Embed Size (px)
Citation preview

iSPOKEN LANGUAGE SYSTEMS
COMPUTER
S C I E N C E
S P O K E NLANGUAGES Y S T E M S
LABORATORY
July 2000
for
2000
for
2000 2000 2000
2000 20002000 2000
2000 2000
2000 2000
2000 2000
2000 2000
2000 2000
2000 2000
2000
2000
2000 2000 20002000 2000
MassachusettsInstitute of Technology

ii SUMMARY OF RESEARCH - JULY 2000
c 2000 Massachusetts Institute of Technology
For information or copies of this report, please contact:
Victoria L. PalayMIT Laboratory for Computer Science545 Technology Square, NE43-601Cambridge, MA 02139 [email protected]
Please visit the Spoken Language Systems Group on theWorld Wide Web at http://www.sls.lcs.mit.edu

iiiSPOKEN LANGUAGE SYSTEMS
R E S E A R C H
covering
July 1, 1999 - June 30, 2000
ofS U M M A RY

iv SUMMARY OF RESEARCH - JULY 2000

vSPOKEN LANGUAGE SYSTEMS
Table of Contents
Summary of ResearchResearch, Technical, Administrative and Support Staff ....................................................... vii-xGraduate Students ............................................................................................................ xi-xivVisitors, Undergraduate Students, Transitions .................................................................xiv-xviResearch Sponsorship ......................................................................................................... xvii
Research HighlightsResearch Highlights, 1999-2000Victor Zue ............................................................................................................................................ 3
Research ProjectsMERCURY
Stephanie Seneff, and Joseph Polifroni ......................................................................................... 9Data Collection and Performance Evaluation of MERCURY
Joseph Polifroni, Stephanie Seneff, James Glass and Victor Zue ................................................. 15Acoustic Modeling Improvements in SUMMIT
Nikko Ström, Lee Hetherington, T.J. Hazen, James Glass and Eric Sandness ........................... 20Confidence Scoring for Use in Speech Understanding Systems
T.J. Hazen ................................................................................................................................. 22MOKUSEI: A Japanese, Telephone-based Conversational System in the Weather Domain
Victor Zue, Stephanie Seneff, Joseph Polifroni, Yasuhiro Minami, Mikio Nakano, T.J. Hazen andJames Glass ............................................................................................................................... 25
MUXING
Chao Wang, Victor Zue, Joseph Polifroni, Stephanie Seneff, Jon Yi and T.J. Hazen ................... 27ORION
Stephanie Seneff, Chian Chuu and Scott Cyphers .................................................................... 29Facilitating Spoken Language System Creation with SPEECHBUILDER
James Glass, Jef Pearlman and Eugene Weinstein ..................................................................... 31Finite-State Transducer-Based Unit Selection for Concatenative Speech Synthesis
Jon Yi, James Glass and Lee Hetherington ................................................................................ 35Barge-in
Nikko Ström .............................................................................................................................. 39
1
2
3

vi SUMMARY OF RESEARCH - JULY 2000
4
5
Thesis ResearchGENESIS-II
Lauren Baptist .........................................................................................................................................43
Modeling Out-of-Vocabulary Words for Robust Speech Recognition
Issam Bazzi ..............................................................................................................................................45
Using Support Vector Machines for Spoken Digit Recognition
Issam Bazzi ..............................................................................................................................................48
Building a Speech Understanding System using Word Spotting Techniques
Theresa Burianek and Timothy J. Hazen .................................................................................................50
A Three-Stage Solution to Flexible Vocabulary Speech Understanding
Grace Chung ...........................................................................................................................................52
Lexical Modeling of Non-Native Speech for Automatic Speech Recognition
Karen Livescu ..........................................................................................................................................55
The Use of Dynamic Reliability Scoring in Speech RecognitionXiaolong Mou .........................................................................................................................................58
Subword-based Approaches to Spoken Document Retrieval
Kenney Ng ...............................................................................................................................................60
Enabling Spoken Language Systems Design for Non-ExpertsJef Pearlman ............................................................................................................................................64
Discriminative Training of Acoustic Models in a Segment-Based Speech RecognizerEric Sandness ...........................................................................................................................................65
Analysis and Transcription of General Audio DataMichelle Spina ......................................................................................................................................... 67
Framework for Joint Recognition of Pronounced and Spelled Proper NamesAtiwong Suchato ......................................................................................................................................70
Robust Pitch tracking for Prosodic Modeling in Telephone SpeechChao Wang ..............................................................................................................................................72
Methods and Tools for Speech Synthesizer Design and DeploymentJon Yi ...................................................................................................................................................... 75
Theses, Publications, Presentations and SeminarsPh.D. and Masters Theses ...................................................................................................... 79Publications .......................................................................................................................... 80Presentations ......................................................................................................................... 81SLS Seminar Series ............................................................................................................... 82

viiSPOKEN LANGUAGE SYSTEMS
Research Staff
VICTOR ZUE
Victor Zue is a Senior Research
Scientist, the head of the
Spoken Language Systems
Group, and an Associate
Director of the Laboratory for
Computer Science. His main
research interest is in the
development of spoken
language interfaces to facilitate
natural human/computer
interactions, and he has taught
many courses and lectured
extensively on this subject. He
is best known for his acoustic
phonetic knowledge, and for
leading his research group in
developing conversational
systems that allow users to
access information using
spoken dialogue. In 1994, Zue
was elected Distinguished
Lecturer by the IEEE Signal
Processing Society. In 1999, he
received the "Sustained
Excellence" Award from
DARPA-DoD. Zue is a Fellow
of the Acoustical Society of
America. He received his Sc.D.
in Electrical Engineering from
MIT in 1976.
JAMES GLASS
James Glass is a Principal
Research Scientist and
Associate Head of the SLS
group. He received his Ph.D. in
Electrical Engineering and
Computer Science from MIT
in 1988. His research interests
include acoustic-phonetic
modeling, speech recognition
and understanding in the
context of conversational
systems, and corpus-based
speech synthesis. In addition
to publishing extensively in
these areas, he has supervised
S.M. and Ph.D. students, and
co-taught courses in spectro-
gram reading and speech
recognition. He served as a
member of the IEEE Acoustics,
Speech, and Signal Processing,
Speech Technical Committee
from 1992-1995. From1997-
1999, he served as an associate
editor for the IEEE Transac-
tions on Speech and Audio
Processing.
T.J. HAZEN
Timothy James (T. J.) Hazen
arrived at MIT in1987 where
he received his S.B. degree in
1991, S.M. degree in 1993 and
PhD in 1998, all in Electrical
Engineering. T.J. joined the
SLS group as an undergraduate
in 1991 and has been with the
group ever since. He is
currently working as a research
scientist in the group. His
primary research interests
include acoustic modeling,
speaker adaptation, automatic
language identification, and
phonological modeling.
SCOTT CYPHERS
D. Scott Cyphers received his
S.B. at MIT in 1982, and S.M.
in 1985. While at MIT, he
worked on program under-
standing, speech recognition,
and systems to support speech
recognition research (Spire). In
1986 he left MIT for
Symbolics, where he worked
on many parts of the operating
system, compiler, and
implemented the CLOS object
system. Scott switched to the
Object-Oriented database world
at Object Design in 1991,
where he worked with schema,
Windows operating system
interactions, COM integration,
and XML. In 1999 Scott
returned to the speech
recognition world at MIT.
Scott’s professional interests
include distributed objects,
natural language processing,
problem solving and knowledge
representation. Scott is also
interested in mathematics,
logic, meta-mathematics,
astronomy, and cosmology.

viii SUMMARY OF RESEARCH - JULY 2000
RAYMOND LAU
Raymond Lau received the B.S.
in Computer Science and
Engineering, the M.S. degree in
Electrical Engineering and
Computer Science, and the
Ph.D. degree in Computer
Science, all from the Massachu-
setts Institute of Technology in
1993, 1994, and 1998,
respectively. He was a National
Science Foundation fellow and
is a member of Eta Kappa Nu.
His current research interests
are in the are area of speech
recognition and spoken
language systems with a
particular focus on subword
modelling, search strategies and
language modelling.
JOSEPH POLIFRONI
Joseph Polifroni's interests
include language generation,
human-computer interaction,
and multilingual systems. He
has worked on the back-end
components of many of the
SLS systems, including GALAXY
and DINEX in addition to his
work on GENESIS, the natural
language generation system that
is part of the overall GALAXY
architecture. He has also
contributed to the Spanish and
Mandarin Chinese systems.
Before joining SLS, Joe worked
in the Speech Group at
Carnegie Mellon University
and was also a consultant for
Carnegie Group Inc. in
Pittsburgh. In addition, Joe
spent two years living in China,
teaching English at Shandong
University in Jinan.
Research Staff
LEE HETHERINGTON
Lee Hetherington received his
S.B., S.M., and Ph.D. degrees
from MIT's Department of
Electrical Engineering and
Computer Science. He
completed his doctoral thesis,
"A Characterization of the the
Problem of New, Out-of-
Vocabulary Words in Continu-
ous-Speech Recognition and
Understanding," and joined
the SLS group in October
1994. His research interests
include many aspects of speech
recognition, including search
techniques, acoustic measure-
ment discovery, and recently
the use of weighted finite-state
transduction for context-
dependent phonetic models,
phonological rules, lexicons,
and language models in an
integrated search.

ixSPOKEN LANGUAGE SYSTEMS
STEPHANIE SENEFF
Stephanie Seneff has a B.S.
degree in Biophysics and M.S.,
E.E., and Ph.D. degrees in
Electrical Engineering and
Computer Science from MIT.
Her research interests span a
wide spectrum of topics related
to conversational systems,
including phonological
modelling, auditory modelling,
computer speech recognition,
statistical language modelling,
natural language understanding
and generation, discourse and
dialogue modelling, and
prosodic analysis. She has
published numerous papers in
these areas, and she is currently
supervising several students at
both master's and doctoral
levels.
NIKKO STRÖM
Nikko Ström received the
Master of Science, (Engineer-
ing Physics) degree in1991, and
the Ph.D. degree in Electrical
Engineering (Department of
Speech, Music,and Hearing) in
1997 at the Royal Institute of
Technology (KTH), Stockholm,
Sweden. He joined SLS in May
1998 as a Postdoctoral
Associate, and was appointed
Research Scientist in January
1999. His main areas of
interest are human/machine
dialogue, lexical search in
automatic speech recognition,
and acoustic/phonetic
modeling. At KTH, he
developed a continuous
automatic speech recognition
system that is still in use in
several dialogue systems. He is
also the author of the NICO
tool kit for Artificial Neural
Networks. The tool kit is
publicly available, and has been
downloaded from more than
1,000 different sites in 55
countries (September 1998).

x SUMMARY OF RESEARCH - JULY 2000
Administrative & Support StaffTechnical Staff
CHRISTINE PAO
Christine Pao has been a
member of the technical
research staff since 1992. She is
primarily involved in the
development and maintenance
of the GALAXY system. Her
research interests are in
discourse and dialog, systems
integration with a focus on
multilingual systems and
language learning, and open
microphone issues such as
rejection and channel
normalization. Christine has a
bachelor's degree in Physics
from MIT.
VICTORIA PALAY
Victoria Palay has been a
member of the Spoken
Language Systems group since
1988. As SLS program
administrator, she manages
personnel, fiscal, publication
and contractual matters as well
as space and other group
resources. In addition, she
supports Victor Zue's duties as
LCS Associate Director by
coordinating EPOCH-IT
activities and distributing
equipment donations made to
the laboratory. Victoria has a
B.A. in Government and
French Studies from Smith
College.
SALLY LEE
Sally Lee joined the Spoken
Language Systems group as
senior secretary in 1993. She
received a B.A. in Studio Art/
Art History from Colby
College in 1984. She also
studied at the Art Institute of
Boston and the New York
Studio School. In addition to
her secretarial duties, Sally has
made many of the animated
and still icons for SLS
programs including GALAXY and
JUPITER. She also is responsible
for transcribing sentences that
are recorded from people
calling into the JUPITER system.

xiSPOKEN LANGUAGE SYSTEMS
Graduate Students
ISSAM BAZZI
Issam Bazzi's research interest is
in the area of subword and
language modeling for auto-
matic speech recognition. He
received his B.E. in computer
and communication engineer-
ing from the American
University of Beirut, Beirut,
Lebanon in 1993 and his S.M.
from MIT in 1997. Between
1993 and 1995, He did research
on networked multimedia
systems at the Center for
Educational Computing
Initiatives at MIT. Before
joining SLS in 1998, Issam was
a member of the Speech and
Language Department at BBN
Technologies, GTE
Internetworking where he did
research on language-indepen-
dent character recognition.
Advisor: James Glass
LAUREN BAPTIST
Lauren Baptist joined the
Spoken Language Systems
Group in September 1999,
with a fellowship from NTT.
She received the S.B. from
Dartmouth College in May
1999. She expects to receive
the S.M. degree from MIT in
August 2000. Her thesis is
entitled “Genesis-II: A
Language Generation Module
for Conversational Systems.”
Advisor: Stephanie Seneff
GRACE GHUNG
Grace Chung graduated in
Electrical Engineering and
Mathematics from the
University of New South
Wales, Sydney, Australia. She
earned a Fulbright scholarship
to attend MIT and completed
her master's degree in June
1997. Her interests are in
acoustic modelling and
prosodic modelling for speech
recognition.
Advisor: Stephanie Seneff
THERESA BURIANEK
Theresa Burianek joined the
Spoken Language Systems
group in September 1999 after
receiving the S.B. from MIT in
Computer Science and
Engineering in June 1999. She
is researching the use of word-
spotting understanding to ease
the creation of spoken
language systems and imple-
mented verbal responses for
direction queries in VOYAGER, an
interactive city guide that uses
verbal human to computer
interaction to process and
retrieve queries between
locations in Boston. She
expects to receive the M.Eng.
degree in July 2000.
Advisor: T.J. Hazen

xii SUMMARY OF RESEARCH - JULY 2000
KENNEY NG
Kenney Ng's current research
interest is in the area of
information retrieval of spoken
documents, which is the task of
identifying those speech
messages stored in a large
collection that are relevant to a
query provided by a user. Prior
to his return to MIT in 1995,
Kenney was a member of the
Speech and Language Depart-
ment at BBN Systems and
Technologies where he did
research on large vocabulary
recognition of conversational
speech, word spotting, topic
spotting, probabilistic
segmental speech models, and
noise compensation. He
received his B.S. and M.S.
degrees in EECS from MIT in
1990 and completed his Ph.D.
in February 2000.
Advisor: Victor Zue
Graduate Students
XIAOLONG MOU
Xiaolong Mou received his
bachelor's degrees in Computer
Science and Enterprises
Management from Tsinghua
University, Beijing, China in
1996. He completed his
Master's thesis on continuous
speech recognition systems and
received his master's degree in
Computer Science from
Tsinghua University in
1998. He is currently pursuing
a Ph.D. in the SLS group.
Xiaolong's research interest
includes conversational speech
systems, automatic speech
recognition and speech
understanding.
Advisor: Victor Zue
KAREN LIVESCU
Karen Livescu received her
B.A. in Physics at Princeton
University in 1996. She spent
the following year at the
Technion in Haifa, Israel, as a
visiting student in the
Electrical Engineering
department. Karen started
graduate study as a National
Science Foundation fellow in
the SLS group in September
1997 and completed her
Master’s thesis on improved
speech recognition for non-
native speakers in September
1999. Her research interests
include statistical modeling and
lexical feature design for speech
recognition.
Advisor: James Glass
ATTILA KONDACS
Attila Kondacs earned his BA
and MSc in mathematics at
Eotvos University, Hungary in
1995. He researched Quantum
Computation, an emerging
area within complexity theory
in computer science. Attila
went on studingat the
University of Cambridge in
England where he recieved a
Diploma in Economics
in 1996. Before starting his
graduate studies at MIT, he
worked for 3 years first in a
telecommunication
startup called TeleMedia,
followed by the product
management branch of a larger
telecom, Matav in Hungary
where he was a product
manager and later the staff
asistant to the director.
Advisor: Victor Zue

xiiiSPOKEN LANGUAGE SYSTEMS
MICHELLE SPINA
Michelle received the B.S.
degree in electrical engineering
from the Rochester Institute of
Technology in 1991, and the
S.M. degree in electrical
engineering from the Massa-
chusetts Institute of Technol-
ogy in 1994. She completed
her Ph.D. degree in May of
2000 in the Spoken Language
Systems Group at the MIT
Laboratory for Computer
Science. Michelle’s research
interests include automatic
indexing of audio content,
speech recognition and
understanding, and biomedical
issues of speech processing as
they relate to automatic speech
recognition. Her Ph.D. thesis
involved general sound
understanding and ortho-
graphic analysis of general
audio data. Michelle was a
1995 Intel Foundation
Graduate Fellow, and is a
member of Tau Beta Pi,
Eta Kappa Nu, and Phi Kappa
Phi.
Advisor: Victor Zue
JEF PEARLMAN
Jef Pearlman joined the Spoken
Language Systems Group in
September 1999. He expects to
complete the M.Eng. degree in
August 2000. His thesis is
entitled “SLS-Lite: Enabling
Spoken Language Systems
Design for Non-Experts.”
Advisor: James Glass
ERIC SANDNESS
Eric Sandness joined the SLS
Group in June 1999 as a
participant in the Undergradu-
ate Research Opportunities
Program. His summer project
was entitled “Real-Time Speech
Recognition.” Eric was
appointed as a Research
Assistant in September 1999.
He received the M.Eng. degree
in June 2000. His thesis is
entitled “Discriminative
Training of Acoustic Models in
a Segment-based Speech
Recognizer.”
Advisor: Lee Hetherington
ATIWONG SUCHATO
Atiwong Suchato joined the
Spoken Language Systems
group in the fall of 1999. He
graduated from Engineering
department at Chulalongkorn
University, Bangkok Thailand
with B. Eng., major in
Electrical Engineering in 1998.
His Master’s thesis is entitled
“Framework for Joint
Recognition between Spelled
and Pronounced Proper
Names” and is expected to be
completed in September 2000.
Advisor: Stephanie Seneff

xiv SUMMARY OF RESEARCH - JULY 2000
Visitors
JON YI
Jon Yi received the S.B. and the
M.Eng. degrees in Electrical
Engineering and Computer
Science from the Massachusetts
Institute of Technology in 1997
and 1998, respectively. He also
graduated in 1997 with a
minor in Music. At SLS he has
worked on developing a
Mandarin Chinese
concatenative speech synthe-
sizer and a UNICODE/Java
World Wide Web interface for
the GALAXY system. His research
interests include speech
synthesis, communications
systems, and multilingual
speech understanding systems.
Advisor: James Glass
CHAO WANG
Chao Wang received her
bachelor's degree in Biomedical
Engineering, with a minor in
Computer Science from
Tsinghua University, Beijing,
China in 1994. She started her
graduate study in MIT in
September 1995 and joined the
SLS group in April 1996.
Chao's master's degree,
completed in June 1997,
worked on porting the GALAXY
system to Mandarin Chinese.
Advisor: Stephanie Seneff
Graduate Students
YI-CHUNG LIN
Yi-Chung Lin received his
Ph.D. in Electrical Engineering
from the Electrical Engineering
Institute of National Tsing Hua
University, Taiwan, in July
1995. In his Ph.D. thesis he
investigated the use of "A Level
Synchronous Approach to Ill-
formed Sentence Parsing and
Error Recovery". He joined SLS
in March 1999 as a Visiting
Scientist. He is interested in
building Chinese conversa-
tional systems for real users.
His main focus has been in the
area of language understand-
ing, language generation
and dialogue management. He
has been working on Chinese
JUPITER, the weather informa-
tion system using spoken
Mandarin Chinese.
EUGENE WEINSTEIN
Eugene joined the Spoken
Language Systems Group in
June 2000 as a Research
Assistant. He is working on
SPEECHBUILDER and expects to
receive his MEng degree in
2001.
Advisor: James Glass

xvSPOKEN LANGUAGE SYSTEMS
YASUHIRO MINAMI
Yasuhiro Minami received the
M. Eng. Degree in Electrical
Engineering and the Ph.D. in
Electrical Engineering from the
Keio University, in 1988 and
1991, respectively. He joined
NTT in 1991. He had worked
in robust speech recognition.
He joined SLS in 1999 as a
visiting researcher. He is
interested in modeling for
robust speech recognition and
building conversational
systems. He has been working
on porting JUPITER to Japanese.
MIKIO NAKANO
Mikio Nakano obtained his
M.S. degree in Coordinated
Sciences and Sc.D. degree in
Information Science from the
University of Tokyo respec-
tively in 1990 and 1998. In
1990 he joined NTT, where he
had worked on unification-
based parsing, spoken language
analysis, and real-time spoken
dialogue systems. He joined the
SLS group in February 2000 as
a visiting scientist. His current
research interests include
spoken language understanding
and generation as well as
building integrated spoken
dialogue systems. He is now
working on multilingual
conversational interface
through the development of
MOKUSEI, the Japanese version
of the JUPITER weather
information system.
ALEJANDRA OLIVIER
MERINO
Alejandra Olivier received her
S.B degree in Computer
Science from the Universidad
de las Americas-Puebla, Mexico,
in 1999. She joined Tlatoa, a
Speech Technology Research
Group, the same year. She had
worked in automatic transcrip-
tions and she is interested
in building conversational
systems. She joined SLS in
June 2000 as a visiting
scientist, where she has been
working on porting JUPITER to
Spanish.
ALCIRA VARGAS
GONZALEZ
Alcira Vargas obtained her S.B
degree in Computer Science
from the Universidad de las
Americas-Puebla, Mexico in
1998 and joined the speech
technology research group
TLATOA. As a visiting
scientist, she joined the SLS
group in January 2000 to work
on the Spanish version of the
JUPITER weather information
system. Her current research
interests include language
modelling, language under-
standing and spoken dialogue
systems.

xvi SUMMARY OF RESEARCH - JULY 2000
Undergraduate Students
Chian ChuuMichael FreedmanMark KnobelVivian MaMatthew Mishrikey
Christine Pao, departed August 1999Simo Kamppari, received M.Eng. September1999Yi-Chung Lin, departed September 1999Scott Cyphers joined October 1999Ray Lau, departed January 2000Kenney Ng, received Ph.D. February 2000Yasu Minami, departed March 2000Michelle Spina, received Ph.D. June 2000Eric Sandness, received M.Eng. June 2000
Transitions

xviiSPOKEN LANGUAGE SYSTEMS
Research Sponsorship
Defense Advanced Research Projects Agency 1
BellSouth IntelliventuresIndustrial Technology Research InstituteNational Science Foundation 2
Nippon Telegraph & Telephone
In addition, discretionary funds for research are provided by ATR Interpreting Telecommunications ResearchLaboratories, Hewlett-Packard Laboratories -Bristol, Hughes Research Laboratories, Science ApplicationsInternational Corporation, Telcordia Technologies, Inc. and VoiceIn VoiceOut Corporation.
1. Contract Nos. N66001-96-C-8526 and N66001-99-1-8904, from the Information Technology Office, monitored by the Naval CommandControl, and Ocean Surveillance Center and contract no. DAAN02-98-K0003, monitored through US Army Soldier Systems Command.
2. NSF grant no. IRI-9618731.

xviii SUMMARY OF RESEARCH - JULY 2000

1SPOKEN LANGUAGE SYSTEMS
R E S E A R C HHIGHLIGHTS

2 SUMMARY OF RESEARCH - JULY 2000

3SPOKEN LANGUAGE SYSTEMS
Research HighlightsVictor Zue
SPEECHSYNTHESIS
LANGUAGEUNDERSTANDING
LANGUAGEGENERATION
SPEECHRECOGNITION
SYSTEMMANAGER
DATABASE
DISCOURSECONTEXT
SEMANTICFRAME
Graphs& Tables
Figure 1. A generic block diagramof a typical MIT conversationalsystem.
During this reporting period, wecontinued our research and development ofhuman language technologies and conversa-tional systems in several directions. Consid-erable efforts have been devoted to improv-ing our speech recognition system’s perfor-mance. These include the use of discrimina-tive training for acoustic models (c.f. page65) and better phonological modeling fornon-native speakers (c.f. page 55). To makethe recognition system more robust, we haveextended the utterance-based confidencemeasures to word-based ones (c.f. page 22).We also introduced the notion of dynamicreliability scoring during recognition thatadjusts the partial path score while therecognizer searches through the lexical andacoustic-phonetic network (c.f. page 58).Related work deals with speech understand-ing using simple word- and phrase-spottingmethods (c.f. page 50).
Almost all speech recognition systemsare formulated as a problem of recognizingthe underlying word sequence. As a result,these systems require the availability of
domain-specific training data to derive thestatistical language models. To separate theuse of domain-independent and -dependentknowledge, we have started a promising lineof investigation on how to develop adomain-independent recognition kernelbased on sub-word units such as the syllable(c.f. page 45) and an entire sub-wordphonological hierarchy, including morphs,syllables and other constituents based onANGIE (c.f. page 52). Related work deals withthe recognition of pronounced and spelledproper names (c.f. page 70).
Much of our group’s research over theyears has been treating speech as an“interface” problem. With the increase ofspeech as a data type on the World WideWeb, speech is fast becoming a “content”problem. Two of our students completedtheir Ph.D. theses in this general area. Inone case, mixed-speaker and -environmentbroadcast data were analyzed and classified(c.f. page 67). In another case, speech-basedinformation retrieval is being pursued byrepresenting the signal as a concatenation of

