Embed Size (px)
Citation preview

Web Intelligence and Agent Systems: An international journal 6 (2008) 0 1IOS Press
Knowledge Reuse for Software Reuse
Frank McCarey∗, Mel O Cinneide and Nicholas KushmerickSchool of Computer Science and Informatics, University College Dublin, Belfield, Dublin 4, Ireland.
Abstract. Software reuse can provide significant improvements in software productivity and quality whilst reducingdevelopment costs. Expressing software reuse intentions can be difficult though. A developer may aspire to reuse asoftware component but experience difficulty expressing their reuse intentions in a manner that is compatible with,or understood by, the component retrieval system. Various intelligent retrieval techniques have been developed thatassist a developer in locating or discovering components in an efficient manner. These solutions share a commonshortcoming: the developer must be capable of anticipating all reuse opportunities and initiating the retrievalprocess. There is a need for a comprehensive technique that not only assists with retrievals but that can alsoidentify reuse opportunities.This paper advocates that component-based reuse can be supported through knowledge collaboration. Often pro-gramming tasks and solutions are replicated; this characteristic of software can be exploited for the benefit offuture developments. Through the mining of existing source code solutions, knowledge, relating to how componentsare used by developers, can be extracted. Based on a developer’s current programming task, this knowledge cansubsequently be filtered and used to recommend a candidate set of reusable components. This novel recommen-dation approach applies and extends commonly used Information Retrieval and Information Filtering techniquessuch as Collaborative Filtering, Content-Based Filtering, and Bayesian Clustering Models, to the software reusedomain. This recommendation technology is applied to several thousand open-source Java classes. The mosteffective recommendation algorithm produces recommendations of a high quality at a low cost.
Keywords: Component-Based Development, Knowledge Collaboration, Recommender Agent, Information Filtering.
1. Introduction
Software reuse has been practised ever since theadvent of programming itself, albeit in a somewhatad-hoc manner [15,34]. Reuse enables developersto leverage past accomplishments and can facili-tate significant improvements in software quality[51]. Additionally, reuse has been shown to im-prove productivity [26], shorten the developmentcycle [7], and reduce development costs [43]. Theseadvantages, combined with smaller developmentbudgets and the increased availability of reusableartefacts, are just some of the reasons why soft-ware reuse has become more prominent of late.
Despite the many benefits, the software reusecommunity has failed in its attempts to establish
∗Corresponding author. E-mail:[email protected]:+353-87-7949237 Fax:+353-1-2697262
reuse as a standard software engineering practice.This is evident from the lack of standard reusepractices even though key reuse research datesback 40 years [34]. This failure can be attributedto numerous factors such as the lack of a standard-ised market place for reusable software artefactsand the inadequacy of reuse support tools.
Candidates for reuse include source code, soft-ware architectures, and support documentation.The focus of this research is limited to sourcecode reuse through software components. Incomponent-based reuse, new applications are com-posed of many small reusable software compo-nents, typically stored in a component library.Components must be accessible, reliable, and ofhigh quality; this paper concentrates on improvingcomponent accessibility. We have identified threeunderlying related problems that restrict compo-nent reuse, these are: the inability of support tools
1570-1263/05/$17.00 2008 – IOS Press and the authors. All rights reserved

2 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
to automatically identify reuse opportunities, theseparation of reuse from mainstream developmentactivities, and the lack of techniques to store andsubsequently distribute task-relevant componentknowledge among developers. Combined, theseact as a major barrier to component reuse and arethe central motivation for this research.
Effective tool support is essential for promotingsoftware component reuse as component librariestend to be large and growing. For example, thelatest version of the Java API library has over 3000classes while the Java Swing library contains morethan 500 classes. In addition to commercial com-ponents, a mature software development organi-sation could maintain a large library of in-housecomponents. Conversancy with all components ina large library is practically impossible. As a re-sult, there are many stored components that devel-opers are unaware of and, accordingly, that theynever make any attempt to reuse.
Typical component support techniques includelibrary browsing agents [6], web-based search ap-proaches [16], and component ranking tools [17].These are described in section 7. Each solutionattempts to assist developers in discovering andlocating components in which they are interested.A common shortcoming of these solutions is thatreuse is viewed as a separate activity from softwaredevelopment; a developer must halt their currentprogramming task, initiate the component searchprocess, and on completion, return to their pro-gram task. As previously noted, developers are notaware of all available methods in a library or maybe unable to express their reuse intentions clearly.If they believe a reusable component for a partic-ular task does not exist then it is less likely thatthey will initiate a component search. Reuse sup-port tools that focus solely on search techniquesare insufficient as they are only useful when a de-veloper makes a reuse attempt.
When such retrieval tools prove inadequate, adeveloper will attempt to acquire knowledge relat-ing to components from peers. Typically a soft-ware component is used by many developers inmany applications. When a developer is attempt-ing to solve a problem or make a reuse attempt,they seek the assistance of developers who havesolved this or a similar problem previously throughthe use of software components. This could involvedirect meetings, email, or telephone exchanges be-tween colleagues. Such approaches may be effec-
tive but are clearly an unreliable and inefficientmeans of sharing knowledge [23].
This research shifts the focus from componentretrieval tools to a component recommendationtechnique that simplifies knowledge collaboration.A methodology is presented in this paper that canautomatically identify reuse opportunities and, ac-cordingly, recommend a candidate set of reusablecomponents to a developer. Recommendations areintelligent, relevant, and of value to individual de-velopers. This methodology capitalises on the sim-ilarities that exist between different source codesolutions. Programming tasks, and consequentlysolutions, are often mirrored inside an organisa-tion, across a community, or within a specific do-main. This explains the phenomenon of sourcecode clones and code duplication [35]. From min-ing existing source code repositories, a collectivecollaborative knowledge-base can be establishedthat can be used to support and predict futurecomponent reuse. At present, much of the knowl-edge ingrained in source code is never captured.
For each reusable component, information re-lating to where that component is used, how itis used, and how it integrates with other compo-nents, can all be collected through mining sourcecode repositories. The methodology presentedin this work uses an intelligent software agentthat employs this collaborative knowledge-base,along with advance filtering algorithms, to iden-tify and to recommend component reuse opportu-nities for a developer. Such recommendations arebased on a developer’s current programming task.Knowledge-based component recommendation im-proves and complements traditional search-basedcomponent retrieval schemes. Our methodology isproactive, requires no additional effort from devel-opers, and easily allows component knowledge tobe shared among developers.
The following are the principal contributions ofthis research:
– The application, mergence, and extension ofseveral Information Retrieval and Informa-tion Filtering schemes to a software reuse do-main. Information Retrieval models are usedwith both conventional and novel filtering al-gorithms to generate component recommen-dations. Using customary and specialisedretrieval metrics, extensive evaluations haveconcluded that highly relevant componentrecommendations can be produced, for a pro-

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 3
grammer, using these algorithms. In partic-ular, the new algorithms, that consider or-dering information, produce encouraging re-sults. Generally, these positive results affirmthe information-rich characteristic of sourcecode.
– A lightweight knowledge-acquisition and know-ledge-sharing methodology that increases theaccessibility of software components. The va-lidity of this agent-based knowledge sharingmethodology is demonstrated using a proto-type software implementation that is appliedwith full rigour to thousands of Java methods.
– A novel, proactive approach to software reusesupport. Unlike previous approaches to thisproblem, our approach is intelligent, proac-tive, and autonomous. Additionally, this eco-nomical solution can easily be adopted: theonly prerequisite is the availability of a sourcecode repository.
The remainder of this paper is organised asfollows. The next section presents an overviewof software reuse and Component-Based Develop-ment. This is followed by a discussion on compo-nent reuse from a developer’s perspective in sec-tion 3. Section 4 describes our prototype compo-nent recommender tool, named RASCAL, whichemploys intelligent agent technology. Componentrecommendation algorithms are fully explained insection 5 and recommendation results are reportedin section 6. Related works are reviewed in section7 and, finally, conclusions are drawn in section 8.
2. Software Reuse and Component-BasedDevelopment
Software reuse is an umbrella concept that hasbeen around for many years. The term was orig-inally coined by McIlroy [34] at the NATO con-ference on Software Engineering in 1968. Gener-ally software reuse can be defined as the processof creating software systems from existing softwarerather than building software systems from scratch[21]. In addition, it can also be defined as reusingexisting software artefacts during the process ofbuilding a new software system. A software arte-fact may be a tangible item such as source code ora test case. An artefact can also refer to a piece offormalised knowledge that can contribute, and be
applied, to the software development process [8].Typical reusable artefacts include product fami-lies, design architectures, and documentation.
This research is limited to source code reusethrough software components. Component-BasedDevelopment (CBD) is an emerging software de-velopment paradigm, promising many benefits in-cluding reduced development and maintenancecosts, and increased productivity. CBD involvesbuilding applications using prefabricated softwarecomponents. No standard definition exists of soft-ware components, however, one widely accepteddefinition is: “A software component is a unit ofcomposition with contractually specified interfacesand explicit context dependencies. An interface isa set of named operations that can be invoked byclients. Context dependencies are specifications ofwhat the deployment environment needs to pro-vide, such that the components can function.” [53]
Components help to reduce the time required todesign, implement, and debug new software whilethe cost of developing reusable components is off-set by repeated use. Popular examples of reusablecomponent libraries include the Sun Swing libraryand the Visual Numerics International Mathemat-ical and Statistical Libraries (IMSL).
Creating reusable components and componentlibraries can be difficult, time-consuming, and ex-pensive. However, positive progress has been madein recent years; for example components can besourced commercially off-the-shelf, from reposito-ries of open-source software, or built in-house aspart of product families. As noted in the intro-duction, the principal focus of this research is onincreasing the accessability of stored componentsrather than populating component libraries.
2.1. Component Retrieval Techniques
This subsection describes several general classesof retrieval schemes; a complete review of principalrelated works in this area is provided in section 7.
Information Retrieval (IR) These approachestypically rely on class or method names,source code comments, and documentation[28]. The reuse query must be expressed ina natural language; this is desirable but it isoften difficult to formulate queries in a waythat ensures irrelevant components are not re-trieved. Such techniques also fail to take intoaccount a developer’s current programmingcontext, and thus, often prove inadequate.

