klippas ut och klistras in. Antingen genom att använda Edit menyn eller med hjälp av kortkommandona Ctrl+C, Ctrl+X och Ctrl+V.
Radering av rader/kolumner En rad/kolumn raderas enklast genom att först markera den och sedan klippa ut den (Ctrl+X). Det går alltså tyvärr inte att använda Delete-knappen i PAST på samma sätt som i Excel när en rad/kolumn skall tas bort.
Importering av data De flesta databaser kan överföras till tabbavgränsade text-format (*.txt) eller Excel-format (*.xls). Därför behandlas endast importering av data från dessa filtyper i detta kompendium, se hjälpmanual för hantering av övriga filformat. Kom ihåg att saknade värden måste skrivas in som frågetecken (?). Detta är oftast enklare att utföra i andra program än PAST, t ex i Excel.
• Tabbavgränsade textdokument (*.txt) kan enkelt öppnas i PAST med menyerna File → Open. Välj därefter den textfil som vill öppnas.
• Data från Excel-dokument kan importeras till PAST på två sätt: 1. Spara Excel-bladet som ett tabbavgränsat textdokument och öppna sedan i PAST
enligt föregående punkt. 2. Kopiera data från Excel-bladet och klistra in i PASTs datablad. Kom ihåg att Edit
mode-boxen måste vara ikryssad. Observera även att om du vill klistra in en hel kolumn inklusive kolumnamn så måste Edit labels-boxen vara ikryssad.
Sortera data Sortering av data görs genom att markera de celler i databladet som skall sorteras, och därefter väljs sort ascending/descending i Transform-menyn.