4 SUMMARY OF RESEARCH - JULY 2000
RESEARCH HIGHLIGHTS
sub-word units (c.f. page 60).For the past three years, we have been
pursuing a concatenative approach tospeech synthesis in our ENVOICE system.While the technique is domain-dependent,requiring a certain amount of domain-specific data, the resulting synthetic speechis quite natural. Besides, it has always beenour intention to relax the domain-depen-dency, so that ENVOICE can eventuallyproduce natural output without the needfor domain-specific data. As a first step inthis direction, we have begun to build a sub-word based version of ENVOICE using finite-state transducers (c.f. pages 35 and 75).
One active area of research for us thisyear has been the development of multilin-gual conversational systems. Our approachto developing multilingual conversationalsystems is predicated on the assumptionthat it is possible to extract a common,language-independent semantic representa-tion from the input, similar to the“interlingua” approach to machine transla-tion. Whether such an approach can beeffective for unconstrained machinetranslation remains to be seen. However,we suspect that the probability of success ishigh for spoken language systems operatingin restricted domains, since the inputqueries will be goal-oriented and thereforemore constrained. In addition, the seman-tic frame may not need to capture all thenuances associated with human-humancommunication, since one of the partici-pants in the conversation is a computer.Thus far, we have applied this formalismsuccessfully across several languages anddomains. Our most recent effort involves
the development of a Japanese version ofour JUPITER weather information systemcalled MOKUSEI (c.f. page 25). This is acollaborative project with NTT. We havealso developed a Mandarin version ofJUPITER called MUXING, partly funded by ITRI(c.f. page 27). Work related to this latterproject deals with the modeling of Manda-rin tones (c.f. page 72). We also have anongoing collaboration with the Universidadde las Americas Puebla in Mexico on thedevelopment of a Spanish version of JUPITER.
The development of multilingualsystems, especially for Asian languages,exposed some of the shortcomings of ourlanguage generation component, GENESIS.As a consequence, considerable effort hasbeen devoted to rewriting GENESIS (c.f. page43). The resulting system, GENESIS-II, canprovide very straightforward methods forsimple generation tasks across multiplelanguages, while also supporting thecapability of handling more challenginggeneration requirements, such as movementphenomena, propagation of linguisticfeatures, and the context-dependentspecification of word sense.
At the system development level, mostof our effort has been devoted to thedevelopment of MERCURY, which can providereal flight schedules and fare information.MERCURY provides a platform for us toinvestigate conversational interfaces thatrequire language generation (c.f. 9) anddialogue management (c.f. 10) that isconsiderably more complex than in previoussystems that we have developed. We havealso collected hundreds of dialogues fromreal users interacting with MERCURY to book

5SPOKEN LANGUAGE SYSTEMS
VICTOR ZUE
real flights, and the data have enabled us topropose some dialogue related metrics toevaluate system performance (c.f. page 15).In related work, we have also begun toinvestigate the use of intelligent barge-in,which can be overridden under certaincircumstances, for example, when thesystem is describing a disclaimer or provid-ing instructions (c.f. page 39).
This reporting period saw the beginningof two new projects that are motivated by alab-wide five year initiative called Oxygen.The goal of the Oxygen project is to create asystem that will bring an abundance ofcomputation and communication to usersthrough natural spoken and visual inter-faces, making it easy for them to collaborate,access knowledge, and automate repetitivetasks. An important aspect of Oxygen is theability to rapidly deploy speech-basedinterfaces for naïve users. In this regard, westarted the development of a researchinfrastructure called SPEECHBUILDER that willenable novice users to develop conversa-tional systems with little or no knowledge ofthe underlying human language technolo-gies (c.f. pages 31 and 64). Another goal ofOxygen is the need to automate some of theinformation-related tasks (e.g., “Call mewhen United flight thirty-four lands.”) Wehave begun the development of a conversa-tional agent called ORION, which can accepttasks specified verbally and deliver theinformation requested at a later time (c.f.page 29). We expect both of these areas toflourish in the coming years.
Finally, the GALAXY Communicatorarchitecture continues to serve as thereference architecture for the DARPACommunicator Program. Recently, we havedecided to make this architecture opensource to promote standard setting. Userscan freely download this architecture, andthe associated libraries, for their own use,unencumbered by IP issues.

6 SUMMARY OF RESEARCH - JULY 2000

7SPOKEN LANGUAGE SYSTEMS
R E S E A R C H
R E P O R T S

8 SUMMARY OF RESEARCH - JULY 2000

9SPOKEN LANGUAGE SYSTEMS
MERCURYStephanie Seneff and Joseph Polifroni
MERCURY is a spoken conversational systemthat allows users to make flight reservationsamong several hundred cities worldwide.MERCURY engages the user in a mixed-initiative dialogue to plan an itinerary.Once the itinerary is fully specified,MERCURY then prices the itinerary and sendsthe user an e-mail message containing adetailed record of the flights and fares.MERCURY runs in both a displayful and adisplayless mode. In displayful mode,MERCURY provides, in addition to the spokenoutput, a paraphrase of the original userquery in a paraphrase window, as well as atext of the verbal response and a table of theset of flights retrieved from the database.MERCURY is configured as a suite of serversthat communicate with one another via acentral programmable hub using theGALAXY Communicator architecture. In thissection, we will highlight two differentaspects of MERCURY where we have spentconsiderable research effort: (1) languagegeneration and (2) dialogue control.
Language GenerationThe generation server plays an important,multi-faceted role in MERCURY, serving allgeneration needs for both natural andformal languages, as indicated in Figure 2and described more fully in [3]. We haverecently developed a new generation server,which we call GENESIS-II [1] (c.f. page 43),which is significantly improved over theoriginal system, in terms of both itscapabilities and ease of use. One of the
most important roles is to generate a naturallanguage response for the user. GENESIS-IIuses a common grammar file but distinctlexicons to convert the response frame intoa well-formed English text to display in thegraphical interface and into a marked-uptext format for further processing by theENVOICE speech synthesizer (c.f. pages 35 and75), to produce the response speechwaveform. Often, just before going to thedatabase, MERCURY paraphrases back to theuser the topic of their question, as in,“Okay, United flights from Boston to Dallason March third. One moment please.” Indisplayful mode, the full paraphrase of theuser query is displayed in a special para-phrase window. These mechanisms serve toinform the user the degree to whichMERCURY understood the question. The fullparaphrase is especially difficult for wh-queries, where a trace mechanism isnecessary to move the wh-marked nounphrase to the front of the surface formstring.
GENESIS-II also handles several instancesof paraphrases into formal languages. Thefirst is to convert the linguistic frame (incontext) that the NL component producesinto a flattened electronic form (E-form), arepresentation that is more convenient forthe dialogue manager to interpret. In thiscase, GENESIS-II produces a string in a simplemark-up language, which is then convertedinto an E-form frame by a GALAXY libraryroutine. Another formal language task is toconvert the E-form into the database queryappropriate for database retrieval. Finally, indisplayful mode, it converts the retrieved listof flights into a hyperlinked HTML tablefor graphical display. The user can click onan item in the table and refer to it verballyin a follow-up question.
Figure 2. Various generation needsin Mercury that are handled by theGenesis-II server.
input query frame —> English paraphrase
—> Electronic Form
database frame —> Database query string
response frame —> English text
—> synthesized speech
flight list —> html table

10 SUMMARY OF RESEARCH - JULY 2000
Dialogue ManagementDialogue modeling is a critical and challeng-ing aspect of conversational systems,particularly when users are permittedflexibility with regard to defining theconstraints of the task. For systems thatadopt a strict system-initiated approach, it isfeasible to define a set of states and statetransitions depending on the usually smallnumber of possible user actions at eachstate. However, MERCURY follows a mixed-initiative dialogue strategy, as do all of ourother systems, where the system may makespecific requests or suggestions, but the useris not required to be compliant. When thethe user is permitted to say anything withinthe scope of the recognizer at any time, afinite-state solution becomes unwieldy.
As described more fully in [2],MERCURY’s dialogue is controlled by a turnmanager that manipulates linguistic andworld knowledge represented in the form ofsemantic frames. At each turn it begins withan E-form representing the constraints ofthe current query as a set of [key: value]pairs. This E-form provides the initial valuesin the dialogue state, which evolves over thecourse of the turn as rules are executed. Theturn manager consults a dialogue controltable to decide which operations to per-form, and typically engages in a module-to-module subdialogue to retrieve tables fromthe database. Finally, it prepares a responseframe, which may or may not includetabular entries.
In addition to the dialogue state,MERCURY also makes use of several otherinternal representations which retain state.These are packaged up into a turn-managerhistory frame which is passed to the hub forsafe-keeping at the end of each turn, andreturned with each subsequent turn. The
user model contains a record of the system’scurrent belief about the state of the user’sflight plan, as well as any user preferencesspecified at enrollment time and all of thedetails of the current flight plan as theybecome available. The turn manager alsoretains internally a list of all the flights thatmatched the user’s constraint specifications,as well as a list of the subset of the flightsthat it has spoken about (e.g., the nonstopflights or the earliest flight).
Given MERCURY’s complex dialogue state,and our desire to have a flexible mixed-initiative dialogue strategy, we have opted touse an “ordered rules” strategy for dialoguecontrol. The activities for a given turntypically involve the sequential execution ofa number of specialized routines, each ofwhich performs a specific part of thedialogue requirements and alters the statevariables in particular ways. To determinewhich of the operations should be per-formed, the system consults a dialoguecontrol table, which is specified in a simplescripting language.
In addition to possibly altering thevalues of variables in the dialogue state,operations also have the responsibility toreturn, upon completion, one of three“move” states. The majority of the opera-tions return the state “CONTINUE” whichmeans simply to continue execution justbeyond the rule that just fired. The twoother possibilities are “STOP,” i.e., exit fromthe dialogue control table, and “RESTART”which means to return to the top of the setof dialogue rules and start over. An (op-tional) distinguished operation, whichhandles activities that should occur rou-tinely at every turn, is executed upon exitingthe dialogue control process. The tests onvariables can be binary, arithmetic, or string
MERCURY

11SPOKEN LANGUAGE SYSTEMS
matching on values. Figure 3 shows severalexamples of actual rules in MERCURY’sdialogue control table.
There are currently a total of over 200rules in MERCURY’s dialogue control table.These rules can be organized logically intothree groups. The first of these deal withthe input query representation, determiningwhat type of information is being asked forand checking that sufficient informationhas been obtained for answering the query.The second group deals with obtaining theanswer to the query, either from thedatabase server (typically in a module-to-module subdialogue) or from a pre-existingflight list. The third group concernspreparing the reply frame, after the databaseretrieval has already taken place. Thepurpose of this last set of rules is to reducethe number of database tuples returned fora given query to a manageable set for aspoken response. In addition to these threebroad categories, there are miscellaneousrules that have to do with updating the usermodel, preparing the intermediate reply,pricing or e-mailing the itinerary, preparingthe database query, filtering flights, orupdating the itinerary.
From the system developers’ point ofview, this dialogue control strategy has madedevelopment of complex systems mucheasier. Although the number of rules cangrow to be as large (or as small) as thedeveloper wants, having one central file that
maps out the control flow through a systemturn introduces a level of abstraction abovethe level of the code itself that facilitatesboth development and debugging. Theoperations specified by each rule are generalfunctions, and it is up to the systemdeveloper to decide how to parcel up thecomputational requirements into theindividual operations.
With experience, one acquires a set ofguidelines to help formalize this process. Asa general rule, it is preferrable to limit theuse of nested function calls. Instead, anoperation can set a variable to indicate thatanother operation needs to be called, andthen the intended subroutine gets promotedto the status of a dialogue control opera-tion. This has the effect of exposing more ofthe internal activities of the system to thedialogue control table, which serves as avery useful outline of system control flow.Another general policy is that each opera-tion should be concerned with a single well-defined task, again in order not to concealcomplexity.
Figure 4 gives an example dialoguebetween MERCURY and a user illustratingsome of the complexities that can arise in amixed-initiative interaction,including early specification of the returndate, the rejection of an offeredairline, and a final adjustment to theoriginal itinerary to improve the fare.
Figure 3. Selected rules from theMERCURY dialogue control table.“&” stands for “AND” and “|”stands for “OR”.
STEPHANIE SENEFF AND JOSEPH POLIFRONI
clause request_keypad —> keypad_input
week | day | rel_date —> resolve_relative_date
flight_number & !airline —> need_airline
clause price & topic itinerary & truth_value deny —> dont_price_itinerary
clause book & num_found =1 —> add_flight_to_itinerary
num_nonstops >1 & num_nonstops <4 & arrival_time —> speak_three_arrivals

12 SUMMARY OF RESEARCH - JULY 2000
Figure 4. Example illustrativedialogue in the MERCURY domaininvolving an initial itinerary that islater adjusted for a cheaper fare.
S: Welcome to the initial development version of the MIT air travelinformation system. This call is being recorded for system develop-ment. You may hang up or ask for help at any time. For enrolled usersplease say your first and last name. Otherwise, say ‘new user.’
U: Joe Polifroni
S: Please speak the month and day you registered as your password, as in‘May first.’
U: I want to key in my password.
S: Okay, Please enter your four digit date password... <keyed in>
S: Welcome, Joe. You have successfully logged onto mercury. How may Ihelp you?
U: I want to fly to San Francisco the first Sunday in November and return thefollowing Thursday.
S: Okay, flights from Boston to San Francisco on Sunday November 5.Can you provide the approximate departure time or airline prefer-ence?
U: Are there any flights in the morning?
S: Okay, flights from Boston to San Francisco departing between 5 a.m.and 12 p.m. on Sunday November 5. One moment please. ... Can youprovide a departure or arrival time? I have flights on American,Frontier, America West, Nordic East Airways, Northwest, and United.The earliest nonstop United flight leaves at 7 a.m. and arrives at 10:20a.m.
U: I don’t want to fly on United.
S: I have a nonstop American flight leaving at 9 a.m. arriving at 12:40p.m. Would that work?
U: Yes, I’ll take that one.
S: American flight 195 has been added to your itinerary. You departBoston at 9 a.m. and arrive in San Francisco at 12:40 p.m. Shall I helpyou with the return flight now?
U: Yes, please.
MERCURY

13SPOKEN LANGUAGE SYSTEMS
S: Okay, American flights from San Francisco to Boston on Thursday Nov.9. One moment please. ... I have three nonstop flights: a flight leavingat 7:30 a.m., a flight leaving at 3:30 p.m. and a flight leaving at 10 p.m.Are any of these okay?
U: what time does the morning flight arrive?
S: American flight 196 arrives at 3:57 p.m. in Boston. Shall I add thisflight to your itinerary?
U: Yes, please.
S: American flight 196 has been added to your itinerary. You depart SanFrancisco at 7:30 a.m. and arrive in Boston at 3:57 p.m. Shall I priceyour itinerary?
U: Yes, please.
S: Pricing your itinerary will take awhile. In the meantime I’ll summa-rize your itinerary for you. On Sunday Nov. 5, on American flight 195,you depart from Boston at 9 a.m. and arrive in San Francisco at 12:40p.m. On Thursday, Nov. 9, on American flight 196 you depart from SanFrancisco at 7:30 a.m. and arrive in Boston at 3:57 p.m. The cheapestprice for your itinerary is $2210.50. Shall I email your itinerary to you?
U: I want to change the first flight in my itinerary.
S: Okay, American flights from Boston to San Francisco on SundayNovember 5. One moment please. ... I have three nonstop flights: aflight leaving at 9 a.m. a flight leaving at 3 p.m. and a flight leaving at5:15 p.m. Would one of these work?
U: What if I leave on Saturday?
S: Okay, American flights from Boston to San Francisco on SaturdayNovember 4. One moment please. ... I have three nonstop flights: aflight leaving at 9 a.m., a flight leaving at 3 p.m. and a flight leaving at5:15 p.m. Do you like any of these?
U: I’ll take the nine o’clock flight.
S: I have changed your itinerary. On Saturday, Nov. 4, on American flight195, you depart from Boston at 9 a.m. and arrive in San Francisco at12:40 p.m. Shall I price your itinerary?
U: Yes, please.
S: Pricing your itinerary will take awhile. In the meantime I’ll summarize
STEPHANIE SENEFF AND JOSEPH POLIFRONI

14 SUMMARY OF RESEARCH - JULY 2000
your itinerary for you. On Saturday Nov. 4, on American flight 195, youdepart from Boston at 9 a.m. and arrive in San Francsco at 12:40 p.m.On Thursday Nov. 9, on American flight 196, you depart from SanFrancsco at 7:30 a.m. and arrive in Boston at 3:57 p.m. ... The cheapestprice for your itinerary is $827.50. Shall I email your itinerary to you?
U: Yes, please
S: Your itinerary has been emailed to [email protected]. Is there some-thing else I can do for you?
U: No thank you. Goodbye.
S: Thanks for using Mercury. Have a nice day!
MERCURY
References[1] L. Baptist and S. Seneff, “GENESIS-II: A Versatile
System for Language Generation inConversational System Applications,” to appearin Proc. ICSLP 2000, Beijing, China, Oct. 2000.
[2] S. Seneff and J. Polifroni, “Formal and NaturalLanguage Generation in the MERCURY
Conversational System,” to appear in Proc. ICSLP2000, Beijing, China, Oct. 2000.
[3] S. Seneff and J. Polifroni, “Dialogue Managementin the MERCURY Flight Reservation System,” Proc.ANLP-NAACL 2000 Satellite Workshop, Seattle,Washington, May, 2000.

15SPOKEN LANGUAGE SYSTEMS
Data Collection and Performance Evaluationof MERCURYJoseph Polifroni, Stephanie Seneff, James Glass and Victor Zue
Data CollectionFor just over three years, our group hasbeen deploying mixed-initiative spokendialogue systems on toll-free telephonenumbers in North America. Our motiva-tion was to perform a wider-scale datacollection than we were able to do withinour laboratory environment. In this regardwe have been quite successful: in the pastyear alone, our JUPITER weather informationline received 70,132 calls (out of approxi-mately 97,000 total) accounting for nearly516,000 utterances. The growth in thenumber of callers to JUPITER in the threeyears of its existence has been very gratify-ing, especially considering that we havedone no overt recruitment for subjects.These data have been invaluable in improv-ing the performance of our speech recogni-tion and understanding components.
Over the past year, we have increasedour efforts in collecting data for theMERCURY flight travel domain, movingbeyond the scenario-based data collectionthat we used initially. We have made thesystem available to users outside the groupand have also encouraged group membersto arrange all business and personal travelthrough MERCURY. Although the totals forMERCURY for the past year, 4464 utterancesfrom 385 callers, dwarfs in comparison withJUPITER, our data collection effort forMERCURY is just getting underway. (Calls toJUPITER have peaked in the last year after acomparably slow start.) Just as with JUPITER,our MERCURY system is designed, first andforemost, to provide useful information tousers who have real problems to solve. Weare currently looking into ways of recruitingsubjects for MERCURY who have real, complextravel plans.
Evaluation Metrics Over the past year, we have begun develop-ing metrics for evaluating system perfor-mance at the dialogue level. Our previouswork has focused on utterance-levelevaluation, moving from word/sentenceerror rates (WER, SER, respectively) toconcept/understanding error rate (CER,UER) [1]. We have found that the GALAXY
Communicator architecture [2] has enabledus to instrument these metrics in a way thatinsures that off-line evaluation is performedon exactly the same configuration as the on-line system [3]. The GALAXY Communicatorarchitecture has been particularly useful inhelping us move beyond utterance-levelevaluation to measuring dialogue perfor-mance. To do this, we have created two newmeasures which can quantify how effectivelya user can provide novel information to asystem, and how efficiently the system canunderstand information concepts from auser. The query density measures the meannumber of new concepts introduced peruser query, while the concept efficiencytabulates the average number of turns ittook for a concept to be successfullyunderstood. In addition to being useful forquantifying longitudinal improvements in aparticular system, we also believe thesemeasures may be useful for comparingdifferent mixed-initiative systems.
Query density, QD , measures the mean
number of new concepts introduced peruser query,
where Nd is the number of dialogues, )(iN q
is the total number of user queries in the i th
dialogue, and )(iNu is the number of unique
�=
=N
ii
QDd
i q
u
d NN
N 1 )()(1

16 SUMMARY OF RESEARCH - JULY 2000
DATA COLLECTION AND PERFORMANCE EVALUATION IN THE MIT MERCURY SYSTEM
concepts understood by the system in the ith
dialogue. A concept in a dialogue is notcounted in Nu if the system had alreadyunderstood it from a previous utterance,and is only counted when it is correctlyunderstood by the system. Thus, a conceptthat is never understood will not contributeto Nu .
To illustrate, consider the two dialoguesin Figure 5. In the dialogue on the left, theuser introduces one concept per turn, thedestination in the first query and the sourcein the second. QD for this dialogue wouldbe 1.0. In the second dialogue, the userintroduces the same two concepts in oneutterance, for a QD of 2. In a recentevaluation on over 200 dialogues from naiveusers of the MERCURY system (see below), wemeasured a QD of 1.47, showing that usersare making use of our system’s ability tounderstand more than one concept perturn.
Concept efficiency, CE, quantifies theaverage number of turns (expressed as areciprocal) necessary for each concept to beunderstood by the system,
where is the total number of conceptsin the ith dialogue. A concept is countedwhenever it was uttered by the user and wasnot already understood by the system.
Since, )()( ii NN uc ≥ , then 10 ≤≤CE .Figure 6 illustrates two dialogues with
contrasting values for CE . In the first
dialogue, there is a misrecognition on thefirst user utterance, leading to a repair inthe second utterance. It took two turns tointroduce one concept, making CE .5 forthis dialogue. In the second dialogue, thedestination is understood correctly in oneturn, making CE 1.0 for that exchange.Measuring CE on the same subset of theMERCURY data used for QD above (seebelow), we obtained a value of .92, meaningthat approximately one in ten concepts hadto be repeated by users.
The criteria for incrementing the counts
for Nu and Nc are based on monitoringconcepts derived from the referencetranscriptions. Increments only take placewhen an input concept, A , is not present
(i.e., ) in the internal dialogue state,meaning that it had not been previouslyunderstood by the system. When this
condition occurs, is incremented, toindicate that the user was trying to convey aconcept to the system. If the concept is alsounderstood by the system (i.e., the hypoth-esis representation also contains concept
A ), then is also incremented.
We believe the QD metric is useful forquantifying the behavior of individualdialogue systems, as well as for making cross-system comparisons. The higher thedensity, the more effectively a user is able tocommunicate concepts to the system.Dialogues which prompt for specificconcepts one-by-one may have lower QDs, aswill those which contain more confirma-tions, or mis-recognitions. The CE is also a
�=
=N
ii
CEd
i c
u
d NN
N 1 )()(1
Figure 5. Two dialoguesillustrating QD. “U” refers to userutterances; “S” refers to systemutterances.
U: I would like to fly to Boston. U: I would like to fly from Boston to Denver.
S: To Boston from where? S: What date will you be travelling on?
U: Denver.
S: What date will you be travelling on?