4 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
Descriptive Whereas IR techniques represent com-ponents by their source text, descriptivemethods rely on abstract descriptions of com-ponents. Examples include sets of keywordsand facets. A limitation of this approachis that it is difficult to implement retrospec-tively, requiring greater upfront planning.
Syntactical The most common syntactical re-trievals are based on signature matching [27,58]. This approach is useful for quickly rulingout components that do not match a devel-oper’s reuse query. Syntactical approaches aremore formal than IR and descriptive meth-ods, and thus, are often challenging for a de-veloper to use. Additionally, signature alonedoes not guarantee the expected behaviour ofa component.
Formal Methods In this approach, a componentis represented using a formal specification lan-guage. Likewise, queries are also submitted ina formal language. Correctness proving sys-tems [61,19] or specification refinement sys-tems [38] are then used to compare storedcomponents with the user query. Typically,formal methods are highly accurate at retriev-ing relevant components but often prove dif-ficult for developers to use.
Artificial Intelligence (AI) AI [47] schemes at-tempt to be smarter than the above tradi-tional methods, in that they endeavor to un-derstand both the library components and thereuse query. These approaches tend to be con-text and environment aware, and generate re-trievals based on this. AI techniques typicallyrequire a knowledge-base but this cost is coun-terbalanced against effective retrievals.
Web Technologies Search and retrieval tech-niques usually applied to web-based searchescan also be applied to component retrieval.The advantages of such approaches includescalability and efficiency while problems in-cluding security and legal concerns [16].
The goal of this research is to develop a newcomponent retrieval methodology that builds andimproves on existing techniques. The limitationsof traditional IR, descriptive, and syntactical ap-proaches have been noted: each technique is unre-liable, require up-front planning, and lack contextinformation. Formal methods are beneficial forproving retrieval correctness but are often difficult
Fig. 1. How Developers Reuse
for developers to use; perhaps the lack of recent re-search in this area can be attributed to this. Morepromising are web-based and knowledge-based AIretrieval approaches. Retrieval alone, though, isnot sufficient to assist a developer with componentreuse.
3. Component Reuse: The Developer’sPerspective
The previous section presented several differentretrieval techniques. The principal goal of suchtechniques is to facilitate and encourage reuse.However, any competent component reuse supporttool that employs these retrieval methods mustalso consider reuse from the developer’s perspec-tive. If a developer is to reuse a component, theymust be able to locate that component with max-imum ease, in minimal time. Frakes and Fox [10,11] discovered that no-attempt-to-reuse accountedfor 24% of software reuse failures. This strength-ens the argument that a reuse programme cannotsucceed without the backing of the developmentteam, and thus, the human factors that hamperreuse need to be addressed.
3.1. Reuse: A Problem Solving Activity
Mili et al. [36] describe reuse-based developmentas a problem solving activity, the problem beingthat of finding a software component that satis-fies a set of user requirements. From a componentreuse perspective, Ye [57] categorises this activityinto three separate tasks: reuse-by-memory, reuse-by-recall, and reuse-by-anticipation as is shown infigure 1.

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 5
Reuse-by-Memory Developers recognise simi-larities between their current developmentand programs that they have previously cre-ated or with components that they have used.This simplifies reuse as the developer can ex-press their reuse intentions clearly.
Reuse-by-Recall Developers vaguely remembercomponents in the library that they believeloosely matches their requirements. Theymay not be exactly sure which componentsthey are or where they are located and thusretrieval tools are important.
Reuse-by-Anticipation Developers are not awareof any components that match their reuseneeds. However, based on their knowledge ofthe component library, they anticipate thata component exists that satisfies their reuserequirements.
Reuse-by-memory and reuse-by-recall are rea-sonably straightforward and can be supportedwell through the component library browsing andretrieval tools previously described. Reuse-by-anticipation is somewhat more complicated:
1. A developer may incorrectly anticipate acomponent that does not exist.
2. It is difficult for a developer to clearly expresstheir reuse intentions.
3. A developer cannot easily evaluate retrievedcomponents due to their limited knowledge.
Assuming a retrieval technology is in place thatovercomes these challenges, there still remains onemajor barrier to reuse: a developer may not antic-ipate the availability of a component which theycan reuse in their current development. Hence,no-attempt-to-reuse is made. In such a situation,the available retrieval tools are merely passive de-vices because they become only useful when a de-veloper decides to make a reuse attempt by antic-ipating the existence of certain components. Theproblem is further exacerbated by the likelihood ofthe component library increasing in size over time.Therefore, an intelligent support tool is requiredthat can notify a developer of what componentsexist and when it is appropriate to reuse them.
3.2. From Development-with-Reuse toReuse-within-Development
This subsection shifts the focus from the cogni-tive barriers to reuse, to the technical challenges
Fig. 2. Development-With-Reuse
Fig. 3. Reuse-Within-Development
that impair reuse in practice. Traditional com-ponent library tools make little effort to addressthe no-attempt-to-reuse problem. They explicitlyassume that a developer will, at the very least,search for a component even if they are unsure thata component exists that fits their requirements.Such component library systems are designed tosupport development-with-reuse [45].
The development-with-reuse paradigm, as shownin figure 2, views reuse as a stand-alone activity,independent of traditional programming activitiesand development tools. It supposes that develop-ers want to reuse, and that they can easily expresstheir reuse intentions and correctly formulate reusequeries. By distinguishing between normal devel-opment tasks and reuse tasks, there is an overheadof task switching between the two. Further to this,the tools used by developers in normal develop-ment typically differ from those used in the reuseprocess. Reuse must be well planned in advancefor development-with-reuse to be successful. How-ever, reuse can not be completely planned before-hand, it happens within the context and process ofdevelopment [49]. Additionally, the Li et al. [25]

6 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
study has shown that reuse is often opportunistic,with components frequently not being selected un-til the detailed design and coding stage. Thus, adevelopment paradigm shift is needed.
Reuse-within-development is a user-centered ap-proach where the focus is on the behaviourand actions of developers, and the aim is tomerge Component-Based Development activitieswith the existing practices of developers [18,37,58]. This is illustrated in figure 3. Reuse-within-development differs from the methodology-centered approach of development-with-reuse whichattempts to change and adapt a programmer’s ac-tions to fit the reuse model. In the user-centeredapproach, the development environment must pro-vide support that: can automatically identify andretrieve relevant reusable components; assists withcomponent understanding and integration; doesnot interfere with a developer’s regular program-ming activities; and reduces the cost of componentreuse.
By assisting with component understanding andintegration, the development environment is notsimply providing a component reminder servicebut rather it is facilitating component reuse withminimal ease. For example, a set of relevant codeexamples could be presented to a developer thatquickly allows her to understand and integrate acomponent [58]. In addition, automatically locat-ing relevant software components and deliveringthese to a developer ensures that developers needonly be aware of a much smaller set of compo-nents. This enables greater component compre-hension. In the next section, we describe RAS-CAL, a prototype tool that supports reuse-within-development in practice.
4. Knowledge Reuse: The RASCALComponent Recommender
This section introduces a knowledge-based agentthat can automatically identify component reuseopportunities. After this, we describe our proto-type component recommender tool, named RAS-CAL, that employs this agent technology.
4.1. Knowledge Reuse with Software Agents
Software development is a knowledge-intensiveactivity. Often, developers lack the specific knowl-
edge that is required for a particular developmenttask. In this scenario, developers typically seekassistance from their peers. LaToza et al. [23]have completed a study at Microsoft to accuratelyasses the impact of this knowledge deficiency prob-lem; it was discovered that 62% of developershad serious problems due to switching tasks be-cause their team-mates requested assistance, and50% had serious problems having to switch tasksbecause they were unable to solve their currenttask without seeking assistance from team-matesor additional resources. This problem will extendto a Component-Based Development environmentwhere component libraries are large and integra-tion is difficult.
The tools and techniques used to share knowl-edge within organisations can vary greatly. Asnoted previously, colleagues can hold informalmeetings, telephone or email each other, or per-haps rely on extensive support materials. Thesetechniques are often effective, but lack efficiencyand reliability. Therefore, we propose an intelli-gent software agent that can automatically shareknowledge among software developers. This issimilar to the work of Lodi et al. [4] where agentsare employed, in a distributed environment, to dis-cover and share knowledge. In the context of ourwork, the agent will shared knowledge relating tosoftware components by identifying opportunitiesfor component reuse.
Software Agents [1,47], like software compo-nents, are loosely defined. Agents differ fromconventional software in that they are long-lived,semi-autonomous, proactive, and adaptive. Agentscarry out some set of operations on behalf of a user,or another program, with a certain degree of in-dependence. In so doing, the agent employs someknowledge or representation of the user’s goals anddesires. This work is concerned with the use ofintelligent agent technology in the CBD domain;such agents will assist a developer to completetheir development and component reuse activitiesin a way that is consistent with the fundamen-tal principles of the reuse-within-development con-cept. To do this, the agent must first learn knowl-edge pertaining to software components.
4.1.1. Learning Knowledge from Source CodeRepositories
When undertaking a development task, pro-grammers often have a sense of deja vu [35]. They

