Embed Size (px)
Citation preview

KI1 / L. Schomaker - 2007
Learning from observations (b)
• How good is a machine learner?
• Experimentation protocols
• Performance measures
• Academic benchmarks vs Real Life

KI1 / L. Schomaker - 2007
Experimentation protocols
• Fooling yourself: training a decision tree on 100 example instances from earth and sending the robot to Mars
training set / test set distinction– both must be of sufficient size:– large training set for reliable ‘h’ (coefficients etc.)– large test set for reliable prediction of real-life
performance

KI1 / L. Schomaker - 2007
Experimentation protocols
• one training set / one test set, four yearsPhD project: still fooling yourself!
• Solution: – training set– test set– final evaluation set with real-life data
• k-Fold evaluation: k subsets fromlarge data base, measuring standard deviationof performance over experiments

KI1 / L. Schomaker - 2007
Experimentation protocols
• What to do if your don’t have enough data?
• Solution: – Leave-one-out: use N-1 samples for training,– use the Nth sample for testing– repeat for all samples– compute the average performance

KI1 / L. Schomaker - 2007
Performance
• Example: % correctly classified samples (P)
• Ptrain
• Ptest
• Preal Ptest
KI1 / L. Schomaker - 2007
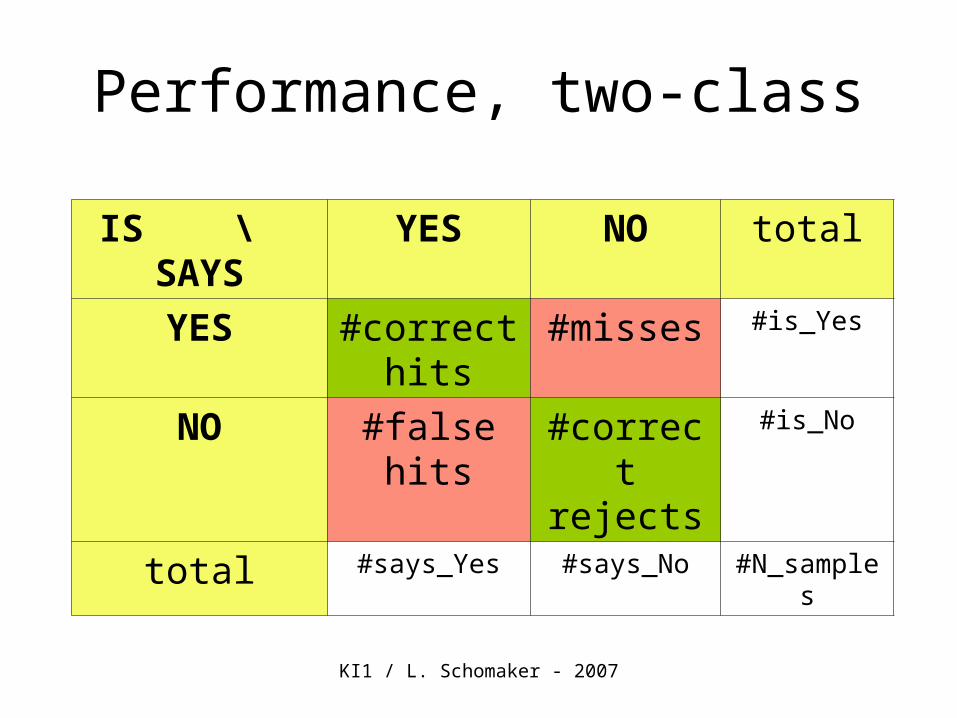
Performance, two-class
IS \ SAYS YES NO total
YES #correcthits
#misses #is_Yes
NO #falsehits
#correctrejects
#is_No
total #says_Yes #says_No #N_samples

KI1 / L. Schomaker - 2007
Performance, two-class
IS \ SAYS YES NO total
YES % correcthits
%misses %is_Yes
NO %falsehits
%correctrejects
%is_No
total %says_Yes %says_No 100 %

KI1 / L. Schomaker - 2007
Performance, two-class
IS \ SAYS YES NO total
YES #correcthits
#misses #is_Yes
NO #falsehits
#correctrejects
#is_No
total #says_Yes #says_No #N_samples
Precision = 100 * #correct_hits / #says_Yes [%]Recall = 100 * #correct_hits / #is_Yes [%]

KI1 / L. Schomaker - 2007
Performance, multi-class SAYSIS
A B C ... Rej total
A #A ok #is A
B #B ok #is B
C #C ok #is C
. #is ...
Noise #correctrejects
#is Noise
total #says
A
#says
B
#says
C
#says
...
#says
Reject
#Nsamples

KI1 / L. Schomaker - 2007
Performance, multi-class SAYSIS
A B C ... Rej total
A 456 0 2 34 5 #is A
B 0 343 #is B
C 20 201 #is C
. 0 603 #is ...
Noise 1 60 #is Noise
total #says
A
#says
B
#says
C
#says
...
#says
Reject
#Nsamples
Confusion matrix

KI1 / L. Schomaker - 2007
Rankings / hit lists
• Given a query Q, systems returns a hitlist of matches M: an ordered set, with instances i in decreasing likelihood of correctness
• Precision: proportion of correct instances M in the hit list
• Recall: proportion of correct instances from totalnumber of target samples in the database

KI1 / L. Schomaker - 2007
Function approximation
• For, e.g. regression models,learning an ‘analog’output
• Example: target function t(x)• Obtained output function o(x)
• For performance evaluation computeroot-mean square error (RMS error):
= ( (o(x)-t(x))2 / N )

KI1 / L. Schomaker - 2007
Learning curves
#epochs (presentations of training set)
P [% OK]