17SPOKEN LANGUAGE SYSTEMS
useful diagnostic metric, as it is an indicatorof recognition or understanding errors.The higher the efficiency, the fewer times auser had to repeat a concept.
EvaluationInfrastructureThe task of evaluating complex conversa-tional systems is inherently difficult. In thefirst place, component technologies areinterdependent. Typically, a spoken dialoguesystem is comprised of multiple modules,each of which performs its task within anoverall framework, sometimes completelyindependently but most often with inputfrom other modules. Secondly, once amechanism is in place for running datathrough an off-line system, a simplereprocessing of data with a new version ofany component can lead to an incoherentinteraction, as only one side of a two-sidedconversation has changed.
The GALAXY Communicator architec-ture, originally developed within our group,has enabled us to duplicate on-line behaviorfor both system development (e.g., newspeech recognition or language understand-ing components) and off-line performanceevaluation. This allows all components tointeract in a consistent manner. We haveachieved this goal by developing two newservers: a “Batchmode” server and an“Evaluate” server.
The batchmode server is used togenerate inputs to a system during off-lineprocessing (as opposed to an on-line system,
which would deploy an audio- and/or GUI-server instead). The batchmode server canbe used to simulate the behavior of a systemduring actual data collection, or can be usedin conjunction with the evaluation server toquantify the performance of pre-recordeddata. The batchmode server can generateinputs from an existing log file (which wasgenerated by the system at the time theinteraction actually took place), or candirectly process waveforms, orthographictranscriptions, word graphs, semanticframes, etc., and pass them to the appropri-ate server via the hub.
The evaluation server is used to gatherperformance statistics for an off-lineevaluation. The server can measure bothword- and concept-level error rates, and canbe used to measure the QD and CE metricsdescribed in the previous section. Tocompute the QD and CE metrics, wereprocess a log file after the orthographictranscription has been provided for the userqueries. As illustrated in Figure 7, both therecognizer hypothesis and the originalorthography are run through the systemutterance by utterance, with the discourseand dialogue states being maintainedexclusively by the recognizer branch. If thedatabase content remains unchanged fromwhen the dialogue originally occurred, thensystem responses derived in this way wouldbe identical to those originally produced bythe system. However, all of our systemsmake use of continually updated, dynamicdata sources. It is therefore virtually
Figure 6. Two dialoguesillustrating CE. “U” refers to userutterances; “S” refers to systemutterances.
JOSEPH POLIFRONI, STEPHANIE SENEFF, JAMES GLASS AND VICTOR ZUE
U: I would like to fly to Boston. U: I would like to fly to Boston.
S: To Austin from where? S: To Boston from where?
U: No, to Boston.
S: To Boston from where?

18 SUMMARY OF RESEARCH - JULY 2000
DATA COLLECTION AND PERFORMANCE EVALUATION IN THE MIT MERCURY SYSTEM
impossible to guarantee that the systemresponses which occur during a subsequentevaluation will be the same as the originalones. Thus, it is possible that dialoguescould become incoherent during anevaluation. The only way to prevent thiswould be to freeze a version of the databaseused at the time, or store the answersretrieved during the dialogues.
Another problem has to do with the useof time expressions in user queries. If thedatabase is static, it is usually just a matterof resetting the reference date of thedialogue so that relative expressions (e.g.,“tomorrow”) can be correctly understood.Where the data are dynamic, and time-sensitive (e.g., short-range weather forecasts,flight schedule and fare information) thesolution is more complex. In the case ofMERCURY for example (described in the nextsection), we shift all dates in the dialogue tomake all references to time occur in thefuture.
ExperimentsTable 1 provides a breakdown of MERCURY
performance on a subset of the datacollected this year. This subset was selected
specifically to maximize for the number ofnaive users solving real problems (i.e., notscenario-based dialogues). The “All”condition reports results for the utterance-based and dialogue-based metrics we havedescribed above for all 648 utterances in thetest set. We then subdivide these data intothree categories. “Accepted” utteranceswere those in which the reference orthogra-phy and recognition hypothesis were bothparsable by our understanding component.“No Hyp” utterances were the ones inwhich the recognition hypothesis failed toparse, while “No Ref” utterances were thecases where the reference orthography couldnot be parsed. CER and UER were notavailable for the “No Ref” conditionbecause we could not automatically producea set of reference concepts. QD and CE areonly reported for the “All” conditionbecause they are intended to quantify thedialogue as a whole.
The WER on the accepted Mercuryutterances is similar to our performance inJUPITER [4]. The CER and overall UER arehigher however, which we attribute to thefact that MERCURY is in its early developmentstages, and because the air-travel domain is
Figure 7. A flow graph illustratingthe procedure for synchronizingdiscourse context during an off-linelog-file evaluation.
Log File
N-best List Discourse TurnManager
Parseand
Select
Orthography Discourse TurnManagerParse
Compare &Tabulate
ReceivedEform
IntendedEform
Context

19SPOKEN LANGUAGE SYSTEMS
inherently more challenging than weather,both in terms of number of concepts, andthe complexity of the interaction. We planto make QD and CE part of our regularevaluations.
Table 1. Evaluation results for aset of recent MERCURY data.
References[1] Polifroni, J, S. Seneff, J. Glass, and T.J. Hazen,
“Evaluation Methodology for a Telephone-basedConversational System,” Proc. LREC ‘98, 43—50,Granada, Spain, 1998.
[2] Seneff, S., E. Hurley, R. Lau, C. Pao, P. Schmid,and V. Zue, “GALAXY-II: A Reference Architecturefor Conversational System Development,” Proc.ICSLP ’98, 931—934, Sydney, Australia, 1998.
[3] Polifroni, J. and S. Seneff. 2000. “GALAXY-II as anArchitecture for Spoken Dialogue Evaluation,”Proc. LREC 2000, 725—730, Athens, Greece, 2000.
[4] Zue, V, S. Seneff, J. Glass, J. Polifroni, C. Pao, T.Hazen, and L. Hetherington, “JUPITER: ATelephone-based Conversational Interface forWeather Information,’’ Proc. IEEE Speech andAudio Processing, 88(1), 85—96, 2000.
Condition # Utts. WER CER UER QD CE
All 648 21.5 24.4 42.3 1.47 0.92
Accepted 551 12.7 22.5 - N/A N/A
No Hyp. 21 47.9 88.5 - N/A N/A
No Ref. 76 48.9 N/A N/A N/A N/A
JOSEPH POLIFRONI, STEPHANIE SENEFF, JAMES GLASS AND VICTOR ZUE

20 SUMMARY OF RESEARCH - JULY 2000
Acoustic Modeling Improvements in SUMMITNikko Ström, Lee Hetherington, T.J. Hazen, Jim Glass, and Eric Sandness
We have recently made several improve-ments to our SUMMIT speech recognitionsystem including the simultaneous use ofboth boundary and segment context-dependent acoustic models to improveaccuracy and the use of Gaussian selectionand Pentium-III optimizations to improvespeed [1,2].
The SUMMIT segment-based speechrecognition system is capable of handlingtwo rather different types of acousticmodels: segment models and boundarymodels. Segment models are intended tomodel hypothesized phonetic segments inan acoustic-phonetic graph, and can becontext-independent or context-dependent.The observation vector for these models isof fixed dimensionality and is typicallyderived from spectral vectors spanning thesegment. Thus we extract a single featurevector and compute a single likelihood for aphone regardless of its duration. In contrast,boundary models are intended to modeltransitions between phonetic units. Theobservation vector for these diphonemodels is also of fixed dimensionality and iscentered at hypothesized phonetic boundarylocations or landmarks. Since somehypothesized boundaries will in fact beinternal to a phone, both internal andtransition boundary models are utilized.Typically, the internal models are context-independent, and the transition modelsrepresent diphones.
Because the observation spaces ofsegment and boundary models differsignificantly, they tend to contributedifferent information about the recognitionsearch and ranking of hypotheses. Thebaseline JUPITER system uses boundarymodels only, and this work investigated theaddition of triphone segment models and
their effect on accuracy and speed.In the early development of the JUPITER
system, context-independent segmentmodels were used. As more data becameavailable, context-dependent (diphone)boundary models were added. The logprobability model scores of the boundaryand segment models were linearly combinedfor every phone. Ideally, this combinationof models should have been more accuratethan either of the segment or boundarymodels separately. However, the boundarymodels, with their higher degree of contextdependency, benefited more from theincreased training data than the segmentmodels, and thus as more data becameavailable the context-independent segmentmodels began to actually degrade perfor-mance as compared to boundary modelsonly.
In our experiments, for boundarymodels we used 61 context-independentinternal models and 715 diphone transitionmodels. For segment models, we used 935triphones, 1190 diphones, and 61monophones. Examining the pronunciationnetwork, we find that 71% of all arcs havetriphone labels, the rest having diphone ormonophone labels. For segment models, theselection of triphones and diphones wasbased on the number of occurrences in thetraining data by using a count threshold of250.
SUMMIT now makes use of finite-statetransducers (FSTs) [3] to represent context,phonological, lexical, and language modelconstraints. In particular, the first (Viterbi)pass of the recognition search makes use ofa single FST composed of all these compo-nents. Such a formulation makes the correctapplication of cross-word context-dependentacoustic models very straightforward.

21SPOKEN LANGUAGE SYSTEMS
7
8
9
10
11
12
13
14
0 1 2 x RTW
ER
Boundaries only CombinationBecause adding triphone segmentmodels more than quadrupled the numberof acoustic models evaluated on average, weincorporated the technique of Gaussianselection [4] to reduce the number ofGaussian mixture model componentsevaluated. The basic idea behind Gaussianselection is to apply vector quantization(VQ) to a feature vector and then evaluateonly those mixture components thatinfluence the mixture sum in the vicinity ofa VQ codeword. Mixture components thatare too far away will not contribute apprecia-bly to the sum when other mixtures aresignificantly closer. The mapping from VQcodeword to mixtures to evaluate can becomputed ahead of time, leaving only VQand reduced mixture computation to do atruntime. In our system, we use binary VQwith 512 codewords. At the pruning levelsused in this work, Gaussian selectionevaluates approximately 20% of themixtures that would otherwise be evaluated.This results in an overall system speedupfactor of about 1.8.
Further speed gains were made by hand-optimizing the key parts of Gaussian code totake advantage of the Pentium III’s floating-point SIMD assembly instructions. Thisoptimization was good for a speedup factorof about 1.8 as well.
Putting all the pieces together, Figure 8shows word error rate vs. speed for theboundary model-only system and thecombined boundary and triphone segmentmodel systems when running on a 500MHzPentium III system. The horizontal axisshows the real-time factor (xRT), with 1.0corresponding to “real-time”, meaning thatour pipelined recognizer can keep up withincoming speech. We see that the combinedsystem can achieve better accuracies, but
only at greater computational effort. Theseresults demonstrate that triphone segmentmodels do offer accuracy gains compared toa boundary-only system, whereas previouslymonophone segment models were detri-mental.
References[1] N. Ström, L. Hetherington, T.J. Hazen, E.
Sandness, J. Glass, “Acoustic ModelingImprovements in a Segment-based SpeechRecognizer,” in Proc. IEEE Automatic SpeechRecognition and Understanding Workshop, Keystone,December 1999.
[2] J. Glass, T.J. Hazen, and L. Hetherington, “Real-time Telephone-based Speech Recognition in theJUPITER Domain,” in Proc. ICASSP, pp. 61-64,Phoenix, March 1999.
[3] E. Roche and Y. Schabes, ed., Finite-State LanguageProcessing, MIT Press, 1997.
[4] E. Bocchieri, “Vector Quantization for theEfficient Computation of Continuous DensityLikelihoods,” in Proc. ICASSP, pp. 692-695,Minneapolis, April 1993.
Figure 8. Word error rate (WER)vs. speed (xRT) for boundary-onlyand combination configurations.

22 SUMMARY OF RESEARCH - JULY 2000
Confidence Scoringfor Use in Speech Understanding SystemsT. J. Hazen, Theresa Burianek, Joseph Polifroni and Stephanie Seneff
Current speech recognition technology isstill far from perfect and must be expectedto make mistakes. A well designed speechunderstanding system should be able torecognize when speech recognition errorsare likely to have occurred and take actionswhich gracefully recover from recognitionerrors in order to avoid frustrating the user.To develop such a system, two specificresearch goals must be addressed. First, arecognition confidence scoring techniquewhich accurately determines when arecognizer’s output hypothesis is reliable orunreliable must be developed. Second,confidence scores must be integrated intothe back-end components of the system(e.g., language understanding and dialoguemodeling) thereby enabling these compo-nents to make an informed decision aboutthe action that should be taken when aconfidence score indicates that a hypothesismay be incorrect. It is these two goals thatwe have strived to address in this research.
Over the last several years we havedeveloped and refined a technique whereconfidence scores are computed at the wordand utterance levels [1,2,3,4]. For eachrecognition hypothesis, a set of confidencemeasures are extracted from the computa-tions performed during the recognitionprocess and combined into a confidencefeature vector. The feature vectors for eachparticular hypothesis are then passedthrough a confidence scoring model whichproduces a single confidence score based onthe entire feature vector.
The same confidence scoring techniqueis used for both word and utterance levelconfidence scoring. To produce a singleconfidence score for a hypothesis, a simplelinear discrimination projection vector istrained. This projection vector reduces the
multi-dimensional confidence feature vectorfrom the hypothesis down to a singleconfidence score. Mathematically this isexpressed as
(1)
where f�
is the feature vector, is theprojection vector, and is the raw confi-dence score. The projection vector istrained using a minimum classification error(MCE) training technique.
Because the raw confidence score issimply a linear combination of a set offeatures, a probabilistic score is generatedfrom the raw score based on the followingmaximum a posteriori probability (MAP)classification expression:
(2)
Note that a constant decision threshold is applied to the score. After the decision
threshold is subtracted, a negative scorefor results in a rejection while a non-negative score results in an acceptance.
To test the confidence scoring tech-niques we utilize the recognizer for theJUPITER weather information system [5,6].The recognizer is trained from over 70,000utterances collected from live telephonecalls to our publicly available system. Therecognizer’s vocabulary has 2,005 words. Atest set of 2,388 JUPITER utterances is utilizedfor evaluation. The recognizer achieved aword error rate of 19.1% on this test set.
When evaluating the utterance levelconfidence scoring mechanism it is foundthat 13% of the test utterances wererejected. The word error rate on this 13% ofthe data was over 100% (e.g., there weremore errors than actual words in thereference orthographies). By comparison,
tincorrectPincorrectrpcorrectPcorrectrp
c −���
�
��
�
�=
)()()()(
log

23SPOKEN LANGUAGE SYSTEMS
the word error rate on the 87% of theutterances that were accepted was 14%.These results indicate that the utterancelevel confidence scoring mechanism isrejecting only the utterances which therecognizer has extreme difficulty recogniz-ing.
To examine the performance of theword confidence scoring mechanism areceiver-operator characteristic (ROC) curvecan be generated. Figure 9 shows the ROCcharacteristics of the three best individualconfidence features and the confidencescoring method which combines the tendifferent individual features. A significantimprovement is achieved by the combinedmodel over all of the individual features.
The performance of the confidencescoring technique can also be examined inseveral other interesting ways. Whenexamining accepted utterances only, thesystem correctly rejects 51% of the incor-rectly hypothesized words while only falselyrejecting 4% of correct words. Furthermore,across all utterances the combination ofutterance and word level scoring correctlydetects 72% of the errors introduced byunknown words and 85% of the errorsintroduced by non-lexical artifacts.
During recognition an N-best list ofsentence hypotheses is generated. Aconfidence score is computed for each wordin each sentence hypothesis. A two-stepprocess is utilized to integrate confidencescores into the TINA natural languageunderstanding component [7,8]. First, if anutterance is rejected at the utterance level,the understanding component does notattempt to understand the utterance andassumes that no useful information forunderstanding can be extracted from therecognizer’s output. If the utterance is
accepted, the second step is to allow thenatural language parser to try to interpretthe utterance, given that some words may bemisrecognized. Words with poor confidencescores can be “rejected” and replaced in theN-best with a rejected word marker. Eitherhard rejection (where rejection of poorlyscoring words is required) or soft rejection(where rejection of poorly scoring words isoptional) can be employed. In order toutilize an N-best list containing rejectedwords, the grammar must be augmented toincorporate rejected words.
To examine the effects of confidencescoring on language understanding, theJUPITER system can be evaluated on the testdata under five different conditions: (1)using the original system which did notutilize word confidence scores, (2) using thenew system which utilizes word confidencescores but does not perform any rejection,(2) using the new system with utterancerejection, (3) using the new system withutterance rejection and optional wordrejection, and (4) using the new system withutterance rejection and hard word rejection.These conditions are investigated using key-value pair concept error rate [9]. The resultsare shown in Table 2 in terms of substitu-tion, insertion, deletion, and total errorrates for each condition. The table shows
Figure 9. The ROC curvesindicating relative word levelconfidence performance for threeindividual confidence features andthe fully combined feature set.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 10
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
False Acceptance Rate
Cor
rect
Acc
epta
nce
Rat
e
10 Combined FeaturesMean Normalized Acoustic ScoreNbest Purity ScoreUtterance Confidence Score

24 SUMMARY OF RESEARCH - JULY 2000
that concept error rate reduction of 35%has been achieved when confidence scoringwith word and utterance level rejection isincorporated into the system.
This work has shown that confidencescoring can provide extremely usefulinformation about the reliability of recogni-tion hypotheses. This information can beused to guide the understanding anddialogue components of the system towardsa useful interpretation and response to theuser. Future work will focus on fullyintegrating these confidence scoringtechniques into all of our publicallyavailable systems, especially MERCURY andVOYAGER. This will involve upgrading thegrammars and dialogue modeling compo-nents of each system. As our understandingof the dialogue modeling issues matures,our systems should develop a range ofdialogue actions based on confidencescoring including such actions as confirma-tion and clarification.
References[1] C. Pao, P. Schmid, and J. Glass, “Confidence
Scoring for Speech Understanding,” Proc. ofICSLP, Sydney, Australia, 1998.
[2] S. Kamppari. Word and Phone Level AcousticConfidence Scoring for Speech Understanding Systems.Master’s thesis, MIT, 1999.
[3] S. Kamppari and T. Hazen, “Word and PhoneLevel Acoustic Confidence Scoring,” Proc. ofICASSP, Istanbul, Turkey, 2000.
[4] T. Hazen, et al, “Recognition Confidence Scoringfor Use in Speech Understanding Systems,” Proc.of ISCA ASR2000 Tutorial and Research Workshop,Paris, France, 2000.
[5] V. Zue, et al, “JUPITER: A Telephone-basedConversational Interface for WeatherInformation,” IEEE Trans. on Speech and AudioProcessing, vol. 8, no. 1, January 2000.
[6] J. Glass, T. Hazen and L. Hetherington, “Real-time Telephone-based Speech Recognition in theJUPITER Domain,” Proc. of ICASSP, Phoenix, AZ,1999.
[7] S. Seneff, “TINA: A Natural Language System forSpoken Language Applications,” ComputationalLinguistics, vol. 18, no. 1, March 1992.
[8] T. Hazen, et al, “Integrating RecognitionConfidence Scoring with LanguageUnderstanding and Dialogue Modeling,” toappear in Proc. of ICSLP, Beijing, China, 2000.
[9] J. Polifroni, et al, “Evaluation Methodology for aTelephone-based Conversational System,” Proc.Int. Conf. on Language Resources and Evaluation,Granada, Spain, 1998.
Table 2. Understanding error ratesas confidence scores and differentlevels of confidence rejection areadded to the system.
Experimental
Conditions Sub. Ins. Del. Total
Original System 1.9 20.2 6.4 28.5
New system w/o rejection 2.1 18.2 16.1 26.3
+ utterance rejection 1.8 12.7 7.1 21.7
+ optional word rejection 1.3 9 8.4 18.7
+ hard word rejection 1 7.2 10.5 18.6
Error Rates (%)
CONFIDENCE SCORING FOR USE IN SPEECH UNDERSTANDING SYSTEMS

25SPOKEN LANGUAGE SYSTEMS
MOKUSEI: A Japanese, Telephone-based,Conversational System in the Weather DomainVictor Zue, Stephanie Seneff, Joseph Polifroni, Yasuhiro Minami, Mikio Nakano, T.J. Hazenand James Glass
In 1997, we introduced the JUPITER weatherinformation system in English [1]. Since itcame on-line via a toll free telephonenumber, we have collected over 600,000utterances from over 100,000 calls, whichprovide a rich corpus for training andrefinement of system capabilities. SinceJUPITER is our most mature conversationalsystem to date, it has become the platformfor our multilingual spoken languageresearch effort. In 1998, we started thedevelopment of MOKUSEI1, a conversationalsystem that provides weather information inJapanese over the telephone [3]. This is acollaborative project between NTT and ourgroup.
Like its English predecessor, MOKUSEI
consists of a number of specialized serversthat communicate with one another via acentral programmable hub, using theGALAXY Communicator architecture [2]. Anaudio server captures the user’s speech andtransmits the waveform to the speechrecognizer. The language understandingcomponent parses a word graph producedby the recognizer and delivers a semanticframe, encoding the meaning of theutterance, to the discourse resolutioncomponent. The output of discourseresolution is the “frame-in-context,” which istransformed into a flattened E-form(electronic form) by the generation server.This E-form is delivered to the dialoguemanager, and provides the settings of thedialogue state. The dialogue managerconsults a dialogue control table to decidewhich operations to perform, and typicallyengages in a module-to-module sub-dialogueto retrieve tables from the database. Itprepares a response frame, containing
weather reports represented as semanticframes, which is sent to the generationcomponent for translation into the targetlanguage2. The speech synthesizer thentranslates the response text into a speechwaveform, which it sends to the audioserver. Finally, the audio server relays thespoken response to the user over thetelephone.
MOKUSEI utilizes most of the samehuman language technology components asJUPITER, although some modifications werenecessary to account for differences betweenEnglish and Japanese. For speech recogni-tion, alternative pronunciations of lexicalitems are generated using a set of phonologi-cal rules appropriate for Japanese. Forexample, one set of phonological rulesaccounts for the deletion of /i/ and /u/,resulting in the word sequence “desu ka”being pronounced as /d e s k a/. Acousticmodels for the MOKUSEI recognizer wereinitially trained entirely from Englishutterances. As Japanese data becameavailable, these models were retrained usinga combination of read and spontaneousutterances. For language modeling, theclass n-gram (consisting of some 50 classes)were either created by hand and trained, orderived automatically from the naturallanguage grammar used by the understand-ing component of the system.
For language understanding, we were atfirst concerned that a top-down parser, TINA,might not be an appropriate choice forJapanese, which is a left-recursive language.The problem is that the system mustpropose the entire parse column above thefirst word before it has seen the rest of thesentence. The solution to this problem was
1 Mokusei is the Japanese name for the planet Jupiter.2 Our English JUPITER system translates weather reports from English back into English.

26 SUMMARY OF RESEARCH - JULY 2000
found through TINA’s trace mechanism.Using this approach each new content wordis parsed first in a shallow parse tree, andthen later moved to a position just after thesubsequent particle that defines its role.The upper columns of the parse tree are notconstructed until after the appropriate rolehas been identified. This has the intendedeffect of reordering the constructs to appearright-recursive. The current grammar forMOKUSEI has more than 900 categories andmore than 2,000 vocabulary entries.
Perhaps the most difficult aspect ofMOKUSEI is the translation of Englishweather reports into Japanese. In attempt-ing to generate well-formed Japanese fromthe semantic frames for the weather reports,we encountered several situations where ourlanguage generation component, GENESIS,was unable to produce a natural Japanesetranslation. We found that more explicitcontrol was needed over the choice of boththe correct alternative translation of a givenword and the correct ordering of certainconstituents that were too deeply embed-ded. To solve these problems, we found itnecessary to completely redesign the GENESIS
system, thus providing far greater flexibilityin translation tasks. Additional features ofthis GENESIS-II system (c.f. page 43) includebetter control over the ordering of constitu-ents (e.g., noun phrase modifiers), and thecapability of selecting for context-dependentlexical realization using the new “push” and“pull” capabilities. These additionalfeatures were essential for high qualitygeneration in Japanese. For MOKUSEI, wehave created nearly 500 generation rules,along with a generation vocabulary of about3,000 entries. For Japanese synthesis, wemade use of FLUET, a software synthesizerprovided by NTT Cyber Space Laboratories.
The database for MOKUSEI is nearlyidentical to the one used by JUPITER.However, we expanded the number ofJapanese cities from 6 to 46 for MOKUSEI.We also provided in a geography tableinformation about the prefecture for eachcity. The weather information for theexpanded Japanese set is obtained from aWeb site.
The current status of MOKUSEI is that theentire system is operational at MIT, and wehave used the system to collect some 2,000read sentences, as well some 6,000 sponta-neous sentences (in over 400 dialogues)from naïve Japanese users who called thesystem from Japan. The current word errorrate, based on a 1,200 utterance test setcontaining no out-of-vocabulary words andwith a test-set bigram perplexity of 22, is15.4%. In the coming months, we plan tocontinue our data collection by installing asystem in Japan, and to improve all compo-nents of MOKUSEI. We will also expand itsdomain of expertise, and evaluate its overallperformance.
References[1] V. Zue, S. Seneff, J. Glass, J. Polifroni, C. Pao, T.
Hazen, and L. Hetherington, “JUPITER: ATelephone-Based Conversational Interface forWeather Information,” IEEE Trans. Speech andAudio Proc., 8(1), 85—96, 2000.
[2] S. Seneff, E. Hurley, R. Lau, C. Pao. P. Schmid,and V. Zue, “GALAXY-II: A Reference Architecturefor Conversational System Development,” Proc.ICSLP, 1153—1156, Sydney, Australia, 1998.
[3] V. Zue, S. Seneff, J. Polifroni, M. Nakano, Y.Minami, T. Hazen, and J. Glass, “From JUPITER toMOKUSEI: Multilingual Conversational System inthe Weather Domain,” to appear in Proc. Workshopon Multi-lingual Speech Communication, Kyoto,Japan, 2000.
MOKUSEI: A JAPANESE, TELEPHONE-BASED, CONVERSATIONAL SYSTEM IN THE WEATHER DOMAIN

27SPOKEN LANGUAGE SYSTEMS
MUXINGChao Wang, Victor Zue, Joe Polifroni, Stephanie Seneff, Jon Yi, and T.J. Hazen
Over three years after deployment, ourJUPITER weather information system hasproven to be a valuable resource for datacollection and system development.Recently, we have become interested inporting JUPITER to other languages besidesEnglish, mostly to address issues of languageportability, but also with the hope thatJUPITER could become a vehicle for foreignlanguage learning. Over the past year, wehave developed a Mandarin Chinese versionof JUPITER, which we call “MUXING1.” MUXING
is now operational end-to-end, and we arecurrently collecting additional data fromnative speakers of Mandarin in order tobegin a process of refinement modelledafter our experiences with English. Thesystem is integrated into our overall GALAXY
Communicator architecture, configured as acentral hub providing the communicationslinks among a suite of servers, each specializ-ing in different aspects of the overall system.
The JUPITER discourse and dialoguecomponents, as well as the database server,are all language-transparent, operating froma meaning representation which we call a“semantic frame,” but which can also beviewed as an interlingua. For the language-dependent components such as speechrecognition, natural language understand-ing, and language generation, the language-specific knowledge, such as acoustic modelsand grammar rules, is provided as controlfiles external to the servers. Currently, the
system uses a software synthesizer providedby ITRI. However, we are in the process ofdeveloping our own Mandarin synthesizerbased on the ENVOICE system (c.f. pages 35and 75).
The recognizer is adapted from thesegment-based SUMMIT system. The initialvocabulary is about 700 words, coveringmore than 400 place names and othercommon words used in weather queries.Chinese syllable initials and finals are usedas acoustic model units. Tone models wereincluded in post-processing the recognizerN-best output, as described in (c.f. page 72)
We were interested in modellingcontextual effects through the use ofboundary models. However, we have notbeen able to train boundary models for theMandarin recognizer in the past, due to thedifficulty in manually grouping cross-phoneboundary classes based on phonologicalknowledge, especially when training data arevery sparse. To address this problem, wehave implemented a data-driven approach toderive boundary classes automatically, usinga decision-tree based clustering technique.Altogether, forty one broad boundaryclasses were obtained in this way.
A hierarchical language model wasdeveloped which gave improved recognitionaccuracy over a class N-gram model. It usesN-gram probabilities to link “concepts,”each of which expands recursively intoweighted sequences of concepts or words.The language model is trained by parsing acorpus using the TINA natural languageformalism. Each grammar rule is decom-posed into a set of trigrams linking leftsiblings with possible right siblings, in thecontext of the parent. A set of distinguished
Table 3. Summary of syllable errorrate in percentage.
Configuration Dev Set Test Set
Baseline 20.1 23.1
+ Boundary 14.5 15.1
+ Tina LM 17.9 19.3
+ Both 13.7 13.9
1Muxing is the Chinese name for the planet Jupiter.