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 7
feel that they have solved this problem before orknow of an existing solution. In general, mediumand low level programming tasks are repeated: ei-ther within a project, an organisation, a domain,or within a community. Similarly, solutions oftenmimic each other. This explains the phenomenonof source code clones and code duplication. De-velopers recognise that a solution exists to theirproblem and decide to copy existing source code.
Instead of simply copying source code, embed-ded knowledge can be extracted or learned fromthe source code and reused in new projects. Theknowledge collected will relate to how componentsare used by developers in practice, and will act asknowledge-base for the intelligent software agent.Subsequently, the agent will be capable of advis-ing a developer, based on previous developers so-lutions, on how best to complete their current pro-gramming task using software components.
4.1.2. Sharing Knowledge with DevelopersJust as it is important for the agent to mine and
learn knowledge, it is also important that the agentcan distribute and share this knowledge with therelevant parties. The agent must initially deter-mine when knowledge is deemed relevant to a de-veloper, and accordingly, must present this knowl-edge in a manner that is effective yet unobtru-sive. Often the agent is offering unsolicited advice.This research concentrates on supplying develop-ers with knowledge that assists component reuse;this typically involves recommending a set of com-ponents for reuse to a developer. The agent must:be easy to use, anticipate reuse opportunities, al-low a developer to quickly assess retrieved compo-nents, and bridge the gap between a developer’sreuse requirements and their actual reuse levels.The following section describes RASCAL, a com-ponent reuse support tool that employs an intelli-gent agent to produce recommendations.
4.2. RASCAL
RASCAL, as shown in figure 4, is a CBD proto-type tool that is designed to support reuse-within-development. This tool incorporates intelligentagent technology and supplies a developer withtask relevant component recommendations. Themain components of RASCAL are now detailed.
4.2.1. Recommender AgentThe recommender agent is responsible for ac-
tively monitoring the current developer’s actions.Based on this, the recommender agent formulatesa reuse intention and proactively recommends acandidate set of ordered library components tothe active developer. Recommendations are pro-duced using the information filtering techniquesexplained in section 5.
The agent does not attempt to understand thefunctionality of the source code that a developer iscoding or the developer’s ultimate goals. Rather,the agent is intended to provide short-term andimmediate assistance to developers. Likewise, theagent does not understand the functionality of thecomponents that it recommends; a component isrecommended simply because the agent believesthat it is appropriate for a particular developer touse this component now. An agent learns suchknowledge from mining source code repositories asdiscussed shortly.
4.2.2. Knowledge-intensive IDE (KIDE)An Integrated Development Environment is used
by developers on a daily basis to complete theirprogramming tasks. RASCAL extends a devel-oper’s current IDE to incorporate the recom-mender agent, so that the agent and the IDE ap-pear as a single entity to the developer. This is re-ferred to as a Knowledge-intensive Integrated De-velopment Environment (KIDE), and supports areuse-within-development paradigm.
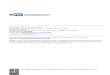
An example of the RASCAL KIDE is shown infigure 5. The screenshot of the Eclipse IDE resem-bles the standard Eclipse Java Perspective withthe exception of the, unobtrusive, recommenderagent that is visible at the bottom right corner ofthe window. As a developer is writing code, RAS-CAL monitors the developer’s source code and em-ploys this information to recommend a set of li-brary components. The developer does not needto explicitly accept nor reject recommendations.
4.2.3. Source Code RepositoryThe source code repository can contain source
code from: existing work, previous projects, andexternal software. Additionally, it is beneficial ifthe code repository contains the work of a het-erogeneous set of developers, who are likely tohave made use of the majority of library compo-nents. The open-source development paradigm is

8 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
Fig. 4. The Main Components of RASCAL
well suited in this context with significant amountsof code available; accordingly, we make use ofthe Sourceforge [40] repository. The code repos-itory must be sufficiently populated to allow ef-fective learning. A large source code repositorywill likely contain information about many com-ponents, which in turn increases the number ofcomponents for which recommendation is possible,but could result in components which have a highdensity-of-use being recommend more frequently.With regard to the effectiveness of RASCAL, ourprevious research has shown that a small popu-lated repository of source code that uses softwarecomponents frequently is more desirable than alarge populated repository of source code that in-frequently employs components [33]. Ideally, thecode in the repository will be of a high quality,having been thoroughly tested.
4.2.4. Information Retrieval (IR) ModelAn IR model is populated from mining the
source code repository. This represents a lot ofthe information contained in the code repositoryin a useful manner. Possible IR models are dis-cussed further in the next section. The recom-mender agent queries this model and, resultantly,recommends a set of library components to the de-veloper. Before the IR model can be built, infor-mation needs to be extracted from the code repos-itory. Source code parsers, such as the ByteCode
Engineering Library (BCEL)[5] used in this re-search, can be employed for this purpose.
4.2.5. Active DeveloperFor each individual active developer, RASCAL
continuously recommends a relevant set of librarycomponents for reuse. The recommendation setcontains components that a developer may or maynot have anticipated. RASCAL only considers thecontent of a developer’s current work and does notuse any historical developer information; for ex-ample, RASCAL does not examine any programsthat a developer has coded in the past. Althougha developer may have made use of certain compo-nents in the past, this does not guarantee that thedeveloper will recall, or identify appropriate op-portunities to reuse, all such components. There-fore, RASCAL merely considers the program un-der development. The developer’s current compo-nent usage information is stored along with order-ing details, as shown in table 1. This latter or-dering information is used by our Content-BasedFiltering algorithm, as explained in section 5.3.
4.2.6. Component LibraryComponent libraries can be populated through
a variety of sources; for example, from built in-house components, open-source software, or fromcommercial components. This research focuses on
F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 9
Fig. 5. RASCAL Eclipse Plugin
Table 1Active Developer’s Component Vector
Component Method User: U1JLabel:setBorder(Border) 1JFrame:setDefaultCloseOperation(int) 1JPanel:add(JLabel) 1JPanel:add(JLabel) 1JPanel:add(JLabel) 1JFrame:setVisible(boolean) 1
improving the accessability of components in a li-brary rather than populating component libraries.
Two important components of RASCAL are therecommender agent and the Information Retrievalmodel. The next section explains the technical as-pects of both.
5. Component Recommendation
The previous section introduced a Knowledge-intensive Integrated Development Environment pro-totype tool, named RASCAL, that incorporatesintelligent agent recommendation technology. Thissection presents the filtering methodology em-ployed by the recommender agent and, to a lesserextent, reviews a number of IR models. The IRmodels employed in this research are standardtechniques and thus deserve minimal explanation.
5.1. Granularity
This subsection clarifies the granularity at whichRASCAL operates by clearly defining three termsthat are commonly used in recommender litera-ture.
Item RASCAL recommends an item to a devel-oper. Specifically, RASCAL recommends areusable Java method from a component li-brary to a developer. Developers are likelyto use several items within their program-ming solution. When statically comparingtwo pieces of source code, the items (meth-ods) invoked within each source code are com-pared. During comparison, method signa-ture is ignored; library methods overloadedwithin a particular class are treated as a sin-gle library item. Typically, overloaded meth-ods perform similar operations but operateon different input data. The recommendationmethodology presented here does not distin-guish between overloaded member methods.Additionally, an object’s precise type is notalways identifiable; for example, in certain cir-cumstances the runtime type of a polymor-phic object may not be known without per-

10 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
forming a runtime analysis, thus the exactitem invoked cannot always be statically de-termined. In this scenario, the correspond-ing item in the parent class is recorded as theinvoked item.
Active User A user is a Java method, written fora previous project, that is stored in the sourcecode repository and invokes items. By exam-ining many users, knowledge about the com-ponent library can be learned. The active useris the method currently being programmed bya developer. The developer, actively workingon this method, can also be considered as theactive user. Dependent on the context of use,it will be apparent when the term active userrefers to a method and when it refers to thedeveloper of that method.
Vote This represents a user’s preference for a par-ticular item. In this context, a vote is simplyan invocation count for a library method.
Notably, the term user and item can both re-fer to Java methods but the distinction should beclear. Based on the active user’s (developer) vote,over several items (library methods), a recommen-dation set of predicted votes can be produced us-ing the following algorithms.
5.2. Collaborative Filtering (CF)Recommendations
The goal of a Collaborative Filtering (CF) algo-rithm is to suggest new items, or to predict theutility of a certain item, for a particular user basedon the user’s previous preferences and on the opin-ions of other like-minded users [48]. CF algorithmsare used in mainstream recommender systems likeMovielens [46]. These systems are founded onthe belief that users can be clustered. Users in acluster share preferences and dislikes for particu-lar items, and are likely to agree on future items.As just noted, a user refers to the developer of auser-defined Java method and an item refers to areusable Java method from the component librarythat can be invoked. Breese et al. [2] classified CFalgorithms into two main classes, Memory-basedand Model-based ; both are explained here.
Fig. 6. Illustration of (kNN) Formation: After comparingthe active user with 43 other users, a recommendation isproduced based on the k=8 most similar source codes.
5.2.1. Memory-based Collaborative FilteringIn a Memory-based CF approach, a recommen-
dation for the active user is derived by consideringall other users in the code repository. Vote vaj cor-responds to the vote by user a for item j. The pre-dicted vote using Memory-based CF for the activeuser a on item j, mem−cf−PVaj , is a weightedsum of the votes of similar users:
mem−cf−PVaj = N∑
b∈kNN
sim (a, b) (vbj − vb)
(1)where vb is user b’s average vote and weightsim(a, b) represents the correlation or similaritybetween the active user a and each user b. kNNis the set of k Nearest Neighbours to the currentuser, as illustrated in figure 6.
A neighbour is a user who has a high similarityvalue, sim(a, b), with the active user. The set ofneighbours is sorted in descending order of sim-ilarity; the technique used to measure similarityis described shortly. Experiments in the followingchapter use a value of k = 8 neighbours. A largenumber of neighbours can translate into a largernumber of items for which recommendation is pos-sible, although, it might be the case that the iden-tified neighbours are not of close similarity whichleads to reduced recommendation accuracy. Thus,a trade-off is required and k = 8 is a reasonablevalue. N is the normalising factor such that theabsolute values of the weights sum to unity.
From equation 1, a user’s vote can be predictedfor any item. In the context of this work, the like-lihood of a reuse opportunity for any method inthe component library can be predicted based onthe active developer’s current preferences. An as-sumption is made that every method in the compo-nent library has been voted for by at least one userpreviously. Library methods are ranked based on