- 6 -
Deskriptiv statistik
Beskrivande mått Centralmått (medelvärde och median), spridningsmått (varians, standardavvikelse och standardfel) och andra beskrivande mått (antal, min och max) kan enkelt beräknas i PAST genom följande steg:
1. Markera de värden som är intressanta (kolumnen age i nedanstående exempel). 2. Välj i menyn: Statistics → Univariate.
I resultatrutan, som automatiskt kommer upp då steg 2 utförts, ser vi att bland dessa (N=241) observationer är medelåldern ca 62 år, standardfelet ca 0.56, osv. Univariate - funktionen hanterar saknade värden (?).
Korrelation Korrelationen mellan två variabler, t ex a_kol (kolesterolvärde vid tidpunkt A) och b_kol (kolesterolvärde vid tidpunkt B) kan bestämmas genom följande steg:
1. Markera kolumnerna som tillhör variablerna vars korrelation skall bestämmas (a_kol och b_kol).
2. Välj i menyerna: Statistics → Correlation . Resultatet får vi enligt nedan:
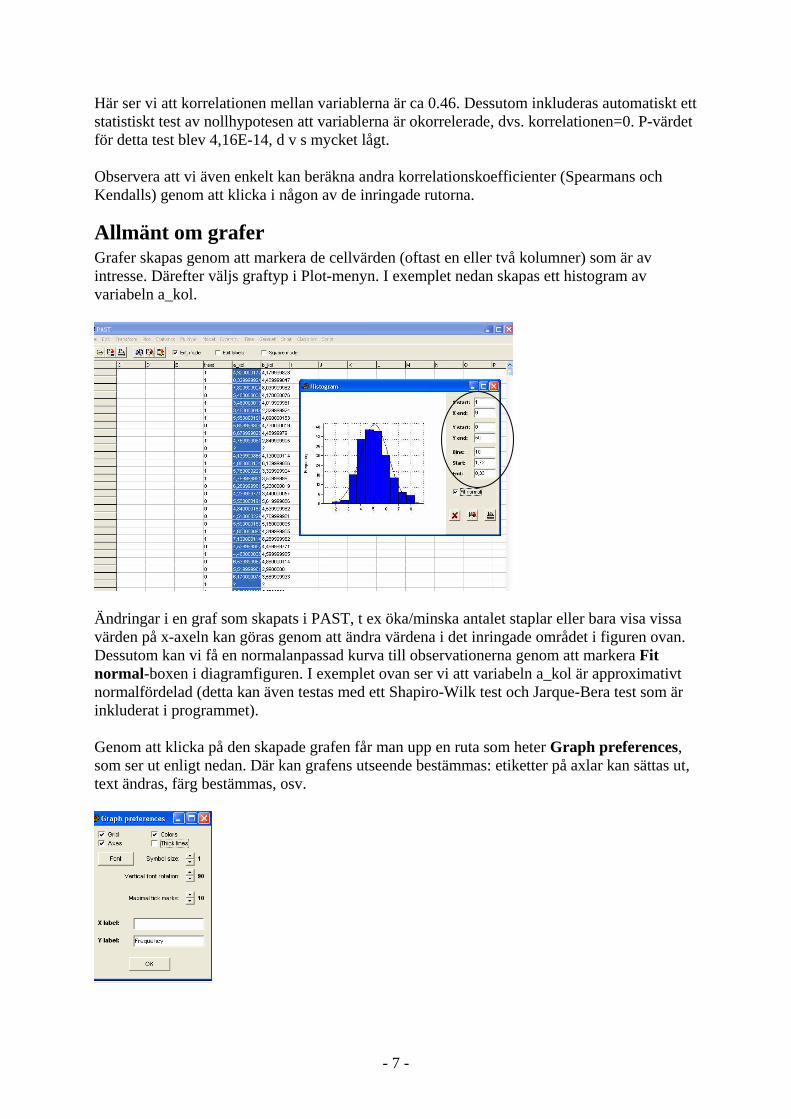
- 7 -
Här ser vi att korrelationen mellan variablerna är ca 0.46. Dessutom inkluderas automatiskt ett statistiskt test av nollhypotesen att variablerna är okorrelerade, dvs. korrelationen=0. P-värdet för detta test blev 4,16E-14, d v s mycket lågt. Observera att vi även enkelt kan beräkna andra korrelationskoefficienter (Spearmans och Kendalls) genom att klicka i någon av de inringade rutorna.
Allmänt om grafer Grafer skapas genom att markera de cellvärden (oftast en eller två kolumner) som är av intresse. Därefter väljs graftyp i Plot-menyn. I exemplet nedan skapas ett histogram av variabeln a_kol.
Ändringar i en graf som skapats i PAST, t ex öka/minska antalet staplar eller bara visa vissa värden på x-axeln kan göras genom att ändra värdena i det inringade området i figuren ovan. Dessutom kan vi få en normalanpassad kurva till observationerna genom att markera Fit normal-boxen i diagramfiguren. I exemplet ovan ser vi att variabeln a_kol är approximativt normalfördelad (detta kan även testas med ett Shapiro-Wilk test och Jarque-Bera test som är inkluderat i programmet). Genom att klicka på den skapade grafen får man upp en ruta som heter Graph preferences, som ser ut enligt nedan. Där kan grafens utseende bestämmas: etiketter på axlar kan sättas ut, text ändras, färg bestämmas, osv.