28 SUMMARY OF RESEARCH - JULY 2000
categories are identified as classes for thetop-layer class n-gram. Once the grammar istrained, it is written out as a finite statetransducer, which can then be composedwith the lexicon to define the search spacefor recognition. Table 3 shows systemperformance as each of these improvementswere added. The error rates are given forsyllables.
One of the most challenging aspects ofmultilingual implementations is naturallanguage generation, since it is essentially atranslation of existing weather reports fromEnglish. In preparing generation rules formultilingual systems, we encountered anumber of new phenomena, which ulti-mately inspired our group to develop anentirely new version of GENESIS, our genera-tion server (c.f. page 43).
Different mappings for particularconcepts in a semantic frame posed aproblem for generation in Chinese. For
{c weather_event:pred
{p becoming:topic
{q weather_act:conditional “mostly”:name “sunny”:pred
{p in_time:topic
{q time_of_day:modifier “late”:name “afternoon” } } } } }
Pinyin Paraphrase:bang4 wan3 zhuan3 zhu3 yao4 wei2 qing2 tian1around evening becoming mostly sunny
Figure 10. Example semanticframe for the sentence, “becomingmostly sunny in late afternoon,”along with its paraphrase intopinyin.
late “ ” ; $:lateafternoon “xia4 wu3” $:late “bang4 wan3”
Figure 11. Selected vocabularyentries to illustrate mechanisms tocreatively combine two words intoa single mapping.
MUXING
example, the semantic frame in Figure 10contains a modifier “late” for the word“afternoon,” translated into Chinese as“bang4 wan3.” However, it is not possible tochoose a single meaning for “late” that iscorrect for “morning,” “afternoon,” and“evening,” and likewise, it is not possible tochoose a single word for “afternoon” that iscorrect for “early,” “late,” or no qualifier.GENESIS-II provides the cabability for avocabulary item to specify a “selector,” thatis used to determine the surface form of anyother vocabulary item that falls within itsscope. Figure 11 contains examples from aGENESIS-II vocabulary file showing theplacement of the selector “$:late” in thevocabulary entry for “late,” and the associa-tion of the surface form “bang4 wan3” withthat selector for the vocabulary item“afternoon.”
Other phenomena such as temporalorder of adjectives and adverbs, which variesgreatly from Chinese to English, wereaccounted for in a similar way in GENESIS-II.GENESIS-II provides a mechanism to allow avocabulary item to generate a [:key value]pair that is inserted directly into thesemantic frame. This mechanism interactswith the message templates to essentiallypost-hoc edit the frame to reassign inappro-priately labelled keys, and, consequently, toreposition their string expansions in thesurface form generation.
MUXING has been deployed on a publiclyavailable phone number, and we are in theprocess of collecting and analyzing dataobtain from real users.
Reference[1] C. Wang, S. Cyphers, X. Mou, J. Polifroni, S.
Seneff, J. Yi, and V. Zue, “MUXING: A Telephone-access Mandarin Conversational System,” toappear in Proc. ICSLP 2000, Beijing, China, Oct.2000.

29SPOKEN LANGUAGE SYSTEMS
ORIONStephanie Seneff, Chian Chuu and Scott Cyphers
Over the past year, we have begun toexplore the idea of off-line delegation, as anatural extension of on-line interaction. Bythis, we mean that the user engages thesystem in a conversation in order to specifya task that the system should perform off-line, contacting the user at a later time toprovide the requested information.
To this end, we have developed a newsystem, ORION, which represents a distinctdeparture from our standard system designin three significant ways: (1) Delayed taskresolution: the user initially engages ORION
in a conversation in order to request that atask be carried out at some designated timein the future. (2) Server acts as a user: ORION
consults other conversational systems atintervals in order to seek information that itneeds to execute the user’s task, and (3)System initiates the call: at the appropriatetime, ORION calls back the user and providesthe requested information. ORION cancurrently handle a variety of different typesof tasks, as suggested by the list of examplequeries in Figure 12. It consults four othersystems to retrieve critical information:MERCURY for flight schedules, PEGASUS forflight status, VOYAGER for traffic conditions,and JUPITER for weather.
The ORION system is configured usingthe GALAXY Communicator architecture.All of the servers communicate via acommon hub. The ORION server plays twodistinct roles, each implemented as aseparate stream. One is devoted to theenrollment of new tasks and the other isconcerned with the execution of existingtasks. Users first enroll by providing criticalinformation about their name, appropriatephone numbers, and e-mail address. To editexisting tasks or add new tasks, the userinteracts with ORION at a web site, using
spoken or typed interaction. The tasks aredisplayed in the graphical interface, andORION engages the user in a mixed-initiativeconversation until the task is fully specified.The user can also enter new tasks in atelephone-only interaction. If a new taskneeds to be executed today, it is sent to theagent stream for an immediate update.Eventually, the system will also supportspeech-only task editing.
Generally there is a stack of pendingtasks being monitored by the agent stream.A structure encoding the status of each taskis examined and updated at strategic times.Updates usually involve enquiring forinformation from one of the other servers,using a module-to-module subdialogue. Forexample, a call-back request on a flightwould involve first determining fromMERCURY the scheduled departure time, thenrequesting information about the actualstatus of the flight from the PEGASUS serverat strategic intervals while the flight shouldbe in the air. Finally, a call to the user islaunched at the predesignated trigger time.
ORION represents the early stages of anambitious long-term project. In the future,we envision that people will be able to takeadvantage of available on-line informationsystems such that routine tasks can bedelegated to the computer as much aspossible, thus freeing humans to attend totasks that truly need their attention. We willexplore how we can build systems that caneasily customize and adapt to the users’needs and desires. In the process, we willalso examine how a system such as ORION
could be made more intelligent by incorpo-rating into its decision-making process allavailable information at its disposal, bothabout the domain and about the individualuser. We believe that ORION has tremendous

30 SUMMARY OF RESEARCH - JULY 2000
potential, although we are still working outthe details of some of the more difficultaspects of its design, including user identifi-cation, customization, resource allocation,and task completion verification.
Figure 12. Examples of userrequests within the ORION domain. “Call me every weekday morning at 6 a.m. to wake me up.”
“Can you call me at 4:30 in the afternoon to remind me to take my medicine?’’
“Call me a half hour before flight 20 lands in Dallas”
“Send me e-mail any time between 6 and 8 a.m. if the traffic on Route 93 Southbound is at a standstill.”
“Call Jim at 4 p.m. at 333-3333 to remind him to go to the dentist.”
Reference[1] S. Seneff, C. Chuu, and D. S. Cyphers,“ORION:
From On-line Interaction to Off-line Delegation”,to appear in Proc. ICSLP 2000, Beijing, China,Oct. 2000.
ORION

31SPOKEN LANGUAGE SYSTEMS
Facilitating Spoken Language System Creationwith SPEECHBUILDER
James Glass, Jef Pearlman and Eugene WeinsteinOver the past decade researchers in theSpoken Language Systems group havedeveloped several different conversationalsystems. These mixed-initiative systems areresearch prototypes which require a largeamount of expertise in human languagetechnology (HLT) by the developers. Thisrequirement represents an impediment tothe rate at which new systems can bedeployed, since it limits the pool of develop-ers. To address this issue, we have begun tocreate a utility called SPEECHBUILDER, whichwill lower the barrier to novice and interme-diate developers, and allow them to rapidlycreate conversational interfaces using state-of-the-art human language technologycomponents.
From a research perspective, there areseveral benefits to making the technologymore accessible to developers. First, there isan issue of automation; can infrastructurebe put in place to fully automate all aspectsof conversational system development? Thistask could involve research in missingtechnologies, such as improved pronuncia-tion generation of new words, or unsuper-vised learning of acoustic and linguisticmodels. Second, there is the issue ofportability; how can the technology be madeto work robustly with a limited amount oftraining data from a new domain? Sincesystem development is often tied to datacollection, any data collected from newapplication domains will benefit research inportability by allowing researchers toevaluate robustness of HLT components.
The SPEECHBUILDER utility is intendedto allow people unfamiliar with speech andlanguage processing to create their ownspeech-based application. The initial focusof SPEECHBUILDER has been to allowdevelopers to specify the knowledge
representation and linguistic constraintsnecessary to automate the design of speechrecognition and natural language under-standing. To do this, SPEECHBUILDER uses asimple web-based interface which allows adeveloper to describe the importantsemantic concepts (e.g., objects, attributes)for their application, and to show, viaexample sentences, what kinds of actions arecapable of being performed. Once thedeveloper has provided this information,along with the URL to their CGI-basedback-end application, they can useSPEECHBUILDER to automatically create theirown spoken dialogue system which they,and others, can talk to in order to accessinformation.
ArchitectureA SPEECHBUILDER application has two basicparts: first, the HLTs which perform speechrecognition, language understanding etc.,and second, the application back-end whichtakes a semantic representation produced bythe language understanding component anddetermines what information to return tothe user. The HLTs are automaticallyconfigured by SPEECHBUILDER using informa-tion provided by the developer, and run oncompute servers residing at MIT. The back-end consists of a program (e.g., Perl script)created by the developer using the CommonGateway Interface (CGI) protocol, runningon a CGI-capable web server anywhere onthe Internet. The semantic representationproduced by the HLTs takes the form ofconventional CGI parameters which getpassed to the back-end via standard HTTPprotocols.
There are four CGI parameters whichare currently used by SPEECHBUILDER: text,action, frame, and history. As may be

32 SUMMARY OF RESEARCH - JULY 2000
FACILITATING SPOKEN LANGUAGE SYSTEM CREATION WITH SPEECHBUILDER
surmised, the text parameter contains thewords which were understood from theuser, while the action parameter specifiesthe kind of action being requested by theuser. The frame parameter lists thesemantic concepts which were found in theutterance. In their simplest form, semanticconcepts are essentially key/value pairs (e.g.,color=blue, city=Boston, etc). Morecomplex semantic concepts have hierarchi-cal structure such as:
time=(hour=11,minute=30,xm=AM),item=(object=box,beside=(object=table)))
The following examples illustratepossible action and frame values fordifferent user queries:
Since a CGI program does not retainany state information (e.g., dialogue), thehistory parameter enables a back-end toprovide information back to the HLTservers that can be used to help interpretsubsequent queries. For example, in thefollowing exchange the history parameter isused to keep track of local discoursecontext:
Knowledge RepresentationSemantic concepts and linguistic constraintsare currently specified in SPEECHBUILDER viakeys and actions. Keys usually define classesof semantically equivalent words or wordsequences, so that all the entries of a keyclass should play the same role in anutterance. All concepts which are expectedto reside in a frame must be a member of akey class. The following table containsexample keys.
Actions define classes of functionallyequivalent sentences, so that all the entriesof an action class perform the sameoperation in the back-end. All examplesentences will generate the appropriateaction CGI parameter if they are spoken bythe user. SPEECHBUILDER will generalize allexample sentences containing particular keyentries to all the entries of the same keyclass. SPEECHBUILDER also tries to generalizethe non-key words in the example sentencesso that it can understand a wider range ofuser queries than were provided by thedeveloper. However, if the user does saysomething that cannot be understood, theaction CGI parameter will have a value of“unknown”, while the frame parameter willcontain all the keys which were decodedfrom speech signal. The following tablecontains example actions.
turn on the lights in the kitchen
action=set&frame=(object=lights, room=kitchen, value=on)
will it be raining in Boston on Friday
action=verify&frame=(city=Boston,day=Friday,property=rain)
are there any chinese restaurants on Main Street
action=identify&frame=(object=(type=restaurant,
cuisine=chinese, on=(street=Main,ext=Street)))
I want to fly from Boston to San Francisco arriving before ten a m
action=list&frame=(src=BOS,dest=SFO,
arrival_time=(relative=before,time=(hour=10,xm=AM)))
what is the phone number of John Smith
action=identify&frame=(property=phone,name=John+Smith)
what about his email address
action=identify&frame=(property=email)
&history=(property=phone,name=John+Smith)
what about Jane Doe
action=identify&frame=(name=Jane+Doe)
&history=(property=email,name=John+Smith)
Key Examples
color red, green, blue
day Monday, Tuesday, Wednesday
room living room, dining room, kitchen
appliance living room, dining room, kitchen

33SPOKEN LANGUAGE SYSTEMS
SPEECHBUILDER allows the developer tobuild a structured grammar when this isdesired. To do this, the developer needs tobracket parts of some of the examplesentences in the action classes, in order thatthe system may learn where the structurelies. For example, a bracketed sentencemight look like “Please put source=(the bluebox) destination=(on the table in thelocation=(kitchen)).” Based on the bracket-ing, SPEECHBUILDER creates hierarchy in themeaning representation and the frameparameter. Hierarchy can be recursive, orconversely, can be flattened so that sub-structure is removed from the final frameparameter. Note that bracketing a sentenceonly involves pointing out the hierarchy asthe keys are still automatically discovered bySPEECHBUILDER.
Web InterfaceThe first version of SPEECHBUILDER has a
web interface which allows developers toedit their domains from anywhere on theInternet. The utility allows a developer tomodify or delete any of the applicationswhich they have previously created, or createnew ones. To create a speech application, adeveloper needs to provide toSPEECHBUILDER 1) a comprehensive set ofsemantic concepts, and example queries fortheir particular domain (specified in termsof keys and actions), and 2) the URL of a
CGI script which will take the CGIparameters produced for a user query, andprovide the appropriate information. Oncethis has been done, the developer 1) pressesa button for SPEECHBUILDER to compile theinformation for their application into aform needed by the human languagecomponents, 2) presses another button tostart the human language components fortheir application running (on an MIT webserver), and 3) calls the SPEECHBUILDER
developer phone number and starts talkingto their system.
The concepts and actions specified bythe developer are stored in an XMLrepresentation which is stored on our localfile system. Since the SPEECHBUILDER utilityis a CGI script, the file is modified everytime changes are made to the domain. If adeveloper wishes to edit the XML filethemselves, it is possible to download theXML file by selecting that option at theupper left of the SPEECHBUILDER utility.Similarly, it is possible to upload an XMLfile into the user’s SPEECHBUILDER directory.
In addition to specifying constraintsand example sentences for their applicationdomain, the developer needs to build theback-end which will provide the actualdomain-specific interaction to the user. Todo this, the developer needs to have accessto a CGI-capable web server, and place thescript to be used at a URL matching the onespecified to SPEECHBUILDER. Because of theflexibility of CGI, it doesn’t matter whetherthe CGI back-end is actually a Perl script, aC program pretending to be a web serveritself, an Apache module, or any otherparticular setup, as long as it adheres to theCGI specification. All of our testing to datehas been done using Perl and CGI.pm. Weprovide each developer with a sample
Action Examples
what is the forecast for Boston
identify what will the temperature be on Tuesday
I would like to know today's weather in Denver
turn the radio on in the kitchen please
set can you please turn off the dining room lights
turn on the tv in the living room
good bye
good_bye thank you very much good bye
see you later
JAMES GLASS, JEF PEARLMAN AND EUGENE WEINSTEIN

34 SUMMARY OF RESEARCH - JULY 2000
application domain when they register, andprovide a useful Perl module for parsing thesemantic arguments for developers creatingtheir CGI script.
Human Language TechnologyThe current focus of SPEECHBUILDER hasbeen on robust understanding so that thediscourse and dialogue components usedfor our mainstream systems (e.g., JUPITER,MERCURY, etc) are not yet incorporated. Inaddition the language generation compo-nent is only used to create CGI parameters,and has not been used for response genera-tion. These activities are the subject ofongoing and future research.
In the area of language understanding,the current interface with the speechrecognizer is via the conventional N-bestinterface. As in all our other systems, arobust parsing mechanism is used to analyzethe utterance if no full parse is found. Forspeech recognition, a bigram languagemodel is derived from the language under-standing component using a hierarchical n-gram structure [1]. Acoustic models aretrained from telephone-based speechcollected from all our domains. A phone-based out-of-vocabulary model is incorpo-rated to more robustly identify spokenwords which were not specified by thedeveloper [2].
Status and PlansAs of this date, the SPEECHBUILDER utilityhas been used internally to create domainsin the control of home appliances, as well asaccess to music and personnel information.Once the necessary infrastructure tosupport multiple developers has been put inplace, we plan to expand the pool ofdevelopers to include people outside of ourgroup.
One of the next phases of research willbe to re-design our discourse component sothat it may be used by SPEECHBUILDER.Future work will also develop an interface tocreate mixed-initiative dialogues which canautomatically interface with our dialoguemodule. Finally, we would like to developan interface for our language generationcomponent, so that we can begin to developmultilingual conversational interfaces withSPEECHBUILDER without having to modifythe application back-end.
References[1] C. Wang, S. Cyphers, X. Mou, J. Polifroni, S.
Seneff, J. Yi and V. Zue, “MUXING: A Telephone-Access Mandarin Conversational System " toappear Proc. 6th International Conference on SpokenLanguage Processing, Beijing, China October 2000.
[2] I. Bazzi and J. Glass, "Modeling Out-of-VocabularyWords for Robust Speech Recognition" to appearProc. 6th International Conference on SpokenLanguage Processing, Beijing, China October 2000.
FACILITATING SPOKEN LANGUAGE SYSTEM CREATION WITH SPEECHBUILDER

35SPOKEN LANGUAGE SYSTEMS
Finite-State Transducer-Based Unit Selectionfor Concatenative Speech SynthesisJon Yi, James Glass, and Lee Hetherington
Corpus-based concatenative methods andunit selection mechanisms have recentlyreceived increasing attention in the speechsynthesis community (e.g., [3,5]). Ourprevious work with speech synthesis hasfocused on using unit selection andwaveform concatenation techniques tosynthesize natural-sounding speech forconstrained spoken dialogue domains [6].Following Hunt and Black [3], we organizedthe synthesis constraints of unit selectioninto concatenation and substitution costs,which essentially prioritize where the speechsignal is spliced and which units areappropriate for concatenation. Ourconcatenative synthesizer, called ENVOICE, isphonologically-based (i.e., symbolic), usesphones as the fundamental synthesis unit,and selects variable-length segments forconcatenation. When combined with adomain-dependent corpus, it has producedvery natural sounding speech for several ofour spoken dialogue domains.
Our recent work has revolved arounddeveloping a more general framework forthis synthesizer that would be easier tomaintain, extend, and deploy. Following oursuccessful use of finite-state transducers(FSTs) for speech recognition [2], we havealso converted our synthesizer to an FST-based representation. Synthesis is nowmodeled as a composition of five FSTcomponents: the word sequence, W, alexicon, L, containing baseform pronuncia-tions, a set of phonological rules, P, a set oftransition phones, T, (used primarily forsearch efficiency), and a synthesis compo-nent, S, which maps all possible phonesequences to waveform segments for a givenspeech corpus. Unit selection is accom-plished with a Viterbi or N-best search. Justas we, and others, have found for speech
recognition, the FST formulation providesclarity, consistency, and flexibility. In ourcase, it also allows leveraging off of ourprevious work with FST-based speechrecognition (e.g., pronunciation modellingand search).
One of the main challenges of convert-ing our phonological synthesis framework toan FST representation was determining anefficient structure for the synthesis FST, S.Our solution was to introduce a series ofdomain-independent intermediate layers,which efficiently encapsulate both thesubstitution and concatenation costsbetween every phonetic segment in a speechcorpus. This structure has the property thatthe size of the intermediate layers is fixed, sothat the size of the FST grows linearly withthe size of the corpus. This allows us toavoid pruning mechanisms which wouldneed to be implemented if we had directlyconnected every segment in the corpus [1].Furthermore, this synthesis frameworkincorporates both concatenation andsubstitution costs as part of the FST, andnot just concatenation costs.
FST RepresentationOne of the key reasons we adopted an FSTrepresentation is its ability to completelyand concisely capture finite-state con-straints. Given a permissible input se-quence, an FST can generate a graph ofoutput sequences [4]. The process oftransforming an input language into anoutput language is guided by the states andarcs specified in the FST topology. Arcshave optional input and output labels (the
absence of a label is represented by the εsymbol), and can also have weights associ-ated with them. For example, a lexicaldictionary can be implemented with an FST

36 SUMMARY OF RESEARCH - JULY 2000
FINITE-STATE TRANSDUCER-BASED UNIT SELECTION FOR CONCATENATIVE SPEECH SYNTHESIS
that maps words to phonemes, with weightspossibly being used to model alternativepronunciations. Since FSTs can be cascadedin succession to effect further mappings, asecond phoneme-to-phone FST could beused to transduce the phonemic sequenceinto a phonetic sequence. The overallcomposition would then map words tophones.
With this representation, unit selectionfor concatenative speech synthesis can bemodeled as a mapping from words towaveform segments. Five FST components,W, L, P, T, and S, perform the interveningsteps. This factoring allows us to indepen-dently model, design, and refine theunderlying processes. When combined witha search, these components work insuccession from an input sequence of wordsto produce a sequence of waveform seg-ments suitable for concatenation. For moredetails of the individual FSTs, see thestudent report by Jon Yi.
SearchThe role of the search component is to findthe least-cost sequence of speech utterancesegments for a given text input. Specifically,the search finds the least-cost path through
the composition of
with S. In keeping with our parallelismbetween recognition and synthesis, thesearch we use is essentially the same Viterbi-style dynamic programming beam searchthat is used for recognition, except thatdifferent graphs are searched. For synthesis,
we optimize TPLW ��� )( and then walk
through its states in topological order,exploring compatible arcs in S at the sametime. Pruning consists of dynamic program-ming pruning plus score- and count-basedbeam pruning, which are tuned to achieve
real-time synthesis.To reduce latency when synthesizing a
long system response, we break the responseinto chunks separated by sentence bound-aries and explicitly referenced pauses orwaveform segments called “shortcuts”(described in the next section). Since thestate of the system is known at theseboundaries, the searches for each chunk canbe performed separately, allowing us toperform waveform output for one chunkwhile performing the search for a subse-quent chunk.
ImplementationBased on the structures and algorithmsdescribed in the previous section, we havedeveloped a set of software tools and serversfor working with this new FST framework.These tools encompass the steps that areperformed in the assembling, testing, andrunning of an FST-based concatenativespeech synthesizer. We use command-lineutilities for lexicon creation, constraintscompilation, and corpus instrumentation,as well as for synthesis testing. The lexiconcreation process reuses tools from ourspeech recognizer. The constraint kernel ofthe synthesis FST is compiled from substitu-tion and concatenation costs matrices. Thesynthesis FST is then populated withphones from a corpus of time-alignedwaveforms. FST synthesis can then be testedwith arbitrary sequences of in-vocabularywords.
We have integrated FST synthesis asnetworked servers into the GALAXY Commu-nicator architecture which we use for all ofour spoken dialogue systems. Two serversfulfill the text-to-speech conversion compo-nent, and handle the separate tasks of unitselection and waveform concatenation.