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 11
Table 2Vector Space Model (VSM) Item-User Matrix for 5 Users
Component Method User VectorsU1 U2 U3 U4 U5
JL:setBorder(Border) 1 1 0 0 1JF:setDefaultCloseOp(int) 1 1 0 0 0JP:add(JLabel) 1 3 1 0 1JP:setBorder(Border) 1 0 3 4 0JF:setContentPane(JPanel) 1 0 1 2 0JF:setSize(int,int) 1 0 1 2 0JF:setVisible(boolean) 1 1 1 2 0
their predicted vote and the top n methods, withthe highest vote, are recommended to the devel-oper. Based on informal observation, the experi-ments in the next section use a maximum value ofn = 7. That is, a recommendation set can contain,at most, seven components. Cognitive and soft-ware engineering studies have shown that seven isan understandable number of options to present toa developer [39,59].
Comparing Users Central to CF is the abilityto determine a set of users who are most rele-vant or similar to the active user for whom therecommendation is being sought. This cor-responds to function sim(a, b), introduced inequation 1. In this research, the Vector SpaceModel [24] is employed. A user vector sim-ply records a user’s invocation count (vote)for all items that can be found in the compo-nent library. The order of invocations is ig-nored; ordering information is used later inthe Content-Based Filtering algorithm, as dis-cussed in section 5.3. Table 2 illustrates anexample of the Vector Space Model. In to-tal, there are 7 library items and 5 user vec-tors. Each user vector contains an invoca-tion count for all library items. A user cor-responds to a Java method as defined in sec-tion 5.1. A user’s vector is collected implicitlyby analysing their source code. The similaritybetween two vectors, belonging to user a anduser b, is calculated as follows:
sim (a, b) =∑
j
vaj√∑k∈Ia
v2ak
∗ vbj√∑k∈Ib
v2bk
(2)where the squared terms in the denominatorare used to ensure that a user who uses manycomponents does not appear more similar toother users. Vote vaj and vbj corresponds to
each user’s vote for item j. Ia and Ib arethe sets of items the user a and user b hasvoted on respectively. The cosine of the angleformed between user a’s vector and user b’svector, sim (a, b), will fall in the range [0, 1]1.A cosine of 1 indicates two users are identi-cal, whereas 0 denotes no similarities. Moredetails can be found in [30].
Algorithm Characteristics To determine thekNN nearest users, the active user must becompared with each user in the code reposi-tory. This property of Memory-based CF al-gorithms has potential implications for scal-ability and runtime performance. In generalthough, Memory-based CF works reasonablywell, is straightforward to implement, and eas-ily allows new users to be added.
5.2.2. Model-based Collaborative FilteringModel-based CF algorithms seek to fit a proba-
bilistic model to the user database through unsu-pervised learning techniques and to subsequentlyuse this model to quickly make predictions. From aprobabilistic perspective, the task of Model-basedCF is to determine the probability that an activeuser has a particular vote value for a specified item.Breese et al. [2] describe two types of probabilis-tic models suited to CF: Bayesian clustering andBayesian network models. In the first model, like-minded users are clustered together into classes.Each item, given the cluster, is treated indepen-dently. A recommendation for an active user isbased on the cluster of which they are a member.In the second model, a Bayesian network is em-ployed. In this case, items are no longer treatedindependently, but rather conditional dependen-cies between items is learned from the data. Fromour previous work, it was discovered that Bayesiannetworks perform poorly in our domain [32]. Inaddition, clustering has been suggested as a natu-ral preprocessing step for CF [54]. This researchuses a similar version of the Bayesian clusteringModel-based CF algorithm described by Breese etal. [2].
Clustering Users Initially, a set of source codeclusters C = c1, c2, ..., cm are created where
1Typically in recommender systems, a user can have anegative vote for an item which results in sim (a, b) fallingin the range of [−1, 1]

12 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
Fig. 7. Illustration of Clustering: The active user must becompared with 9 other clusters as opposed to 43 users whenusing the kNN Memory-based algorithm.
m is the number of unique clusters, as shownin figure 7. The probability that an activeuser, user a, belongs to a particular cluster cx,Pr(cx, a), is estimated. After establishing thecluster of which user a is mostly likely to bea member, a modified version of equation 1 isused to predict the vote for user a on item j:
mod−cf−PVaj = va + Pr(cx, a)(vcxj) (3)
where cx is the classified cluster and vcxj is theaverage vote for item j in cluster cx. To pro-duce a recommendation set, the top n itemswith the highest predicted vote are recom-mended. Like the Memory-based CF algo-rithm, a value of n = 7 is used in the experi-ments in the next section.The clustering algorithm is implemented us-ing a simple Naıve-Bayes model [22]. Theprobability that user a belongs to cluster cx
is calculated as follows:
Pr(cx|a) = P (cx)n∏
j
P (vj |cx) (4)
where n is the number of items, j is one li-brary item and P (cx) is the prior probabil-ity of this particular cluster cx. P (cx) can beestimated by counting the training examplesthat fall into cluster cx and dividing by thesize of the training set. P (vj |cx) is the proba-bility of the active user’s vote for item j giventhat this user is a member of cluster cx. Byexamining all clusters, it can be determinedwhich cluster has the highest posterior prob-ability given the active user. That cluster isthen used by the recommendation algorithmin equation 3. Full implementation details ofthis algorithm can be found in [31].
Characteristics A considerable benefit of Model-based CF is that it only requires the pa-rameters of the model to be kept in mem-ory when making predictions. This requiresless space than the entire item-user matrix re-quired by the Memory-based approach. Un-like the Memory-based scheme, the Model-based technique requires an initial learningphase and it can be difficult to add new users.
5.3. Content-Based Filtering (CBF)Recommendations
Like Collaborative Filtering, the goal of Content-Based Filtering (CBF) [50] is to suggest, or topredict, the utility of certain items for a particu-lar user. CBF recommendations are based solelyon an analysis of the items for which the currentuser has shown preference. Unlike CF, users areassumed to operate independently. Items whichcorrelate closely with the user’s preferences arelikely to be recommended. For example, in a newsrecommender system, keywords from the currentuser’s preference would be analysed to recommendnews stories which contain similar keywords.
We propose that software components are com-monly used, by developers, in similar patterns andthat by examining these patterns future compo-nent use can be predicted. In this work, the CBFalgorithm examines the order in which a user em-ploys a set of methods from a component library.This novel technique is quite unlike standard CBFsystems. As stated in subsection 4.2.5, the iteminvocation order, for each user, is stored in a list.From this, it can be determined that user a in-voked item x followed by item y. When making aContent-Based prediction for item j to the activeuser a, the set of all users who voted for item jneeds to be examined. Assuming there is only oneuser, user b, in the code repository that has votedfor item j, then the predicted vote for user a onitem j is calculated as follows:
– Firstly, the last item that the active user ainvoked, Preva, is reviewed.
– The item that user b invoked previous to itemj, Prevbj , is also examined.
– If Preva is identical to Prevbj , then intu-itively, and based on our earlier proposal, it islikely that the active user will want to invokeitem j next.

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 13
5.3.1. Worked ExampleFor clarity, the CBF algorithm is explained
with an example based on figure 8. When mak-ing a recommendation for the active user a onthe item setSize(int,int), which is used bya randomly selected user b, a check is done tosee if the last item invoked by the active user(setContentPane(JPanel)) is the same as theitem user b invoked previous to setSize(int,int).These two items are the same, therefore, it is ex-pected that setSize(int,int) would be recom-mended to user a next. Using CF, setSize(int,int) and setVisible(boolean) would be recom-mended equally with the same predicted vote,assuming user b is a close neighbour of user aor that user a is a member of the same clus-ter as user b. The CBF technique ensuressetSize(int,int) is recommended first but couldresult in setVisible(boolean) not being recom-mended.
Unlike our previous work that only investigatedthe sequence of two method invocations [30], thistechnique is extended to look back for the longestmethod invocation-order similarities between twousers. A long sequence of invocations, identical tothe active user’s, helps to produce recommenda-tions with a high confidence value. Analysing theitem preferences of only one other user, user b, thecorrelation or similarity between user a and userb’s invocation lists, sim(a, b), is defined as follows:
sim(a, b) =|Uab||Ia| ∗
indexa
|Ia| (5)
where Ia is the set of items user a has voted on,Uab is the longest set of items that both user aand b invoked in identical order. The index vari-able in this novel algorithm denotes the most re-cent position where both users invoked the sameitem. Consider another example where user a anduser b both invoked 10 methods and the methodsetSize(int,int) is invoked twice by each user.The method setSize(int,int) is the first methodinvoked by user a and is subsequently invokedagain, by user a, at position 8 (where position 10would be the last method invoked). Similarly, userb invoked the method setSize(int,int) at posi-tion 2 and position 6. In this example, indexa
would equal 8 and indexb, as introduced shortly,would equal 6. Ideally, indexa will equal |Ia|, i.e.the last method invoked by the active user.
In figure 8, there are two users: a and b. Thesize of the set of items that user a invoked, Ia, is5. The size of the set of items that user a anduser b invoked in identical order, Uab, is 4. Theindexa is 5 as setContentPane(JPanel) is the lastidentical item that both user a and user b invoked,and hence sim (a, b) evaluates to 0.8. The indexfor user b, indexb, is also stored which is needed inequation 6; indexb is 6 in this example. The indexvalue has significance. The aim of this recommen-dation is to predict the next invocation for user a,and thus order similarities towards the latter partof user a are the most important.
The previous example only considered one userin the code repository that invoked item j. A newrecommendation algorithm that considers all usersin the code repository is now presented. The pre-dicted vote for user a on item j, cbf−PV aj, isdefined as follows:
cbf−PVaj = N∑
b∈A
sim (a, b) (bjNextInvoked)
(6)where A is the set of all users in the code repositorywho voted for item j, N is the normalising factorsuch that the absolute values of the weights sumto unity, and sim(a, b) is calculated using equa-tion 5. bjNextInvoked is a boolean value thatsimply denotes whether item j is invoked directlyafter user b’s index (indexb). Referring back tofigure 8, and assuming user b is the only user inthe code repository, if a prediction is being madefor user a’s vote on the item setSize(int,int)then bjNextInvoked would equal 1. If, however,a prediction is being made for user a’s vote on theitem setVisible(boolean) then bjNextInvokedwould equal 0, and this method would not be rec-ommended. From equation 6, the vote for any itemusing CBF can now be predicted.
Characteristics Compared with regular Collab-orative Filtering, it would appear that CBF iscomputationally expensive; for example, theCBF algorithm must find the longest sequenceof invocation similarities. Notably though,the number of item invocations for each useris typically quite small; based on the datasetused in this work, we found each user invokesan average of 11 items. Additionally, unlikethe CF technique where all users are exam-