- 8 -
Den skapade figuren kan kopieras genom att klicka på . Därefter kan grafen enkelt klistras in i t ex Word.
Box-plot Tyvärr finns det inget sätt att beräkna percentiler i PAST, detta måste göras i något annat program (görs enkelt i t ex Excel). Däremot kan vi i PAST med hjälp av en box-plot skaffa oss en uppfattning om kvartilerna genom följande steg:
1. Markera de värden som är intressanta (t ex kolumnen a_kol). 2. Välj i menyn: Plot → Box plot.
I exemplet ser vi att den undre kvartilen (25%-percentilen) är ca 4.2 och den övre kvartilen (75%-percentilen) är ca 5.9.
Spridningsdiagram För att plotta två variabler mot varandra (a_kol och b_kol i nedanstående exempel) utförs följande steg:
1. Markera de kolumner som skall plottas (a_kol och b_kol). 2. Välj XY graph i plot-menyn.
- 9 -
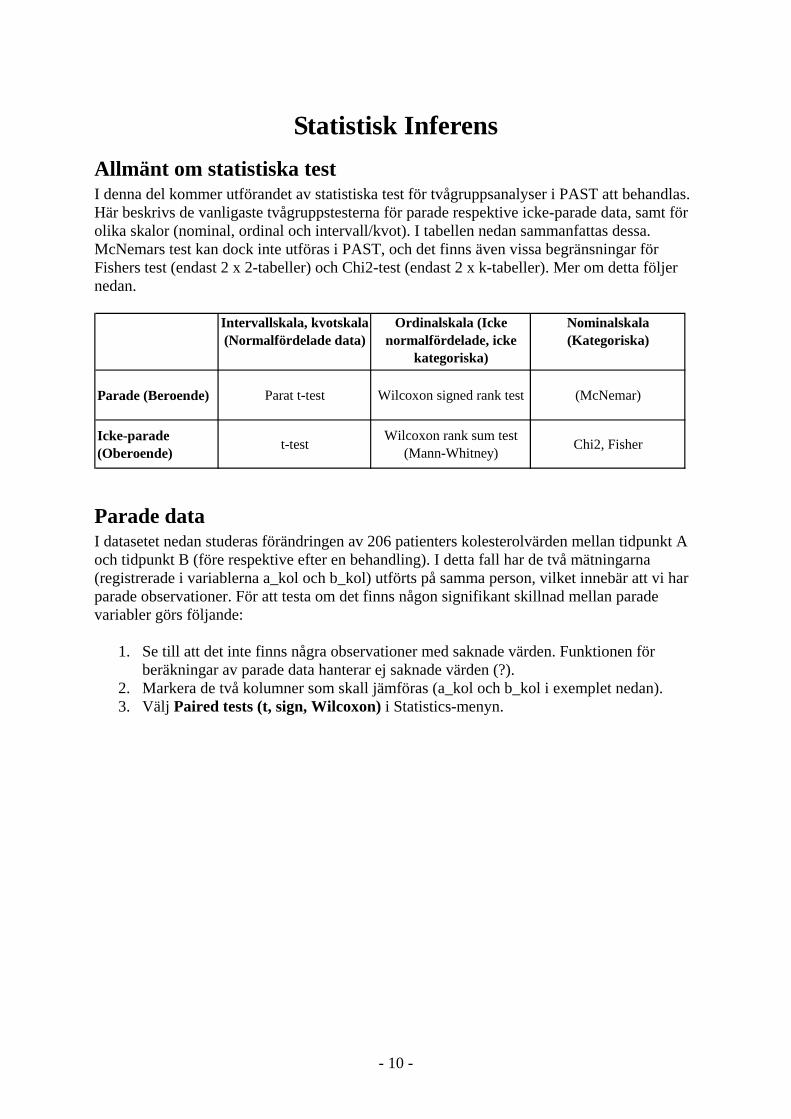
Konfidensintervall och t-test av teoretiskt medelvärde I exemplet nedan beräknas ett 95% konfidensintervall för medelåldern i studiepopulationen. Dessutom utförs ett t-test mot det teoretiska medelvärdet 63 år. Detta görs på följande sätt:
1. Markera kolumnen som innehåller den aktuella variabeln (age i detta exempel). 2. Välj T test (one sample) i Statistics – menyn. 3. Skriv in det teoretiska medelvärdet i resultatrutan som kommer upp. 4. Tryck compute i resultatrutan.
Vi ser att det 95%-iga konfidensintervallet för studiepopulationen är 60.96 – 63.19 och att p=0.1033 för t-testet mot det teoretiska medelvärdet 63 år.
- 10 -
Statistisk Inferens
Allmänt om statistiska test I denna del kommer utförandet av statistiska test för tvågruppsanalyser i PAST att behandlas. Här beskrivs de vanligaste tvågruppstesterna för parade respektive icke-parade data, samt för olika skalor (nominal, ordinal och intervall/kvot). I tabellen nedan sammanfattas dessa. McNemars test kan dock inte utföras i PAST, och det finns även vissa begränsningar för Fishers test (endast 2 x 2-tabeller) och Chi2-test (endast 2 x k-tabeller). Mer om detta följer nedan.
Intervallskala, kvotskala (Normalfördelade data)
Ordinalskala (Icke normalfördelade, icke
kategoriska)
Nominalskala (Kategoriska)
Parade (Beroende) Parat t-test Wilcoxon signed rank test (McNemar)
Icke-parade (Oberoende)
t-testWilcoxon rank sum test
(Mann-Whitney)Chi2, Fisher
Parade data I datasetet nedan studeras förändringen av 206 patienters kolesterolvärden mellan tidpunkt A och tidpunkt B (före respektive efter en behandling). I detta fall har de två mätningarna (registrerade i variablerna a_kol och b_kol) utförts på samma person, vilket innebär att vi har parade observationer. För att testa om det finns någon signifikant skillnad mellan parade variabler görs följande:
1. Se till att det inte finns några observationer med saknade värden. Funktionen för beräkningar av parade data hanterar ej saknade värden (?).
2. Markera de två kolumner som skall jämföras (a_kol och b_kol i exemplet nedan). 3. Välj Paired tests (t, sign, Wilcoxon) i Statistics-menyn.