KI1 / L. Schomaker - 2007
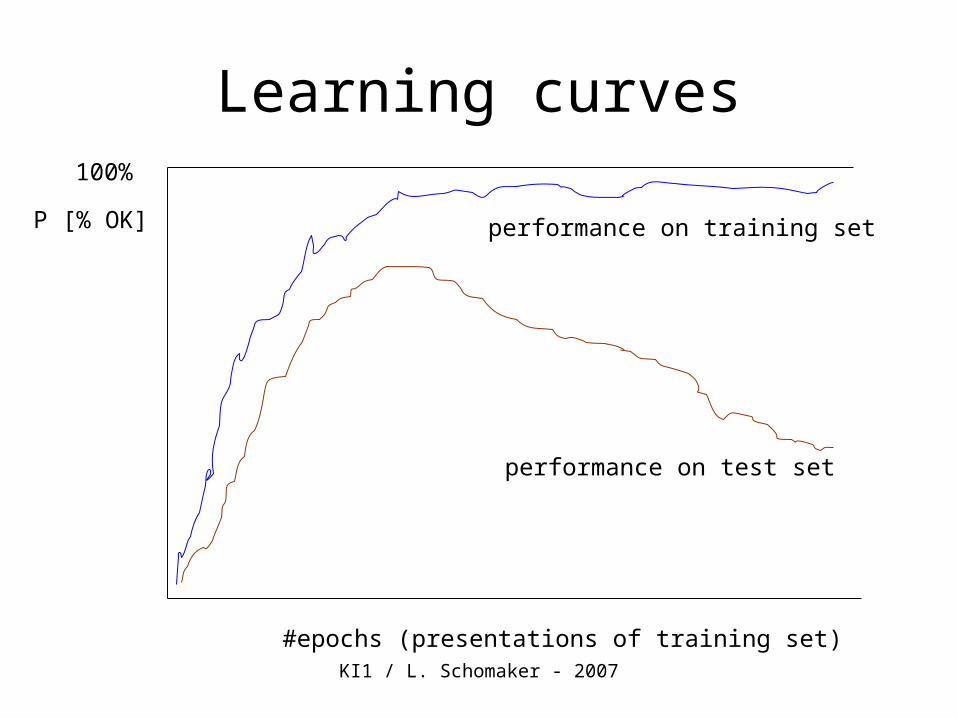
Learning curves
#epochs (presentations of training set)
P [% OK]performance on training set
performance on test set
KI1 / L. Schomaker - 2007
Learning curves
#epochs (presentations of training set)
P [% OK] performance on training set
performance on test set
100%

KI1 / L. Schomaker - 2007
Learning curves
#epochs (presentations of training set)
P [% OK] performance on training set
performance on test set
100%
Stop!
no generalization,overfit

KI1 / L. Schomaker - 2007
Overfitting
• The learner learns the training set
• Even perfectly, like a lookup table (LUT) memorizing training instances
• without correctly handling unseen data
• Usual cause: more parameters in the learner than in the data

KI1 / L. Schomaker - 2007
Preventing Overfit
• For good generalization:
– number of training examples must be much larger than the number of attributes (features):
Nsamples / Nattr >> 1

KI1 / L. Schomaker - 2007
Preventing Overfit
• For good generalization:
– also: Nsamples >> Ncoefficients
e.g.: solving linear equation: 2 coefficients, needing 2 data points in 2D
Coefficients: model parameters, weights etc.

KI1 / L. Schomaker - 2007
Preventing Overfit• For good generalization:
– Ndatavalues >> Ncoefficients
Coefficients: model parameters, weights etc.
Ndatavalues = Nsamples * Nattributes
e.g.: use Ndatavalues/Ncoefficients for system comparison

KI1 / L. Schomaker - 2007
Example: machine-print OCR
• Very accurate, today, but:• Needs 5000 examples of each character• Printed on ink-jet, laser printers, matrix
printers, fax copies • of many brands of printers• on many paper types
for 1 font & point size!A .
...
.

KI1 / L. Schomaker - 2007
Ensemble methods
• Boosting:– train a learner h[m]– weigh each of the instances– weigh the method m– train a new learner h[m+1]– perform majority voting on ensemble
opinions

KI1 / L. Schomaker - 2007The advantage of democracy: partly intelligent, independent deciders

KI1 / L. Schomaker - 2007
Learning methods
• Gradient descent, parameter finding(multi-layer perceptron, regression)
• Expectation Maximization (smart Monte Carlo search for best model, given the data)
• Knowledge-based, symbolic learning (Version Spaces)
• Reinforcement learning• Bayesian learning

KI1 / L. Schomaker - 2007
Memory-based ‘learning’
• Lookup-table (LUT)
• Nearest neighbour argmin(dist)
• k-Nearest neighbour
majority(Nargmin(dist,k)

KI1 / L. Schomaker - 2007
Unsupervised learning
• K-means clustering
• Kohonen self-organizing maps (SOM)
• Hierarchical clustering

KI1 / L. Schomaker - 2007
Summary (1)
• Learning needed for unknown environments (and/or) lazy designers
• Learning agent = performance element + learning element
• Learning method depends on type of performance element, available
• feedback, type of component to be improved, and its representation

KI1 / L. Schomaker - 2007
Summary (2)
• For supervised learning, the aim is to find a simple hypothesis
• that is approximately consistent with training examples
• Decision tree learning using information gain: entropy-based
• Learning performance = prediction accuracy measured on test set(s)





![Payslip Italy [1] Company KI1 - Business Institute - Italy ... · Payslip Italy Company KI1 - Business Institute - Italy Month 03/2002 Tax Code INAIL Position INPS Code Establishment](https://img.pdfslide.net/doc/110x75/5e72dd29a1bd4356a33171c6/payslip-italy-1-company-ki1-business-institute-italy-payslip-italy-company.jpg)






