14 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
Fig. 8. Using Collaborative Filtering, RASCAL will recommend that the active developer, user a, should invoke JFramemethods setSize() and setVisible(). However, it is desirable that setSize() is invoked before setVisible().
ined, a CBF recommendation for an item jonly considers user who have invoked thatitem previously; this is likely to increase per-formance.The ability of this CBF algorithm to predictcomponent usage, based on component order-ing, is an important advantage over the CF al-gorithms explained earlier. Though, it couldbe argued that the CBF recommendations areshort-sighted, whereas CF recommendationsallow a developer to better anticipate futurecomponent use. Additionally, it can be statedthat developers do not invoke methods in or-der; in such circumstances CF algorithms aremore appropriate.When making a recommendation, the Content-Based Filtering algorithm previously describedexamines several users to determine the or-der in which they invoke particular methods.Some practitioners may argue that this filter-ing algorithm does not strictly confirm withthe standard definition of CBF, as users arenot treated independently. The validity ofthese concerns is recognised and we acknowl-edge that our algorithm widely differs fromstandard CBF techniques. However, it is stillbelieved that the term CBF adequately de-scribes this approach. Currently when thepredicted vote of an item is calculated, each
user of that item is examined. With littlemodification, knowledge relating to the invo-cation order of items could be initially learnedby analysing the source code repository. Forexample, it could be learned that setX() istypically invoked prior to setY(). Subse-quently, this knowledge could be reused in fu-ture recommendations, eliminating the needto examine other users. This correspondswith the idea of learning information pertain-ing to genre in a movie or music CBF recom-mender system. Additionally, this modifica-tion would improve the performance of equa-tion 6.
5.4. Hybrid Recommendations
This subsection describes how the previous twofiltering techniques can be merged. By mergingthese filtering algorithms, it is anticipated that arecommendation set will contain a broad set ofuseful recommendations in a meaningful order.
5.4.1. Memory-based CollaborativeContent-Based Filtering
The similarity measure, sim(a, b), defined inequation 2, and used in the Memory-based CFequation 1, can be extended to include the invoca-tion order similarity defined in equation 5. Each

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 15
similarity value is given an arbitrary weighting ofws = 0.5, where ws is the predefined weight givento the CF measure. Similarity is now determinedas follows:
sim (a, b) =( |Uab||Ia| ∗
indexa
|Ia| ∗ (1− ws))
+
ws ∗
∑
j
vaj√∑k∈Ia
v2ak
∗ vbj√∑k∈Ib
v2bk
(7)
The CBF algorithm also needs to be modified.Currently using CBF, a predicted vote for an itemis based on every user, in the code repository, ofthat item. This is updated so that only the near-est neighbours are examined, as determined usingequation 7. Equation 6 is modified as follows:
mem−cbf−PVaj =
N∑
b∈kNN
sim (a, b) (bjNextInvoked) (8)
where kNN is the set of nearest neighbours. Thefinal equation for calculating the predicted vote foractive user a on item j using Memory-based Collab-orative Content-Based Filtering, mem−ccbf−PVaj ,is as follows:
mem−ccbf−PVaj = (mem−cf−PVaj) (w)+
(mem−cbf−PVaj) (1− w)(9)
where w is the predefined weight given to theCF prediction value. Initially, the predicted votefor an item, using standard Memory-based CF,mem−cf−PVaj , is calculated using equation 1.This examines each neighbour’s vote for this item.The predicted vote is then weighted. The resultis added to the Content-Based Filtering predictedvote. Equation 8 is used to calculate the CBF vote,mem−cbf−PVaj . This also examines each neigh-bour to determine if item j is directly called afterthe neighbour’s indexb variable. The index vari-able denotes the most recent position where boththe active user and its neighbour invoked the sameitem. The CBF vote is also weighted. The exper-iments in the next section use a arbitrary value ofw = 0.5.
5.4.2. Model-based Collaborative Content-BasedFiltering
This subsection again presents a new algorithmfor producing recommendations. The probabilitymeasure, Pr(cx, a), is the probability that user abelongs to cluster x. Using the probability equa-tion 4, it can be determined which cluster that usera has the highest posterior probability of belong-ing to. Assuming this is determined, then the CBFalgorithm defined in equation 6 can be modified asfollows:
mod−cbf−PVaj =
N∑
b∈cx
sim (a, b) (bjNextInvoked)
(10)
where cx is the cluster that user a is most similartoo. This cluster is likely to contain several uniqueusers. Using the CBF technique, a vote is onlypredicted for all the items which the users in clus-ter cx have invoked at code-writing time. Our finalequation for calculating the predicted vote for theactive user a on item j using Model-based Collab-orative Content-Based Filtering, mod−ccbf−PVaj ,is as follows:
mod−ccbf−PVaj = (mod−cf−PVaj) (w)+
(mod−cbf−PVaj) (1− w)(11)
where w is the predefined weight given to the CFprediction value. Initially the predicted vote foran item is calculated using the standard Model-based CF equation 3, mod−cf−PVaj . This isthen weighted. The result is added to the CBFpredicted vote. To calculate the CBF vote,mod−cbf−PVaj , equation 10 is used. The CBFvote is also weighted. The experiments in the nextsection use a arbitrary value of w = 0.5.
5.4.3. CharacteristicsReferring back to figure 8, the hybrid Memory-
based equation 9 and Model-based equation 11 aredesigned to ensure both setSize(int,int) andsetVisible(boolean) are recommended. How-ever, setSize(int,int) will have a higher pre-dicted vote and will appear before setVisible(boolean) in the recommendation set. The nextsection evaluates these algorithms.

16 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
6. Evaluation
6.1. Dataset
Over 35,000 recommendations were producedfor 3481 methods mined from Sourceforge [40].Each method invoked an average of 11 items fromthe component library. Recommendations weremade for both the SWING and AWT libraries; intotal there was 2090 library methods that were in-voked at least once in our code repository. Sincewe have the complete source code, a recommen-dation for a piece of code can be automaticallyevaluated by checking whether the recommendedmethod was in fact called subsequently.
For each user method, several recommendationswere made. For clarity, an example is given. Oneuser, a fully developed Java method, is taken fromthe code repository. This user is now the activeuser and will not be used by any of the filtering al-gorithms when making a recommendation. In to-tal, this active user calls ten Swing library meth-ods (items) at the code-writing stage, as opposedto runtime. The tenth invocation is automaticallyremoved from the active user’s invocation list anda recommendation set is produced for the activeuser based on the preceding nine invocations. Theaim is to verify if the proposed recommendationmethodology can predict the missing method. Fol-lowing this recommendation, the ninth invocationis also removed from the active user’s invocationlist and a new recommendation set is formed basedon the preceding eight invocations. This processis continued until all-but-one invocation remains.
6.2. Evaluation
Precision and Recall are the most popular met-rics for evaluating information retrieval systems.Precision is defined as the ratio of relevant recom-mended items to the total number of items rec-ommended; P = nrs/ns, where nrs is the numberof relevant items selected and ns is the numberof items selected. This represents the probabilitythat a recommended library method is relevant.A library method is deemed relevant if it is usedby the developer for whom the recommendation isbeing sought. Recall is defined as the ratio of rel-evant items selected to the total number of rele-vant items; R = nrs/nr, where nrs is the numberof relevant items selected and nr is the number
of relevant items. This represents the probabil-ity that a relevant library method will be recom-mended. Several approaches have been taken tocombine precision and recall into a single metric.The F1 measure, initially introduced by van Rijs-bergen [55], combines both with an equal weightin the following form: F1 = 2PR/ (P + R).
It is particularly important that RASCAL rec-ommends methods in a relevant order i.e. the invo-cation order. We will evaluate this using a simplebinary Next Recommended (NR) metric; NR = 1if we successfully predict or recommend the nextmethod a developer will use, otherwise NR = 0.The time taken to query a library can strongly im-pact a developer’s perception of that library. Adeveloper will become frustrated if retrieval timesare long and thus we also evaluate this.
These automated experiments cannot evaluatethe impact of incorrect or irrelevant recommenda-tions. There is also an assumption that the devel-opers of the original source code made optimal useof the available component libraries, and thus rel-evancy or irrelevancy can be precisely defined. Weacknowledge this limitation of our existing workand the need for practical experimentation to fullyevaluate RASCAL.
6.3. Results
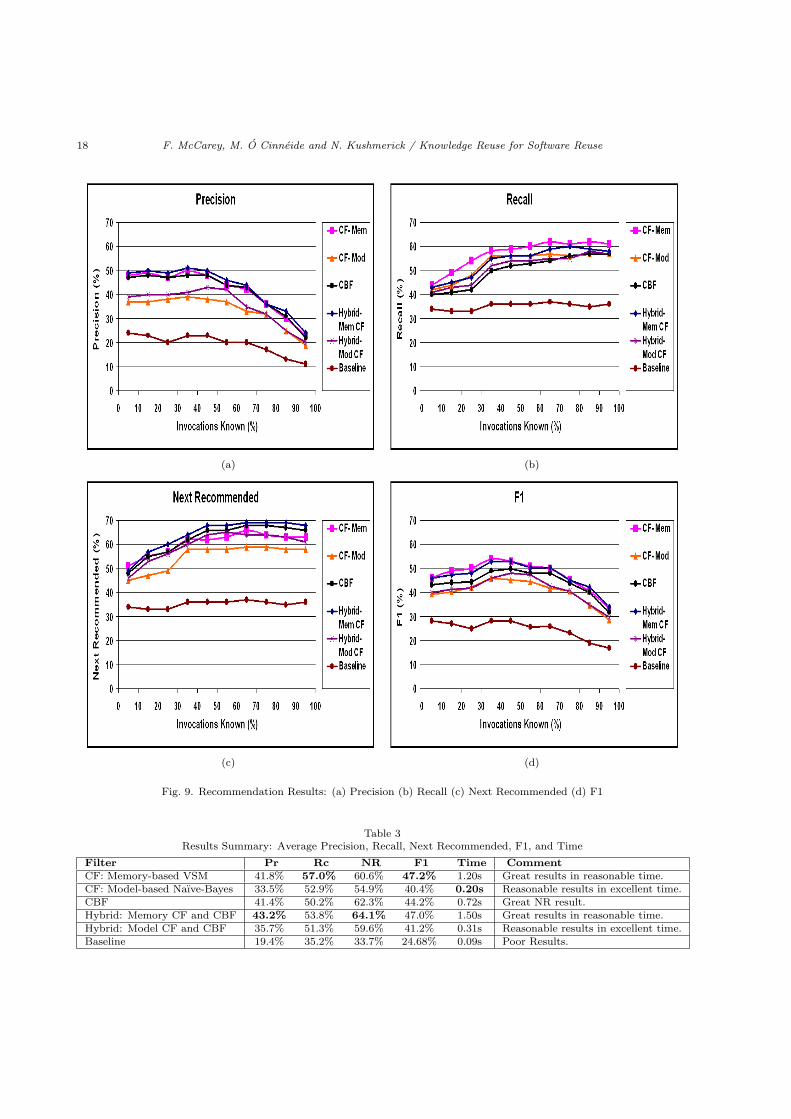
Figure 9 displays the results for each of theaforementioned algorithms. Result values are sim-ilar, and so for clarity, the average result of eachtechnique is listed in table 3. For both the pureand hybrid model-based CF algorithms, the num-ber of cluster is 850. This is a significant reduc-tion from the original 3481 users used in the otheralgorithms. A baseline result is also presented.Baseline recommendations were produced by rec-ommending, at each recommendation stage, theseven most commonly invoked library methods.
Two universal trends quickly become apparentin the following results: precision typically de-creases as more information is known regardingthe active user, while recall increases. Consider anactive user who uses a total of ten library meth-ods. When a recommendation is made for thisuser, when only one library method is simulated asbeing used, then there is a set of nine possible re-maining methods to recall. The chances of recall-ing all relevant methods is quite low and hence therecall result is lower in earlier recommendations.