- 11 -
I detta exempel är vi främst intresserade av resultatet av det parade tvåsidiga t-testet eftersom variablerna som jämförs (a_kol och b_kol) är approximativt normalfördelade. Vi kan se i resultatrutan ovan att p-värdet är ca 0,0009 för detta test. Dessutom inkluderas automatiskt även resultatet av Wilcoxon signed-rank test (p=0,01977), teckentest (p=0,5307) och från en Monte Carlo simulering (p=0,01997). Detta innebär att om vi i stället skulle vilja utföra ett Wilcoxon signed-rank test där vi jämför parade variabler på ordinalskala, t ex smärtnivå på en skala 1 till 5 före respektive efter behandling, kan vi på samma sätt använda de tre stegen som just beskrivits.
Icke-parade data I följande exempel vill vi jämföra kolesterolvärdet vid en studies start (variabel a_kol) mellan två oberoende patientgrupper, där den ena gruppen behandlas med ett tidigare etablerat läkemedel (treat=0) och den andra får ett nytt läkemedel (treat=1). Data ser ut enligt följande:

- 12 -
Variabeln a_kol är normalfördelad (se tidigare histogram) vilket innebär att vi kan utföra ett vanligt (icke-parat) t-test i det här fallet. Detta är tyvärr lite krångligare i PAST än i andra statistiska program (Stata, SAS, SPSS) eftersom det först krävs lite omstrukturering av data. Detta görs på följande sätt:
1. Sortera data med avseende på gruppvariabel (treat i exemplet ovan). 2. Kopiera därefter observationerna av den variabeln vi vill jämföra (a_kol) som tillhör
respektive behandlingsgrupp och placera dem i varsin kolumn.
Observationerna markerade med (*) i figuren ovan kopieras således till kolumnen ”treat=0” och de som är markerade med (**) till ”treat=1”. När denna omorganisering av data är gjord utförs t-testet genom att:
3. Markera kolumnerna som vill jämföras (”treat=0” och ”treat=1” i exemplet). 4. Välj F and T tests (two samples) i Statistics-menyn.
(*)
(**)