37SPOKEN LANGUAGE SYSTEMS
Based on a client-server architecture, theycommunicate with a central hub whichcoordinates all tasks in a conversationalsystem. The two servers are pipelined andperform synthesis at speeds sufficient forinteractive purposes.
Within our GALAXY Communicatorimplementation, the first step of synthesisactually begins in our natural languagegeneration server, GENESIS (c.f. page 43).GENESIS recursively expands internalmeaning representations into text stringswhich can be displayed directly on a display,or sent to a synthesis server. The serverrelies on a message or template file, alexicon, and a set of rewrite rules to performgeneration. For synthesis, the message file isidentical to that used for text generation.The lexicon can optionally be modified toexpand abbreviations, or explicitly representwaveform segments. These synthesis“shortcuts” allow the developer to bypassthe search when desired, and providebackwards compatibility with our earlierword and phrase concatenation work.Another feature of GENESIS which we use forsynthesis is the ability to specify features forentries in the lexicon. We have used this tohelp select words and syllables with thecorrect prosodic context.
The GENESIS rewrite rules can be used toperform text preparation for synthesisbeyond what may be needed for textgeneration. For example, we have designedregular-expression rules that rewrite flightnumbers and times originally in numericalform into written form (e.g., 6425 –> sixtyfour twenty five, 11:05 –> eleven oh five).This configuration performs the responsi-bilities typically assumed by a TTS text pre-processing stage. Because it is part of thegeneration component, it offers increased
accuracy (e.g., unambiguous abbreviationexpansion) and flexibility when developingmultiple domains and languages.
In the next step of the synthesis chain,the unit selection server receives pre-processed text to synthesize from the naturallanguage generation component. The wordsequence is converted into a phoneticsequence by the lexical FST and preparedfor searching by the transition label FST. Ifthe word sequence is interrupted withwaveform segment “shortcuts”, phoneticcontext must be maintained before andafter the waveform segment to ensurecorrectness of the search.
Based on the results of the unitselection search, the waveform concatena-tion component receives instructions toconcatenate the appropriate waveformsegments. Currently, concatenation isperformed without signal processing. Forperformance considerations, the waveformconcatenation server loads the entire corpusof utterances from disk into memory atstartup time. As concatenation instructionsare received, waveform samples are streamedto the output audio server. The waveformconcatenation and output audio servers canbe co-located for efficiency.
We have converted several of ourdomains to use the ENVOICE synthesizer wehave developed [6]. The most recent systemconsists of the MERCURY air travel domain forflight information and pricing (c.f. page 9).Synthesizer development typically beginsonce the natural language generationcomponent has been completed for adisplayful system. Since the synthesizercurrently relies on a domain-dependentcorpus, the most time-consuming process isusually the design of a set of prompts to beread. As utterances are recorded, they can
JON YI, JAMES GLASS, AND LEE HETHERINGTON

38 SUMMARY OF RESEARCH - JULY 2000
be transcribed with a speech recognizer andinserted into the synthesis FST.
For domain specific synthesis, we haveused both manual and semi-automaticmeans of designing recording prompts. Forexample, static responses are recorded as awhole. For covering responses with moredynamic content, we use an underlyinggeneration template and fill it in withdifferent vocabulary items, such as numbers,and names of cities and airlines. We havealso experimented with semi-automaticmeans of selecting recording prompts. Inthe past, for the purpose of synthesizingproper nouns, we have used iterative, greedymethods to compactly cover an inventory ofstress-marked, syllable-like units [6].
There are many other issues which weplan to address in future work. In order toreduce the abruptness of some concatena-tion artifacts, we have begun to explore theuse of signal processing techniques tomodify both fundamental frequency andsegment duration. To date, we have takenadvantage of the constrained nature ofoutputs in our conversational domains, andhave avoided the use of any kind of prosodicgeneration module. Prosody has mainlybeen incorporated at the lexical level in ourGENESIS language generation module, andwith our ongoing design of a general corpusfor the natural-sounding synthesis ofarbitrary words (e.g., proper nouns). Wewould like to investigate corpus-basedprosodic generation in future work,however.
Finally, we are interested in developingsynthesis capabilities for languages otherthan English, and are actively working on aversion for Mandarin Chinese in a weatherinformation domain (c.f. page 27). Thissystem is currently using syllable onsets and
rhymes as the fundamental synthesis unitswith tokenized phrases as the lexicalrepresentation. We also have plans to workon Spanish and Japanese synthesizers in thenear future.
References[1] M. Beutnagel, M. Mohri, and M. Riley, “Rapid
Unit Selection from a Large Speech Corpus forConcatenative Speech Synthesis,” Proc. Eurospeech,607-610, Budapest, Hungary. 1999.
[2] J. Glass, T. J. Hazen, and L. Hetherington, “Real-time Telephone-based Speech Recognition in theJUPITER domain,” Proc. ICASSP, 61-64, Phoenix,AZ, 1999.
[3] A. J. Hunt and A. W. Black, “Unit Selection in aConcatenative Speech Synthesis System Using aLarge Speech Database,” Proc. ICASSP, Atlanta,GA, 373-376, 1996.
[4] E. Roche and Y. Shabes (eds.), Finite-StateLanguage Processing, MIT Press, 1997.
[5] Y. Sagisaka, “Speech Synthesis by Rule Using anOptimal Selection of Non-uniform SynthesisUnits,” Proc. ICASSP, 679-682, New York, 1988.
[6] J. Yi and J. Glass, “Natural-sounding SpeechSynthesis Using Variable-length Units,” Proc.ICSLP, 1167-1170, Sydney, 1998.
FINITE-STATE TRANSDUCER-BASED UNIT SELECTION FOR CONCATENATIVE SPEECH SYNTHESIS

39SPOKEN LANGUAGE SYSTEMS
Barge-inNikko Ström
An important aspect of conversationalsystem design is the degree of naturalnessafforded the user in interacting with thesystem. However, it is difficult to design asystem which can deal with the complexnature of turn taking in a way that mimicsnatural human-human interactions. Whileit is desirable that the user be permitted tointerrupt the system at any time, in practicethis poses some technical difficulties thatmay actually lead to intrusive disruptions ofthe dialogue. The main problem is that it isextremely difficult to design a capability todetect true interruptions without evermistaking random environmental noises asspeech. One approach is to terminate theverbal response only after carefully verifyingthat the detected speech “makes sense,” i.e.,that the recognition and understandingcomponents can interpret it as meaningfulspeech. However, this approach suffers fromtwo problems: (1) the user perceives that thesystem is unresponsive to their interruption,due to the perceptibly long delay before itstops talking, and (2) the superposition ofsystem speech intermixed with user speechcauses a degradation in recognitionperformance, because the echo cancellationsignal processing is not 100% effective.
Given the above considerations, wehave implemented a barge-in capabilitywithin the telephony server of our GALAXY
system which has a sophisticated modelpermitting the system to respond immedi-ately to perceived interrupts, and thencontinue in a graceful and intuitive fashionif the interrupt turns out to be a false alarm.The system is designed as follows:
1. As soon as a candidate input speechsignal is detected, stop talking.
2. Process the recorded signal throughrecognition and understanding.
3. If recognition confidence is suffi-ciently high and the understandingcomponent produces a meaningfulsemantic frame, proceed on to thenext turn.
4. Otherwise, the system speaks a filled-pause signal (“um”), and continuestalking, beginning at the most recentphrase boundary before the stoppingpoint.
This approach allows the barge-indetector to occasionally make mistakes,since the recovery process is natural andnon-disruptive.
The detection is based on a thresholdon the amount of energy detected at thefundamental frequency of voicing. A simpleF0 detection algorithm provides a frequencyestimate, and the energy in theautocorrelation coefficient at that frequencyis the thresholded parameter.
There may be times when it is desirablethat the system disallow barge-in, forexample if a disclaimer is presented, orperhaps there is an advertisement that thelistener is required to hear. In these cases,the system communicates to the user thatbarege-in is disallowed by “raising its voice.”This percept is implemented by a simplehigh-frequency boost combined with a gainin the total energy. This prosodic signal isvery clear and effective in communicating tothe user the desired message, that barging inis not possible at this point.

40 SUMMARY OF RESEARCH - JULY 2000

41SPOKEN LANGUAGE SYSTEMS
T H E S I SR E S E A R C H

42 SUMMARY OF RESEARCH - JULY 2000

43SPOKEN LANGUAGE SYSTEMS
GENESIS-IILauren Baptist
Language generation is a fundamentalcomponent of dialogue systems. In theGALAXY conversational systems, the genera-tion component, GENESIS, transforms ameaning representation into a string in atarget “language” (e.g., English, Japanese,SQL, speech waveforms). GENESIS’ role hasslowly expanded over time, and, conse-quently, the original system is poorly suitedto some of the tasks for which it has beenadapted. In many cases, GENESIS exerts toomuch control by “hardwiring” certainfeatures, such as conjunction generationand wh-query movement, making itdifficult, if not impossible, to generateappropriately in some situations. Further-more, as we discovered through ourexperiences with multilingual systemdevelopment, GENESIS’ method for orderingconstituents was often too constraining,leading to awkward realizations in the targetlanguage. Finally, the original system has asomewhat idiosyncratic specification, usingdifferent generation mechanisms for clauses,predicates, topics, lists, and keywords.
Over the past year, we have imple-mented a new version of GENESIS to resolvemany of the original system’s idiosyncrasiesand shortcomings. The resulting system,GENESIS-II, has fulfilled our main goals,which were to provide very straightforwardmethods for simple generation tasks, whilealso supporting the capability of handlingmore challenging generation requirements,such as movement phenomena, propagationof linguistic features, structural reorganiza-tion, generation from lists, and the context-dependent specification of word sense.
In GENESIS-II, generation is controlled bya set of generation rules in conjunction witha lexicon mapping terminal strings to theirsurface form realization. In defining the
syntax of the generation rules, we havefocused on creating an expressive languagewith generalized mechanisms. This wasachieved by carefully designing notationsand commands in a generic way, so thatthey would enjoy wider utility. Thus, thesame generation mechanism is used forclauses, predicates, topics, and keywords.Furthermore, users can explicitly (butrecursively) specify the ordering of allconstituents in the target string, allowing forthe correct generation of strings that wereimpossible to generate in the originalsystem. Similarly, notations and commandswere carefully designed such that theirutility would extend beyond the originalrequirement to other related aspects. Forexample, we added selectors to allow forcontext-sensitive word-sense disambiguation,which were also effective in prosodicselection for speech synthesis needs.
GENESIS-II also provides generic mecha-nisms for handling conjunctions and wh-query movement. Since the mechanisms forwh-movement involve reorganizing framehierarchies, they also turned out to beuseful in the generation of foreign languageswith substantially different syntacticorganizations.
GENESIS-II allows frames to be groupedinto class hierarchies associated withcommon generation templates, resulting ina significant size reduction over the corre-sponding rules in GENESIS-I. For example, wewere able to reduce the rule files for SQL inthe JUPITER weather domain by 50%. Thisgenerality also leads to more efficientporting to new languages.
We have thus far used GENESIS-II in anumber of specific domains and languages,both formal and natural. In our JUPITER
domain, weather reports are being trans-

44 SUMMARY OF RESEARCH - JULY 2000
lated into three languages besides English:Spanish, Japanese, and Mandarin Chinese.The quality of the translation is greatlyimproved over what could have beenachieved using the original GENESIS system.In the realm of formal languages, we useGENESIS-II both to convert a linguistic frameinto an E-form and to generate databasequeries, often represented in SQL. In ourMERCURY flight reservation domain, com-mon generation rules are used for bothspeech and text generation, where selectedentries in the speech lexicon can mapdirectly to pre-recorded waveforms, selectedfor prosodic context when appropriate.
GENESIS-II
Reference[1] L. Baptist. GENESIS-II: A Language Generation Module
for Conversational Systems. MIT Department ofElectrical Engineering and Computer Science.S.M. thesis expected August 2000.

45SPOKEN LANGUAGE SYSTEMS
Modeling Out-of-Vocabulary Wordsfor Robust Speech RecognitionIssam Bazzi
Current speech recognizers are capable ofrecognizing only a fixed set of wordsreferred to as the recognizer vocabulary. Nomatter how large this vocabulary is, thereare always out-of-vocabulary (OOV) wordsthat cannot be correctly recognized. OOVwords are a common occurrence in manyspeech recognition applications, and are aknown source of recognition errors. Forexample, in our JUPITER weather informationdomain the OOV rate is approximately 2%,and over 13% of the utterances containOOV words [1]. JUPITER utterances contain-ing OOV words have a word error rate(WER) of 51%, while those containing onlyin-vocabulary words have a much lowerWER of 10.4%. Although part of theincreased WER on these OOV data is dueto out-of-domain queries and spontaneousspeech artifacts such as partial words, it is
true that OOV words contribute to theincreased WER. In this work, we introducea tactic for incorporating an explicit OOVword model as part of the recognizer itselfto allow for OOV detection and recogni-tion.
To incorporate an explicit OOV modelinto the recognizer we start with a word-based recognizer. The search space forrecognition can be viewed as finding thebest path(s) in the composition
where P represents the scored phoneticgraph, L is the lexicon mapping pronuncia-tions to lexical units, and G is the languagemodel. Since an OOV word can consist ofany sequence of phones (subject to languageconstraints), we construct a generic OOVword model that allows for arbitrary phone
,GLPS ��=
Figure 13. The hybrid recognitionconfiguration.

46 SUMMARY OF RESEARCH - JULY 2000
Figure 14. ROC curve for OOVdetection
MODELING OUT-OF-VOCABULARY WORDS FOR ROBUST SPEECH RECOGNITION
unknown word in the vocabulary.The experiments we conducted for this
work are within the JUPITER weatherinformation domain [1]. The baselinesystem is a word-based system that uses a setof context-dependent diphone acousticmodels, whose feature representation wasbased on the first 14 MFCCs averaged over8 regions near hypothesized phoneticboundaries [2]. Diphones were modeledusing diagonal Gaussians with a maximumof 50 mixtures per model. The word lexiconconsisted of a total of 2,009 words, many ofwhich have multiple pronunciations.Bigram language models were used both atthe word-level, as well as at the phone-levelfor the OOV model. The main goal of theseexperiments was to demonstrate whether wecan detect OOV words without significantlydegrading the performance of the wordrecognizer on IV utterances. For this reasonwe measured word error rates (WERs) andOOV false detection (alarm) rates on In-Vocabulary. We also measured the OOVdetection rate on the OOV test data to seehow well we could detect OOV words.
For the series of experiments we presenthere, we varied the OOV penalty C
oov.
Figure 14 shows the Receiver OperatingCharacteristics (ROC) curve for severalvalues of C
oov. Figure 15 shows the WER for
the IV test set as the false alarm rateincreases on the IV data. As expected theWER increases with the increase in the falsealarm rate. The results we obtained so farare quite encouraging. With a very simplegeneric word model, we were able to detectaround half of the OOV words (47%) with avery small degradation in WER (0.3%) aswell as a low false alarm (1.3%).
sequences during recognition. One of thesimplest word models is a phone recognizer.In FST terms, a phone recognizer can berepresented as:
Where Lp and Gp are the phone lexiconand grammar, respectively.
To incorporate this OOV model intothe word recognizer, we create a hybridrecognizer by adding an OOV word to thebaseline word recognizer’s vocabulary. Theunderlying model for this OOV word is thegeneric word model. Figure 13 shows howthe word search space is augmented withthe generic word model. We simply allowthe search to have transitions into and outof the generic word model.
The transition into the generic wordmodel is controlled via an OOV penalty (orcost) C
oov . This penalty is related to the
probability of observing an OOV word andis used to balance the contribution of theOOV phone grammar to the overall score ofthe utterance. The hybrid recognizer can berepresented with FSTs as follows:
where SH is the hybrid search space. Toov is
the topology of the OOV word. G′ is
simply the same as except for the extra
GLS pppP ��=
0%
20%
40%
60%
80%
100%
0% 20% 40% 60% 80% 100%
False Alarm
Det
ecti
on
GLP TGLS oovppH′∗∪= ���� ))((

47SPOKEN LANGUAGE SYSTEMS
Figure 15. IV WER versus falsealarm rate.
ISSAM BAZZI
For our future work, we are working onincorporating a probabilistic durationmodel for OOV words. This durationmodel will require a minimum number ofphones for an OOV word as well asprobability scores for different word lengths.Another aspect of the approach we areworking on is the use of larger units(syllables) to model the OOV word.Syllables should provide a more robust sub-word unit to model generic words. Inaddition, we are considering the use ofclasses of OOV words (instead of only one)such as an OOV model for city names,another for weather terms, and so on.
References[1] J. Glass, J. Chang, and M. McCandless, “A
Probabilistic Framework for Feature-based SpeechRecognition,” Proc. ICSLP, pp. 2277—2280,Philadelphia, PA, 1996.
[2] V. Zue, et al., “JUPITER: A Telephone-basedConversational Interface for WeatherInformation,” Proc. Speech and Audio Processing,88(1), 85—96, January, 2000.
0%
20%
40%
60%
80%
100%
0% 20% 40% 60% 80% 100%
False Alarm
IV W
ER

48 SUMMARY OF RESEARCH - JULY 2000
Using Support Vector Machinesfor Spoken Digit RecognitionIssam Bazzi
would result in a variable size feature setsince different words have different dura-tion. The approach we adopted is based onremoving MFCC vectors at points in timewhere the MFCCs change the least untilonly a fixed number of MFCC vectors areleft in the feature set.
An SVM is only a binary or a 2-wayclassifier. For our problem of digit recogni-tion, we need to be able to classify among10 classes. Performing N-way classificationwith a 2-way classifier is usually done usingeither a voting or a scoring mechanism. Thefirst approach we explored was to train 10binary classifiers. Each of the binaryclassifiers is trained to recognize a particulardigit from all other digits. Having these 10classifiers, we can test membership of a testpoint by running it through all of them. Ifall but one test negative, the one that testspositive will be our classification choice.This is not usually the case since more thanone classifier could test positive (or none).Hence, we used a more general scheme: the
class of choice is Copt such that:
Where [ ]Cd iSVM is the distance of the testpoint from the separating hyper-plane for
classifier Ci . In the second approach, webuild classifiers for each pair of digits, hencethe term pair-wise classifiers. For 10 digits,the number of classifier is 45 (10-choose-2).Running the test point through eachclassifier gives us 45 hypotheses for thepossible class the point could belong to. The
class of choice is Copt such that:
Where NSVM is the number of classifiers
voting for class Ci . Hence deciding on the
Support Vector Machines (SVM) is a novelpattern classification technique that hasbeen successfully applied to many patternrecognition problems in the areas ofmachine vision, text classification, market-ing, and medicine [1]. The SVM frameworkis based on minimizing the expected risk ofmaking a classification error. In contrast totraditional Bayesian classification methods,where probability density estimation isrequired for each class, an SVM does notrequire any density estimation. An SVMtransfers the training data to a highdimensional space via a kernel function.Then, it finds an optimal separating hyper-plane that divides this high dimensionalspace into decision regions. The appeal ofthe SVM framework for speech recognitionis twofold. First, SVMs have a great ability togeneralize even with a small number ofexamples and a high-dimension featurespace. Second, a trained SVM needs a smallamount of computation to perform therecognition task. As a result, SVM consti-tutes an inexpensive classifier for systemswith a small vocabulary.
In this work, we address the problem ofrecognizing isolated spoken digits inEnglish. Although the problem is simple, itallows us to examine the potential use ofSVMs for speech recognition, the prepro-cessing required to extract a fixed sizefeature vector from the temporal speechsignal, and the size of the feature space thatcan be used in this recognition framework.
The input to the SVM classifier is afixed-size feature vector that represents awhole word (digit). The SVM feature vectoris generated from the Mel Frequencycepstral coefficients (MFCCs). However,concatenating all MFCC vectors associatedwith a word into one SVM feature vector
[ ]CdC iSVMiopt maxarg=
[ ]CNC iSVMiopt maxarg=

49SPOKEN LANGUAGE SYSTEMS
class is done via a voting scheme among allclassifiers.
For our work we used the 1992 and1994 OGI speech database. For theexperiments we conducted, we used thedigit utterances from 133 speakers (twothirds for training and one third for testing).For the baseline, we used a Gaussianmixture classifier, where the best accuracywas 90.7% (9.3% classification error rate).
In one set of experiments, we investigatevarying an important parameter of the SVMclassifier, the variance of the Gaussiankernel used to map the feature space.Results are shown in Figure 16 for the 1-versus-N classifier with 60 PCA features.
In another set of experiments, we lookat the impact of varying the number of PCAfeatures on the accuracy of the 1-versus-Nclassifier with a Gaussian kernel. Figure 17summarizes the results. The graphs indicatethat we obtain the best performance whenwe use 45 PCA features.
Our best performing SVM classifierachieves a 94.9% accuracy on digit recogni-tion and outperforms a Gaussian mixtureclassifier for the same training and testingdata. However, current speech recognitionsystems can achieve 99% or more accuracyfor the task of spoken digit recognition forphone numbers [2]. Given the scope of thiswork, the simplified approach we followed,and the fact that our method was purelybased on the acoustic evidence, we believethat our results are quite encouraging as ourfirst attempt to using the SVM frameworkfor speech recognition. Current speechsystems rely heavily on various sources ofinformation that we did not utilize in ourapproach. There is much that can be doneto improve the performance such as the useof more training data and incorporating
phonological and pronunciation rules andhigher-level language constraints into therecognition process.
References [1] C. Burges, “A Tutorial on Support Vector
Machines for Pattern Recognition,” Data Miningand Knowledge Discovery, 2(2), 1998.
[2] J. Makhoul, et al, “State of the Art in ContinuousSpeech Recognition,” Proceeding Natl. Acad. Sci.USA, Vol 92 pp.9956-9963, 1995.
Figure 16. 1-vs-N classifierperformance vs Gaussian variance.
Figure 17. The effect of varyingthe number of PCA features.

50 SUMMARY OF RESEARCH - JULY 2000
Building a Speech Understanding System UsingWord Spotting TechniquesTheresa Burianek and Timothy J. Hazen
This work discusses the development andevaluation of a simple word and phrasespotting understanding component within aspoken language system [1]. This use ofsimple word and phrase spotting techniquesis explored as an alternative to the use ofTINA, a natural language understandingsystem which attempts to perform fullunderstanding of input utterances [2]. Thistopic is explored because the developmentof word and phrase spotting grammars issimpler and faster than the development oftypical full TINA grammars. This approachmay be easier for system developers who arenot knowledgeable in linguistics or do nothave the time to spend to develop a full-understanding grammar.
A word spotting understanding serverwas implemented within the GALAXY
Communicator architecture. The grammarfor this server is specified using the JavaSpeech Grammar Format (JSGF), which canrepresent basic context free grammars. Theserver reads the JSGF grammar andconverts in into a finite state transducer(FST) representation whose input is wordsand whose output is concept [key:value]pairs. This approach is quite flexible andcan even be incorporated directly into therecognizer without requiring an additionalunderstanding server. The use of anexternal server allows additional pre-
processing of the recognizer’s hypothesizedword strings, such as confidence scoringrejection, to occur before the understandingFST is applied.
An evaluation of the capabilities of thisserver was conducted in the context of theJUPITER weather information domain [3].The initial word spotting grammar wasinitially developed in a matter of hours andwas refined over the course of a few daysbased on performance evaluations on adevelopment test set. The word spottingtechnique was evaluated on an independenttest set of JUPITER utterances by comparingits concept [key:value] pair understandingerror rate against that of the TINA naturallanguage understanding component [4]. Theunderstanding evaluation also incorporatedthe use of word rejection based on confi-dence scoring. The results, presented in thetable below, were encouraging and sustainedthe hypothesis that simple word and phrasespotting grammars can perform adequatelyfor basic understanding tasks. Regardless ofthe use of word rejection, the full TINA
grammar had approximately 25% fewererrors than the word spotting system.However, considerably more effort wasexpended on developing the TINA grammarand additional effort applied to the wordand phrase spotting grammar should resultin further reductions in its error rate.