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 17
However, when this user has called 9 methods andthere is only 1 possible method left to recall, thenthe chances of this method being in the recommen-dation set is quite high. In contrast, the more invo-cations mimicked as being invoked, the fewer thereare to correctly recommend, and hence, there is agreater probability of recommending an irrelevantlibrary method. Thus, precision decreases in lat-ter recommendations. The results of all techniquesare compared below.
Precision The superior recommendation tech-nique, based on precision, is a hybrid ofMemory-based CF and CBF. The averageprecision is 43.2% when using this algorithm.This compares with 41.8% when using onlythe Memory-based CF algorithm and 41.4%when using the CBF algorithm. Notably, allthree algorithms produce similar results. Thehybrid Model-based technique does not per-form as well, only achieving a precision valueof 35.7%. Though, this is an improvement onthe pure Model-based CF precision of 33.5%.The poor performance of the Model-basedtechnique suggests that it is difficult to de-velop a cluster model that fits the data well.As a result, the accuracy of recommendationssuffer. It is believed that members in a clus-ter agree on many items (based on the recallresults that follow) but that there is wide dis-agreement among cluster members on otheritems, thus reducing precision.
Recall Memory-based CF, at 57%, produces thebest recall value of all algorithms. When ei-ther of the CF algorithms is merged with theCBF algorithm, the recall value drops. Froma CBF perspective though, merging a CF al-gorithm with a CBF algorithm improves re-call. The hybrid Memory-based algorithmachieves an average recall value of 53.8%,while the Model-based hybrid approach hasan average recall value of 51.3%. In termsof supporting software reuse, all algorithmsare very effective at recalling relevant com-ponents. Pure CF examines a general setof neighbours when making a recommenda-tion, based on all of the current user’s in-vocations. Contrarily, CBF only examinesusers that have invoked the particular itemfor which recommendation is sought. There-fore, it is understandable that the CF algo-
rithm produces a broad recommendation setthat recalls more relevant components whileCBF technique is short sighted and only re-calls immediately relevant components.
Next Recommended A hybrid of Memory-basedCF and CBF is the most effective techniquefor predicting the next method that a devel-oper uses. Using this approach, the averageNR value is 64.1%. This compares with 60.6%when only the Memory-based CF algorithm isused and with 62.3% when only the CBF algo-rithm is used. The Model-based CF algorithmsignificantly improves when merged with theCBF technique. Originally, the average NRvalue was 54.9%, but this now increases to59.6%. It is expected that the hybrid algo-rithm and the pure CBF algorithm performbest as these are the only techniques to con-sider the order of invocations, and thus themost likely to identify the next useful item.
F1 The pure Memory-based CF algorithm pro-duces the best F1 result, with an averageof 47.2%. This is followed closely by theMemory-based hybrid algorithm which has anF1 value of 47%. Again, the efficient Model-based CF algorithm improves when mergedwith the CBF technique. The F1 value in-creases from 40.4% to 41.2% when using thelatter hybrid approach.
Time Memory-based CF recommendations takean average of 1.2 seconds, the Model-basedCF algorithm usually produces a recommen-dation within 0.2 seconds, and CBF recom-mendations typically take 0.72 seconds. Thehybrid Memory-based Collaborative Content-Based Filtering algorithm produces recom-mendations, on average, in 1.5 seconds. TheModel-based Collaborative Content-Based Fil-tering algorithm takes an average of 0.31 sec-onds to produce a recommendation. Withthe Memory-based hybrid approach, each userin the code repository needs to be examinedto determine the active user’s set of near-est neighbours. Additionally, a CBF sim-ilarity measure must also be calculated forall users, this decreases recommendation ef-ficiency. However, using the Model-basedhybrid technique, only each user in the se-lected cluster needs to be examined to deter-mine CBF similarity. Therefore, the efficiencyof the Model-based CF algorithm is not ad-versely effected when it is merged with CBF.
18 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
(a) (b)
(c) (d)
Fig. 9. Recommendation Results: (a) Precision (b) Recall (c) Next Recommended (d) F1
Table 3Results Summary: Average Precision, Recall, Next Recommended, F1, and Time
Filter Pr Rc NR F1 Time CommentCF: Memory-based VSM 41.8% 57.0% 60.6% 47.2% 1.20s Great results in reasonable time.CF: Model-based Naıve-Bayes 33.5% 52.9% 54.9% 40.4% 0.20s Reasonable results in excellent time.CBF 41.4% 50.2% 62.3% 44.2% 0.72s Great NR result.Hybrid: Memory CF and CBF 43.2% 53.8% 64.1% 47.0% 1.50s Great results in reasonable time.Hybrid: Model CF and CBF 35.7% 51.3% 59.6% 41.2% 0.31s Reasonable results in excellent time.Baseline 19.4% 35.2% 33.7% 24.68% 0.09s Poor Results.

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 19
6.4. Results Conclusions
If a relatively small dataset is used, as in theseexperiments, then the hybrid Memory-based Col-laborative Content-Based Filtering algorithm isideal. Recommendations are of a good quality andcan be produced within a reasonable time. Outprevious research, when compared with these re-sults, has shown that increasing the size of thecode repository does not actually improve recom-mendations [33]. Rather, this can be achieved bypopulating the code repository with users who fre-quently use the component library. For example,in these experiments, each user had a minimum ofeight library method invocations.
If the number of library components increasesdramatically, then it may be necessary to addmany new users to the code repository. In such asituation, the hybrid Memory-based algorithm be-comes inefficient, as each user in the code repos-itory must be examined. Instead, the Model-based hybrid technique should be used, as this canproduce good quality recommendations efficiently.This efficiency is due to the number of clustersnot growing linearly with the number of users. Incomparison with the Memory-based hybrid algo-rithm, this technique results in a small decrease inrecommendation accuracy.
The results presented here are heartening. Sig-nificant values of precision, recall, NR, and F1 canall be achieved. Further, recommendations canbe produced very quickly. As a means of sup-porting component reuse, these recommendationalgorithms prove highly effective. Average recall,for all algorithms is over 50% while the averageNR result is as high as 64% when using the hy-brid memory algorithm. An interesting future di-rection would be to compare the success of RAS-CAL across different domains; for example, cur-rent experiments are based on the Swing and AWTGraphic User Interface (GUI) libraries. It is pos-sible that such libraries encourage a linear style ofprogramming and thus improve RASCALs perfor-mance. Further analysis is merited
Based on the current results, a reuse supporttool, such as RASCAL, will greatly assist a devel-oper. In particular, RASCAL is capable of identi-fying reuse opportunities that may not be obviousto the developer. Depending on an individual’senvironment or circumstances, the importance ofeach of the evaluation criteria described earlier will
differ. Therefore, the RASCAL tool can be con-figured to use either of the five variations of therecommendation algorithm.
7. Related Work
This section reviews related work in the areaof component retrieval and software reuse sup-port. For background purposes, traditional re-trieval techniques are detailed. These rely heavilyon primitive IR and descriptive techniques. Fol-lowing this, more sophisticated retrieval and rec-ommendation techniques are presented that typi-cally employ intelligent IR approaches.
7.1. Traditional Component Retrieval
Traditional retrieval schemes focused generallyon basic IR techniques [9], and on descriptivemethods such as keyword search [29] and facetedclassification [44]. Other syntactic-based ap-proaches such as signature matching have beenused by Zaremski and Wing [60] for retrieval.Many of these techniques are not ideal. When us-ing a keyword search, too many or too few compo-nents may be returned because only keywords areused in the search. Signature matching queries arestrict and formal. Additionally, signature alonedoes not guarantee the expected behaviour of thecomponent. With faceted classification, the tax-onomy must be well defined and each componentmust explicitly fit the classification scheme.
Many of these techniques have been extendedto include semantic-based retrieval features. Typ-ically while querying the component library, thedeveloper specifies component requirements usingnatural languages which are then interpreted usinga language ontology as a knowledge-base. Com-ponents in the repository also have a natural lan-guage description. Both the developer query andcomponent descriptions are formalised and close-ness is computed. A set of potentially reusablecomponents are then ranked based on their close-ness value. Unlike the earlier retrieval schemes,domain information and component relationshipsare generally considered. Empirical results indi-cate that semantic-based retrieval schemes are su-perior to traditional approaches [52].