- 13 -
Vi ser i resultatrutan att p-värdet för t-testet där lika varians i behandlingsgrupperna antas är 0,83886, och 0,83904 när det antas finnas en skillnad mellan varianserna. Vi ser även att ett test av lika varians mellan grupperna (F-test) är inkluderat (p= 0,2239), dvs. varianserna är tillräckligt lika och vi kan genomföra ett t-test (same variance). Vi får även ett p-värde från ett permutationstest (p=0,8396), vilket i allmänhet ligger nära p-värdet för t-testet. Om vi i stället vill utföra ett Wilcoxon rank-sum (Mann-Whitney) test där vi jämför variabler på ordinalskala (eller variabler som inte är normalfördelade), t ex smärtnivå på en skala 1 till 5 mellan två oberoende behandlingsgrupper, utförs först steg 1-3 ovan och därefter väljs Mann-Whitney i Statistics-menyn. Resultatrutan ser ut enligt nedan, testets p-värde är alltså 0,8514 i detta exempel.
Chi2 - test I följande exempel vill vi undersöka om det finns något samband mellan två kategoriska variabler, CHD (indikerar om en person drabbats av en kranskärlsjukdom) och CAT (visar om personen har hög katekolaminnivå). För att kunna utföra ett chi2-test i PAST måste följande steg utföras:

- 14 -
1. Data måste aggregeras i en 2 x k – tabell (OBS: Chi2 – test för t ex en 3 x 3 – tabell kan ej genomföras). I exemplet nedan innebär detta att observationerna som är ordnade i kolumner (kolumn chd och cat) först måste ordnas i en 2 x 2 tabell (k=2) på samma sätt som i det inringade området i figuren nedan. Etiketter (CHD=0, CAT=0, osv) behöver ej sättas ut som i exemplet nedan, dessa finns endast med för tydlighetens skull. Tyvärr finns det inget kommando i PAST som automatiskt aggregerar data till en 2 x k –tabell utan detta måste göras i ett annat program, t ex Excel (se pivottabell).
2. Markera de celler som utgör 2 x k – tabellen. Se det inringade området i exemplet nedan.
3. Välj chi^2 (two samples) i Statistics-menyn. 4. Boxen med one constraint måste vara ifylld.
I detta exempel ser vi att p-värdet är 5,56E-05 för chi2-testet. Observera att även Fishers exakta test (p=0.0002049) och en Monte Carlo simulering (p=0,0001) inkluderas automatiskt.
Fishers exakta test I exemplet som följer studeras sambandet mellan rökning och lungcancer. Eftersom ett av de förväntade cellvärdena i 2 x 2 – tabellen nedan kommer att vara mindre än 5 vill vi använda Fishers exakta test. Detta utförs alltså med samma steg som för ett Chi2-test.

- 15 -
P-värdet som i första hand intresserar oss, från Fishers test, är 0.01193. P-värdet från ett vanligt chi2-test medföljer dock automatiskt. Observera att Fishers exakta test endast kan utföras för 2 x 2 –tabeller i PAST.





![d.a.t. - Il Sileno · 2020. 10. 21. · [d.a.t.] Pag.01 [divulgazioneaudiotestuale] NUMERO 7 PREFAZIONE a cura di Maurizio Pisati Diffusione audiotestuale Istruzioni per l'uso d.a.tteriologicamente](https://img.pdfslide.net/doc/110x75/60b23f569009da3146485096/dat-il-2020-10-21-dat-pag01-divulgazioneaudiotestuale-numero-7.jpg)


![[d.a.t.] Abstract[d.a.t.] Pag.97 [divulgazioneaudiotestuale] NUMERO 5 THE ICY FACE OF NAPLES: CONTEMPORARY LANDSCAPES OF PIANO MUSIC FIRST SECTION LORENZO PONE [ENGLISH TRANSLATION](https://img.pdfslide.net/doc/110x75/6107870d7fac5755943820fa/dat-abstract-dat-pag97-divulgazioneaudiotestuale-numero-5-the-icy-face.jpg)

















![[d.a.t.] Abstract](https://img.pdfslide.net/doc/110x75/622c7c7ac2af8f5223686027/dat-abstract.jpg)