51SPOKEN LANGUAGE SYSTEMS
Table 4. Concept error rates of theword and phrase spottingunderstanding server versus theTINA natural language server whenusing and not using rejection ofwords with poor recognitionconfidence scores.
Understanding Word RejectionApproach Used? Sub Ins Del TotalWord Spotting No 3.9 18.5 12.9 35.2TINA No 2.6 13.8 9 27.1Word Spotting Yes 2.6 6.2 17.8 26.6TINA Yes 1.8 4.3 13.6 19.7
Concept Error Rates (%)
References[1] T. Burianek, Building a Speech Understanding System
Using Word Spotting Techniques, Master’s thesis,MIT, Expected July 2000.
[2] S. Seneff, “TINA: A Natural Language System forSpoken Language Applications,” ComputationalLinguistics, vol. 18, no. 1, March, 1992.
[3] V. Zue, et al, “JUPITER: A Telephone-basedConversational Interface for WeatherInformation,” IEEE Transactions on Speech andAudio Processing, vol. 8, no. 1, January 2000.
[4] J. Polifroni, et al, “Evaluation Methodology for aTelephone-based Conversational System,”Proceedings of the International Conference onLanguage Resources and Evaluation, Granada, Spain,1998.

52 SUMMARY OF RESEARCH - JULY 2000
A Three-Stage Solutionto Flexible Vocabulary Speech UnderstandingGrace Chung
For most conversational systems today, thegap in performance between sentences without-of-vocabulary words and in-vocabularysentences remains wide. It is important forsystems to detect the incidence of unknownwords and handle them intelligently. In theJUPITER weather domain, many user queriespertain to weather information for un-known cities, and currently the systemeither misunderstands the utterance orrejects it. We envision a future system thatcan inform the user whenever weather forthe city in question is unavailable, andadditionally incorporate this previouslyunseen city name into the lexicon. Thissystem would be able to detect out-of-vocabulary items, dynamically incorporatingthem during recognition time. In the past,we have proposed a two-stage architecturewhere a domain-independent first stage,utilizing sublexical models, is interfaced viaa phonetic network to a second-stagerecognizer that utilizes probabilistic contextfree grammars for both subword and higherlevel linguistic knowledge in an integratedsearch. Recently, we have developed a three-stage implementation that enables ourspeech understanding system to detectunknown words, hypothesize their phoneticand orthographic transcriptions, andpossibly incorporate them without addi-tional training.
The current architecture consists of thefollowing stages. The first stage utilizessublexical information derived from theANGIE framework. ANGIE, first introduced in[3], models sublexical phenomena via ahierachical structure which is trainable andprobabilistic. Our work focuses on novelways to incorporate low-level linguisticmodels, including those derived from ANGIE,efficiently in the first stage. The output
from the first stage is a phonetic lattice. Thisguides the second-stage search which yields aword graph, indicating the locations of anydetected unknown words. Finally, the thirdstage involves the application of a probabi-listic natural language model by using theTINA natural language system [2].
Our first stage is designed to be flexibleso that novel phonetic sequences associatedwith new words are supported by thelanguage models, while recognition accuracyon in-vocabulary data is maintained. This isaccomplished by maximizing linguisticconstraints that utilize only low-leveldomain-independent information. Ourmethods are facilitated by a system whichhas adopted finite-state transducers (FSTs)to represent its language models. Previouslyin [1], we developed a method for encapsu-lating the hierarchical models of ANGIE
within an FST. We have since introducedthe column-bigram method, which trans-lates more efficiently the context-freeformalism of ANGIE into the more tractableFST representation for integration with arecognizer. After training on in-vocabularydata, this FST is capable of accepting, withnon-zero probabilities, novel phoneticsequences pertaining to unknown words.While our previous representation simplymemorizes training data and their assignedANGIE probabilities, the column-bigram FSTgeneralizes across unseen data with similarsubstructures. Yet it remains a compactrepresentation of ANGIE’s rich hierarchicalspace.
A second feature is the ability toaugment the column-bigram FST withgrapheme information. We are motivated bythe desire to (1) derive letter spellingsdirectly during recognition upon encounter-ing an unknown word, and (2) utilize

53SPOKEN LANGUAGE SYSTEMS
grapheme information as an additionalsource of low-level constraint in the firststage. We have designed an ANGIE grammarthat simultaneously captures letter-to-soundinformation and phonological phenomenain the probability models. A set of hybrid“letter-phonemes” enriches the probabilityspace by encoding both spelling andphonemic information. These units weredesigned by augmenting the original set ofphonemes with carefully chosen characteris-tics such as spelling, pronunciation, syllable-position and stress, (e.g. ea_l+ is a stressedlong vowel with spelling “ea.”) In the JUPITER
domain, the new enhanced ANGIE grammarleads to perplexity reduction, an indicationof the tighter linguistic constraint it offers.This “letter-phoneme” grammar is subse-quently used in a column-bigram FST thatrepresents the corresponding ANGIE models.
The third feature of the first stage is theuse of an optimized lexical space that hasbeen automatically generated. This is drivenby the need for greater efficiency in stageone but at the same time using linguisticmodels that combine syllable n-gramknowledge and sublexical probabilitiestogether with spelling information. Oursolution is to derive a novel set of syllable-level units via an autmatic procedure whichaims to improve the probability likelihoodat every iteration. This procedure beginswith the column-bigram FST and iterativelybuilds novel syllable-sized units by concat-enating grapheme-based sequences. At eachiteration, lexical units are chosen to improveprobability modeling and reduce perplexity.Upon achieving convergence, a morecompact syllable lexicon is produced.
The phonetic lattice from the first stageconstrains a best-first search in the secondstage. This recognizer allows the incidence
of unknown words and employs ANGIE’sdynamic parse mechanism to guide pho-netic hypotheses. In the case where a novelphonetic sequence is proposed, and anANGIE parse has succeeded, the associatedprobability score is returned with an out-of-vocabulary flag. A hypothesized spelling mayalso be accessed from ANGIE.
In the third stage, TINA parses wordgraphs constructed during the second stage,which may possibly contain unknownwords. The highest scoring sentencehypothesis is selected according to TINA
models. This method also computes ameaning representation for further process-ing in the dialogue system.
This flexible vocabulary system has beenimplemented in the JUPITER weatherinformation domain and we conductedrecognition experiments on utterancescontaining unknown city names. On anindependent test set, we compare word(WER) and understanding (UER) error ratewith a baseline recognizer that does nothave the capability to handle unknownwords. We also experiment with a two-stagevariant that employs TINA integrated withANGIE in the second-stage search [1]. In bothcases, TINA has been trained such thatunknown words are permitted to occurexclusively when an unknown city categorycan be admitted in the grammar. Comparedwith the baseline, we achieve up to 29.3%reduction in WER (from 24.6% to 17.4%)and 67.5% reduction in UER (from 67.0%to 21.8%) in the three-stage system. Suchsignificant improvements are derived fromincreased in-vocabulary recognitionperformance combined with success indetecting unknown word occurrences. In aseparate pilot experiment, we extractspelling hypotheses directly from our ANGIE

54 SUMMARY OF RESEARCH - JULY 2000
models during recognition. For the subsetof utterances where an unknown city iscorrectly detected, we computed the letteraccuracy to be 42.2%. Thus, we demon-strate the possibility of instantaneouslyincorporating the unknown city.
References[1] G .Chung and S. Seneff, “Towards Multi-Domain
Speech Understanding Using a Two-StageRecognizer,” in Proc. Eurospeech ’99, pp. 2655—2658, Budapest, Hungary, September 1999.
[2] S. Seneff, “TINA: A Natural Language System forSpoken Language Applications,” in ComputationalLinguistics, 18(1):61—86, March 1992.
[3] S. Seneff, R. Lau, and H. Meng, “ANGIE: A NewFramework for Speech Analysis Based onMorpho-phonological Modelling,” in Proc. ICSLP’96, Vol. 1, pp. 110—113, Philadelphia, PA,October 1996.
A THREE-STAGE SOLUTION TO FLEXIBLE VOCABULARY SPEECH UNDERSTANDING

55SPOKEN LANGUAGE SYSTEMS
Lexical Modeling of Non-Native Speechfor Automatic Speech RecognitionKaren Livescu
Automatic speech recognizers have beenobserved to perform drastically worse onnon-native speakers than on native speakers.We have investigated the effect of non-native speech on several components of aspeech recognizer. Here we describe oneaspect of this work, namely a technique formodeling the ways in which non-nativespeakers pronounce words differently fromnative speakers [2, 3].
In order to better model non-nativepronunciation, or lexical, patterns, we haveexplored modifications to the lexicon toaccount for pronunciation variants thatnon-native speakers are likely to use. Ideally,we would like to collect entire wordpronunciations and train their probabilitiesfrom real non-native data. However, sincethere are not enough instances of each wordin the non-native training data available tous, we have instead chosen to derive simplerrules from the data, which we then apply tothe baseline lexicon. Specifically, we haveconstrained ourselves in this initial investi-gation to context-independent phoneticconfusion rules, i.e., substitutions, dele-tions, and insertions of phones irrespectiveof the neighboring phones. Althoughcontext-dependent rules would containmore information, the larger requirednumber of parameters would be difficult totrain from the limited amount of availabletraining data.
The speech recognizer for theseexperiments can be represented as acomposition of finite-state transducers(FSTs), each of which models one of thecomponents of the recognizer (acoustic-phonetic graph, lexicon, language model).In this framework, phonetic confusion rulescan be easily and naturally incorporatedinto the recognizer by adding a simple
transducer between the acoustic-phoneticand lexicon FSTs. Each of the confusions isassociated with a probability of thatconfusion occurring. This is equivalent toadding a large number of pronunciations tothe lexicon, corresponding to applying eachof the confusions to each of the baselinepronunciations, with two importantdistinctions: (1) we need not actually rebuildthe lexicon for each experiment, therebysaving the space that would be needed tostore all of the lexicons, and (2) we canperform the composition of the confusionFST with the lexicon during recognition,dynamically pruning out unlikely hypoth-eses and again reducing the space require-ments of the recognizer. Using this architec-ture, then, we can experiment with manydifferent versions of the confusion rulessimply by changing the correspondingtransducer.
In order to estimate the probabilities ofthe confusions, we need a phonetic tran-scription for each training utterance,aligned with the corresponding pronuncia-tion according to the baseline lexicon. Inour approach, these transcriptions aregenerated automatically (as described below)and aligned with the lexicon using anautomatic string alignment procedure. Oncethe alignments are obtained, we estimatethe probability of each phonetic confusionfrom its frequency in the alignments.
We have performed recognitionexperiments on utterances recorded fromusers of JUPITER [1], a conversational systemproviding weather information. For theinitial set of experiments, we obtained thephonetic transcription of each non-nativeutterance by recognizing it with a phoneticrecognizer. This produces an errorfultranscription, since it does not use any
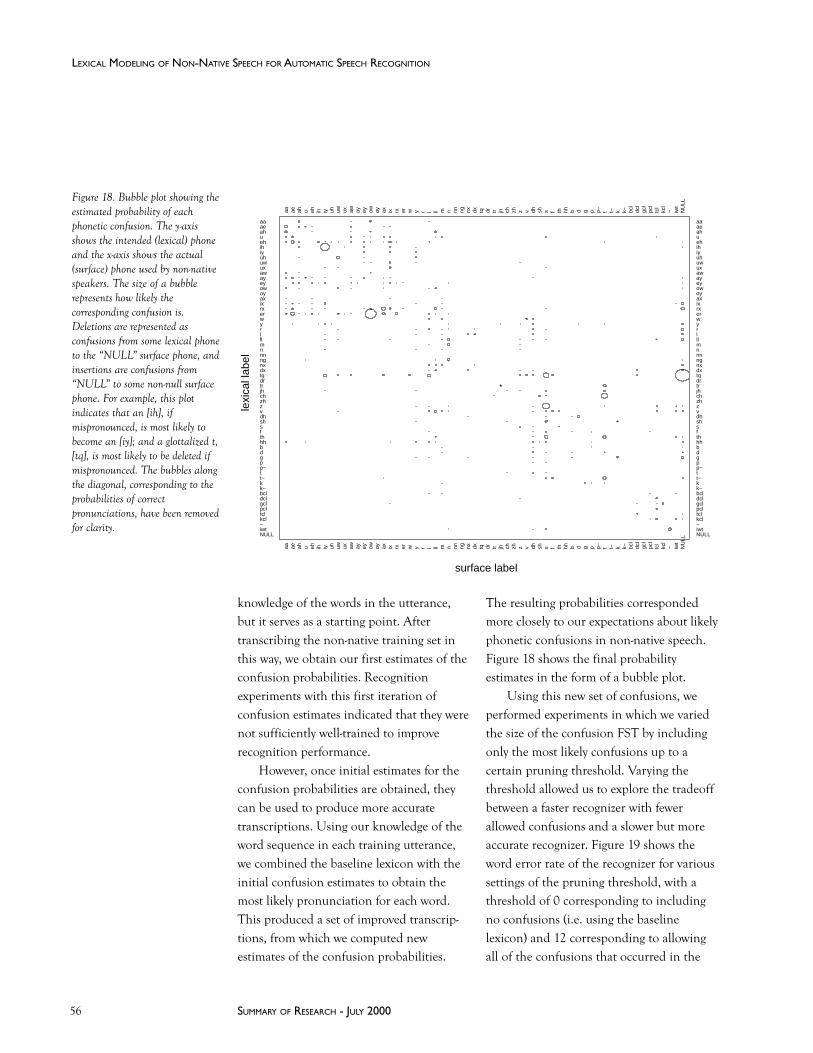
56 SUMMARY OF RESEARCH - JULY 2000
knowledge of the words in the utterance,but it serves as a starting point. Aftertranscribing the non-native training set inthis way, we obtain our first estimates of theconfusion probabilities. Recognitionexperiments with this first iteration ofconfusion estimates indicated that they werenot sufficiently well-trained to improverecognition performance.
However, once initial estimates for theconfusion probabilities are obtained, theycan be used to produce more accuratetranscriptions. Using our knowledge of theword sequence in each training utterance,we combined the baseline lexicon with theinitial confusion estimates to obtain themost likely pronunciation for each word.This produced a set of improved transcrip-tions, from which we computed newestimates of the confusion probabilities.
The resulting probabilities correspondedmore closely to our expectations about likelyphonetic confusions in non-native speech.Figure 18 shows the final probabilityestimates in the form of a bubble plot.
Using this new set of confusions, weperformed experiments in which we variedthe size of the confusion FST by includingonly the most likely confusions up to acertain pruning threshold. Varying thethreshold allowed us to explore the tradeoffbetween a faster recognizer with fewerallowed confusions and a slower but moreaccurate recognizer. Figure 19 shows theword error rate of the recognizer for varioussettings of the pruning threshold, with athreshold of 0 corresponding to includingno confusions (i.e. using the baselinelexicon) and 12 corresponding to allowingall of the confusions that occurred in the
Figure 18. Bubble plot showing theestimated probability of eachphonetic confusion. The y-axisshows the intended (lexical) phoneand the x-axis shows the actual(surface) phone used by non-nativespeakers. The size of a bubblerepresents how likely thecorresponding confusion is.Deletions are represented asconfusions from some lexical phoneto the “NULL” surface phone, andinsertions are confusions from“NULL” to some non-null surfacephone. For example, this plotindicates that an [ih], ifmispronounced, is most likely tobecome an [iy]; and a glottalized t,[tq], is most likely to be deleted ifmispronounced. The bubbles alongthe diagonal, corresponding to theprobabilities of correctpronunciations, have been removedfor clarity.
LEXICAL MODELING OF NON-NATIVE SPEECH FOR AUTOMATIC SPEECH RECOGNITION
aa ae ah u eh ih iy uh uw ux aw ay ey ow oy ax ix rx er w y r l ll m n nn ng nx dx tq dr tr jh ch zh z v dh sh s f th hh b d g p p− t t− k k− bcl dcl gcl pcl tcl kcl − iwt NULL
aa ae ah u eh ih iy uh uw ux aw ay ey ow oy ax ix rx er w y r l ll m n nn ng nx dx tq dr tr jh ch zh z v dh sh s f th hh b d g p p− t t− k k− bcl dcl gcl pcl tcl kcl − iwt NULL
aa
ae
ah
u
eh
ih
iy
uh
uw
ux
aw
ay
ey
ow
oy
ax
ix
rx
er
w
y
r
l
ll
m
n
nn
ng
nx
dx
tq
dr
tr
jh
ch
zh
z
v
dh
sh
s
f
th
hh
b
d
g
p
p−
t
t−
k
k−
bc
l
dcl
gc
l
pcl
tc
l
kcl
−
iwt
N
ULL
aa
ae
ah
u
eh
ih
iy
uh
uw
ux
aw
ay
ey
ow
oy
ax
ix
rx
er
w
y
r
l
ll
m
n
nn
ng
nx
dx
tq
dr
tr
jh
ch
zh
z
v
dh
sh
s
f
th
hh
b
d
g
p
p−
t
t−
k
k−
bc
l
dcl
gc
l
pcl
tc
l
kcl
−
iwt
N
ULL
lexi
cal l
abel
surface label

57SPOKEN LANGUAGE SYSTEMS
training set. The word error rate monotoni-cally decreases as we add more confusions.When all of the confusions are included,the error rate is reduced to 18.8%, a highlysignificant improvement from the baselineerror rate of 20.9%.
These results demonstrate that, if therecognizer knows that an input utterance isnon-native, then it can do significantlybetter by including simple context-indepen-dent phonetic confusion rules. These rulescan be automatically extracted from a non-native training set and easily incorporatedinto a finite-state transducer-based recogni-tion architecture. It is noteworthy that usingthe recognizer that achieved the bestperformance on non-native speakers did notdegrade the performance on native speakers(although it did increase the running time),which is an encouraging sign for futurework combining native and non-native
Figure 19. Word error rate on anon-native test set as a function ofpruning threshold on the confusionprobabilities, compared to abaseline recognizer with noconfusions. The threshold cprunecorresponds to a negative logprobability rather than aprobability; therefore, the higher thethreshold, the more confusions areallowed. The word error rate ishigher than baseline at the lowerpruning thresholds because ofmeasures that were taken to savecomputation time.
recognition. Other possibilities for futurework in this area include performingadditional iterations of confusion probabil-ity estimation, reducing the running timeand memory requirements of the modifiedrecognizer, and modeling context-dependentconfusions as more data become available.
References:[1] J. R. Glass and T. J. Hazen, “Telephone-based
Conversational Speech Recognition in the JUPITER
Domain,” in Proc. ICSLP ’98, Sydney, Australia,December 1998.
[2] K. Livescu, Analysis and Modeling of Non-NativeSpeech for Automatic Speech Recognition. S.M. thesis,MIT Department of Electrical Engineering andComputer Science, September 1999.
[3] K. Livescu and J. Glass, “Lexical Modeling ofNon-native Speech for Automatic SpeechRecognition,” in Proc. ICASSP 2000, Istanbul,Turkey, June 2000.
KAREN LIVESCU
0 2 4 6 8 10 1218.5
19
19.5
20
20.5
21
21.5
22
22.5
23
23.5
cprune
wor
d er
ror
rate
(%
)
CFSTbaseline

58 SUMMARY OF RESEARCH - JULY 2000
The Use of Dynamic Reliability Scoringin Speech RecognitionXiaolong Mou
Speech recognition is usually formulated asa problem of searching for the best string ofsymbols, subject to the constraints imposedby the acoustic and language models. Inimplementing such a formulation, systemstypically apply the constraints uniformlyacross the entire utterance. This does nottake into account the fact that some unitsalong the search path may be modeled andrecognized more reliably than others. Onepossible way to incorporate reliabilityinformation is through word- and utterance-level rejection [1]. However, this approachonly provides confidence information afterthe recognition is done. In contrast, weattempt to dynamically incorporate reliabil-ity information into the search phase inorder to help the recognizer find the correctpath.
In this work, we introduce the notion ofdynamic reliability scoring that adjusts thepartial path score while the recognizersearches through the composed lexical andacoustic-phonetic network. In our scheme,the recognizer evaluates the reliability ofchoosing a hypothesized arc to extend thecurrent path by adding a weighted phoneticreliability score to the current path score.The reliability score is obtained from areliability model that gives the likelihood ofextending the current path using onespecific arc as opposed to using its immedi-ate competing alternatives. The reliabilitymodels are trained from transcribed speechdata. First a forced alignment search isconducted to obtain the references tocorrect paths. Then, for each partial pathalong the forced path, the score of the arcthat extends the forced path, denoted s ,and the scores of the arcs that are not in theforced path, denoted , are collected.After that, Gaussian models for the correct
scoring (i.e., scores of arcs that are in theforced path), sM , and incorrect scoring (i.e.,scores of those not in the forced path), tM ,
are trained. Figure 20 shows typical trainedreliability models sM and tM for a given arcin the lexical network. The further apart thetwo models and the smaller their variancesare, the easier it would be to distinguish thecorrect arc from its immediate competingalternatives while searching.
After all the models are trained, we canobtain reliability measurement on the flywhile searching through the network. Thereliability measurement is essentially thelikelihood that a particular arc in thenetwork with score s is in the right pathwhile its immediate competitors withacoustic scores are not in the rightpath. It is given by the following formula(assuming the correct and competing pathsare independent):
)|,,()|()|(
)|,()|(
21
1
tnt
s
tns
MtttspMspMsp
MttpMsp
�
�
=
Because we try to use the reliabilityscore to help the recognizer choose ahypothesis arc from its immediate competing
arcs, )|,,( 21 tn Mtttsp � is a constant factor
here, and we can then just use the logdomain score ))|()|(log( ts MspMsp as the
reliability measurement, which saves a lot ofcomputation effort during the search.
The recognizer’s acoustic models andreliability models are trained and evaluatedin an English weather information domaincalled JUPITER and a development MandarinChinese weather information domain calledPANDA. For the JUPITER domain, the trainingset consists of 24,182 live utterancesrecorded over the phone and the test setconsists of 1,806 utterances randomly

59SPOKEN LANGUAGE SYSTEMS
selected from the data collection indepen-dent of the training set. Both di-phone andsegment models are used, and the reliabilitymodels are built on the normalized andcombined boundary and segment scores.For the PANDA domain, the training setconsists of 1,455 utterances and the test setconsists of 244 utterances. Only segmentmodels are used because of insufficienttraining data, and the reliability models arebuilt on the normalized segment scores.
We have incorporated the reliabilityscheme into the segment-based, SUMMIT [2]speech recognition system. On the JUPITER
test set of 1,806 utterances without out-of-vocabulary (OOV) words, we achieve 9.8%reduction in word error rate (WER) afterusing the reliability modeling schemedescribed above. On the PANDA test set of244 utterances without OOV words, weachieve 12.4% reduction in WER. Thisdemonstrates that reliability models can beused to address the fact that units along thesearch path are modeled and recognizedwith different reliability, and to help earlyrecovery of search errors.
Figure 20. The reliability models
sM (correct scoring) and tM(incorrect scoring) trained for anarc labeled [t] in the lexicalnetwork of the word “want”.
References[1] C. Pao, P. Schmid, and J. Glass, “Confidence
Scoring for Speech Understanding Systems,” inProc. ICSLP ‘98, Sydney, 1998.
[2] J. Glass, J. Chang, and M. McCandless, “AProbabilistic Framework for Feature-based SpeechRecognition,” in Proc. ICSLP ‘96, Philadelphia,1996.
15 10 5 0 5 100
0.05
0.1
0.15
0.2
0.25
0.3
0.35
prob
abili
ty d
ensi
ty
acoustic score
Ms
Mt

60 SUMMARY OF RESEARCH - JULY 2000
Subword-based Approachesfor Spoken Document RetrievalKenney Ng
This thesis explored approaches to theproblem of spoken document retrieval(SDR), which is the task of automaticallyindexing and then retrieving relevant itemsfrom a large collection of recorded speechmessages in response to a user specifiednatural language text query. We investigatedthe use of subword unit representations forSDR as an alternative to words generated byeither keyword spotting or continuousspeech recognition. Our investigation ismotivated by the observation that word-based retrieval approaches face the problemof either having to know the keywords tosearch for a priori, or requiring a very largerecognition vocabulary in order to cover thecontents of growing and diverse messagecollections. The use of subword units in therecognizer constrains the size of thevocabulary needed to cover the language;and the use of subword units as indexingterms allows for the detection of new user-specified query terms during retrieval. Fourresearch issues were addressed:
1) What are suitable subword units andhow well can they perform?
2) How can these units be reliablyextracted from the speech signal?
3) What is the behavior of the subwordunits when there are speech recogni-tion errors and how well do theyperform?
4) How can the indexing and retrievalmethods be modified to take intoaccount the fact that the speechrecognition output will be errorful?
In this thesis, we made the followingcontributions to research in the area ofspoken document retrieval:
- An empirical study of the ability ofdifferent subword units to performspoken document retrieval and theirbehavior in the presence of speechrecognition errors.
- The development of a number of robustindexing and retrieval methods that canimprove retrieval performance whenthere are speech recognition errors.
- The development of a novel spokendocument retrieval approach with atighter coupling between the recogni-tion and retrieval components thatresults in improved retrieval perfor-mance when there are speech recogni-tion errors.
- The development of a novel probabilis-tic information retrieval model thatachieves state-of-the-art performance onstandardized text retrieval tasks.
In the following sections, we give a briefsummary of the main chapters in the thesisand finally close by mentioning somepossible directions for future work.
Feasibility of SubwordUnits for InformationRetrievalWe first explored a range of subword unitsof varying complexity derived from error-free phonetic transcriptions and measuredtheir ability to effectively index and retrievespeech messages [5,6]. These experimentsprovide an upper bound on the perfor-mance of the different subword units sincethey assume that the underlying phoneticrecognition is error-free. In particular, weexamined overlapping, fixed-length phonesequences and broad phonetic classsequences, and non-overlapping, variable-length, phone sequences derived automati-