20 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
7.2. Intelligent Component Retrieval
More recently, several intelligent component re-trieval tools have been proposed. Gu et al. [13]present a Conversational Case-based componentRetrieval Model (CCRM) that helps developers lo-cate reusable components. The previous retrievaltechniques assume that a developer can clearly andaccurately formulate queries. In this approach,software components are represented as cases. Aknowledge-intensive case-based reasoning methodis adopted to explore context-based semantic sim-ilarities, between a developer’s query and storedcomponents. A conversational approach is usedto collect developer requirements interactively andincrementally. Like our work, the authors recog-nise that developers find it difficult to express theirreuse intentions and use discriminative questionsto extract further information from a developerand to more clearly define the query. This tool isuseful but lacks the ability to proactively infer adeveloper’s reuse requirements.
Just as we employ a software agent to delivercomponent recommendations to a developer, asoftware agent has been developed by Drummondet al. to assist library browsing [6]. The authorsdescribe active browsing: an active browser sug-gests to the developer components it estimates tobe close to the target search. A developer usesthe library browsing system for retrieving compo-nents in a normal manner. In addition, the activeagent attempts to recognise the developer’s intentand subsequently provides guidance that acceler-ates the search. Based on experimental results, theagent identified the developer’s search goal 40%of the time before the developer reached the goal.This work is intended to complement, rather thanreplace, browsing.
7.3. Web-based Retrieval
Several web-based commercial and open-sourcecomponent retrieval techniques have been devel-oped such as ComponentSource [3], and Planet-Sourcecode [42]. Similar to the Google search en-gine [41], ComponentRank [17] is one such tech-nique that harnesses web-based search approaches.Components are ranked based on analysing userelations among the components and propagatingthe significance of a component through the userelations; this is similar to our technique which
examines how components are used in practice.This technique is effective at giving a high rank tostable general components, which are likely to behighly reusable, and a lower rank to non-standardspecialised components.
Hummel and Atkinson [16] have carried out astudy on using the web as a reuse repository. Theyevaluated several specialised source code search en-gines such as PlanetSourceCode and Koders [20],and more general search engines such as Googleand Yahoo. They discovered that there is a magni-tude of accessible code resources on the web. Manyof these specialised search engines offer featuresfor choosing language, selecting syntactic require-ments such as a method name or parameter type,and accessing API information. However, theydiscovered that the non-specialised search enginesproduced comparable results. They also identifiedsome of the advantages of web-based approachessuch as scalability and efficiency, and noted limi-tations such as security and legal concerns. Suchresources could potentially be used by RASCALto learn new component information.
7.4. Component Retrieval by Example
Reuse support through code examples is a pop-ular research theme. Grabert and Bridge [12]present a software tool for examplet reuse. Theydefine examplets as consisting of two parts. Thefirst is a snippet of source code, Java in their ex-ample, which shows how to accomplish a task us-ing library components. The second part of theexamplet is a statement of the source code goalin free text. They have developed a tool that al-lows developers to specify their reuse goal in nat-ural text. Like RASCAL, this tool automaticallytakes into account the source code that the devel-oper is working on. The system combines text re-trieval with a semantic net representation of thesource code to retrieve relevant examplets. Whileit is feasible that example source code is availablewhich uses library components, it is less likely thatall source code will have an associated exampletdescription.
Another notable tool for finding code examplesis Strathcona [14]. This tool is used to find rele-vant source code in an example repository of manyprojects by matching the code a developer is cur-rently writing with all code in the example repos-itory. Similarity is based on multiple structural

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 21
matching heuristics, such as examining inheritancerelationships, method calls, and class instantia-tions. These measures are applied to the code cur-rently being written by the developer and, subse-quently, matched examples from the repository areretrieved and recommended to the developer. Un-like the work of Grabert and Bridge [12], queriesare automatically created by Strathcona once a de-veloper requests an example piece of code. Likeour work, this tool benefits from being able to pop-ulate its example code repository from any code orframework irrespective of coding conventions, asall code incorporates structure.
7.5. Proactive Recommendation: CodeBroker
A common shortcoming of the above solutionsis that they are developer dependent. A developermust be capable of anticipating all reuse oppor-tunities and initiating the retrieval process. How-ever, if a developer believes a reusable compo-nent for a particular task does not exist then theyare less likely to search the component repository.Thus, no-attempt-to-reuse is made.
Ye et al. [57,58] present a proactive recom-mender tool named CodeBroker that addressesthis key problem. CodeBroker infers a developer’sneed, or opportunity, to reuse a set of softwarecomponents, and then proactively recommendsthese. The need for a component is inferred bymonitoring the comments a developer writes alongwith method signatures. Based on this, a set ofmatching components is retrieved and presentedto the developer for reuse. This solution greatlyimproves on previous approaches. Nevertheless,the technique used to implement this approach isnot ideal. Reusable components in the componentlibrary must be sufficiently commented to allowmatching; this may, in effect, exclude the possiblerecommendation of many existing components. Inaddition, developers must also actively and cor-rectly comment their code. These pragmatic con-cerns restrict the applicability of CodeBroker in anindustrial setting.
This work is strongly related to CodeBroker,and to a lesser extent with Strathcona [14]. LikeRascal, CodeBroker recommends a set of meth-ods from the component library that a developershould consider invoking. This differs from theStrathcona tool which delivers a set of code exam-ples to a developer. At present, our experiments
are automated and reasonably large, use sourcecode from a variety of open-source projects, andrecommend methods from the Swing and AWTGUI component libraries. Contrarily, CodeBro-ker is evaluated manually using five programmersand a small number of programming tasks, re-quires HTML-based online documentation that isgenerated by running Javadoc over Java sourceprograms, and produces recommendations for theJava 1.1.8 Core API library and Java General Li-brary (JGL) [56]. As CodeBroker is a fully de-veloped tool, previous CodeBroker experimentstended to focus on the cognitive aspects of the re-search whereas in this work the focus is largely onthe accuracy of the recommendation algorithms.This makes a direct comparison difficult; nonethe-less, it is believed that our technique is the easi-est to adopt and the most effective recommenderin terms of correct ordering, while CodeBroker isa more mature system having been evaluated inpractical setting.
7.6. Review
Modern research on component retrieval tendsto take a more comprehensive approach than itstraditional counterparts. Gu et al. [13] and Drum-mond et al. [6] focus on developers. They advo-cate the need for an iterative approach to queryformulation as it is often difficult for a developerto initially express their reuse intentions clearly.Inoue et al. [17] consider component quality.They assess how components are used in prac-tice, and rank components based on this. Web-based retrieval techniques focus on scalability, per-formance, and availability. Component retrievalby example techniques [12,14] acknowledge the im-portance of program context and the developmentenvironment. Queries using this approach considerthe source code that the developer is currentlyworking on. The CodeBroker tool [58] recognisesdeveloper cognitive challenges and aims to addressthese through proactive component recommenda-tion.
Our work is similar to a number of the areasmentioned above but several key differences ex-ist that distinguish this work from others. Wehave presented an autonomous software agentthat can automatically identify reuse opportuni-ties and, based on this, recommends a set of rele-vant reusable components to an active developer.

22 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
Unlike existing component retrieval tools, the de-veloper does not need to initiate retrieval or per-form any additional tasks. The RASCAL agentlearns knowledge from existing source repositoriesand uses this knowledge to automatically identifyreuse opportunities.
Component recommendation techniques vastlyimprove on passive component retrieval tools.Tools, such as CodeBroker and Strathcona, haveimportant advantages over our work. For example,these tools are fully developed, provide source codeexamples that assist developers to understand therationale behind recommendations, and have beenevaluated in user trials. Similarly, RASCAL hasseveral distinct advantages. Our tool places astrong emphasis on the order of component recom-mendations and this is evaluated using the NextRecommended metric. In addition, our tool is notdependent on any particular coding styles or con-ventions, does not record developer coding histo-ries, and does not place additional requirements ondevelopers. This, combined with our efficient al-gorithms, ensures recommendations are performedquickly. Incorporated within the popular EclipseIDE, RASCAL is an effective, efficient, and easy-to-use component support tool.
8. Conclusion
Software reuse and Component-Based Develop-ment is difficult, hampered by the inadequacy ofexisting component reuse support strategies andtools. Key concerns are the inability of supporttools to automatically identify reuse opportuni-ties and formulate reuse queries; the separation ofreuse from development tasks; and the lack of tech-niques to store and distribute task-relevant com-ponent knowledge among developers. We have ar-gued that knowledge collaboration tools can beemployed to effectively support Component-BasedDevelopment by identifying unanticipated reuseopportunities. Such tools capitalise on the simi-larities that frequently exist between programmingsolutions; through the mining of source code repos-itories, knowledge can be extracted pertaining tothe use of software components and a collaborativeknowledge-base can be established. This is thenbe used to produce component recommendations.
From extensive experiments, we have concludedthat our filtering algorithms can efficiently pro-
duce reliable recommendations. Each proposedalgorithm significantly outperformed the baselineexperiment, and each has unique characteristicsthat will determine their suitability based on a de-veloper’s priorities. For instance, a recommenda-tion set, produced using a hybrid of Memory-basedCollaborative Filtering and Content-Based Filter-ing, can recall, on average, 54% of the reusablecomponents that a developer is interested in, whilethere is a 64% likelihood that the set will containthe next component a developer invokes.
Sophisticated knowledge-based component re-trieval and recommendation schemes are no silverbullets, and these alone will not elevate componentreuse to a standard software engineering practice.Other non-technical impediments need to be ad-dressed, for example, reuse needs to be nurturedand developers need to be rewarded for their reuseefforts. Nonetheless, this paper has described anintelligent agent solution that will encourage com-ponent reuse by utilising knowledge collaborationand component recommendation techniques. Thisdeveloper-centric methodology is both lightweightand easily adopted. In addition, the support tooldescribed in this research is an important step to-wards systematic component reuse.
9. Acknowledgements
Funding for this research was provided bythe Irish Research Council for Science, Engi-neering and Technology (IRCSET) under grantRCS/2003/127.
References
[1] Jeffrey M. Bradshaw. Software Agents. AAAI Press,1997.
[2] John S. Breese, David Heckerman, and Carl Kadie.Empirical analysis of predictive algorithms for col-laborative filtering. In 14th Annual Conference onUncertainty in Artificial Intelligence, pages 43–52,Madison, Wisconsin, USA, 1998.
[3] ComponentSource. www.componentsource.com. 2007.[4] Josenildo Costa da Silva, Matthias Klusch, Stefano
Lodi, and Gianluca Moro. Privacy-preserving agent-based distributed data clustering. Web Intelli. andAgent Sys., 4(2):221–238, 2006.
[5] M. Dahm. Byte code engineering with the bcel api.Technical Report B-17-98, 2001.
[6] Christopher G. Drummond, Dan Ionescu, andRobert C. Holte. A learning agent that assists thebrowsing of software libraries. IEEE Transactions onSoftware Engineering, 26(12):1179–1196, 2000.