61SPOKEN LANGUAGE SYSTEMS
cally (multigrams) and by rule (syllables).We found that many different subwordunits are able to capture enough informa-tion to perform effective retrieval. We sawthat overlapping subword units performbetter than non-overlapping units. There isalso a tradeoff between the number ofphonetic class labels and the sequencelength required to achieve good perfor-mance. With the appropriate choice ofsubword units it is possible to achieveretrieval performance approaching that oftext-based word units if the underlyingphonetic units are recognized correctly.Although we were able to automaticallyderive a meaningful set of subword “stop”terms, experiments using the stop-list didnot result in significant improvements inretrieval performance.
Extracting Subword Unitsfrom Spoken DocumentsNext, we trained and tuned a phoneticrecognizer to operate on the radio broadcastnews domain and used it to process thespoken document collection to generatephonetic transcriptions [7]. We thenexplored a range of subword unit indexingterms of varying complexity derived fromthese errorful phonetic transcriptions andmeasured their ability to perform spokendocument retrieval. We found that in thepresence of phonetic recognition errors,retrieval performance degrades, as expected,compared to using error-free phonetictranscriptions or word-level text units:performance falls to 60% of the cleanreference performance. However, manysubword unit indexing terms still givereasonable performance even without theuse of any error compensation techniques.We also observed that there is a strong
correlation between recognition andretrieval performance: better phoneticrecognition performance leads to improvedretrieval performance. These experimentsestablish a lower bound on the retrievalperformance of the different subword unitssince no error compensation techniques areused. We know that there are speechrecognition errors, but we are not doinganything about them. Hopefully improvingthe performance of the recognizer anddeveloping robust indexing and retrievalmethods to deal with the recognition errorswill help improve retrieval performance.
Robust Indexing andRetrieval MethodsWe investigated a number of robustmethods in an effort to improve spokendocument retrieval performance when thereare speech recognition errors [2]. In thefirst approach, the original query is modi-fied to include near-miss terms that couldmatch erroneously recognized speech. Thesecond approach involves developing a newdocument-query retrieval measure usingapproximate term matching designed to beless sensitive to speech recognition errors.In the third method, the document isexpanded to include multiple recognitioncandidates to increase the chance ofcapturing the correct hypothesis. The fourthmethod modifies the original query usingautomatic relevance feedback to includenew terms as well as approximate matchterms. The last method involves combininginformation from multiple subword unitrepresentations. We studied the differentmethods individually and then explored theeffects of combining them. We found thatusing a new approximate match retrievalmetric, modifying the queries via automatic

62 SUMMARY OF RESEARCH - JULY 2000
relevance feedback, and expanding thedocuments with N-best recognition hypoth-eses improved performance; subword unitfusion, however, resulted in only marginalgains. Combining the approaches resultedin additive performance improvements.Using these robust methods improvedretrieval performance using subword unitsgenerated from errorful phonetic recogni-tion transcriptions by 23%.
Probabilistic InformationRetrieval ModelWe presented a novel probabilistic informa-tion retrieval model and demonstrated itscapability to achieve state-of-the-art perfor-mance on large standardized text collections[3]. The retrieval model scores documentsbased on the relative change in the docu-ment likelihoods, expressed as the ratio ofthe conditional probability of the documentgiven the query and the prior probability ofthe document before the query is specified.Statistical language modeling techniques areused to compute the document likelihoodsand the model parameters are estimatedautomatically and dynamically for eachquery to optimize well-specified maximumlikelihood objective functions. An auto-matic relevance feedback strategy that isspecific to the probabilistic model was alsodeveloped. The procedure automaticallycreates a new query (based on the originalquery and a set of top-ranked documentsfrom a preliminary retrieval pass) byselecting and weighting query terms so as tomaximize the likelihood ratio scores of theset of documents presumed to be relevant tothe query. To benchmark the performanceof the new retrieval model, we used thestandard ad hoc text retrieval tasks from theTREC-6 and TREC-7 text retrieval confer-
ences. Official evaluation results on the1999 TREC-8 ad hoc text retrieval task werealso reported [1]. Experimental resultsindicated that the model is able to achieveperformance that is competitive withcurrent state-of-the-art retrieval approaches.
Integrated Recognitionand RetrievalWe presented a novel approach to spokendocument retrieval where the speechrecognition and information retrievalcomponents are more tightly integrated.This was accomplished by developing newrecognizer and retrieval models where theinterface between the two components isbetter matched and the goals of the twocomponents are consistent with each otherand with the overall goal of the combinedsystem. We presented a new probabilisticretrieval model which makes direct use ofterm occurrence probabilities that can becomputed by the recognizer. We thendescribed several ways to compute thedesired term probabilities including usingthe top one recognition hypothesis, using N-best recognition hypotheses, expanding theterm set to include approximate matchterms, and modifying the speech recognizerto enable it to output the term occurrenceprobabilities directly. We evaluated theperformance of the integrated approach andfound that the probabilistic model performsslightly better than the baseline vector spaceretrieval model, and the addition ofautomatic relevance feedback resulted in asignificant performance improvement. Wethen measured the retrieval performance ofthe integrated approach as differentmethods for estimating the term occurrenceprobabilities are used. We found thatretrieval performance improves as more
SUBWORD-BASED APPROACHES FOR SPOKEN DOCUMENT RETRIEVAL

63SPOKEN LANGUAGE SYSTEMS
sophisticated estimates are used. The bestperformance was obtained using termoccurrence probabilities computed directlyfrom the speech recognizer. The integratedapproach improved retrieval performance byover 28% from the baseline. This iscompared to an improvement of 23% usingthe robust methods.
Future DirectionsThe experimental results presented in thisthesis demonstrate that subword-basedapproaches to spoken document retrievalare feasible and merit further research.There are a large number of areas forextension of this work. One area is toimprove the performance of the extractionof the subword units from the speech signal.For example, more training data can beused to improve model robustness and moredetailed and complex models can be used totry to capture more information from thespeech signal. Another approach would beto modify the speech recognizer to recognizethe subword units directly from the speech,rather than constructing them from aphonetic string. Another area of work is toimprove the probabilistic informationretrieval model. More sophisticated modelssuch as higher order statistical n-gramlanguage models and alternative probabilitysmoothing techniques should be explored.Another interesting and potentially profit-able area of research is on informationfusion methods for spoken documentretrieval [4]. We briefly looked at somesimple methods for combining multiplesubword unit representations. Although theperformance improvements we obtainedwere small, the method of informationcombination still holds promise. Finally,the approaches presented in the thesis
should be evaluated on larger sets of data.This includes both the spoken documentcollection and the training set for thespeech recognizer. More data will allow usto build more robust models and to furthertest the scalability and behavior of oursystems.
References[1] Harman, D. K. (Ed.) (1999). Eighth Text Retrieval
Conference (TREC-8), Gaithersburg, MD, USA.National Institute for Standards and Technology.
[2] Ng, K. (1998). “Towards Robust Methods forSpoken Document Retrieval.” In Proc. ICSLP ’98,Sydney, Australia.
[3] Ng, K. (1999). “A Maximum Likelihood RatioInformation Retrieval Model.” In Eighth TextRetrieval Conference (TREC-8),Gaithersburg, MD,USA.
[4] Ng, K. (2000). “Information Fusion for SpokenDocument Retrieval.” In Proc. ICASSP ‘00,Istanbul, Turkey.
[5] Ng, K. and V. Zue (1997). “An Investigation ofSubword Unit representations for SpokenDocument Retrieval.” In Proceedings of the 20thAnnual International ACM SIGIR Conference onResearch and Development in Information Retrieval,Posters: Abstracts, pp. 339.
[6] Ng, K. and V. Zue (1997). “Subword UnitRepresentations for Spoken Document Retrieval.”In Proc. Eurospeech ’97, Rhodes, Greece, pp. 1607-1610.
[7] Ng, K. and V. Zue (1998). “Phonetic Recognitionfor Spoken Document Retrieval.” In Proc. ICASSP’98, Seattle, WA, USA, pp. 325-328.
KENNEY NG

64 SUMMARY OF RESEARCH - JULY 2000
Enabling Spoken Language Systems Designfor Non-ExpertsJef Pearlman
For my thesis research I designed andimplemented a utility for allowing non-experts to build and run spoken languagesystems. This involved the creation of botha web interface for the developer and a setof programs to support the constructionand execution of the required internalsystems. As shown in Figure 21, the utilitymade use of the underlying GALAXY
Communicator architecture. The architec-ture was augmented by a server whichallowed developers to communicate withtheir CGI-based application remotely overthe web.
For this research, we concentrated onconfiguring the language understandingcomponents of a spoken language system.By learning the required grammar from aset of simple concepts and sentenceexamples provided by the developer, we
were able to build a system where non-experts could build grammars and speechsystems. Developers could also easily specifyhierarchy in domains where a more complexgrammar was appropriate.
We demonstrated the utility, originallyknown as SLS-Lite, now calledSPEECHBUILDER, by building several proto-type domains ourselves, and allowing othersto build their own. These includeddomains for controlling the appliances in ahouse, querying a directory of people in theMIT Laboratory for Computer Science,manipulating fictional objects, and askingquestions about music.
Reference[1] J. Pearlman. SLS-Lite: Enabling Spoken Language
Systems Design for Non-Experts. MIT Department ofElectrical Engineering and Computer Science,M.Eng. thesis, expected August 2000.
DialogueManagement
DialogueManagement
DatabaseDatabase
ContextTrackingContextTracking
Hub Developer’sCGI Back-endDeveloper’s
CGI Back-end
TurnManagement
TurnManagement
SLS LiteBack-end
Server
SLS LiteBack-end
Server
GENESISGENESIS
SUMMITSUMMIT
DECtalkDECtalk
TINATINA
DialogicDialogichttp
Figure 21. GALAXY architectureused by SPEECHBUILDER utility.

65SPOKEN LANGUAGE SYSTEMS
Discriminative Training of Acoustic Modelsin a Segment-Based Speech RecognizerEric Sandness
In this thesis work we investigated discrimi-native training of acoustic models withinthe SUMMIT system [1,2]. In particular, wedeveloped a new technique we calledkeyword-based discriminative training whichfocuses on optimizing a keyword error rate,rather than the error rate on all words. Wehypothesize that improvements in keyworderror rate correlate with improvements inunderstanding error rates. Keyword-baseddiscriminative training is accomplished bymodifying a standard minimum classifica-tion error (MCE) training algorithm so thatonly segments of speech relevant to keyworderrors are used in the acoustic modeldiscriminative training. When both thestandard and keyword-based techniques areused to adjust Gaussian mixture weights, wefind that keyword error rate reductioncompared to baseline maximum likelihood(ML) trained models isnearly twice as largefor the keyword-based approach. The overallword accuracy is also found to be improvedfor keyword-based training, and we ranexperiments to investigate this phenom-enon.
In this work we used an utterance-levelMCE criterion [3,4] to train the Gaussianmixture weights. We also attempted to trainthe mixture means and variances, buttraining convergence was unreliable andconsiderably slower. All experiments werecarried out in the JUPITER weather informa-tion domain, with boundary diphoneacoustic models with up to 50 mixtures permodel, and a bigram word-class languagemodel.
For each training utterance, completerecognizer scores are computed for thecorrect word sequence and an N-best list ofcompeting hypotheses. These scores are asum of acoustic and non-acoustic (i.e.,
lexical and language model) scores. Theacoustic scores are updated at each iterationwhile the non-acoustic scores remainconstant.
We make use of what we call “hotboundaries” to perform keyword-baseddiscriminative training. A hot boundary is aboundary (potential phone boundary)where the correct word sequence andcompeting N-best hypotheses contain amismatched keyword. (See [1,2] for details.)In regions of the utterance where there areno keywords (correct or hypothesized) orthere are no keyword mismatches, there willbe no hot boundaries. In this way, hotboundaries represent the regions of theutterance relevant to optimizing thekeyword error rate.
The keywords we used were selected byhand. Of JUPITER’s nearly 2,000-wordvocabulary, we identified 1,066 keywords,primarily consisting of place names (e.g.,Boston, Europe, India), weather terms (e.g.,snow, humidity, weather, advisories), anddates/times (e.g., tomorrow, tonight,Thursday, weekend).
On a test set of 500 in-vocabularyutterances, the baseline ML-trained systemachieved a keyword error rate of 6.0%. Thebaseline MCE-trained improved to 5.7%.The keyword-based MCE-trained systemachieved more than twice the improvementat 5.2%.
Evaluating the overall word-error ratesyielded surprising results. The baseline MLword error rate was 10.4%, and the baselineMCE improved to 9.7%. Surprisingly, thekeyword-based MCE-trained system im-proved even more to 9.3%.
We did not expect the keyword-trainedsystem to do as well over all words, andperformed some follow up experiments to

66 SUMMARY OF RESEARCH - JULY 2000
deduce the reason. We hypothesized thatmany of the non-keywords (e.g., functionwords) are poorly articulated and thus maycontribute to inferior acoustic models. Inone experiment, we set the keywords to beall words except for 148 manually chosenfunction words. Training with this set ofkeywords produced an overall word errorrate of 9.4%, very similar to the 9.3% weachieved with the manually selectedkeywords.
Other work in this thesis included theimplementation of Gaussian selection [5,6].The goal of Gaussian selection is to speedup computation of Gaussian mixturemodels by preselecting a reduced subset ofmixtures to evaluate for each region of thefeature space. We used binary vectorquantization with 512 code words to dividethe feature space. For each code word,mixtures whose mean is within a distancethreshold of the code word mean are noted,with at least one mixture for each modelassociated with each code word. At runtime, a feature vector is rapidly quantizedand the relevant mixture componentslooked up and evaluated. Overall, the use ofGaussian selection speeds up SUMMIT in theJUPITER domain by a factor of 1.8 with thepruning thresholds used.
References[1] E. D. Sandness, Discriminative Training of Acoustic
Models in a Segment-Based Speech Recognizer, M.Eng.thesis, Dept. of Electrical Engineering andComputer Science, Massachusetts Institute ofTechnology, May 2000.
[2] E. D. Sandness and I. L. Hetherington, “Keyword-Based Discriminative Training of AcousticModels,” to appear in Proc. ICSLP ‘00, Beijing,vol. 3, pp. 135-138, October 2000.
[3] W. Chou, B.-H. Juang, and C.-H. Lee, “SegmentalGPD Training of HMM based SpeechRecognizer,” in Proc. ICASSP ‘92, San Francisco,pp. 473-476, March 1992.
[4] F. Beaufays, M. Weintraub, and Y. Konig,“Discriminative Mixture Weight Estimation forLarge Gaussian Mixture Models,” in Proc. ICASSP‘99 Phoenix, pp. 337-340, March 1999.
[5] E. Bocchieri, “Vector Quantization for theEfficient Computation of Continuous DensityLikelihoods,” in Proc. ICASSP ‘93, Minneapolis,pp. 692-695, April 1993.
[6] K. Knill, M. Gales, and S. Young, “Use ofGaussian Selection in Large VocabularyContinuous Speech Recognition Using HMMs,”in Proc. ICSLP ‘96, Philadelphia, pp. 470-473,October 1996.
DISCRIMINATIVE TRAINING OF ACOUSTIC MODELS IN A SEGMENT-BASED SPEECH RECOGNIZER

67SPOKEN LANGUAGE SYSTEMS
Analysis and Transcription of General Audio DataMichelle S. Spina
In addition to the vast amount of text-basedinformation available on the World WideWeb, an increasing amount of video andaudio based information is becomingavailable to users as a result of emergingmultimedia computing technologies. Theaddition of these multimedia sources ofinformation have presented us with newresearch challenges. Mature informationretrieval (IR) methods have been developedfor the problem of finding relevant itemsfrom a large collection of text-basedmaterials given a query from a user. Onlyrecently has there been any work onsimilarly indexing the content of multime-dia sources of information.
In this work, we focus on general audiodata (GAD) as a new source of data forinformation retrieval systems. The maingoal of this research is to understand theissues posed in describing the content ofGAD. We are interested in understandingthe general nature of GAD, both lexicallyand acoustically, and in discovering how ourfindings may impact an automatic indexingsystem. Specifically, three research issues areaddressed. First, what are the lexicalcharacteristics of GAD, and how do theyimpact an automatic recognition system?Second, what general sound classes exist inGAD, and how well can they be distin-guished automatically? And third, how canwe best utilize the training data to develop aGAD transcription system?
In our attempt to answer these ques-tions, we first developed an extensive GADcorpus for study in this work. We chose tofocus on the National Public Radio (NPR)broadcast of the Morning Edition (ME)news program. NPR-ME is broadcast onweekdays from 6 to 9 a.m. in the US, and itconsists of news reports from national and
local studio anchors as well as reportersfrom the field, special interest editorials andmusical segments. We chose NPR-ME afterlistening to a selection of radio shows,noting that NPR-ME had the most diversecollection of speakers and acoustic condi-tions and would therefore be the mostinteresting for study. We collected andorthographically transcribed 102 hours ofdata for lexical analysis. Ten hours werefurther processed for acoustic analysis andrecognition experiments.
Next, we studied the lexical propertiesof GAD to gain a better understanding ofthe data, and to see how these data comparewith those typically used in the ASRcommunity. We then studied the propertiesof the GAD vocabulary [1]. We are inter-ested in determining the size of the NPR-ME vocabulary and in observing how thevocabulary grows with time. This analysisdiscovered some potential problems for ageneral large vocabulary continuous speechrecognition approach to the transcription ofGAD. Figure 22 plots the relationshipbetween the number of distinct wordsencountered (i.e., the recognizer’s vocabu-lary) and the size of the training set as thetraining set size is increased. The uppercurve of Figure 22 shows the cumulativesum of all the distinct words, and thereforerepresents the potential vocabulary of therecognizer. While the size of the vocabularyafter 102 shows (over 30,000 words) iswithin the capabilities of current-day ASRsystems, it is quite alarming that the growthof the vocabulary shows no sign of abating.Next, we found that even for large trainingset sizes and vocabularies, new words werestill regularly encountered. With a trainingset of nearly one million words (resulting inover 30,000 unique vocabulary words), the
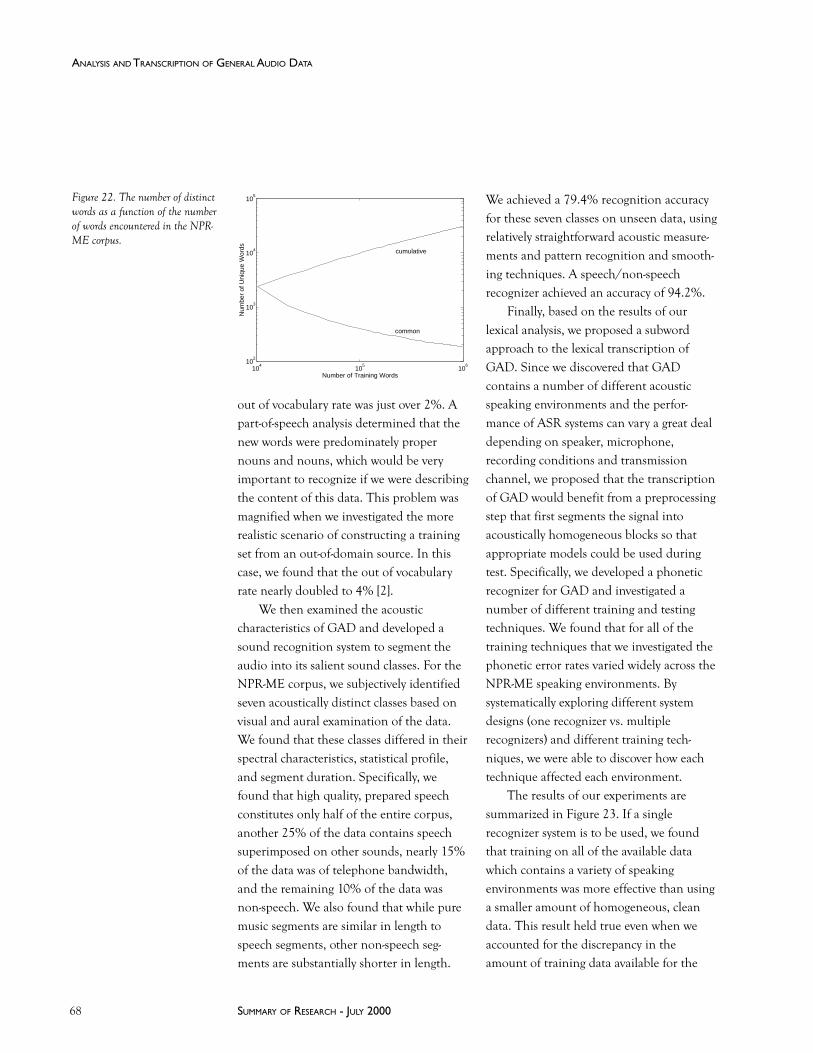
68 SUMMARY OF RESEARCH - JULY 2000
ANALYSIS AND TRANSCRIPTION OF GENERAL AUDIO DATA
out of vocabulary rate was just over 2%. Apart-of-speech analysis determined that thenew words were predominately propernouns and nouns, which would be veryimportant to recognize if we were describingthe content of this data. This problem wasmagnified when we investigated the morerealistic scenario of constructing a trainingset from an out-of-domain source. In thiscase, we found that the out of vocabularyrate nearly doubled to 4% [2].
We then examined the acousticcharacteristics of GAD and developed asound recognition system to segment theaudio into its salient sound classes. For theNPR-ME corpus, we subjectively identifiedseven acoustically distinct classes based onvisual and aural examination of the data.We found that these classes differed in theirspectral characteristics, statistical profile,and segment duration. Specifically, wefound that high quality, prepared speechconstitutes only half of the entire corpus,another 25% of the data contains speechsuperimposed on other sounds, nearly 15%of the data was of telephone bandwidth,and the remaining 10% of the data wasnon-speech. We also found that while puremusic segments are similar in length tospeech segments, other non-speech seg-ments are substantially shorter in length.
We achieved a 79.4% recognition accuracyfor these seven classes on unseen data, usingrelatively straightforward acoustic measure-ments and pattern recognition and smooth-ing techniques. A speech/non-speechrecognizer achieved an accuracy of 94.2%.
Finally, based on the results of ourlexical analysis, we proposed a subwordapproach to the lexical transcription ofGAD. Since we discovered that GADcontains a number of different acousticspeaking environments and the perfor-mance of ASR systems can vary a great dealdepending on speaker, microphone,recording conditions and transmissionchannel, we proposed that the transcriptionof GAD would benefit from a preprocessingstep that first segments the signal intoacoustically homogeneous blocks so thatappropriate models could be used duringtest. Specifically, we developed a phoneticrecognizer for GAD and investigated anumber of different training and testingtechniques. We found that for all of thetraining techniques that we investigated thephonetic error rates varied widely across theNPR-ME speaking environments. Bysystematically exploring different systemdesigns (one recognizer vs. multiplerecognizers) and different training tech-niques, we were able to discover how eachtechnique affected each environment.
The results of our experiments aresummarized in Figure 23. If a singlerecognizer system is to be used, we foundthat training on all of the available datawhich contains a variety of speakingenvironments was more effective than usinga smaller amount of homogeneous, cleandata. This result held true even when weaccounted for the discrepancy in theamount of training data available for the
104
105
106
102
103
104
105
Number of Training Words
Num
ber
of U
niqu
e W
ords cumulative
common
Figure 22. The number of distinctwords as a function of the numberof words encountered in the NPR-ME corpus.