F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse 23
[7] R. Due. The economics of component based develop-ment. Information Systems Management, 17(1):92–95, 2000.
[8] Liesbeth Dusink and Jan van Katwijk. Reuse dimen-sions. In Symposium on Software Reusability, pages137–149, Seattle, Washington, United States, 1995.ACM Press.
[9] W B Frakes and B A Nejmeh. Software reuse throughinformation retrieval. SIGIR Forum, 21(1-2):30–36,1987.
[10] William B. Frakes and Christopher J. Fox. Sixteenquestions about software reuse. Communications ofthe ACM, 38(6):75–ff., 1995.
[11] William B. Frakes and Christopher J. Fox. Qual-ity improvement using a software reuse failure modesmodel. IEEE Transactions on Software Engineering,22(4):274–279, 1996.
[12] Markus Grabert and Derek Bridge. Case-based reuseof software examplets. Journal of Universal Com-puter Science, 9:627–640, 2003.
[13] Mingyang Gu, Agnar Aamodt, and Xin Tong. Com-ponent retrieval using knowledge-intensive conver-sational cbr. In 19th International Conference onIndustrial, Engineering and Other Applications ofApplied Intelligent Systems, pages 27–30, Annecy,France, 2006.
[14] Reid Holmes and Gail C. Murphy. Using structuralcontext to recommend source code examples. In 27thInternational Conference on Software Engineering,pages 117–125, St. Louis, MO, USA, 2005.
[15] Grace Murray Hopper. The education of a com-puter. In 1952 ACM National Meeting, pages 243–249. ACM Press, 1952.
[16] Oliver Hummel and Colin Atkinson. Using the webas a reuse repository. In 9th International Conferenceon Software Reuse, pages 298–311, Turin, Italy, 2006.
[17] Katsuro Inoue, Reishi Yokomori, Tetsuo Yamamoto,Shinji Kusumoto, and Makoto Matsushita. Rankingsignificance of software components based on use re-lations. IEEE Transactions on Software Engineering,31(3):213–225, 2005.
[18] Stan Jarzabek and Riri Huang. The case for user-centered case tools. Communications of the ACM,41(8):93–99, 1998.
[19] Tetsuro Kakeshita and Miyuki Murata. Specification-based component retrieval by means of examples. InProceedings of the 1999 International Symposium onDatabase Applications in Non-Traditional Environ-ments, page 411, Washington, DC, USA, 1999. IEEEComputer Society.
[20] Koders. www.koders.com. 2007.[21] Charles W. Krueger. Software reuse. ACM Comput-
ing Survey, 24(2):131–183, 1992.[22] Pat Langley, Wayne Iba, and Kevin Thompson. An
analysis of bayesian classifiers. In 10th National Con-ference on Artificial Intelligence, pages 223–228, SanJose, California, USA, 1992. AAAI Press.
[23] Thomas D. LaToza, Gina Venolia, and Robert De-Line. Maintaining mental models: a study of devel-oper work habits. In 28th International Conferenceon Software Engineering, pages 492–501, Shanghai,China, 2006. ACM Press.
[24] Todd A. Letsche and Michael W. Berry. Large-scaleinformation retrieval with latent semantic indexing.Information Science, 100(1-4):105–137, 1997.
[25] Jingyue Li, Marco Torchiano, Reidar Conradi, OddPetter N. Slyngstad, and Christian Bunse. A state-of-the-practice survey of off-the-shelf component-baseddevelopment processes. In 9th International Confer-ence on Software Reuse ICSR, pages 16–28, Torino,Italy, 2006. Springer-Verlag.
[26] Wayne C. Lim. Strategy-driven reuse: Bringing reusefrom the engineering department to the executiveboardroom. Annals of Software Engineering, 5:85–103, 1998.
[27] Luqi and Jiang Guo. Toward automated retrievalfor a software component repository. In IEEE Con-ference and Workshop on Engineering of Computer-based Systems, pages 99–105, USA, 1999.
[28] Yoelle S. Maarek, Daniel M. Berry, and Gail E.Kaiser. An information retrieval approach for au-tomatically constructing software libraries. IEEETransactions on Software Engineering, 17(8):800–813, 1991.
[29] Y. Matsumoto. A software factory: An overall ap-proach to software production. In ITT Workshop onReusability in Programming, Newport, USA, 1993.IEEE Computer Society Press.
[30] Frank McCarey, Mel O Cinneide, and NicholasKuskmerick. Rascal: A recommender agent for agilereuse. Artificial Intelligence Review, 24(3-4):253–276,November 2005.
[31] Frank McCarey, Mel O Cinneide, and NicholasKuskmerick. A recommender agent for software li-braries: An evaluation of memory-based and model-based collaborative filtering. In International Con-ference on Intelligent Agent Technology, Honk Kong,December 2006.
[32] Frank McCarey, Mel O Cinneide, and NicholasKuskmerick. Recommending library methods: Anevaluation of bayesian network classifiers. In 2nd In-ternational Workshop on Supporting Knowledge Col-laboration in Software Development, Tokyo, Japan,September 2006.
[33] Frank McCarey, Mel O Cinneide, and NicholasKuskmerick. Recommending library methods: Anevaluation of the vector space model (vsm) and latentsemantic indexing (lsi). In 8th International Confer-ence on Software Reuse, Torino, Italy, June 2006.
[34] M. D. McIlroy. Mass produced software compo-nents. In NATO Software Engineering Conference,volume 1, pages 138–150, Germany, October 1968.
[35] Bertrand Meyer. Object-Oriented Software Construc-tion (2nd ed.). Prentice-Hall, Inc., NJ, USA, 1997.
[36] Hafedh Mili, Fatma Mili, and Ali Mili. Reusing soft-ware: Issues and research directions. Software Engi-neering, 21(6):528–562, 1995.
[37] Hefedh Mili, Ali Mili, Sherif Yacoub, and Ed-ward Addy. Reuse-based Software Engineering:Techniques, Organization, and Controls. Wiley-Interscience, New York, USA, 2001.
[38] Rym Mili, Ali Mili, and Roland T. Mittermeir. Stor-ing and retrieving software components: A refinementbased system. IEEE Transactions on Software Engi-neering, 23(7):445–460, 1997.
[39] George A. Miller. The magical number seven, plusor minus two. The Psychological Review, 63:81–97,1956.

24 F. McCarey, M. O Cinneide and N. Kushmerick / Knowledge Reuse for Software Reuse
[40] OSTG. Sourceforge.net is owned by the open sourcetechnology group inc (ostg), a subsidiary of va soft-ware corporation. http://sourceforge.net. 2004.
[41] Lawrence Page, Sergey Brin, Rajeev Motwani, andTerry Winograd. The pagerank citation ranking:Bringing order to the web. Technical Report SIDL-WP-1999-0120, 1998.
[42] PlanetSourceCode. www.planetsourcecode.com. ’07.[43] Jeffrey Poulin. The business case for software reuse:
Reuse metrics, economic models, organizational is-sues, and case studies. In 9th International Con-ference on Software Reuse, page 439, Italy, 2006.Springer.
[44] Ruben Prieto-Diaz. Implementing faceted classifica-tion for software reuse. Communications of the ACM,34(5):88–97, 1991.
[45] R. Rada. Software Reuse: Principles, Methodologiesand Practices. Ablex Publishing, NJ, USA, 1995.
[46] P. Resnick, N. Iacovou, M. Suchak, P. Bergstorm,and J. Riedl. GroupLens: An Open Architecture forCollaborative Filtering of Netnews. In ACM Con-ference on Computer Supported Cooperative Work,pages 175–186, Chapel Hill, North Carolina, 1994.
[47] Stuart Russell and Peter Norvig. Artificial Intelli-gence: A Modern Approach. Prentice Hall, Engle-wood Cliffs, NJ, 1995.
[48] Badrul M. Sarwar, George Karypis, Joseph A. Kon-stan, and John Reidl. Item-based collaborative fil-tering recommendation algorithms. In World WideWeb, pages 285–295, Hong Kong, 2001.
[49] Arun Sen. The role of opportunism in the softwaredesign reuse process. IEEE Transactions on SoftwareEngineering, 23(7):418–436, 1997.
[50] Upendra Shardanand and Patti Maes. Social infor-mation filtering: Algorithms for automating “word ofmouth”. In Proceedings of ACM CHI’95 Conferenceon Human Factors in Computing Systems, volume 1,pages 210–217, 1995.
[51] David Sprott. Enterprise resource planning: Compo-nentizing the enterprise application packages. Com-munications of the ACM, 43(4):63–69, 2000.
[52] Vijayan Sugumaran and Veda C. Storey. A semantic-based approach to component retrieval. SIGMISDatabase, 34(3):8–24, 2003.
[53] Clemens Szyperski. Component Software: BeyondObject-Oriented Programming. Addison Wesley, NewYork, USA, 2002.
[54] L. Ungar and D. Foster. Clustering methods for col-laborative filtering. In Workshop on Recommenda-tion Systems at the 15th National Conference on Ar-tificial Intelligence, Madison, Wisconsin, USA, 1998.AAAI Press, Menlo Park California.
[55] C.J. van Rijsbergen. Information Retrieval. Butter-worths, London, 1979.
[56] Yunwen Ye. Supporting Component-Based SoftwareDevelopment with Active Component Repository Sys-tems. PhD thesis, University of Colorado, 2001.
[57] Yunwen Ye and Gerhard Fischer. Information deliv-ery in support of learning reusable software compo-nents on demand. In 7th International Conference onIntelligent User Interfaces, pages 159–166, San Fran-cisco, California, USA, 2002. ACM Press.
[58] Yunwen Ye and Gerhard Fischer. Reuse-conducivedevelopment environments. Automated Software En-gineering, 12(2):199–235, 2005.
[59] Edward Yourdon. Modern Structured Analysis. Your-don Press, Upper Saddle River, NJ, USA, 1989.
[60] Amy Moormann Zaremski and Jeannette M. Wing.Signature matching: A key to reuse. In 1st ACMSIGSOFT Symposium on Foundations of SoftwareEngineering, pages 182–190, US, 1993. ACM Press.
[61] Amy Moormann Zaremski and Jeannette M. Wing.Signature matching: a tool for using software li-braries. ACM Transactions on Software Engineeringand Methodology, 4(2):146–170, 1995.