69SPOKEN LANGUAGE SYSTEMS
two approaches. While we originally feltthat the transcription of GAD wouldbenefit from a preprocessing step that firstsegments the data into acoustically homoge-neous blocks so that appropriate modelscould be used during test, overall, we foundthat such a multiple recognizer systemachieved performance similar to a singlemulti-style recognizer. However, upon closerinspection of the results we found that themulti-style system primarily benefitted fromthe increased amount of data available fortraining. We may be able to utilize thestrengths of both the multi-style andenvironment-specific approaches bydeveloping interpolated models. By interpo-lating between the well-trained multi-stylemodels and the more detailed environment-specific models, we may be able to improveour phonetic recognition results.
Figure 23. Summary of phoneticerror rate results for differenttraining methods. The multi-style1system uses all of the availabletraining data, the clean speechsystem uses only studio quality,wideband training data, the multi-style2 system uses an amount oftraining data comparable to theclean speech system and the multi-style3 uses an amount of trainingdata comparable to each of the testspeaking environment systems.Each of the environment-specificsystems used the sound recognitionsystem as a preprocessor to selectthe appropriate models for testing.The env-specific1 system uses thefour original speaking classes, theenv-specific2 system collapses musicand noisy speech into a single class,and the env-specific3 system addsbandlimited models for the fieldspeech data.
30
31
32
33
34
35
36
37
38
39
40
41
Training Data
Ove
rall
Pho
netic
Err
or R
ate
(%)
mult
istyle
3
clean
spee
ch
mult
istyle
2
envs
pecif
ic1
envs
pecif
ic2
envs
pecif
ic3
mult
istyle
1
References:[1] M.S. Spina and V.W. Zue, “Automatic
Transcription of General Audio Data: PreliminaryAnalysis,” Proc. ICSLP ‘96, Philadelphia, PA,October 1996.
[2] M.S. Spina. Analysis and Transcription of GeneralAudio Data. Ph.D. thesis, MIT Department ofElectrical Engineering and Computer Science,May 2000.
[3] M.S. Spina and V.W. Zue, “AutomaticTranscription of General Audio Data: Effect ofEnvironment Segmentation on PhoneticRecognition,” Proc. Eurospeech ‘97, Rhodes,Greece, September 1997.
MICHELLE SPINA

70 SUMMARY OF RESEARCH - JULY 2000
Framework for Joint Recognitionof Pronounced and Spelled Proper NamesAtiwong Suchato
The goal of this thesis was to demonstratethat a spoken name along with a spokenversion of the spelling of the name could becombined to produce a proposed pronun-ciation and spelling to augment thevocabulary of an existing recognizer.
The system involves two recognizers,both implemented within the SUMMIT
framework. The first one is based on avocabulary consisting of a set of “morph”units that cover the majority of the syllablesappearing in peoples’ names. The otherrecognizer has the 26 letters of the Englishalphabet as its vocabulary, and is used torecognize spoken spellings of the words.
The procedure is to first recognize theletters, supported by a letter trigramlanguage model, into a set of candidate N-best spellings. The TINA system is used toparse the letter hypotheses into a set ofcandidate morph sequences, with associatedprobabilities, that are then written out as afinite state transducer, to serve as a support-ing language model for the pronunciationrecognition task.
Subsequently, the pronunciation of thepaired hypothesis is processed through themorph recognizer, constrained by themorph graph obtained from the letterrecognition task. The best scoring hypoth-esis is then consistent with both the spellingand the pronunciation, and its quality isthen conditioned on the joint performanceof the two recognizers.
We experimented with two versions ofthe morph lexicon, one of which (type-i)attempted to distinguish homomorphs(same spelling, different pronunciation) asdistinct vocabulary entries, whereas theother one (type-ii) simply allowed multiple
pronunciations for the homomorphs,represented as a shared lexical unit. Thelatter made it much easier to create alexicon of names decomposed into morphs,because the distinct homomorphs did nothave to be specified lexically. We found thatthe collapsed homomorphs were in generalbetter behaved, both in terms of overallrecognition accuracy and in terms of theability of the spellings to provide support tothe pronunciation recognition task.
Our speech corpus consisted of materialobtained from the Oregon GraduateInstitute through the Linguistic DataConsortium, augmented with data obtainedby asking users of the Jupiter weatherdomain to speak a name when they are firstgreeted. We separated the corpus into atraining and a test set, and evaluated thesystem on both sets in order to assess thedegree of generality of the learned statistics.
For language modelling, we obtained atext corpus of over 100,000 names, whichwere converted into morph sequencesthrough a semi-automatic procedure. Thiscorpus was used to train both the lettertrigram for the letter recognizer and therecursive grammar that converts letters tomorphs.
We performed a number of experi-ments, varying the conditions of the n-gramtraining and testing corpus and the size ofthe morph lexicon. We also tested the idealcondition where the letter recognition was“perfect,” which of course resulted in a hugegain in accuracy of the pronunciation task.In all cases, we measured phone recogition,letter recognition, and morph recognitionaccuracies. Details of the results can befound in the thesis, which showed that

71SPOKEN LANGUAGE SYSTEMS
slight gains were obtained in phoneaccuracy with the support of the errorfulletter sequences from the letter-recognitiontask, and, likewise, the phone informationled to slight gains in the letter-recognitiontask, but only for the type-ii morph lexicon,as discussed above.
Reference[1] A. Suchato. Framework for Joint Recognition of
Pronounced and Spelled Proper Names. MITDepartment of Electrical Engineering andComputer Science, S.M thesis expectedSeptember 2000.

72 SUMMARY OF RESEARCH - JULY 2000
Robust Pitch Tracking for Prosodic Modeling inTelephone SpeechChao Wang
Reliable pitch detection is very crucial to theanalysis and modeling of speech prosody.The fundamental frequency (F0) is found tobe highly correlated with prosodic featuressuch as lexical stress and tone, whichprovide important perceptual cues tohuman speech communication. However,most current automatic speech recognitionand understanding (ASRU) systems under-utilize prosodic features, especially thoserelated to F0. This is partially due to thelack of a robust parameter space forstatistical modeling. More specifically, errorsin F0 contours, both in terms of pitchaccuracy and voicing decision, can affectfeature measurements dramatically.
Various pitch detection algorithms(PDAs) have been developed in the past [1].While some have very high accuracy forvoiced pitch hypotheses, the error rateconsidering voicing decision is still quitehigh; and the performance degradessignificantly as the signal condition deterio-rates. We are interested in developing aPDA that is particularly robust for tele-phone quality speech and prosodic model-ing applications. In particular, we addresstwo problems: 1) missing fundamental andhigh noise level in telephone speech, and 2)discontinuity in the F0 contour due to thevoiced/unvoiced dichotomy. To address thefirst problem, we adopt a frequency-domainsignal representation and rely on the overallharmonic structure to estimate F0. To dealwith discontinuity of the F0 space forprosodic modeling, we believe that it ismore advantageous to emit an F0 value foreach frame, even in unvoiced regions, andto provide separately a parameter to reflectprobability of voicing. This is based on theconsiderations that, first, voicing decisionerrors will not be manifested as absent pitch
values; second, features such as thosedescribing the shape of the pitch contourare more robust to segmental mis-align-ments; and third, a voicing probability ismore appropriate than a “hard” decision of0 and 1, when used in statistical models.
On a logarithmic frequency scale,harmonic peaks appear at log F0, log F0 +log 2, log F0 + log 3, ..., etc. To find the F0value, one can sum the spectral energyspaced by log 2, log 3, ..., etc., from thepitch candidate and choose the maximum[2]. This is equivalent to correlating thespectrum with an n-pulse template, where nis the number of included harmonics. Weadopt a similar method to find log F0 foreach frame, using a carefully constructedtemplate in place of the pulse sequence.More importantly, we also obtain a reliableestimate of delta log F0 across two adjacentvoiced frames of the speech by simplecorrelation. These two constraints arecombined in a Dynamic Programming (DP)search to find an overall optimum solution.In the following, we introduce each modulein more detail.
The logarithmically spaced spectrumwas obtained by sampling a narrow bandspectrum in the low-frequency region atlinear intervals in the logarithmic frequencydimension. We define this representation asa discrete logarithmic Fourier transform (DLFT).Figure 24 shows the waveform, Fouriertransform and DLFT for a 200 Hz pulsetrain and a voiced speech signal. The DLFTof the speech signal, sampled between 150and 1500 Hz, has been normalized by mu-law conversion to flatten out the formantpeaks. The weighted DLFT of the pulsetrain will be used as a template for F0estimation.

73SPOKEN LANGUAGE SYSTEMS
The constraints for log F0 and delta logF0 estimations are captured by two correla-tion functions. The “template-frame”correlation provides log F0 estimation byaligning the speech DLFT with the tem-plate. The position of the correlationmaximum should correspond to thedifference of log F0 between the voicedsignal and the impulse train. The “cross-frame” correlation provides delta log F0constraints by aligning two adjacent framesof the signal DLFT spectra. The maximumof the correlation gives a robust estimationof the log F0 difference across two voicedframes. For unvoiced regions, it is observedthat the “template-frame” correlation ismore or less random, and the “cross-frame”correlation stays fairly flat both within anunvoiced region and upon transition ofvoicing status. This has important implica-tions for our DP based continuous pitchtracking as described next.
We can easily formulate the problem ofpitch tracking as a DP search given the twocorrelation constraints. We define the scorefunction as the sum of the best past score asweighted by the cross-frame correlation andthe template-frame correlation. The searchis forced to find a pitch value for everyframe, even in unvoiced regions. This isfeasible because the cross-frame correlationstays relatively flat when at least one frameis unvoiced. Thus, upon transition intounvoiced regions, the best past score will beinherited by all candidate nodes; and thescores become somewhat random. However,once in voiced regions, the sequence ofnodes corresponding to the true pitchvalues will emerge because of high internalscores enhanced by high cross-framecorrelation coefficients.
We evaluated our PDA for both voicedpitch accuracy and tone classificationaccuracy, and compared the performanceswith those of an optimized PDA providedby Xwaves [3].
The Keele pitch extraction referencedatabase [4] was used for voiced pitchaccuracy evaluation, because it providesreference pitch as “ground truth.” WhileXwaves performs well on studio speech, theperformance degraded severely for tele-phone speech, particularly with regard tovoicing decisions. Our PDA performssubstantially better than Xwaves fortelephone speech, and the overall grosserror rate for studio and telephone condi-tions is nearly the same (4.25% vs. 4.34%).
We compared the tone classificationperformance using F0 contours derived byour system and Xwaves on a telephone-quality, Mandarin digit corpus [5]. Wefound that the classification error rate usingour system was much lower than that using
Figure 24. Windowed waveform,FT, and adjusted DLFT (refer tothe text for details) for a pulsetrain and a speech signal.
0 50 100 150 200 2500
0.2
0.4
0.6
0.8
1Waveform of Pulse Train
Time Index
Am
plitu
de
0 50 100 150 200 250−1000
−500
0
500
1000Waveform of Speech Signal
Time Index
Am
plitu
de
200 400 600 800 10000
0.5
1
1.5
2
2.5
3
3.5
4FT of Pulse Train
Frequency (Hz)
Mag
nitu
de o
f FT
500 1000 15000
50
100
150
200FT of Speech Signal
Frequency (Hz)
Mag
nitu
de o
f FT
0 100 200 300 400 5000
0.5
1
1.5
2
2.5
3
3.5
4Weighted DLFT of Pulse Train
Logrithmic Frequency Index
Mag
nitu
de o
f DLF
T
0 100 200 300 400 5000
50
100
150
200Ulawed DLFT of Speech Signal
Logrithmic Frequency Index
Mag
nitu
de o
f DLF
T

74 SUMMARY OF RESEARCH - JULY 2000
Xwaves (19.2% vs. 25.4%); and the inclu-sion of an average voicing probabilityfeature reduced error further down to18.2% for our system. We tried twoapproaches to deal with the unvoiced frameswhen using Xwaves: 1) interpolate F0 fromthe surrounding voiced frames, and 2) biasthe V/UV decision threshold to greatlyfavor “voiced”, followed by interpolation.However, neither method was particularlysuccessful.
References[1] W. Hess, Pitch Determination of Speech Signals.
Springer-Verlag, 1983.
[2] D. Hermes, “Measurement of Pitch bySubharmonic Summation,” in JASA, vol. 83, no.1, pp. 257-273, 1988.
[3] D. Talkin, “A Robust Algorithm for PitchTracking (RAPT),” in Speech Coding and Synthesis(Elsevier, ed.), pp. 495-518, 1995.
[4] F. Plante, G. Meyer, and W. Ainsworth, “A PitchExtration Reference Database,” in Proc. Eurospeech‘95, pp. 837-840, Madrid, Spain, 1995.
[5] C. Wang and S. Seneff, “A Study of Tones andTempo in Continuous Mandarin Digit Stringsand Their Application in Telephone QualitySpeech Recognition,” in Proc. ICSLP ‘98, pp. 635-638, Sydney, Australia, 1998.
ROBUST PITCH TRACKING FOR PROSODIC MODELING IN TELEPHONE SPEECH

75SPOKEN LANGUAGE SYSTEMS
Methods and Toolsfor Speech Synthesizer Design and DeploymentJon Yi
In the recent year, we have re-engineeredour concatenative speech synthesis tools inan effort to make them easier to use. Weadopted finite-state methods to conciselycapture principles of concatenative speechsynthesis laid out in earlier works [1,2]. As aresult we now have a set of tools to rapidlydesign concatenative speech synthesizers forconstrained understanding domains. Thedeployment is made possible by a suite ofnetworked servers operating within theGALAXY Communicator framework. Speechsynthesizers which convert meaningrepresentations to speech waveforms havebeen prototyped for the MERCURY, JUPITER
and MUXING domains.Because many aspects of automatic
speech recognition can be modelled byfinite-state automata (e.g., dictionary lookupand pronunciation variation), finite-statemethods which seek to unify representationhave recently gained popularity within thespeech community. More specifically,weighted finite-state transducers (FST),which map an input regular language to anoutput regular language, have become theabstraction of choice. This transformationof input symbols to output symbols can beprioritized by weights. Once the algebraicalgorithms have been implemented tomanipulate and optimize transducers, theresearcher is free to focus on the actualgraphical structure of the transducers.
Lexical access in automatic speechrecognition and unit selection in automaticspeech synthesis ultimately make use of asearch algorithm to seek the least-cost paththrough a search space. Just as researchers inour group (and elsewhere) have convertedthe speech recognition framework to makeuse of FSTs, we sought to do the same forspeech synthesis, the inverse problem.
While pronunciation generation andvariation components could be re-used fromrecognition, it was imperative to design atransducer structure that maps phoneticsymbols to waveform segments. Thisstructure, which is the key contribution ofour recent work [3], participates in a Viterbi-style dynamic programming search duringthe final stage of unit selection.
In corpus-based concatenative speechsynthesis approaches one finds the classicaltrade-off between knowledge and data.While synthesis constraints govern whichunits and where to concatenate, a corpusmust provide enough examples of units inall potential contexts. Our new tools allowthe complementary components to beseparately refined. A language expert cancraft the language-dependent synthesisconstraints independently of the domain,whereas a domain expert can design andacquire a synthesis corpus according to thedistributional properties of in-domainresponses. As delineated in a companionresearch summary piece, a flexible FSTarchitecture was designed to encapsulateboth the synthesis constraints and corpus ina scalable fashion.
In concatenative speech synthesis thereare essentially two tasks: unit selection andwaveform generation. In our implementa-tion, unit selection is achieved through FSTmethods as described above. Currently,waveform generation simply consists ofsample re-sequencing. The actual deploy-ment of our FST-based speech synthesisframework is facilitated through twoCommunicator-compliant components. Afat server performs unit selection andtransmits the lightweight search result to athin client which performs waveformgeneration using locally stored audio

76 SUMMARY OF RESEARCH - JULY 2000
waveforms. By moving waveform splicingcloser to the end user, such a frameworkcould be deployed in low-bandwidthenvironments (i.e., not sufficient for real-time audio transmission), where a mono-lithic approach might fail.
In summary, the concatenative speechsynthesis system, ENVOICE, has undergone anextensive rewrite that should make for easieruse and quicker development cycles.Knowledge and data are coupled in a finite-state transducer structure used for corpus-based unit selection. Finally, complementarysearch and waveform components work intandem to produce interactive responses inspoken dialogue systems.
References[1] Jon R. W. Yi, Natural-Sounding Speech Synthesis
Using Variable-Length Units, M.Eng. thesis, MITDepartment of Electrical Engineering andComputer Science, May 1998.
[2] Jon R. W. Yi and James R. Glass. Natural-Sounding Speech Synthesis Using Variable-Length Units. In Proc. ICSLP ‘98, Sydney,Australia, December 1998.
[3] Jon R. W. Yi, James R. Glass, and I. LeeHetherington. A Flexible, Scalable Finite-StateTransducer Architecture for Corpus-BasedConcatenative Speech Synthesis. To appear Proc.ICSLP ‘00, Beijing, China, October 2000.
METHODS AND TOOLS FOR SPEECH SYNTHESIZER DESIGN AND DEPLOYMENT

77SPOKEN LANGUAGE SYSTEMS
T H E S E SPUBLICATIONS
PRESENTATIONS
S E M I N A R S

78 SUMMARY OF RESEARCH - JULY 2000

79SPOKEN LANGUAGE SYSTEMS
Doctoral Theses
CompletedK. Ng, Subword-based Approaches for SpokenDocument Retrieval. February 2000.
M. Spina, Analysis and Transcription ofGeneral Audio Data. June 2000.
Masters ThesesS.M. Thesis CompletedK. Livescu. Analysis and Modeling of Non-Native Speech for Automatic Speech Recognition.Supervisor: J. Glass. August 1999.
M.Eng. Theses CompletedS. Kamppari. Word and Phone Level AcousticConfidence Scoring for Speech UnderstandingSystems. Supervisor: T.J. Hazen. September1999.
E. Sandness. Discriminative Training ofAcoustic Models in a Segment-based SpeechRecognizer. Supervised by I.L. Hetherington.May 2000.
In ProgressG. Chung. Towards Multi-Domain SpeechUnderstanding with Flexible and DynamicVocabulary. Expected December 2000.
C. Wang. Incorporation of Prosody into SpeechRecognition and Understanding.Expected 2001.
In ProgressT. Burianek. Building a Speech UnderstandingSystem Using Word Spotting Techniques. M.Eng.thesis. Supervisor: T.J. Hazen. Expected July2000.
L. Baptist. GENESIS-II: A Language GenerationModule for Conversational Systems. S.M. thesis.Supervisor: S. Seneff. Expected August2000.
J. Pearlman, SLS-Lite: Enabling SpokenLanguage Systems Design for Non-Experts,M.Eng. thesis. Supervisor: J. Glass.ExpectedAugust 2000.
A. Suchato, Framework for Joint Recognition ofPronounced and Spelled Proper Names. S.M.thesis. Supervisor: S. Seneff. Expected:September 2000.

80 SUMMARY OF RESEARCH - JULY 2000
Publications
G. Chung, S. Seneff and I.L. Hetherington,"Towards Multi-Domain Speech Under-standing Using a Two-Stage Recognizer,"Proc. Eurospeech 99, Budapest, Hungary,September 1999.
S. Seneff, R. Lau and J. Polifroni, "Organiza-tion, Communication, and Control in theGALAXY-II Conversational System," Proc.Eurospeech 99, Budapest, Hungary, Septem-ber 1999.
J. Glass, "Challenges for Spoken DialogueSystems," Proc. 1999 IEEE ASRU Workshop,Keystone, CO, December 1999.
N. Strom, L. Hetherington, T.J. Hazen, E.Sandness and J. Glass, "Acoustic ModelingImprovements in a Segment-Based SpeechRecognizer," Proc. 1999 IEEE ASRUWorkshop, Keystone, CO, December 1999.
V. Zue, et al., "JUPITER: A Telephone-BasedConversational Interface for WeatherInformation" IEEE Transactions on Speech andAudio Processing, Vol. 8 , No. 1, January2000.
J. Polifroni and S. Seneff, "GALAXY-II as anArchitecture for Spoken Dialogue Evalua-tion" Proc. Second International Conference onLanguage Resources and Evaluation (LREC),Athens, Greece, May 31-June 2, 2000.
I. Bazzi and J. Glass, "Heterogeneous LexicalUnits for Automatic Speech Recognition:Preliminary Investigations" Proc.ICASSP2000, Istanbul, Turkey, June 2000.
S. Kamppari and T.J. Hazen, "Word andPhone Level Acoustic Confidence Scoring"Proc. ICASSP2000, Istanbul, Turkey, June2000.
K. Livescu and J. Glass, "Lexical Modelingof Non-native Speech for Automatic SpeechRecognition" Proc. ICASSP2000, Istanbul,Turkey, June 2000.
K. Ng, "Information Fusion for SpokenDocument Retrieval" Proc. ICASSP2000,Istanbul, Turkey, June 2000.
C. Wang and S. Seneff, "Robust PitchTracking for Prosodic Modeling in Tele-phone Speech" Proc. ICASSP2000, Istanbul,Turkey, June 2000.

81SPOKEN LANGUAGE SYSTEMS
Presentations
V. Zue. “Next Generation Speech-basedInterfaces.” Invited talk at the Bell AtlanticSpeech Symposium. September 23, 1999.
V. Zue. “2001: Why the Hal Not?” Invitedtalk at SpeechWorks International, Boston,MA, September 28, 1999.
V. Zue. “Speech is It”. Presentation atDARPA. September 29, 1999.
J. Glass. “Challenges for Spoken DialogueSystems.” IEEE Automatic Speech Recogni-tion and Understanding Workshop,Keystone, Colorado, December 1999.
V. Zue. “Introduction to the MITLaboratory for Computer Science”.Presentation at NTT-MIT CollaborationMeeting, Tokyo, Japan. January 2000.
S. Seneff. “Multilingual ConversationalInterfaces: An NTT-MIT Collaboration”.NTT-MIT Collaboration Meeting, Tokyo,Japan. January 13, 2000
V. Zue. “The DARPA Communicator:An MIT Progress Report”. Presentation atthe DARPA Communicator PI Meeting,Charleston, SC, January 20, 2000
V. Zue. “Conversational Interfaces”.Presentation to NOKIA, Helsinki, Finland,January 25, 2000.
V. Zue. “2001: Why the Hal Not?”Invited talk at the Telephony Voice UserInterface Meeting, Pheonix, AZ, February 3,2000.
V. Zue and J. Glass. “ConversationalInterfaces: Advances and Challenges”.February 8, 2000. IEEE
V. Zue “Introduction to the MIT Laboratoryfor Computer Science”. Invited talk atMITRE, March 1, 2000.
V. Zue. “@ the Human Interface”. Panelmoderator at the Intel CCC Meeting, SanFrancisco, CA, March 16, 2000.
J. Glass. “Overview of the MIT LanguageGeneration and Speech Synthesis Systems”.DARPA Workshop on Corpus-Based TextGeneration and Synthesis, Seattle, WA,April 30, 2000.
S. Seneff. and J. Polifroni. “DialogueManagement in the MERCURY FlightReservation System”. Satellite Workshop onConversational Systems following ANLP/NAACL 2000, Seattle, Washington.May 4, 2000,
S. Seneff. “Spoken Dialogue Systems:Dialogue Management and System Evalua-tion Issues”. Panel at Satellite Workshop onConversational Systems following ANLP/NAACL 2000, Seattle, Washington, May 4,2000.
S. Seneff. “Spoken Language TechnologyResearch at MIT: A Progress Report”. ITRI,June 15, 2000.
V. Zue “Acoustic Properties of Speech”.Johns Hopkins workshop, Baltimore, MD,July 2000.

82 SUMMARY OF RESEARCH - JULY 2000
SLS Seminar Series
October 18, 1999“Jana Speech API: Developing Speech Appsin Java”Andrew Hunt & Willie WalkerSun Microsystems
October 25, 1999“Toward Automatic Summarization ofBroadcast News Speech”Sadaoki FuruiTokyo Institute of Technology
February 28, 2000“Persuasive Multi-modal ConversationalSystems”Ganesh RamaswamyIBM TJ Watson Research center
March 27, 2000“Stochastic Suprasegmentals: RelationshipsBetween Redundancy, Prosodic Structureand Core Articulation in SpontaneousSpeech”Matthew AylettUniversity of Edinburgh
March 6, 2000“Building Telephone-Based Spoken DialogApplications”Mike PhillipsSpeechWorks International
May 1, 2000“Natural Language in L&H Voice Xpress:An Overview”Jeff AdamsLernout & Hauspie Speech products
May 22, 2000Issues in Mandarin TTS SystemsMin ChuMicrosoft Research China

83SPOKEN LANGUAGE SYSTEMS
Photography by Tony Rinaldo

84 SUMMARY OF RESEARCH - JULY 2000
20002000 2000
2000 20002000
2000 2000
2000
2000 2000 2000
2000
2000 2000 2000 2000 2000
2000 2000 2000 2000
2000200020002000
2000 2000 2000 2000
2000
200020002000
2000 2000 2000 2000
2000
MassachusettsInstitute of Technology

85SP
OK
EN L
AN
GU
AG
E SY
STEM
S
July 2000 MIT Laboratory for Computer Science - Spoken Language Systems Group MIT/LCS





























